A Hybrid Spoken Language Processing System for Smart Device Troubleshooting


Abstract
1. Introduction
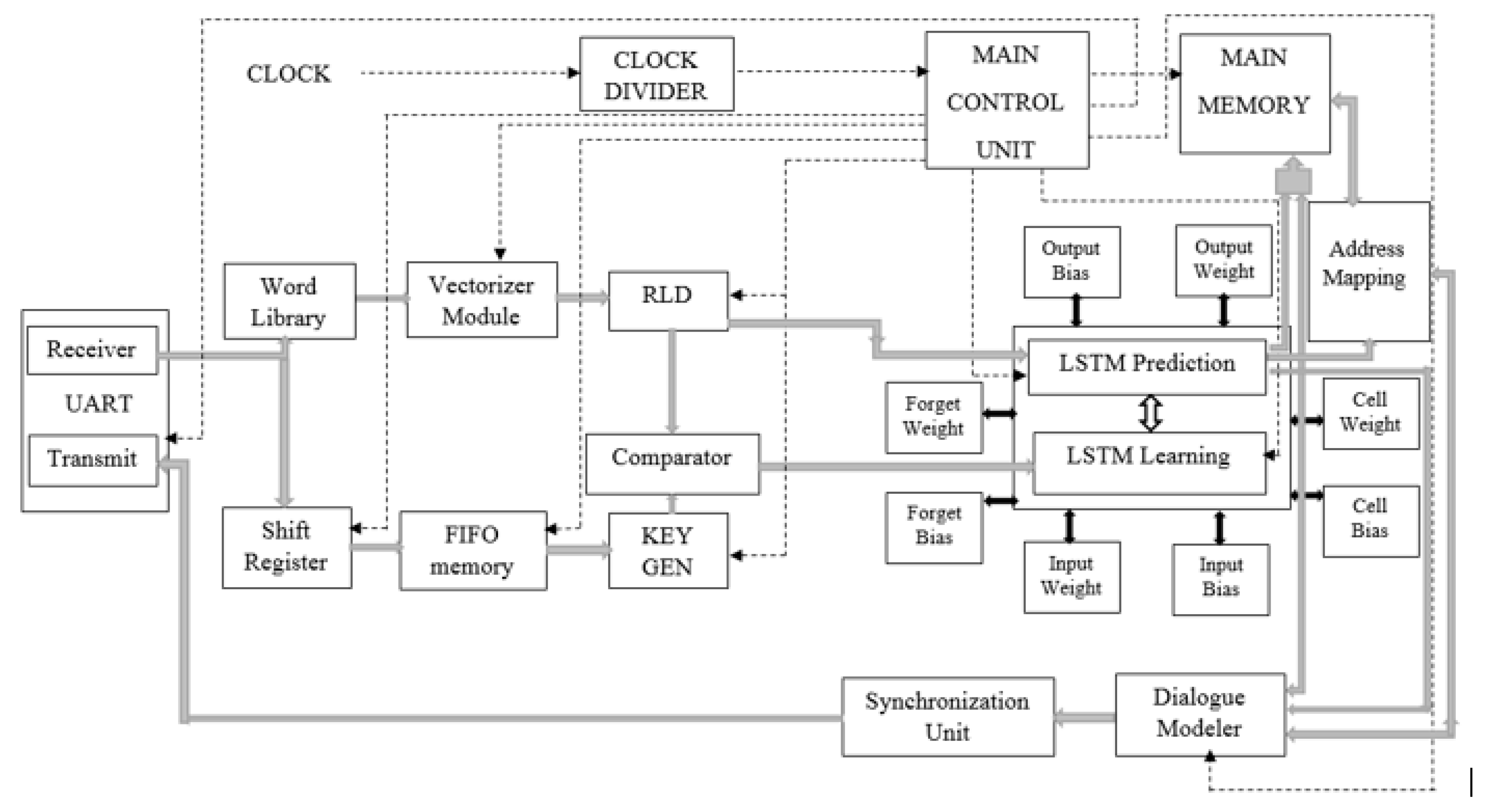
2. Design and Implementation
2.1. BLSTM-Based Speech Recognition
2.2. LSTM-Based Language Processor
2.2.1. Universal Asynchronous Receiver Transmitter (UART) Module
2.2.2. Vectorizer
- The UART receiver receives a byte of data and transfers it to the shift register.
- In the shift register, the maximum word length is fixed at 80 bits. It is monitored by a counter. The shift register receives data until the maximum length is reached or the word end is detected.
- The FIFO length is variable. However, for the current implementation, it is fixed as the first 8 words of a sentence. At the end of each word, the FIFO moves on to the next value, when indicated by a counter’s (~W/R) active-low signal. When the FIFO becomes full, the (~W/R) becomes active-high, indicating that the FIFO can be read sequentially.
- The vectorizer module reads each word from the FIFO and converts it to an 8-bit value mapping the information dictionary, followed by a key encoder.
- The Key encoder receives each byte value and encodes it into a unique 8-bit key.
2.2.3. Information Text Generation
2.2.4. Key Encoder
2.2.5. LSTM Decoder
2.2.6. Dialogue Modeler
2.2.7. Main Control Unit
3. Results and Discussion
3.1. Experiment 1
3.2. Experiment 2
3.3. Experiment 3
4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chollet, F. Deep Learning with Python; Manning Publications Co.: Shelter Island, NY, USA, 2017; Available online: https://www.manning.com/books/deep-learning-with-python (accessed on 6 May 2019).
- Rabiner, L.R.; Schafer, R.W. Theory and Applications of Digital Speech Processing; Pearson: Upper Saddle River, NJ, USA, 2011; p. 64. [Google Scholar]
- Graves, A.; Jaitly, N. Towards End-to-End Speech Recognition with Recurrent Neural Networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1764–1772. [Google Scholar]
- Miao, Y.; Gowayyed, M.; Metze, F. EESEN: End-to-End Speech Recognition Using Deep RNN Models and WFST-Based Decoding. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 167–174. [Google Scholar] [CrossRef]
- Rao, K.; Sak, H.; Prabhavalkar, R. Exploring Architectures, Data and Units for Streaming End-to-End Speech Recognition with Rnn-Transducer. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 193–199. [Google Scholar]
- Zhang, C.; Woodland, P. High Order Recurrent Neural Networks for Acoustic Modelling. arXiv 2018, arXiv:1802.08314V1. [Google Scholar]
- Yao, K.; Peng, B.; Zhang, Y.; Yu, D.; Zweig, G.; Shi, Y. Spoken Language Understanding Using Long-Short-Term Memory Neural Networks. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 189–194. [Google Scholar]
- Mesnil, G.; Dauphin, Y.; Yao, K.; Bengio, Y.; Deng, L.; Dilek, H.-T.; He, X.; Heck, L.; Tur, G.; Yu, D.; et al. Using Recurrent Neural Networks for SLOT filling in Spoken Language Understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 530–539. [Google Scholar] [CrossRef]
- Liu, X.; Sarikaya, R.; Sarikaya, R.; Zhao, L.; Pan, Y. Personalized Natural Language Understanding; Interspeech: Dresden, Germany, 2016; pp. 1146–1150. [Google Scholar]
- Dyer, C.; Ballesteros, M.; Ling, W.; Matthewset, A.; Smith, N.A. Transition-Based Dependency Parsing with Stack Long Short-Term Memory. arXiv 2015, arXiv:150508075v1. [Google Scholar]
- Barone, A.V.; Heicl, J.; Sennrich, R.; Haddow, B.; Birch, A. Deep Architectures for Neural Machine Translation. In Proceedings of the Workshop on Machine Translations, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Han, S.; Kang, J.; Mao, H.; Hu, Y.; Li, X.; Li, Y.; Xie, D.; Luo, H.; Yao, S.; Wang, Y.; et al. Ese: Efficient Speech Recognition ENGINE With sparse lstm on Fpga. In Proceedings of the 2017 ACM/SIGDA. International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; ACM: New York, NY, USA, 2017; pp. 75–84. [Google Scholar]
- Wang, S.; Li, Z.; Ding, C.; Yuan, B.; Qiu, Q.; Wang, Y.; Liang, Y. C-lstm: Enabling Efficient lstm Using Structured Compression Techniques on Fpgas. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; ACM: New York, NY, USA, 2018; pp. 11–20. [Google Scholar]
- Li, Z.; Ding, C.; Wang, S.; Wen, W.; Zhuo, Y.; Liu, C.; Qiu, Q.; Xu, W.; Lin, X.; Qian, X.; et al. E-RNN: Design Optimization for Efficient Recurrent Neural Networks in FPGAs. arXiv 2018, arXiv:1812.07106. [Google Scholar]
- Wani, M.A.; Bhat, F.A.; Afzal, S.; Khan, A.I. Basics of Supervised Deep Learning. In Advances in Deep Learning; Springer: Singapore, 2020; pp. 13–29. [Google Scholar]
- Ševčík, B.; Brančík, L.; Kubíček, M. Analysis of Pre-Emphasis Techniques for Channels with Higher-Order Transfer Function. Int. J. Math. Models Methods Appl. Sci. 2011, 5, 433–444. [Google Scholar]
- Podder, P.; Khan, T.Z.; Khan, M.H.; Rahman, M.M. Comparative performance analysis of hamming, hanning and blackman window. Int. J. Comput. Appl 2014, 96, 1–7. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Schafer, R.W. From frequency to quefrency: A history of the cepstrum. IEEE Signal Process. Magazine 2004, 21, 95–106. [Google Scholar] [CrossRef]
- Kumar, K.; Kim, C.; Stern, R.M. Delta-spectral cepstral coefficients for robust speech recognition. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2011; pp. 4784–4787. [Google Scholar]
- Garofolo, J.S. TIMIT Acoustic Phonetic Continuous Speech Corpus; Linguistic Data Consortium: Philadelphia, PA, USA, 1993. [Google Scholar]
- Chang, A.X.M.; Martini, B.; Culurciello, E. Recurrent neural networks hardware implementation on FPGA. arXiv 2015, arXiv:1511.05552. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Comparison Parameters | Encoder Output |
|---|---|---|
| 1 | Qtext start | Output Value: 8′d127 |
| 2 | Qtext end | Output Value: 8′d63 |
| 3 | Itext == Qtext | Output Value: 8′d191 |
| 4 | Itext <> Qtext | Output Value: 8′d0 |
| No. | Sentences Used | Accuracy (%) | |
|---|---|---|---|
| BLSTM 1 | BLSTM 2 | ||
| 1 | This is Samsung S6 | 90 | 90 |
| 2 | Lee Byung is Samsung founder | 90 | 90 |
| 3 | S6 has a touch screen | 100 | 100 |
| 4 | Is camera working? | 80 | 90 |
| 5 | Samsung has Android OS | 80 | 80 |
| 6 | The Wi-Fi is ON | 80 | 70 |
| 7 | My name is Max | 50 | 70 |
| 8 | What is your name? | 70 | 70 |
| 9 | Hi to all! | 100 | 80 |
| 10 | Conclude the event | 70 | 80 |
| Average Accuracy | 81 | 82 | |
| No. | Sentences Used | HMM 1 | HMM 2 | HMM 3 |
|---|---|---|---|---|
| 1 | This is Samsung S6 | 26.1 | 25.6 | 25.8 |
| 2 | Lee Byung is Samsung founder | 20.8 | 21.1 | 21.7 |
| 3 | S6 has a touch screen. | 19.4 | 20.3 | 17.2 |
| 4 | Is camera working? | 24.5 | 23.3 | 25.4 |
| 5 | Samsung has Android OS | 26.1 | 24.8 | 24.5 |
| 6 | The Wi-Fi is ON | 24.1 | 25.2 | 21.5 |
| 7 | My name is Max | 24.6 | 25.5 | 24.1 |
| 8 | What is your name? | 25.1 | 24.9 | 23.9 |
| 9 | Hi to all! | 23.9 | 22.1 | 24.3 |
| 10 | Conclude the event. | 23.3 | 20.3 | 21.3 |
| Average Word Error Rate (WER) | 23.79 | 23.31 | 22.97 | |
| No. | Query and Response | Accuracy (%) | Processing Time (s) | F1 Score |
|---|---|---|---|---|
| 1 | Give the founder of Samsung? The founder of Samsung is Lee Byung | 90 | 0.59 | 94.7 |
| 2 | Identify the current focus of Samsung Samsung current focus is on smartphones | 90 | 0.59 | 94.7 |
| 3 | Which OS is present in S6? S6 uses Android OS | 90 | 0.59 | 94.7 |
| 4 | Give the location of Samsung? Samsung location is in South Korea | 90 | 0.59 | 94.7 |
| 5 | S6 was released in? S6 was released in 2015 | 90 | 0.59 | 94.7 |
| 6 | What is the main feature of S6 S6 main feature is cost-effective | 90 | 0.59 | 94.7 |
| 7 | Tell the RAM size of S6 S6 RAM size is 3GB | 90 | 0.59 | 94.7 |
| 8 | How much does S6 cost? S6 cost is 1000 Ringgits | 90 | 0.59 | 94.7 |
| 9 | Is Samsung a local company? Samsung is an Multinational (MNC) company | 90 | 0.59 | 94.7 |
| 10 | The main competitor of Samsung is Samsung main competitor is Apple | 100 | 0.59 | 100 |
| AVERAGE | 91 | 0.59 | 95.2 | |
| No. | Query and Response | Accuracy (%) | Processing Time (s) | F1 Score (%) |
|---|---|---|---|---|
| 1 | Give the founder of Samsung? The founder of Samsung is Lee Byung. | 100 | 2.12 | 94.7 |
| 2 | Identify the current focus of Samsung Samsung current focus is on smartphones | 90 | 2.11 | 88.8 |
| 3 | Which OS is present in S6? S6 uses Android OS | 100 | 2.11 | 100 |
| 4 | Give the location of Samsung? Samsung location is in South Korea | 100 | 2.11 | 100 |
| 5 | S6 was released in? S6 was released in 2015 | 90 | 2.13 | 88.8 |
| 6 | What is the main feature of S6 S6 main feature is cost-effective | 90 | 2.11 | 94.7 |
| 7 | Tell the RAM size of S6 S6 RAM size is 3GB | 90 | 2.13 | 94.7 |
| 8 | How much does S6 cost? S6 cost is 1000 Ringgits | 90 | 2.13 | 94.7 |
| 9 | Is Samsung a local company Samsung is an MNC company | 90 | 2.12 | 94.7 |
| 10 | The main competitor of Samsung is Samsung main competitor is Apple | 90 | 2.12 | 94.7 |
| AVERAGE | 93 | 2.12 | 94.58 | |
| No. | Query Sentence | SLPS 1 | SLPS 2 | SLPS 3 | SLPS 4 |
|---|---|---|---|---|---|
| 1 | Where is Samsung located | 40 | 70 | 40 | 70 |
| 2 | Who is the founder of Samsung | 80 | 80 | 60 | 70 |
| 3 | What is the current focus of Samsung | 80 | 70 | 80 | 90 |
| 4 | When was S6 released | 70 | 100 | 50 | 50 |
| 5 | Which OS is present in Samsung | 90 | 80 | 80 | 100 |
| 6 | Is Samsung a national company | 50 | 80 | 70 | 70 |
| 7 | The main Competitor of Samsung is | 90 | 60 | 80 | 70 |
| 8 | How much does S6 cost | 40 | 70 | 90 | 80 |
| 9 | Tell the RAM size of S6 | 50 | 40 | 50 | 70 |
| 10 | Airasias main office is located in | 60 | 60 | 80 | 100 |
| 11 | AK021′s arrival time is | 50 | 70 | 90 | 100 |
| 12 | Alternate flight to Perth | 40 | 60 | 70 | 70 |
| 13 | Research office is at | 100 | 90 | 80 | 70 |
| 14 | Does the computer have a name | 50 | 60 | 90 | 90 |
| 15 | Coming Eureca conference happens in | 70 | 80 | 70 | 60 |
| 16 | Conclude the Event | 80 | 70 | 70 | 90 |
| 17 | Greet everyone | 70 | 80 | 80 | 70 |
| 18 | Your native is | 70 | 70 | 60 | 80 |
| 19 | Which university are you studying at | 90 | 100 | 80 | 100 |
| 20 | Thank you for the details | 100 | 80 | 80 | 80 |
| F1 Score (%) | 81.30 | 84.7 | 84.05 | 88.2 | |
| Standard deviation | 2.00 | 1.42 | 1.41 | 1.44 |
| No. | System Type (Real-Time) | Speech Recognition | Natural Language Processing | References | |||
|---|---|---|---|---|---|---|---|
| Accuracy (%) | Training Time (s/Epoch) | Processing Time (s) | Hardware Utilization (%) | F1 Score (%) | |||
| 1 | Full Software (V) | 85.05 | 1.1 | 95.6 | [8] | ||
| 2 | Full Hardware (X) | 79.31 | 0.082 ms | 74.7 | [14] | ||
| 3 | Full Hardware (Y) | 0.932 | 10.1 | 89.1 | [21] | ||
| 4 | Full Hardware (Z) | −79.68 | 0.932 | 61.3 | [13] | ||
| 5 | Proposed System (Software/Hardware) | 81.5 | 1.125 | 0.59 | 5 | 88.2 | |
| Variation with Existing System | <4.15% | >2.27% | <36.7% | <50.4% | <7.7% | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
James, P.E.; Mun, H.K.; Vaithilingam, C.A. A Hybrid Spoken Language Processing System for Smart Device Troubleshooting. Electronics 2019, 8, 681. https://doi.org/10.3390/electronics8060681
James PE, Mun HK, Vaithilingam CA. A Hybrid Spoken Language Processing System for Smart Device Troubleshooting. Electronics. 2019; 8(6):681. https://doi.org/10.3390/electronics8060681
Chicago/Turabian StyleJames, Praveen Edward, Hou Kit Mun, and Chockalingam Aravind Vaithilingam. 2019. "A Hybrid Spoken Language Processing System for Smart Device Troubleshooting" Electronics 8, no. 6: 681. https://doi.org/10.3390/electronics8060681
APA StyleJames, P. E., Mun, H. K., & Vaithilingam, C. A. (2019). A Hybrid Spoken Language Processing System for Smart Device Troubleshooting. Electronics, 8(6), 681. https://doi.org/10.3390/electronics8060681