An Energy-Efficient and Fast Scheme for Hybrid Storage Class Memory in an AIoT Terminal System


Abstract
1. Introduction
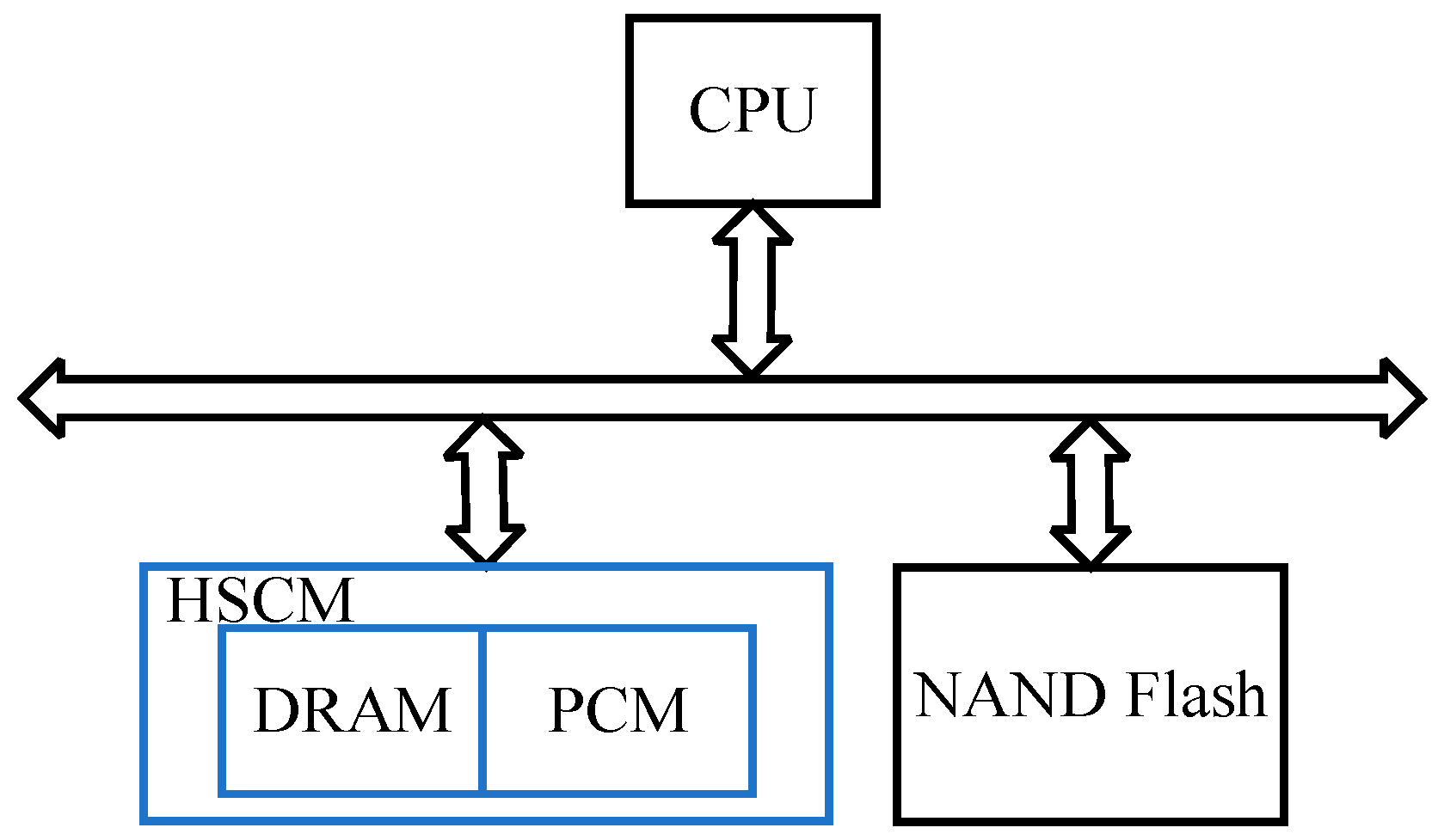
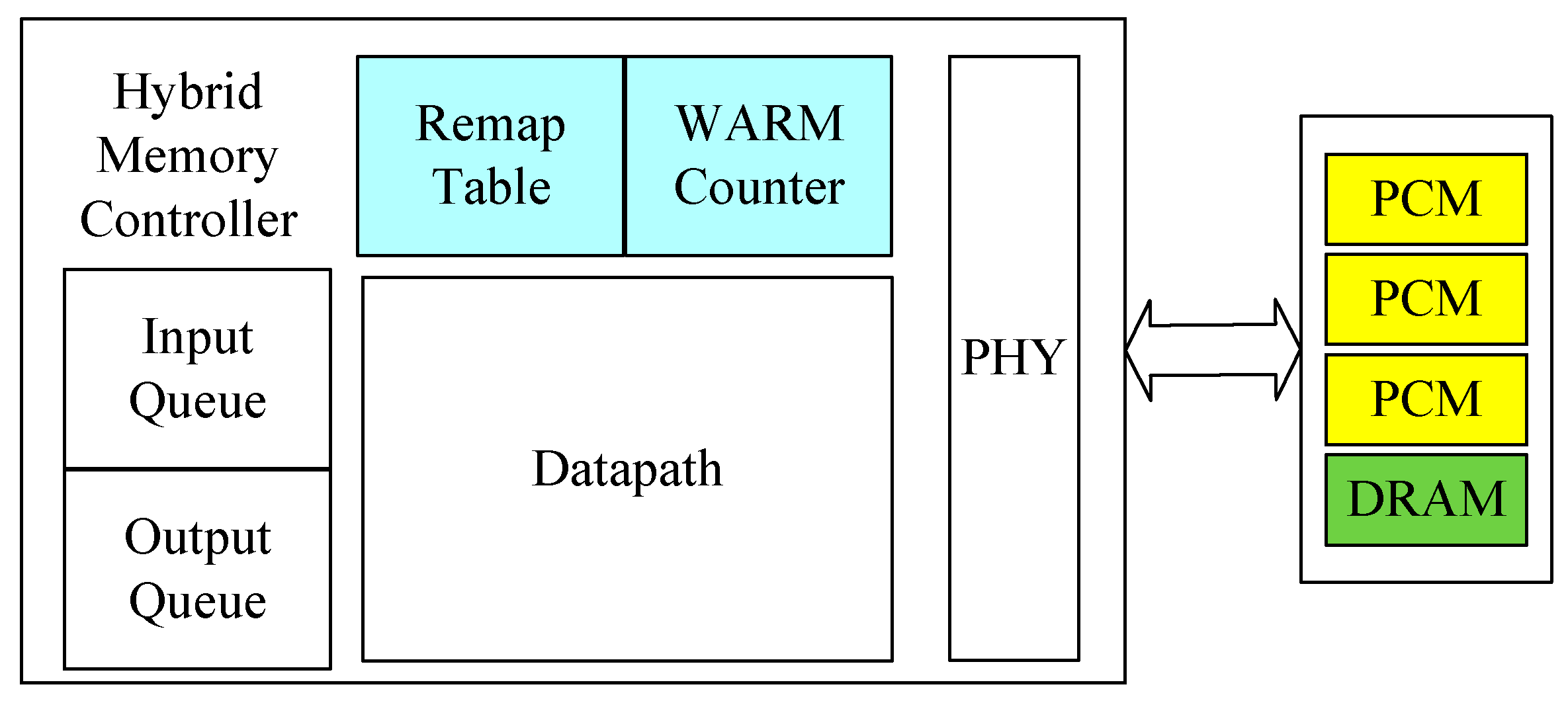
2. Hybrid Storage Class Memory
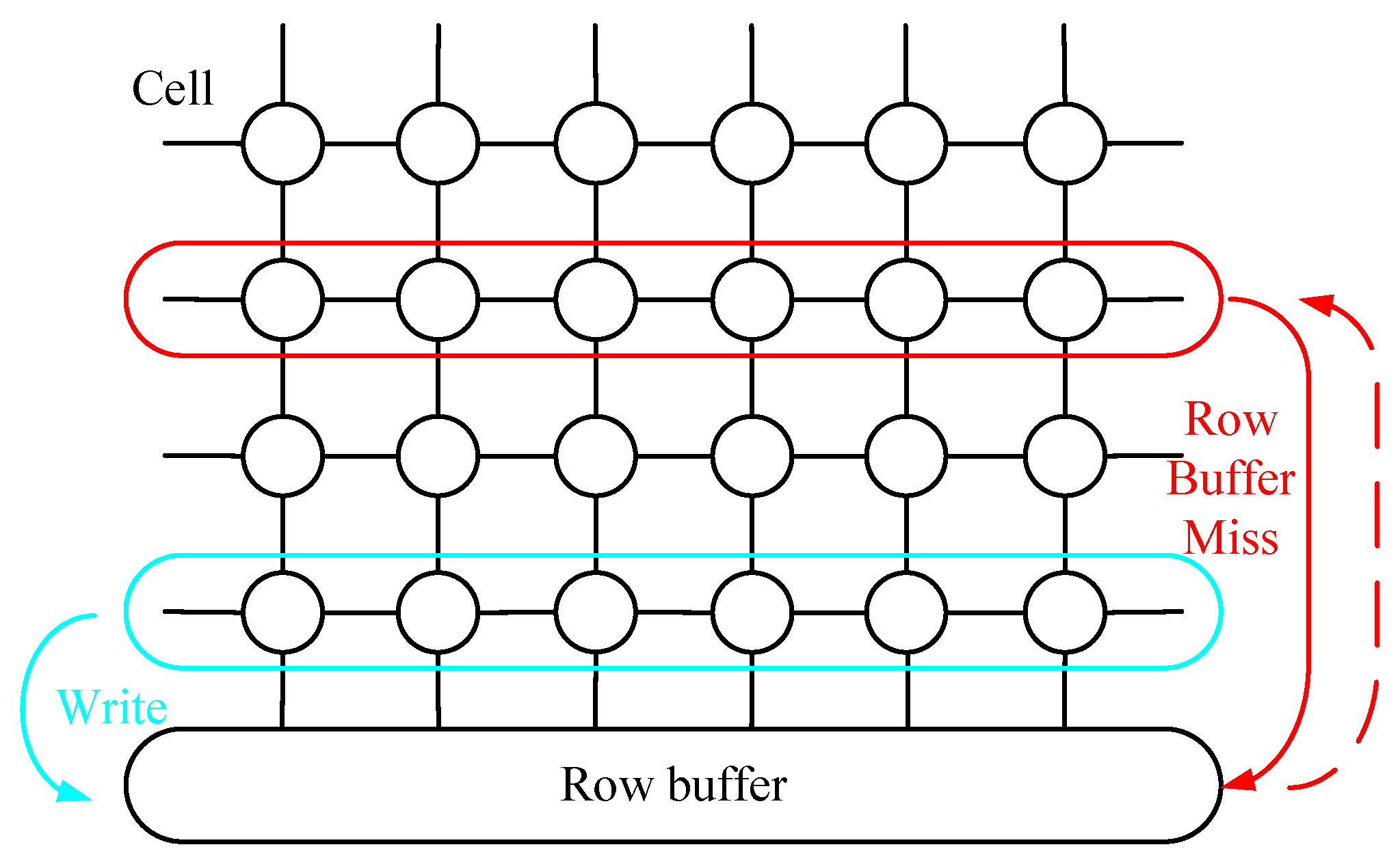
2.1. Row Buffer Architecture
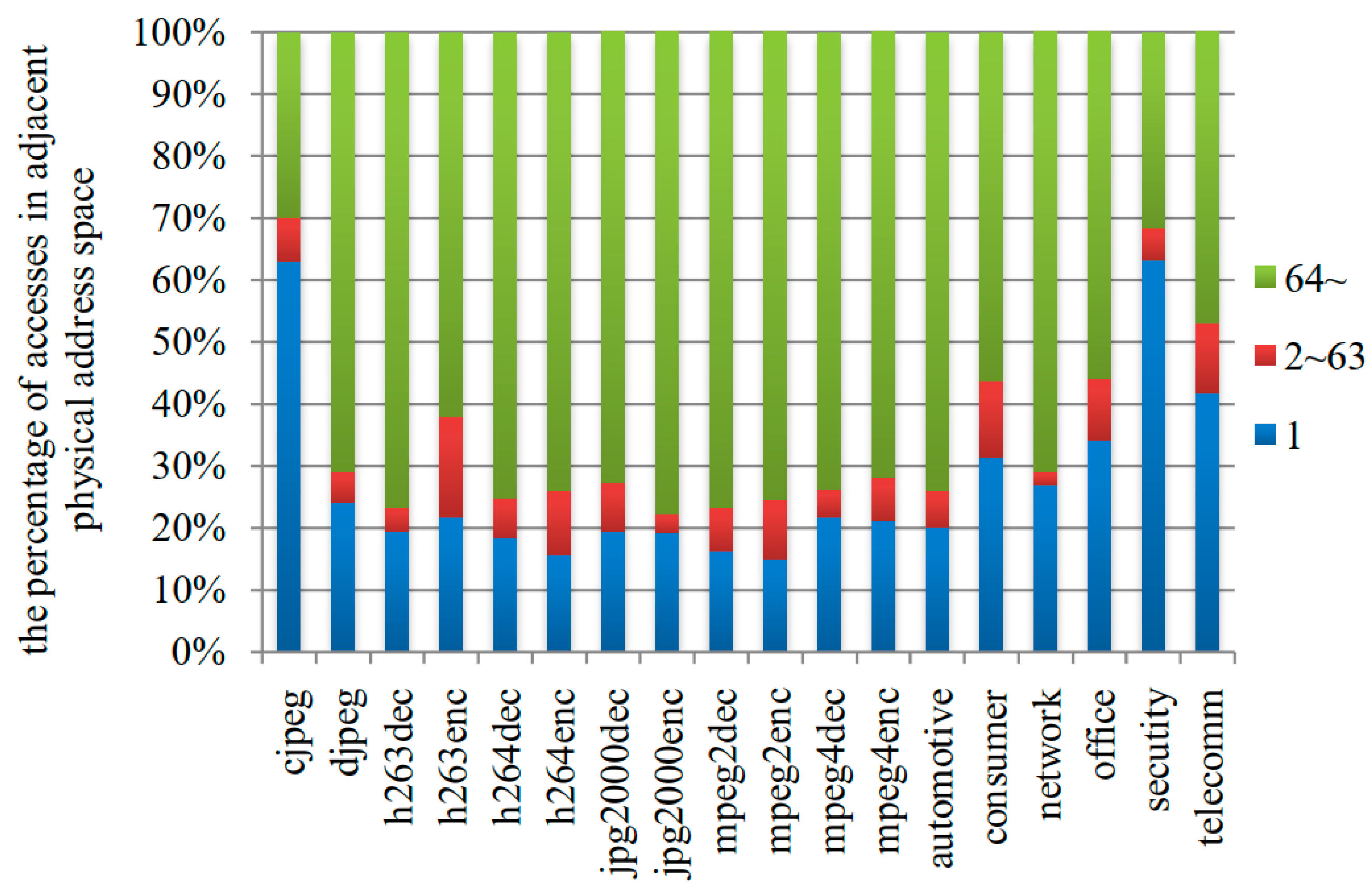
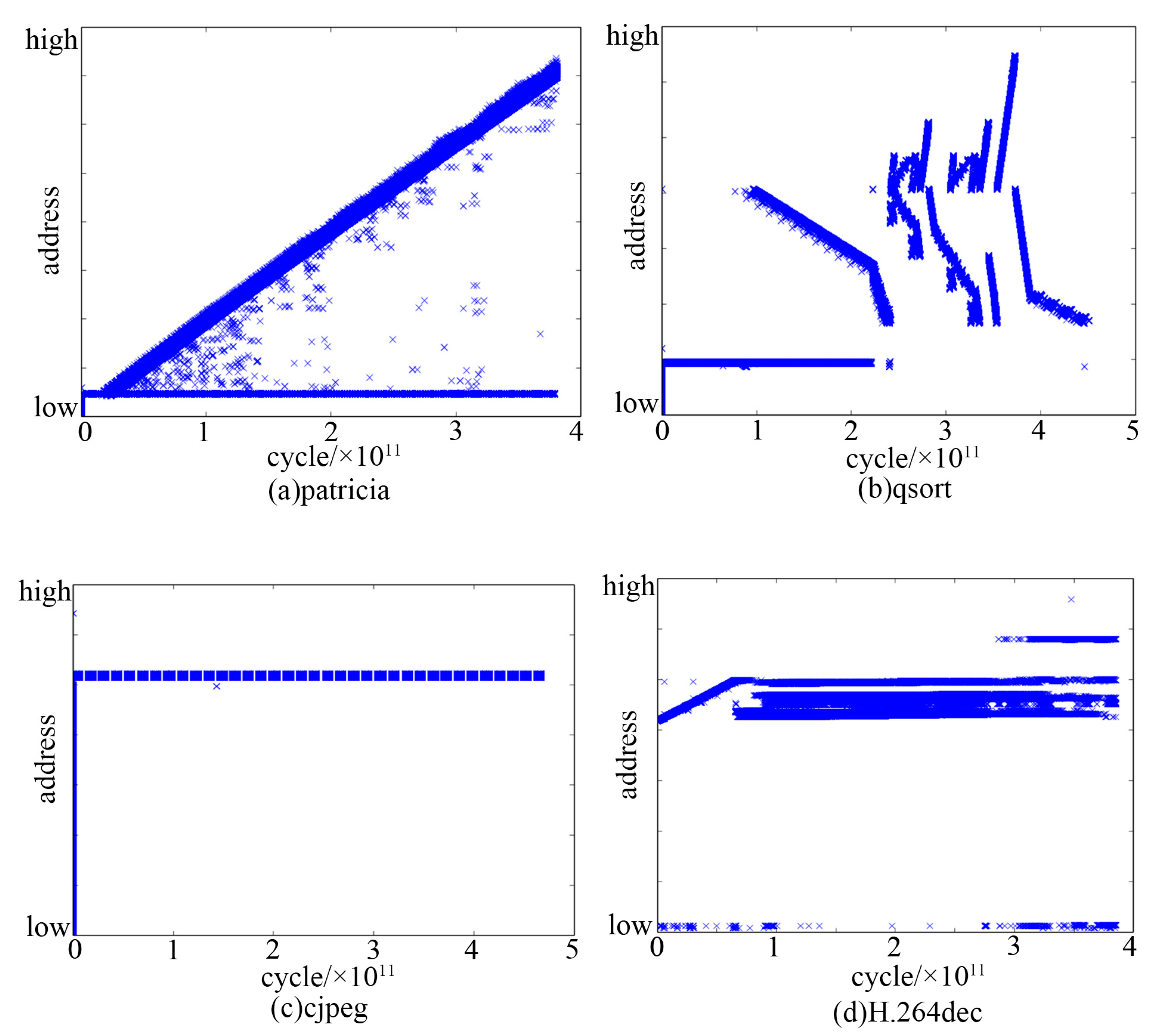
2.2. Memory Access Pattern in IoT Applications
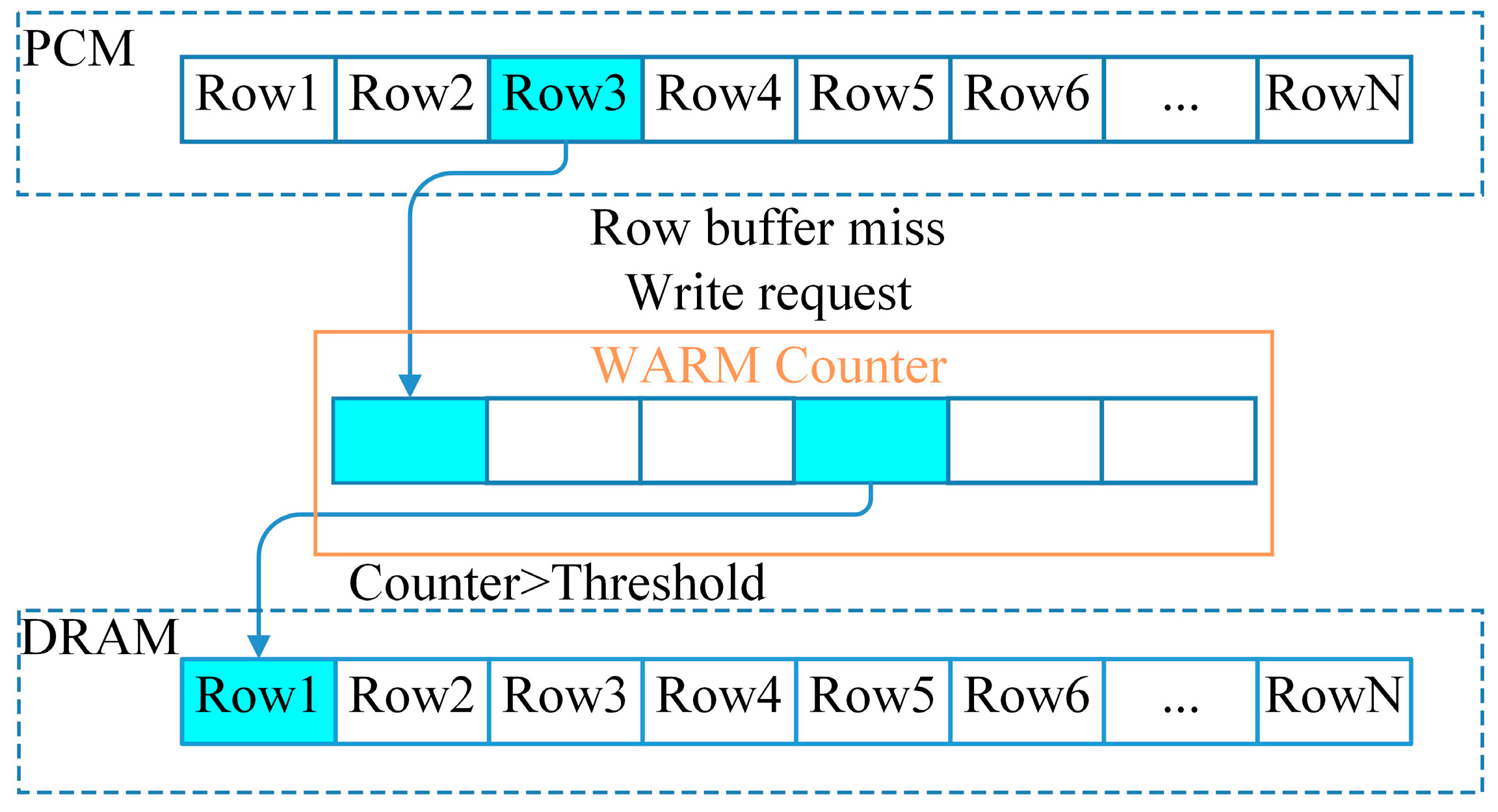
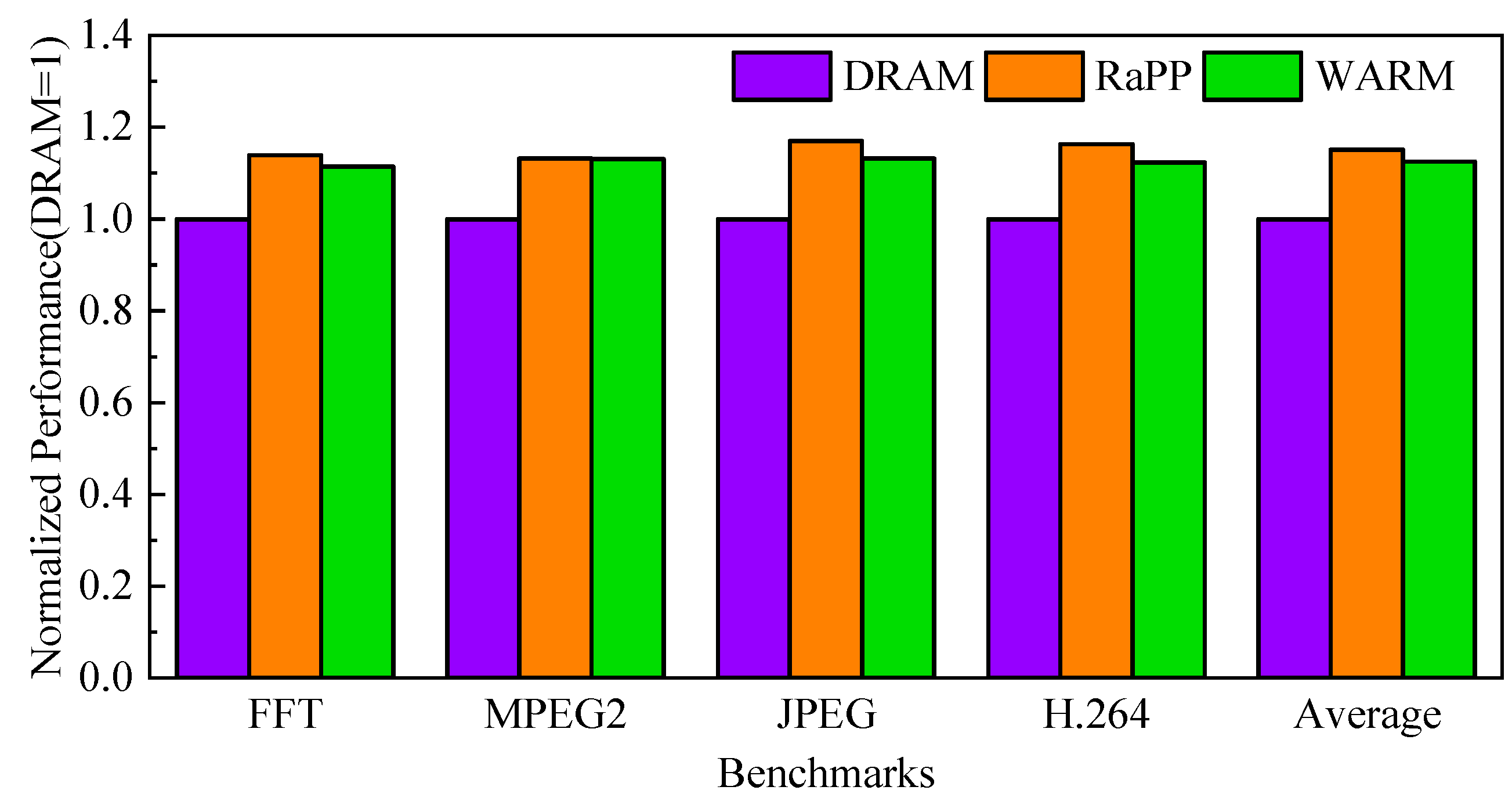
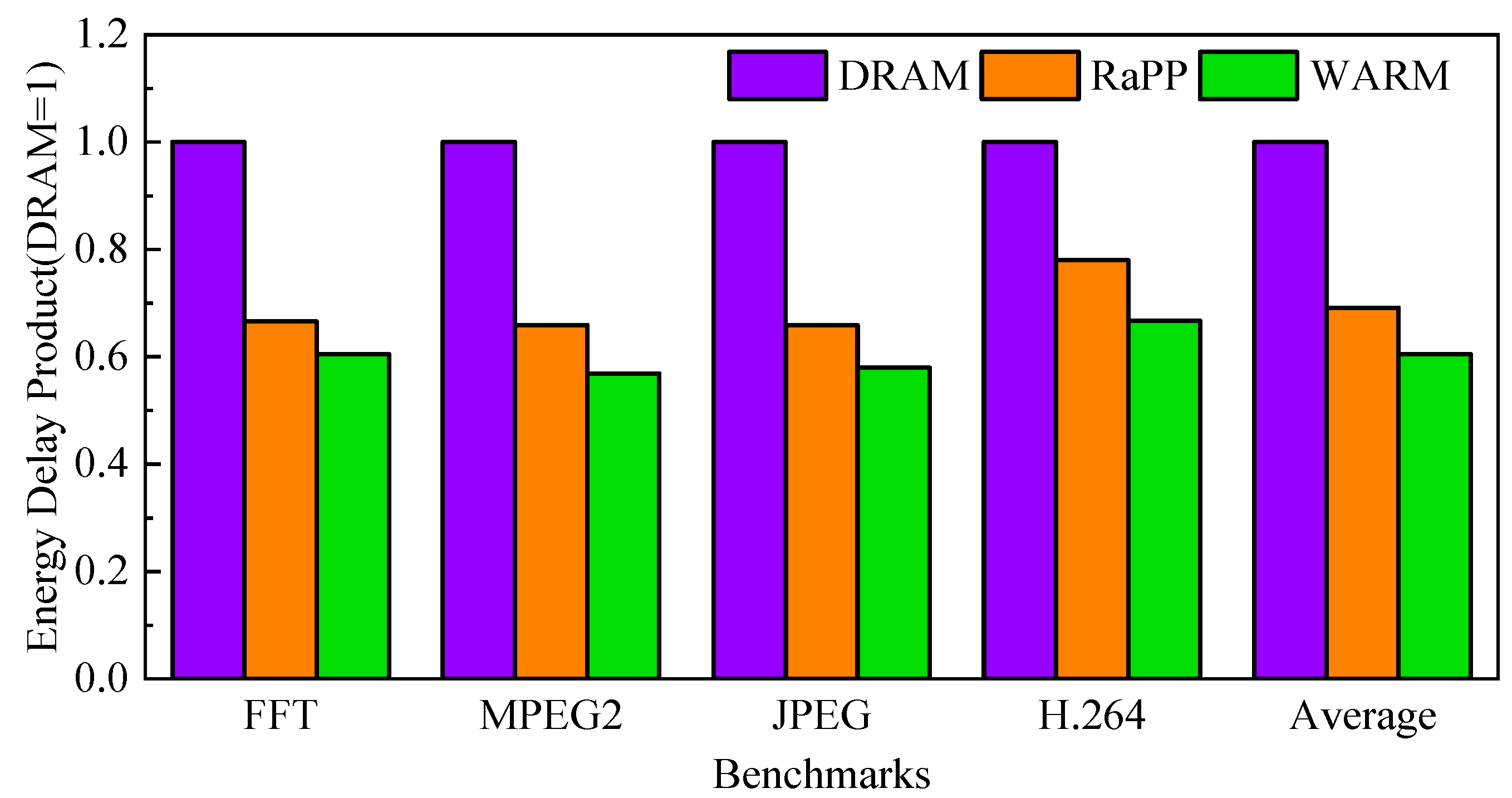
2.3. Row Buffer Locality and Write Aware Scheme
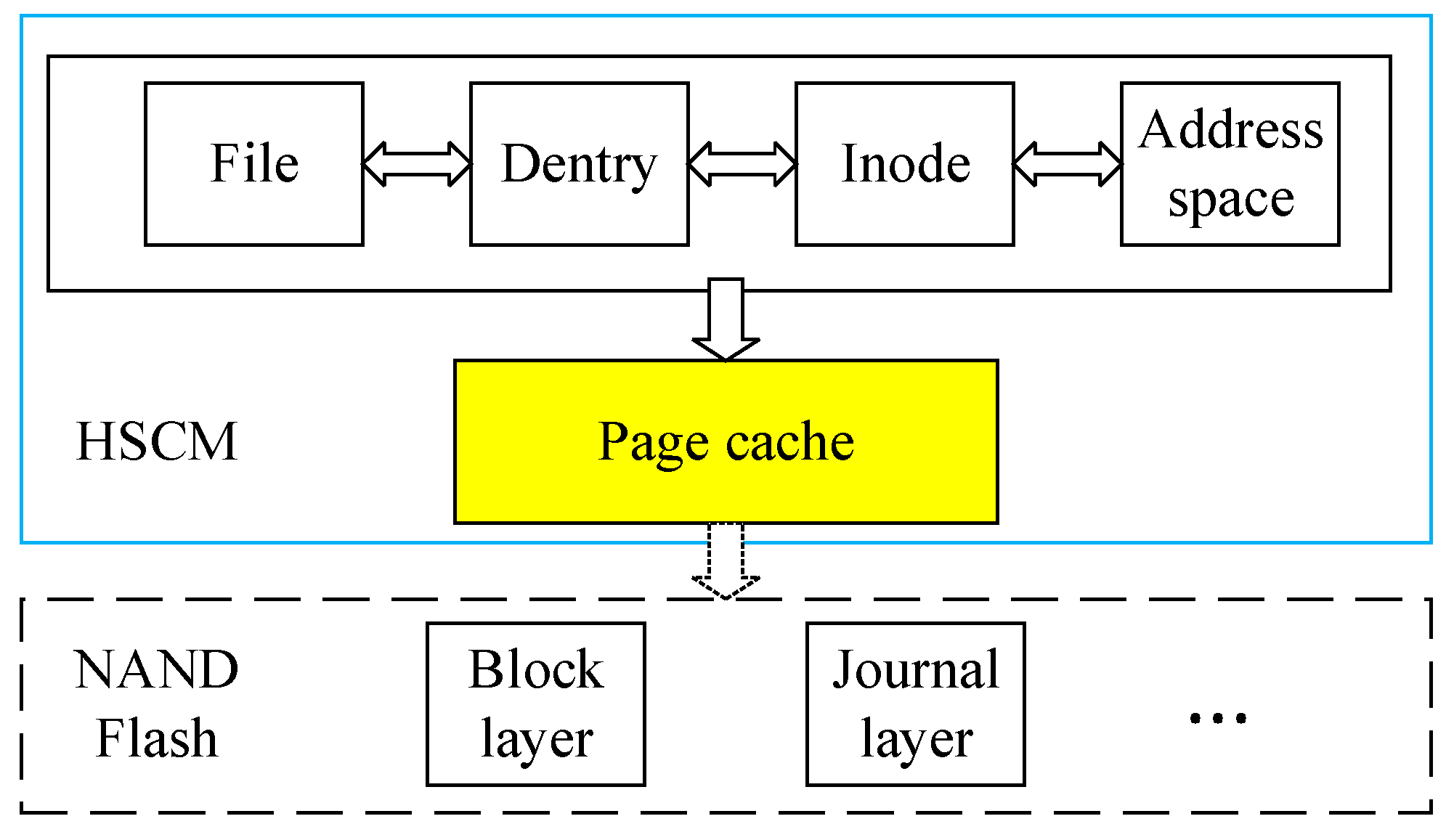
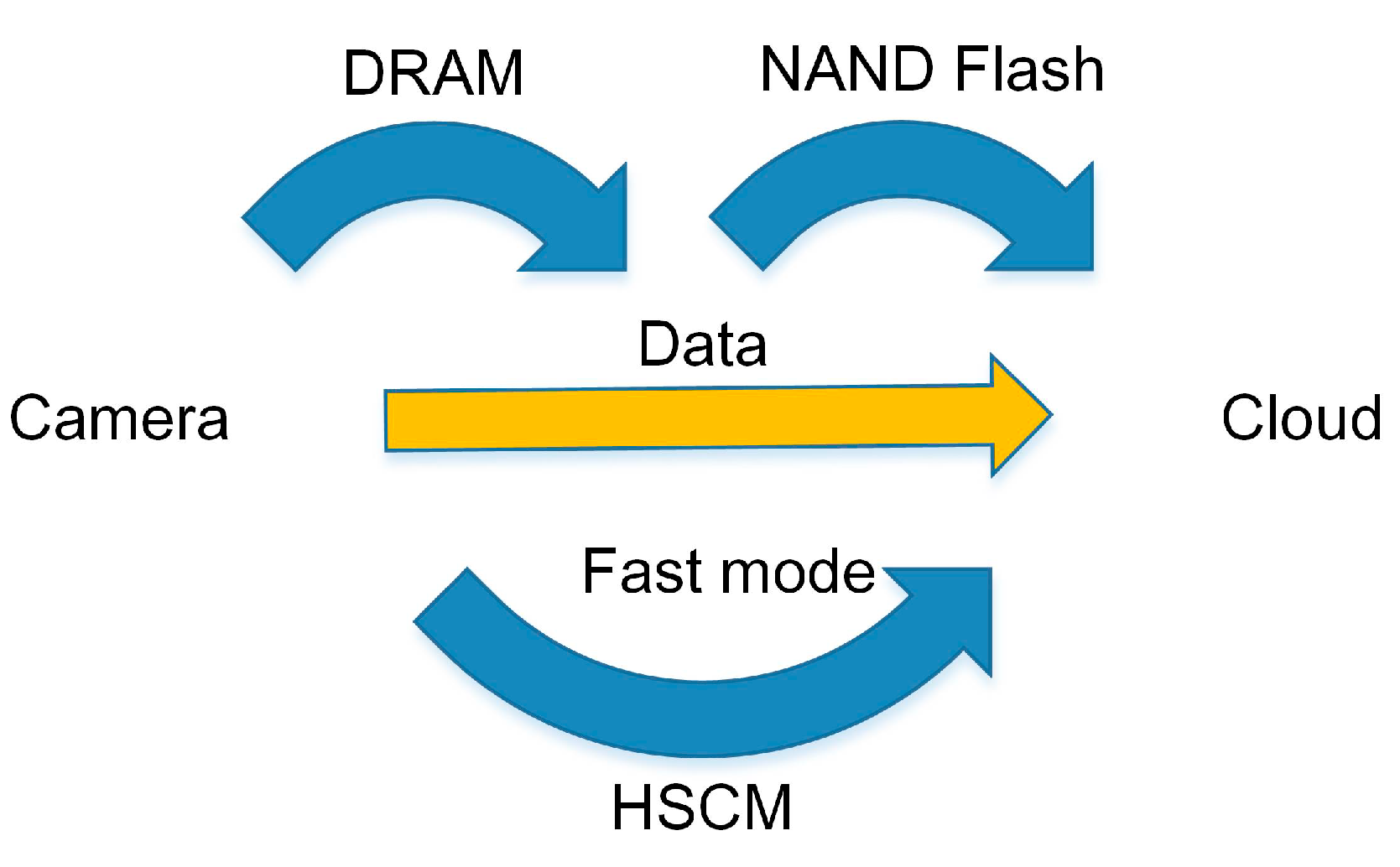
3. Fast Mode for HSCM with In-Memory File System
4. Evaluation
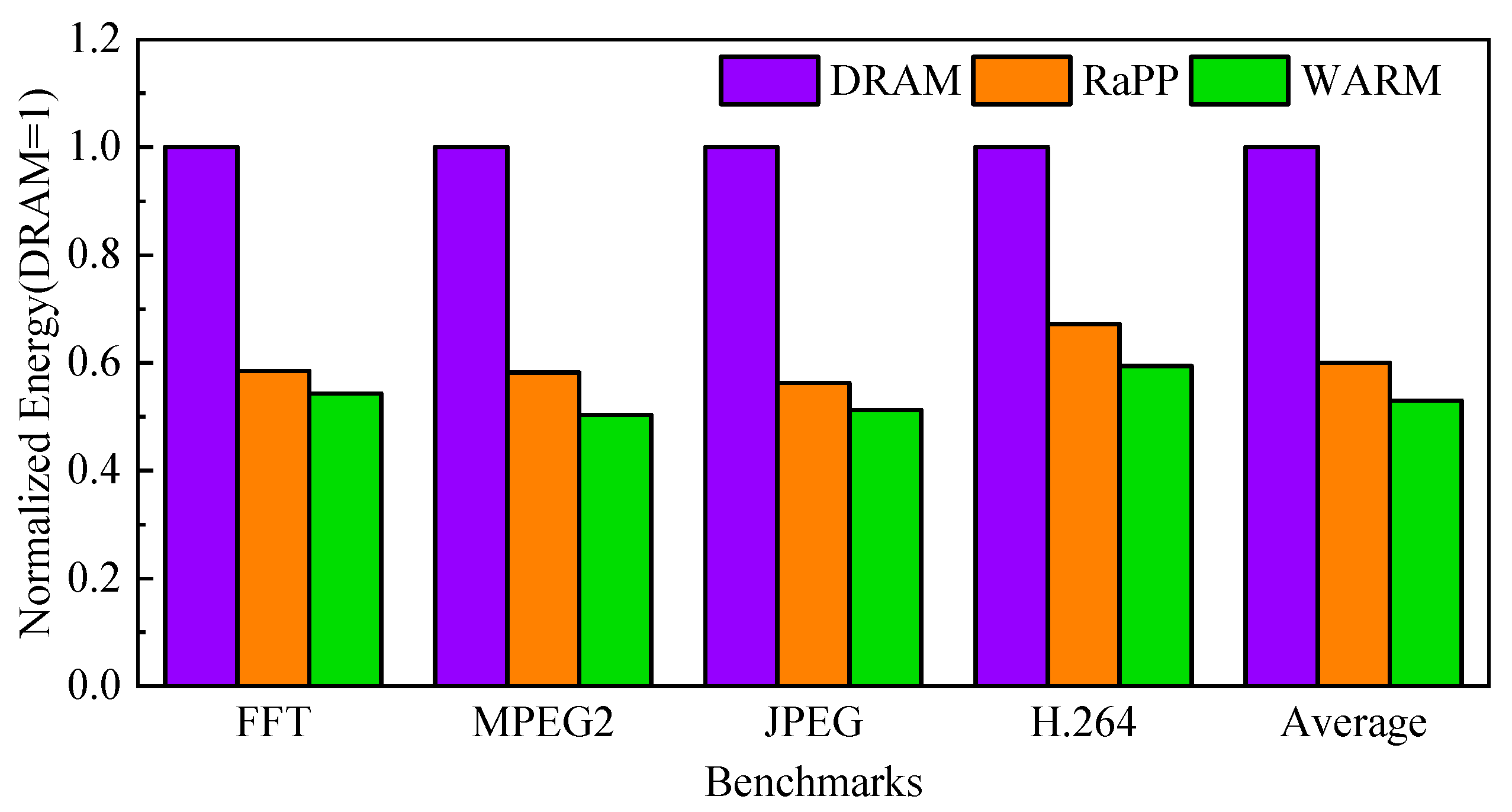
4.1. Evaluation of Hybrid Storage Class Memory
4.2. Performance of the Fast Mode
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Samie, F.; Bauer, L.; Henkel, J. IoT technologies for embedded computing: A survey. In Proceedings of the Eleventh IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis—CODES ’16, Pittsburgh, PA, USA, 2–7 October 2016; pp. 1–10. [Google Scholar]
- Hassan, N.; Gillani, S.; Ahmed, E.; Yaqoob, I.; Imran, M. The Role of Edge Computing in Internet of Things. IEEE Commun. Mag. 2018, 56, 110–115. [Google Scholar] [CrossRef]
- Song, W.; Zhou, Y.; Zhao, M.; Ju, L.; Xue, C.J.; Jia, Z. EMC: Energy-Aware Morphable Cache Design for Non-Volatile Processors. IEEE Trans. Comput. 2019, 68, 498–509. [Google Scholar] [CrossRef]
- Yun, J.-T.; Yoon, S.-K.; Kim, J.-G.; Burgstaller, B.; Kim, S.-D. Regression Prefetcher with Preprocessing for DRAM-PCM Hybrid Main Memory. IEEE Comput. Arch. Lett. 2018, 17, 163–166. [Google Scholar] [CrossRef]
- Wong, H.-S.P.; Raoux, S.; Kim, S.; Liang, J.; Reifenberg, J.P.; Rajendran, B.; Asheghi, M.; Goodson, K.E. Phase Change Memory. Proc. IEEE 2010, 98, 2201–2227. [Google Scholar] [CrossRef]
- Kim, N.S.; Song, C.; Cho, W.Y.; Huang, J.; Jung, M. LL-PCM: Low-Latency Phase Change Memory Architecture. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Apalkov, D.; Ong, A.; Driskill-Smith, A.; Krounbi, M.; Khvalkovskiy, A.; Watts, S.; Nikitin, V.; Tang, X.; Lottis, D.; Moon, K.; et al. Spin-transfer torque magnetic random access memory (STT-MRAM). J. Emerg. Technol. Comput. Syst. 2013, 9, 1–35. [Google Scholar] [CrossRef]
- Akinaga, H.; Shima, H. Resistive Random Access Memory (ReRAM) Based on Metal Oxides. Proc. IEEE 2010, 98, 2237–2251. [Google Scholar] [CrossRef]
- Foong, A.; Hady, F. Storage As Fast As Rest of the System. In Proceedings of the 2016 IEEE 8th International Memory Workshop (IMW), Paris, France, 15–18 May 2016; pp. 1–4. [Google Scholar]
- Boukhobza, J.; Rubini, S.; Chen, R.; Shao, Z. Emerging NVM: A survey on architectural integration and research challenges. ACM Trans. Des. Autom. Electron. Syst. 2017, 23, 1–32. [Google Scholar] [CrossRef]
- Asadinia, M.; Bobda, C. Enhancing Lifetime of PCM-Based Main Memory with Efficient Recovery of Stuck-at Faults. In Proceedings of the 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Hong Kong, China, 8–11 July 2018; pp. 357–362. [Google Scholar]
- Zilberberg, O.; Weiss, S.; Toledo, S. Phase-change memory: An architectural perspective. ACM Comput. Surv. 2013, 45, 1–33. [Google Scholar] [CrossRef]
- Chen, X.; Sha, E.H.-M.; Jiang, W.; Zhuge, Q.; Chen, J.; Qin, J.; Zeng, Y. The design of an efficient swap mechanism for hybrid DRAM-NVM systems. In Proceedings of the 13th International Conference on Embedded Software—EMSOFT ’16, Pittsburgh, PA, USA, 2–7 October 2016; pp. 1–10. [Google Scholar]
- Salkhordeh, R.; Asadi, H. An Operating System Level Data Migration Scheme in Hybrid DRAM-NVM Memory Architecture. In Proceedings of the 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 936–941. [Google Scholar]
- Liu, D.; Zhong, K.; Zhu, X.; Li, Y.; Long, L.; Shao, Z. Non-Volatile Memory Based Page Swapping for Building High-Performance Mobile Devices. IEEE Trans. Comput. 2017, 66, 1918–1931. [Google Scholar] [CrossRef]
- Bock, S.; Childers, B.R.; Melhem, R.; Mosse, D. Concurrent Migration of Multiple Pages in software-managed hybrid main memory. In Proceedings of the 2016 IEEE 34th International Conference on Computer Design (ICCD), Scottsdale, AZ, USA, 2–5 October 2016; pp. 420–423. [Google Scholar]
- Jia, G.; Han, G.; Xie, H.; Du, J. Hybrid-LRU Caching for Optimizing Data Storage and Retrieval in Edge Computing-Based Wearable Sensors. IEEE Internet Things J. 2019, 6, 1342–1351. [Google Scholar] [CrossRef]
- Ramos, L.E.; Gorbatov, E.; Bianchini, R. Page placement in hybrid memory systems. In Proceedings of the ICS ’11: International Conference on Supercomputing, Tucson, AZ, USA, 1–4 June 2011; pp. 85–95. [Google Scholar]
- Alawneh, T.A. A Dynamic Row-Buffer Management Policy for Multimedia Applications. In Proceedings of the 2019 27th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Pavia, Italy, 13–15 February 2019; pp. 148–157. [Google Scholar]
- Guthaus, M.R.; Ringenberg, J.S.; Ernst, D.; Austin, T.M.; Mudge, T.; Brown, R.B. MiBench: A free, commercially representative embedded benchmark suite. In Proceedings of the Fourth Annual IEEE International Workshop on Workload Characterization, WWC-4 (Cat. No.01EX538), Austin, TX, USA, 2 December 2001; pp. 3–14. [Google Scholar]
- Fritts, J.E.; Steiling, F.W.; Tucek, J.A.; Wolf, W. MediaBench II Video: Expediting the next generation of video systems research. Microprocess. Microsyst. 2009, 33, 301–318. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, L.; Hao, X. Hybrid memory system using memory access-aware remapping mechanism. J. Chin. Comput. Syst. 2014, 6, 1201–1206. [Google Scholar]
- Binkert, N.; Sardashti, S.; Sen, R.; Sewell, K.; Shoaib, M.; Vaish, N.; Hill, M.D.; Wood, D.A.; Beckmann, B.; Black, G.; et al. The gem5 simulator. ACM SIGARCH Comput. Archit. News. 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Li, Y.; Ghose, S.; Choi, J.; Sun, J.; Wang, H.; Mutlu, O. Utility-Based Hybrid Memory Management. In Proceedings of the 2017 IEEE International Conference on Cluster Computing (CLUSTER), Honolulu, HI, USA, 5–8 September 2017; pp. 152–165. [Google Scholar]
- Dulloor, S.R.; Kumar, S.; Keshavamurthy, A.; Lantz, P.; Reddy, D.; Sankaran, R.; Jackson, J. System software for persistent memory. In Proceedings of the Ninth European Conference on Computer Systems—EuroSys ’14, Amsterdam, The Netherlands, 14–16 April 2014; pp. 1–15. [Google Scholar]
- Xu, J.; Swanson, S. NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories. In Proceedings of the FAST’16: Proceedings of the 14th Usenix Conference on File and Storage Technologies, Santa Clara, CA, USA, 22–25 February 2016; pp. 323–338. [Google Scholar]
- Wu, X.; Qiu, S.; Narasimha Reddy, A.L. SCMFS: A File System for Storage Class Memory and its Extensions. ACM Trans. Storage 2013, 9, 1–23. [Google Scholar] [CrossRef]
- Siegl, P.; Buchty, R.; Berekovic, M. Data-Centric Computing Frontiers: A Survey On Processing-In-Memory. In Proceedings of the Second International Symposium on Memory Systems - MEMSYS ’16, Alexandria, VA, USA, 3–6 October 2016; pp. 295–308. [Google Scholar]
- Kim, H.; Ahn, J.; Ryu, S. In-Memory File System for Non-Volatile Memory. In Proceedings of the RACS ’13: Proceedings of the 2013 Research in Adaptive and Convergent Systems, Montreal, QC, Canada, 1–4 October 2013; pp. 479–484. [Google Scholar]
- Poremba, M.; Zhang, T.; Xie, Y. NVMain 2.0: A User-Friendly Memory Simulator to Model (Non-)Volatile Memory Systems. IEEE Comput. Arch. Lett. 2015, 14, 140–143. [Google Scholar] [CrossRef]
- Liu, H.; Chen, Y.; Liao, X.; Jin, H.; He, B.; Zheng, L.; Guo, R. Hardware/software cooperative caching for hybrid DRAM/NVM memory architectures. In Proceedings of the International Conference on Supercomputing—ICS ’17, Chicago, IL, USA, 14–16 June 2017; pp. 1–10. [Google Scholar]
- Salkhordeh, R.; Mutlu, O.; Asadi, H. An Analytical Model for Performance and Lifetime Estimation of Hybrid DRAM-NVM Main Memories. IEEE Trans. Comput. 2019, 68, 1114–1130. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| CPU Frequency | ARM (1 core) 1 GHz |
| L1 cache | 32 kB instruction cache 32 kB data cache |
| L2 cache | 512 kB |
| Memory | 1-GB DRAM 3-GB PCM |
| DRAM | PCM | |
|---|---|---|
| Latency | tCL = 15 ns tRCD = 15 ns tCWD = 13 ns tWR = 15 ns | tCL = 15 ns tRCD = 48 ns tCWD = 13 ns tWR = 300 ns |
| Energy | Array read = 1.17 pJ/bit Array write = 0.39 pJ/bit Row buffer read = 0.93 pJ/bit Row buffer write = 1.02 pJ/bit | Array read = 2.47 pJ/bit Array write = 16.82 pJ/bit Row buffer read = 0.93 pJ/bit Row buffer write = 1.02 pJ/bit |
| IO Size | 1 kB | 2 kB | 4 kB | 8 kB | 16 kB | Average |
|---|---|---|---|---|---|---|
| Ratio | 38.74 | 54.62 | 19.31 | 14.64 | 23.02 | 30.07 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, H.; Chen, L.; Hao, X.; Liu, C.; Ni, M. An Energy-Efficient and Fast Scheme for Hybrid Storage Class Memory in an AIoT Terminal System. Electronics 2020, 9, 1013. https://doi.org/10.3390/electronics9061013
Sun H, Chen L, Hao X, Liu C, Ni M. An Energy-Efficient and Fast Scheme for Hybrid Storage Class Memory in an AIoT Terminal System. Electronics. 2020; 9(6):1013. https://doi.org/10.3390/electronics9061013
Chicago/Turabian StyleSun, Hao, Lan Chen, Xiaoran Hao, Chenji Liu, and Mao Ni. 2020. "An Energy-Efficient and Fast Scheme for Hybrid Storage Class Memory in an AIoT Terminal System" Electronics 9, no. 6: 1013. https://doi.org/10.3390/electronics9061013
APA StyleSun, H., Chen, L., Hao, X., Liu, C., & Ni, M. (2020). An Energy-Efficient and Fast Scheme for Hybrid Storage Class Memory in an AIoT Terminal System. Electronics, 9(6), 1013. https://doi.org/10.3390/electronics9061013