Abstract
In this paper, we introduce the three-dimensional Maximum Range-Sum (3D MaxRS) problem and the Maximum Spatiotemporal Range-Sum Change (MaxStRSC) problem. The 3D MaxRS problem tries to find the 3D range where the sum of weights across all objects inside is maximized, and the MaxStRSC problem tries to find the spatiotemporal range where the sum of weights across all objects inside is maximally increased. The goal of this paper is to provide efficient methods for data analysts to find interesting spatiotemporal regions in a large historical spatiotemporal dataset by addressing two problems. We provide a mathematical explanation for each problem and propose several algorithms for them. Existing methods tried to find the optimal region over two-dimensional datasets or to monitor a burst region over two-dimensional data streams. The majority of them cannot directly solve our problems. Although some existing methods can be used or modified to solve the 3D MaxRS problems, they have limited scalability. In addition, none of them can be used to solve the MaxStRS-RC problem (a type of MaxStRSC problem). Finally, we study the performance of the proposed algorithms experimentally. The experimental results show that the proposed algorithms are scalable and much more efficient than existing methods.
1. Introduction
Technological advances in mobile devices, location tracking, and wireless communication lead to the emergence of new types of services, such as location-based social networking services. Nowadays, a vast amount of user-generated spatiotemporal data has been collected from these services. Analyzing these spatiotemporal data often provides insights into understanding customers’ behaviors in the real world. For example, suppose that data analysts work for a coffeehouse chain that has over 2000 retail stores across the globe. In addition, suppose that they obtain a large historical dataset by having collected geo-tagged posts that mentioned their coffeehouse from several Location-Based Social Network Services (LBSNSs) to analyze customer satisfaction. Each collected object o is represented by a tuple of the form , where is the spatiotemporal point at which o is posted, and w is the weight of o.
In this scenario, the following queries may help develop a marketing strategy.
- Query 1. “find the (1 km × 1 km × 1 h) spatiotemporal range which maximizes the number of objects inside."
- Query 2. “find the (1 km × 1 km × 1 h) spatiotemporal range where the number of objects inside is maximally increased within one hour.
Figure 1 describes query examples on an example dataset. We draw only four representative ranges (i.e., A, B, C, and D), but note that there are an infinite number of (1 km × 1 km × 1 h) ranges in the entire space. The result of query 1 is B because no other spatiotemporal ranges contain more than five objects. However, the result of query 2 is not B but C. Let us draw the ‘previous’ range below each range, as shown in Figure 1. For example, we draw below A so that is adjacent to A. Observe that the number of objects inside A is increased by one compared to that inside . As shown in Figure 1b, C is the region where the number of posts inside is maximally increased.
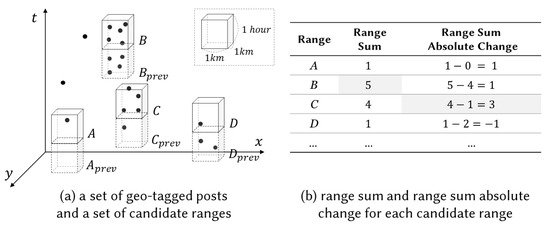
Figure 1.
An example dataset and query examples.
It is helpful for data analysts to use these queries to understand customers’ behavior. In addition, they can provide more valuable insights into customers’ satisfaction with a slight modification. For example, suppose that we set the weight of each geo-tagged post by quantifying the emotional state of the poster (e.g., for positive and for negative) using existing sentiment analysis methods. Then, data analysts can carry out case-studies for marketing research by using the following queries:
- Query 3. “find the (1 km × 1 km × 1 h) spatiotemporal range which maximizes the number of all positive geo-tagged posts inside.”
- Query 4. “find the (1 km × 1 km × 1 h) spatiotemporal range where the number of negative geo-tagged posts inside is maximally increased within one hour.”
If we plan to host an event for marketing in a restricted area and time, these queries may be useful to prepare this event. The goal of this paper is to provide efficient methods for data analysts to find such interesting spatiotemporal regions in a large historical spatiotemporal dataset. We formulate two mathematical problems: the maximum three-dimensional range-sum (3D MaxRS) problem and the maximum spatiotemporal range-sum change (MaxStRSC) problem. The 3D MaxRS problem tries to find the spatiotemporal range where the sum of weights across all objects inside is maximized. On the other hand, the MaxStRSC problem tries to find the spatiotemporal range where the sum of weights across all objects inside is maximally increased.
Recently, many researchers have proposed methods for analyzing spatiotemporal data to support decision-making processes. Existing methods try to find the optimal region over 2D datasets or to monitor a burst region over 2D data streams. However, the majority of them cannot directly solve our problems. Although some existing methods can be used or modified to solve the 3D MaxRS problems, they have limited scalability. In addition, none of them can be used to solve the MaxStRS-RC problem (a type of MaxStRSC problem). To our knowledge, this is the first research addressing the 3D MaxRS problem and the MaxStRSC problem in historical spatiotemporal datasets.
We summarize our contribution as follows: (1) We introduce two problems (3D MaxRS, MaxStRSC), which try to find interesting spatiotemporal regions in a large historical spatiotemporal dataset. To our knowledge, this is the first research that studies these problems over large-scale historical spatiotemporal datasets. (2) We provide a mathematical explanation and propose several scalable algorithms for each problem. (3) We experimentally study the performance of the proposed algorithms. We extend existing methods so that they can handle the 3D MaxRS problem or the MaxStRSC problem for comparison. The experimental results show that our algorithms are much more efficient and scalable than existing methods.
We organize the rest of this paper as follows: We give a formal definition for each problem in Section 2. We survey the related works in detail in Section 3. Then, we describe our algorithms for the 3D MaxRS problem (Section 4) and the MaxStRSC problem (Section 5 and Section 6). In Section 7, we discuss the experimental results. In Section 8, we summarize the conclusion of this paper and our future work.
2. Preliminaries
In this section, we give a formal definition of the 3D MaxRS problem and the MaxStRSC problem.
2.1. 3D MaxRS Problem
Let us consider a set O of spatiotemporal objects whose cardinality is too large to fit into main memory. An object is defined as a tuple , where represents the spatiotemporal point, and w is the weight of o.
We now introduce some useful notations to express geometric objects compactly. We use to denote the axis-parallel cuboid centered at a point , where P is the entire spatiotemporal space. In addition, for a cuboid c, we denote the set of objects inside c by (i.e., and is inside ). Without loss of generality, an object on the boundary of a cuboid is not said to be ‘inside’ the cuboid.
Using these notations, we define the three-dimensional Maximum Spatiotemporal Range Sum (3D MaxRS) problem as follows:
Definition 1.
(3D MaxRS problem). Given O, the size of a query cuboid, find the set of all points such that:
where P is the entire spatiotemporal space.
As its name implies, the 3D MaxRS problem is a three-dimensional version of the 2D MaxRS problem [1,2], a well-known problem studied in computational geometry community.
2.2. MaxStRSC Problem
We introduce another notation before we formulate the maximum range sum change problem. We use to denote the axis-parallel cuboid centered at the point , where . The Maximum Spatiotemporal Range Sum Change (MaxStRSC) problem is defined as follows:
Definition 2.
(MaxStRSC problem). Given O, the size of a query cuboid, and a function change: , find the set of all points such that:
where P is the entire spatiotemporal space.
The MaxStRSC tries to find the location p such that the change between the aggregate weight of objects in and the aggregate weight of objects in is maximized. The answer to an instance of the MaxStRSC problem depends on the choice of a function . We propose two types of the MaxStRSC problem called Maximum Spatiotemporal Range-Sum Absolute-Change (MaxStRS-AC), and Maximum Spatiotemporal Range-Sum Relative-Change (MaxStRS-RC) as follows:
- MaxStRS-AC: The MaxStRSC problem with the absolute change measurement function , where
- MaxStRS-RC: The MaxStRSC problem with the relative change measurement functionwhere . Without loss of generality, we assume that if =0.
3. Related Work
We categorize related works into four groups as follows: (1) Range Aggregate Query, (2) MaxRS and its variants in 2D Space, (3) Max-enclosure Problem in 3D Space, and (4) Burst Detection.
3.1. Range Aggregate Query
Suppose that we have a set O of spatiotemporal objects, where each has weight . The range aggregate query [3,4,5,6,7,8] returns the aggregate value over objects inside the query range. Although it is possible to solve the 3D MaxRS problem by issuing range-aggregate queries, this method needs too high computational costs even for solving the 2D MaxRS problem as described in [1].
3.2. MaxRS and Its Variants in 2D Space
For the given set O of weighted objects and the size of a query rectangle (or cuboid), the 2D MaxRS problem tries to find the location of the area where the sum of weights of all objects is maximized. The majority of studies in this category [1,2,9,10,11,12,13,14] aim to process the 2D MaxRS query on static spatial objects. Choi et al. [1,2] proposed scalable algorithms, by modifying the in-memory plane-sweep algorithm [15], and Zhou et al. [9] proposed an index-based method that solves the MaxRS query. Several variants of the MaxRS problem [10,11,12,13,14] also have been proposed. Some researchers proposed methods [16,17,18,19,20] for continuously monitoring the MaxRS problem over spatial data streams.
The existing methods mentioned above are not targeted at the historical spatiotemporal data analysis. While the input of the 3D MaxRS problem and the MaxStRSC problem is a set of spatiotemporal objects, the input of the MaxRS problem of each study above is either a set of spatial objects or a spatial data stream in a two-dimensional space. Most of them cannot be directly extended to solve the 3D MaxRS problem or the MaxStRSC problem. Although we can use one of some existing algorithms [1,2] as a sub-routine in our method at least for solving the 3D MaxRS problem, it degrades the performance due to redundant computations. We describe this in detail in Section 4.2.3, and Section 7.2.1.
3.3. Max-Enclosure Problem in 3D Space
We found one study [15] that can be directly applied to solve the 3D MaxRS problem. Subhas C. Nandy and Bhaswar B. Bhattacharya [15] proposed an in-memory algorithm for the max-enclosing cuboid problem, a special case of the 3D MaxRS problem where every object has weight 1. The main idea of their approach is to take the projections of all the input objects on the -plane and compute the set S of candidate coordinates. Although their method is simple to implement, it has the following drawbacks: (1) it needs an expensive preprocessing to compute all the potential coordinates; (2) it has limited scalability since large amounts of points can be created in the first phase as the data size increases. We extend it so that it can handle the 3D MaxRS problem and externalize it by employing STR-tree [21] for better scalability, but the experimental results show that it is much more inefficient than the proposed methods.
3.4. Burst Detection
Some existing work [22,23] tried to identify burst regions (hot spots), which is similar to our MaxStRS-AC problem. For example, Mathioudakis et al. [22] propose the spatial burst problem, which seeks to find ‘spatial bursts’ where related documents exhibit a surge. They tried to find ‘burst cells’, where notable events happen over a grid. Conceptually, it may seem similar to our works, but they are different. The answer to the MaxStRSC problem can be an arbitrary region that does not need to be one of the pre-defined cells, unlike that of the spatial burst problem of [22].
Recently, Feng et al. [23] proposed the continuous bursty region detection (SURGE) problem, which tries to monitor a bursty region from a stream of spatial objects. For the given size of a query rectangle, a bursty region is the rectangular region of size with the maximum burst score. The burst score of a rectangular region r is defined over two consecutive temporal windows . The higher the change of the aggregate value of objects inside r for between that of objects inside r for , the higher tends to be the burst score of r over . Unlike studies for the MaxRS problem or its variations, Feng et al. [23] focuses on the change of the aggregate value of the region between two consecutive temporal windows.
Although The SURGE problem is similar conceptually to the MaxStRS-AC problem, they are different. They assume a stream environment, so it is not feasible to use their solution to analyze the large historical spatiotemporal dataset. We can extend it to solve the MaxStRS-AC problem, but it has limited scalability (see Section 7.3). In addition, it is impossible to extend the algorithm for the SURGE problem to solve the MaxStRS-RC problem (see Section 7.1).
4. Algorithms for 3D MaxRS
We solve the 3D MaxRS problem by transforming it into an equivalent problem with a finite set of objects to be examined. We present an alternative definition of the 3D MaxRS problem and show how to transform the problem in Section 4.1. Then, we describe our algorithms for the 3D MaxRS in Section 4.2 and Section 4.3.
4.1. Alternative Definition of 3D MaxRS
In this subsection, we show how to transform the 3D MaxRS problem into an equivalent problem by generalizing the idea of [15] to 3D space. We first introduce notations used to define the new version of the 3D MaxRS problem:
Definition 3.
(Weighted Cuboid) For an object , the weighted cuboid is defined as the axis-parallel cuboid which is centered at ,,, whose size is , and whose weight is the same as . We denote the weight of a cuboid by . In addition, for the set O of objects, the set C of weighted cuboids is defined as .
Definition 4.
(Point-Weight). Let C be the set of weighted cuboids. For a point p in P, the point-weight of p is defined as , where , and is denoted by .
Definition 5.
(Weighted Cuboid Partition) For the set C of weighted cuboids, a weighted cuboid partition is a set of disjoint, weighted cuboids satisfying the following conditions:
- 1.
- is a set of disjoint weighted cuboids, that is, any pair of cuboids in are not overlapping.
- 2.
- The geometric union of cuboids in is the same as the geometric union of cuboids in C.
- 3.
- For each cuboid , the point-weight of any is the same as .
Figure 2 gives an example of these new concepts. Figure 2a shows the set of objects , where each object has weight 1. As illustrated in Figure 2b, we create a corresponding weighted cuboid for each object. Let us denote the set of created cuboids by . Figure 2c describes a set of seven weighted cuboids, where the weight of the shaded cuboid (i.e., ) is set to 2, and weights of the other cuboids are all set to 1. Note that is the common intersection area of and . We show that satisfies three conditions of Definition 5. First, it is trivial that satisfies the first and second conditions, as shown in Figure 2c. In addition, satisfies the third condition as well: (1) the point-weight of each point in is 2 since is enclosed by and ; (2) for each cuboid c in , the point-weight of every point p in c is 1 since p is covered by one cuboid. In other words, is the valid weighted cuboid partition of the given C.
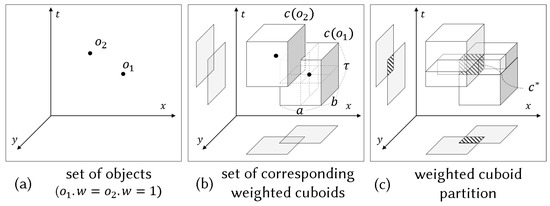
Figure 2.
An example of the set of weighted cuboids and a weighted cuboid partition.
We now introduce an alternative definition of the 3D MaxRS problem, which is equivalent to the original version as follows:
Definition 6.
(Alternative version of the 3D MaxRS problem). For a set C of weighted cuboids, find the set of all cuboids such that , where is a weighted cuboid partition of C.
If we can obtain a weighted cuboid partition of C, it is easy to solve the alternative version since it enables us to solve the problem with a finite set of cuboids to be examined. Going back to the example of Figure 2, suppose that we have an instance of the original 3D MaxRS problem with input , and of a query cuboid. Then, the corresponding input for the alternative version is . It is easy to obtain the answer to the alternative version by selecting the set of cuboids with the maximum weight (i.e., ) among all cuboids in the provided weighted cuboid partition .
We now show the equivalence of the two versions with the example of Figure 2. For any point , p is one of: (1) not covered by any cuboid in , (2) inside a cuboid in , and (3) inside . Observe that the point-weight is smaller than in the first case ( = 0) and second case ( = 1). Thus, every point inside belongs to the answer set of the alternative version because it has the maximum point-weight ( = 2).
4.2. Nested Plane-Sweep Algorithm
If we obtain a weighted cuboid partition of C, it is easy to obtain the set of optimal cuboids. In this section, we present a nested plane-sweep (NPS) algorithm which solves the transformed 3D MaxRS problem by computing a weighted cuboid partition with the plane-sweep paradigm. Throughout this section, we use the problem instance shown in Figure 2 as a running example to explain the algorithm. We show how the NPS algorithm eventually finds the shaded cuboid in Figure 2c.
4.2.1. The Outline of the NPS Algorithm
As its name implies, the NPS algorithm uses the plane-sweep paradigm to solve the problem. To illustrate the idea, let us consider an imaginary plane perpendicular to the t-axis, as shown in Figure 3. While sweeping the plane from bottom to top across the entire space, the algorithm performs some geometric operations whenever the plane meets the top or bottom rectangle of a cuboid. We call such rectangles event rectangles and the imaginary plane as sweep-plane. In addition, we say a cuboid c is active if and only if the sweep-plane has encountered the bottom of c but has not entirely passed over the top of c yet. From now on, we assume that each object in O has different t-axis value for the sake of simplicity. The algorithm terminates after a sweep-plane encounters the ()-th (or ()-th) event rectangle.
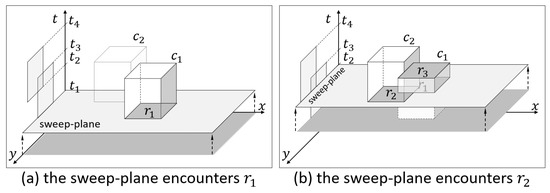
Figure 3.
The plane sweep approach.
Let us explain terms related to this approach with the example of Figure 2b. Since we sweep the plane from bottom to top, the first event rectangle encountered by the sweep-plane is , the bottom of (at ) as shown in Figure 3a. At this moment, there is only one active cuboid, . As shown in Figure 3b, the second event rectangle encountered by the sweep-plane is , the bottom of (at ). Then, the set of active cuboids at becomes . When the sweep-plane encounters , the top of at ; then, becomes inactive. Thus, the set of active cuboids at becomes .
The plane-sweep approach enables us to convert the 3D geometric problem into a series of 2D problems. To demonstrate this idea clearly, let us use to denote the i-th event rectangle encountered by the sweep-plane and to denote the t-axis value of the sweep-plane at which the plane encounters . Then, the following observation allows us to find the local solution in the subspace by just investigating the 2D plane .
Observation 1.
For any point p in , the point-weight of p is the same as the point-weight of .
Proof.
We prove this observation by contradiction. Suppose that . Then, (see Definition 4), which means that either there exists a cuboid which contains p but does not contain or there exists a cuboid which contains but does not contain p. Both cases imply that an event rectangle must exist in , which leads to the following contradiction: there is no event rectangle in . □
By Observation 1, the point-weight of p is the same as the point-weight of , the projection of p onto the plane . Thus, it is easy to compute a weighted cuboid partition if we know the point weight of every point on the plane . To investigate the point-weight of each point on the plane , we need the set of cuboids intersecting with the plane. This set, in fact, is the set of active cuboids at . By taking the projection of each active cuboid onto the plane , we can obtain a set R of weighted rectangles. Then, we compute the weighted rectangular partition for R, a 2D version of the weighted cuboid partition. We give formal definitions of the weighted rectangle and the weighted rectangular partition as follows.
Definition 7.
(Weighted Rectangle) a weighted rectangle r is an axis-parallel rectangle with a real-valued weight .
Definition 8.
(Weighted Rectangular Partition) For the set R of weighted rectangles, a weighted rectangular partition is a set of weighted rectangles satisfying following conditions: (1) any pair of rectangles in are not overlapping, (2) the geometric union of rectangles in is the same as the geometric union of rectangles in R. (3) for each rectangle , the point-weight of is .
Now, we show how to find the local solution in the subspace by solving a 2D geometric problem. Suppose that we have an algorithm for computing a weighted rectangular partition at . contains information of the point-weight of every point on . Thus, we can obtain a subset of the weighted cuboid partition as follows: for each , we create the weighted cuboid which is bounded by two plane and , whose bottom rectangle is r, and whose weight is . By selecting the set of cuboids with the maximum weight among the created cuboids, we can obtain the local solution in the subspace .
By iterating this procedure until there are no event rectangles, the NPS algorithm can find the optimal solution. The outline of the NPS algorithm is summarized as follows. The NPS algorithm has a nested plane-sweep structure: the outer plane-sweep structure (lines 4–15 of Algorithm 1) and the inner plane-sweep algorithm (Algorithm 2). In the outer plane-sweep structure, the NPS algorithm calls the inner plane-sweep algorithm (line 14 of Algorithm 1) for each event rectangle encountered by the sweep-plane. The inner plane-sweep algorithm computes the weighted rectangular partition by using the plane-sweep approach on a two-dimensional plane with a data structure defined in Definition 9. By using the outcome of the inner plane-sweep algorithm, the NPS algorithm computes the local solution (lines 5–7 of Algorithm 1). When there are no event rectangles, the NPS can obtain the global optimal solution by selecting the set of cuboids with the maximum weight among the local solutions. To describe our algorithm in detail, we introduce a data structure in Section 4.2.2. Then, we explain the inner plane-sweep algorithm in Section 4.2.3 and the outer plane-sweep structure in Section 4.2.4.
| Algorithm 1: Nested Plane-Sweep Algorithm |
 |
| Algorithm 2: The Inner Plane-Sweep Algorithm |
 |
4.2.2. Data Structure for Weighted Rectangles
We define a data structure named y-line for weighted rectangles as follows:
Definition 9.
(y-line) y-line is a horizontal line parallel to the x-axis. Formally, y-line is defined as a tuple where y is the y-axis value and is a sequence of split-points. Each split-point is a tuple , where x is a partitioning point on the x-axis, and is the sum of weights of rectangles intersecting with .
We use a set of y-lines to represent a weighted rectangular partition on a plane as shown in the example of Figure 4. In Figure 4a, we have four y-lines. They define five weighted rectangles in Figure 4b. Specifically, each consecutive pair (, ) of them defines a set of rectangles bounded by two horizontal line and . For example, and defines a set of rectangles bounded by and . Each consecutive pair (, ) of split points in of a y-line defines a rectangle which is bounded by two vertical line and , and whose weight is . For example, we show that the shaded rectangle in Figure 4b can be represented by two y-lines and their split points. Let us consider , where as illustrated in Figure 4a. The shaded rectangle in Figure 4b is the rectangle whose bottom-left corner coordinate is , whose top-right corner coordinate is , and whose weight is .

Figure 4.
An example of y-lines.
4.2.3. The Inner Plane-Sweep Algorithm
In Section 4.2.1, we described the inner plane-sweep algorithm as if it took a set R, the set of projections of all the active cuboids onto sweep-plane, as an input. It should be noted, however, that R is a conceptual notation to help readers understand the overall algorithm rather than an actual input (we will explain the actual input later). In fact, we can obtain the weighted rectangular partition of R by using existing methods [1,2]. However, using one of them in our NPS algorithm may cause redundant computations since only a small portion of the weighted rectangular partition of the current R (at ) differ from that of the previous R (at ). We can avoid those redundant computations if we reuse the previously computed weighted rectangular partition and update it partially. (We implement an algorithm which uses the existing method proposed in [1] instead of our inner plane-sweep algorithm as a baseline algorithm and compare it with our NPS algorithm in Section 7.)
We show how the inner plane-sweep algorithm computes the weighted cuboid partition by reusing the previously computed result. Suppose that the sweep-plane encounters a new event rectangle r. Let be the previous R, be the current R which is updated with r, and Y be the set of y-lines representing the weighted rectangular partition of . The inner-sweep algorithm takes (Y, r) as input, and returns , which represents the weighted rectangular partition of . While sweeping a line parallel to the x-axis from bottom to top, it incrementally computes . We call this line the sweep-line to avoid confusion with the ‘sweep-plane’ of the outer plane sweep structure. Since we do not have to consider y-lines which are not intersecting with r, the algorithm starts from the y-line right below (or on) the bottom line of r. Similarly, it terminates when the sweep-line encountered the y-line right above (or on) the top line of r.
We give a pseudo-code of the inner plane-sweep algorithm in Algorithm 2. Let us explain it with the running example. Figure 5, Figure 6 and Figure 7 illustrate the step by step procedures of the NPS algorithm to solve the problem instance of Figure 2b. We draw a non-visited object as a transparent cuboid and a current visiting object as a half-transparent cuboid. Also, we illustrate thirteen cases that line 10 of Algorithm 2 can encounter during execution in Figure 8. Table 1 summarizes the update policy for each case.
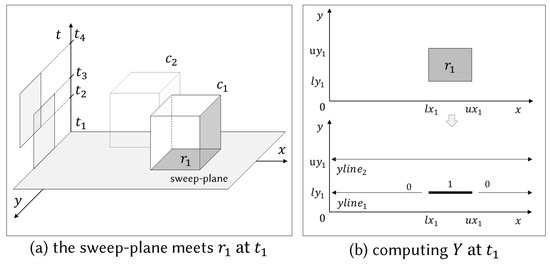
Figure 5.
Sweep-plane encounters at .
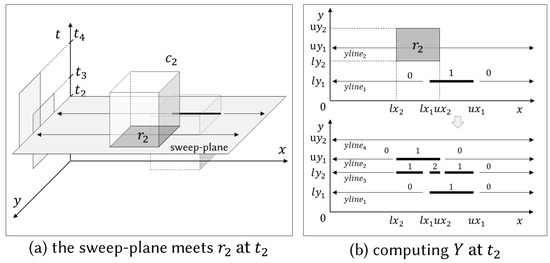
Figure 6.
Sweep-plane encounters at .
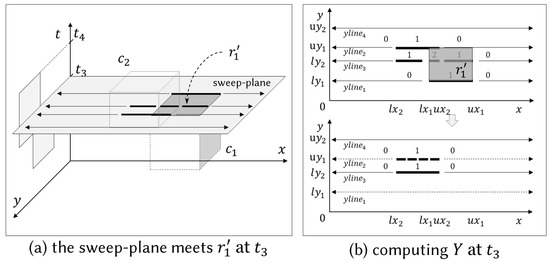
Figure 7.
Sweep-plane encounters at .

Figure 8.
Cases of a pair of consecutive y-lines.

Table 1.
Update policy for each case.
Figure 5a depicts the scenario when the sweep-plane encounters . Since is the first rectangle encountered by the sweep-plane, Y is set to an empty array. This instance corresponds to case 0 in Figure 8. It is trivial to compute for a single rectangle: the algorithm creates two y-lines (line 4 of Algorithm 2). Since there are no ‘redundant y-lines’, they just are sorted by their y values (line 16). We will explain redundant y-lines and the function ‘SortAndDeleteRedundant’ later. The output is a sorted array of , which represents this single rectangle as described in the bottom of Figure 5b.
Figure 6a depicts the scenario when the sweep-plane encounters . As shown in the top of Figure 6b, Y is given by , the previously computed array of y-lines. The algorithm starts by searching the y-line right below , namely (line 7). Then, it fetches the next y-line, namely (line 9). We now have a consecutive pair (, ) of y-lines. From now on, we denote the lower y-line by and the upper y-line by as described in Algorithm 2 (i.e., =, and =). As shown in Figure 8, this instance corresponds to the case 4 where is below and intersects with . In this case, we need an additional y-line (namely, ) to represent new area where point-weight changes (lines 10–11). To compute , the algorithm makes a copy of , and updates it by creating or updating split-points for . The underlying principle of creating/updating y-lines is the same as that of [1,15]. In particular, let be the first two element of , where and . Then, the algorithm updates it to be , , , where , , , and as shown in Figure 6b.
After creating , the sweep-line moves to the next y-line, namely . In other words, becomes (line 12). Since is lower than (line 8), the algorithm does not terminate, so it tries to fetch the next y-line (line 9). However, is set to null because there are no y-lines any more. This instance corresponds to the case 3, so the algorithm updates and creates a new y-line at by the update policy of Table 1 as shown in the bottom of Figure 6 (we omit the detail update procedure due to the space limitation). Finally, the algorithm returns as an output the sorted array of four y-lines, which represents weighted rectangular partitions for .
Figure 7a shows the scenario when the sweep-plane encounters , the top of . The input is given by , and the array Y of four y-lines representing the weighted rectangular partition of , . This example is different from the previous examples since it meets the top of a cuboid. In this case, we adopt the following trick instead of recomputing the weighted rectangular partition from the beginning. Setting the weight of to , we invoke the inner plane sweep algorithm with input (Y, ) to compute the weighted rectangular partition of , , . Since cancels out the effect of , we can obtain the weighted rectangular partition of . The algorithm finally computes four y-lines, as shown in the bottom of Figure 7b. However, the dashed y-lines (i.e., , ) are removed (line 16) because has an empty sequence of split-points, and has the same sequence of split-points as its previous y-line except for the y-value. If a y-line has the same configuration as its previous y-line, then it means that the point-weight of every point remains unchanged. If the bottommost y-line has an empty sequence, then it is meaningless. By a similar reason, if two consecutive split-points have the same sum of weight, then the upper split-point is removed.
4.2.4. The Outer Plane-Sweep Structure of NPS
The NPS algorithm scans each cuboid from bottom to top in its outer plane-sweep structure. While scanning each cuboid, it computes local solutions incrementally by invoking the inner plane-sweep algorithm (line 14 of Algorithm 1). First, the algorithm initializes variables , Y, and : the set of cuboids with the maximum weight is set to ∅, the array Y of y-lines is set to an empty array, and the previous timestamp is set to (lines 1–3 of Algorithm 1).
Suppose that the sweep-plane p encounters the i-th event rectangle r at (line 4) after it visited the (i-1)-th event rectangle at . Since the sweep-plane moved upwards to encounter r, we need to update before we update Y. To update , the NPS algorithm computes , a local solution in . Let be the weighted rectangular partition represented by , previously computed at t = . Then, the function ‘GetLocalMaxWeightedCuboids’ finds the local solution as follows (line 6): (1) for , it creates a cuboid whose bottom rectangle is r, which is bounded by two planes and , and whose weight is , (2) and select the cuboid with the maximum weight in the created set of cuboids. The NPS algorithm updates by selecting the cuboids with the maximum weight in (line 7). After updating , it computes Y which represents the weighted rectangular partition for R, where R is the set of bottom rectangles of active cuboids (lines 9–14).
The NPS algorithm iterates this process until there are no event rectangles. When the while-loop ends, the NPS algorithm updates for the last event rectangle (lines 16–17), and returns it as a result. In the running example, the cuboid with weight 2, which is bounded by , , , , , and is the final result (see Figure 6 and Figure 7). Observe that this cuboid is identical to of Figure 2.
4.2.5. Analysis of the NPS Algorithm
The time complexity of the NPS algorithm is + , where is the maximum number of elements in Y of y-lines, and is the maximum number of elements in the sequence of split-points among the created y-lines during the entire processing operation.
In particular, it requires operations for sorting cuboids for the outer plane-sweep structure. The inner plane-sweep algorithm has the complexity of : it takes to search within a sorted array Y, and the upper bound of the number of iterations (lines 8–13 of Algorithm 2) is , the upper bound of rectangles represented by y-lines. In addition, function ‘GetLocalMaxWeightedCuboids’ has the complexity of . Thus, the total time complexity for processing each event rectangle is . Finally, the upper bound for the total time complexity of the NPS algorithm is + .
The NPS algorithm is straightforward but has limited scalability. If it takes a large dataset or a large query cuboid, then it may create too many y-lines. Consequently, the time complexity dramatically increases since and increases.
To reduce computational overhead to search y-lines, we implement an improved NPS algorithm which manages y-lines with an in-memory height-balanced tree structure, named Rectangular Partition Tree (RP-Tree). Our RP-Tree satisfies the following characteristics: (1) it provides efficient retrieval of y-lines intersecting with a rectangle; (2) it provides an efficient in-order traversal from an arbitrary y-line. Since RP-Tree is similar to B+Tree [24,25], we omit the description of the improved NPS algorithm. Although we observed that the improved algorithm is more efficient than the original NPS algorithm, the improved one also has limited scalability because RP-Tree itself cannot reduce or .
4.3. Divide and Conquer Algorithm
We can reduce the computational complexity by dividing the whole problem into independent smaller sub-problems. If each sub-problem deals with a small number of objects, it can be solved more effectively (this is because is reduced). This approach is also known as the divide-and-conquer (DC) strategy, a natural way to cope with optimization problems in computational geometry. For example, Choi et al. [1,2] proposed a DC-based scalable algorithm for the two-dimensional MaxRS problem. Similar to [1,2], we propose an improved algorithm based on DC strategy.
4.3.1. Division Phase
First, our DC algorithm creates for each . Then, it recursively divides the entire space into a set of subspaces until each subspace has a small enough number of cuboids. However, unlike in [1,2], the number of cuboids in each subspace does not have to fit in the main memory in our method necessarily. We will explain the reason for this later.
Specifically, to split the entire space P into M disjoint subspaces, it creates planes perpendicular to the x-axis. Each cuboid c in C may be split into several cuboids by planes. As shown in Figure 9, if a subspace overlaps with a cuboid c, then c is one of: (1) covered by ; (2) partially intersecting with ; and (3) spanning . It is trivial to handle the first and second cases: the intersection (of c and ) is assigned to . However, the third case is non-trivial because it may cause infinite recursion. Let us consider an extreme scenario, where every cuboid spans . No matter how we divide , there exists a subspace where the number of cuboids inside remains the same. A similar case, where a rectangle spans a subspace, is demonstrated in [1,2]. Authors of [1,2] solve this problem by preventing spanning objects from being passed to the next level recursion and processing them later in the merging phase together with intermediate results of sub-problems. Since spanning rectangles are excluded, it is possible to obtain a set of subspaces where each subspace has a small enough number of cuboids to fit into the main memory.
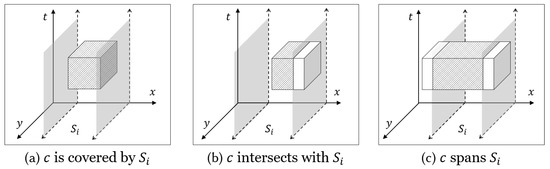
Figure 9.
Cases when subspace overlaps with c.
However, this method may not be the best solution in a spatiotemporal space for two critical reasons. First, the intermediate result of each sub-problem tends to be large to guarantee the correctness. Suppose that we have a sub-problem in a subspace where a small number of cuboids are inside. We can obtain , the answer to the 3D MaxRS problem with input , by using the NPS algorithm. Note that, if it is guaranteed that the is the solution in the subspace , then we can return alone as an intermediate result. However, may not be the exact solution in because a spanning cuboid may exist in . Thus, for every single pair of consecutive timestamp (, t), we have to report cuboids with the maximum weight in (line 7 in Algorithm 1). In the merging phase, we have to consider every cuboid reported in each subspace and every spanning cuboid altogether to obtain the correct answer.
Second, we do not necessarily have to load all cuboids in a subspace into the main memory. We observed that memory accesses for input objects are not the bottleneck for computing the 3D MaxRS problem. In fact, each event rectangle is read once, and we can linearly scan all event rectangles after sorting them. Thus, accessing them from a sequential access memory (i.e., disk-storage) after sorting them does not significantly affect the overall execution time.
Due to these reasons, the number of cuboids in each subspace does not have to fit into the main memory necessarily. To prevent spanning rectangles from being created, our DC algorithm terminates recursion when the number of cuboids inside the subspace fits into the main memory, or the length of the space along the x-axis is equal to or smaller than a. Suppose that we obtain a set S of subspaces. For each , it solves the 3D MaxRS problem with input of cuboids inside . Although there may exist a subspace such that all cuboids in cannot be loaded at the same time into main memory, we can compute the answer set efficiently by using the NPS algorithm.
4.3.2. Merging Phase
Our dividing method not only reduces the size of intermediate results significantly, but also makes the merging phase simple. Suppose that a subspace contains a set of weighted cuboids, and a set is the answer set of cuboids to the 3D MaxRS problem with input . Unlike in [1,2], it is guaranteed that is the optimal solution in the subspace since there are no spanning objects. Thus, the remaining task is selecting the set of cuboids with the maximum weight in A, where , which is trivial to compute.
5. Algorithms for MaxStRS-AC
In this section, we show that the MaxStRS-AC problem is polynomially reducible to the 3D MaxRS problem. In addition, we introduce the baseline algorithm for the MaxStRS-AC problem and then present the extension of the baseline algorithm based on the divide-and-conquer approach.
5.1. Overview
The MaxStRS-AC problem tries to find the set of all points such that:
To examine a point p whether it belongs to the answer set or not, we need to consider two different cuboids (i.e., and ) at the same time. Thus, it may seem that it is not feasible to solve the MaxStRS-AC problem with the plane-sweep approach at first glance. However, we observe an interesting property of the MaxStRS-AC problem: we can transform the MaxStRS-AC problem into the 3D MaxRS problem. We first present a novel idea to transform the MaxStRS-AC problem to the 3D MaxRS problem.
We illustrate the idea with a motivating example in Figure 10. Figure 10a shows a set O of objects. Since encloses , and encloses , , - is equal to + - - . Observe that we need to consider both and to examine p whether it belongs to the answer set or not. To transform the problem, we create a virtual object for each object as illustrated in Figure 10b. Let be the set of created objects and be the union of O and (i.e., ). We now show that we no longer need to consider in the transformed problem. First, observe that encloses not only , , but also , , as shown in Figure 10c. Thus, the sum of the weights of all the object in is + + + , which is identical to + - - . In other words, - of Figure 10a is equivalent to of Figure 10c. Therefore, the goal of the MaxStRS-AC problem for O is equivalent to the goal of the 3D MaxRS problem for .
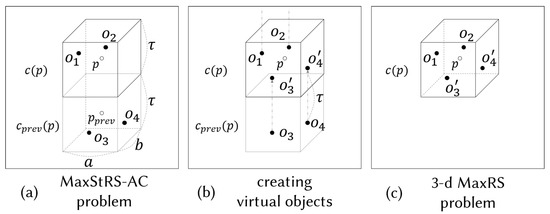
Figure 10.
A motivating example of transforming the MaxStRS-AC problem to the 3D-MaxRS problem.
Here, we give a mathematical justification for our method. To prove the reducibility, we need additional terminologies. For an object , we use to denote the virtual object . Similarly, for a set O of objects, we use to denote . Lemma 1 and Theorem 1 show that we can transform the MaxStRS-AC problem into the 3D MaxRS problem.
Lemma 1.
Given O, the size of a query cuboid, the following equation holds for every p in the entire space:
Proof.
We present the proof of Lemma 1 in the Appendix A. □
Theorem 1.
The answer to the MaxStRS-AC problem with input O and the size of a query cuboid is equivalent to the answer to the 3D-MaxRS problem with input and the size of the query cuboid.
Proof.
The point belongs to the answer set of the MaxStRS-AC problem if it satisfies the following equation:
Using Lemma 1, we can safely rewrite as follows:
Observe that Equation (2) is the form of the expression for the answer to the 3D MaxRS problem with input and the size of of the query cuboid. □
5.2. Baseline Algorithm for MaxStRS-AC
We present a two-phase nested plane-sweep based algorithm (NPS-AC) for the MaxStRS-AC problem.Suppose that we aim to solve the MaxStRS-AC problem with input O and the size of a query cuboid. This algorithm consists of two phases: (1) generating a set of cuboids such that , where C, and ; (2) finding the answer set by using the NPS algorithm with input . Theorem 1 guarantees the correctness of this algorithm.
5.3. Divide and Conquer Algorithm
We introduce a divide-and-conquer based algorithm for the MaxStRS-AC (DC–AC) as an extension of the baseline algorithm. It also consists of two phases. In the first phase of each algorithm, is generated, as in that of the NPS-AC algorithm. In the second phase, the divide-and-conquer based algorithm for the MaxStRS-AC (DC–AC) finds the answer set based on the DC algorithm.
6. Algorithms for MaxStRS-RC
In this section, we show how to solve the MaxStRS-RC problem by computing a modified weighted cuboid partition, and then introduce the baseline algorithm for it. In addition, we present extensions of it, which is more scalable.
6.1. Overview
The MaxStRS-RC problem tries to find the set of all points such that:
To solve this problem, we introduce a new notation and an alternative version of the MaxStRS-RC problem as follows:
Definition 10.
(Modified Weighted Cuboid Partition) For the set C of weighted cuboids, a modified weighted cuboid partition is a set of disjoint cuboids, where each cuboid c has two different weight , , satisfying the following conditions:
- 1.
- is a set of disjoint cuboids, that is, any pair in are not overlapping.
- 2.
- The geometric union of cuboids in is the same as the geometric union of cuboids in , where .
- 3.
- For each cuboid , the point-weight of for any is the same as .
- 4.
- For any point p in each cuboid , the change between the point-weight of p and the past-point-weight of p (i.e., ) is the same as .
Definition 11.
(Alternative version of the MaxStRS-RC). Let be a modified weighted cuboid partition of the set C of weighted cuboids. Then, find such that:
Similar to Section 4.1, the alternative version of the MaxStRS-RC problem is equivalent to the original MaxStRS-RC problem, and it is easy to solve the alternative version if we have a valid modified weighted partition of C.
Now, we show that computing a modified weighted cuboid partition can be transformed into computing a weighted cuboid partition. Suppose that is a weighted cuboid partition of , and is a weighted cuboid partition of (). For each point p in a cuboid , the point-weight of p is same as (by Definitions 4 and 5). By Lemma 1. holds. Thus, the point-weight of each point p in a cuboid is , which equals (i.e., denominator of Equation (4)). Similarly, the point-weight of each point p equals (i.e., numerator of Equation (4)). Therefore, if and are provided, we can obtain a modified weighted cuboid partition by partitioning them all together again. We describe the method in detail in the next subsection.
6.2. Baseline Algorithm for MaxStRS-RC
In this subsection, we propose a nested plane-sweep based algorithm (NPS-RC) for the MaxStRS-RC problem. The NPS-RC algorithm also consists of two phases. First, it creates set . In the second phase, it computes a modified weighted cuboid partition and selects the set of cuboids with the maximum value of in .
The basic idea of the second phase of the NPS-RC algorithm is to compute and concurrently to obtain while scanning each cuboid in . To do so, we introduce a modified version of y-line as follows:
Definition 12.
(modified-y-line) modified-y-line, a horizontal line parallel to the x-axis, is defined as a tuple , where y is the y-axis value and is a sequence of modified-split-points. Each modified-split-point is a tuple , , where x is a partitioning point on the x-axis, is the change between the weight-sums, and is the previous weight-sum.
Unlike an original y-line, a modified-y-line has a set of modified-split-points where each element contains two variables and instead of a variables . Conceptually, is used to represent , and is used to represent . In particular, if the sweep-plane encounters an event rectangle r which belongs to , then the NPS-RC algorithm updates and variables in modified-y-lines intersecting with r. On the other hand, if the sweep-plane encounters an event rectangle which belongs to C, then it updates variables in modified-y-lines intersecting with r. Before updating the array of modified-y-lines, it computes a subset of , and updates the current set of cuboids with the maximum value of . It iterates this procedure until there are no event rectangles.
6.3. Divide and Conquer Algorithm
We introduce a divide-and-conquer based algorithm (DC–RC) for the MaxStRS-RC problem. This algorithm first generates . Then, it finds the answer set for the input based on the divide-and-conquer strategy as follows. In the division phase, it divides the problem into sub-problems with the same manner in the division phase of the DC-Algorithm. Then, it solves each sub-problem using the NPS-RC algorithm. In the merging phase, it selects the set of cuboids maximizing .
7. Experimental Result
In this section, we evaluate the performance of the proposed algorithms and compare it with existing methods.
7.1. Experimental Setup
We evaluate the performance of algorithms both on synthetic and real datasets. First, we generate synthetic datasets in a spatiotemporal space of size , where the first two dimensions correspond to space, and the third dimension corresponds to time. We use both Uniform distribution and Gaussian distribution for generating datasets in order to study how skewness affects the total response time. To create Gaussian-distributed datasets, we generate tuples by sampling a random number from a Gaussian distribution , ) for each dimension. We create datasets of different sizes (10,000 to 500,000) for each data distribution. In addition, we collected a set of geo-tagged text data from Twitter using the Twitter Streaming API from 25 January 2018, to 28 June 2018. This real dataset contains 162,011 geo-tagged tweets that mentioned the keyword ‘restaurant’.
We evaluate the performance of the NPS-based algorithm (optimized by RP-Tree) and DC-based algorithm comparing with existing methods by the response time and compare it against existing methods. Since no existing methods are directly applicable to the 3D MaxRS problem and the MaxStRSC problem, we extend existing algorithms for comparison as follows. For the 3D MaxRS problem, we extend the algorithm of [15], which tries to solve the max-enclosure problem in three-dimensional space in memory to solve the 3D MaxRS problem, and externalize it by employing STR-Tree [21] for better scalability. We call this algorithm ‘UNIFIED’ named after the title of their paper. Since the UNIFIED algorithm is somewhat outdated, we also implement another algorithm called ’BASELINE’ Algorithm, as mentioned in Section 4.2.3. The BASELINE algorithm is similar to the NPS algorithm, but uses the algorithm proposed in [1] instead of our inner plane-sweep algorithm.
For the MaxStRS-AC problem, we extend the algorithm of [23]. We call this algorithm ‘SURGE’. The original SURGE algorithm tries to continuously monitor the generalized version of the MaxStRS-AC problem over data streams. Thus, we first generate a data stream where each object in a set of historical spatiotemporal objects arrives in increasing order of timestamps and invoke the SURGE algorithm to handle this stream. By keeping track of the point with the maximum burst score, we can obtain at least one point which belongs to the answer set to the MaxStRS-AC problem. However, note that it is impossible to extend the SURGE algorithm to solve the MaxStRS-RC problem since its pruning rules are no longer valid when we try to maximize .
We conduct experiments by varying parameters such as data cardinality, cuboid size, buffer size. We set the default experimental parameters as follows: data cardinality is , a is 100, b is 100, t is 100, the buffer size is 2 MB, and the block size is 8 KB. We implemented all the algorithms in JAVA assuming that those algorithms will be deployed on environments based on a big data pipeline architecture such as Apache Hadoop and Spark, since programs written in JAVA are easily integrated into such architectures. We run all experiments on an Ubuntu (16.04 LTS) PC with Intel Xeon E5-1620 (3.6 Ghz Quad-core) and 32 GB memory.
7.2. Results of the 3D MaxRS Problem
We conduct various experiments for the 3D MaxRS problem on synthetic datasets as follows.
7.2.1. Effect of Data Size
Experimental results for varying the size of a dataset are summarized in Figure 11, where the y-axis shows the response time in the log scale. Observe that our DC algorithm shows superior performance in all the cases. Although the NPS algorithm shows the worse performance than the DC algorithm, it is more efficient than the UNIFIED algorithm or the BASELINE algorithm. Observe that the response time of the DC algorithm does not rapidly increase when the size of the dataset increases, which means it is scalable. In addition, the DC algorithm is less sensitive to data skewness compared to the other algorithm.
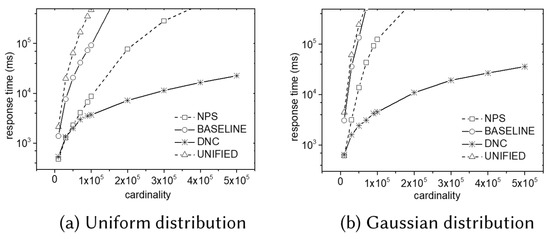
Figure 11.
Effect of data size in 3D MaxRS.
7.2.2. Effect of Query Cuboid Size
We conduct two experiments to investigate the effect of query cuboid size. We do not plot the result of the BASELINE algorithm and the UNIFIED algorithm because they are much more inefficient than the NPS or the DC algorithm. Figure 12a summarizes the experimental results for varying the size of the spatial range (fixing the length of the temporal window to be 100). We use squares for the spatial range. In both distributions, the DC algorithm is more efficient than the NPS algorithm. While the performance of the NPS algorithm deteriorates as the size of the spatial range increases, the performance of the DC algorithm is stable. In addition, observe that the response time of the NPS algorithm severely increases in Gaussian distribution as the size of the spatial range increases. The reason for this is that the number of cuboids in the weighted cuboid partition increases extraordinarily in the Gaussian distribution. However, the performance of the DC algorithm in the Gaussian distribution is relatively stable since it reduces the computational cost by dividing the skewed space into several subspaces.
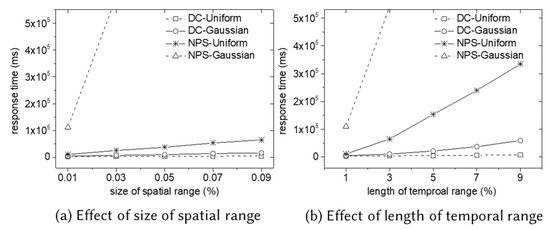
Figure 12.
Effect of query cuboid size in 3D MaxRS.
7.2.3. Results Related to the Buffer Size
We conduct experiments to evaluate I/O-related efficiency. Since the other algorithms are in-memory algorithms, we only evaluate the performance of the DC algorithm by varying the size of (in-memory) buffer and the size of data (50k, 100k, and 150k) in both distributions. Although the UNIFIED algorithm takes advantage of a buffered data structure named STR-tree, we do not plot its performance because it is too inefficient.
As shown in Figure 13a, the response time of the DC algorithm decreases as we increase the buffer size in the uniform distribution. On the contrary, the response time of the DC algorithm tends to increase as we increase the buffer size in the Gaussian distribution. It means that using a larger size buffer does not always guarantee better performance, especially in the skewed data distribution. Recall that, if the number of cuboids in each subspace fits into the buffer, the DC algorithm stops to divide space in its division phase. If the buffer size increases, then the subspace of each sub-problem gets enlarged. Meanwhile, it may take more time to solve sub-problems in dense regions in the highly skewed data distribution. Thus, if the buffer size becomes too large in skewed data distribution, it may take much more time to solve some sub-problems in large subspaces.
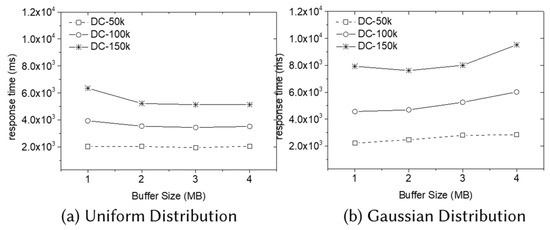
Figure 13.
Results related to the I/O in 3D MaxRS.
7.3. Results of the MaxStRSC Problem
We investigate the performance of the DC–AC algorithm for the MaxStRS-AC problem and the DC–RC algorithm for the MaxStRS-RC problem on synthetic data sets in both distributions by varying the size of the dataset. As shown in Figure 14, we do not plot the performance of NPS-based algorithms since they are much more inefficient than DC-based algorithms. Instead, we plot the performance of the DC algorithm for the 3D MaxRS problem and the performance of the SURGE algorithm [23] for the MaxStRS-AC problem on the same input datasets for comparison.
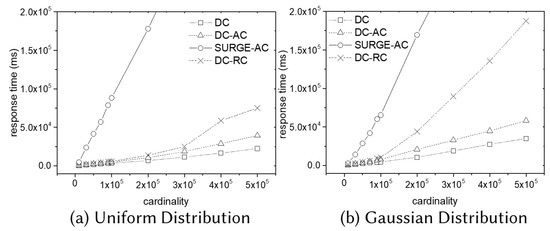
Figure 14.
Effect of data size in MaxstRSC.
The experimental results of the MaxStRSC problem are summarized in Figure 14, where the y-axis shows the response time in the log scale. The DC–AC algorithm has a slightly higher response time than the DC algorithm in both distributions because it has to deal with two times more objects (i.e., ). In addition, the DC–RC algorithm has a higher response time than the DC–AC algorithm in both distributions because the DC–RC algorithm computes a modified weighted cuboid partition, which is more complicated than the original weighted cuboid partition. The SURGE algorithm is about ten times slower than the DC–AC algorithm in both data distributions. We observe that the DC–RC algorithm is more sensitive to data skewness. We guess the reason for this as follows. Since the DC–RC algorithm needs additional geometric operations and memory space for managing modified-y-lines, the DC–RC algorithm takes more time than the DC–AC algorithm takes for the same dataset. This tendency becomes worse in the skewed data distribution.
7.4. Experimental Results in Real Dataset
We conduct two experiments to investigate the effect of query cuboid size, as shown in Figure 15 in the real dataset collected from Twitter. We do not plot the result of the existing methods because they are much more inefficient than the NPS or the DC algorithms. For example, the response time of the SURGE algorithm with the size of query cuboid (0.1 km × 0.1 km × 100 s) on the Twitter dataset is more than one hour (5,263,782 ms).
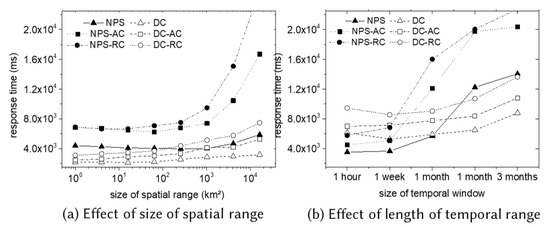
Figure 15.
Experimental results in a real dataset.
Figure 15a summarizes the experimental results for varying the size of the spatial range (fixing the length of the temporal window to be one month). The DC-based algorithms are more efficient than NPS algorithms. While the performance of NPS-based algorithms deteriorates as the size of the spatial range increases, the performance of the DC-based algorithms is stable. Figure 15b shows the experimental results for varying the size of the temporal window (i.e., ), fixing the size of the spatial range to be 4 km × 4 km. For the short-term (less than one month), the NPS-based methods are usually better than the DC-based algorithms. However, the DC-based algorithms are more efficient than the NPS algorithms for a long-term period. The DC-based algorithm is less sensitive to the length of the temporal window.
8. Conclusions
In this paper, we introduce the 3D MaxRS problem and the MaxStRSC problem which can be used to find interesting spatiotemporal regions in a large historical spatiotemporal dataset. We first propose a nested plane sweep (NPS) algorithm for the 3D MaxRS problem, and then propose the divide-and-conquer algorithm (DC) for better scalability. In addition, we give a mathematical explanation for reducing the MaxStRSC problem to the 3D MaxRS problem and propose several algorithms for the MaxStRSC problem. The experimental results show that our DC-based algorithm is scalable and much more efficient than other algorithms (including existing methods) in general. As part of future work, we intend to build a system which executes analytical queries over the set of historical data and stream data in a distributed and parallel environment such as Apache Spark [26]. By executing the 3D MaxRS problem and the MaxStRSC problem in a distributed and parallel environment, we expect that it can provide more efficient and scalable support for spatiotemporal analysis over a large-scale spatiotemporal dataset.
Author Contributions
Conceptualization, W.C., K.-S.H., and S.-Y.J.; methodology, W.C.; validation, J.C. and K.P.; formal analysis, W.C.; investigation, W.C. and K.-S.H.; resources, J.C.; writing—original draft preparation, W.C.; writing—review and editing, S.-Y.J. and K.P.; visualization, W.C.; supervision, K.P.; project administration, S.-Y.J. and K.P.; funding acquisition, K.P.. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIP) (NRF-2018R1D1A1B07047618).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MaxRS | Maximum Range-Sum |
| MaxStRSC | Maximum Spatiotemporal Range-Sum Change |
| NPS | Nested Plane-Sweep algorithm |
Appendix A. Proof of Lemma 1
We prove Lemma 1 using the following notations. For an object , we use to denote the object , and to denote the object . For a set of objects O, we denote to denote , and to denote .
Proof.
□
References
- Choi, D.W.; Chung, C.W.; Tao, Y. A Scalable Algorithm for Maximizing Range Sum in Spatial Databases. Proc. VLDB Endow. 2012, 5, 1088–1099. [Google Scholar] [CrossRef][Green Version]
- Choi, D.W.; Chung, C.W.; Tao, Y. Maximizing Range Sum in External Memory. ACM Trans. Database Syst. 2014, 39, 21:1–21:44. [Google Scholar] [CrossRef]
- Jurgens, M.; Lenz, H.J. The Ra*-tree: An improved R*-tree with materialized data for supporting range queries on OLAP-data. In Proceedings of the Ninth International Workshop on Database and Expert Systems Applications (Cat. No.98EX130), Vienna, Austria, 24–28 August 1998; pp. 186–191. [Google Scholar] [CrossRef]
- Papadias, D.; Kalnis, P.; Zhang, J.; Tao, Y. Efficient OLAP Operations in Spatial Data Warehouses. In Proceedings of the 7th International Symposium on Advances in Spatial and Temporal Databases (SSTD ’01), Redondo Beach, CA, USA, 12–15 July 2001; Springer: London, UK, 2001; pp. 443–459. [Google Scholar]
- Tao, Y.; Papadias, D. Historical Spatio-temporal Aggregation. ACM Trans. Inf. Syst. 2005, 23, 61–102. [Google Scholar] [CrossRef]
- Cho, H.J.; Chung, C.W. Indexing range sum queries in spatio-temporal databases. Inf. Softw. Technol. 2007, 49, 324–331. [Google Scholar] [CrossRef]
- Tao, Y.; Papadias, D. MV3R-Tree: A Spatio-Temporal Access Method for Timestamp and Interval Queries. In Proceedings of the 27th International Conference on Very Large Data Bases (VLDB ’01), Roma, Italy, 11–14 September 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 431–440. [Google Scholar]
- Lazaridis, I.; Mehrotra, S. Progressive Approximate Aggregate Queries with a Multi-resolution Tree Structure. In Proceedings of the 2001 ACM SIGMOD International Conference on Management of Data (SIGMOD ’01), Santa Barbara, CA, USA, 21–24 May 2001; ACM: New York, NY, USA, 2001; pp. 401–412. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, W.; Xu, J. General Purpose Index-Based Method for Efficient MaxRS Query. In Database and Expert Systems Applications; Hartmann, S., Ma, H., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Tao, Y.; Hu, X.; Choi, D.W.; Chung, C.W. Approximate MaxRS in Spatial Databases. Proc. VLDB Endow. 2013, 6, 1546–1557. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Y.; Wong, R.C.W.; Xiong, J.; Cheng, X.; Chen, P. Rotating MaxRS queries. Inf. Sci. 2015, 305, 110–129. [Google Scholar] [CrossRef]
- Nakayama, Y.; Amagata, D.; Hara, T. Probabilistic MaxRS Queries on Uncertain Data. In Database and Expert Systems Applications; Benslimane, D., Damiani, E., Grosky, W.I., Hameurlain, A., Sheth, A., Wagner, R.R., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 111–119. [Google Scholar]
- Zhou, X.; Wang, W. An Index-Based Method for Efficient Maximizing Range Sum Queries in Road Network. In Databases Theory and Applications; Cheema, M.A., Zhang, W., Chang, L., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 95–109. [Google Scholar]
- Feng, K.; Cong, G.; Bhowmick, S.S.; Peng, W.C.; Miao, C. Towards best region search for data exploration. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; ACM: New York, NY, USA, 2016; pp. 1055–1070. [Google Scholar]
- Nandy, S.C.; Bhattacharya, B.B. A unified algorithm for finding maximum and minimum object enclosing rectangles and cuboids. Comput. Math. Appl. 1995, 29, 45–61. [Google Scholar] [CrossRef]
- Amagata, D.; Hara, T. Monitoring MaxRS in Spatial Data Streams. In Proceedings of the EDBT, Bordeaux, France, 15–16 March 2016. [Google Scholar]
- Amagata, D.; Hara, T. A General Framework for MaxRS and MaxCRS Monitoring in Spatial Data Streams. ACM Trans. Spat. Algorithms Syst. 2017, 3, 1:1–1:34. [Google Scholar] [CrossRef]
- Mostafiz, M.I.; Mahmud, S.M.F.; Hussain, M.M.u.; Ali, M.E.; Trajcevski, G. Class-based Conditional MaxRS Query in Spatial Data Streams. In Proceedings of the 29th International Conference on Scientific and Statistical Database Management (SSDBM ’17), Chicago, IL, USA, 27–29 June 2017; ACM: New York, NY, USA, 2017; pp. 13:1–13:12. [Google Scholar] [CrossRef]
- Qi, J.; Kumar, V.; Zhang, R.; Tanin, E.; Trajcevski, G.; Scheuermann, P. Continuous Maintenance of Range Sum Heat Maps. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018. [Google Scholar]
- Hussain, M.U.; Trajcevski, G.; Islam, K.; Ali, E. Towards Efficient Maintenance of Continuous MaxRS Query for Trajectories. In Proceedings of the 20th International Conference on Extending Database Technology (EDBT 2017), Venice, Italy, 21–24 March 2017. [Google Scholar] [CrossRef]
- Leutenegger, S.T.; Lopez, M.A.; Edgington, J. STR: A simple and efficient algorithm for R-tree packing. In Proceedings of the 13th International Conference on Data Engineering, Birmingham, UK, 7–11 April 1997; pp. 497–506. [Google Scholar] [CrossRef]
- Mathioudakis, M.; Bansal, N.; Koudas, N. Identifying, Attributing and Describing Spatial Bursts. Proc. VLDB Endow. 2010, 3, 1091–1102. [Google Scholar] [CrossRef][Green Version]
- Feng, K.; Guo, T.; Wang, G.C.H.; Bhowmick, S.S.; Ma, S. SURGE: Continuous Detection of Bursty Regions Over a Stream of Spatial Objects. In Proceedings of the 34th IEEE International Conference on Data Engineering, ICDE 2017, Paris, France, 16–19 April 2018. [Google Scholar]
- Bayer, R.; McCreight, E.M. Organization and maintenance of large ordered indexes. Acta Inform. 1972, 1, 173–189. [Google Scholar] [CrossRef]
- Comer, D. Ubiquitous B-Tree. ACM Comput. Surv. 1979, 11, 121–137. [Google Scholar] [CrossRef]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache Spark: A Unified Engine for Big Data Processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).