2.1. Satellite Networks Topology
The LEO system is modeled as a direct graph
, where
represents the set of satellites and
represents the set of inter-satellite links (ISLs). Each satellite has four ISLs, including two intra-plane ISLs and two inter-plane ISLs [
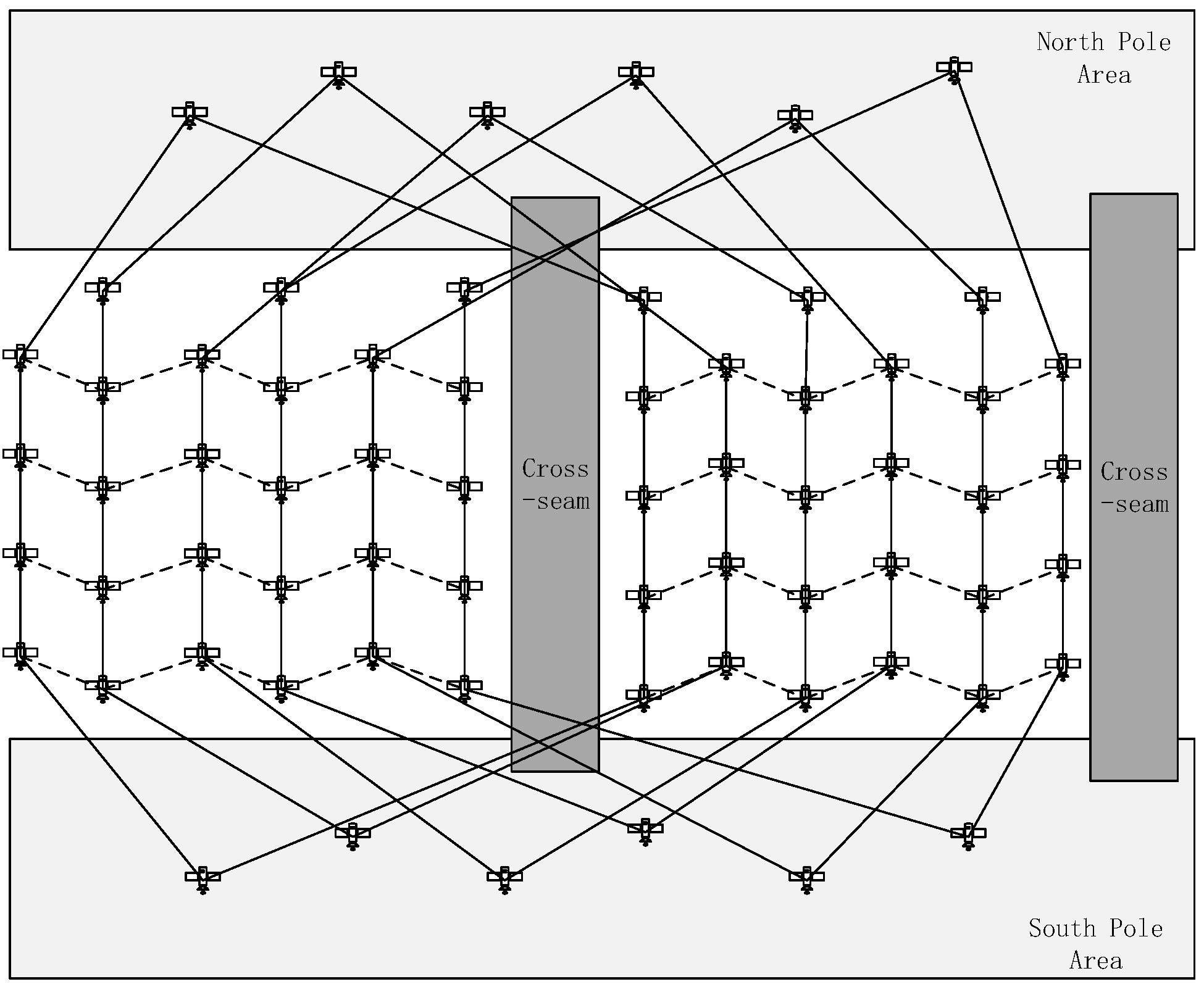
19]. Due to the extreme variation of the angular velocity of inter-plane ISLs—the ISLs within cross-seam—the north and south pole area cannot be built. As to simplify the change of network topology, we adopt the Virtual Node (VN) strategy to set up a satellite networks topology. In VN-based topology, a virtual node is supposed to be the current physical satellite, which is above the specific surface of the earth [
20]. A virtual node and a physical satellite correspond one to one at any time, and the correspondence will change if a physical satellite moves out of the coverage of current VN or into the coverage of another VN [
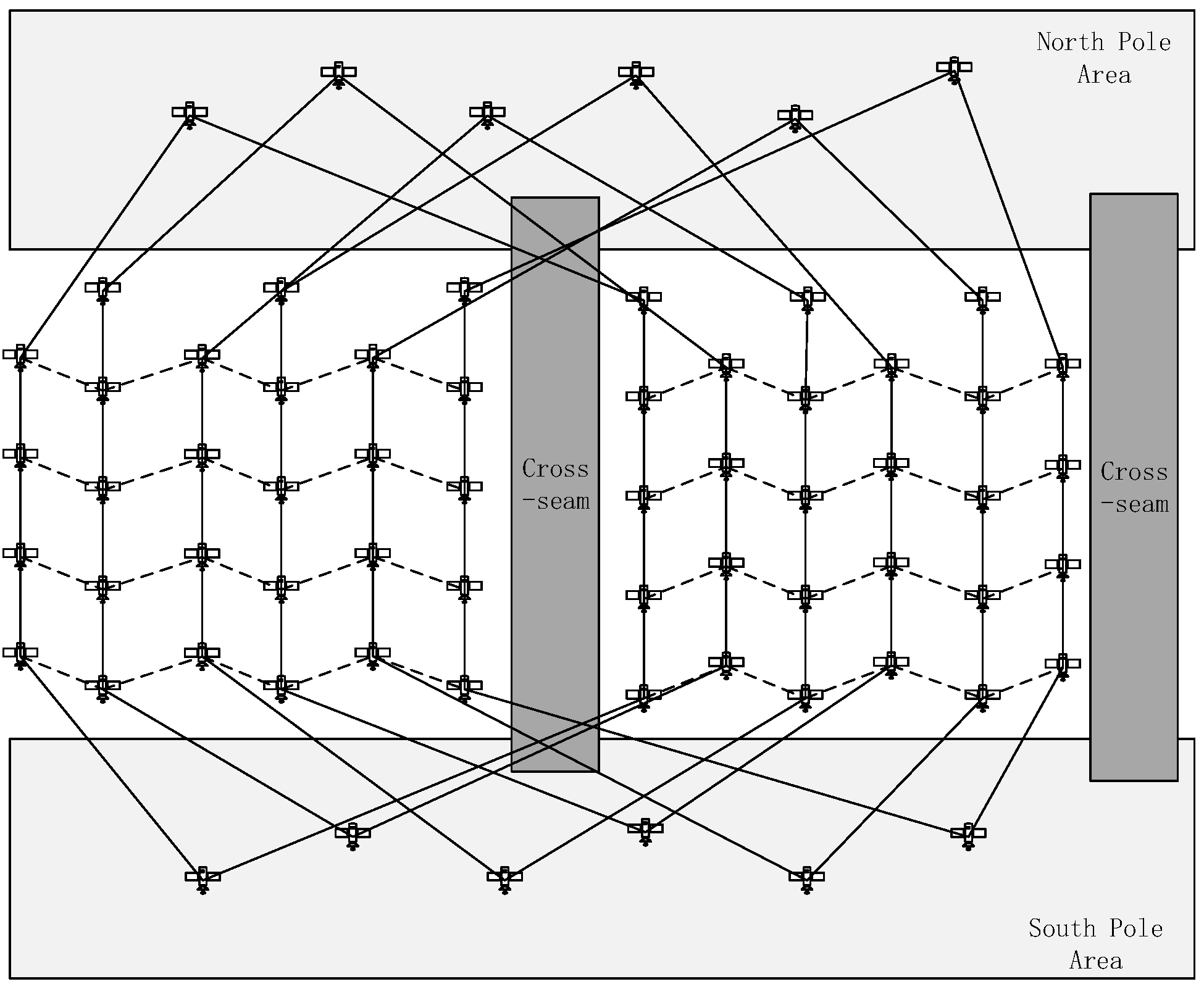
21]. The process of correspondence changing is called handoff. When a handoff happens, the state information will be transferred from the former physical satellite to the latter. In this way, rotating physical satellites can be converted into fixed virtual nodes, and the dynamic topology is also transformed into an accordingly static one. As it is shown in
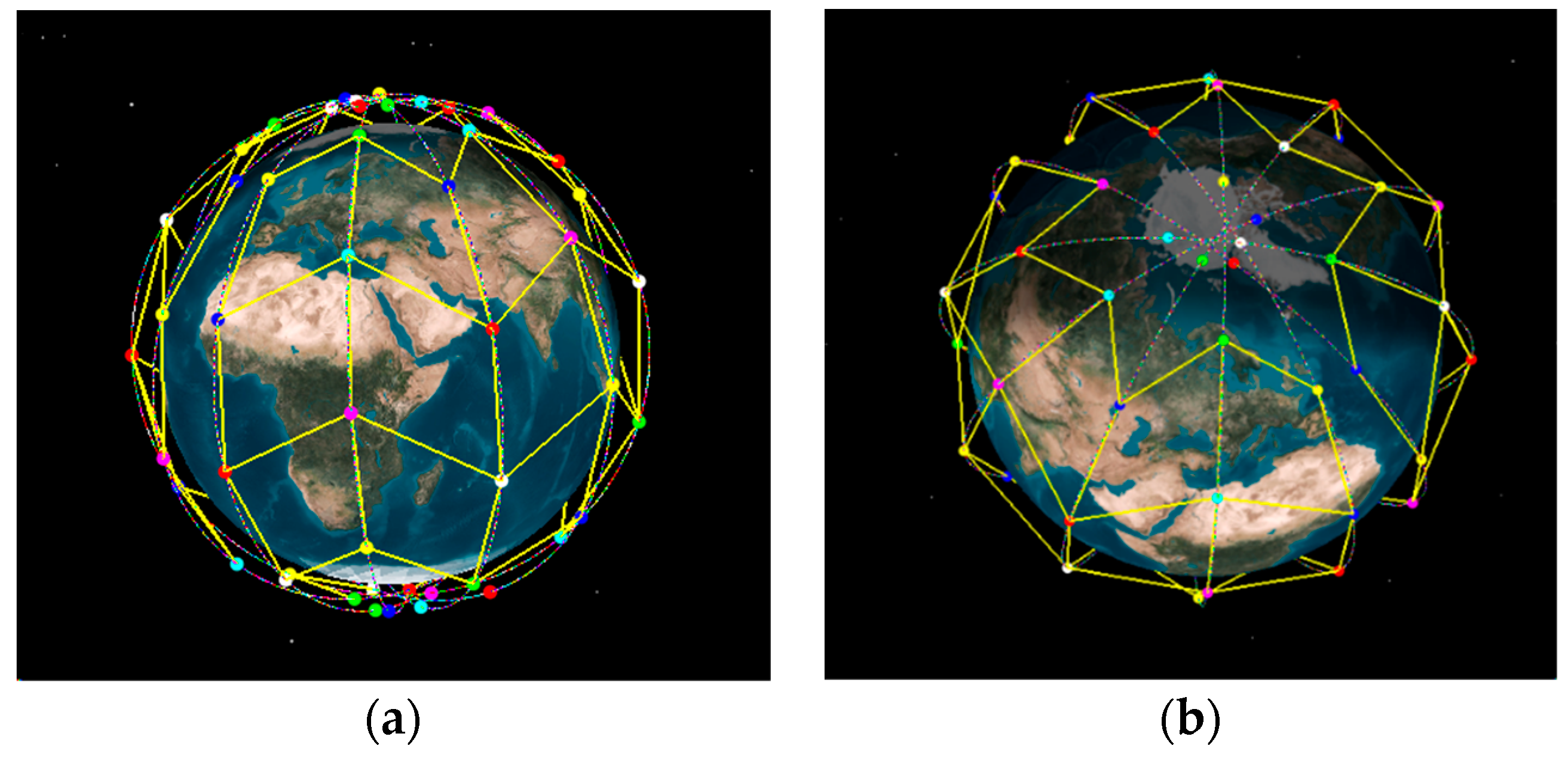
Figure 1, we construct the LEO satellite networks based on STK.
2.2. Setup and Update of Link State
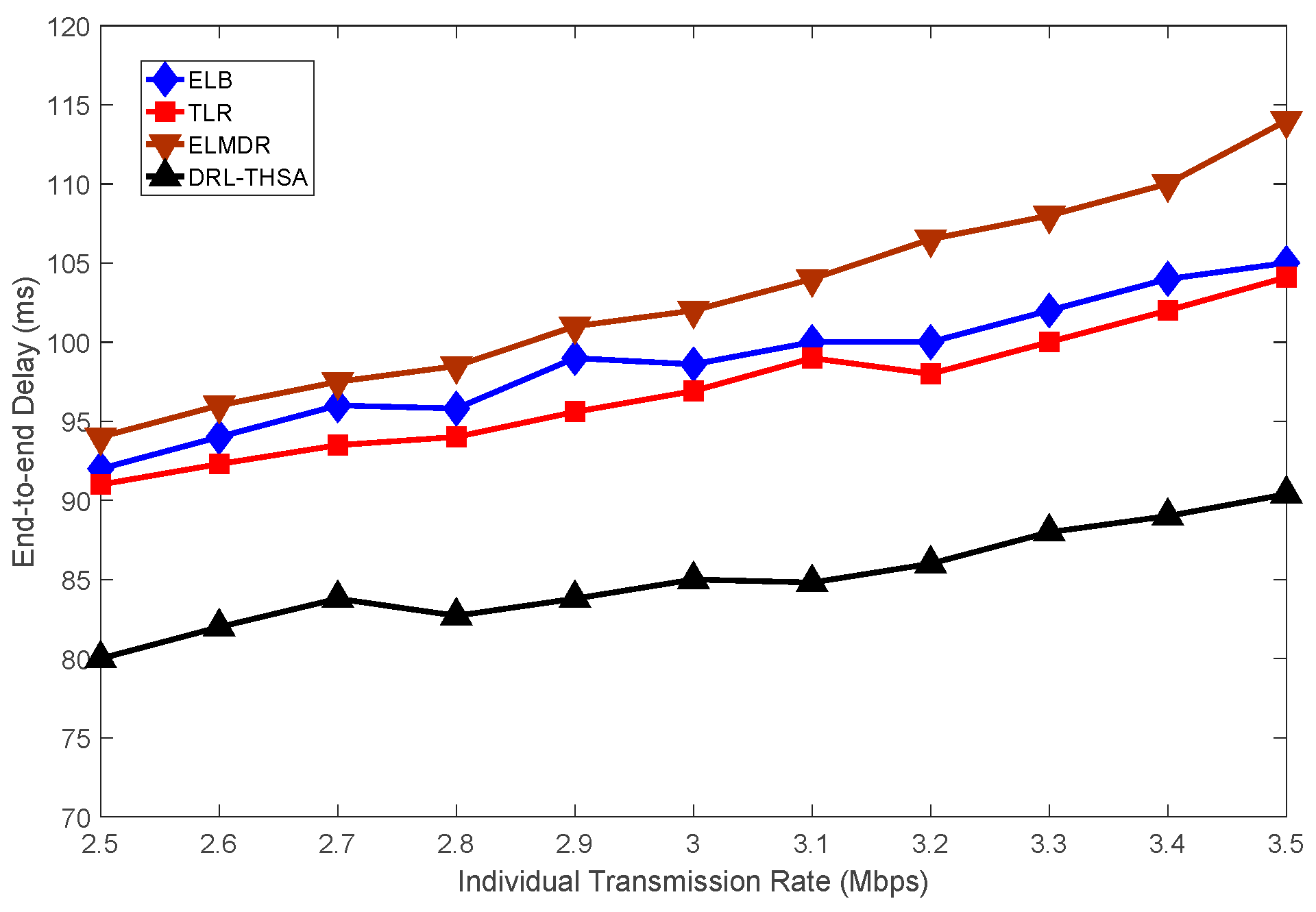
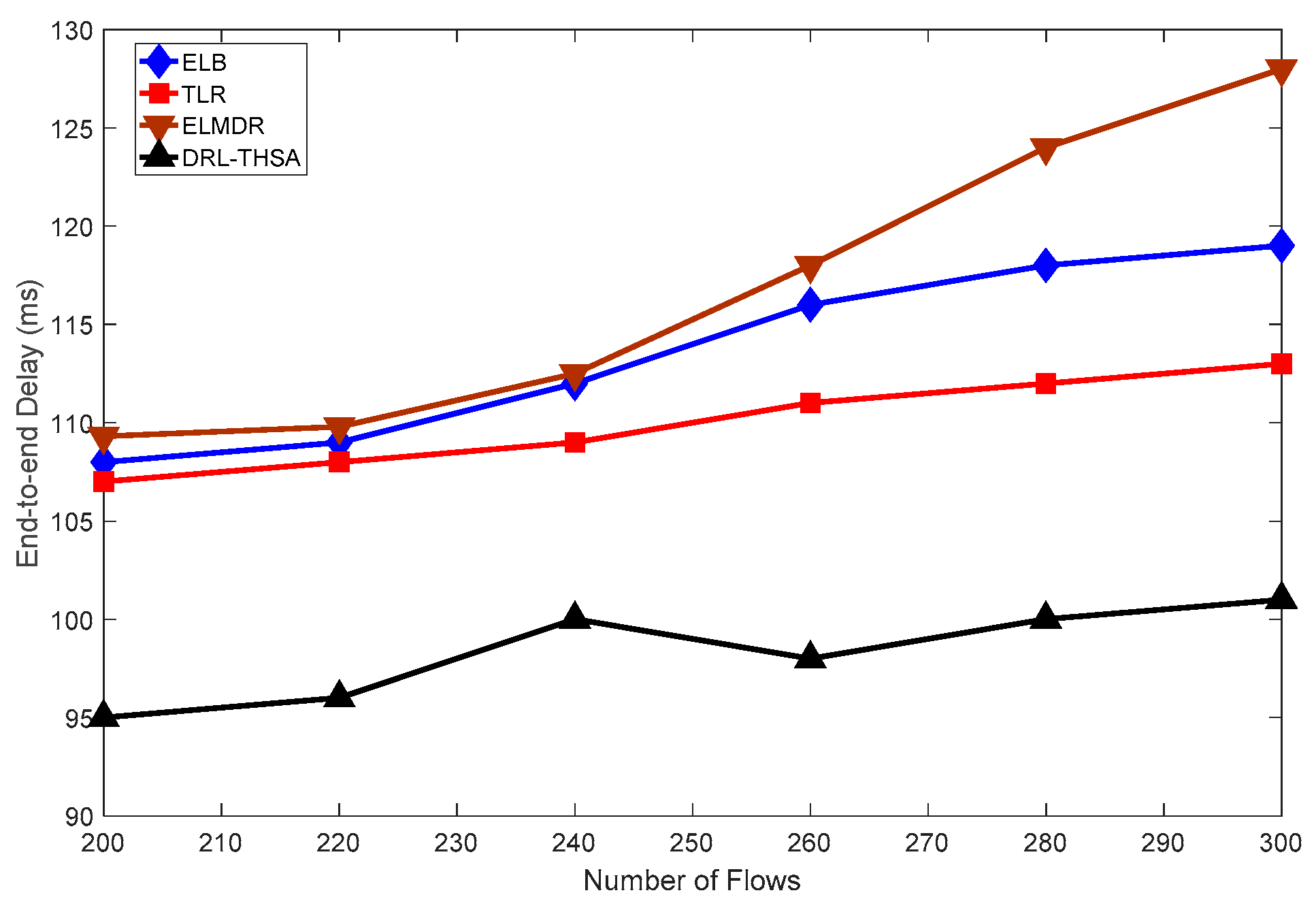
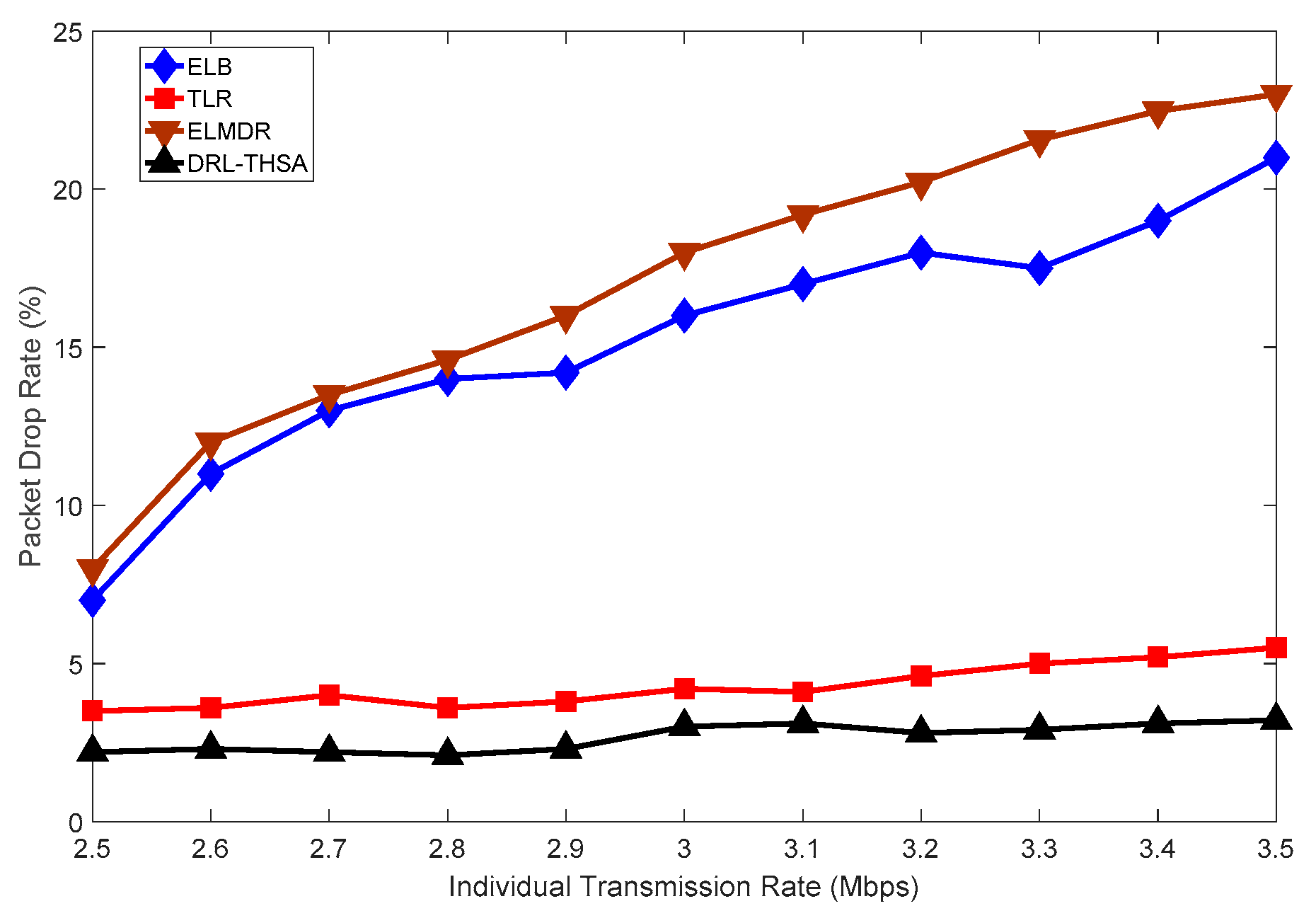
In satellite networks, when satellite receives a packet, the packet is inserted into the buffer queue at one direction by sequence, waiting to be sent out. However, the buffer space is limited, and accumulated packets will fill up the whole queue if the traffic is too heavy. Then the packets which still get into the queue will be dropped. Therefore, it is essential to monitor the queue to reduce unnecessary packets loss.
Let
denote the queue check interval, according to the average input packet rate
and the average output packet rate
in the past, and we predict the average input packet rate
and the average output packet rate
in the next
seconds with Equations (1) and (2):
where
and
represent the weight of the past average input rate and the past average output rate, respectively,
,
. These weights act as filters. The average input packet rate and the average output packet rate are desired to represent the long average packet rate, which should be counted over a long period. The short-term light traffic load needs to be filtered. Therefore, the selection of
and
are essential. If these weights are too large, the average packet rate will nearly equal the instantaneous traffic load. Otherwise, if these weights are too small, it is hard for the average packet rate to represent the long-range traffic load, which results in ineffective estimation and routing computation. In this paper, the values of
and
are assigned dynamically according to the traffic load by Equations (3) and (4).
Thus, the estimated average rate does not change much when the instantaneous traffic load is closed to the estimated traffic load in the last interval. The short-term light traffic load is filtered, and the average packet rate can be estimated effectively.
In DRL-THSA, for a given direction,
denotes the max length of the buffer queue, and
represents the current length of the buffer queue. Therefore, the queue occupancy rate is calculated by Equation (5).
To avoid dropping a packet, it is crucial to make sure that the queue is not full before the next check. The predicted queue occupancy rate is calculated by Equation (6).
In this way, two cases can be envisioned:
Considering the extreme situation, we get
The link state is marked as Free State (FS) when is below T1 and is considered to be Busy State (BS) if is between and . It is defined as Congested State (CS) when exceeds .
To monitor and control the load effectively, if the link state is BS or CS, the satellite should send a notification including the traffic reduction ratio to its neighbor and request it to decrease the input packet rate to .
When the satellite enters BS, assuming the desired time for a satellite to reside in FS is set to be
, the traffic reduction ratio is calculated by Equations (11) and (12).
When the satellite enters CS, it should require its neighbor to stop transmitting the packet immediately. Therefore, is set to be 0.
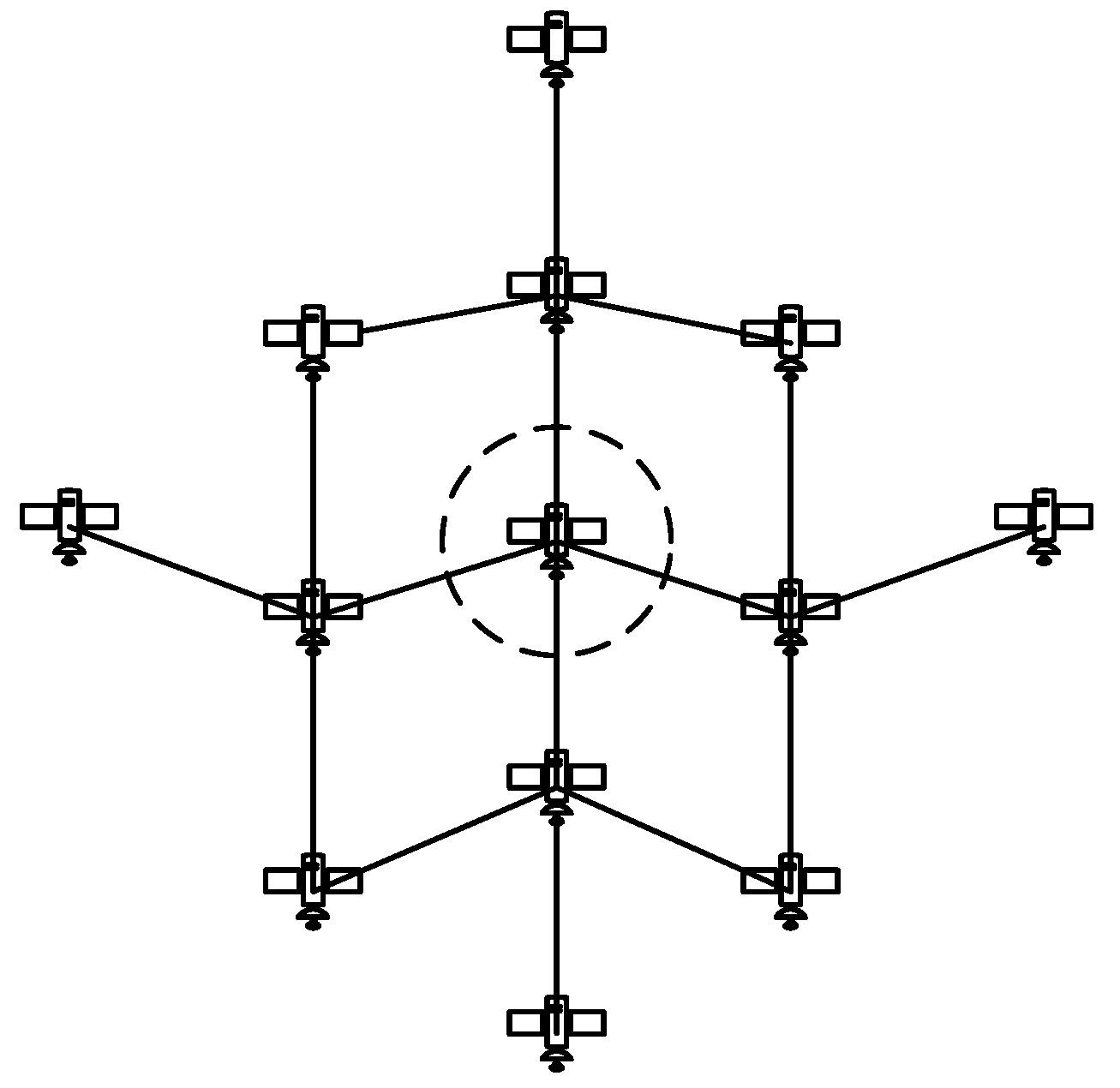
2.3. Two-Hops State Aware Updating
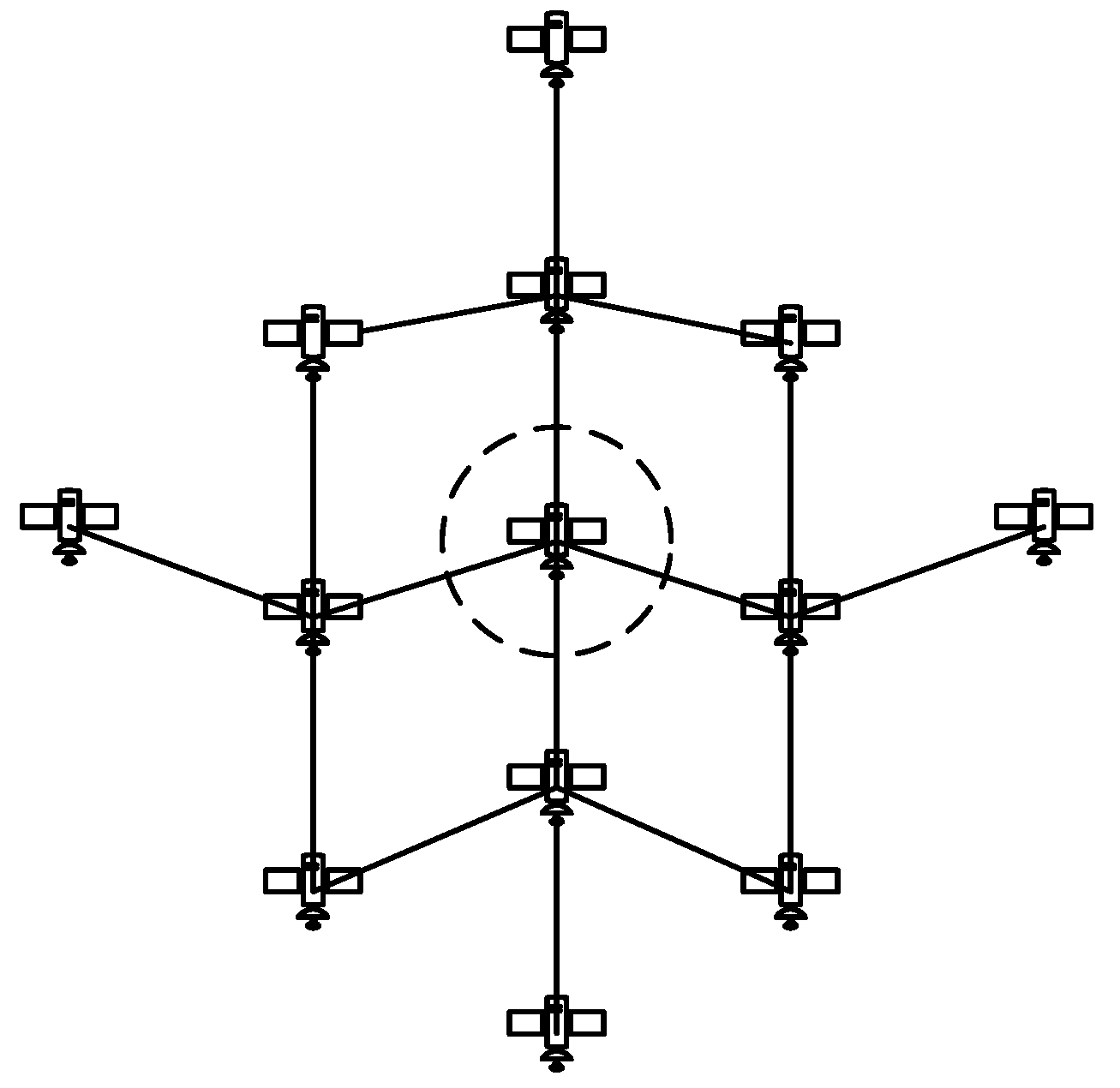
Taking a given satellite as the center, two-hops states consist of the link states of all the ISLs within two-hops. It is shown in
Figure 2.
In DRL-THSA, each satellite keeps both link state table (LST) and neighbors’ link state tables (NLST). The link states are stored as the style in
Table 2.
To monitor the link connectedness, we adopt the HELLO packet strategy proposed in the open shortest path first routing scheme [
22]. The satellite sends HELLO packets to its neighbors with the period
The connectedness is defined to be off if the current satellite does not receive the acknowledgment (ACK) message from the direction
within
. It may not change states until it receives the HELLO packets periodically. When the change happens, the current satellite updates its LST and broadcasts the connectedness change messages to all the other neighbors.
To monitor the link state, satellites check the buffer queue of all the directions with the period . If the current link state is different from the previous one, the current satellite will update its LST and send the link state change messages to its neighbor satellites.
When satellite receives the message from neighbors, it updates NLST according to the information contained in the message. The process of dynamic two-hops state aware updating is shown in Algorithm 1.
| Algorithm 1 Dynamic Two-Hops State Aware Updating |
| Connectedness Updating: |
| while true do |
| broadcast HELLO packets |
| wait |
| end while |
| if receive ACK within then |
| if ( is up to date) then |
| LST().connectedness ← On |
| else |
| drop the message |
| end if |
| else |
| LST().connectedness ← Off |
| end if |
| Link State Updating: |
| while true do |
| calculate and |
| evaluate link state |
| LST().state← |
| wait tc |
| end while |
| Neighbor Link State Updating: |
| Receive link change message |
| if ( is up to date) then |
| continue |
| else |
| drop the message |
| end if |
| if (NLST().state is not equal to ) then |
| NLST().state← |
| else |
| drop the message |
| end if |


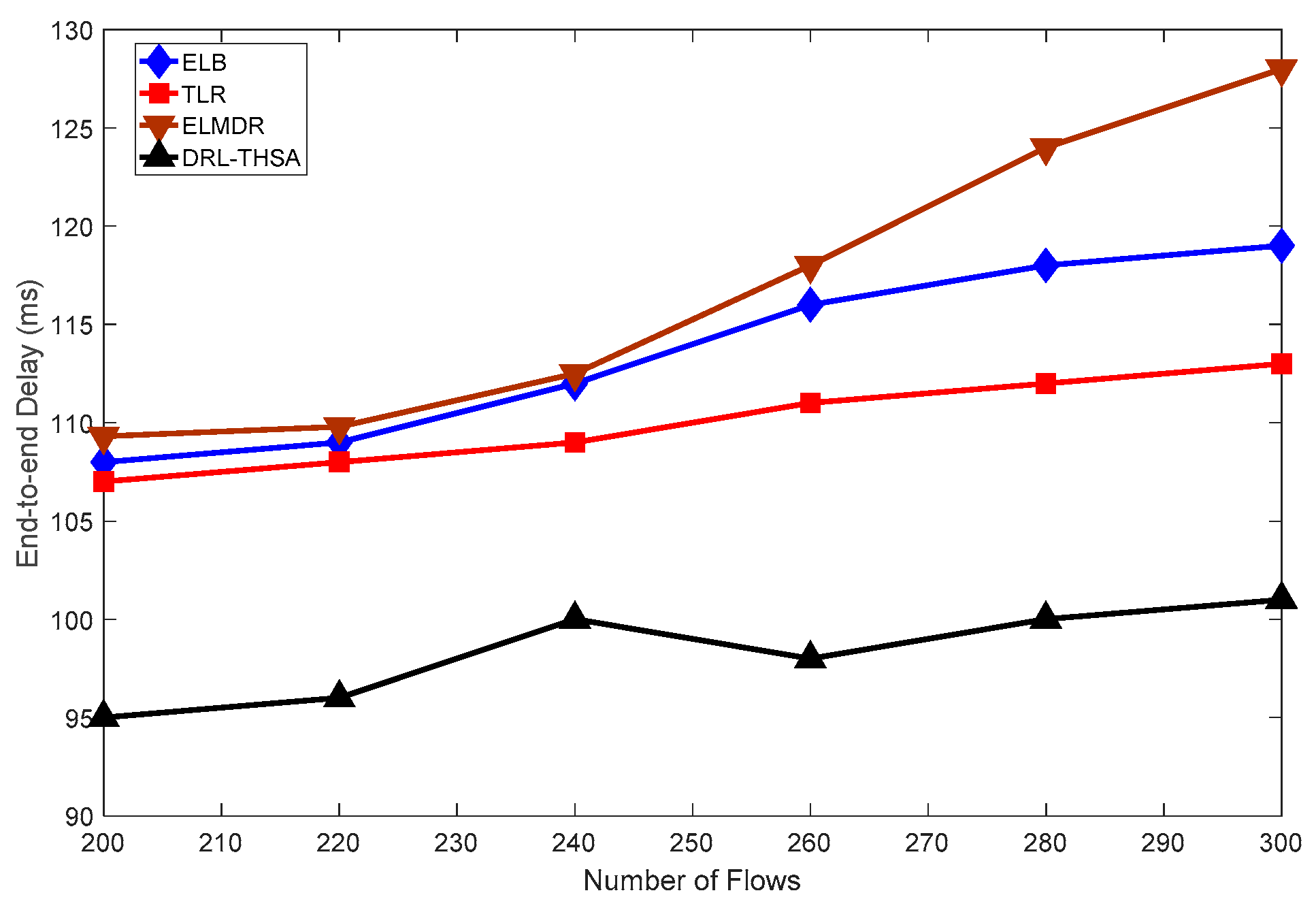

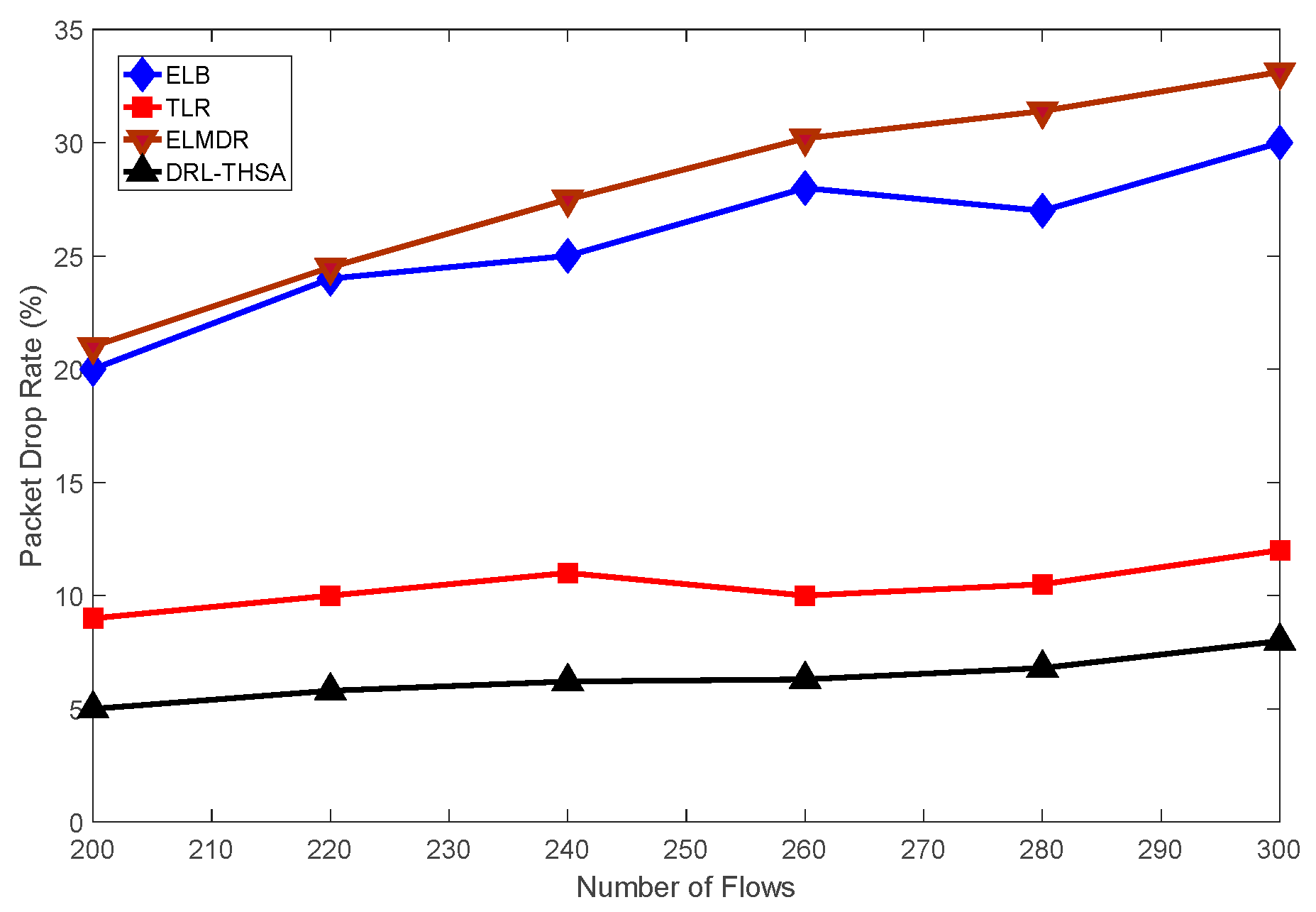
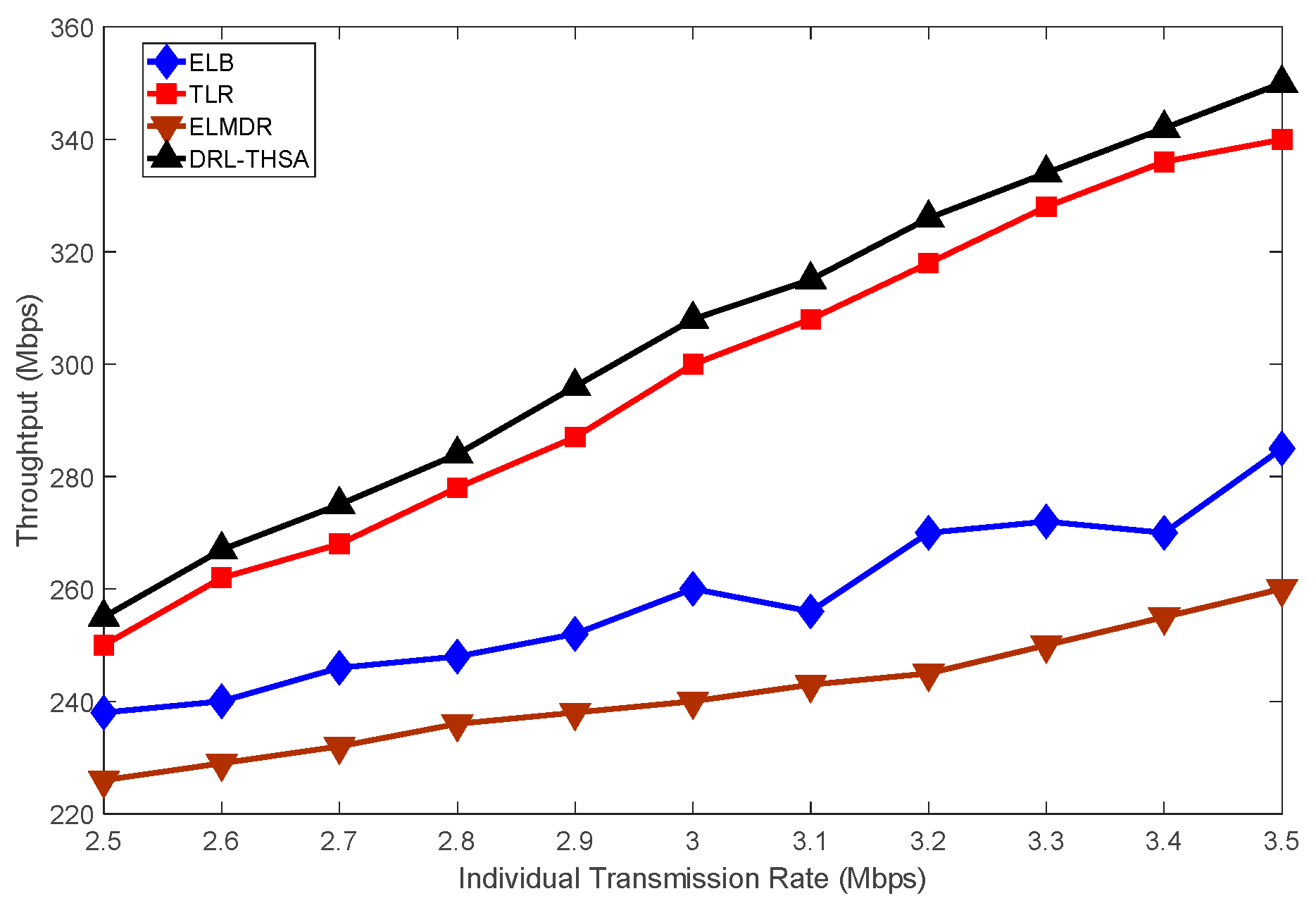
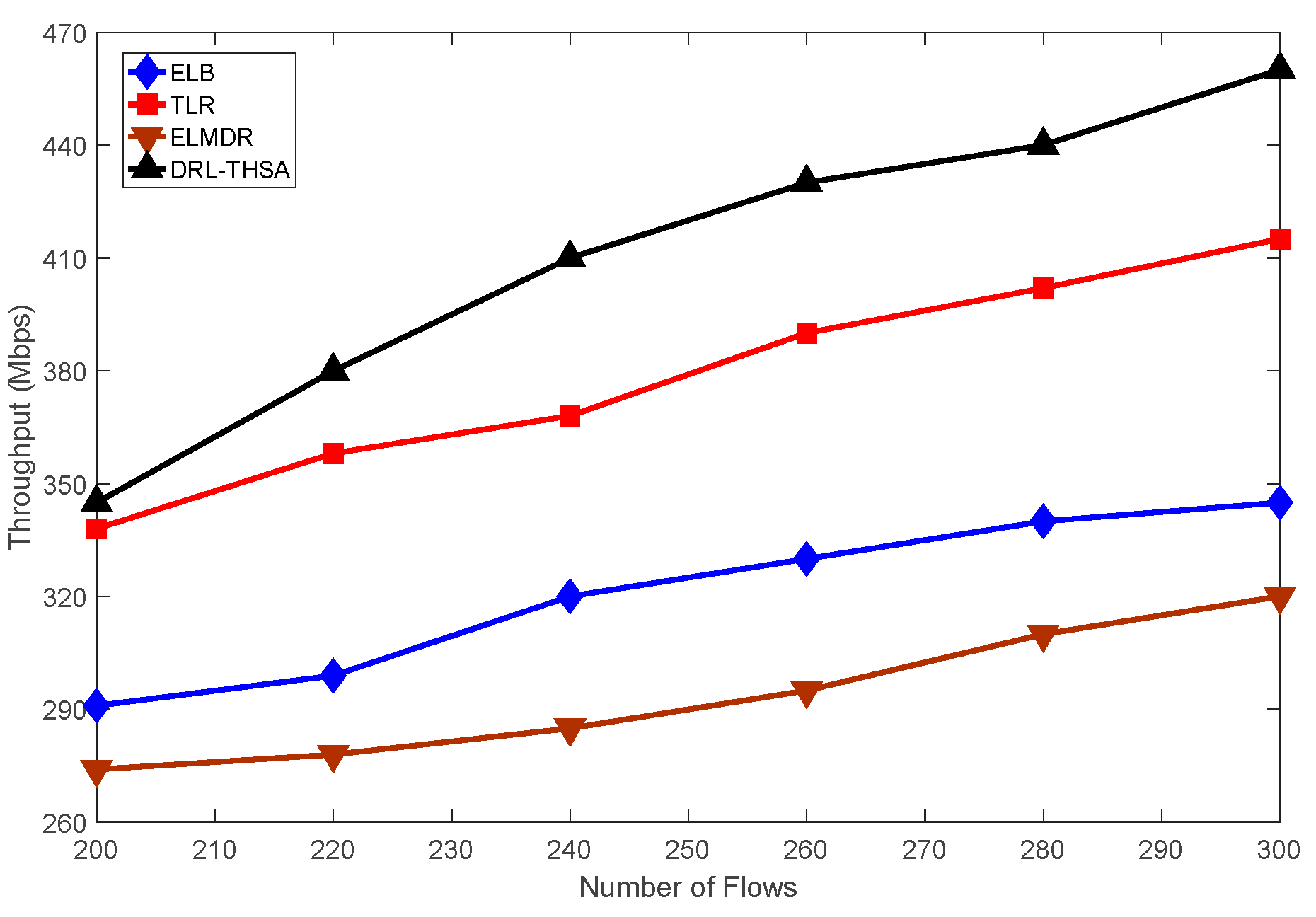
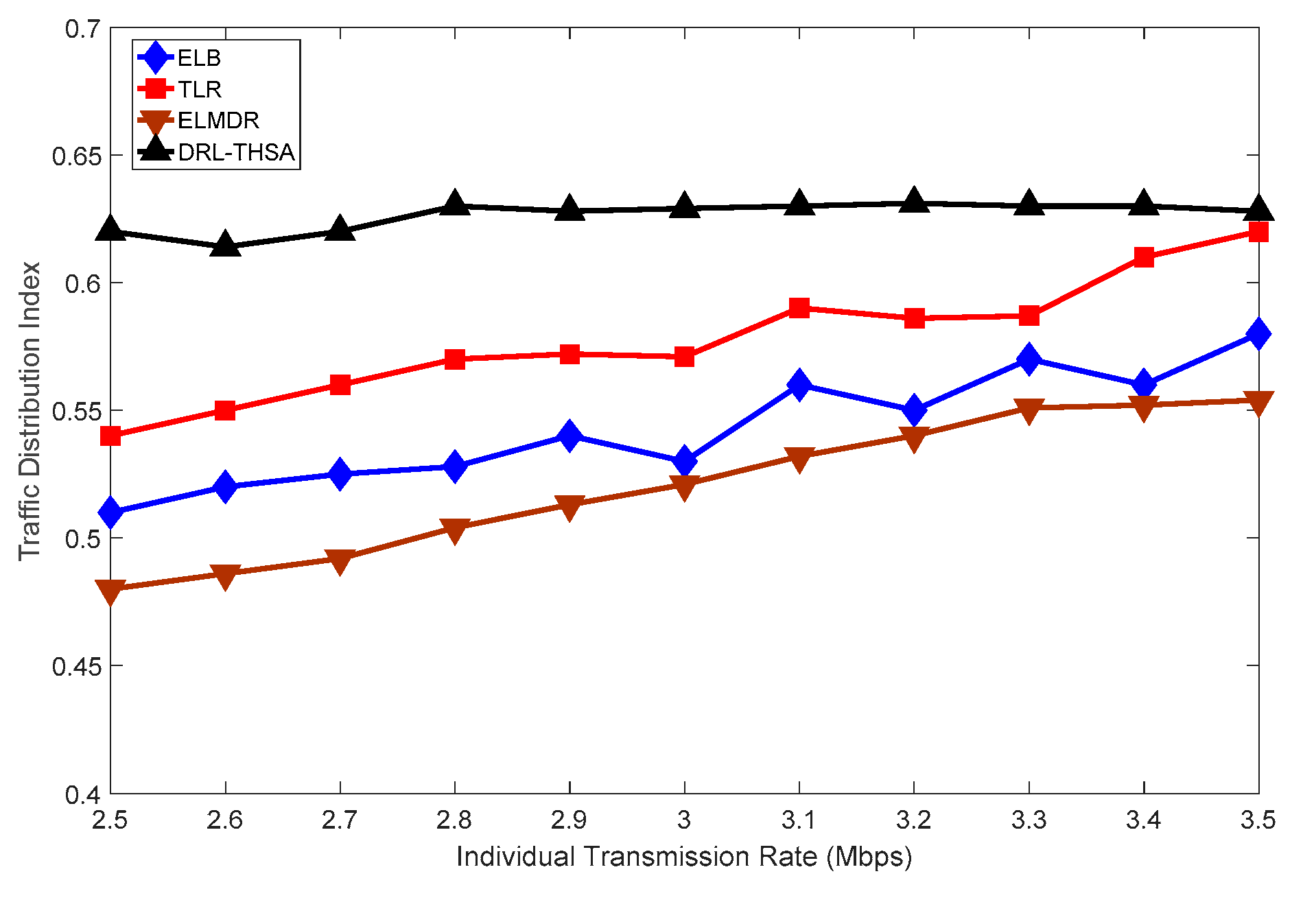
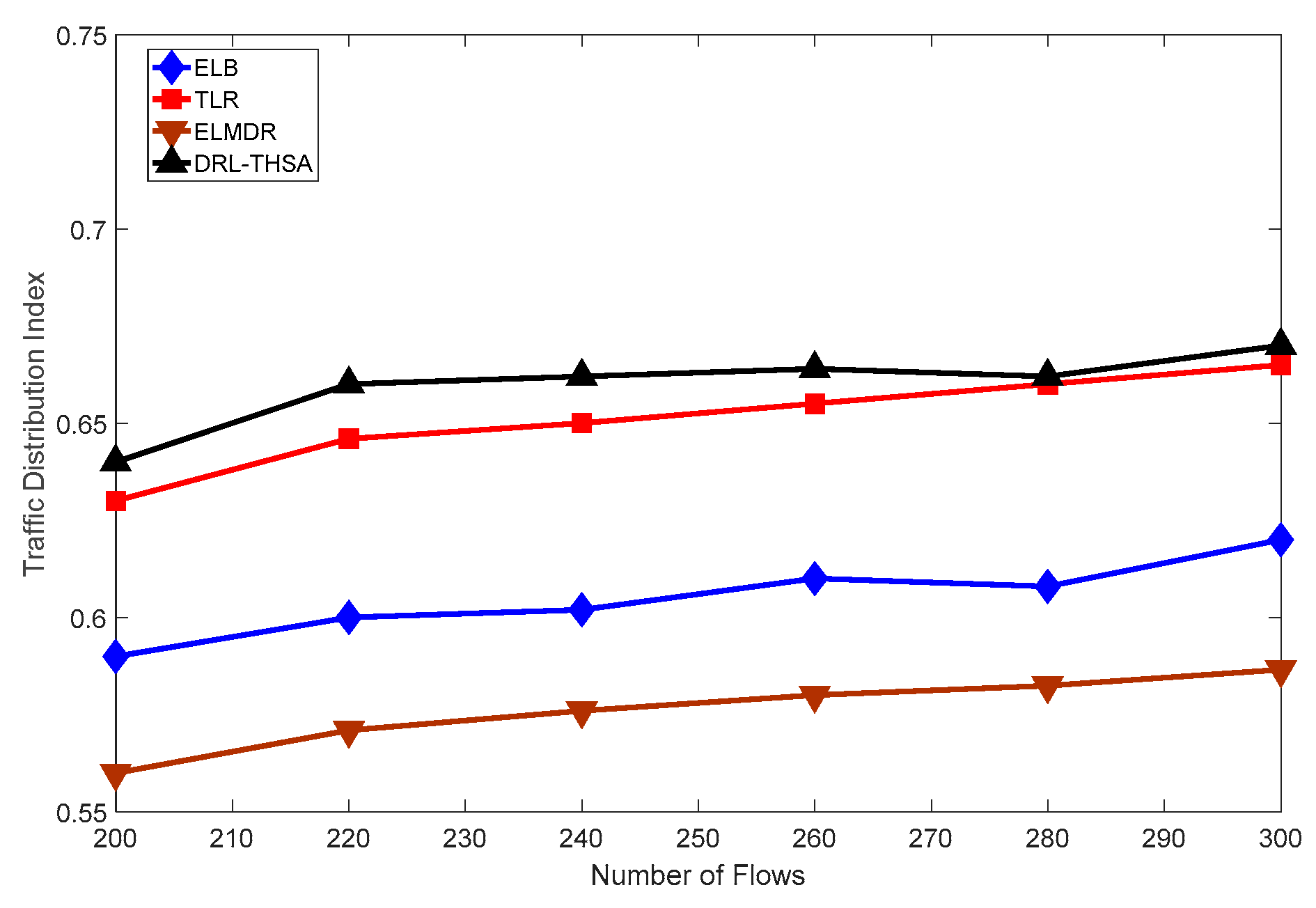
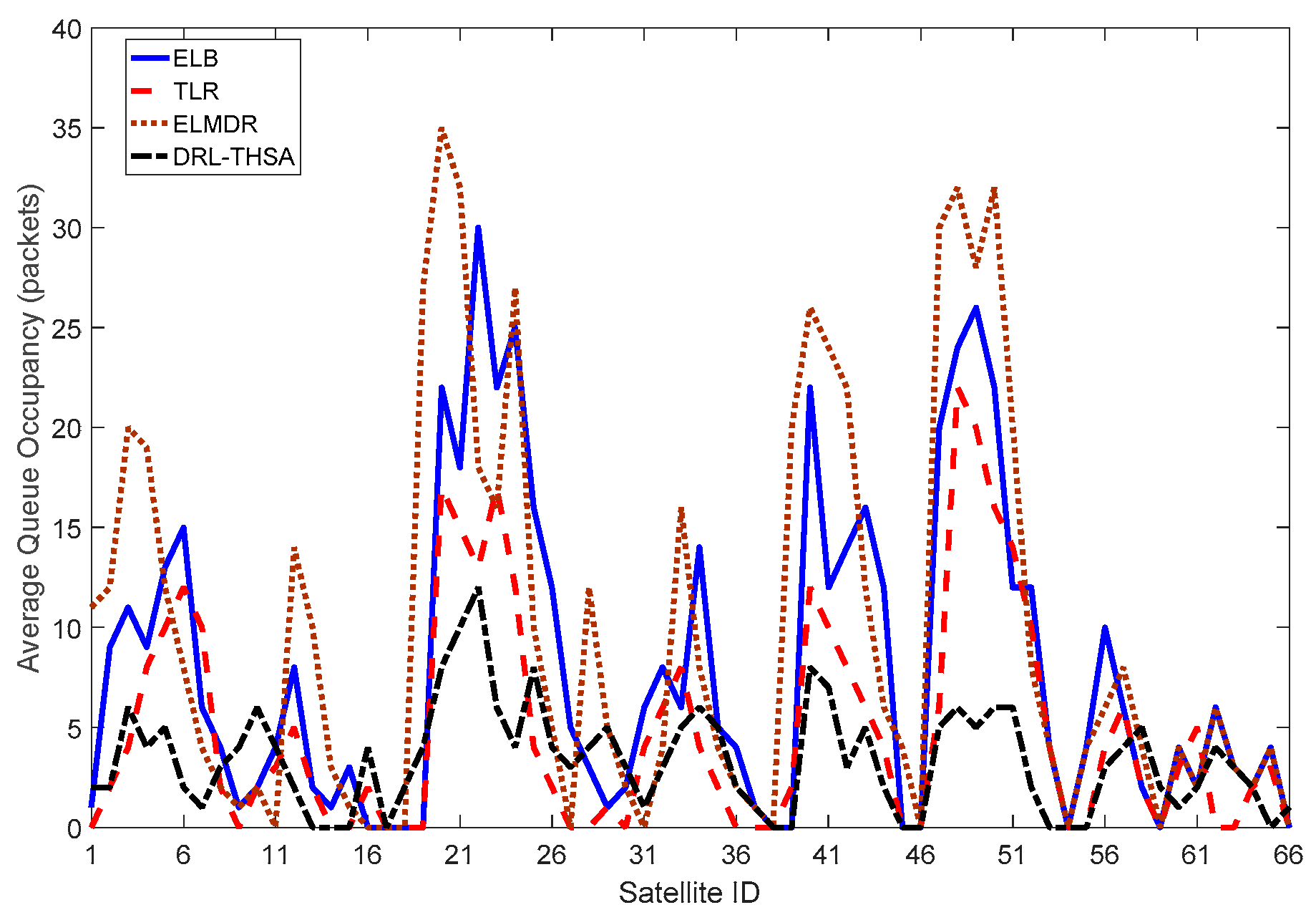

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}