Steganalysis of Adaptive Multi-Rate Speech Based on Extreme Gradient Boosting

 ,
,  ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Featured Application
Abstract
1. Introduction
2. Preliminary and Relate Work
2.1. AMR-Based Steganography Method
2.2. Review of the State-Of-The-Art for AMR-Based Steganalysis
2.3. XGBoost Model
2.3.1. Boosting
2.3.2. Decision Trees
2.3.3. XGBoost
3. Proposed Scheme
3.1. Convergence Features Based on Markov Chain
3.2. Analysis of the Combination of Convergence Feature and Statistical Characteristics of Pulse Pairs
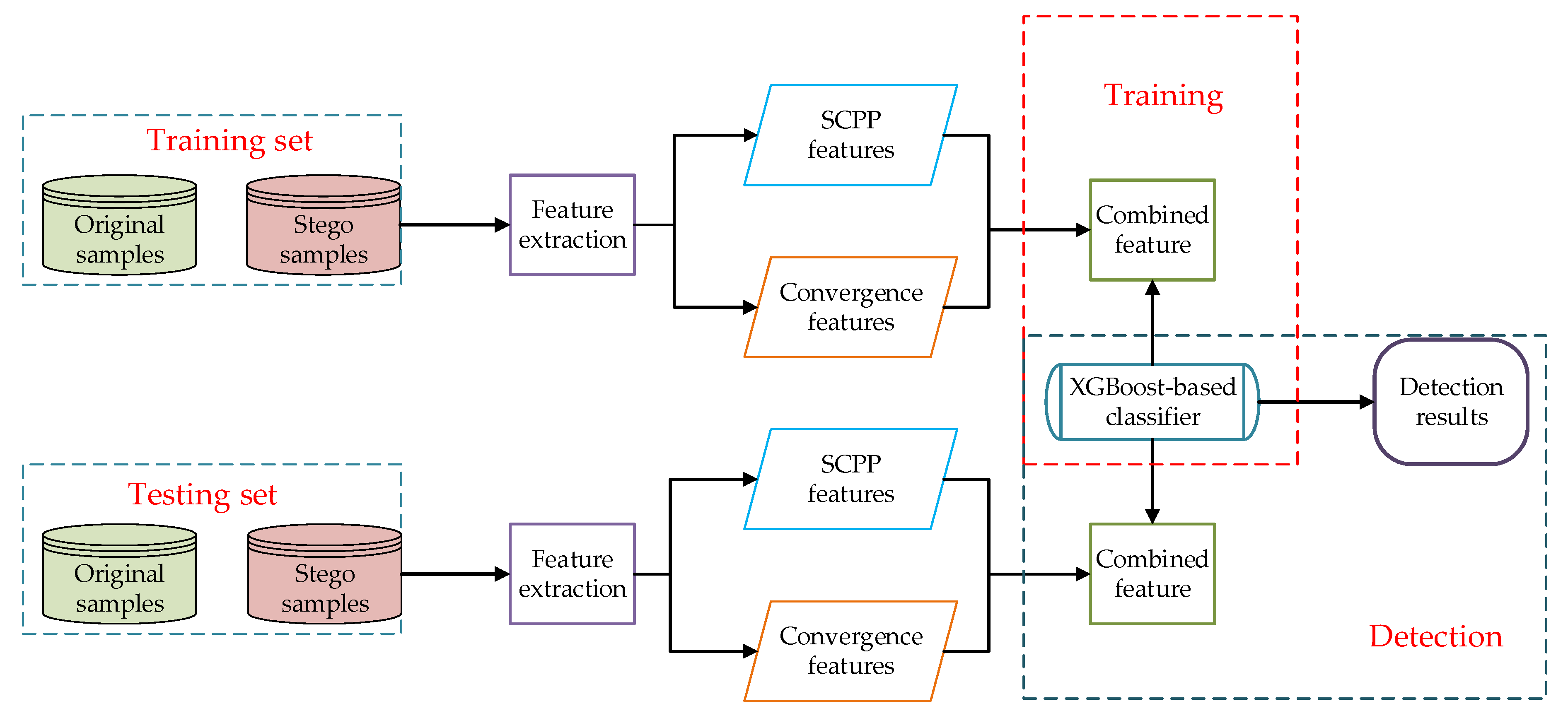
3.3. XGBoost-Based Steganalysis Scheme
4. Experimental Result and Analysis
4.1. Experimental Setup, Data, and Metrics
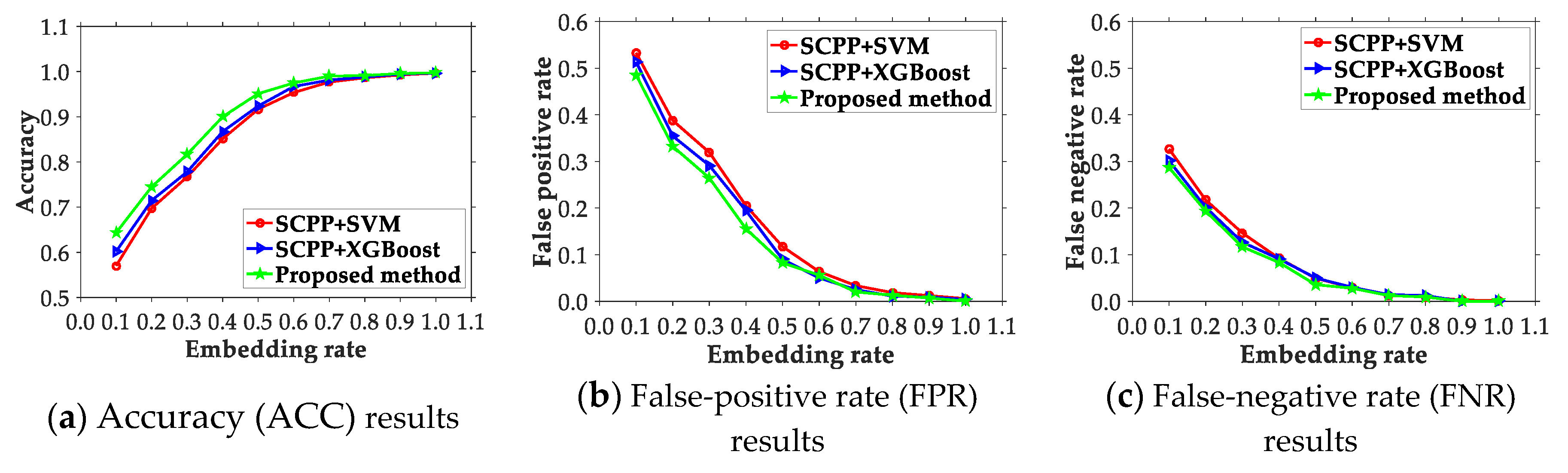
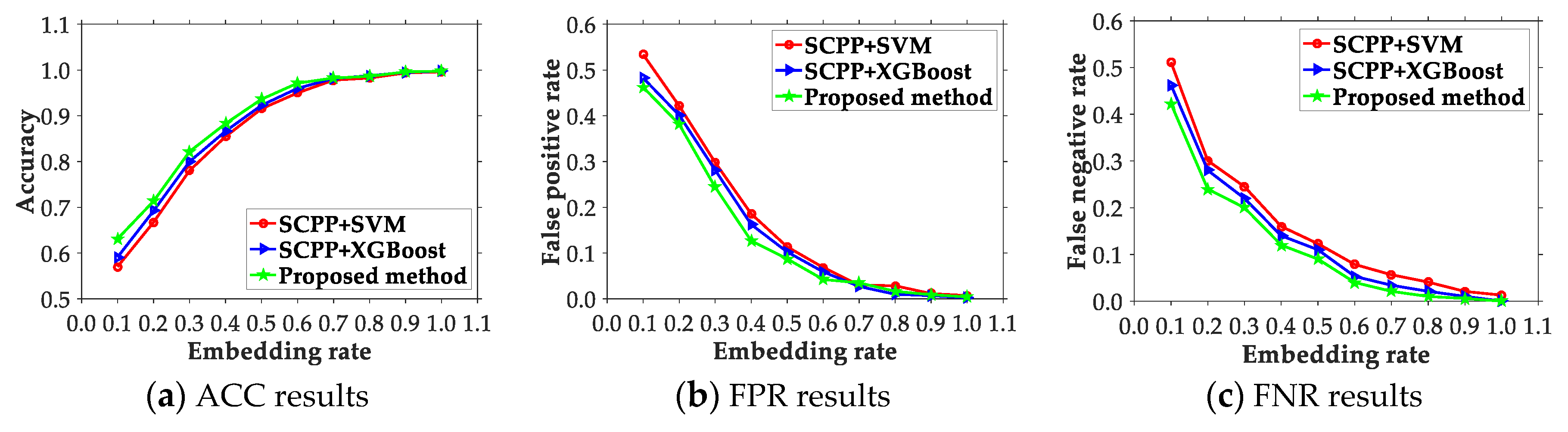
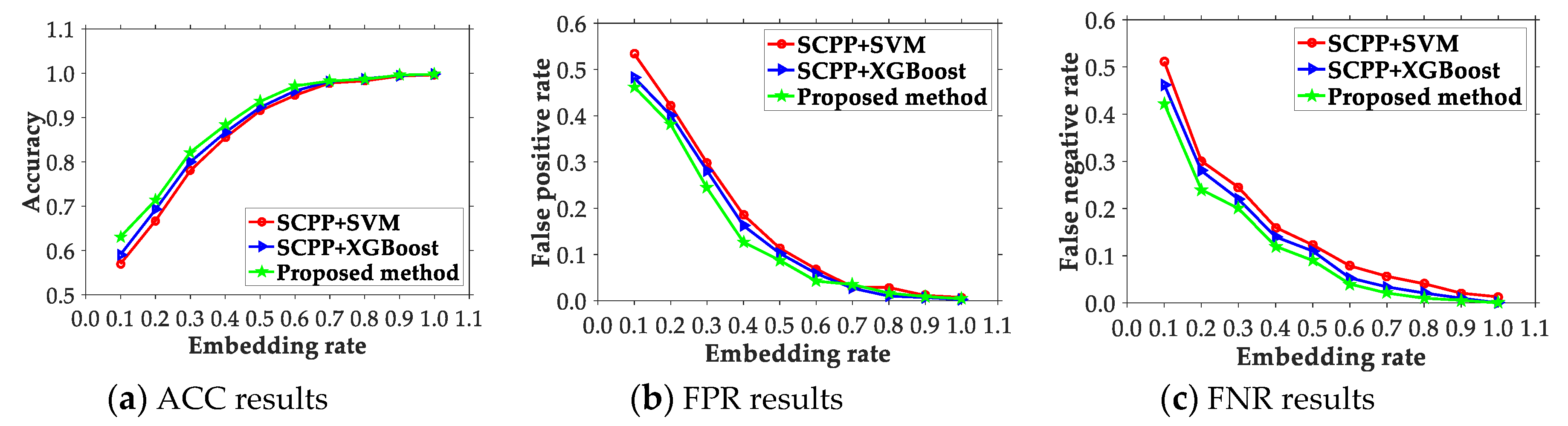
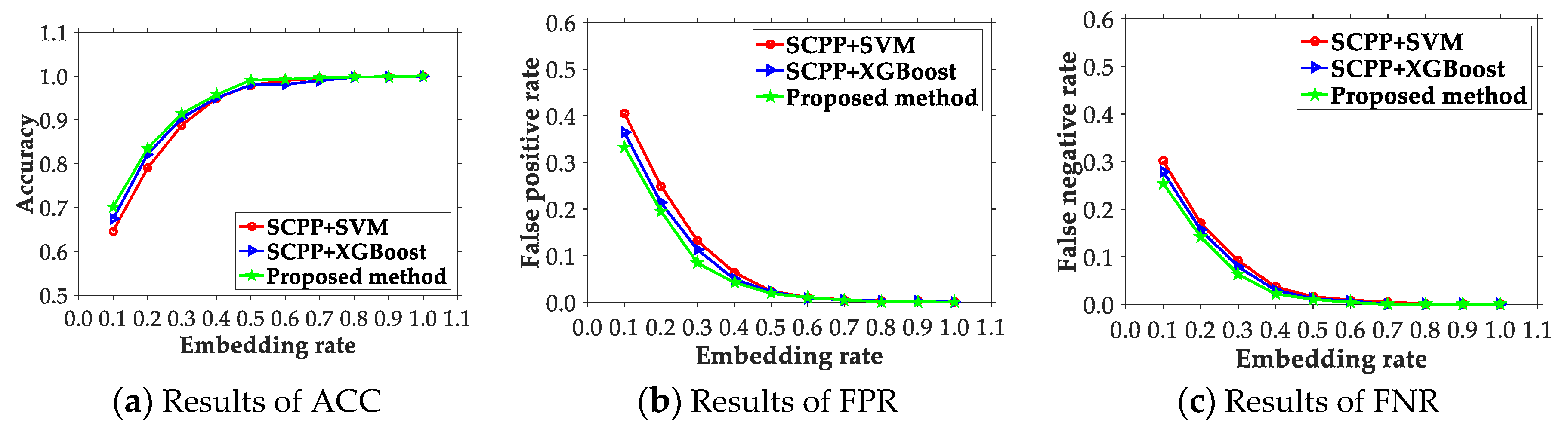
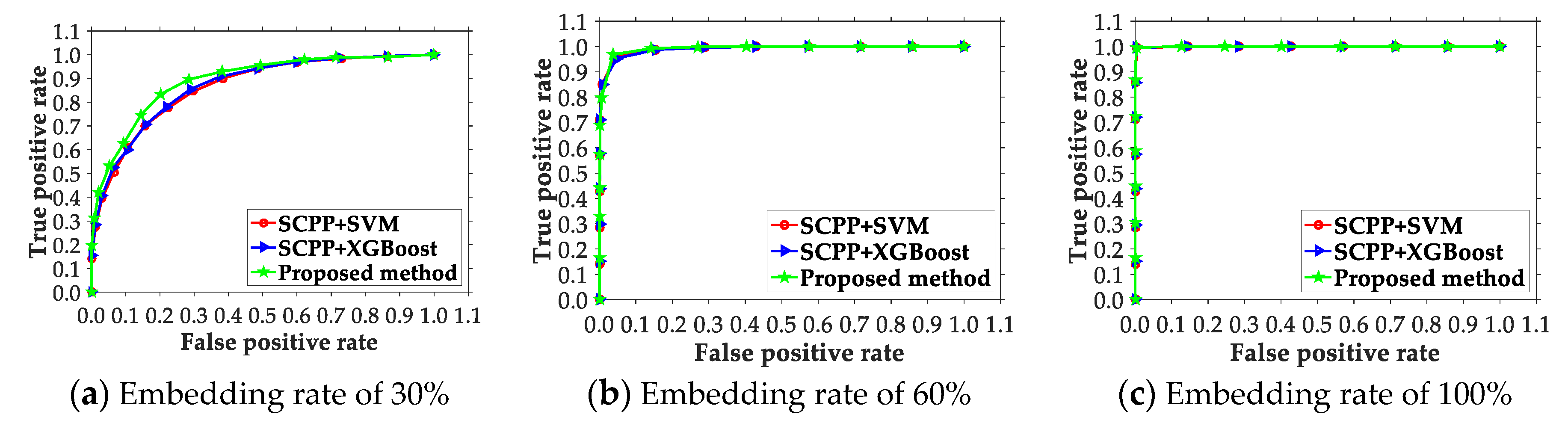
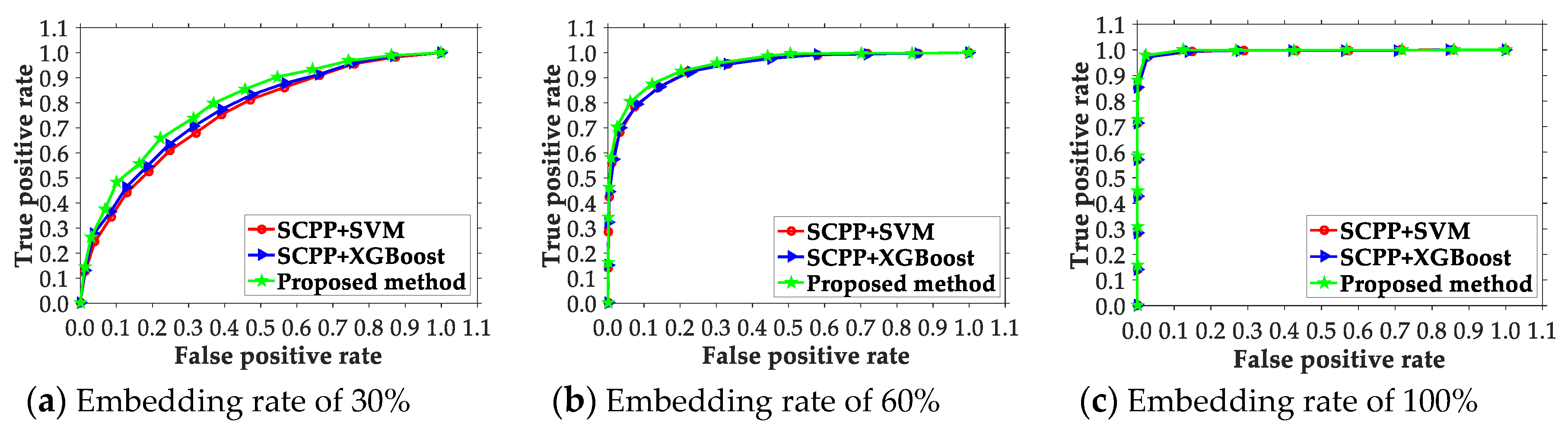
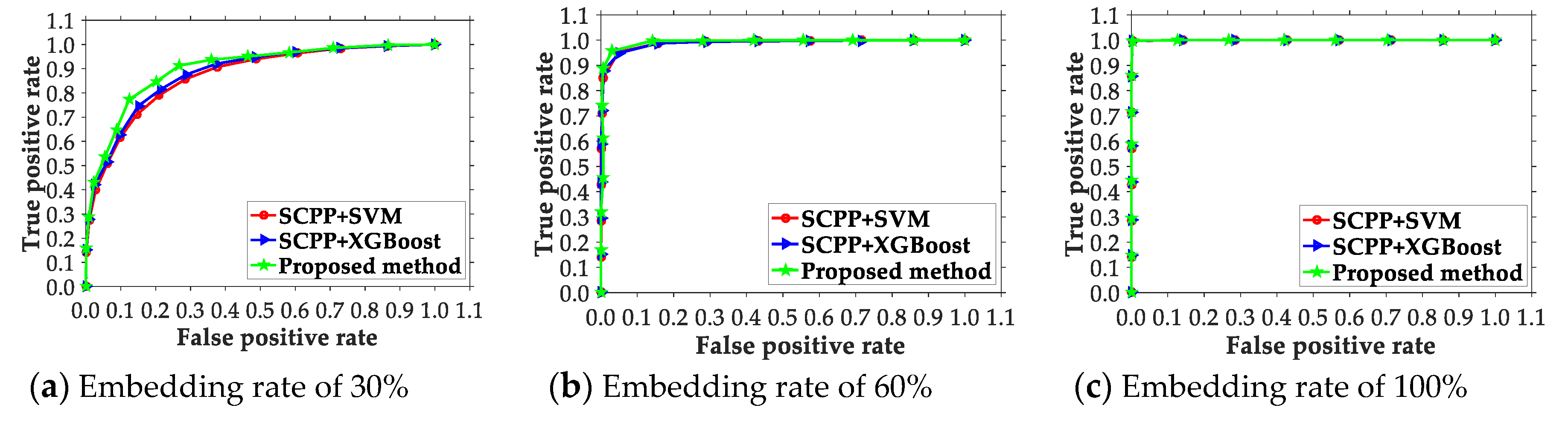
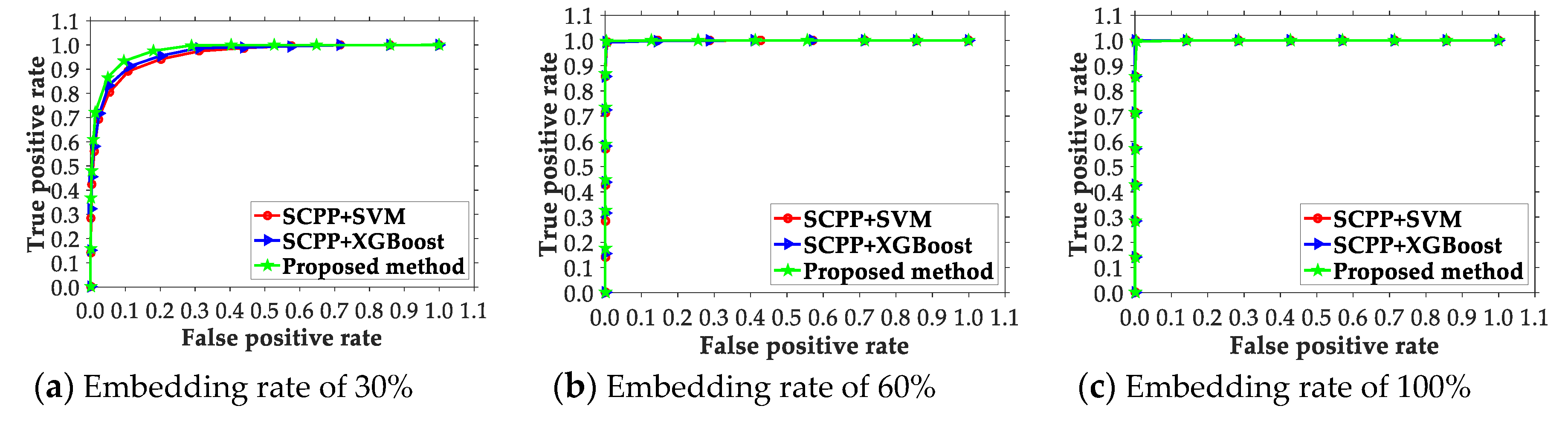
4.2. Comparison of the Presented Scheme and Existing Ones
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Provos, N.; Honeyman, P. Hide and seek: An introduction to steganography. IEEE Secur. Priv. 2003, 99, 32–44. [Google Scholar] [CrossRef]
- Cheddad, A.; Condell, J.; Curran, K.; McKevitt, P. Digital image steganography: Survey and analysis of current methods. Signal Process. 2010, 90, 727–752. [Google Scholar] [CrossRef]
- Li, B.; Wang, M.; Li, X.; Tan, S.; Huang, J. A strategy of clustering modification directions in spatial image steganography. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1905–1917. [Google Scholar]
- Malik, A.; Sikka, G.; Verma, H.K. A high capacity text steganography scheme based on LZW compression and color coding. Eng. Sci. Technol. Int. J. 2016, 20, 72–79. [Google Scholar] [CrossRef]
- Xiang, L.; Wu, W.; Li, X. A linguistic steganography based on word indexing compression and candidate selection. Multimed. Tools Appl. 2018, 77, 28969–28989. [Google Scholar] [CrossRef]
- Jiang, B.; Yang, G.; Chen, W. A CABAC based HEVCC video steganography algorithm without bitrate increase. J. Comput. Inf. Syst. 2015, 11, 2121–2130. [Google Scholar]
- Ramalingam, M.; Isa, N.A.M. A data-hiding technique using scene-change detection for video steganography. Comput. Electr. Eng. 2016, 54, 423–434. [Google Scholar] [CrossRef]
- Singh, N.; Bhardwaj, J.; Raghav, G. Network Steganography and its Techniques: A Survey. Int. J. Comput. Appl. 2017, 174, 8–14. [Google Scholar] [CrossRef]
- Mazurczyk, W.; Wendzel, S.; Zander, S.; Houmansadr, A.; Szczypiorski, K. Information Hiding in Communication Networks: Fundamentals, Mechanisms, Applications, and Countermeasures; Wiley-IEEE Press: Hoboken, NJ, USA, 2016. [Google Scholar]
- Hussain, A.A.; Edwar, G.L.; Zaidan, A.A. High capacity, transparent and secure audio steganography model based on fractal coding and chaotic map in temporal domain. Multimed. Tools Appl. 2018, 77, 31487–31516. [Google Scholar]
- Hua, G.; Huang, J.; Shi, Y.Q.; Goh, J.; Thing, V.L.L. Twenty years of digital audio watermarking—A comprehensive review. Signal Process. 2016, 128, 222–242. [Google Scholar] [CrossRef]
- Ali, A.H.; Mokhtar, M.R.; George, L.E. Enhancing the hiding capacity of audio steganography based on block mapping. J. Theor. Appl. Inf. Technol. 2017, 95, 1441–1448. [Google Scholar]
- Mazurczyk, W. VoIP steganography and its detection-a survey. ACM Comput. Surv. 2013, 46, 20. [Google Scholar] [CrossRef]
- Tian, H.; Qin, J.; Guo, S. Improved adaptive partial matching steganography for Voice over IP. Comput. Commun. 2015, 70, 95–108. [Google Scholar] [CrossRef]
- Tian, H.; Qin, J.; Huang, Y. Optimal matrix embedding for Voice-over-IP steganography. Signal Process. 2015, 117, 33–43. [Google Scholar] [CrossRef]
- Jiang, Y.; Tang, S.; Zhang, L.; Xiong, M.; Yip, Y.J. Covert voice over internet protocol communications with packet loss based on fractal interpolation. ACM Trans. Multimed. Comput. Commun. Appl. 2016, 12, 1–20. [Google Scholar] [CrossRef]
- 3GPP/ETSI. AMR Speech Codec: General Description, Version 10.0.0; Technical Report TS 26 171; Sophia Antipolis: Valbonne, France, April 2011. [Google Scholar]
- 3GPP/ETSI. Performance Characterization of the Adaptive Multi-Rate (AMR) Speech Codec; Technical Report TR 126 975; Sophia Antipolis: Valbonne, France, January 2009. [Google Scholar]
- 3GPP/ETSI. Digital Cellular Telecommunications System (Phase 2+); Universal Mobile Telecommunications System (UMTS); LTE: Mandatory Speech Codec Speech Processing Functions; Adaptive Multi-Rate (AMR) Speech Codec; Transcoding Functions (3GPP TS 26.090 Version 13.0.0 Release 13); Technical Report TR 126 090; Sophia Antipolis: Valbonne, France, January 2016. [Google Scholar]
- Geiser, B.; Vary, P. High rate data hiding in ACELP speech Codecs. In Proceedings of the IEEE International Conference on Acoustics, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 4005–4008. [Google Scholar]
- Miao, H.; Huang, L.; Chen, Z.; Yang, W.; Al-Hawbani, A. A new scheme for covert communication via 3G encoded speech. Comput. Electr. Eng. 2012, 38, 1490–1501. [Google Scholar] [CrossRef]
- Janicki, A.; Mazurczyk, W.; Szczypiorski, K. Steganalysis of transcoding steganography. Ann. Telecommun. Ann. Telecommun. 2014, 69, 449–460. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, X.; Sun, X.; Wang, B. Steganalysis of least significant bit matching using multi-order differences. Secur. Commun. Netw. 2014, 7, 1283–1291. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Low-complexity features for JPEG steganalysis using undecimated DCT. IEEE Trans. Inf. Forensics Secur. 2015, 10, 219–228. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, X.; Sun, X.; Liu, Q.; Xiong, N. Steganalysis of LSB matching using differences between nonadjacent pixels. Multimed. Tools Appl. 2016, 75, 1947–1962. [Google Scholar] [CrossRef]
- Tang, W.; Li, H.; Luo, W.; Huang, J. Adaptive steganalysis based on embedding probabilities of pixels. IEEE Trans. Inf. Forensics Secur. 2016, 11, 734–744. [Google Scholar] [CrossRef]
- Yu, J.; Li, F.; Cheng, H.; Zhang, X. Spatial steganalysis using contrast of residuals. IEEE Signal Process. Lett. 2016, 23, 989–992. [Google Scholar] [CrossRef]
- Denemark, T.; Boroumand, M.; Fridrich, J. Steganalysis features for content-adaptive JPEG steganography. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1736–1746. [Google Scholar] [CrossRef]
- Tian, H.; Wu, Y.; Cai, Y. Distributed steganalysis of compressed speech. Soft Comput. 2017, 21, 795–804. [Google Scholar] [CrossRef]
- Tian, H.; Wu, Y.; Chang, C.C. Steganalysis of analysis-by-synthesis speech exploiting pulse-position distribution characteristics. Secur. Commun. Netw. 2016, 9, 2934–2944. [Google Scholar] [CrossRef]
- Miao, H.; Huang, L.; Shen, Y.; Lu, X.; Chen, Z. Steganalysis of compressed speech based on Markov and entropy. In Proceedings of the 12th International Workshop on Digital-Forensics and Watermarking (IWDW), Auckland, New Zealand, 1–4 October 2013; pp. 63–76. [Google Scholar]
- Ren, Y.; Cai, T.; Tang, M.; Wang, L. AMR steganalysis based on the probability of same pulse position. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1801–1811. [Google Scholar]
- Tian, H.; Wu, Y.; Huang, Y. Steganalysis of adaptive multi-Rate speech using statistical characteristics of pulse pairs. Signal Process. 2017, 134, 9–22. [Google Scholar] [CrossRef]
- Guo, L.; Ge, P.-S.; Zhang, M.-H.; Li, L.-H.; Zhao, Y.-B. Pedestrian detection for intelligent transportation systems combining AdaBoost algorithm and support vector machine. Exp. Syst. Appl. 2012, 39, 4274–4286. [Google Scholar] [CrossRef]
- Mitrophanov, A. Sensitivity and convergence of uniformly ergodic Markov chains. J. Appl. Probab. 2005, 4, 1003–1014. [Google Scholar] [CrossRef]
- Roberts, G.; Tweedie, R. Rates of convergence of stochastically monotone and continuous time Markov models. J. Appl. Probab. 2000, 37, 359–373. [Google Scholar] [CrossRef]
- Mitrophanov, A. Stability and exponential convergence of continuous-time Markov chains. J. Appl. Probab. 2003, 40, 970–979. [Google Scholar] [CrossRef]
- Zhou, H.; Chen, C.; Wang, M.; Ma, Q.; Yu, B. Predicting Golgi-resident Protein Types Using Conditional Covariance Minimization with XGBoost Based on Multiple Features Fusion. IEEE Access 2019, 7, 144154–144164. [Google Scholar] [CrossRef]
- Torlay, L.; Perrone-Bertolotti, M.; Thomas, E. Machine learning–XGBoost analysis of language networks to classify patients with epilepsy. Brain Inform. 2017, 4, 159–169. [Google Scholar] [CrossRef] [PubMed]
- Ogunleye, A.A.; Qing-Guo, W. XGBoost Model for Chronic Kidney Disease Diagnosis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019. [Google Scholar] [CrossRef]
- Mahmud, S.; Hasan, M.; Chen, W.Y.; Jahan, H.; Liu, Y.S.; Sujan, N.; Ahmed, S. iDTi-CSsmoteB: Identification of Drug–Target Interaction Based on Drug Chemical Structure and Protein Sequence Using XGBoost With Over-Sampling Technique SMOTE. Access IEEE 2019, 7, 48699–48714. [Google Scholar] [CrossRef]
- Jiancheng, Z.; Yusu, S.; Wei, P. XGBFEMF: An XGBoost-based Framework for Essential Protein Prediction. IEEE Trans. NanoBiosci. 2018, 17, 243–250. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 22–27 August 2016; pp. 785–794. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hiroshi, S.; Nazrul, I. Convergence across Chinese provinces: An analysis using Markov transition matrix. China Econ. Rev. 2008, 19, 66–79. [Google Scholar]
- He, X.; Yang, X.S.; Karamanoglu, M. Global Convergence Analysis of the Flower Pollination Algorithm: A Discrete-Time Markov Chain Approach. Procedia Comput. Sci. 2017, 108, 1354–1363. [Google Scholar] [CrossRef]
- Pan, X.; Liu, Q.; Peng, X. Spatial club convergence of regional energy efficiency in China. Ecol. Indic. 2015, 51, 25–30. [Google Scholar] [CrossRef]
- Dubois, D.; Liu, W.R.; Ma, J.B.; Prade, H. The basic principles of uncertain information fusion. An organised review of merging rules in different representation frameworks. Inf. Fusion 2016, 32, 12–39. [Google Scholar] [CrossRef]
- Rahman, M.A.; Liu, S.; Wong, Y.C.; Lin, S.C.F.; Liu, S.C.; Kwok, N.M. Multi-focal image fusion using degree of focus and fuzzy logic. Digit. Signal Process. 2017, 60, 1–19. [Google Scholar] [CrossRef]
- Li, S.T.; Kang, X.D.; Hu, J.W. Image Fusion with Guided Filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [PubMed]
- Chen, Y.; Zhou, L.; Pei, S. KNN-BLOCK DBSCAN: Fast Clustering For Large Scale Data. IEEE Trans. Syst. Man Cybern. Syst. 2019. [Google Scholar] [CrossRef]
- Chen, Y.; Hu, X.; Fan, W. Fast Density Peak Clustering for Large Scale Data Based On kNN. Knowl. Based System. 2020, 187, 104824. [Google Scholar] [CrossRef]
- Chen, Y.; Tan, S.; Nizar, B. A Fast Clustering Algorithm based on pruning unnecessary distance computations in DBSCAN for High-Dimensional Data. Pattern Recognit. 2018, 83, 375–387. [Google Scholar] [CrossRef]









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Tian, H.; Chang, C.-C.; Chen, Y.; Cai, Y.; Du, Y.; Chen, Y.-H.; Chen, C.C. Steganalysis of Adaptive Multi-Rate Speech Based on Extreme Gradient Boosting. Electronics 2020, 9, 522. https://doi.org/10.3390/electronics9030522
Sun C, Tian H, Chang C-C, Chen Y, Cai Y, Du Y, Chen Y-H, Chen CC. Steganalysis of Adaptive Multi-Rate Speech Based on Extreme Gradient Boosting. Electronics. 2020; 9(3):522. https://doi.org/10.3390/electronics9030522
Chicago/Turabian StyleSun, Congcong, Hui Tian, Chin-Chen Chang, Yewang Chen, Yiqiao Cai, Yongqian Du, Yong-Hong Chen, and Chih Cheng Chen. 2020. "Steganalysis of Adaptive Multi-Rate Speech Based on Extreme Gradient Boosting" Electronics 9, no. 3: 522. https://doi.org/10.3390/electronics9030522
APA StyleSun, C., Tian, H., Chang, C.-C., Chen, Y., Cai, Y., Du, Y., Chen, Y.-H., & Chen, C. C. (2020). Steganalysis of Adaptive Multi-Rate Speech Based on Extreme Gradient Boosting. Electronics, 9(3), 522. https://doi.org/10.3390/electronics9030522