Sentiment Analysis Based on Deep Learning: A Comparative Study




Abstract
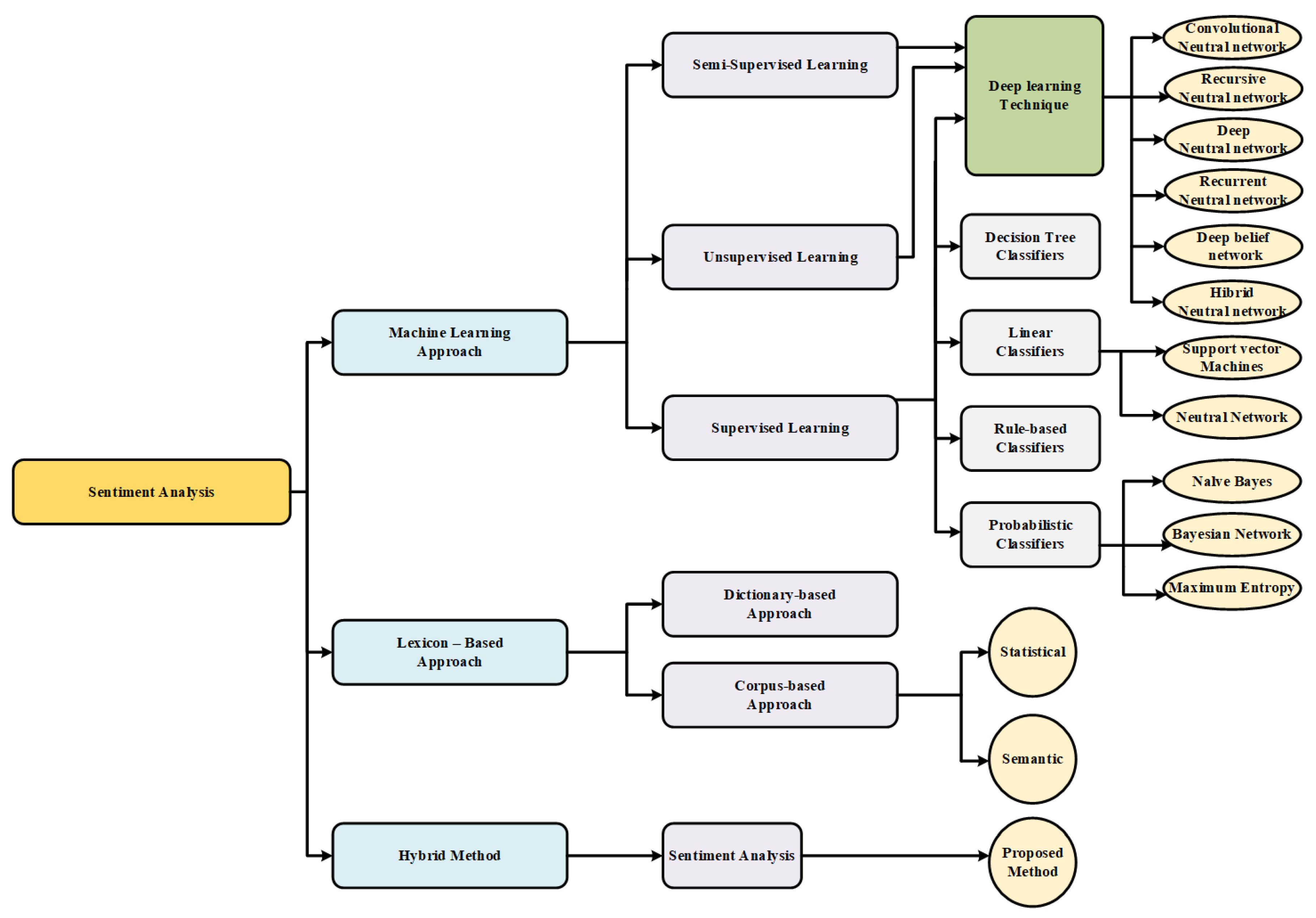
1. Introduction
2. Background
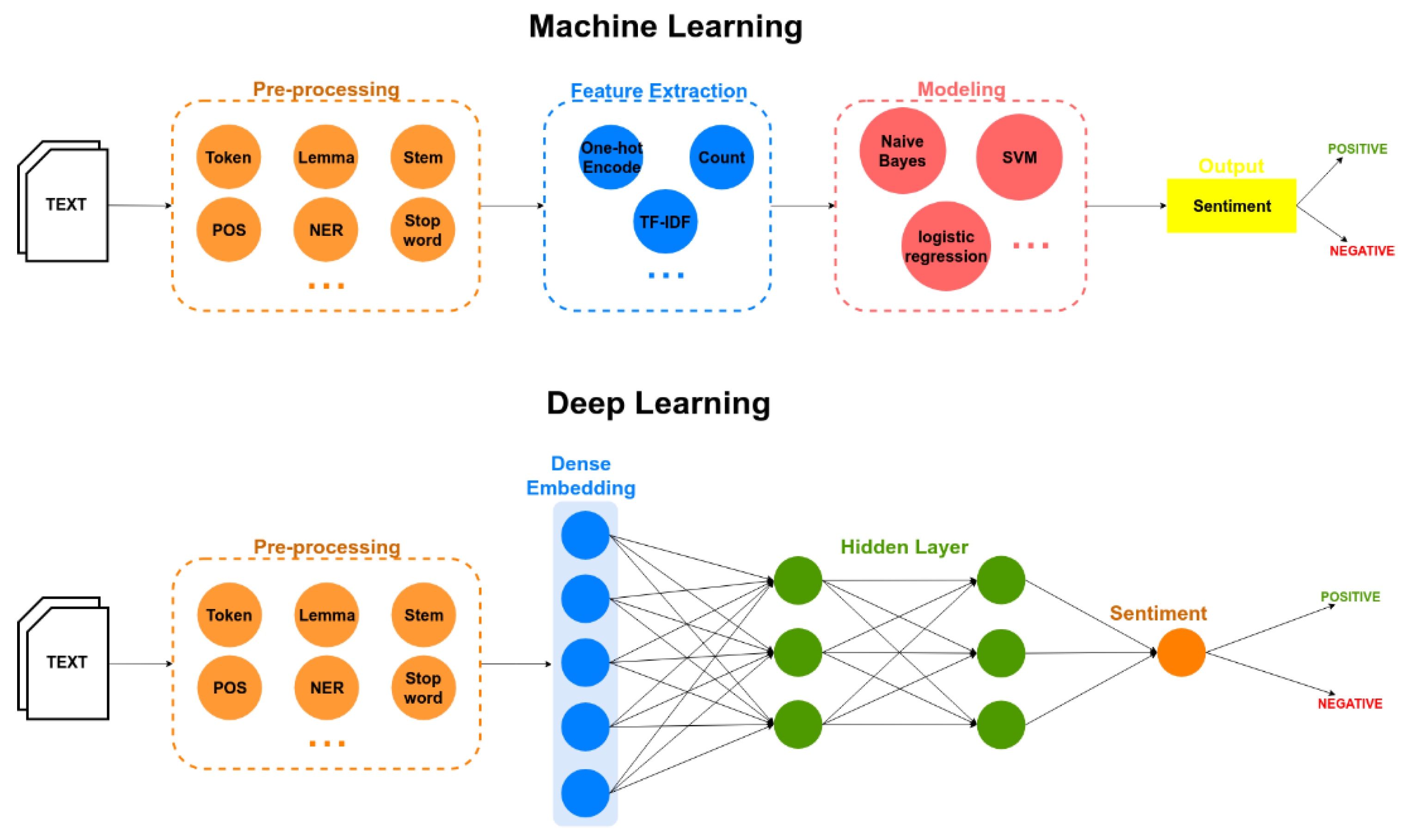
2.1. Deep Learning
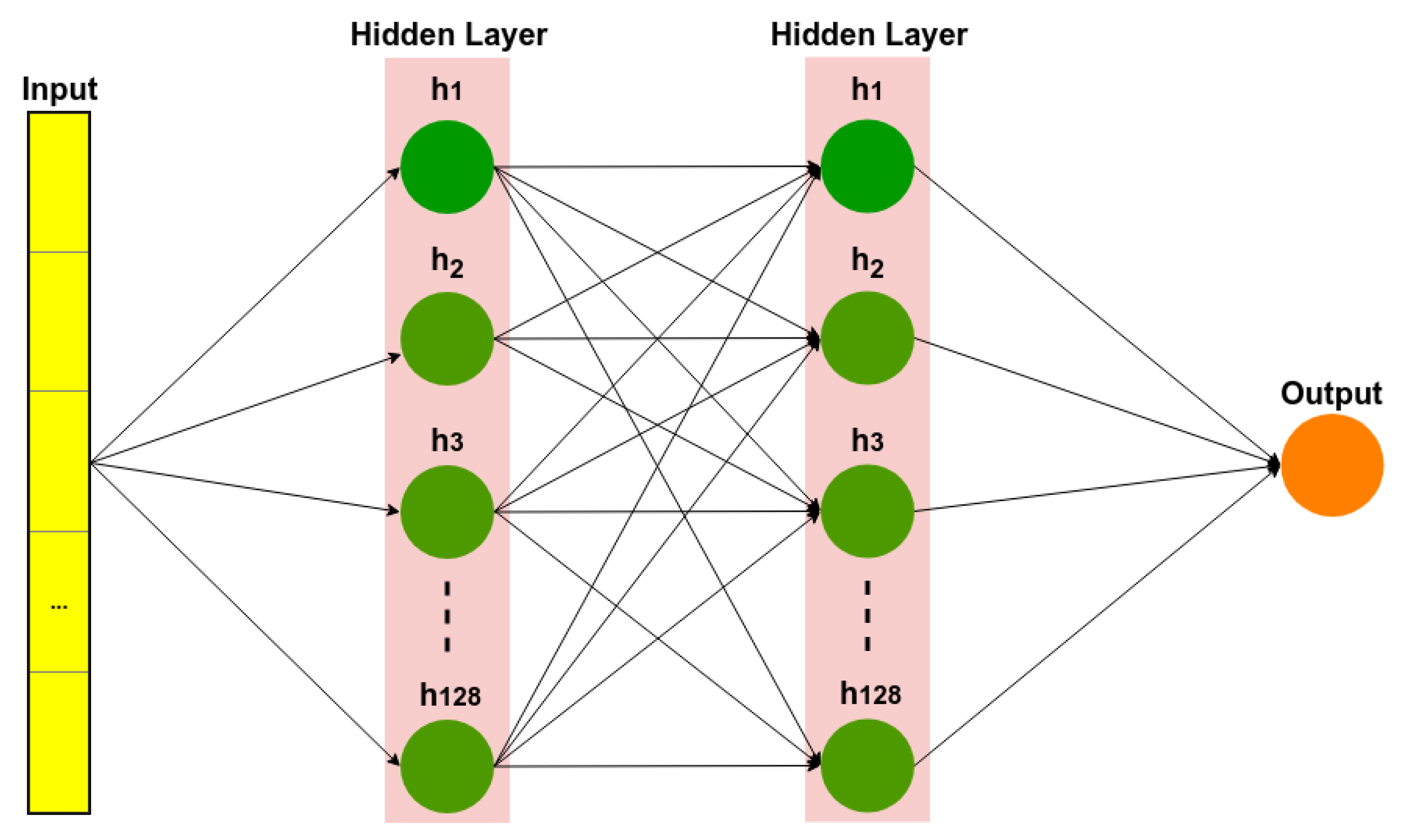
2.1.1. Deep Neural Networks (DNN)
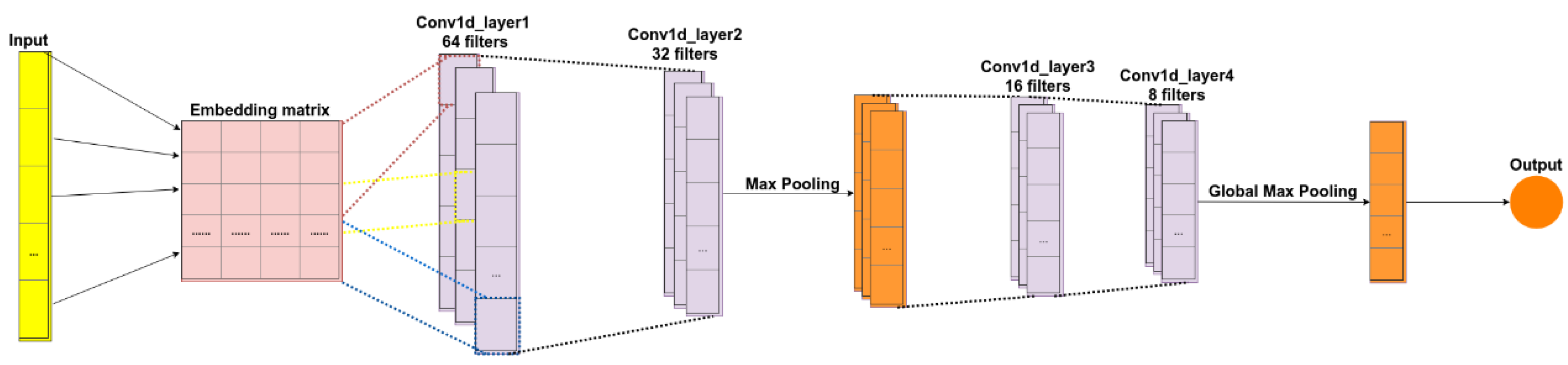
2.1.2. Convolutional Neural Networks (CNN)
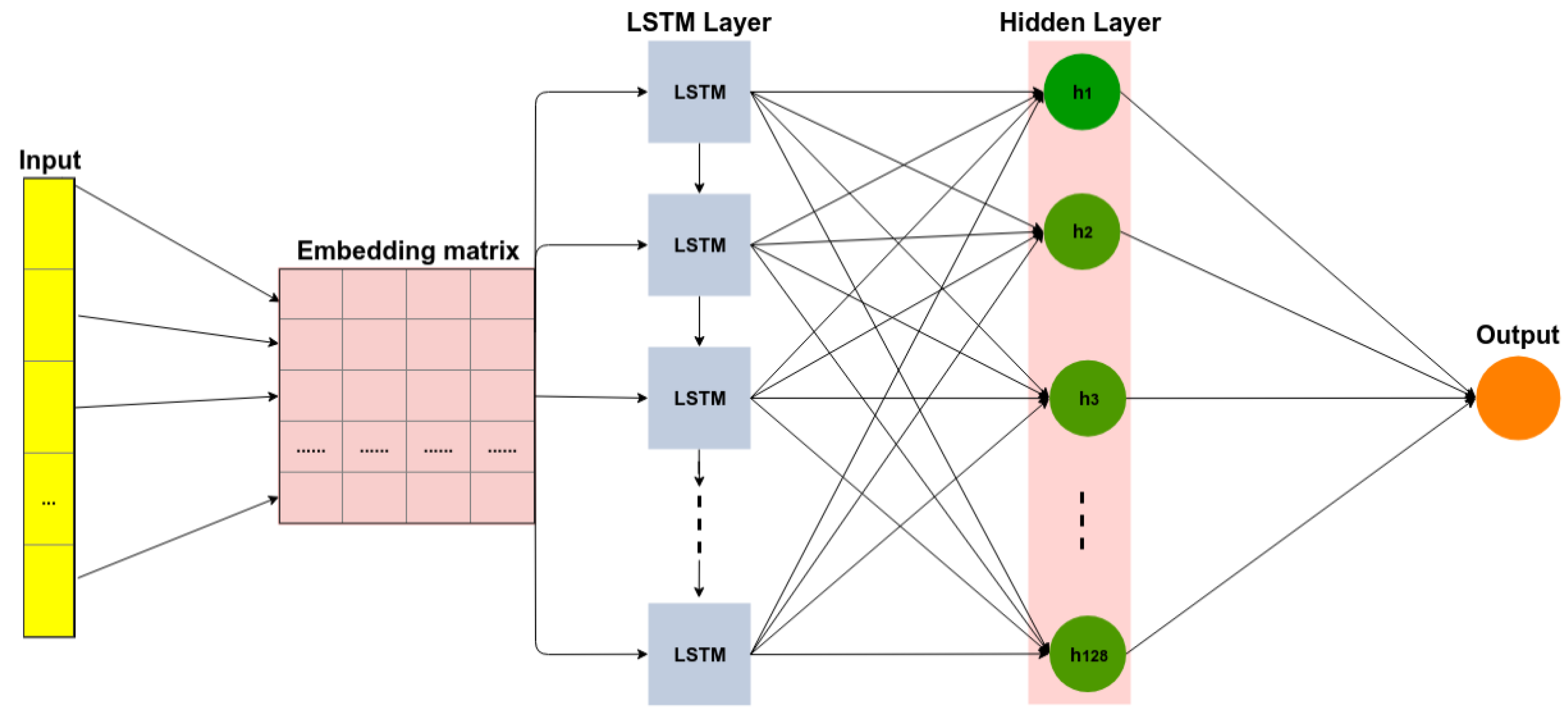
2.1.3. Recurrent Neural Networks (RNN)
2.1.4. Other Neural Networks
2.2. Sentiment Analysis
2.3. Application of Sentiment Analysis
3. Related Work
4. Comparative Study
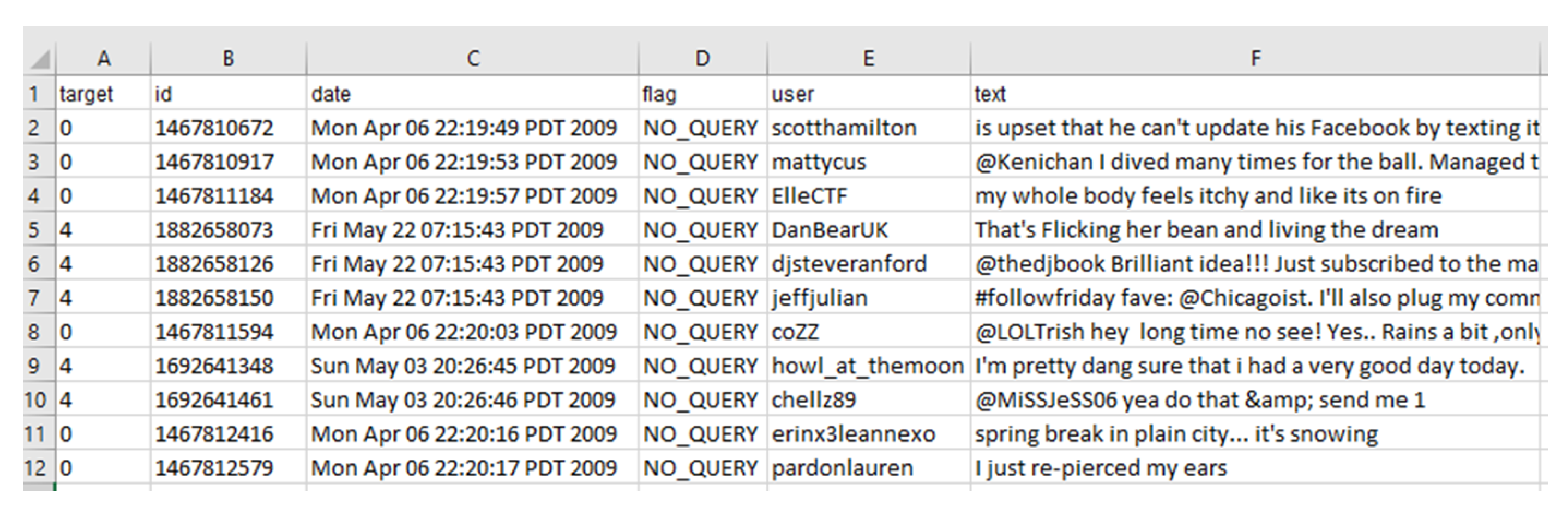
4.1. Datasets
- Sentiment140 was obtained from Stanford University [68]. It contains 1.6 million tweets about products or brands. The tweets were already labeled with the polarity of the sentiment conveyed by the person writing them (0 = negative, 4 = positive).
- Tweets Airline [69] is a tweet dataset containing user opinions about U.S. airlines. It was crawled in February 2015. It has 14,640 samples, and it was divided into negative, neutral, and positive classes.
- Tweets SemEval [70] is a tweet dataset that includes a range of named geopolitical entities. This dataset has 17,750 samples, and it was divided into positive, neutral, and negative classes.
- IMDB Movie Reviews [71] is a dataset of comments from audiences about the stories in films. It has 25,000 samples divided into positive and negative.
- IMDB Movie Reviews was obtained from Stanford University [72]. This dataset contains comments from audiences about the story of films. It has 50,000 samples, which are divided into positive and negative.
- Cornell Movie Reviews [73] contains comments from audiences about the stories in films. This dataset includes 10,662 samples for training and testing, which are labeled negative or positive.
- Book Reviews and Music Reviews is a dataset obtained from the Multidomain Sentiment of the Department of Computer Science of Johns Hopkins University. Biographies, Bollywood, Boom Boxes, and Blenders: Domain Adaptation for Sentiment Classification [74] contains user comments about books and music. Each has 2,000 samples with two classes—negative and positive.
- “target” is the polarity of the tweet;
- “id” is the unique ID of each tweet;
- “date” is the date of the tweet;
- “query_string” indicates whether the tweet has been collected with any particular query keyword (for this column, 100% of the entries labeled are with the value “NO_QUERY”);
- “user” is the Twitter handle name of the user who tweeted;
- “text” is the verbatim text of the tweet.
4.2. Methodological Approach
4.3. Sentiment Classification
- Cleaning the Twitter RTs, @, #, and the links from the sentences;
- Stemming or lemmatization;
- Converting the text to lower case;
- Cleaning all the non-letter characters, including numbers;
- Removing English stop words and punctuation;
- Eliminating extra white spaces;
- Decoding HTML to general text.
4.4. Sentiment Model
5. Experimental Results
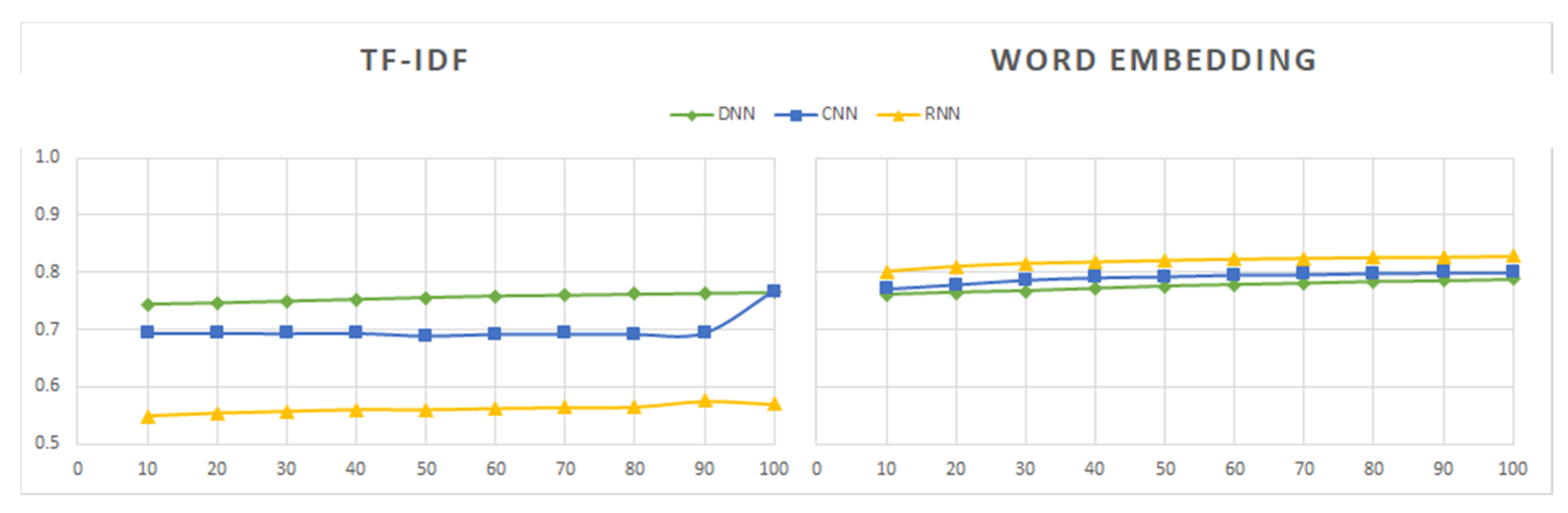
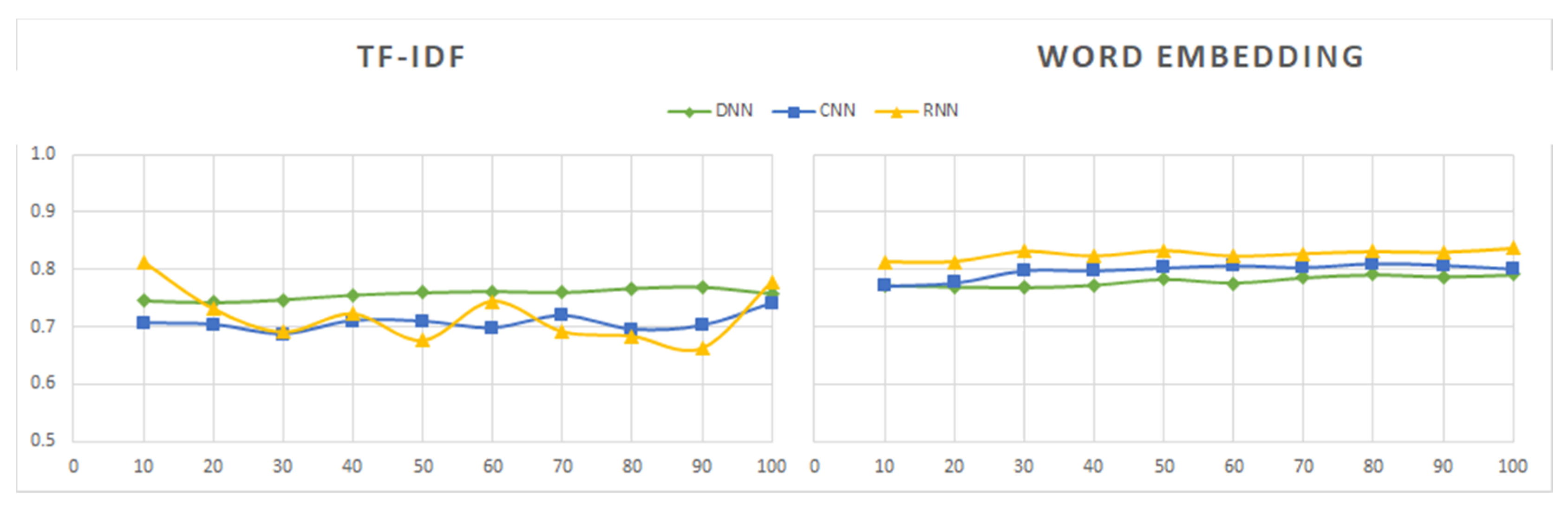
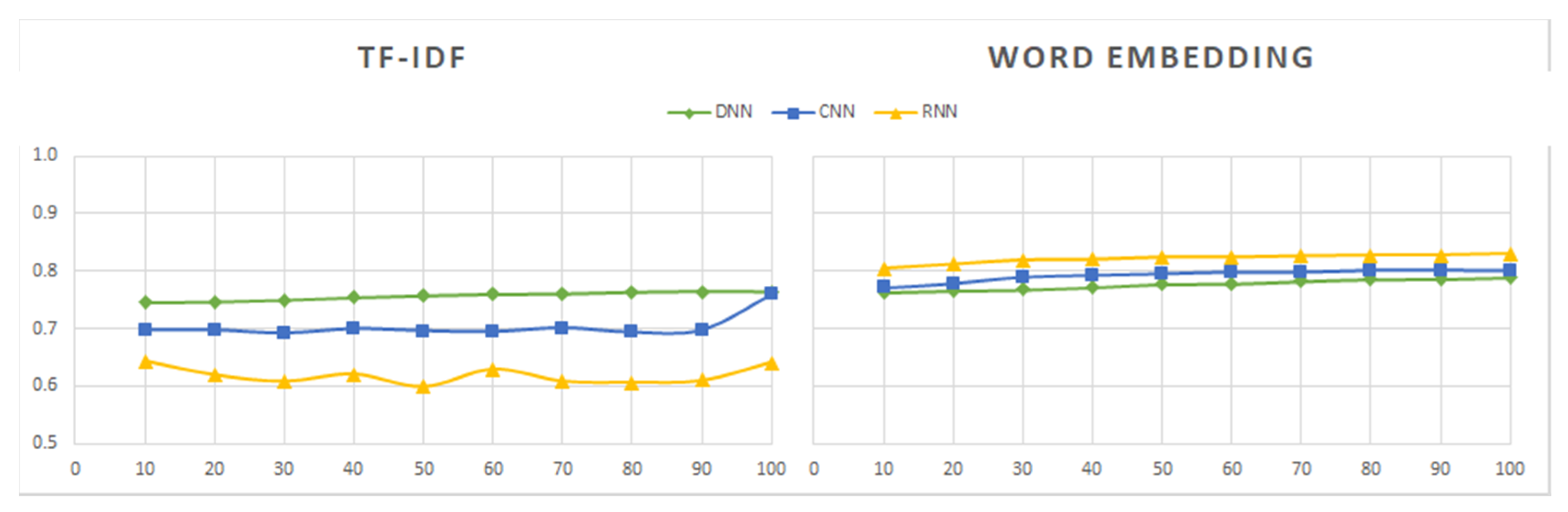
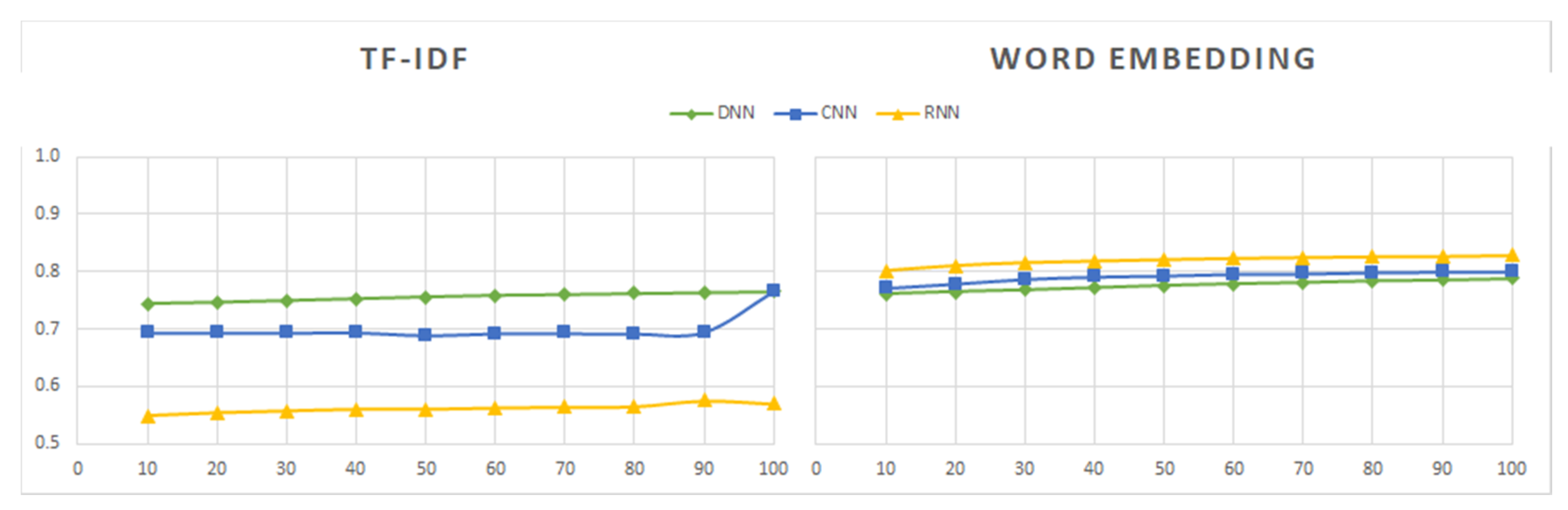
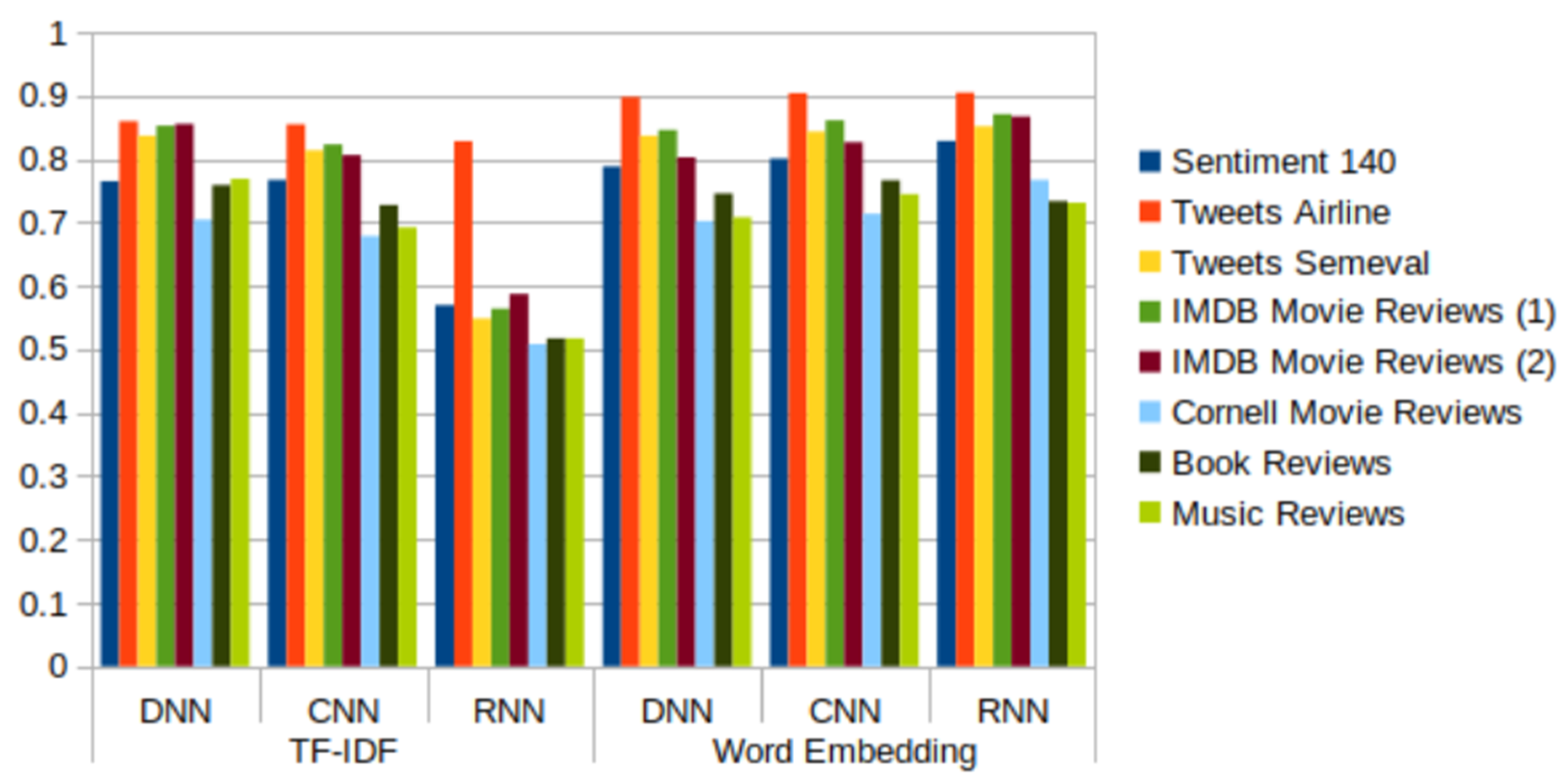
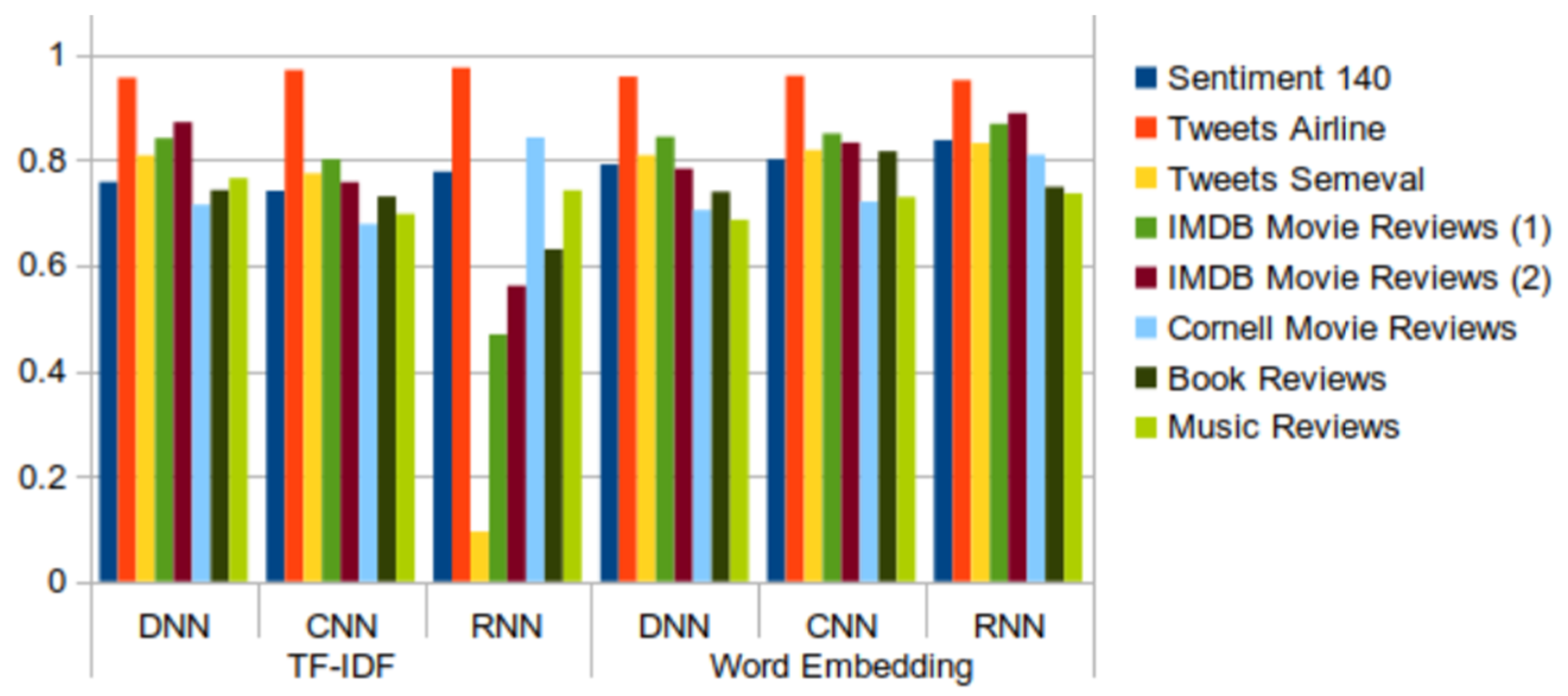
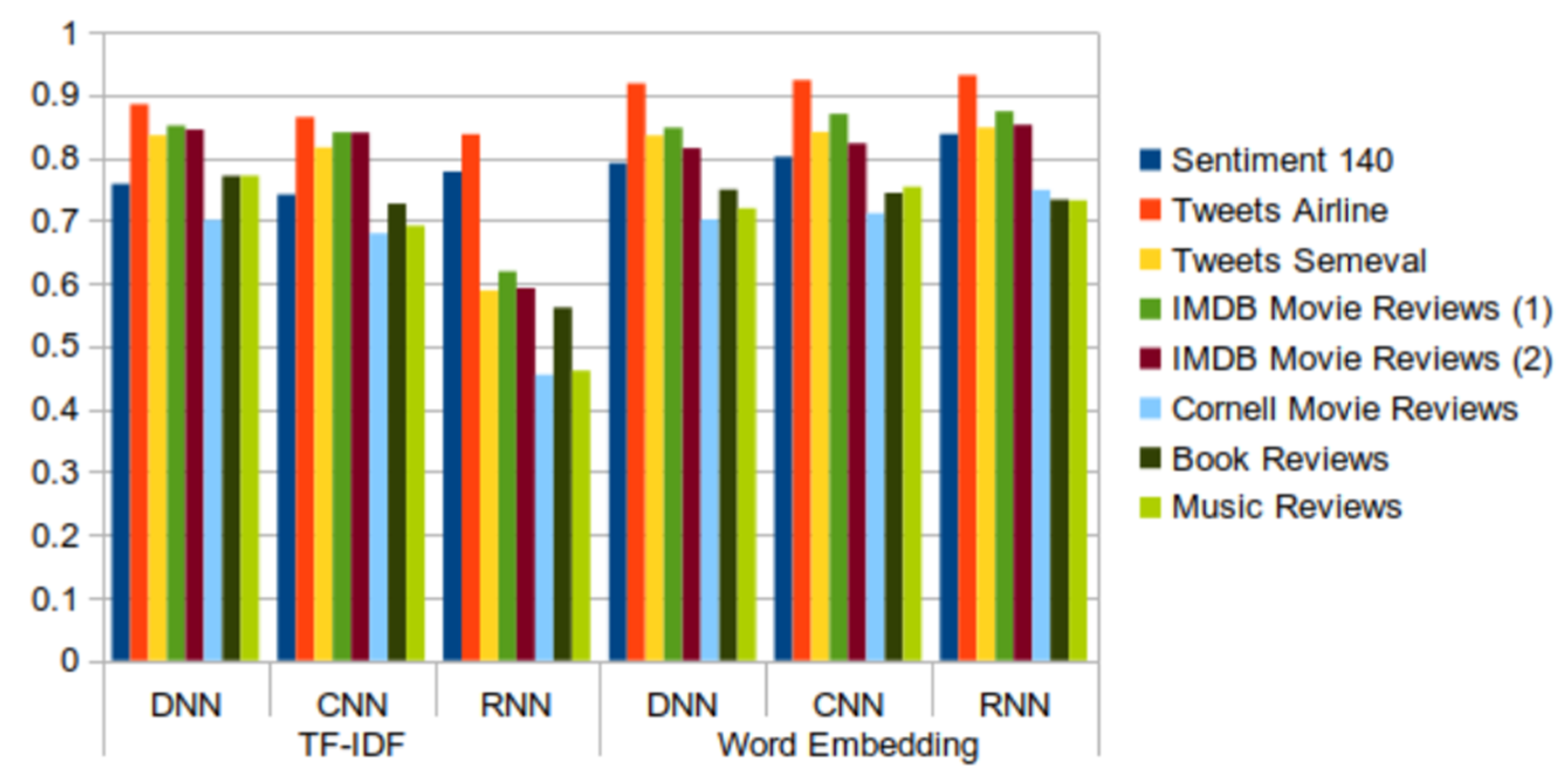
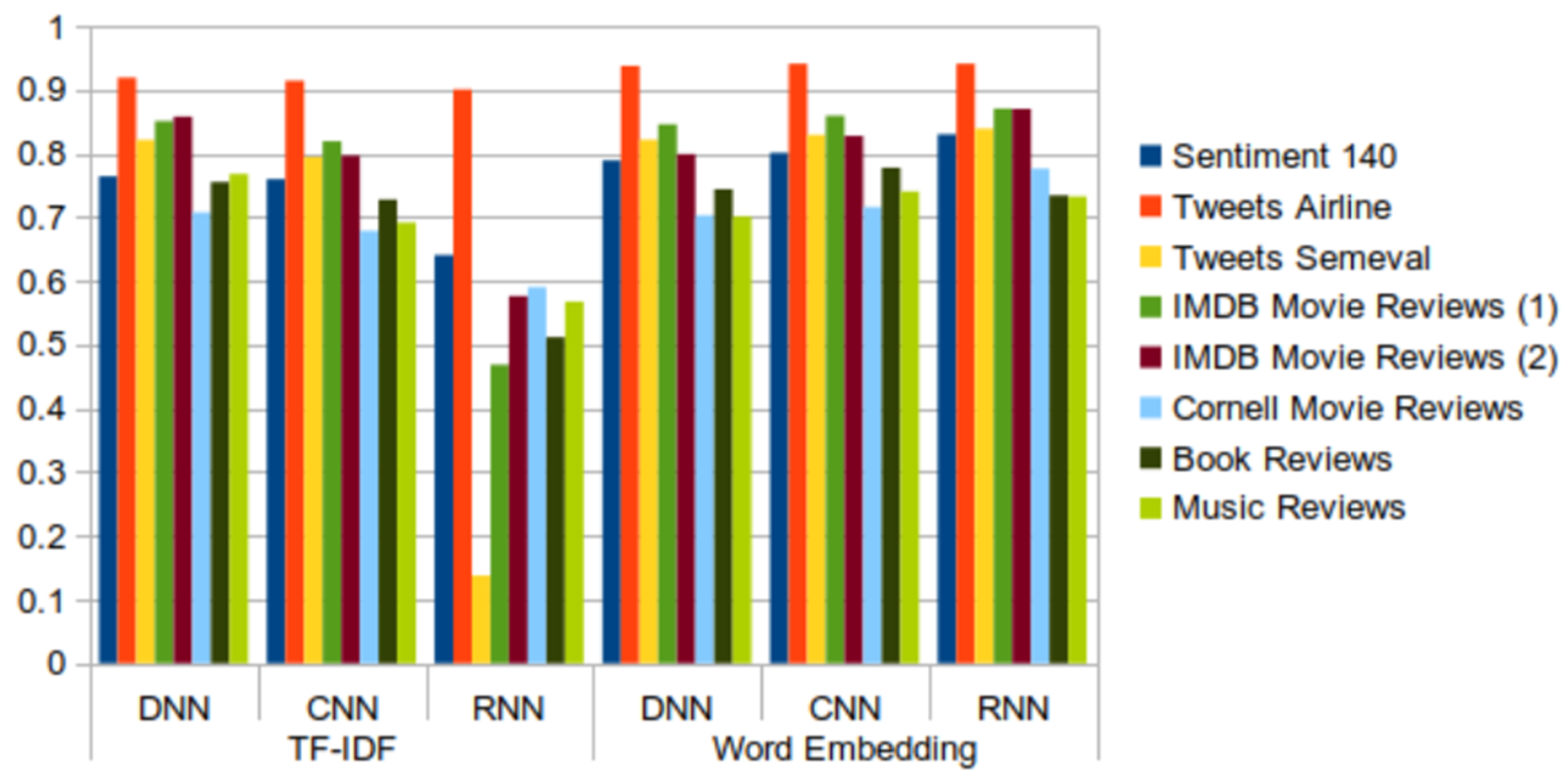
- The DNN model is simple to implement and provides results within a short period of time—around 1 min for the majority of datasets, except dataset Sentiment140, for which the model took 12 min to obtain the results. Although the model is quick to train, the overall accuracy of the model is average (around 75% to 80%) in all of the tested datasets, including tweets and reviews.
- The CNN model is also fast to train and test, although possibly a bit slower than DNN. The model offers higher accuracy (over 80%) on both tweet and review datasets.
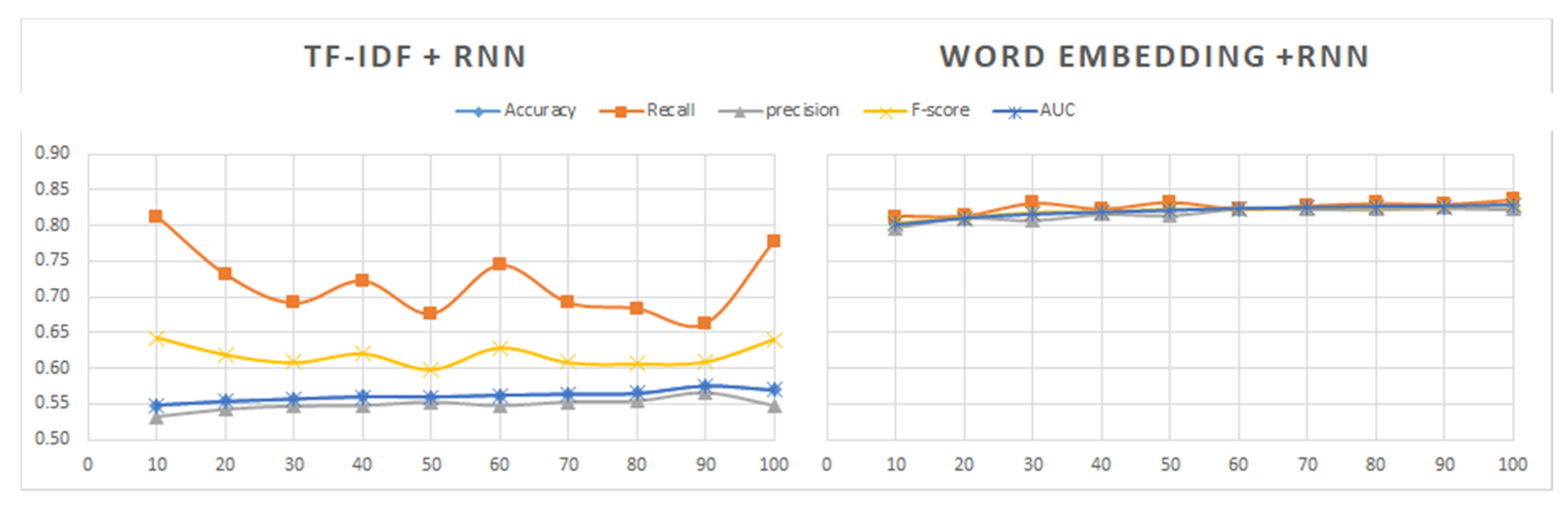
- The RNN model has the highest reliability when word embedding is applied, however its computational time is also the highest. When using RNN with TF-IDF, it takes a longer time than other models and results in lower accuracy (around 50%) in the sentiment analysis of tweet and review datasets.
- Three deep learning models (DNN, CNN, and RNN) were used to perform sentiment analysis experiments. The CNN model was found to offer the best tradeoff between the processing time and the accuracy of results. Although the RNN model had the highest degree of accuracy when used with word embedding, its processing time was 10 times longer than that of the CNN model. The RNN model is not effective when used with the TF-IDF technique, and its far higher processing time leads to results that are not significantly better. DNN is a simple deep learning model that has average processing times and yields average results. Future research on deep learning models can focus on ways of improving the tradeoff between the accuracy of results and the processing times.
- Related techniques (TF-IDF and word embedding) are used to transfer text data (tweets, reviews) into a numeric vector before feeding them into a deep learning model. The results when TF-IDF is used are poorer than when word embedding is used. Moreover, the TF-IDF technique used with the RNN model takes has a longer processing time and yields less reliable results. However, when RNN is used with word embedding, the results are much better. Future work can explore how to improve these and other techniques to achieve even better results.
- The results from the datasets containing tweets and IMDB movie review datasets are better than the results from the other datasets containing reviews. Regarding tweets data, the models induced from the Tweets Airline dataset, focused on a specific topic, show better performance than those built from datasets about generic topics.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E.E.; Dimitriou, A.; Papavassiliou, S. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 2015 13th International Conference on Telecommunications (ConTEL), Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar]
- Thai, M.T.; Wu, W.; Xiong, H. Big Data in Complex and Social Networks; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Cambria, E.; Das, D.; Bandyopadhyay, S.; Feraco, A. A Practical Guide to Sentiment Analysis; Springer: Berlin, Germany, 2017. [Google Scholar]
- Hussein, D.M.E.-D.M. A survey on sentiment analysis challenges. J. King Saud Univ. Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Sohangir, S.; Wang, D.; Pomeranets, A.; Khoshgoftaar, T.M. Big Data: Deep Learning for financial sentiment analysis. J. Big Data 2018, 5, 3. [Google Scholar] [CrossRef]
- Jangid, H.; Singhal, S.; Shah, R.R.; Zimmermann, R. Aspect-Based Financial Sentiment Analysis using Deep Learning. In Proceedings of the Companion of the The Web Conference 2018 on The Web Conference, Lyon, France, 23–27 April 2018; pp. 1961–1966. [Google Scholar]
- Keenan, M.J.S. Advanced Positioning, Flow, and Sentiment Analysis in Commodity Markets; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Satapathy, R.; Cambria, E.; Hussain, A. Sentiment Analysis in the Bio-Medical Domain; Springer: Berlin, Germany, 2017. [Google Scholar]
- Rajput, A. Natural Language Processing, Sentiment Analysis, and Clinical Analytics. In Innovation in Health Informatics; Elsevier: Amsterdam, The Netherlands, 2020; pp. 79–97. [Google Scholar]
- Qian, J.; Niu, Z.; Shi, C. Sentiment Analysis Model on Weather Related Tweets with Deep Neural Network. In Proceedings of the 2018 10th International Conference on Machine Learning and Computing, Macau, China, 26–28 February 2018; pp. 31–35. [Google Scholar]
- Pham, D.-H.; Le, A.-C. Learning multiple layers of knowledge representation for aspect based sentiment analysis. Data Knowl. Eng. 2018, 114, 26–39. [Google Scholar] [CrossRef]
- Preethi, G.; Krishna, P.V.; Obaidat, M.S.; Saritha, V.; Yenduri, S. Application of deep learning to sentiment analysis for recommender system on cloud. In Proceedings of the 2017 International Conference on Computer, Information and Telecommunication Systems (CITS), Dalian, China, 21–23 July 2017; pp. 93–97. [Google Scholar]
- Ain, Q.T.; Ali, M.; Riaz, A.; Noureen, A.; Kamran, M.; Hayat, B.; Rehman, A. Sentiment analysis using deep learning techniques: A review. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 424. [Google Scholar]
- Gao, Y.; Rong, W.; Shen, Y.; Xiong, Z. Convolutional neural network based sentiment analysis using Adaboost combination. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1333–1338. [Google Scholar]
- Hassan, A.; Mahmood, A. Deep learning approach for sentiment analysis of short texts. In Proceedings of the Third International Conference on Control, Automation and Robotics (ICCAR), Nagoya, Japan, 24–26 April 2017; pp. 705–710. [Google Scholar]
- Kraus, M.; Feuerriegel, S. Sentiment analysis based on rhetorical structure theory: Learning deep neural networks from discourse trees. Expert Syst. Appl. 2019, 118, 65–79. [Google Scholar] [CrossRef]
- Li, L.; Goh, T.-T.; Jin, D. How textual quality of online reviews affect classification performance: A case of deep learning sentiment analysis. Neural Comput. Appl. 2018, 1–29. [Google Scholar] [CrossRef]
- Singhal, P.; Bhattacharyya, P. Sentiment Analysis and Deep Learning: A Survey; Center for Indian Language Technology, Indian Institute of Technology: Bombay, Indian, 2016. [Google Scholar]
- Alharbi, A.S.M.; de Doncker, E. Twitter sentiment analysis with a deep neural network: An enhanced approach using user behavioral information. Cogn. Syst. Res. 2019, 54, 50–61. [Google Scholar] [CrossRef]
- Abid, F.; Alam, M.; Yasir, M.; Li, C.J. Sentiment analysis through recurrent variants latterly on convolutional neural network of Twitter. Future Gener. Comput. Syst. 2019, 95, 292–308. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: Berlin, Germany, 2018. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Britz, D. Recurrent Neural Networks Tutorial, Part 1–Introduction to Rnns. Available online: http://www.wildml.com/2015/09/recurrent-neural-networkstutorial-part-1-introduction-to-rnns/ (accessed on 12 March 2020).
- Hochreiter, S.; Schmidhuber, J. LSTM can solve hard long time lag problems. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; pp. 473–479. [Google Scholar]
- Ruangkanokmas, P.; Achalakul, T.; Akkarajitsakul, K. Deep Belief Networks with Feature Selection for Sentiment Classification. In Proceedings of the 2016 7th International Conference on Intelligent Systems, Modelling and Simulation (ISMS), Bangkok, Thailand, 25–27 January 2016; pp. 9–14. [Google Scholar]
- Socher, R.; Lin, C.C.; Manning, C.; Ng, A.Y. Parsing natural scenes and natural language with recursive neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 129–136. [Google Scholar]
- Long, H.; Liao, B.; Xu, X.; Yang, J. A hybrid deep learning model for predicting protein hydroxylation sites. Int. J. Mol. Sci. 2018, 19, 2817. [Google Scholar] [CrossRef]
- Vateekul, P.; Koomsubha, T. A study of sentiment analysis using deep learning techniques on Thai Twitter data. In Proceedings of the 2016 13th International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016; pp. 1–6. [Google Scholar]
- Ghosh, R.; Ravi, K.; Ravi, V. A novel deep learning architecture for sentiment classification. In Proceedings of the 2016 3rd International Conference on Recent Advances in Information Technology (RAIT), Dhanbad, India, 3–5 March 2016; pp. 511–516. [Google Scholar]
- Bhavitha, B.; Rodrigues, A.P.; Chiplunkar, N.N. Comparative study of machine learning techniques in sentimental analysis. In Proceedings of the 2017 International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 10–11 March 2017; pp. 216–221. [Google Scholar]
- Salas-Zárate, M.P.; Medina-Moreira, J.; Lagos-Ortiz, K.; Luna-Aveiga, H.; Rodriguez-Garcia, M.A.; Valencia-García, R.J.C. Sentiment analysis on tweets about diabetes: An aspect-level approach. Comput. Math. Methods Med. 2017, 2017. [Google Scholar] [CrossRef] [PubMed]
- Huq, M.R.; Ali, A.; Rahman, A. Sentiment analysis on Twitter data using KNN and SVM. IJACSA Int. J. Adv. Comput. Sci. Appl. 2017, 8, 19–25. [Google Scholar]
- Pinto, D.; McCallum, A.; Wei, X.; Croft, W.B. Table extraction using conditional random fields. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 235–242. [Google Scholar]
- Soni, S.; Sharaff, A. Sentiment analysis of customer reviews based on hidden markov model. In Proceedings of the 2015 International Conference on Advanced Research in Computer Science Engineering & Technology (ICARCSET 2015), Unnao, India, 6 March 2015; pp. 1–5. [Google Scholar]
- Zhang, X.; Zheng, X. Comparison of Text Sentiment Analysis Based on Machine Learning. In Proceedings of the 2016 15th International Symposium on Parallel and Distributed Computing (ISPDC), Fuzhou, China, 8–10 July 2016; pp. 230–233. [Google Scholar]
- Malik, V.; Kumar, A. Communication. Sentiment Analysis of Twitter Data Using Naive Bayes Algorithm. Int. J. Recent Innov. Trends Comput. Commun. 2018, 6, 120–125. [Google Scholar]
- Mehra, N.; Khandelwal, S.; Patel, P. Sentiment Identification Using Maximum Entropy Analysis of Movie Reviews; Stanford University: Stanford, CA, USA, 2002. [Google Scholar]
- Wu, H.; Li, J.; Xie, J. Maximum entropy-based sentiment analysis of online product reviews in Chinese. In Automotive, Mechanical and Electrical Engineering; CRC Press: Boca Raton, FL, USA, 2017; pp. 559–562. [Google Scholar]
- Firmino Alves, A.L.; Baptista, C.d.S.; Firmino, A.A.; Oliveira, M.G.d.; Paiva, A.C.D. A Comparison of SVM versus naive-bayes techniques for sentiment analysis in tweets: A case study with the 2013 FIFA confederations cup. In Proceedings of the 20th Brazilian Symposium on Multimedia and the Web, João Pessoa, Brazil, 18–21 November 2014; pp. 123–130. [Google Scholar]
- Pandey, A.C.; Rajpoot, D.S.; Saraswat, M. Twitter sentiment analysis using hybrid cuckoo search method. Inf. Process. Manag. 2017, 53, 764–779. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Jain, A.P.; Dandannavar, P. Application of machine learning techniques to sentiment analysis. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Karnataka, India, 21–23 July 2016; pp. 628–632. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Deep learning for sentiment analysis: Successful approaches and future challenges. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 292–303. [Google Scholar] [CrossRef]
- Sharef, N.M.; Zin, H.M.; Nadali, S. Overview and Future Opportunities of Sentiment Analysis Approaches for Big Data. JCS 2016, 12, 153–168. [Google Scholar] [CrossRef]
- Rojas-Barahona, L.M. Deep learning for sentiment analysis. Lang. Linguist. Compass 2016, 10, 701–719. [Google Scholar] [CrossRef]
- Roshanfekr, B.; Khadivi, S.; Rahmati, M. Sentiment analysis using deep learning on Persian texts. In Proceedings of the 2017 Iranian Conference on Electrical Engineering (ICEE), Tehran, Iran, 2–4 May 2017; pp. 1503–1508. [Google Scholar]
- Jeong, B.; Yoon, J.; Lee, J.-M. Social media mining for product planning: A product opportunity mining approach based on topic modeling and sentiment analysis. Int. J. Inf. Manag. 2019, 48, 280–290. [Google Scholar] [CrossRef]
- Gupta, U.; Chatterjee, A.; Srikanth, R.; Agrawal, P. A sentiment-and-semantics-based approach for emotion detection in textual conversations. arXiv 2017, arXiv:1707.06996. [Google Scholar]
- Ramadhani, A.M.; Goo, H.S. Twitter sentiment analysis using deep learning methods. In Proceedings of the 2017 7th International Annual Engineering Seminar (InAES), Yogyakarta, Indonesia, 1–2 August 2017; pp. 1–4. [Google Scholar]
- Paredes-Valverde, M.A.; Colomo-Palacios, R.; Salas-Zárate, M.D.P.; Valencia-García, R. Sentiment analysis in Spanish for improvement of products and services: A deep learning approach. Sci. Program. 2017, 2017. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, H.; Jiang, B.; Li, K.J. Aspect-based sentiment analysis with alternating coattention networks. Inf. Process. Manag. 2019, 56, 463–478. [Google Scholar] [CrossRef]
- Do, H.H.; Prasad, P.; Maag, A.; Alsadoon, A.J. Deep Learning for Aspect-Based Sentiment Analysis: A Comparative Review. Expert Syst. Appl. 2019, 118, 272–299. [Google Scholar] [CrossRef]
- Schmitt, M.; Steinheber, S.; Schreiber, K.; Roth, B. Joint Aspect and Polarity Classification for Aspect-based Sentiment Analysis with End-to-End Neural Networks. arXiv 2018, arXiv:1808.09238. [Google Scholar]
- Balabanovic, M.; Shoham, Y. Combining content-based and collaborative recommendation. Commun. ACM 1997, 40, 66–72. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, M.; Xu, W. A sentiment-enhanced hybrid recommender system for movie recommendation: A big data analytics framework. Wirel. Commun. Mob. Comput. 2018, 2018. [Google Scholar] [CrossRef]
- Singh, V.K.; Mukherjee, M.; Mehta, G.K. Combining collaborative filtering and sentiment classification for improved movie recommendations. In Proceedings of the International Workshop on Multi-disciplinary Trends in Artificial Intelligence, Hyderabad, India, 7–9 December 2011; pp. 38–50. [Google Scholar]
- Chen, Z.; Liu, B. Lifelong machine learning. Synth. Lect. Artif. Intell. Mach. Learn. 2018, 12, 1–207. [Google Scholar] [CrossRef]
- Stai, E.; Kafetzoglou, S.; Tsiropoulou, E.E.; Papavassiliou, S.J. A holistic approach for personalization, relevance feedback & recommendation in enriched multimedia content. Multimed. Tools Appl. 2018, 77, 283–326. [Google Scholar]
- Wu, C.; Wu, F.; Wu, S.; Yuan, Z.; Liu, J.; Huang, Y. Semi-supervised dimensional sentiment analysis with variational autoencoder. Knowl. Based Syst. 2019, 165, 30–39. [Google Scholar] [CrossRef]
- Zhang, Z.; Zou, Y.; Gan, C. Textual sentiment analysis via three different attention convolutional neural networks and cross-modality consistent regression. Neurocomputing 2018, 275, 1407–1415. [Google Scholar] [CrossRef]
- Tang, D.; Zhang, M. Deep Learning in Sentiment Analysis. In Deep Learning in Natural Language Processing; Springer: Berlin, Germany, 2018; pp. 219–253. [Google Scholar]
- Araque, O.; Corcuera-Platas, I.; Sanchez-Rada, J.F.; Iglesias, C.A. Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Syst. Appl. 2017, 77, 236–246. [Google Scholar] [CrossRef]
- Liu, J.; Chang, W.-C.; Wu, Y.; Yang, Y. Deep learning for extreme multi-label text classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 115–124. [Google Scholar]
- Chen, M.; Wang, S.; Liang, P.P.; Baltrušaitis, T.; Zadeh, A.; Morency, L.-P. Multimodal sentiment analysis with word-level fusion and reinforcement learning. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 163–171. [Google Scholar]
- Al-Sallab, A.; Baly, R.; Hajj, H.; Shaban, K.B.; El-Hajj, W.; Badaro, G. Aroma: A recursive deep learning model for opinion mining in arabic as a low resource language. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2017, 16, 1–20. [Google Scholar] [CrossRef]
- Kumar, S.; Gahalawat, M.; Roy, P.P.; Dogra, D.P.; Kim, B.-G.J.E. Exploring Impact of Age and Gender on Sentiment Analysis Using Machine Learning. Electronics 2020, 9, 374. [Google Scholar] [CrossRef]
- Available online: http://help.sentiment140.com/site-functionality (accessed on 12 March 2020).
- Available online: https://www.kaggle.com/crowdflower/twitter-airline-sentiment (accessed on 12 March 2020).
- Available online: http://alt.qcri.org/semeval2017/ (accessed on 12 March 2020).
- Available online: https://www.kaggle.com/c/word2vec-nlp-tutorial/data (accessed on 12 March 2020).
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Available online: http://www.cs.cornell.edu/people/pabo/movie-review-data/ (accessed on 12 March 2020).
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 440–447. [Google Scholar]
- Kim, Y.; Sidney, J.; Buus, S.; Sette, A.; Nielsen, M.; Peters, B. Dataset size and composition impact the reliability of performance benchmarks for peptide-MHC binding predictions. BMC Bioinform. 2014, 15, 241. [Google Scholar] [CrossRef]
- Choi, Y.; Lee, H.J. Data properties and the performance of sentiment classification for electronic commerce applications. Inf. Syst. Front. 2017, 19, 993–1012. [Google Scholar] [CrossRef]
- Neppalli, V.K.; Caragea, C.; Squicciarini, A.; Tapia, A.; Stehle, S.J. Sentiment analysis during Hurricane Sandy in emergency response. Int. J. Disaster Risk Reduct. 2017, 21, 213–222. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Year | Study | Research Work | Method | Dataset | Target |
|---|---|---|---|---|---|---|
| 1 | 2019 | Alharbi el al. [19] | Twitter sentiment analysis | CNN | SemEval 2016 workshop | Feature extraction from user behavior information |
| 2 | 2019 | Kraus et al. [16] | Sentiment analysis based on rhetorical structure theory | Tree-LSTM and Discourse-LSTM | Movie Database (IMD), food reviews (Amazon) | Aim to improve accuracy |
| 3 | 2019 | Do et al. [53] | Comparative review of sentiment analysis based on deep learning | CNN, LSTM, GRU, and hybrid approaches | SemEval workshop and social network sites | Aspect extraction and sentiment classification |
| 4 | 2019 | Abid et al. [20] | Sentiment analysis through recent recurrent variants | CNN, RNN | Domain-specific word embedding | |
| 5 | 2019 | Yang et al. [52] | Aspect-based sentiment analysis | Coattention-LSTM, Coattention-MemNet, Coattention-LSTM + location | Twitter, SemEval 2014 | Target-level and context-level feature extraction |
| 6 | 2019 | Wu et al. [60] | Sentiment analysis with variational autoencoder | LSTM, Bi-LSTM | Facebook, Chinese VA, Emobank | Encoding, sentiment prediction, and decoding |
| 7 | 2018 | Pham et al. [11] | Aspect-based sentiment analysis | LRNN-ASR, FULL-LRNN-ASR | Tripadvisor | Enriching knowledge of the input through layers |
| 8 | 2018 | Sohangir et al. [5] | Deep learning for financial sentiment analysis | LSTM, doc2vec, and CNN | StockTwits | Improving the performance of sentiment analysis for StockTwits |
| 9 | 2018 | Li et al. [17] | How textual quality of online reviews affect classification performance | SRN, LSTM, and CNN | Movie reviews from imdb.com | Impact of two influential textual features, namely the word count and review readability |
| 10 | 2018 | Zhang et al. [61] | Textual sentiment analysis via three different attention convolutional neural networks and cross-modality consistent regression | CNN | SemEval 2016, Sentiment Tree Bank | LSTM attention and attentive pooling is integrated with CNN model to extract sentence features based on sentiment embedding, lexicon embedding, and semantic embedding |
| 11 | 2018 | Schmitt et al. [54] | Joint aspect and polarity classification for aspect-based sentiment analysis | CNN, LSTM | SemEval 2017 | Approach based on aspect sentiment analysis to solve two classification problems (aspect categories + aspect polarity) |
| 12 | 2018 | Qian et al. [10] | Sentiment analysis model on weather-related tweets | DNN, CNN | Twitter, social network sites | Feature extraction |
| 13 | 2018 | Tang et al. [62] | Improving the state-of-the-art in many deep learning sentiment analysis tasks | CNN, DNN, RNN | Social network sites | Sentiment classification, opinion extraction, fine-grained sentiment analysis |
| 14 | 2018 | Zhang et al. [22] | Survey of deep learning for sentiment analysis | CNN, DNN, RNN, LSTM | Social network sites | Sentiment analysis with word embedding, sarcasm analysis, emotion analysis, multimodal data for sentiment analysis |
| 15 | 2017 | Choudhary et al. [30] | Comparative study of deep-learning-based sentimental analysis with existing techniques | CNN, DNN, RNN, lexicon, hybrid | Social network sites | Domain dependency, sentiment polarity, negation, feature extraction, spam and fake review, huge lexicon, bi-polar words |
| 16 | 2018 | Jangid et al. [6] | Financial sentiment analysis | CNN, LSTM, RNN | Financial tweets | Aspect-based sentiment analysis |
| 17 | 2017 | Araque et al. [63] | Enhancing deep learning sentiment analysis with ensemble techniques in social applications | Deep-learning-based sentiment classifier using a word embedding model and a linear machine learning algorithm | SemEval 2013/2014, Vader, STS-Gold, IMDB, PL04, and Sentiment140 | Improving the performance of deep learning techniques and integrating them with traditional surface approaches based on manually extracted features |
| 18 | 2017 | Jeong et al. [48] | A product opportunity mining approach based on topic modeling and sentiment analysis | LDA-based topic modeling, sentiment analysis, and opportunity algorithm | Twitter, Facebook, Instagram, and Reddit | Identification of product development opportunities from customer-generated social media data |
| 19 | 2017 | Gupta et al. [49] | Sentiment-/semantic-based approaches for emotion detection | LSTM-based deep learning | Combining sentiment and semantic features | |
| 20 | 2017 | Preethi et al. [12] | Sentiment analysis for recommender system in the cloud | RNN, naïve Bayes classifier | Amazon | Recommending the places that are near to the user’s current location by analyzing the different reviews and consequently computing the score grounded on it |
| 21 | 2017 | Ramadhani et al. [50] | Twitter sentiment analysis | DNN | Handling a huge amount of unstructured data | |
| 22 | 2017 | Ain et al. [13] | A review of sentiment analysis using deep learning techniques | CNN, RNN, DNN, DBN | Social network sites | Analyzing and structuring hidden information extracted from social media in the form of unstructured data |
| 23 | 2017 | Roshanfekr et al. [47] | Sentiment analysis using deep learning on Persian texts | NBSVM-Bi, Bidirectional-LSTM, CNN | Customer reviews from www.digikala.com | Evaluating deep learning methods using the Persian language |
| 24 | 2017 | Paredes-Valverde et al. [51] | Sentiment analysis for improvement of products and services | CNN + Word2vec | Twitter in Spanish | Detecting customer satisfaction and identifying opportunities for improvement of products and services |
| 25 | 2017 | Jingzhou Liu et al. [64] | Extreme multilabel text classification | XML-CNN | RCV1, EUR-Lex, Amazon, and Wiki | Capturing richer information from different regions of the document |
| 26 | 2017 | Hassan et al. [15] | Sentiment analysis of short texts | CNN, LSTM, on top of pretrained word vectors | Stanford Large Movie Review, IMDB, Stanford Sentiment Treebank, SSTb | Achieving comparable performances with fewer parameters on sentiment analysis tasks |
| 27 | 2017 | Chen et al. [65] | Multimodal sentiment analysis with word-level fusion and reinforcement learning | Gated multimodal embedding LSTM with temporal attention | CMU-MOSI | Developing a novel deep architecture for multimodal sentiment analysis that performs modality fusion at the word level |
| 28 | 2017 | Al-Sallab et al. [66] | Opinion mining in Arabic as a low-resource language | Recursive deep learning | Online comments from QALB, Twitter, and Newswire articles written in MSA | Providing more complete and comprehensive input features for the autoencoder and performing semantic composition |
| 29 | 2016 | Vateekul et al. [28] | A study of sentiment analysis in Thai | LSTM, DCNN | Finding the best parameters of LSTM and DCNN | |
| 30 | 2016 | Singhal, et al. [18] | A survey of sentiment analysis and deep learning | CNN, RNTN, RNN, LSTM | Sentiment Treebank dataset, movie reviews, MPQA, and customer reviews | Comparison of classification performance of different models on different datasets |
| 31 | 2016 | Gao et al. [14] | Sentiment analysis using AdaBoost combination | CNN | Movie reviews and IMDB | Studying the possibility of leveraging the contribution of different filter lengths and grasping their potential in the final polarity of the sentence |
| 32 | 2016 | Rojas-Barahona et al. [46] | Overview of deep learning for sentiment analysis | CNN, LSTM | Movie reviews, Sentiment Treebank, and Twitter | To extract the polarity from the data |
| Datasets | TF-IDF | Word Embedding | ||||
|---|---|---|---|---|---|---|
| DNN | CNN | RNN | DNN | CNN | RNN | |
| Sentiment140 | 0.76497407 | 0.76688544 | 0.56957939 | 0.78816761 | 0.80060849 | 0.82819948 |
| Tweets Airline | 0.85936944 | 0.85451457 | 0.82809226 | 0.8979309 | 0.90373439 | 0.90451624 |
| Tweets SemEval | 0.83674669 | 0.81377485 | 0.54857318 | 0.83674748 | 0.84313431 | 0.85172402 |
| IMDB Movie Reviews (1) | 0.85232000 | 0.82300000 | 0.56392000 | 0.84572000 | 0.86072000 | 0.87052000 |
| IMDB Movie Reviews (2) | 0.85512000 | 0.80628002 | 0.58724000 | 0.80252000 | 0.82624000 | 0.86688000 |
| Cornell Movie Reviews | 0.70437264 | 0.67867751 | 0.50787764 | 0.70221434 | 0.71365671 | 0.76693790 |
| Book Reviews | 0.75876443 | 0.72741509 | 0.5169437 | 0.74560455 | 0.76630924 | 0.73347052 |
| Music Reviews | 0.76850000 | 0.69200000 | 0.5170000 | 0.70800000 | 0.74450000 | 0.73100000 |
| Datasets | TF-IDF | Word Embedding | ||||
|---|---|---|---|---|---|---|
| DNN | CNN | RNN | DNN | CNN | RNN | |
| Sentiment140 | 0.75775700 | 0.74076035 | 0.77731305 | 0.79096262 | 0.80080020 | 0.83692316 |
| Tweets Airline | 0.95565582 | 0.97003680 | 0.97417837 | 0.9577253 | 0.95924821 | 0.95086398 |
| Tweets SemEval | 0.80817204 | 0.7744086 | 0.09462366 | 0.80860215 | 0.81827957 | 0.83139785 |
| IMDB Movie Reviews (1) | 0.84072000 | 0.80080000 | 0.46880000 | 0.84360000 | 0.84960000 | 0.86808000 |
| IMDB Movie Reviews (2) | 0.87112000 | 0.75744000 | 0.56088000 | 0.78304000 | 0.83248000 | 0.88832000 |
| Cornell Movie Reviews | 0.71468474 | 0.67811554 | 0.84203575 | 0.70455552 | 0.72050860 | 0.80943813 |
| Book Reviews | 0.74221810 | 0.73009689 | 0.63040610 | 0.73912595 | 0.81599670 | 0.74824778 |
| Music Reviews | 0.76500000 | 0.69700000 | 0.74200000 | 0.68600000 | 0.72900000 | 0.73600000 |
| Datasets | TF-IDF | Word Embedding | ||||
|---|---|---|---|---|---|---|
| DNN | CNN | RNN | DNN | CNN | RNN | |
| Sentiment140 | 0.75775700 | 0.74076035 | 0.77731305 | 0.79096262 | 0.80080020 | 0.83692316 |
| Tweets Airline | 0.88451273 | 0.86396543 | 0.83664149 | 0.91759076 | 0.92284682 | 0.93061436 |
| Tweets SemEval | 0.83504669 | 0.81594219 | 0.58839133 | 0.83492767 | 0.84024502 | 0.84745555 |
| IMDB Movie Reviews (1) | 0.85057402 | 0.83996428 | 0.61862397 | 0.84727512 | 0.8689903 | 0.87328478 |
| IMDB Movie Reviews (2) | 0.84410853 | 0.83943612 | 0.59209526 | 0.81478398 | 0.82221871 | 0.85179503 |
| Cornell Movie Reviews | 0.70070694 | 0.67920909 | 0.45431496 | 0.70142346 | 0.71117779 | 0.74808808 |
| Book Reviews | 0.77071809 | 0.72645030 | 0.56145983 | 0.74877856 | 0.74335207 | 0.73283058 |
| Music Reviews | 0.77097163 | 0.69126657 | 0.46068591 | 0.71900797 | 0.75328872 | 0.73186536 |
| Datasets | TF-IDF | Word Embedding | ||||
|---|---|---|---|---|---|---|
| DNN | CNN | RNN | DNN | CNN | RNN | |
| Sentiment140 | 0.76383225 | 0.75932297 | 0.64044056 | 0.78876610 | 0.80063705 | 0.82967613 |
| Tweets Airline | 0.91863362 | 0.91385701 | 0.90011208 | 0.93720980 | 0.94064543 | 0.94059646 |
| Tweets SemEval | 0.82114704 | 0.79433397 | 0.13751971 | 0.82130776 | 0.82884635 | 0.83874720 |
| IMDB Movie Reviews (1) | 0.85057402 | 0.81871110 | 0.46834558 | 0.84540045 | 0.85908973 | 0.87020187 |
| IMDB Movie Reviews (2) | 0.85740157 | 0.79633290 | 0.57606508 | 0.79859666 | 0.82731754 | 0.86967419 |
| Cornell Movie Reviews | 0.70731859 | 0.67852670 | 0.59007189 | 0.70290291 | 0.71560412 | 0.77594109 |
| Book Reviews | 0.75501388 | 0.72758940 | 0.51163296 | 0.74364502 | 0.77728796 | 0.73395298 |
| Music Reviews | 0.76770393 | 0.69126657 | 0.56736672 | 0.70080624 | 0.74026385 | 0.73207829 |
| Datasets | TF-IDF | Word Embedding | ||||
|---|---|---|---|---|---|---|
| DNN | CNN | RNN | DNN | CNN | RNN | |
| Sentiment140 | 0.76499683 | 0.76535951 | 0.56950939 | 0.78816189 | 0.80062146 | 0.82818031 |
| Tweets Airline | 0.73510103 | 0.68790047 | 0.61740993 | 0.81170789 | 0.82367939 | 0.83767632 |
| Tweets SemEval | 0.83484059 | 0.81115021 | 0.51834041 | 0.83487221 | 0.84147827 | 0.85037175 |
| IMDB Movie Reviews (1) | 0.85232000 | 0.82300000 | 0.56392000 | 0.84572000 | 0.86072000 | 0.87052000 |
| IMDB Movie Reviews (2) | 0.85512000 | 0.80628000 | 0.58724000 | 0.80252000 | 0.82624000 | 0.86688000 |
| Cornell Movie Reviews | 0.70437264 | 0.67867751 | 0.50787764 | 0.70221434 | 0.71365671 | 0.76693790 |
| Book Reviews | 0.75875593 | 0.72740157 | 0.51676458 | 0.74558854 | 0.76630592 | 0.73348794 |
| Music Reviews | 0.76850000 | 0.69200000 | 0.51700000 | 0.70800000 | 0.74450000 | 0.73207829 |
| Dataset (%) | TF-IDF | Word Embedding | ||||
|---|---|---|---|---|---|---|
| DNN | CNN | RNN | DNN | CNN | RNN | |
| 10 | 1 min 37 s | 1 min 14 s | 11 min 18 s | 25.8 s | 39.6 s | 4 min 58 s |
| 20 | 2 min 32 s | 2 min 25 s | 22 min 14 s | 41.3 s | 1 min 18 s | 11 min 59 s |
| 30 | 3 min 26 s | 3 min 34 s | 32 min 56 s | 1 min | 1 min 53 s | 18 min 57 s |
| 40 | 4 min 19 s | 4 min 53 s | 44 min 1 s | 1 min 21 s | 2 min 32 s | 25 min 9 s |
| 50 | 5 min 12 s | 6 min 9 s | 54 min 32 s | 1 min 44 s | 3 min 10 s | 31 min 29 s |
| 60 | 6 min 33 s | 7 min 23 s | 1h 5 min 26 s | 2 min 10 s | 3 min 52 s | 37 min 35 s |
| 70 | 7 min 47 s | 10 min 20 s | 1 h15 min5 s | 2 min 45 s | 4 min 38 s | 44 min 16 s |
| 80 | 9 min 4 s | 18 min 32 s | 1 h27 min22 s | 3 min 19 s | 5 min 31 s | 50 min 47 s |
| 90 | 10 min 14 s | 29 min 49 s | 1 h37 min59 s | 3 min 47 s | 6 min 12 s | 57 min 3 s |
| 100 | 11 min 55 s | 38 min 17 s | 1 h48 min52 s | 4 min 18 s | 7 min 3 s | 1 h 4 min 16 s |
| Dataset | TF-IDF | Word Embedding | ||||
|---|---|---|---|---|---|---|
| DNN | CNN | RNN | DNN | CNN | RNN | |
| Sentiment140 | 11 min 55 s | 3 8min 17 s | 1h48 min 52 s | 4 min 18 s | 7 min 3 s | 1 h 4 min 16 s |
| Tweets Airline | 1 min | 34.41 s | 1 h 54 s | 30.66 s | 1 min 22 s | 2 min 41 s |
| Tweets SemEval | 20.53 s | 24.5 s | 23 min 52 s | 26.75 s | 1 min 11 s | 2 min 43 s |
| IMDB Movie Reviews (1) | 1 min 11 s | 1 min 7 s | 1 h25 min 48 s | 21.13 s | 32.66 s | 7 min 42 s |
| IMDB Movie Reviews (2) | 17.78 s | 22.05 s | 30 min 21 s | 31.32 s | 36.81 s | 8 min 23 s |
| Cornell Movie Reviews | 23.2 s | 16.83 s | 31 min 55 s | 12.9 s | 21.26 s | 4 min 40 s |
| Book Reviews | 11.93 s | 10.12 s | 21 min 9 s | 16.21 s | 20.6 s | 2 min17 s |
| Music Reviews | 26.48 s | 17.35 s | 29 min 50 s | 13.94 s | 16.89 s | 4 min 42 s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics 2020, 9, 483. https://doi.org/10.3390/electronics9030483
Dang NC, Moreno-García MN, De la Prieta F. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics. 2020; 9(3):483. https://doi.org/10.3390/electronics9030483
Chicago/Turabian StyleDang, Nhan Cach, María N. Moreno-García, and Fernando De la Prieta. 2020. "Sentiment Analysis Based on Deep Learning: A Comparative Study" Electronics 9, no. 3: 483. https://doi.org/10.3390/electronics9030483
APA StyleDang, N. C., Moreno-García, M. N., & De la Prieta, F. (2020). Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics, 9(3), 483. https://doi.org/10.3390/electronics9030483