A Detection Approach Using LSTM-CNN for Object Removal Caused by Exemplar-Based Image Inpainting


Abstract
1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Main Contribution
- We present a CNN based nearest neighbor image patch matching algorithm to quickly search for abnormal similar patches in images;
- We design a false alarm removal module based on the CNN and LSTM network. In this module, CNN and LSTM are combined to identify the normal texture consistent area in the image, and then remove the false alarm patches from the suspicious patches;
- We present a post-processing feature filtering algorithm. In the detection of tampered images, the CNN network is more focused on learning the trace features introduced by image tampering;
- The LSTM-CNN network, based on the encoder-decoder architecture for image inpainting forensics, is proposed in this paper.
2. Background
3. The Solutions to Key Problems
- (1)
- Due to the need of similarity measurement between any two patches in the whole image, the search for similar patches is very time-consuming, especially for large images.
- (2)
- The detection of image inpainting only depends on finding the abnormal similarity of patches. In a normal image, there are some very similar patches (such as blue sky, grassland and other uniform regions), although there are still differences in the details. However, it is very easy to be confused in the actual feature classification, and it is difficult to correctly identify the classification of pixels in such kinds of patches.
- (3)
- There is no robust and effective forensics method for image inpainting with multiple post-processing combined operations.
3.1. The Search of Abnormal Similar Patches
- (1)
- The nearest neighborhood patch is defined as the function f: A→R2, where A represents the reference patch, and R is the offset between the possible nearest neighborhood patches (with the center of patch as the reference).
- (2)
- For the selected reference patch, check the nearest neighborhood patch and its corresponding relationship. If the nearest neighbor patch produces the best similarity value, the corresponding benchmark of the reference patch is updated through the activation function [20]. Assuming that a reference patch centered at the pixel p(x, y) is selected, propagation starts from the neighborhood patch to search for the current match; for example, q = (x + R, y + R) ↔ s = (i, j, k), where (i, j) is the center of the kth neighborhood patch. Then, check whether the Euclidean distance between q and s = (i − j, j − 1, k) is less than the current Euclidean distance stored by p. If less than, update the corresponding benchmark and reference patch, and repeat the above steps iteratively.
- (3)
- In order to further speed up the matching of similar patches, the activation tensor of hidden layer in the network is used as the image descriptor to extract the patch representation. The image descriptor of the reference patch is compared with the image descriptor of each nearest neighbor patch, and then the first k pairs of the most similar patch pairs are selected. In this way, the calculation cost can be reduced and the matching efficiency can be improved.
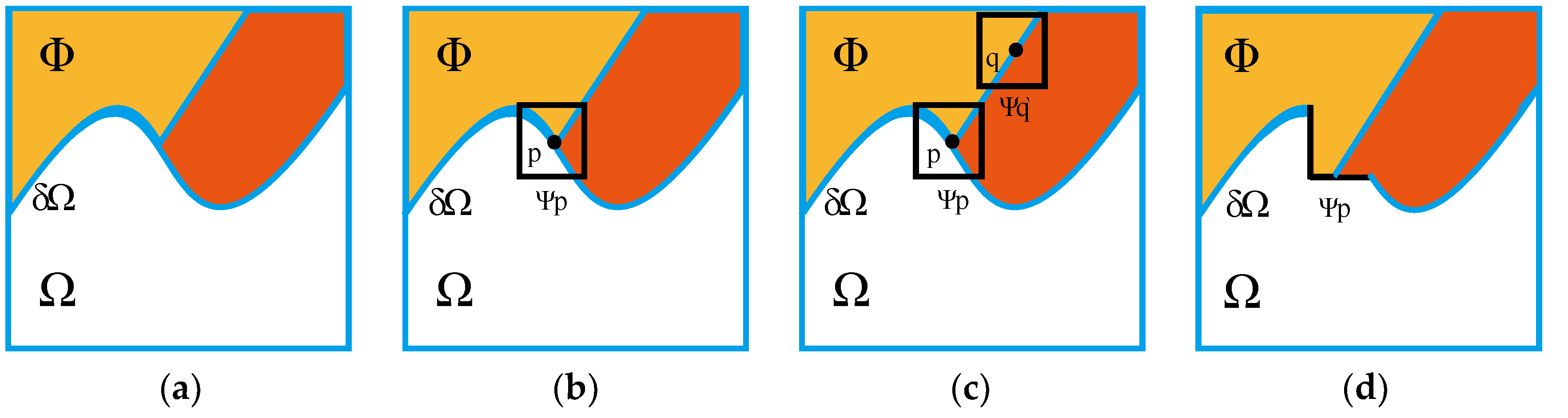
3.2. Reduction of False Alarm Rate
3.3. Filtering of Post-Processing Features
3.3.1. The Filter of JPEG Compression
| Algorithm 1. JPEG compression feature filtering algorithm |
| 1: Input: test image I |
| 2: Output: feature map |
| 3: Initial: the filter weight ωk (k = 1) is randomly selected, and the batch data size is N |
| 4: Begin: |
| 5: The test image I is decomposed into M blocks (i) with size of 32 × 32, where i = 1, 2, …, M; |
| 6: for each block(i) |
| 7: the back-propagation algorithm is used to train the network; |
| 8: ωk is updated with Adam algorithm and back propagation error; |
| 9: the center position (0, 0) of recommended window is determined with ωk; |
| 10: for k <= max_filter_number |
| 11: ωk (0, 0) = 0; |
| 12: ωk (x, y) is updated according to the learning rule as Equation (10); |
| 13: k = k + 1; |
| 14: end for |
| 15 i = i + 1; |
| 16 end for |
| 17: End. |
3.3.2. Gaussian Noise Feature Filtering
- The training set including image IG-noise and image Iclean is created;
- Assuming that the batch size is N, N images are extracted from the training set each time. The first k images are Gaussian noise images, i.e., {I1G-noise, I2G-noise, …, IKG-noise, IK+1clean, IK+2clean, …, INclean};
- Through the weighted sum of IG-noise image and Iclean image, the losses of batch N images are calculated, which are expressed as Equation (14):where α is the weight parameter, generally 0.2;
- Create a class label for the input image. LGn-true is the real label of IG-noise image, LC-true is the real label of Iclean image, LGn-pre is the prediction label of IG-noise image, LC-pre is the prediction label of Iclean image. In order to make the prediction label closer to the real label, the Adam optimization algorithm is used to update the weight of loss function.
- The gradient direction can be found by calculating the partial derivative of LGn-pre label image. Using the least likelihood class method (LLCM) [25], noise images are classified into the least likelihood class, and the losses of batch N images are minimized in the gradient direction.
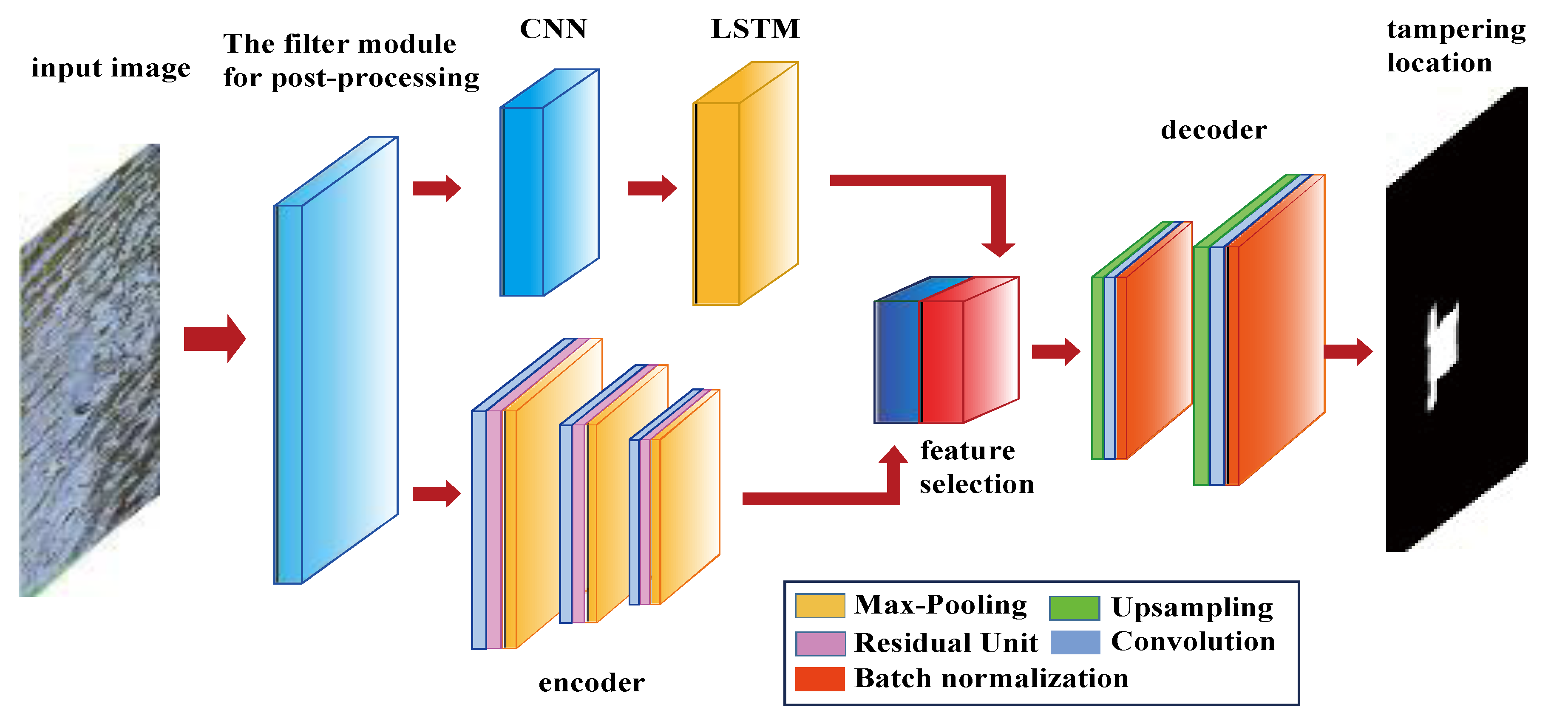
4. Network Architecture
4.1. Encoder Network
4.1.1. Convolution Layer
4.1.2. Residual Unit
4.1.3. Pooling Layer
4.2. Decoder Network
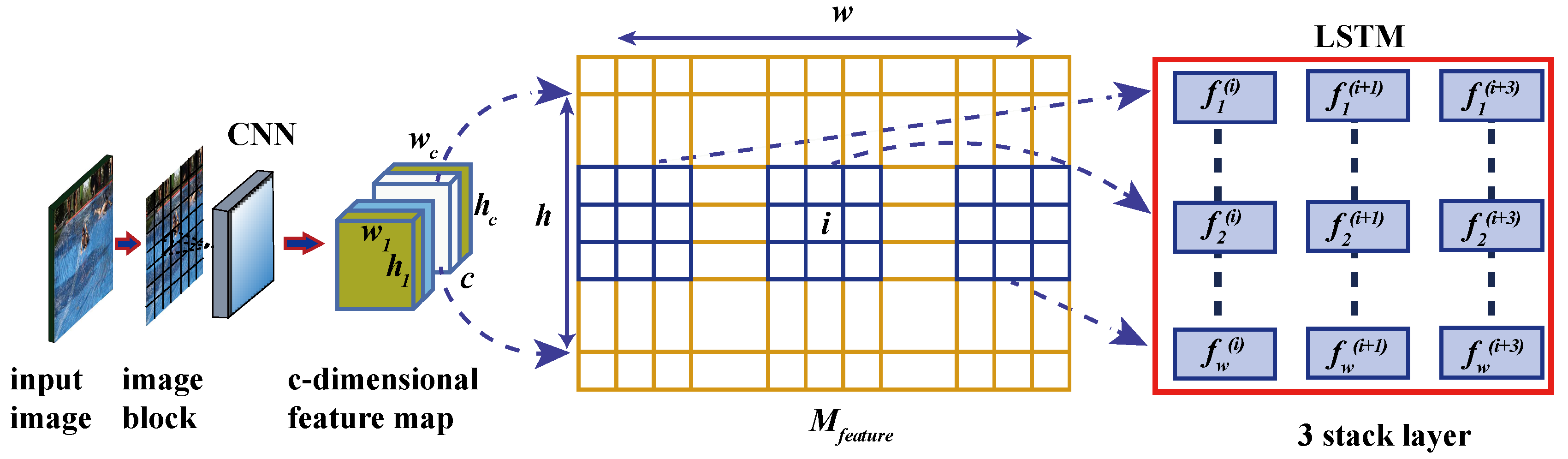
4.3. LSTM Network
- (1)
- Input gate is defined as Equation (17):It = σ (xt W xi + ht−1 W hi + v W vi + yt−1 W yi)
- (2)
- Output gate is defined as Equation (18):Ot = σ (xt W xo + ht−1 W ho + v W vo + yt−1 W yo)
- (3)
- Forget gate is defined as Equation (19):each gate has a value from 0 to 1, which is activated by σ function, and the candidate update unit state (Ct) ~, generated by each LSTM unit, is activated by tanh function, then (Ct) ~ can be expressed as Equation (20):Ft = σ (xt W xf + ht−1 W hf + v W vf + yt−1 W yf)(Ct) ~ = tanh (xt W xc + ht−1 W hc + v W vc + yt−1 W yc)
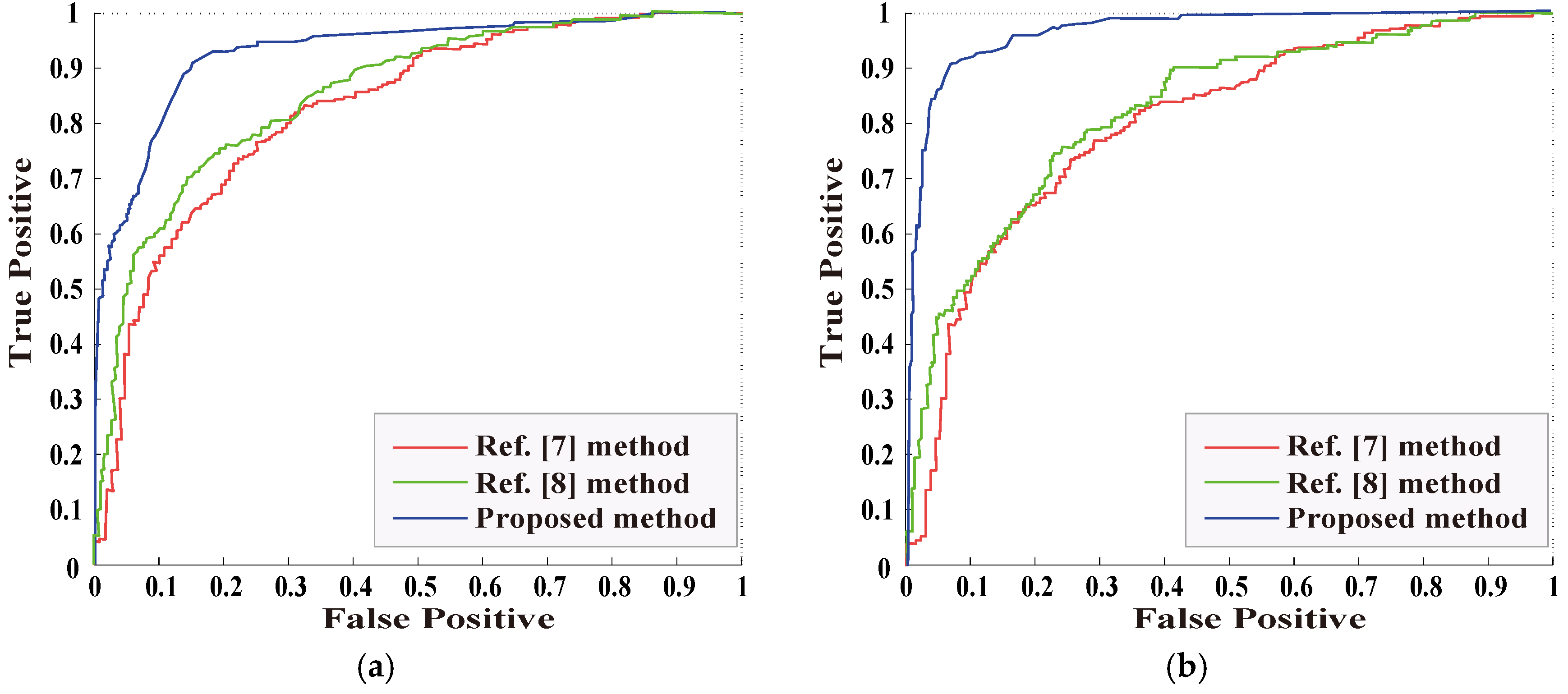
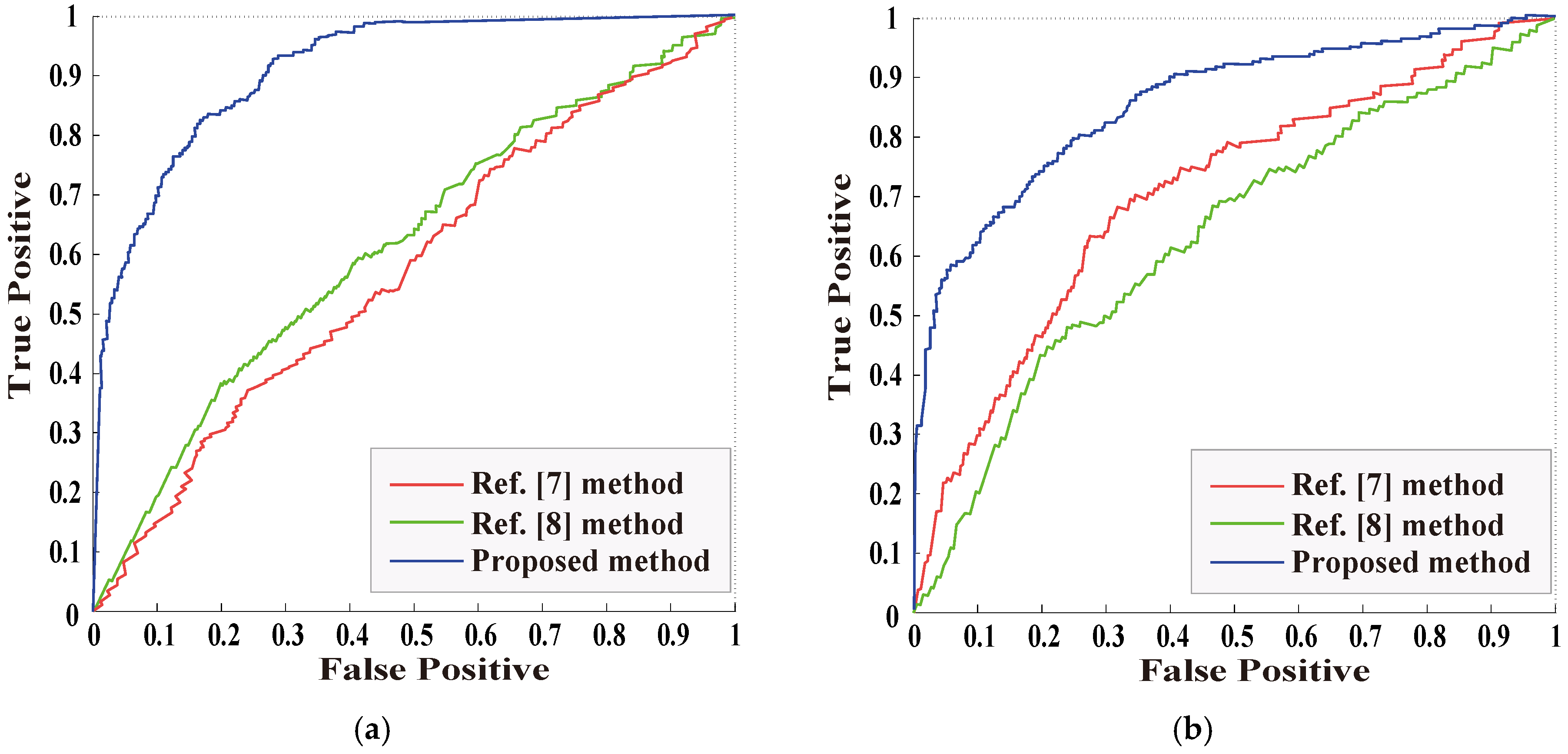
5. Experimental Results and Analysis
5.1. Experimental Setup
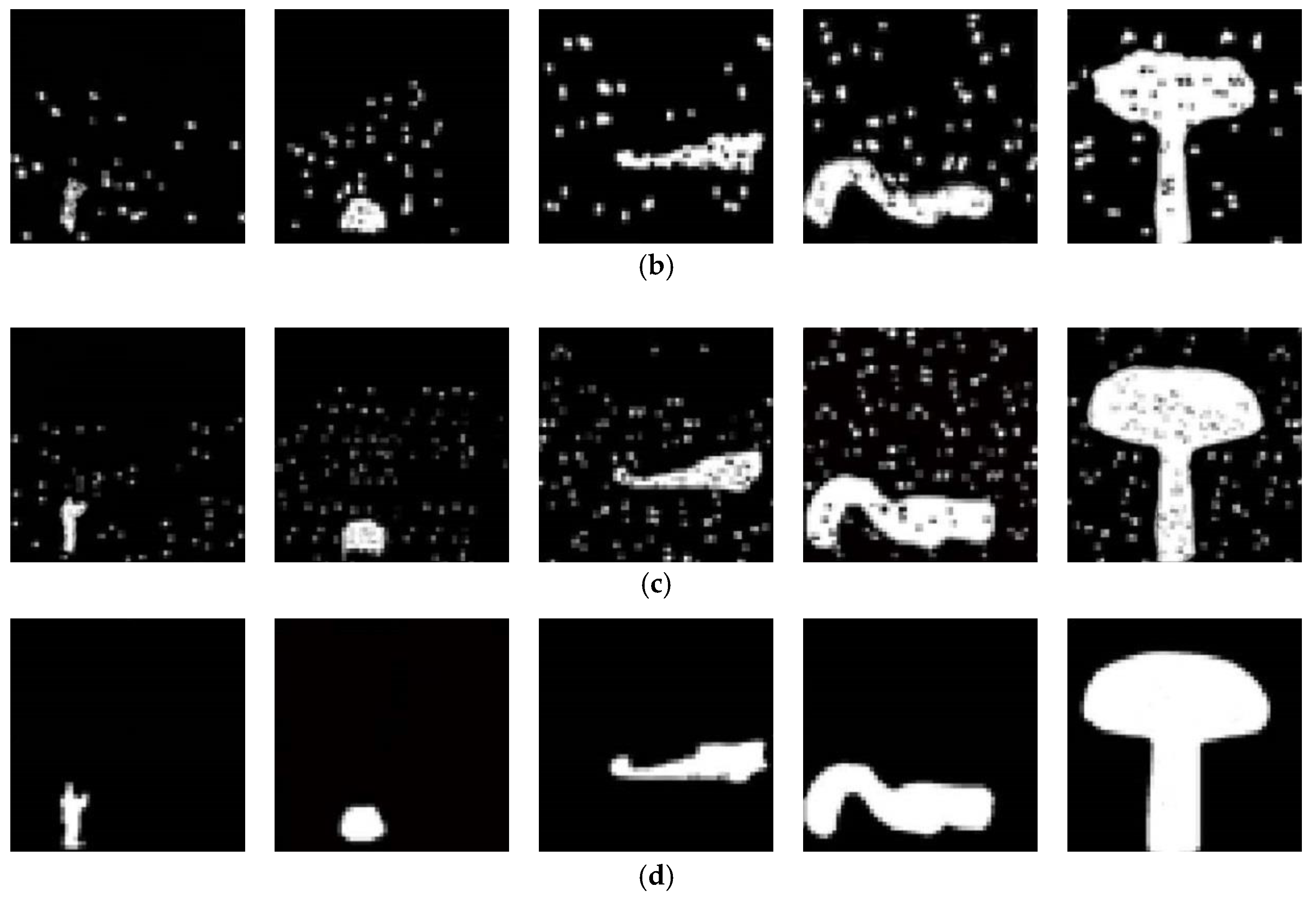
5.2. The Detection for Image Object Removal Without Post-Processing
5.3. The Detection for Image Object Removal with Single Post-Processing
5.3.1. The Detection for Object Removal with JPEG Compression
5.3.2. The Detection for Object Removal with Gaussian Noise
5.4. The Detection for Image Object Removal with Combined Post-Processing
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Criminisi, A.; Prez, P.; Toyama, K. Region filling and object removal by exemplar based image inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef]
- Awati, P. Digital image inpainting based on median diffusion and directional median filtering. Int. J. Comput. Appl. 2014, 3, 35–39. [Google Scholar]
- Guillemot, C.; Meur, O.L. Image inpainting: Overview and recent advances. IEEE Signal Process. Mag. 2014, 31, 127–144. [Google Scholar] [CrossRef]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Balleste, C. Image Inpainting. In Proceedings of the International Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 10–13 July 2000; pp. 417–424. [Google Scholar]
- Wu, Q.; Sun, S.; Zhu, W.; Li, G.H.; Tu, D. Detection of digital doctoring in exemplar-based inpainted Images. In Proceedings of the IEEE International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; IEEE: Los Alamitos, CA, USA, 2008; pp. 1222–1226. [Google Scholar]
- Bacchuwar, K.; Ramakrishnan, K. A jump patch-block match algorithm for multiple forgery detection. In Proceedings of the IEEE International Multi-Conference on Automation, Computing, Communication, Control and Compressed Sensing, Kottayam, India, 12–14 June 2013; pp. 723–728. [Google Scholar]
- Chang, I.; Yu, J.; Chang, C. A forgery detection algorithm for exemplar-based inpainting images using multi-region relation. Image Vis. Comput. 2013, 31, 57–71. [Google Scholar] [CrossRef]
- Liang, Z.; Yang, G.; Ding, X.; Li, L. An efficient forgery detection algorithm for object removal by exemplar-based image inpainting. J. Vis. Commun. Image Represent. 2015, 30, 75–85. [Google Scholar] [CrossRef]
- Zhao, Y.; Liao, M.; Shih, F.; Shi, Y. Tampered region detection of inpainting JPEG images. Opt. Int. J. Light Electron Opt. 2013, 124, 2487–2492. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, B.; Sung, A.; Qiao, M. Exposing in painting forgery in JPEG images under recompression attacks. In Proceedings of the IEEE International Conference on Machine Learning and Applications, Anaheim, CA, USA, 18–20 December 2016; pp. 164–169. [Google Scholar]
- Zhang, D.; Liang, Z.; Yang, G.; Li, Q.; Li, L.; Sun, X. A robust forgery detection algorithm for object removal by exemplar-based image inpainting. Multimed. Tools Appl. 2018, 77, 11823–11842. [Google Scholar] [CrossRef]
- Jung, M.; Bresson, X.; Chan, T. Nonlocal Mumford–Shah regularizers for color image restoration. IEEE Trans. Image Process. 2011, 20, 1583–1598. [Google Scholar] [CrossRef] [PubMed]
- Shen, J.; Chan, T.F. Mathematic models for local non-Texture inpainting. Siam J. Appl. Math. 2001, 62, 1019–1043. [Google Scholar] [CrossRef]
- Xu, L.; W, Y.; Zhang, B. Image inpainting algorithm based on adaptive high order variation in eight neighbors. J. Graph. 2017, 38, 129–138. [Google Scholar]
- Chan, T.F.; Shen, J. Nontexture inpainting by curvature-driven diffusions. J. Vis. Commun. Image Represent. 2001, 12, 436–449. [Google Scholar] [CrossRef]
- Liu, Y.; Caselles, V. Exemplar-based image inpainting using multiscale graph cuts. IEEE Trans. Image Process. 2013, 22, 1699–1711. [Google Scholar] [PubMed]
- Jing, W.; Ke, L.; Pan, D.; He, B.; Bing, K.B. Robust object removal with an exemplar-based image inpainting approach. Neurocomputing 2014, 123, 150–155. [Google Scholar]
- Barnes, C.; Hechtman, E.; Goldman, D.; Finkelstein, A. The generalized patch match correspondence algorithm. Eur. Conf. Comput. Vis. 2010, 6313, 29–43. [Google Scholar]
- Sun, T.; Sun, L.; Yeung, D. Fine-grained categorization via CNN-based automatic extraction and integration of object-level and part-level features. Image Vis. Comput. 2017, 64, 47–66. [Google Scholar] [CrossRef][Green Version]
- Kamaledin, G. Generalizing the convolution operator in convolutional neural networks. Neural Process. Lett. 2019, 2, 1–15. [Google Scholar]
- Hsieh, T.; Su, L.; Yang, Y.H. A Streamlined Encoder/decoder Architecture for Melody Extraction. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Saman, S. French Word Recognition through a Quick Survey on Recurrent Neural Networks Using Long-Short Term Memory RNN-LSTM. Am. Sci. Res. J. Eng. Technol. Sci. 2018, 39, 250–267. [Google Scholar]
- Pinheiro, P.; Collobert, R. Recurrent convolutional neural networks for scene labeling. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Bondi, L.; Lameri, S.; Guera, D.; Bestagini, P.; Delp, E.J.; Tubar, S. Tampering detection and localization through clustering of camera-based cnn features. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1855–1864. [Google Scholar]
- Ishikawa, S.; Zhukova, A.; Iwasaki, W.; Gascuel, O. A Fast Likelihood Method to Reconstruct and Visualize Ancestral Scenarios. Mol. Biol. Evol. 2019, 9, 2069–2085. [Google Scholar] [CrossRef]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. Comput. Sci. 2015, 15, 1511–1613. [Google Scholar]
- Shi, Z.; Shen, X.; Kang, H.; Lv, Y. Image Manipulation Detection and Localization Based on the Dual-Domain Convolutional Neural Networks. IEEE Access 2018, 6, 76437–76453. [Google Scholar] [CrossRef]
- Chen, Y.; Kang, X.; Shi, Y.Q.; Wang, Z.J. A multi-purpose image forensic method using densely connected convolutional neural networks. J. Real Time Image Process. 2019, 16, 725–740. [Google Scholar] [CrossRef]
- Bondi, L.; Baroffio, L.; Güuera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. First Steps Toward Camera Model Identification with Convolutional Neural Networks. IEEE Signal Process. Lett. 2016, 24, 259–263. [Google Scholar] [CrossRef]
- Shan, C.; Guo, X.; Ou, J. Deep leaky single-peaked triangle neural networks. Int. J. Control Autom. Syst. 2019, 17, 5786. [Google Scholar] [CrossRef]
- Dong, N.; Li, W.; Adeli, E.; Lao, C.; Lin, W.; Shen, D. 3-d fully convolutional networks for multimodal isointense infant brain image segmentation. IEEE Trans. Cybern. 2019, 49, 1123–1136. [Google Scholar]
- Wang, Y.; Li, M.; Pan, Z.; Zheng, J. Pulsar candidate classification with deep convolutional neural networks. Res. Astron. Astrophys. 2019, 19, 133. [Google Scholar] [CrossRef]
- Hu, J.; Chen, Z.; Yang, M.; Zhang, R.; Cui, W. A multi-scale fusion convolutional neural network for plant leaf recognition. IEEE Signal Process. Lett. 2018, 25, 853–857. [Google Scholar] [CrossRef]
- Nguyen, V.-H.; Nguyen, M.-T.; Choi, J.; Kim, Y.-H. NLOS Identification in WLANs Using Deep LSTM with CNN Features. Sensors 2018, 18, 4057. [Google Scholar] [CrossRef]
- Chollet, F.; Keras, F. Deep Learning Library for Theano and Tensorflow. Available online: https://github.com/fchollet/keras (accessed on 6 November 2019).
- Yang, G.; Yang, J.; Li, S.; Hu, J. Modified cnn algorithm based on dropout and adam optimizer. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2018, 46, 122–127. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. Adv. Neural Inf. Process. Syst. 2014, 27, 487–495. [Google Scholar]
- Schaefer, G.; Stich, M. UCID-an uncompressed color image database. Storage Retr. Methods Appl. Multimed. 2004, 5307, 472–480. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tampering Ratio (%) | Ref. [7] Method (%) | Ref. [8] Method (%) | Proposed Method (%) |
|---|---|---|---|
| 2 | 80.65 | 82.87 | 84.28 |
| 5 | 84.36 | 86.98 | 88.46 |
| 10 | 87.62 | 88.91 | 93.64 |
| 20 | 91.28 | 92.66 | 95.45 |
| 30 | 95.31 | 96.56 | 96.78 |
| MIX | 90.35 | 91.58 | 93.87 |
| Tampering Ratio (%) | Ref. [7] Method (%) | Ref. [8] Method (%) | Proposed Method (%) |
|---|---|---|---|
| 0–5 | 78.57 | 79.26 | 87.86 |
| 5–10 | 81.65 | 82.98 | 90.36 |
| 10–20 | 84.28 | 86.11 | 94.64 |
| 20–30 | 88.28 | 89.66 | 96.95 |
| 30–40 | 92.31 | 93.56 | 97.89 |
| MIX | 85.59 | 86.88 | 94.87 |
| Quality Factor (%) | Ref. [7] Method (%) | Ref. [8] Method (%) | Proposed Method (%) |
|---|---|---|---|
| 65 | 45.75 | 45.89 | 86.63 |
| 70 | 52.95 | 53.28 | 88.86 |
| 80 | 66.48 | 66.96 | 91.64 |
| 90 | 82.58 | 83.66 | 93.95 |
| 95 | 92.03 | 93.56 | 96.89 |
| MIX | 71.92 | 72.38 | 91.75 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, M.; Niu, S. A Detection Approach Using LSTM-CNN for Object Removal Caused by Exemplar-Based Image Inpainting. Electronics 2020, 9, 858. https://doi.org/10.3390/electronics9050858
Lu M, Niu S. A Detection Approach Using LSTM-CNN for Object Removal Caused by Exemplar-Based Image Inpainting. Electronics. 2020; 9(5):858. https://doi.org/10.3390/electronics9050858
Chicago/Turabian StyleLu, Ming, and Shaozhang Niu. 2020. "A Detection Approach Using LSTM-CNN for Object Removal Caused by Exemplar-Based Image Inpainting" Electronics 9, no. 5: 858. https://doi.org/10.3390/electronics9050858
APA StyleLu, M., & Niu, S. (2020). A Detection Approach Using LSTM-CNN for Object Removal Caused by Exemplar-Based Image Inpainting. Electronics, 9(5), 858. https://doi.org/10.3390/electronics9050858