4.1. Idea and Overview
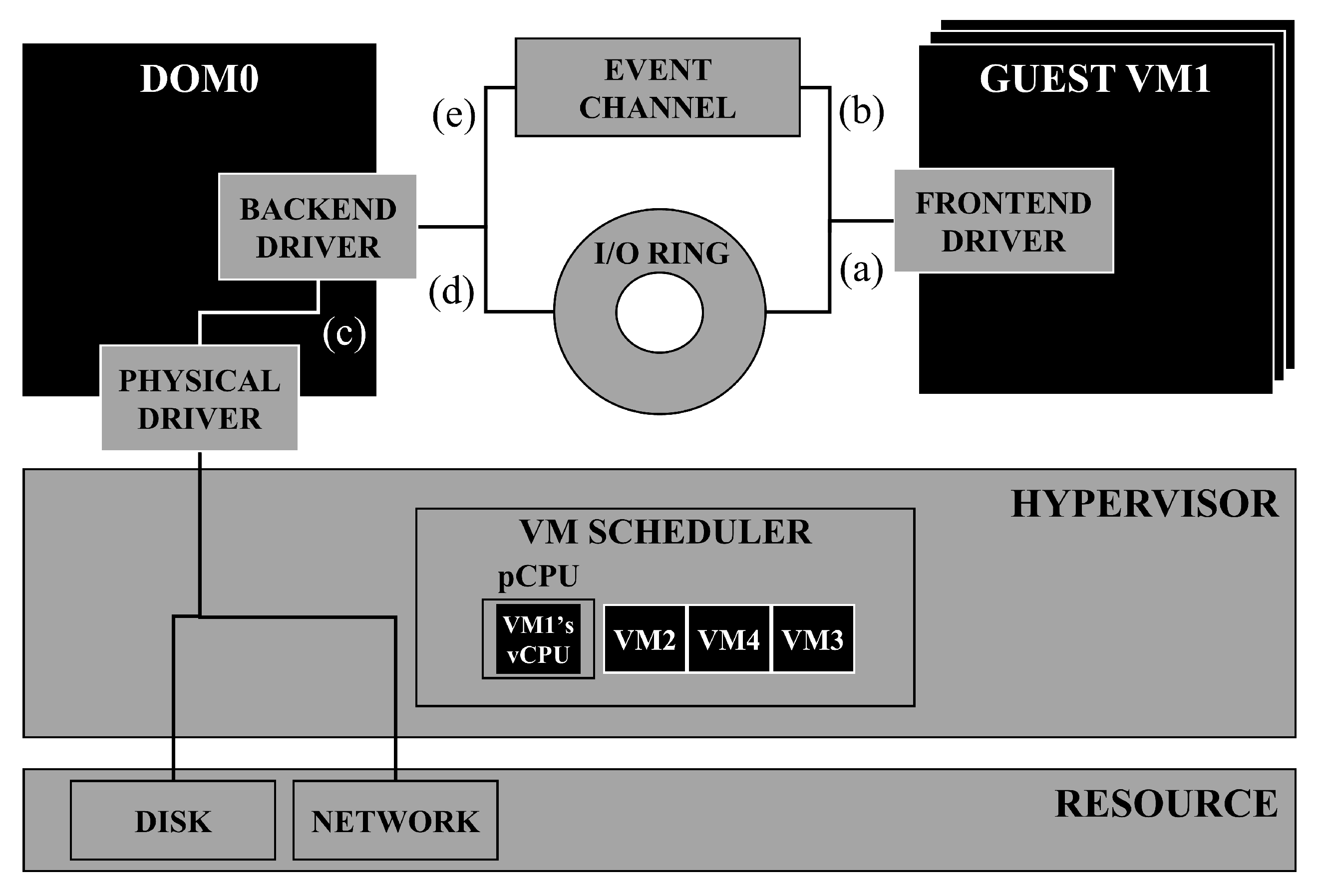
The awareness of workloads per vCPU rather than per VM can provide a diverse scheduling environment that provides a chance to improve the I/O performance of VMs. ISACS recognizes the degree of I/O workloads for each VM’s vCPU using the split-driver architecture in Xen without leveraging the exterior monitoring module.
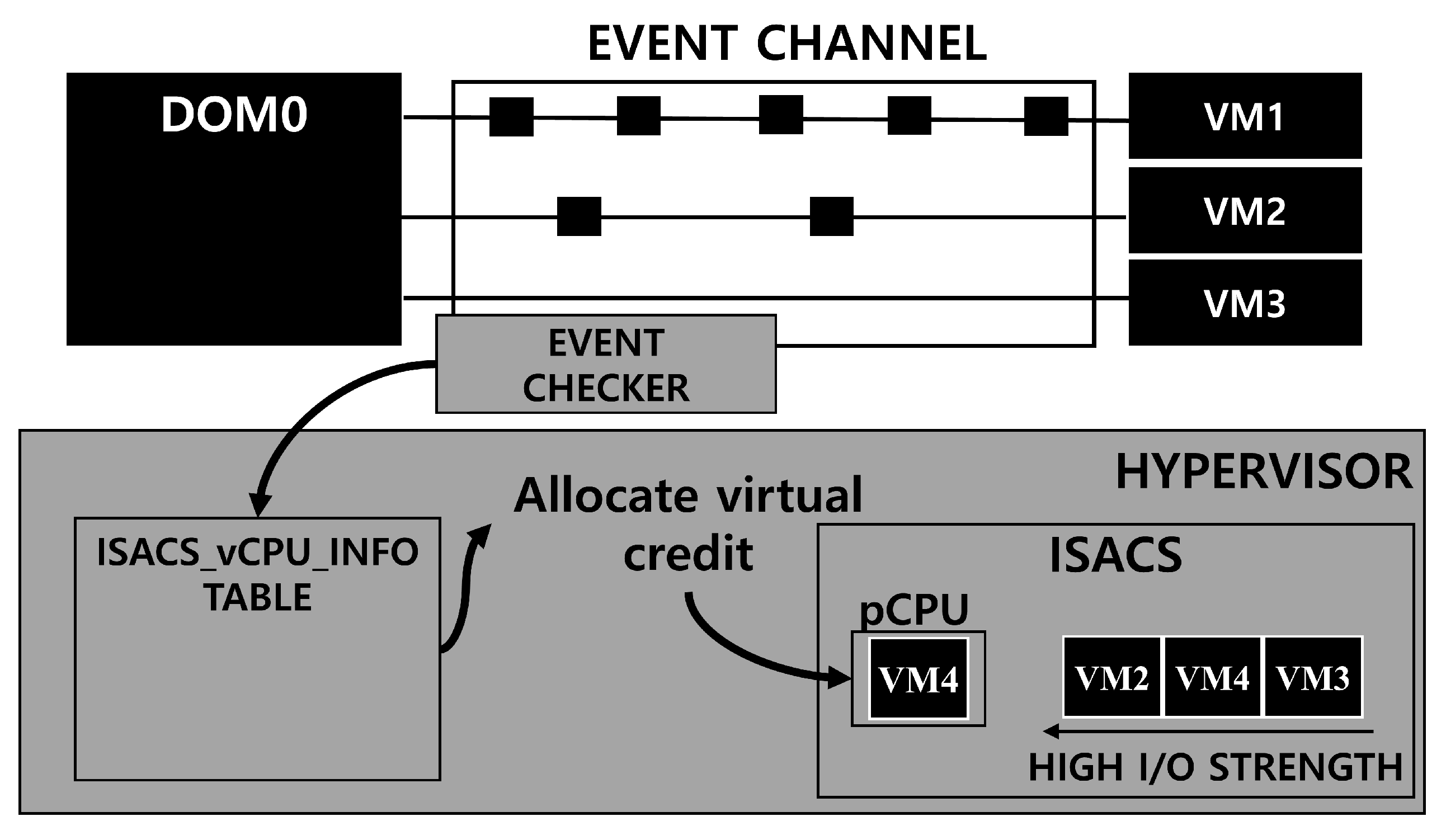
Figure 2 shows the architecture of ISACS. In ISACS, EVENT CHECKER, shown in
Figure 2, gathers the I/O information regarding the vCPUs that handle I/O-intensive workloads for all guest VMs. Then, using the information gathered by EVENT CHECKER, ISACS provides an I/O virtual credit (IVCredit) that is mapped to the degree of I/O workloads of I/O-intensive vCPUs to guarantee pCPU occupancy. To avoid the degradation of CPU performance in VMs, ISACS gives a CPU virtual credit (CVCredit) to CPU-intensive vCPUs to ensure CPU performance. In this section, we explain ISACS’s design and structure with regard to guaranteeing the I/O performance of I/O-intensive vCPUs for various workloads in a virtualized environment.
4.1.1. Mapped vCPU Information of Three Areas
ISACS uses extended scheduling parameters that are not dependent on the exterior monitoring module that measures the resource usage of each VM. As the exterior monitoring module acts independently, it has to be synchronized with the scheduling parameter of the hypervisor scheduler. Moreover, DOM0 adds additional overload because of unnecessary information investigation and continuous load tracking of all VMs. Therefore, leveraging the exterior monitoring module creates an unnecessary overhead for resource management in a virtualized [
9,
26,
34,
35,
36,
37].
In the Credit1 scheduler, the degree of I/O load on the vCPU can be known easily through only the BOOST mechanism in the scheduling area. However, because there is no BOOST mechanism in the Credit2 scheduler, it is difficult to know the degree of I/O occurrence for the vCPU based on only the scheduler. To avoid the overhead arising from leveraging the exterior monitoring module and to determine I/O occurrence based on the Credit2 scheduler, ISACS leverages the event channel mechanism in Xen.
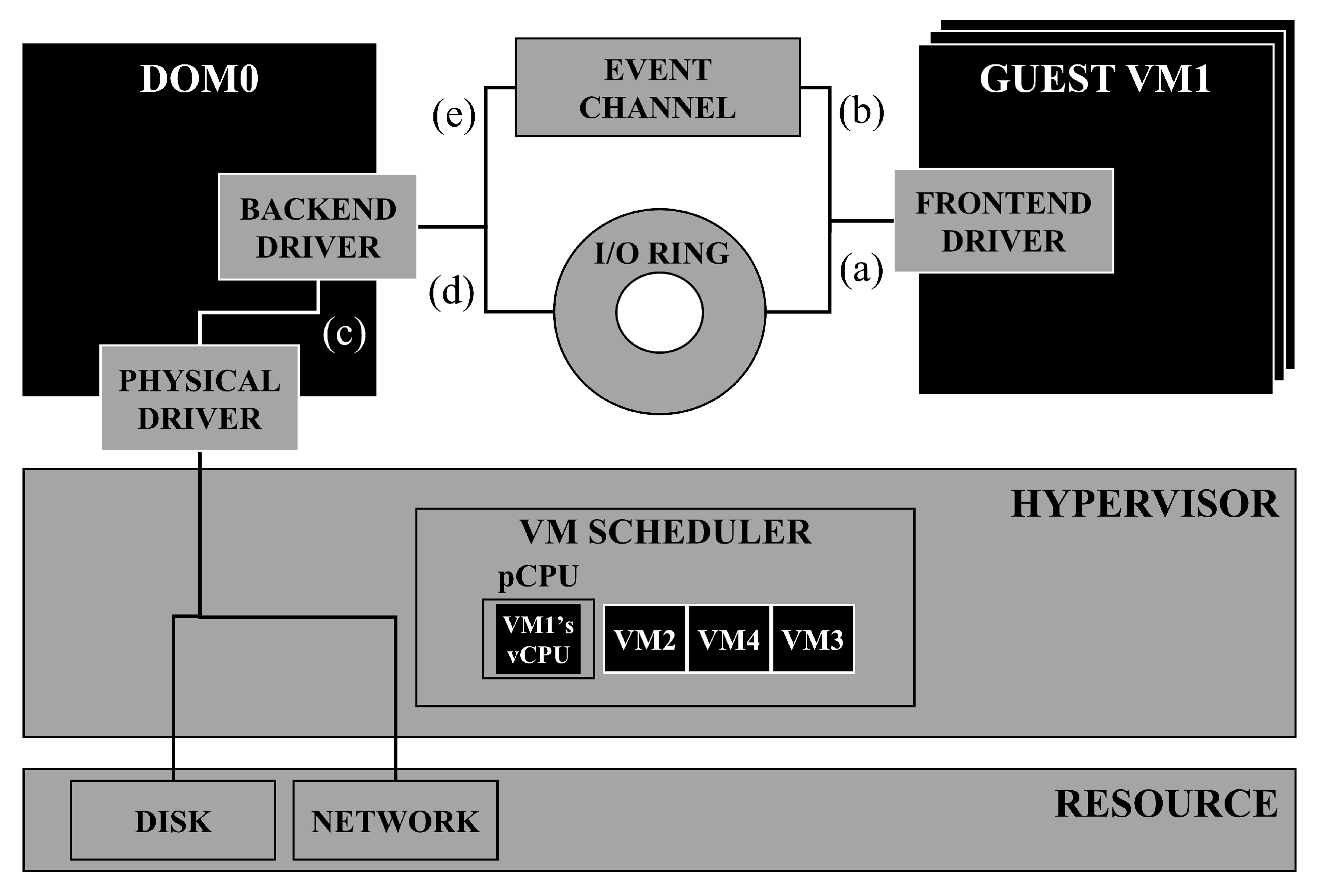
In the split-driver architecture of Xen, the asynchronous I/O notification mechanism based of the event channel and vCPU scheduling are independently executed over different areas; thus, the event channel cannot know the scheduling information for each vCPU, and the scheduler cannot know the number of I/O response events occurring for each vCPU [
3,
21,
23,
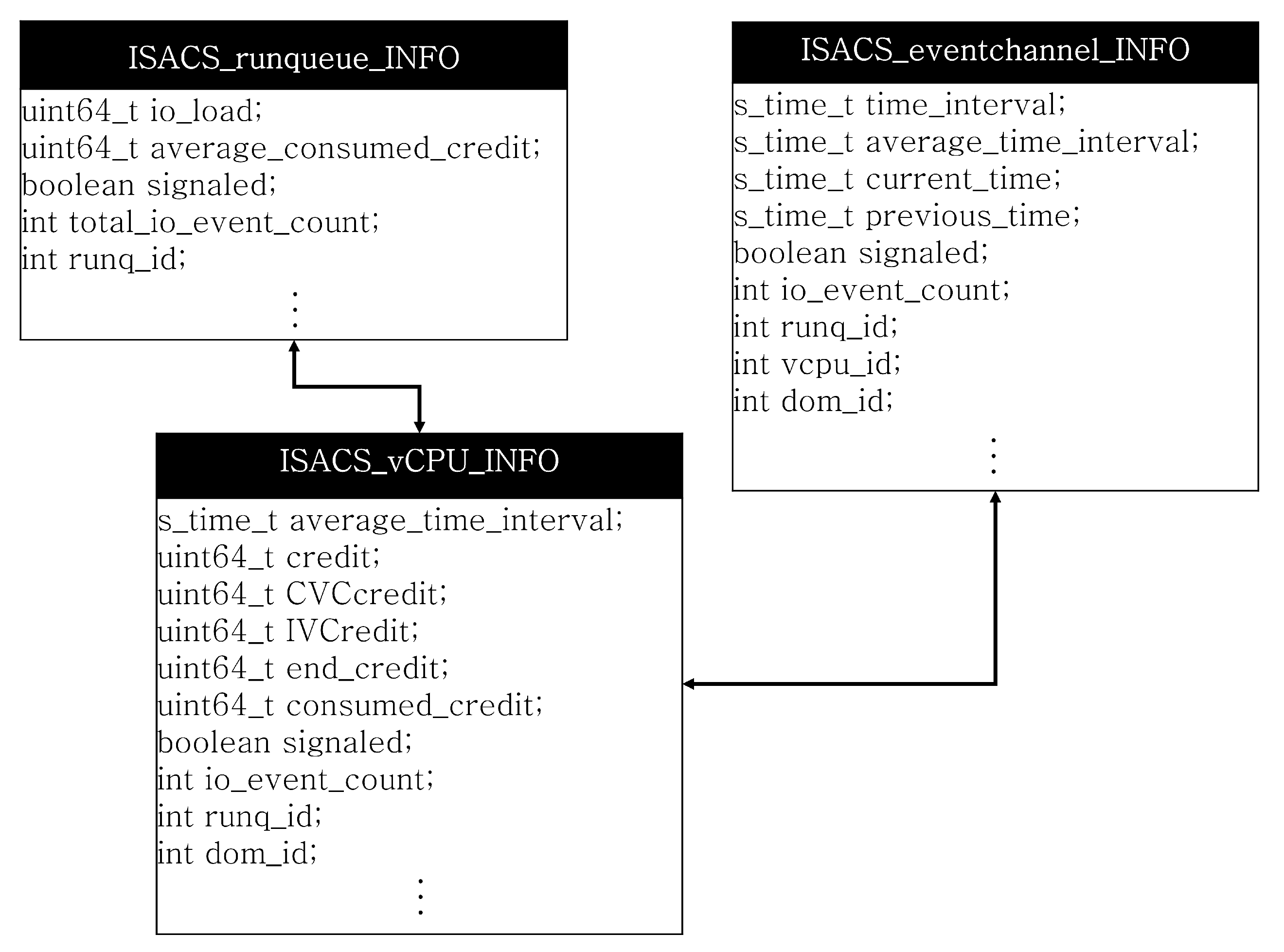
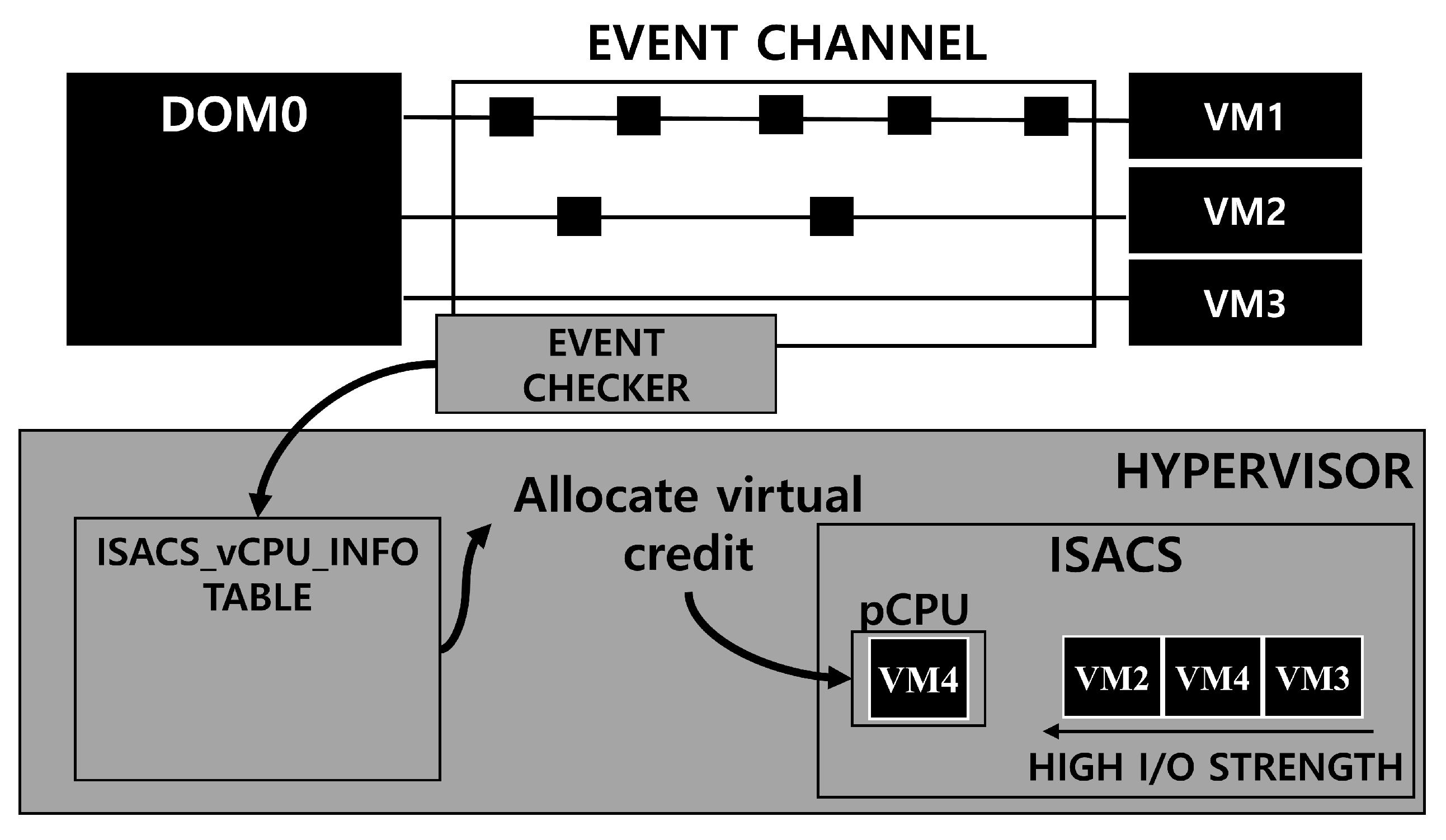
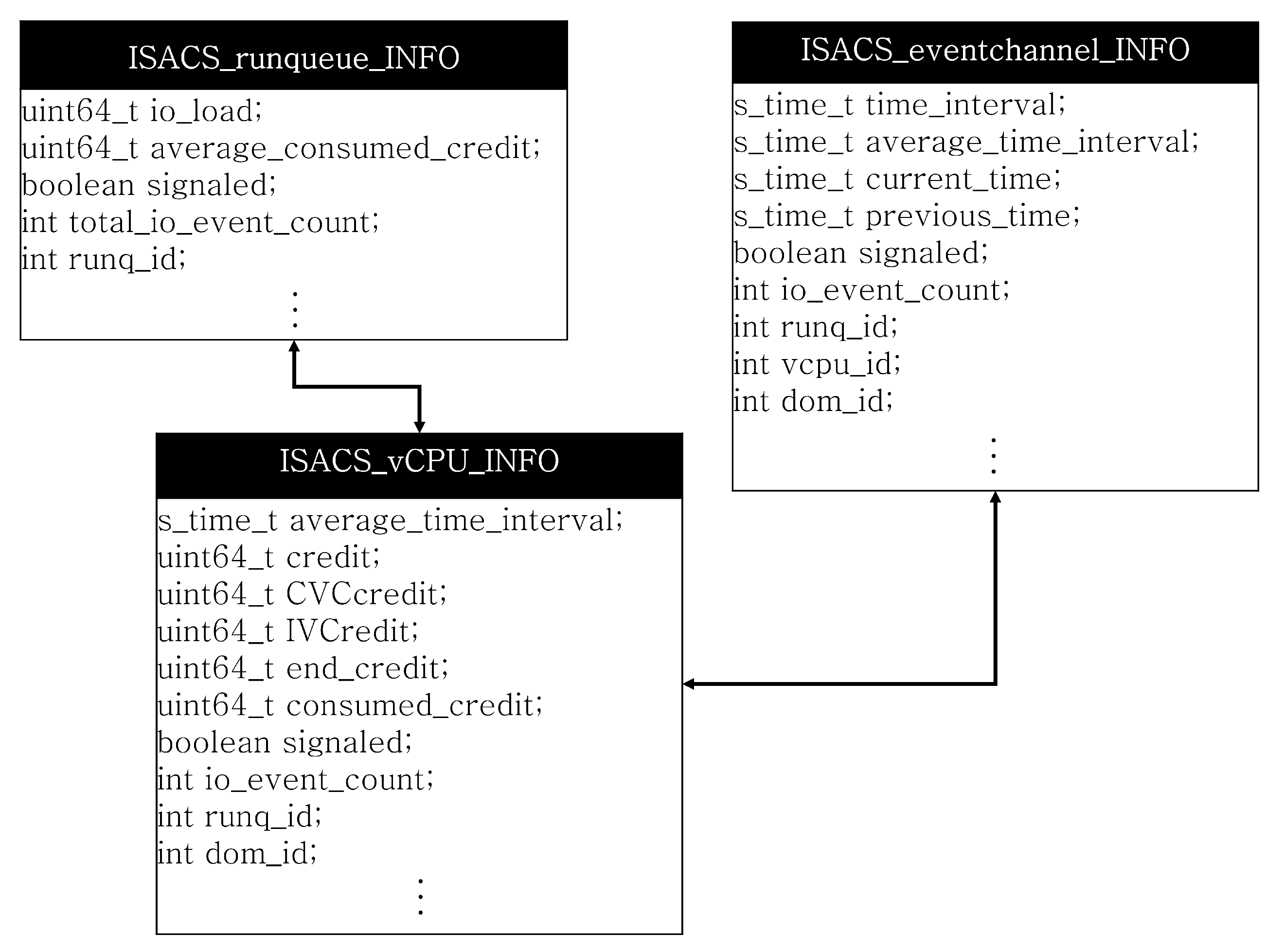
38]. Furthermore, credit reallocation for each run-queue in the Credit2 scheduler is independently performed. This is because it depends on the number of vCPUs waiting for scheduling and because the degree of credit consumption of each vCPU placed in the run-queue depends on the workload distribution trend of each vCPU. To integrate the up-to-date status information of vCPUs that can be obtained from these three independent areas and expand the range of scheduling parameters that can be derived, ISACS manages the extended vCPU scheduling structure ISACS_vCPU_INFO, which can allow bidirectional communication through shared memory communication.
Figure 3 shows the structure of the scheduling parameter of ISACS. ISACS_vCPU_INFO in
Figure 3 is configured based on the extended scheduling information of the vCPU. ISACS_vCPU_INFO consolidates and maintains the up-to-date information of the vCPU regarding I/O response events, which can be obtained from the event channel through the shared memory mechanism and the run-queue information, which is that the vCPU is assigned. Thus, in ISACS, the event channel and scheduler can recognize each other’s existence and keep up-to-date status of three areas including run-queue information.
4.1.2. Finding a Good Degree of pCPU Occupancy for vCPU with Different Workloads
In the Credit2 scheduler, the amount of credits denotes the run-time of the vCPU on a pCPU and the priority of the vCPU for pCPU occupancy. Because the virtualized server has limited resources, if a specific vCPU preempts more pCPUs, it means that the vCPU seizes more resources than the other vCPUs. Therefore, we leverage and carefully select the additional scheduling parameters mentioned above to derive the virtual credits to be assigned to vCPUs. ISACS gives IVCredits to I/O-intensive vCPUs, giving them the opportunity to occupy pCPUs more frequently than CPU-intensive vCPUs. The key aspect of the ISACS model is to derive the degree of guaranteed pCPU occupancy according to the I/O strength of each vCPU in the run-queue. In addition, the pCPU occupancy of I/O-intensive vCPUs should not interfere with that of CPU-intensive vCPUs; this is to guarantee good CPU performance. Therefore, ISACS allocates CVCredits based on the the amount of the IVCredit for all I/O-intensive vCPUs in the run-queue to prevent CPU performance degradation because of guaranteed pCPU occupancy of the I/O-intensive vCPUs. Thus, it can ensure the maximum performance of CPU-intensive vCPUs. Finally, ISACS calculates the I/O load for each run-queue and performs vCPU migration to prevent a biased I/O-intensive vCPU placement among the run-queues.
4.3. IVCredit Derivation
An IVCredit is a virtual credit provided by ISACS to guarantee the pCPU occupation of an I/O-intensive vCPU. Each vCPU’s I/O resource occupancy is determined based on the IVCredit allocated to it by considering I/O strength. Tracking the detailed I/O operations of each VM to determine its workload type requires modification of the real I/O driver in DOM0, making the hypervisor scheduler less portable. Analyzing the I/O request types of all VMs increases the memory overhead. In ISACS, to avoid the complicated process of recognizing the completion of I/O by modifying the physical driver of DOM0 that performs the actual I/O operation in a virtualized environment, ISACS obtains the I/O request processing time of the specific vCPU of the guest VM based on the interval of the I/O response event transmitted from DOM0. As explained earlier, DOM0 is a driver domain that can handle all I/O requests from all guest VMs. Therefore, the interval between I/O response events of vCPUs of the guest VM can be referred to as the processing time of DOM0 for I/O requests. To measure the I/O strength of a vCPU, ISACS obtains the number of I/O response events and the average interval between I/O response events for I/O-intensive vCPUs of the VM from the EVENT CHECKER.
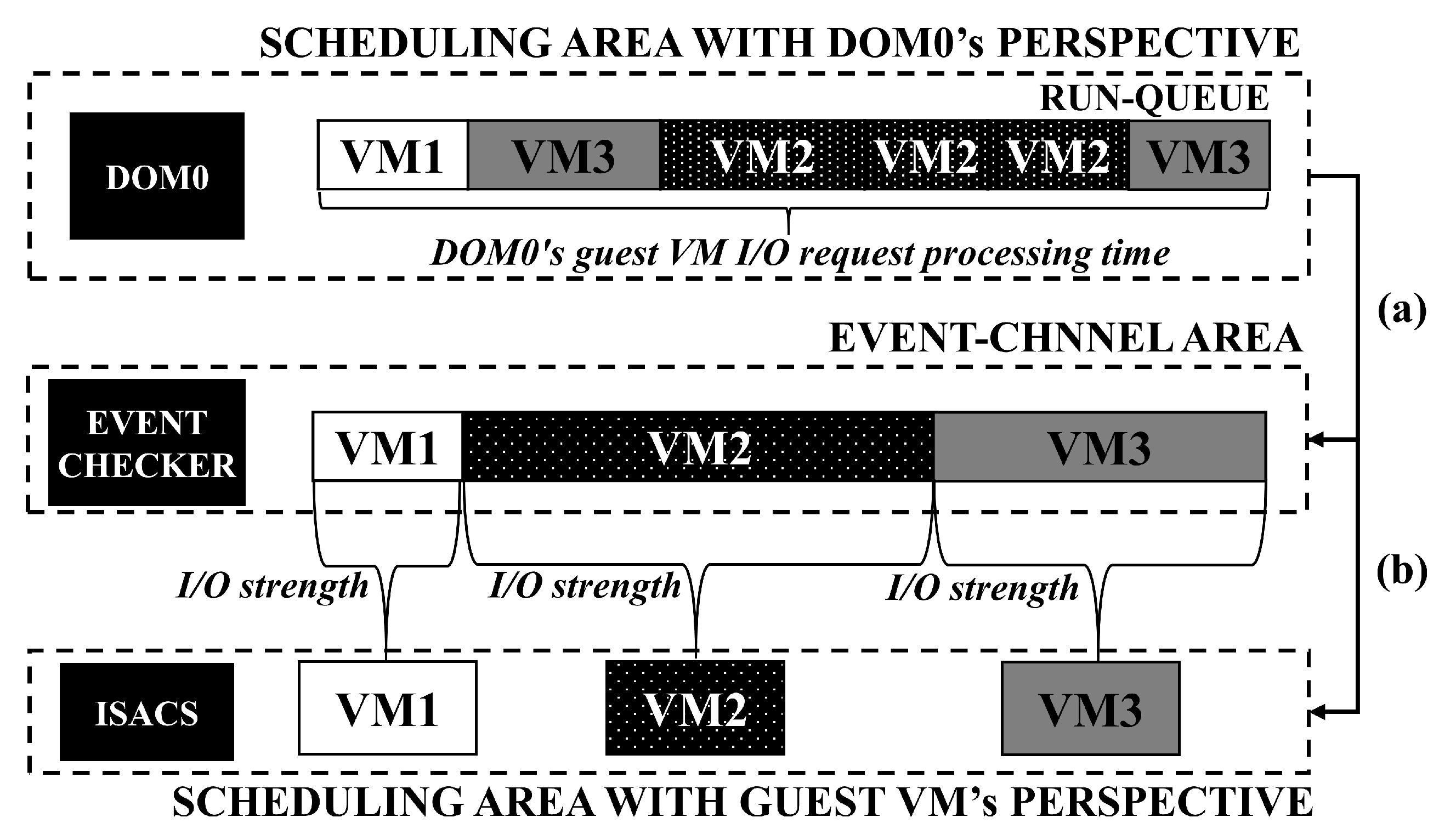
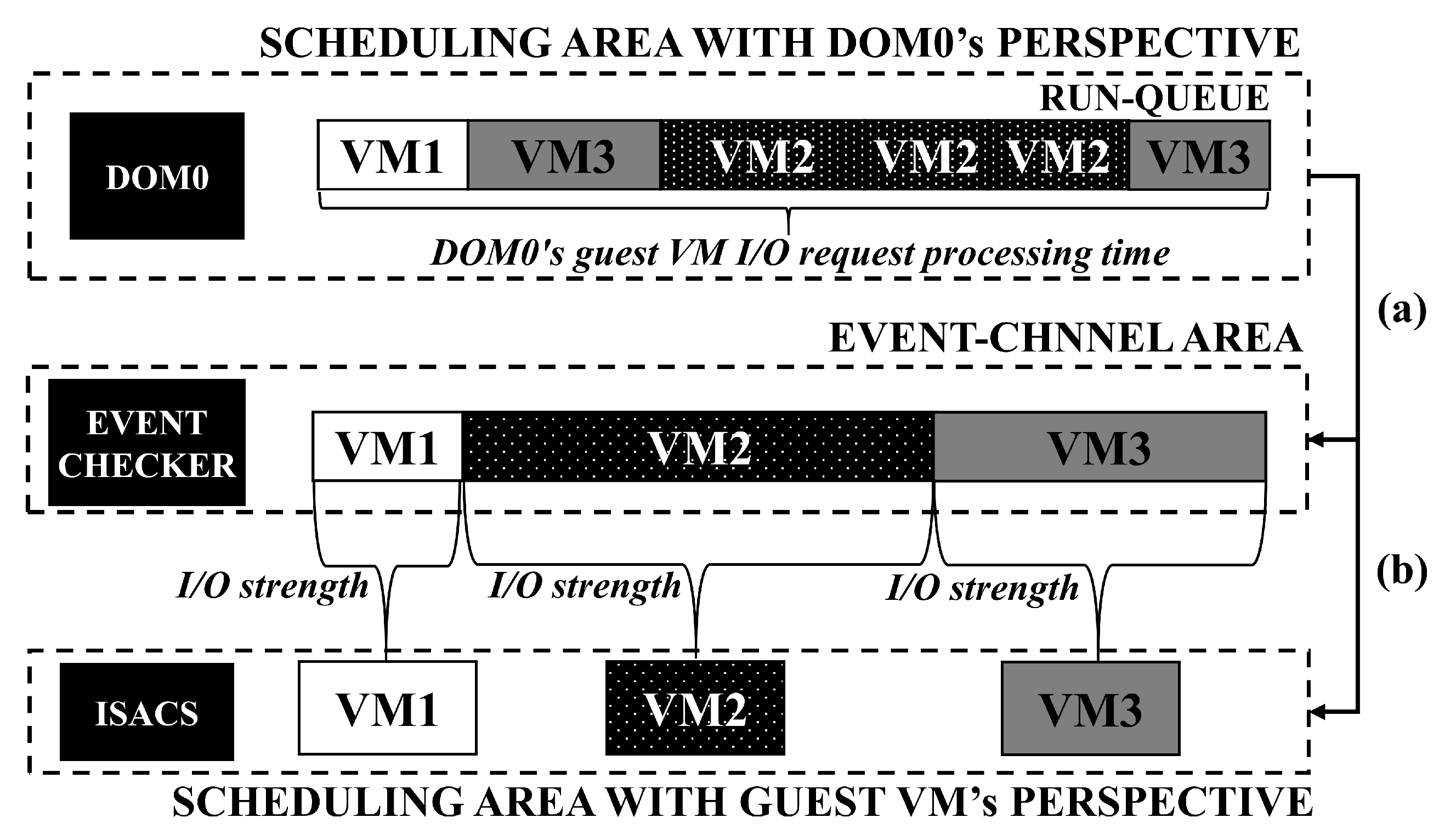
Figure 4 shows the procedure of measuring the I/O strength of each vCPU of the VM in ISACS. The first dotted box at the top of
Figure 4 depicts the perspective of only DOM0 processing the I/O requests of each VM. The boxes in the run-queue indicate the amount of time for which DOM0’s vCPU has processed I/O requests received from a specific VM. The second dotted box at the top in
Figure 4 shows an amount of accumulated time interval in which DOM0 generates an I/O response event for each VM’s I/O request based on a split-driver mechanism. Here, the EVENT CHECKER tracks the vCPUs receiving the I/O response event and derive the average interval of the I/O respond events with EMA applied. The third dotted box at the top indicates the process of allocating IVCredits according to the I/O strength by leveraging the ISACS_vCPU_INFO structure, which is synchronized with the EVENT CHECKER through shared memory communication. At this time, the VM box indicates the I/O-intensive vCPU of a specific VM which receives and handles the I/O response event from DOM0. As shown in
Figure 4, the I/O strength of the vCPU is determined by the processing time of DOM0 for I/O requests of VMs, which has the same meaning for the interval between I/O response events from DOM0 to VM in ISACS. In
Figure 4a,b represent the procedure corresponding to Equations (1) and (2) respectively.
Equations (1) and (2) represent the procedure of deriving IVCredit for each vCPU in the run-queue when credit reallocation is performed. For Equation (1), which entails the same procedure as that shown in
Figure 4a,
denotes the arrival time of the
eth I/O response event that vCPU received from DOM0; thus,
denotes the time interval between the I/O response events and is expressed as
. Here, in order to avoid allocating IVCredits to the vCPUs with infrequent I/O, ISACS will not reflect I/O information for that vCPU when the value of
exceeds 10 ms. Just ISACS initializes
to the current time for that vCPU. Therefore, vCPUs with infrequent I/O are allocated a relatively small amount of IVCredit. For the average interval between I/O response events until credit reallocation is performed, the EMA with a smoothing constant of 0.9 is applied. By applying EMA to Equation (1), ISACS can apply the latest trend for the change in the interval between I/O response events to IVCredit based on the degree of the current I/O workload of I/O-intensive vCPUs.
In Equation (2), which has the same procedure as that shown in
Figure 4b,
denotes the number of I/O response events that vCPU receives from DOM0 until credit reallocation is performed. Based on
, which multiplies the number of I/O events received from DOM0 for a vCPU and the average interval of I/O events after applying the EMA, we can derive the differentiated I/O strength of a specific vCPU among the vCPUs inside the run-queue. The value of
for a CPU-intensive vCPU will be zero or a value smaller than that for an I/O-intensive vCPU because CPU-intensive vCPU has a low probability of receiving an I/O response event from DOM0 or generating an I/O request event to DOM0. Therefore, ISACS recognizes vCPUs with an IVCredit that is greater than zero as I/O-intensive vCPUs considering the value of
in Equation (2). Then, to reflect the credit consumption for the actual workload of I/O-intensive vCPUs in the run-queue where vCPU is placed,
is multiplied by the result of
. For
,
represents the amount of credit consumed before credit reallocation is performed for the vCPU to which the IVCredit will be allocated.
n denotes the total number of vCPUs in the run-queue and
means the
of each vCPU in the run-queue. Using Equations (1) and (2), IVCredit is provided to the I/O-intensive vCPUs inside each run-queue when credit reallocation is completed. After credit reallocation, the I/O-intensive vCPUs will have more credits than the CPU-intensive vCPUs. Thus, the I/O-intensive vCPUs have a higher probability of pCPU occupancy than the CPU-intensive vCPUs. However, the CPU performance may be degraded on CPU-intensive vCPUs because IVCredit is assigned to the I/O-intensive vCPUs. To avoid CPU performance degradation on the CPU-intensive vCPUs, ISACS provides CVCredits to vCPUs considering the degree of CPU-intensiveness. In the Xen architecture, CPU-intensive vCPUs have a low degree of I/O request events and I/O response events occurring owing to the I/O processes of VMs. Therefore, because the amount of IVCredit represents the I/O-intensiveness of vCPUs, the vCPUs with a relatively low I/O workload can be categorized based on their IVCredit amount. Equation (3) refers to the condition that defines the vCPU to which CVCredit should be allocated. In Equation (3),
is the amount of IVCredit allocated to
, which is placed in the run-queue.
n denotes the total number of vCPUs in the run-queue and
k represents the number of vCPUs that the amount of IVCredit greater than zero in the run-queue.
represents the amount of IVCredits allocated through Equation (2) for the vCPU to which Equation (3) applies.
Regarding Equation (3), a vCPU with a relatively high amount of IVCredit in the run-queue will have a value less than 1; thus, CVCredit will not be assigned to such a vCPU by ISACS. After ISACS judges all vCPUs in the run-queue and decides whether to assign CVCredit or not, it places the vCPUs satisfying Equation (3) in the CPU-BOOST GROUP of specific run-queue. The CPU-BOOST GROUP is the pool of CPU-intensive vCPUs that satisfy Equation (3) and is managed by a run-queue unit. After ISACS configures the CPU-BOOST GROUP, it calculates the amount of CVCredit to be given to all vCPUs that belong to the CPU-BOOST GROUP using Equation (4). In Equation (4), j denotes the number of vCPUs that belong to the CPU-BOOST GROUP, and n is the total number of vCPUs in the run-queue. represents amount of CVCredits be allocated to the CPU-intensive vCPU inside the run-queue based on total amounts of IVCredits for all I/O-intensive vCPUs. Here, ISACS can guarantee pCPU occupancy for CPU-intensive vCPUs based on the amount of actual pCPU run-time for vCPU of DOM0 to handle the I/O request from I/O-intensive VMs. Then, is multiplied to provide a differentiated CVCredit according to the actual degree of CPU workload for the target vCPU. CVCredit is assigned to all vCPUs belonging to the CPU-BOOST GROUP after IVCredit has been assigned to the vCPUs. When the next vCPU to be scheduled satisfies the credit reallocation condition of ISACS, it enters the CPU-BOOST STATE, where only the vCPUs in the CPU-BOOST GROUP are scheduled. While CVCredit is consumed in the CPU-BOOST STATE, if the CVCredit of the next scheduled vCPU becomes less than zero, credit reallocation occurs for all vCPUs in the run-queue.
4.4. Credit Concealing Method
In the previous section, we described equations to derive the amount of virtual credits, such as IVCredit and CVCredit, according to the degree of workload and workload type of the vCPU unit. However, a vCPU that is assigned an IVCredit can have more credits than a neighbor vCPU. Therefore, a fair pCPU run-time for each vCPU is not guaranteed, and this can lead to biases in I/O and CPU performance. For example, when allocating IVCredits to vCPUs, I/O-intensive vCPUs obtain more credits than the CPU-intensive ones, resulting in unfair pCPU run-time. Therefore, ISACS should ensure that all vCPUs in the run-queue have the same amount of credit as much as possible. To avoid unfair pCPU run-time over all vCPUs in the run-queue, ISACS adopts a credit concealing method for all vCPUs to allocate a fair amount of credit for all vCPUs in the run-queue. In this section, we explain the credit concealing method that mitigates the unfairness arising from the amount of credit allocated to each vCPU placed in the same run-queue. This method provides a fair pCPU run-time for each vCPU by defining the limit of the amount of credit that can be consumed by considering the type of virtual credit.
The Credit2 scheduler first schedules the vCPU that has a high amount of credits. ISACS leverages this scheduling policy to increase the probability of preempting the pCPU for I/O-intensive vCPUs using a credit concealing method.
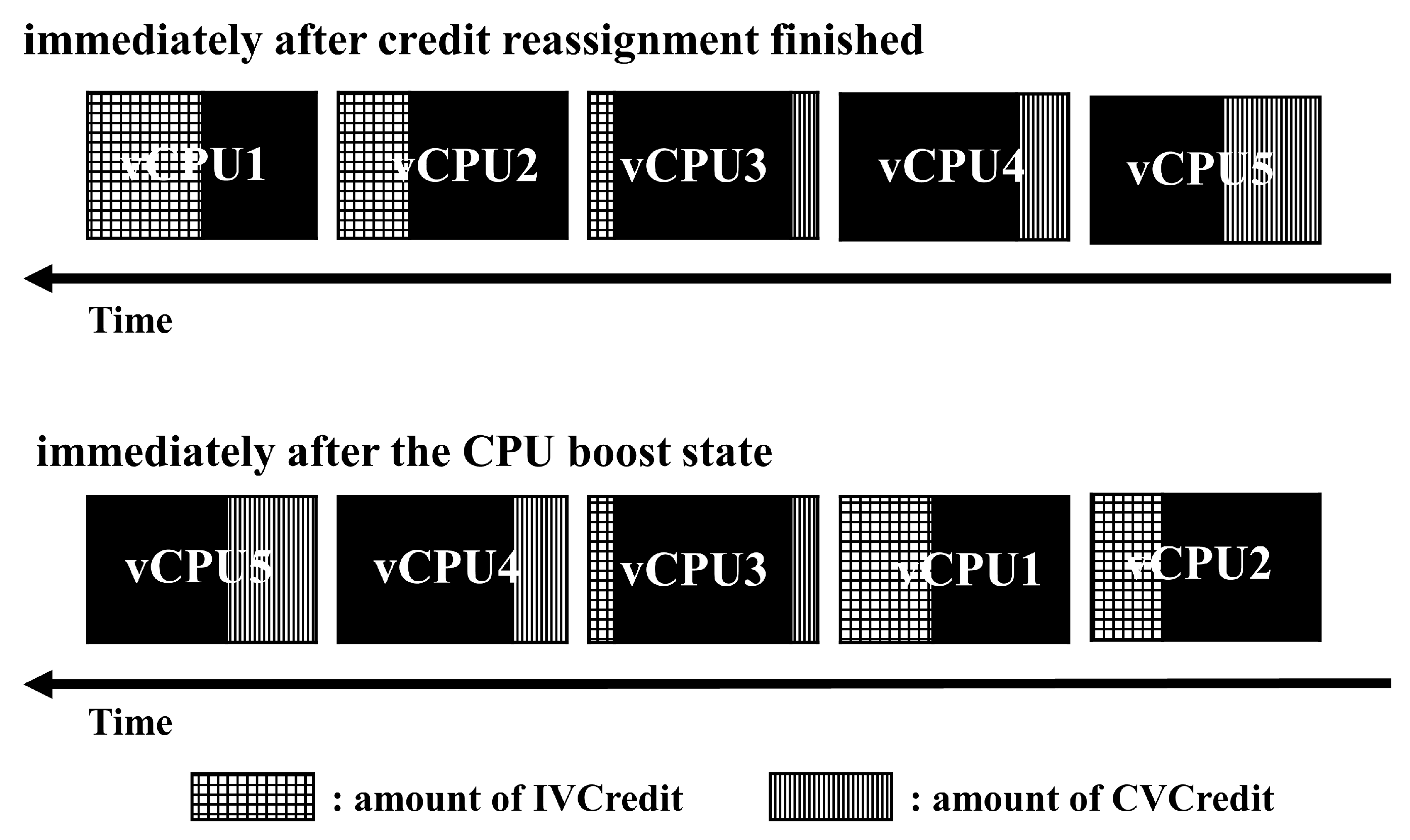
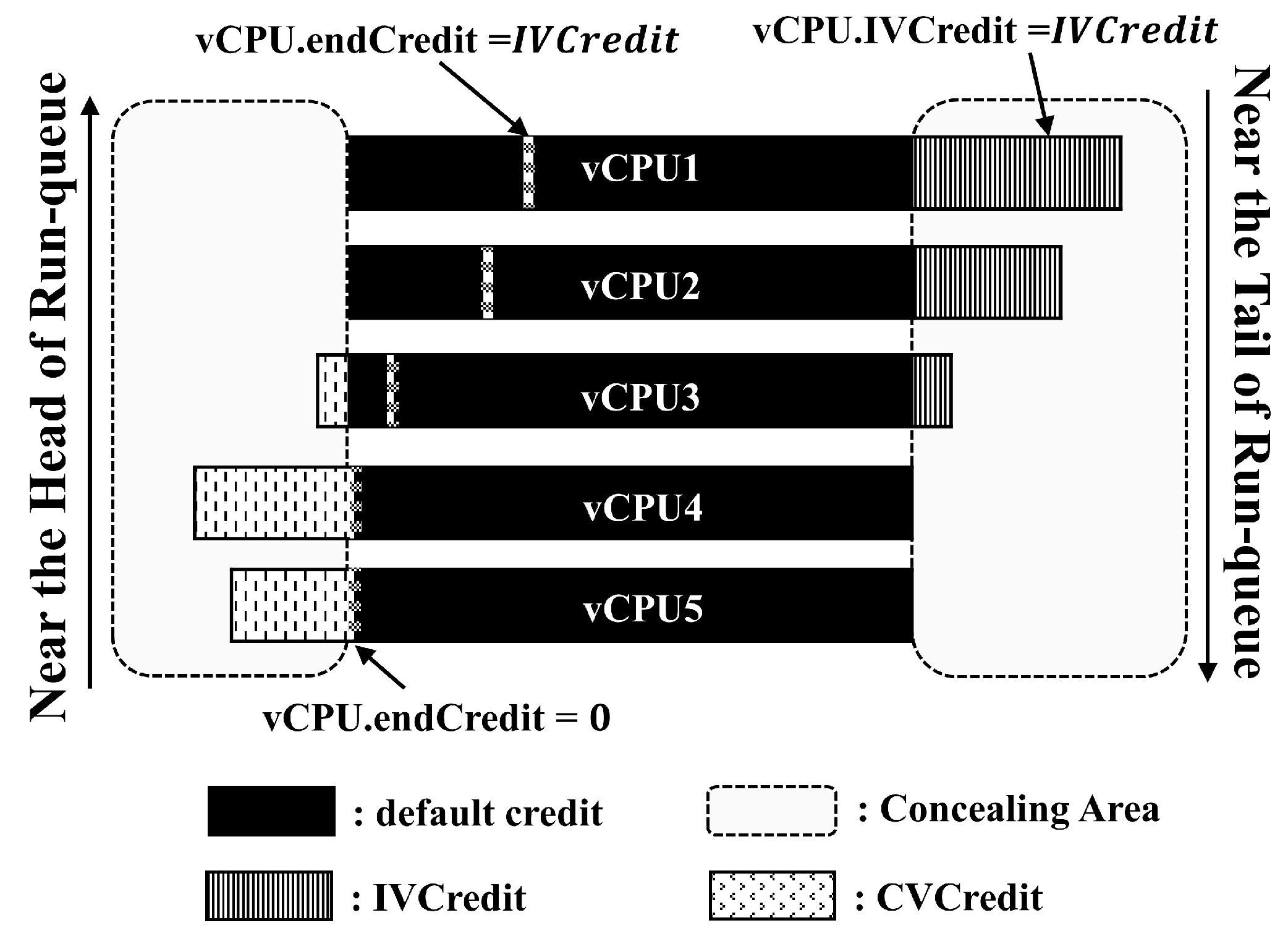
Figure 5 shows the result of the credit concealing method after credit reallocation. The concealing area refers to the virtual credit provided by ISACS. For concealing area in the
Figure 5, vCPU1 and vCPU2 are I/O-intensive vCPUs and have an IVCredit granted by ISACS. vCPU4 and vCPU5 are CPU-intensive vCPUs and are allocated a CVCredit by ISACS to guarantee the CPU performance. vCPU3, unlike vCPU1 and vCPU2, meets Equation (3) for the average IVCredit in the run-queue. Therefore, IVCredit and CVCredit together represent the assigned state. In the Credit2 scheduler, all vCPUs inside the run-queue are assigned a default credit when the credit amount for the next scheduled vCPU is less than zero. Therefore, for the credit reallocation condition in the Credit2 scheduler, we can state that
. When IVCredit is assigned to the I/O-intensive vCPU, we get
. However, if the credit reallocation condition is less than IVCredit and not zero, then
.
is erased from both sides of the credit reallocation condition; thus,
. Therefore, in ISACS, all vCPUs in the run-queue takes the same amount of credits whenever credit reallocation is performed, regardless of the type of workload that each vCPU handles when ISACS is not in CPU-BOOST STATE. ISACS guarantees that the same amount of credit can be assigned to all vCPUs in the run-queue by ensuring that credit reallocation is performed when the amount of credit is less than the value of vCPU.endcredit in
Figure 5, not when the amount of credit is less than zero.
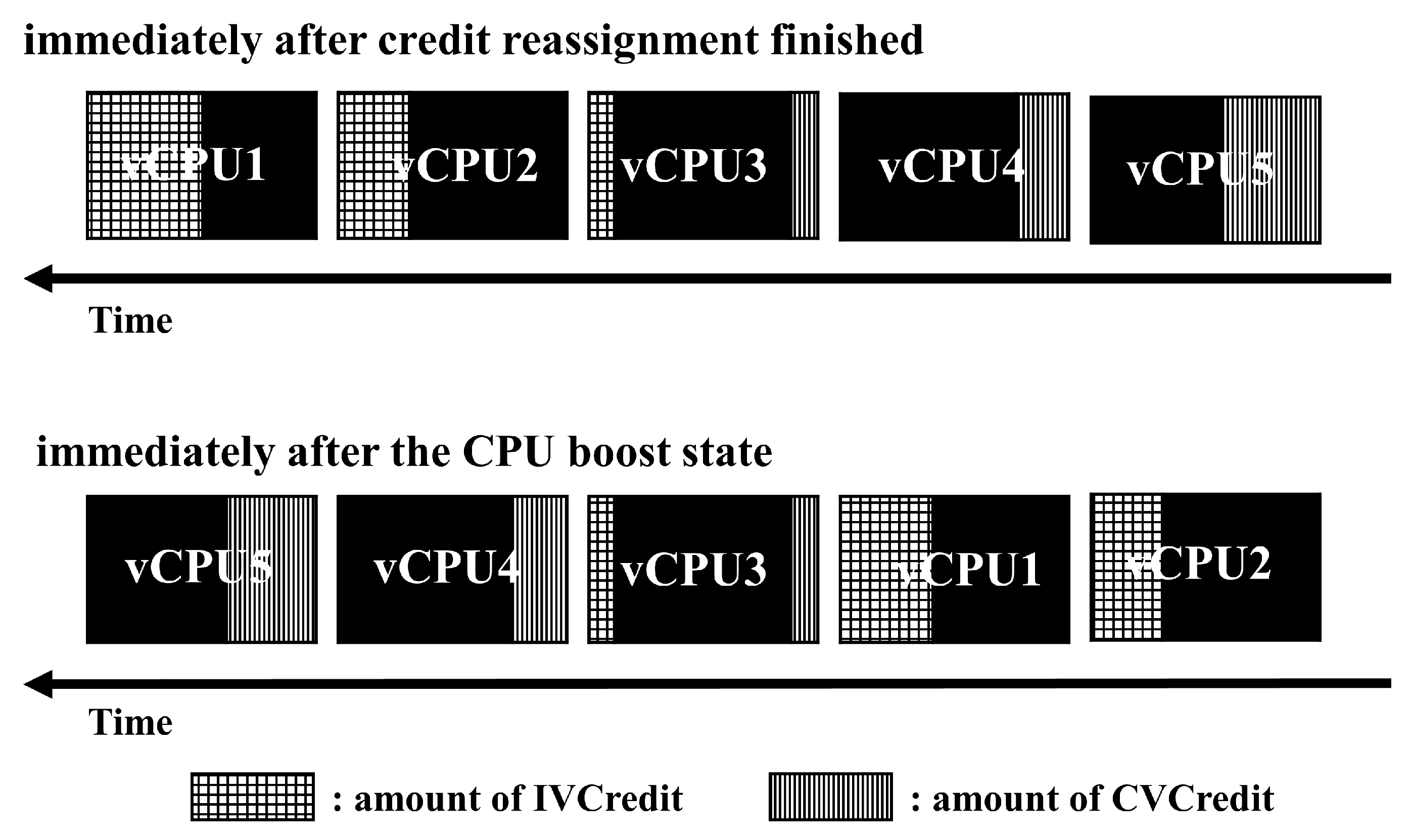
Figure 6 shows the order of vCPU placement in the run-queue when credit reallocation is completed and when the CPU-BOOST STATE occurs based on
Figure 5. As shown in
Figure 5, ISACS schedules a vCPU with a high IVCredit first after credits are reallocated in a specific run-queue. If the next vCPU to be scheduled has less credit than vCPU.endcredit, ISACS enters a CPU-BOOST STATE and schedules the vCPU with the highest CVCredit first. Finally, in the CPU-BOOST STATE, when the CVCredit amount of the next vCPU to be scheduled is less than zero, credit reallocation is performed for all vCPUs within the run-queue. Algorithm 1 shows the entire scheduling procedure of ISACS.
| Algorithm 1: ISACS: scheduling algorithm. |
Current vCPU on the pCPU Next vCPU to Run - 1:
ifthen - 2:
- 3:
- 4:
if then - 5:
- 6:
- 7:
end if - 8:
end if - 9:
ifthen - 10:
- 11:
- 12:
if then - 13:
- 14:
- 15:
- 16:
for do - 17:
- 18:
- 19:
- 20:
- 21:
end for - 22:
for do - 23:
if then - 24:
- 25:
- 26:
end if - 27:
end for - 28:
end if - 29:
end if - 30:
|
4.5. I/O Load Balancing
The Credit2 scheduler has a limitation of performing load balancing according to the degree of I/O load on each run-queue. This is because, in the Credit2 scheduler, vCPUs are migrated considering the run-queue load, which considers only the number of vCPUs and the execution time of each vCPU in the run-queue. In ISACS, we add a very simple load-balancing mechanism with considering I/O load of each run-queue after credit reallocation for all vCPUs in the run-queue is finished. When migrating vCPUs to prevent I/O workload concentration to a specific core, the degree of I/O load of the run-queue to which a vCPU is migrated should be carefully considered.
ISACS employs a migration condition based on the total number of I/O events received from all vCPUs in the run-queue and the degree of I/O load of the run-queue. To explain the migration conditions of ISACS, we define several terms.
is the total number of I/O events received by all vCPUs in the run-queue, and
denotes the vCPU to be migrated.
denotes the run-queue to which
will be migrated, and
denotes the run-queue that performs credit reallocation. The condition for selecting
is
where
is the candidate of the
excluding
. Once
is selected, to prevent it from having an increased I/O load among run-queues, ISACS finds the vCPU which meets the following conditions:
. When ISACS finds a vCPU that meets the above condition, it sets the vCPU as
and migrates it to
. Algorithm 2 shows the I/O load balancing performed by ISACS.
| Algorithm 2: ISACS: I/O load-balancing. |
- 1:
fordo - 2:
if then - 3:
- 4:
end if - 5:
if then - 6:
- 7:
end if - 8:
end for - 9:
fordo - 10:
if then - 11:
- 12:
end if - 13:
end for - 14:
if!=NULL then - 15:
- 16:
- 17:
end if - 18:
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
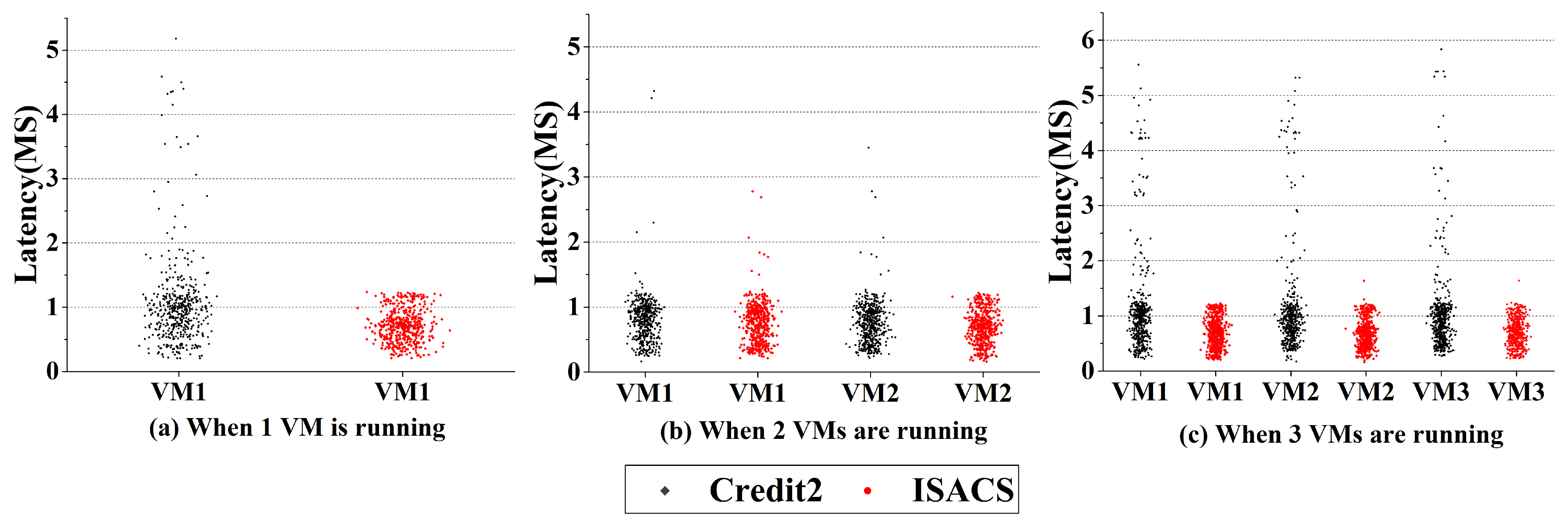{kind=link}
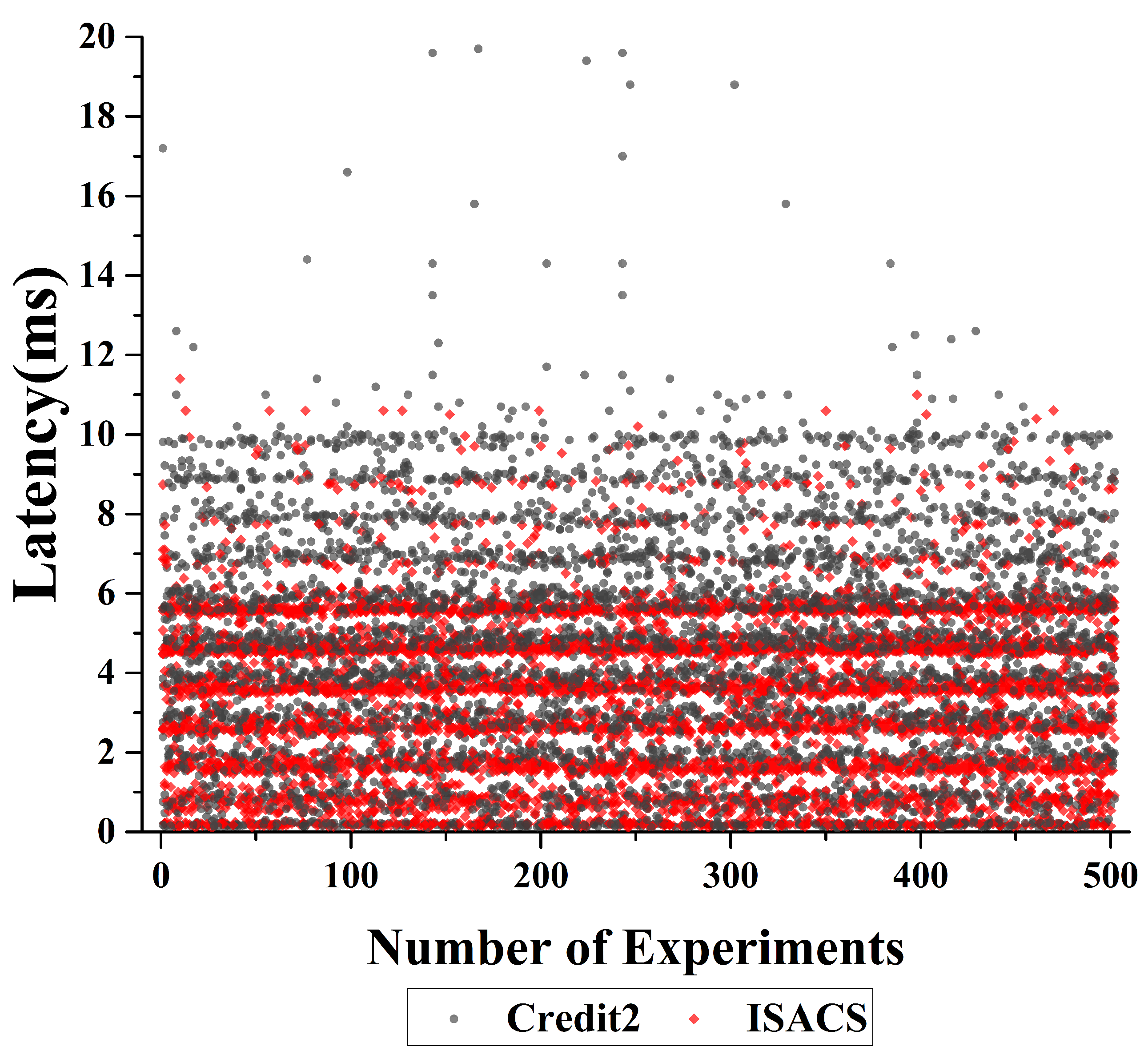{kind=link}
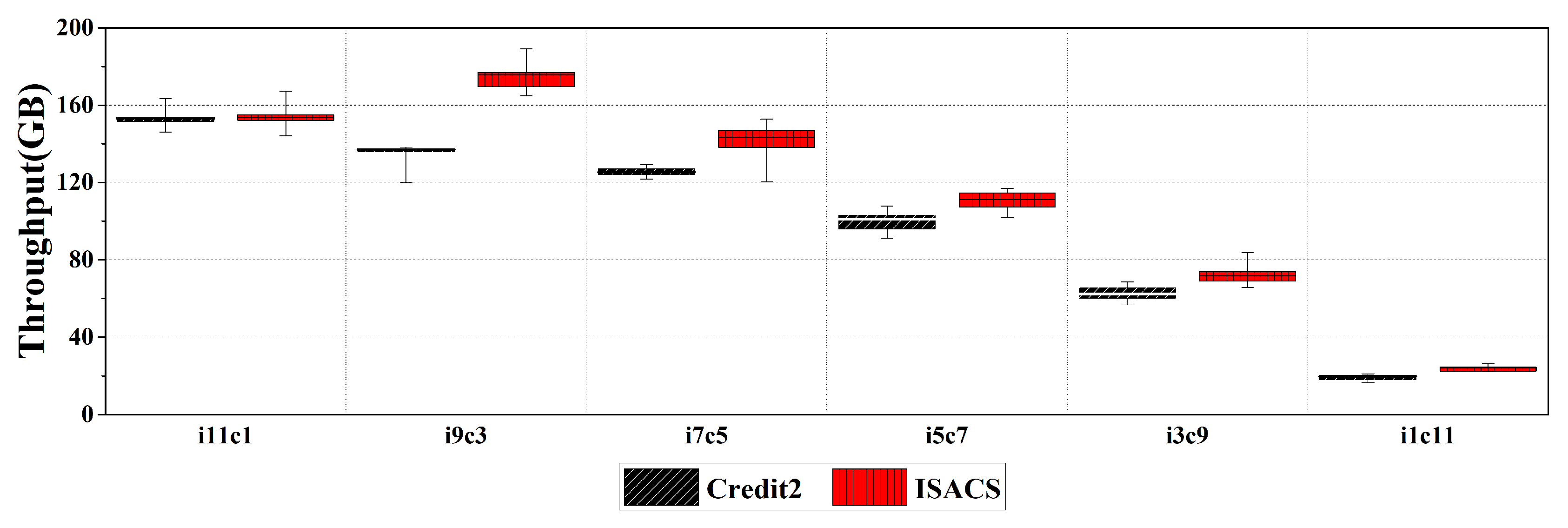{kind=link}
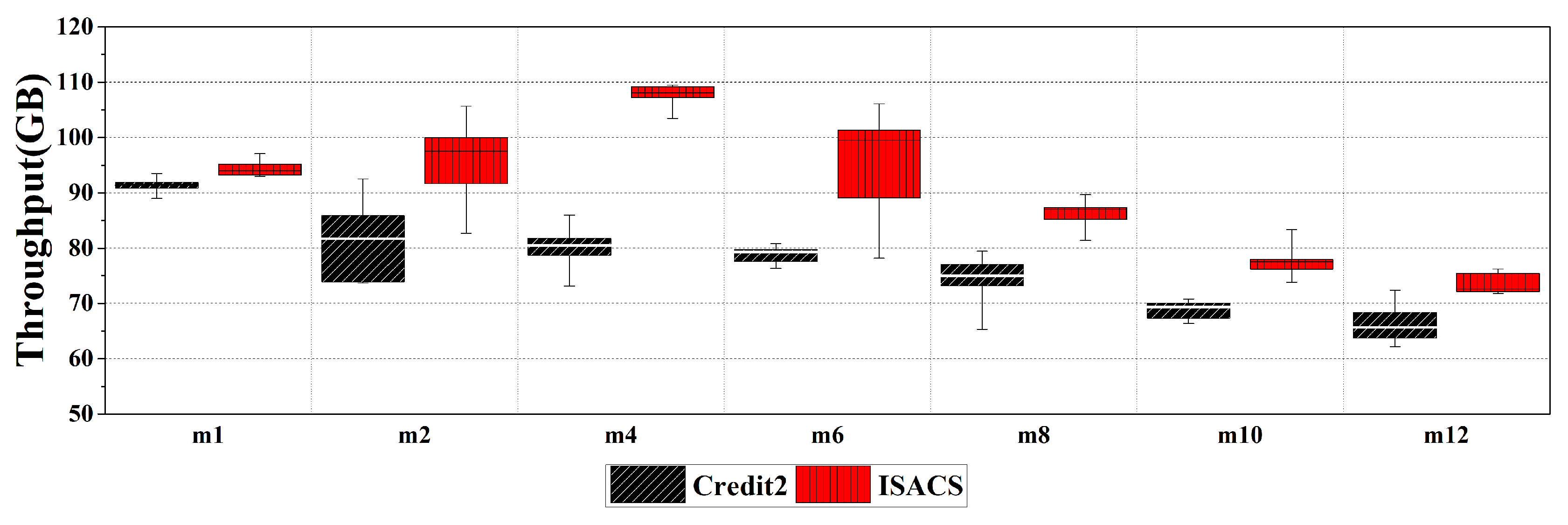{kind=link}
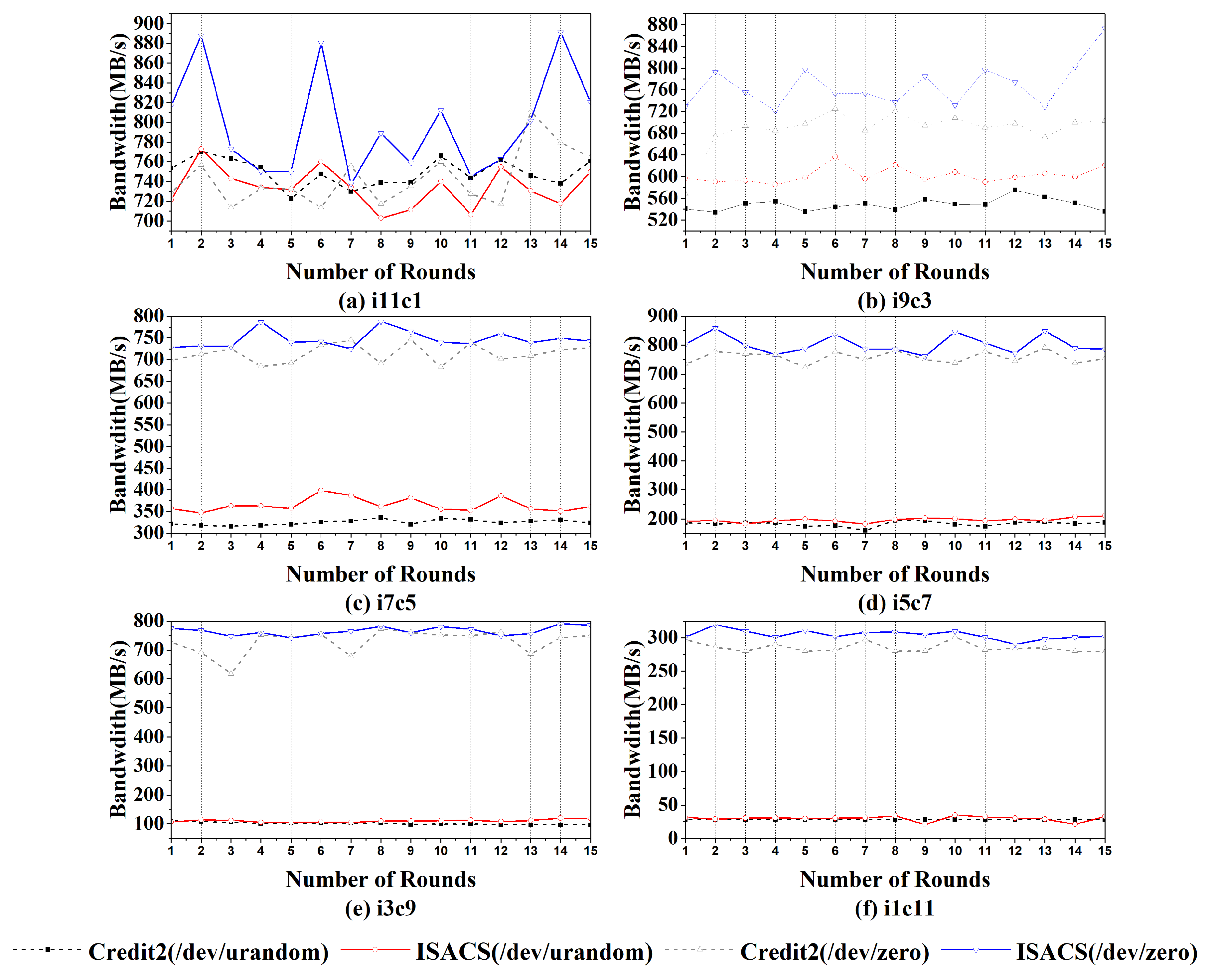{kind=link}
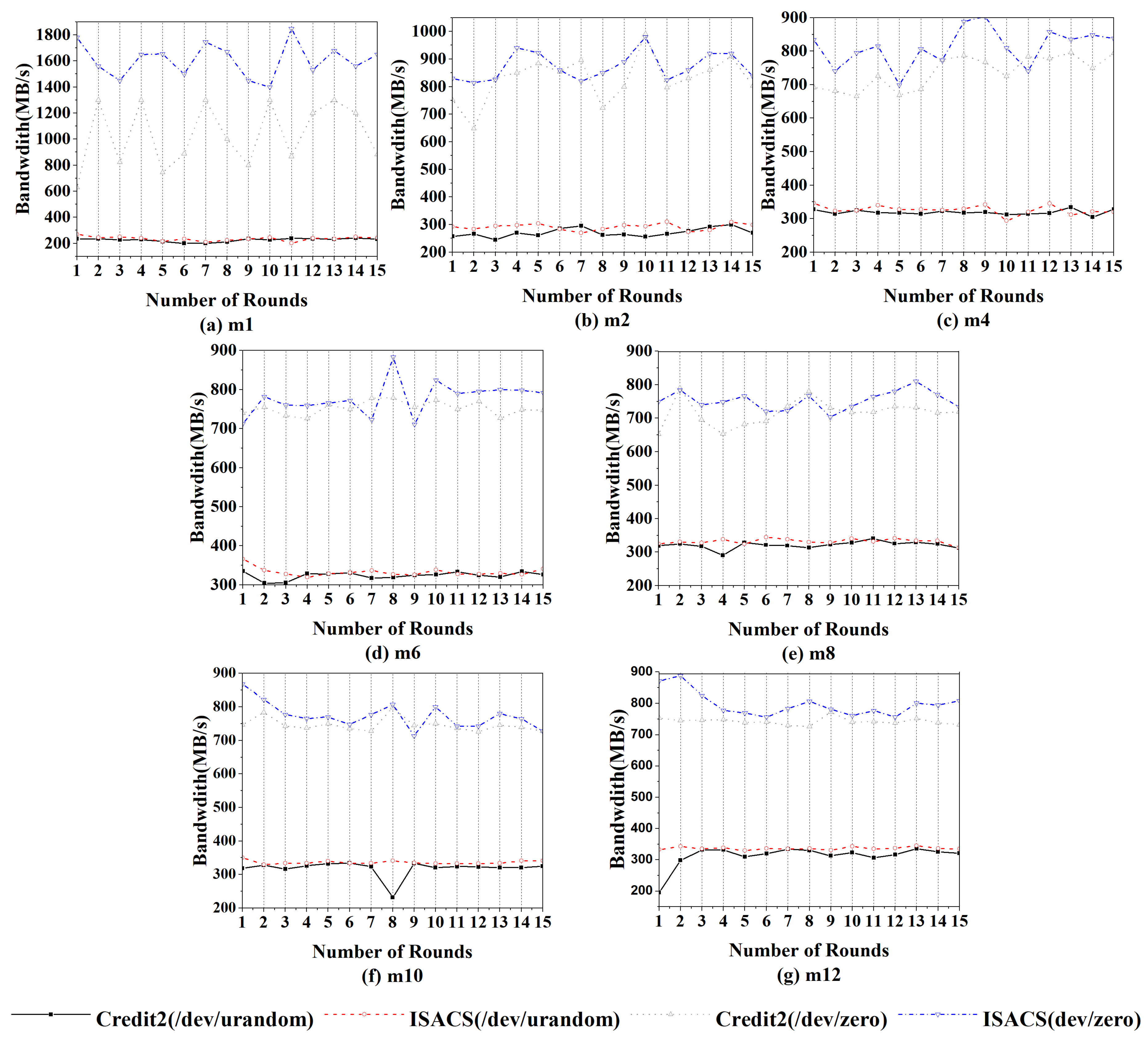{kind=link}
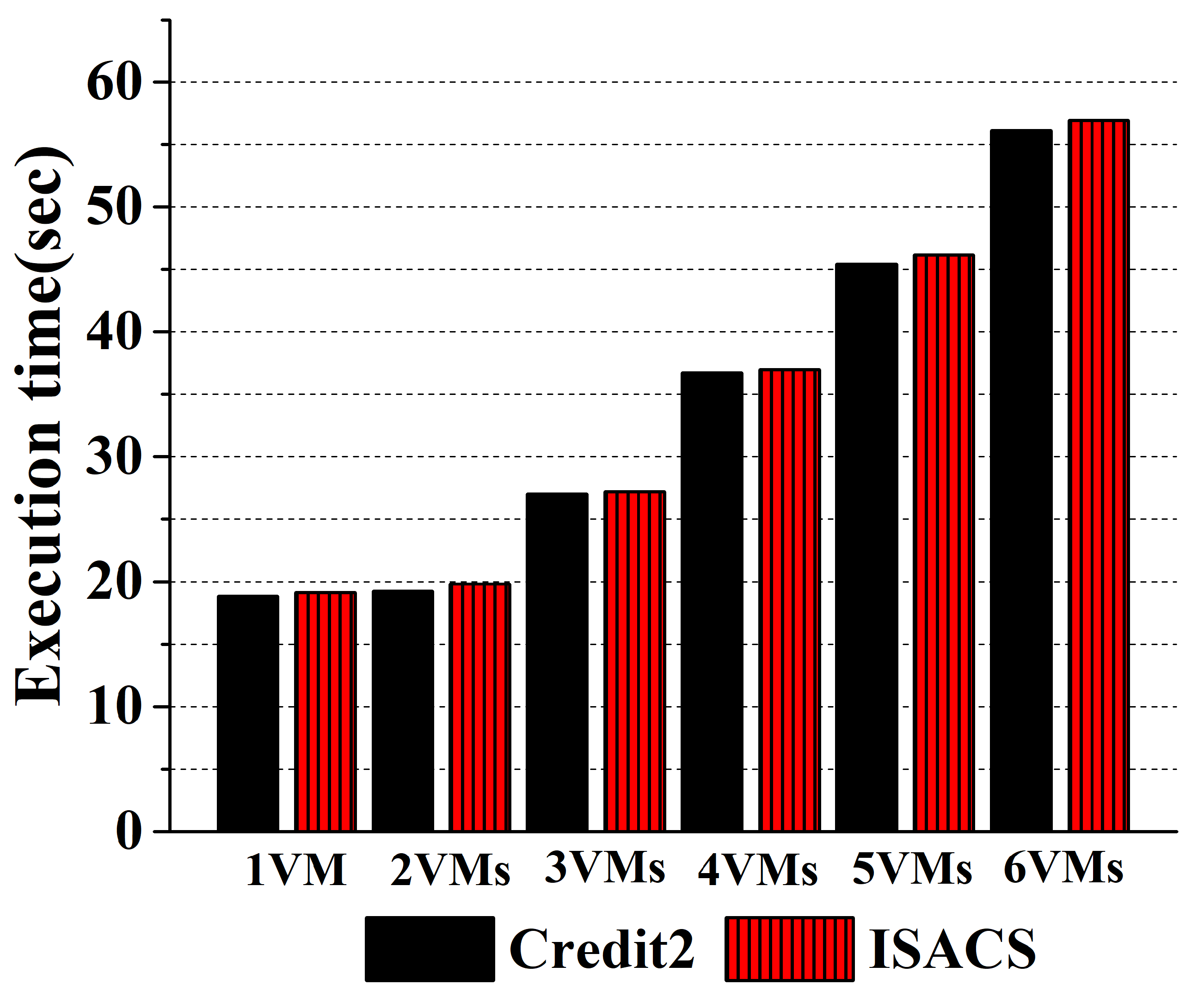{kind=link}
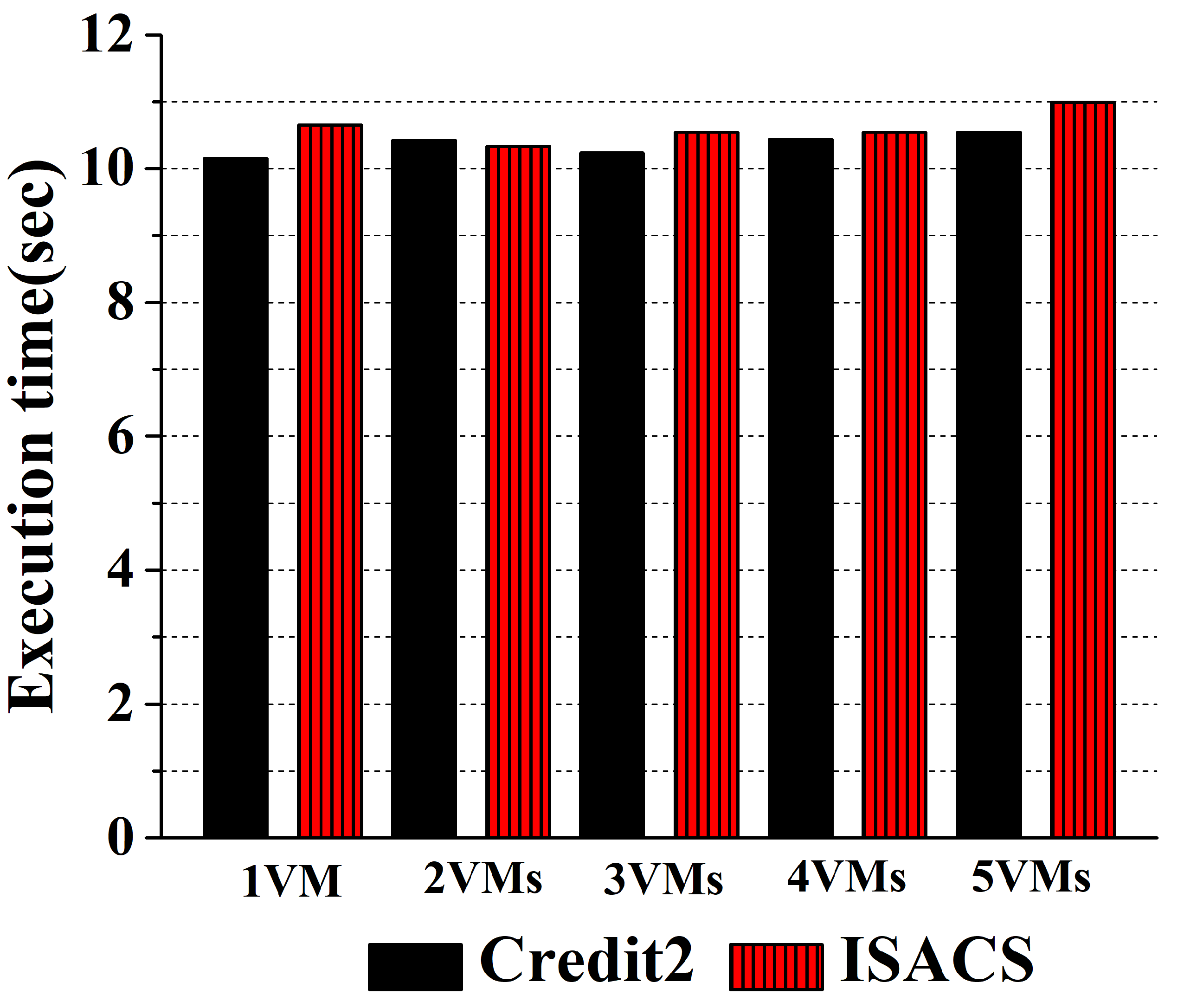{kind=link}
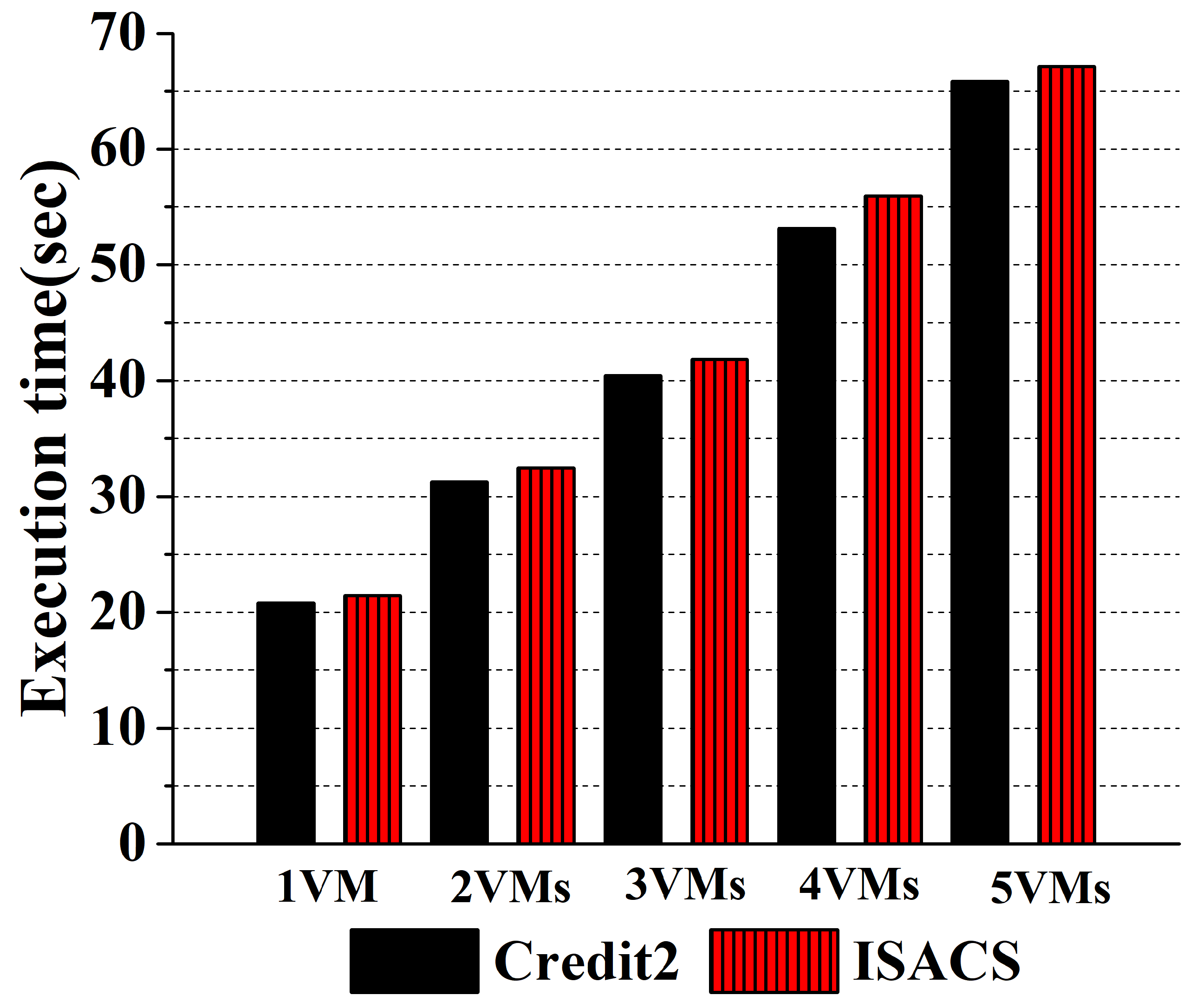{kind=link}