3.1. Architecture
In the distributed in-memory environments, when requests are concentrated on a specific node, an overload problem occurs, and the overall system performance is degraded. Therefore, a load balancing scheme is required to address the load imbalance by distributing the load of the overloaded node. In the existing load balancing schemes, the load is distributed using a scheme that replicates or migrates the data considering only a specific situation in which the node overload occurs. When the data is replicated to the neighbor nodes, the data can be stored again in one of those nodes when a node with the replicated data is removed, resulting in the overload problem again. In addition, if hot data exists in a node when the data is migrated, the hash spaces are significantly adjusted, and a large amount of data is migrated. In an environment where the memory sizes are different and when a node with a small memory manages a large hash space, it must manage a large amount of data. However, the storage is limited due to the memory size, resulting in frequent data replacements.
In this paper, a load balancing scheme considering the load condition of the nodes is proposed to distribute the load in the distributed in-memory environments. The proposed scheme extracts the overloaded nodes and hot data based on the node and the data loads, and distributes the load through a data replication and migration process. In an environment where the memory sizes of the nodes are different, load balancing is performed by adjusting the initial hash spaces according to the memory size. If the hot data exists when a node is overloaded, the hash spaces are evenly divided, and the hot data is replicated to a node with a low load for load balancing. If there is no hot data, the data of the node with the lowest load is distributed considering the loads of the neighbor nodes, and load balancing is performed by selecting the node as the predecessor node of the node with the highest load and by adjusting the hash space. In distributed environments, nodes can be added or removed. In a situation where a node is added, the new node is added as the predecessor node of the overloaded node in order to distribute the load of the overloaded node. In a situation where a node is removed, the hash spaces are adjusted and the data is migrated considering the loads of the successor node, and the predecessor node of the node to be removed.
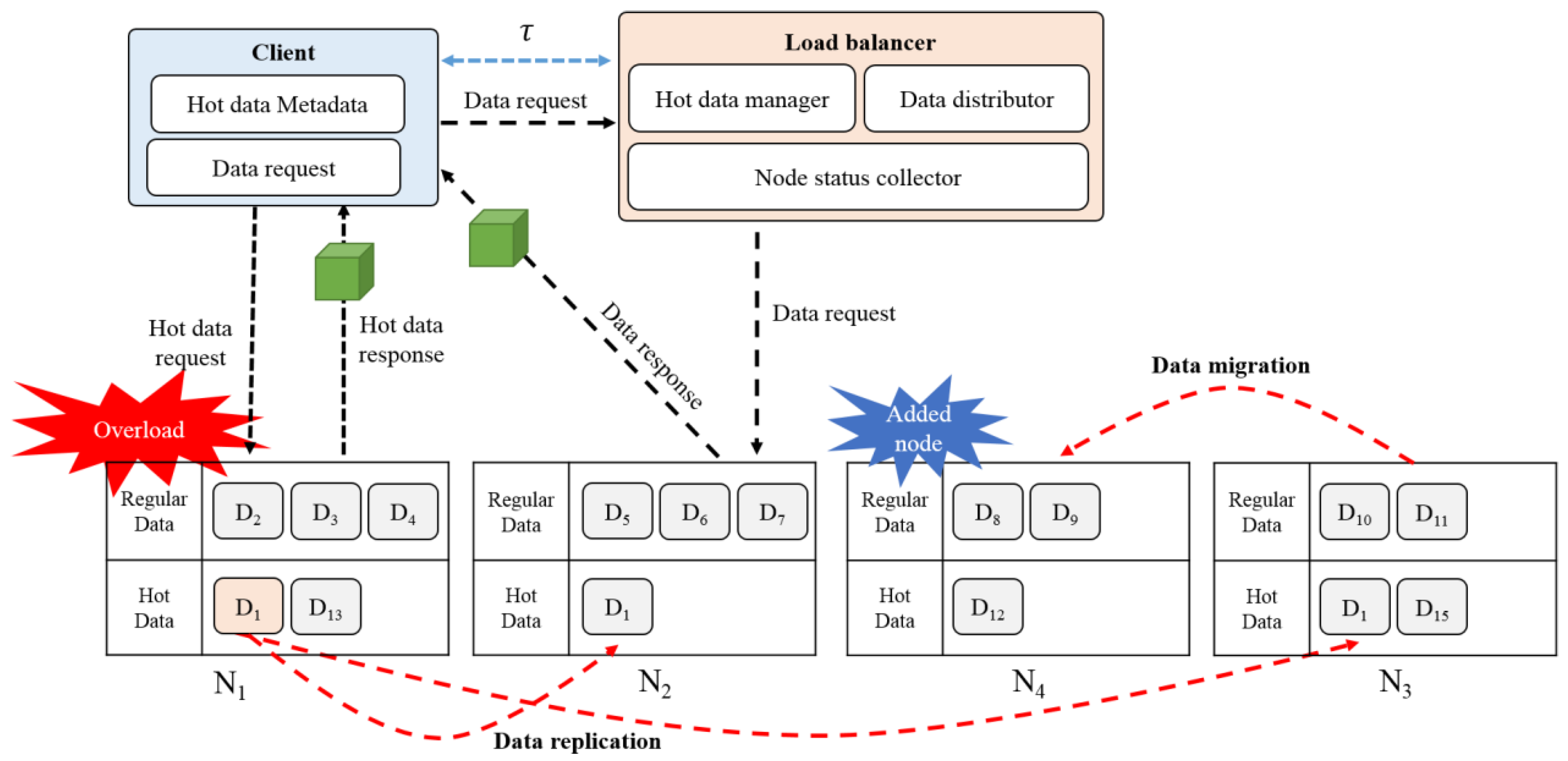
Figure 1 shows the proposed load balancing system. A load balancer operates in a node acting as a central server, distributes the data to the nodes for storage, and performs load balancing for the distributed memory. When the user’s data request is received, the load balancer determines whether the requested data exists in the distributed memory, and delivers the data node information. If there is no user requested data in the memory, the load balancer loads the data from the disk into the memory, and transfers the data to the user. If the data requested by the user is not stored in the memory of the node, the data distributor designates a node for the storage of the data and stores it. The hot data manager collects and separately manages the hot data information generated from the nodes, and synchronizes the metadata of the hot data through periodic communications with the clients.
When an overload occurs at a node, the node sends its current status information to the load balancer. The load balancer that receives the information of the overloaded node collects the load status of all the current nodes based on the access frequency, and stores the status information to distribute the load. The load balancer also collects and stores hot data information from all the nodes. The load balancer distributes the load through a hot data replication and data migration process, based on the load information and the hot data information received from each node. If there is hot data in the overloaded node, the load balancer replicates the hot data to another node, and manages the metadata information of the replicated hot data. If there is no hot data, the load balancer adjusts the hash spaces based on the load on the node, maintains the adjusted hash space of the node, and accesses the node using the adjusted hash space when a data request is received.
3.2. Initial Data Distribution
In the distributed in-memory environments, when nodes are added or removed, the data must be redistributed to the distributed nodes. In general, in distributed environments, however, all data of the existing nodes must be redistributed when the nodes are added or removed. The ring-based hashing scheme, however, does not redistribute all the data when the nodes are added or removed. It only redistributes some data by adjusting the hash space to be managed by other adjacent nodes. This reduces the overall load on the system, thereby increasing the data redistribution efficiency in the distributed environments. Therefore, the proposed scheme is based on the ring-type chord [
38,
39]. In the distributed in-memory environments, the memory size of each node may be different. In this instance, when a node with a small memory size manages a large hash space, a large amount of data must be stored in the node, requiring more frequent data replacement due to the limited memory. In this case, the data replacement causes considerable cost, and the performance of the node may be degraded. Therefore, the proposed scheme distributes the initial nodes considering the memory of the nodes, and addresses the problem caused by data replacement.
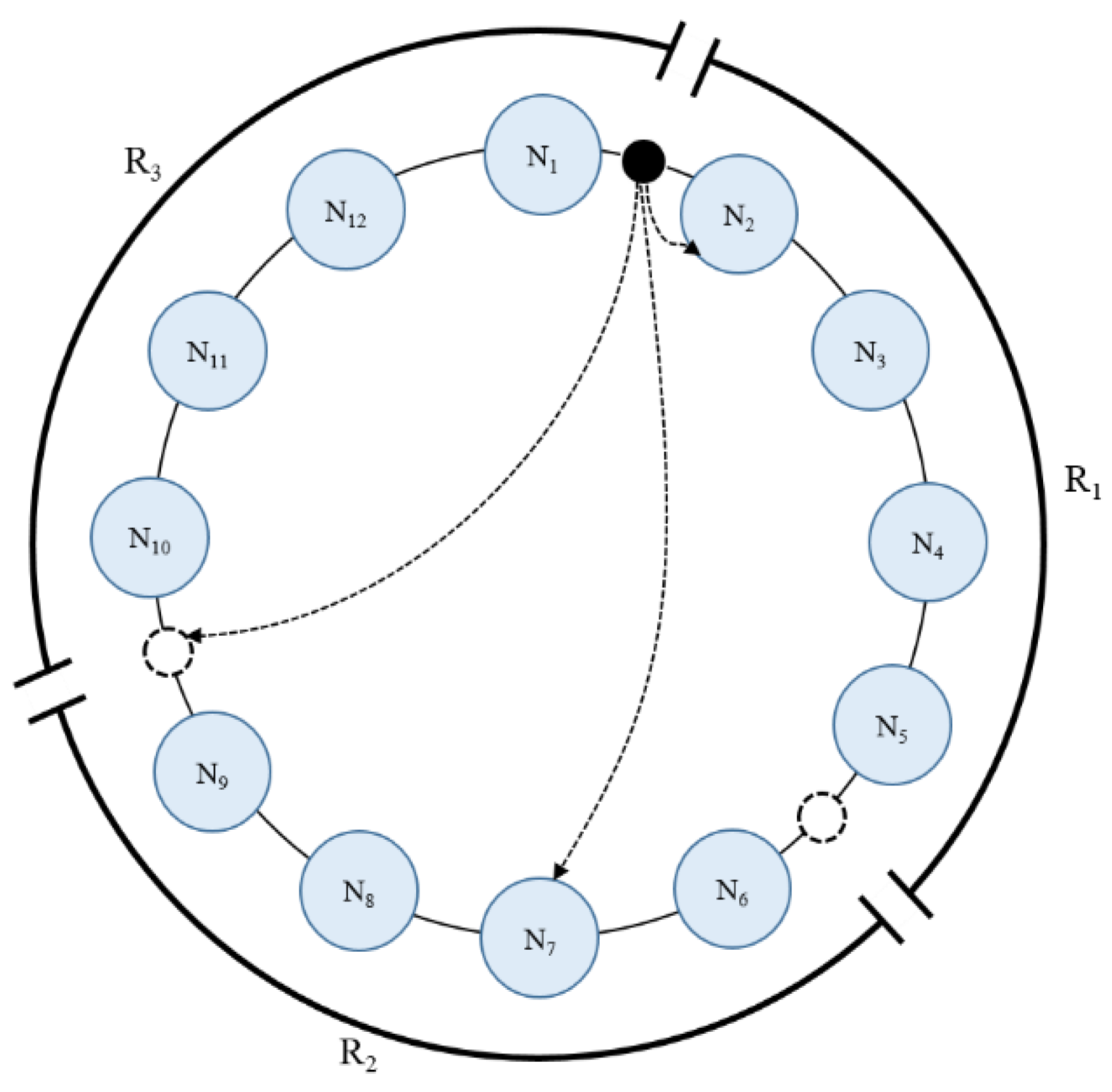
Figure 2 shows an example of the identifier space of the ring-type chord.
to
represent the nodes constituting the identifier space. The adjacent node located in the counterclockwise direction of the node,
, is referred to as the predecessor of the node,
, and is expressed as a predecessor (
). The adjacent node located in the clockwise direction of the node,
, is referred to as the successor of the node,
, and is expressed as a successor (
). The chord scheme hashes the nodes and data, and maps them to a single value on the ring. The node manages the hash space between itself and its predecessor node, and stores the data of the corresponding hash value in the node. If a node is approached by comparing the hash values to read the value stored in the node, the requested value is returned.
The proposed scheme uses a modified chord applying a ring-based hashing scheme in order to distribute the initial nodes in environments with different memory sizes. In environments with different node sizes, the initial nodes are distributed considering the memory size of each node. In the existing distribution scheme, the nodes are distributed by hashing their unique values. In this case, the nodes with a large memory may manage a small hash space while the nodes with a small memory may manage a large hash space. Therefore, through the distribution of the initial nodes according to their memory sizes, the memory sizes are fully used, and the problem of frequent data replacement is addressed.
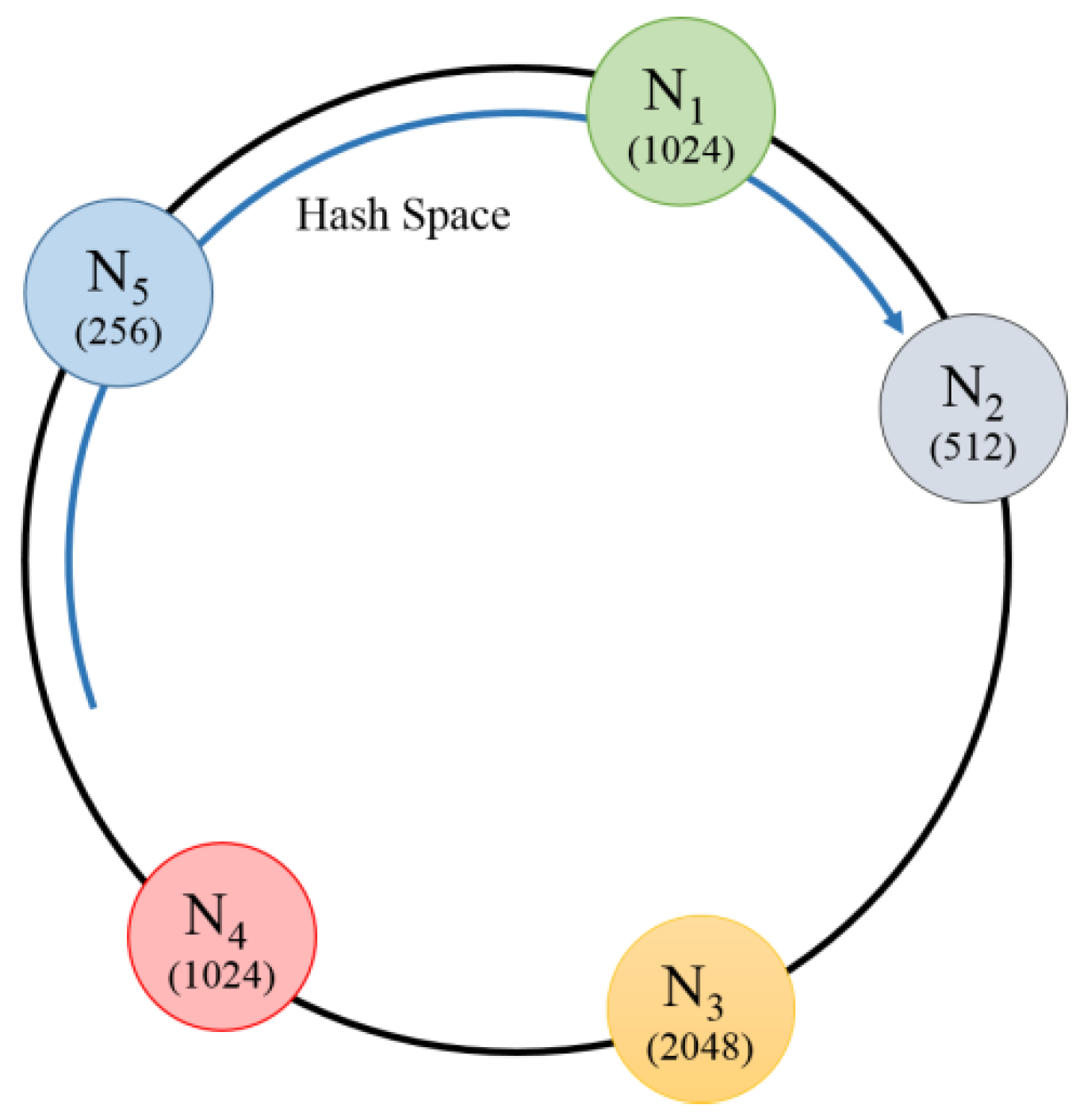
Figure 3 shows the initial node distribution that consists of five nodes and uses a basic hash scheme. The number displayed on each node represents the memory size. When the nodes are distributed, the basic ring-based hashing scheme distributes the nodes by hashing information that can identify the node, such as in IP. In this instance,
, with a smaller memory size than
, may manage more hash spaces than
. Therefore, the memory of the node,
, is easily filled and cache replacement frequently occurs.
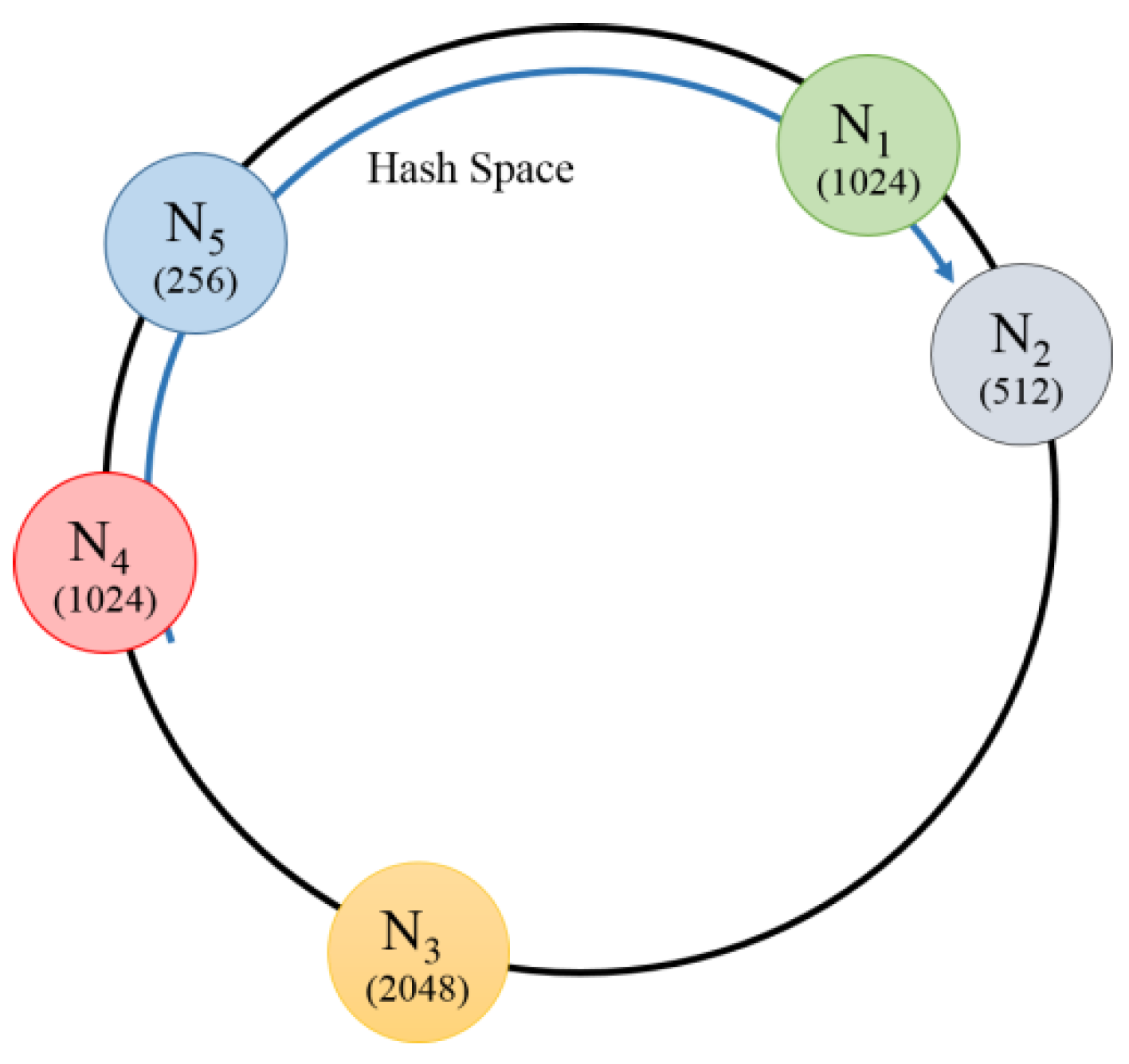
Figure 4 shows the initial node distribution of the proposed scheme with five nodes. The proposed scheme adjusts the hash spaces considering the memory sizes based on the existing initial node distribution. For example, as
has a larger memory size than
, the hash space of
is adjusted to manage more data. In addition, as
has a smaller memory size than
, the hash space of
is not adjusted.
Equation (1) is used to adjust the hash space of each node considering the memory size. If
’s memory size is greater than that of
’s successor node,
, the size of the hash space using Equation (1) is increased. Here,
is the hash space of
before adjustment and
is the hash space of the node,
, before adjustment, and
is the adjusted hash space of the node,
:
Figure 5 shows the proposed initial node allocation algorithm. We assume
and
are the hash space of the node,
, and the successor node of
, respectively. Node
compares the memory size of its own memory with that of the successor node. If the memory size of node,
, is larger than the memory size of the successor node, the proposed scheme increases the hash space using Equation (1) to store more data. If the memory size of the successor node is larger than its own memory size, it does not adjust the hash space.
3.3. Load Balancing Processing
In distributed environments, the data is distributed to multiple nodes and is shared. As the data in each node is different in distributed environments, the data requests may be concentrated on a specific node, and the performance may be degraded due to an increase in the load. In many cases, a node overload is caused by the occurrence of hot data where loading is concentrated on a specific data, or the limited node performance. Therefore, in distributed environments, it is important to identify the cause of a node overload, distribute the load, and prevent the node from overloading. To address the node overload problem that can occur in various situations, a load balancing scheme is required according to the situation.
The proposed method largely distributes the load through data replication and migration. It determines whether the current node is overloaded using the load status of the node, and identifies the hot data using the node and data loads. If hot data exists in the overloaded node, the hot data is replicated to another node to distribute the load. If there is no hot data, the hash space of the node with a low load is adjusted to reduce the load of the overloaded node and migrates the data of the overloaded node.
Figure 6 shows the data replication and migration procedure. The nodes are distributed using the ring-based hashing scheme, and each node holds data according to its hash space. When an overload occurs in a node, the load is distributed through the replication or migration of the data. The data replication process distributes the load by replicating the hot data that causes a large load to another node. In this instance, the hash spaces are divided as evenly as possible based on the hash ring, and the hot data is replicated to the nodes without overload. The overlapping hot data can be stored in one node when a node with the replicated hot data is removed, preventing any problems. In addition, the hash spaces of the overloaded node and the underloaded node are adjusted to migrate the data and distribute the load. For example, if
is overloaded and has
(hot data), it replicates the hot data to the nodes,
and
, that are not overloaded. As the overloaded
does not have hot data, the hash spaces are adjusted and
is migrated from
to
.
The performance of a node is reduced when the amount of load that can be processed by the node is exceeded. Therefore, in such a case, the node is identified as an overloaded node and the load is distributed. If the amount of the load that can be processed by a node exceeds the threshold value as shown in Equation (2), the node is identified as an overloaded node. Here,
represents the threshold value of the overloaded node,
is a parameter that determines the amount of the load, and
is the load status of the current node:
If an overloaded node occurs, the hot data must be determined for data replication. The hot data is determined based on the loads of data and node as shown in Equation (3). Here,
is the whole load of node
,
is the load of data
stored in node
, and
is the threshold value. The hot data is determined based on the ratio of the load generated by the data to the total load on the node. When the load generated by the data exceeds the threshold value of the total load, such data is regarded as hot data:
Figure 7 shows the load balancing processing procedure algorithm. If a particular node is an overloaded node for a certain period of time, then data replication or data migration is performed depending on whether hot data exists on the overload node. If hot data exists on an overload node, then replication to the hot data is performed and otherwise the hash space is adjusted to migrate the data. If a node performing the service in a distributed environment is added or removed, the hash space to migrate the data is adjusted. If a new node is added, the proposed scheme sets the added node to the predecessor node of the overload node and adjusts the hash space of the overload node to migrate data to the new node. If an existing node is removed, the hash space is adjusted according to the load status of the predecessor node and the successor node, and the data stored on the removed node is migrated to the predecessor node and the successor node.
3.4. Load Balancing through Data Replication
Hot data refers to the data that is frequently used and causes a large load on a node. As the hot data greatly increases the load on a node, the load balancing processing scheme that uses such data is important. The load imbalance due to the hot data can be solved by replicating such hot data to other nodes to distribute the load of the hot data to other nodes. When the hot data is replicated to the neighbor nodes, however, if one of those nodes is removed, the hot data can be stored again in another node, causing an overload again. Therefore, the proposed scheme addresses the problem of such overlapping storage of hot data. It divides the hash spaces evenly based on the hot data and stores one replica in each divided hash space considering the load on the corresponding node. This can address the problem of overlapping data storage when a node is removed.
Figure 8 shows the procedure of hot data replication. The entire hash space is evenly divided according to the number of the hot data to be replicated. In each divided hash space, the nodes are checked for overload sequentially from the one with the low hash value, and the hot data is replicated to the node without overload. In this instance, the basic number of replicas is three, including the original data. Therefore, the entire hash space is divided into three ranges based on the hash value of the original data. The original data is retained in the previously stored node. The first replica is stored in
after examining the loads in a sequence. The examination in
starts from
, the first node of
. If
is overloaded, the next node,
, is examined. If
is not overloaded, the second hot data is stored in
. For the second replica,
, the first node of
, is examined. If it is not overloaded, the replica is stored in
.
When a node is removed, the data of the node is migrated to the neighbor node. If the hot data is replicated to the consecutive neighbor nodes, and a node with the replicated hot data is removed, the hot data can be stored again in another node. In this case, as two hot data replicas are stored in one node, the memory space is wasted and the load is also concentrated. Therefore, if the hot data is stored in the hash space and divided as evenly as possible considering the loads of the nodes, the overlapping of data storage in one node can be prevented even if a node with a replica is removed.
Equations (4) and (5) are used to obtain the hash space for the data replication. Equation (4) calculates the hash value that is used to obtain the hash space for data replication. Here,
is the hash value that is used to obtain the replication range,
is the entire hash space,
is the number of replicas, and
is the hash value of hot data. Equation (5) calculates the hash space,
, for data replication using the hash value calculated through Equation (4). Here,
is the hash space, and
are the hash ranges obtained using the hash value calculated through Equation (4). For hot data replication, the ranges in the hash space are determined using the calculated value, and one data is replicated to each range to prevent the data from being replicated to the consecutive neighbor nodes:
After the load balancing through data replication, it is necessary to examine the load status of the overloaded node, and confirm whether the distribution has been performed well. When an overload occurs and the load is distributed, the load of the overloaded node decreases as shown in Equation (6). Here,
is the load of node
before replication,
is the number of replicas,
is the number of hot data in node
,
is the load of hot data
in node
, and
is the load of node
after the replication of hot data. After the data replication, the load status of the node is examined through the calculated load value, and then the load status of the node is determined based on the calculated value:
3.5. Load Balancing through Data Migration
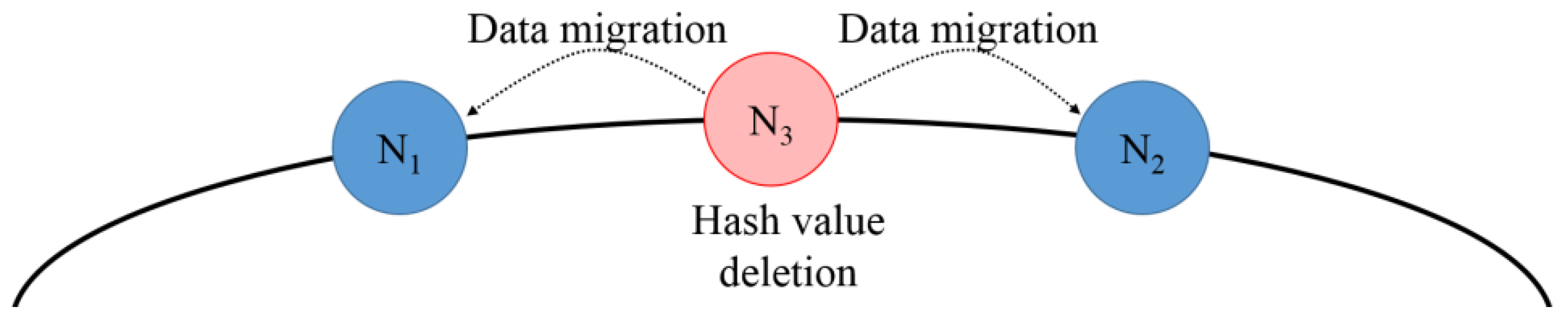
An overloaded node may occur due to uniform access to the data held by the node rather than frequent access to its specific data. In this case, the load can be distributed by adjusting the hash spaces and by performing data migration. In the proposed scheme, the node with the lowest load is selected and its hash value is deleted. In this instance, the hash space managed by the underloaded node is adjusted and distributed by considering the loads of the predecessor node and the successor node. The underloaded node with the deleted hash value is assigned a hash value as the predecessor node of the node with the largest load node to reduce the load of the overloaded node.
Figure 9 shows the procedure of deleting the hash value of the underloaded node with the lowest load. To remove the underloaded node from the distributed environment, the managed hash space is distributed considering the loads of the predecessor node and the successor node. The hash space is distributed to the predecessor node and the successor node as the load increases significantly for the successor node if it manages all the hash space. For example, if
is a node with the lowest load, the hash value of
is deleted and the hash space and data of
are distributed to the predecessor node,
, and the successor node,
.
Equation (7) is used to delete the hash value of an underloaded node with the low load in a distributed environment. The loads of the neighbor nodes on both sides of the underloaded node are compared and then the hash space of the underloaded node is distributed to those nodes. Here,
is the hash space of the predecessor node,
;
is the load on node
;
is the load on the adjacent node,
, of node
; and
is the hash space of the node to be removed. For example, if the hash space managed by
is 501–1000, the load on
is 20, and the load on
is 30;
additionally manages the hash space of 501–800 among the hash space of
, and
additionally manages the hash space of 801–1000 for the load balancing:
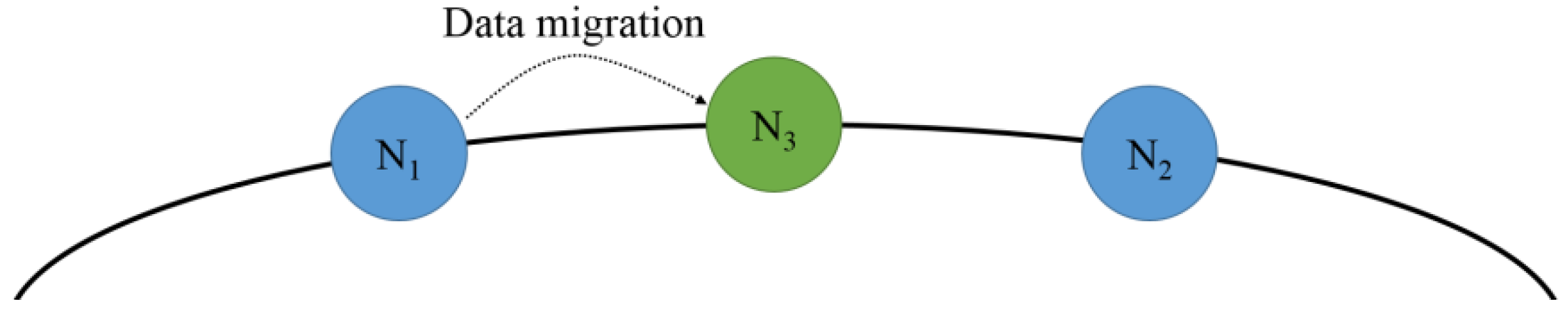
Figure 10 shows the added underloaded node with the deleted hashed value for reducing the load on the node with the highest overload. The underloaded node is assigned a hash value as the predecessor node of the overloaded node with the highest load node to reduce the load. If
is an overloaded node, the underloaded node,
, with a deleted hash value is assigned a hash value as the predecessor node of
, and the hash space and data are distributed for load balancing.
When an underloaded node is assigned a new hash value, it manages part of the hash space of the existing node and migrates the data. Equation (8) is used to adjust the hash range when the removed underloaded node is added. Here,
is the hash value of the added underloaded node,
, and
is the hash range of the node,
, with the highest load. For example, if
is the node with the highest load and manages the hash range of 0–1,000, the underloaded node,
, is added as the predecessor node of
and manages 0–500, half of the hash space of
. The load of the existing overloaded node is reduced by the newly added node, which manages part of the hash space of the node with the highest load:
After the load balancing through data migration, it is necessary to examine the load status of the overloaded node and confirm whether the distribution has been performed well. Equation (9) calculates the load of the overloaded node after the data migration. The load of the overloaded node has been reduced by the load of the migrated data. Here,
is the load of the node,
, after data migration;
is the load of the node,
, before data migration;
is the number of the migrated data; and
is the load of the migrated data,
. The load status of the node is examined through the load value calculated after the data migration, and then, the load status of the node is determined based on the calculated value:
3.6. Load Balancing by Node Addition and Removal
In distributed environments, when a new node is added or a node is removed due to a failure, the data must be redistributed to the distributed nodes. If all the data is redistributed due to the addition or removal of a node, a load occurs on the entire system, resulting in delays in processing user requests. When a node is added or removed, the ring-based hashing scheme does not redistribute all data, but redistributes only some data by adjusting the hash space that needs to be managed by other neighbor nodes. This reduces the overall system load.
In the proposed scheme, the hash spaces are adjusted by considering the load status of the nodes when a node is added or removed using the ring-based hashing scheme. When a node is added, the new node is added at the position of the predecessor node of the overloaded node to reduce the load on the node with the highest overload. When a node is removed in the existing scheme, the successor node of the removed node manages the hash space of the removed node. In this case, the load on the successor node increases significantly. In the proposed scheme, the hash space of the removed node is distributed to the predecessor node and the successor node considering their load status.
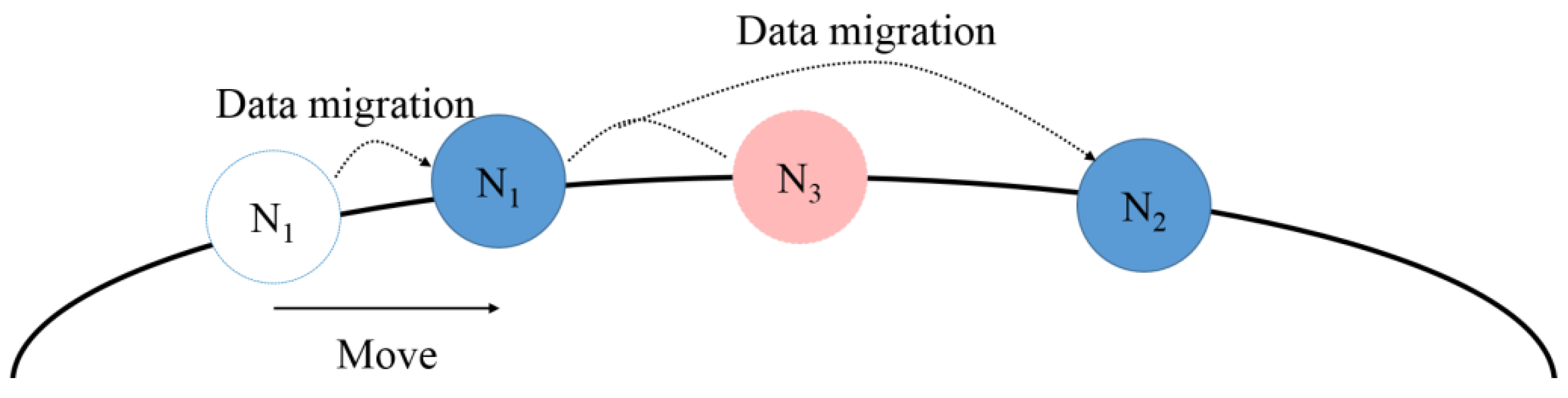
Figure 11 shows the procedure of adding a new node. The added node is added as the predecessor node of the node with the highest load among all the nodes, thereby reducing the load of the node with the highest load. For example, if
is newly added, it is added as the predecessor node of
with the highest load, and it reduces the load on
by migrating the hash space and data. The new node has 50% of the hash space of the node with the highest load, and the data contained in the hash space of the new node is migrated from the existing node. The hash value of the newly added node is calculated using Equation (7).
Figure 12 shows the procedure of removing a node. If the node is removed, the successor node manages the hash space of the removed node. The successor node of the removed node then manages more hash space, and its amount of data increases, resulting in an increased load. To address this problem, the hash spaces of the predecessor node and the successor node of the removed node are adjusted considering their load status. When the node,
, is removed,
, the predecessor node of
, and
, the successor node, divide and manage the hash space of
. When a node is removed, the hash values of the predecessor node and the successor node are calculated using Equation (6).
3.7. Metadata Synchronization of Hot Data
In the distributed environments, the nodes that hold the data are accessed through the load balancer. If the data requests an increase, however, the load on the load balancer increases and its performance is degraded, lowering the overall system performance. In addition, as clients request data to the nodes, the data used by the nodes are changed, and the metadata information of the hot data managed by the load balancer is also modified. In this instance, if the metadata information of the hot data held by the clients differs from that of the load balancer, it is highly probable that incorrect accesses are performed upon data requests. The probability of incorrect accesses is lowered by organically adjusting the communication cycle (τ) of each client, and by updating the hot data metadata information of the clients. As each client directly accesses the nodes without going through the load balancer, the time required to access the hot data is reduced.
Figure 13 represents the update of the hot data metadata according to the communication cycle. The client #1 organically communicates with the load balancer at every communication cycle (τ) and updates its hot data metadata information. The communication cycle (τ) with the load balancer for the hot data update of the client is determined according to the update rate of the metadata updated by the load balancer. If the update rate of the client exceeds the threshold value, the load balancer updates the metadata of the client. This is because the old metadata information held by the client is replaced with the up-to-date metadata information of the load balancer. If the update rate is lower than the threshold value, the metadata information of the load balancer is updated. As the clients and the load balancer update and synchronize hot data metadata through an organic communication cycle, when client #1 requests
, it can directly access the node and obtain
without going through the load balancer, thereby reducing the unnecessary processing time.
If the organic cache metadata update policy is not applied, when the user requests , client #1 retrieves its metadata and accesses the node to obtain . If is not present in the node due to data replacement, however, client #1 must communicate with the load balancer to determine the location where is stored and request . When this problem occurs, it takes a long time to access the data if the hot data metadata of the load balancer and that of the client are not synchronized.
Figure 14 shows the algorithm for the hot data metadata synchronization of the client. The load balancer updates the metadata for the hot data and calculates the update rate of the metadata through Equation (10) at each communication cycle. At this time, t represents the time of updating the metadata,
represents the renewal rate at time t of the metadata,
represents the number of metadata updated at time t, and
represents the number of metadata held by the client at time t. If the renewal rate is above the threshold, the client’s metadata through metadata synchronization is updated



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
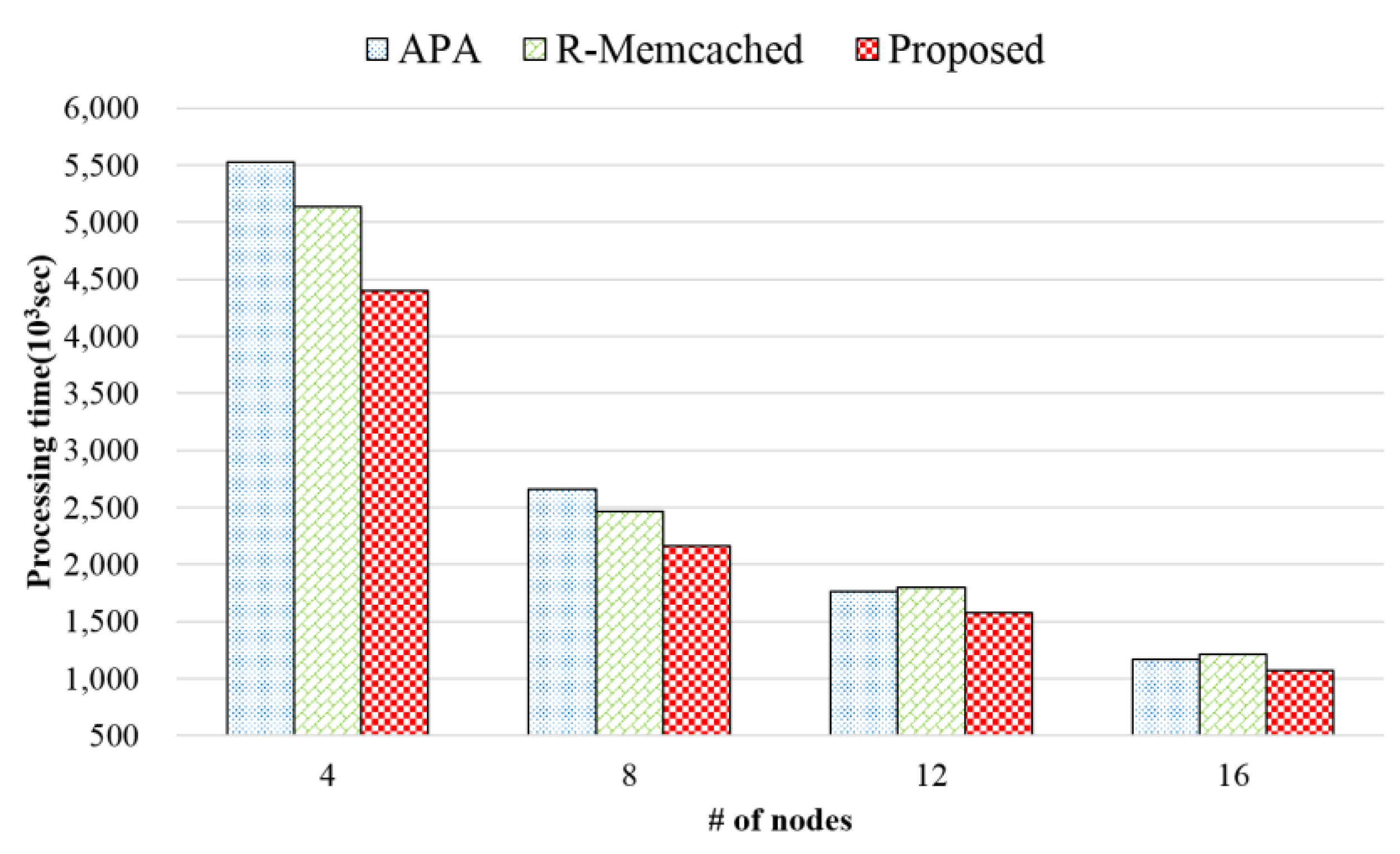{kind=link}