Development of Curriculum Design Support System Based on Word Embedding and Terminology Extraction


Abstract
1. Introduction
2. Related Work
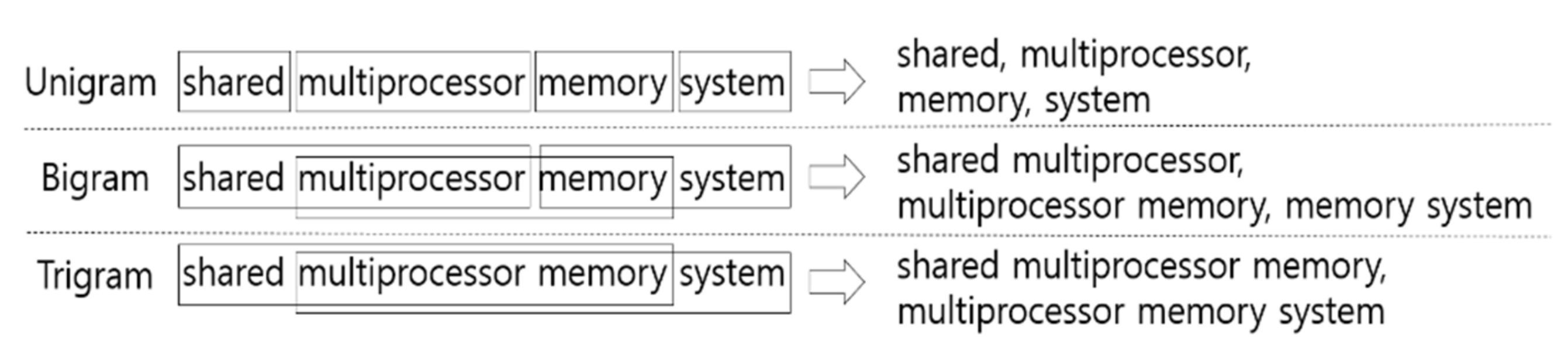
2.1. Terminology Extraction
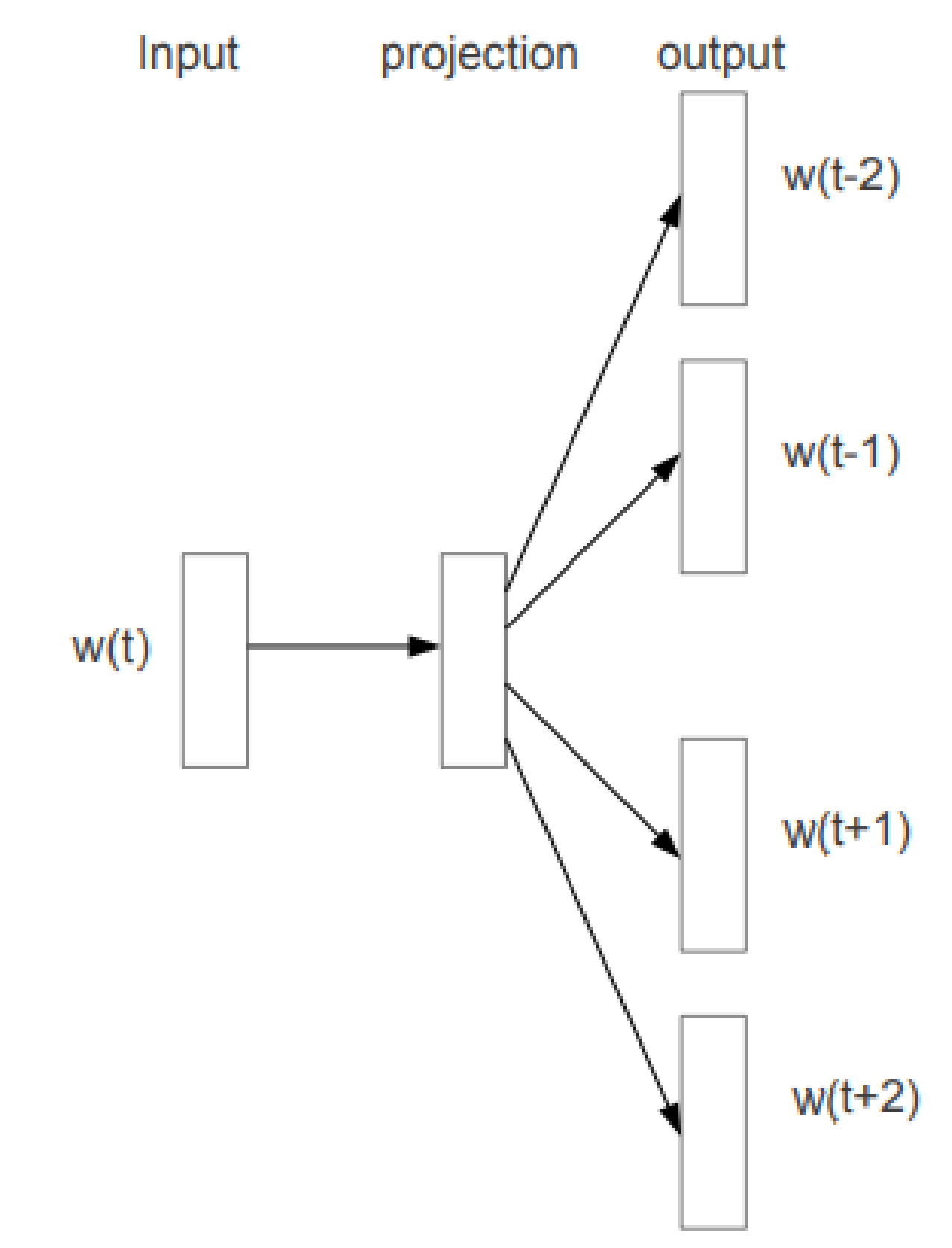
2.2. Word2vec
3. Computer Science Terminology and Knowledge Areas
4. Terminology Extraction System
4.1. Construction of a Terminology Dictionary
- Adjectives + singular nouns;
- Singular nouns + singular nouns;
- Adjectives + singular nouns + singular nouns;
- Present participle + singular noun;
- Singular nouns + singular nouns + singular nouns.
4.2. Development of the Terminology Extraction System
4.3. System Application and Evaluation
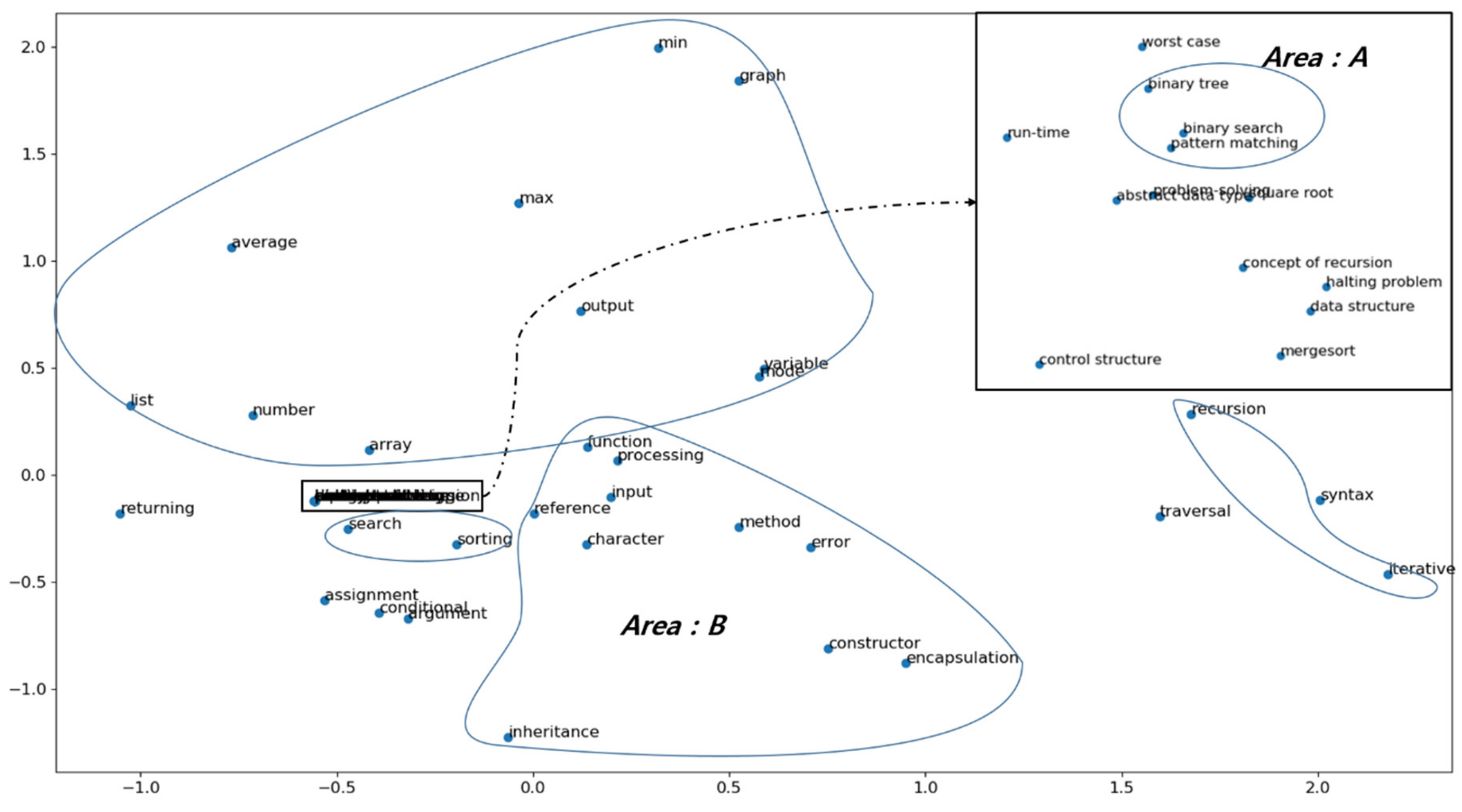
4.4. Knowledge Area Composition Using Word2vec
5. Curriculum Development
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Talebifard, P.; Leung, V.C.M. Context-aware Dissemination of Information and Services in Heterogeneous Network Environments. J. Ambient Intell. Humaniz. Comput. 2014, 5, 775–787. [Google Scholar] [CrossRef]
- Jin, S.; Lin, W.; Yin, H.; Yang, S.; Li, A.; Deng, B. Community structure mining in big data social media networks with MapReduce. Clust. Comput. 2015, 18, 999–1010. [Google Scholar] [CrossRef]
- Yoon, J.; Hong, T.; Choi, J.; Park, C.; Kim, K.; Yu, H. Evaluation of P2P and cloud computing as platform for exhaustive key search on block ciphers. Peer-to-Peer Netw. Appl. 2018, 11, 1206–1216. [Google Scholar] [CrossRef]
- Sohn, I.; Yoon, S.W.; Lee, S.H. Distributed scheduling using belief propagation for internet-of-things (IoT) networks. Peer-to-Peer Netw. Appl. 2018, 11, 152–161. [Google Scholar] [CrossRef]
- Woo, H.; Kim, J.; Lee, W. A Comparative Analysis of Domestic Universities’ Curriculum Based on Overseas Higher Informatics Standard Curriculum. Korean Assoc. Comput. Educ. 2017, 20, 27–38. [Google Scholar]
- Choi, G.; Lee, J.; Yoon, H. Development of a quantitative analysis model of creative problem-solving ability in computer textbooks. Clust. Comput. 2015, 18, 733–745. [Google Scholar] [CrossRef]
- Noh, K. A study on the position of CDO for improving competitiveness based big data in cluster computing environment. Clust. Comput. 2016, 19, 1659–1667. [Google Scholar] [CrossRef]
- Park, J.; Hwang, D. A Terminology Extraction System; Korean Institute of Information Scientists and Engineers: Busan, Korea, 2000; Volume 27, pp. 381–383. [Google Scholar]
- Pantel, P.; Lin, D. A Statistical Corpus-based Term Extractor. In Proceedings of the Biennial Conference of the Canadian Society on Computational Studies of Intelligence, Ottawa, ON, Canada, 7–9 June 2001; pp. 36–46. [Google Scholar]
- Yang, Y.; Zhao, T.; Lu, Q.; Zheng, D.; Yu, H. Chinese Term Extraction Using Different Types of Relevance. In Proceedings of the ACLIJCNLP, Suntec, Singapore, 2–7 August 2009; pp. 213–216. [Google Scholar]
- Lin, Y.; Chen, Z.B.; Sun, Q. Computer Domain Term Automatic Extraction and Hierarchical Structure Building. Comput. Eng. 2011, 37, 172–174. [Google Scholar]
- Jiang, S.; Dang, Y. Research on Automatic Extraction of Chinese New Domain-Specific Terms Comprising Letteredwords. Comput. Eng. 2007, 33, 47–49. [Google Scholar]
- Piao, S.S.L.; Sun, G.; Rayson, P.; Yuan, Q. Automatic Extraction of Chinese Multiword Expressions with a Statistical Tool. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics Workshop on Multiword Expressions in a Multilingual Context, Trento, Italy, 3–7 April 2006. [Google Scholar]
- Thurmair, G. Making Term Extraction Tools Usable. In Proceedings of the Joint Conference of the Eighth Workshop of the European Association for Machine Translation and the Fourth Controlled Language Applications Workshop, Dublin, Ireland, 15–17 May 2003. [Google Scholar]
- Bourigault, D. Surface Grammatical Analysis for the Extraction of Terminological Noun Phrase. In Proceedings of the 14th International Conference on Computational Linguistics, Nantes, France, 23–28 August 1992; pp. 977–981. [Google Scholar]
- Zheng, J.; Du, Y.; Liu, C. The Initial Research on the Method of Dynamically Acquiring Domain-Specific Lexicons Based on Corpus. Comput. Eng. 2002, 28, 64–66. [Google Scholar]
- Justeson, J.S.; Katz, S.M. Technical Terminology: Some Linguistic Properties and an Algorithm for Identification in Text. Nat. Lang. Eng. 1995, 1, 9–27. [Google Scholar] [CrossRef]
- Ariav, T. Curriculum Analysis and Curriculum Evaluation: A Contrast. Stud. Educ. Eval. 1986, 12, 139–147. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Yang, Z.-T.; Zheng, J. Research on Chinese Text Classification Based on Word2vec. In Proceedings of the IEEE International Conference on Computer and Communications, Chengdu, China, 14–17 October 2016; pp. 14–17. [Google Scholar]
- Li, R.; Zhang, Q.; Liu, J.Y. Microblog Sentiment Analysis Base on Weighted Word2vec. Commun. Technol. 2017, 50, 502–506. [Google Scholar]
- Joint Task Force for Computing Curricula. Computing Curricula 2005: The Overview Report; IEEE Computer Society: New York, NY, USA, 2005; Available online: https://www.acm.org/binaries/content/assets/education/curricula-recommendations/cc2005-march06final.pdf (accessed on 16 March 2019).
- Computer Science Education Committee. Curriculum Standard Computer Science J07-CS; Japan Information Processing Society: Tokyo, Japan, 2007. [Google Scholar]
- ACM; IEEE Computer Society. Computer Science Curriculum 2008: An Interim Revision of CS 2001; IEEE Computer Society: New York, NY, USA, 2008. [Google Scholar]
- Association for Computing Machinery (ACM); IEEE Computer Society. Computer Science Curricula 2013; IEEE Computer Society: New York, NY, USA, 2013. [Google Scholar]
- The ACM K-12 Task force Curriculum Committee. A Model Curriculum for K-12 Computer Science; CSTA: New York, NY, USA, 2003. [Google Scholar]
- The CSTA Standard Task force. CSTA K-12 Computer Science Standards; Santa Fe Institute: Santa Fe, NM, USA, 2011. [Google Scholar]
- Hirankitti, V.; Mai, T.X. A meta-logical approach for reasoning with an OWL 2 Ontology. J. Ambient Intell. Humaniz. Comput. 2012, 3, 293–303. [Google Scholar] [CrossRef]
- Reqqass, M.; Lakhouaja, A.; Mazroui, A. Amelioration of the Interactive Dictionary of Arabic Language. Int. J. Comput. Sci. Appl. 2015, 12, 94–107. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AL) Algorithms and Complexity | AR) Architecture and Organization | CN) Computational Science |
| DS) Discrete Structures | GV) Graphics and Visualization | HCI) Human-Computer Interaction |
| IAS) Information Assurance and Security | IM) Information Management | IS) Intelligent Systems |
| NC) Networking and Communication | OS) Operating System | PBD) Platform-based Development |
| PD) Parallel and Distributed Computing | PL) Programming Language | SDF) Software Development Fundamentals |
| SE) Software Engineering | SF) Systems Fundamentals | SP) Social Issues and Professional Practice |
| KA | Topic (Sentence) Count of CS2013 | Technical Term Count of Dictionary | ||||||
|---|---|---|---|---|---|---|---|---|
| Tier1 | Tier2 | Elective | Total | Tier1 | Tier2 | Elective | Total | |
| AL | 21 | 14 | 29 | 64 | 94(+73) | 71(+57) | 134(+105) | 299(+235) |
| AR | 0 | 39 | 16 | 55 | 0(+0) | 176(+137) | 59(+43) | 235(+180) |
| CN | 5 | 0 | 27 | 32 | 18(+13) | 0(+0) | 315(+288) | 333(+301) |
| DS | 35 | 5 | 0 | 40 | 149(+114) | 10(+5) | 0(+0) | 159(+119) |
| GV | 4 | 3 | 58 | 65 | 42(+38) | 20(+17) | 250(+192) | 312(+247) |
| HCI | 10 | 8 | 58 | 76 | 69(+59) | 32(+24) | 327(+269) | 428(+352) |
| IAS | 17 | 19 | 65 | 101 | 62(+45) | 110(+91) | 301(+236) | 473(+372) |
| IM | 4 | 16 | 78 | 98 | 17(+13) | 54(+38) | 323(+245) | 394(+296) |
| IS | 0 | 21 | 62 | 83 | 0(+0) | 99(+78) | 312(+250) | 411(+328) |
| NC | 10 | 22 | 4 | 36 | 62(+52) | 55(+33) | 9(+5) | 126(+90) |
| OS | 12 | 19 | 32 | 63 | 50(+38) | 62(+43) | 110(+78) | 222(+159) |
| PBD | 0 | 0 | 21 | 21 | 0(+0) | 0(+0) | 67(+46) | 67(+46) |
| PD | 10 | 12 | 33 | 55 | 47(+37) | 101(+89) | 198(+165) | 346(+291) |
| PL | 11 | 20 | 60 | 91 | 90(+79) | 189(+169) | 245(+185) | 524(+433) |
| SDF | 24 | 0 | 0 | 24 | 144(+120) | 0(+0) | 0(+0) | 144(+120) |
| SE | 9 | 36 | 40 | 85 | 64(+55) | 228(+192) | 198(+158) | 490(+405) |
| SF | 24 | 16 | 6 | 46 | 138(+114) | 72(+56) | 30(+24) | 240(+194) |
| SP | 29 | 14 | 34 | 77 | 140(+111) | 61(+47) | 170(+136) | 371(+294) |
| Total | 225 | 264 | 623 | 1112 | 1186(+961) | 1340(+1076) | 3048(+2425) | 5574(+4462) |
| KA | CS2013 | India | Israel | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Tier1 | Tier2 | Elective | Tier1 | Tier2 | Elective | Tier1 | Tier2 | Elective | |
| AL | 21(9.3) | 14(5.3) | 29(4.7) | 4(5.6) | 2(2.9) | 4(3.4) | 6(8.8) | 2(3.2) | 4(4.2) |
| AR | 0(0) | 40(15.1) | 16(2.6) | 0(0) | 11(16.2) | 1(0.9) | 0(0) | 13(21) | 0(0) |
| CN | 5(2.2) | 0(0) | 27(4.3) | 2(2.8) | 0(0) | 16(13.7) | 2(2.9) | 0(0) | 19(19.8) |
| DS | 35(15.6) | 5(1.9) | 0(0) | 5(6.9) | 1(1.5) | 0(0) | 5(7.4) | 0(0) | 0(0) |
| GV | 4(1.8) | 3(1.1) | 58(9.3) | 3(4.2) | 1(1.5) | 4(3.4) | 2(2.9) | 1(1.6) | 10(10.4) |
| HCI | 10(4.4) | 8(3) | 58(9.3) | 6(8.3) | 3(4.4) | 16(13.7) | 5(7.4) | 3(4.8) | 9(9.4) |
| IAS | 17(7.6) | 19(7.2) | 65(10.4) | 2(2.8) | 6(8.8) | 5(4.3) | 4(5.9) | 4(6.5) | 1(1) |
| IM | 4(1.8) | 16(6) | 78(12.5) | 1(1.4) | 3(4.4) | 25(21.4) | 1(1.5) | 3(4.8) | 13(13.5) |
| IS | 0(0) | 21(7.9) | 62(10) | 0(0) | 4(5.9) | 7(6) | 0(0) | 3(4.8) | 6(6.3) |
| NC | 10(4.4) | 22(8.3) | 4(0.6) | 8(11.1) | 4(5.9) | 0(0) | 2(2.9) | 1(1.6) | 0(0) |
| OS | 12(5.3) | 19(7.2) | 32(5.1) | 6(8.3) | 2(2.9) | 7(6) | 2(2.9) | 2(3.2) | 7(7.3) |
| PBD | 0(0) | 0(0) | 21(3.4) | 0(0) | 0(0) | 3(2.6) | 0(0) | 0(0) | 0(0) |
| PD | 10(4.4) | 12(4.5) | 33(5.3) | 0(0) | 0(0) | 0(0) | 2(2.9) | 2(3.2) | 5(5.2) |
| PL | 11(4.9) | 20(7.5) | 60(9.6) | 7(9.7) | 13(19.1) | 13(11.1) | 7(10.3) | 10(16.1) | 9(9.4) |
| SDF | 24(10.7) | 0(0) | 0(0) | 11(15.3) | 0(0) | 0(0) | 13(19.1) | 0(0) | 0(0) |
| SE | 9(4) | 36(13.6) | 40(6.4) | 1(1.4) | 10(14.7) | 4(3.4) | 4(5.9) | 12(19.4) | 5(5.2) |
| SF | 24(10.7) | 16(6) | 6(1) | 6(8.3) | 5(7.4) | 2(1.7) | 5(7.4) | 4(6.5) | 1(1) |
| SP | 29(12.9) | 14(5.3) | 34(5.5) | 10(13.9) | 3(4.4) | 10(8.5) | 8(11.8) | 2(3.2) | 7(7.3) |
| Total | 225(100) | 265(100) | 623(100) | 72(100) | 68(100) | 117(100) | 68(100) | 62(100) | 96(100) |
| Extracted technical terms | |
|---|---|
| India | variable, assignment, number, character, list, array, average, syntax, min, mode, max, control structure, recursion, pattern matching, argument, function, method, reference, encapsulation, inheritance, constructor, error, sorting, binary search, traversal, run-time |
| Israel | problem-solving, input, processing, output, control structure, data structure, list, graph, square root, variable, assignment, number, character, array, syntax, conditional, concept of recursion, iterative, reference, argument, returning, function, abstract data type, error, halting problem, sorting, merge sort, search, binary tree, traversal, worst case, square root, run-time |
| KA | Topic | Compatibility | Feasibility |
|---|---|---|---|
| Information Society and Information Technology | Information technology development and social change | 4.17 | 4.33 |
| Information technology and problem solving | |||
| Algorithm Overview | Algorithm Concepts | 4.33 | 4.58 |
| Method of Representation of Algorithms | |||
| Algorithm design | |||
| Data structure | Basic data structure | 4.25 | 4.45 |
| - linear data structure | |||
| - nonlinear data structure | |||
| Programming Basics | Configuration of Programming | 4.25 | 4.42 |
| I/O function | |||
| Variable, type, expression, assignment | |||
| Selection structure | 4.08 | 4.50 | |
| Repeating structure | |||
| Passing Functions and Parameters | |||
| Project | 3.83 | 4.33 | |
| Design and Implementation of Algorithms | Sorting algorithm type | 3.83 | 4.33 |
| Types of search algorithms | 3.67 | 4.25 | |
| Project | 3.83 | 4.25 | |
| Algorithm Performance Analysis Basics | Basics of algorithm efficiency analysis | 3.33 | 3.92 |
| Space Complexity and Time Complexity | |||
| Measure the performance of the algorithm | |||
| Implementation of algorithm performance analysis | Comparison of efficiency between algorithms | 3.25 | 3.83 |
| KA | DKA | Topics |
|---|---|---|
| Information | Social influence of information technology | Information technology development and social change |
| Information culture | ||
| Technology Overview | Utilization of information technology | |
| Algorithm | Algorithm Overview | Algorithm Concepts |
| Method of Representation of Algorithms | ||
| Basic data structure | ||
| Algorithm design | Sorting algorithm | |
| Search algorithm | ||
| Analysis of algorithm performance | Algorithm complexity | |
| Programming | Programming Basics | Programming environment |
| I / O function | ||
| Variables, data types, operators | ||
| Selection structure | ||
| Repeating structure | ||
| Passing Functions and Parameters | ||
| Program implementation | Implementation of sorting algorithm | |
| Implementation of search algorithm |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Woo, H.; Kim, J.; Lee, W. Development of Curriculum Design Support System Based on Word Embedding and Terminology Extraction. Electronics 2020, 9, 608. https://doi.org/10.3390/electronics9040608
Woo H, Kim J, Lee W. Development of Curriculum Design Support System Based on Word Embedding and Terminology Extraction. Electronics. 2020; 9(4):608. https://doi.org/10.3390/electronics9040608
Chicago/Turabian StyleWoo, HoSung, JaMee Kim, and WonGyu Lee. 2020. "Development of Curriculum Design Support System Based on Word Embedding and Terminology Extraction" Electronics 9, no. 4: 608. https://doi.org/10.3390/electronics9040608
APA StyleWoo, H., Kim, J., & Lee, W. (2020). Development of Curriculum Design Support System Based on Word Embedding and Terminology Extraction. Electronics, 9(4), 608. https://doi.org/10.3390/electronics9040608