A Robust Structured Tracker Using Local Deep Features


Abstract
:1. Introduction
- Proposing a deep features-based structured local sparse tracker, which employs CNN deep features of the local patches within a target candidate and keeps the relative spatial structure among the local deep features of a target candidate.
- Developing a convex optimization model, which combines nine local features of each target candidate with a group-sparsity regularization term to encourage the tracker to sparsely select appropriate local patches of the same subset of templates.
- Designing a fast and parallel numerical algorithm by deriving the augmented Lagrangian of the optimization model into two close-form problems: the quadratic problem and the Euclidean norm projection onto probability simplex constraints problem by adopting the alternating direction method of multiplier (ADMM).
- Utilizing the accelerated proximal gradient (APG) method to update the CNN deep feature-based template by casting it as a Lasso problem.
2. Notations
3. Proposed Method
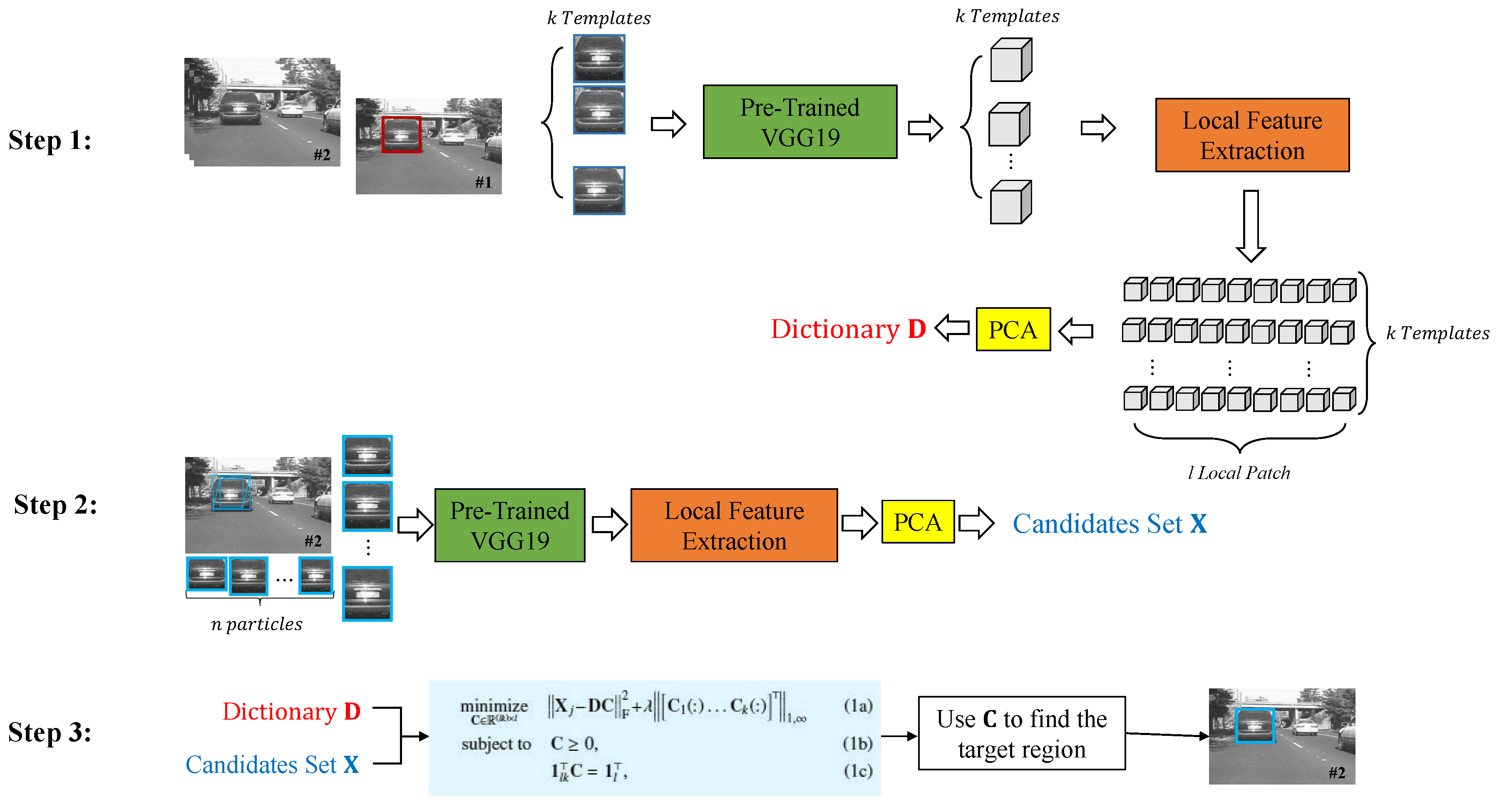
3.1. Structured Tracker Using Local Deep Features (STLDF)
3.2. Numerical Algorithm
3.3. Local Deep Feature Extraction
3.4. Template Update
3.5. STLDF Summary
4. Experimental Results
4.1. Evaluation Metrics
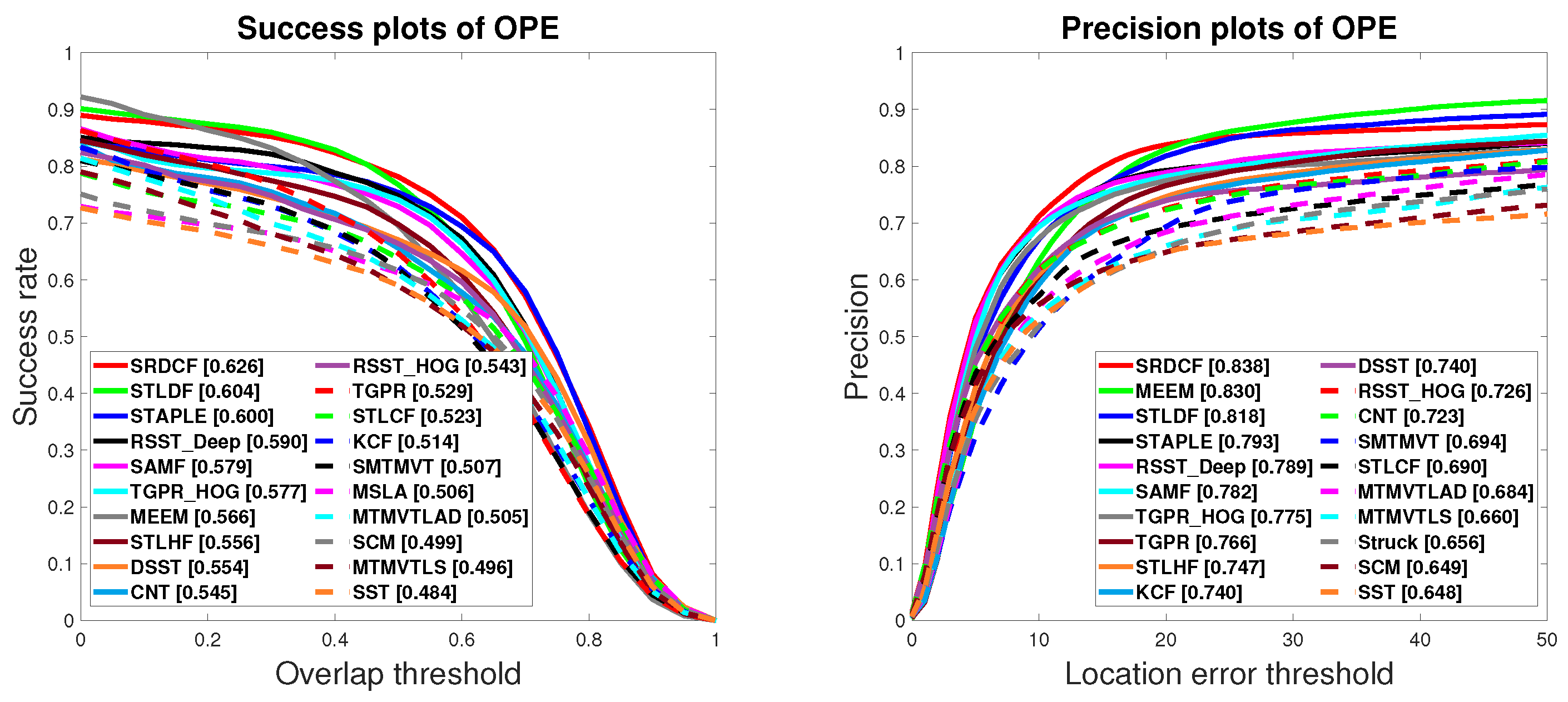
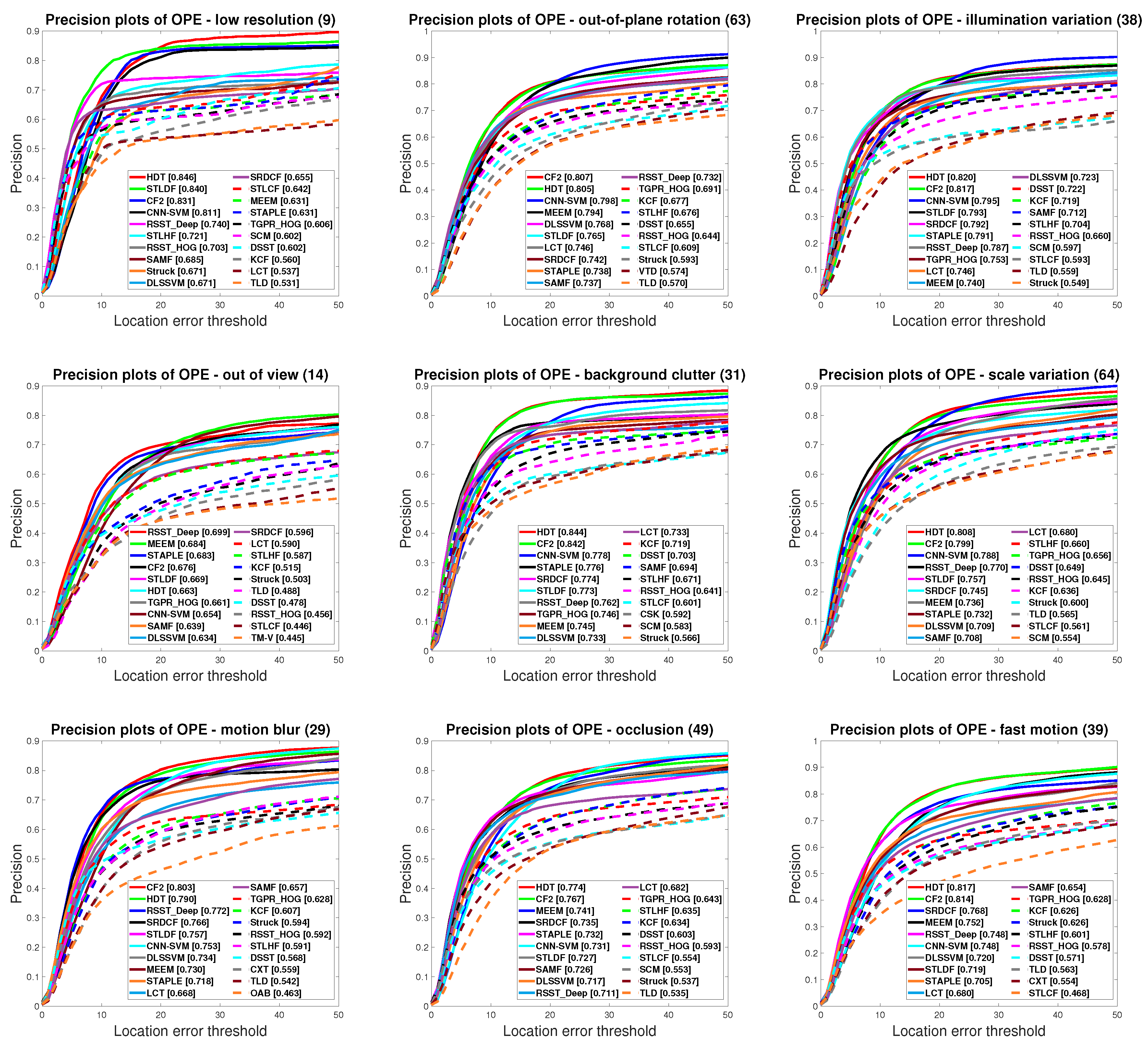
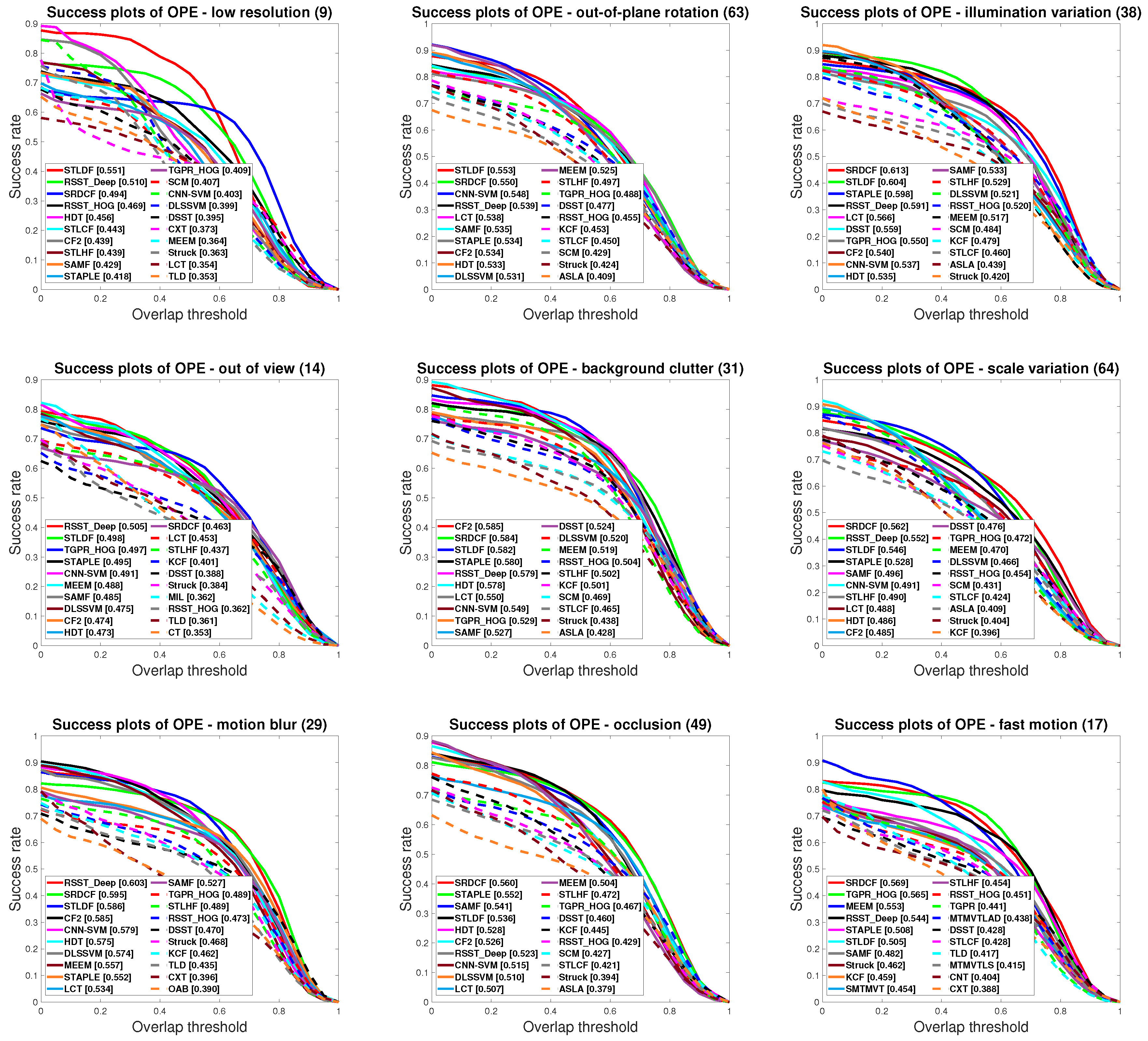
4.2. Experimental Results on OTB50
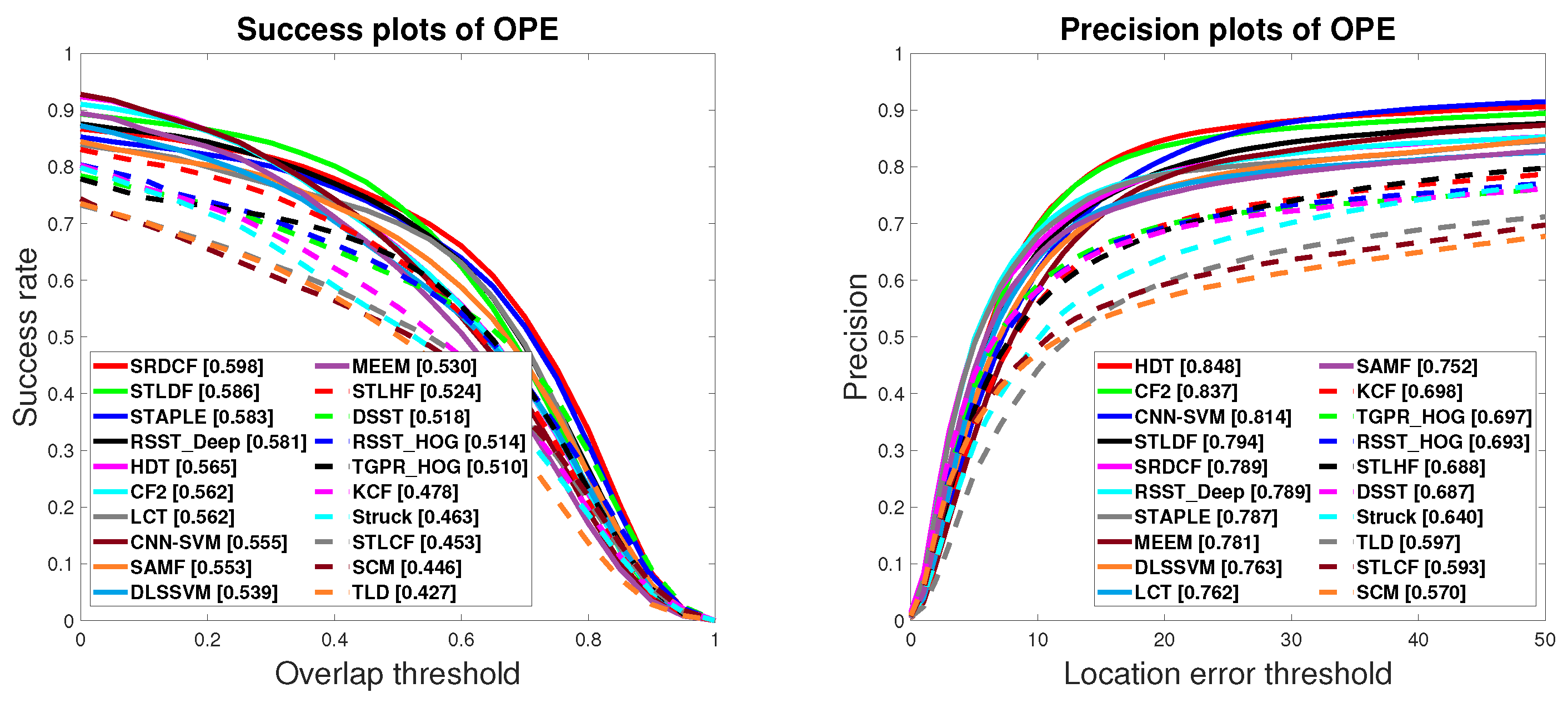
4.3. Experimental Results on OTB100
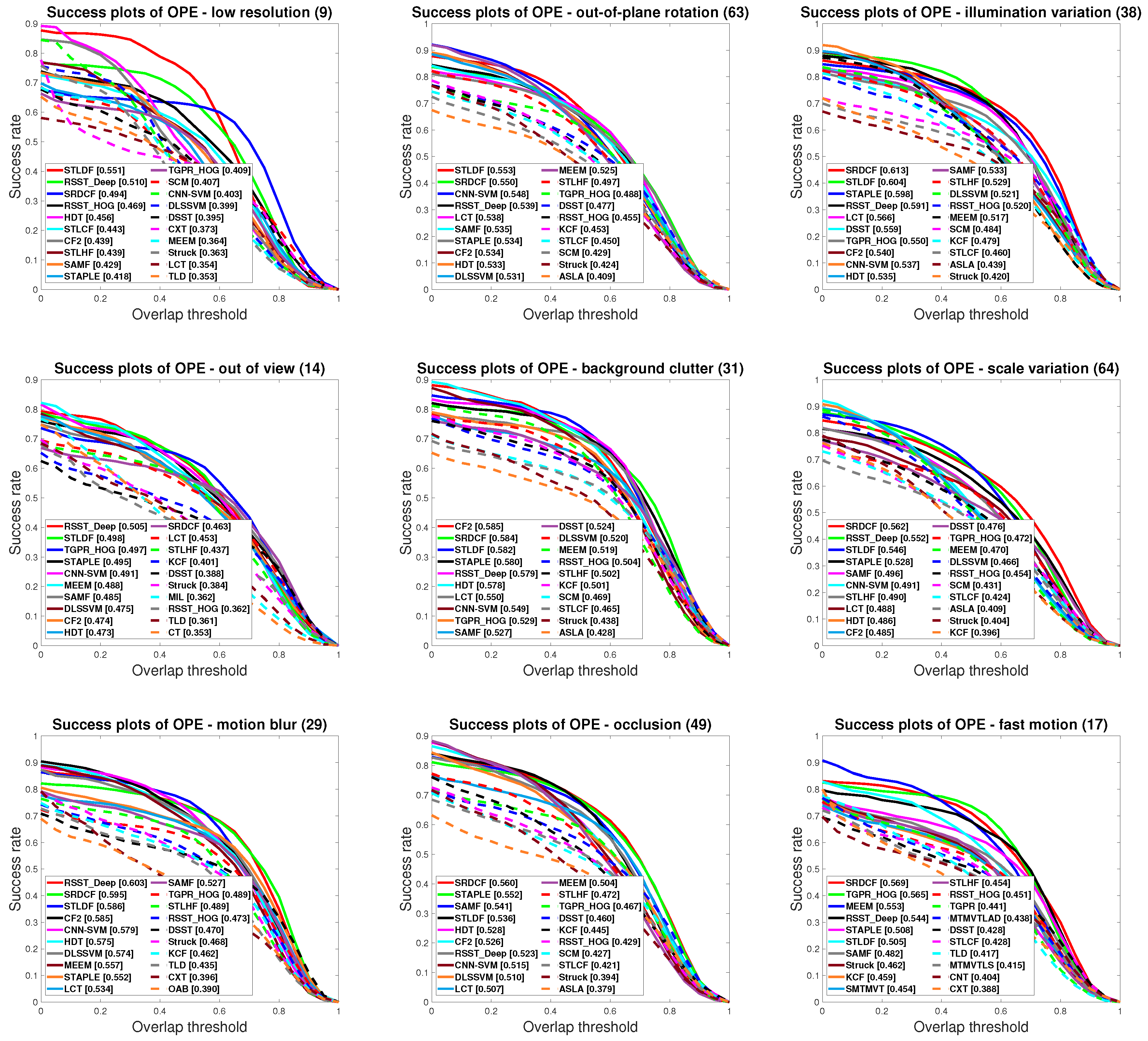
4.4. Qualitative Results
- basketball: IV, OCC, DEF, OPR, BC;
- doll: IV, SV, OCC, IPR, OPR;
- football: OCC, IPR, OPR, BC;
- faceOcc2: IV, OCC, IPR, OPR;
- board: SV, MB, FM, OPR, OV, BC;
- car2: IV, SV, MB, FM, BC.
4.5. Discussions
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. Acm Comput. Surv. (CSUR) 2006, 38, 13. [Google Scholar] [CrossRef]
- Salti, S.; Cavallaro, A.; Di Stefano, L. Adaptive appearance modeling for video tracking: Survey and evaluation. IEEE Trans. Image Process. 2012, 21, 4334–4348. [Google Scholar] [CrossRef] [PubMed]
- Pang, Y.; Ling, H. Finding the best from the second bests-inhibiting subjective bias in evaluation of visual tracking algorithms. In Proceedings of the IEEE International Conference on Computer Vision, Portland, OR, USA, 23–28 June 2013; pp. 2784–2791. [Google Scholar]
- Kristan, M.; Matas, J.; Leonardis, A.; Felsberg, M.; Cehovin, L.; Fernandez, G.; Vojir, T.; Hager, G.; Nebehay, G.; Pflugfelder, R. The visual object tracking vot2015 challenge results. In Proceedings of the 2015 IEEE International Conference on Computer Vision workshops (ICCV), Araucano, Park Las Condes, Chile, 11–18 December 2015; pp. 1–23. [Google Scholar]
- Zhang, T.; Liu, S.; Xu, C.; Yan, S.; Ghanem, B.; Ahuja, N.; Yang, M.H. Structural sparse tracking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 150–158. [Google Scholar]
- Zhang, T.; Bibi, A.; Ghanem, B. In defense of sparse tracking: Circulant sparse tracker. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3880–3888. [Google Scholar]
- Avidan, S. Ensemble tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 261–271. [Google Scholar] [CrossRef] [PubMed]
- Grabner, H.; Leistner, C.; Bischof, H. Semi-supervised on-line boosting for robust tracking. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2008; pp. 234–247. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual tracking with online multiple instance learning. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 983–990. [Google Scholar]
- Black, M.J.; Jepson, A.D. Eigentracking: Robust matching and tracking of articulated objects using a view-based representation. Int. J. Comput. Vis. 1998, 26, 63–84. [Google Scholar] [CrossRef]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental learning for robust visual tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Mei, X.; Ling, H. Robust visual tracking and vehicle classification via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2259–2272. [Google Scholar] [PubMed] [Green Version]
- Mei, X.; Hong, Z.; Prokhorov, D.; Tao, D. Robust multitask multiview tracking in videos. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2874–2890. [Google Scholar] [CrossRef] [PubMed]
- Jia, X.; Lu, H.; Yang, M.H. Visual tracking via coarse and fine structural local sparse appearance models. IEEE Trans. Image Process. 2016, 25, 4555–4564. [Google Scholar] [CrossRef] [PubMed]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 971–987. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Wang, N.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. In Advances in Neural Information Processing Systems, Proceedings of the 27th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–8 December 2013; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2013; pp. 809–817. [Google Scholar]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual tracking with fully convolutional networks. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3119–3127. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, Q.; Lim, J.; Yang, M.H. Hedged deep tracking. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4303–4311. [Google Scholar]
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.H. Robust visual tracking via convolutional networks without training. IEEE Trans. Image Process. 2016, 25, 1779–1792. [Google Scholar] [CrossRef] [PubMed]
- Ning, J.; Yang, J.; Jiang, S.; Zhang, L.; Yang, M.H. Object tracking via dual linear structured SVM and explicit feature map. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4266–4274. [Google Scholar]
- Zhang, T.; Xu, C.; Yang, M.H. Robust structural sparse tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 473–486. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Liu, T.; Wang, G.; Chan, K.L.; Yang, Q. Video tracking using learned hierarchical features. IEEE Trans. Image Process. 2015, 24, 1424–1435. [Google Scholar] [CrossRef] [PubMed]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 597–606. [Google Scholar]
- Wang, N.; Li, S.; Gupta, A.; Yeung, D.Y. Transferring rich feature hierarchies for robust visual tracking. arXiv 2015, arXiv:1501.04587. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Jung, I.; Son, J.; Baek, M.; Han, B. Real-Time MDNet. arXiv 2018, arXiv:1808.08834. [Google Scholar]
- Nam, H.; Baek, M.; Han, B. Modeling and propagating cnns in a tree structure for visual tracking. arXiv 2016, arXiv:1608.07242. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.; Yang, M.H. Vital: Visual tracking via adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018; pp. 8990–8999. [Google Scholar]
- Pu, S.; Song, Y.; Ma, C.; Zhang, H.; Yang, M.H. Deep attentive tracking via reciprocative learning. In Advances in Neural Information Processing Systems, Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; MIT Press: Cambridge, MA, USA, 2018; pp. 1931–1941. [Google Scholar]
- Javanmardi, M.; Qi, X. Structured group local sparse tracker. IET Image Process. 2019, 13, 1391–1399. [Google Scholar] [CrossRef] [Green Version]
- Jia, X.; Lu, H.; Yang, M.H. Visual tracking via adaptive structural local sparse appearance model. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1822–1829. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical convolutional features for visual tracking. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3074–3082. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 702–715. [Google Scholar]
- Vedaldi, A.; Lenc, K. Matconvnet: Convolutional neural networks for matlab. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; ACM: New York, NY, USA, 2015; pp. 689–692. [Google Scholar]
- Hong, Z.; Mei, X.; Prokhorov, D.; Tao, D. Tracking via robust multi-task multi-view joint sparse representation. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 649–656. [Google Scholar]
- Javanmardi, M.; Qi, X. Robust Structured Multi-Task Multi-View Sparse Tracking. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Ling, H.; Hu, W.; Xing, J. Transfer learning based visual tracking with gaussian processes regression. In European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 188–203. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; BMVA Press: Durham, UK, 2014. [Google Scholar]
- Wang, D.; Lu, H. Visual tracking via probability continuous outlier model. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 3478–3485. [Google Scholar]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: robust tracking via multiple experts using entropy minimization. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Li, Y.; Zhu, J. A scale adaptive kernel correlation filter tracker with feature integration. In European Conference on Computer Vision; Springer: Zuric, Switzerland, 2014; pp. 254–265. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4310–4318. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Zhong, W.; Lu, H.; Yang, M.H. Robust object tracking via sparsity-based collaborative model. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1838–1845. [Google Scholar]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.M.; Hicks, S.L.; Torr, P.H. Struck: Structured output tracking with kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bao, C.; Wu, Y.; Ling, H.; Ji, H. Real time robust l1 tracker using accelerated proximal gradient approach. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1830–1837. [Google Scholar]
- Zhang, T.; Ghanem, B.; Liu, S.; Ahuja, N. Robust visual tracking via multi-task sparse learning. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2042–2049. [Google Scholar]
- Ma, C.; Yang, X.; Zhang, C.; Yang, M.H. Long-term correlation tracking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5388–5396. [Google Scholar]
- Choi, J.; Chang, H.J.; Yun, S.; Fischer, T.; Demiris, Y.; Choi, J.Y. Attentional Correlation Filter Network for Adaptive Visual Tracking. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2, p. 7. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 749–765. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 850–865. [Google Scholar]
- Zhang, T.; Ghanem, B.; Liu, S.; Ahuja, N. Low-rank sparse learning for robust visual tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 470–484. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Score | L1APG | ASLA | MTT | MTMVTLAD | MSLA | SST | RSST | Proposed Method | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Color | HOG | Deep | STLCF | STLHF | STLDF | |||||||
| AUC | 0.380 | 0.434 | 0.376 | 0.505 | 0.506 | 0.484 | 0.520 | 0.543 | 0.590 | 0.523 | 0.556 | 0.604 |
| Precision | 0.485 | 0.532 | 0.479 | 0.684 | 0.631 | 0.648 | 0.691 | 0.726 | 0.789 | 0.690 | 0.747 | 0.818 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Javanmardi, M.; Farzaneh, A.H.; Qi, X. A Robust Structured Tracker Using Local Deep Features. Electronics 2020, 9, 846. https://doi.org/10.3390/electronics9050846
Javanmardi M, Farzaneh AH, Qi X. A Robust Structured Tracker Using Local Deep Features. Electronics. 2020; 9(5):846. https://doi.org/10.3390/electronics9050846
Chicago/Turabian StyleJavanmardi, Mohammadreza, Amir Hossein Farzaneh, and Xiaojun Qi. 2020. "A Robust Structured Tracker Using Local Deep Features" Electronics 9, no. 5: 846. https://doi.org/10.3390/electronics9050846
APA StyleJavanmardi, M., Farzaneh, A. H., & Qi, X. (2020). A Robust Structured Tracker Using Local Deep Features. Electronics, 9(5), 846. https://doi.org/10.3390/electronics9050846