Innovative Deep Neural Network Modeling for Fine-Grained Chinese Entity Recognition

Abstract
1. Introduction
2. Related Work
2.1. Fine-Grained Named Entity Recognition
2.2. Bidirectional LSTM Networks
2.3. Pre-Trained Models
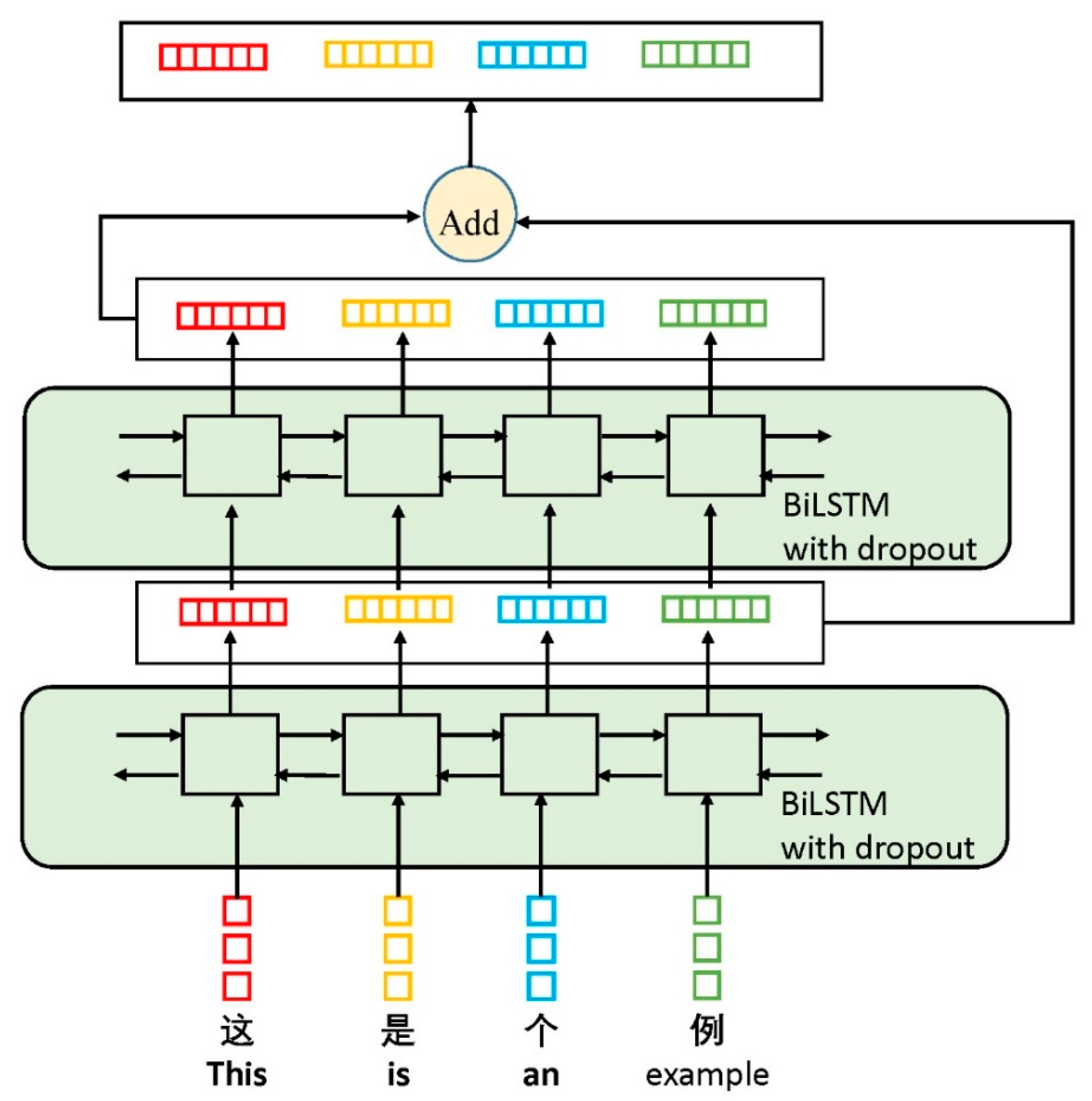
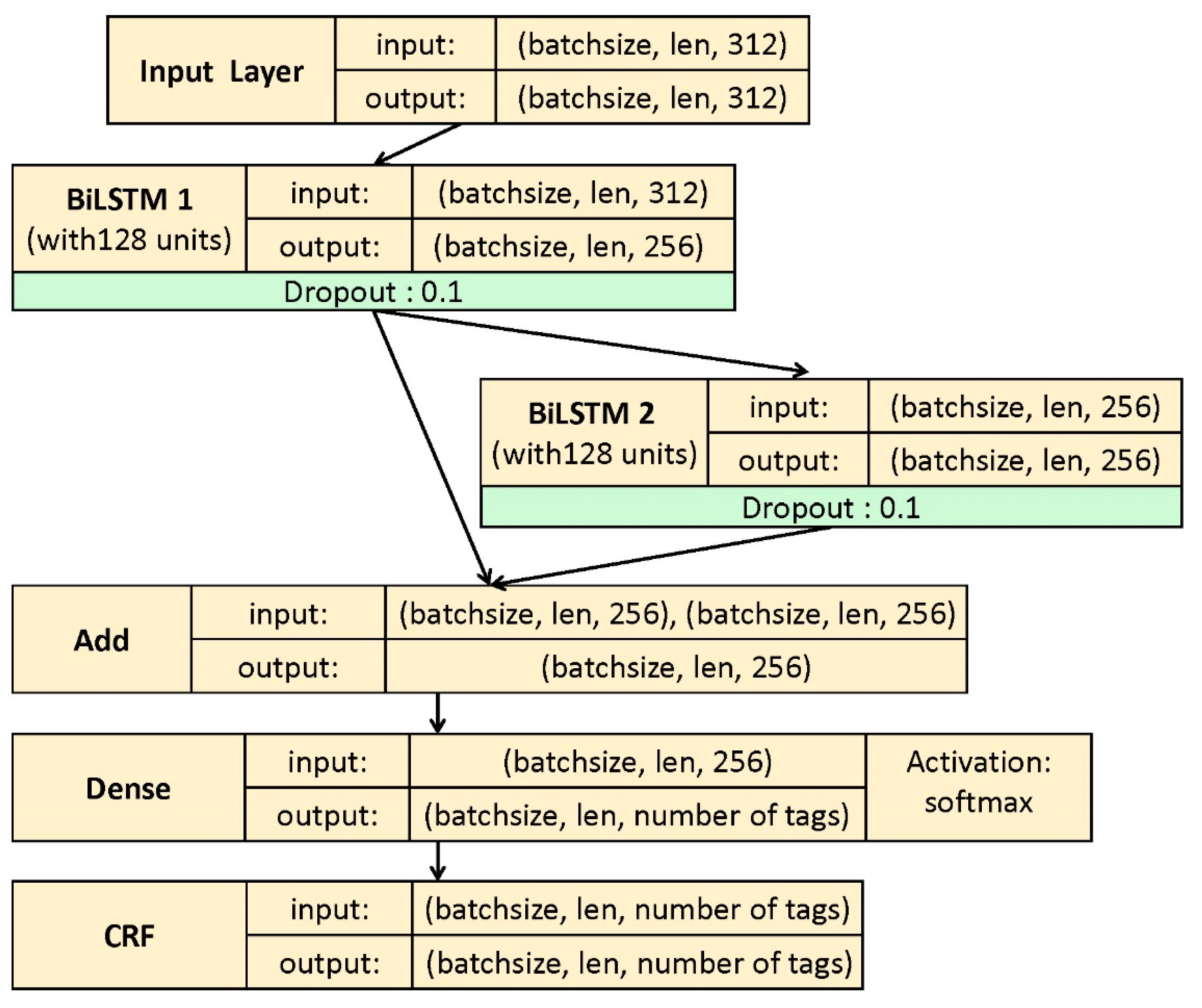
3. Proposed Method
3.1. Initial Encoding Layer
3.2. Enhanced Encoding Layer
3.3. Decoding Layer
3.4. Hyperparameters of the Proposed Model
4. Experiments and Settings
4.1. Dataset Description
4.1.1. CLUENER2020
4.1.2. People’s Daily Ner Corpus
4.2. Evaluation Metrics
- PrecisionPrecision refers to how many positive samples are true positive samples;
- RecallThe recall indicates how many of the positive samples in all samples were predicted correctly;
- F1-scoreThe F1-score is a comprehensive indicator, which is the harmonic average of precision and recall. Therefore, it is more commonly used in various NER tasks.
4.3. Baselines
4.3.1. ALBERT + BiLSTM + CRF
4.3.2. ALBERT + CRF
4.3.3. ALBERT + BiLSTM
4.3.4. BiLSTM-CRF-NER
4.3.5. BERT-NER
4.3.6. RoBERTa-NER
4.3.7. Human Performance
4.3.8. BiLSTM_Model
4.3.9. BiGRU_Model
4.3.10. BiGRU_CRF_Model
4.4. Experimental Settings
5. Results and Discussion
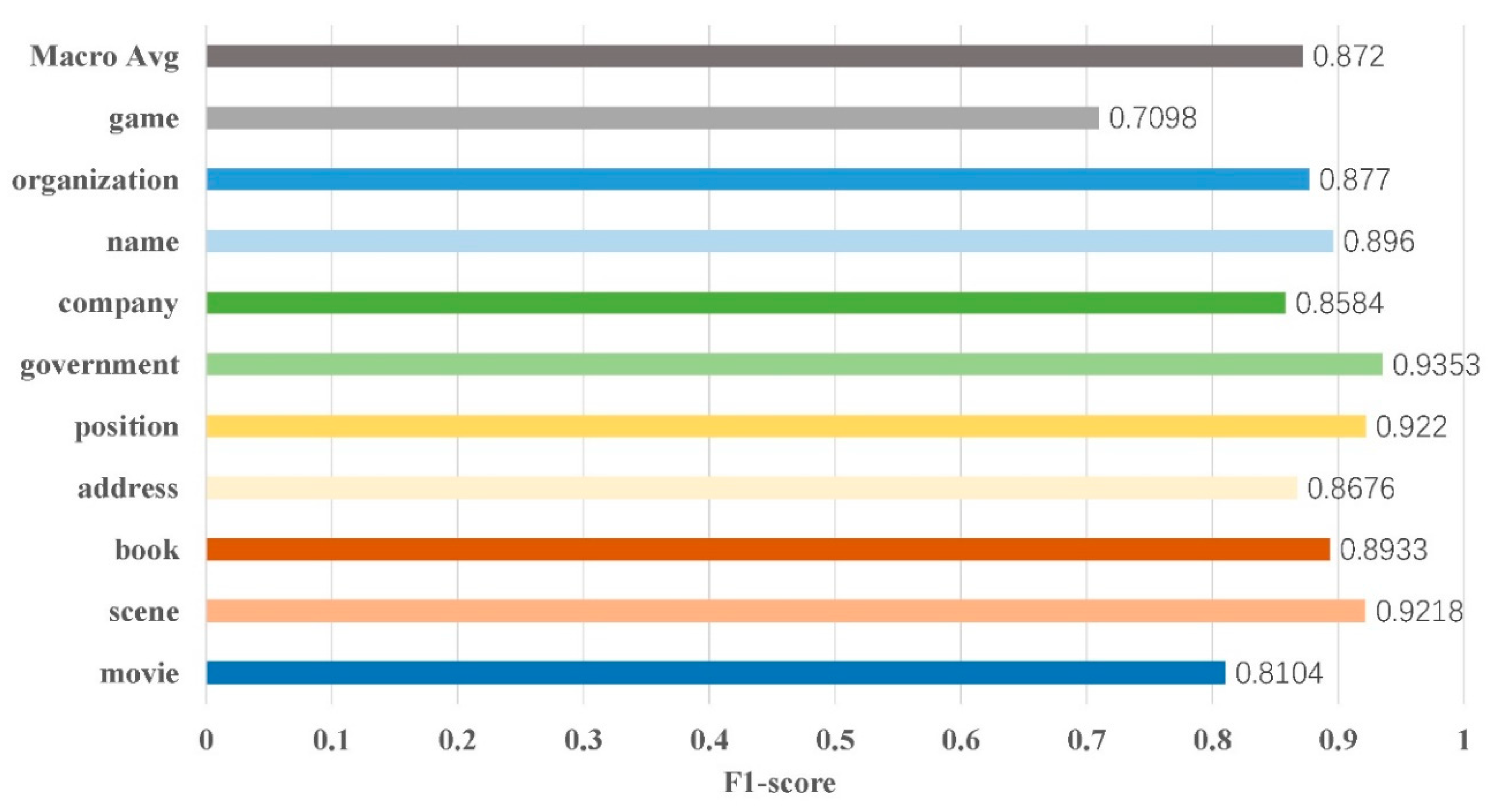
5.1. Overall Experimental Results and Discussion
5.2. Detailed Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sang, E.F.; De Meulder, F. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. arXiv 2003, arXiv:0306050. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Ritter, A.; Clark, S.; Etzioni, O. Named entity recognition in tweets: An experimental study. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; Volume 7, pp. 1524–1534. [Google Scholar]
- Peng, N.; Dredze, M. Named entity recognition for chinese social media with jointly trained embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Volume 9, pp. 548–554. [Google Scholar]
- Settles, B. Biomedical named entity recognition using conditional random fields and rich feature sets. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications (NLPBA/BioNLP), Geneva, Switzerland, 28–29 August 2004; pp. 107–110. [Google Scholar]
- Habibi, M.; Weber, L.; Neves, M.; Wiegandt, D.L.; Leser, U. Deep learning with word embeddings improves biomedical named entity recognition. Bioinformatics 2017, 33, i37–i48. [Google Scholar] [CrossRef]
- Lee, C.; Hwang, Y.G.; Oh, H.J.; Lim, S.; Heo, J.; Lee, C.H.; Kim, H.G.; Wang, J.H.; Jang, M.G. Fine-grained named entity recognition using conditional random fields for question answering. In Proceedings of the Asia Information Retrieval Symposium, Singapore, 16–18 October 2006; Springer: Berlin/Heidelberg, Germany, 2006; Volume 10, pp. 581–587. [Google Scholar]
- Xu, L.; Dong, Q.; Yu, C.; Tian, Y.; Liu, W.; Li, L.; Zhang, X. CLUENER2020: Fine-grained Name Entity Recognition for Chinese. arXiv 2020, arXiv:2001.04351. [Google Scholar]
- Gao, J.; Li, M.; Huang, C.N.; Wu, A. Chinese word segmentation and named entity recognition: A pragmatic approach. Comput. Linguist. 2005, 31, 531–574. [Google Scholar] [CrossRef]
- Zhenggao, P. Research on the recognition of Chinese named entity based on rules and statistics. Inf. Sci. 2012, 30, 708–712. [Google Scholar]
- Zhou, G.; Su, J. Named entity recognition using an HMM-based chunk tagger. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; Volume 7, pp. 473–480. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Sun, Y.; Li, L.; Xie, Z.; Xie, Q.; Li, X.; Xu, G. Co-training an improved recurrent neural network with probability statistic models for named entity recognition. In Proceedings of the International Conference on Database Systems for Advanced Applications, Suzhou, China, 27–30 March 2017; Volume 3, pp. 545–555. [Google Scholar]
- Chiu, J.P.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Strubell, E.; Verga, P.; Belanger, D.; McCallum, A. Fast and accurate entity recognition with iterated dilated convolutions. arXiv 2017, arXiv:1702.02098. [Google Scholar]
- Hammerton, J. Named entity recognition with long short-term memory. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL, Edmonton, AB, Canada, 31 May–1 June 2003; Volume 4, pp. 172–175. [Google Scholar]
- Zhu, Q.; Li, X.; Conesa, A.; Pereira, C. GRAM-CNN: A deep learning approach with local context for named entity recognition in biomedical text. Bioinformatics 2018, 34, 1547–1554. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Liu, Y.; Sun, C.; Lin, L.; Wang, X. Learning natural language inference using bidirectional LSTM model and inner-attention. arXiv 2016, arXiv:1605.09090. [Google Scholar]
- Na, S.H.; Kim, H.; Min, J.; Kim, K. Improving LSTM CRFs using character-based compositions for Korean named entity recognition. Comput. Speech Lang. 2019, 54, 106–121. [Google Scholar] [CrossRef]
- Dong, C.; Zhang, J.; Zong, C.; Hattori, M.; Di, H. Character-based LSTM-CRF with radical-level features for Chinese named entity recognition. In Natural Language Understanding and Intelligent Applications; Springer: Cham, Switzerland, 2016; pp. 239–250. [Google Scholar]
- McCallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL, Edmonton, AB, Canada, 31 May–1 June 2003; Volume 4, pp. 188–191. [Google Scholar]
- Finkel, J.R.; Kleeman, A.; Manning, C.D. Efficient, feature-based, conditional random field parsing. In Proceedings of the ACL-08: HLT, Columbus, OH, USA, 15–20 June 2008; Volume 6, pp. 959–967. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Gold, S.; Rangarajan, A. Softmax to softassign: Neural network algorithms for combinatorial optimization. J. Artif. Neural Netw. 1996, 2, 381–399. [Google Scholar]
- Liu, L.; Ren, X.; Shang, J.; Peng, J.; Han, J. Efficient contextualized representation: Language model pruning for sequence labeling. arXiv 2018, arXiv:1804.07827. [Google Scholar]
- Jia, C.; Liang, X.; Zhang, Y. Cross-Domain NER using Cross-Domain Language Modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Volume 7, pp. 2464–2474. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, L. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Kitaev, N.; Klein, D. Constituency parsing with a self-attentive encoder. arXiv 2018, arXiv:1805.01052. [Google Scholar]
- Cui, L.; Zhang, Y. Hierarchically-Refined Label Attention Network for Sequence Labeling. arXiv 2019, arXiv:1908.08676. [Google Scholar]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5754–5764. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- albert_zh (albert_tiny_zh). Available online: https://github.com/brightmart/albert_zh (accessed on 30 April 2020).
- Kashgari (v1.1.5). Available online: https://kashgari.readthedocs.io/en/v1.1.5/index.html (accessed on 30 April 2020).
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Performance Report. Available online: https://kashgari.readthedocs.io/en/v1.1.5/tutorial/text-labeling.html#performance-report (accessed on 30 April 2020).
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Categories | Train | Test | Size |
|---|---|---|---|---|
| CLUENER2020 | 10 | 10,748 | 1343 | 13 kB |
| People’s Daily Ner Corpus | 3 | 20,864 | 4636 | 23 kB |
| Dataset | Test | Entity | Support |
|---|---|---|---|
| CLUENER2020 | 1343 | movie book government company position scene organization name address game | 150 152 244 366 425 199 344 451 364 287 |
| People’s Daily Ner Corpus | 4636 | PER LOC ORG | 1864 3658 2185 |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| ALBERT + BiLSTM + CRF | 0.8876 | 0.8270 | 0.8555 |
| ALBERT + CRF | 0.8094 | 0.6120 | 0.6936 |
| ALBERT + BiLSTM | 0.7736 | 0.8132 | 0.7925 |
| Our En2BiLSTM-CRF | 0.9156 | 0.8337 | 0.8720 |
| BiLSTM-CRF-NER | 0.7106 | 0.6897 | 0.7000 |
| BERT-NER | 0.7724 | 0.8046 | 0.7882 |
| RoBERTa-NER | 0.7926 | 0.8169 | 0.8042 |
| Human Performance | 0.6574 | 0.6217 | 0.6341 |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| ALBERT + BiLSTM + CRF | 0.9674 | 0.9229 | 0.9446 |
| ALBERT + CRF | 0.8315 | 0.6974 | 0.7580 |
| ALBERT + BiLSTM | 0.9455 | 0.9096 | 0.9270 |
| Our En2BiLSTM-CRF | 0.9784 | 0.9306 | 0.9538 |
| BiLSTM_Model (Random Init) | N/A | N/A | 0.74147 |
| BiLSTM_CRF_Model (Random Init) | N/A | N/A | 0.81378 |
| BiGRU_Model (Random Init) | N/A | N/A | 0.74375 |
| BiGRU_CRF_Model (Random Init) | N/A | N/A | 0.82516 |
| BiLSTM_Model (BERT) | N/A | N/A | 0.92727 |
| BiLSTM_CRF_Model (BERT) | N/A | N/A | 0.94013 |
| BiGRU_Model (BERT) | N/A | N/A | 0.92700 |
| BiGRU_CRF_Model (BERT) | N/A | N/A | 0.94319 |
| BiLSTM_Model (ERNIE) | N/A | N/A | 0.93109 |
| BiLSTM_CRF_Model (ERNIE) | N/A | N/A | 0.94460 |
| BiGRU_Model (ERNIE) | N/A | N/A | 0.93512 |
| BiGRU_CRF_Model (ERNIE) | N/A | N/A | 0.94218 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Xia, C.; Yan, H.; Xu, W. Innovative Deep Neural Network Modeling for Fine-Grained Chinese Entity Recognition. Electronics 2020, 9, 1001. https://doi.org/10.3390/electronics9061001
Liu J, Xia C, Yan H, Xu W. Innovative Deep Neural Network Modeling for Fine-Grained Chinese Entity Recognition. Electronics. 2020; 9(6):1001. https://doi.org/10.3390/electronics9061001
Chicago/Turabian StyleLiu, Jingang, Chunhe Xia, Haihua Yan, and Wenjing Xu. 2020. "Innovative Deep Neural Network Modeling for Fine-Grained Chinese Entity Recognition" Electronics 9, no. 6: 1001. https://doi.org/10.3390/electronics9061001
APA StyleLiu, J., Xia, C., Yan, H., & Xu, W. (2020). Innovative Deep Neural Network Modeling for Fine-Grained Chinese Entity Recognition. Electronics, 9(6), 1001. https://doi.org/10.3390/electronics9061001