Detecting Predictable Segments of Chaotic Financial Time Series via Neural Network


Abstract
1. Introduction
2. Methodology
2.1. Phase Space Construction-Related Technologies
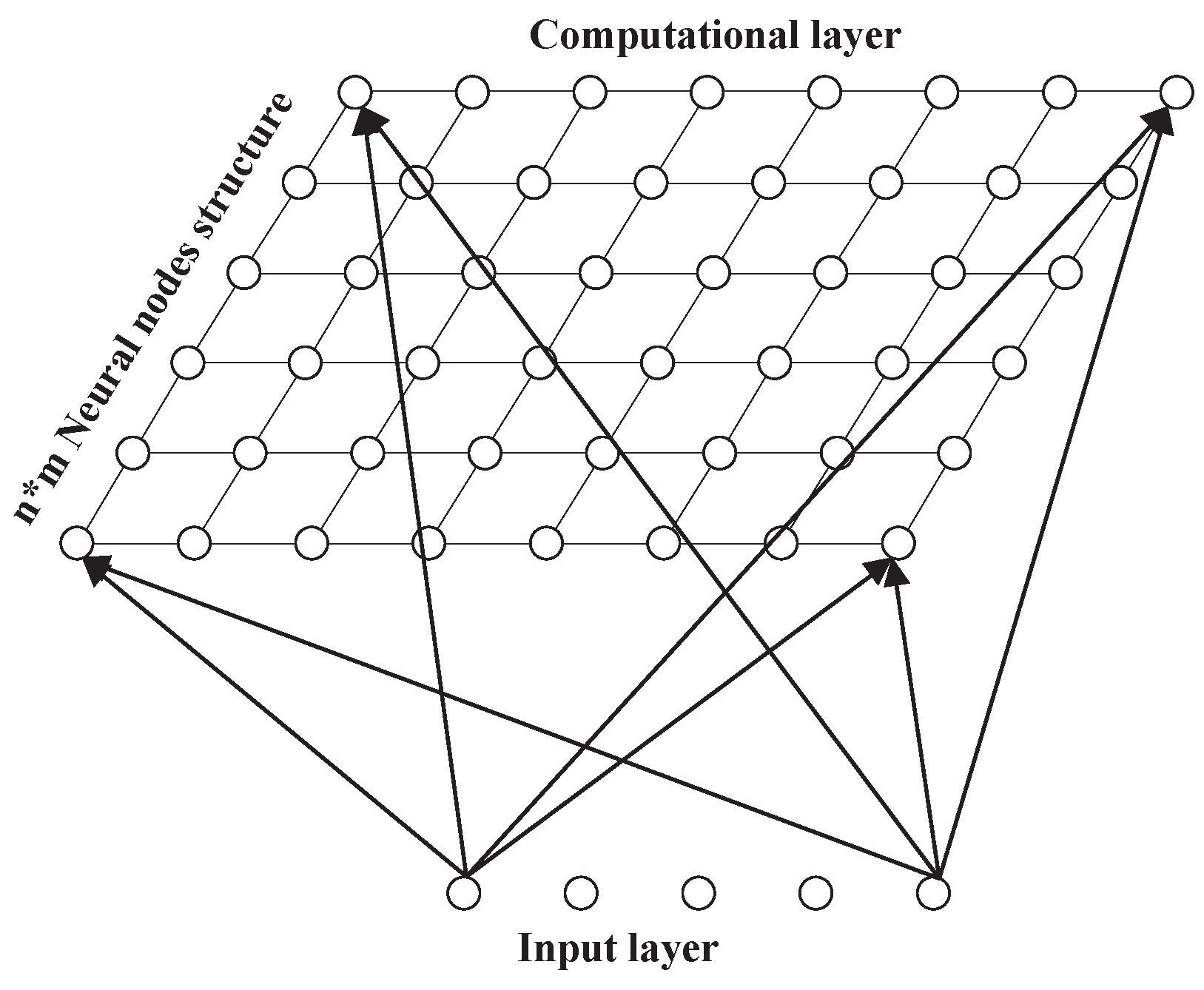
2.2. Self Organizing Maps for Clustering Time Series
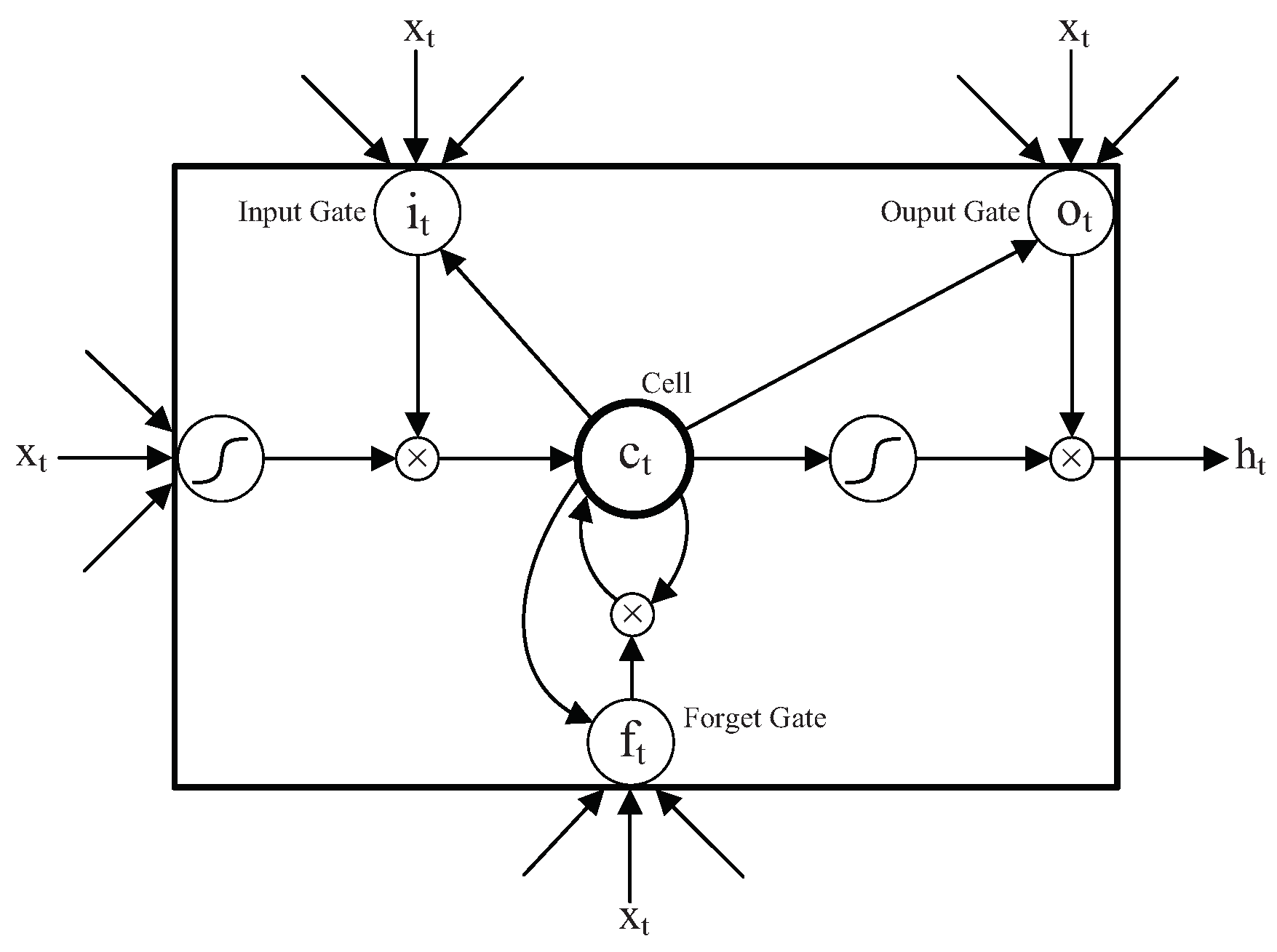
2.3. Long Short-Term Memory Model
- (1)
- First, calculate the value of the candidate memory cell ; is the weight matrix, is the bias.
- (2)
- Calculate the value of the input gate . The input gate controls the updating of the current input data to the state value of the memory cell. is a sigmoid function, is the weight matrix and is the bias.
- (3)
- Calculate the value of the forget gate; the forget gate controls the updating of the historical data to the state value of the memory cell. is the weight matrix and is the bias.
- (4)
- Calculate the value of the current moment memory cell , and is the state value of the last LSTM unit.where “.” represents dot product. The update of memory cell depends on the state value of the last cell and the candidate cell, and it is controlled by input gate and forget gate.
- (5)
- Calculate the value of the output gate ; the output gate controls the output of the state value of the memory cell. is the weight matrix and is the bias.
- (6)
- Finally, calculate the output of LSTM unit .
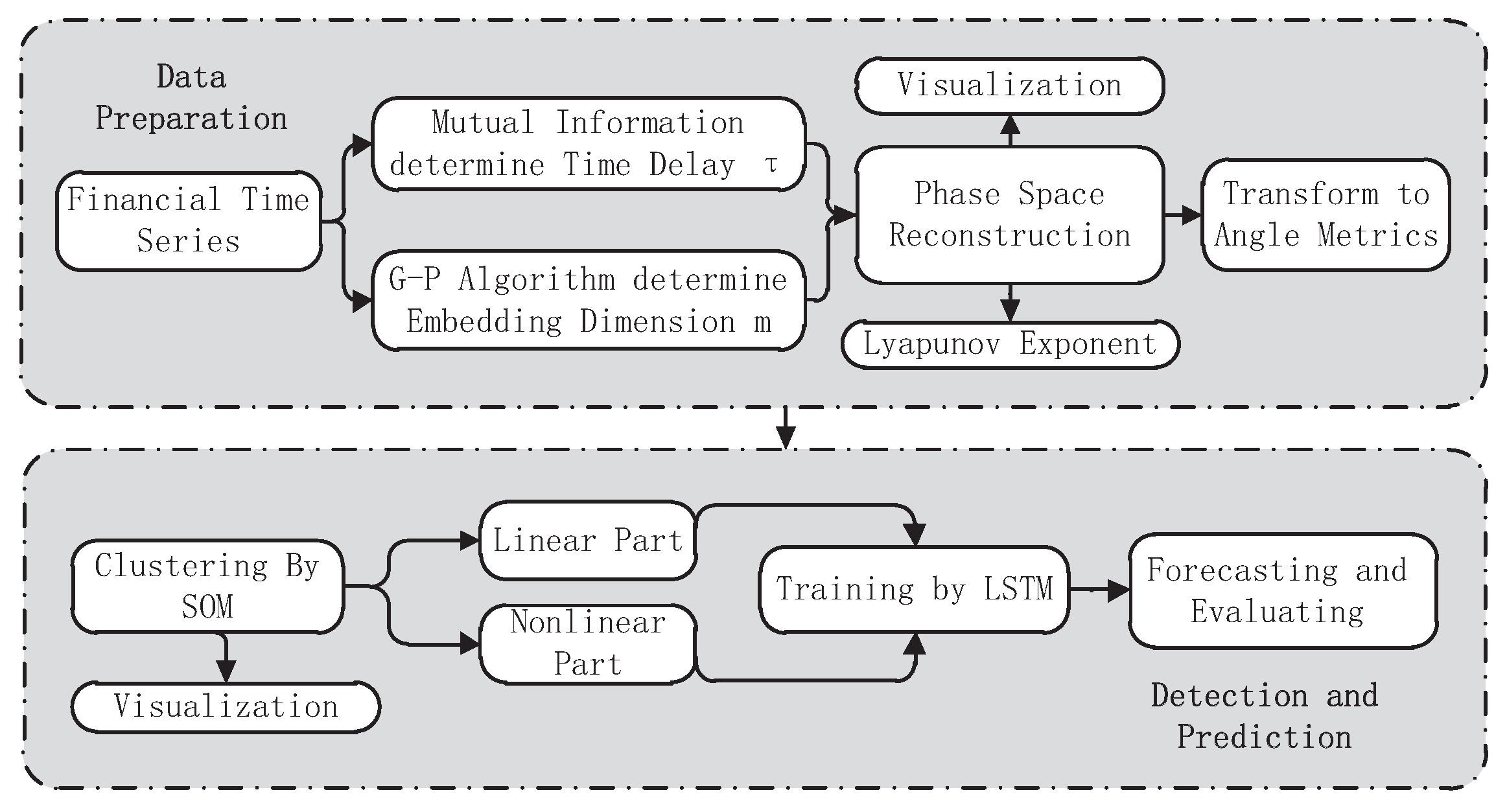
3. Technical Frameworks
3.1. Data Preparation
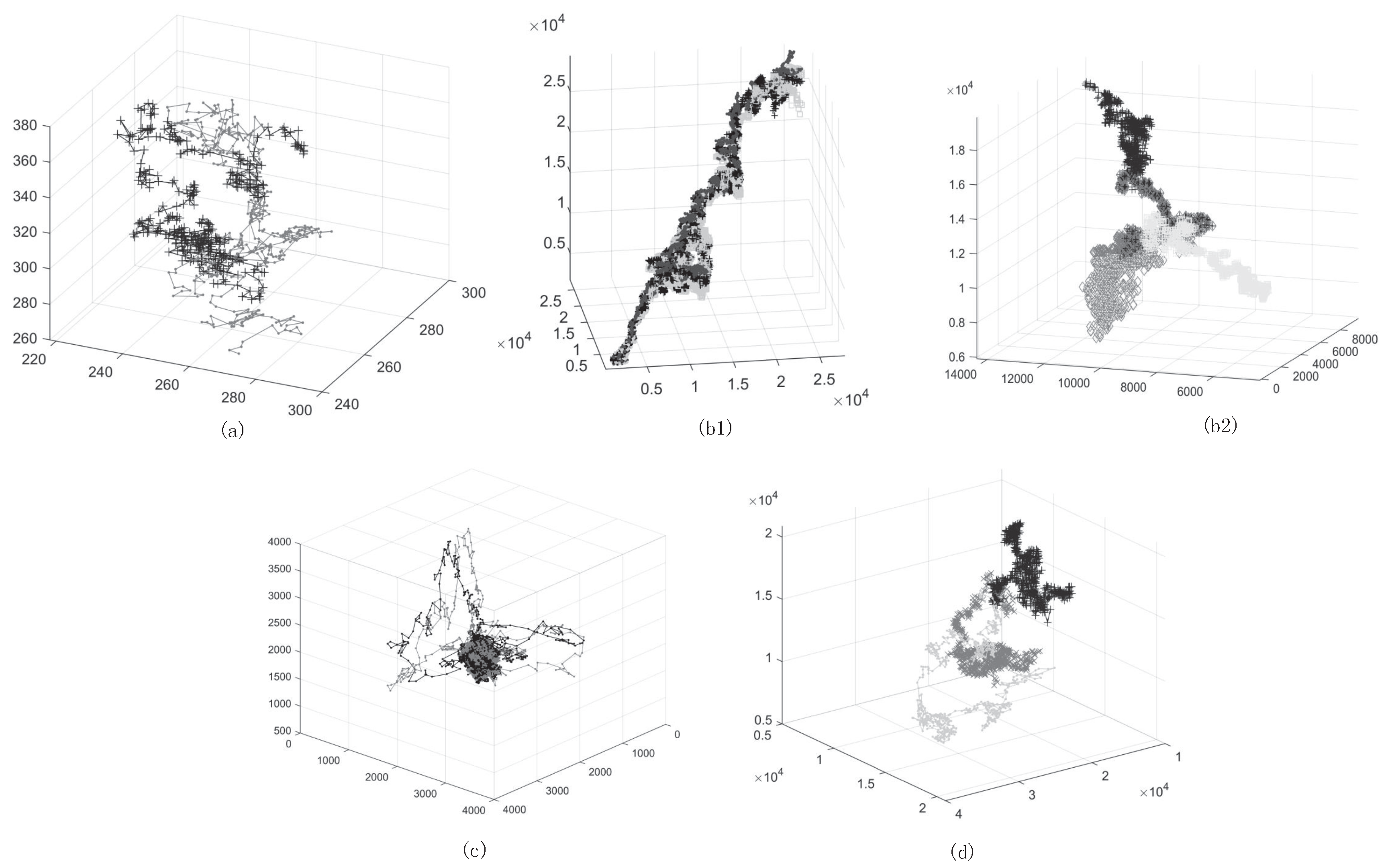
3.1.1. Phase Space Reconstruction and Visualization of Time Series Dynamics
3.1.2. Generating Angle Metrics
3.2. Detection and Prediction
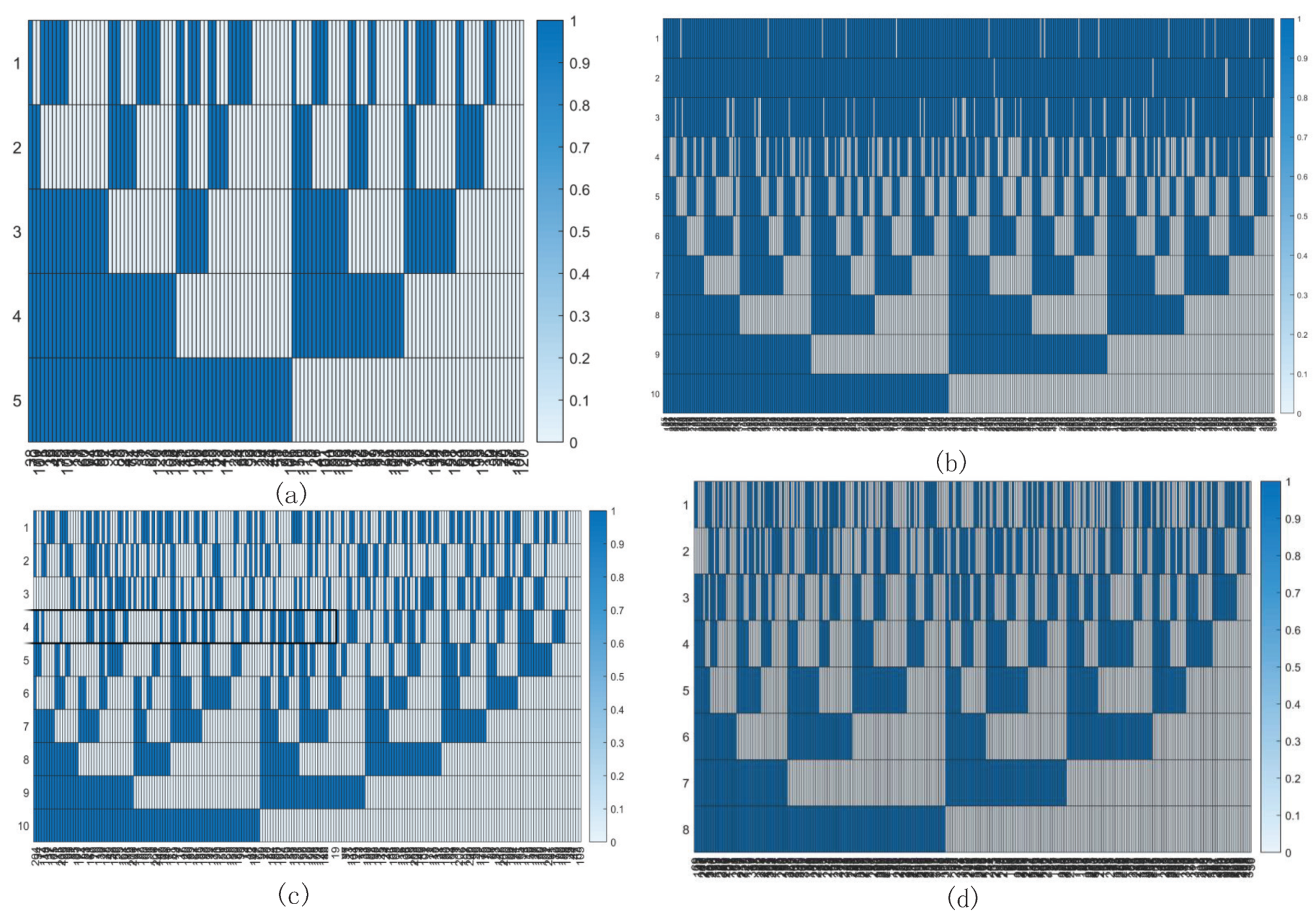
3.2.1. Detecting the Boundary between Linear and Nonlinear by SOM
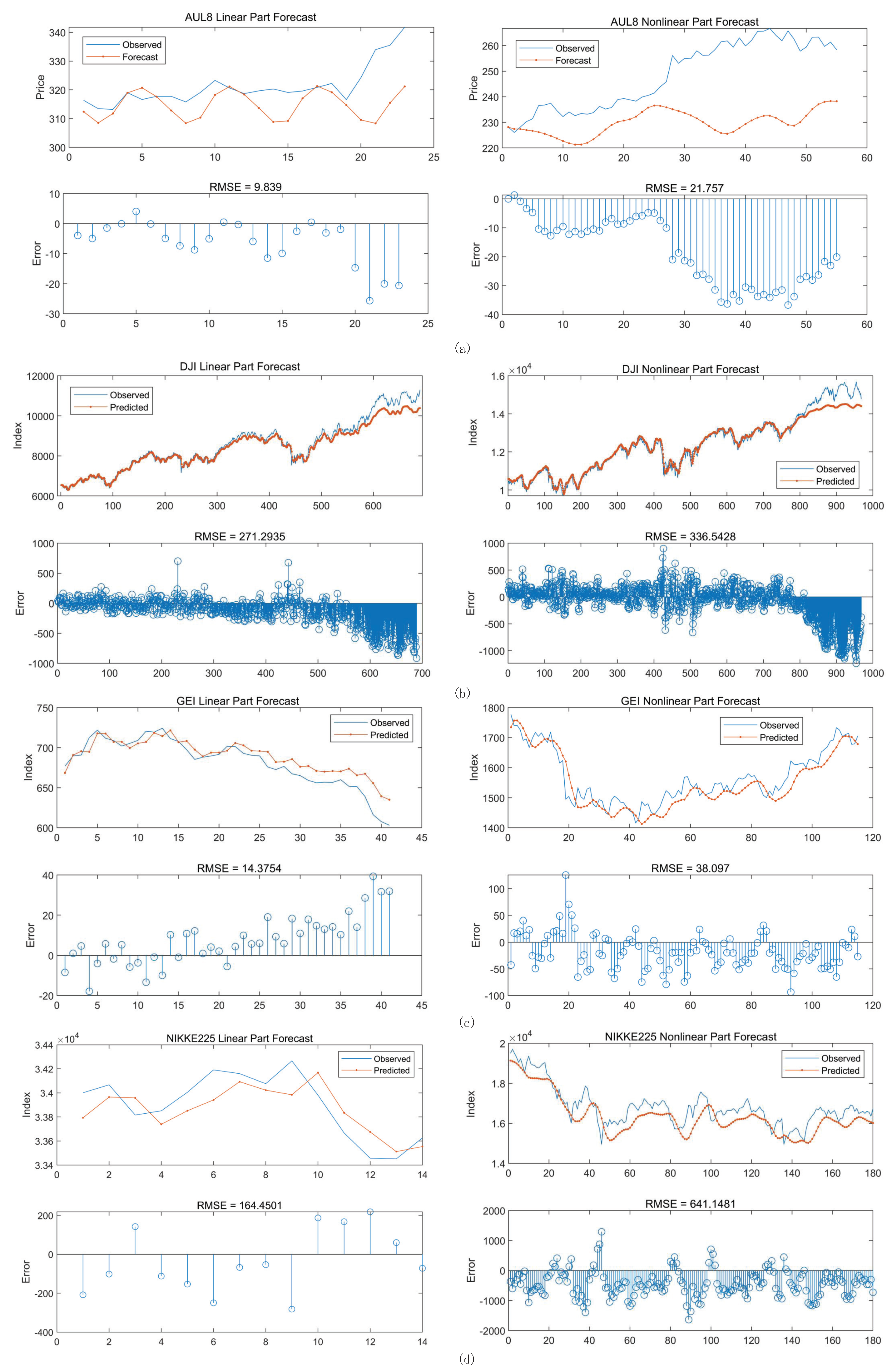
3.2.2. Predicting and Evaluating by LSTM Neural Network
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| PSR | Phase Space Reconstruction |
| SOM | Self Organizing Maps |
| DJI | Dow Jones index |
| NIKKE225 | Nikkei index |
| GEI | China growth enterprise market index |
| AUL8 | Gold Index of China |
| LSTM | Long Short-Term Memory |
| RMSE | Root Mean Square Error |
| MAPE | Mean Absolute Percentage Error |
| The Coefficient of Determination |
References
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Appl. 2019, 519, 127–139. [Google Scholar] [CrossRef]
- Wang, J.Q.; Du, Y.; Wang, J. LSTM based long-term energy consumption prediction with periodicity. Energy 2020, 197, 117197. [Google Scholar] [CrossRef]
- Shen, Z.; Zhang, Y.; Lu, J.; Xu, J.; Xiao, G. A novel time series forecasting model with deep learning. Neurocomputing 2019. [Google Scholar] [CrossRef]
- Zhou, T.; Gao, S.; Wang, J.; Chu, C.; Todo, Y.; Tang, Z. Financial time series prediction using a dendritic neuron model. Knowl. Based Syst. 2016, 105, 214–224. [Google Scholar] [CrossRef]
- Lahmiri, S.; Bekiros, S. Chaos, randomness and multi-fractality in Bitcoin market. Chaos Solitons Fractals 2018, 106, 28–34. [Google Scholar] [CrossRef]
- Kristoufek, L. Fractal markets hypothesis and the global financial crisis: Scaling, investment horizons and liquidity. Adv. Complex Syst. 2012, 15, 1250065. [Google Scholar] [CrossRef]
- Wolf, A.; Swift, J.B.; Swinney, H.L.; Vastano, J.A. Determining Lyapunov exponents from a time series. Phys. D Nonlinear Phenom. 1985, 16, 285–317. [Google Scholar] [CrossRef]
- Bianchi, F. The great depression and the great recession: A view from financial markets. J. Monet. Econ. 2019. [Google Scholar] [CrossRef]
- Takens, F. Detecting Strange Attractors in Turbulence; Springer: Berlin, Germany, 1981; pp. 366–381. [Google Scholar]
- Grassberger, P.; Procaccia, I. Estimation of the Kolmogorov entropy from a chaotic signal. Phys. Rev. A 1983, 28, 2591. [Google Scholar] [CrossRef]
- Zhiqiang, G.; Huaiqing, W.; Quan, L. Financial time series forecasting using LPP and SVM optimized by PSO. Soft Comput. 2013, 17, 805–818. [Google Scholar] [CrossRef]
- Zhang, L.; Tian, F.; Liu, S.; Dang, L.; Peng, X.; Yin, X. Chaotic time series prediction of E-nose sensor drift in embedded phase space. Sens. Actuators B Chem. 2013, 182, 71–79. [Google Scholar] [CrossRef]
- Fan, X.; Li, S.; Tian, L. Chaotic characteristic identification for carbon price and an multi-layer perceptron network prediction model. Expert Syst. Appl. 2015, 42, 3945–3952. [Google Scholar] [CrossRef]
- Shang, P.; Na, X.; Kamae, S. Chaotic analysis of time series in the sediment transport phenomenon. Chaos Solitons Fractals 2009, 41, 368–379. [Google Scholar] [CrossRef]
- Ghadiri, S.M.E.; Mazlumi, K. Adaptive protection scheme for microgrids based on SOM clustering technique. Appl. Soft Comput. 2020, 88, 106062. [Google Scholar] [CrossRef]
- Teichgraeber, H.; Brandt, A.R. Clustering methods to find representative periods for the optimization of energy systems: An initial framework and comparison. Appl. Energy 2019, 239, 1283–1293. [Google Scholar] [CrossRef]
- Dose, C.; Cincotti, S. Clustering of financial time series with application to index and enhanced index tracking portfolio. Phys. A Stat. Mech. Appl. 2005, 355, 145–151. [Google Scholar] [CrossRef]
- Niu, H.; Wang, J. Volatility clustering and long memory of financial time series and financial price model. Digit. Signal Process. 2013, 23, 489–498. [Google Scholar] [CrossRef]
- Pattarin, F.; Paterlini, S.; Minerva, T. Clustering financial time series: An application to mutual funds style analysis. Comput. Stat. Data Anal. 2004, 47, 353–372. [Google Scholar] [CrossRef]
- Dias, J.G.; Vermunt, J.K.; Ramos, S. Clustering financial time series: New insights from an extended hidden Markov model. Eur. J. Oper. Res. 2015, 243, 852–864. [Google Scholar] [CrossRef]
- Nie, C.X. Dynamics of cluster structure in financial correlation matrix. Chaos Solitons Fractals 2017, 104, 835–840. [Google Scholar] [CrossRef]
- Liu, G.; Zhu, L.; Wu, X.; Wang, J. Time series clustering and physical implication for photovoltaic array systems with unknown working conditions. Sol. Energy 2019, 180, 401–411. [Google Scholar] [CrossRef]
- Li, H. Multivariate time series clustering based on common principal component analysis. Neurocomputing 2019, 349, 239–247. [Google Scholar] [CrossRef]
- Song, X.; Shi, M.; Wu, J.; Sun, W. A new fuzzy c-means clustering-based time series segmentation approach and its application on tunnel boring machine analysis. Mech. Syst. Signal Process. 2019, 133, 106279. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Fraser, A.M.; Swinney, H.L. Independent coordinates for strange attractors from mutual information. Phys. Rev. A 1986, 33, 1134–1140. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Data Length N | Embeding Dimension m | Time Delay | _Revision | Reconstructed Structure | Lyapunov Exponent | Predictable Steps |
|---|---|---|---|---|---|---|---|
| AUL8 | 1574 | 5 | 649 | 300 | 5 × 374 | 0.0558 | 17.92114695 |
| DJI | 8588 | 10 | 3294 | 800 | 10 × 1388 | 0.0082 | 121.9512195 |
| GEI | 2353 | 8 | 859 | 200 | 8 × 953 | 0.0044 | 227.2727273 |
| NIKKE225 | 7826 | 10 | 3503 | 800 | 10 × 626 | 0.0101 | 99.00990099 |
| Index | Clustering Boundary | Total Linear Part Percent | 80 % Linear Region | 80% Nonlinear Region |
|---|---|---|---|---|
| AUL8 | 138 | 49.90% | t1219–t1455 | t75–t632 |
| DJI | 138 | 45% | t1–t3448 | t5060–t6996 |
| GEI | 135 | 44% | t197–t608 | t1114–t2264 |
| NIKKE225 | 145 | 45.70% | t139–t285 | t5179–t6986 |
| Index | AUL8 (Linear/Nonlinear) | DJI (Linear/Nonlinear) | GEI (Linear/Nonlinear) | NIKKE225 (Linear/Nonlinear) |
|---|---|---|---|---|
| RMSE | 9.839/21.76 | 271.3/336.5 | 14.37/38.1 | 164.5/641.1 |
| MAPE | 1.069%/1.275% | 1.190%/3.184% | 1.565%/1.870% | 0.7139%/3.337% |
| R2 | 99.98%/99.97% | 99.98%/99.79% | 99.95%/99.94% | 99.98%/99.77% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, T.; Chu, C.; Xu, C.; Liu, W.; Yu, H. Detecting Predictable Segments of Chaotic Financial Time Series via Neural Network. Electronics 2020, 9, 823. https://doi.org/10.3390/electronics9050823
Zhou T, Chu C, Xu C, Liu W, Yu H. Detecting Predictable Segments of Chaotic Financial Time Series via Neural Network. Electronics. 2020; 9(5):823. https://doi.org/10.3390/electronics9050823
Chicago/Turabian StyleZhou, Tianle, Chaoyi Chu, Chaobin Xu, Weihao Liu, and Hao Yu. 2020. "Detecting Predictable Segments of Chaotic Financial Time Series via Neural Network" Electronics 9, no. 5: 823. https://doi.org/10.3390/electronics9050823
APA StyleZhou, T., Chu, C., Xu, C., Liu, W., & Yu, H. (2020). Detecting Predictable Segments of Chaotic Financial Time Series via Neural Network. Electronics, 9(5), 823. https://doi.org/10.3390/electronics9050823