Underwater-Sonar-Image-Based 3D Point Cloud Reconstruction for High Data Utilization and Object Classification Using a Neural Network


Abstract
1. Introduction
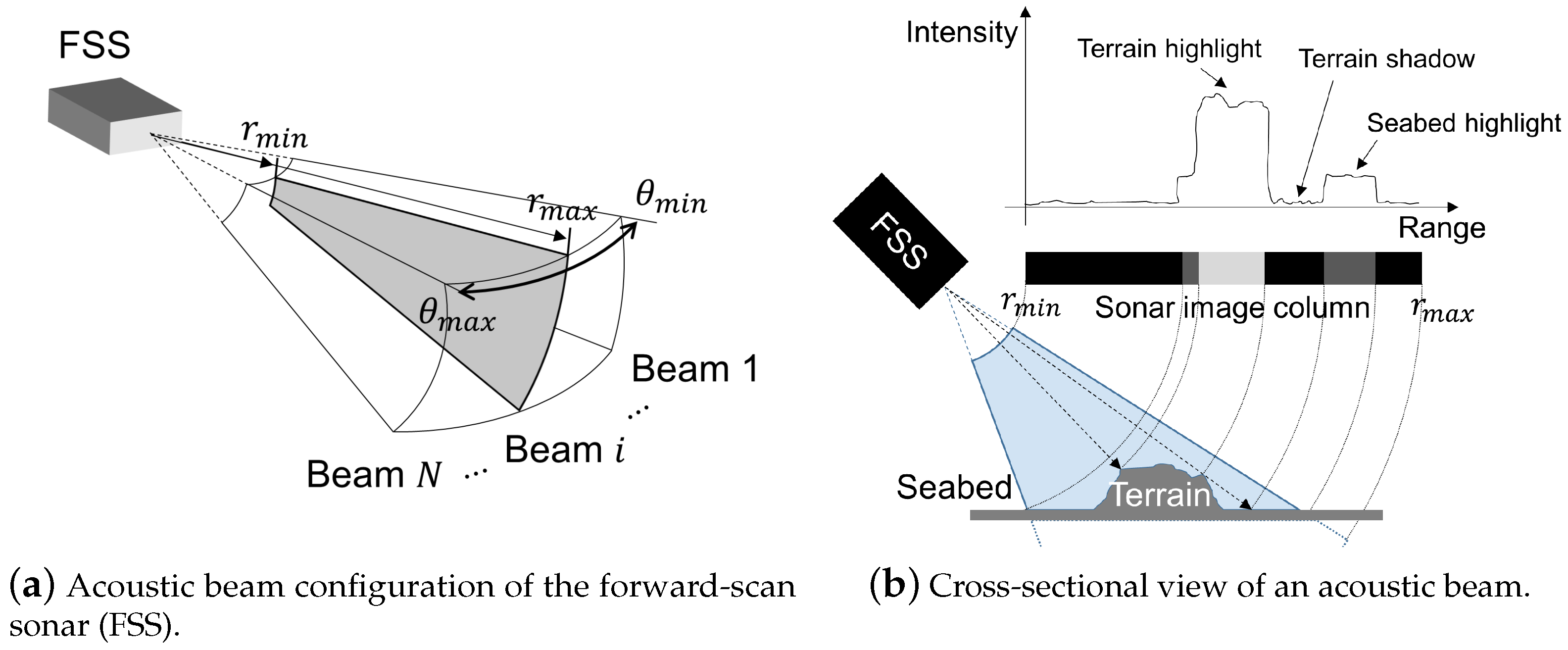
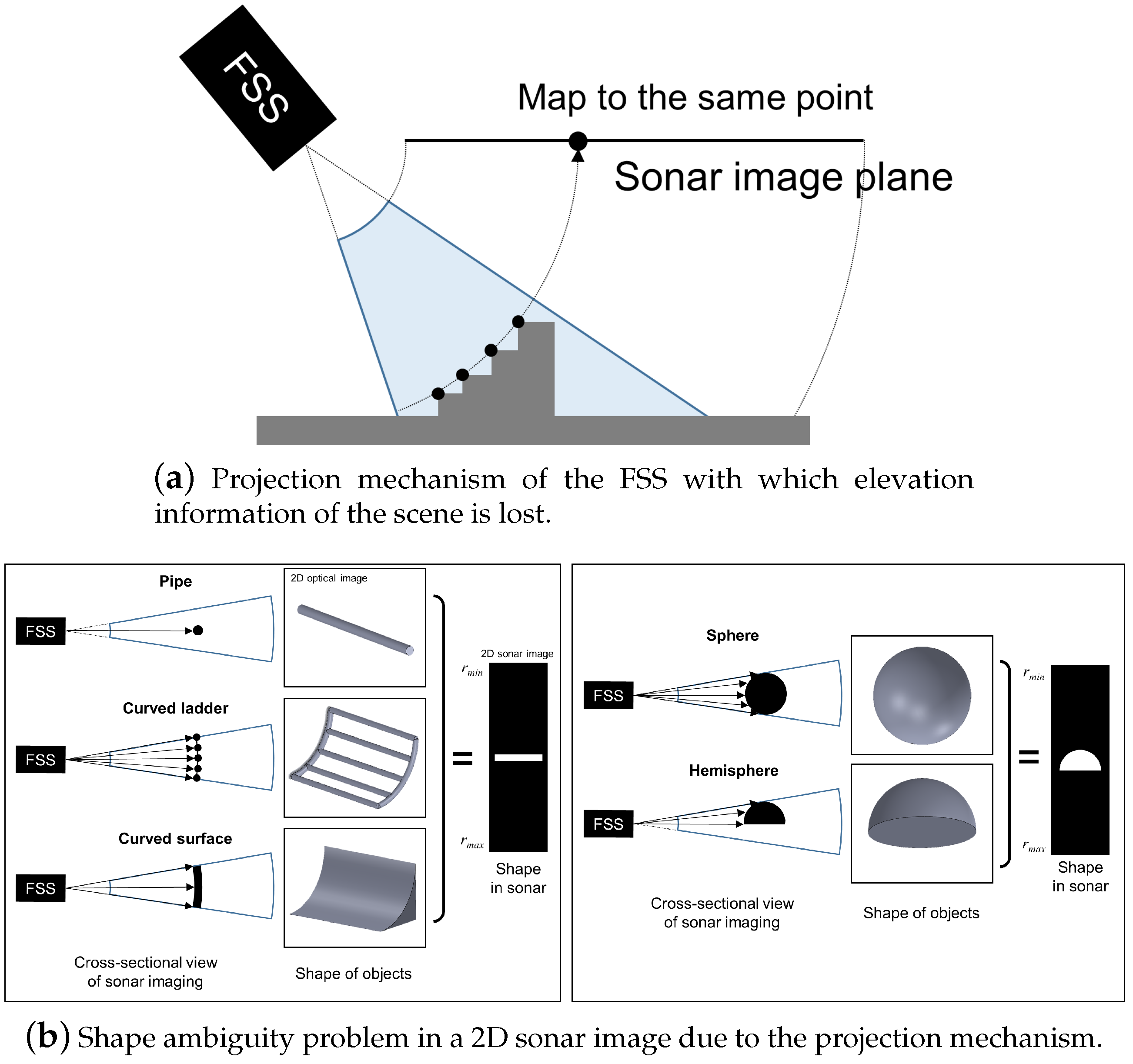
2. Problem Statement
3. 3D-Geometry-Reconstruction-Based Underwater Object Classification
3.1. Target Scenario
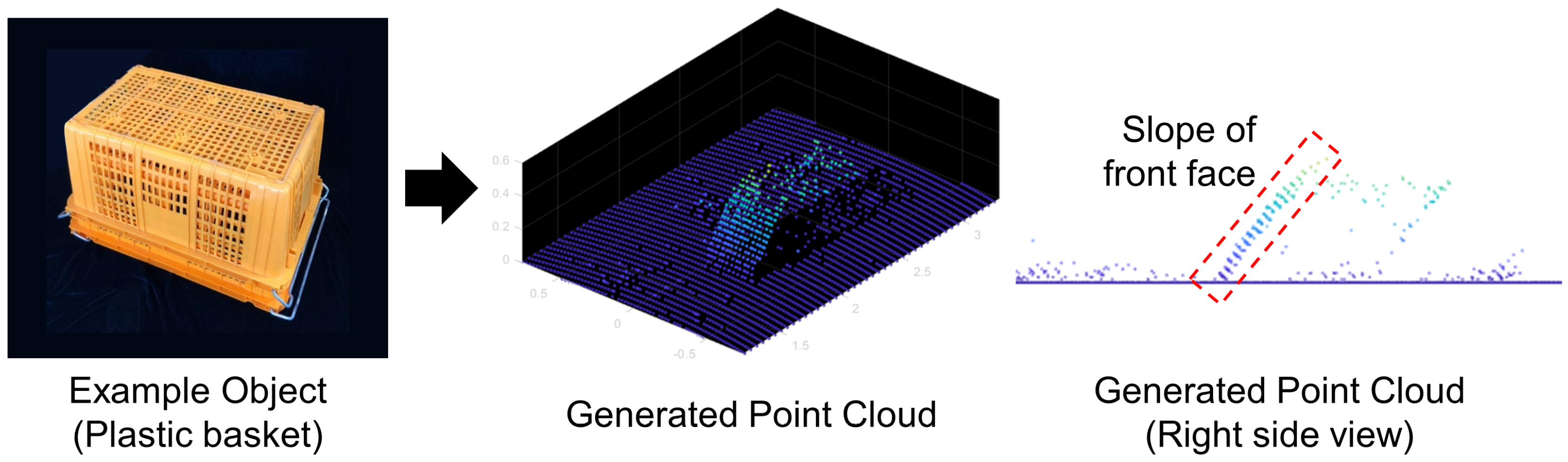
3.2. Reconstruction of the 3D Point Cloud of an Object Using FSS
3.3. Object Classification Based on a Point Cloud Using PointNet
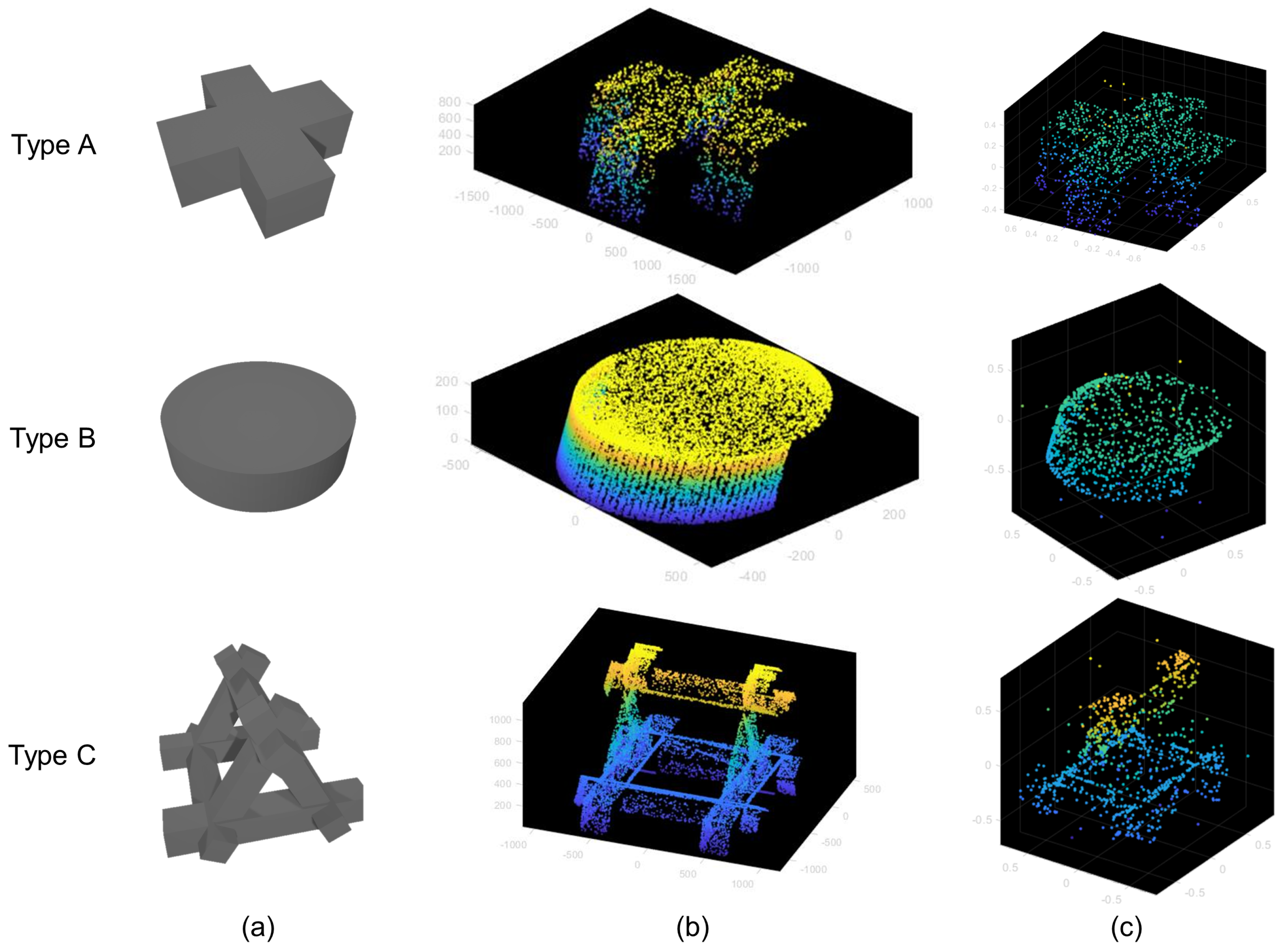
3.4. Training Point Cloud Synthesis
4. Experiment
4.1. Simulation Experiment
4.1.1. Sonar Image Simulator
4.1.2. Simulation Experiment Results
4.2. Field Experiment
4.2.1. Training of the Proposed Object Classifier
4.2.2. Field Experiment Setup
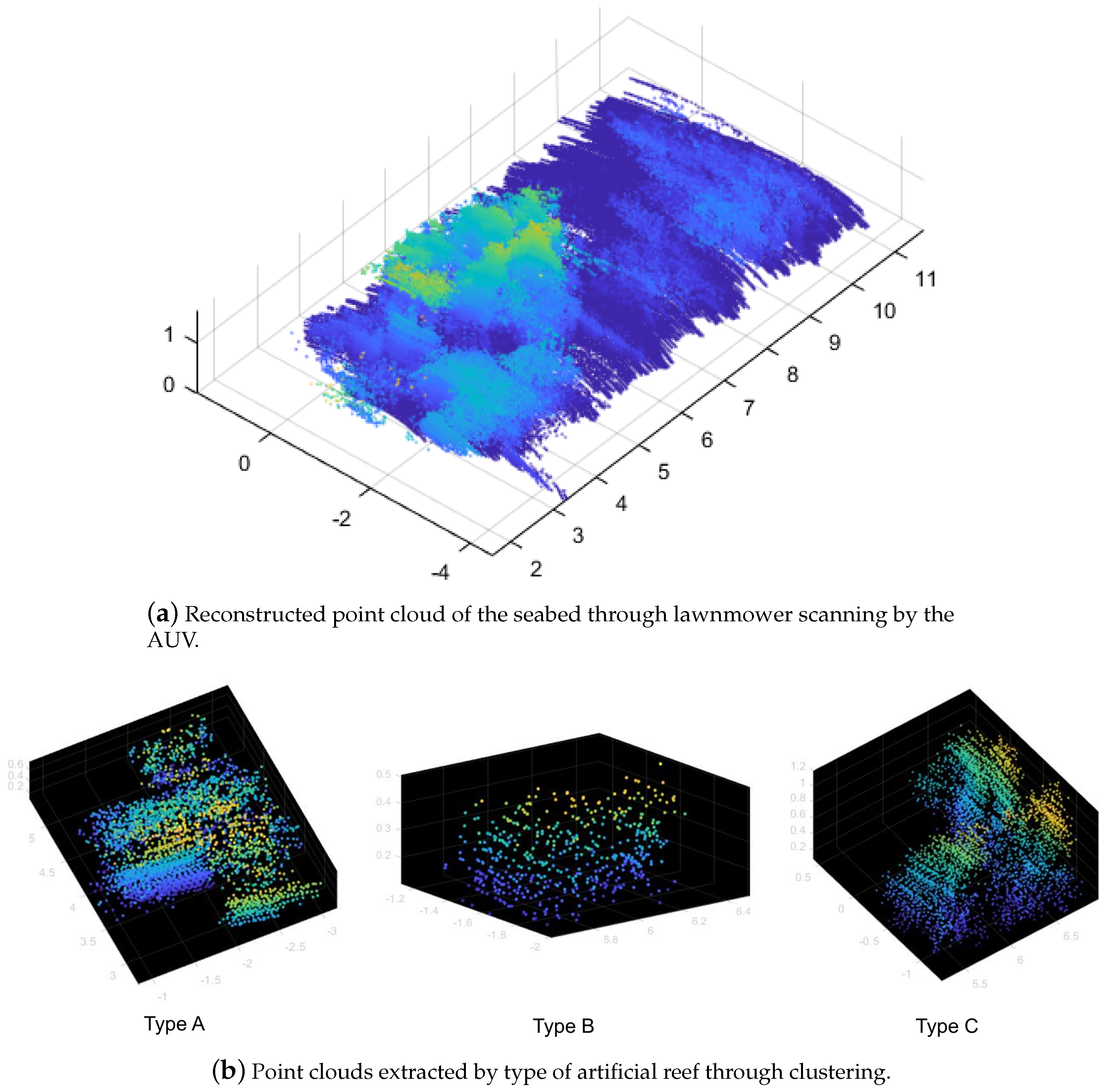
4.2.3. Field Experiment Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AUV | autonomous underwater vehicle |
| SNR | signal-to-noise ratio |
| NN | neural network |
| TOF | time of flight |
| DBSCAN | density-based spatial clustering of applications with noise |
| CAD | computer-aided design |
| DIDSON | dual-frequency identification sonar |
References
- Kim, T.; Kim, J.; Byun, S.W. A comparison of nonlinear filter algorithms for terrain-referenced underwater navigation. Int. J. Control Autom. Syst. 2018, 16, 2977–2989. [Google Scholar] [CrossRef]
- Lee, D.; Kim, G.; Kim, D.; Myung, H.; Choi, H.T. Vision-based object detection and tracking for autonomous navigation of underwater robots. Ocean Eng. 2012, 48, 59–68. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, Z.; Lu, J.; Ma, G.; Zhang, P. Underwater robot detection system based on fish’s lateral line. Electronics 2019, 8, 566. [Google Scholar] [CrossRef]
- Johannsson, H.; Kaess, M.; Englot, B.; Hover, F.; Leonard, J. Imaging sonar-aided navigation for autonomous underwater harbor surveillance. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 4396–4403. [Google Scholar]
- Bingham, B.; Foley, B.; Singh, H.; Camilli, R.; Delaporta, K.; Eustice, R.; Mallios, A.; Mindell, D.; Roman, C.; Sakellariou, D. Robotic tools for deep water archaeology: Surveying an ancient shipwreck with an autonomous underwater vehicle. J. Field Robot. 2010, 27, 702–717. [Google Scholar] [CrossRef]
- Stokey, R.P.; Roup, A.; von Alt, C.; Allen, B.; Forrester, N.; Austin, T.; Goldsborough, R.; Purcell, M.; Jaffre, F.; Packard, G.; et al. Development of the REMUS 600 autonomous underwater vehicle. In Proceedings of the OCEANS 2005 MTS/IEEE, Washington, DC, USA, 17–23 September 2005; pp. 1301–1304. [Google Scholar]
- Nakatani, T.; Ura, T.; Ito, Y.; Kojima, J.; Tamura, K.; Sakamaki, T.; Nose, Y. AUV “TUNA-SAND” and its Exploration of hydrothermal vents at Kagoshima Bay. In Proceedings of the OCEANS 2008-MTS/IEEE Kobe Techno-Ocean, Kobe, Japan, 8–11 April 2008; pp. 1–5. [Google Scholar]
- Reed, S.; Petillot, Y.; Bell, J. An automatic approach to the detection and extraction of mine features in sidescan sonar. IEEE J. Ocean Eng. 2003, 28, 90–105. [Google Scholar] [CrossRef]
- Kim, B.; Yu, S.C. Imaging sonar based real-time underwater object detection utilizing adaboost method. In Proceedings of the 2017 IEEE Underwater Technology (UT), Busan, Korea, 21–24 February 2017; pp. 1–5. [Google Scholar]
- Karimanzira, D.; Renkewitz, H.; Shea, D.; Albiez, J. Object Detection in Sonar Images. Electronics 2020, 9, 1180. [Google Scholar] [CrossRef]
- Maki, T.; Horimoto, H.; Ishihara, T.; Kofuji, K. Tracking a Sea Turtle by an AUV with a Multibeam Imaging Sonar: Toward Robotic Observation of Marine Life. Int. J. Control Autom. Syst. 2020, 18, 597–604. [Google Scholar] [CrossRef]
- Kim, J.; Kim, T.; Kim, J.; Rho, S.; Song, Y.w.; Yu, S.C. Simulation and Feasibility Test of Mini-ROVs with AUV for the Manipulation Purpose. In Proceedings of the OCEANS 2019 MTS/IEEE SEATTLE, Seattle, WA, USA, 27–31 October 2019; pp. 1–6. [Google Scholar]
- Lee, S.; Park, B.; Kim, A. Deep learning from shallow dives: Sonar image generation and training for underwater object detection. arXiv 2018, arXiv:1810.07990. [Google Scholar]
- Myers, V.; Williams, D.P. Adaptive multiview target classification in synthetic aperture sonar images using a partially observable Markov decision process. IEEE J. Ocean Eng. 2011, 37, 45–55. [Google Scholar] [CrossRef]
- Cho, H.; Gu, J.; Yu, S.C. Robust sonar-based underwater object recognition against angle-of-view variation. IEEE Sens. J. 2015, 16, 1013–1025. [Google Scholar] [CrossRef]
- Lee, M.; Kim, J.; Yu, S.C. Robust 3D Shape Classification Method using Simulated Multi View Sonar Images and Convolutional Nueral Network. In Proceedings of the OCEANS 2019-Marseille, Marseille, France, 17–20 June 2019; pp. 1–5. [Google Scholar]
- Das, J.; Rajany, K.; Frolovy, S.; Pyy, F.; Ryany, J.; Caronz, D.A.; Sukhatme, G.S. Towards marine bloom trajectory prediction for AUV mission planning. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 4784–4790. [Google Scholar]
- Cho, H.; Kim, B.; Yu, S.C. AUV-based underwater 3-D point cloud generation using acoustic lens-based multibeam sonar. IEEE J. Ocean Eng. 2017, 43, 856–872. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Cho, Y.; Jang, H.; Malav, R.; Pandey, G.; Kim, A. Underwater Image Dehazing via Unpaired Image-to-image Translation. Int. J. Control Autom. Syst. 2020, 18, 605–614. [Google Scholar] [CrossRef]
- Wang, W.; Yu, R.; Huang, Q.; Neumann, U. Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2569–2578. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Joe, H.; Kim, J.; Yu, S.C. 3D Reconstruction Using Two Sonar Devices in a Monte-Carlo Approach for AUV Application. Int. J. Control Autom. Syst. 2020, 18, 587–596. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Manhães, M.M.M.; Scherer, S.A.; Voss, M.; Douat, L.R.; Rauschenbach, T. UUV simulator: A gazebo-based package for underwater intervention and multi-robot simulation. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016; pp. 1–8. [Google Scholar]
- Cieślak, P. Stonefish: An Advanced Open-Source Simulation Tool Designed for Marine Robotics, with a ROS Interface. In Proceedings of the OCEANS 2019-Marseille, Marseille, France, 17–20 June 2019; pp. 1–6. [Google Scholar]
- Kim, J.; Sung, M.; Yu, S.C. Development of Simulator for Autonomous Underwater Vehicles utilizing Underwater Acoustic and Optical Sensing Emulators. In Proceedings of the 2018 18th International Conference on Control, Automation and Systems (ICCAS), Daegwallyeong, Korea, 17–20 October 2018; pp. 416–419. [Google Scholar]
- Catmull, E. A Subdivision Algorithm for Computer Display of Curved Surfaces; Technical Report; Utah Univ. Salt Lake City School Of Computing: Salt Lake City, UT, USA, 1974. [Google Scholar]
- Perreault, C.; Auclair-Fortier, M.F. Speckle simulation based on B-mode echographic image acquisition model. In Proceedings of the Fourth Canadian Conference on Computer and Robot Vision (CRV’07), Montreal, QC, Canada, 28–30 May 2007; pp. 379–386. [Google Scholar]
- Sin, H. Artificial Reef Information Book. 2020. Available online: https://www.fira.or.kr/fira/fira_040301.jsp?mode=view&article_no=26351 (accessed on 22 October 2020).
- Pyo, J.; Cho, H.; Joe, H.; Ura, T.; Yu, S.C. Development of hovering type AUV “Cyclops” and its performance evaluation using image mosaicing. Ocean Eng. 2015, 109, 517–530. [Google Scholar] [CrossRef]
- Belcher, E.; Hanot, W.; Burch, J. Dual-frequency identification sonar (DIDSON). In Proceedings of the 2002 Interntional Symposium on Underwater Technology (Cat. No. 02EX556), Tokyo, Japan, 19 April 2002; pp. 187–192. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Specifications |
|---|---|
| Dimension | 0.9 m (width) × 1.5 m (length) × 0.9 m (height) |
| Weight | 210 kg in air |
| Depth rating | 100 m |
| Power source | 600 Wh Li-Po battery × 2 |
| Computing System | PC-104 (Intel Atom @ 1.66 GHz) × 2 |
| Propulsion | 8 thrusters (2 for surge, 4 for sway, 2 for heave) |
| Max speed | 2 knots |
| Sensors | Forward-Scan Sonar (1.8 MHz) |
| Doppler Velocity Logger (1.2 MHz) | |
| Digital pressure transducer | |
| Fiber-optic gyro |
| Features | Specifications |
|---|---|
| Operating frequency | 1.8 MHz |
| Field of view | 0.42–46.25 m (in range) |
| −14.5–14.5 (in azimuth) | |
| −7–7 (in elevation) | |
| Beam spreading angle | 14 |
| Beam width | 0.3 |
| Max resolution | 0.3 |
| Image size | 512 × 96 |
| Frame rate | 4–21 fps |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sung, M.; Kim, J.; Cho, H.; Lee, M.; Yu, S.-C. Underwater-Sonar-Image-Based 3D Point Cloud Reconstruction for High Data Utilization and Object Classification Using a Neural Network. Electronics 2020, 9, 1763. https://doi.org/10.3390/electronics9111763
Sung M, Kim J, Cho H, Lee M, Yu S-C. Underwater-Sonar-Image-Based 3D Point Cloud Reconstruction for High Data Utilization and Object Classification Using a Neural Network. Electronics. 2020; 9(11):1763. https://doi.org/10.3390/electronics9111763
Chicago/Turabian StyleSung, Minsung, Jason Kim, Hyeonwoo Cho, Meungsuk Lee, and Son-Cheol Yu. 2020. "Underwater-Sonar-Image-Based 3D Point Cloud Reconstruction for High Data Utilization and Object Classification Using a Neural Network" Electronics 9, no. 11: 1763. https://doi.org/10.3390/electronics9111763
APA StyleSung, M., Kim, J., Cho, H., Lee, M., & Yu, S.-C. (2020). Underwater-Sonar-Image-Based 3D Point Cloud Reconstruction for High Data Utilization and Object Classification Using a Neural Network. Electronics, 9(11), 1763. https://doi.org/10.3390/electronics9111763