Improving Classification Accuracy of Hand Gesture Recognition Based on 60 GHz FMCW Radar with Deep Learning Domain Adaptation




Abstract
1. Introduction
2. Preliminaries to Radar-Based Gesture Recognition and Domain Adaptation
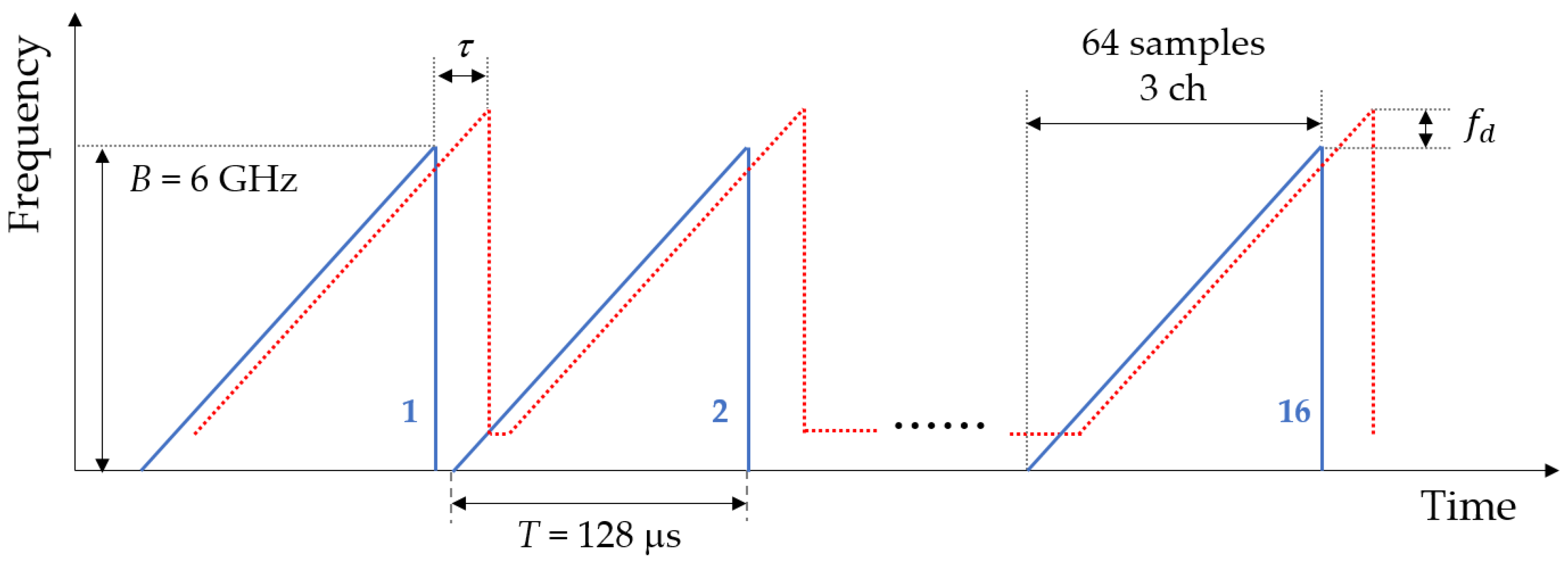
2.1. 60 GHz FMCW Radar
2.1.1. Radar System Overview
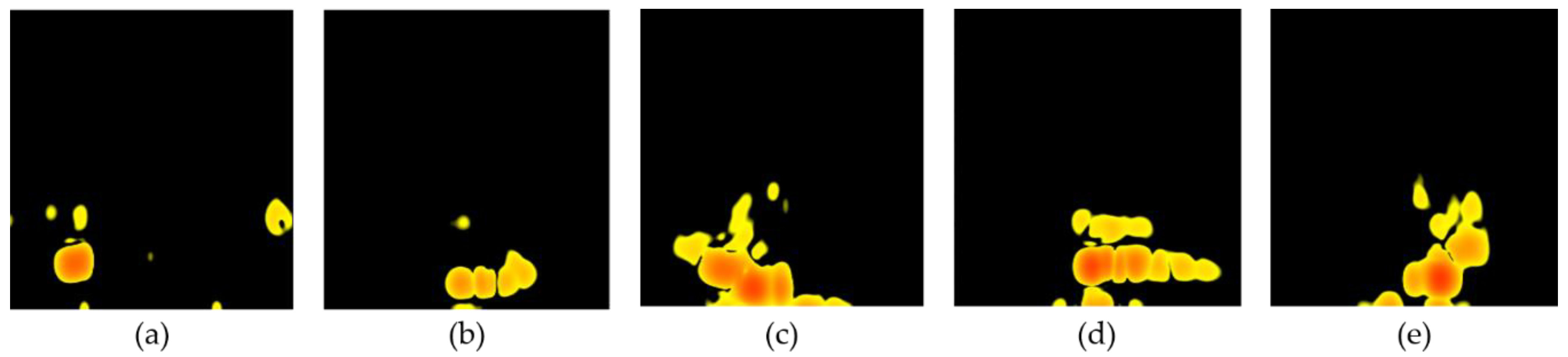
2.1.2. Radar Signal Processing for Gesture Recognition
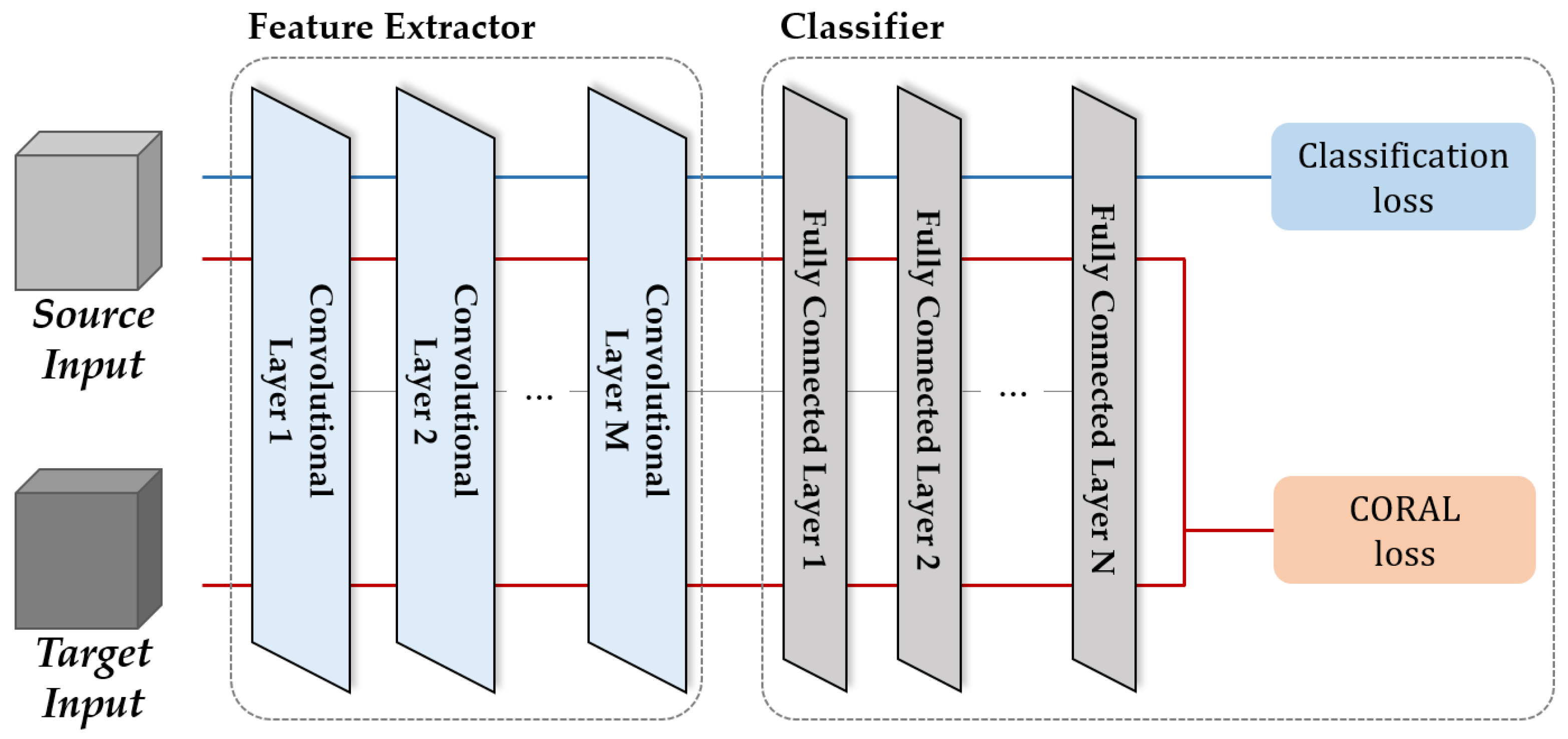
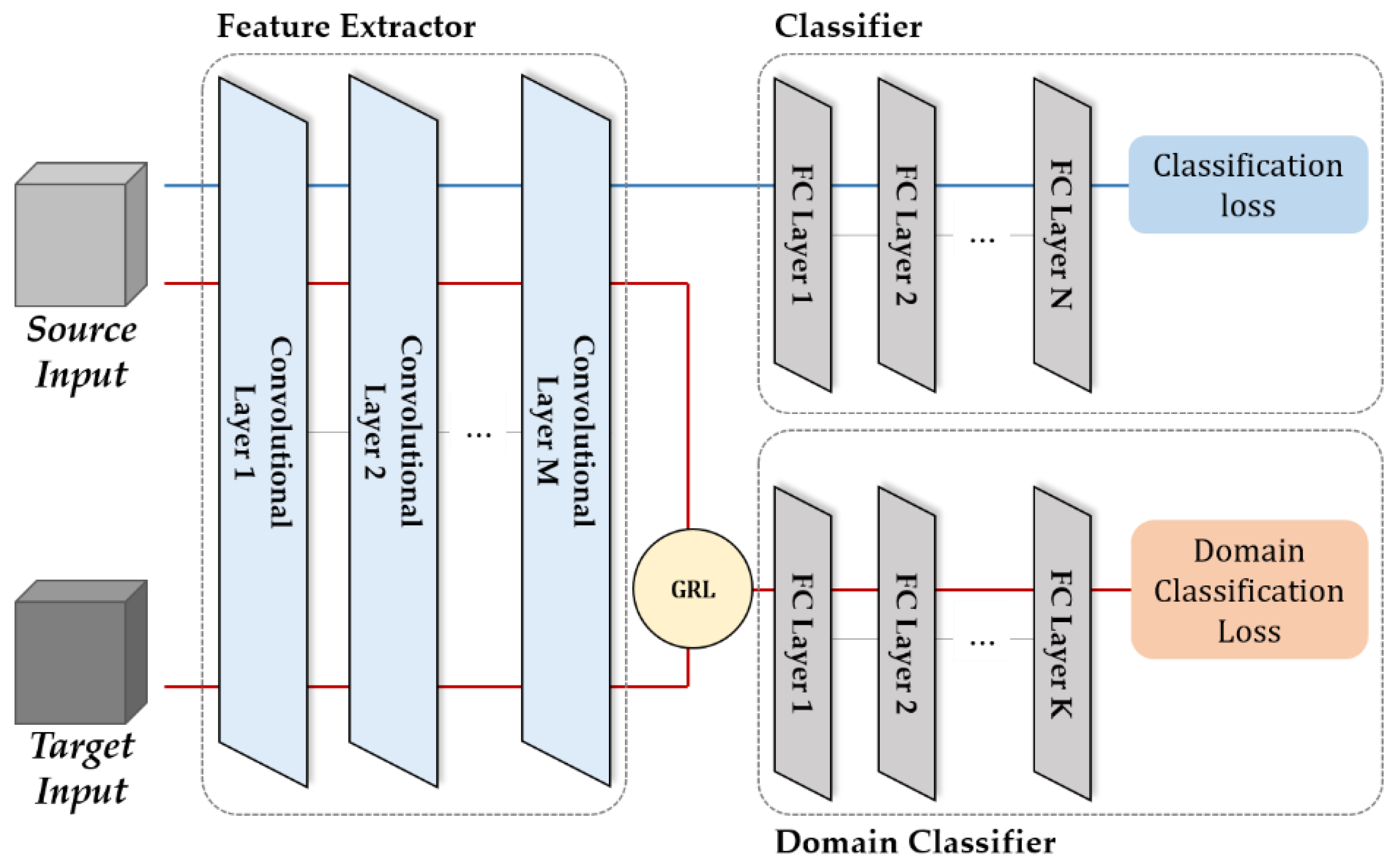
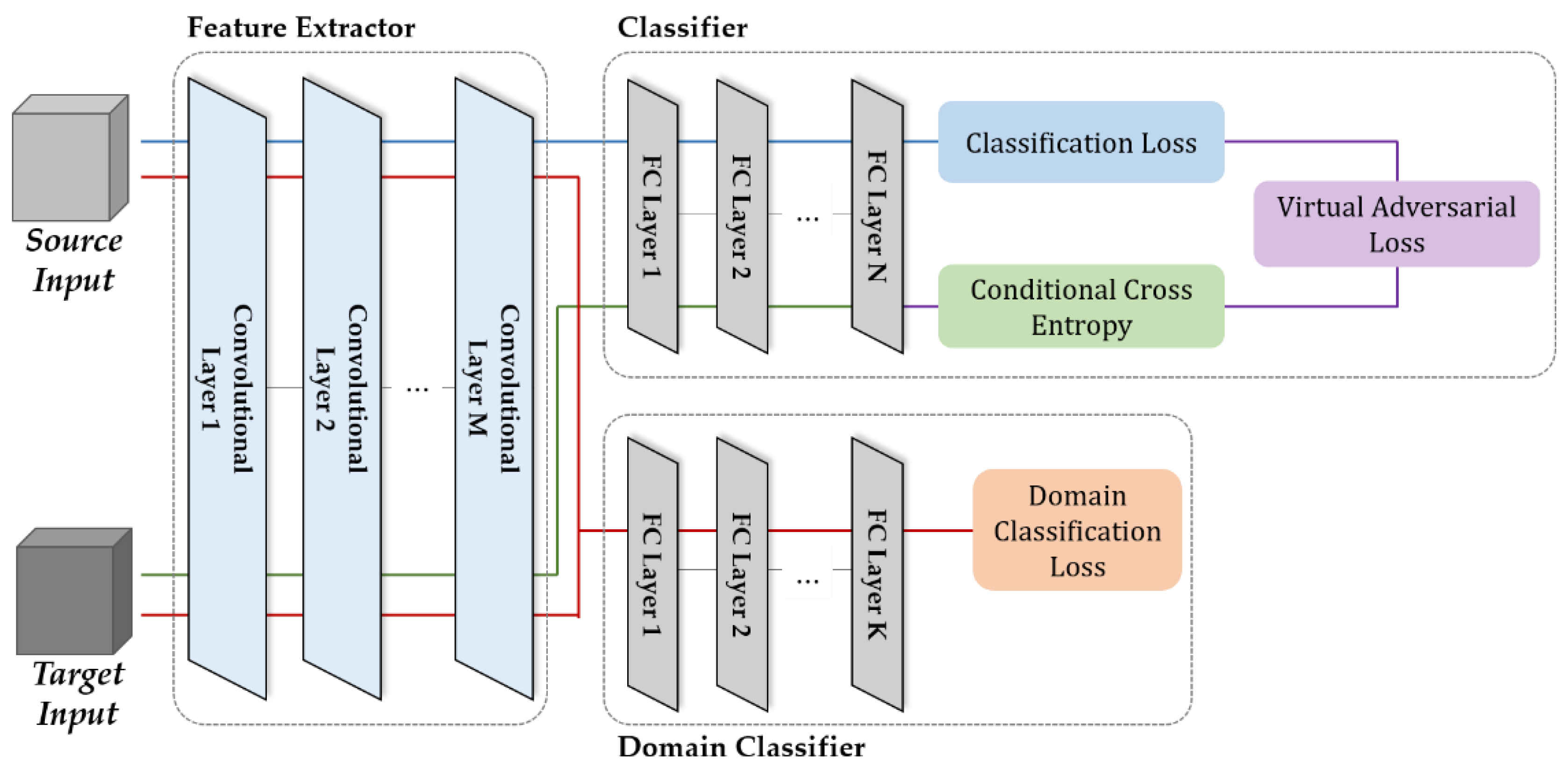
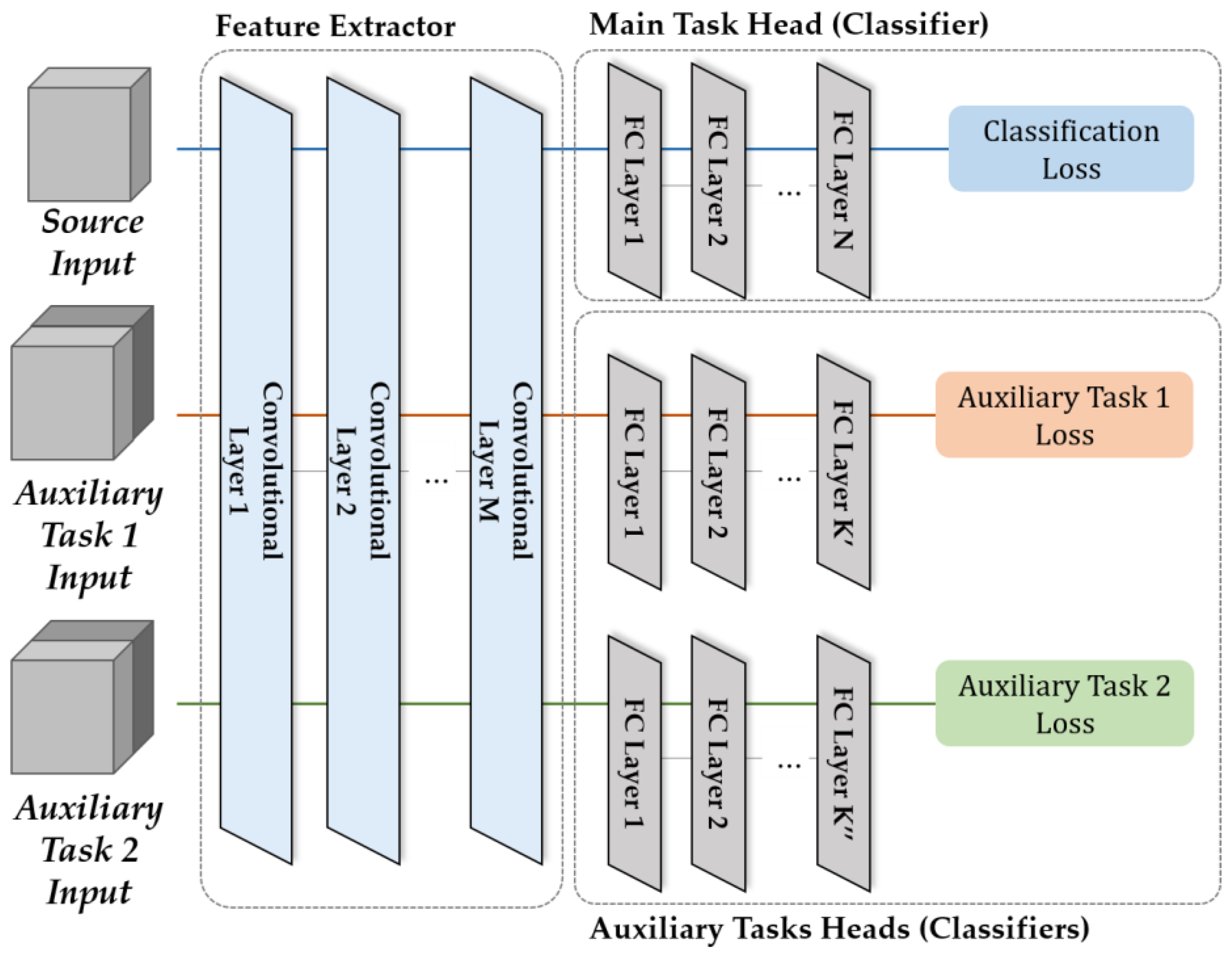
2.2. Domain Adaptation
3. Hand Gesture Recognition System
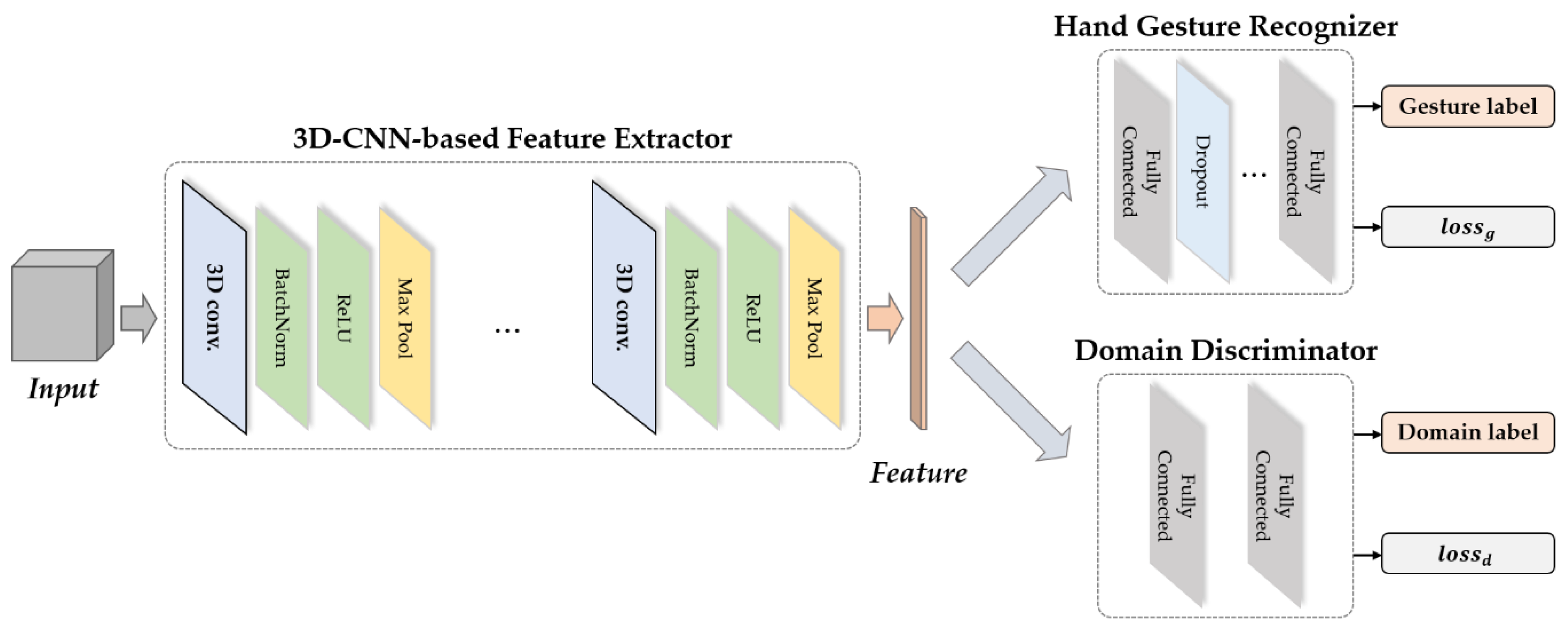
3.1. System Overview
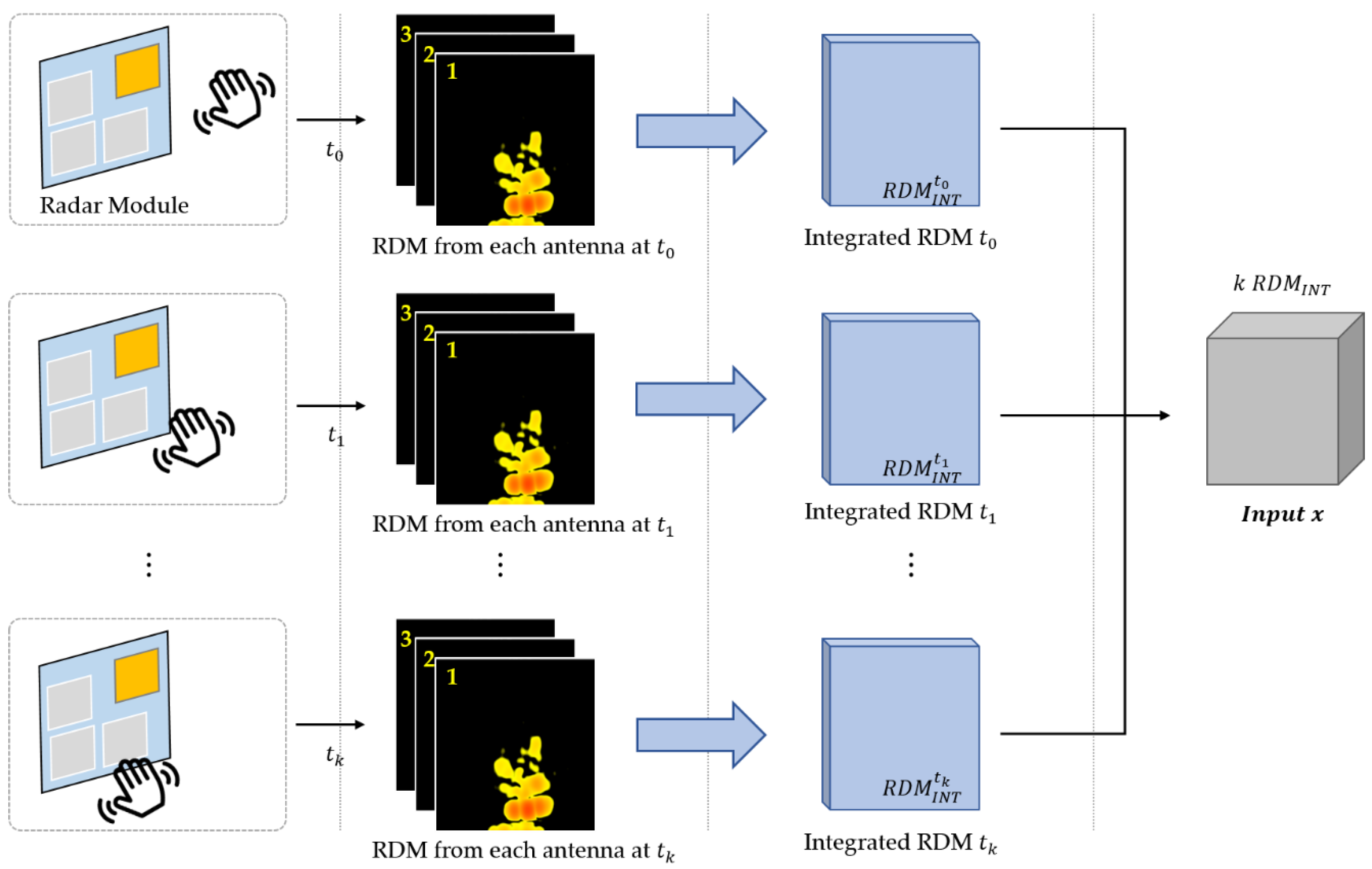
3.2. Input Dataset
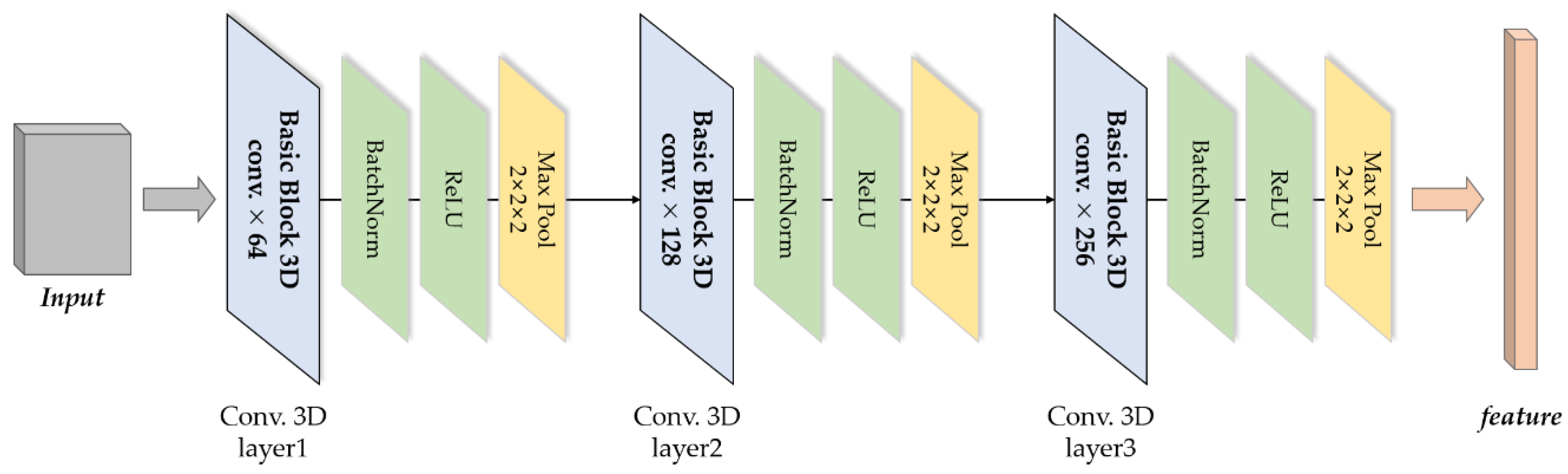
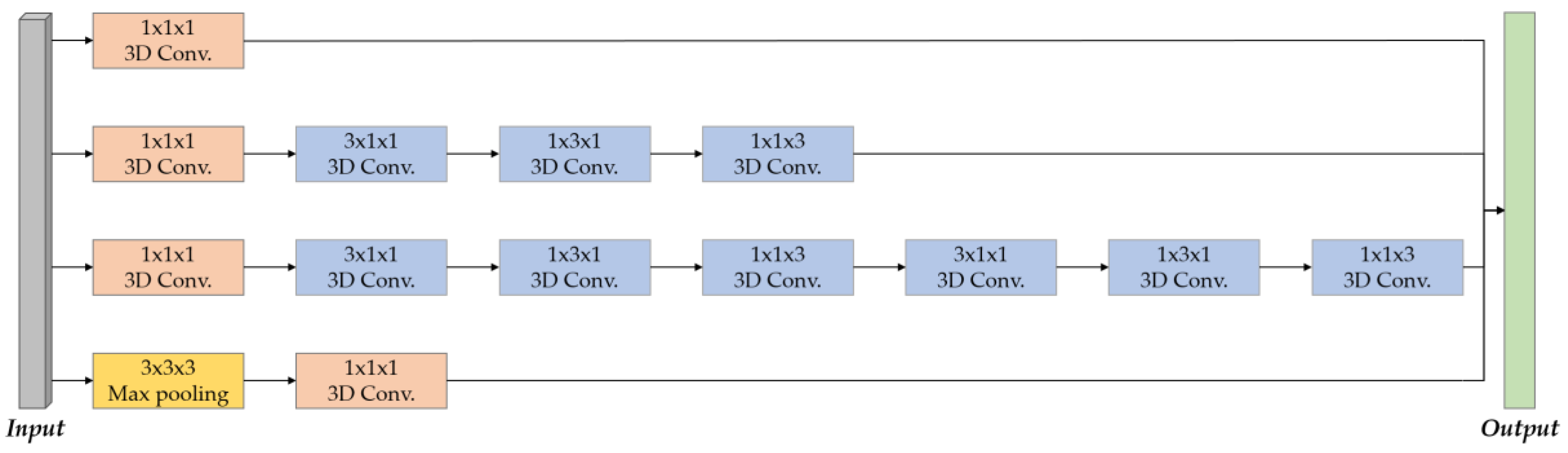
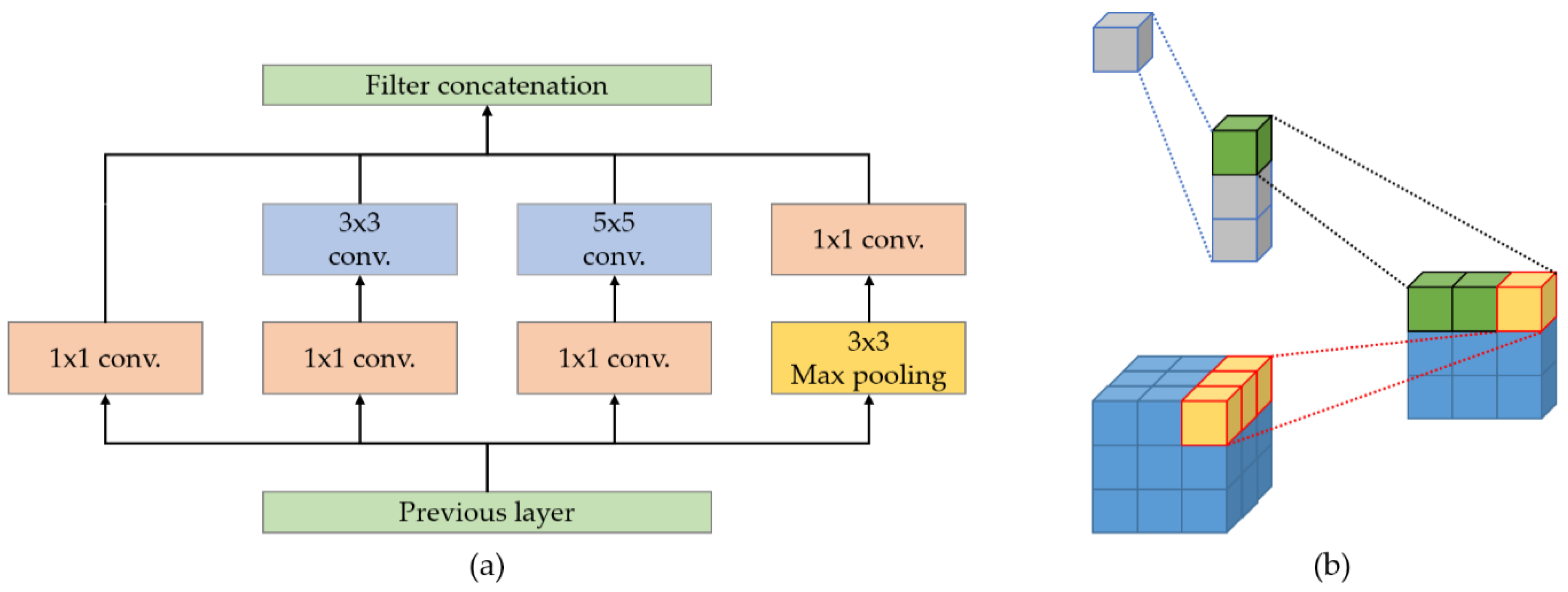
3.3. Feature Extractor
3.4. Gesture Recognizer
3.5. Domain Discriminator
4. Experiments
4.1. Experimental Setup
4.2. Implementation
4.3. Dataset
4.4. Compared Gesture Recognition Algorithm
5. Performance Evaluation
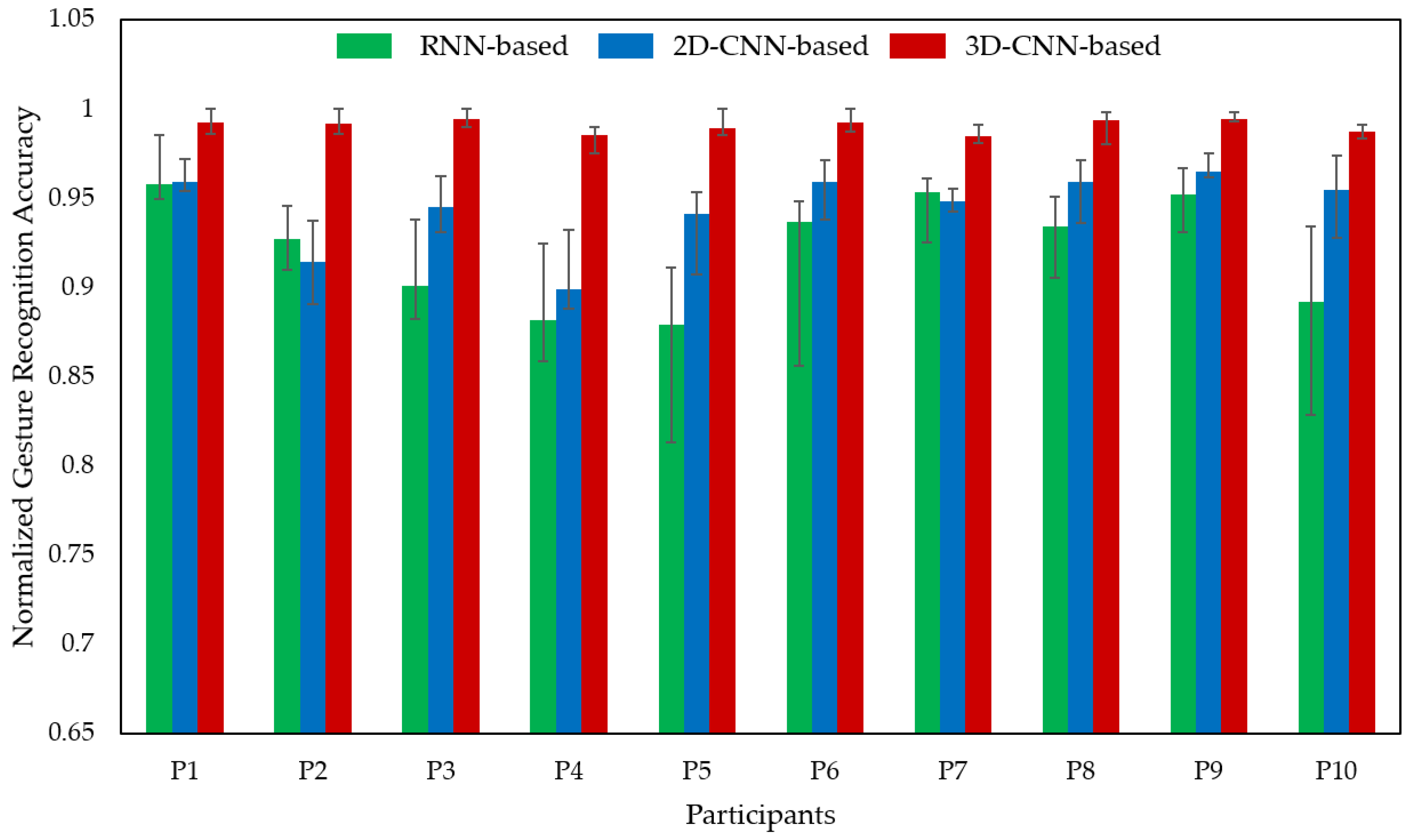
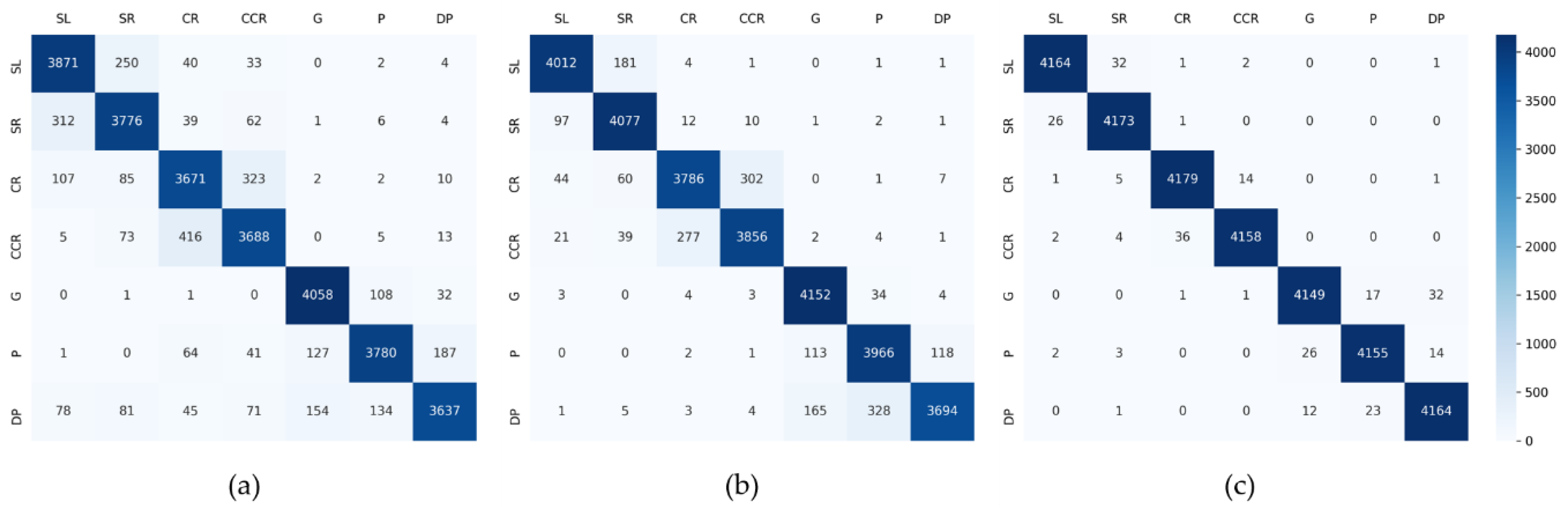
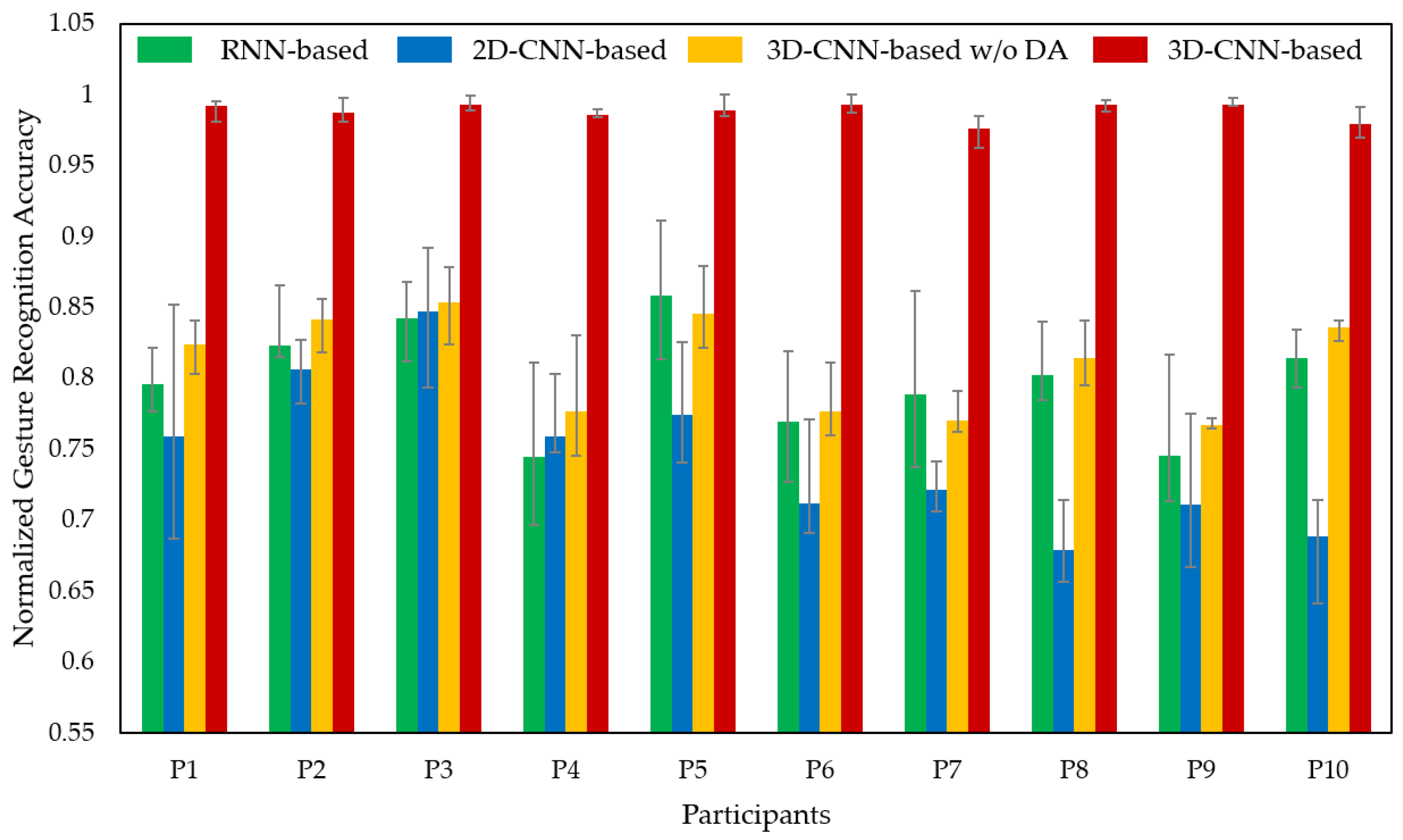
5.1. Offline Test with Source Domain Dataset
5.2. Offline Test with Target Domain Dataset
5.3. Online Test
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jobanputra, C.; Bavishi, J.; Doshi, N. Human activity recognition: A survey. Procedia Comput. Sci. 2019, 155, 698–703. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A review on human activity recognition using vision-based method. J. Healthc. Eng. 2017. [Google Scholar] [CrossRef] [PubMed]
- Bux, A.; Angelov, P.; Habib, Z. Vision based human activity recognition: A review. In Advances in Computational Intelligence Systems; Springer: Cham, Switzerland, 2017; pp. 341–371. [Google Scholar]
- Elbasiony, R.; Gomaa, W. A survey on human activity recognition based on temporal signals of portable inertial sensors. In International Conference on Advanced Machine Learning Technologies and Applications; Springer: Cham, Switzerland, 2019; pp. 734–745. [Google Scholar]
- Feng, C.; Arshad, S.; Zhou, S.; Cao, D.; Liu, Y. Wi-multi: A three-phase system for multiple human activity recognition with commercial wifi devices. IEEE Internet Things J. 2019, 6, 7293–7304. [Google Scholar] [CrossRef]
- Liu, J.; Liu, H.; Chen, Y.; Wang, C. Wireless sensing for human activity: A survey. IEEE Commun. Surv. Tutor. 2019. [Google Scholar] [CrossRef]
- Abdelnasser, H.; Youssef, M.; Harras, K.A. Wigest: A ubiquitous wifi-based gesture recognition system. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Kowloon, Hong Kong, 26 April–1 May 2015; pp. 1472–1480. [Google Scholar]
- Zhao, Y.; Lian, C.; Zhang, X.; Sha, X.; Shi, G.; Li, W.J. Wireless IoT motion-recognition rings and a paper keyboard. IEEE Access 2019, 7, 44514–44524. [Google Scholar] [CrossRef]
- Yan, Y.; Yu, C.; Shi, Y.; Xie, M. PrivateTalk: Activating Voice Input with Hand-On-Mouth Gesture Detected by Bluetooth Earphones. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology, New Orleans, LA, USA, 23 October 2019; pp. 1013–1020. [Google Scholar]
- Ding, C.; Zhang, L.; Gu, C.; Bai, L.; Liao, Z.; Hong, H.; Li, Y.; Zhu, X. Non-contact human motion recognition based on UWB radar. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 306–315. [Google Scholar] [CrossRef]
- Qi, R.; Li, X.; Zhang, Y.; Li, Y. Multi-Classification Algorithm for Human Motion Recognition Based on IR-UWB Radar. IEEE Sens. J. 2020, 20, 12848–12858. [Google Scholar] [CrossRef]
- Khan, W.M.; Zualkernan, I.A. Sensepods: A zigbee-based tangible smart home interface. IEEE Trans. Consum. Electron. 2018, 64, 145–152. [Google Scholar] [CrossRef]
- Li, H.; He, X.; Chen, X.; Fang, Y.; Fang, Q. Wi-Motion: A robust human activity recognition using WiFi signals. IEEE Access 2019, 7, 153287–153299. [Google Scholar] [CrossRef]
- Tan, B.; Woodbridge, K.; Chetty, K. A real-time high resolution passive WiFi Doppler-radar and its application. In Proceedings of the 2014 International Radar Conference, Lille, France, 13–17 October 2014; pp. 1–6. [Google Scholar]
- Kang, T.; Chae, M.; Seo, E.; Kim, M.; Kim, J. DeepHandsVR: Hand Interface Using Deep Learning in Immersive Virtual Reality. Electronics 2020, 9, 1863. [Google Scholar] [CrossRef]
- Nguyen, D.T.A.; Lee, H.G.; Jeong, E.R.; Lee, H.L.; Joung, J. Deep Learning-Based Localization for UWB Systems. Electronics 2020, 9, 1712. [Google Scholar] [CrossRef]
- Sulikowski, P.; Zdziebko, T. Deep Learning-Enhanced Framework for Performance Evaluation of a Recommending Interface with Varied Recommendation Position and Intensity Based on Eye-Tracking Equipment Data Processing. Electronics 2020, 9, 266. [Google Scholar] [CrossRef]
- Nurmaini, S.; Darmawahyuni, A.; Sakti Muikti, A.N.; Rachmatullah, M.N.; Firdaus, F.; Tutuko, B. Deep Learning-Based Stacked Denoising and Autoencoder for ECG Heartbeat Classification. Electronics 2020, 9, 135. [Google Scholar] [CrossRef]
- Smith, K.A.; Csech, C.; Murdoch, D.; Shaker, G. Gesture recognition using mm-wave sensor for human-car interface. IEEE Sens. Lett. 2018, 2, 1–4. [Google Scholar] [CrossRef]
- Kim, Y.; Toomajian, B. Hand gesture recognition using micro-Doppler signatures with convolutional neural network. IEEE Access 2016, 4, 7125–7130. [Google Scholar] [CrossRef]
- Dekker, B.; Jacobs, S.; Kossen, A.S.; Kruithof, M.C.; Huizing, A.G.; Geurts, M. Gesture recognition with a low power FMCW radar and a deep convolutional neural network. In Proceedings of the 2017 European Radar Conference (EURAD), Nuremberg, Germany, 11–13 October 2017; pp. 163–166. [Google Scholar]
- Zhang, Z.; Tian, Z.; Zhou, M. Latern: Dynamic continuous hand gesture recognition using FMCW radar sensor. IEEE Sens. J. 2018, 18, 3278–3289. [Google Scholar] [CrossRef]
- Suh, J.S.; Ryu, S.; Han, B.; Choi, J.; Kim, J.H.; Hong, S. 24 GHz FMCW radar system for real-time hand gesture recognition using LSTM. In Proceedings of the 2018 Asia-Pacific Microwave Conference (APMC), Kyoto, Japan, 6–9 November 2018; pp. 860–862. [Google Scholar]
- Ryu, S.J.; Suh, J.S.; Baek, S.H.; Hong, S.; Kim, J.H. Feature-based hand gesture recognition using an FMCW radar and its temporal feature analysis. IEEE Sens. J. 2018, 18, 7539–7602. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 443–450. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096-2030. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein distance guided representation learning for domain adaptation. arXiv 2017, arXiv:1707.01217. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. Cycada: Cycle-consistent adversarial domain adaptation. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 1994–2003. [Google Scholar]
- Zhao, H.; Zhang, S.; Wu, G.; Moura, J.M.; Costeira, J.P.; Gordon, G.J. Adversarial multiple source domain adaptation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 8568–8579. [Google Scholar]
- Shu, R.; Bui, H.H.; Narui, H.; Ermon, S. A dirt-t approach to unsupervised domain adaptation. arXiv 2018, arXiv:1802.08735. [Google Scholar]
- Sun, Y.; Tzeng, E.; Darrell, T.; Efros, A.A. Unsupervised domain adaptation through self-supervision. arXiv 2019, arXiv:1909.11825. [Google Scholar]
- Lien, J.; Gillian, N.; Karagozler, M.E.; Amihood, P.; Schwesig, C.; Olson, E.; Raja, H.; Poupyrev, I. Soli: Ubiquitous gesture sensing with millimeter wave radar. ACM Trans. Graph. (TOG) 2016, 35, 1–19. [Google Scholar]
- Project Soli. Available online: http://atap.google.com/soli/ (accessed on 27 October 2020).
- Molchanov, P.; Gupta, S.; Kim, K.; Pulli, K. Short-range FMCW monopulse radar for hand-gesture sensing. In Proceedings of the IEEE Radar Conference (RadarCon), Arlington, VA, USA, 10–15 May 2015; pp. 1491–1496. [Google Scholar]
- Song, M.; Lim, J.; Shin, D.J. The velocity and range detection using the 2D-FFT scheme for automotive radars. In Proceedings of the 2014 4th IEEE International Conference on Network Infrastructure and Digital Content, Beijing, China, 19–21 September 2014; pp. 507–510. [Google Scholar]
- Zheng, Q.; Yang, L.; Xie, Y.; Li, J.; Hu, T.; Zhu, J.; Song, C.; Xu, Z. A Target Detection Scheme with Decreased Complexity and Enhanced Performance for Range-Doppler FMCW Radar. IEEE Trans. Instrum. Meas. 2020. [Google Scholar] [CrossRef]
- Meta, A.; Hoogeboom, P.; Ligthart, L.P. Signal processing for FMCW SAR. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3519–3532. [Google Scholar] [CrossRef]
- Kim, K.S.; Jin, Y.; Lee, J. Low-complexity joint range and Doppler FMCW radar algorithm based on number of targets. Sensors 2020, 20, 51. [Google Scholar] [CrossRef]
- Zivkovic, Z.; Van Der Heijden, F. Efficient adaptive density estimation per image pixel for the task of background subtraction. Pattern Recognit. Lett. 2006, 27, 773–780. [Google Scholar] [CrossRef]
- Garcia, F.D.A.; Rodriguez, A.C.F.; Fraidenraich, G.; Santos Filho, J.C.S. CA-CFAR detection performance in homogeneous Weibull clutter. IEEE Geosci. Remote Sens. Lett. 2018, 16, 887–891. [Google Scholar] [CrossRef]
- Xu, C.; Li, Y.; Ji, C.; Huang, Y.; Wang, H.; Xiz, Y. An improved CFAR algorithm for target detection. In Proceedings of the 2017 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Xiamen, China, 6–9 November 2017; pp. 883–888. [Google Scholar]
- Rohling, H. Radar CFAR thresholding in clutter and multiple target situations. IEEE Trans. Aerosp. Electron. Syst. 1983, 608–621. [Google Scholar] [CrossRef]
- Choi, J.W.; Ryu, S.J.; Kim, J.H. Short-range radar based real-time hand gesture recognition using LSTM encoder. IEEE Access 2019, 7, 33610–33618. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural network from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- HYO RYUN LEE. Radar-Based Hand Gesture Recognition Test Setup Example and Real-time Experiment [Video file]. Available online: https://youtu.be/GNL-M_dkqV8 (accessed on 9 December 2020).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fold-1 | Fold-2 | Fold-3 | Fold-4 | Fold-5 | Avg. (std.) | |
|---|---|---|---|---|---|---|
| RNN | 91.72 | 90.19 | 89.98 | 90.52 | 88.97 | 90.27 (±0.89) |
| 2D-CNN | 92.54 | 94.41 | 93.53 | 91.83 | 95.61 | 93.58 (±1.34) |
| 3D-CNN | 98.79 | 99.14 | 99.07 | 99.38 | 98.91 | 99.06 (±0.20) |
| Fold-1 | Fold-2 | Fold-3 | Fold-4 | Fold-5 | Avg. (std.) | |
|---|---|---|---|---|---|---|
| RNN | 81.61 | 77.63 | 78.16 | 76.82 | 80.85 | 79.01 (±1.87) |
| 2D-CNN | 72.12 | 73.59 | 75.40 | 71.48 | 71.65 | 72.85 (±1.47) |
| 3D-CNN | 98.66 | 98.75 | 99.10 | 98.55 | 99.04 | 98.82 (±0.21) |
| (w/o DA) | 84.47 | 82.18 | 83.67 | 81.80 | 83.58 | 83.14 (±0.99) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.R.; Park, J.; Suh, Y.-J. Improving Classification Accuracy of Hand Gesture Recognition Based on 60 GHz FMCW Radar with Deep Learning Domain Adaptation. Electronics 2020, 9, 2140. https://doi.org/10.3390/electronics9122140
Lee HR, Park J, Suh Y-J. Improving Classification Accuracy of Hand Gesture Recognition Based on 60 GHz FMCW Radar with Deep Learning Domain Adaptation. Electronics. 2020; 9(12):2140. https://doi.org/10.3390/electronics9122140
Chicago/Turabian StyleLee, Hyo Ryun, Jihun Park, and Young-Joo Suh. 2020. "Improving Classification Accuracy of Hand Gesture Recognition Based on 60 GHz FMCW Radar with Deep Learning Domain Adaptation" Electronics 9, no. 12: 2140. https://doi.org/10.3390/electronics9122140
APA StyleLee, H. R., Park, J., & Suh, Y.-J. (2020). Improving Classification Accuracy of Hand Gesture Recognition Based on 60 GHz FMCW Radar with Deep Learning Domain Adaptation. Electronics, 9(12), 2140. https://doi.org/10.3390/electronics9122140