Supervised Single Channel Speech Enhancement Based on Dual-Tree Complex Wavelet Transforms and Nonnegative Matrix Factorization Using the Joint Learning Process and Subband Smooth Ratio Mask


Abstract
:1. Introduction
2. Problem Formulation
3. Non-Negative Matrix Factorization (NMF)
4. Dual-Tree Complex Wavelet Transform (DTCWT)
- Shift variance.
- Oscillation.
- Aliasing.
- Lack of orientation.
- Approximate shift invariance.
- Perfect reconstruction.
- Limited redundancy, independent of the number of levels, it has 2:1 redundancy.
- Efficient order—N computation, only twice the DWT.
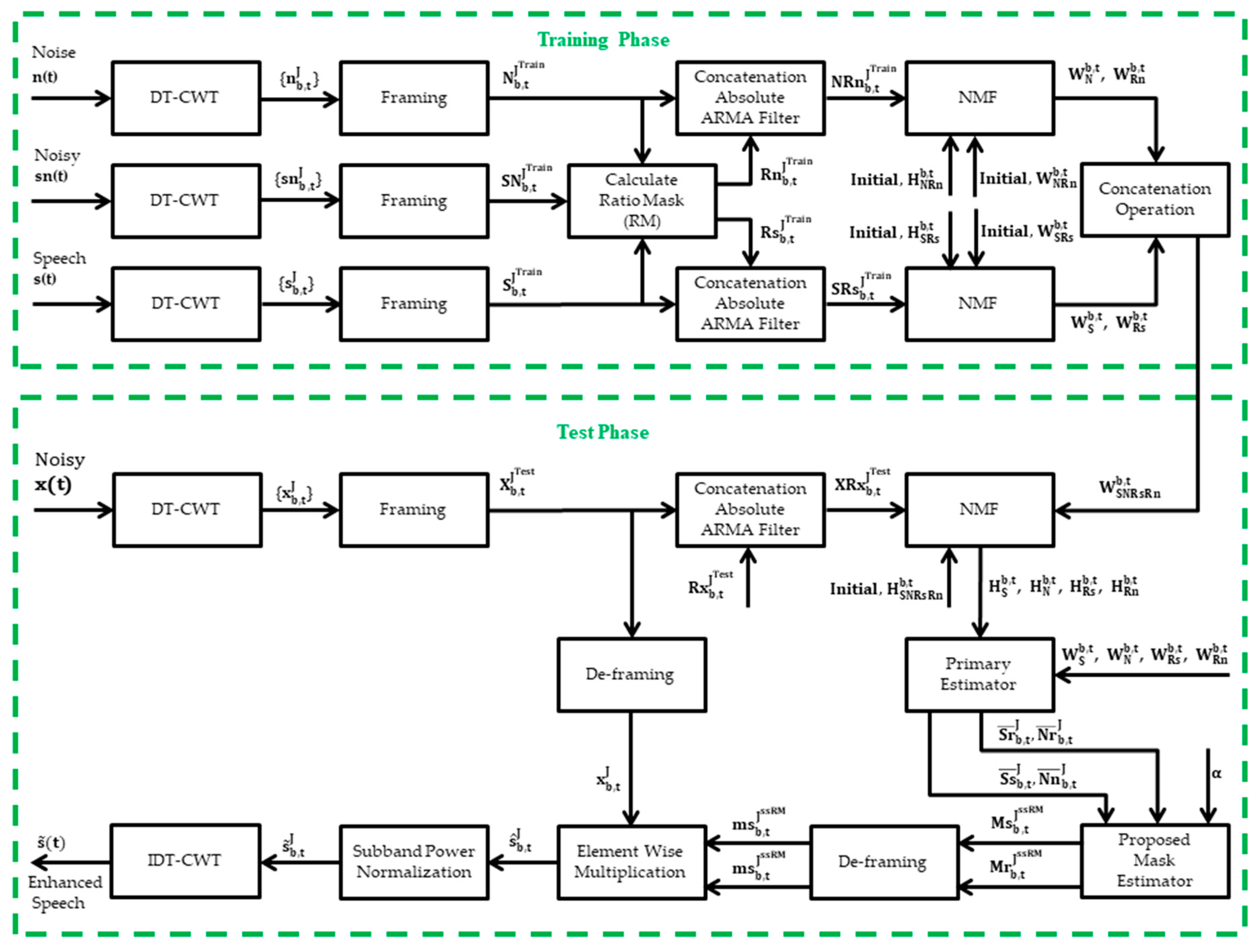
5. DT-CWT-NMF Based Speech Enhancement System
5.1. Training Phase
- (a)
- Calculate the wavelet coefficients, and , from the speech and noise training data via DTCWT, as well as the wavelet coefficients, , of the train noisy signal.
- (b)
- Apply the framing scheme on the wavelet coefficients and obtain the matrices, , , and , for training speech, noise, and noisy signal, respectively.
- (c)
- Calculate and according to Equations (15) and (16) and arrange the speech, , and noise, , training sets according to Equations (17) and (18).
- (d)
- Take the absolute value and apply the ARMA filter to the and .
- (e)
- Decompose the matrices, , for using NMF with the KL cost function and prepare the matrix, , using Equation (19).
5.2. Test Phase
- (a)
- Extract the wavelet coefficients, , from the noisy test signal via DTCWT.
- (b)
- Apply the framing scheme on the wavelet coefficients, , and obtain the matrices, .
- (c)
- Prepare the noisy test matrix, , using the concatenation and ARMA filtering operations on the matrix, , and RM matrix, (i.e., is the one’s matrix and is the same size as the matrix,).
- (d)
- Learn the weight matrix, , jointly from the noisy test signal, , while keeping the basis matrix, , fixed: .
- (e)
- Find the rough estimate of speech, speech RM, noise, and noise RM in the noisy test signal as since and .
5.3. Subband Smooth Ratio Mask (ssRM)
5.4. Subband Power Normalization
6. Experiments and Discussion
6.1. Experimental Setup
6.2. Evaluation Methods
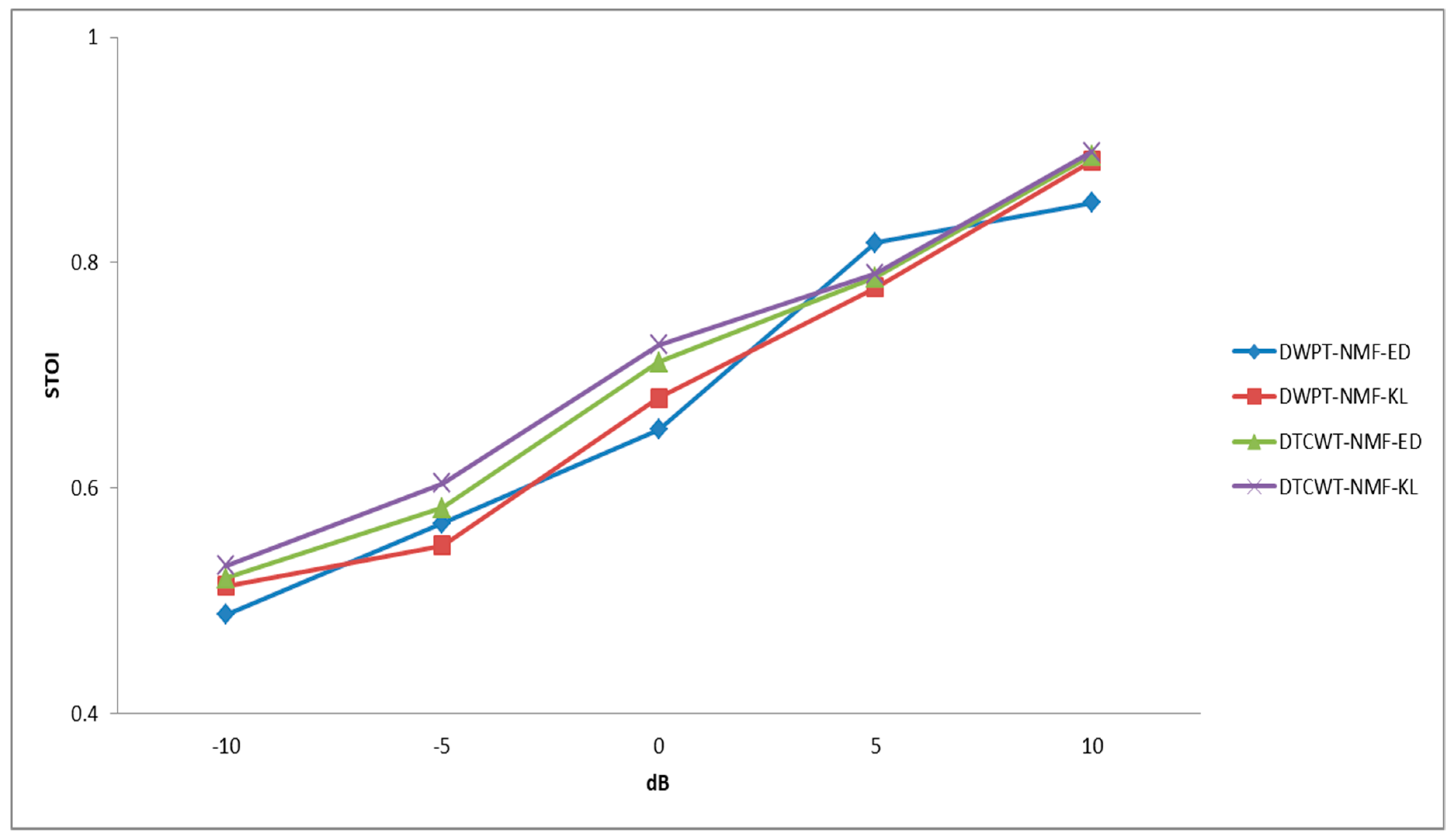
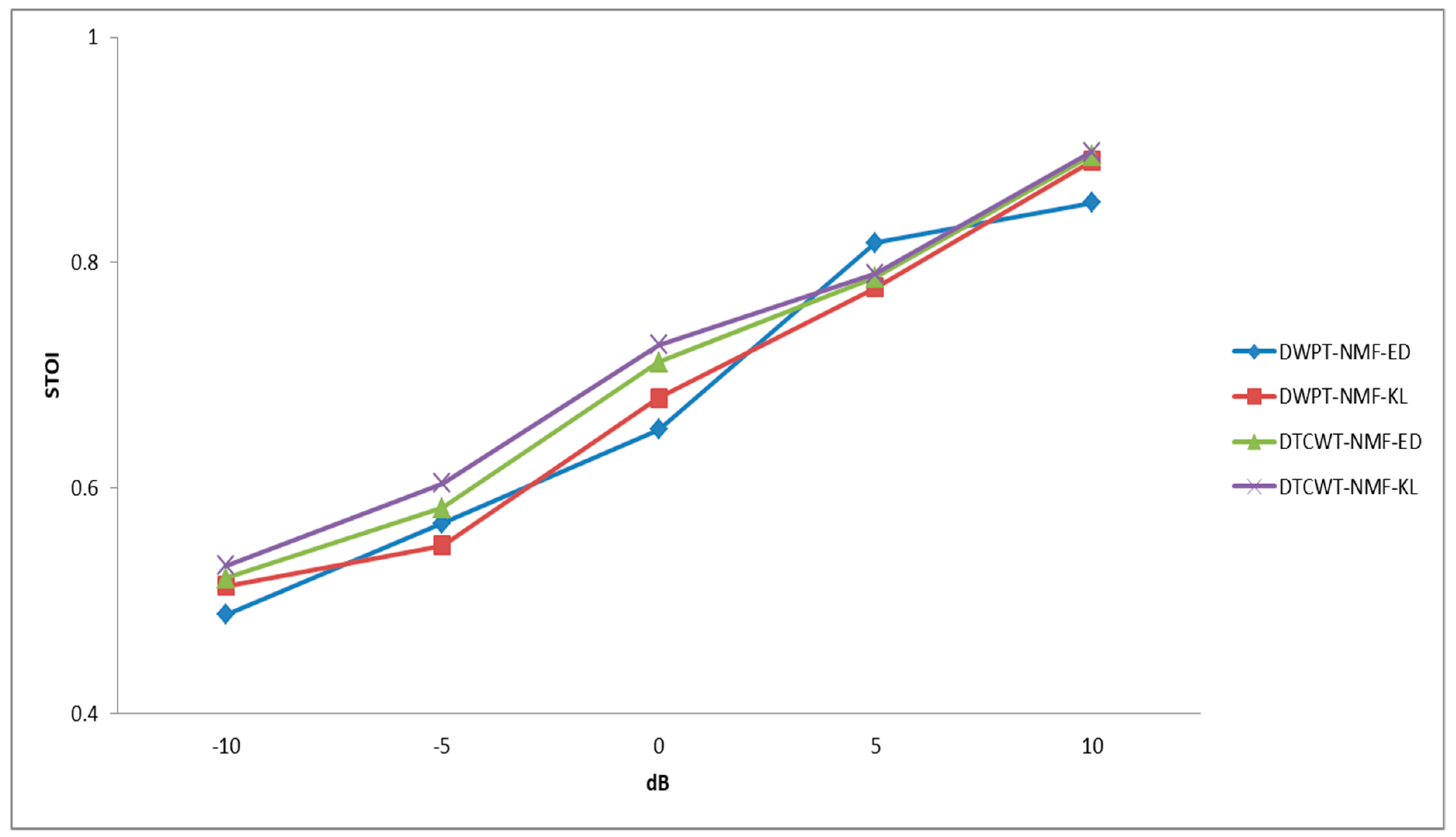
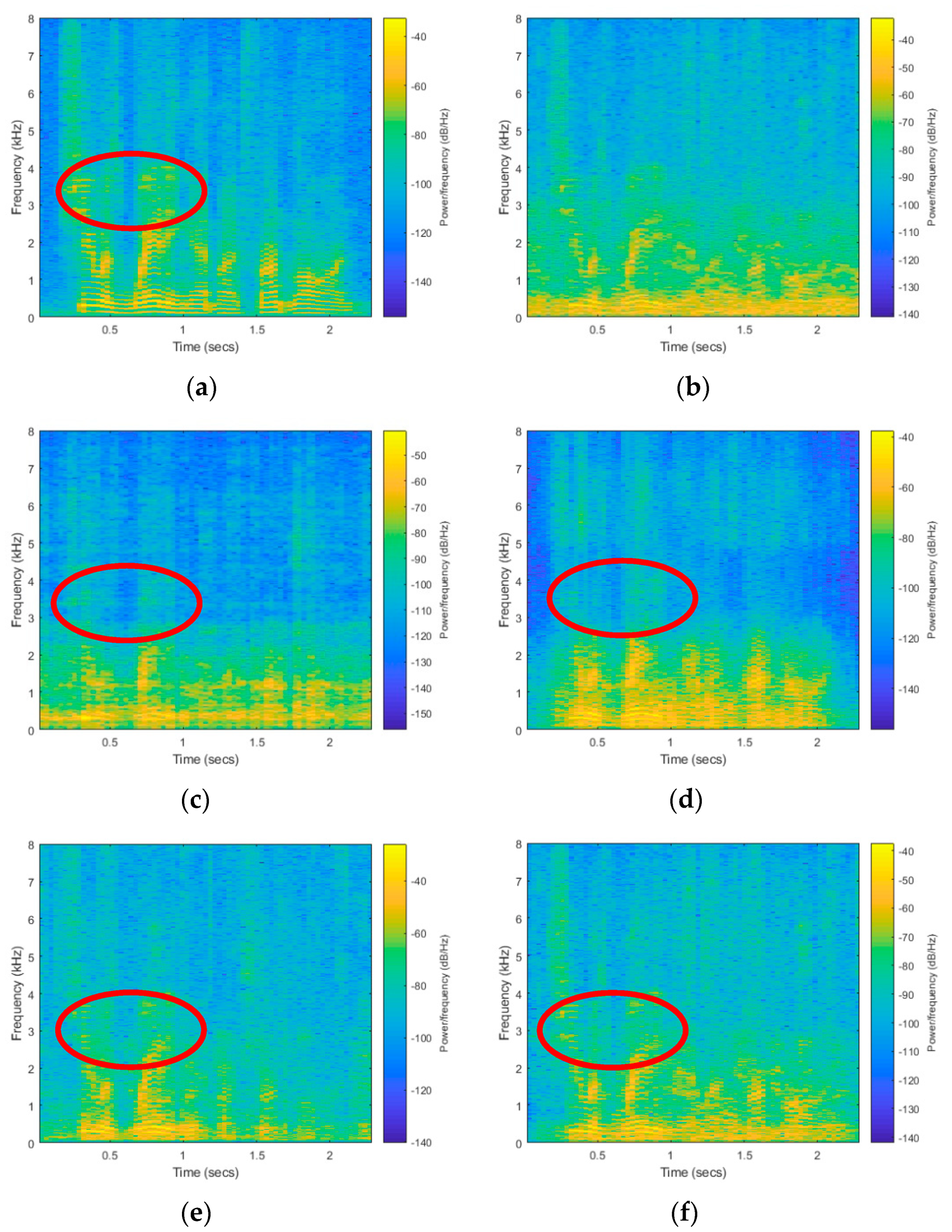
6.3. The Efficiency of the Proposed System
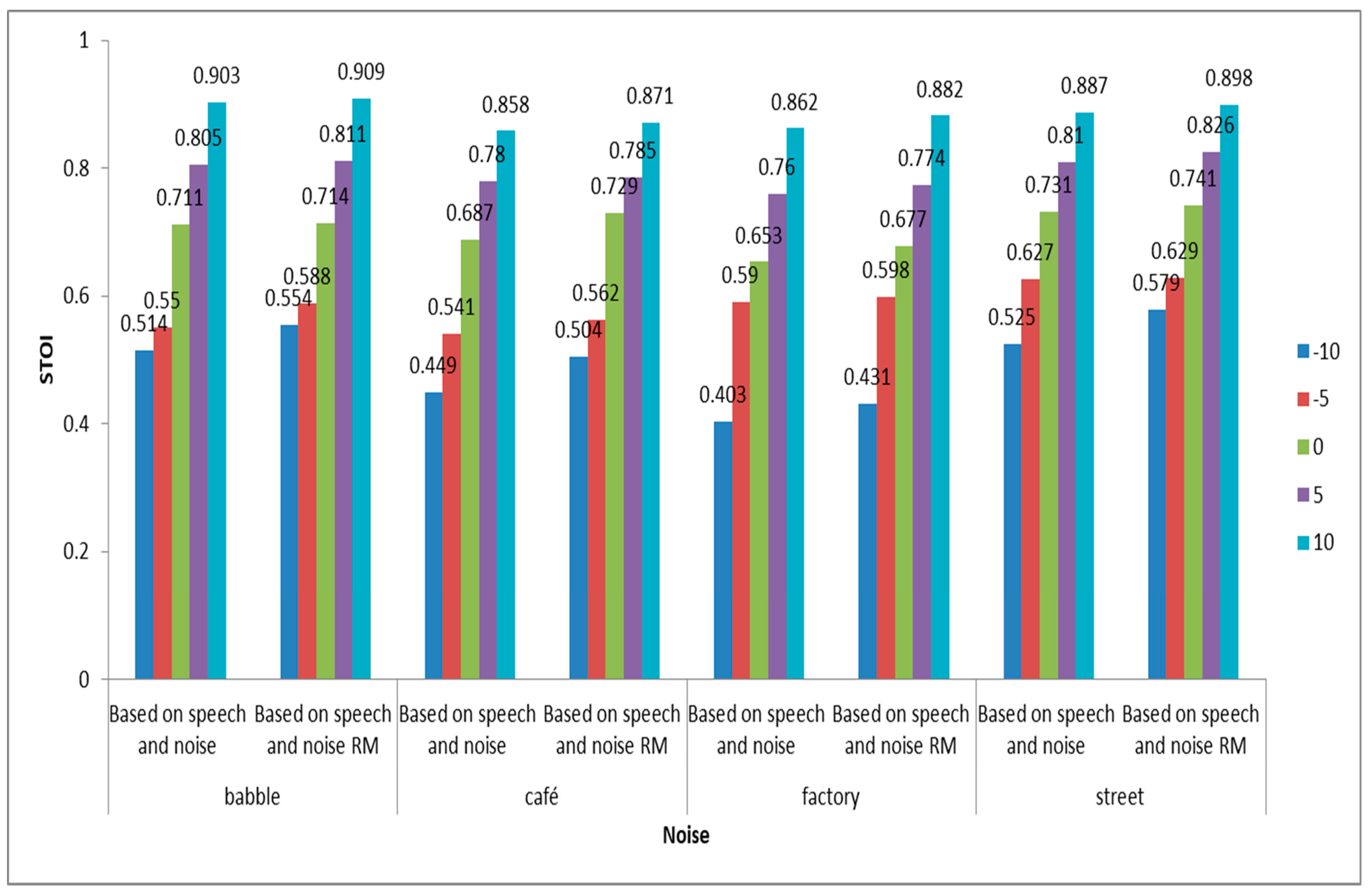
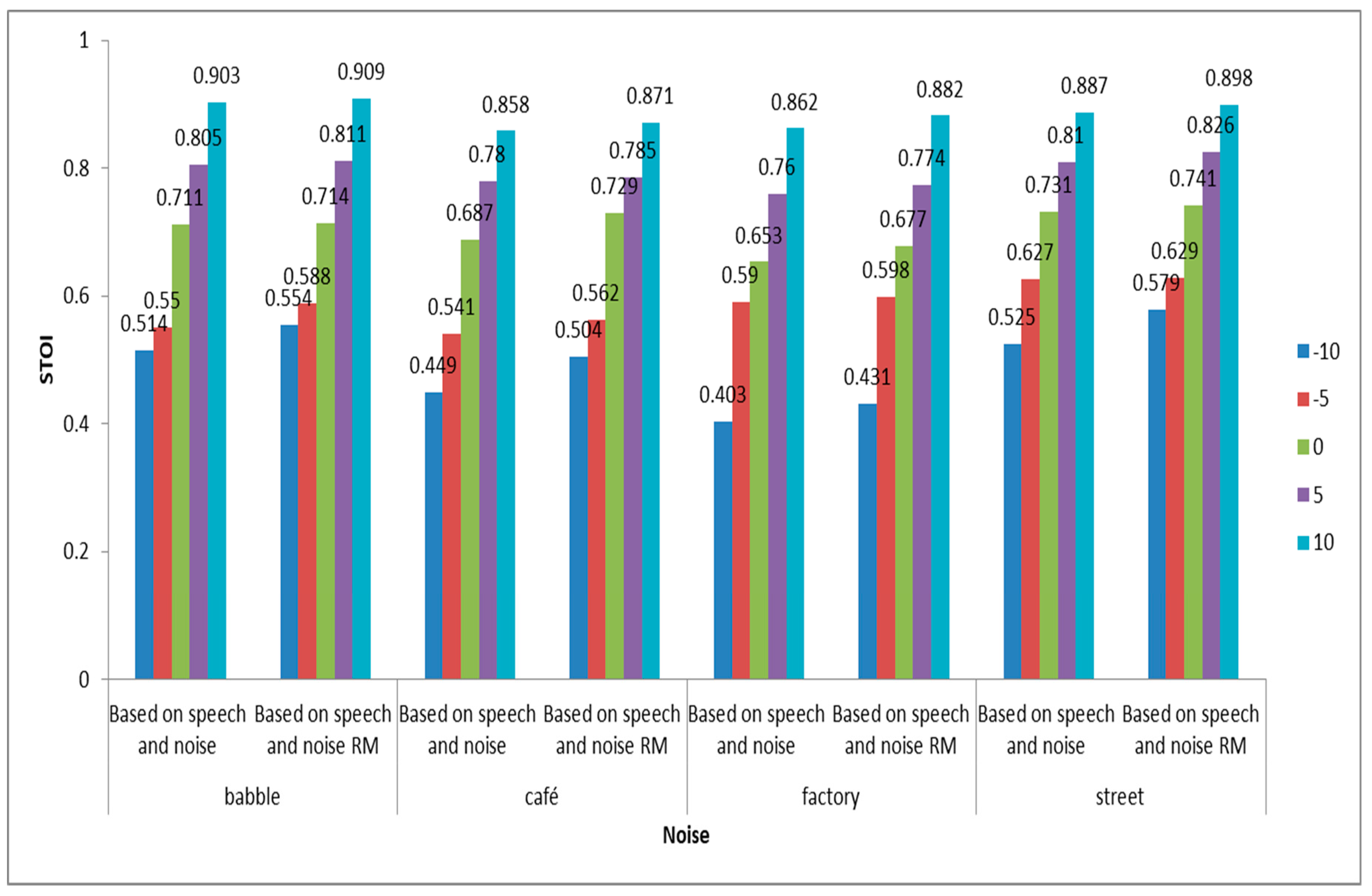
6.4. The Effect of Speech and Noise Ratio Mask
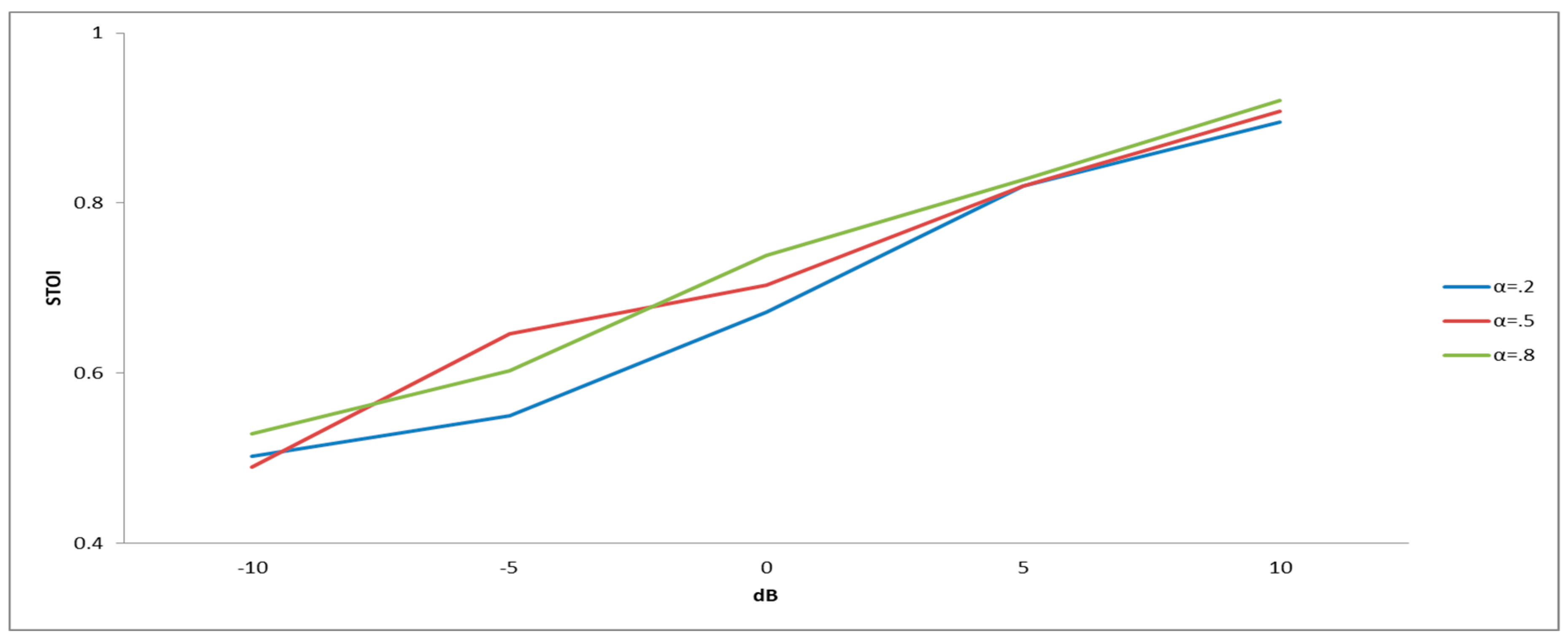
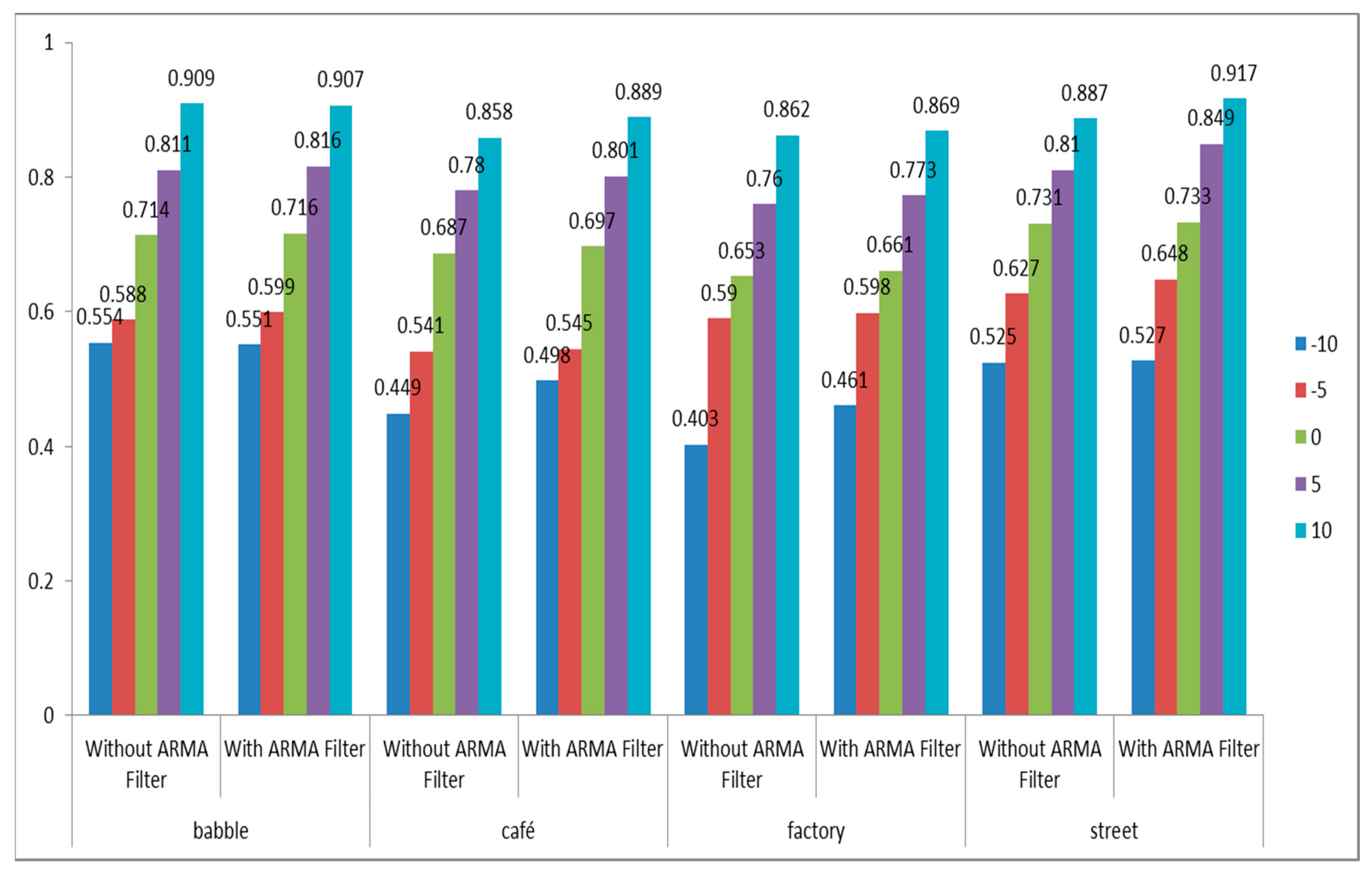
6.5. The Effect of the ARMA Filter
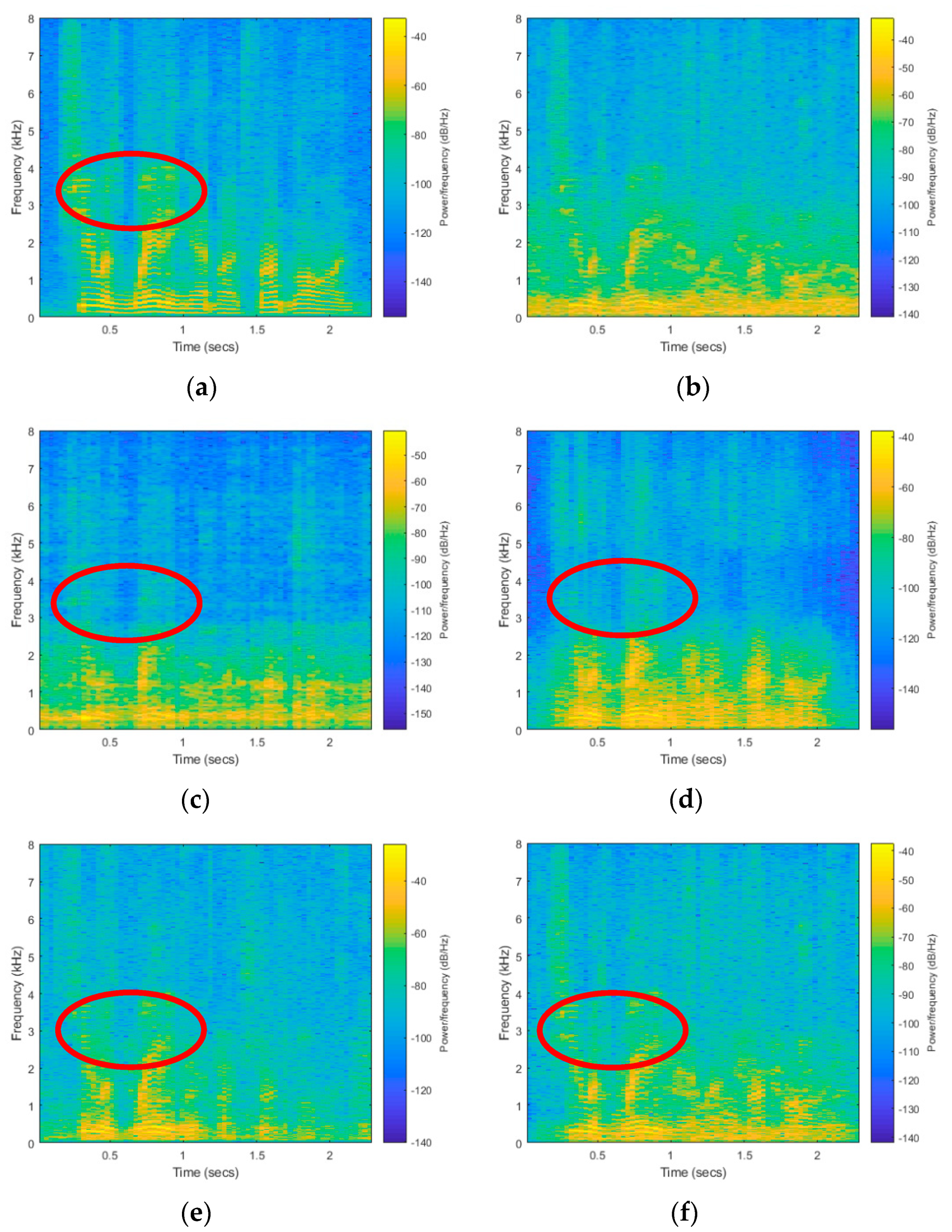
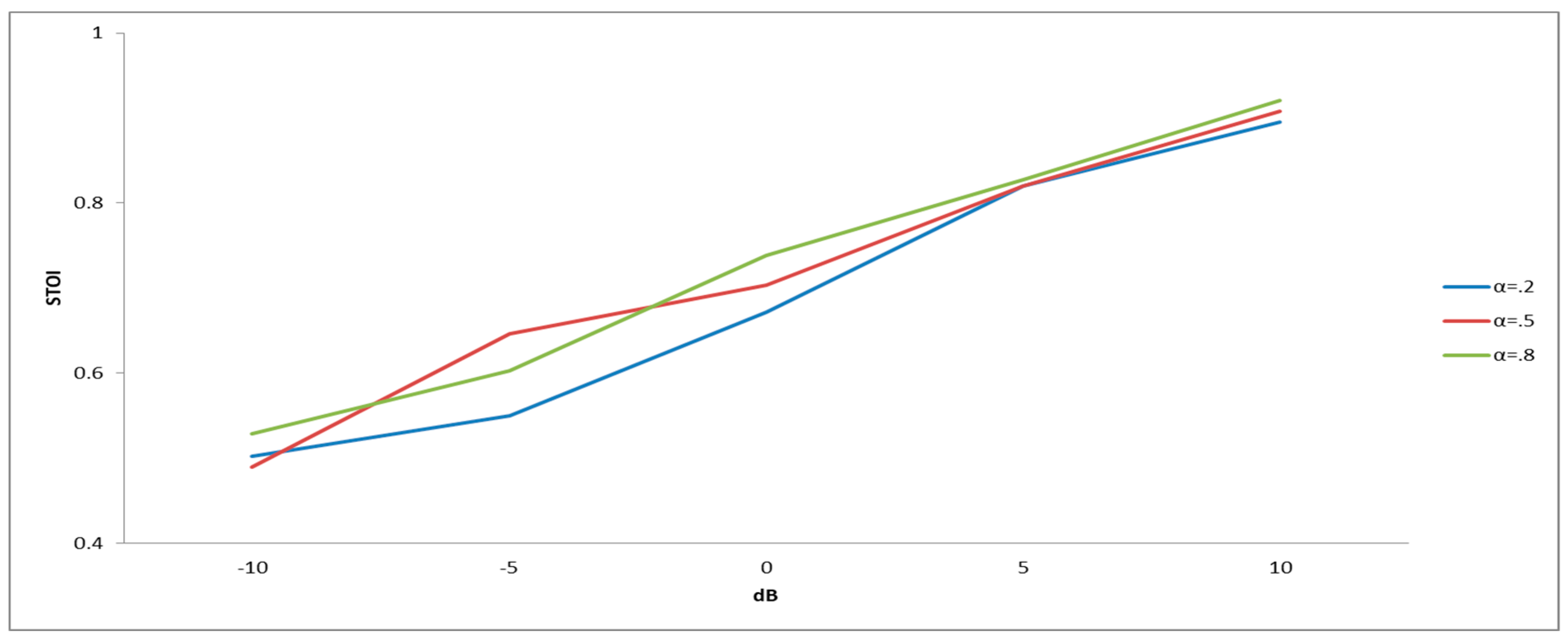
6.6. Impact of the Proposed Subband Smooth Ratio Mask
6.7. Overall Performance Evaluation
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Boll, S.F. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef]
- Wang, J.; Liu, H.; Zheng, C.; Li, X. Spectral subtraction based on two-stage spectral estimation and modified cepstrum thresholding. Appl. Acoust. 2013, 19, 450–458. [Google Scholar] [CrossRef]
- Mcaulay, R.; Malpass, M. Speech enhancement using a soft-decision noise suppression filter. IEEE Trans. Acoust. Speech Signal Process. 1980, 65, 137–145. [Google Scholar] [CrossRef]
- Lotter, T.; Vary, P. Speech enhancement by map spectral amplitude estimation using a super-gaussian speech model. EURASIP J. Appl. Signal Process. 2005, 7, 1110–1126. [Google Scholar] [CrossRef]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef]
- Saleem, N.; Khattak, M.I.; Shafi, M. Unsupervised speech enhancement in low SNR environments via sparseness and temporal gradient regularization. Appl. Acoust. 2018, 141, 333–347. [Google Scholar] [CrossRef]
- Scalart, P.; Filho, J.V. Speech enhancement based on a priori signal to noise estimation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Atlanta, GA, USA, 9 May 1996; Volume 2, pp. 629–632. [Google Scholar]
- Djendi, M.; Bendoumia, R. Improved subband-forward algorithm for acoustic noise reduction and speech quality enhancement. Appl. Soft Comput. 2016, 42, 132–143. [Google Scholar] [CrossRef]
- Ephraim, Y.; Trees, H.L.V. A signal subspace approach for speech enhancement. IEEE Trans. Speech Audio Process. 1995, 3, 251–266. [Google Scholar] [CrossRef]
- Narayanan, A.; Wang, D.L. Ideal ratio masks estimation using deep neural networks for robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7092–7096. [Google Scholar]
- Kang, T.G.; Kwon, K.; Shin, J.W.; Kim, N.S. NMF-based target source separation using deep neural network. IEEE Signal Process. Lett. 2015, 22, 229–233. [Google Scholar] [CrossRef]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. In Proceedings of the INTERSPEECH, Lyon, France, 25–29 August 2013; pp. 436–440. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Lee, H.; Battle, A.; Raina, R.; Ng, A.Y. Efficient sparse coding algorithms. Adv. Neural Inf. Process. Syst. 2007, 19, 801–808. [Google Scholar]
- Chen, Z.; Ellis, D. Speech enhancement by sparse, low-rank, and dictionary spectrogram decomposition. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 20–23 October 2013; pp. 1–4. [Google Scholar]
- He, Y.; Sun, G.; Han, J. Spectrum enhancement with sparse coding for robust speech recognition. Digit. Signal Process. 2015, 43, 59–70. [Google Scholar] [CrossRef]
- Luo, Y.; Bao, G.; Xu, Y.; Ye, Z. Supervised monaural speech enhancement using complementary joint sparse representations. IEEE Signal Process. Lett. 2016, 23, 237–241. [Google Scholar] [CrossRef]
- Wilson, K.W.; Raj, B.; Smaragdis, P.; Divakaran, A. Speech denoising using nonnegative matrix factorization with priors. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 4029–4032. [Google Scholar]
- Lee, S.; Han, D.K.; Ko, H. Single-channel speech enhancement method using reconstructive NMF with spectrotemporal speech presence probabilities. Appl. Acoust. 2017, 117, 257–262. [Google Scholar] [CrossRef]
- Mowlaee, P.; Saeidi, R.; Stilanou, Y. Phase importance in speech processing applications. In Proceedings of the INTERSPEECH, Singapore, 14–18 September 2014; pp. 1623–1627. [Google Scholar]
- Ghanbari, Y.; Karami-Mollaei, M.R. A new approach for speech enhancement based on the adaptive thresholding of the wavelet packets. Speech Commun. 2006, 48, 927–940. [Google Scholar] [CrossRef]
- Ghribi, K.; Djendi, M.; Berkani, D. A wavelet-based forward BSS algorithm for acoustic noise reduction and speech enhancement. Appl. Acoust. 2016, 105, 55–66. [Google Scholar] [CrossRef]
- Jung, S.; Kwon, Y.; Yang, S. Speech enhancement by wavelet packet transform with best fitting regression line in various noise environments. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, Toulouse, France, 14–19 May 2006; Volume 1, pp. 14–19. [Google Scholar]
- Wang, S.-S.; Chern, A.; Tsao, Y.; Hung, J.-W.; Lu, X.; Lai, Y.-H.; Su, B. Wavelet speech enhancement based on nonnegative matrix factorization. IEEE Signal Process. Lett. 2016, 23, 1101–1105. [Google Scholar] [CrossRef]
- Messaoud, M.A.B.; Bouzid, A.; Ellouze, N. Speech enhancement based on wavelet packet of an improved principal component analysis. Comput. Speech Lang. 2016, 35, 58–72. [Google Scholar] [CrossRef]
- Mavaddaty, S.; Ahadi, S.M.; Seyedin, S. Speech enhancement using sparse dictionary learning in wavelet packet transform domain. Comput. Speech Lang. 2017, 44, 22–47. [Google Scholar] [CrossRef]
- Mortazavi, S.H.; Shahrtash, S.M. Comparing Denoising Performance of DWT, DWPT, SWT and DT-CWT for Partial Discharge Signals. In Proceedings of the 43rd International Universities Power Engineering Conference, Padova, Italy, 1–4 September 2008; pp. 1–6. [Google Scholar]
- Williamson, D.S.; Wang, Y.; Wang, D.L. Reconstruction techniques for improving the perceptual quality of binary masked speech. J. Acoust. Soc. Am. 2014, 136, 892–902. [Google Scholar] [CrossRef]
- Wang, Y.; Narayanan, A.; Wang, D.L. On training targets for supervised speech separation. IEEE-ACM Trans. Audio Speech Lang. Process. 2014, 22, 1849–1858. [Google Scholar] [CrossRef] [PubMed]
- Williamson, D.S.; Wang, Y.; Wang, D.L. Complex ratio masking for monaural speech separation. IEEE-ACM Trans. Audio Speech Lang. Process. 2016, 24, 483–493. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. Adv. Neural Inf. Process. Syst. 2001, 13, 556–562. [Google Scholar]
- Kingsbury, N.G. The dual-tree complex wavelet transform: A new efficient tool for image restoration and enhancement. In Proceedings of the 9th European Signal Process Conference, EUSIPCO 1998, Rhodes, Greece, 8–11 September 1998; pp. 319–322. [Google Scholar]
- Selenick, I.W.; Baraniuk, R.G.; Kingsbury, N.G. The dual-tree complex wavelet transforms. IEEE Signal Process. Mag. 2005, 22, 123–151. [Google Scholar] [CrossRef]
- Mohammadiha, N.; Taghia, J.; Leijon, A. Single channel speech enhancement using bayesian nmf with recursive temporal updates of prior distributions. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 4561–4564. [Google Scholar]
- Chen, C.-P.; Bilmes, J. MVA Processing of Speech Features. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 257–270. [Google Scholar] [CrossRef]
- Rothauser, E.H. IEEE recommended practice for speech and quality measurements. IEEE Trans. Audio Electroacoust. 1969, 17, 225–246. [Google Scholar]
- Hirsch, H.G.; Pearce, D. The AURORA experimental framework for the performance evaluations of speech recognition systems under noisy conditions. In Proceedings of the ISCA Tutorial and Research Workshop, ISCA ITRWASR, Paris, France, 18–20 September 2000; pp. 181–188. [Google Scholar]
- Varga, A.; Steeneken, H.J.M. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Kates, J.M.; Arehart, K.H. The hearing-aid speech quality index (HASQI). J. Audio Eng. Soc. 2010, 58, 363–381. [Google Scholar]
- Kates, J.M.; Arehart, K.H. The hearing-aid speech perception index (HASPI). Speech Commun. 2014, 65, 75–93. [Google Scholar] [CrossRef]
- Rix, A.; Beerends, J.; Hollier, M.; Hekstra, A. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the IEEE International Conference on Acoustics, Speech, Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Tall, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Cooke, M.; Barker, J.; Cunningham, S.; Shao, X. An audio-visual corpus for speech perception and automatic speech recognition. J. Acoust. Soc. Am. 2006, 120, 2421–2424. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | −10 | −5 | 0 | 5 | 10 |
|---|---|---|---|---|---|
| Baseline | 0.058 | 0.079 | 0.110 | 0.143 | 0.180 |
| STFT-NMF | 0.053 | 0.086 | 0.139 | 0.183 | 0.204 |
| DWPT-NMF | 0.067 | 0.127 | 0.216 | 0.298 | 0.359 |
| DTCWT-NMF | 0.121 | 0.216 | 0.354 | 0.505 | 0.633 |
| Method | −10 | −5 | 0 | 5 | 10 |
|---|---|---|---|---|---|
| Baseline | 0.307 | 0.398 | 0.571 | 0.731 | 0.848 |
| STFT-NMF | 0.269 | 0.468 | 0.763 | 0.933 | 0.970 |
| DWPT-NMF | 0.333 | 0.596 | 0.886 | 0.978 | 0.993 |
| DTCWT-NMF | 0.547 | 0.787 | 0.970 | 0.997 | 0.999 |
| Method | −10 | −5 | 0 | 5 | 10 |
|---|---|---|---|---|---|
| Baseline | 1.435 | 1.539 | 1.709 | 1.899 | 2.035 |
| STFT-NMF | 1.463 | 1.559 | 1.733 | 1.930 | 2.053 |
| DWPT-NMF | 1.493 | 1.659 | 1.851 | 2.041 | 2.216 |
| DNN-IRM | 1.520 | 1.716 | 2.031 | 2.465 | 2.761 |
| DTCWT-NMF | 1.551 | 1.725 | 2.006 | 2.298 | 2.614 |
| Method | −10 | −5 | 0 | 5 | 10 |
|---|---|---|---|---|---|
| Baseline | 0.533 | 0.591 | 0.652 | 0.717 | 0.784 |
| STFT-NMF | 0.451 | 0.504 | 0.578 | 0.632 | 0.677 |
| DWPT-NMF | 0.522 | 0.623 | 0.717 | 0.787 | 0.835 |
| DNN-IRM | 0.547 | 0.654 | 0.757 | 0.844 | 0.905 |
| DTCWT-NMF | 0.572 | 0.660 | 0.757 | 0.841 | 0.903 |
| Method | −10 | −5 | 0 | 5 | 10 |
|---|---|---|---|---|---|
| STOI/PESQ | STOI/PESQ | STOI/PESQ | STOI/PESQ | STOI/PESQ | |
| Baseline | 0.551/1.352 | 0.641/1.646 | 0.734/1.901 | 0.829/2.256 | 0.902/2.540 |
| U-STFT-NMF | 0.477/1.349 | 0.545/1.553 | 0.609/1.775 | 0.682/1.987 | 0.728/2.188 |
| U-DWPT-NMF | 0.534/1.407 | 0.623/1.666 | 0.716/1.962 | 0.789/2.307 | 0.847/2.584 |
| U-DNN-IRM | 0.542/1.427 | 0.652/1.681 | 0.764/1.970 | 0.855/2.343 | 0.917/2.692 |
| U-DTCWT-NMF | 0.569/1.437 | 0.667/1.707 | 0.765/1.973 | 0.849/2.323 | 0.909/2.642 |
| Method | −10 | −5 | 0 | 5 | 10 |
|---|---|---|---|---|---|
| STOI/PESQ | STOI/PESQ | STOI/PESQ | STOI/PESQ | STOI/PESQ | |
| DWPT-NMF | 0.495/1.37 | 0.572/1.591 | 0.665/1.782 | 0.724/2.041 | 0.796/2.216 |
| DNN-IRM | 0.522/1.481 | 0.614/1.686 | 0.731/1.985 | 0.832/2.381 | 0.912/2.653 |
| DTCWT-NMF | 0.531/1.551 | 0.632/1.702 | 0.729/1.981 | 0.829/2.195 | 0.892/2.46 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.S.; Al Mahmud, T.H.; Khan, W.U.; Ye, Z. Supervised Single Channel Speech Enhancement Based on Dual-Tree Complex Wavelet Transforms and Nonnegative Matrix Factorization Using the Joint Learning Process and Subband Smooth Ratio Mask. Electronics 2019, 8, 353. https://doi.org/10.3390/electronics8030353
Islam MS, Al Mahmud TH, Khan WU, Ye Z. Supervised Single Channel Speech Enhancement Based on Dual-Tree Complex Wavelet Transforms and Nonnegative Matrix Factorization Using the Joint Learning Process and Subband Smooth Ratio Mask. Electronics. 2019; 8(3):353. https://doi.org/10.3390/electronics8030353
Chicago/Turabian StyleIslam, Md Shohidul, Tarek Hasan Al Mahmud, Wasim Ullah Khan, and Zhongfu Ye. 2019. "Supervised Single Channel Speech Enhancement Based on Dual-Tree Complex Wavelet Transforms and Nonnegative Matrix Factorization Using the Joint Learning Process and Subband Smooth Ratio Mask" Electronics 8, no. 3: 353. https://doi.org/10.3390/electronics8030353
APA StyleIslam, M. S., Al Mahmud, T. H., Khan, W. U., & Ye, Z. (2019). Supervised Single Channel Speech Enhancement Based on Dual-Tree Complex Wavelet Transforms and Nonnegative Matrix Factorization Using the Joint Learning Process and Subband Smooth Ratio Mask. Electronics, 8(3), 353. https://doi.org/10.3390/electronics8030353