1. Introduction
Finding corresponding image features between two images is a key step in many computer vision applications, such as image retrieval, image classification, object detection, visual odometry, object tracking, and image stitching [
1]. Since these applications usually require the processing of numerous data points or to run on devices with limited computational resources, feature descriptor is employed to represent specific meaningful structure in the image for fast computation and memory efficiency. In recent years, the increase in the amount of visual inputs drives researchers to investigate new, robust, and efficient feature description and matching algorithms to meet the demand for efficiency and accuracy.
Feature points from two images must be detected first and then described uniquely before they can be matched. Because images are captured at different times and even from different perspectives, a good feature description algorithm must uniquely describe the feature region and should be robust against scaling, rotation, occlusion, blurring, illumination, and perspective variations between images [
2].
Feature description algorithms can be roughly categorized into intensity and binary descriptors. The Scale-Invariant Feature Transform (SIFT) [
3] and the Speeded-Up Robust Features (SURF) [
4] are arguably the two most popular and accurate intensity-based algorithms. Both SIFT and SURF include all three steps of the correspondence problem: feature detection, description, and matching. Although they perform well on intensity images and are robust against image variations, these algorithms require complex computations and large memory storage. These requirements are not desirable for resource-limited embedded applications and applications that require real-time performance.
Several binary feature description algorithms have been developed to use simpler computation to provide descriptor with smaller size. Binary Robust Independent Elementary Features (BRIEF) [
5] and the Binary Robust Invariant Scalable Key-points (BRISK) [
6] are two representative and popular algorithms. A newer and improved version of BRIEF called ORB or rBRIEF has been developed [
7] to cope with rotation invariance. These binary descriptors algorithms are sensitive to image variations and can have fewer accurate matches and a reduced match count compared to SIFT and SURF. A more detailed comparison of these algorithms is included in the next section.
In our previous work, a new binary descriptor algorithm called SYnthetic BAsis (SYBA) descriptor was developed to obtain a higher percentage of correct matches [
8]. SYBA performs binary comparisons between the binarized feature region and synthetic basis images to obtain a compact feature descriptor. SYBA’s performance and size are comparable to other binary feature descriptors. However, like other binary feature descriptors, SYBA’s feature point matching accuracy suffers under large amounts of image variations.
In this paper, we introduce an improved version of SYBA called robust-SYBA (rSYBA). rSYBA maintains the same reduced descriptor size and computational complexity as the original SYBA while increasing the number of correct matches and matching precision, especially with the presence of rotation and scaling variation. We created a dataset of 10 images with varying rotation and scaling variations to demonstrate rSYBA’s impressive performance over the original SYBA. We then used the Oxford dataset to compare rSYBA against three representative algorithms, intensity-based (SURF), binary-based (BRISK), and the new ORB algorithm. This paper also includes applications that highlight the robustness of rSYBA, including monocular visual odometry and image stitching.
This paper is organized as follows.
Section 2 briefly surveys the related work for feature detection, description, and matching algorithms.
Section 3 describes the rSYBA descriptor. The performance of rSYBA is evaluated on BYU rotation and scaling dataset and Oxford Affine dataset in
Section 4. Applications of rSYBA for visual odometry and image stitching are provided to show the robustness of rSYBA in
Section 5. We conclude this paper in
Section 6.
2. Related Work
SIFT [
3] and SURF [
4] are the two representative and popular feature description algorithms. SIFT achieves scaling invariance and increases tolerance of blurriness by using multiple copies of the feature region at different scales and blurriness. It uses the difference of Laplacian of Gaussians [
9] for feature detection. SIFT computes the gradient magnitude and dominant orientation to construct a histogram of gradients to uniquely describe the feature region. The dominant gradient of the feature region is subtracted from the gradient descriptor to make the descriptor rotation invariant.
SURF uses an approach similar to SIFT with a few improvements to speed up the process [
10]. It applies a threshold to the determinant of Hessian matrix for feature detection. SURF utilizes Gaussian kernels to generate Gaussian blurred images to reduce the number of generated images compared to SIFT. It uses integral images to simplify and speed up the computation of Gaussian images. Haar transforms are used to assess the primary direction of the feature. Its feature vector is a 64-dimension vector consisting of sums of the x and y gradients and absolute of x and y gradients.
Compared to SIFT, SURF is faster, more resilient to noise, and more easily adapted to parallel processing. It is slightly less accurate and not as invariant to illumination and viewpoint changes as SIFT. These two robust descriptors come at the cost of complex computations which require an increased amount of data storage and compute time. They are thus non-ideal for embedded platforms that have limited resources and certain real-time applications.
Several binary feature description algorithms have been developed aiming at simpler computation and smaller descriptor size. Unlike SIFT and SURF that use intensity gradients as the descriptor, these algorithms simplify the computation and reduce the descriptor size by using pixel-level intensity comparisons to compute the descriptor. Some examples include Binary Robust Independent Elementary Features (BRIEF) [
5], Binary Robust Invariant Scalable Keypoints (BRISK) [
6], Oriented Fast and Rotated BRIEF (ORB), and Aggregated LOcal HAar (ALOHA) [
11].
BRIEF consists of a binary string that contains the results of simple image intensity comparisons at random pre-determined pixel locations. BRISK relies on configurable circular sampling patterns from which it computes brightness comparisons to obtain a binary descriptor. As a newer version of BRIEF, ORB has been developed to use a specific set of 256 learned pixel pairs to reduce correlation among the binary tests [
7] instead of random pixel locations. ORB descriptor requires only 32 bytes to represent a feature region. Compared to BRIEF, ORB addresses the issue of image transformations relating to rotation which helps improve its performance. ALOHA compares the intensity of two groups of pixels using 32 designed haar-like pixel patterns in the feature region. These algorithms are with the benefit of smaller storage space and faster execution time, but it comes at the cost of description robustness, feature matching accuracy, and a smaller number of matched features. A thorough survey on local feature descriptors was reported in 2018 [
12]. Besides the aforementioned more common and popular feature descriptors, more sophisticated and less known descriptors such as WLD [
13], LDAHash [
14], and WLBP [
15] are discussed.
There are two other feature descriptors that are designed specifically for limited-resource applications, BAsis Sparse-coding Inspired Similarity (BASIS) feature descriptor utilizes sparse coding to provide a generic description of feature characteristics [
16]. BASIS is designed to not use float point operations and has a reduced descriptor size. An improved version of BASIS called TreeBASIS is developed to drastically reduce the descriptor size. It creates a vocabulary tree using a small sparse coding basis dictionary to partition a training set of feature region images [
17,
18]. A limitation with these descriptors is that they do not perform well for long baseline, significant viewing angle and scaling variations.
In recent years, due to the advancements in computing hardware, an entirely different family of algorithms based on deep learning has become a popular approach for image feature extraction, description, and matching. Due to space limitation, only a select few of recent developments are discussed here. A novel deep architecture and a training strategy are developed to learn a local feature pipeline from scratch using collections of images without the need for human supervision [
19]. A kernelized deep local-patch descriptor based on efficient match kernels of neural network activations is the latest development using deep-learning architecture for feature description [
20]. A robust, unified descriptor network that considers a large context region with high spatial variance is developed for dense pixel matching for applications such as stereo vision and optical flow estimation [
21]. Another new end-to-end trainable matching network based on receptive field, RF-Net, is developed to compute sparse correspondence between images [
22].
Another improvement on feature matching is developed to address geometrically inconsistent keypoint matches [
23]. This novel, more discriminative, descriptor includes not only local feature representation, but also information about the geometric layout of neighboring keypoints. It uses a Siamese architecture that learns a low-dimensional feature embedding of keypoint constellation by maximizing the distances between non-corresponding pairs of matched image patches, while minimizing it for correct matches. Two other convolutional neural networks-based feature matching networks are developed for image retrieval [
24] and multimodal image matching [
25].
All these deep-learning based methods are new developments in the last two years and perform very well for their specific purposes and applications. They are a deviation from the more traditional approaches that compute the feature descriptor directly from pixel values. They mostly require extensive and complicated training and prediction processes. With appropriate computing hardware to speed up the computation, these methods certainly are good alternative methods for feature description and matching.
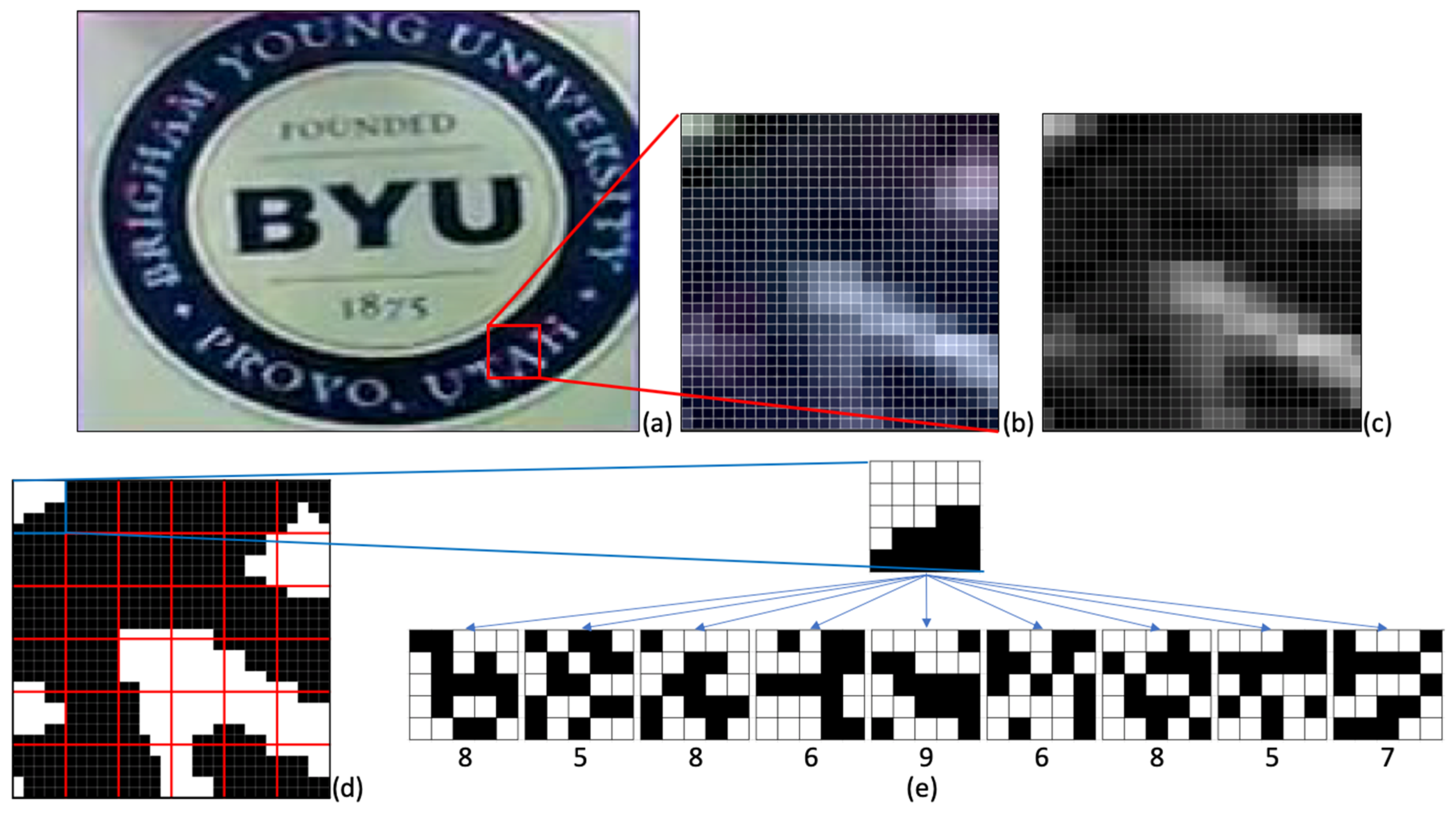
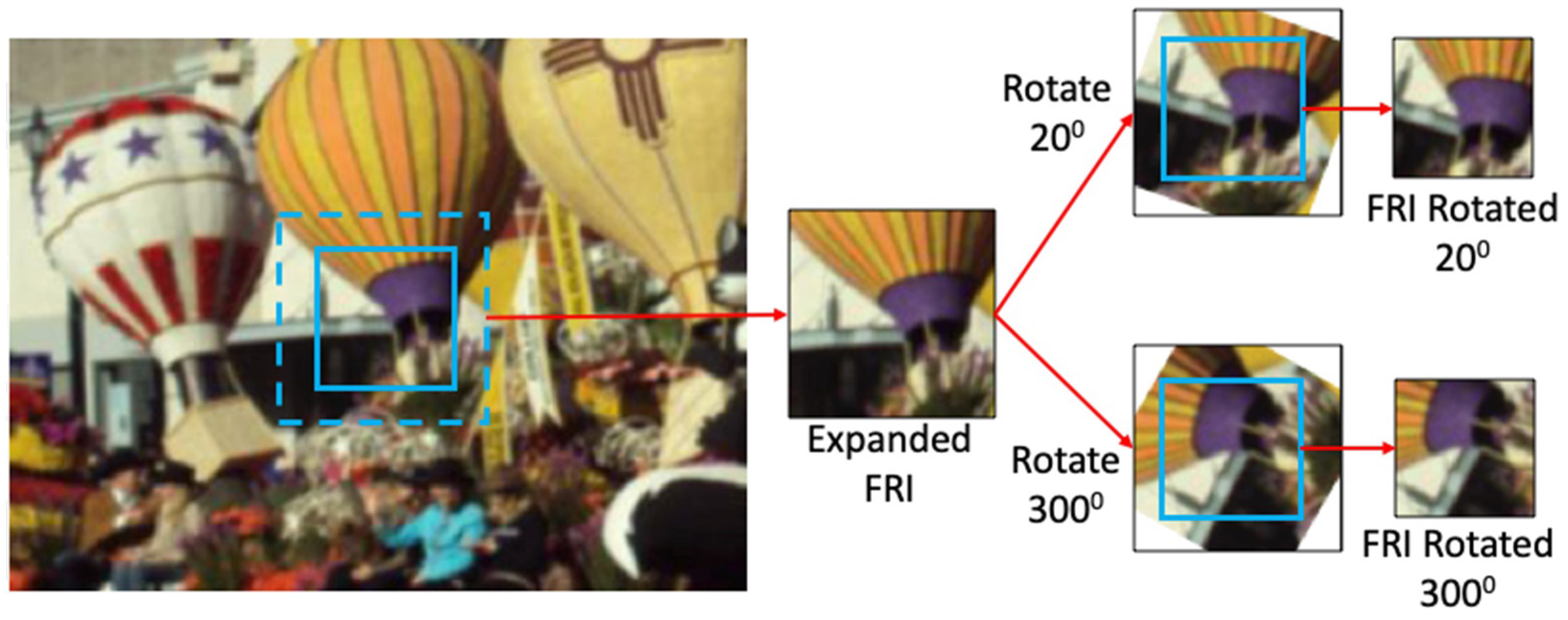
SYnthetic BAsis (SYBA) descriptor uses synthetic basis images overlaid onto a feature region to generate binary numbers that uniquely describe the feature region [
8]. To efficiently detect the location of the features, SYBA can be used in conjunction with feature detection algorithms such as SIFT, or SURF to improve the process. SYBA’s descriptor of a feature region is simplified, resulting in reduced space needed to describe the feature region of interest (FRI) and time needed for comparison. Despite complexity benefits, matching accuracy of SYBA suffers due to large variations in rotation, and scaling of the feature region in the second image. If the feature is rotated or scaled differently, the pixels contained in the FRI of the subsequent image would be different or located at a different point in the FRI. This results in a significantly different descriptor value between two images which produces poor matching results. Using affine feature points as shown in [
26], points likely to deform in subsequent images can be removed, however this comes at the cost of potential matches and reduces the percentage of features matched.
This paper proposes new methods that make SYBA rotation and scale invariant. Rotation invariance is achieved by manipulating the FRI in each image such that the rotation of the FRI is normalized. Scale invariance is achieved by scaling the FRI to different scales and comparing the FRI of the first image to the different scaled versions of the next. Using these methods, SYBA’s matching accuracy and total number of matches is greatly improved.
4. Experiments
Feature detection is the first step of feature matching. As the start of the algorithm, feature detection is exerted on the input image frame to find feature points. In general, any feature detection algorithms could be employed. In this work, SURF is selected to detect feature points for its performance and popularity, as well as the convenience and fairness for comparison [
8].
Two datasets were used to compare the algorithm performance to prove that rSYBA results in improvement under large amounts of rotation and scaling image variation. The first dataset is the BYU Scaling and Rotation dataset. This dataset consists of images that are scaled to 0.8, 0.9, 1.1, and 1.2 and images that are rotated by 5, 7, 10, and 15 degrees. The scaling factors and rotation angles are known in this dataset. We use this dataset to demonstrate that rSYBA has superior scaling and rotation invariance than the original SYBA. The second dataset is the Oxford Affine dataset [
26]. The Oxford Affine dataset consists of image sequences that were designed to test the robustness of feature descriptor algorithms with image perturbations such as blurring, lighting variation, viewpoint change, zoom and rotation, and image compression. Since this work focuses primarily on rotation and scaling, the “Boat” sequence of zoomed and rotated images was used for comparing rSYBA with the other algorithms.
4.1. Comparison Metrics
To quantify the merit of one algorithm versus another, common metrics such as precision and recall are used. Precision and recall are computed as Equations (6) and (7).
Using these metrics, we can plot a precision vs. recall curve to get an approximation of how accurate the feature matches are as well as the efficiency of the algorithm in producing correct feature matches. Because the total number of possible matches (the denominator of recall in Equation (7)) is unknown or subjective but remains constant for each image, it is equivalent to use the total number of correct matches as recall for our comparisons. We also compute the accuracy as the percentage of the matches found that there are correct matches. It is similar to calculating the precision when the maximum number of correct matches is found.
To determine the correctness of the final matched feature pairs between two images, the homography matrix was used [
8]. We used the matched pairs to find the homography matrix, which transforms the image points in one image to their corresponding locations in the second image. Equation (8) shows this,
where
H is the homography matrix,
p1 is the point in the first image, and
p2 is the point in the second image. Outliers and incorrect matches are filtered out in the computation of the homography matrix using the RANSAC algorithm [
30]. This homography calculation is not necessary for benchmark datasets that often provide a ground truth homography. To determine if a match is correct, the matched feature point must be within a certain range of the mapped feature point. For these experiments, the error bound was set to five pixels.
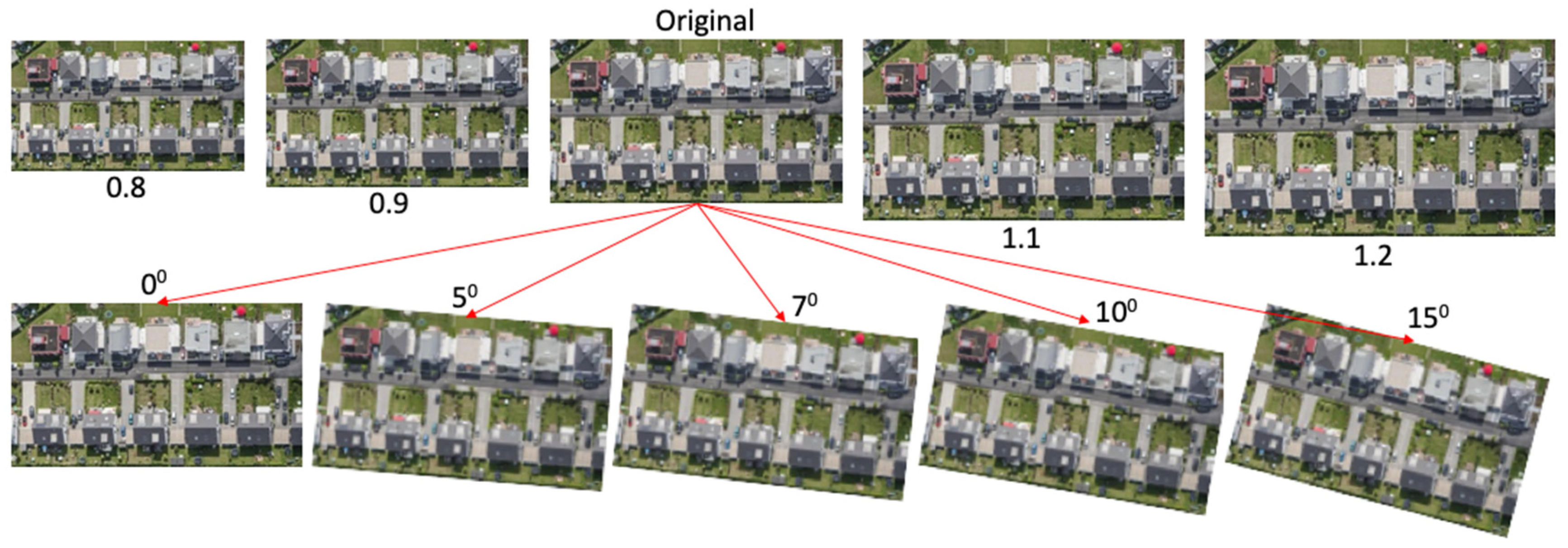
4.2. BYU Scaling and Rotation Dataset
This experiment focuses on demonstrating the improvements we made for rSYBA provide better scaling and rotation invariance than the original SYBA. We created a small dataset called BYU Rotation and Scaling Dataset for this experiment. It starts with one aerial image. This original image is then scaled to 0.8, 0.9, 1.1, and 1.2. It is then rotated by 5, 7, 10, and 15 degrees. The size of the original image is maintained the same for the rotation set. All these images in the dataset are shown in
Figure 5.
In our experiments, features detected at the edge of the image were filtered as they are the most likely to be incorrect matches due to kernel filtering. Features were then matched using SYBA and rSYBA. Feature matches were ranked based on the L1 norm distance as well as the distance to the next best match. The smaller the L1 norm distance and the larger the distance to the second-best match resulted in a larger confidence of being a good match.
We matched features detected from the original image to the features in the scaled and rotated images to compute the matching accuracy as explained in
Section 4.1. We also computed precision vs. recall in terms of the number of correct matches for comparison. Visual results for scaling sequence are shown in
Figure 6a SYBA and
Figure 6b rSYBA, where the yellow lines connect the correct matches.
The results for the rotation sequence also demonstrated a significant improvement from SYBA to rSYBA. Visual results are shown in
Figure 7a SYBA and
Figure 7b rSYBA.
Table 1 and
Table 2 show all the computed metrics for SYBA and rSYBA for each image comparison in each sequence. We compute the accuracy as the percentage of the matches found that are correct matches when the maximum number of correct matches is found. As explained in
Section 4.1, the feature count is the denominator and can be cancelled out when plotting the precision vs. recall curve. We set the feature count to 300 to calculate the recall because the maximum features found are all below 300.
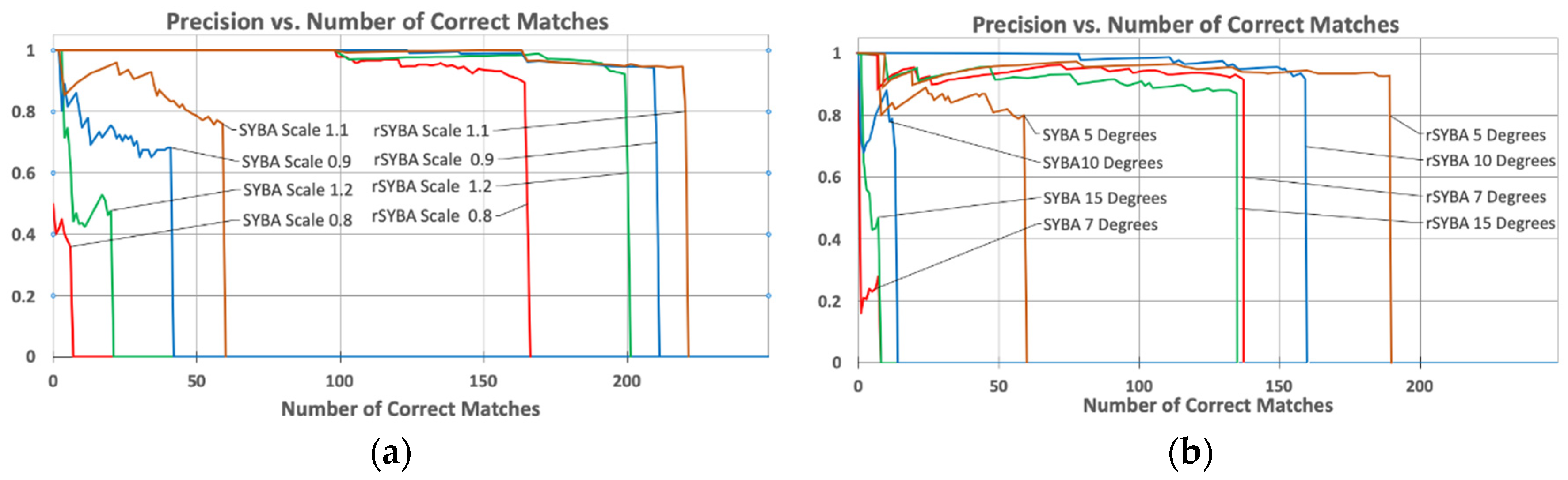
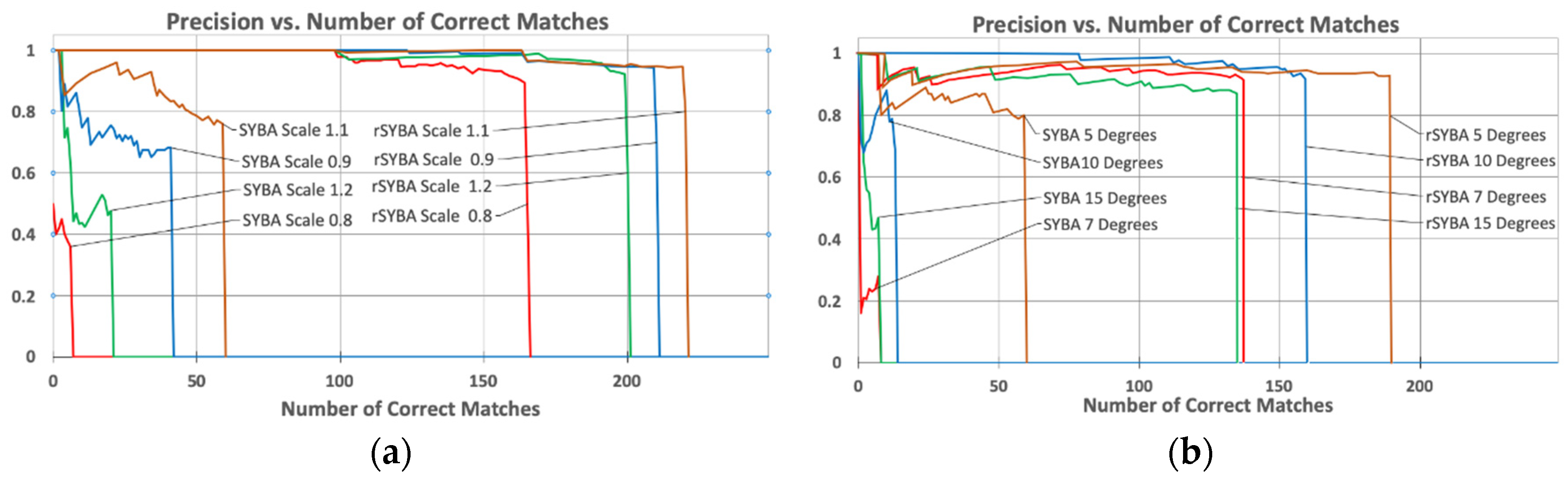
We included a scale of 1.05 to test the accuracy when there is a very small variation. As shown in the tables, rSYBA provides a significant increase in number of matches and number of correct matches compared to SYBA. On average across the test cases for the scaling dataset, rSYBA improved recall percentage by 53.578% and accuracy by 32.132%. On average across the test cases for the rotation dataset, rSYBA improved recall percentage by 44.55% and accuracy by 39.85%.
Overall precision of rSYBA and SYBA was also compared. We performed matching precision comparison by adjusting the matching parameters to generate different numbers of correct matches and computing their corresponding precision. As explained in
Section 4.1, we use the number of correct matches to represent the recall percentage. For this comparison, these precision metrics were calculated for each algorithm applied to each image with differing amounts of image variation. Results of this investigation, as well as a visual comparison of the final total number of correct matches, for each sequence are shown in
Figure 8a for scaling and
Figure 8b for rotation variations.
Data analysis results support that rSYBA will consistently outperform SYBA even if the algorithms are forced to match all possible features (irrespective of matching thresholds). The dips at the beginning of the graph are due to an incorrect match detected early in the data acquisition when the total number match count is low. Despite these dips, the trends will smooth and integrate out over time as the match count increases. These graphs show the trend until the matching algorithm can no longer produce any more matches, which is represented by the sudden drop of precision to 0.
4.3. Oxford Affine Dataset
Extensive comparisons between SYBA and other mainstream methods have been performed and reported in [
8] to show SYBA’s superior performance. In this work, we focus only on the improvement of rSYBA over SYBA. We include comparisons between rSYBA and representative intensity (SURF), binary (BRISK), and the new ORB descriptors. SURF is the most widely used feature detection algorithm and contains aspects which account for rotation and scaling variance between images. BRISK is a commonly used compressed feature description algorithm. ORB is the improved version of BRIEF that is designed to provide robust rotation invariance.
Oxford Affine Features dataset was used for this experiment [
26]. It contains sets of 6 images, with increasing variation in each consecutive image. For example, Image 1 in each set of images represents the original image. Images 2–6 are images with increasing image deformation. We used the “boat” dataset in the Oxford dataset which contains images with zoom and rotation variance. We used the same methods discussed in
Section 4.1 for comparison. rSYBA’s overall performance was compared with SURF, BRISK, and ORB using Image 1 versus Image 2 and Image 1 versus Image 3 of the dataset in Matlab. We did not compare with more images contained in the dataset because no algorithm produced enough matches to give sufficient data for a meaningful comparison.
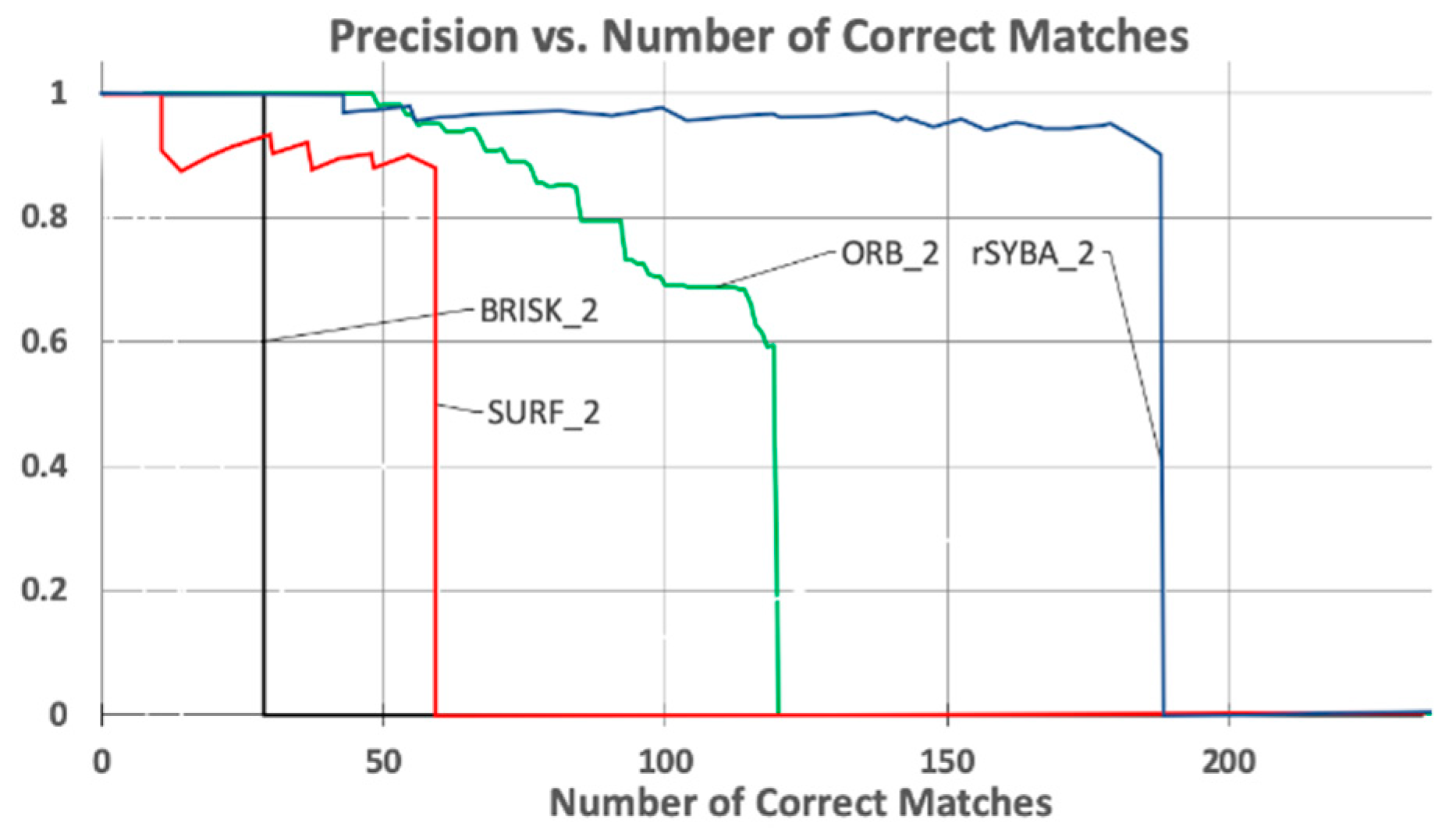
Figure 9 shows the matching results between Images 1 and 2 in the Oxford boat sequence with rSYBA, SURF, BRISK, and ORB respectively.
Table 3 shows the metrics for the output of each of these algorithms. Precision vs. recall curve is shown in
Figure 10.
Overall, although with higher accuracy between 1 and 2, BRISK produced very few matches and very few correct matches for real-world applications. For image pair 1 and 2, ORB produced 3 more matches than rSYBA (200 vs. 197) but only 119 of its 200 matches were considered correct matches (within five pixels of the mapped features from homography) as opposed to rSYBA’s 190 of 197. In comparison, rSYBA produced a significant higher number of correct matches and maintained a high accuracy as compared to SURF, BRISK, and ORB. This demonstrates that rSYBA can improve results as compared with mainstream algorithms in applications that contain a large amount of image variation.
We calculated the recall using Equation (7). As explained in
Section 4.1, the number of possible matches is unknown or subjective, we picked the number of possible matches to be large enough to include all correct matches. In this case, the number of possible of matches was set to 500. Recalls shown in
Table 3 are the correct matches divided by 500. We plot the precision vs. recall curve in
Figure 10. Instead of using Equation (7) to calculate recalls for this plot, we plot the curve using the number of correct matches (the numerator of Equation (7)) because the denominator (500) can be cancelled.
5. Applications of rSYBA
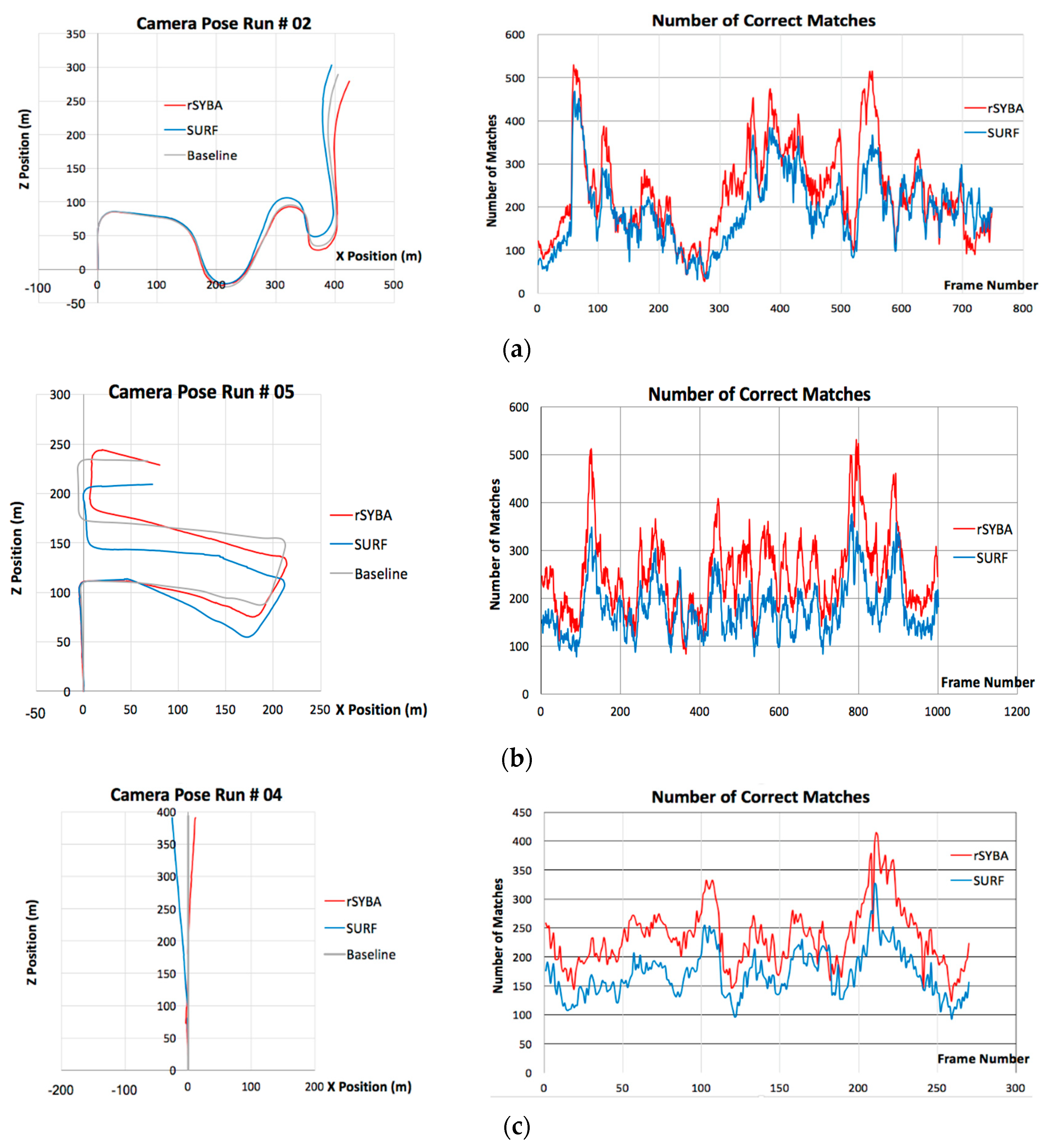
This paper exerts rSYBA in two applications that utilize high amounts of image variation to demonstrate its improvements over the original SYBA. The first shows camera pose plotting for a ground-based vehicle using monocular visual odometry. The second consists of generating panoramic images through image stitching and image transforms. Both applications contain large amounts of image variation between image frames and therefore requires a significant amount of correct feature matches to generate acceptable results. As shown in
Table 3, although ORB produces more matched features and correct matches, SURF has the best accuracy among the three representative algorithms we compared. In this section, we only include results from SURF for comparison.
5.1. Visual Odometry
In this subsection, we describe an application of a Monocular Visual Odometry (VO) to detect the 3D camera positioning with a ground vehicle. We used the rSYBA feature descriptor algorithm to obtain accurate feature matches to be used in the VO application. Additionally, we compared our 3D camera positioning results using rSYBA with results taken using SURF. Results were taken using the industry standard VO dataset called KITTI [
31].
To start the VO algorithm, feature points are extracted from the current image frame (
Ik) and the previous image frame (
Ik−1). Feature matching is then performed using the rSYBA descriptor algorithm between frame
Ik−1 and
Ik. The essential matrix between these two frames is computed using feature correspondences and then decomposed into rotation (
Rk) and translation matrices (
tk) which can be used to extract 3D positioning information [
32]. Feature point positioning is then updated using the techniques discussed in [
28] to reduce drift and error between frames. Camera motion between time
k−1 and
k is rearranged in the form of the rigid body transformation
:
where
the rotation matrix, and
the translation vector. The set
P contains the camera motion in all subsequent frames. Using the rotation and translation vectors, we have the 3D transformation matrices necessary to transform the camera pose in the previous frame to find the camera pose in the current frame. The current camera pose can be computed by concatenating all the transforms for each frame up to and including the transform for the current frame.
The proposed method was evaluated by using publicly available real-world datasets from the KITTI benchmark suite [
31]. The KITTI dataset contains images for stereo VO, but for this application we used a single camera video sequence or monocular VO.
For performance evaluation of this application, the relative error in distance and the root mean square error (RMSE) were found and used as comparison metrics between rSYBA and SURF. The relative error in distance is calculated as shown in Equation (10).
This measures the difference between the calculated length of VO path and the actual distance traveled. RMSE is calculated based on each position transformation matrix (Pk). The RMSE matrix indicates the sample standard deviation of the transformation difference between the ground truth and the visual odometry result. RMSE provides a very good measurement of the average error of the entire image sequence to determine the algorithm’s frame-to-frame performance.
The RED alone is not able to evaluate the performance very well because it only evaluates the accuracy of the distance traveled. The relative error could end up very small (measured distance is close to the actual distance travel) but along a completely different path. The RMSE measures the individual frame-to-frame accuracy and provides a better evaluation of overall performance. The RMSE computed and shown in the experimental results is the average across all the images in the sequence. For comparing feature matching accuracy, the same VO algorithm and feature detection methods were used to produce as accurate a comparison as possible between rSYBA and SURF.
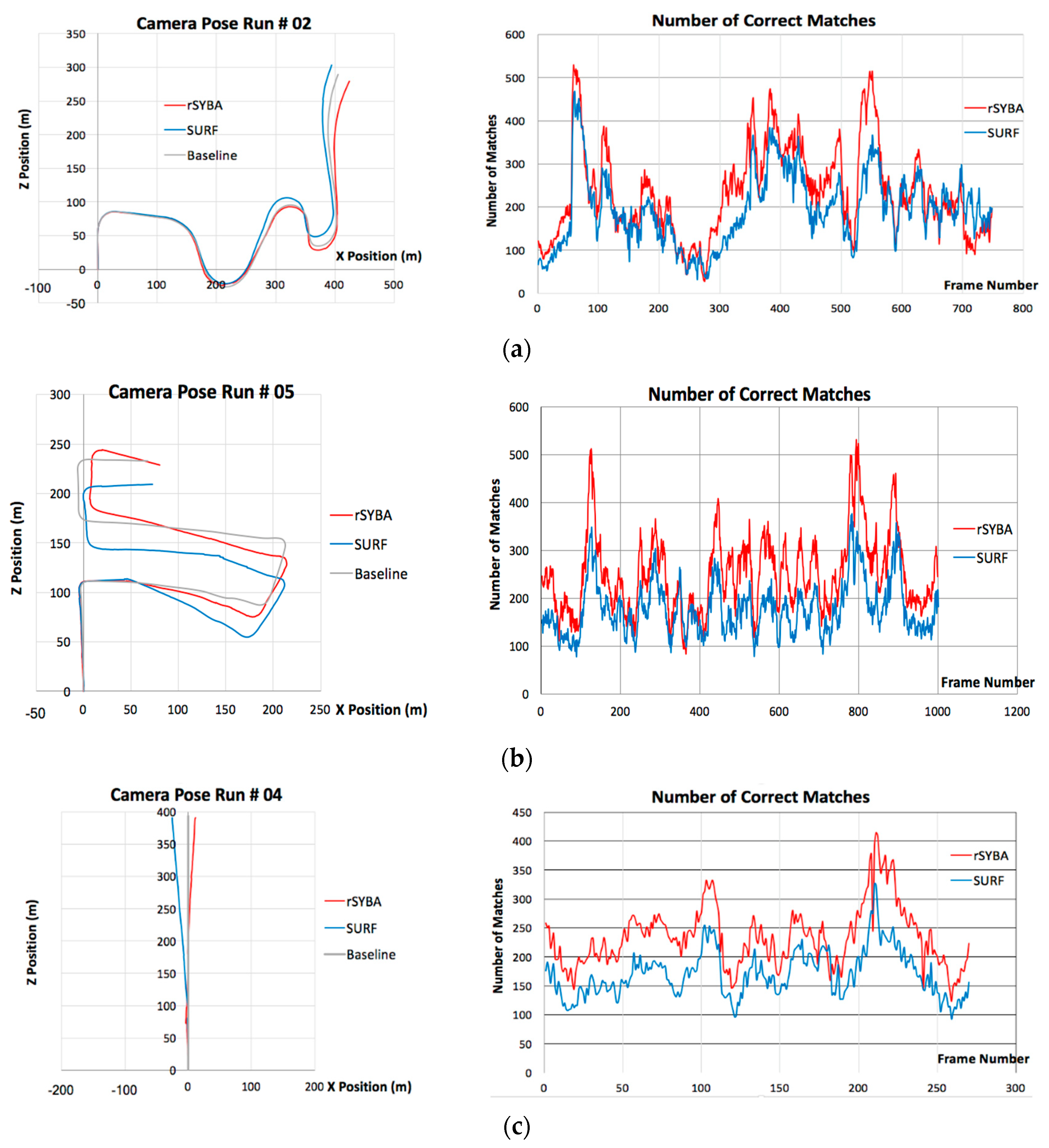
In the experiment, country, urban, and country and urban mixed sequences were used for comparisons. All these sequences were recorded at different times of the day and a variety of locations which include different lighting conditions, shadow presence, numbers of cars, pedestrians, cyclists, etc. as well as paved winding roads with high slopes. Results for each case for the camera positioning plotting and the number of correct matched feature pairs are shown in
Figure 11 For the camera position plotting, the X and Z dimensions of the plots are shown as these are the most significant when plotting for an autonomous vehicle (height of the ground is not really incorporated in ground vehicle navigation). The Y dimension is still included in error computations to help assess the accuracy of the feature matching algorithms with VO. It is shown that rSYBA produced more inlier matches than SURF on most of the frames in the sequence.
The overall results for the RMSE between each frame the relative error in distance for each case can be seen in
Table 4. It is apparent from these results that rSYBA outperformed SURF in each sequence. For example, in the case of urban sequence, rSYBA reduced RMSE error compared to SURF in the X, Y, and Z dimension by 0.6602, 6.8302, and 15.5501 m respectively.
Figure 11 and
Table 4 show rSYBA produces a more substantial number of accurate feature matches than SURF in every test case. This assists in generating a more accurate essential matrix which correspondingly shows a smaller error. Compared to SURF, rSYBA is also more suited to be implemented in hardware for embedded applications.
5.2. Image Stitching
For image stitching to be successful, correlation must be found between the images taken which can then be used to transform each image and overlap them to form the panoramic image. In this subsection, we present results with applying the feature-based image stitching approach with rSYBA and forego any blending technique as we are focused on the image transform results. Results were taken using the Adobe Panorama dataset, which contains 10 image sets with image transform ground truths [
33]. Again, results were only compared against SURF because its high accuracy and a reasonable number of correct matches.
To start image stitching, the homographic image transform is found between each adjacent image in the panorama. The homography transform matrix is computed by using the correctly matched features between the overlapping regions in the images. After the homographies are found between each subsequent image, a new homography is computed for each image. The algorithm iterates through each homography matrix and computes the new homography transform. To normalize the panorama and center the view on the middle image in the set, the homographies are multiplied by the inversion of the center images’ computed homography. Then, the extreme transformed points are found contained within the homography transforms to find the bounds of the panoramic view. After the bounds for the new image are found, a blank image or canvas is created and masking is then used to insert all the transformed images into the panorama.
For this research, the Adobe image dataset was used for experimentation [
33]. Eight images were used for each view sequence, resulting in seven homographies computed. Included in the dataset are the ground truths for the homography matrices. For the comparison metrics, the average relative error was computed for each of the values within the
homography matrix across all the images in the panorama. The relative error is computed as follows:
Results for each of the panoramic views were taken using rSYBA and SURF. Feature locations were detected using the SURF feature detection algorithm and were kept constant with all algorithms to allow for accurate comparisons.
Figure 12 shows image sequences used for testing. The images include moving subjects, which may introduce some artifacts in the panorama as the subjects that move may not align properly. The final results of the image stitching application can be seen in
Figure 13. Individual images were transformed using the resulting homographies and the camera intrinsic parameters. The results for the relative error across stitching all the frames for all the algorithms can be seen in
Table 5. Results were computed using the ground truth homographies provided with the dataset. From these results, it is shown that rSYBA, on average, produced more accurate homographies than SURF. This resulted in a more accurate panoramic view.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}