A Study on Machine Vision Techniques for the Inspection of Health Personnels’ Protective Suits for the Treatment of Patients in Extreme Isolation


Abstract
1. Introduction
2. Materials and Methods
2.1. Classification Algorithms
2.1.1. Logistic Regression
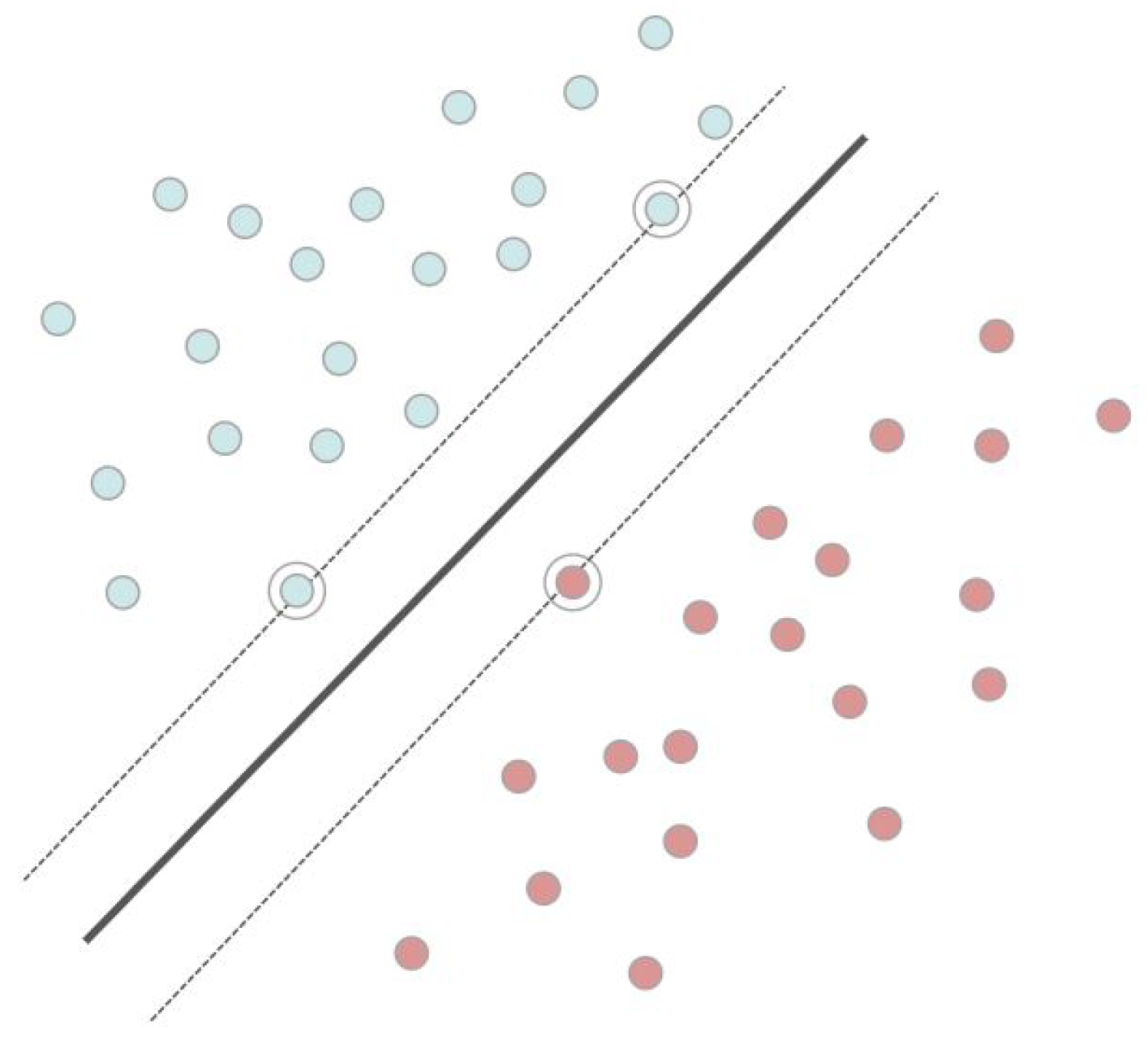
2.1.2. Support Vector Machine
2.1.3. Random Forest
2.1.4. Adaptive Boosting
2.1.5. Gradient Boosting
2.1.6. eXtreme Gradient Boosting
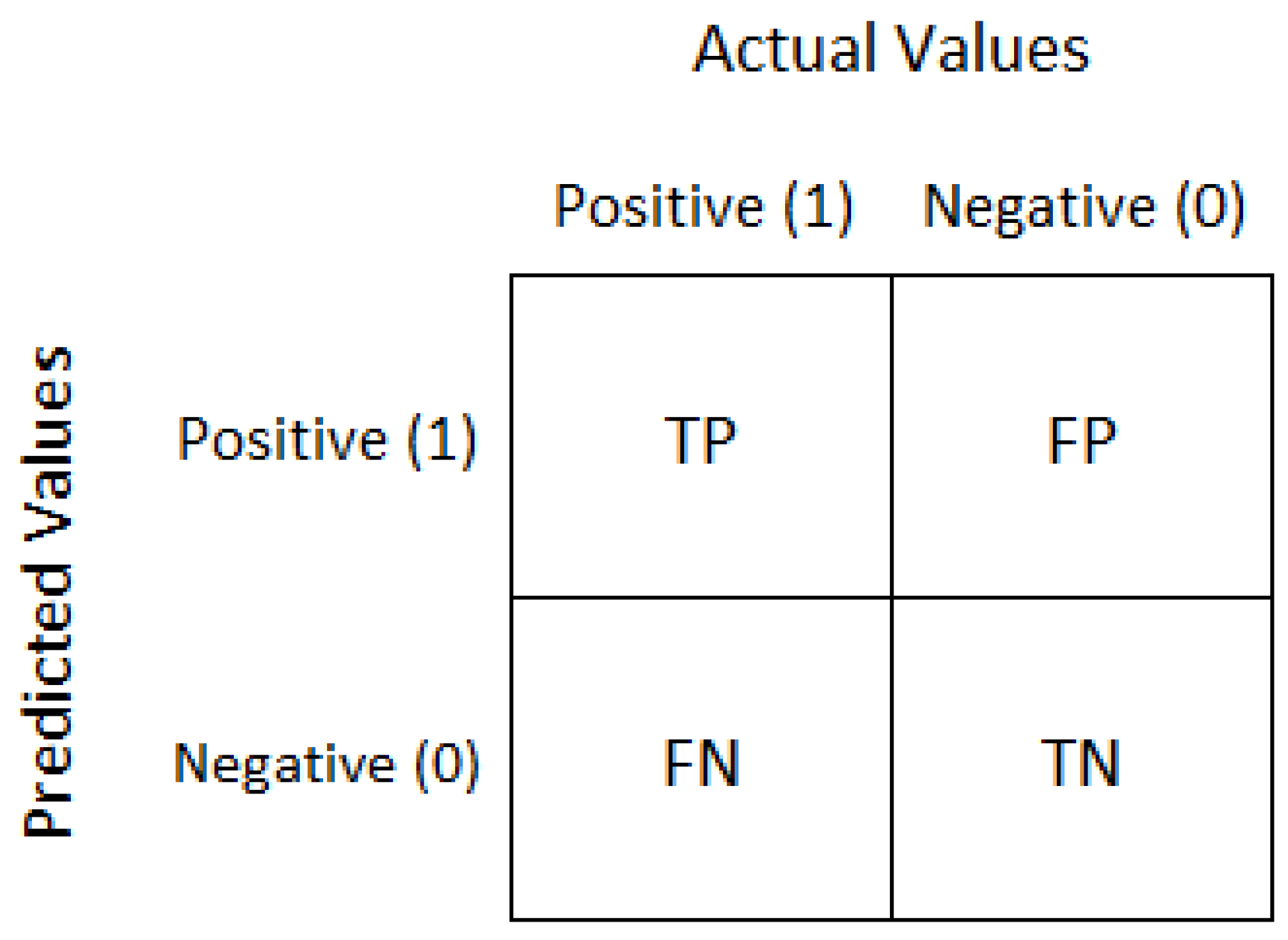
2.2. Performance Metrics Analyzed
3. Experimental Setup
3.1. Synthetic Dataset
3.2. Physical Emulated Dataset
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Ebola Situation Report-8 April 2015. Available online: http://apps.who.int/ebola/current-situation/ebola-situation-report-8-april-2015 (accessed on 21 June 2019).
- World Health Organization (Regional Office for Europe). Antimicrobial Resistance-Data and Statistics. Available online: https://web.archive.org/web/20170318012903/http://www.euro.who.int/en/health-topics/disease-prevention/antimicrobial-resistance/data-and-statistics (accessed on 21 June 2019).
- Mayer, A.; Korhonen, E. Assessment of the Protection Efficiency and Comfort of Personal Protective Equipment in Real Condition of Use. Int. J. Occup. Saf. Ergon. 1999, 5, 347–360. [Google Scholar] [CrossRef][Green Version]
- Bell, T.; Smoot, J.; Patterson, J.; Smalligan, R.; Jordan, R. Ebola virus disease: The use of fluorescents as markers of contamination for personal protective equipment. IDCases 2015, 2, 27–30. [Google Scholar] [CrossRef][Green Version]
- Hall, S.; Poller, B.; Bailey, C.; Gregory, S.; Clark, R.; Roberts, P.; Tunbridge, A.; Poran, V.; Evans, C.; Crook, B. Use of ultraviolet-fluorescence-based simulation in evaluation of personal protective equipment worn for first assessment and care of a patient with suspected high-consequence infectious disease. J. Hosp. Infect. 2018, 99, 218–228. [Google Scholar] [CrossRef]
- Kang, J.; O’Donnell, J.; Colaianne, B.; Bircher, N.; Ren, D.; Smith, K. Use of personal protective equipment among health care personnel: Results of clinical observations and simulations. Am. J. Infect. Control 2017, 45, 17–23. [Google Scholar] [CrossRef]
- Loibner, M.; Hagauer, S.; Schwantzer, G.; Berghold, A.; Zatlouk, K. Limiting factors for wearing personal protective equipment (PPE) in a health care environment evaluated in a randomised study. PLoS ONE 2019. [Google Scholar] [CrossRef]
- Gao, P.; King, W.; Shaffer, R. Review of chamber design requirements for testing of personal protective clothing ensembles. J. Occup. Environ. Hyg. 2007, 4, 562–571. [Google Scholar] [CrossRef]
- Lim, S.; Cha, W.; Chae, M.; Jo, I. Contamination during doffing of personal protective equipment by healthcare providers. Clin. Exp. Emerg. Med. 2015, 2, 162–167. [Google Scholar] [CrossRef]
- European Committee for Standardization (CEN). Respiratory Protective Devices—Filtering Half Masks to Protect Against Particles—Requirements, Testing, Marking; European Standard EN 149:2001 + A1:2009; CEN: Rome, Italy, 2018; Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=OJ:C:2018:209:FULL (accessed on 21 June 2019).
- Ministerio de Sanidad, Servicios Sociales e Igualdad. Protocolo de Actuación Frente a Casos Sospechosos de Enfermedad por Virus Ébola (EVE). 2015. Available online: http://www.mscbs.gob.es/profesionales/saludPublica/ccayes/alertasActual/ebola/documentos/16.06.2015-Protocolo_Ebola.pdf (accessed on 21 June 2019).
- Japkowicz, N. The Class Imbalance Problem: Significance and Strategies; Faculty of Computer Science DalTech, Dalhousie University 6050 University: Halifax, NS, Canada, 2000. [Google Scholar]
- Rahman, M.M.; Davis, D.N. Addressing the Class Imbalance Problem in Medical Datasets. Int. J. Mach. Learn. Comput. 2013, 3, 224. [Google Scholar] [CrossRef]
- Burez, J.; Van den Poel, D. Handling class imbalance in customer churn prediction. Expert Syst. Appl. 2006, 36, 4626–4636. [Google Scholar] [CrossRef]
- Huanga, Y.; Hunga, C.; Jiaub, H. Evaluation of neural networks and data mining methods on a credit assessment task for class imbalance problem. Nonlinear Anal. Real World Appl. 2006, 7, 720–747. [Google Scholar] [CrossRef]
- Kubat, M.; Holte, R.; Matwin, S. Machine learning for the detection of oil spills in satellite radar images. Mach. Learn. 1998, 30, 195–215. [Google Scholar] [CrossRef]
- Longadge, R.; Dongre, S.; Malik, L. Class Imbalance Problem in Data Mining: Review. arXiv 2013, arXiv:1305.1707. [Google Scholar]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2003, 250, 113–141. [Google Scholar] [CrossRef]
- Estabrooks, A.; Jo, T.; Japkowicz, N. A Multiple Resampling Method For Learning From Imbalanced Data Sets. Comput. Intell. 2004, 20, 18–36. [Google Scholar] [CrossRef]
- Lewis, D.; Catlett, J. Heterogeneous Uncertainty Sampling for Supervised Learning. In Machine Learning, Proceedings of the Eleventh International Conference, New Brunswick, NJ, USA, 10–13 July 1994; Rutgers University: New Brunswick, NJ, USA, 1994; pp. 148–156. [Google Scholar]
- García, V.; Sánchez, J.; Mollineda, R. On the effectiveness of preprocessing methods when dealing with different levels of class imbalance. Knowl.-Based Syst. 2012, 25, 13–21. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Trans. Syst. Man Cybern.-Part C Appl. Rev. 2011, 42, 463–484. [Google Scholar] [CrossRef]
- Haixianga, G.; Yijinga, L.; Shang, J.; Mingyuna, G.; Yuanyuea, H.; Binge, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Dai, W.; Brisimi, T.; Adams, W.; Melac, T.; Saligramaa, V.; Paschalidis, I. Prediction of hospitalization due to heart diseases by supervised learning methods. Int. J. Med. Inform. 2015, 84, 189–197. [Google Scholar] [CrossRef]
- Ling, C.; Sheng, V. Cost-Sensitive Learning and the Class Imbalance Problem. In Encyclopedia of Machine Learning; Sammut, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Weiss, G.; McCarthy, K.; Zabar, B. Cost-Sensitive Learning vs. Sampling: Which Is Best for Handling Unbalanced Classes with Unequal Error Costs? Department of Computer and Information Science Fordham University Bronx: Bronx, NY, USA, 2017. [Google Scholar]
- Kiang, M. A comparative assessment of classification methods. Decis. Support Syst. 2003, 35, 441–454. [Google Scholar] [CrossRef]
- Brown, I.; Mues, C. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Syst. Appl. 2012, 39, 3446–3453. [Google Scholar] [CrossRef]
- Ubeyli, E. Comparison of different classification algorithms in clinical decision-making. Expert Syst. 2007, 24, 17–31. [Google Scholar] [CrossRef]
- Li, M.; Ma, L.; Blaschke, T.; Cheng, L.; Tiede, D. A systematic comparison of different object-based classification techniques using high spatial resolution imagery in agricultural environments. Int. J. Appl. Earth Obs. Geoinf. 2016, 49, 87–89. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of Classification Algorithms and Training Sample Sizes in Urban Land Classification with Landsat Thematic Mapper Imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R.A. Survey of Predictive Modelling under Imbalanced Distributions; LIAAD-INESC-TEC, DCC-Faculdade de Ciencias, Universidade do Porto: Porto, Portugal, 2015. [Google Scholar]
- Stoltzfus, J. Logistic Regression: A Brief Primer. Res. Methods Stat. 2011, 18, 1099–1104. [Google Scholar] [CrossRef] [PubMed]
- Dreiseitla, S.; Ohno-Machadob, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Isozaki, H.; Kazawa, H. Efficient Support Vector Classifiers for Named Entity Recognition; NTT Communication Science Laboratories Nippon Telegraph and Telephone Corporation: Kyoto, Japan, 2002. [Google Scholar]
- Rejab, F.; Nouira, K.; Trabelsi, A. RTSVM: Real Time Support Vector Machines. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014. [Google Scholar]
- Papageorgiou, C.; Oren, M.; Poggio, T. A General Framework for Object Detection. In Proceedings of the International Conference on Computer Vision, Bombay, India, 4–7 January 1998. [Google Scholar]
- Sadri, J.; Suen, C.; Bui, T. Application of Support Vector Machines for Recognition of Handwritten Arabic/Persian Digits. In Proceedings of the Second Iranian Conference on Machine Vision and Image Processing (MVIPS), Zanjan, Iran, 10–12 September 2003. [Google Scholar]
- Joachims, T. Text Categorization with Support Vector Machines: Learning with Many Relevant Features. In Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998. [Google Scholar]
- Song, D.; Lau, R.; Bruza, P.; Wong, K.; Chen, D. An intelligent information agent for document title classification and filtering in document-intensive domains. Decis. Support Syst. 2007, 44, 251–265. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Nguyen, C.; Wang, Y.; Nguyen, H. Random forest classifier combined with feature selection for breast cancer diagnosis and prognostic. J. Biomed. Sci. Eng. 2013, 6, 551–560. [Google Scholar] [CrossRef]
- Gislason, P.; Benediktsson, J.; Sveinsson, J. Random Forests for Land Cover Classification; Department of Electrical and Computer Engineering, University of Iceland: Reykjavik, Iceland, 2005. [Google Scholar]
- Rodriguez-Galiano, V.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Feng, K.; Cai, Y.; Chou, K. Boosting classifier for predicting protein domain structural class. Biochem. Biophys. Res. Commun. 2005, 334, 213–217. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Gupte, A.; Joshi, S.; Gadgul, P.; Kadam, A. Comparative Study of Classification Algorithms used in Sentiment Analysis. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 6261–6264. [Google Scholar]
- Caoa, D.; Xub, Q.; Lianga, Y.; Zhanga, L.; Li, H. The boosting: A new idea of building models. Chemom. Intell. Lab. Syst. 2010, 100, 1–11. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Wei, X.; Jiang, F.; Wei, F.; Zhang, J.; Liao, W.; Cheng, S. An Ensemble Model for Diabetes Diagnosis in Large-scale and Imbalanced Dataset. In Proceedings of the Computing Frontiers Conference, Siena, Italy, 15–17 May 2017. [Google Scholar]
- Jeni, L.; Cohn, J.; Torre, F.D.L. Facing Imbalanced Data Recommendations for the Use of Performance Metrics. In Proceedings of the Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013. [Google Scholar]
- Forman, G.; Scholz, M. Apples-to-Apples in Cross-Validation Studies: Pitfalls in Classifier Performance Measurement. ACM SIGKDD Explor. Newslett. 2010, 12, 49–57. [Google Scholar] [CrossRef]
- Nguyen, T.; Armitage, G. A Survey of Techniques for Internet Traffic Classification using Machine Learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Weng, C.; Poon, J. A New Evaluation Measure for Imbalanced Datasets. In Proceedings of the 7th Australasian Data Mining Conference (AusDM’08), Glenelg, Australia, 27–28 November 2008. [Google Scholar]
- Stazio, A.; Victores, J.; Estevez, D.; Balaguer, C. Datasets for: A Study on Machine Vision Techniques…. Available online: https://www.doi.org/10.5281/zenodo.3251898 (accessed on 21 June 2019).
- Foster + Freeman. Forensic Light Sources. Available online: http://www.fosterfreeman.com/forensic-light-sources/360-crime-liter-82w-2.html (accessed on 21 June 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acc | Pr | Re | [Min] | ||
|---|---|---|---|---|---|
| Logit | 0.9998 | 0.9913 | 0.9779 | 0.9846 | 2 |
| SVM | 0.9999 | 0.9945 | 0.9820 | 0.9882 | 720 |
| RF (n_est = 100) | 0.9990 | 0.8297 | 0.9987 | 0.9064 | 45 |
| RF (n_est = 50) | 0.9989 | 0.8234 | 0.9987 | 0.9026 | 20 |
| RF (n_est = 30) | 0.9989 | 0.8267 | 0.9986 | 0.9046 | 10 |
| AdaBoost (n_est = 100) | 0.9996 | 0.9998 | 0.9139 | 0.9549 | 25 |
| AdaBoost (n_est = 50) | 0.9994 | 0.9999 | 0.8897 | 0.9416 | 12 |
| AdaBoost (n_est = 30) | 0.9992 | 1.0000 | 0,8323 | 0.9085 | 8 |
| GB (n_est = 100) | 0.9988 | 0.9799 | 0.7831 | 0.8705 | 30 |
| GB (n_est = 50) | 0.9988 | 0.9799 | 0.7831 | 0.8705 | 12 |
| GB (n_est = 20) | 0.9994 | 0.9441 | 0.9405 | 0.9423 | 5 |
| XGB (n_est = 200) | 0.9998 | 0.9969 | 0.9659 | 0.9812 | 15 |
| XGB (n_est = 100) | 0.9996 | 0.9997 | 0.9271 | 0.9620 | 8 |
| XGB (n_est = 50) | 0.9994 | 0.9998 | 0.8897 | 0.9415 | 4 |
| XGB (n_est = 20) | 0.9994 | 0.9996 | 0.8863 | 0.9395 | 2 |
| Acc | Pr | Re | [Min] | ||
|---|---|---|---|---|---|
| Logit | 0.9902 | 0.8860 | 0.6513 | 0.7507 | 6 |
| SVM | - | - | - | - | >10,080 |
| RF (n_est = 100) | 0.9709 | 0.4321 | 0.8888 | 0.5815 | 300 |
| RF (n_est = 50) | 0.9708 | 0.4312 | 0.8887 | 0.5807 | 160 |
| RF (n_est =30) | 0.9708 | 0.4312 | 0.8884 | 0.5806 | 90 |
| AdaBoost (n_est = 100) | 0.9904 | 0.9028 | 0.6466 | 0.7535 | 75 |
| AdaBoost (n_est = 50) | 0.9893 | 0.9577 | 0.5552 | 0.7029 | 40 |
| AdaBoost (n_est = 30) | 0.9880 | 0.8543 | 0.5670 | 0.6816 | 25 |
| GB (n_est = 100) | 0.9918 | 0.9160 | 0.7026 | 0.7952 | 60 |
| GB (n_est = 50) | 0.9909 | 0.9196 | 0.6591 | 0.7679 | 35 |
| GB (n_est = 20) | 0.9884 | 0.8922 | 0.5549 | 0.6843 | 15 |
| XGB (n_est = 200) | 0.9923 | 0.9336 | 0.7103 | 0.8068 | 35 |
| XGB (n_est = 100) | 0.9917 | 0.9384 | 0.6776 | 0.7870 | 20 |
| XGB (n_est = 50) | 0.9906 | 0.9534 | 0.6162 | 0.7486 | 10 |
| XGB (n_est = 20) | 0.9872 | 0.8986 | 0.4941 | 0.6376 | 5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stazio, A.; Victores, J.G.; Estevez, D.; Balaguer, C. A Study on Machine Vision Techniques for the Inspection of Health Personnels’ Protective Suits for the Treatment of Patients in Extreme Isolation. Electronics 2019, 8, 743. https://doi.org/10.3390/electronics8070743
Stazio A, Victores JG, Estevez D, Balaguer C. A Study on Machine Vision Techniques for the Inspection of Health Personnels’ Protective Suits for the Treatment of Patients in Extreme Isolation. Electronics. 2019; 8(7):743. https://doi.org/10.3390/electronics8070743
Chicago/Turabian StyleStazio, Alice, Juan G. Victores, David Estevez, and Carlos Balaguer. 2019. "A Study on Machine Vision Techniques for the Inspection of Health Personnels’ Protective Suits for the Treatment of Patients in Extreme Isolation" Electronics 8, no. 7: 743. https://doi.org/10.3390/electronics8070743
APA StyleStazio, A., Victores, J. G., Estevez, D., & Balaguer, C. (2019). A Study on Machine Vision Techniques for the Inspection of Health Personnels’ Protective Suits for the Treatment of Patients in Extreme Isolation. Electronics, 8(7), 743. https://doi.org/10.3390/electronics8070743