An Enhanced Design of Sparse Autoencoder for Latent Features Extraction Based on Trigonometric Simplexes for Network Intrusion Detection Systems



Abstract
1. Introduction
1.1. Background
1.2. Key Contributions
1.3. Paper Organization
2. Related Work
3. Proposed Methodology
3.1. Data Preprocessing
3.2. Hassan–Nelde–Mead Algorithm
- Step 1.
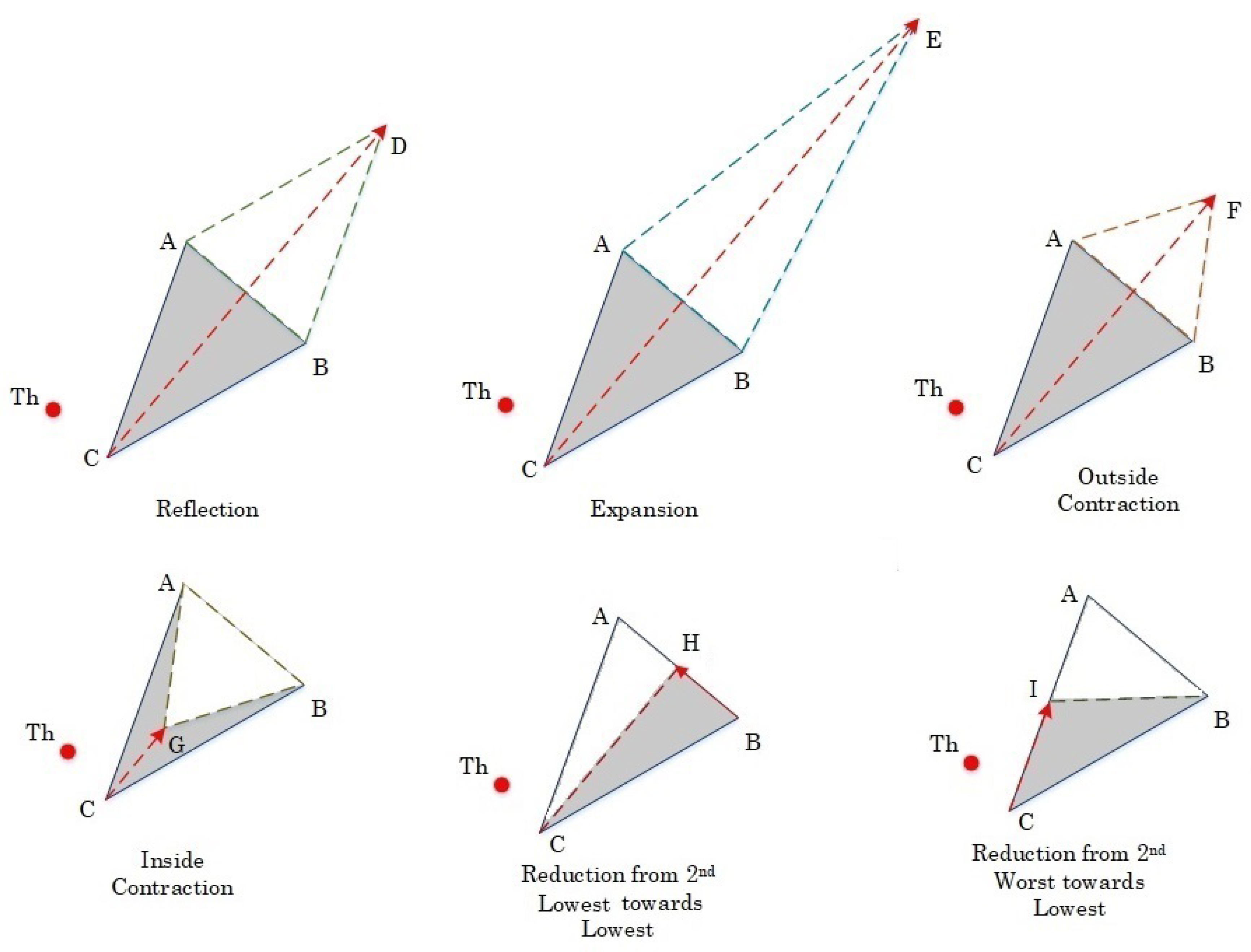
- Initialize Triangular Simplex and Threshold , as shown in Figure 2:A tetrahedron simplex is a geometrical object that has three vertices. Each vertex has n components, where n is the dimension of the mathematical problem. Since the HNM algorithm is employed to optimize three hyperparameters of SAE, n in our case equals to 3. Next, we sort the simplex vertices in descending order according to an error function that is defined later in the process to obtain four points associated with the lowest, second lowest, second highest, and highest values, such that . Note, each of have three axial components (dimensions). The HNM algorithm optimizes a single component in each iteration, while pursuing to explore the curvatures of the through six basic operations.
- Step 2.
- Reflection D:The HNM performs reflection along the line segment that is connecting the worst vertex C and the center of gravity, which is H to evaluate . The vector formula for D is given below.
- Step 3.
- Expansion E:If , then the HNM executes expansion because it found a descent in that direction (see Figure 2). E is found by the following equation.a. If , then we replace the threshold point with E, and go to Step 6.b. Otherwise is replaced by D, and the algorithm goes to Step 4.
- Step 4.
- Contraction F or G:If , then another point must be tested, which is F. If , then F is kept and replaced with . If the condition of F is not met, then perhaps a better point is found somewhere between C and the centroid H. The point G is computed to see whether this point has a smaller function value than or not. The vector formulas for F and G are as follows.a. If either F or G has smaller values than , then is updated and the algorithm goes to Step 6.b. Otherwise, the algorithm moves to Step 5.
- Step 5.
- Reduction H or I:The HNM algorithm performs two types of shrinkage operations. It shrinks the simplex either at the vertex that has the second lowest value to evaluate H or at the second highest vertex to evaluate I. The HNM verifies the value of . If the condition of point H is not satisfied, then HNM shrinks the simplex along the line segment and evaluates . The HNM goes to Step 6. The new vertices are given by:
- Step 6.
- Termination Test:The termination tests are problem-based and user-defined. In this work, the stopping criterion is primarily characterized by the designed error function of the SAE. It is encountered in examining the deviation of the error function from the true minimum by , as indicated by the inequality below.The termination criterion is evaluated for a predefined number of iterations (N). correspond to the number of nodes in the hidden layer, learning rate of the hidden layer, and learning rate of the output layer, respectively.If the condition of the termination test is satisfied, the HNM algorithm stops and returns the best architecture of SAE and the learning rates for the different layers of the back-propagation algorithm. Otherwise, the algorithm sorts the simplex vertices and the and goes to Step 2.
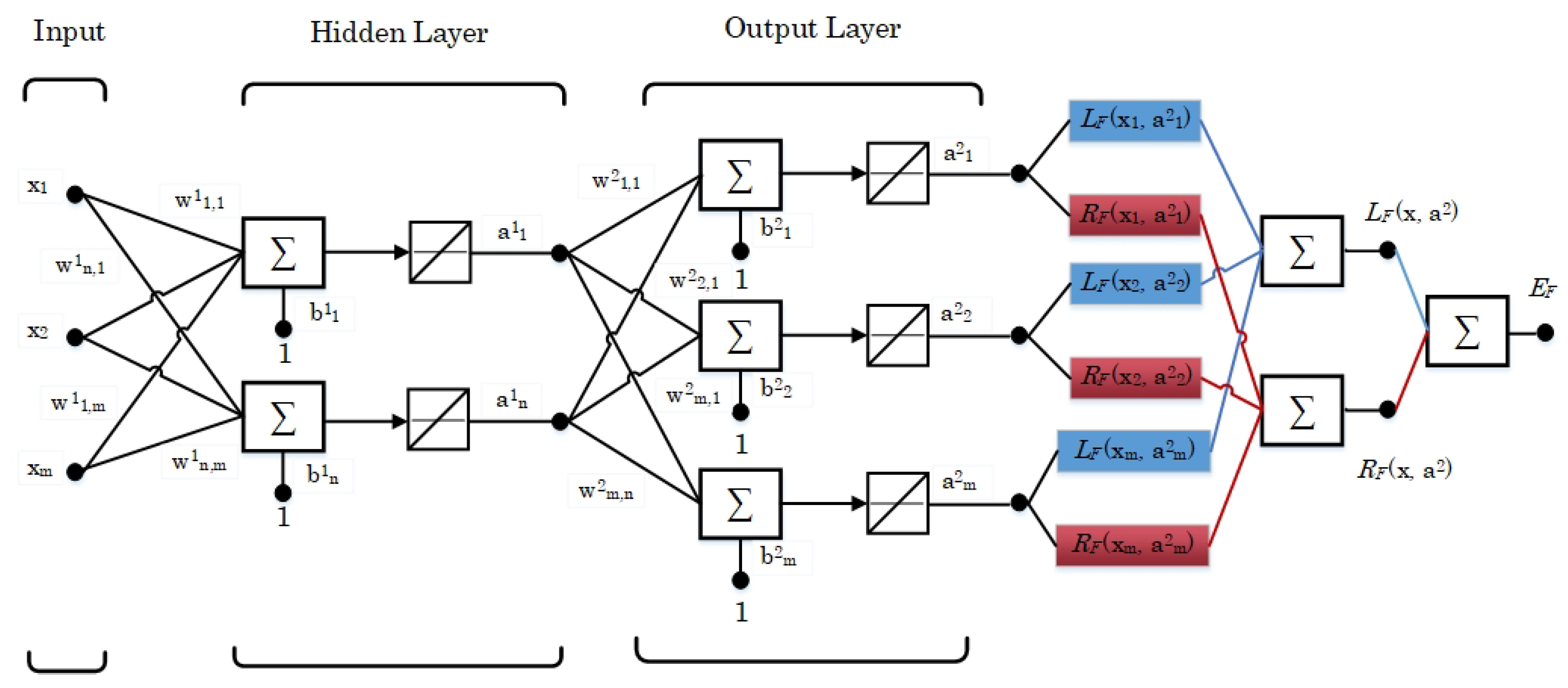
3.3. Proposed Sparse Autoencoder
4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Accuracy | |
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural Network |
| Number of Classes | |
| DBN | Deep Belief Network |
| DDoS | Distributed Denial-of-Service |
| DL-SVM | Deep Learning - Support Vector Machine |
| DMLP | Deep Multi-layer Perceptron |
| DoS | Denial-of-Service |
| DT | Decision Tree |
| Error Function | |
| F-measure | |
| HNM | Hassan–Nelde–Mead |
| IDS | Intrusion Detection Systems |
| KNN | K-Nearest Neighbor |
| Loss Function | |
| ML | Machine Learning |
| MLE-SVMs | Multi-layer Ensemble Support Vector Machines |
| MLP-PC | Multi-layer Perceptron-Payload Classifier |
| RF | Random Forest |
| Regularization Function | |
| SAE | Sparse Autoencoder |
| SGD | Stochastic Gradient Descent |
| SQL | Structured Query Language |
| Training set | |
| Testing set | |
| XSS | Cross-site Scripting |
References
- Liao, H.J.; Lin, C.H.; Lin, Y.C.; Tung, K.Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Anwar, S.; Mohamad, Z.J.; Zolkipli, M.F.; Inayat, Z.; Khan, S.; Anthony, B.; Chang, V. From intrusion detection to an intrusion response system: Fundamentals, requirements, and future directions. Algorithms 2017, 10, 39. [Google Scholar] [CrossRef]
- APCERT Annual Report 2018. Available online: https://www.apcert.org/documents/pdf/APCERT_Annual_Report_2018.pdf (accessed on 11 January 2020).
- Almseidin, M.; Alzubi, M.; Kovacs, S.; Alkasassbeh, M. Evaluation of machine learning algorithms for intrusion detection system. In Proceedings of the IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; pp. 000277–000282. [Google Scholar]
- Abdulhammed, R.; Faezipour, M.; Abuzneid, A.; AbuMallouh, A. Deep and machine learning approaches for anomaly-based intrusion detection of imbalanced network traffic. IEEE Sensors Lett. 2019, 3, 1–4. [Google Scholar] [CrossRef]
- Abdulhammed, R.; Musafer, H.; Alessa, A.; Faezipour, M.; Abuzneid, A. Features Dimensionality Reduction Approaches for Machine Learning Based Network Intrusion Detection. Electronics 2019, 8, 322. [Google Scholar] [CrossRef]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. arXiv 2018, arXiv:1802.09089. [Google Scholar]
- Kang, M.J.; Kang, J.W. Intrusion detection system using deep neural network for in-vehicle network security. PloS ONE 2016, 11, e0155781. [Google Scholar] [CrossRef] [PubMed]
- Musafer, H.A.; Mahmood, A. Dynamic Hassan Nelde—Mead with Simplex Free Selectivity for Unconstrained Optimization. IEEE Access 2018, 6, 39015–39026. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Madeira, Portugal, 22–24 January 2018; pp. 108–116. [Google Scholar]
- Abdulhammed, R.; Faezipour, M.; Musafer, H.; Abuzneid, A. Efficient network intrusion detection using pca-based dimensionality reduction of features. In Proceedings of the International Symposium on Networks, Computers and Communications (ISNCC), Istanbul, Turkey, 18–20 June 2019; pp. 1–6. [Google Scholar]
- Sarker, I.H.; Kayes, A.S.; Watters, P. Effectiveness analysis of machine learning classification models for predicting personalized context-aware smartphone usage. J. Big Data 2019, 6, 57. [Google Scholar] [CrossRef]
- Watson, G. A Comparison of Header and Deep Packet Features when Detecting Network Intrusions; Technical Report; University of Maryland: College Park, MD, USA, 2018. [Google Scholar]
- Aksu, D.; Üstebay, S.; Aydin, M.A.; Atmaca, T. Intrusion detection with comparative analysis of supervised learning techniques and fisher score feature selection algorithm. In Proceedings of the International Symposium on Computer and Information Sciences, Poznan, Poland, 27–28 October 2018; pp. 141–149. [Google Scholar]
- Gu, Q.; Li, Z.; Han, J. Generalized fisher score for feature selection. arXiv 2012, arXiv:1202.3725. [Google Scholar]
- Marir, N.; Wang, H.; Feng, G.; Li, B.; Jia, M. Distributed abnormal behavior detection approach based on deep belief network and ensemble svm using spark. IEEE Access 2018, 6, 59657–59671. [Google Scholar] [CrossRef]
- Aksu, D.; Aydin, M.A. Detecting port scan attempts with comparative analysis of deep learning and support vector machine algorithms. In Proceedings of the International Congress on Big Data, Deep Learning and Fighting Cyber Terrorism (IBIGDELFT), Ankara, Turkey, 3–4 December 2018; pp. 77–80. [Google Scholar]
- Ustebay, S.; Turgut, Z.; Aydin, M.A. Intrusion Detection System with Recursive Feature Elimination by Using Random Forest and Deep Learning Classifier. In Proceedings of the 2018 International Congress on Big Data, Deep Learning and Fighting Cyber Terrorism (IBIGDELFT), ANKARA, Turkey, 3–4 December 2018; pp. 71–76. [Google Scholar]
- Arai, K.; Kapoor, S.; Bhatia, R. Intelligent Computing: Proceedings of the 2018 Computing Conference; Springer: Philadelphia, PA, USA, 2018; Volume 1, pp. 408–409. [Google Scholar]
- Nelder, J.A.; Mead, R. A simplex method for function minimization. Comput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Albelwi, S.; Mahmood, A. A framework for designing the architectures of deep convolutional neural networks. Entropy 2018, 19, 242. [Google Scholar]
- Ng, A. Sparse autoencoder. CS294A Lect. Notes 2011, 27, 1–9. [Google Scholar]
- Heaton, J.; Goodfellow, I.; Bengio, Y.; Courville, A. Deep learning. In Genetic Programming and Evolvable Machines; Springer: Philadelphia, PA, USA, 2018; Volume 19, pp. 305–307. [Google Scholar]
- Makhzani, A. Unsupervised representation learning with autoencoders. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2018. [Google Scholar]
- Ranzato, M.A.; Boureau, Y.L.; Cun, Y.L. Sparse feature learning for deep belief networks. In Advances in Neural Information Processing Systems 20 (NIPS 2007), Proceedings of the Neural Information Processing Systems 2007, Vancouver, BC, Canada, 3–6 December 2007; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2007; pp. 1185–1192. [Google Scholar]
- Demuth, H.B.; Beale, M.H.; De Jesús, O.; Hagan, M.T. Neural Network Design; Martin Hagan: Lawrence, KS, USA, 2014. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Experiment | n | Epoch | Time (s) | ||||
|---|---|---|---|---|---|---|---|
| First | 12 | 0.01037246 | 0.1032246 | 22% | 32% | 180 | 4091 |
| Second | 5 | 0.00173640 | 0.0524296 | 22% | 34% | 126 | 2394 |
| Algorithm | Experiment Criteria | Performance Measure | Feature Extraction |
|---|---|---|---|
| 1. MLP-PC [13] | (27) | ||
| 2. KNN [14] | FS (30) | ||
| 3. MLE-SVMs [16] | DBN (16) | ||
| 4. DL-SVM [17] | (85) | ||
| 5. DMLP [18] | RF (10) | ||
| 6. RF [6] | SAE (59) | ||
| 7. SAE-RF | 0.996)99.63 | Proposed SAE(12) | |
| 8. SAE-RF | 0.996)99.56 | Proposed SAE(5) |
| Experiment | True Positive Rate | False Positive Rate | Precision | Recall | Epoch | Time (s) |
|---|---|---|---|---|---|---|
| First | 0.996 | 0.009 | 0.996 | 0.996 | 76 | 3925 |
| Second | 0.996 | 0.011 | 0.996 | 0.996 | 27 | 2034 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Musafer, H.; Abuzneid, A.; Faezipour, M.; Mahmood, A. An Enhanced Design of Sparse Autoencoder for Latent Features Extraction Based on Trigonometric Simplexes for Network Intrusion Detection Systems. Electronics 2020, 9, 259. https://doi.org/10.3390/electronics9020259
Musafer H, Abuzneid A, Faezipour M, Mahmood A. An Enhanced Design of Sparse Autoencoder for Latent Features Extraction Based on Trigonometric Simplexes for Network Intrusion Detection Systems. Electronics. 2020; 9(2):259. https://doi.org/10.3390/electronics9020259
Chicago/Turabian StyleMusafer, Hassan, Abdelshakour Abuzneid, Miad Faezipour, and Ausif Mahmood. 2020. "An Enhanced Design of Sparse Autoencoder for Latent Features Extraction Based on Trigonometric Simplexes for Network Intrusion Detection Systems" Electronics 9, no. 2: 259. https://doi.org/10.3390/electronics9020259
APA StyleMusafer, H., Abuzneid, A., Faezipour, M., & Mahmood, A. (2020). An Enhanced Design of Sparse Autoencoder for Latent Features Extraction Based on Trigonometric Simplexes for Network Intrusion Detection Systems. Electronics, 9(2), 259. https://doi.org/10.3390/electronics9020259