Task-Agnostic Object Recognition for Mobile Robots through Few-Shot Image Matching

 ,
,
Abstract
1. Introduction
- We test state-of-the-art methods for Deep few-shot image matching on a novel task-agnostic data set, including 2D views of common object types drawn from a combination of ShapeNet [16] and Google Images.
- We compare these against other shallow methods explored as part of our prior work [19], which are based on colour and shape similarity, to assess whether meaningful features can be transferred after learning on a different image domain, i.e., ImageNet, without any prior feature engineering.
- We also evaluate the performance effects of (i) imprinting the weights [15] of a two-branch CNN [13], i.e., thus extending the framework in [13] with a novel weight configuration; (ii) applying L2 normalisation to the embeddings of a Convolutional Siamese Network [12], to include the case of binary classification in our assessment.
2. Background and Related Work
3. Proposed Approach and Contributions
4. Data Preparation
5. Few-Shot Image Matching
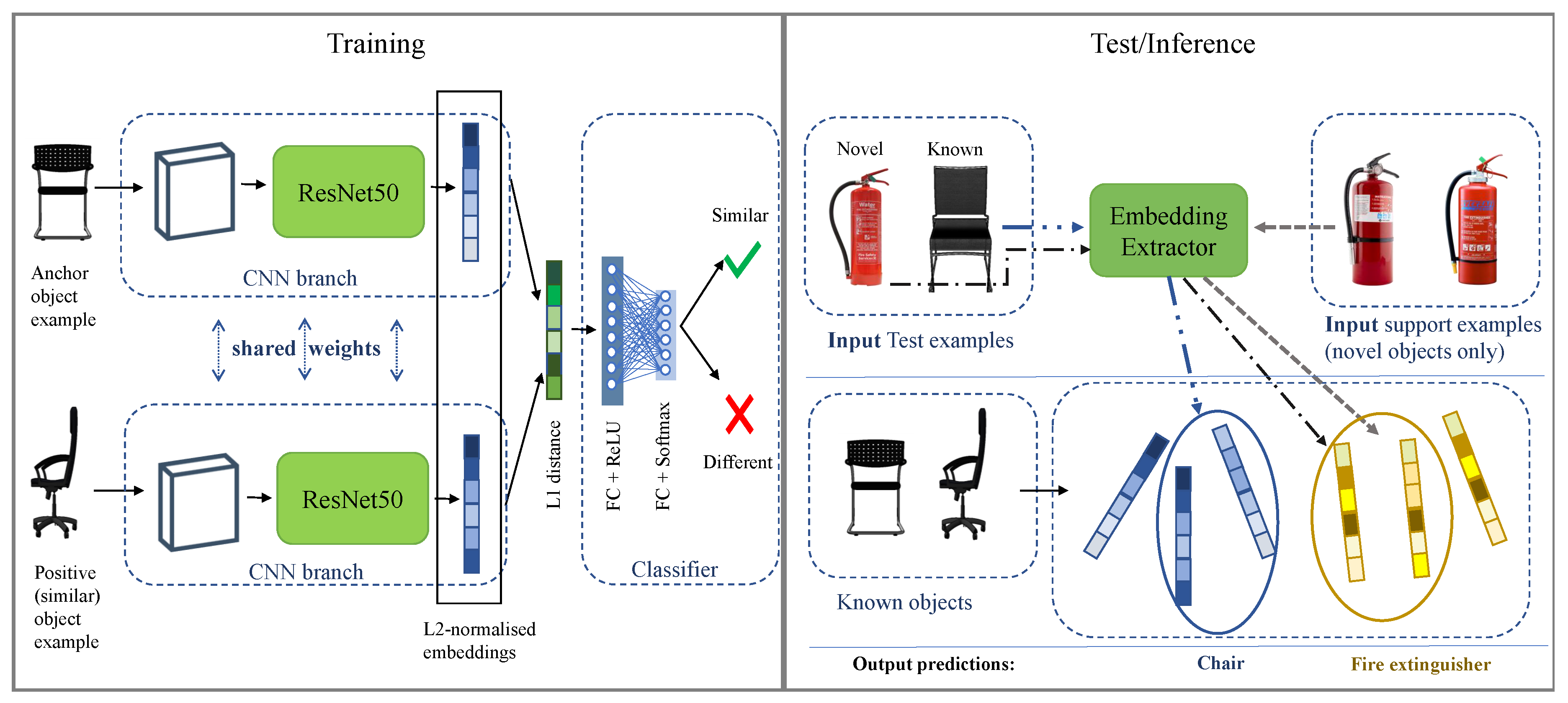
5.1. Model Architecture
5.2. Implementation Details
5.3. Model Evaluation
- Baseline NN is the chosen baseline, where features are extracted from a ResNet50 pre-trained on ImageNet without further fine-tuning, and, for each extracted image embedding in the test set, labels are predicted through finding the Nearest Neighbour based on the L2 distance.
- N-net is our implementation of the architecture leading to the best performance on novel object classes, among the ones presented in [13]. N-net is a two-branch Network, i.e., weights are learned independently on each branch, differently from Siamese-based models, where weights are tied across the two twin Networks (see also Section 2). Each CNN branch is a ResNet50 pre-trained on ImageNet. At training time, the Network is fed with data triplets formed so that each training example (anchor) is compared against a positive (similar image) and a negative example (dissimilar image). Here, for each input image, the anchor embedding to compare against is automatically-picked, based on its L2-distance from the input embedding (a technique referred to as “multi-anchor switch” in the original paper [13]). Then, parameter update is based on the objective of minimising the Triplet Loss [42]. In this way, the Network optimisation is directed towards minimising the L2-distance between matching pairs, while also maximising the L2-distance between dissimilar pairs.
- K-net was derived from N-net, by summing up a second component based on softmax classification (see also Equations (5) and (7)) to the Triplet Loss. Zeng et al. [13] found that this choice helped to boost performance on known object classes, at the expense of novel object recognition. Our implementation of both the K-net and the N-net architectures only differs by the fact that we have fine-tuned both ResNet50 branches. In the original design, the Network is fed with images belonging to two different visual domains, i.e., the robot-collected images and the product catalogue images. Then, only the CNN branch devoted to the robot-collected frames is re-trained, while in the product image branch features are extracted without further re-training. In our case, however, where both data streams consist of synthetic object models, if we simply extracted features from both branches without re-training, the resulting architecture would have reduced to the already tested baseline NN.
- SiamResNet50 follows the same general architecture of [12], but relies on a pre-trained ResNet50 for each CNN branch. The main differences with K-net and N-net [13] are that, in this case, (i) weights were shared across the two CNN streams and (ii) training is based on a binary classifier, regularised through a cross-entropy objective (i.e., the same training routine explained in Section 5.1).
- Imprinted K-net is a K-net where the classification layer used as auxiliary component for the training loss is initialised with imprinted weights, instead of random weights. The weight imprinting approach proposed in [15] is based on the intuition that the embedding layer activations of a CNN, if opportunely scaled and L2-normalised, are mathematically comparable to the weight vectors of a softmax classification layer and can thus be added directly to the classifier’s weight matrix, as soon as a new labelled (training) example is collected. We refer to [15] for a complete mathematical demonstration of this argument. Following the same notation introduced in Section 5.1, let be the vectorised representation of an input training point, its related class label, and b the weight vector and bias parameters of the softmax activation layer used to classify the input over M classes. In the weight imprinting routine, each is L2-normalised, yielding (see also Equation (1)) and then multiplied by a scaling factor . Furthermore, b is set to zero in the softmax classification layer. Then, the m-th column of the W matrix () is initialised with . If training examples are available for class m, i.e., as in the case of this experiment, first the average embedding of all in class m is computed asthen is L2-normalised again to . Finally, is initialised to .
- L2normL1 + SiamResNet50 is the architecture in Figure 1. It is based on SiamResNet50, with the exception that the embeddings output of each branch is L2-normalised before any further transformation. A more detailed description of this ablation is provided in Section 5.1.
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- SPARC. Strategic Research Agenda for Robotics in Europe 2014–2020. EU Robotics. 2014. Available online: https://www.eu-robotics.net/cms/upload/topic_groups/SRA2020_SPARC.pdf (accessed on 21 February 2020).
- Tiddi, I.; Bastianelli, E.; Daga, E.; d’Aquin, M.; Motta, E. Robot–City Interaction: Mapping the Research Landscape—A Survey of the Interactions Between Robots and Modern Cities. Int. J. Soc. Robot. 2019, 1–26. [Google Scholar] [CrossRef]
- Bastianelli, E.; Bardaro, G.; Tiddi, I.; Motta, E. Meet HanS, the Health&Safety Autonomous Inspector. In Proceedings of the ISWC 2018 Posters & Demonstrations, Industry and Blue Sky Ideas Tracks, 17th International Semantic Web Conference (ISWC 2018), CEUR Workshop Proceedings, Monterey, CA, USA, 8–12 October 2018. [Google Scholar]
- Mollaret, C.; Mekonnen, A.A.; Pinquier, J.; Lerasle, F.; Ferrané, I. A multi-modal perception based architecture for a non-intrusive domestic assistant robot. In Proceedings of the The 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Christchurch, New Zealand, 7–10 March 2016; pp. 481–482. [Google Scholar]
- Ferri, G.; Manzi, A.; Salvini, P.; Mazzolai, B.; Laschi, C.; Dario, P. DustCart, an autonomous robot for door-to-door garbage collection: From DustBot project to the experimentation in the small town of Peccioli. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 655–660. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4444–4451. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE Computer Society: Washington, DC, USA, 2017; Volume 39, pp. 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 10–11 July 2015; Volume 2. [Google Scholar]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2009; pp. 248–255. [Google Scholar]
- Qi, H.; Brown, M.; Lowe, D.G. Low-shot learning with imprinted weights. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5822–5830. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar]
- Chiatti, A.; Bardaro, G.; Bastianelli, E.; Tiddi, I.; Mitra, P.; Motta, E. Exploring Task-agnostic, ShapeNet-based Object Recognition for Mobile Robots. In Proceedings of the EDBT/ICDT 2019 Joint Conference, Lisbon, Portugal, 26 March 2019. [Google Scholar]
- Chen, Z.; Liu, B. Lifelong machine learning. Synth. Lect. Artif. Intell. Mach. Learn. 2018, 12, 1–207. [Google Scholar]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- French, R.M. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [PubMed]
- Grossberg, S.T. Studies of Mind and Brain: Neural Principles of Learning, Perception, Development, Cognition, and Motor Control; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 70. [Google Scholar]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2990–2999. [Google Scholar]
- Aljundi, R.; Belilovsky, E.; Tuytelaars, T.; Charlin, L.; Caccia, M.; Lin, M.; Page-Caccia, L. Online continual learning with maximal interfered retrieval. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; 2019; pp. 11849–11860. [Google Scholar]
- Tenorth, M.; Beetz, M. Representations for robot knowledge in the KnowRob framework. Artif. Intell. 2017, 247, 151–169. [Google Scholar]
- Nolfi, S.; Parisi, D. Learning to adapt to changing environments in evolving neural networks. Adapt. Behav. 1996, 5, 75–98. [Google Scholar]
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive neural networks. arXiv 2016, arXiv:1606.04671. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [PubMed]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Rosch, E.; Mervis, C.B.; Gray, W.D.; Johnson, D.M.; Boyes-Braem, P. Basic objects in natural categories. Cogn. Psychol. 1976, 8, 382–439. [Google Scholar]
- Posner, M.I. Abstraction and the process of recognition. Psychol. Learn. Motiv. 1969, 3, 43–100. [Google Scholar]
- Neumann, P.G. Visual prototype formation with discontinuous representation of dimensions of variability. Mem. Cogn. 1977, 5, 187–197. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Nathan Silberman, Derek Hoiem, P.K.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Shi, J.; Dong, Y.; Su, H.; Stella, X.Y. Learning non-lambertian object intrinsics across shapenet categories. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5844–5853. [Google Scholar]
- Xiang, Y.; Fox, D. DA-RNN: Semantic mapping with data associated recurrent neural networks. arXiv 2017, arXiv:1703.03098. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]


{kind=link}
| Object | SNS1 | SNS2 |
|---|---|---|
| Chair | 14 | 10 |
| Bottle | 12 | 10 |
| Paper | 8 | 10 |
| Book | 8 | 10 |
| Table | 8 | 10 |
| Box | 8 | 10 |
| Window | 6 | 10 |
| Door | 4 | 10 |
| Sofa | 8 | 10 |
| Lamp | 6 | 10 |
| Total | 82 | 100 |
| Object | SNG-20 Train | SNG-20 Val | SNG-20 Test | |
|---|---|---|---|---|
| Known | Chair | 10 | 5 | 5 |
| Bottle | 10 | 5 | 5 | |
| Paper | 10 | 5 | 5 | |
| Book | 10 | 5 | 5 | |
| Desk | 10 | 5 | 5 | |
| Box | 10 | 5 | 5 | |
| Window | 10 | 5 | 5 | |
| Emergency exit sign | 10 | 5 | 5 | |
| Coat rack | 10 | 5 | 5 | |
| Radiator | 10 | 5 | 5 | |
| Novel | Fire extinguisher | 10 | 5 | 5 |
| Desktop PC | 10 | 5 | 5 | |
| Electric heater | 10 | 5 | 5 | |
| Lamp | 10 | 5 | 5 | |
| Power cable | 10 | 5 | 5 | |
| Monitor | 10 | 5 | 5 | |
| Person | 10 | 5 | 5 | |
| Plant | 10 | 5 | 5 | |
| Bin | 10 | 5 | 5 | |
| Door | 10 | 5 | 5 | |
| Total | 200 | 100 | 100 | |
| Approach | Dataset SNS1 v. SNS2 |
|---|---|
| Random label assigment | 0.10 |
| Shape-only L3 | 0.19 |
| Colour-only Hellinger | 0.32 |
| Shape+Color (weighted sum) | 0.32 |
| Baseline NN | 0.82 |
| Approach | Known | Novel | Mixed | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | P | R | F1 | A | P | R | F1 | A | P | R | F1 | |
| Baseline NN | 0.76 | 0.91 | 0.76 | 0.79 | 0.84 | 0.93 | 0.84 | 0.85 | 0.80 | 0.85 | 0.80 | 0.79 |
| N-net [13] | 0.70 | 0.97 | 0.70 | 0.78 | 0.74 | 0.83 | 0.74 | 0.75 | 0.72 | 0.79 | 0.72 | 0.72 |
| K-net [13] | 0.76 | 0.94 | 0.76 | 0.81 | 0.70 | 0.78 | 0.70 | 0.73 | 0.78 | 0.73 | 0.73 | 0.73 |
| SiamResNet50 [12,37] | 0.76 | 0.91 | 0.76 | 0.79 | 0.84 | 0.93 | 0.84 | 0.85 | 0.78 | 0.83 | 0.78 | 0.77 |
| Imprinted K-net | 0.74 | 0.98 | 0.74 | 0.82 | 0.80 | 0.86 | 0.80 | 0.82 | 0.77 | 0.83 | 0.77 | 0.77 |
| L2norm L1 SiamResNet50 | 0.80 | 0.91 | 0.80 | 0.83 | 0.84 | 0.95 | 0.84 | 0.87 | 0.82 | 0.86 | 0.82 | 0.81 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chiatti, A.; Bardaro, G.; Bastianelli, E.; Tiddi, I.; Mitra, P.; Motta, E. Task-Agnostic Object Recognition for Mobile Robots through Few-Shot Image Matching. Electronics 2020, 9, 380. https://doi.org/10.3390/electronics9030380
Chiatti A, Bardaro G, Bastianelli E, Tiddi I, Mitra P, Motta E. Task-Agnostic Object Recognition for Mobile Robots through Few-Shot Image Matching. Electronics. 2020; 9(3):380. https://doi.org/10.3390/electronics9030380
Chicago/Turabian StyleChiatti, Agnese, Gianluca Bardaro, Emanuele Bastianelli, Ilaria Tiddi, Prasenjit Mitra, and Enrico Motta. 2020. "Task-Agnostic Object Recognition for Mobile Robots through Few-Shot Image Matching" Electronics 9, no. 3: 380. https://doi.org/10.3390/electronics9030380
APA StyleChiatti, A., Bardaro, G., Bastianelli, E., Tiddi, I., Mitra, P., & Motta, E. (2020). Task-Agnostic Object Recognition for Mobile Robots through Few-Shot Image Matching. Electronics, 9(3), 380. https://doi.org/10.3390/electronics9030380