Framework for Delay Guarantee in Multi-Domain Networks Based on Interleaved Regulators


Abstract
1. Introduction
2. Proposed Framework for Delay Guarantee
- Flows are divided into high priority and low priority.
- Low priority flows are put in a single FIFO queue at the output port of all nodes and processed in strict priority mode with preemption.
- High priority flows are handled as follows.
- Select an appropriately sized network.
- The flows with the same {input, output port} in the network are aggregated into a single FA.
- In a network node, a fair queuing-based scheduling is performed per FA with a queue for each FA. (Note that IntServ nodes schedule per flow and TSN ATS nodes schedule per class.)
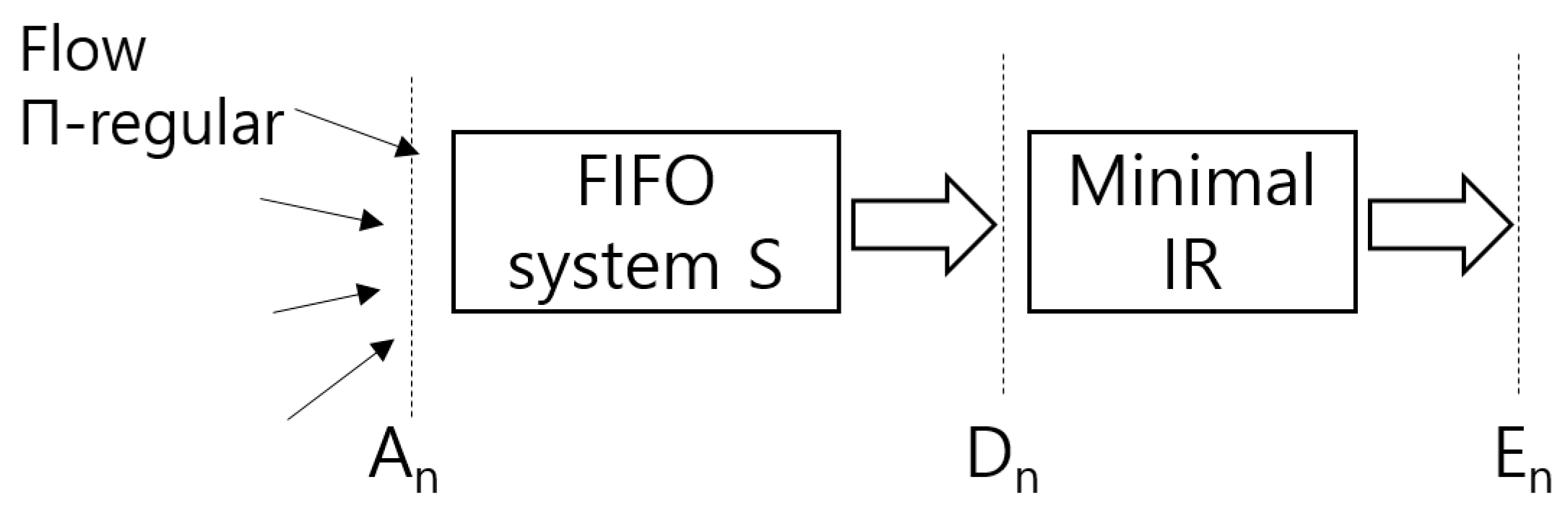
- Install minimal IRs per FA at the edges of networks. See Figure 3.
- Only the flows conforming the initial arrival curve or the flows from the IR are accepted to the network.
- The networks with IRs are interconnected to form an entire network. See Figure 4.
3. Numerical Analysis
3.1. A Signle Network Case
3.1.1. PGPS Scheduler Case
3.1.2. DRR Scheduler Case
3.1.3. ATS Framework with FIFO Scheduler Case
3.2. Internetwork of Multiple Networks Case
4. Discussion on the Comparison of the Frameworks
5. Conclusions
Funding
Conflicts of Interest
References
- ITU-T Focus Group on Technologies for Network 2030 (FG Net-2030). New Services and Capabilities for Network 2030: Description, Technical Gap and Performance Target Analysis. 2019. Available online: staging.itu.int/en/ITU-T/focusgroups/net2030/Documents/Deliverable_NET2030.pdf (accessed on 23 January 2020).
- Joung, J. Regulating Scheduler (RSC): A Novel Solution for IEEE 802.1 Time Sensitive Network (TSN). Electronics 2019, 8, 189. [Google Scholar] [CrossRef]
- IEEE 802.1 Time-Sensitive Networking Task Group Home Page. Available online: http://www.ieee802.org/1/pages/tsn.html (accessed on 23 January 2020).
- Specht, J.; Samii, S. Urgency-Based Scheduler for Time-Sensitive Switched Ethernet Networks. In Proceedings of the 28th Euromicro Conference on Real-Time Systems (ECRTS), Toulouse, France, 5–8 July 2016; pp. 75–85. [Google Scholar]
- Le Boudec, J.-Y. A theory of traffic regulators for deterministic networks with application to interleaved regulators. IEEE ACM Trans. Netw. 2018, 26. [Google Scholar] [CrossRef]
- Stiliadis, D.; Varma, A. Latency-Rate Servers: A General Model for Analysis of Traffic Scheduling Algorithms. IEEE ACM Trans. Netw. 1998, 6, 611–624. [Google Scholar] [CrossRef]
- Lenzini, L.; Mingozzi, E.; Stea, G. Tradeoffs between low complexity, low latency, and fairness with deficit round-robin schedulers. IEEE ACM Trans. Netw. 2004, 12, 681–693. [Google Scholar] [CrossRef]
- Shreedhar, M.; Varghese, G. Efficient fair queueing using deficit round-robin. IEEE ACM Trans. Netw. 1996, 4, 375–385. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Quantity |
|---|---|
| Maximum packet length of flow | |
| Maximum packet length of all the flows in a scheduler | |
| Link capacity | |
| Arrival rate of flow | |
| Maximum burst size of flow | |
| Quantum value assigned for flow | |
| Latency of flow at scheduler | |
| h | Number of hops in a network |
| n | Number of flows in a flow aggregate |
| p | Number of ports in a node |
| d | Number of networks in a flow’s entire path |
| Network Parameters | Core Network Scenario (p = 2, E = 16, F = 216 = 65536, r = 1 Gbps, L = 10 Kbit) | Local Network Scenario (p = 8, E = 4, F = 84 = 4096, r = 1 Gbps, L = 10 Kbit) | |
|---|---|---|---|
| Frameworks | |||
| IntServ | 10.486 s | 0.164 s | |
| ATS | 20.97 s | 0.328 s | |
| Proposed framework | 1.347 s with h = 8 | 0.083 s with h = 2 | |
| Scheduler | Flow-Based | Based on FA with {Input, Output Port} of a Network | FIFO | |
|---|---|---|---|---|
| IR Locations | ||||
| Zero IR | IntServ | Proposed Framework | ||
| IR between networks | ||||
| IR at every node | ATS | |||
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joung, J. Framework for Delay Guarantee in Multi-Domain Networks Based on Interleaved Regulators. Electronics 2020, 9, 436. https://doi.org/10.3390/electronics9030436
Joung J. Framework for Delay Guarantee in Multi-Domain Networks Based on Interleaved Regulators. Electronics. 2020; 9(3):436. https://doi.org/10.3390/electronics9030436
Chicago/Turabian StyleJoung, Jinoo. 2020. "Framework for Delay Guarantee in Multi-Domain Networks Based on Interleaved Regulators" Electronics 9, no. 3: 436. https://doi.org/10.3390/electronics9030436
APA StyleJoung, J. (2020). Framework for Delay Guarantee in Multi-Domain Networks Based on Interleaved Regulators. Electronics, 9(3), 436. https://doi.org/10.3390/electronics9030436