A Study of Cross-Linguistic Speech Emotion Recognition Based on 2D Feature Spaces


 ,
,  , and
, and
Abstract
1. Introduction
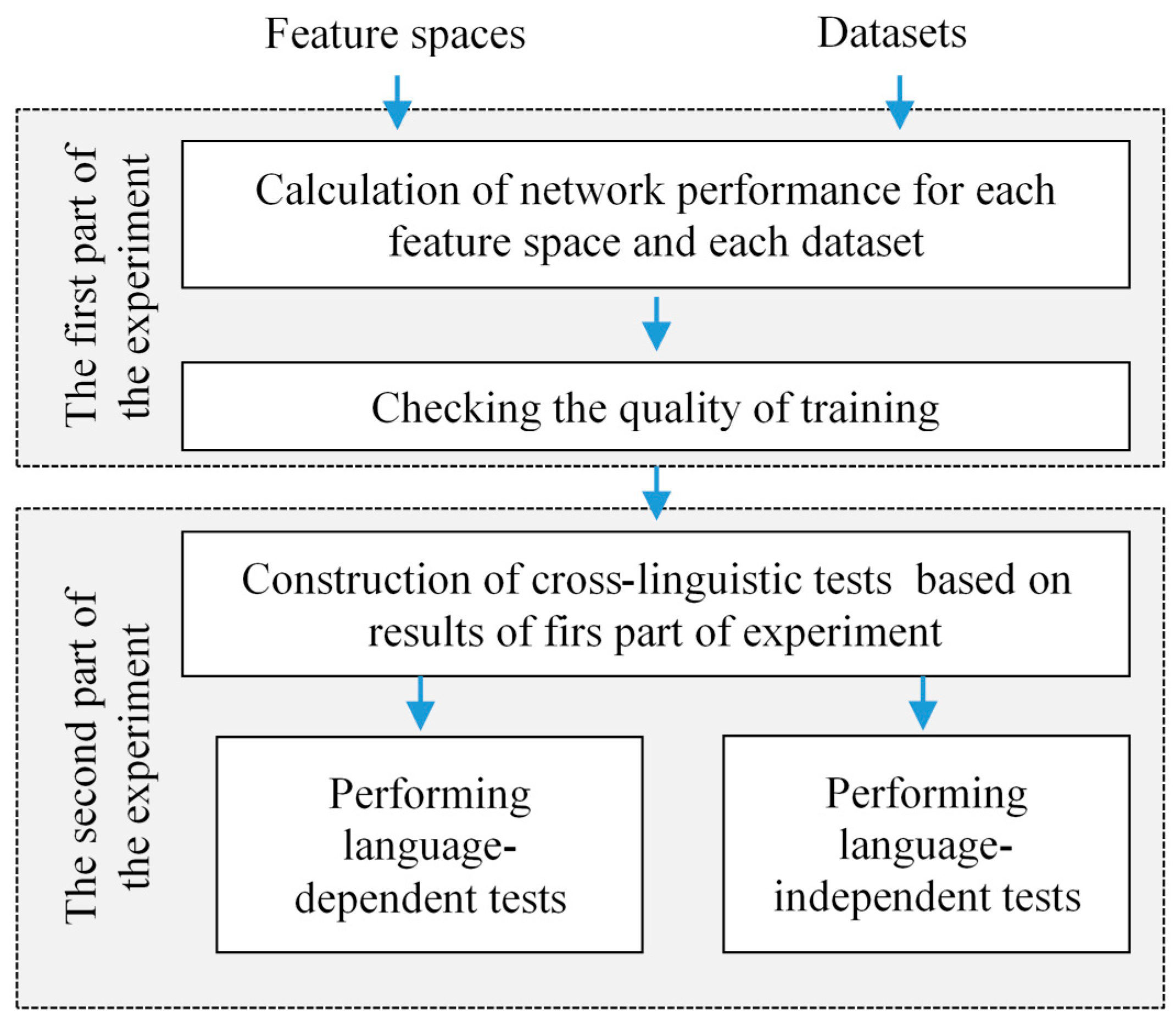
2. Methodology
2.1. Description of Feature Spaces
2.1.1. Spectrograms
2.1.2. Mel-Cepstrograms
2.1.3. Cochleagrams
2.1.4. Fractal Dimension-Based Features
2.2. CNN Architecture
3. Datasets
4. Experimental Results
- Two-dimensional feature maps enable us to deliver temporal information in addition to the selected acoustic features of the emotion. This should save the emotion global (suprasegmental) features for the analysis in the network and enhance the decision process. The sequential framing-based analysis of the speech prevents this, as all suprasegmental information is lost.
- We extract the same features for all the languages we analyze. This analysis scheme does not require any merging, mixing or any other joint processing of different language data. Furthermore, our feature maps are based on the single analysis technique, but we cannot deny the probable need to join different analysis techniques to improve the discriminative power of the feature maps.
- We have analyzed six different languages, which makes our study truly multilingual. The results of the cross-lingual emotion recognition are not impressive, but they reveal very clear challenges in the future: the need of multilingual emotional speech data (especially for low-resource languages), the undefined feature systems for the multilingual emotions, and the possible variation of the results for different languages.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Lo, S.L.; Cambria, E.; Chiong, R.; Cornforth, D. Multilingual sentiment analysis: From formal to informal and scarce resource languages. Artif. Intell. Rev. 2017, 48, 499–527. [Google Scholar] [CrossRef]
- Li, M.; Xu, H.; Liu, X.; Lu, S. Emotion recognition from multichannel EEG signals using K-nearest neighbor classification. Tech. Health Care 2018, 26, 509–519. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.Z. Stress emotion recognition based on RSP and EMG signals. In Advanced Materials Research; Trans. Tech. Publications Ltd.: Zurich, Switzerland, 2013; Volume 709, pp. 827–831. [Google Scholar]
- Yu, Y.; Kim, Y.J. Attention-LSTM-attention model for speech emotion recognition and analysis of IEMOCAP database. Electronics 2020, 9, 713. [Google Scholar] [CrossRef]
- Tamulevičius, G.; Karbauskaitė, R.; Dzemyda, G. Speech emotion classification using fractal dimension-based features. Nonlinear Anal. Model. Control 2019, 24, 679–695. [Google Scholar] [CrossRef]
- Laurinčiukaitė, S.; Telksnys, L.; Kasparaitis, P.; Kliukienė, R.; Paukštytė, V. Lithuanian speech corpus liepa for development of human-computer interfaces working in voice recognition and synthesis mode. Informatica 2018, 29, 487–498. [Google Scholar] [CrossRef]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Dewaele, J. Emotions in Multiple Languages; Palgrave Macmillan: London, UK, 2010. [Google Scholar] [CrossRef]
- Vryzas, N.; Kotsakis, R.; Liatsou, A.; Dimoulas, C.A.; Kalliris, G. Speech emotion recognition for performance interaction. J. Audio Eng. Soc. 2018, 66, 457–467. [Google Scholar] [CrossRef]
- Torres-Boza, D.; Oveneke, M.C.; Wang, F.; Jiang, D.; Verhelst, W.; Sahli, H. Hierarchical sparse coding framework for speech emotion recognition. Speech Commun. 2018, 99, 80–89. [Google Scholar] [CrossRef]
- Swain, M.; Routray, A.; Kabisatpathy, P. Databases, features and classifiers for speech emotion recognition: A review. Int. J. Speech Tech. 2018, 21, 93–120. [Google Scholar] [CrossRef]
- Li, X.; Akagi, M. Improving multilingual speech emotion recognition by combining acoustic features in a three-layer model. Speech Commun. 2019, 110, 1–12. [Google Scholar] [CrossRef]
- Heracleous, P.; Yoneyama, A. A comprehensive study on bilingual and multilingual speech emotion recognition using a two-pass classification scheme. PLoS ONE 2019, 14, e0220386. [Google Scholar] [CrossRef] [PubMed]
- Ntalampiras, S. Toward language-agnostic speech emotion recognition. J. Audio Eng. Soc. 2020, 68, 7–13. [Google Scholar] [CrossRef]
- Matuzas, J.; Tišina, T.; Drabavičius, G.; Markevičiūtė, L. Lithuanian Spoken Language Emotions Database, Baltic Institute of Advanced Language. 2015. Available online: http://datasets.bpti.lt/lithuanian-spoken-language-emotions-database/ (accessed on 15 October 2020).
- Livingstone, S.R.; Russo, F.A. The ryerson audio-visual database of emotional speech and song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed]
- Haq, S.; Jackson, P.J.; Edge, J. Speaker-dependent audio-visual emotion recognition. In Proceedings of the AVSP 2009—International Conference on Audio-Visual Speech Processing University of East Anglia, Norwich, UK, 10–13 September 2009; pp. 53–58. [Google Scholar]
- Dupuis, K.; Pichora-Fuller, M.K. Toronto Emotional Speech Set (TESS). 2010. Available online: https://tspace.library.utoronto.ca/handle/1807/24487 (accessed on 15 October 2020).
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Jovicic, S.T.; Kasic, Z.; Dordevic, M.; Rajkovic, M. Serbian emotional speech database: Design, processing and evaluation. In Proceedings of the SPECOM 2004: 9th Conference Speech and Computer, Saint-Peterburg, Russia, 20–22 September 2004; pp. 77–81. [Google Scholar]
- Lavagetto, F. (Ed.) INTERFACE Project, Multimodal Analysis/Synthesis System for Human Interaction to Virtual and Augmented Environments; EC IST-1999-No 10036; 2000–2002; Elra-s0329. Available online: http://catalog.elra.info (accessed on 15 October 2020).
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- TECHMO. Polish Emotional Speech Database. Available online: http://techmo.pl/ (accessed on 15 October 2020).
- Żelasko, P.; Ziółko, B.; Jadczyk, T.; Skurzok, D. AGH corpus of Polish speech. Lang. Resour. Eval. 2016, 50, 585–601. [Google Scholar] [CrossRef]
- Acted Emotional Speech Dynamic Database—AESDD. Available online: http://m3c.web.auth.gr/research/aesdd-speech-emotion-recognition/ (accessed on 15 October 2020).
- Pan, S.; Tao, J.; Li, Y. The CASIA audio emotion recognition method for audio/visual emotion challenge 2011. In International Conference on Affective Computing and Intelligent Interaction; Springer: Berlin/Heidelberg, Germany, 2011; pp. 388–395. [Google Scholar]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Costantini, G.; Iaderola, I.; Paoloni, A.; Todisco, M. EMOVO corpus: An Italian emotional speech database. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Battocchi, A.; Pianesi, F.; Goren-Bar, D. Dafex: Database of facial expressions. In International Conference on Intelligent Technologies for Interactive Entertainment; Springer: Berlin/ Heidelberg, Germany, 2005; pp. 303–306. [Google Scholar]
- Liogienė, T.; Tamulevičius, G. Multi-stage recognition of speech emotion using sequential forward feature selection. Electr. Control Commun. Eng. 2016, 10, 35–41. [Google Scholar] [CrossRef]
- Noroozi, F.; Kaminska, D.; Sapinski, T.; Anbarjafari, G. Supervised vocal-based emotion recognition using multiclass support vector machine, random forests, and adaboost. J. Audio Eng. Soc. 2017, 65, 562–572. [Google Scholar] [CrossRef]
- Bhavan, A.; Chauhan, P.; Shah, R.R. Bagged support vector machines for emotion recognition from speech. Knowl. Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Hassan, A.; Damper, R.I. Classification of emotional speech using 3DEC hierarchical classifier. Speech Commun. 2012, 54, 903–916. [Google Scholar] [CrossRef]
- Kerkeni, L.; Serrestou, Y.; Raoof, K.; Mbarki, M.; Mahjoub, M.A.; Cleder, C. Automatic speech emotion recognition using an optimal combination of features based on EMD-TKEO. Speech Commun. 2019, 114, 22–35. [Google Scholar] [CrossRef]
- Vlasenko, B.; Schuller, B.; Wendemuth, A.; Rigoll, G. Combining frame and turn-level information for robust recognition of emotions within speech. In Proceedings of the INTERSPEECH 2007, 8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007; pp. 2225–2228. [Google Scholar]
- Vryzas, N.; Vrysis, L.; Matsiola, M.; Kotsakis, R.; Dimoulas, C.; Kalliris, G. Continuous speech emotion recognition with convolutional neural networks. J. Audio Eng. Soc. 2020, 68, 14–24. [Google Scholar] [CrossRef]
- Etienne, C.; Fidanza, G.; Petrovskii, A.; Devillers, L.; Schmauch, B. CNN+ LSTM architecture for speech emotion recognition with data augmentation. arXiv 2018, arXiv:1802.05630. [Google Scholar]
- Fu, C.; Dissanayake, T.; Hosoda, K.; Maekawa, T.; Ishiguro, H. Similarity of speech emotion in different languages revealed by a neural network with attention. In Proceedings of the 2020 IEEE 14th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 3–5 February 2020; pp. 381–386. [Google Scholar]
- Neumann, M.; Vu, N.T. Cross-lingual and multilingual speech emotion recognition on english and french. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5769–5773. [Google Scholar]
- Sagha, H.; Matejka, P.; Gavryukova, M.; Povolný, F.; Marchi, E.; Schuller, B.W. Enhancing Multilingual Recognition of Emotion in Speech by Language Identification. In Proceedings of the 17th Annual Conference of the International Speech Communication Association (INTERSPEECH 2016): Understanding Speech Processing in Humans and Machines, San Francisco, CA, USA, September 8–12 2016; pp. 2949–2953. [Google Scholar]
- Hozjan, V.; Kačič, Z. Context-independent multilingual emotion recognition from speech signals. Int. J. Speech Tech. 2003, 6, 311–320. [Google Scholar] [CrossRef]
- Sahoo, T.K.; Banka, H.; Negi, A. Novel approaches to one-directional two-dimensional principal component analysis in hybrid pattern framework. Neural Comput. Appl. 2020, 32, 4897–4918. [Google Scholar] [CrossRef]
- Han, K.; Yu, D.; Tashev, I. Speech emotion recognition using deep neural network and extreme learning machine. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 223–227. [Google Scholar]
- Deng, J.; Xu, X.; Zhang, Z.; Frühholz, S.; Schuller, B. Semisupervised autoencoders for speech emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 26, 31–43. [Google Scholar] [CrossRef]
- Xie, Y.; Liang, R.; Liang, Z.; Huang, C.; Zou, C.; Schuller, B. Speech emotion classification using attention-based LSTM. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1675–1685. [Google Scholar] [CrossRef]
- Korvel, G.; Treigys, P.; Tamulevicus, G.; Bernataviciene, J.; Kostek, B. Analysis of 2d feature spaces for deep learning-based speech recognition. J. Audio Eng. Soc. 2018, 66, 1072–1081. [Google Scholar] [CrossRef]
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion recognition in human-computer interaction. IEEE Signal. Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Treigys, P.; Korvel, G.; Tamulevičius, G.; Bernatavičienė, J.; Kostek, B. Investigating feature spaces for isolated word recognition. In Data Science: New Issues, Challenges and Applications; Springer: Cham, Switzerland, 2020; pp. 165–181. [Google Scholar]
- Lyon, R.F. Human and Machine Hearing; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- McDermott, J.H. Audition. In Stevens’ Handbook of Experimental Psychology and Cognitive Neuro-Science, 4th ed.; Wixted, J.T., Serences, J., Eds.; Sensation, Perception, and Attention; Wiley: Hoboken, NJ, USA, 2018; Volume 2, pp. 63–120. [Google Scholar]
- Muthusamy, Y.K.; Cole, R.A.; Slaney, M. Speaker-independent vowel recognition: Spectrograms versus cochleagrams. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; pp. 533–536. [Google Scholar] [CrossRef]
- Patterson, R.D.; Holdsworth, J. A functional model of neural activity patterns and auditory images. In Advances in Speech, Hearing and Language Processing; JAI Press Inc.: Stamford, CT, USA, 1996; Volume 3. [Google Scholar]
- Slaney, M. An efficient implementation of the Patterson-Holdsworth auditory filter bank. Apple Comput. Percept. Group Tech. Rep. 1993, 35. [Google Scholar]
- Glasberg, B.R.; Moore, B.C. Derivation of auditory filter shapes from notched-noise data. Hearing Res. 1990, 47, 103–138. [Google Scholar] [CrossRef]
- Maskeliunas, R.; Raudonis, V.; Damasevicius, R. Recognition of emotional vocalizations of canine. Acta Acust. United Acust. 2018, 104, 304–314. [Google Scholar] [CrossRef]
- Vryzas, N.; Vrysis, L.; Kotsakis, R.; Dimoulas, C. Speech emotion recognition adapted to multimodal semantic repositories. In Proceedings of the 13th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Zaragoza, Spain, 6–7 September 2018; pp. 31–35. [Google Scholar] [CrossRef]
- Vazhenina, D.; Markov, K. End-to-end noisy speech recognition using Fourier and Hilbert spectrum features. Electronics 2020, 9, 1157. [Google Scholar] [CrossRef]


{kind=link}
| Dataset and the Number of Emotions | Classifier | Task | Refs | Accuracies (%) |
|---|---|---|---|---|
| Lithuanian (5) | kNN | Monolingual | Liogienė and G. Tamulevičius [31] | 81.7 |
| English SAVEE (7) | Majority voting between multi-class SVM, RF, and Adaboost | Monolingual | Noroozi et al. [32] | 75.71 |
| English RAVDESS (7) | SVM | Monolingual | Bhavan et al. [33] | 75.69 |
| Serbian (5) | 3DEC hierarchical classifier | Monolingual | Hassan and Damper [34] | 94.7 |
| Spanish (7) | RNN | Monolingual | Kerkeni et al. [35] | 91.16 |
| German (4) | GMM + SVM | Monolingual | Vlasenko et al. [36] | 89.90 |
| Adaptive neuro- fuzzy inference systems (ANFIS) | Monolingual | Li and Akagi [13] | 93.00 | |
| Adaptive neuro- fuzzy inference systems (ANFIS) | Multilingual | Li and Akagi [13] | 91.00 | |
| Polish (6) | Majority voting between multi-class SVM, RF, and Adaboost | Monolingual | Noroozi et al. [32] | 88.33 |
| Greek AESDD (5) | SVM | Monolingual | Vryzas et al. [37] | 60.8 (max acc.) |
| CNN | Monolingual | Vryzas et al. [3] | 69.2 (max acc.) | |
| Chinese IEMOCAP (5) | CNN + LSTM | Monolingual | Etienne et al. [38] | 65.3 |
| Italian EMOVO (7) German (4) | GMM | Cross-language | Ntalampiras [15] | 70.1 |
| German, Chinese, and Italian (5) | CNN and bi-directional LSTM with an attention | Multilingual | Fu et al. [39] | 61.14 (for Chinese) 69.26 (for German) 34.50 (for Italian) |
| English and French (2) | Attentive CNN | cross-lingual | Neuman and Vu [40] | From 47.5 to 61.3 |
| English and French (2) | Attentive CNN | multilingual | Neuman and Vu [40] | From 49.3 to 70.1 |
| Dataset | Emotions | ||||
|---|---|---|---|---|---|
| Anger | Sadness | Fear | Neutral | Happiness | |
| Lithuanian | 1000 | 1000 | 1000 | 1000 | 1000 |
| English | 652 | 652 | 652 | 556 | 652 |
| Serbian | 180 | 180 | 180 | 180 | 180 |
| Spanish | 724 | 728 | 735 | 734 | 732 |
| German | 127 | 62 | 69 | 79 | 71 |
| Polish | 164 | 176 | 147 | 197 | 192 |
| Dataset | Training Acc. | Validation Acc. | Test Acc. | F1 Score |
|---|---|---|---|---|
| Spectrograms | ||||
| Lithuanian | 0.9636 | 0.8215 | 0.82 | 0.82 |
| English | 0.9999 | 0.9475 | 0.95 | 0.95 |
| Serbian | 0.9971 | 0.8981 | 0.91 | 0.91 |
| Spanish | 1 | 0.9471 | 0.94 | 0.94 |
| Polish | 1 | 0.8189 | 081 | 0.81 |
| German | 1 | 0.9282 | 0.92 | 0.91 |
| Mel-cepstrograms | ||||
| Lithuanian | 0.8794 | 0.7453 | 0.76 | 0.76 |
| English | 0.9999 | 0.9659 | 0.97 | 0.97 |
| Serbian | 0.9969 | 0.9537 | 0.94 | 0.94 |
| Spanish | 0.9997 | 0.8984 | 0.91 | 0.90 |
| Polish | 0.9994 | 0.7768 | 0.77 | 0.76 |
| German | 1 | 0.9726 | 0.96 | 0.96 |
| Fractal dimension-based features | ||||
| Lithuanian | 0.9469 | 0.6581 | 0.65 | 0.65 |
| English | 0.9252 | 0.8109 | 0.83 | 0.82 |
| Serbian | 0.8841 | 0.8093 | 0.85 | 0.83 |
| Spanish | 0.9301 | 0.7293 | 0.74 | 0.74 |
| Polish | 0.9363 | 0.7172 | 0.71 | 0.71 |
| German | 0.9702 | 0.8820 | 0.85 | 0.85 |
| Cochleagrams | ||||
| Lithuanian | 0.9999 | 0.9681 | 1 | 1 |
| English | 1 | 0.9991 | 1 | 1 |
| Serbian | 0.9963 | 0.9938 | 1 | 1 |
| Spanish | 1 | 0.9971 | 1 | 1 |
| Polish | 1 | 0.9872 | 0.99 | 0.99 |
| German | 1 | 1 | 1 | 1 |
| Spectrograms | Cochleagrams | |||
|---|---|---|---|---|
| Test Acc. | F1 Score | Test Acc. | F1 Score | |
| Lithuanian | 0.82 | 0.82 | 0.97 | 0.97 |
| English | 0.27 | 0.26 | ||
| Serbian | 0.37 | 0.18 | 0.41 | 0.36 |
| Spanish | 0.3 | 0.19 | 0.35 | 0.2 |
| Polish | 0.21 | 0.17 | 0.20 | 0.19 |
| German | 0.49 | 0.27 | 0.42 | 0.40 |
| Spectrograms | Cochleagrams | |||
|---|---|---|---|---|
| Test Acc. | F1 Score | Test Acc. | F1 Score | |
| Lithuanian | 0.85 | 0.85 | 0.95 | 0.95 |
| English | 0.94 | 0.94 | 0.99 | 0.99 |
| Serbian | 0.91 | 0.91 | 0.98 | 0.98 |
| Spanish | 0.35 | 0.34 | 0.31 | 0.30 |
| Polish | 0.33 | 0.21 | 0.30 | 0.25 |
| German | 0.55 | 0.52 | 0.51 | 0.49 |
| Spectrograms | Cochleagrams | |||
|---|---|---|---|---|
| Test Acc. | F1 Score | Test Acc. | F1 Score | |
| Lithuanian | 0.82 | 0.82 | 0.88 | 0.88 |
| English | 0.92 | 0.92 | 0.94 | 0.94 |
| Serbian | 0.87 | 0.87 | 0.94 | 0.94 |
| Spanish | 0.9 | 0.9 | 0.94 | 0.94 |
| Polish | 0.34 | 0.34 | 0.26 | 0.24 |
| German | 0.56 | 0.49 | 0.58 | 0.53 |
| Spectrograms | Cochleagrams | |||
|---|---|---|---|---|
| Test Acc. | F1 Score | Test Acc. | F1 Score | |
| Lithuanian | 0.83 | 0.83 | 0.89 | 0.89 |
| English | 0.92 | 0.92 | 0.96 | 0.96 |
| Serbian | 0.89 | 0.89 | 0.94 | 0.94 |
| Spanish | 0.91 | 0.91 | 0.95 | 0.95 |
| Polish | 0.76 | 0.76 | 0.88 | 0.88 |
| German | 0.88 | 0.88 | 0.95 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tamulevičius, G.; Korvel, G.; Yayak, A.B.; Treigys, P.; Bernatavičienė, J.; Kostek, B. A Study of Cross-Linguistic Speech Emotion Recognition Based on 2D Feature Spaces. Electronics 2020, 9, 1725. https://doi.org/10.3390/electronics9101725
Tamulevičius G, Korvel G, Yayak AB, Treigys P, Bernatavičienė J, Kostek B. A Study of Cross-Linguistic Speech Emotion Recognition Based on 2D Feature Spaces. Electronics. 2020; 9(10):1725. https://doi.org/10.3390/electronics9101725
Chicago/Turabian StyleTamulevičius, Gintautas, Gražina Korvel, Anil Bora Yayak, Povilas Treigys, Jolita Bernatavičienė, and Bożena Kostek. 2020. "A Study of Cross-Linguistic Speech Emotion Recognition Based on 2D Feature Spaces" Electronics 9, no. 10: 1725. https://doi.org/10.3390/electronics9101725
APA StyleTamulevičius, G., Korvel, G., Yayak, A. B., Treigys, P., Bernatavičienė, J., & Kostek, B. (2020). A Study of Cross-Linguistic Speech Emotion Recognition Based on 2D Feature Spaces. Electronics, 9(10), 1725. https://doi.org/10.3390/electronics9101725