1. Introduction
In the field of electronics and information, signal processing is a hot research topic, and as a special signal, the study of image has attracted the attention of scholars all over the world [
1,
2,
3]. In image processing, image restoration is one of the most important issues and this issue has received extensive attention in the past few decades [
4,
5,
6,
7,
8,
9,
10,
11]. Image restoration is a technology that uses degraded images and some prior information to restore and reconstruct clear images, to improve image quality. At present, this technology has been widely used in many fields, such as medical imaging [
12,
13], astronomical imaging [
14,
15], remote sensing image [
16,
17], and so on. In this paper, the problem of image deblurring under impulse noise is considered. Normally, camera shake, and relative motion between the target and the imaging device may cause image blurring; while in digital storage and image transmission, impulse noise may be generated.
In the process of image deblurring under impulse noise, the main task is to find the unknown true image
from the observed image
defined by
where
denote the process of image degradation by impulse noise, and
is a blurring operator. It is known that when
is unknown, the model deals with blind restoration, and when
is known, it deals with image denoising.
There are two main types of impulse noise: salt-and-pepper noise and random-valued noise. Suppose the dynamic range of
to be
, for all
, the
is the gray value of an image
at location
, and
. For 8-bit images,
and
. Then for salt-and-pepper noise, the noisy version
at pixel location
is defined as
where
s is the noise level of the salt-and-pepper noise.
For random-valued noise, the noisy version
at pixel location
is defined as
where
is uniformly distributed in
and
r is the noise level of random-valued noise. It is clear that compared with salt-and-pepper noise, the random-valued noise is more difficult to remove since it can be arbitrary number in
.
For image-restoration problem contaminated by impulse noise, the widely used model is composed of data fidelity term measured by
norm and the TV regularization term, which is called TVL1 model [
18,
19,
20]. TVL1 model can effectively preserve image boundary information and eliminate the influence of outliers, so it is especially effective to deal with non-Gaussian additive noise such as impulse noise. Now, it has been widely and successfully applied in medical image and computer vision.
However, TVL1 model has its own shortcomings, which makes it ineffective in dealing with high-level noise, such as 90% salt-and-pepper noise and 70% random-valued noise [
21]. In recent years, a large number of scholars have devoted themselves to this research, and a lot of algorithms have been proposed [
22,
23,
24,
25,
26,
27]. In 2009, Cai et al. [
22] proposed a two-phase method, and in the first phase, damaged pixels of the contaminated image were explored, then in the second phase, undamaged pixels were used to restore images. Numerical experiments show that the two-phase method is superior to TVL1 model, it can handle as high as 90% salt-and-pepper noise, and as high as 55% random-valued noise, while it cannot perform effectively when the level of random-valued noise is higher than 55%. Similarly, considering the problem that TVL1 model may deviate from the data-acquisition model and the prior model, especially for high levels of noise, Bai et al. [
23] introduced an adaptive correction procedure in TVL1 model and proposed a new model called the corrected TVL1 (CTVL1) model. The main idea is to improve the sparsity of the TVL1 model by introducing an adaptive correction procedure. The CTVL1 method also uses two steps to restore the corrupted image, the first step generates an initial estimator by solving the TVL1 model, and the second step generates a higher accuracy recovery from the initial estimator which is generated by TVL1 model. Meanwhile, for higher salt-and-pepper noise and higher random-valued noise, by repeating the correction step for several times, high levels of noise can be removed very well. Numerical experiments show that the CTVL1 model can remove salt-and-pepper noise as high as 90%, and remove random-valued noise as high as 70%, which is superior to the two-phase method.
Similar to CTVL1 method, Gu et al. [
24] combined TV regularization with smoothly clipped absolute deviation (SCAD) penalty for data fitting, and proposed TVSCAD model; Gong et al. [
25] used minimax concave penalty (MCP) in combination with TV regularization for data fitting, and he proposed TV-MCP model. Numerical experiments show that both TVSCAD model and TV-MCP model can achieve better effects than two-phase method. But compared with CTVL1 method, their contributions mainly focus on the convergence rate, and they did not improve much in terms of impulse noise removal.
However, as is described in [
28], TV norm may transform the smooth area to piecewise constants, the so-called staircase effect. To overcome this deficiency, the efficient way is to replace the TV norm by a high-order TV norm [
29]. In particular, second-order TV regularization schemes are widely studied for overcoming the staircase effects while preserving the edges well in the restored image. In [
30], Si Wang proposed a combined total variation and high-order total variation model to restore blurred images corrupted by impulse noise or mixed Gaussian plus impulse noise. In [
27], based on Chen and Cheng’s an effective TV-based Poissonian image deblurring model, Jun Liu introduced an extra high-order total variation (HTV) regularization term to this model, which can effectively remove Poisson noise, and its effect is better than Chen and Cheng’s model. In [
31], Gang Liu combined the TV regularizer and the high-order TV regularizer term, and proposed HTVL1 model, which can better remove the impulse noise contrast to TVL1 model. However, since TVL1 model has its own defects, the restoration of HTVL1 model is limited. Besides, the author did not consider the removal effect of random-valued noise.
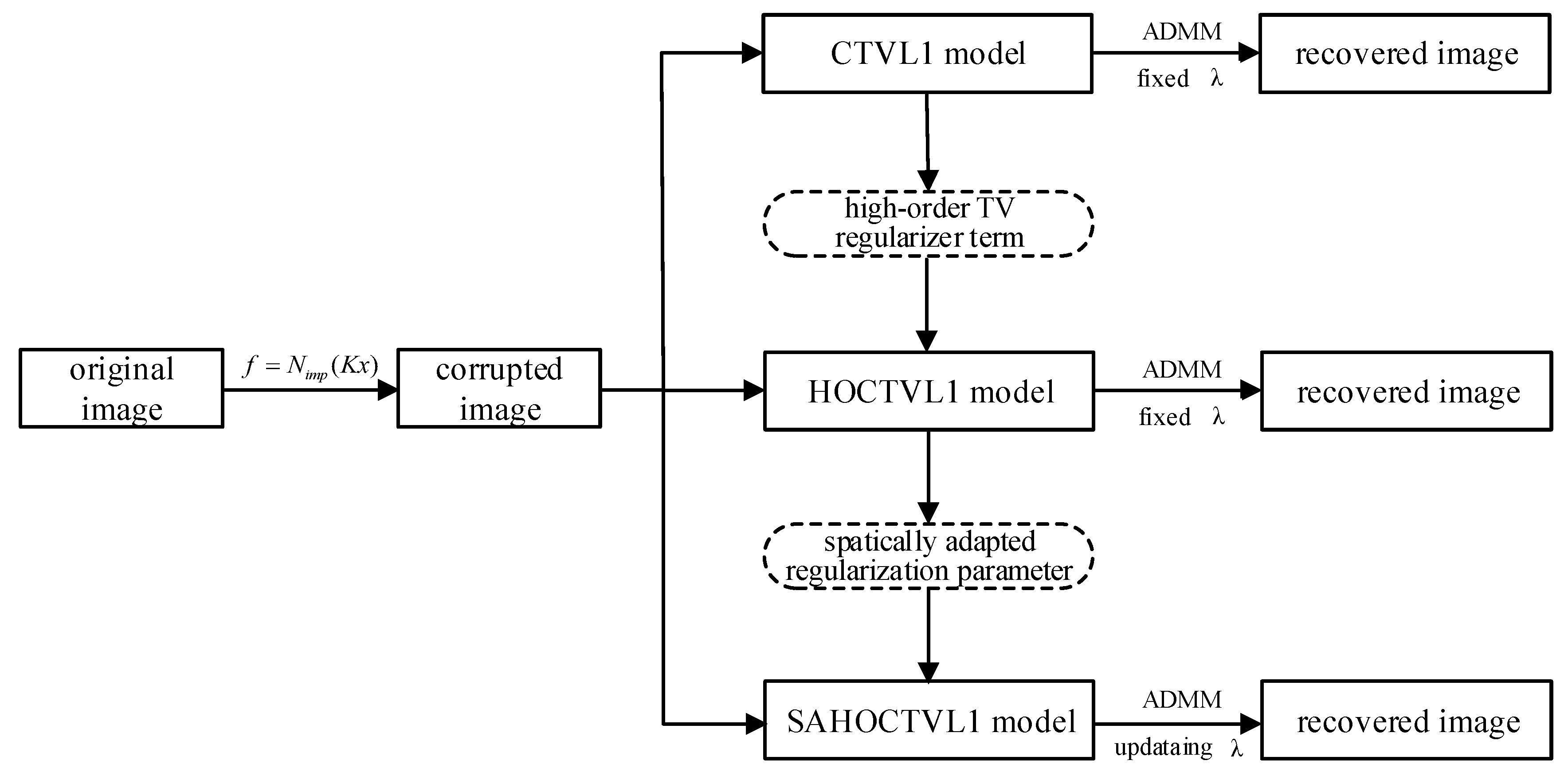
In this paper, we continue to study the problem of image deblurring under impulse noise. The main contributions of this paper include: (1) Combining high-order TV regularizer term with CTVL1 model, a new model named high-order corrected TVL1(HOCTVL1) model is proposed and the alternating direction method of multipliers (ADMM) is used to solve this new model. Compared with existing models, our model can get higher signal-to-noise (SNR) in dealing with image deblurring under impulse noise. (2) The spatially adapted regularization parameter is introduced into the HOCTVL1 model and SAHOCTVL1 model is proposed. Compared to HOCTVL1 model, SAHOCTVL1 model can further improve the effects of image restoration in some degree.
The rest of this paper is organized as follows. In
Section 2, a brief review of related work is made. In
Section 3, the presentation of HOCTVL1 model is discussed, and the HOCTVL1 algorithm is concluded.
Section 4 introduces the spatially adapted regularization parameter selection scheme, and SAHOCTVL1 model is proposed. Numerical experiments are carried out in
Section 5 and finally, the conclusion is presented in
Section 6.
2. Brief Review of Related Work
For recovering the image corrupted by blur and impulse noise, the classic method is TVL1 model. Since a lot of literature [
19,
20,
31,
32,
33] demonstrates that using L1-fidelity term for image restoration under impulse noise can achieve good effects, the TVL1 model is expressed as
where
is the observed image,
denotes the restoration image,
is a blur matrix,
is a regularization parameter which is greater than zero,
represents the discrete TV norm and is defined as
. Here,
denotes the discrete gradient operator (under periodic boundary conditions). The norm in
can be taken as
norm or
norm. When the
norm is used, the resulting TV term is isotropic and when the
norm is used, the result is anisotropic. For more details about the TV norm, readers can refer to [
18].
Since one of the unique characteristics of impulse noise is that an image corrupted with impulse noise still has intact pixels, the impulse noise can be modeled as sparse components, whereas the underlying intact image retains the original image characteristics [
34]. Therefore, TVL1 model can efficiently remove abnormal value noise signals, and some points of the solution of the TVL1 model are close to the points of the original image. However, Nikolova [
21] pointed out from the viewpoint of MAP that the solutions of the TVL1 model substantially deviate from both the data-acquisition model and the prior model, and Minru Bai [
23] further pointed out that the TVL1 model does not perform well at the sparsity of
and there are many biased estimates produced by the TVL1 model. To overcome this shortcoming, Bai et al. took a correction step to generate an estimator to obtain a better recovery performance.
Given a reasonable initial estimator
generated by TVL1 model, let
, then she established a model called CTVL1 model, which is defined as
Compared with TVL1 model, CTVL1 model is added a correction term
, and
:
is an operator defined as
and the scalar function
:
takes the form
where
and
. Numerical results show that the CTVL1 model improves the sparsity of the data fidelity term
greatly for the images deblurring under impulse noise, to achieve a good denoising effect.
Since TV regularization term may come into staircase effects, in the past few years, a lot of researchers have devoted to solving this problem, and they concluded that replacing the TV norm by a high-order TV norm can get a better effect. The majority of the high-order norms involve second-order differential operators because piecewise-vanishing second-order derivatives lead to piecewise-linear solutions that better fit smooth intensity changes [
35]. The second-order TV norm is defined as
where
denote the second-order difference of the
th entry of the vector
. Here we just briefly mention the concept of second-order TV norm, for more details, readers can refer to [
36].
Figure 1 shows the diagram of image restoration. In this paper, two models named HOCTVL1 model and SAHOCTVL1 model are proposed and are used to recover the corrupted images.
4. SAHOCTVL1 Model
It is known that the regularization parameter
controls the trade-off between the fidelity and the smoothness of the solution. Usually in most models,
is a fixed value. In [
39], Dong et al. developed a new automated spatially adapted regularization parameter selection method, and had a good effect on the Gaussian noise removal. In [
27,
40], the authors proposed a spatially adapted regularization parameter selection scheme for Poissonian image deblurring. In [
31], the authors used the spatially adapted regularization parameter selection scheme for the impulse noise removal, while this method did not always show good results. In this section, the spatially adapted regularization parameter selection scheme described in [
39] is adopted into the HOCTVL1 model, and SAHOCTVL1 algorithm is concluded.
Firstly, the SAHOCTVL1 model is defined as
where ∘ represents the pointwise product. Here,
is a matrix as the same size of
, and its all elements equal to one constant when we set its initial value.
As described in [
39], the local window filter is defined as
with
fixed, and
.
Let
r represents the noise level, and
represents the control constant for controlling the fidelity term. For the salt-and-pepper noise removal, we set
and the
updating rule is expressed as
where
L is a large constant to ensure
is finite,
,
is a local window with the center on
, and
,
.
For the random-valued noise removal, the
is defined as
Then the
updating rule is expressed as
where the parameters
,
L,
, and
are the same as before.
Now, the spatially adapted HOCTVL1 Algorithm 2 can be concluded.
| Algorithm 2: Spatially adapted algorithm for solving the SAHOCTVL1 model |
Input: , Maxiter, . Initialization: , , , , , , . Step 1. Solve the model Equation ( 22) by Algorithm 1, and get , Step 2. Update via Equations ( 24)–( 26) for salt-and-pepper noise, Update via Equations ( 27)–( 29) for random-valued noise, Step 3. stop or set and return to Step 1. Output: .
|
5. Numerical Results
In this section, numerical results will be presented to illustrate the efficiency of the proposed models. Firstly the HOCTVL1 model is compared with TVL1 [
20], HTVL1 [
31], CTVL1 [
23], then four state-of-the-art methods are selected for comparisons and the methods include LpTV-ADMM [
26], the Adaptive Outlier Pursuit (AOP) method [
41], the Penalty Decomposition Algorithm (PDA) [
42], L0TV-PADMM [
43]. It should be noted that we all only use HOCTVL1 model in these tests for comparison. In the last subsection, the efficiency of SAHOCTVL1 model will be compared with HOCTVL1 separately. In this section, the convergence of HOCTVL1 model is analyzed too. The test images are mainly: Lena, camera, pepper, boat, which are shown in
Figure 3. In the experiments, for ease of comparison, we only consider “Gaussian” blurring kernel, since the model is also suitable for other blurring kernels. Besides, signal-to-noise ratio (SNR) is used to evaluate the quality of restoration, which is defined as
where
and
denote the original and restored image respectively, and
represents the mean of
. To evaluate the convergence rate, the running time of every algorithm is considered. For fairness, the stop criterion is the same among the algorithms mentioned in the experiments, which is expressed as
All experiments are operated under the Windows 10 and MATLAB R2018a with the platform Lenovo of Intel (R) Core (TM) i5-4200M CPU@2.50GHz 2.50 GHz made in Beijing, China.
5.1. Parameter Setting
In this subsection, we mainly define the values of some parameters in the experiments. In [
23], the author set
for TVL1 model, and
,
,
for CTVL1 model. In [
31], the author set
,
,
, the local window size
for HTVL1 model. In this paper, firstly we decide the value of
. Choose camera as test image and add salt-and-pepper noise with noise level 30%, the blurring kernel is Gaussian (hsize = 7, standard deviation = 5). When setting
(not the most appropriate
) and varying
from 500 to 30,000, the trend of SNR of the restored image is shown in
Figure 4. From
Figure 4, it can be seen that with the increasing of
, SNR is also increasing, and when
, the trend keeps stable. In order to obtain good numerical results, in this paper, we set
.
Then considering the selection of
, it is often a troublesome thing. In most cases, scholars obtain the appropriate
through experience or a lot of attempts. In [
24], Gong defined a selection scheme of
based on numerical experiments, which is expressed as follows.
where
denotes the “best”
found for TVL1 model,
c is a constant and
r represents the noise level. It means that we still need to struggle for the
of TVL1 model. Through a large number of simulation experiments, we find that the difficulty in selecting
mainly lies in the initial value of
when the noise level is 10%, and as the noise increases, the value of
decreases.
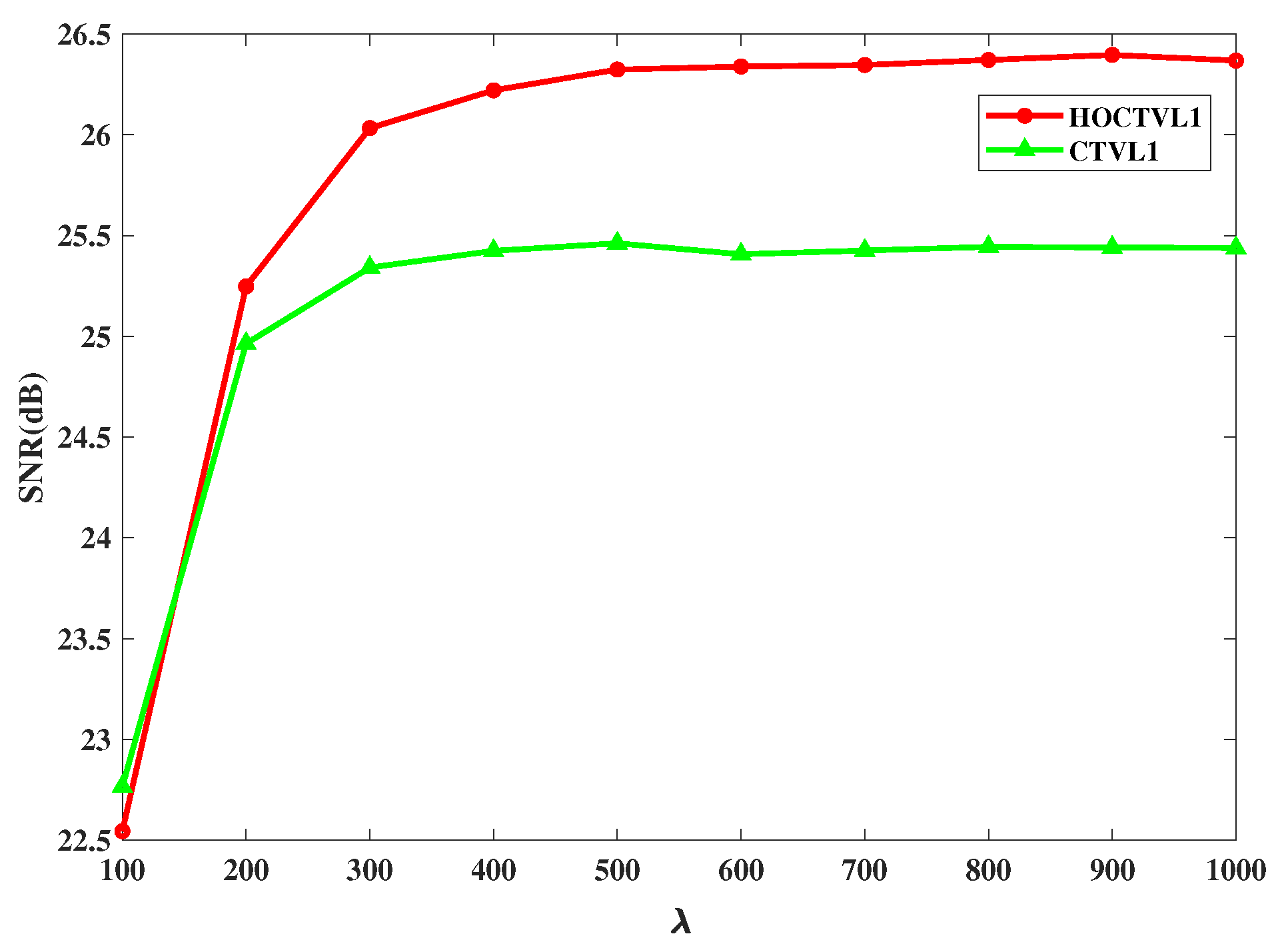
Figure 5 shows the results of HOCTVL1 model and CTVL1 model corrupted by 10% salt-and-pepper noise with different
and it can be seen that the appropriate
for HOCTVL1 is almost the same with the
for CTVL1. Therefore, similarly, we can adopt the
for CTVL1 model in our HOCTVL1 model, and we set
for impulse noise with noise level 10%.
The size of local window
is a factor that may influence the noise removal effect of SAHOCTVL1 model. In [
33], the author illustrated through experiments that it can reduce more noise and recover more details when
. Here, we also make an experiment. We choose camera as test image, and add 30% salt-and-pepper noise. When varying
from 3 to 31, the SNR of the restored image is shown in
Figure 6. From
Figure 6, generally speaking, SNR does not change much, and when
, SNR tends to be stable. Therefore, in this paper, we still set
and the other parameters are the same as mentioned before.
5.2. Convergence Analysis of HOCTVL1 Model
In this subsection, the convergence of HOCTVL1 algorithm will be analyzed. In [
23], the author has proved that the CTVL1 model can converge to an optimal solution and its dual. Let
be the iterative sequence generated by the ADMM approach, and set
,
,
. It is obvious that
,
, and
are closed proper convex functions. Then according to the subsection 4.3 of [
23], it is easy for us to obtain the convergence result of HOCTVL1 model. Here, we verify the convergence property of HOCTVL1 model from another point of view. We observe the changes of SNR and
with the iterations by considering the camera image of size of
corrupted by Gaussian blur (hsize = 15, standard deviation = 5) and 50% salt-and-pepper noise,
, as are shown in
Figure 7.
It can be seen that the SNR value (or the function ) increases (or decreases) monotonically, which can demonstrate the convexity of the model. Besides, it can be seen that after 130th iteration, the SNR values keep stable, and the function remains unchanged after 70th iteration, which means that the model has converged to an optimal solution.
5.3. Comparisons of TVL1, HTVL1 and CTVL1 Models
In this subsection, some experiments are made to illustrate the superiority of HOCTVL1 model in removing the impulse noise and overcoming the staircase effects. By comparing the restoration effect of TVL1, HTVL1 and CTVL1 models, the superiority of our model is further illustrated. For CTVL1 model and HOCTVL1 model, the results of TVL1 model are used as the initial value, and the initial value is same. The blurring kernel is Gaussian (hsize = 15, standard deviation = 5). Next, the experiments will be carried out from three aspects: (1) Deblurring image under salt-and-pepper noise. (2) Deblurring image under random-valued noise. (3) Analysis of convergence rate.
5.3.1. For Salt-and-Pepper Noise
Firstly, the visual comparisons of Lena image corrupted by Gaussian blur and salt-and-pepper noise with noise levels 30%, 50%, 70% are carried out, and the results are shown in
Figure 8,
Figure 9 and
Figure 10 respectively. The unit of SNR value is dB.
From
Figure 8,
Figure 9 and
Figure 10, it can be found that for noise levels 30% and 50%, four models can all remove the salt-and-pepper noise effectively, but the quality of the restored images is different. The restored image by HOCTVL1 model is closer to the original image and its SNR is the highest. For noise level 70%, the restored image by TVL1 model is not clear. The restored image by HTVL1 model is clearer than the restored image by TVL1 model, but there are some noise points in the image that have not been removed, while both CTVL1 model and HOCTVL1 model can get a good restored result. By comparing the results of TVL1 model and HTVL1 model, the image quality can be indeed improved by introducing the high-order TV regularizer term. However, since the poor performance of TVL1 model, the results of HTVL1 is not very good. Since an adaptive correction procedure is introduced in CTVL1 model, which can greatly enhance the effect of image deblurring. While we combine the CTVL1 model with second-order TV regularizer term, which can further improve the effect of image deblurring. Both for removing the salt-and-pepper noise with noise level from 30% to 70%, HOCTVL1 model can have a great performance. It cannot only provide a very good visual effect, but also achieve a higher SNR. Especially for noise level 30%, the SNR value of the restored image by HOCTVL1 model is more than 1 dB higher than that by CTVL1 model and for noise level 50%, the SNR value obtained by HOCTVL1 model is also about 0.6 dB higher than CTVL1 model.
For noise level 90%, HOCTVL1 model can also use the step correction to improve the removal effect, as shown in
Figure 11.
Figure 11 shows the results of CTVL1 model and HOCTVL1 model during five correction steps. It can be seen that after several correction steps, two models both can improve the effect of image deblurring though the effect of TVL1 model is worse. However, from first correction step to fifth correction step, the SNR of our HOCTVL1 model is always higher than CTVL1 model. After first correction step, the SNR of recovered image by HOCTVL1 model is about 0.6 dB higher than CTVL1 model. Meanwhile, after three correction steps, the SNR of the restored image keeps stable, and the noise is eliminated, which shows that the correction efficiency of HOCTVL1 model is very high.
Table 1 shows the results of the four models for restoring the corrupted images with noise levels 10%, 30%, 50%, 70% and 90%. The test images are what are shown in
Figure 3. It should be noted that the values of CTVL1 and HOCTVL1 model for noise level 90% are the SNR of the restored images after first correction step. From
Table 1, it can be seen that compared with other three models, HOCTVL1 model can achieve a higher SNR value. It can also be seen that there is a great improvement in HOCTVL1 model compared with TVL1 and HTVL1 model no matter what the noise level is. Compared with CTVL1 model, there is about 1 dB higher in restoring the Lena, pepper and boat images when noise levels are 10% and 30%. Even for recovering camera image, the SNR of the restored image by HOCTVL1 model is still at least 0.5 dB higher than CTVL1 model when noise levels are 10% and 30%. For noise level 90%, the SNR of our HOCTVL1 model is the highest among the four model, though there is only a slight improvement in the camera image.
5.3.2. For Random-Valued Noise
For the sake of testing the performance of HOCTVL1 model in removing random-valued noise, we also carry out a series of experiments.
Figure 12 and
Figure 13 show the visual comparisons of Lena image corrupted by Gaussian blur and random-valued with noise levels 30% and 50%. It can be seen that for noise level 30%, both four models can effectively restore the corrupted image, but the image restored by TVL1 is still somewhat blurred, the images recovered by other three models are clearer and the recovered image by HOCTVL1 model is closer to the original image and its SNR is the highest. For noise level 50%, there is a little noise in
Figure 13b,c, which shows that TVL1 and HTVL1 models cannot completely remove the 50% random-valued noise though HTVL1 model has a better performance. While CTVL1 model and HOCTVL1 model can remove noise very well, and the recovered image by HOCTVL1 model is clearer than that by CTVL1 model, which illustrates that high-order regularizer term can effectively restrain the staircase effects. Meanwhile, the value of SNR of HOCTVL1 model also illustrates this point.
Figure 14 shows the results of TVL1, five correction steps of CTVL1 model and eighth correction steps of HOCTVL1 model for removing the random-valued noise with noise level 70%. Though the performance of TVL1 model is not good, after several correction steps, both CTVL1 model and HOCTVL1 model can improve the restoration effect. Meanwhile, it can be found that the SNR of the new model is always higher than CTVL1 model after the same correction step. Besides, after the eighth correction step, there are only a few noise points in the image and the restored image is very clear, which shows the superiority of HOCTVL1 model.
Table 2 shows the results of the four models for restoring the corrupted images with noise levels 10%, 30%, 50%, 70%. The values of CTVL1 and HOCTVL1 models for noise level 70% in
Table 2 are also the SNR of the restored images after first correction step. The values show the superiority of our model for removing the random-valued noise. Different to removing salt-and-pepper noise, there is only a little improvement compared to CTVL1 model for removing noise as high as 70%. But when the noise level is lower than 70%, the improvement is remarkable.
5.3.3. Analysis of Convergence Rate
Now, we analyze the convergence rate of four models. We choose Lena as the test image, and use the running time to evaluate the convergence rate.
Figure 15 shows the time that four models spend restoring the corrupted Lena image under impulse noise with different level. It can be seen that when dealing with the same noise, TVL1 and CTVL1 model cost relatively less time. Because of the combination of high-order TV regularizer term, which increases the computational complexity of the algorithm, HTVL1 and HOCTVL1 models consume more time compared to TVL1 and CTVL1 model. While HOCTVL1 model can effectively reduce the staircase effect and restore more details, it is worthwhile taking more time.
Figure 16 shows the change of
with the iteration number when dealing with the salt-and-pepper noise with noise levels 30% and 50%. It can be seen that the convergence rate of HOCTVL1 model is slower than CTVL1 model, and the iteration number is about twice as much as that of CTVL1 model.
5.4. Comparisons of Some Other Methods
In this subsection, we compare the effect of the HOCTVL1 model with some other methods for image deblurring under impulse noise, mainly include: LpTV-ADMM [
26], AOP [
41], PDA [
42] and L0TV-PADMM [
43]. Since in [
23], the author has shown the superiority of CTVL1 model by numerical experiments compared with two-phase method, in this subsection, we do not consider two-phase method. In this experiment, for ease of comparison, we choose “Gaussian” blurring kernel with hsize =9 and standard deviation =7, which is same with [
43] and the parameter settings of these methods also obey to the related papers and readers can refer to them for details.
Firstly, we show the visual results of the pepper image corrupted by salt-and-pepper noise and random-valued noise with noise level 50% respectively, as are shown in
Figure 17 and
Figure 18.
From
Figure 17 and
Figure 18, it can be seen that the restoration effect of HOCTVL1 model is very remarkable. It is obvious that HOCTVL1 model has the highest SNR, followed by PDA and AOP methods, and the Lp-ADMM method has the lowest SNR. When removing 50% salt-and-pepper noise, as shown in
Figure 17, compared with Lp-ADMM method, the SNR of (f) is more than twice as (b). Compared with L0-PADMM method, the SNR of our model is also 4 dB higher. When removing 50% random-valued noise, compared with L0-PADMM method, our model has only about 2 dB improvement in SNR, which is less than that in removing salt-and-pepper noise. But similarly, compared with Lp-ADMM method, our model has more than 100% improvement.
Table 3 shows the results of the five methods for restoring the corrupted images by impulse noise with different noise level, respectively. The value on the left of “/” represents the result after the first correction step and the value on the right of “/” represents the result after multi-correction steps. For removing salt-and-pepper noise, it is obvious that Lp-ADMM and PDA methods perform poorly, and when noise level is 90%, Lp-ADMM method has the worst effect. When the noise level varies from 30% to 70%, HOCTVL1 model has the highest SNR in most cases, except the SNR of L0TV-PADMM when dealing with the camera image with noise level 70%. It can also be seen that L0TV-PADMM method has the best restoration effect and its SNR value is higher than our model when the noise level is 90%. For dealing with random-valued noise, it can be seen that our model has the highest SNR when noise level varies from 30% to 50%. Similarly, for noise level 70%, L0TV-PADMM method has certain advantages; however, it can be seen from Lena and boat images that our model can achieve a higher SNR than L0TV-PADMM method after multi-correction steps.
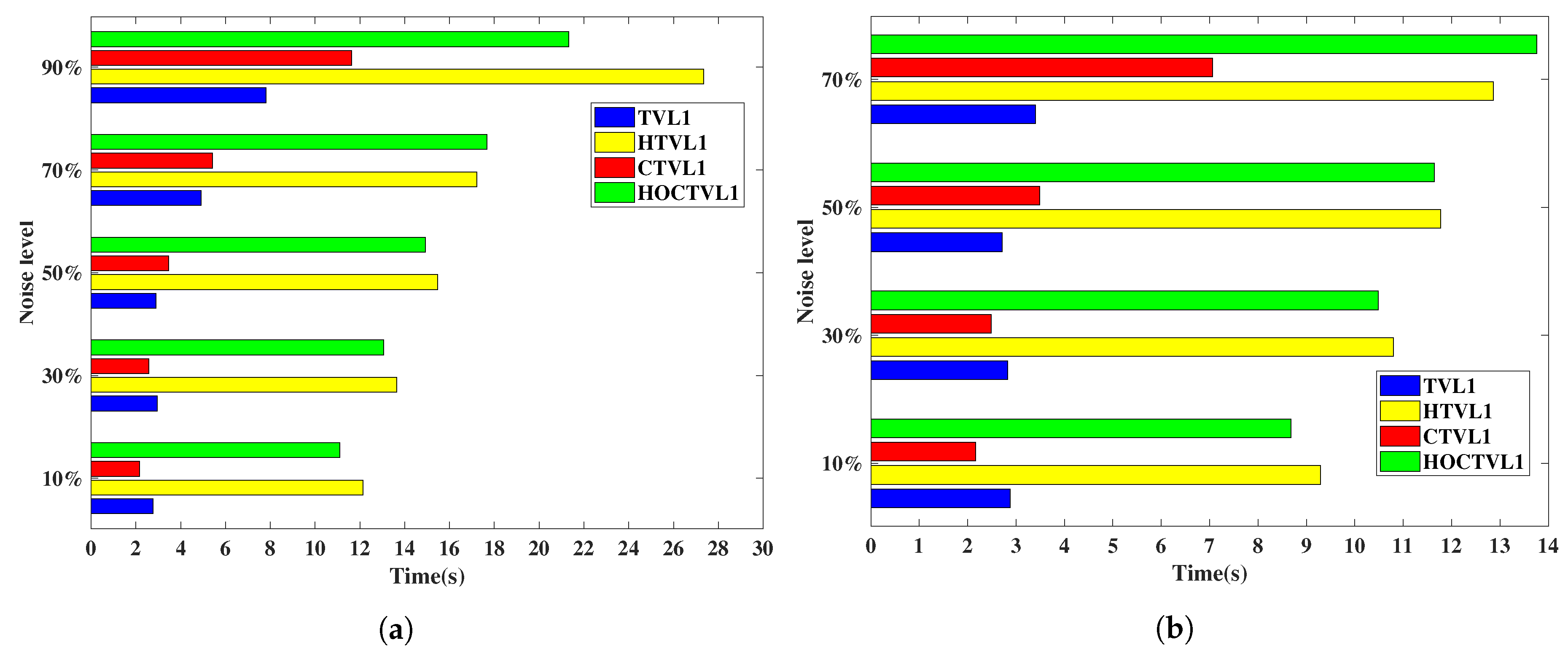
Figure 19 shows the running time of the five methods for restoring the corrupted pepper image. When dealing with 90% salt-and-pepper noise and 70% random-valued noise, HOCTVL1 model needs multi-correction steps, which costs a lot time, here we only show the time of removing salt-and-pepper noise as high as 70% and random-valued noise as high as 50%. It can be seen that compared to other four methods, our HOCTVL1 model spends the least time whatever the noise level is. It can also be found that the other four methods take several times as much time as our model, which illustrates the advantages of our model.
5.5. Comparisons between SAHOCTVL1 Model and HOCTVL1 Model
In this subsection, the restoration effect of SAHOCTVL1 model will be analyzed. We choose camera and Lena as test images, we use “Gaussian” blurring with hsize = 15 and standard deviation = 5, and we set the spatially adapted iteration number
. Since we have shown the superiority of HOCTVL1 model by many simulation experiments, here we only compare the effect of SAHOCTVL1 model and HOCTVL1 model on image restoration. Meanwhile, since we have shown the huge advantage of HOCTVL1 model compared to HTVL1 model, while the effect of SAHTVL1 model is similar to HTVL1 model, therefore we do not consider SAHTVL1 model in [
31] either. In this subsection we do not consider the 90% salt-and-pepper noise and 70% random-valued noise since the multi-correction steps take much time. We evaluate the results by SNR and running time, and the restoration results are shown in
Table 4.
From
Table 4, as is shown, generally speaking, SAHOCTVL1 model can achieve at least the same effect as HOCTVL1 model. For camera image, when noise is 30% and 50% salt-and-pepper noise, the SNR of SAHOCTVL1 model is about 0.4 dB higher than HOCTVL1 model and when noise is 50% random-valued noise, there is 0.6 dB higher than HOCTVL1 model. For Lena image, the advantage of SAHOCTVL1 model is little, and the SNR improves by about 0.1 dB when noise levels are 50% and 70%. Meanwhile, because we set
, which makes the algorithm run 3 times, making the time SAHOCTVL1 model takes be about 3 times as much as that HOCTVL1 model takes. But we think it is worthwhile to obtain high SNR at the expense of running time.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}