1. Introduction
Learning algorithms such as deep learning are making major advances in solving problems that have resisted different attempts by the artificial intelligence community for many years [
1,
2]. The advantages of learning algorithms in discovering the structure of complex high-dimensional data make them widely used in many fields such as engineering technology and scientific development. However, due to the complexity of learning algorithms such as deep neural networks, their applications face enormous challenges. Prior to the advent of new and more effective learning algorithms, improving the performance of existing learning algorithms is a major task in the field of artificial intelligence. How to improve the performance of the learning algorithm when solving practical problems is a common challenge faced by the academic community. As a sub-topic of this issue, choosing good hyper-parameter values for learning algorithms is also an effective way to improve the performance of learning algorithms.
The process of searching for good values of hyper-parameters in machine learning algorithms can be considered as an optimization process that attempts to find hyper-parameters for the best objective performance such as verification errors. The hyper-parameters optimization problem can be abstracted into a mathematical model as shown in Equation (1) [
3]. In this model,
is a learning algorithm and
is the hyper-parameters of
. The ultimate goal of the hyper-parameters optimization is to find the hyper-parameter combination
to minimize the generalization error
of the learning algorithm
on dataset
(a finite set of samples from
).
In the early period, the development of learning algorithms was in its infancy, the algorithm model was relatively simple, and the number of main hyper-parameters in the model was small. The manual search [
4] was an effective way to determine hyper-parameters. Manual search does not require the high computational overhead, but requires a high level of expertise. Manual search is mainly suitable for solving the hyper-parameter selection problem of early simple learning algorithms. As learning algorithms become complex, the manual search has been difficult to use to provide good performance. At present, the automatic hyper-parameter optimization algorithm is the main trend in development, especially with the development of computer technology.
Larochelle et al. proposed a Grid Search [
5] method for hyper-parameter optimization. The Grid search is simple to implement and reliable in the low-dimensional space, but it becomes trapped in dimensionality disasters in the high-dimensional space. It can be seen from Equation (1) that when the number of
is large and the range of each
is wide, the search process will become complicated. The amount of computation required will increase exponentially, and the search algorithm will easily fall into the dimension disaster. Grid search has been proven to be easily fall into dimensionality disasters in a high-dimensional hyper-parameter space [
3]. Hinton et al. [
6] combined the manual search and grid search to train restricted Boltzmann machines. But this approach cannot completely avoid the shortcomings of the manual search and grid search. Bergstra et al. proposed a Random Search method [
3] for the hyper-parameter optimization. This method is proven to be superior to the grid search, and the method is simple and easy to parallelize. However, the random search is somewhat similar to the grid search, and there is no guarantee that the result is optimal, or that the random search is non-adaptive.
Sequential model-based optimization methods [
7,
8] and particularly Bayesian optimization methods [
9,
10,
11,
12,
13,
14] were also used in the hyper-parameter optimization. Bayesian search uses a completely different approach compared to the grid search and random search, as the latter ignores the information of the previous search point in the search process, but Bayesian search makes full use of the previous search point information. The Bayesian optimization method also has its limitations. Once it searches for a maximum value point, it will continue to sample continuously around the highest value point, which makes it easy to fall into a local optimum. In addition, evaluating the hyper-parameter settings of the learning algorithm requires fitting the model and verifying its performance on the dataset. The computational overhead of this process is so huge that makes a sequential hyper-parameter optimization on a single computational unit impractical. It is undeniable that the sequence model based optimization and Bayesian optimization methods are essentially sequential. Although a certain degree of parallelization can be achieved by computing the optimal solution of multiple acquisition functions [
15,
16], a perfect parallelization is difficult to achieve.
Meta-heuristic algorithms are widely used to solve various optimization problems. In recent years, they have also been used for hyper-parameters optimization problems. Francescomarino et al. [
17] and Zhang et al. [
18] used Genetic Algorithms to optimize the hyper-parameters of learning algorithms and achieved good results in practical problems. Young et al. [
19] and Furtuna et al. [
20] used Evolutionary Algorithms to optimize hyper-parameters of learning algorithms. As an improved evolutionary algorithm, CMA-ES (Covariance Matrix Adaptation Evolution Strategy) was also used to optimize learning algorithms [
21]. Soon et al. [
22] and Lorenzo et al. [
23] used Particle Swarm Optimization to optimize deep neural network models. However, a single meta-heuristic algorithm has a common shortcoming. When the objective function is non-convex, it is easy fall into the local optimal solution. With the absence of a reasonable strategy to jump out of the optimal solution, a single meta-heuristic algorithm is difficult to use to find the optimal hyper-parameter combination.
In addition to the methods mentioned above, there are several recently proposed methods. Tang et al. [
24] proposed a novel methodology that uses the geometric characteristics of line-segment representations to optimize hyper-parameters for deep networks. Diaz et al. [
25] addressed the problem of choosing appropriate parameters for neural networks by formulating it as a box-constrained mathematical optimization problem, and applying a derivative-free optimization tool that automatically and effectively searches the parameter space. Maclaurin et al. [
26] proposed a gradient-based hyper-parameter optimization method. However, their research is limited to the use of their own methods to optimize a model to solve practical problems, and is not compared to several hyper-parameter optimization algorithms that are widely considered to be excellent. Their methods are less versatile for different machine learning algorithms.
The existing hyper-parameter optimization methods have made great contributions in solving the problem of selecting appropriate hyper-parameters for learning algorithms, but they still have some problems. One of them is that the computational overhead during the search process is huge. Both the sequence model-based optimization and single meta-heuristic algorithm optimization methods have this problem. It is worth noting that with development of the computer hardware, especially the development of GPU, the computational overhead has been greatly reduced compared to the past. But for complex learning algorithms like deep neural networks, the optimization process can still take several weeks. Although several new methods have been proposed in recent years with good performance, they are limited to several specific models, and their generalization ability is poor.
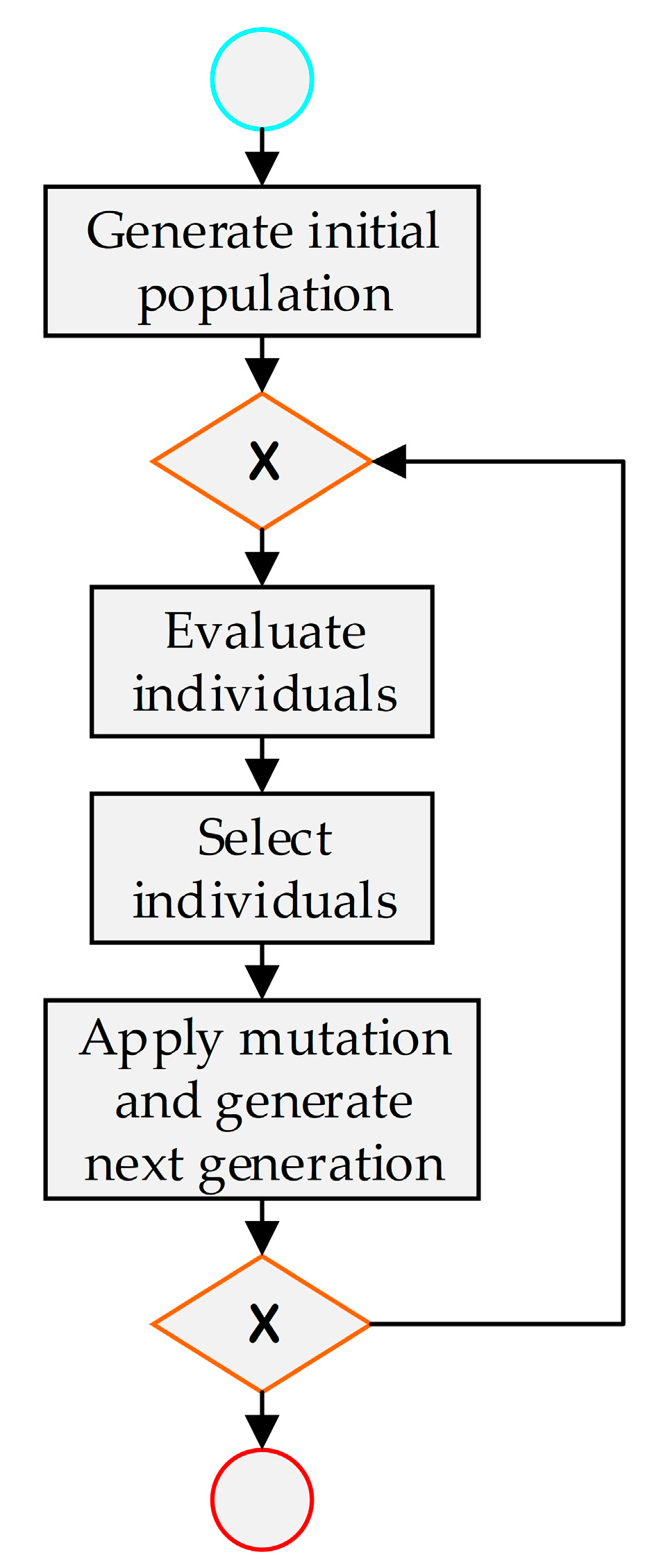
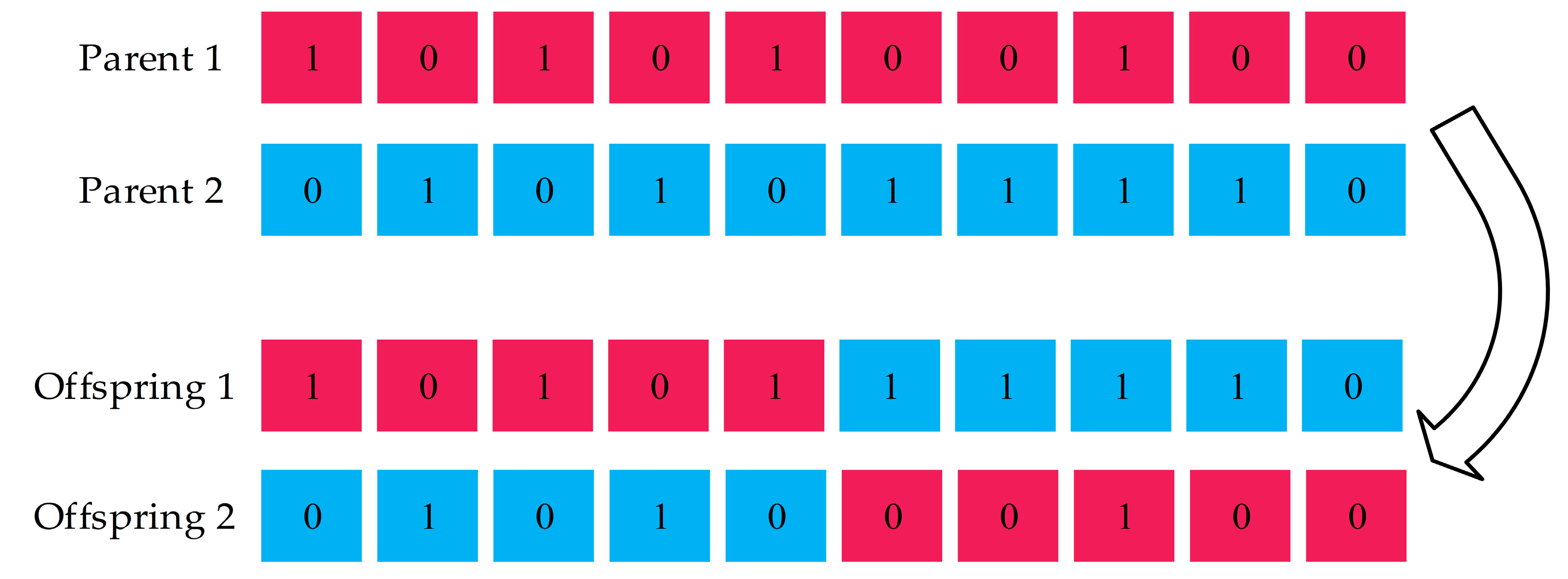
The hyper-parameter optimization process of learning algorithms often wastes a lot of unnecessary computational overhead due to repeated searches of hyper-parameter points. In the existing hyper-parameter optimization method, a grid search can effectively avoid repeated searches of hyper-parameter points. But an obvious problem with the grid search is that the computational overhead grows exponentially as the number of hyper-parameters increases. We want to use genetic algorithms to optimize the hyper-parameters of deep neural networks, and to establish a mechanism like grid search to avoid repeated searches. For genetic algorithms, repeated searches are an inevitable problem. The mechanism for setting up a Tabu list in the Tabu search algorithm can effectively avoid repeated searches. In other heuristic algorithms, there is no suitable way to avoid repeated searches. Based on this, we have come up with the idea of combining Tabu search and genetic algorithms.
Considering the problem that the current method is easily fall into the local optimal solution and the computational cost is huge, we use genetic algorithms as the basic algorithm to solve this problem, and find ways to avoid falling into local optimal solutions in order to improve search efficiency. Through our research, a new hyper-parameter optimization method is proposed, this method is defined as the Tabu_Genetic Algorithm (Tabu_GA). In order to avoid falling into local optimal solutions, methods of the crossover, mutation and selection in Tabu_GA have been improved. At the same time, in order to reduce the computational overhead during the whole search process, the idea of setting up a Tabu list in Tabu Search has also been incorporated into Tabu_GA. Compared to the existing methods, this method can significantly reduce the computational overhead during the search process with good adaptability to different learning algorithms. In later experiments, Tabu_GA has been proven to be superior to several existing hyper-parametric optimization methods.
The key contribution of our research is the development of a Tabu_GA algorithm and applying it to better solve the hyper-parameter optimization problem of learning algorithms. This makes the learning algorithms such as deep learning perform better when solving practical problems.
3. Experiments
In order to verify the performance of Tabu_GA and prove that our improvement is meaningful, we have designed two sets of experiments, including main experiments and additional experiments. In the main experiments, we compared the performance of Tabu_GA with several algorithms that are currently considered to be excellent. In the additional experiments, we compared the optimization performance of Tabu_GA with GA (without Tabu Search) and Tabu Search (TS).
The experiments were performed on a computer equipped with NVIDIA GTX1080Ti GPU and Intel Core i7 CPU. The software platform is based on Tensorflow. Tabu_GA, GA and TS are programmed using Python 3. The other four methods are called from Hyperopt [
33,
34]. The experimental details are described below.
3.1. Main Experiments
In the main experiments, two sets of experiments were performed to verify the reliability and adaptability of Tabu_GA. In order to verify the performance of Tabu_GA on different datasets, experiments were conducted on two sets of datasets, one experiment on the MNIST dataset and the other on Flower-5 dataset. Convolutional neural networks were used as the optimization object in both experiments. In order to verify the search effect of Tabu_GA in the low-dimensional space and high-dimensional space, two different convolutional neural network models were selected. The experiment on the MNIST dataset selected the classic LetNet-5 convolutional neural network as the optimized object. The LetNet-5 convolutional neural network has a simple structure and a relatively small number of hyper-parameters. The experiment on the MNIST dataset simulates the hyper-parametric search process of relatively simple learning algorithms, which can also be considered as the search process in a low-dimensional space. The experiment on the Flower-5 dataset selected a more complex deep convolutional neural network model as the optimized object. The experiment on the Flower-5 dataset simulates the hyper-parametric search process of relatively complex learning algorithms, which can also be considered as the search process in a high-dimensional space. Both results of experiments are used to compare the performance of Tabu_GA with the Bayesian optimization method, Simulated Annealing Algorithm (SA), CMA-ES and Random Search. Bayesian optimization methods, simulated annealing, CMA-ES and random search are several hyper-parametric optimization algorithms that generally considered to be excellent methods applied in the field. Therefore, we chose these four methods to compare with Tabu_GA in the experiment. The Bayesian optimization method chosen for this experiment is Tree-structured Parzen Estimator Approach (TPE) [
10].
3.1.1. Convolutional Neural Network
Convolutional Neural Network (CNN) is a well-known deep learning architecture inspired by the natural visual perception mechanism of living creatures [
35]. The convolutional neural network relies on convolution and pooling operations to identify information. It has been widely used in target detection, image classification [
36] and other fields [
37]. There are many types of convolutional neural networks, such as LetNet-5 [
38,
39] and AlexNet [
40]. The experiment on the MNIST dataset selected the classic LetNet-5 convolutional neural network as the optimized object. The LetNet-5 convolutional neural network is an early convolutional neural network model with a simple structure and is also trained through back-propagation. The experiment on the Flower-5 dataset selected a more complex deep convolutional neural network model as the optimized object. The model can be found on GitHub (
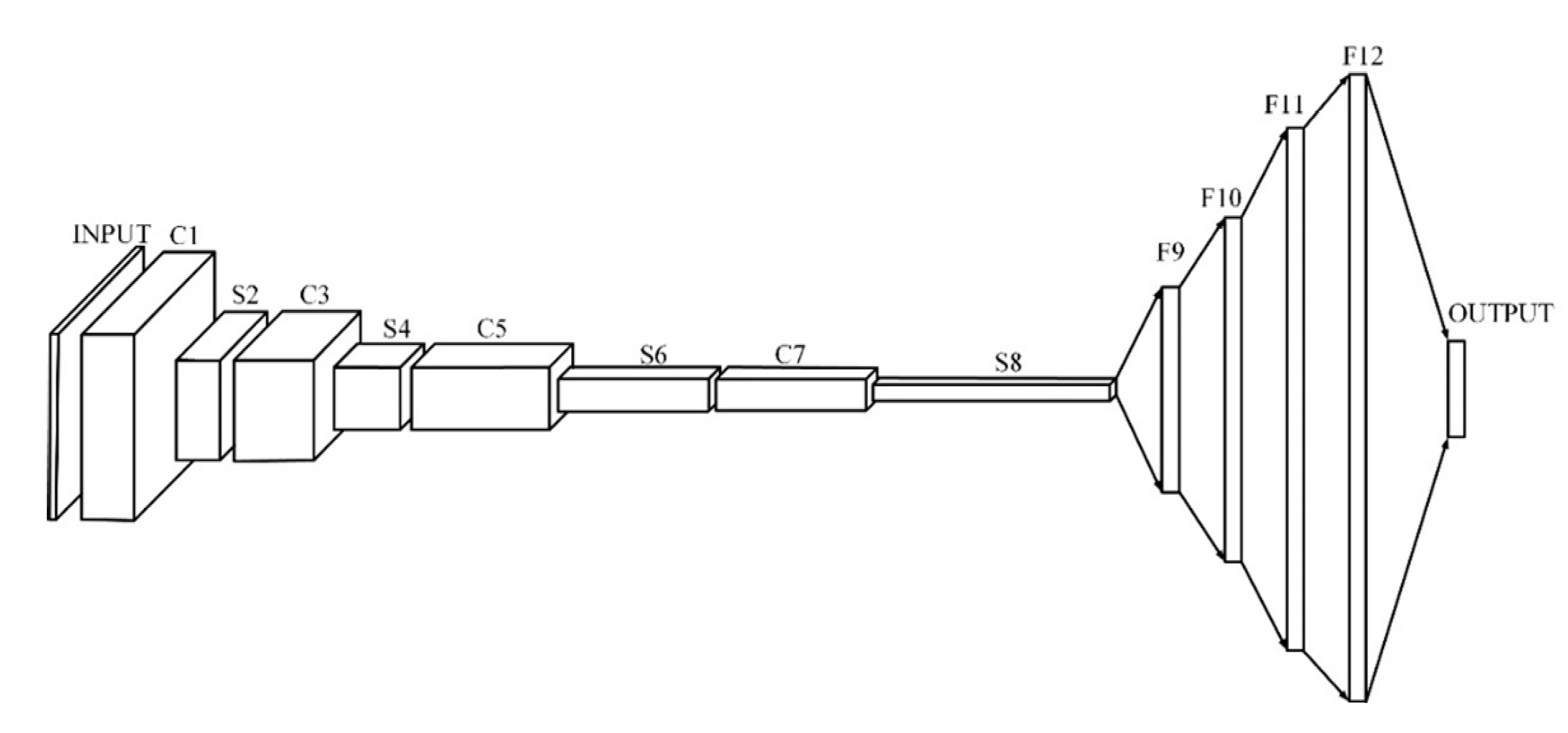
https://github.com/deep-diver/CIFAR10-img-classification-tensorflow) and its structure is shown in
Figure 4, which consists of four convolutional layers, four pooling layers, and four hidden layers. It is a deep convolutional neural network model.
3.1.2. Experiment on MNIST Dataset
The MNIST dataset (
http://yann.lecun.com/exdb/mnist/) is a classic dataset used in classification problems of machine learning. The dataset consists of 60,000 of grayscale handwritten digits, which are divided into 10 categories, i.e. numbers 0-9. The 60000 images are divided into verification sets and training sets. In many papers and practical questions, the MNIST data set is used to evaluate the performance of the model.
Figure 5 are some examples of handwriting in the MNIST data set.
Hutter et al. proposed an efficient approach for assessing the hyper-parameter importance [
41] and proved that even in very high dimensional cases—the most performance variation is attributable to just a few hyper-parameters. Five important hyper-parameters of the LetNet-5 convolutional neural network are selected as objects to search, including learning rate, batch size, number of full-connected layer1 (F1) units, dropout rate and L2 weight decay. For the learning rate, the dropout rate and L2 weight decay will use the log scale sampling mentioned in
Section 2, while the batch size and Number of F1 units use uniform sampling. The range of values for each hyper-parameter is shown in
Table 1. This gets about 1.96 million hyper-parameter combinations after discretizing the five hyper-parameters.
Table 2 shows some parameters and settings of the LetNet-5 convolutional neural network that do not change during the experiment.
A standard for evaluating algorithms in experiments is the smallest validation error found in all epochs when the training time (including the time spent on model building) is limited [
21]. The generalization error of learning algorithms on the verification set is one of the important indicators to measure its performance. This can indirectly reflect the performance of the optimization method. The relevant settings during the experiment are shown in
Table 3.
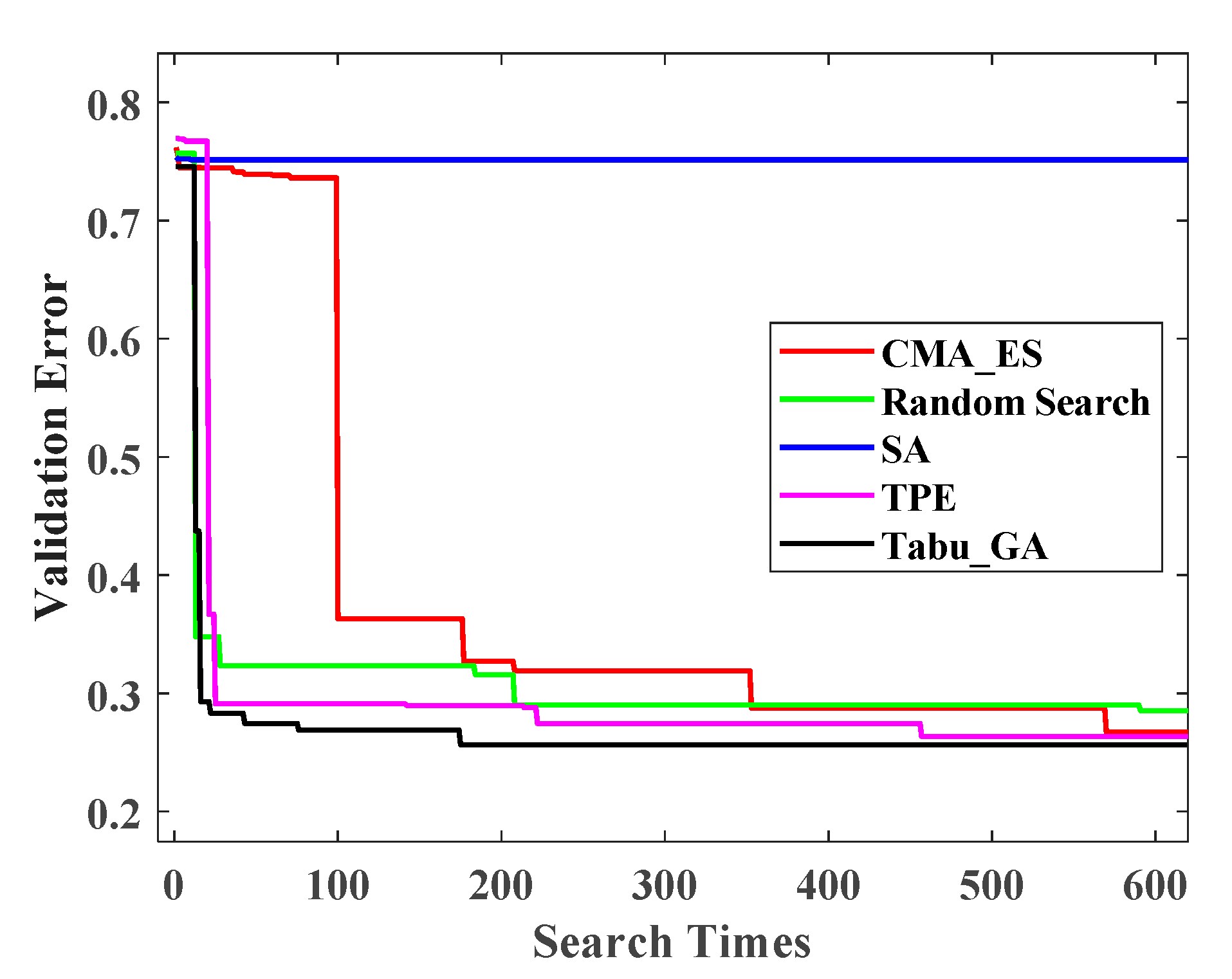
The experimental results on the MNIST dataset are shown in
Figure 6.
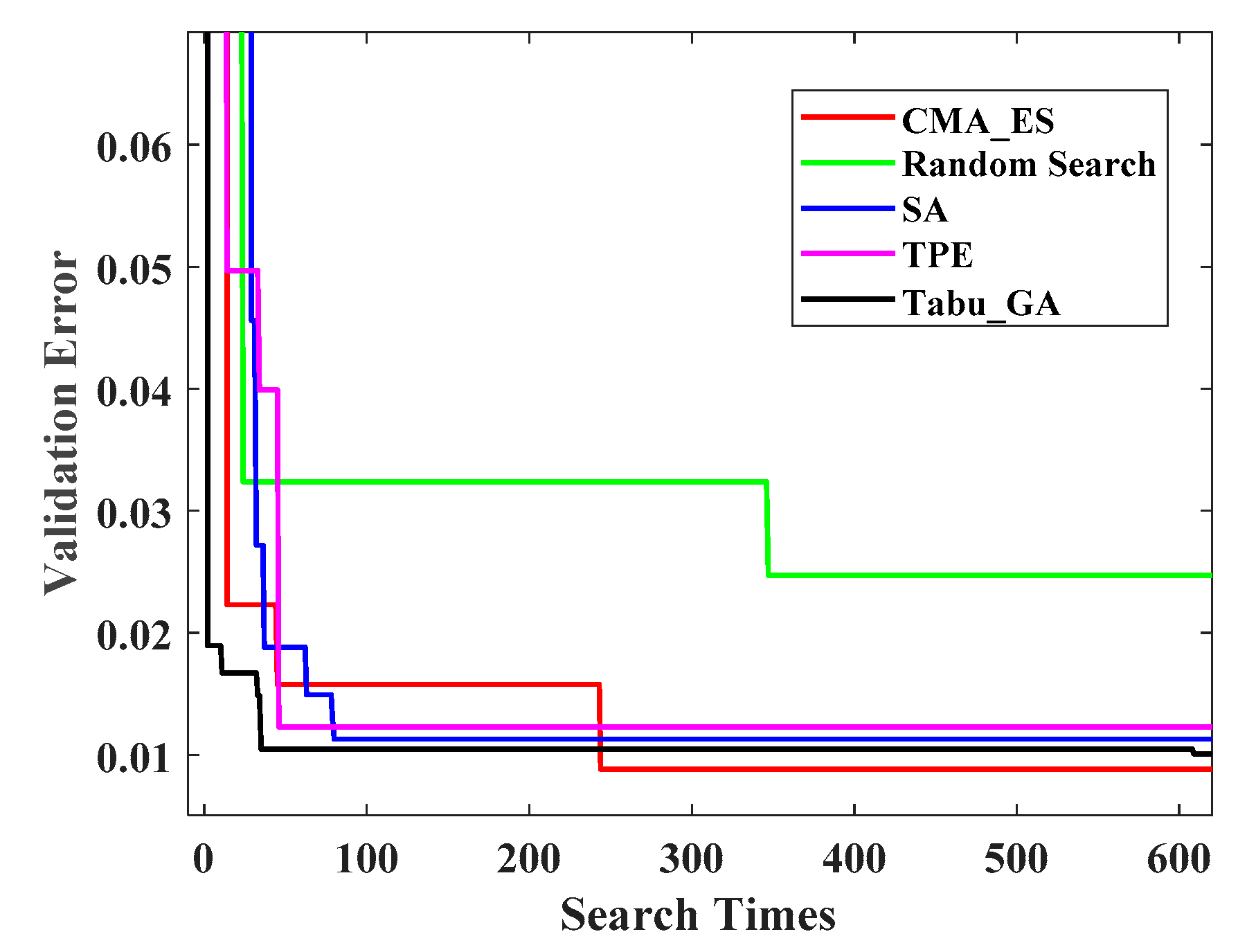
Figure 6 depicts the verification set error curve of the convolutional neural network model optimized by the five optimization methods in the experiment on the MNIST data set. It can be seen from
Figure 6 that the convolutional neural network model optimized by Random Search performs poorly. In contrast, the performance of the convolutional neural network model optimized by the other four methods is basically consistent. The model optimized by CMA-ES finally achieved the best performance. But that was after nearly 250 evaluation searches. Tabu_GA found the sub-optimal model with less than 100 searches. Tabu_GA finds a better model in less time, which is preferable. Tabu_GA is superior to the Bayesian optimization and random search. Experiments on the MNIST dataset demonstrate that Tabu_GA is efficient for searching good values of hyper-parameters for simple learning algorithms, to reach or surpass the level of several well-known methods.
3.1.3. Experiment on Flower-5 Dataset
Another set of experiments was performed on the Flower-5 dataset. Flower-5 dataset (
https://www.kaggle.com/alxmamaev/flowers-recognition) includes approximately 4000 images of five type flowers, includes daisy, dandelion, rose, sunflower, and tulip, as shown in
Figure 7. There are about 800 images for each type of flower. The Flower-5 dataset is more complex than the MNIST dataset, and is very sensitive to the setting of hyper-parameters. The difficulty of performing classification tasks on the Flower-5 dataset is greater than on the MNIST dataset.
The experiment on the Flower-5 dataset selected a more complex deep convolutional neural network model as the optimized object. The model can be found on GitHub (
https://github.com/deep-diver/CIFAR10-img-classification-tensorflow) and its structure is shown in
Figure 4, which consists of four convolutional layers, four pooling layers, and four hidden layers. It is a deep convolutional neural network model. The eleven hyper-parameters of this deep convolutional neural network model were selected as search objects for this experiment, as shown in
Table 4. The experiment steps performed on the Flower-5 data set were identical to the experimental performed on the MNIST data set. Only some specific details are different.
Experiments performed on the Flower-5 dataset still use the method described in
Section 2 to discretize the hyper-parameters with the same coding method. There are about 5 × 10
12 pairs of hyper-parameter combinations after eleven hyper-parameters are discretely completed.
Table 5 shows parameters and settings of the deep convolutional neural network that do not change during the experiment. Relevant settings in the experiment are shown in
Table 6. The evaluation criteria for the method in the experiment are same as the experiment on the MNIST dataset.
Experimental results on the Flower-5 dataset are shown in
Figure 8.
Figure 8 depicts verification set error curves of the deep convolutional neural network model optimized by five optimization methods in the experiment on the Flower-5 dataset. It can be seen from
Figure 8 clearly that the deep convolutional neural network model optimized by SA has an extremely poor performance. In order to prove that this situation is not caused by mistakes in experimental operations, a second identical experiment was performed according to the same criteria. In the end, we found that this situation was not caused by mistakes in experimental operations. This phenomenon is caused by defects of SA itself. The search process of SA falls into a local optimal solution and continues to oscillate around it. This shows that SA is not suitable for use in the high-dimensional space. The performance of the model optimized by the other four methods is basically the same. However, Tabu_GA is still the best. Compared to the Bayesian optimization method, CMA-ES and Random Search, the model searched by Tabu_GA performs better. Tabu_GA finds a better model in less time. Experiments on the Flower-5 dataset demonstrate that Tabu_GA has good search capabilities even in high-dimensional cases and is superior to Random Search and Bayesian optimization methods.
3.1.4. Summary of the Main Experiment
In order to further compare the five methods involved in the experiment, the experimental results are specifically shown in
Table 7 and
Table 8, including the maximum number of assessments that reach the optimal model, the maximum accuracy that can be achieved, and the average accuracy. Both results of experiments on MNIST and Flower-5 show that Tabu_GA is more preferable. As shown in
Table 7, Tabu_GA does not significantly improve the classification accuracy on the MNIST dataset. The MNIST data set is easy to be classified, and the convolutional neural network can achieve a high classification accuracy. However, based on solutions in
Table 7, Tabu_GA reduces the number of iterations required for the model to achieve the highest classification accuracy, and improve the classification efficiency. In addition,
Table 8 shows that for a more complex data set such as Flower-5, Tabu_GA improves the classification accuracy of the model for more than 1% by optimizing the hyper-parameter of the model. This means that Tabu_GA can bring great benefits in the face of complex data sets and models. The above analysis results also show that Tabu_GA is feasible and effective for the hyper-parameter optimization of learning algorithms.
3.2. The Additional Experiment
The purpose of our additional experiments was to compare the performance of Tabu_GA, GA and Tabu Search in optimization, and to analyze whether our improvements are meaningful. Although the previous experimental results have shown that Tabu_GA is better than several excellent algorithms, this is not enough strong evidence showing the improvement. In order to further verify the experimental solutions, we conducted additional experiments.
The additional experiments used the same data set and convolutional neural network model as the previous experiments did, and were conducted under the same experimental environment on the MNIST dataset and Flower-5 dataset, respectively. The same GA (without tabu search) and TS were chosen as the comparison object for Tabu_GA.
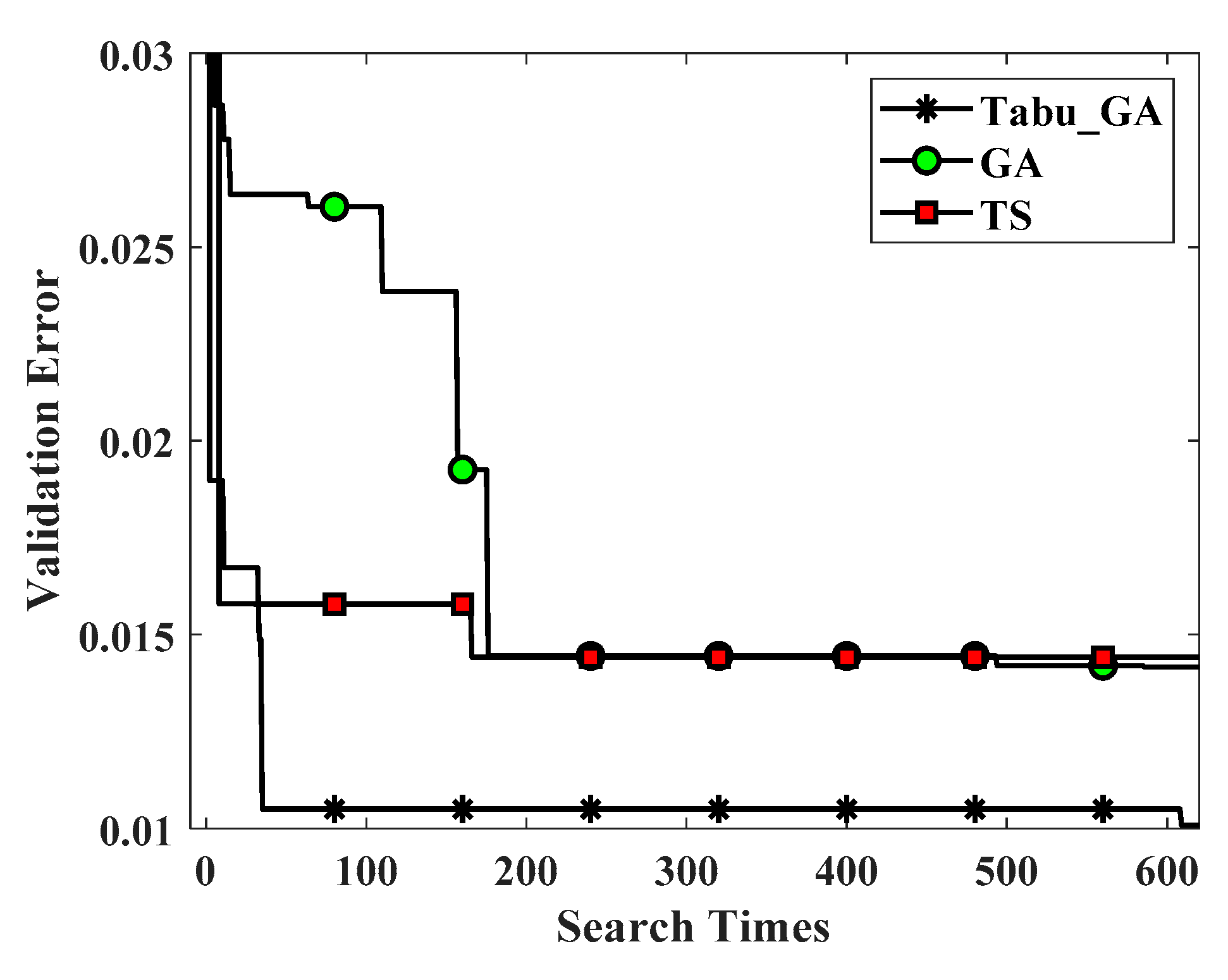
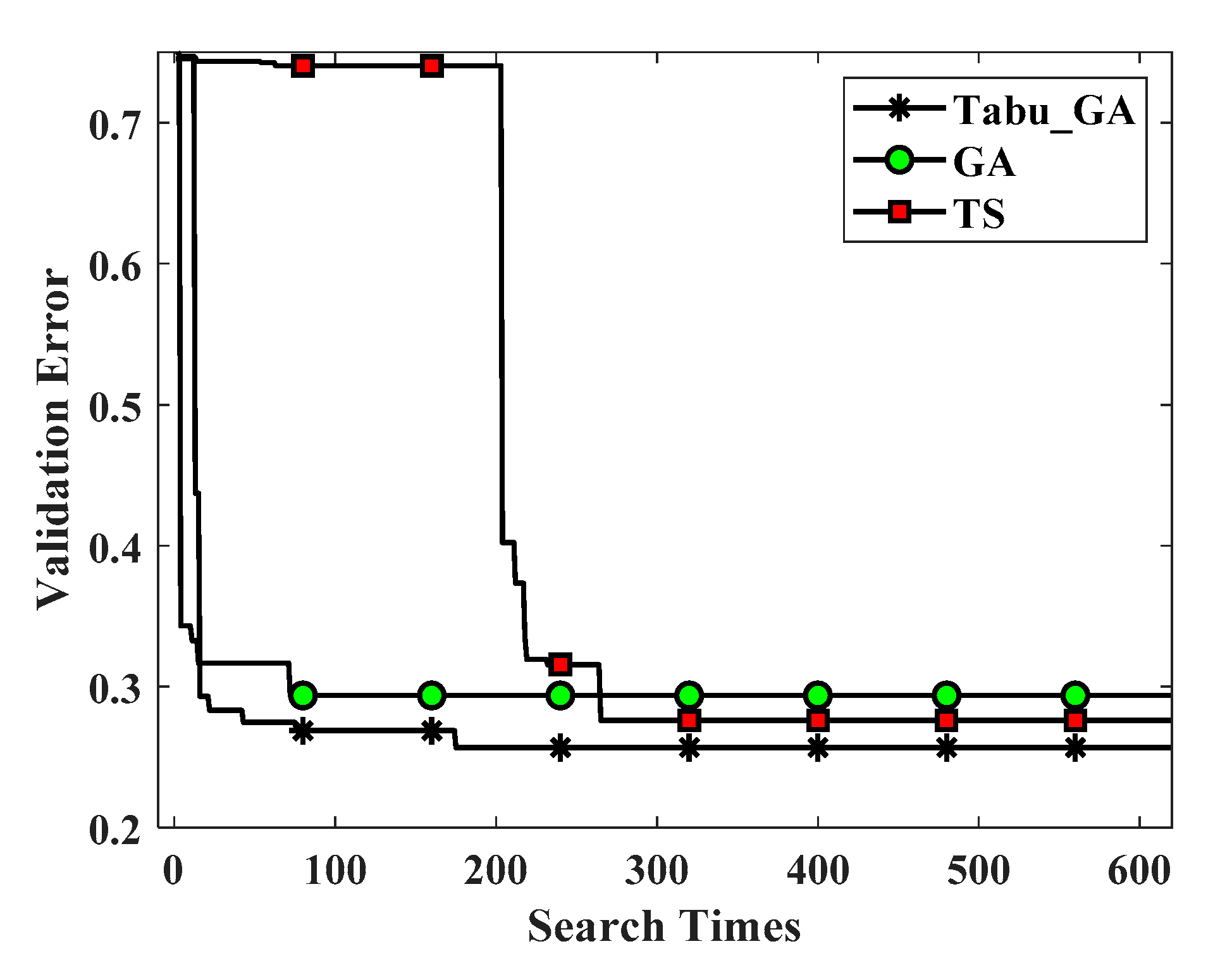
From experimental results shown in
Figure 9 and
Figure 10, Tabu_GA performs better than GA and TS, both on the experiment of MNIST dataset and Flower-5 dataset. We also found that TS can achieve better results in optimizing hyper-parameters of the model. According to our survey, no scholars have used TS to optimize the hyper-parameters in deep neural networks or other machine learning algorithms. In addition, the experimental results also show that advantages of Tabu_GA compared to GA and TS become more apparent as the complexity of data sets and models increases. This can be seen from
Figure 9 and
Figure 10. The verification error of the deep convolutional neural network model optimized by Tabu_GA on the Flower-5 dataset is about 3.7% lower than that of GA. Results of additional experiments show that our improvement is correct and meaningful. Tabu_GA has better performance than GA and TS. Compared to GA and TS, Tabu_GA has obtained a better convolutional neural network model with less time.
3.3. Stability Analysis of Tabu_GA
In the above experiment, the hyper-parameter value was first generated by a set of random seeds and different random seeds may cause different experimental results. In order to analyze whether the optimized performance of Tabu_GA is affected by this randomness, we performed five additional experiments (different random seeds for each set of experiments). It should be noted that there are no other differences between the five sets of experiments except for the random seeds. The experimental setup is the same as the experiment in
Section 3.1. We use the standard deviation and mean of experimental results to show the effect of random seeds on Tabu_GA. We separately consider the mean and standard deviation of the maximum and average accuracy that the model can achieve in each set of experiments although getting the best model is our ultimate goal.
The experimental results are shown in
Table 9 and
Table 10 for the mean and standard deviation of multiple sets of experimental results on MNIST and Flower-5. As can be seen from
Table 9, results of five sets experiments show that the model optimized by Tabu_GA can achieve a high classification accuracy on the MNIST dataset. The mean of both the average accuracy and maximum accuracy remains at a higher value. Moreover, the standard deviation of the maximum accuracy and average accuracy is also in a very small range. This shows the fact that the final experimental results of the five sets of experiments are almost identical, and that Tabu_GA is stable in optimizing the LetNet-5 convolutional neural network model. Similarly, experimental results on the Flower-5 data set can be seen in
Table 10. The mean of the average accuracy is smaller than the mean of the maximum accuracy. The main reason of this phenomenon is that Flower-5 is a relatively complex data set, and the convolutional neural network cannot achieve a good classification accuracy in the initial stage of optimization. Therefore, when calculating the average accuracy of a set of experimental results, it is bound to occur that the final mean is lower due to the low classification accuracy in the initial stage of optimization. This is different from the experiment on the MNIST dataset. Because the MNIST data set is easier to classify, and the convolutional neural network model can achieve the high classification accuracy with only a small number of optimization iterations. In
Table 10, the maximum accuracy of the five sets of experiments is at a higher level than the maximum accuracy achieved by the other four methods as shown in
Table 8. In addition, based on data in
Table 10, the standard deviation of the average accuracy and maximum accuracy of the five sets of experiments on the Flower-5 data set is also in a small range. This also shows that the optimization performance of Tabu_GA is not affected by randomness. Therefore, Tabu_GA is sufficiently stable.
By analyzing experimental results of the above 10 sets of experiments, it can be concluded that the optimization performance of Tabu_GA is not affected by randomness. This also verifies that Tabu_GA has good stability and adaptability.
4. Discussion
The hyper-parameter optimization problem of learning algorithms is currently the main challenge for its application. Before the advent of better learning algorithms, the key to solving this problem is to find better hyper-parametric optimization algorithms. Excellent hyper-parameter optimization methods will make the current learning algorithm obtain better performance in solving practical problems.
For a long time, Gird Search, Random Search and Bayesian optimization methods have been considered as the most effective way to solve the hyper-parameter optimization problem of learning algorithms. They are commonly used as natural benchmarks. The optimization method based on heuristic algorithms and other methods proposed in recent years are also used in the hyper-parameter optimization problem of learning algorithms, but the performance is general, and most of them are only suitable for solving a specific problem without universality. Heuristic algorithms are not the first choice among the popular hyper-parameter optimization methods. However, our results suggest that heuristic algorithms have great potential in solving the hyper-parameter optimization problem of learning algorithms. The proposed Tabu_GA is superior to the existing popular methods in performance. This provides a new research idea for solving the problem of learning algorithms for the hyper-parameter optimization, which is to study the hyper-parameter optimization method based on heuristic algorithms. Although we did not verify the performance of Tabu_GA through a real data set, we still recommend Tabu_GA as a method to optimize the hyper-parameter of the learning algorithm in practical applications. The performance of Tabu_GA on the MNIST dataset and Flower-5 dataset can be representative of the actual application to a certain degree.
The results of this work also suggest that the research on the hybrid meta-heuristic algorithm is meaningful. Hybrid optimization methods will be a major trend in the future. This is not limited to the hybridization between different meta-heuristics, but also the hybrid use of meta-heuristics and other algorithms. The combined use of two different methods provides the original strengths of both, and the two methods complement each other. Tabu_GA is also a hybrid meta-heuristic. The performance of Tabu_GA also shows the value of the above development direction.
We found the Tabu_GA when solving the hyper-parameter optimization problem of convolutional neural networks, and achieved good results. Tabu_GA is essentially an optimization method. In a sense, Tabu_GA can be used to solve other optimization problems. As it is limited to the specific problems discussed in this article, we have not proved its application in other problems, but this is an area worthy of study, and may achieve unexpected results.
5. Conclusions
In this work, a new method of Tabu_GA is proposed for the hyper-parameter optimization of learning algorithms such as deep neural networks.
The experiments prove that Tabu_GA is an excellent hyper-parameter optimization method. Experiments on both the MNIST and Flower-5 data sets show that the effectiveness of Tabu_GA. In dealing with the hyper-parameter optimization problem of simple learning algorithm, it is verified by experiments on the MNIST dataset. Moreover, experiments on the MNIST dataset also show that Tabu_GA can find a better solution while reducing the computation time by 50% compared to the current mainstream optimization methods. Another set of experiments on the Flower-5 dataset shows that Tabu_GA is also excellent for the optimization of complex learning algorithms like deep neural networks. Although this advantage is not obvious, it exists objectively. Through these two sets of experiments, we can conclude that Tabu_GA can be used as a hyper-parameter optimization method for learning algorithms. Tabu_GA is equally applicable for both simple and complex learning algorithms.
The additional experimental results also prove that the proposed improvement method for GA is effective. Improving methods of the crossover, mutation and selection enable Tabu_GA avoid falling into local optimal solutions effectively. At the same time, the idea of setting up a Tabu list in Tabu_GA clearly reduces the computational overhead during the whole search process. Moreover, we analyzed the mean and standard deviation of the results in multiple sets experiments, and found that the optimization performance of Tabu_GA is stable and not affected by randomness.
In fact, based on the experimental results, we can conclude that the Tabu_GA can be used as a method to optimize the hyper-parameter of learning algorithms in a good adaptability. However, the Tabu list in our algorithm needs the extra memory during the search process, the memory demand will be increased as the depth of the search increases. We will continue to optimize Tabu_GA in the future work. In addition, Tabu_GA seems more suitable for optimizing complex models with more parameters. For a simple model with a small number of parameters, although Tabu_GA can achieve better optimization results, the cost performance will be not as good as some simple traditional methods.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}