EANN: Energy Adaptive Neural Networks




Abstract
:1. Introduction
- Precision scaling: the data is represented as fixed-point numbers and the word length is reduced to reduce the number of bits per word. Correspondingly, the sizes of multiplier, accumulators, and activation function are reduced and the area, power, and accuracy are reduced as well.
- Inaccurate arithmetic: As the neural network uses many multipliers and adders which are power-hungry hardware units. These units should be implemented in approximate versions to save power and area.
- Neuron skipping(pruning): It is another approximation technique in which the neurons that have the least contribution in the outputs are skipped from the computation or at least they are implemented with approximation. This reduces the number of cycles needed to perform the operations and reduces the total required energy as well.
- Computation skipping: The input data might contain lots of zeros which do not affect the result after multiplication or addition. Thus, there is a hardware unit that checks the input value and bypasses the upcoming computations if this input value equals zero. This lowers the activity factor and saves much dynamic power. This technique is valuable only in the case when the input contains many zeros. Otherwise, it would consume area and power for the zero-detection hardware unit without decreasing the dynamic power.
- Approximate activation function: The commonly used activation function is Sigmoid which contains exponential in its formula. If it is implemented in an exact way it consumes large area and power. Therefore, the approximated version of the Sigmoid function such as Piece-Wise Linear (PWL) approximation helps in saving power and area with degradation in accuracy.
2. Related Work
3. Research Hypothesis, Design Approach and Methodology
3.1. Research Hypothesis
3.2. Approximate Computing Techniques for Energy Savings
3.2.1. Precision Scaling
3.2.2. Inaccurate Arithmetic
3.2.3. Computation Skipping
3.2.4. Neurons Skipping
3.2.5. Activation Function Approximations
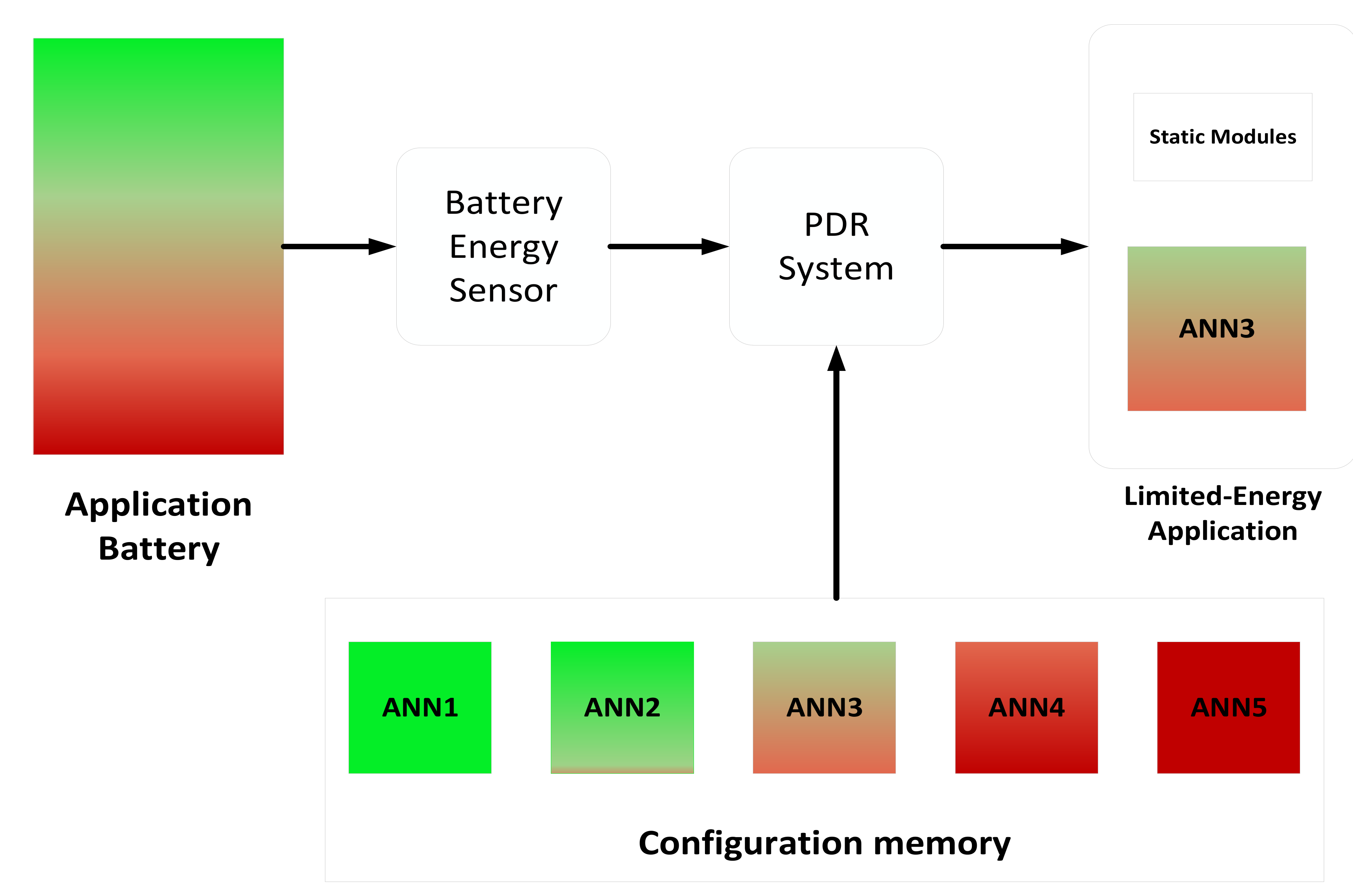
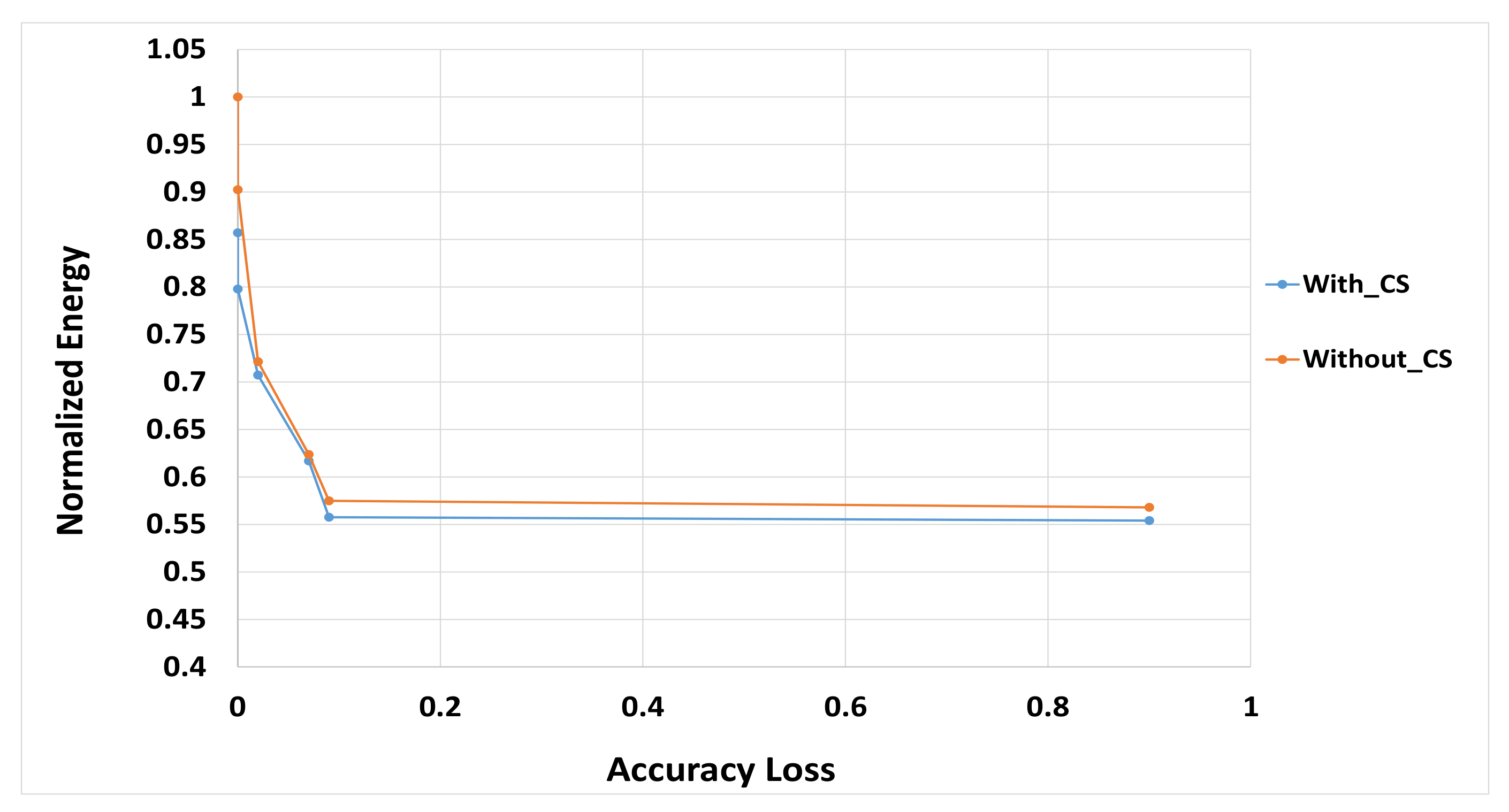
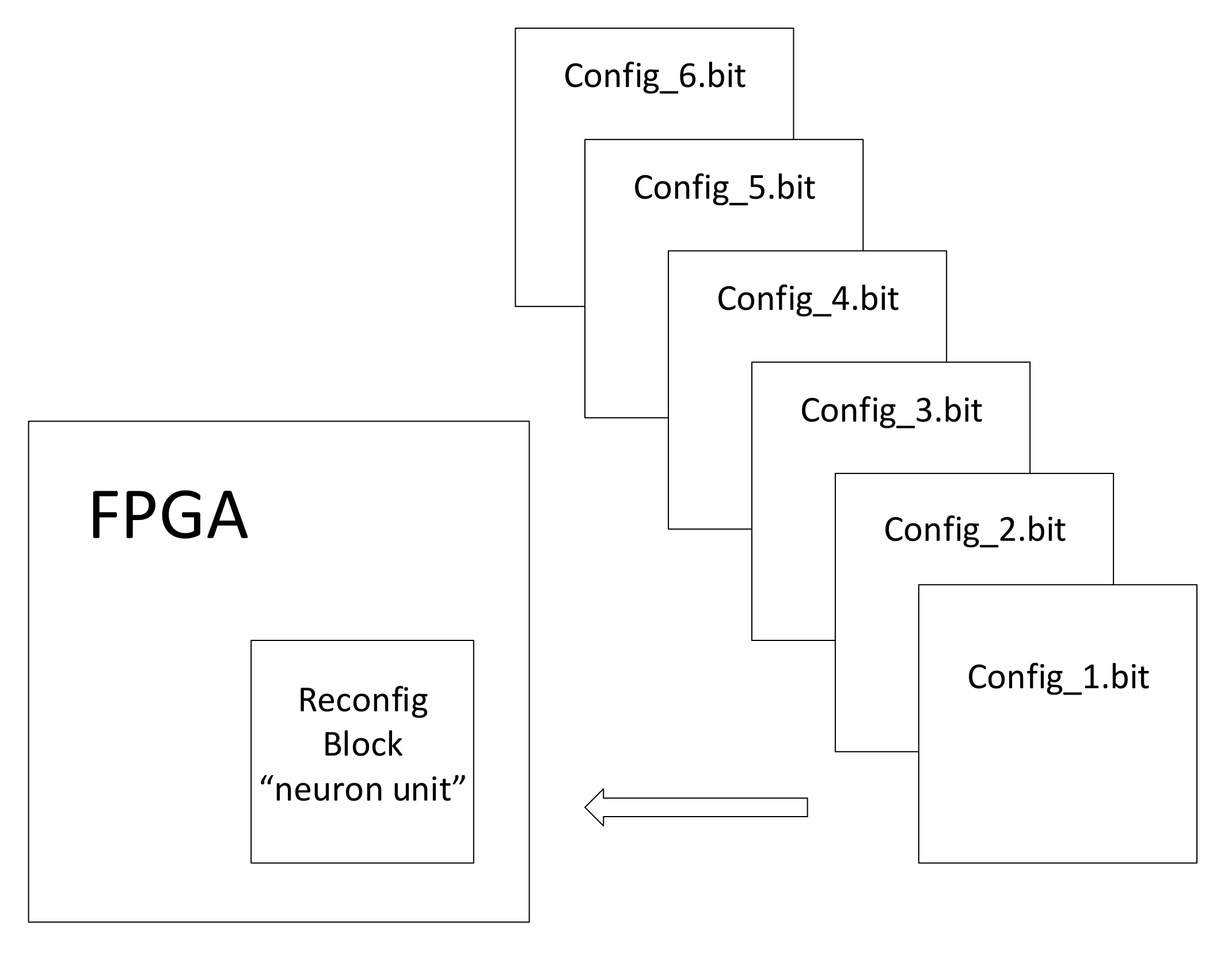
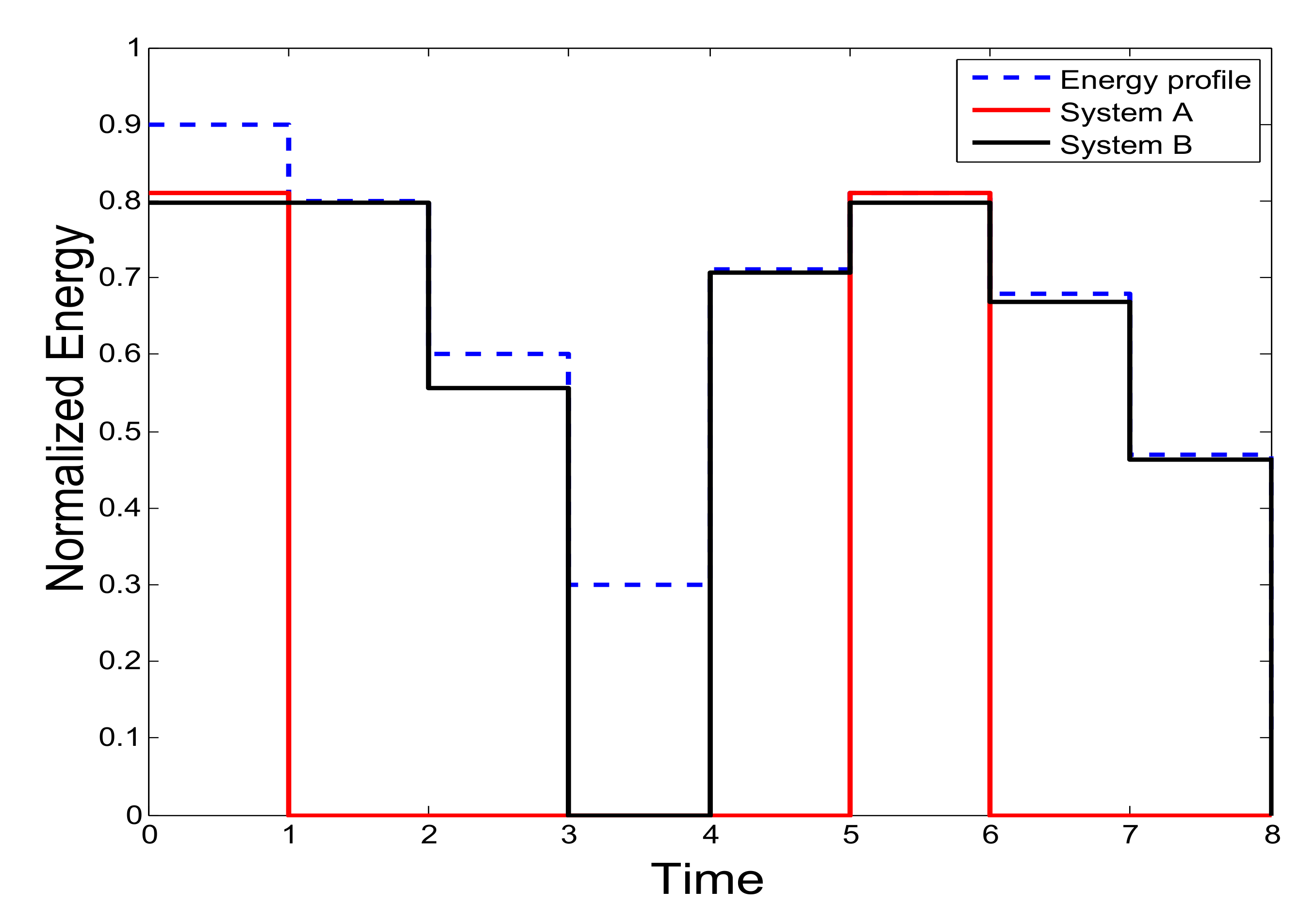
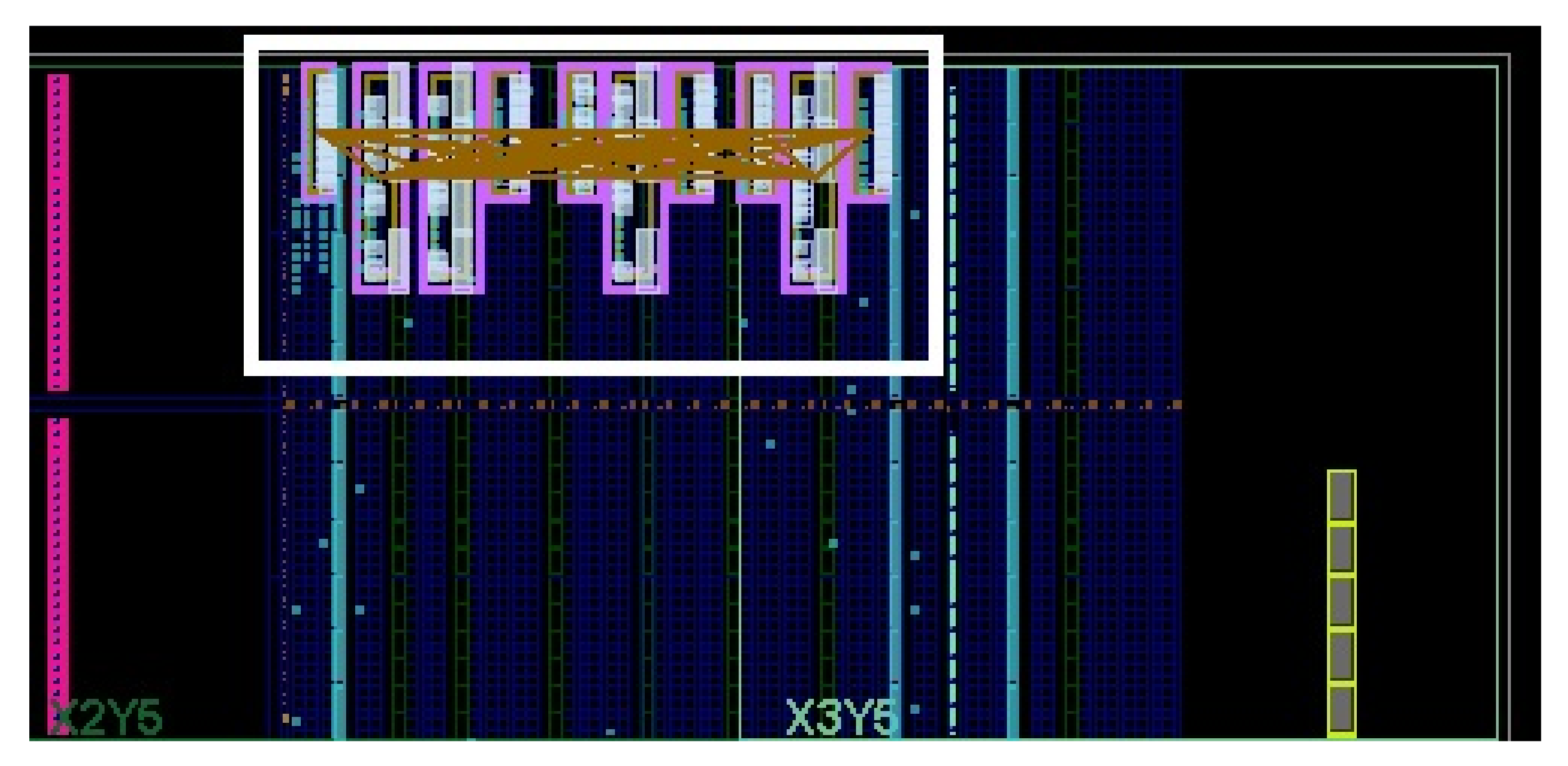
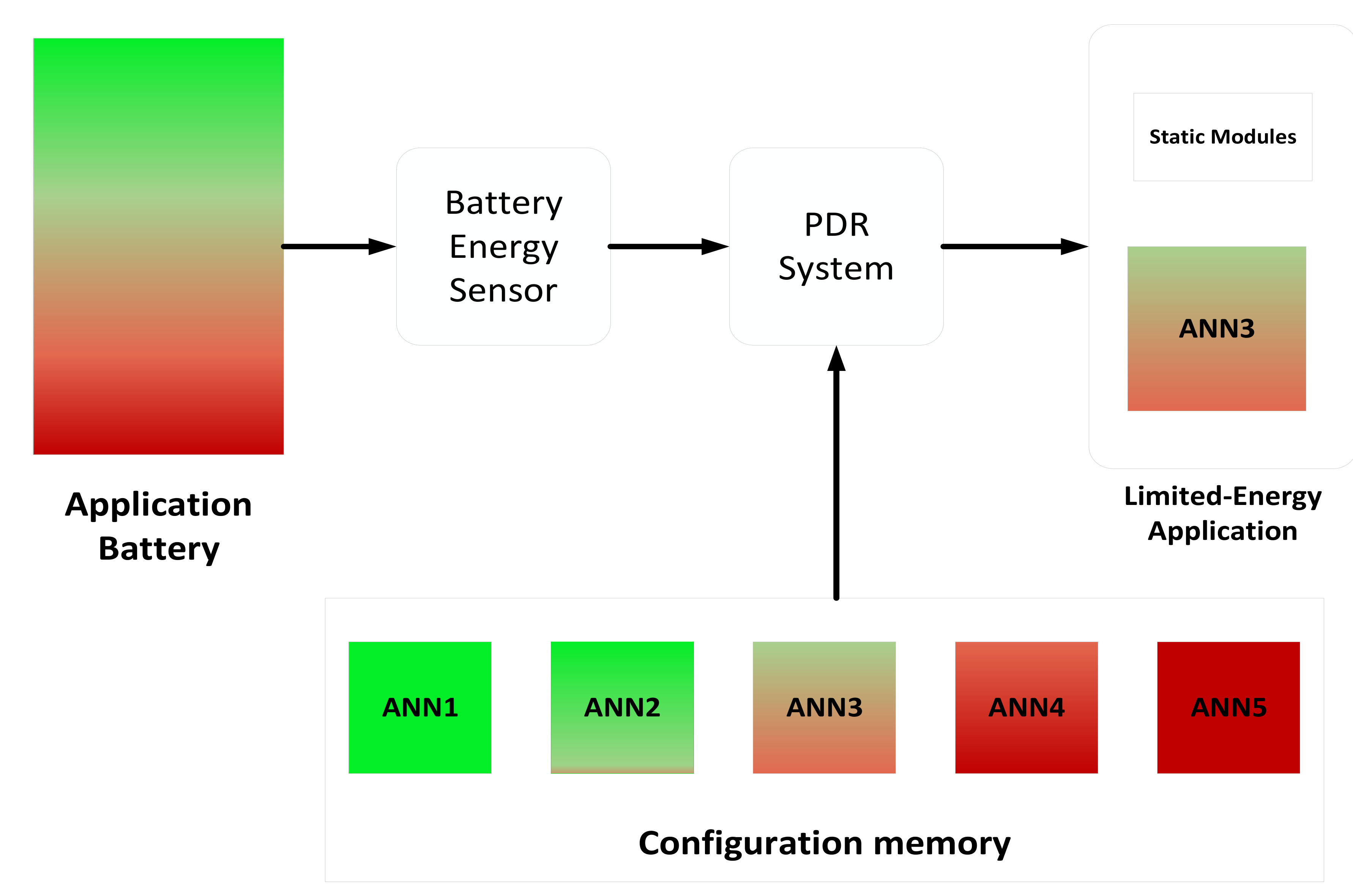
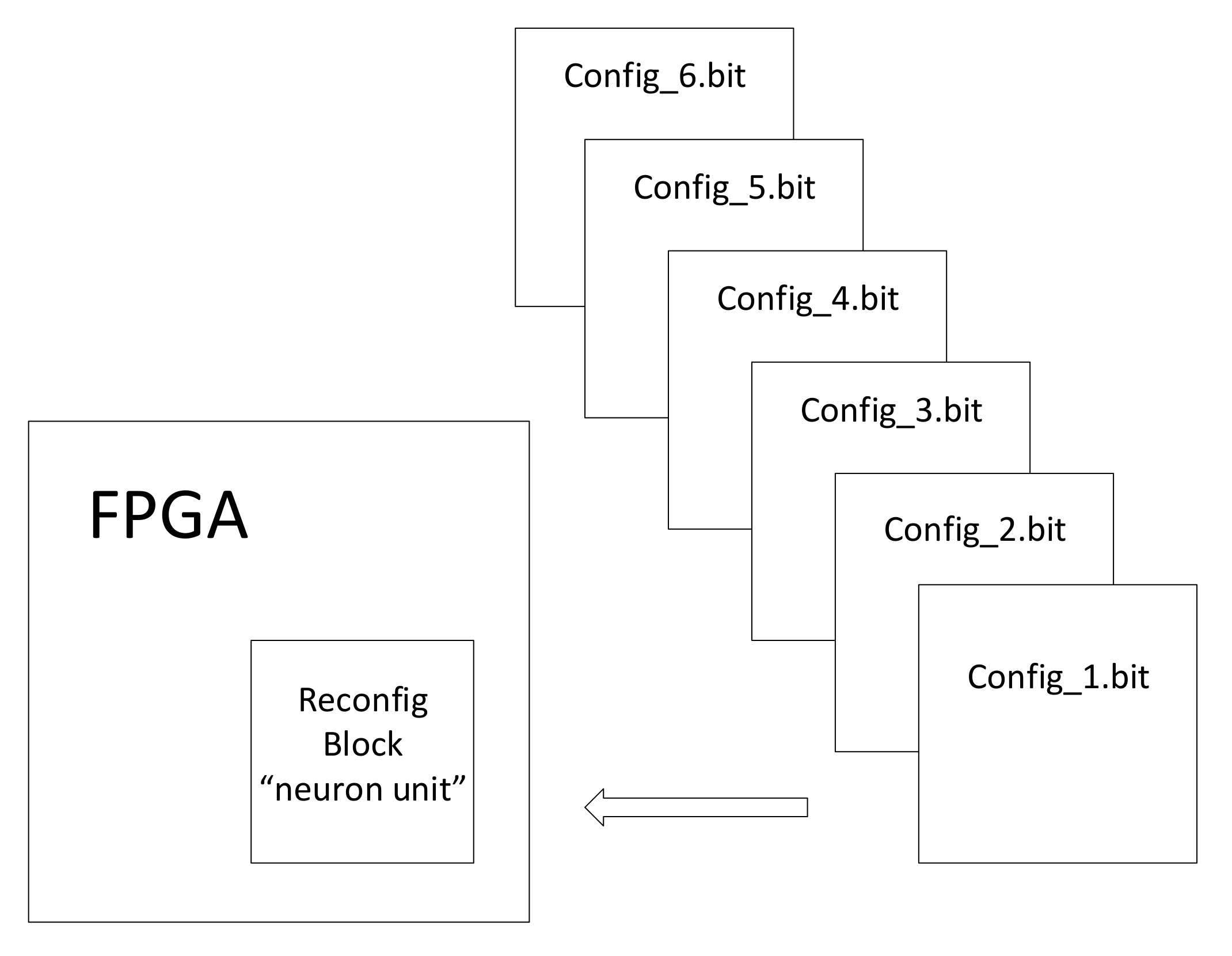
3.3. Partial Dynamic Reconfiguration (PDR)
4. Experimental Results
4.1. Experimental Setup
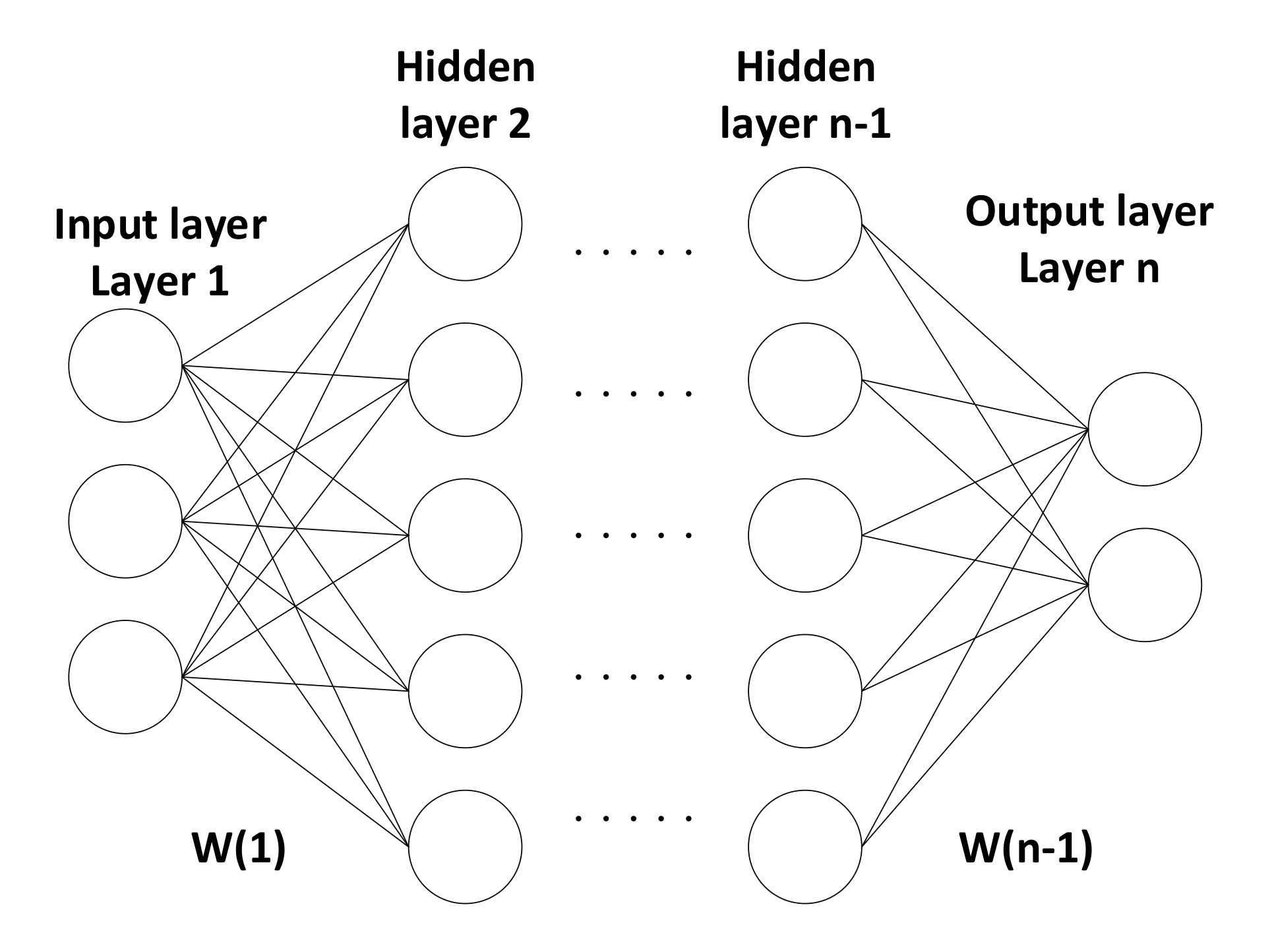
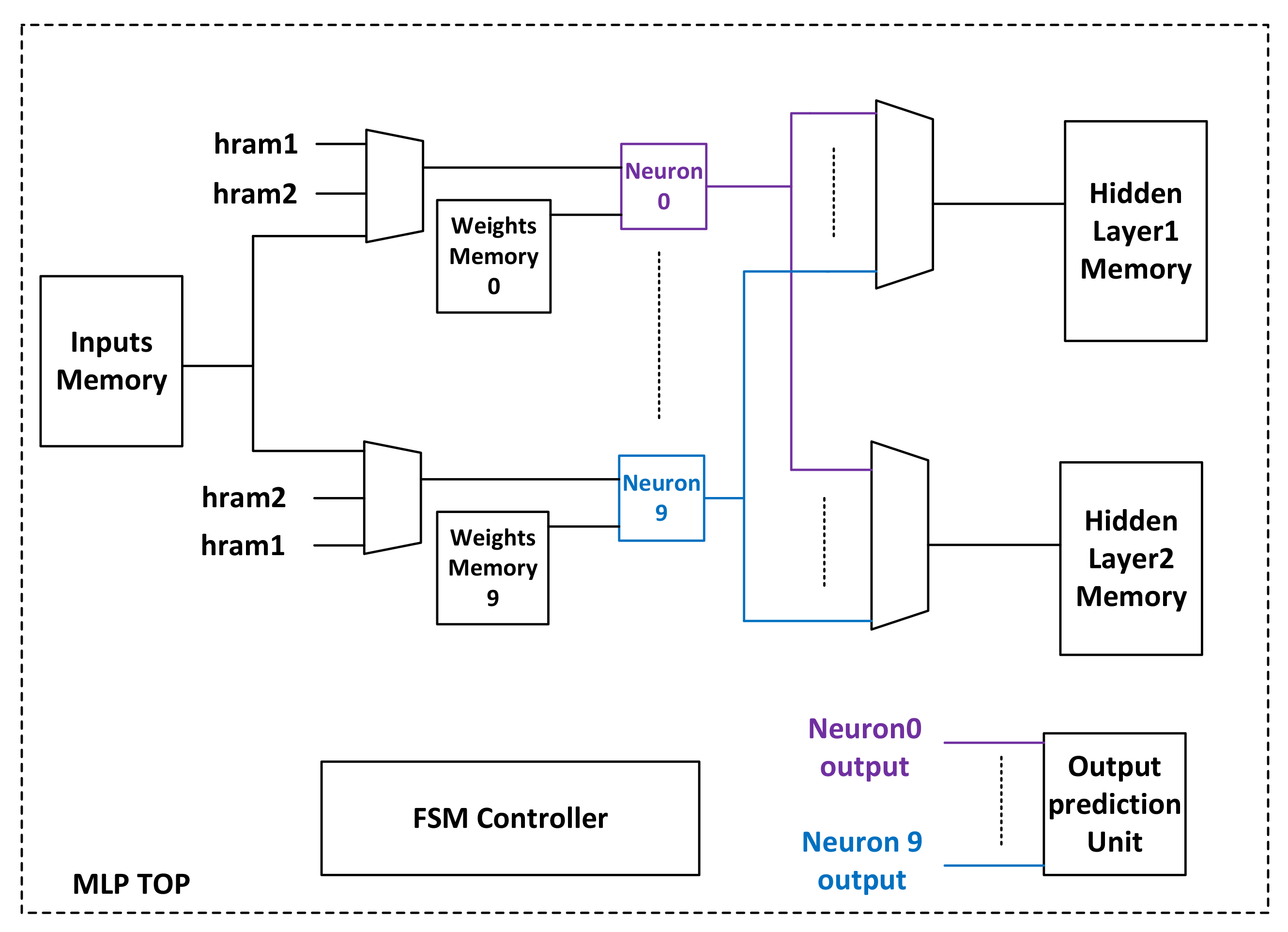
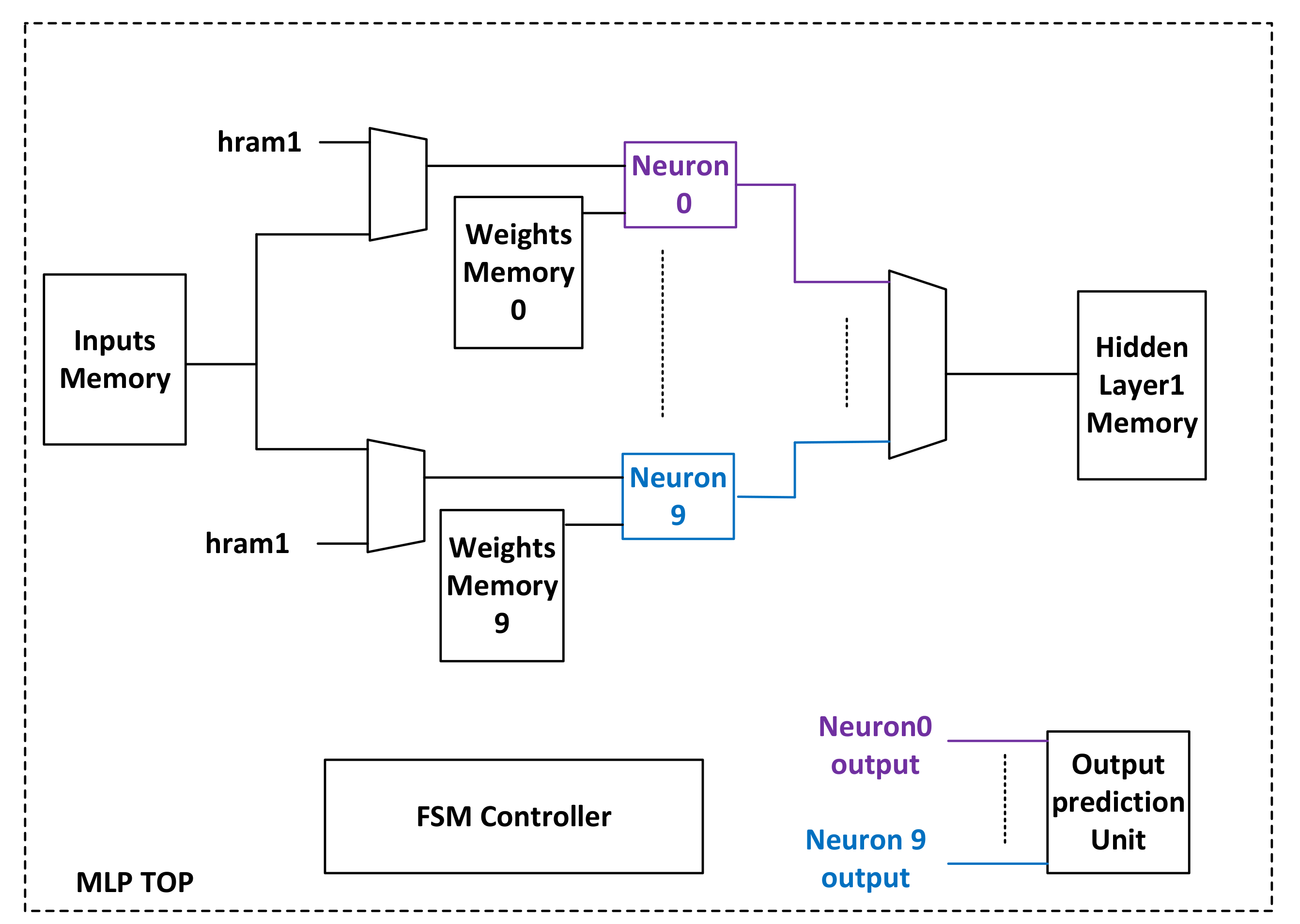
4.2. Block Diagram and Hardware Implementation of the Neural Network Used for MNIST Dataset
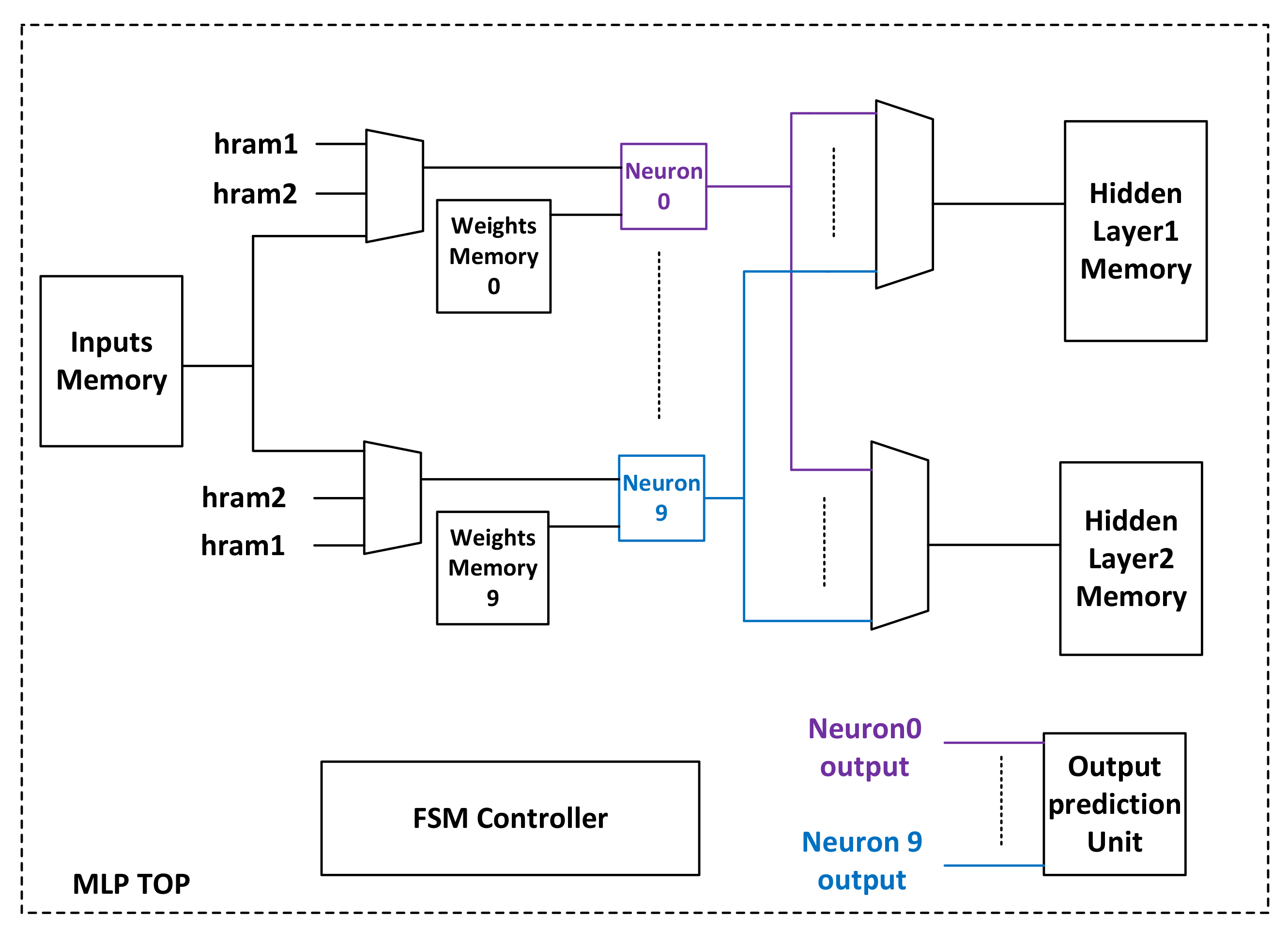
4.3. Block Diagram and Hardware Implementation of the Neural Network Used for SVHN Dataset
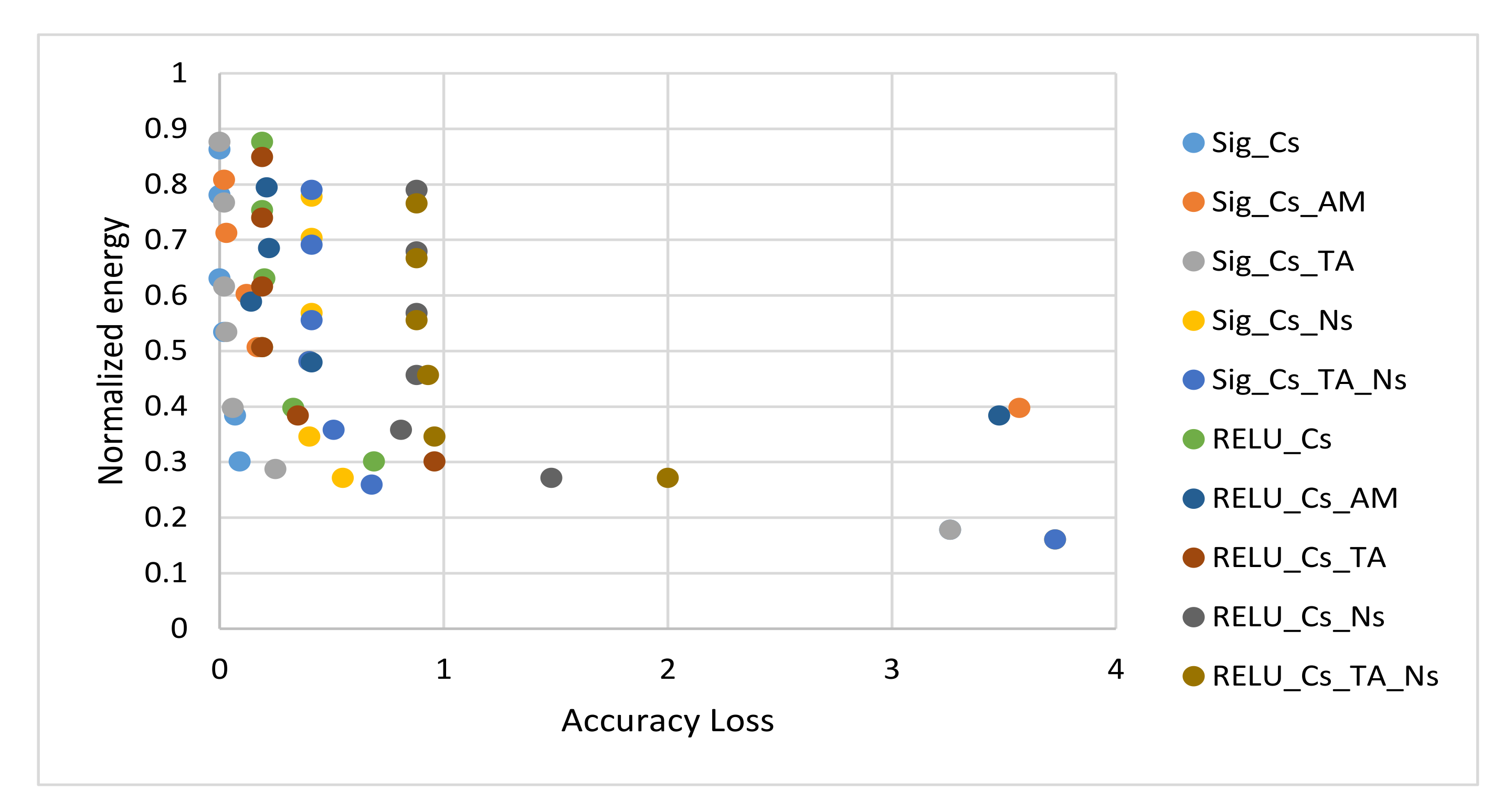
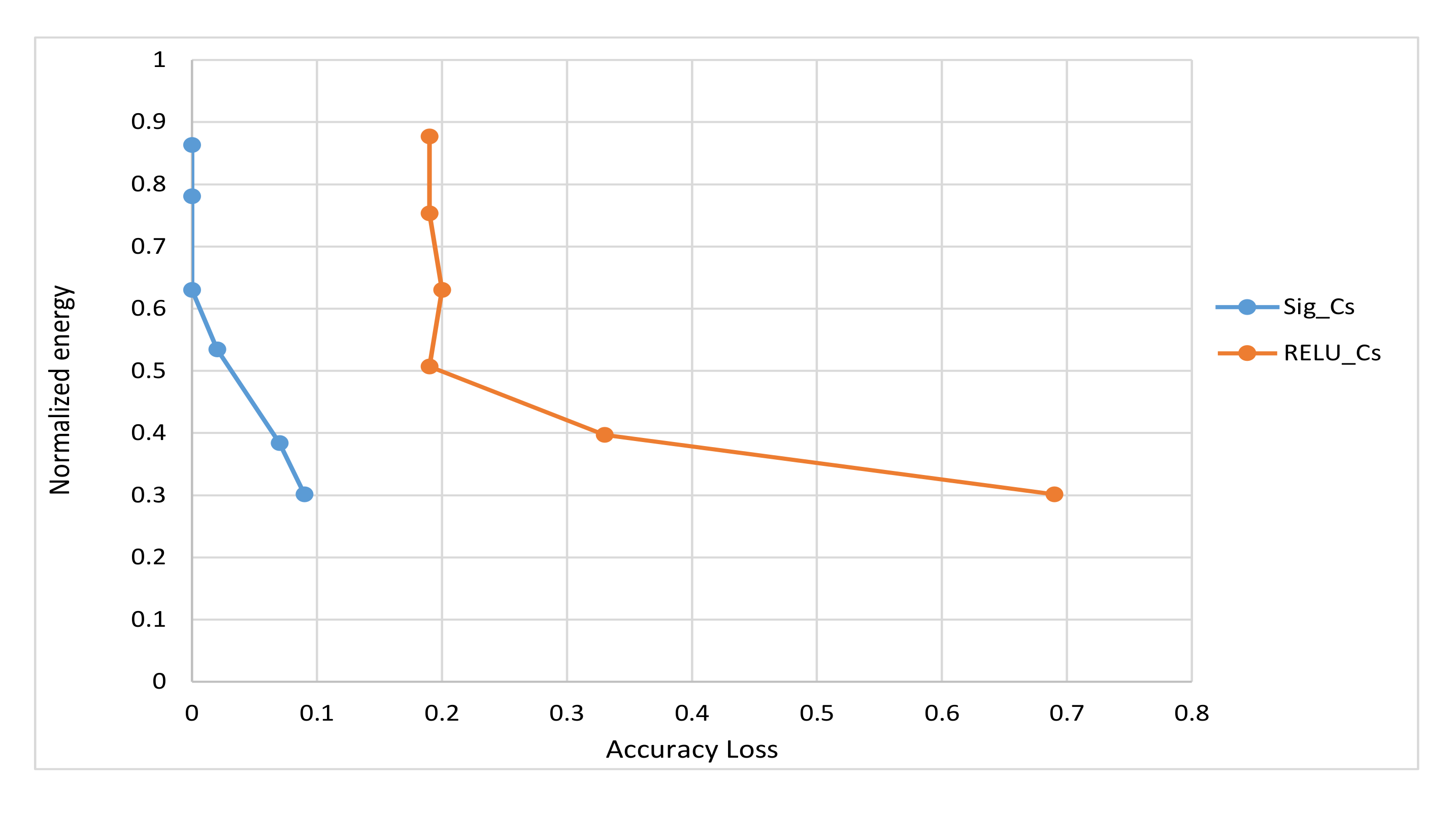
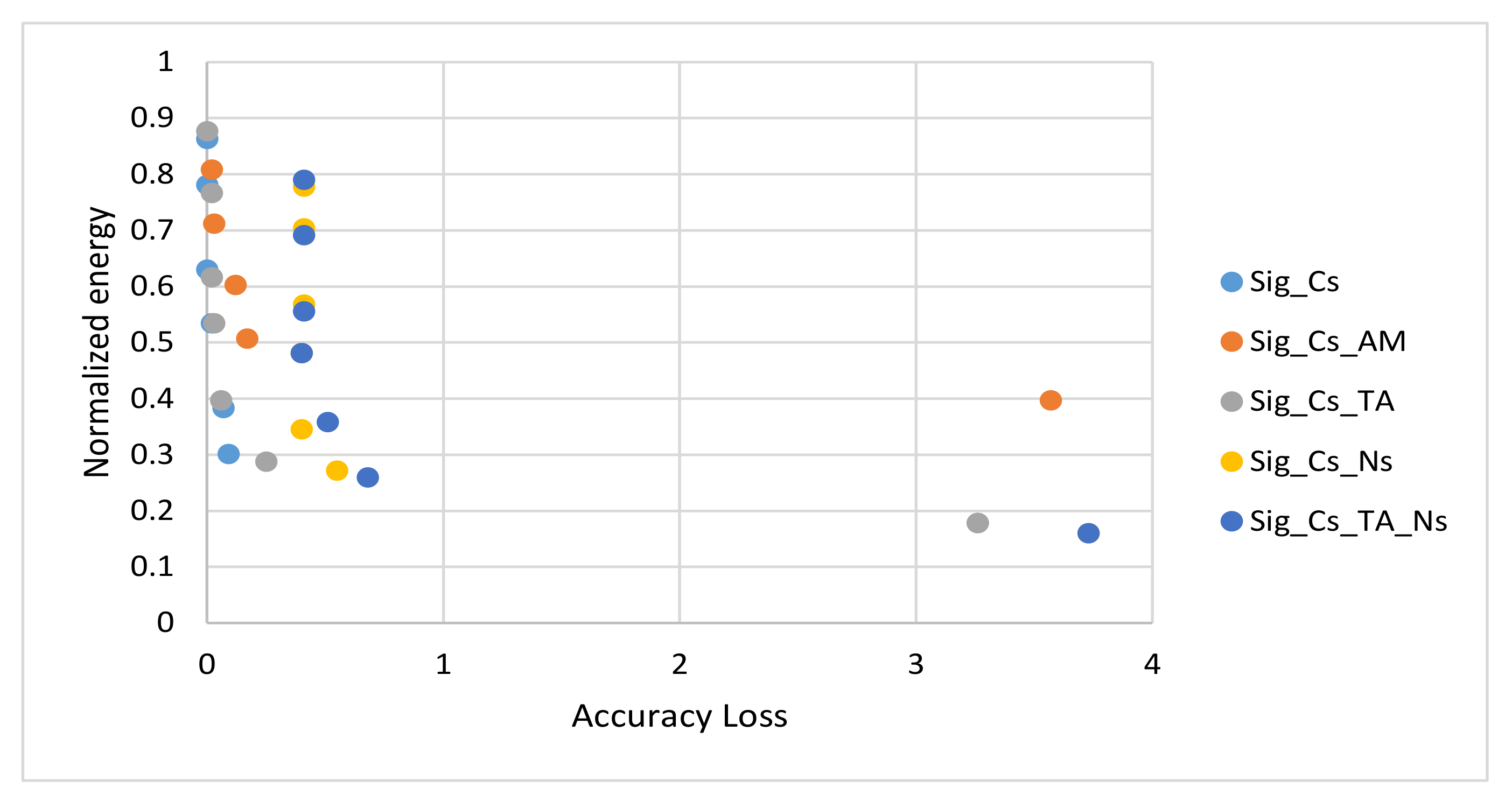
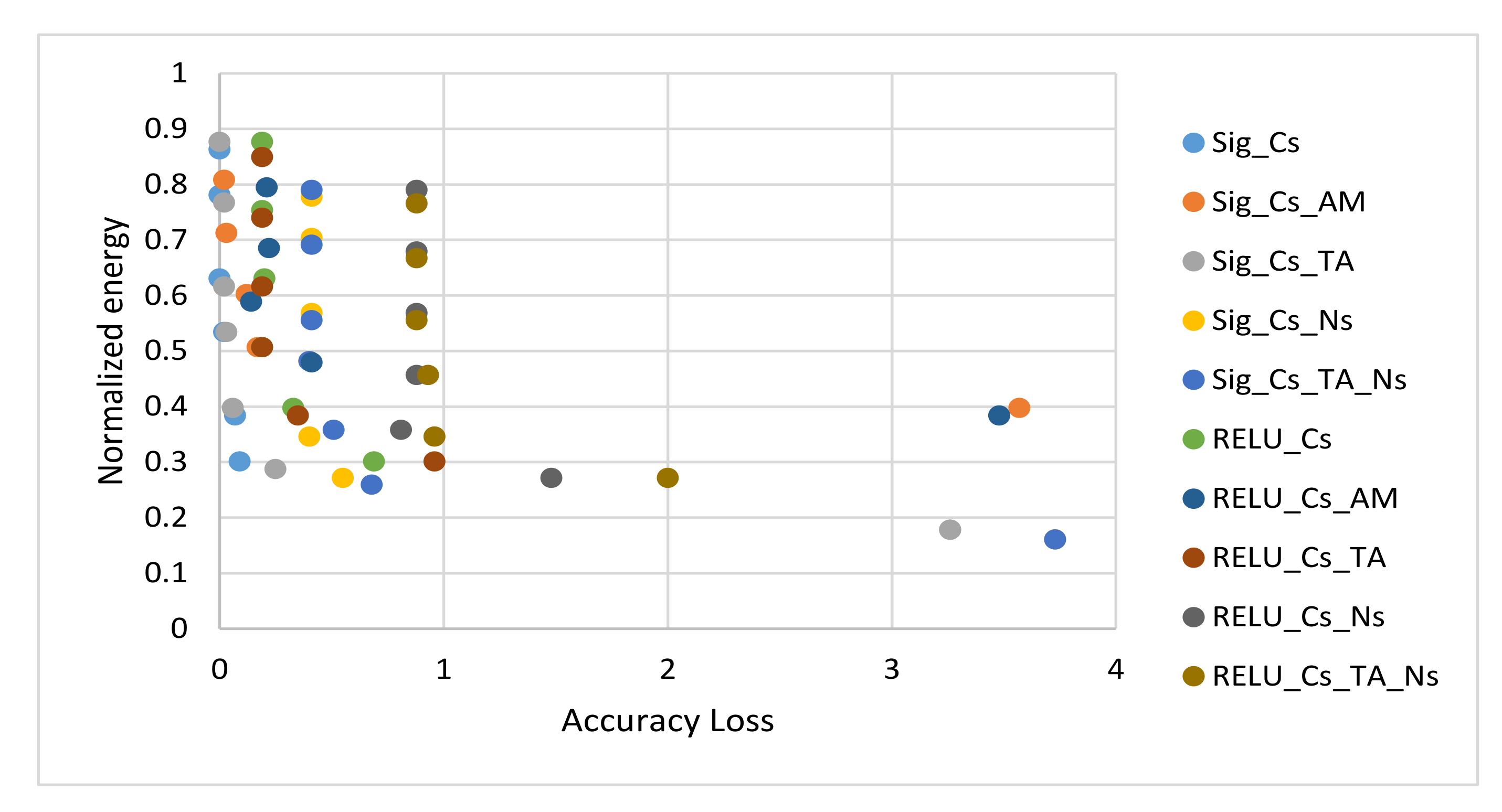
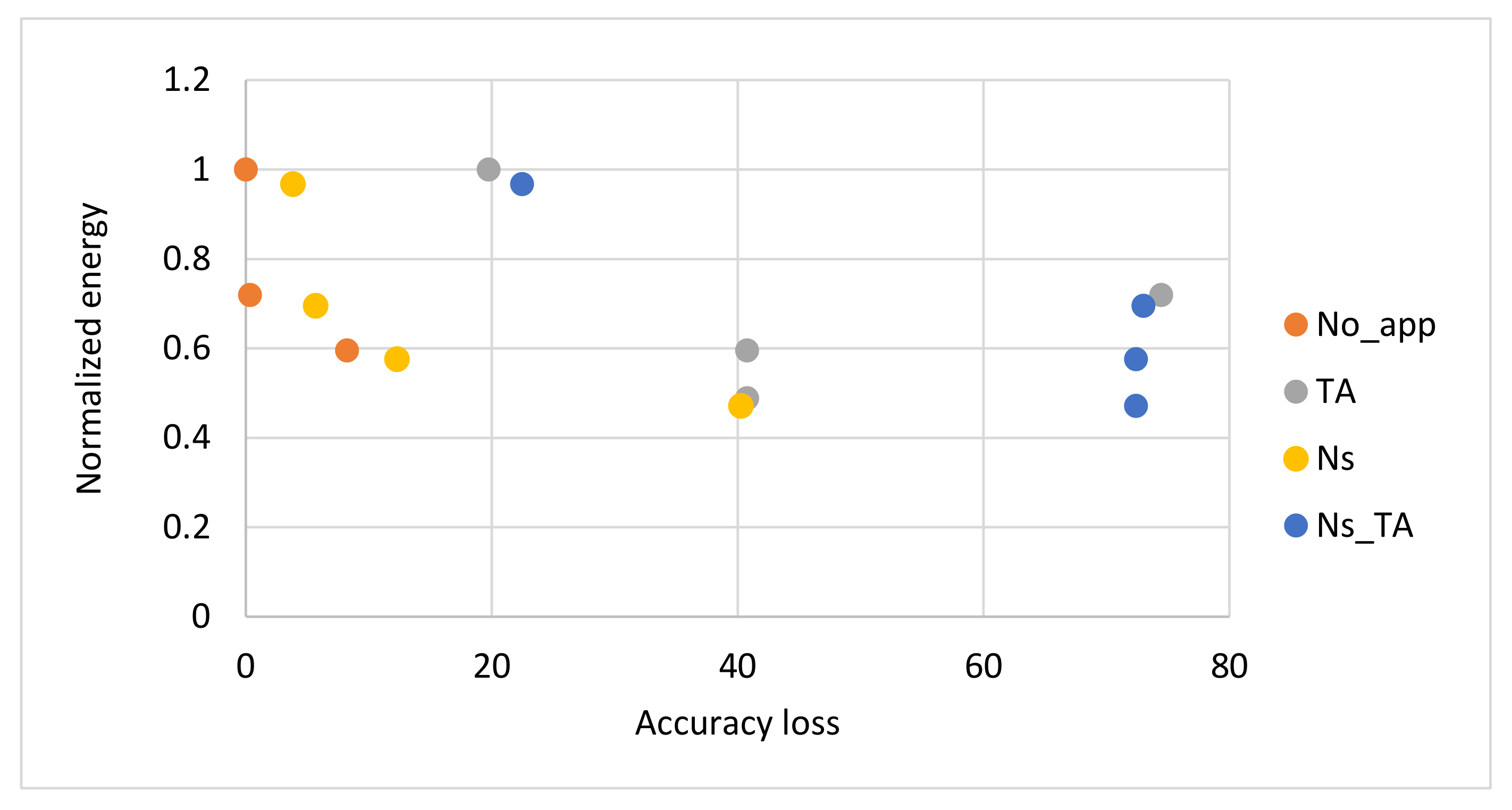
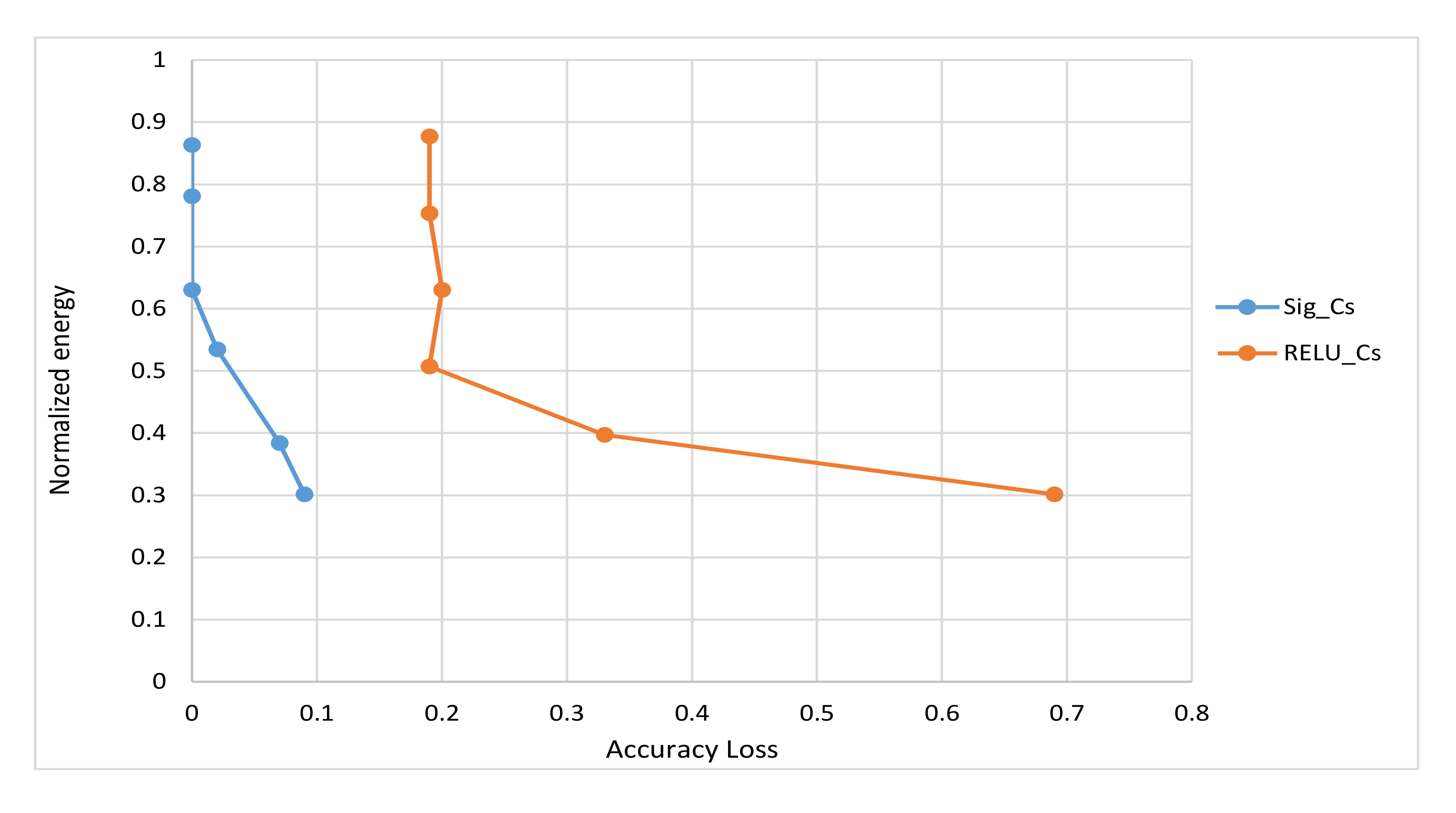
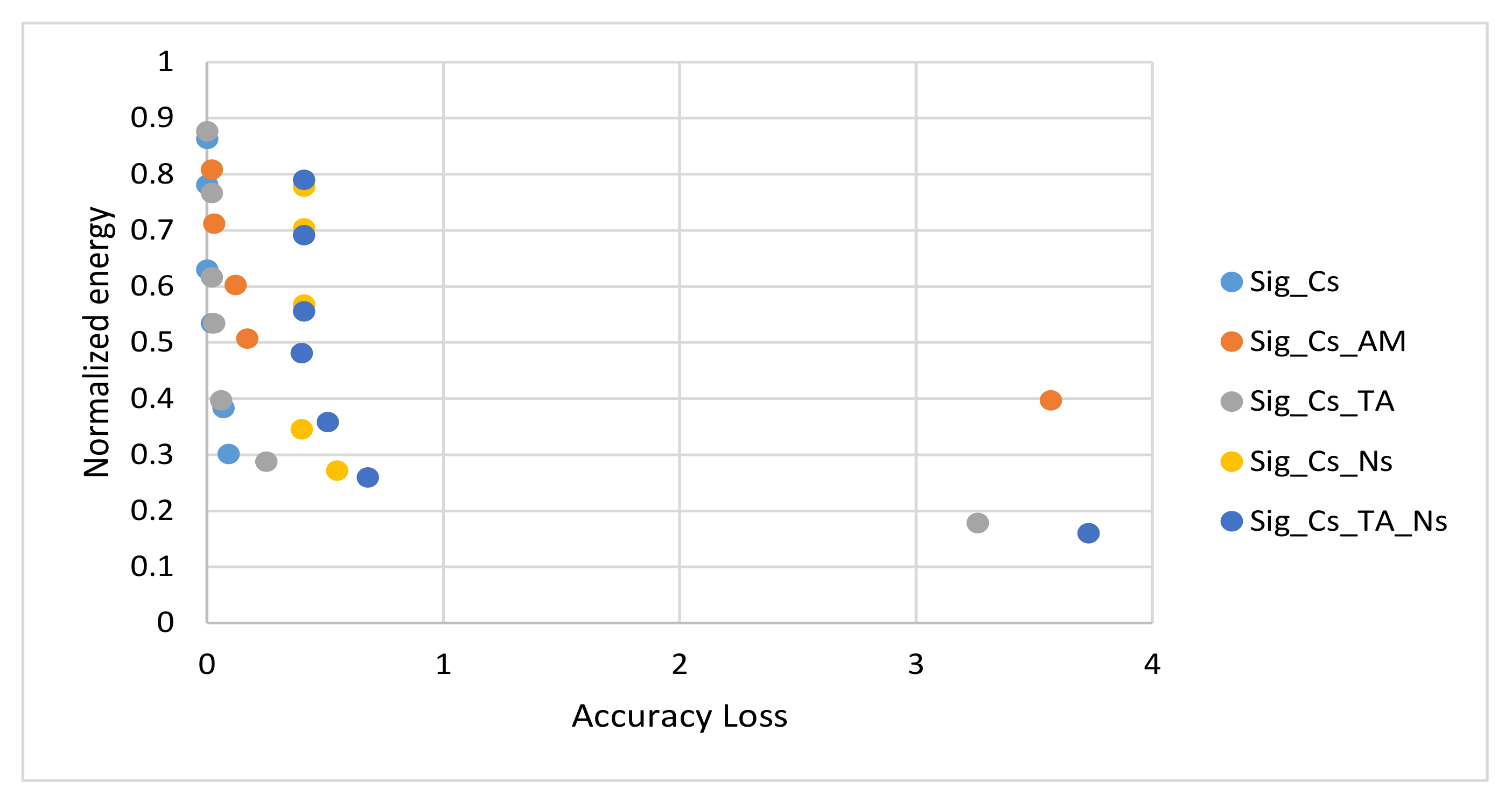
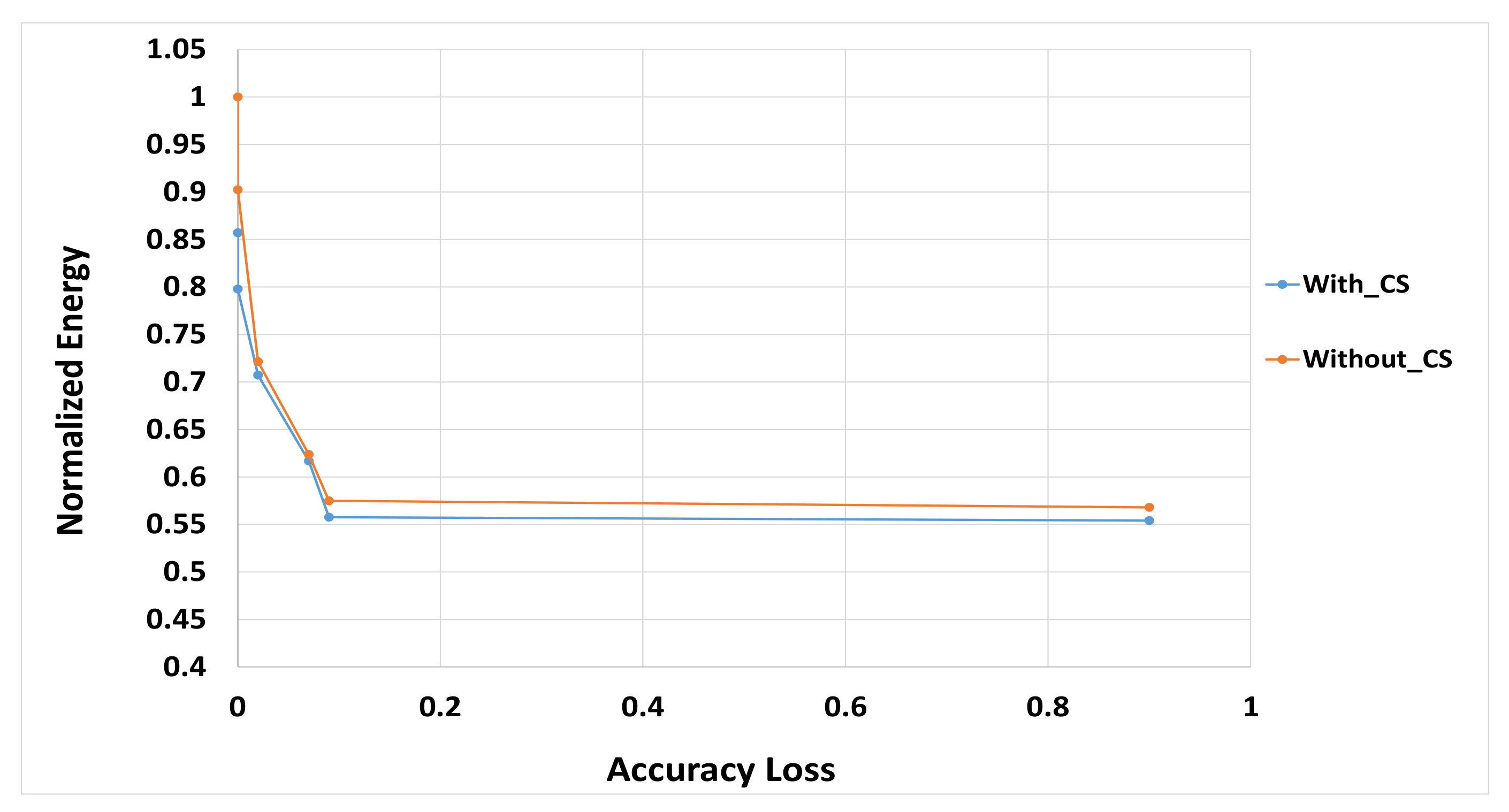
4.4. Simulation Results and Discussions
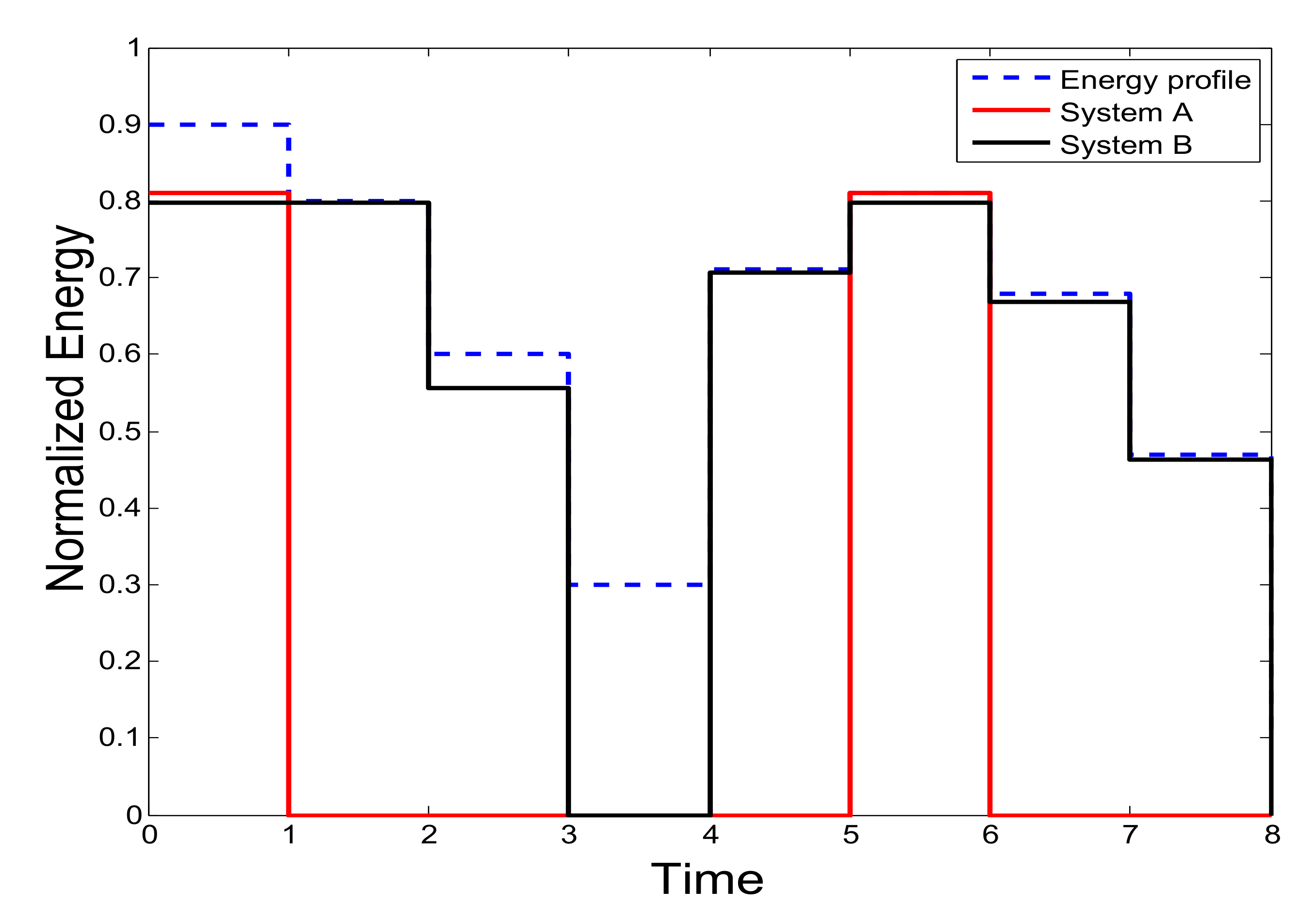
4.5. Proposed Algorithm and Configurations Selection
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kalogirou, S.A. Applications of artificial neural-networks for energy systems. Appl. Energy 2000, 67, 17–35. [Google Scholar] [CrossRef]
- Janardan, M.; Indranil, S. Artificial neural networks in hardware: A survey of two decades of progress. Neurocomputing 2010, 74, 239–255. [Google Scholar]
- Venkataramani, S.; Ranjan, A.; Roy, K.; Raghunathan, A. AxNN: Energy-efficient neuromorphic systems using approximate computing. In Proceedings of the IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), La Jolla, CA, USA, 11–13 August 2014; pp. 27–32. [Google Scholar]
- Zhang, Q.; Wang, T.; Tian, Y.; Yuan, F.; Xu, Q. ApproxANN: An approximate computing framework for artificial neural network. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 701–706. [Google Scholar]
- Jaeha, K.; Duckhwan, K.; Saibal, M. A power-aware digital feedforward neural network platform with backpropagation driven approximate synapses. In Proceedings of the IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Rome, Italy, 22–24 July 2015; pp. 85–90. [Google Scholar]
- Sarwar, S.S.; Venkataramani, S.; Raghunathan, A.; Roy, K. Multiplier-less artificial neurons exploiting error resiliency for energy-efficient neural computing. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 145–150. [Google Scholar]
- Mrazek, V.; Sarwar, S.S.; Sekanina, L.; Vasicek, Z.; Roy, K. Design of power-efficient approximate multipliers for approximate artificial neural networks. In Proceedings of the 35th International Conference on Computer-Aided Design, Austin, TX, USA, 7–10 November 2016. [Google Scholar]
- Duckhwan, K.; Jaeha, K.; Saibal, M. A power-aware digital multilayer perceptron accelerator with on-chip training based on approximate computing. IEEE Trans. Emerg. Top. Comput. 2017, 5, 164–178. [Google Scholar]
- Gerald, E. Reconfigurable computer origins: The UCLA fixed-plus-variable (F + V) structure computer. IEEE Ann. Hist. Comput. 2002, 24, 3–9. [Google Scholar]
- Kamaleldin, A.; Hosny, S.; Mohamed, K.; Gamal, M.; Hussien, A.; Elnader, E.; Shalash, A.; Obeid, A.M.; Ismail, Y.; Mostafa, H. A reconfigurable hardware platform implementation for software defined radio using dynamic partial reconfiguration on Xilinx Zynq FPGA. In Proceedings of the IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1540–1543. [Google Scholar]
- Sparsh, M. A survey of techniques for approximate computing. ACM Comput. Surv. (CSUR) 2016, 48, 1–33. [Google Scholar]
- Cong, L.; Jie, H.; Fabrizio, L. A low-power, high-performance approximate multiplier with configurable partial error recovery. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 24–28 March 2014; pp. 1–4. [Google Scholar]
- Uroš, L.; Patricio, B. Applicability of approximate multipliers in hardware neural networks. Neurocomputing 2012, 96, 57–65. [Google Scholar]
- Moons, B.; Brabandere, B.D.; Gool, L.V.; Verhelst, M. Energy-efficient convnets through approximate computing. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–8. [Google Scholar]
- Panda, P.; Sengupta, A.; Sarwar, S.S.; Srinivasan, G.; Venkataramani, S.; Raghunathan, A.; Roy, K. Cross-layer approximations for neuromorphic computing: From devices to circuits and systems. In Proceedings of the 53rd Annual Design Automation Conference, Austin, TX, USA, 5–9 June 2016; pp. 1–6. [Google Scholar]
- Parag, K.; Puneet, G.; Milos, E. Trading accuracy for power with an underdesigned multiplier architecture. In Proceedings of the 24th Internatioal Conference on VLSI Design, Chennai, India, 2–7 January 2011; pp. 346–351. [Google Scholar]
- Mahdiani, H.R.; Ahmadi, A.; Fakhraie, S.M.; Lucas, C. Bio-inspired imprecise computational blocks for efficient VLSI implementation of soft-computing applications. IEEE Trans. Circuits Syst. 2009, 57, 850–862. [Google Scholar] [CrossRef]
- Petra, N.; Caro, D.D.; Garofalo, V.; Napoli, E.; Strollo, A.G.M. Truncated binary multipliers with variable correction and minimum mean square error. IEEE Trans. Circuits Syst. 2009, 57, 1312–1325. [Google Scholar] [CrossRef]
- MNIST. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 22 October 2019).
- SVHN. Available online: http://ufldl.stanford.edu/housenumbers/ (accessed on 22 October 2019).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
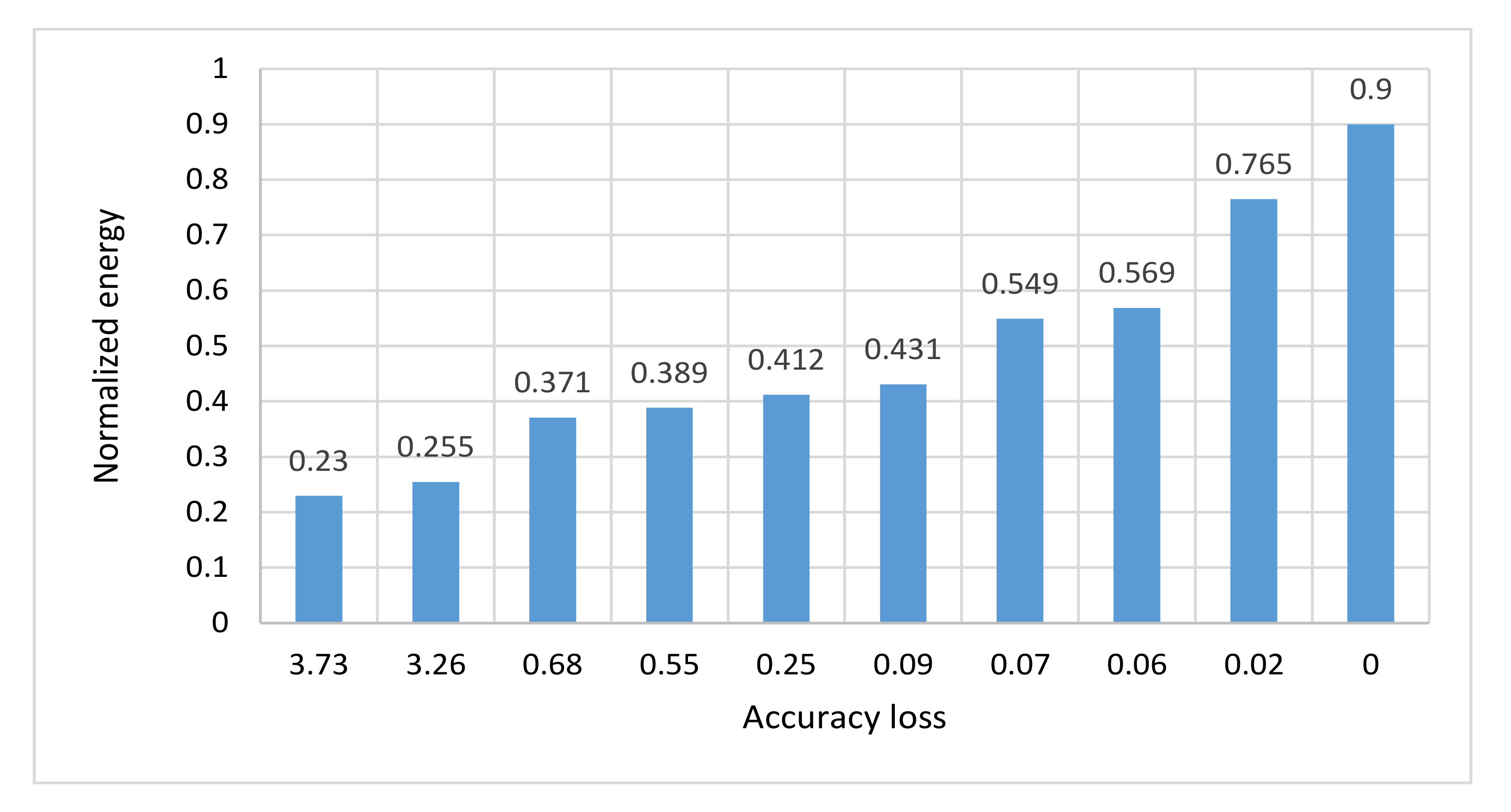
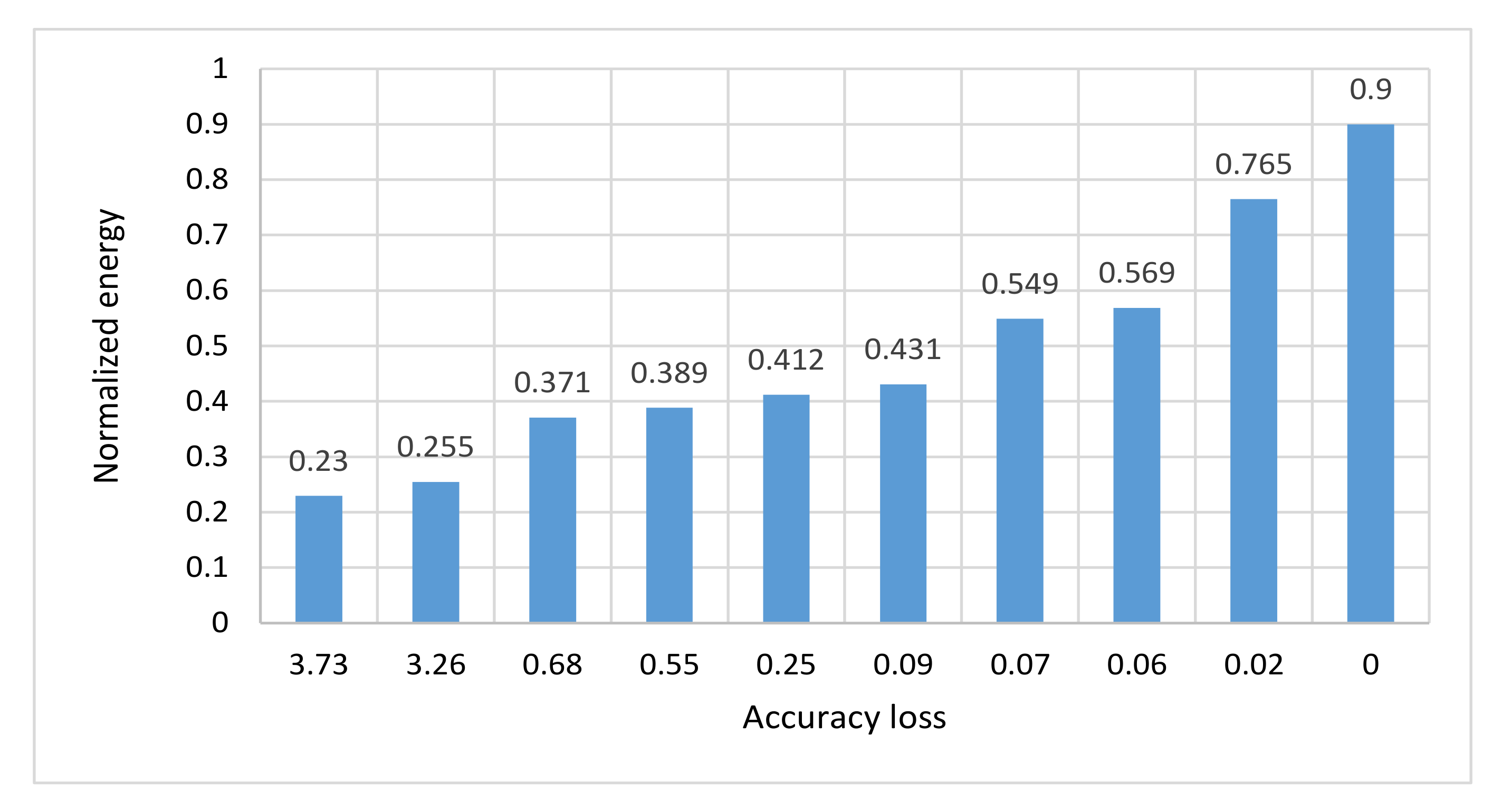
| Normalized Energy | Accuracy Loss% | Configurations |
|---|---|---|
| 0.230 | 3.73 | Cs_TA_Ns_4 |
| 0.255 | 3.26 | Cs_TA_4 |
| 0.371 | 0.68 | Cs_TA_Ns_6 |
| 0.389 | 0.55 | Cs_Ns_6 |
| 0.412 | 0.25 | Cs_TA_6 |
| 0.431 | 0.09 | Cs_6 |
| 0.549 | 0.07 | Cs_8 |
| 0.569 | 0.06 | Cs_TA_8 |
| 0.765 | 0.02 | Cs_10 |
| 0.9 | 0 | Cs_12 |
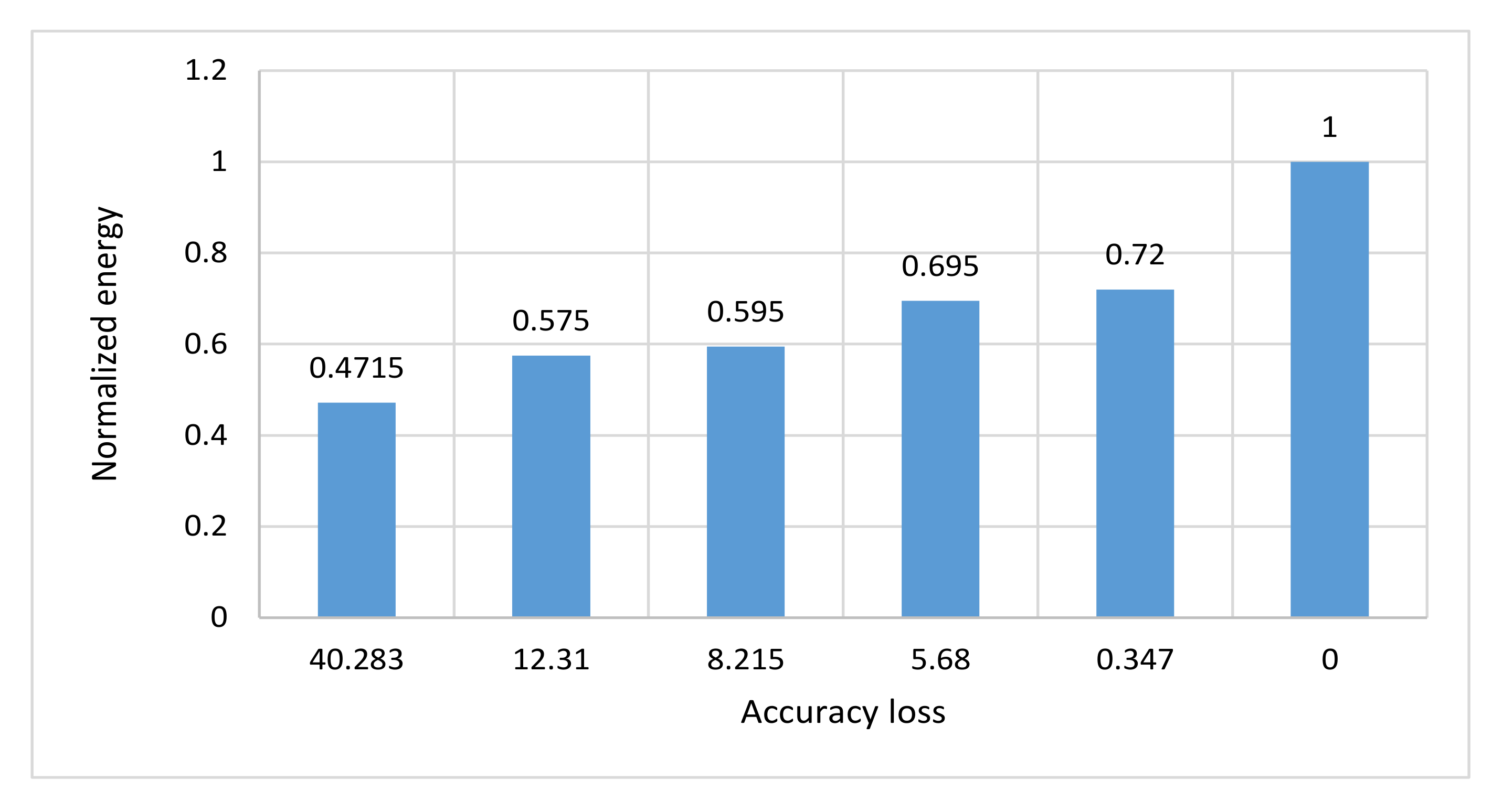
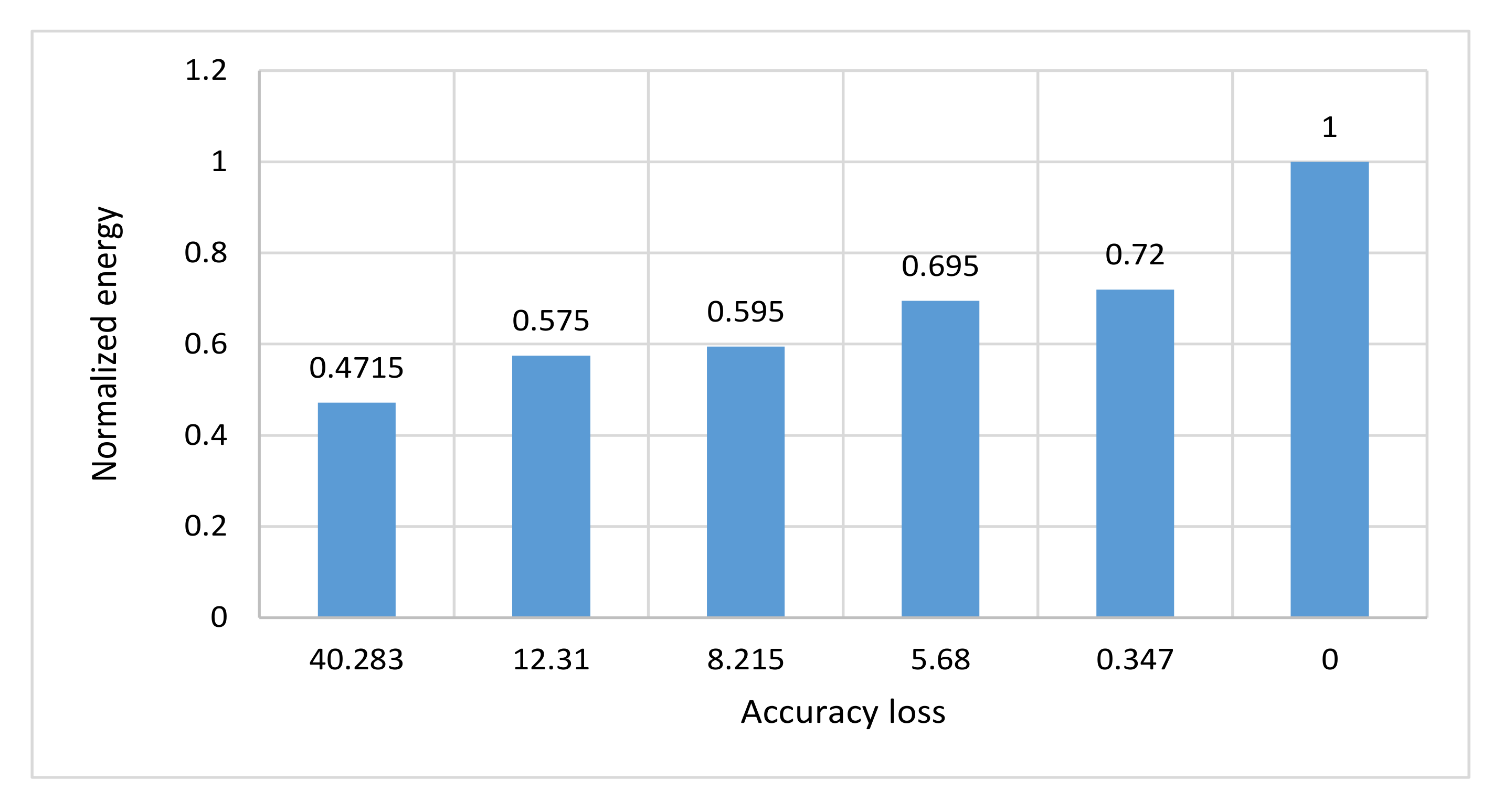
| Normalized Energy | Accuracy Loss% | Configurations |
|---|---|---|
| 0.472 | 40.3 | Ns_4 |
| 0.575 | 12.3 | Ns_5 |
| 0.595 | 8.2 | NoApp_5 |
| 0.695 | 5.7 | Ns_6 |
| 0.720 | 0.35 | NoApp_6 |
| 1 | 0 | NoApp_8 |
| Configuration | Area | Power(mW) | Accuracy(%) | |
|---|---|---|---|---|
| CLB | BRAM | |||
| WL_8 | 4297 | 161.5 | 121 | 80.58 |
| WL_6 | 3015 | 121.5 | 87 | 80.30 |
| WL_5 | 2489 | 101.5 | 72 | 73.96 |
| WL_4 | 2173 | 81.5 | 59 | 47.73 |
| Configuration | Area | Power(mW) | Accuracy(%) | |
|---|---|---|---|---|
| CLB | BRAM | |||
| Cs_12 | 7369 | 31 | 46 | 97.92 |
| Cs_10 | 5715 | 26 | 39 | 97.90 |
| Cs_TA_8 | 3736 | 21 | 28 | 97.86 |
| Cs_8 | 3980 | 21 | 29 | 97.85 |
| Cs_6 | 2728 | 15.5 | 22 | 97.83 |
| Cs-_TA_6 | 2606 | 15.5 | 21 | 97.67 |
| Cs_TA_4 | 1853 | 10.5 | 13 | 94.66 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, S.; Attia, S.; Salama, K.N.; Mostafa, H. EANN: Energy Adaptive Neural Networks. Electronics 2020, 9, 746. https://doi.org/10.3390/electronics9050746
Hassan S, Attia S, Salama KN, Mostafa H. EANN: Energy Adaptive Neural Networks. Electronics. 2020; 9(5):746. https://doi.org/10.3390/electronics9050746
Chicago/Turabian StyleHassan, Salma, Sameh Attia, Khaled Nabil Salama, and Hassan Mostafa. 2020. "EANN: Energy Adaptive Neural Networks" Electronics 9, no. 5: 746. https://doi.org/10.3390/electronics9050746
APA StyleHassan, S., Attia, S., Salama, K. N., & Mostafa, H. (2020). EANN: Energy Adaptive Neural Networks. Electronics, 9(5), 746. https://doi.org/10.3390/electronics9050746