1. Introduction
Discrete convolution is found in many applications in science and engineering. Above all, it plays a key role in modern digital signal and image processing. In digital signal processing, it is the basis of filtering, multiresolution decomposition, and optimization of the calculation of orthogonal transform [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. In digital image processing, convolution is a basic operation of denoising, smoothing, edge detection, blurring, focusing, etc. [
11,
12,
13]. There are two types of discrete convolutions: the cyclic convolution and the linear convolution. General principles for the synthesis of convolution algorithms were described in [
1,
2,
3]. The main emphasis in these works was made primarily on the calculation of cyclic convolution, while in many digital signal and image processing applications, the calculation of linear convolutions is required.
In recent years, convolution has found unusually wide application in neural networks and deep learning. Among the various kinds of deep neural networks, convolutional neural networks (CNNs) are most widely used [
14,
15,
16,
17]. In CNNs, linear convolutions are the most computationally intensive operations, since in a typical implementation, their multiple computations occupy more than 90% of the CNN execution time [
14]. Only one convolutional level in a typical CNN requires more than two thousand multiplications and additions. Usually, there are several such levels in the CNN. That is why developers of such type of networks seek and design efficient ways of implementing linear convolution using the smallest possible number of arithmetic operations.
To speed up linear convolution computation, various algorithmic methods have been proposed. The most common approach to effective calculating linear convolution is dipping it in the space of a double-size cyclic convolution with the subsequent application of a fast Fourier transform (FFT) algorithm [
15,
16,
17]. The FFT-based linear convolution method is traditionally used for large length finite impulse response (FIR) filters; however, modern CNNs use predominantly small length FIR filters. In this situation, the most effective algorithms used in the computation of a small-length linear convolution are the Winograd-like minimal filtering algorithms [
18,
19,
20], which are the most used currently. The algorithms compute linear convolution over small tiles with minimal complexity, which makes them more effective with small filters and small batch sizes; however, these algorithms do not calculate the whole convolution. They calculate only two inner products of neighboring vectors formed from the current data stream by a moving time window of length
N; therefore, these algorithms do not compute the true linear convolution.
At the same time, there are a number of CNNs in which it is necessary to calculate full-size small-length linear convolutions. In addition, in many applications of digital signal processing, there is the problem of calculating a one-dimensional convolution using its conversion into a multidimensional convolution. The algorithm thus obtained has a modular structure, and each module calculates a short-length one-dimensional convolution [
21].
The most popular sizes of sequences being convoluted are sequences of length 2, 3, 4, 5, 6, 7, and 8. However, in the papers known to the authors, there is no description of resource-efficient algorithms for calculation of linear convolutions for lengths greater than four [
1,
4,
6,
21,
22]. In turn, the solutions given in the literature for
N = 2,
N = 3, and
N = 4 do not give a complete imagination about the organization of the linear convolution calculation process, since their corresponding signal flow graphs are not presented anywhere. In this paper, we describe a complete set of solutions for linear convolution of small length
N sequences from 2 to 8.
2. Preliminaries
Let
and,
,
,
be two finite sequences of length
M and
N, respectively. Their linear convolution is the sequence
,
defined by [
1]:
where we take
, if
.
As a rule, the elements of one of the sequences to be convolved are constant numbers. For definiteness, we assume that it will be a sequence .
Because sequences
and
are finite length, then their linear convolution (
1) can also be implemented as matrix-vector multiplication:
where
In the future, we assume that is a vector of input data, is a vector of output data, and is a vector containing constants.
Direct computation of (
3) takes
MN multiplications and (
M − 1)(
N − 1) addition. This means that the fully parallel hardware implementation of the linear convolution operation requires
MN multipliers and
N +
M − 3 multi-input adders with a different number of inputs, which depends on the length of the sequences being convolved. Traditionally, the convolution for which
M =
N is assumed as a basic linear convolution operation. Resource-effective cyclic convolution algorithms for benchmark lengths (
N = 2, 3,...,16) have long been published [
1,
2,
3,
4,
5,
6,
7,
8,
9]. For linear convolution, optimized algorithms are described only for the cases
N = 2, 3, 4 [
4,
6,
21,
22]. Below we show how to reduce the implementation complexity of some benchmark-lengths linear convolutions for the case of completely parallel hardware their implementation. For completeness, we also consider algorithms for the sequences of lengths
M =
N = 2, 3, and 4.
So, considering the above, the goal of this article is to develop and describe fully parallel resource-efficient algorithms for N = 2, 3, 4, 5, 6, 7, 8.
3. Algorithms for Short-Length Linear Convolution
The main idea of presented algorithm is to transform the linear convolution matrix into circular matrix and two Toeplitz matrices. Then we can rewrite (
3) in following form:
where
and
are matrices that are horizontal concatenations of null matrices and left-triangular or right-triangular Toeplitz matrices, respectively:
which gives
A circulant matrix
is a matrix of cyclic convolution
HN with rows cyclically shifted by
n positions down:
where
- is permutation matrix obtained from the identity matrix by cyclic shift of its columns by
n positions to the left and:
The coefficients K and L are natural numbers arbitrary taken and fulfilling the dependence K + L = N − 1. These values are selected heuristically for each N separately.
The product is calculated using the well-known fast convolution algorithm. The products of and are also calculated using fast algorithms for matrix-vector multiplication with Toeplitz matrices. We use all of the above techniques to synthesize the final short-length linear convolution algorithms with reduced multiplicative complexity.
3.1. Algorithm for N = 2
Let
and
be 2-dimensional data vectors being convolved and
be an input vector representing a linear convolution. The problem is to calculate the product
where
Direct computation of (
5) takes four multiplications and one addition. It is easy to see that the matrix
possesses an uncommon structure. By the Toom–Cook algorithmic trick, the number of multiplications in the calculation of the 2-point linear convolution can be reduced [
1,
21].
With this in mind, the rationalized computational procedure for computing 2-point linear convolution has the following form:
where
Figure 1 shows a signal flow graph for the proposed algorithm, which also provides a simplified schematic view of a fully parallel processing unit for resource-effective implementing of 2-point linear convolution. In this paper, the all data flow graphs are oriented from left to right. Straight lines in the figures denote the data transfer (data path) operations. The circles in these figures show the operation of multiplication (multipliers in the case of hardware implementation) by a number inscribed inside a circle. Points where lines converge denote summation (adders in the case of hardware implementation) and dotted lines indicate the sign-change data paths (data paths with multiplication by −1). We use the usual lines without arrows on purpose, so as not to clutter the picture [
23].
As it can be seen, the calculation of 2-point linear convolution requires only three multiplications and three additions. In terms of arithmetic units, a fully parallel hardware implementation of the processor unit for calculating a 2-point convolution will require three multipliers, one two-input adder, and one three-input adder. In terms of arithmetic units, a fully parallel hardware implementation of the processor unit for calculating a 2-point convolution will require three multipliers, one two-input adder, and one three-input adder instead of four multipliers and one two-input adder in the case of completely parallel implementation of (
6). So, we exchanged one multiplier for one three-input adder.
3.2. Algorithm for N = 3
Let
and
be 3-dimensional data vectors being convolved and
be an input vector represented linear convolution for
N = 3. The problem is to calculate the product
where
Direct computation of (
9) takes nine multiplications and five addition. Because the matrix
also possesses uncommon structure, the number of multiplications in the calculation of the 3-point linear convolution can be reduced too [
1,
4,
21].
An algorithm for computation 3-point linear convolution with reduced multiplicative complexity can be written with the help of following matrix-vector calculating procedure:
where
Figure 2 shows a signal flow graph of the proposed algorithm for the implementation of 3-point linear convolution. As it can be seen, the calculation of 3-point linear convolution requires only 6 multiplications and 10 additions. Thus, the proposed algorithm saves six multiplications at the cost of six extra additions compared to the ordinary matrix-vector multiplication method.
In terms of arithmetic units, a fully parallel hardware implementation of the processor unit for calculating a 3-point linear convolution (
11) will require only six multipliers, four two-input adders, one three-input adder, and one four-input adder instead of 12 multipliers, 2 two-input adders, and 1 two-input adder in the case of fully parallel implementation of (
9).
3.3. Algorithm for N = 4
Let and be 4-dimensional data vectors being convolved and be an input vector represented linear convolution for N = 4.
The problem is to calculate the product:
where
Direct computation of (
14) takes 16 multiplications and 9 addition. Due to the specific structure of matrix
, the number of multiplication operations in the calculation of (
14) can be significantly reduced.
An algorithm for computation 4-point linear convolution with reduced multiplicative complexity can be written using the following matrix-vector calculating procedure:
where
where
is anidentity
matrix,
is the
Hadamard matrix, and sign,”⊕” denotes direct sum of two matrices [
23,
24,
25].
Figure 3 shows a signal flow graph of the proposed algorithm for the implementation of 4-point linear convolution. So, the proposed algorithm saves 7 multiplications at the cost of 11 extra additions compared to the ordinary matrix-vector multiplication method.
In terms of arithmetic units, a fully parallel hardware implementation of the processor unit for calculating a 4-point linear convolution will require only 9 multipliers, 13 two-input adders, 2 three-input adders, and 1 four-input adder instead of 16 multipliers, 2 two-input adders, 2 three-input adders, and 1 four-input adder in the case of fully parallel implementation of (
14).
3.4. Algorithm for N = 5
Let and be 5-dimensional data vectors being convolved and be an input vector representing a linear convolution for N = 5.
The problem is to calculate the product:
where
Direct computation of (
16) takes 25 multiplications and 16 addition. Due to the specific structure of matrix
, the number of multiplication operations in the calculation of (
16) can be significantly reduced.
Thus, an algorithm for computation 5-point linear convolution with reduced multiplicative complexity can be written using the following matrix-vector calculating procedure:
where
and
is a null matrix of order
[
23,
24,
25],
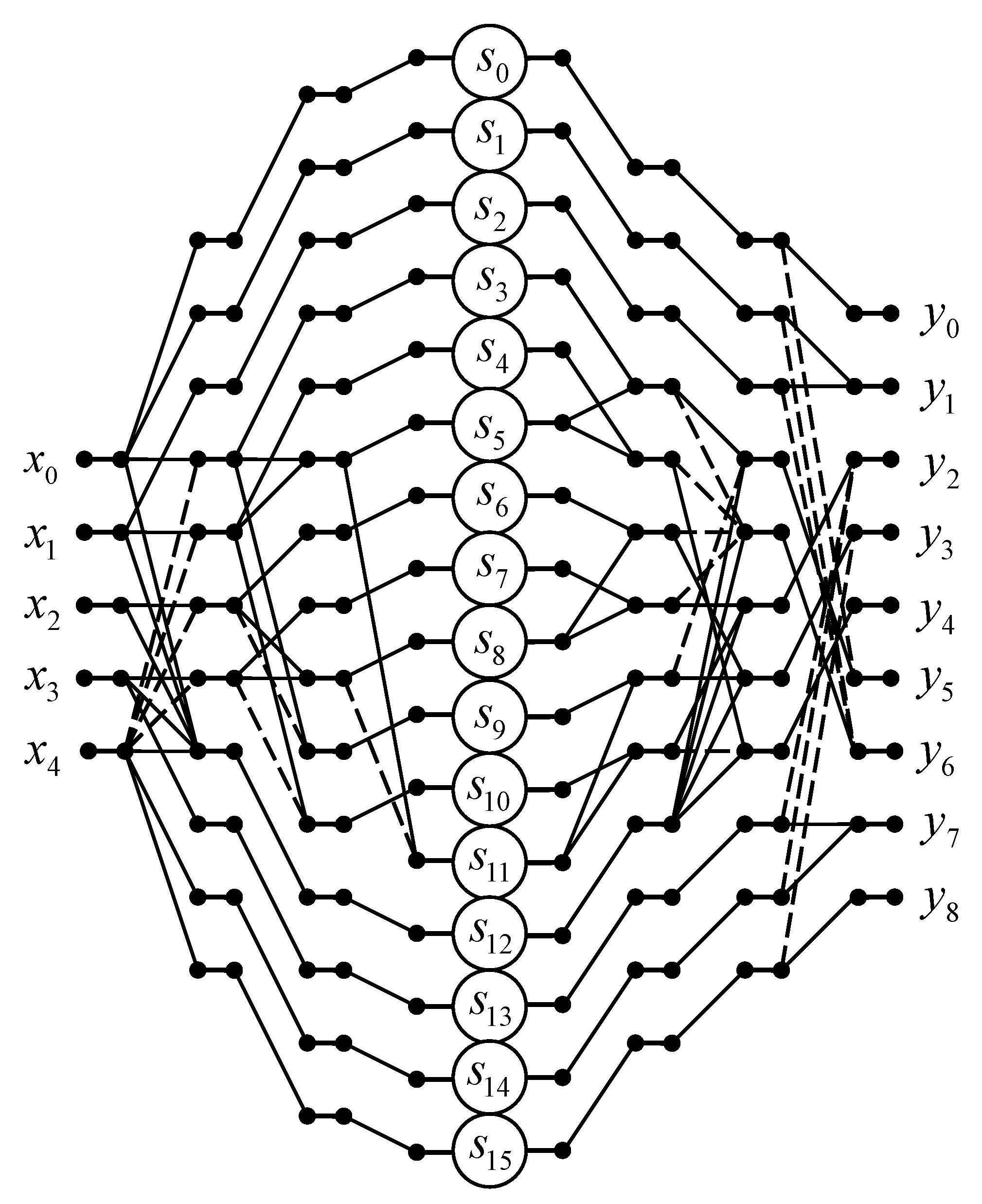
Figure 4 shows a data flow diagram of the proposed algorithm for the implementation of 5-point linear convolution. The algorithm saves 9 multiplications at the cost of 22 extra additions compared to the ordinary matrix-vector multiplication method.
In terms of arithmetic units, a fully parallel hardware implementation of the processor unit for calculating a 5-point linear convolution will require 16 multipliers, 20 two-input adders, 2 three-input adders, 1 four-input adder, and 1 five-input adder instead of 25 multipliers, 2 two-input adders, 2 three-input adders, 2 four-input adders, and 1 five-input adder in the case of fully parallel implementation of expression (
16).
3.5. Algorithm for N = 6
Let and be 6-dimensional data vectors being convolved and be an input vector representing a linear convolution for N = 6.
The problem is to calculate the product:
where
Direct computation of (
18) takes 36 multiplications and 25 addition. We proposed an algorithm that takes only 16 multiplications and 44 additions. It saves 20 multiplications at the cost of 19 extra additions compared to the ordinary matrix-vector multiplication method.
Proposed algorithm for computation 6-point linear convolution can be written with the help of following matrix-vector calculating procedure:
where
and sign “⊗” denotes tensor or Kronecker product of two matrices [
23,
24,
25].
Figure 5 shows a data flow diagram of the proposed algorithm for the implementation of 6-point linear convolution.
In terms of arithmetic units, a fully parallel hardware implementation of the processor unit for calculating a 6-point linear convolution will require 16 multipliers, 32 two-input adders, and 5 three-input adders, instead of 36 multipliers, 2 two-input adders, 2 three-input adders, 2 four-input adders, 2 five-input adders, and 1 six-input adder in the case of completely parallel implementation of expression (
18).
3.6. Algorithm for N = 7
Let and be 7-dimensional data vectors being convolved and be an input vector representing a linear convolution for N = 7.
The problem is to calculate the product:
where
Direct computation of (
20) takes 49 multiplications and 36 addition. We developed an algorithm that contains only 26 multiplications and 79 additions. It saves 23 multiplications at the cost of 43 extra additions compared to the ordinary matrix-vector multiplication method.
The proposed algorithm for computation 7-point linear convolution with reduced multiplicative complexity can be written using the following matrix-vector calculating procedure:
where
and
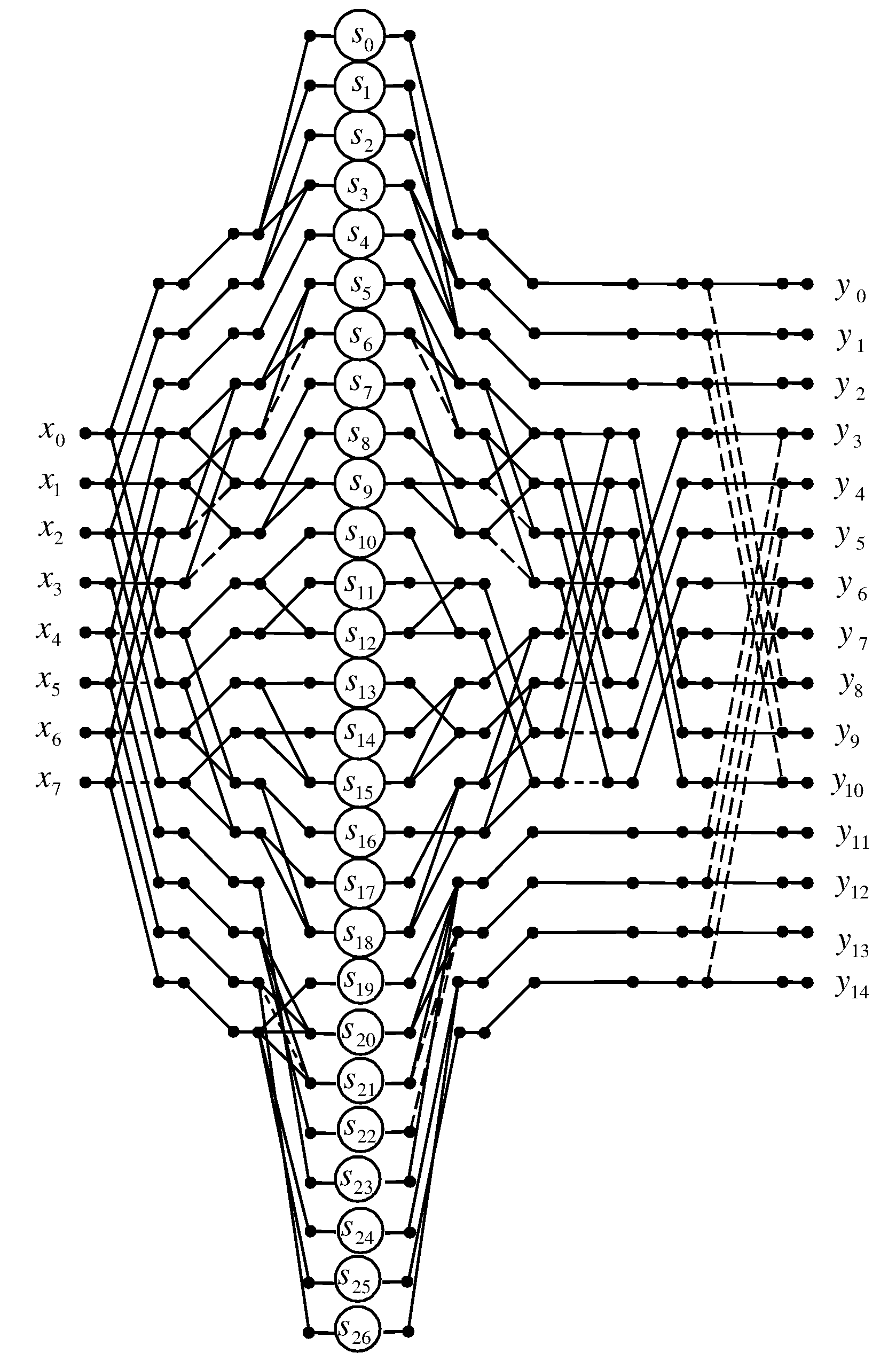
Figure 6 shows a data flow diagram of the proposed algorithm for the implementation of 7-point linear convolution.
In terms of arithmetic units, a fully parallel hardware implementation of the processor unit for calculating a 7-point linear convolution will require 27 multipliers, 49 two-input adders, 7 three-input adders, and 5 four-input adders, instead of 49 multipliers, 2 two-input adders, 2 three-input adders, 2 four-input adders, 2 five-input adders, 2 six-input adders, and 1 seven-input adder in the case of completely parallel implementation of expression (
20).
3.7. Algorithm for N = 8
Let and be 8-dimensional data vectors being convolved and be an input vector representing a linear convolution for N = 8.
The problem is to calculate the product:
where
Direct computation of (
22) takes 64 multiplications and 49 addition. We developed an algorithm that contains only 27 multiplications and 67 additions. Thus, the proposed algorithm saves 22 multiplications at the cost of 18 extra additions compared to the ordinary matrix-vector multiplication method.
Proposed algorithm for computation 8-point linear convolution with reduced multiplicative complexity can be written using the following matrix-vector calculating procedure:
where
Figure 7 shows a data flow diagram of the proposed algorithm for the implementation of 8-point linear convolution.
In terms of arithmetic units, a fully parallel hardware implementation of the processor unit for calculating a 8-point linear convolution will require 27 multipliers, 57 two-input adders, 4 three-input adders and 1 four-input adder, instead of 64 multipliers, 2 two-input adders, 2 three-input adders, 2 four-input adders, 2 five-input adders, 2 six-input adders, 2 seven-point adders and 1 eight-input adder in the case of completely parallel implementation of expression (
22).
4. Implementation Complexity
Since the lengths of the input sequences are relatively small, and the data flow graphs representing the organization of the computation process are fairly simple, it is easy to estimate the implementation complexity of the proposed solutions.
Table 1 shows estimates of the number of arithmetic blocks for the fully parallel implementation of the short lengths linear convolution algorithms. Since a parallel
N-input adder consists of
N-1 two-input adders, we give integrated estimates of the implementing costs of the sets of adders for each proposed solution expressed as the sums of two-input adders. The penultimate column of the
Table 1 shows the percentage reduction in the number of multipliers, while the last column shows the percentage increase in the number of adders. As you can see, the implementation of the proposed algorithms requires fewer multipliers than the implementation based on naive methods of performing the linear convolution operations.
It should be noted that our solutions are primarily focused on efficient implementation in application specific integrated circuits (ASICs). In low-power designing low-power digital circuits, optimization must be performed both at the algorithmic level and at the logic level. From the point of view of designing an ASIC-chip that implements fast linear convolution, you should pay attention to the fact that the hardwired multiplier is a very resource-intensive arithmetic unit. The multiplier is also the most energy-intensive arithmetic unit, occupying a large crystal area [
26] and dissipating a lot of energy [
27]. Reducing the number of multipliers is especially important in the design of specialized fully parallel ASIC-based processors because minimizing the number of necessary multipliers reduces power dissipation and lowers the cost implementation of the entire system being implemented. It is proved that the implementation complexity of a hardwired multiplier grows quadratically with operand size, while the hardware complexity of a binary adder increases linearly with operand size [
28]. Therefore, a reduction in the number of multipliers, even at the cost of a small increase in the number of adders, has a significant role in the ASIC-based implementation of the algorithm. Thus, it can be argued categorically that algorithmic solutions that require fewer hardware multipliers in an ASIC-based implementation are better than those that require more embedded multipliers.
This statement is also true for field-programmable gate array (FPGA)-based implementations. Most modern high-performance FPGAs contain a number of built-in multipliers. This means that instead of implementing the multipliers with a help of a set of conventional logic gates, you can use the hardwired multipliers embedded in the FPGA. Thus, all multiplications contained in a fully parallel algorithm can be efficiently implemented using these embedded multipliers; however, their number may not be enough to meet the requirements of a fully parallel implementation of the algorithm. So, the developer uses the embedded multipliers to implement the multiplication operations until all of the multipliers built into the chip have been used. If the embedded multipliers available in the FPGA run out, the developer will be forced to use ordinary logic gates instead. This will lead to significant difficulties in the design and implementation of the computing unit. Therefore, the problem of reducing the number of multiplications in fully parallel hardware-oriented algorithms is critical. It is clear that you can go the other way—use a more complex FPGA chip from the same or another family, which contains a larger number of embedded multipliers; however, it should be remembered that the hardwired multiplier is a very resource-intensive unit. The multiplier is the most resource-intensive and energy-consuming arithmetic unit, occupying a large area of the chip and dissipating a lot of power; therefore, the use of complex and resource-intensive FPGAs containing a large number of multipliers without a special need is impractical.
Table 2 shows FPGA devices of the Spartan-3 family, in which the number of hardwired multipliers allows one to implement the linear convolution operation in a single chip. So, for example, a 4-point convolution implemented using our proposed algorithm can be implemented using a single Spartan XC3S200 device, while a 4-point convolution implemented using a naive method requires a more voluminous Spartan XC3S400 device. A 5-point convolution implemented using our proposed algorithm can be implemented using a single Spartan XC3S200A chip, while a 5-point convolution implemented using a naive method requires a more voluminous Spartan XC3S1500A chip, and so on.
Thus, the hardware implementation of our algorithms requires fewer hardware multipliers than the implementation of naive calculation methods, all other things being equal. Taking into account the previously listed arguments, this proves their effectiveness.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}