Automated Malware Detection in Mobile App Stores Based on Robust Feature Generation


Abstract
1. Introduction
- 1)
- Dataset
- 2)
- Type of features
- 3)
- Feature-weighting scheme
- 4)
- Feature-selection algorithm used to select the most prominent features
- 5)
- Classification algorithm used to categorize apps as malicious or clean
- 6)
- Classifier’s parameter values
Contributions of This Study
- Robust system: A fully automated tool for classifying mobile applications as clean or malicious is presented.
- Lightweight analysis: The proposed system does not drain smartphone resources and analyzes a large set of real-world data in a reasonable time.
- Feature selection: The proposed system compares different feature-selection algorithms to reduce the feature-vector dimensions.
- Relevant features: Different numbers of features are investigated to identify the lowest number of features that can obtain optimal results, evaluated based on the detection accuracy and speed of training and testing.
- Detection rate: An empirical study of ten supervised machine algorithms indicates that the proposed tool is effective on real-world data.
2. Related Work
3. Experimental Design
3.1. App Collection
| Algorithm 1 |
| Require: D*, a set of features Require: A*, a set of Android applications Require: D*, a set of features Require: C*, a set of classifiers ∈ {Naïve Bayes, Random Forest, k-NN, SMO, etc.} Require: TD*, a set of training datasets Require: VD*, a set of validation datasets Require: PF, a set of variables for normalization Require: S*, Boolean score for the respective zones: q occurs/0 does not occur Require Labels: L = {Malicious, Clean} For each application in A*: Generate MD5, SHA1, SHA256, and SHA512 for . using Androguard Extract features D* For each (); ] // normalize frequencies End for End for While ≠ ≠ Nil // weighting with TF-IDF Do if Else if Else Return scores For each // Feature selection Select top selected features D* using ANOVA Select top selected features D* using Chi-Square End for For each in C*: End for For each in C*: = classify (, ) Add () End for |
3.2. Feature Extraction
3.3. Feature Selection Metrics
3.3.1. Analysis of Variance (F-Value)
3.3.2. Chi-Square
4. Classification-Based Malware Detection
5. Performance Evaluation Metrics
6. Results
6.1. Detection Accuracy Using ANOVA-Based Feature Selection
6.2. Detection Accuracy Using Chi-Square-Based Feature Selection
7. Discussion
8. Conclusion
Author Contributions
Funding
Conflicts of Interest
References
- Lueth, K. State of the IoT 2018: Number of IoT Devices Now at 7B–Market Accelerating. Available online: https://iot-analytics.com/state-of-the-iot-update-q1-q2-2018-number-of-iot-devices-now-7b/ (accessed on 20 November 2019).
- Deyan. 60+ Smartphone Statistics in 2019. Available online: https://techjury.net/stats-about/smartphone-usage/ (accessed on 20 November 2019).
- Alazab, M.; Alazab, A.; Batten, L. Smartphone malware based on Synchronisation Vulnerabilities. In Proceedings of the 7th International Conference on Information Technology and Applications (ICITA 2011), Sydney, Australia, 21–24 November 2011; pp. 1–6. [Google Scholar]
- Batten, L.M.; Moonsamy, V.; Alazab, M. Smartphone applications, malware and data theft. In Computational Intelligence, Cyber Security and Computational Models; Springer: Singapore, 2016; pp. 15–24. [Google Scholar]
- Alazab, M. Forensic Identification and Detection of Hidden and Obfuscated Malware. Ph.D. Thesis, School of Science, Information Technology and Engineering, University of Ballarat, Victoria, Australia, 2012. [Google Scholar]
- Alazab, M.; Venkatraman, S.; Watters, P.; Alazab, M.; Alazab, A. Cybercrime: The Case of Obfuscated Malware. In Global Security, Safety and Sustainability & e-Democracy; Georgiadis, C., Jahankhani, H., Pimenidis, E., Bashroush, R., Al-Nemrat, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 99, pp. 204–211. [Google Scholar]
- Kaspersky. Malicious Android App Had More Than 100 Million Downloads in Google Play. Available online: https://www.kaspersky.com/blog/camscanner-malicious-android-app/28156/ (accessed on 20 November 2019).
- Allix, K.; Bissyandé, T.F.; Klein, J.; le Traon, Y. Androzoo: Collecting millions of android apps for the research community. In Proceedings of the 2016 IEEE/ACM 13th Working Conference on Mining Software Repositories (MSR), Austin, TX, USA, 14–15 May 2016; pp. 468–471. [Google Scholar]
- Jung, J.; Kim, H.; Shin, D.; Lee, M.; Lee, H.; Cho, S.J.; Suh, K. Android malware detection based on useful API calls and machine learning. In Proceedings of the 2018 IEEE First International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Laguna Hills, CA, USA, 26–28 September 2018; pp. 175–178. [Google Scholar]
- Alazab, M.; Alazab, M.; Shalaginov, A.; Mesleh, A.; Awajan, A. Intelligent mobile malware detection using permission requests and API calls. Future Gener. Comput. Syst. 2020, 107, 509–521. [Google Scholar]
- Kim, H.; Kim, J.; Kim, Y.; Kim, I.; Kim, K.J.; Kim, H. Improvement of malware detection and classification using API call sequence alignment and visualization. Clust. Comput. 2019, 22, 921–929. [Google Scholar] [CrossRef]
- Alazab, M.; Venkatraman, S.; Watters, P.; Alazab, M. Zero-day malware detection based on supervised learning algorithms of api call signatures. In Proceedings of the Ninth Australasian Data Mining Conference-Volume 121; Australian Computer Society: Ballarat, Australia, 2011; pp. 171–182. [Google Scholar]
- Moonsamy, V.; Alazab, M.; Batten, L. Towards an Understanding of the Impact of Advertising on Data Leaks. Int. J. Secur. Netw. 2012, 7, 181–193. [Google Scholar] [CrossRef]
- Alazab, M.; Monsamy, V.; Batten, L.; Lantz, P.; Tian, R. Analysis of Malicious and Benign Android Applications. In Proceedings of the 2012 32nd International Conference on Distributed Computing Systems Workshops (ICDCSW), Macau, China, 18–21 June 2012; pp. 608–616. [Google Scholar]
- Alazab, M.; Venkataraman, S.; Watters, P. Towards understanding malware behaviour by the extraction of API calls. In Proceedings of the 2010 Second Cybercrime and Trustworthy Computing Workshop, Ballarat, Australia, 19–20 July 2010; pp. 52–59. [Google Scholar]
- Alazab, M.; Layton, R.; Venkataraman, S.; Watters, P. Malware Detection Based on Structural and Behavioural Features of Api Calls; Australian Computer Society: Ballarat, Australia, 2010. [Google Scholar]
- Alazab, A.; Hobbs, M.; Abawajy, J.; Alazab, M. Using feature selection for intrusion detection system. In Proceedings of the 2012 international symposium on communications and information technologies (ISCIT), Gold Coast, Australia, 2–5 October 2012; pp. 296–301. [Google Scholar]
- Farivar, F.; Haghighi, M.S.; Jolfaei, A.; Alazab, M. Artificial intelligence for detection, estimation, and compensation of malicious attacks in nonlinear cyber physical systems and industrial IoT. IEEE Trans. Ind. Inform. 2019. [Google Scholar] [CrossRef]
- Karim, A.; Azam, S.; Shanmugam, B.; Kannoorpatti, K.; Alazab, M. A Comprehensive Survey for Intelligent Spam Email Detection. IEEE Access 2019, 7, 168261–168295. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Soman, K.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep learning approach for intelligent intrusion detection system. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Alazab, M. Profiling and classifying the behavior of malicious codes. J. Syst. Softw. 2015, 100, 91–102. [Google Scholar] [CrossRef]
- Alazab, A.; Alazab, M.; Abawajy, J.; Hobbs, M. Web application protection against SQL injection attack. In Proceedings of the 7th International Conference on Information Technology and Applications, Sydney, Australia, 21–24 November 2011; pp. 1–7. [Google Scholar]
- Masabo, E.; Kaawaase, K.S.; Sansa-Otim, J.; Ngubiri, J.; Hanyurwimfura, D. Improvement of Malware Classification Using Hybrid Feature Engineering. SN Comput. Sci. 2020, 1, 17. [Google Scholar] [CrossRef]
- Alazab, M.; Batten, L. Survey in Smartphone Malware Analysis Techniques. Available online: https://www.igi-global.com/chapter/survey-in-smartphone-malware-analysis-techniques/131400 (accessed on 20 November 2019).
- Hussain, S.J.; Ahmed, U.; Liaquat, H.; Mir, S.; Jhanjhi, N.; Humayun, M. IMIAD: Intelligent Malware Identification for Android Platform. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; pp. 1–6. [Google Scholar]
- Aminordin, A.; MA, F.; Yusof, R. Android Malware Classification Base On Application Category Using Static Code Analysis. J. Theor. Appl. Inf. Technol. 2018, 96, 11. [Google Scholar]
- Chavan, N.; di Troia, F.; Stamp, M. A Comparative Analysis of Android Malware. arXiv 2019, arXiv:1904.00735. [Google Scholar]
- Moonsamy, V.; Batten, L. Zero permission android applications-attacks and defenses. In Proceedings of the 3rd Applications and Technologies in Information Security Workshop, Melbourne, Australia, 7 November 2012. [Google Scholar]
- Shao, Y.; Chen, Q.A.; Mao, Z.M.; Ott, J.; Qian, Z. Kratos: Discovering Inconsistent Security Policy Enforcement in the Android Framework; In NDSS ’16; Academic Press: San Diego, CA, USA, 2016; ISBN 1-891562-41-X. [Google Scholar] [CrossRef]
- Brodeur, P. Zero-Permission Android Applications Part 2. Available online: http://www.leviathansecurity.com/blog/zero-permission-android-applications-part-2/ (accessed on 20 November 2019).
- Milosevic, N.; Dehghantanha, A.; Choo, K.-K.R. Machine learning aided Android malware classification. Comput. Electr. Eng. 2017, 61, 266–274. [Google Scholar] [CrossRef]
- Idrees, F.; Rajarajan, M.; Conti, M.; Chen, T.M.; Rahulamathavan, Y. PIndroid: A novel Android malware detection system using ensemble learning methods. Comput. Secur. 2017, 68, 36–46. [Google Scholar] [CrossRef]
- Yerima, S.Y.; Sezer, S.; McWilliams, G.; Muttik, I. A New Android Malware Detection Approach Using Bayesian Classification. In Proceedings of the IEEE 27th International Conference on Advanced Information Networking and Applications (AINA), Barcelona, Spain, 25–28 March 2013. [Google Scholar]
- Google. Google Play. Available online: https://play.google.com/ (accessed on 20 November 2019).
- AndroZoo. Available online: https://androzoo.uni.lu/markets (accessed on 20 November 2019).
- Allix, K.; Bissyandé, T.F.; Jérome, Q.; Klein, J.; le Traon, Y. Empirical assessment of machine learning-based malware detectors for Android. Empir. Softw. Eng. 2016, 21, 183–211. [Google Scholar] [CrossRef]
- Desnos, A. Androguard Reverse Engineering, Malware and Goodware Analysis of Android Applications and More (Ninja!). Available online: http://code.google.com/p/androguard/ (accessed on 20 November 2019).
- Scikit-Learn. Scikit-Learn: Machine Learning in Python. Available online: https://scikit-learn.org/stable/ (accessed on 20 November 2019).
- Zhang, T.; Ge, S.S. An Improved TF-IDF Algorithm Based on Class Discriminative Strength for Text Categorization on Desensitized Data. In Proceedings of the 2019 3rd International Conference on Innovation in Artificial Intelligence, Suzhou, China, 15–18 March 2019; pp. 39–44. [Google Scholar]
- Yao, L.; Wang, X.; Sheng, Q.Z.; Benatallah, B.; Huang, C. Mashup recommendation by regularizing matrix factorization with API co-invocations. IEEE Trans. Serv. Comput. 2018. [Google Scholar] [CrossRef]
- Babaagba, K.O.; Adesanya, S.O. A Study on the Effect of Feature Selection on Malware Analysis using Machine Learning. In Proceedings of the 2019 8th International Conference on Educational and Information Technology, Cambridge, UK, 2–4 March 2019; pp. 51–55. [Google Scholar]
- Alazab, M. Analysis on Smartphone Devices for Detection and Prevention of Malware. Ph.D. Thesis, Faculty of Science, Engineering and Built Environment, Deakin University, Victoria, Australia, 2014. [Google Scholar]
- Chen, Y.-J.; Kuo, W.-H.; Tsai, S.-Y.; Chen, J.-L.; Chen, Y.-H.; Xu, W.-Z. Artificial Intelligence Hybrid Learning Architecture for Malware Families Classification. In Proceedings of the 2019 21st International Conference on Advanced Communication Technology (ICACT), Kwangwoon_Do, Korea, 17–20 February 2019; pp. 503–510. [Google Scholar]
- Calvert, C.L.; Khoshgoftaar, T.M. Impact of class distribution on the detection of slow HTTP DoS attacks using Big Data. J. Big Data 2019, 6, 67. [Google Scholar] [CrossRef]
- Kumar, P. Naive bayes Classifier for word sense disambiguation of punjabi language. Malays. J. Comput. Sci. 2018, 31, 188–199. [Google Scholar]
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep learning for classification of malware system call sequences. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, Australia, 5–8 December 2016. [Google Scholar]
- Yerima, S.Y.; Sezer, S.; Muttik, I. High accuracy android malware detection using ensemble learning. IET Inf. Secur. 2015, 9, 313–320. [Google Scholar] [CrossRef]
- Li, L.; Bissyandé, T.F.; Octeau, D.; Klein, J. Reflection-aware static analysis of android apps. In Proceedings of the 2016 31st IEEE/ACM International Conference on Automated Software Engineering (ASE), Singapore, 3–7 September 2016; pp. 756–761. [Google Scholar]
- Wen, L.; Yu, H. An Android malware detection system based on machine learning. Available online: https://aip.scitation.org/doi/abs/10.1063/1.4992953 (accessed on 20 November 2019).
- Rana, M.S.; Rahman, S.S.M.M.; Sung, A.H. Evaluation of tree based machine learning classifiers for android malware detection. In Proceedings of the International Conference on Computational Collective Intelligence, Bristol, UK, 5–7 September 2018; pp. 377–385. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kernels | Formula | Parameters | |
|---|---|---|---|
| Polynomial Kernel | K: Constant | (8) | |
| Normalized Polynomial Kernel | d: Degree of polynomial | (9) | |
| PUK | : Pearson width parameters | (10) | |
| RBF | γ: Kernel dimension | (11) |
| Impurity Measure | FORMULA | |
|---|---|---|
| Entropy | (15) | |
| Gini | (16) | |
| Classification Error | (17) | |
| Parameters | is the training data in node | |
| Feature Name | Rank |
|---|---|
| Landroid/content/Context;->getResources()Landroid/content/res/Resources | 1 |
| Landroid/view/View;->findViewById(I)Landroid/view/View | 2 |
| Landroid/view/View;->setVisibility(I)V | 3 |
| Ljava/lang/Enum;-><init>(Ljava/lang/String; I)V’ | 4 |
| Ljava/lang/Enum;->valueOf(Ljava/lang/Class; Ljava/lang/String;)Ljava/lang/Enum;’ | 5 |
| Ljava/lang/Math;->min(I I)I’ | 6 |
| Ljava/util/HashSet;-><init>()V | 7 |
| Ljava/util/Iterator;->hasNext()Z | 8 |
| Ljava/util/Iterator;->next()Ljava/lang/Object; numeric | 9 |
| Ljava/util/Map;->clear()V numeric | 10 |
| Feature Name | Rank |
|---|---|
| java/javax/mmmmm;->sendTextMessage(Ljava/lang/String;Ljava/lang/String; Ljava/lang/String; Landroid/app/PendingIntent; Landroid/app/PendingIntent;)V | 1 |
| Landroid/util/Pair;-><init>(Ljava/lang/Object; Ljava/lang/Object;)V | 2 |
| Landroid/view/View;->findViewById(I)Landroid/view/View; | 3 |
| Ljava/lang/Character;-><init>(C)V | 4 |
| Ljava/lang/Class;->getMethod(Ljava/lang/String; Ljava/lang/Class;)Ljava/lang/reflect/Method; | 5 |
| Ljava/lang/StringBuilder;-><init>()V | 6 |
| Ljava/lang/StringBuilder;->append(Ljava/lang/String;)Ljava/lang/StringBuilder; | 7 |
| Ljava/lang/reflect/Method;->invoke(Ljava/lang/Object; Ljava/lang/Object;)Ljava/lang/Object; | 8 |
| Ljava/util/Hashtable;->puut(Ljava/lang/Object; Ljava/lang/Object;)Ljava/lang/Object; | 9 |
| Ljava/util/Vector;->elementAt(I)Ljava/lang/Object; | 10 |
| Algorithm | 10 | 25 | 50 | 100 | 200 | 300 | 500 | 1000 | 3000 | 5000 | 7000 | 9000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Naïve Bayes | 0.729 | 0.807 | 0.798 | 0.836 | 0.826 | 0.865 | 0.835 | 0.874 | 0.923 | 0.913 | 0.913 | 0.913 |
| k-Nearest neighbors | 0.865 | 0.913 | 0.904 | 0.904 | 0.904 | 0.904 | 0.894 | 0.923 | 0.933 | 0.855 | 0.815 | 0.814 |
| SMO (Polynomial Kernel) | 0.817 | 0.817 | 0.855 | 0.884 | 0.894 | 0.904 | 0.933 | 0.942 | 0.962 | 0.952 | 0.962 | 0.952 |
| SMO (NormalizedPolynomial Kernel) | 0.798 | 0.885 | 0.894 | 0.923 | 0.942 | 0.933 | 0.942 | 0.932 | 0.932 | 0.923 | 0.932 | 0.923 |
| SMO (PUK Kernel) | 0.875 | 0.904 | 0.933 | 0.932 | 0.903 | 0.874 | 0.864 | 0.844 | 0.774 | 0.763 | 0.774 | 0.772 |
| SMO (RBF Kernel) | 0.695 | 0.702 | 0.73 | 0.827 | 0.846 | 0.836 | 0.865 | 0.904 | 0.913 | 0.904 | 0.894 | 0.885 |
| Random Forests | 0.846 | 0.904 | 0.942 | 0.952 | 0.952 | 0.942 | 0.952 | 0.933 | 0.942 | 0.942 | 0.942 | 0.942 |
| J48 | 0.836 | 0.894 | 0.846 | 0.885 | 0.855 | 0.923 | 0.904 | 0.904 | 0.923 | 0.923 | 0.942 | 0.933 |
| Logistic Regression | 0.798 | 0.817 | 0.894 | 0.933 | 0.904 | 0.837 | 0.865 | 0.817 | 0.952 | 0.971 | 0.952 | 0.904 |
| AdaBoost–decision stump model | 0.827 | 0.837 | 0.874 | 0.875 | 0.836 | 0.933 | 0.942 | 0.913 | 0.933 | 0.933 | 0.962 | 0.962 |
| Random Committee | 0.846 | 0.913 | 0.904 | 0.942 | 0.923 | 0.971 | 0.933 | 0.933 | 0.942 | 0.952 | 0.942 | 0.942 |
| JRip | 0.817 | 0.856 | 0.904 | 0.904 | 0.894 | 0.904 | 0.971 | 0.884 | 0.904 | 0.933 | 0.913 | 0.933 |
| Simple Logistics | 0.817 | 0.808 | 0.923 | 0.923 | 0.923 | 0.933 | 0.942 | 0.923 | 0.942 | 0.923 | 0.913 | 0.923 |
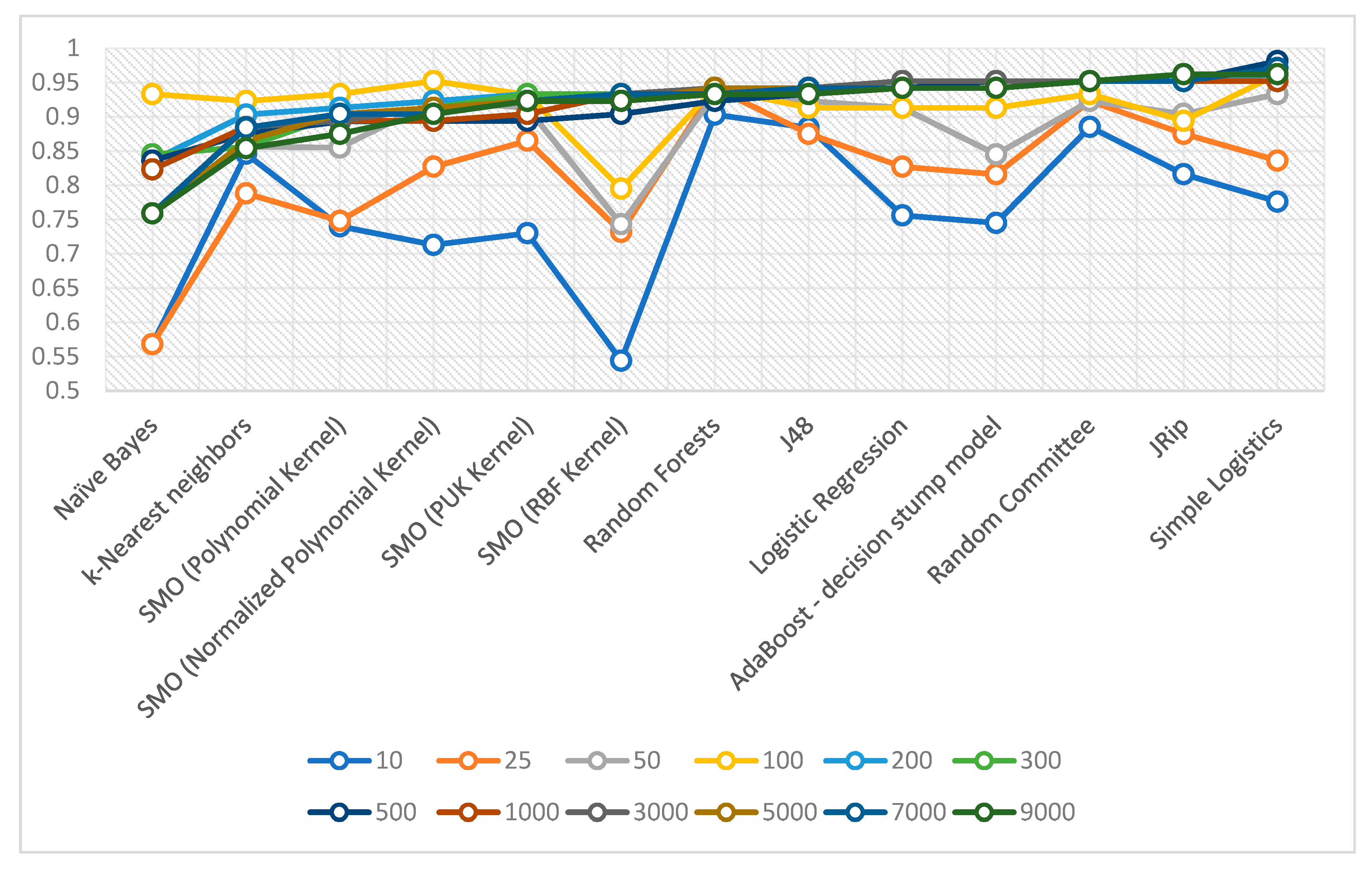
| Algorithm | 10 | 25 | 50 | 100 | 200 | 300 | 500 | 1000 | 3000 | 5000 | 7000 | 9000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Naïve Bayes | 0.568 | 0.568 | 0.759 | 0.933 | 0.836 | 0.845 | 0.836 | 0.823 | 0.759 | 0.759 | 0.759 | 0.759 |
| k-Nearest neighbors | 0.846 | 0.788 | 0.856 | 0.923 | 0.903 | 0.856 | 0.875 | 0.885 | 0.885 | 0.865 | 0.884 | 0.854 |
| SMO (Polynomial Kernel) | 0.74 | 0.748 | 0.855 | 0.933 | 0.913 | 0.904 | 0.893 | 0.894 | 0.894 | 0.904 | 0.904 | 0.875 |
| SMO (NormalizedPolynomial Kernel) | 0.713 | 0.827 | 0.923 | 0.952 | 0.923 | 0.913 | 0.894 | 0.894 | 0.913 | 0.913 | 0.904 | 0.904 |
| SMO (PUK Kernel) | 0.73 | 0.865 | 0.913 | 0.932 | 0.933 | 0.933 | 0.894 | 0.904 | 0.923 | 0.923 | 0.923 | 0.923 |
| SMO (RBF Kernel) | 0.544 | 0.732 | 0.743 | 0.795 | 0.933 | 0.933 | 0.904 | 0.933 | 0.933 | 0.923 | 0.933 | 0.923 |
| Random Forests | 0.903 | 0.942 | 0.933 | 0.942 | 0.933 | 0.942 | 0.923 | 0.933 | 0.942 | 0.942 | 0.933 | 0.933 |
| J48 | 0.884 | 0.875 | 0.923 | 0.913 | 0.942 | 0.942 | 0.933 | 0.942 | 0.942 | 0.942 | 0.942 | 0.933 |
| Logistic Regression | 0.756 | 0.827 | 0.913 | 0.913 | 0.942 | 0.952 | 0.942 | 0.952 | 0.952 | 0.942 | 0.942 | 0.942 |
| AdaBoost–decision stump model | 0.745 | 0.816 | 0.845 | 0.913 | 0.942 | 0.952 | 0.952 | 0.952 | 0.952 | 0.942 | 0.942 | 0.942 |
| Random Committee | 0.885 | 0.923 | 0.923 | 0.933 | 0.952 | 0.952 | 0.952 | 0.952 | 0.952 | 0.952 | 0.952 | 0.952 |
| JRip | 0.816 | 0.875 | 0.904 | 0.894 | 0.952 | 0.962 | 0.952 | 0.952 | 0.952 | 0.952 | 0.952 | 0.962 |
| Simple Logistics | 0.776 | 0.836 | 0.933 | 0.962 | 0.962 | 0.962 | 0.981 | 0.952 | 0.971 | 0.971 | 0.971 | 0.962 |
| Ref | Dataset | Feature Type | Feature Selection | # of Features | Machine Learning | Accuracy | Speed |
|---|---|---|---|---|---|---|---|
| [1] | Mal = 2925 Clean = 3938 | Combined app attributes and Permission features (CAPF) | IG | 20 50 | 1. Naïve Bayes 2. Simple logistic 3. Decision tree, 4. Random tree | 97.5% | 6.41 s |
| [2] | Mal = 250 Clean = 250 | Static feature and dynamic features | ? | 202 | 1. SVM 2. C4.5 3. Naive Bayes 4. LR 5. MLP 6. Deep Learning | 96.5% | ? |
| [3] | Apps = 50,000 | CFGs | IG | 50, 250 500, 1000, 1500, 5000 | 1. Random Forest 2. J48, 3. JRip 4. SVM | 96% | ? |
| [4] | Mal = 1000 Clean = 1000 | Static feature and dynamic features | PCA-RELIEF | ? | SVM | 95.2% | ? |
| [5] | Apps = 400. Best result with Mal = 22 Clean = 10 | 1. Permission-Based Clustering. 2. Permission-Based Classification. 3. Source Code-Based Clustering. 4. Source Code-Based Classification. | ? | ? | 1. C4.5 decision trees. 2. Random forest. 3. Naive Bayes. 4. Bayesian networks. 5. SVM with SMO. 6. JRip 7. Logistic regression | 95.1% | Less than 10 s |
| [6] | Mal =5560 Clean = 5560 | Hardware Components, Requested Permissions, AppComponents, Filtered Intents, Restricted API Calls, Used Permissions, Suspicious API Calls, and Network Address | Substring-Based Feature Selection | 8 | 1. Decision Tree. 2. Random Forest 3. Extremely Randomized Tree 4.GradientTree Boosting | 97.2% | ? |
| [7] | Apps = 8177 | Permissions and sensitive API calls | IG | 82 | 1. Naïve Bayes 2. SVM 3. Decision Tree-J48 4. Random Forest | 95.1% | ? |
| [8] | Mal = 5,774 Clean = 500 | Static feature and dynamic features | 1. IG 2. PCA | 10 | 1. Decision Tree 2. Gradient Boosting 3. Random Forest 4. Nave Bayes | 95% | ? |
| [9] | Mal = 2,657 Clean = 989 | Permissions | IG | 74 | 1. Decision Trees 2. Random Forests 3. SVM 4. Logistic Model Trees 5. AdaBoost 6. ANN | 95% | ? |
| (The Proposed System) | Mal = 200 Clean = 200 | Source Code | 1. ANOVA 2. Chi-Square | 10, 25 50, 100 200,300 500, 1000 3000,5000, 7000,9000 | 1. Naïve Bayes 2. kNN 3. Random Forest 4. J48 5. SMO 6. Logistic Regressions 7. Adaboost, 8. Random committee 9. JRip 10. Simple logistics | 98.1% | 1.3 s |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alazab, M. Automated Malware Detection in Mobile App Stores Based on Robust Feature Generation. Electronics 2020, 9, 435. https://doi.org/10.3390/electronics9030435
Alazab M. Automated Malware Detection in Mobile App Stores Based on Robust Feature Generation. Electronics. 2020; 9(3):435. https://doi.org/10.3390/electronics9030435
Chicago/Turabian StyleAlazab, Moutaz. 2020. "Automated Malware Detection in Mobile App Stores Based on Robust Feature Generation" Electronics 9, no. 3: 435. https://doi.org/10.3390/electronics9030435
APA StyleAlazab, M. (2020). Automated Malware Detection in Mobile App Stores Based on Robust Feature Generation. Electronics, 9(3), 435. https://doi.org/10.3390/electronics9030435