A State-of-the-Art Survey on Deep Learning Theory and Architectures


 ,
, 
Abstract
:1. Introduction
1.1. Type of Deep Learning Approaches
1.1.1. Deep Supervised Learning
1.1.2. Deep Semi-supervised Learning
1.1.3. Deep Unsupervised Learning
1.1.4. Deep Reinforcement Learning (RL)
1.2. Feature Learning
1.3. Why and When to apply DL
- Absence of a human expert (navigation on Mars)
- Humans are unable to explain their expertise (speech recognition, vision, and language understanding)
- The solution to the problem changes over time (tracking, weather prediction, preference, stock, price prediction)
- Solutions need to be adapted to the particular cases (biometrics, personalization).
- The problem size is too vast for our limited reasoning capabilities (calculation webpage ranks, matching ads to Facebook, sentiment analysis).
1.4. The State-of-the-art Performance of DL
1.5. Why DL?
1.5.1. Universal Learning Approach
1.5.2. Robust
1.5.3. Generalization
1.5.4. Scalability
1.6. Challenges of DL
- Big data analytics using DL
- Scalability of DL approaches
- Ability to generate data which is important where data is not available for learning the system (especially for computer vision task, such as inverse graphics).
- Energy efficient techniques for special purpose devices, including mobile intelligence, FPGAs, and so on.
- Multi-task and transfer learning or multi-module learning. This means learning from different domains or with different models together.
- Dealing with causality in learning.
2. Deep Neural Network
2.1. The History of DNN
2.2. Gradient Descent
2.3. Stochastic Gradient Descent (SGD)
2.4. Back-Propagation (BP)
2.5. Momentum
2.6. Learning Rate
2.7. Weight Decay
3. Convolutional Neural Network (CNN)
3.1. CNN Overview
3.1.1. Convolutional Layer
3.1.2. Sub-sampling Layer
3.1.3. Classification Layer
3.1.4. Network Parameters and Required Memory for CNN
3.2. Popular CNN Architectures
3.2.1. LeNet (1998)
3.2.2. AlexNet (2012)
3.2.3. ZFNet / Clarifai (2013)
3.2.4. Network in Network (NiN)
3.2.5. VGGNET (2014)
3.2.6. GoogLeNet (2014)
3.2.7. Residual Network (ResNet in 2015)
3.2.8. Densely Connected Network (DenseNet)
3.2.9. FractalNet (2016)
3.3. CapsuleNet
3.4. Comparison of Different Models
3.5. Other DNN Models
3.6. Applications of CNNs
3.6.1. CNNs for Solving A Graph Problem
3.6.2. Image Processing and Computer Vision
3.6.3. Speech Processing
3.6.4. CNN for Medical Imaging
4. Advanced Training Techniques
4.1. Preparing Dataset
4.2. Network Initialization
4.3. Batch Normalization
| Algorithm 1: Batch Normalization (BN) |
| Inputs: Values of x over a mini-batch: |
| Outputs: |
| // mini-batch mean |
| // mini-batch variance |
| // normalize |
| // Scaling and shifting |
- Increase the learning rate
- Dropout (batch normalization does the same job)
- L2 weight regularization
- Accelerating the learning rate decay
- Remove Local Response Normalization (LRN) (if you used it)
- Shuffle training sample more thoroughly
- Useless distortion of images in the training set
4.4. Alternative Convolutional Methods
4.5. Activation Function
4.6. Sub-Sampling Layer or Pooling Layer
4.7. Regularization Approaches for DL
4.8. Optimization Methods for DL
5. Recurrent Neural Network (RNN)
5.1. Introduction
5.2. Long Short-Term Memory (LSTM)
5.3. Gated Recurrent Unit (GRU)
5.4. Convolutional LSTM (ConvLSTM)
5.5. A Variant of Architectures of RNN with Respective to the Applications
5.6. Attention-based Models with RNN
5.7. RNN Applications
6. Auto-Encoder (AE) and Restricted Boltzmann Machine (RBM)
6.1. Review of Auto-Encoder (AE)
6.2. Variational Autoencoders (VAEs)
6.3. Split-Brain Autoencoder
6.4. Applications of AE
6.5. Review of RBM
7. Generative Adversarial Networks (GAN)
7.1. Review on GAN
- The lack of a heuristic cost function (as pixel-wise approximate means square errors (MSE))
- Unstable to train (sometimes that can because of producing nonsensical outputs)
7.2. Applications of GAN
7.2.1. GAN for Image Processing
7.2.2. GAN for Speech and Audio Processing
7.2.3. GAN for Medical Information Processing
7.2.4. Other Applications
8. Deep Reinforcement Learning (DRL)
8.1. Review on DRL
8.2. Q-Learning
- is an estimated utility function—it tells us how good an action is given in a certain state
- immediate reward for making an action best utility (Q) for the resulting state
- Convergence of Q-function: Approximation will be converged to the true Q-function, but it must visit possible state-action pair infinitely many times.
- The state table size can be vary depending on the observation space and complexity.
- Unseen values are not considered during observation.
| Algorithm 2: Q-Learning |
| Initialization: |
| For each state-action pair |
| initialize the table entry to zero |
| Steps: |
| 1. Observed the current state s |
2. REPEAT:
|
8.3. Recent Trends of DRL with Applications
9. Bayesian Deep Learning (BDL)
10. Transfer Learning
10.1. Transfer Learning
10.2. What Is A Pre-trained Model?
10.3. Why Will You Use Pre-trained Models?
10.4. How Will You Use Pre-trained Models?
10.5. Working with Inference
10.6. The Myth about Deep Learning
- Possible to learn useful representations from unlabeled data.
- Transfer learning can help learned representation from the related task [306].
11. Energy Efficient Approaches and Hardware for DL
11.1. Overview
- The first approach is to optimize the internal operational cost with an efficient network structure;
- Second design a network with low precision operations or a hardware efficient network.
11.2. Binary or Ternary Connect Neural Networks
- It is observed that the binary multiplication on GPU is almost seven times faster than traditional matrix multiplication on GPU
- In forward pass, BNNs drastically reduce memory size and accesses, and replace most arithmetic operation with bit-wise operations, which lead great increase of power efficiency
- Binarized kernels can be used in CNNs which can reduce around 60% complexity of dedicated hardware.
- It is also observed that memory accesses typically consume more energy compared to the arithmetic operation and memory access cost increases with memory size. BNNs are beneficial with respect to both aspects.
12. Hardware for DL
13. Other topics
14. Summary
Funding
Acknowledgments
Conflicts of Interest
Appendix A
A.1. Frameworks
- Tensorflow: https://www.tensorflow.org/
- KERAS: https://keras.io/
- Torch: http://torch.ch/
- PyTorch: http://pytorch.org/
- DL4J (DeepLearning4J): https://deeplearning4j.org/
- Chainer: http://chainer.org/
- CNTK (Microsoft): https://github.com/Microsoft/CNTK
- MatConvNet: http://www.vlfeat.org/matconvnet/
- MINERVA: https://github.com/dmlc/minerva
- OpenDeep: http://www.opendeep.org/
- PyLerarn2: http://deeplearning.net/software/pylearn2/
- TensorLayer: https://github.com/zsdonghao/tensorlayer
A.2. SDKs
- TensorRT: https://developer.nvidia.com/tensorrt
- DeepStreamSDK: https://developer.nvidia.com/deepstream-sdk
- cuSPARSE: http://docs.nvidia.com/cuda/cusparse/
A.3. Benchmark Datasets
A.3.1. Image Classification or Detection or Segmentation
- CIFAR 10/100: https://www.cs.toronto.edu/~kriz/cifar.html
- SVHN/ SVHN2: http://ufldl.stanford.edu/housenumbers/
- CalTech 101/256: http://www.vision.caltech.edu/Image_Datasets/Caltech101/
- SUN-dataset: http://groups.csail.mit.edu/vision/SUN/
- ImageNet: http://www.image-net.org/
- National Data Science Bowl Competition: http://www.datasciencebowl.com/
- MS COCO DATASET: http://mscoco.org/
- MIT-67 scene dataset: http://web.mit.edu/torralba/www/indoor.html
- Caltech-UCSD Birds-200 dataset: http://www.vision.caltech.edu/visipedia/CUB-200-2011.html
- Pascal VOC 2007 dataset: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/
- H3D Human Attributes dataset: https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/shape/poselets/
- Face recognition dataset: http://vis-www.cs.umass.edu/lfw/
- For more data-set visit: https://www.kaggle.com/
- Recently Introduced Datasets in Sept. 2016:
- Google Open Images (~9M images)—https://github.com/openimages/dataset
- Youtube-8M (8M videos: https://research.google.com/youtube8m/
A.3.2. Text Classification
- Reuters-21578 Text Categorization Collection: http://kdd.ics.uci.edu/databases/reuters21578/reuters21578.html
- Sentiment analysis from Stanford: http://ai.stanford.edu/~amaas/data/sentiment/
- Movie sentiment analysis from Cornel: http://www.cs.cornell.edu/people/pabo/movie-review-data/
A.3.3. Language Modeling
- Free eBooks: https://www.gutenberg.org/
- Brown and stanford corpus on present americal english: https://en.wikipedia.org/wiki/Brown_Corpus
- Google 1Billion word corpus: https://github.com/ciprian-chelba/1-billion-word-language-modeling-benchmark
A.3.4. Image Captioning
- Flickr-30k
- Common Objects in Context (COCO):
A.3.5. Machine Translation
- Pairs of sentences in English and French: https://www.isi.edu/natural-language/download/hansard/
- European Parliament Proceedings parallel Corpus 196-2011: http://www.statmt.org/europarl/
- The statistics for machine translation: http://www.statmt.org/
A.3.6. Question Answering
- Stanford Question Answering Dataset (SQuAD): https://rajpurkar.github.io/SQuAD-explorer/
- Dataset from DeepMind: https://github.com/deepmind/rc-data
- Amazon dataset:
A.3.7. Speech Recognition
- Voxforge: http://voxforge.org/
- Open Speech and Language Resources: http://www.openslr.org/12/
A.3.8. Document Summarization
A.3.9. Sentiment Analysis:
- IMDB dataset: http://www.imdb.com/
A.3.10. Hyperspectral Image Analysis
A.4. Journals and Conferences
A.4.1. Conferences
- Neural Information Processing System (NIPS)
- International Conference on Learning Representation (ICLR): What are you doing for Deep Learning?
- International Conference on Machine Learning (ICML)
- Computer Vision and Pattern Recognition (CVPR): What are you doing with Deep Learning?
- International Conference on Computer Vision (ICCV)
- European Conference on Computer Vision (ECCV)
- British Machine Vision Conference (BMVC)
A.4.2. Journal
- Journal of Machine Learning Research (JMLR)
- IEEE Transaction of Neural Network and Learning System (ITNNLS)
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- Computer Vision and Image Understanding (CVIU)
- Pattern Recognition Letter
- Neural Computing and Application
- International Journal of Computer Vision
- IEEE Transactions on Image Processing
- IEEE Computational Intelligence Magazine
- Proceedings of IEEE
- IEEE Signal Processing Magazine
- Neural Processing Letter
- Pattern Recognition
- Neural Networks
- ISPPRS Journal of Photogrammetry and Remote Sensing
A.4.3. Tutorials on Deep Learning
- Courses on Reinforcement Learning: http://rll.berkeley.edu/deeprlcourse/
A.4.4. Books on Deep Learning
References
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; LeCun, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv, 2013; arXiv:1312.5602. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. arXiv, 2013; arXiv:1311.2901. [Google Scholar]
- Simonyan, K.; Zisserman, A. deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv, 2016; arXiv:1605.07678. [Google Scholar]
- Zweig, G. Classification and recognition with direct segment models. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4161–4164. [Google Scholar]
- He, Y.; Fosler-Lussier, E. Efficient segmental conditional random fields for one-pass phone recognition. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Abdel-Hamid, O.; Deng, L.; Yu, D.; Jiang, H. Deep segmental neural networks for speech recognition. Interspeech 2013, 36, 70. [Google Scholar]
- Tang, H.; Wang, W.; Gimpel, K.; Livescu, K. Discriminative segmental cascades for feature-rich phone recognition. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 561–568. [Google Scholar]
- Song, W.; Cai, J. End-to-End Deep Neural Network for Automatic Speech Recognition. 1. (Errors: 21.1), 2015. Available online: https://cs224d.stanford.edu/reports/SongWilliam.pdf (accessed on 17 January 2018).
- Deng, L.; Abdel-Hamid, O.; Yu, D. A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6669–6673. [Google Scholar]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Bengio, C.L.Y.; Courville, A. Towards end-to-end speech recognition with deep convolutional neural networks. arXiv, 2017; arXiv:1701.02720. [Google Scholar]
- Deng, L.; Platt, J. Ensemble deep learning for speech recognition. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Chorowski, J.K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 577–585. [Google Scholar]
- Lu, L.; Kong, L.; Dyer, C.; Smith, N.A.; Renals, S. Segmental recurrent neural networks for end-to-end speech recognition. arXiv, 2016; arXiv:1603.00223. [Google Scholar]
- Van Essen, B.; Kim, H.; Pearce, R.; Boakye, K.; Chen, B. LBANN: Livermore big artificial neural network HPC toolkit. In Proceedings of the Workshop on Machine Learning in High-Performance Computing Environments, Austin, TX, USA, 15–20 November 2015; p. 5. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Graph Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. arXiv, 2017; arXiv:1707.01926. [Google Scholar]
- Md, Z.A.; Aspiras, T.; Taha, T.M.; Asari, V.K.; Bowen, T.J. Advanced deep convolutional neural network approaches for digital pathology image analysis: A comprehensive evaluation with different use cases. In Proceedings of the Pathology Visions 2018, San Diego, CA, USA, 4–6 November 2018. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Alom, M.Z.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Nuclei Segmentation with Recurrent Residual Convolutional Neural Networks based U-Net (R2U-Net). In Proceedings of the NAECON 2018-IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 23–26 July 2018; pp. 228–233. [Google Scholar]
- Alom, M.Z.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Microscopic Blood Cell Classification Using Inception Recurrent Residual Convolutional Neural Networks. In Proceedings of the NAECON 2018-IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 23–26 July 2018; pp. 222–227. [Google Scholar]
- Chen, X.-W.; Lin, X. Big Data Deep Learning: Challenges and Perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Chawla, N.V.; Jin, Y.; Williams, G.J. Big data opportunities and challenges: Discussions from data analytics perspectives. IEEE Comput. Intell. Mag. 2014, 9, 62–74. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Kaiser, L.; Gomez, A.N.; Shazeer, N.; Vaswani, A.; Parmar, N.; Jones, L.; Uszkoreit, J. One model to learn them all. arXiv, 2017; arXiv:1706.05137. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G.; et al. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Linguist. 2017, 5, 339–351. [Google Scholar] [CrossRef]
- Argyriou, A.; Evgeniou, T.; Pontil, M. Multi-task feature learning. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2007; pp. 41–48. [Google Scholar]
- Singh, K.; Gupta, G.; Vig, L.; Shroff, G.; Agarwal, P. Deep Convolutional Neural Networks for Pairwise Causality. arXiv, 2017; arXiv:1701.00597. [Google Scholar]
- Yu, H.; Wang, J.; Huang, Z.; Yang, Y.; Xu, W. Video paragraph captioning using hierarchical recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4584–4593. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. arXiv, 2017; arXiv:1703.05192. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv, 2016; arXiv:1605.05396. [Google Scholar]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. arXiv, 2015; arXiv:1512.07108. [Google Scholar]
- Sze, V.; Chen, Y.; Yang, T.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Kwon, D.; Kim, H.; Kim, J.; Suh, S.C.; Kim, I.; Kim, K.J. A survey of deep learning-based network anomaly detection. Cluster Comput. 2017, 1–13. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv, 2017; arXiv:1701.07274. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Schuman, C.D.; Potok, T.E.; Patton, R.M.; Birdwell, J.D.; Dean, M.E.; Rose, G.S.; Plank, J.S. A survey of neuromorphic computing and neural networks in hardware. arXiv, 2017; arXiv:1705.06963. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed]
- Minsky, M.; Papert, S.A. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A hierarchical neural network capable of visual pattern recognition. Neural Netw. 1988, 1, 119–130. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Cogn. Model. 1988, 5, 1. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. Int. Conf. Mach. Learning. 2013, 28, 1139–1147. [Google Scholar]
- Yoshua, B.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy Layer-Wise Training of Deep Network. In Advances in Neural Information Processing Systems 19 (NIPS 2006); MIT Press: Cambridge, MA, USA, 2007; pp. 153–160. [Google Scholar]
- Erhan, D.; Manzagol, P.; Bengio, Y.; Bengio, S.; Vincent, P. The difficulty of training deep architectures and the effect of unsupervised pre-training. Artif. Intell. Stat. 2009, 5, 153–160. [Google Scholar]
- Mohamed, A.-R.; Dahl, G.E.; Hinton, G. Acoustic modeling using deep belief networks. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 14–22. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P. Extracting and composing robust features with denoising autoencoders. In Proceedings of the Twenty-fifth International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv, 2013; arXiv:1312.4400. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv, 2014; arXiv:1412.6806. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. FractalNet: Ultra-Deep Neural Networks without Residuals. arXiv, 2016; arXiv:1605.07648. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv, 2016; arXiv:1602.07261. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv, 2016; arXiv:1605.07146. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. arXiv, 2016; arXiv:1611.05431. [Google Scholar]
- Veit, A.; Wilber, M.J.; Belongie, S. Residual networks behave like ensembles of relatively shallow networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 550–558. [Google Scholar]
- Abdi, M.; Nahavandi, S. Multi-Residual Networks: Improving the Speed and Accuracy of Residual Networks. arXiv, 2016; arXiv:1609.05672. [Google Scholar]
- Zhang, X.; Li, Z.; Loy, C.C.; Lin, D. Polynet: A pursuit of structural diversity in very deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 718–726. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Improved inception-residual convolutional neural network for object recognition. arXiv, 2017; arXiv:1712.09888. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2017; pp. 3856–3866. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv, 2016; arXiv:1610.02357. [Google Scholar]
- Liang, M.; Hu, X. Recurrent convolutional neural network for object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M. Inception Recurrent Convolutional Neural Network for Object Recognition. arXiv, 2017; arXiv:1704.07709. [Google Scholar]
- Li, Y.; Ouyang, W.; Wang, X.; Tang, X. Vip-cnn: Visual phrase guided convolutional neural network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7244–7253. [Google Scholar]
- Bagherinezhad, H.; Rastegari, M.; Farhadi, A. LCNN: Lookup-based Convolutional Neural Network. arXiv, 2016; arXiv:1611.06473. [Google Scholar]
- Bansal, A.; Chen, X.; Russell, B.; Gupta, A.; Ramanan, D. Pixelnet: Representation of the pixels, by the pixels, and for the pixels. arXiv, 2017; arXiv:1702.06506. [Google Scholar]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep networks with stochastic depth. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 646–661. [Google Scholar]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Proceedings of the Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; pp. 562–570. [Google Scholar]
- Pezeshki, M.; Fan, L.; Brakel, P.; Courville, A.; Bengio, Y. Deconstructing the ladder network architecture. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2368–2376. [Google Scholar]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 4068–4076. [Google Scholar]
- Ba, J.; Caruana, R. Do deep nets really need to be deep? In Advances in Neural Information Processing Systems; NIPS Proceedings; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Urban, G.; Geras, K.J.; Kahou, S.E.; Aslan, O.; Wang, S.; Caruana, R.; Mohamed, A.; Philipose, M.; Richardson, M. Do deep convolutional nets really need to be deep and convolutional? arXiv, 2016; arXiv:1603.05691. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv, 2014; arXiv:1412.6550. [Google Scholar]
- Mishkin, D.; Matas, J. All you need is a good init. arXiv, 2015; arXiv:1511.06422. [Google Scholar]
- Pandey, G.; Dukkipati, A. To go deep or wide in learning? arXiv, 2014; arXiv:1402.5634. [Google Scholar]
- Ratner, A.J.; de Sa, C.M.; Wu, S.; Selsam, D.; Ré, C. Data programming: Creating large training sets, quickly. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 3567–3575. [Google Scholar]
- Aberger, C.R.; Lamb, A.; Tu, S.; Nötzli, A.; Olukotun, K.; Ré, C. Emptyheaded: A relational engine for graph processing. ACM Trans. Database Syst. 2017, 42, 20. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5 mb model size. arXiv, 2016; arXiv:1602.07360. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. arXiv, 2015; arXiv:1510.00149. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning Convolutional Neural Networks for Graphs. arXiv, 2016; arXiv:1605.05273. [Google Scholar]
- Awesome Deep Vision. Available online: https://github.com/kjw0612/awesome-deep-vision (accessed on 17 January 2018).
- Jia, X.; Xu, X.; Cai, B.; Guo, K. Single Image Super-Resolution Using Multi-Scale Convolutional Neural Network. In Pacific Rim Conference on Multimedia; Springer: Cham, Switzerland, 2017; pp. 149–157. [Google Scholar]
- Ahn, B.; Cho, N.I. Block-Matching Convolutional Neural Network for Image Denoising. arXiv, 2017; arXiv:1704.00524. [Google Scholar]
- Ma, S.; Liu, J.; Chen, C.W. A-Lamp: Adaptive Layout-Aware Multi-Patch Deep Convolutional Neural Network for Photo Aesthetic Assessment. arXiv, 2017; arXiv:1704.00248. [Google Scholar]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral Image Classification With Markov Random Fields and a Convolutional Neural Network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [PubMed]
- De Vos, B.D.; Berendsen, F.F.; Viergever, M.A.; Staring, M.; Išgum, I. End-to-end unsupervised deformable image registration with a convolutional neural network. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 204–212. [Google Scholar]
- Wang, X.; Oxholm, G.; Zhang, D.; Wang, Y. Multimodal transfer: A hierarchical deep convolutional neural network for fast artistic style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2, p. 7. [Google Scholar]
- Babaee, M.; Dinh, D.T.; Rigoll, G. A deep convolutional neural network for background subtraction. arXiv, 2017; arXiv:1702.01731. [Google Scholar]
- Alom, M.Z.; Sidike, P.; Hasan, M.; Taha, T.M.; Asari, V.K. Handwritten Bangla Character Recognition Using the State-of-the-Art Deep Convolutional Neural Networks. Comput. Intell. Neurosci. 2018, 2018, 6747098. [Google Scholar] [CrossRef] [PubMed]
- Alom, M.Z.; Awwal, A.A.S.; Lowe-Webb, R.; Taha, T.M. Optical beam classification using deep learning: A comparison with rule-and feature-based classification. In Proceedings of the Optics and Photonics for Information Processing XI, San Diego, CA, USA, 6–10 August 2017; Volume 10395. [Google Scholar]
- Sidike, P.; Sagan, V.; Maimaitijiang, M.; Maimaitiyiming, M.; Shakoor, N.; Burken, J.; Mockler, T.; Fritschi, F.B. dPEN: deep Progressively Expanded Network for mapping heterogeneous agricultural landscape using WorldView-3 satellite imagery. Remote Sens. Environ. 2019, 221, 756–772. [Google Scholar] [CrossRef]
- Alom, M.Z.; Alam, M.; Taha, T.M.; Iftekharuddin, K.M. Object recognition using cellular simultaneous recurrent networks and convolutional neural network. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2873–2880. [Google Scholar]
- Ronao, C.A.; Cho, S.-B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, convolutional, and recurrent models for human activity recognition using wearables. arXiv, 2016; arXiv:1604.08880. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Rad, N.M.; Kia, S.M.; Zarbo, C.; van Laarhoven, T.; Jurman, G.; Venuti, P.; Marchiori, E.; Furlanello, C. Deep learning for automatic stereotypical motor movement detection using wearable sensors in autism spectrum disorders. Signal Process. 2018, 144, 180–191. [Google Scholar]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G. Deep learning for human activity recognition: A resource efficient implementation on low-power devices. In Proceedings of the 2016 IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN), San Francisco, CA, USA, 14–17 June 2016; pp. 71–76. [Google Scholar]
- Alom, M.Z.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Microscopic Nuclei Classification, Segmentation and Detection with improved Deep Convolutional Neural Network (DCNN) Approaches. arXiv, 2018; arXiv:1811.03447. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv, 2014; arXiv:1412.7062. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv, 2015; arXiv:1511.00561. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation. arXiv, 2018; arXiv:1802.06955. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A. A-fast-rcnn: Hard positive generation via adversary for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Hou, J.-C.; Wang, S.; Lai, Y.; Tsao, Y.; Chang, H.; Wang, H. Audio-Visual Speech Enhancement Using Multimodal Deep Convolutional Neural Networks. arXiv, 2017; arXiv:1703.10893. [Google Scholar]
- Xu, Y.; Kong, Q.; Huang, Q.; Wang, W.; Plumbley, M.D. Convolutional gated recurrent neural network incorporating spatial features for audio tagging. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3461–3466. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Xie, Y.; Xing, F.; McGough, M.; Yang, L. Mdnet: A semantically and visually interpretable medical image diagnosis network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6428–6436. [Google Scholar]
- Tran, P.V. A fully convolutional neural network for cardiac segmentation in short-axis MRI. arXiv, 2016; arXiv:1604.00494. [Google Scholar]
- Tan, J.H.U.; Acharya, R.; Bhandary, S.V.; Chua, K.C.; Sivaprasad, S. Segmentation of optic disc, fovea and retinal vasculature using a single convolutional neural network. J. Comput. Sci. 2017, 20, 70–79. [Google Scholar] [CrossRef]
- Moeskops, P.; Viergever, M.A.; Mendrik, A.M.; de Vries, L.S.; Benders, M.J.N.L.; Išgum, I. Automatic segmentation of MR brain images with a convolutional neural network. IEEE Trans. Med Imaging 2016, 35, 1252–1261. [Google Scholar] [CrossRef] [PubMed]
- Alom, M.Z.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Breast Cancer Classification from Histopathological Images with Inception Recurrent Residual Convolutional Neural Network. arXiv, 2018; arXiv:1811.04241. [Google Scholar]
- LeCun, Y.; Bottou, L.; Orr, G. Efficient BackProp. In Neural Networks: Tricks of the Trade; Orr, G., Müller, K., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2012. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1026–1034. [Google Scholar]
- Vedaldi, A.; Lenc, K. Matconvnet: Convolutional neural networks for matlab. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 689–692. [Google Scholar]
- Laurent, C.; Pereyra, G.; Brakel, P.; Zhang, Y.; Bengio, Y. Batch normalized recurrent neural networks. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2657–2661. [Google Scholar]
- Lavin, A.; Gray, S. Fast algorithms for convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4013–4021. [Google Scholar]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv, 2015; arXiv:1511.07289. [Google Scholar]
- Li, Y.; Fan, C.; Li, Y.; Wu, Q.; Ming, Y. Improving deep neural network with multiple parametric exponential linear units. Neurocomputing 2018, 301, 11–24. [Google Scholar] [CrossRef]
- Jin, X.; Xu, C.; Feng, J.; Wei, Y.; Xiong, J.; Yan, S. Deep Learning with S-Shaped Rectified Linear Activation Units. AAAI 2016, 3, 2–3. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv, 2015; arXiv:1505.00853. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 346–361. [Google Scholar]
- Yoo, D.; Park, S.; Lee, J.; Kweon, I.S. Multi-scale pyramid pooling for deep convolutional representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 71–80. [Google Scholar]
- Graham, B. Fractional max-pooling. arXiv, 2014; arXiv:1412.6071. [Google Scholar]
- Lee, C.-Y.; Gallagher, P.W.; Tu, Z. Generalizing pooling functions in convolutional neural networks: Mixed, gated, and tree. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 464–472. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv, 2012; arXiv:1207.0580. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; le Cun, Y.; Fergus, R. Regularization of neural networks using dropconnect. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1058–1066. [Google Scholar]
- Bulò, S.R.; Porzi, L.; Kontschieder, P. Dropout distillation. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 99–107. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv, 2016; arXiv:1609.04747. [Google Scholar]
- Le, Q.V.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June –2 July 2011; pp. 265–272. [Google Scholar]
- Koushik, J.; Hayashi, H. Improving stochastic gradient descent with feedback. arXiv, 2016; arXiv:1611.01505. [Google Scholar]
- Sathasivam, S.; Abdullah, W.A. Logic learning in Hopfield networks. arXiv, 2008; arXiv:0804.4075. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Jordan, M.I. Serial order: A parallel distributed processing approach. Adv. Psychol. 1997, 121, 471–495. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies; IEEE Press: New York, NY, USA, 2001. [Google Scholar]
- Schmidhuber, J. Habilitation Thesis: Netzwerkarchitekturen, Zielfunktionen und Kettenregel (Network architectures, objective functions, and chain rule). Ph.D. Thesis, Technische Universität München, München, Germany, 15 April 1993. [Google Scholar]
- Gers, F.A.; Schmidhuber, J. Recurrent nets that time and count. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks, Como, Italy, 24–27 July 2000; Volume 3. [Google Scholar]
- Gers, F.A.; Schraudolph, N.N.; Schmidhuber, J. Learning precise timing with LSTM recurrent networks. J. Mach. Learn. Res. 2002, 3, 115–143. [Google Scholar]
- Socher, R.; Lin, C.C.; Manning, C.; Ng, A.Y. Parsing natural scenes and natural language with recursive neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 129–136. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association. Makuhari, Chiba, Japan, 26–30 September 2010; Volume 2. [Google Scholar]
- Xingjian, S.H.I.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Advances in Neural Information Processing Systems (NIPS); NIPS Proceedings; MIT Press: Cambridge, MA, USA, 2015; pp. 802–810. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv, 2014; arXiv:1412.3555. [Google Scholar]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the 32nd International Conference on Machine Learning (ICML-15), Lille, France, 6–11 July 2015. [Google Scholar]
- Yao, K.; Cohn, T.; Vylomova, K.; Duh, K.; Dyer, C. Depth-gated recurrent neural networks. arXiv, 2015; arXiv:1508.03790. [Google Scholar]
- Koutnik, J.; Greff, K.; Gomez, F.; Schmidhuber, J. A clockwork rnn. arXiv, 2014; arXiv:1402.3511. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Li, F.-F. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv, 2014; arXiv:1402.3722. [Google Scholar]
- Kunihiko, F. Neural network model for selective attention in visual pattern recognition and associative recall. Appl. Opt. 1987, 26, 4985–4992. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G. A dual-stage attention-based recurrent neural network for time series prediction. arXiv, 2017; arXiv:1704.02971. [Google Scholar]
- Xiong, C.; Merity, S.; Socher, R. Dynamic memory networks for visual and textual question answering. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Oord, A.v.d.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel recurrent neural networks. arXiv, 2016; arXiv:1601.06759. [Google Scholar]
- Xue, W.; Nachum, I.B.; Pandey, S.; Warrington, J.; Leung, S.; Li, S. Direct estimation of regional wall thicknesses via residual recurrent neural network. In International Conference on Information Processing in Medical Imaging; Springer: Cham, Switzerland, 2017; pp. 505–516. [Google Scholar]
- Tjandra, A.; Sakti, S.; Manurung, R.; Adriani, M.; Nakamura, S. Gated recurrent neural tensor network. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 448–455. [Google Scholar]
- Wang, S.; Jing, J. Learning natural language inference with LSTM. arXiv, 2015; arXiv:1512.08849. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2014; pp. 3104–3112. [Google Scholar]
- Lakhani, V.A.; Mahadev, R. Multi-Language Identification Using Convolutional Recurrent Neural Network. arXiv, 2016; arXiv:1611.04010. [Google Scholar]
- Längkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef]
- Malhotra, P.; Vishnu, T.V.; Vig, L.; Agarwal, P.; Shroff, G. TimeNet: Pre-trained deep recurrent neural network for time series classification. arXiv, 2017; arXiv:1706.08838. [Google Scholar]
- Soltau, H.; Liao, H.; Sak, H. Neural speech recognizer: Acoustic-to-word LSTM model for large vocabulary speech recognition. arXiv, 2016; arXiv:1610.09975. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Adavanne, S.; Pertilä, P.; Virtanen, T. Sound event detection using spatial features and convolutional recurrent neural network. arXiv, 2017; arXiv:1706.02291. [Google Scholar]
- Chien, J.-T.; Misbullah, A. Deep long short-term memory networks for speech recognition. In Proceedings of the 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP), Tianjin, China, 17–20 October 2016. [Google Scholar]
- Choi, E.; Schuetz, A.; Stewart, W.F.; Sun, J. Using recurrent neural network models for early detection of heart failure onset. J. Am. Med Inform. Assoc. 2016, 24, 361–370. [Google Scholar] [CrossRef] [PubMed]
- Azzouni, A.; Pujolle, G. A Long Short-Term Memory Recurrent Neural Network Framework for Network Traffic Matrix Prediction. arXiv, 2017; arXiv:1705.05690. [Google Scholar]
- Olabiyi, O.; Martinson, E.; Chintalapudi, V.; Guo, R. Driver Action Prediction Using Deep (Bidirectional) Recurrent Neural Network. arXiv, 2017; arXiv:1706.02257. [Google Scholar]
- Kim, B.D.; Kang, C.M.; Lee, S.H.; Chae, H.; Kim, J.; Chung, C.C.; Choi, J.W. Probabilistic vehicle trajectory prediction over occupancy grid map via recurrent neural network. arXiv, 2017; arXiv:1704.07049. [Google Scholar]
- Richard, A.; Gall, J. A bag-of-words equivalent recurrent neural network for action recognition. Comput. Vis. Image Underst. 2017, 156, 79–91. [Google Scholar] [CrossRef]
- Bontemps, L.; McDermott, J.; Le-Khac, N.-H. Collective Anomaly Detection Based on Long Short-Term Memory Recurrent Neural Networks. In International Conference on Future Data and Security Engineering; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Kingma, D.P.; Welling, M. Stochastic gradient VB and the variational auto-encoder. In Proceedings of the Second International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Ng, A. Sparse autoencoder. CS294A Lect. Notes 2011, 72, 1–19. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. arXiv, 2016; arXiv:1611.09842. [Google Scholar]
- Lu, J.; Deshpande, A.; Forsyth, D. CDVAE: Co-embedding Deep Variational Auto Encoder for Conditional Variational Generation. arXiv, 2016; arXiv:1612.00132. [Google Scholar]
- Chicco, D.; Sadowski, P.; Baldi, P. Deep Autoencoder Neural Networks for Gene Ontology Annotation Predictions. In Proceedings of the 5th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics—BCB ’14, Niagara Falls, NY, USA, 2–4 August 2010; pp. 533–540. [Google Scholar]
- Alom, M.Z.; Taha, T.M. Network Intrusion Detection for Cyber Security using Unsupervised Deep Learning Approaches. In Proceedings of the Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 27–30 June 2017. [Google Scholar]
- Song, C.; Liu, F.; Huang, Y.; Wang, L.; Tan, T. Auto-encoder based data clustering. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Ahmad, M.; Protasov, S.; Khan, A.M. Hyperspectral Band Selection Using Unsupervised Non-Linear Deep Auto Encoder to Train External Classifiers. arXiv, 2017; arXiv:1705.06920. [Google Scholar]
- Freund, Y.; Haussler, D. Unsupervised learning of distributions on binary vectors using two layer networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1992; pp. 912–919. [Google Scholar]
- Larochelle, H.; Bengio, Y. Classification using discriminative restricted Boltzmann machines. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar]
- Salakhutdinov, R.; Hinton, G.E. Deep Boltzmann machines. AISTATS 2009, 1, 3. [Google Scholar]
- Alom, M.Z.; Bontupalli, V.R.; Taha, T.M. Intrusion detection using deep belief networks. In Proceedings of the Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 16–19 June 2015. [Google Scholar]
- Alom, M.Z.; Sidike, P.; Taha, T.M.; Asari, V.K. Handwritten bangla digit recognition using deep learning. arXiv, 2017; arXiv:1705.02680. [Google Scholar]
- Albalooshi, F.A.; Sidike, P.; Sagan, V.; Albalooshi, Y.; Asari, V.K. Deep Belief Active Contours (DBAC) with Its Application to Oil Spill Segmentation from Remotely Sensed Aerial Imagery. Photogramm. Eng. Remote Sens. 2018, 84, 451–458. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. arXiv, 2016; arXiv:1606.03498. [Google Scholar]
- Vondrick, C.; Pirsiavash, H.; Torralba, A. Generating videos with scene dynamics. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 613–621. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Wang, X.; Gupta, A. Generative image modeling using style and structure adversarial networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Im, D.J.; Kim, C.D.; Jiang, H.; Memisevic, R. Generating images with recurrent adversarial net- works. arXiv, 2016; arXiv:1602.05110. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. arXiv, 2017; arXiv:1611.07004. [Google Scholar]
- Liu, M.-Y.; Tuzel, O. Coupled generative adversarial networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv, 2016; arXiv:1605.09782. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv, 2017; arXiv:1703.10717. [Google Scholar]
- Martin, A.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv, 2017; arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5767–5777. [Google Scholar]
- He, K.; Wang, Y.; Hopcroft, J. A powerful generative model using random weights for the deep image representation. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kos, J.; Fischer, I.; Song, D. Adversarial examples for generative models. arXiv, 2017; arXiv:1702.06832. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv, 2016; arXiv:1609.03126. [Google Scholar]
- Park, N.; Anand, A.; Moniz, J.R.A.; Lee, K.; Chakraborty, T.; Choo, J.; Park, H.; Kim, Y. MMGAN: Manifold Matching Generative Adversarial Network for Generating Images. arXiv, 2017; arXiv:1707.08273. [Google Scholar]
- Laloy, E.; Hérault, R.; Jacques, D.; Linde, N. Efficient training-image based geostatistical simulation and inversion using a spatial generative adversarial neural network. arXiv, 2017; arXiv:1708.04975. [Google Scholar]
- Eghbal-zadeh, H.; Widmer, G. Probabilistic Generative Adversarial Networks. arXiv, 2017; arXiv:1708.01886. [Google Scholar]
- Fowkes, J.; Sutton, C. A Bayesian Network Model for Interesting Itemsets. In Joint European Conference on Machine Learning and Knowledge Disco in Databases; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Mescheder, L.; Nowozin, S.; Geiger, A. Adversarial variational bayes: Unifying variational autoencoders and generative adversarial networks. arXiv, 2017; arXiv:1701.04722. [Google Scholar]
- Nowozin, S.; Cseke, B.; Tomioka, R. f-gan: Training generative neural samplers using variational divergence minimization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Du, C.; Zhu, J.; Zhang, B. Learning Deep Generative Models with Doubly Stochastic Gradient MCMC. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 3084–3096. [Google Scholar] [CrossRef] [PubMed]
- 242. Hoang, Quan, Tu Dinh Nguyen, Trung Le, and Dinh Phung. Multi-Generator Gernerative Adversarial Nets. arXiv, 2017; arXiv:1708.02556.
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 7. [Google Scholar]
- Kansky, K.; Silver, T.; Mély, D.A.; Eldawy, M.; Lázaro-Gredilla, M.; Lou, X.; Dorfman, N.; Sidor, S.; Phoenix, S.; George, D. Schema networks: Zero-shot transfer with a generative causal model of intuitive physics. arXiv, 2017; arXiv:1706.04317. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv, 2016; arXiv:1609.04802. [Google Scholar]
- Souly, N.; Spampinato, C.; Shah, M. Semi and Weakly Supervised Semantic Segmentation Using Generative Adversarial Network. arXiv, 2017; arXiv:1703.09695. [Google Scholar]
- Dash, A.; Gamboa, J.C.B.; Ahmed, S.; Liwicki, M.; Afzal, M.Z. TAC-GAN-text conditioned auxiliary classifier generative adversarial network. arXiv, 2017; arXiv:1703.06412. [Google Scholar]
- Zhang, H.; Dana, K. Multi-style Generative Network for Real-time Transfer. arXiv, 2017; arXiv:1703.06953. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image De-raining Using a Conditional Generative Adversarial Network. arXiv, 2017; arXiv:1701.05957. [Google Scholar]
- Serban, I.V.; Sordoni, A.; Bengio, Y.; Courville, A.C.; Pineau, J. Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models. AAAI 2016, 16, 3776–3784. [Google Scholar]
- Pascual, S.; Bonafonte, A.; Serrà, J. SEGAN: Speech Enhancement Generative Adversarial Network. arXiv, 2017; arXiv:1703.09452. [Google Scholar]
- Yang, L.-C.; Chou, S.-Z.; Yang, Y.-I. MidiNet: A convolutional generative adversarial network for symbolic-domain music generation. In Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR’2017), Suzhou, China, 23–27 October 2017. [Google Scholar]
- Yang, Q.; Yan, P.; Zhang, Y.; Yu, H.; Shi, Y.; Mou, X.; Kalra, M.K.; Zhang, Y.; Sun, L.; Wang, G. Low-dose CT image denoising using a generative adversarial network with Wasserstein distance and perceptual loss. IEEE Trans. Med. Imaging 2018, 37, 1348–1357. [Google Scholar] [CrossRef] [PubMed]
- Rezaei, M.; Harmuth, K.; Gierke, W.; Kellermeier, T.; Fischer, M.; Yang, H.; Meinel, C. A conditional adversarial network for semantic segmentation of brain tumor. In International MICCAI Brainlesion Workshop; Springer: Cham, Switzerland, 2017; pp. 241–252. [Google Scholar]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. Segan: Adversarial network with multi-scale l 1 loss for medical image segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef] [PubMed]
- Mardani, M.; Gong, E.; Cheng, J.Y.; Vasanawala, S.; Zaharchuk, G.; Alley, M.; Thakur, N.; Han, S.; Dally, W.; Pauly, J.M.; et al. Deep generative adversarial networks for compressed sensing automates MRI. arXiv, 2017; arXiv:1706.00051. [Google Scholar]
- Choi, E.; Biswal, S.; Malin, B.; Duke, J.; Stewart, W.F.; Sun, J. Generating Multilabel Discrete Electronic Health Records Using Generative Adversarial Networks. arXiv, 2017; arXiv:1703.06490. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional gans. arXiv, 2017; arXiv:1706.02633. [Google Scholar]
- Hayes, J.; Melis, L.; Danezis, G.; de Cristofaro, E. LOGAN: evaluating privacy leakage of generative models using generative adversarial networks. arXiv, 2017; arXiv:1705.07663. [Google Scholar]
- Gordon, J.; Hernández-Lobato, J.M. Bayesian Semisupervised Learning with Deep Generative Models. arXiv, 2017; arXiv:1706.09751. [Google Scholar]
- Abbasnejad, M.E.; Shi, Q.; Abbasnejad, I.; van den Hengel, A.; Dick, A. Bayesian conditional generative adverserial networks. arXiv, 2017; arXiv:1706.05477. [Google Scholar]
- Grnarova, P.; Levy, K.Y.; Lucchi, A.; Hofmann, T.; Krause, A. An online learning approach to generative adversarial networks. arXiv, 2017; arXiv:1706.03269. [Google Scholar]
- Li, Y.; Swersky, K.; Zemel, R. Generative moment matching networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1718–1727. [Google Scholar]
- Li, C.-L.; Chang, W.; Cheng, Y.; Yang, Y.; Póczos, B. Mmd gan: Towards deeper understanding of moment matching network. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 2203–2213. [Google Scholar]
- Nie, X.; Feng, J.; Xing, J.; Yan, S. Generative partition networks for multi-person pose estimation. arXiv, 2017; arXiv:1705.07422. [Google Scholar]
- Saeedi, A.; Hoffman, M.D.; DiVerdi, S.J.; Ghandeharioun, A.; Johnson, M.J.; Adams, R.P. Multimodal prediction and personalization of photo edits with deep generative models. arXiv, 2017; arXiv:1704.04997. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International Conference on Information Processing in Medical Imaging; Springer: Cham, Switzerland, 2017; pp. 146–157. [Google Scholar]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 700–708. [Google Scholar]
- Mehrotra, A.; Dukkipati, A. Generative Adversarial Residual Pairwise Networks for One Shot Learning. arXiv, 2017; arXiv:1703.08033. [Google Scholar]
- Sordoni, A.; Galley, M.; Auli, M.; Brockett, C.; Ji, Y.; Mitchell, M.; Nie, J.; Gao, J.; Dolan, B. A neural network approach to context-sensitive generation of conversational responses. arXiv, 2015; arXiv:1506.06714. [Google Scholar]
- Yin, J.; Jiang, X.; Lu, Z.; Shang, L.; Li, H.; Li, X. Neural generative question answering. arXiv, 2015; arXiv:1512.01337. [Google Scholar]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv, 2016; arXiv:1609.03499. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 4467–4475. [Google Scholar]
- Mahmud, M.; Kaiser, M.S.; Hussain, A.; Vassanelli, S. Applications of deep learning and reinforcement learning to biological data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2063–2079. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. Starcraft ii: A new challenge for reinforcement learning. arXiv, 2017; arXiv:1708.04782. [Google Scholar]
- Koenig, S.; Simmons, R.G. Complexity Analysis of Real-Time Reinforcement Learning Applied to Finding Shortest Paths in Deterministic Domains; Tech. Report, No. CMU-CS-93-106; Computer Science Department, Carnegie-Mellon University: Pittsburgh PA, Decemver, 1992. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.I.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning (ICML-15), Lille, France, 6–11 July 2015; Volume 37, pp. 1889–1897. [Google Scholar]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A brief survey of deep reinforcement learning. arXiv, 2017; arXiv:1708.05866. [Google Scholar]
- Zhu, F.; Liao, P.; Zhu, X.; Yao, Y.; Huang, J. Cohesion-based online actor-critic reinforcement learning for mhealth intervention. arXiv, 2017; arXiv:1703.10039. [Google Scholar]
- Zhu, F.; Guo, J.; Xu, Z.; Liao, P.; Yang, L.; Huang, J. Group-driven reinforcement learning for personalized mhealth intervention. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2018; pp. 590–598. [Google Scholar]
- Steckelmacher, D.; Roijers, D.M.; Harutyunyan, A.; Vrancx, P.; Plisnier, H.; Nowé, A. Reinforcement learning in POMDPs with memoryless options and option-observation initiation sets. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Hu, H.; Zhang, X.; Yan, X.; Wang, L.; Xu, Y. Solving a new 3d bin packing problem with deep reinforcement learning method. arXiv, 2017; arXiv:1708.05930. [Google Scholar]
- Everitt, T.; Krakovna, V.; Orseau, L.; Hutter, M.; Legg, S. Reinforcement learning with a corrupted reward channel. arXiv, 2017; arXiv:1705.08417. [Google Scholar]
- Wu, Y.; Mansimov, E.; Grosse, R.B.; Liao, S.; Ba, J. Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5279–5288. [Google Scholar]
- Denil, M.; Agrawal, P.; Kulkarni, T.D.; Erez, T.; Battaglia, P.; de Freitas, N. Learning to perform physics experiments via deep reinforcement learning. arXiv, 2016; arXiv:1611.01843. [Google Scholar]
- Hein, D.; Hentschel, A.; Runkler, T.; Udluft, S. Particle swarm optimization for generating interpretable fuzzy reinforcement learning policies. Eng. Appl. Artif. Intell. 2017, 65, 87–98. [Google Scholar] [CrossRef]
- Islam, R.; Henderson, P.; Gomrokchi, M.; Precup, D. Reproducibility of benchmarked deep reinforcement learning tasks for continuous control. arXiv, 2017; arXiv:1708.04133. [Google Scholar]
- Inoue, T.; de Magistris, G.; Munawar, A.; Yokoya, T.; Tachibana, R. Deep reinforcement learning for high precision assembly tasks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 819–825. [Google Scholar]
- Li, K.; Burdick, J.W. Inverse Reinforcement Learning in Large State Spaces via Function Approximation. arXiv, 2017; arXiv:1707.09394. [Google Scholar]
- Liu, N.; Li, Z.; Xu, J.; Xu, Z.; Lin, S.; Qiu, Q.; Tang, J.; Wang, Y. A hierarchical framework of cloud resource allocation and power management using deep reinforcement learning. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 372–382. [Google Scholar]
- Cao, Q.; Lin, L.; Shi, Y.; Liang, X.; Li, G. Attention-aware face hallucination via deep reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 690–698. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? In Advances in Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. arXiv, 2017; arXiv:1705.07115. [Google Scholar]
- Google Photos labeled black people ‘gorillas’. Available online: https://www.usatoday.com/story/tech/2015/07/01/google-apologizes-after-photos-identify-black-people-as-gorillas/29567465/ (accessed on 1 March 2019).
- Gal, Y.; Ghahramani, Z. Bayesian convolutional neural networks with Bernoulli approximate variational inference. arXiv, 2015; arXiv:1506.02158. [Google Scholar]
- Kumar, S.; Laumann, F.; Maurin, A.L.; Olsen, M.; Bayesian, M.L. Convolutional Neural Networks with Variational Inference. arXiv, 2018; arXiv:1704.02798. [Google Scholar]
- Vladimirova, M.; Arbel, J.; Mesejo, P. Bayesian neural networks become heavier-tailed with depth. In Proceedings of the Bayesian Deep Learning Workshop during the Thirty-Second Conference on Neural Information Processing Systems (NIPS 2018), Montréal, QC, Canada, 7 December 2018. [Google Scholar]
- Hu, S.X.; Champs-sur-Marne, F.; Moreno, P.G.; Lawrence, N.; Damianou, A. β-BNN: A Rate-Distortion Perspective on Bayesian Neural Networks. In Proceedings of the Bayesian Deep Learning Workshop during the Thirty-Second Conference on Neural Information Processing Systems (NIPS 2018), Montréal, QC, Canada, 7 December 2018. [Google Scholar]
- Salvator, L.; Han, J.; Schroers, C.; Mandt, S. Video Compression through Deep Bayesian Learning Bayesian. In Proceedings of the Deep Learning Workshop during the Thirty-Second Conference on Neural Information Processing Systems (NIPS 2018), Montréal, QC, Canada, 7 December 2018. [Google Scholar]
- Krishnan, R.; Subedar, M.; Tickoo, O. BAR: Bayesian Activity Recognition using variational inference. arXiv, 2018; arXiv:1811.03305. [Google Scholar]
- Chen, T.; Goodfellow, I.; Shlens, J. Net2net: Accelerating learning via knowledge transfer. arXiv, 2015; arXiv:1511.05641. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. arXiv, 2014; arXiv:1409.7495. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096–2130. [Google Scholar]
- Taylor, M.E.; Stone, P. Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- McKeough, A. Teaching for Transfer: Fostering Generalization in Learning; Routledge: London, UK, 2013. [Google Scholar]
- Raina, R.; Battle, A.; Lee, H.; Packer, B.; Ng, A.Y. Self-taught learning: transfer learning from unlabeled data. In Proceedings of the 24th international conference on Machine learning, Corvallis, OR, USA, 20–24 June 2007; pp. 759–766. [Google Scholar]
- Wenyuan, D.; Yang, Q.; Xue, G.; Yu, Y. Boosting for transfer learning. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 193–200. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv, 2016; arXiv:1609.08144. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going deeper with embedded fpga platform for convolutional neural network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Lin, Z.; Courbariaux, M.; Memisevic, R.; Bengio, Y. Neural networks with few multiplications. arXiv, 2015; arXiv:1510.03009. [Google Scholar]
- Courbariaux, M.; David, J.-E.; Bengio, Y. Training deep neural networks with low precision multiplications. arXiv, 2014; arXiv:1412.7024. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.-P. Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Hubara, I.; Soudry, D.; El Yaniv, R. Binarized Neural Networks. arXiv, 2016; arXiv:1602.02505. [Google Scholar]
- Kim, M.; Smaragdis, P. Bitwise neural networks. arXiv, 2016; arXiv:1601.06071. [Google Scholar]
- Dettmers, T. 8-Bit Approximations for Parallelism in Deep Learning. arXiv, 2015; arXiv:1511.04561. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep learning with limited numerical precision. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1737–1746. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv, 2016; arXiv:1606.06160. [Google Scholar]
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Steven, K.E.; Merolla, P.A.; Arthur, J.V.; Cassidy, A.S. Convolutional networks for fast, energy-efficient neuromorphic computing. Proc. Natl. Acad. Sci. USA 2016, 27, 201604850. [Google Scholar]
- Zidan, M.A.; Strachan, J.P.; Lu, W.D. The future of electronics based on memristive systems. Nat. Electron. 2018, 1, 22. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, T.; Liu, S.; Zhang, S.; He, L.; Wang, J.; Li, L.; Chen, T.; Xu, Z.; Sun, N.; et al. Dadiannao: A machine-learning supercomputer. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; pp. 609–622. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient inference engine on compressed deep neural network. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 243–254. [Google Scholar]
- Zhang, X.; Zou, J.; Ming, X.; He, K.; Sun, J. Efficient and accurate approximations of nonlinear convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1984–1992. [Google Scholar]
- Novikov, A.; Podoprikhin, D.; Osokin, A.; Vetrov, D.P. Tensorizing neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2005; pp. 442–450. [Google Scholar]
- Zhu, C.; Han, S.; Mao, H.; Dally, W.J. Trained ternary quantization. arXiv, 2016; arXiv:1612.01064. [Google Scholar]
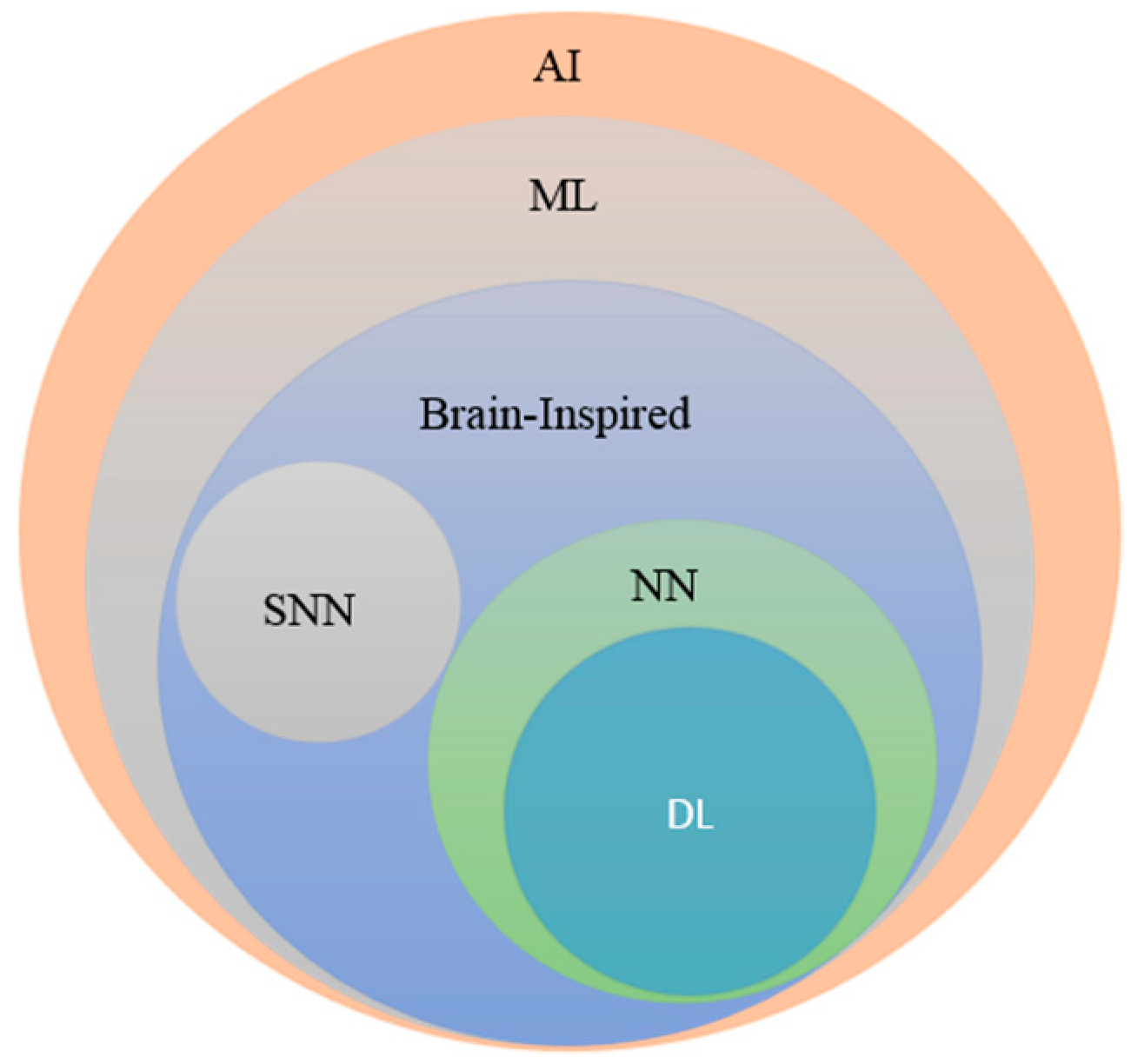
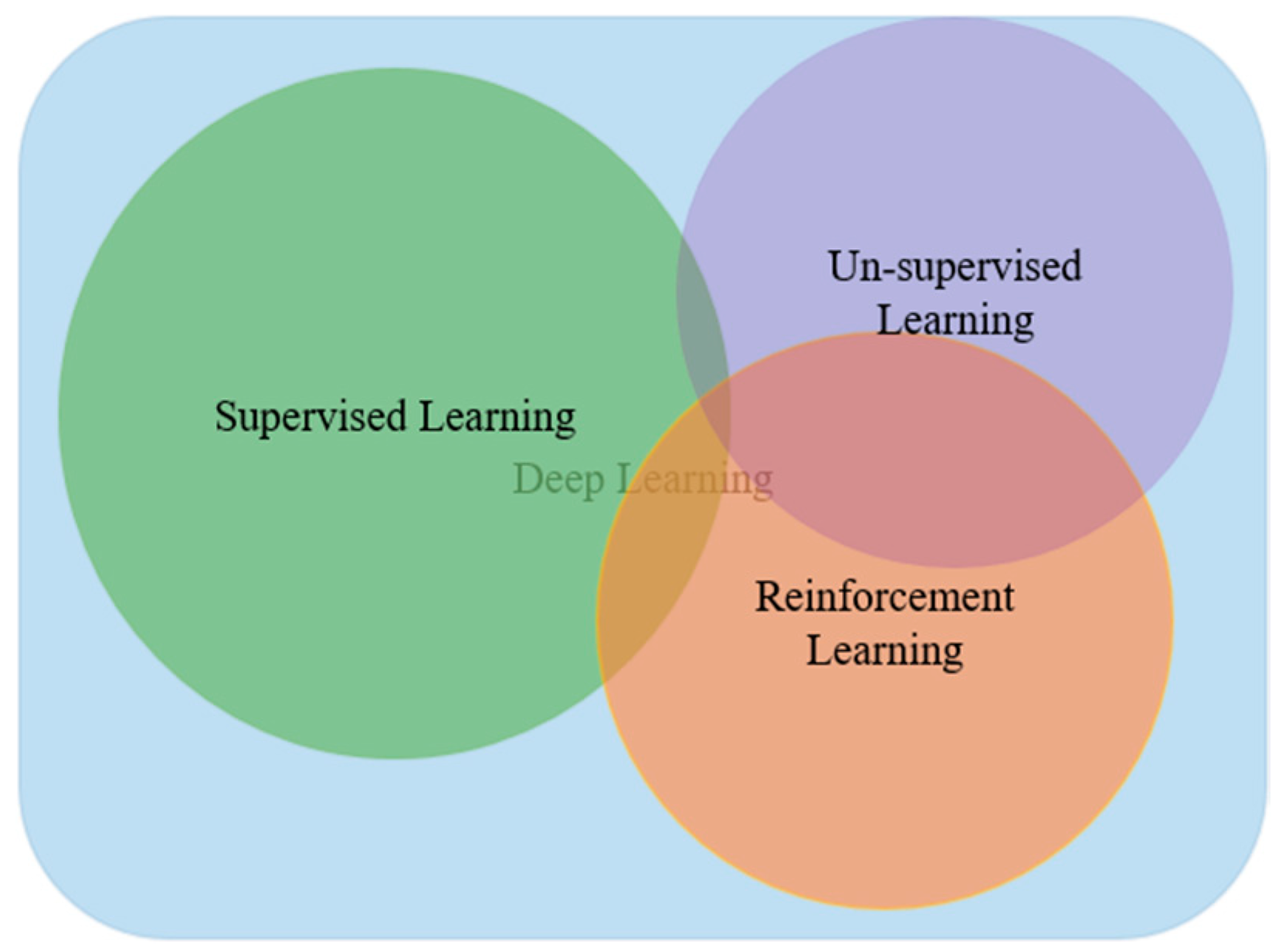
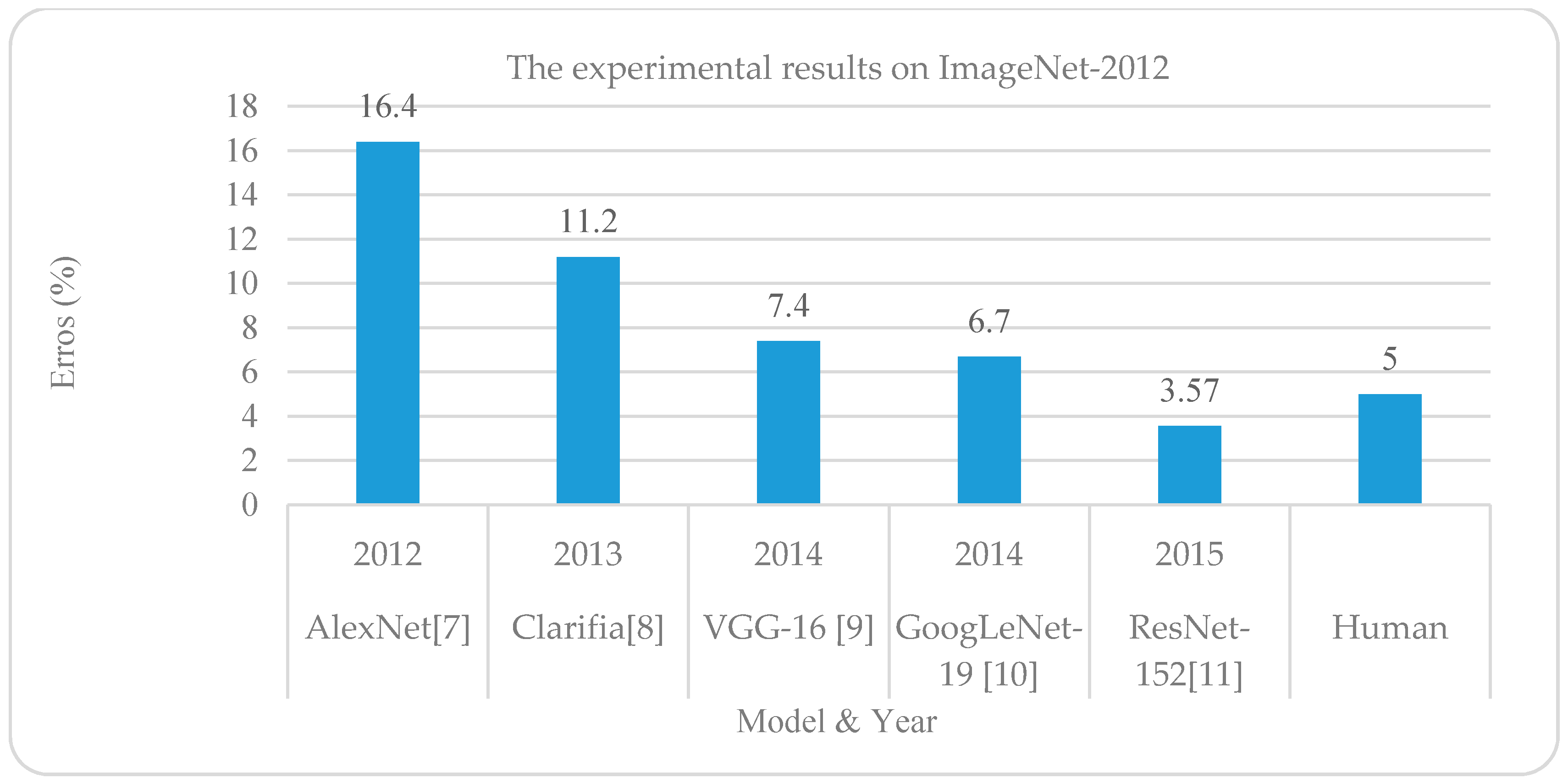
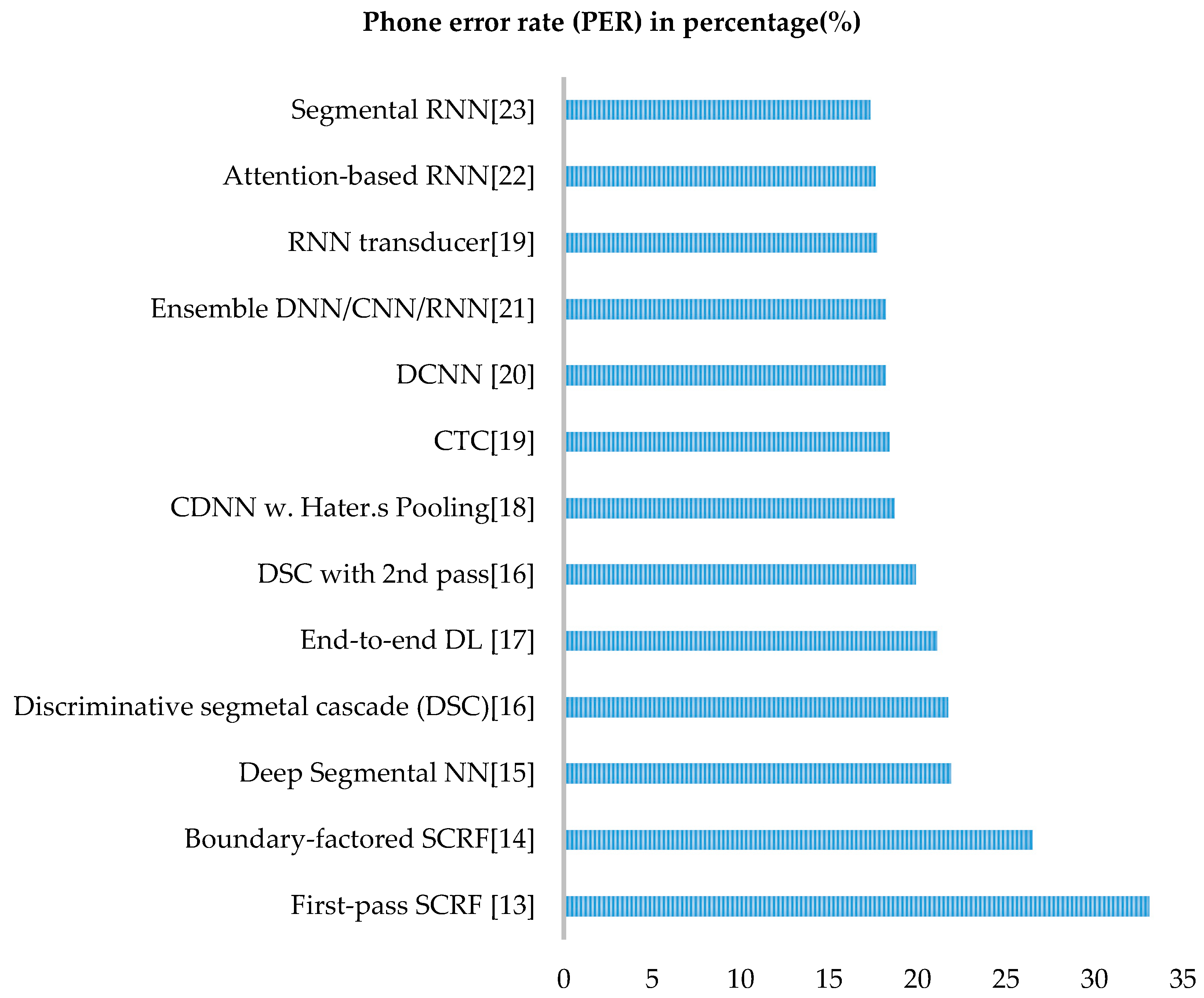
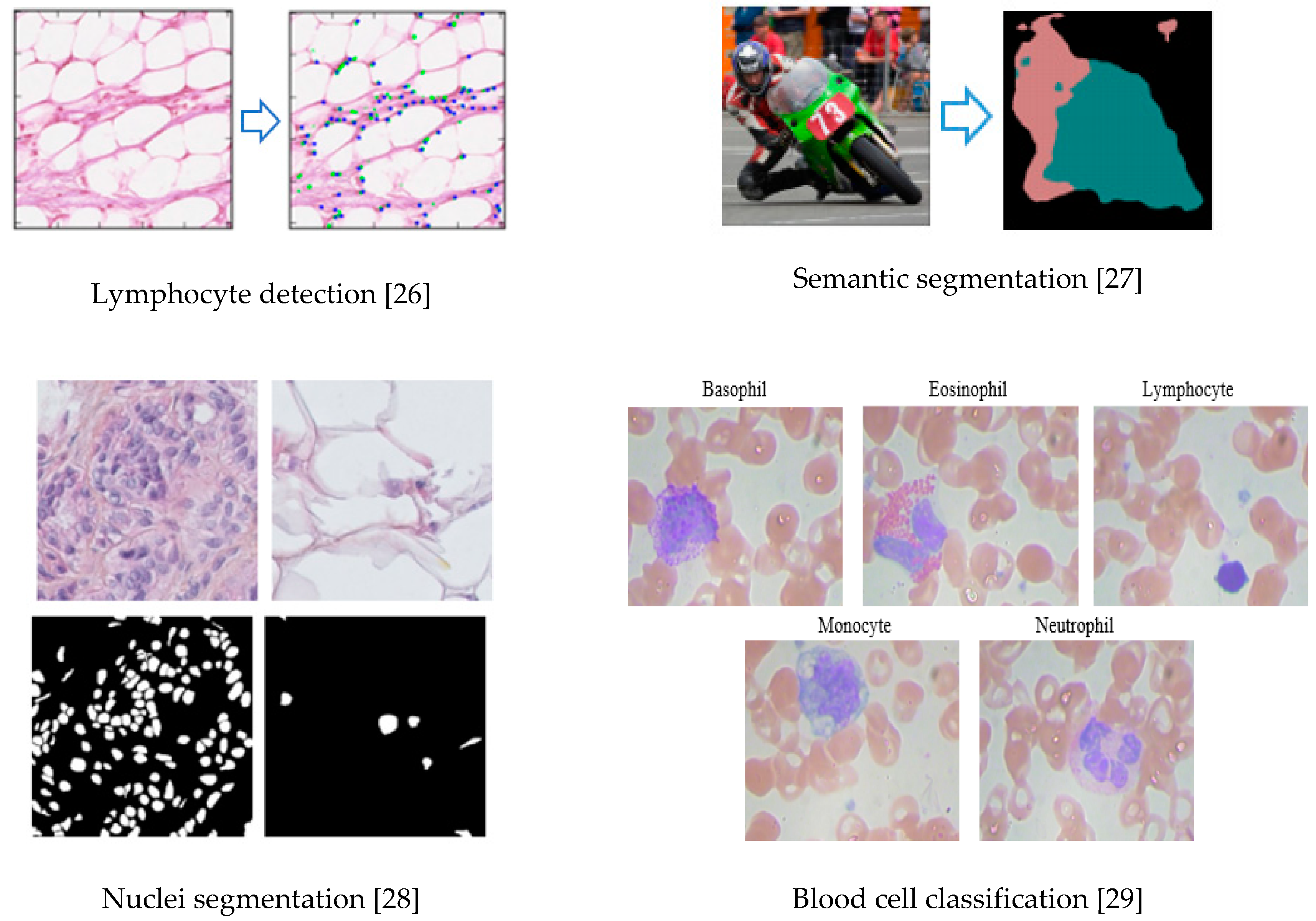
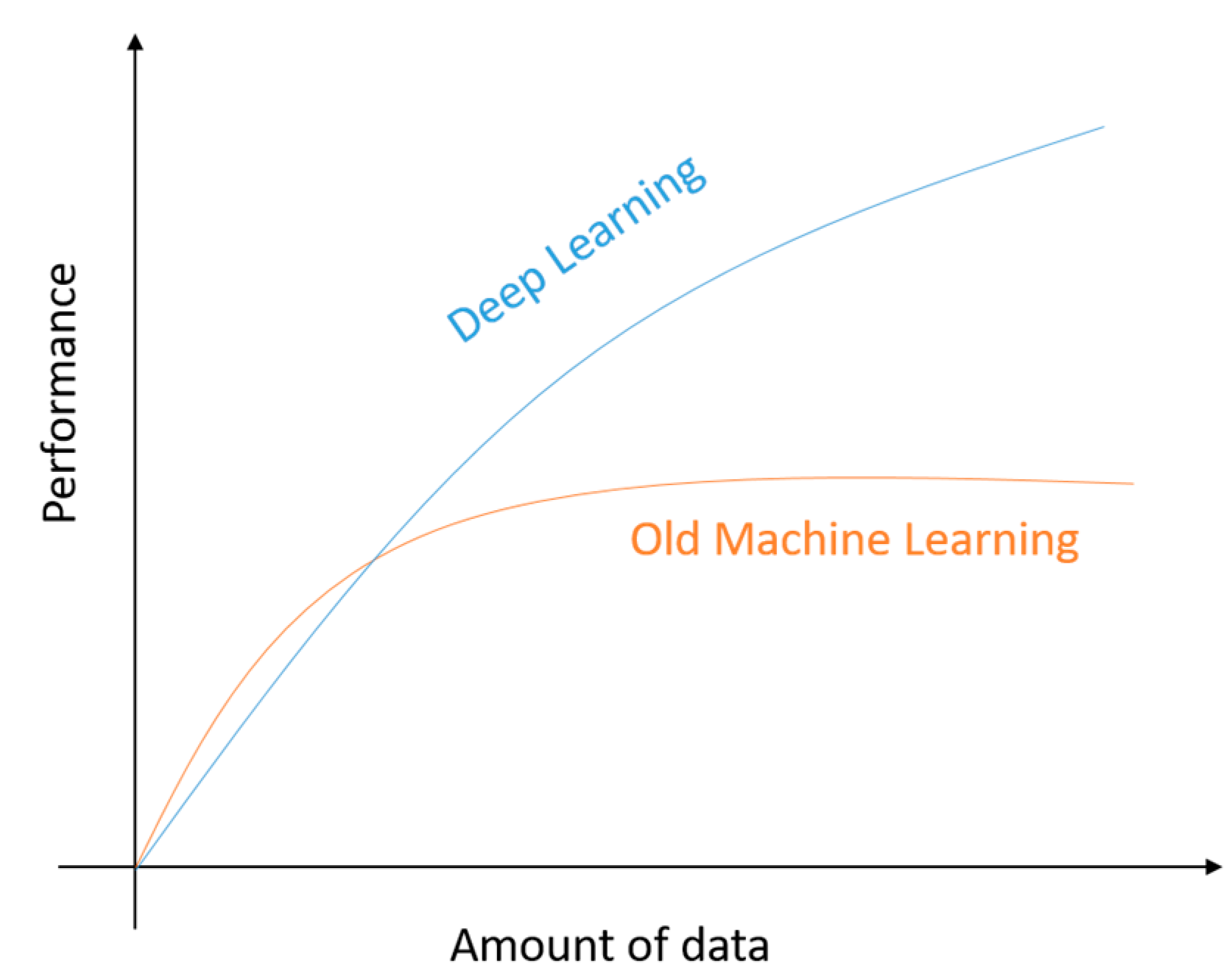

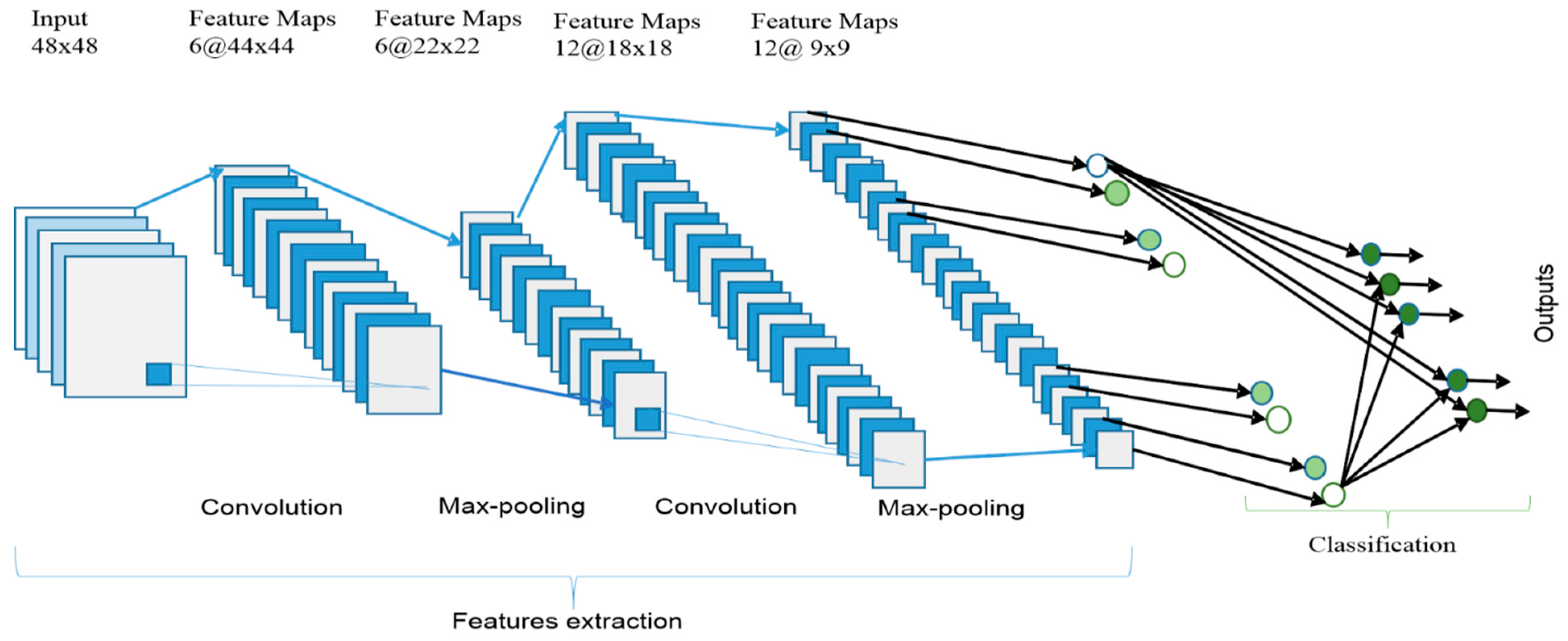
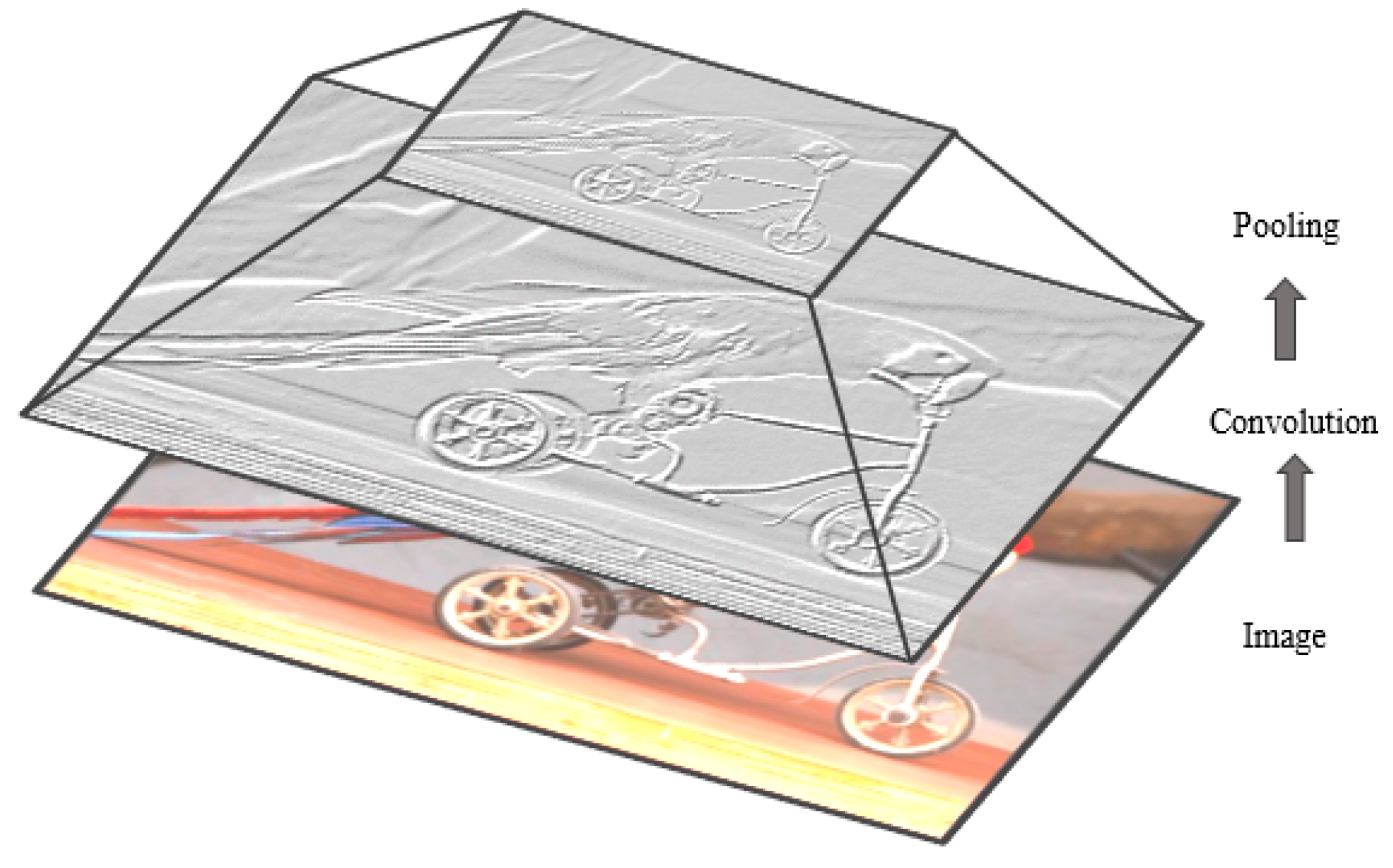
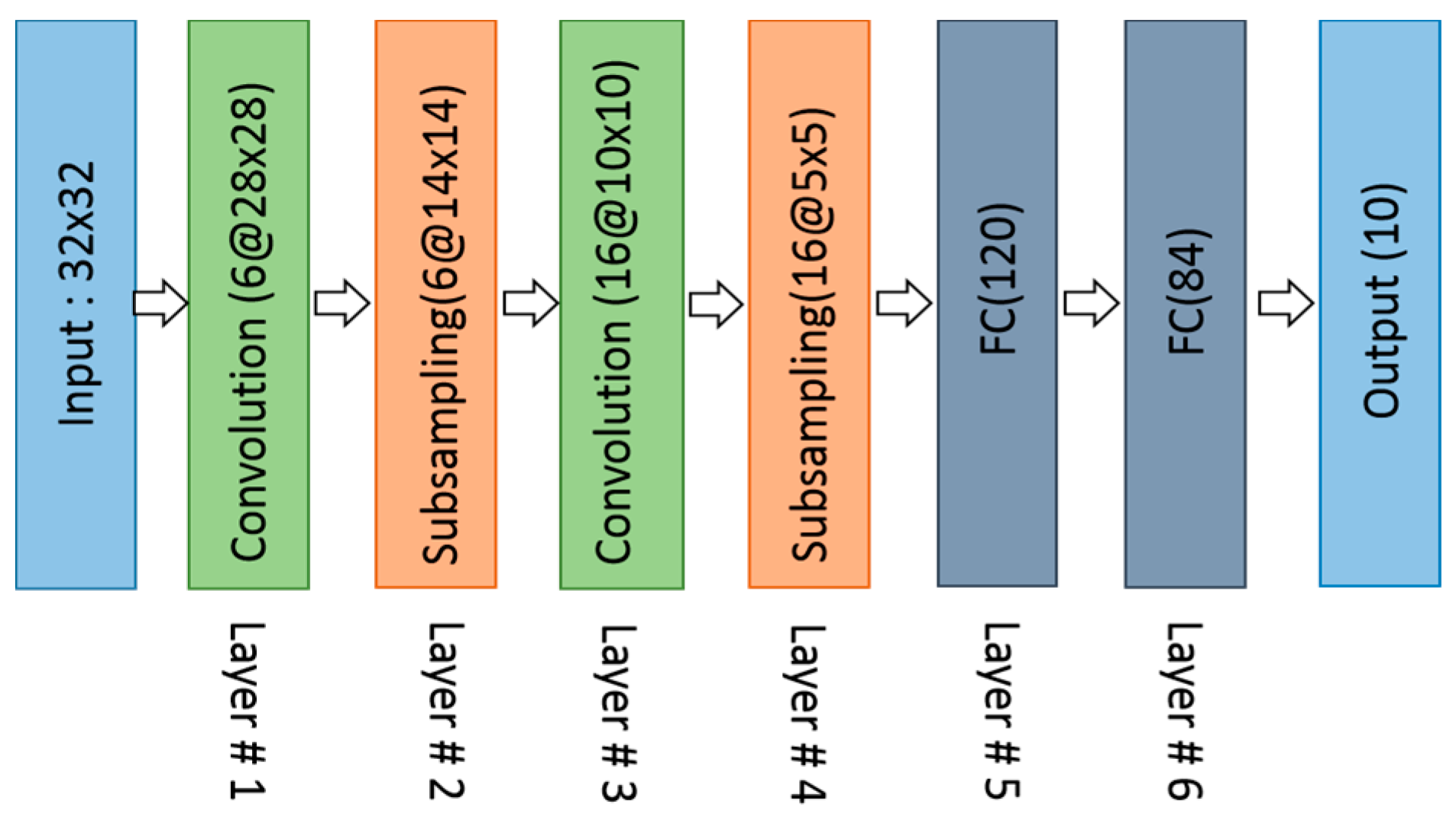
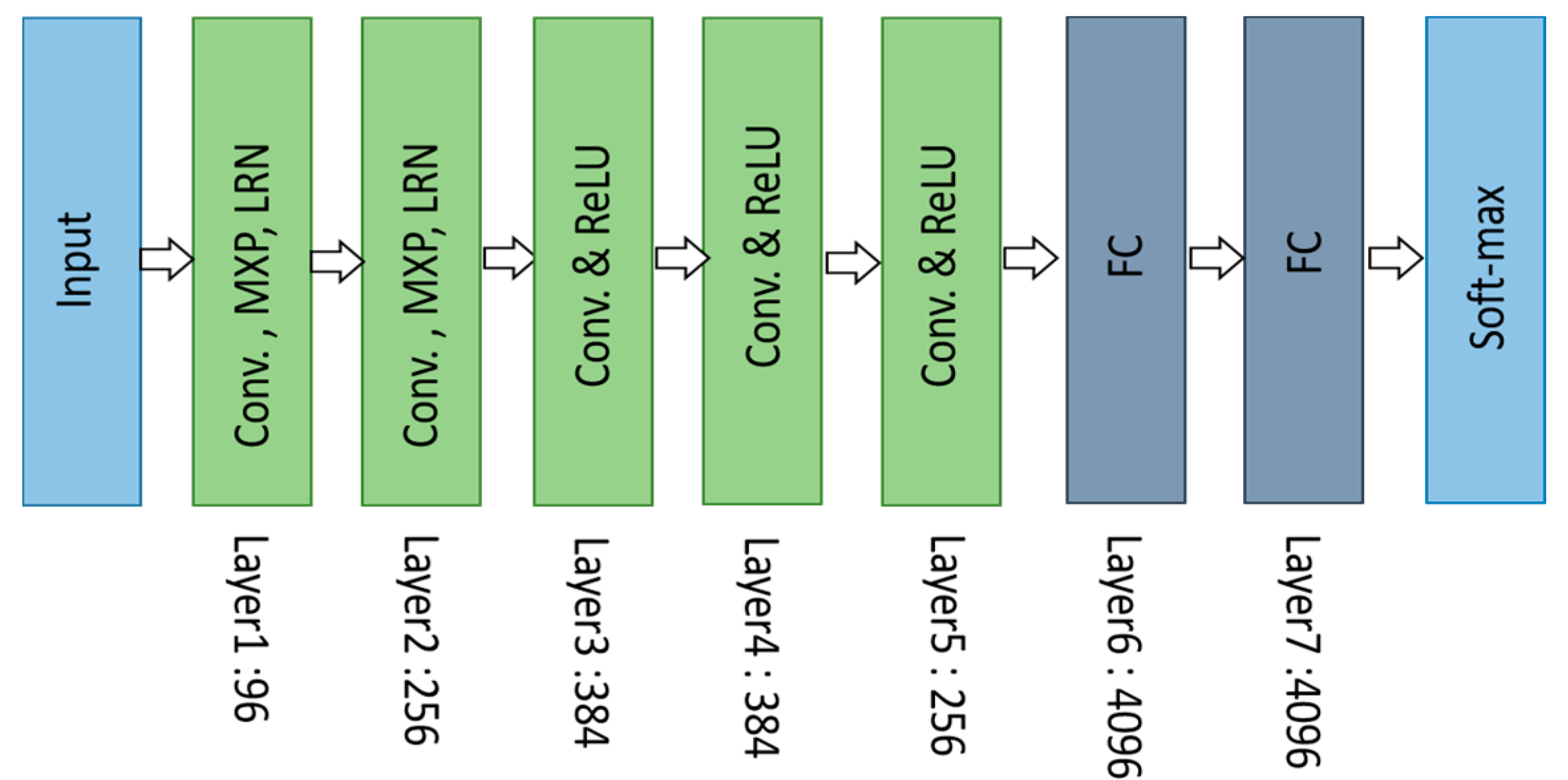
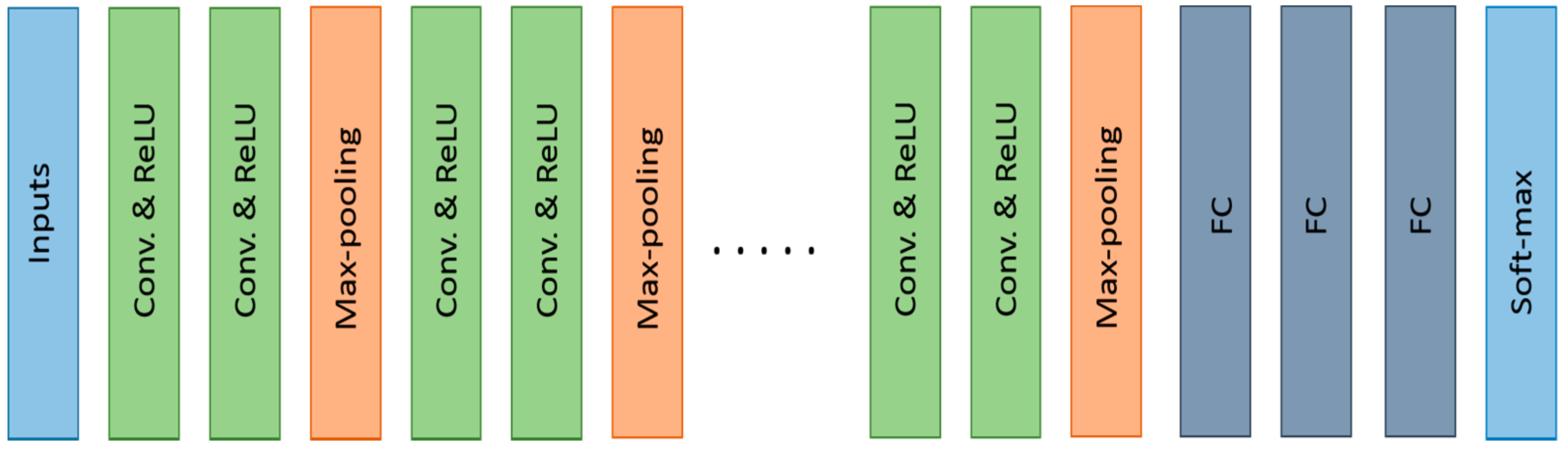
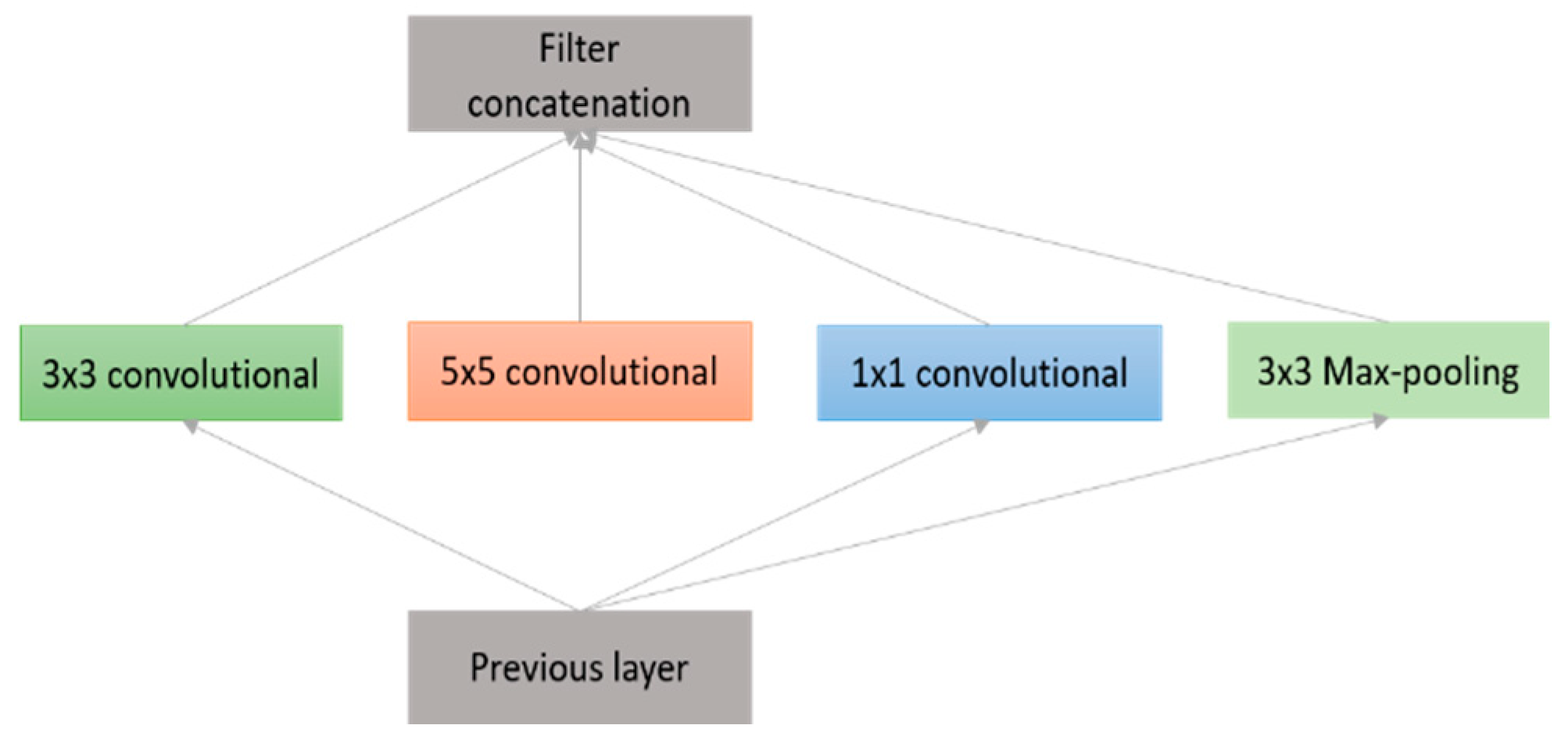
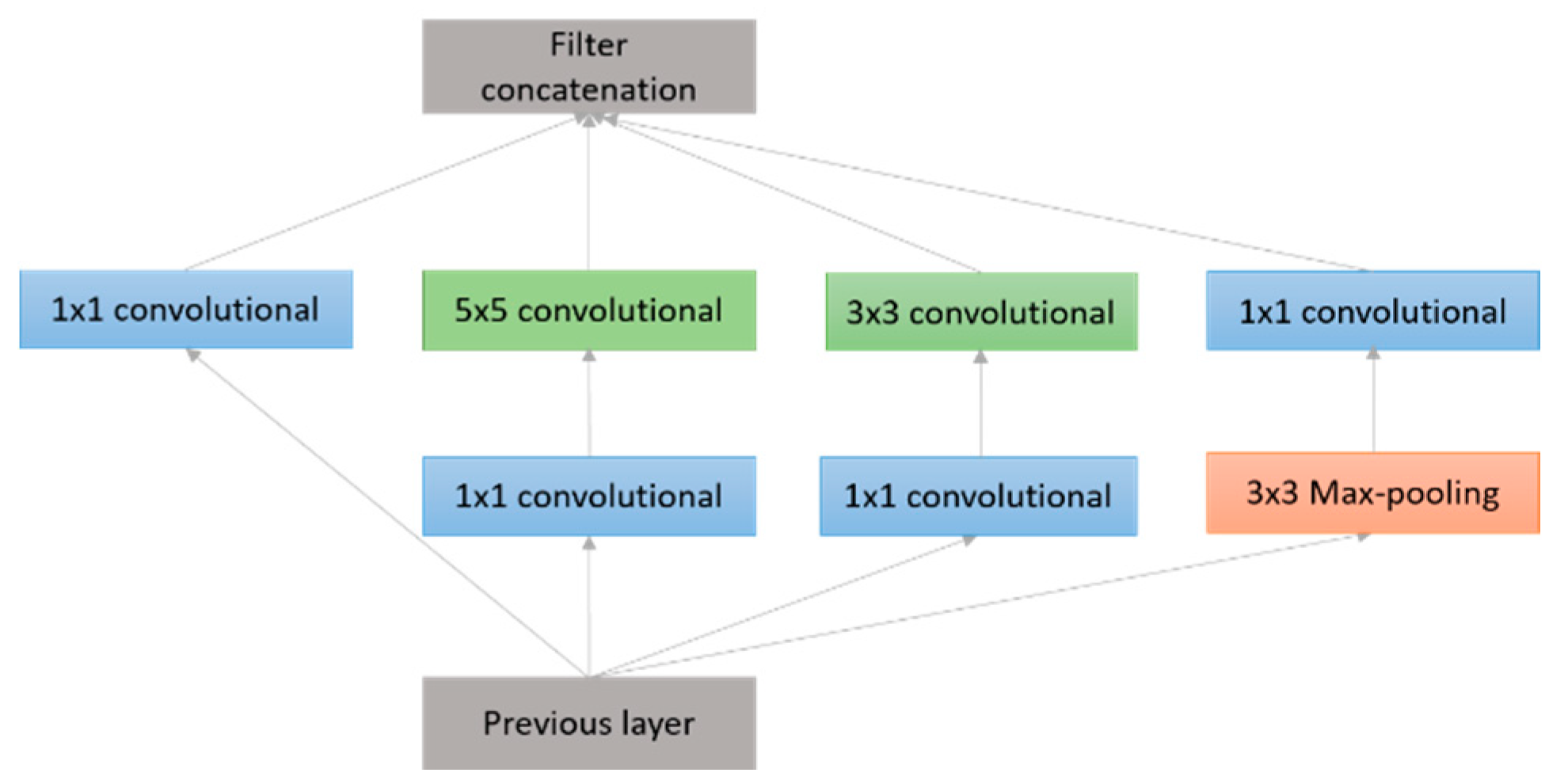
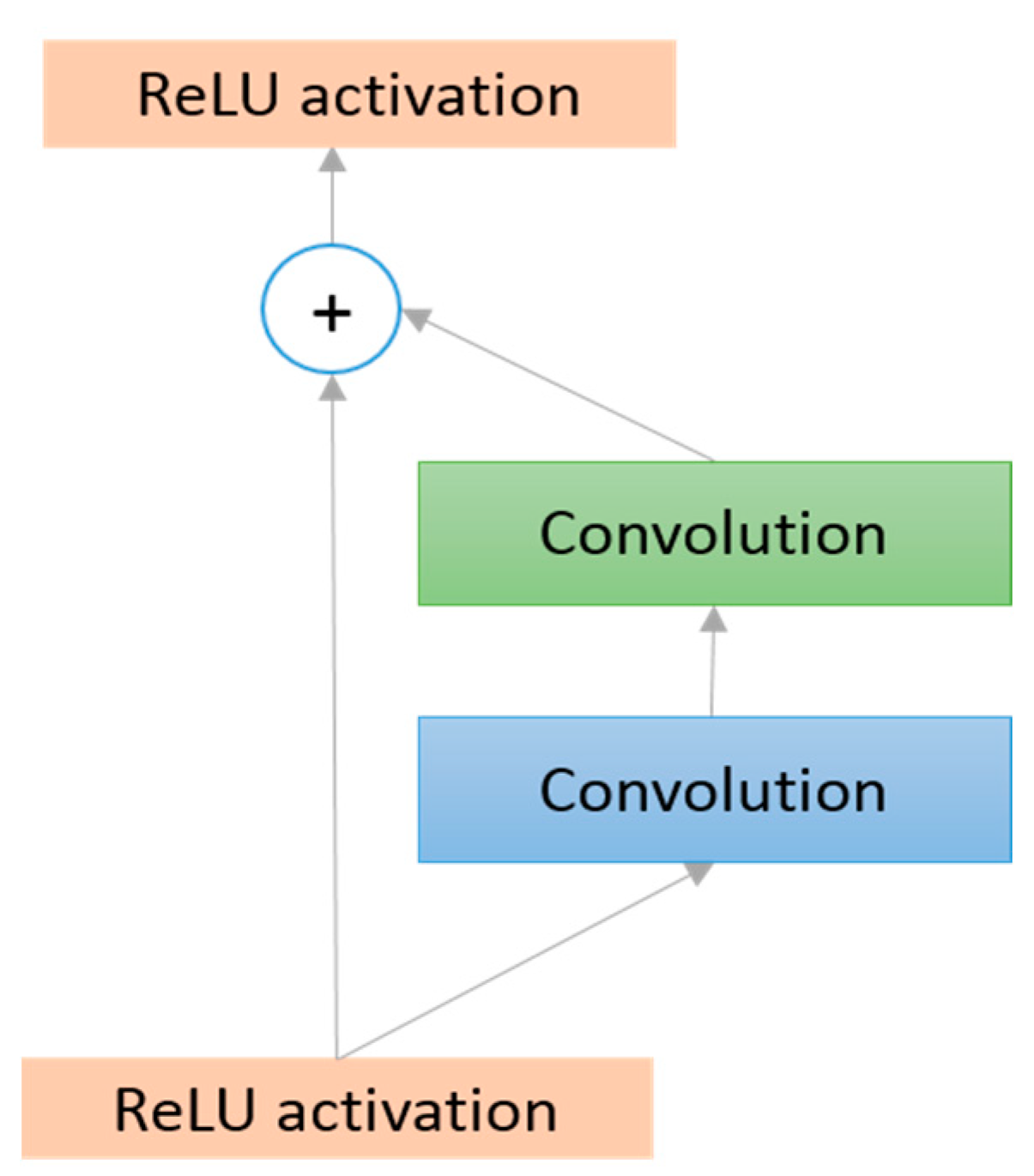
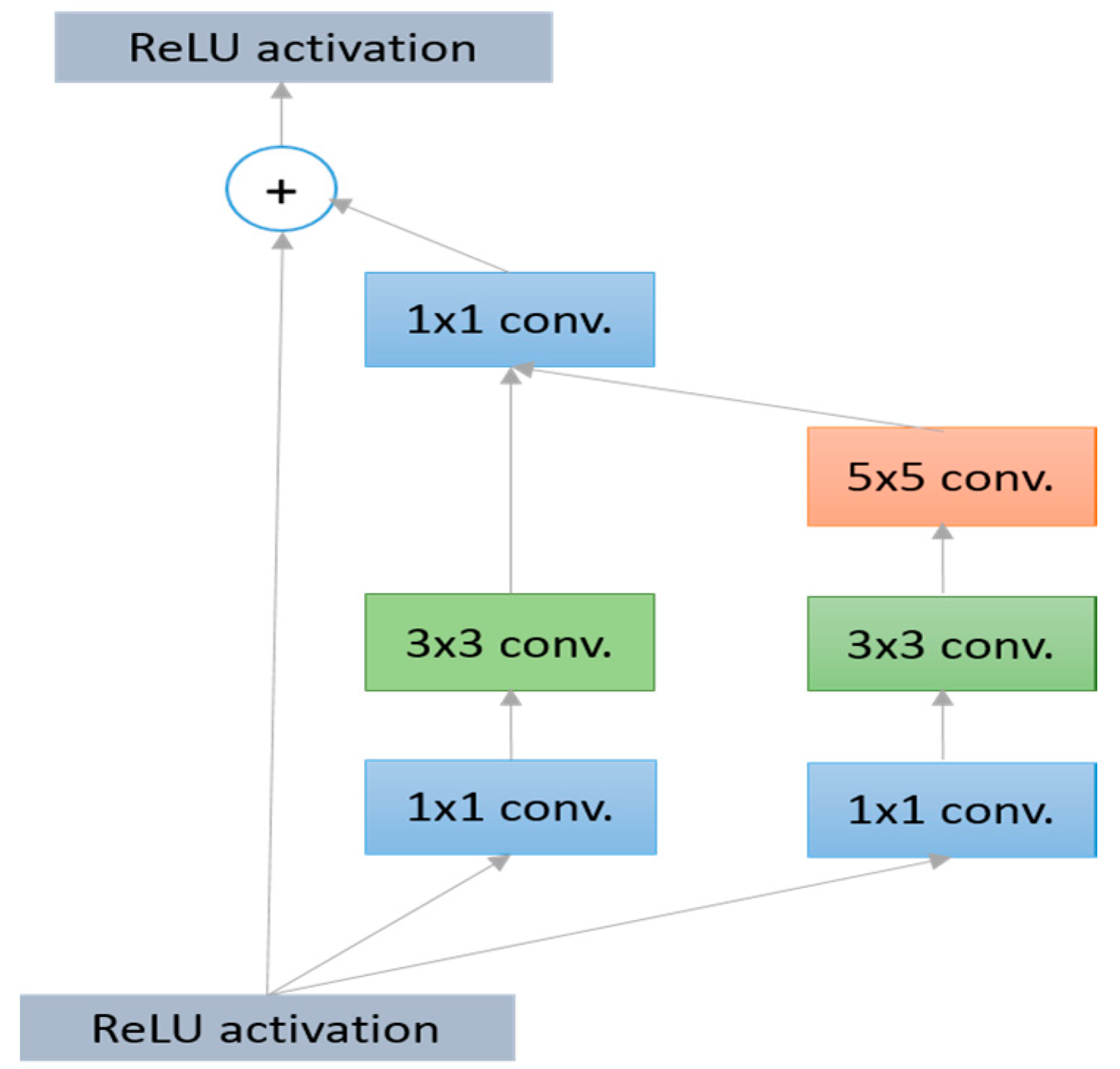
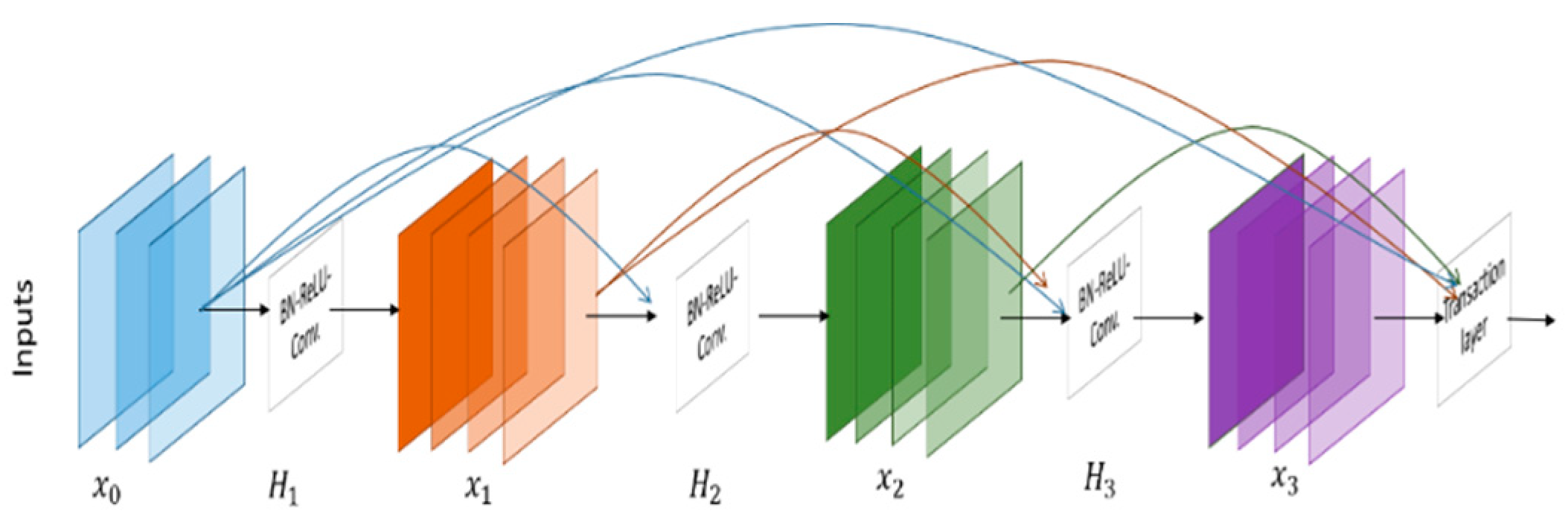
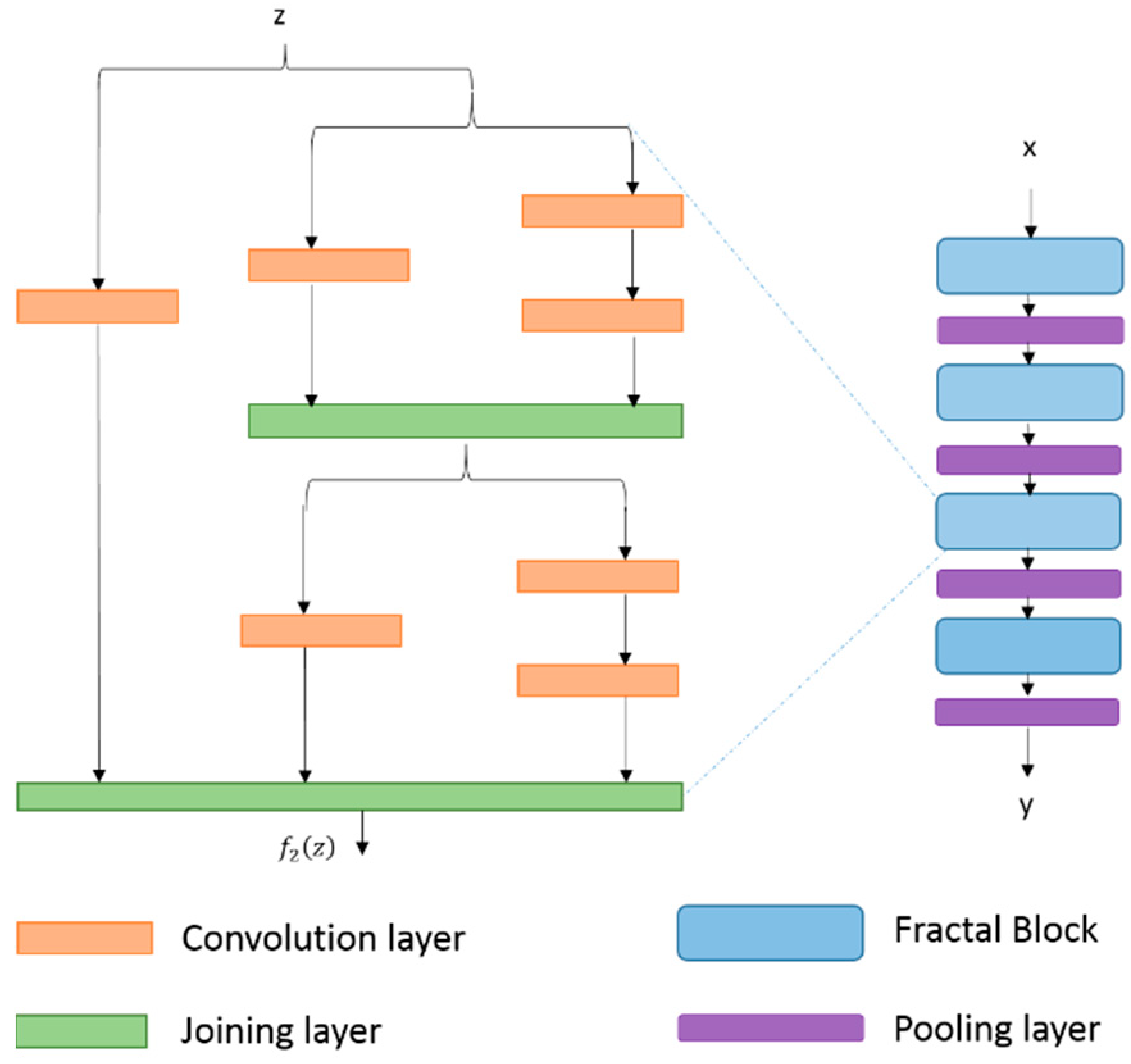
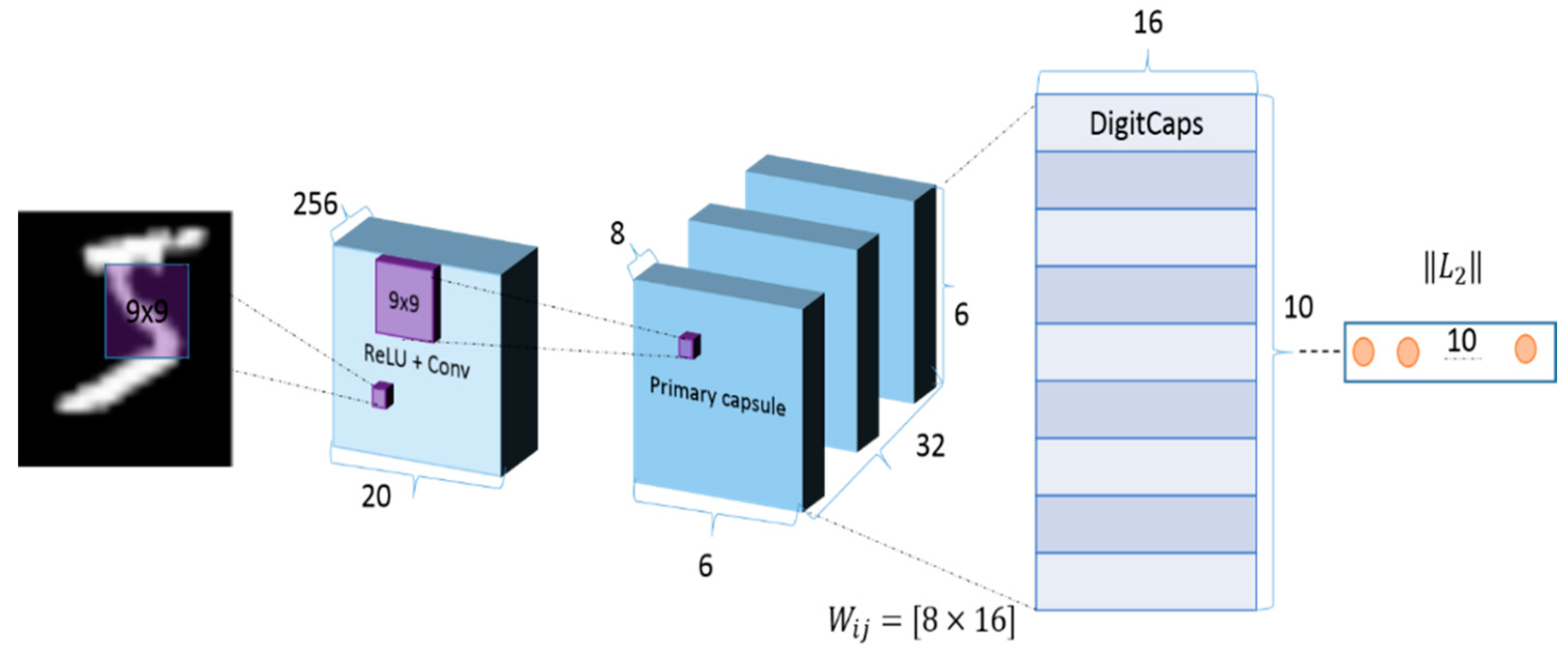
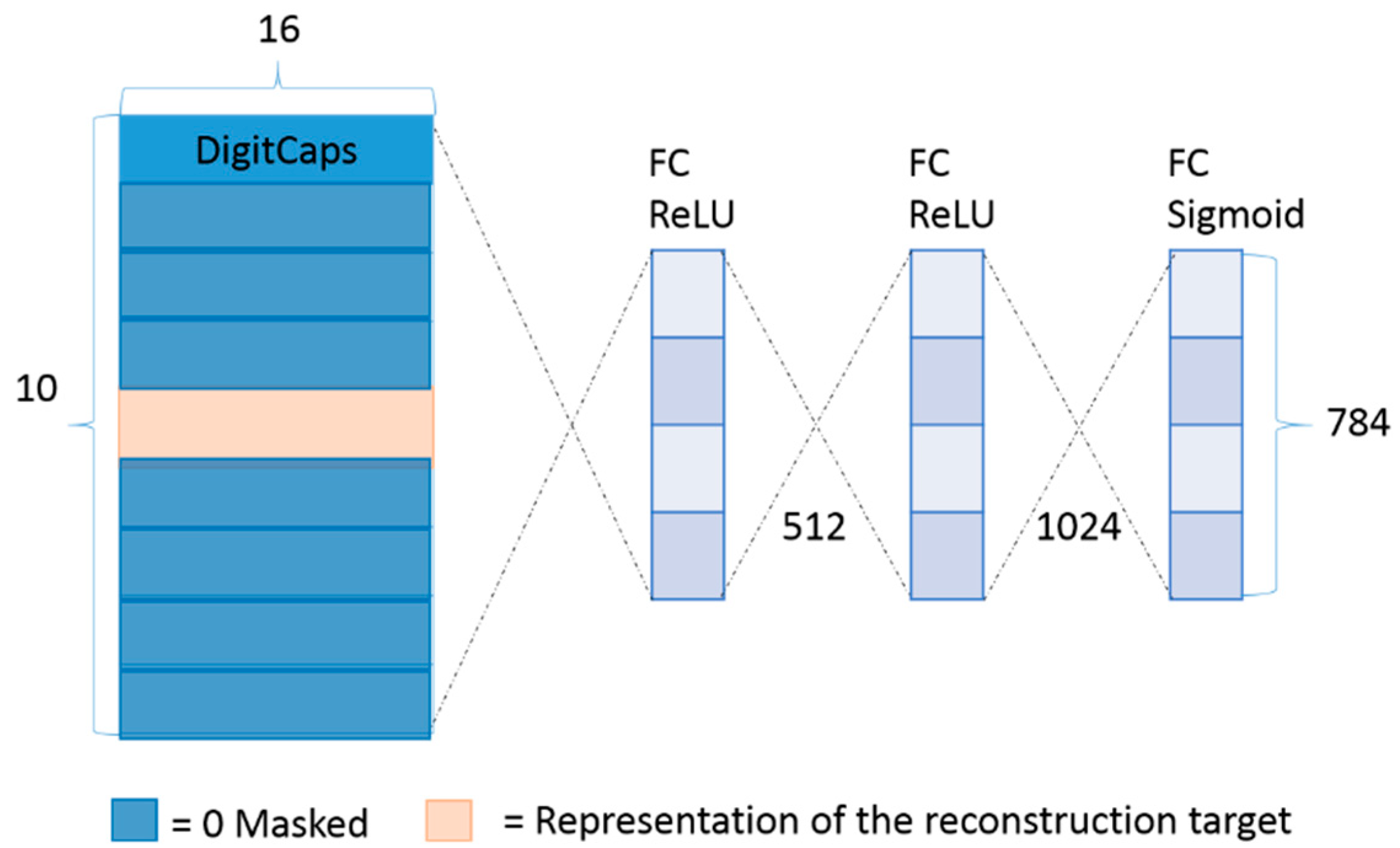
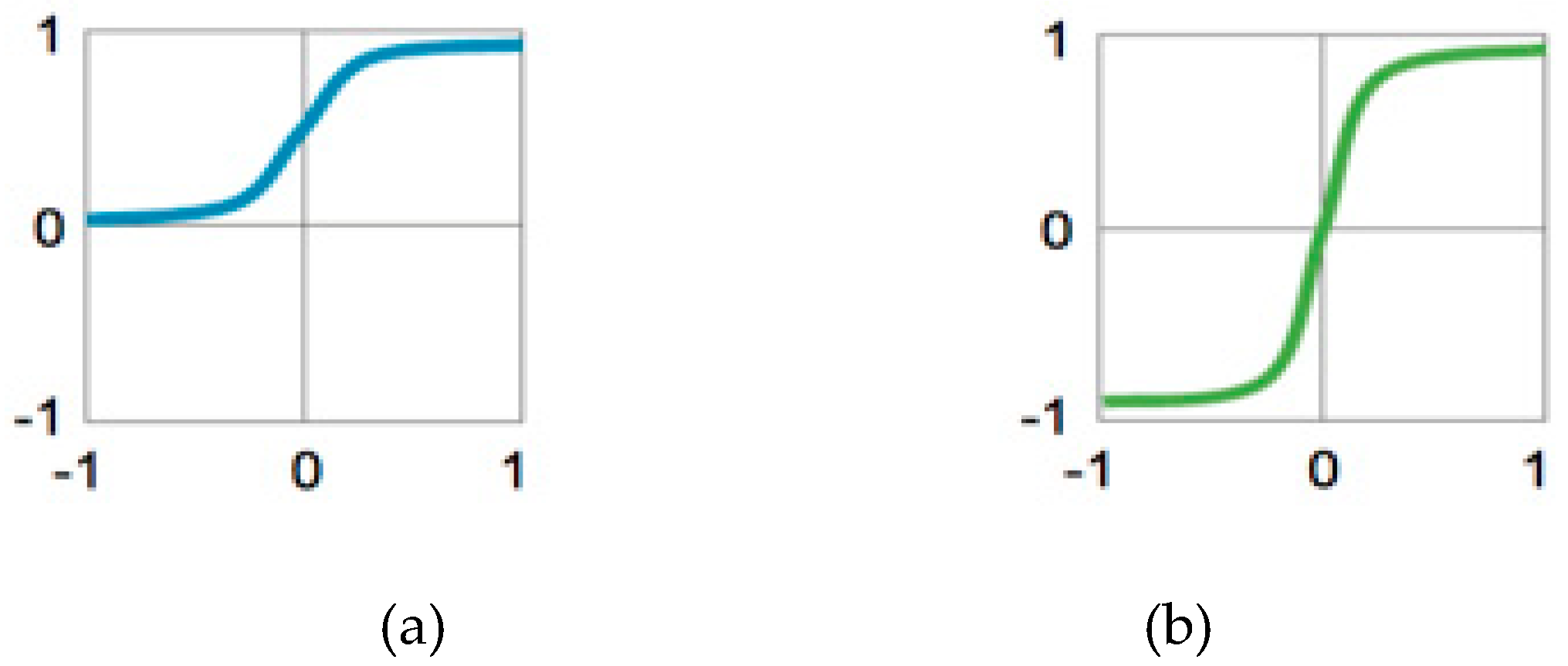
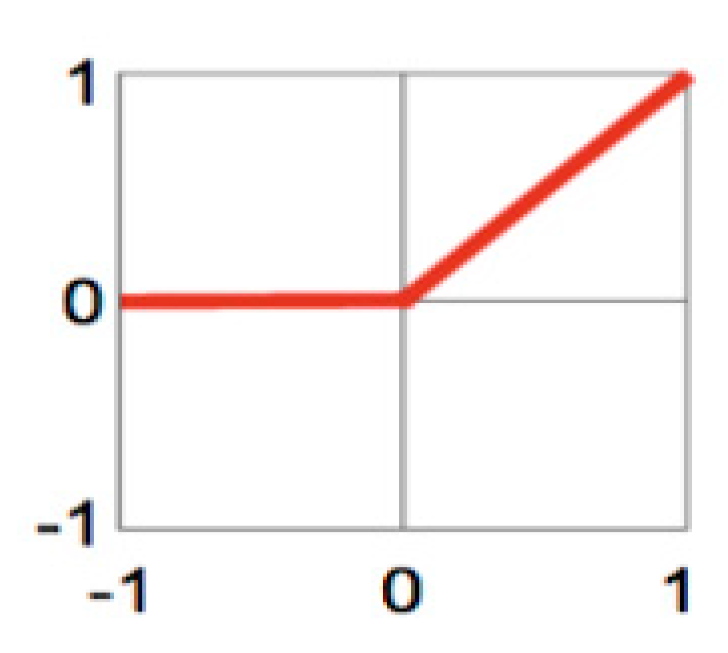
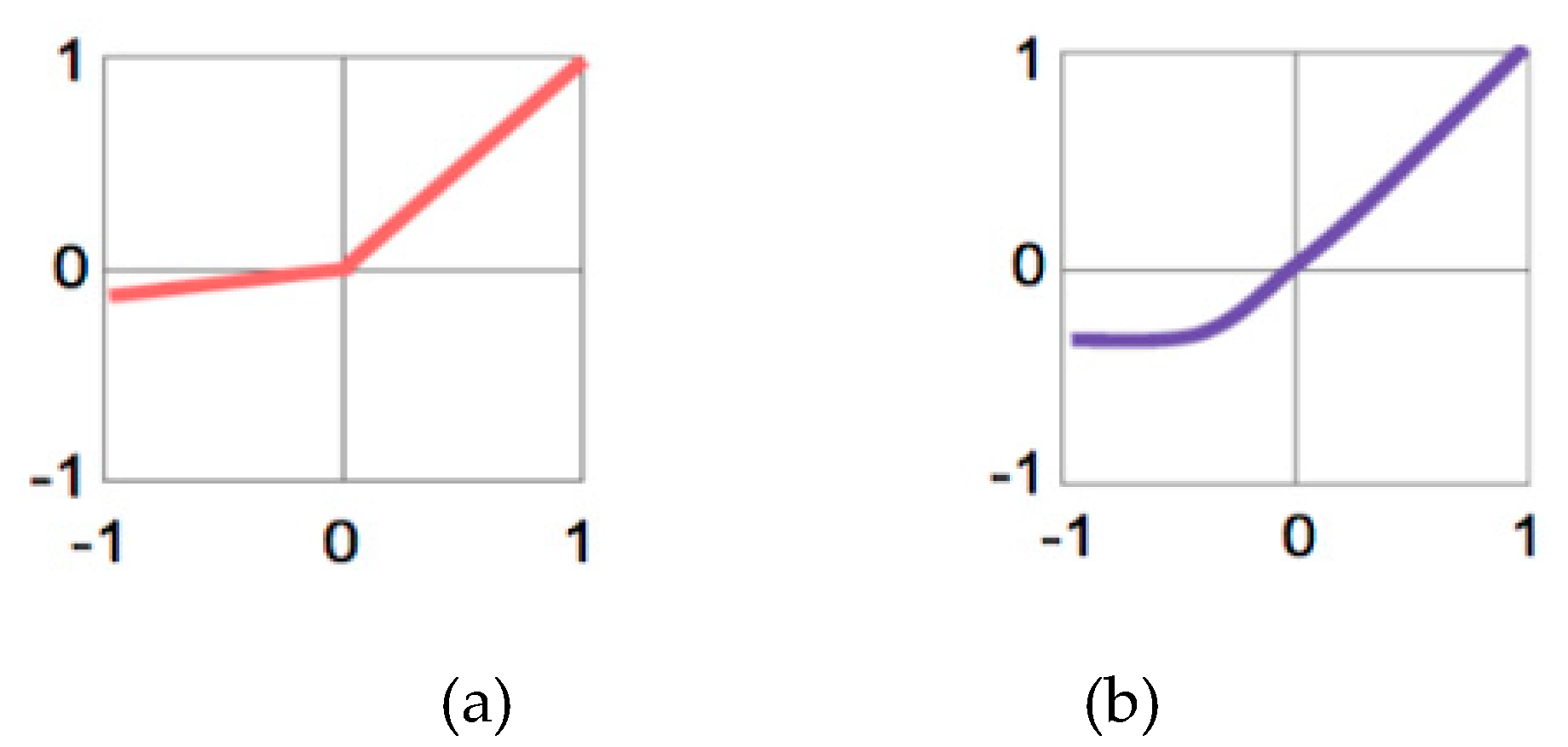
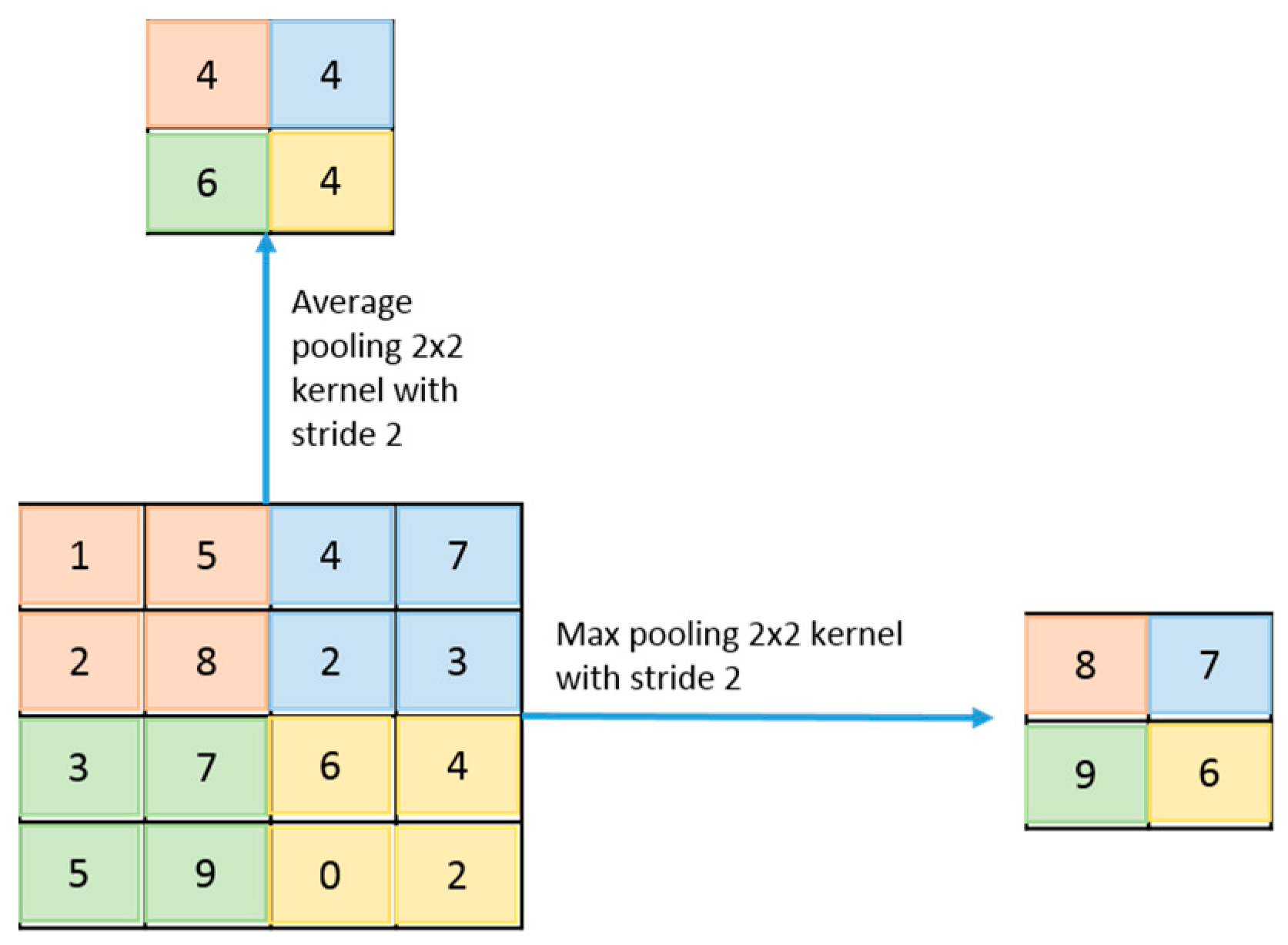

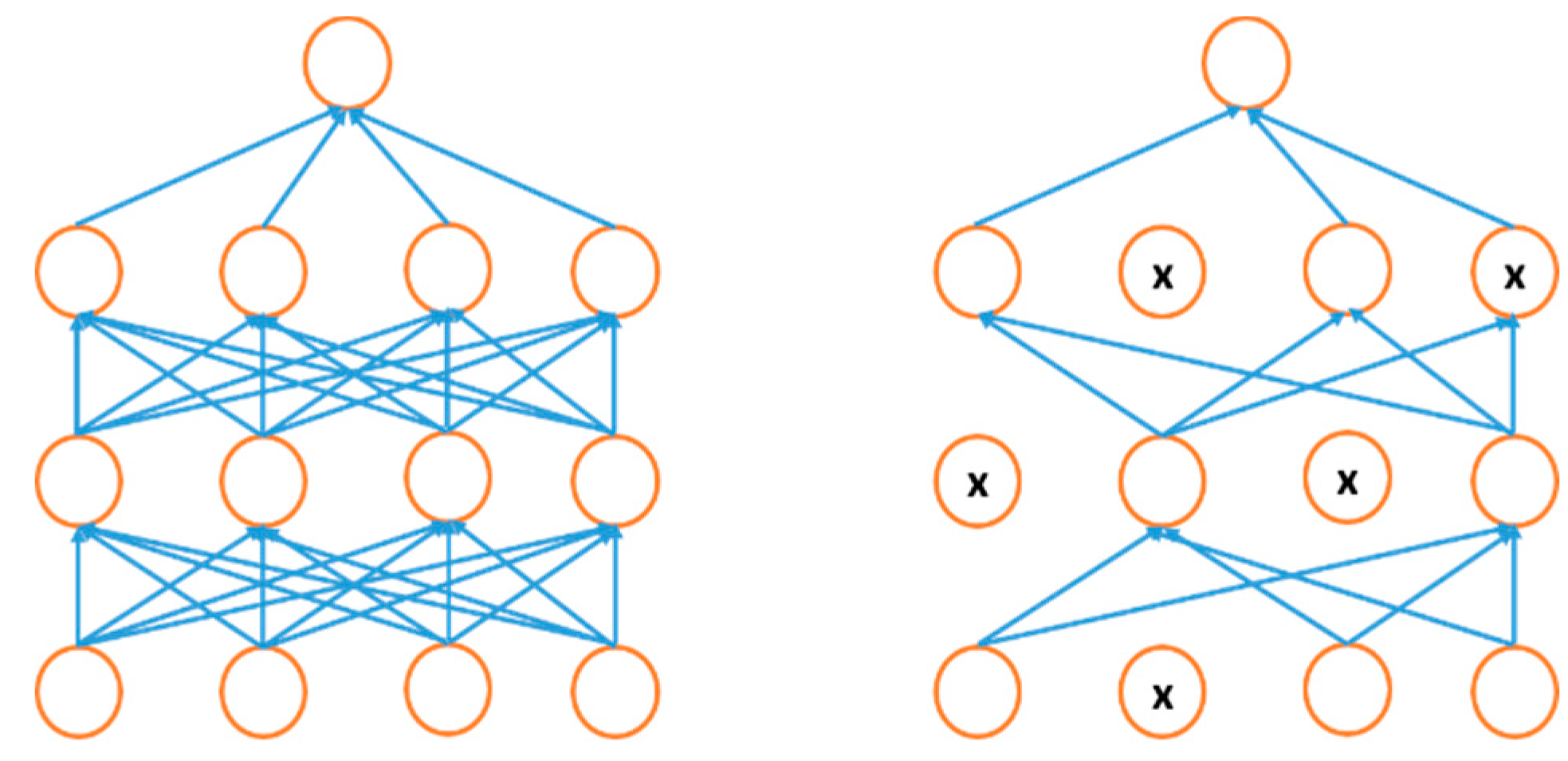
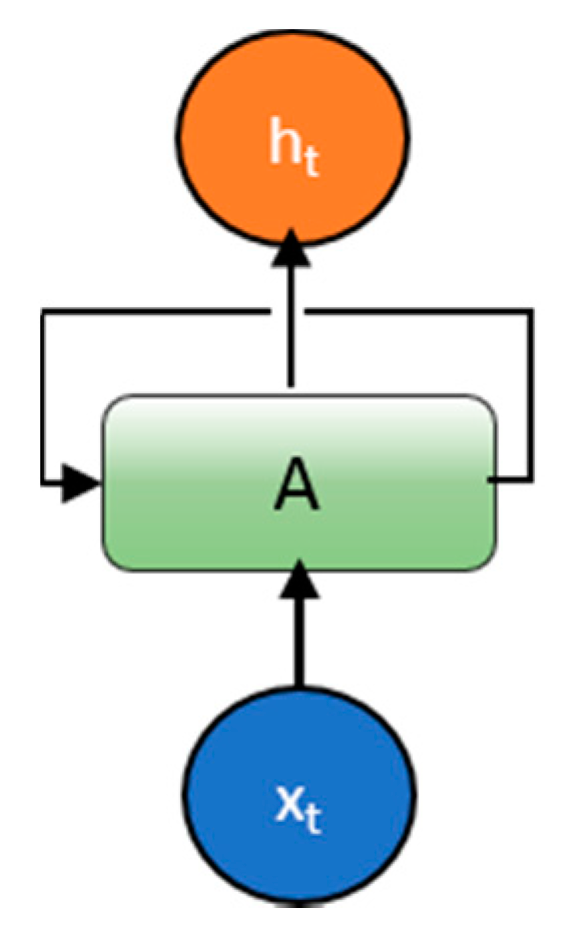
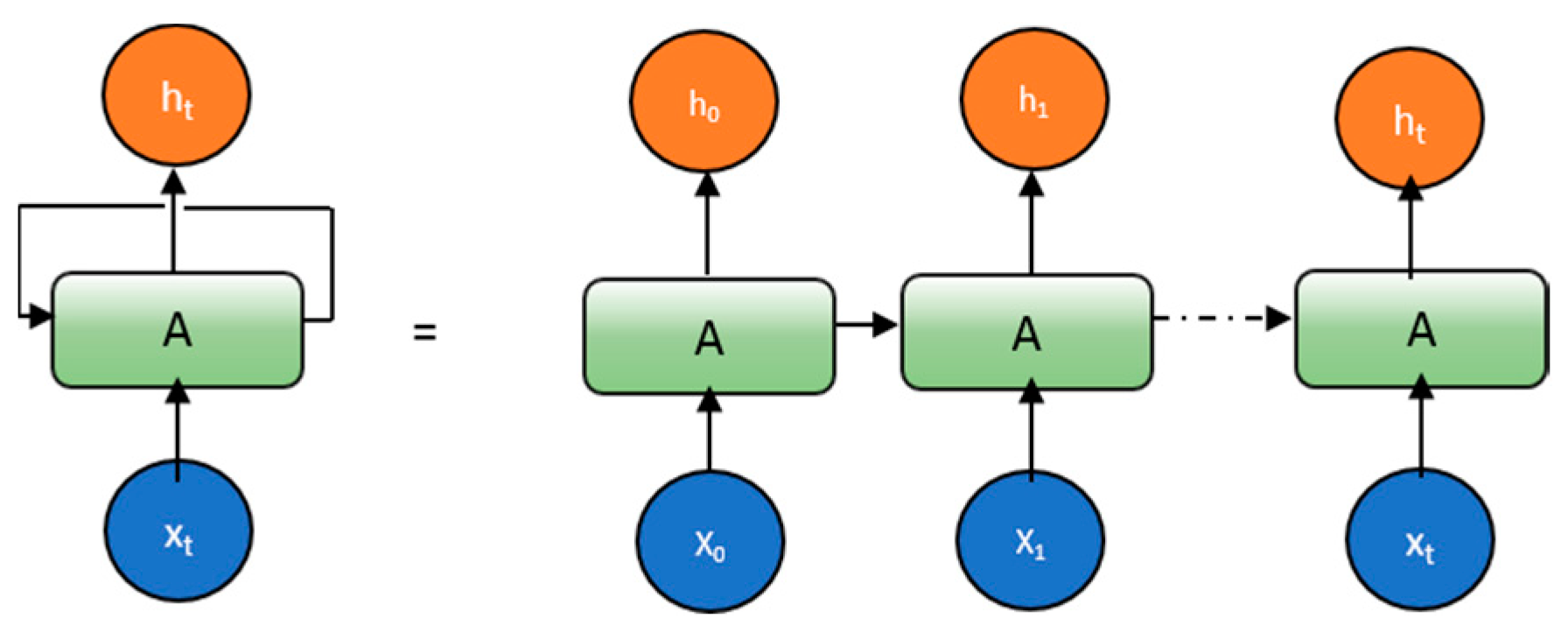
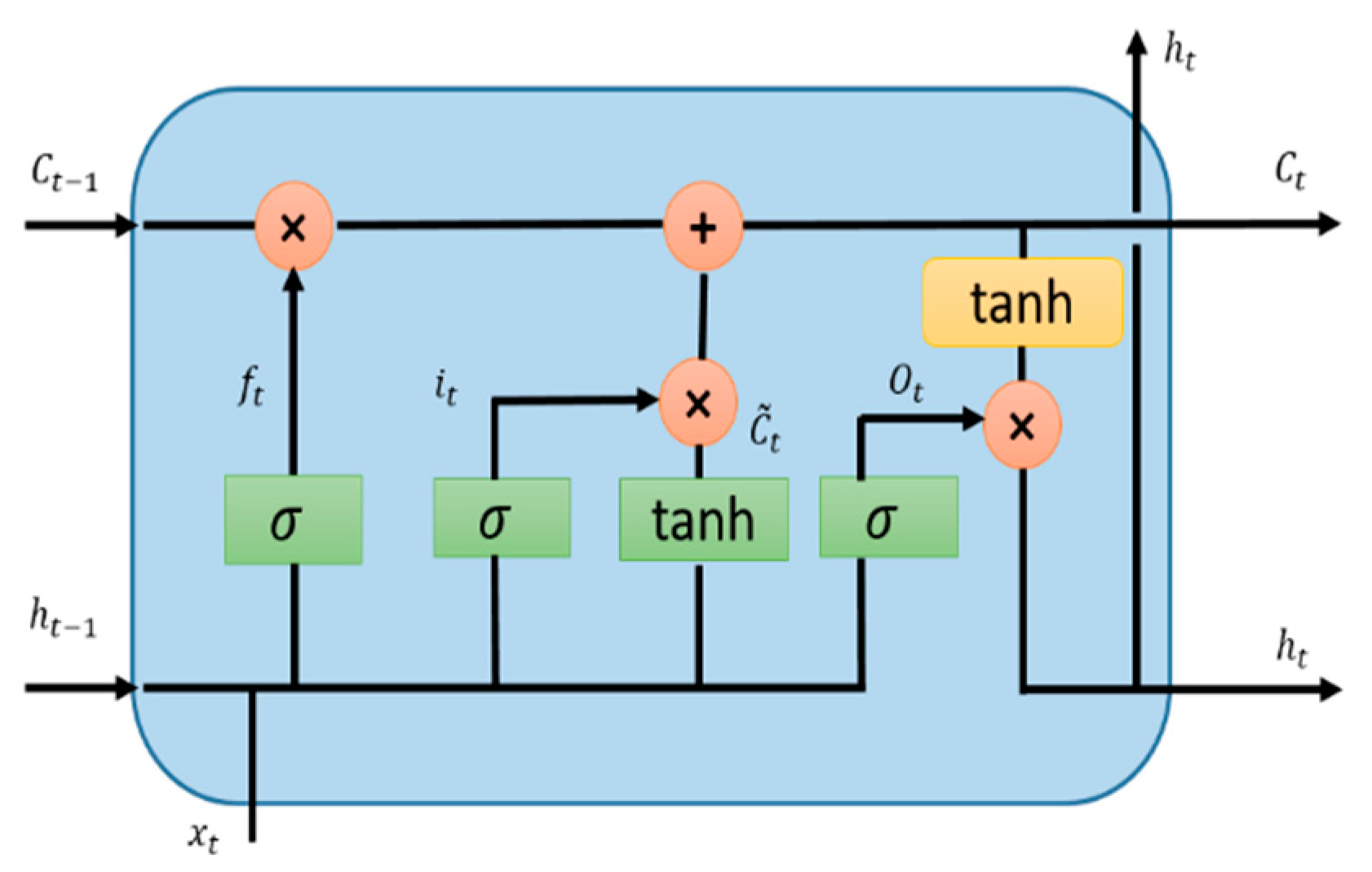
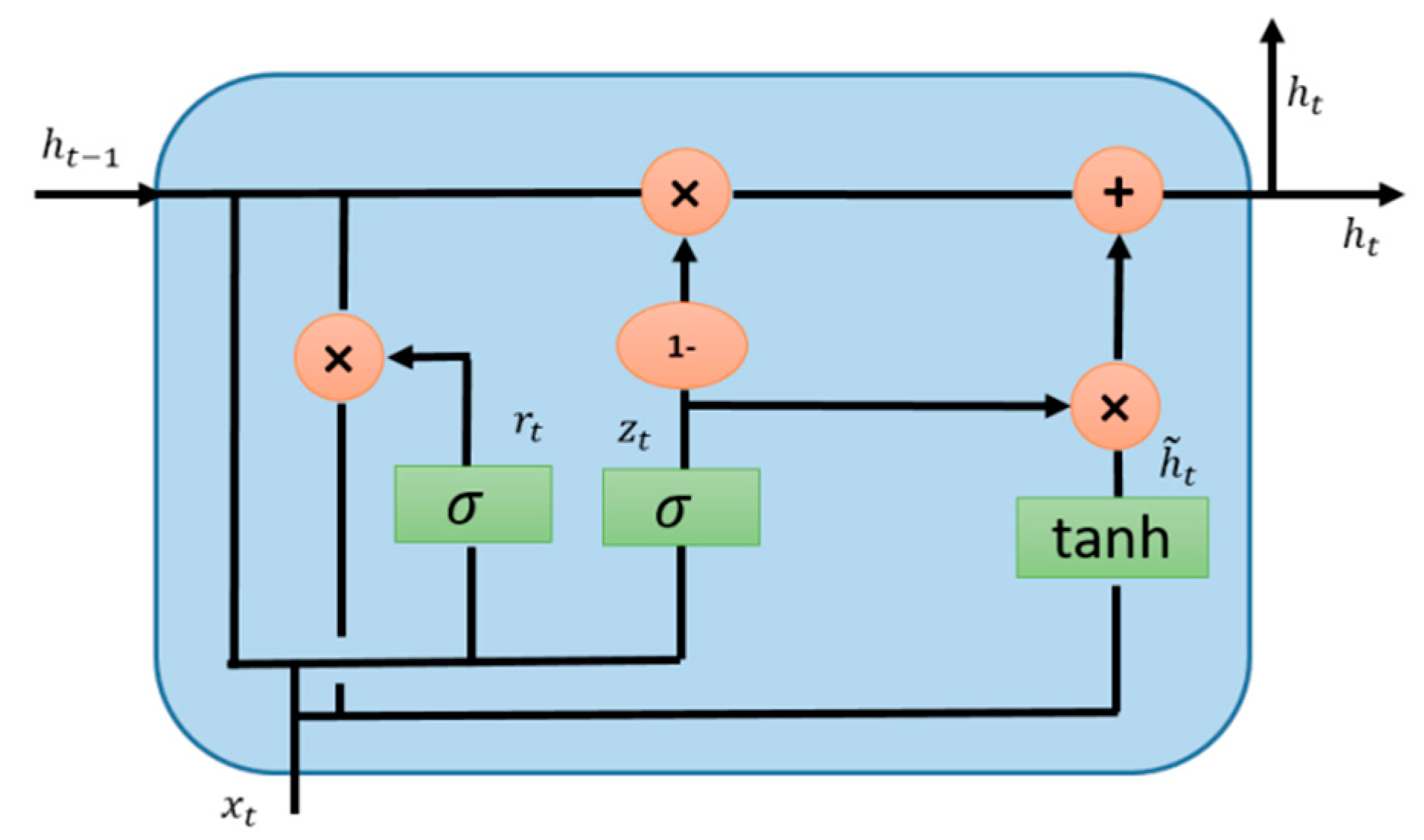
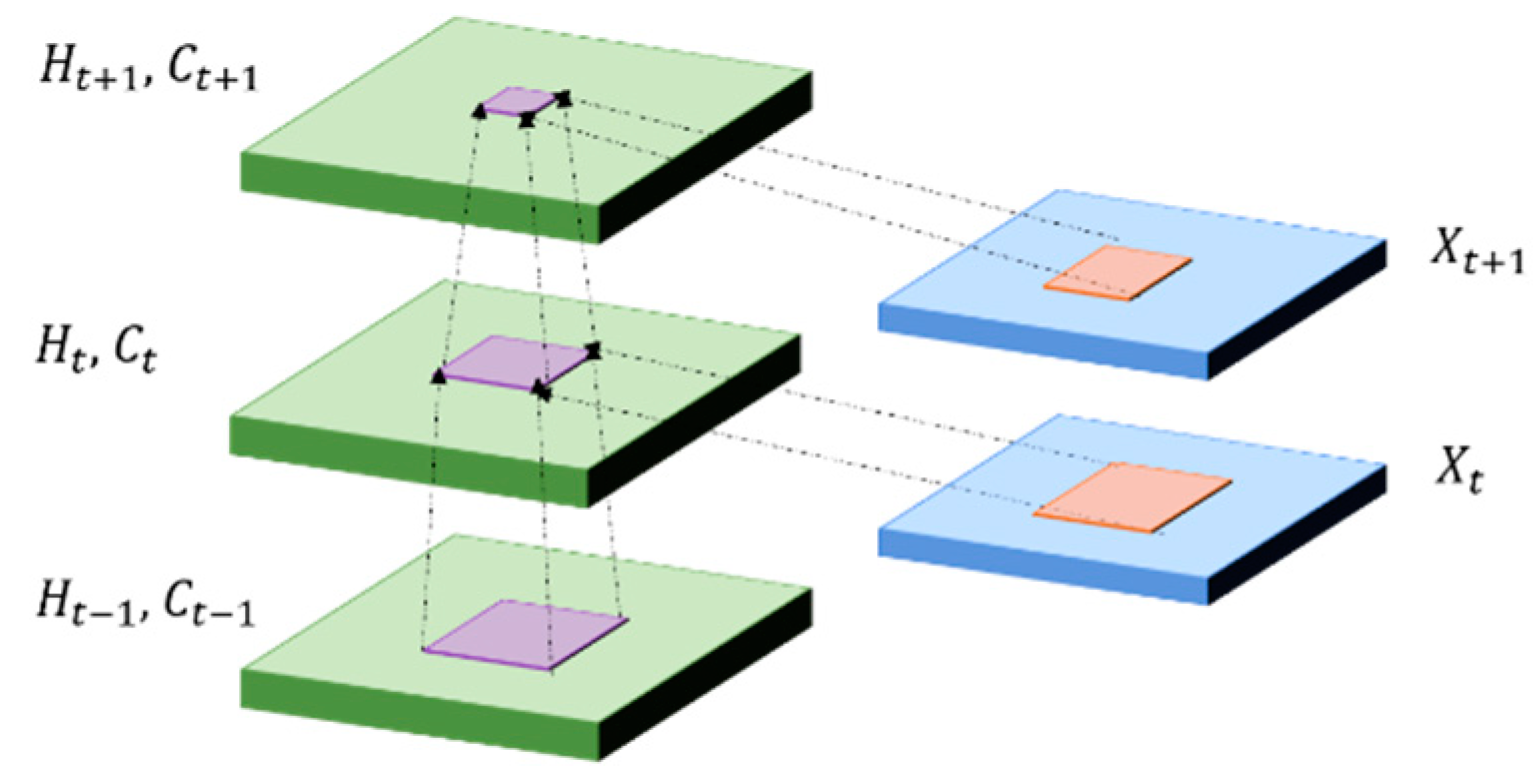
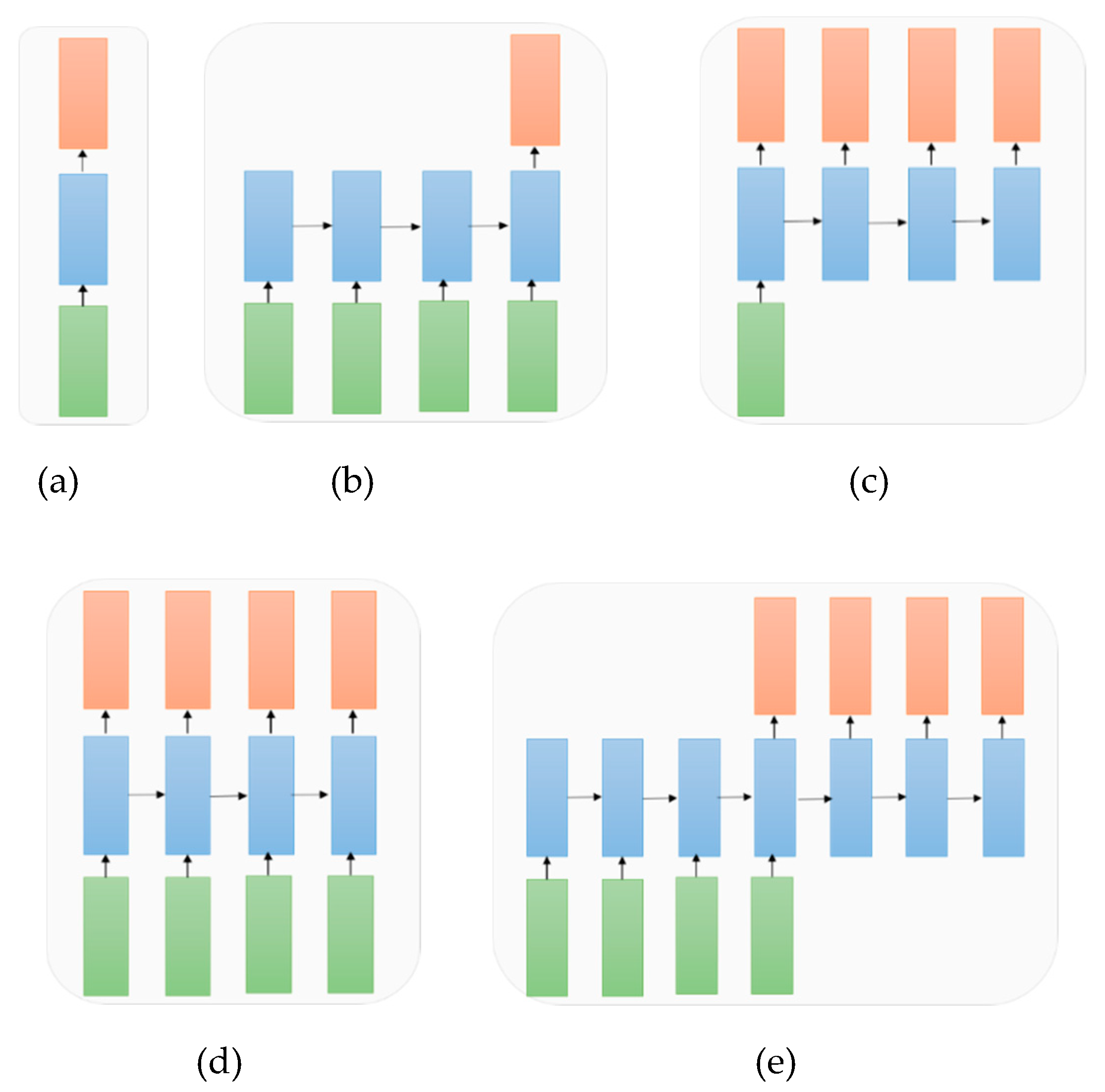
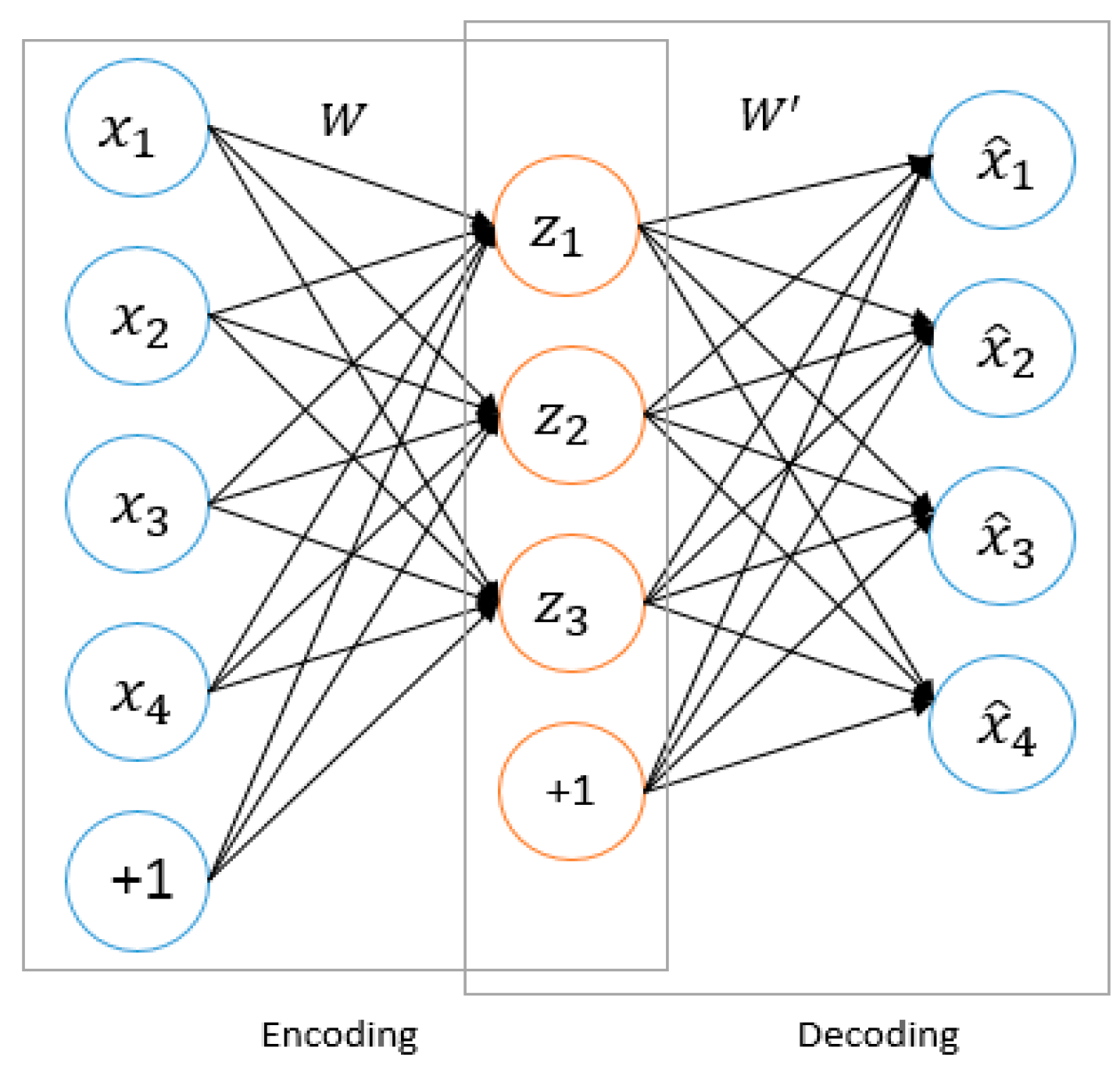
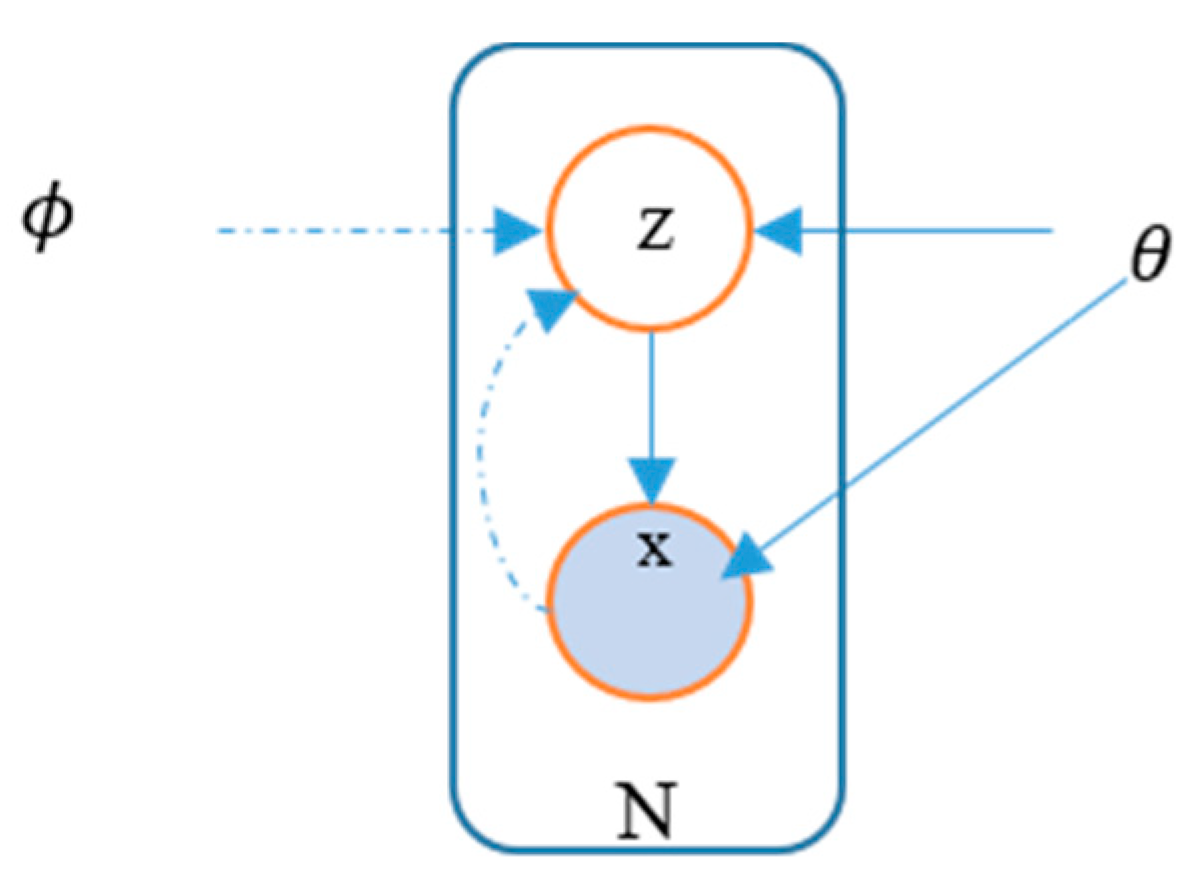
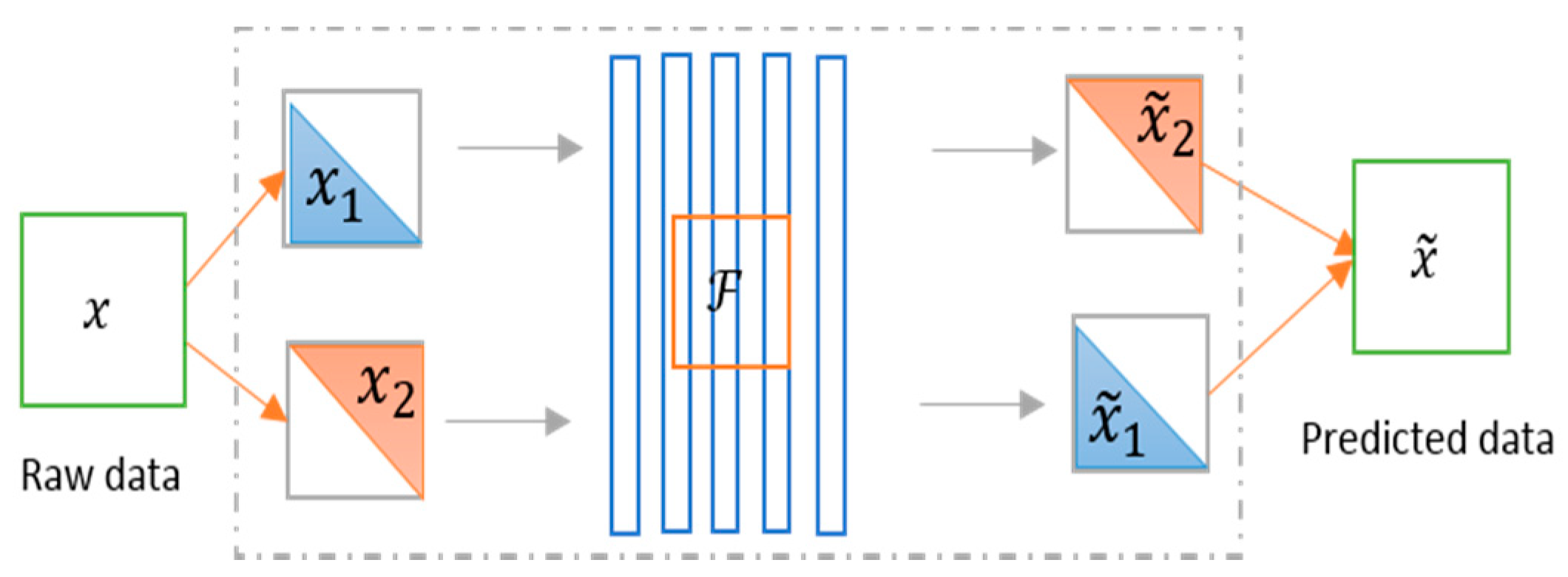
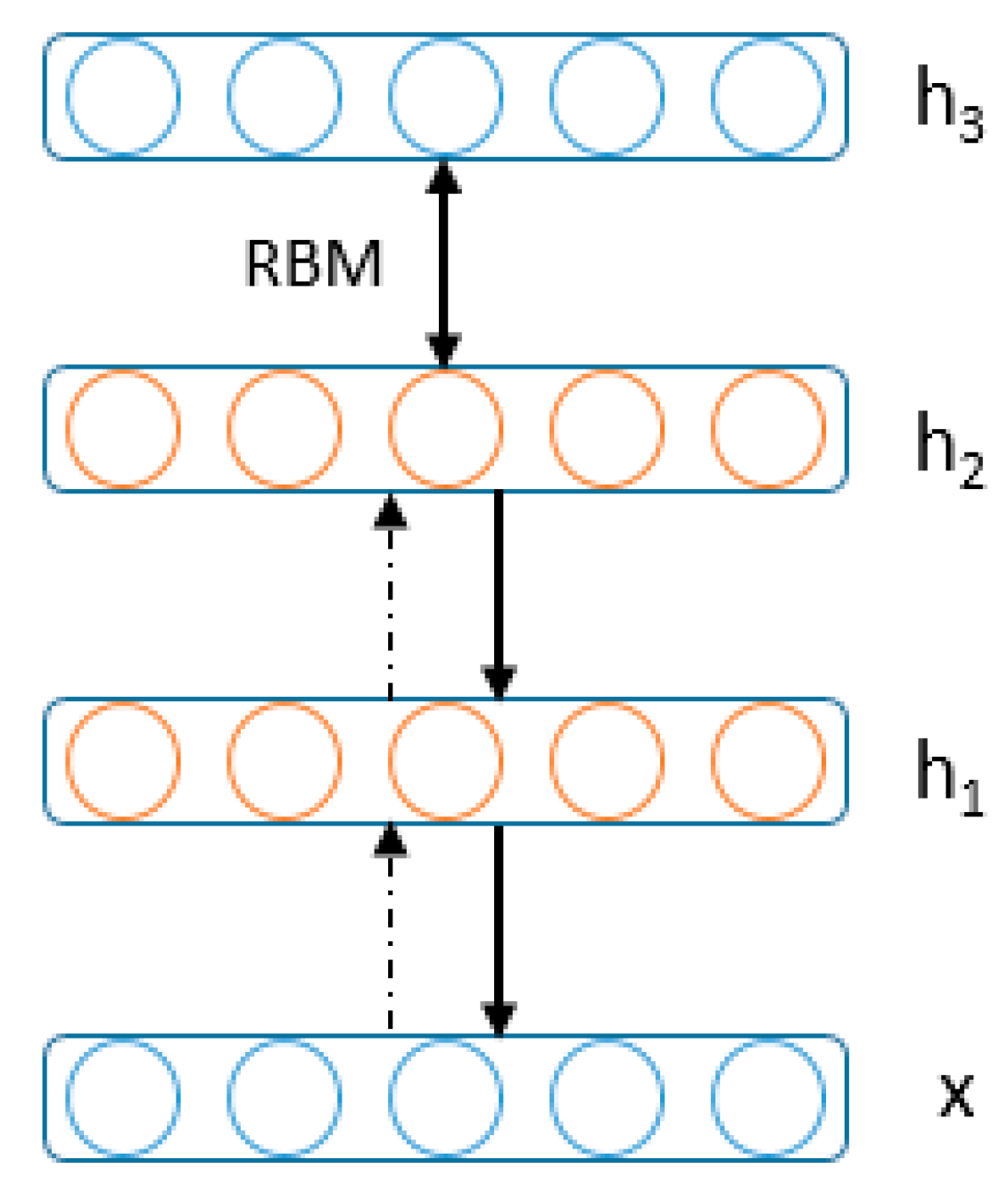
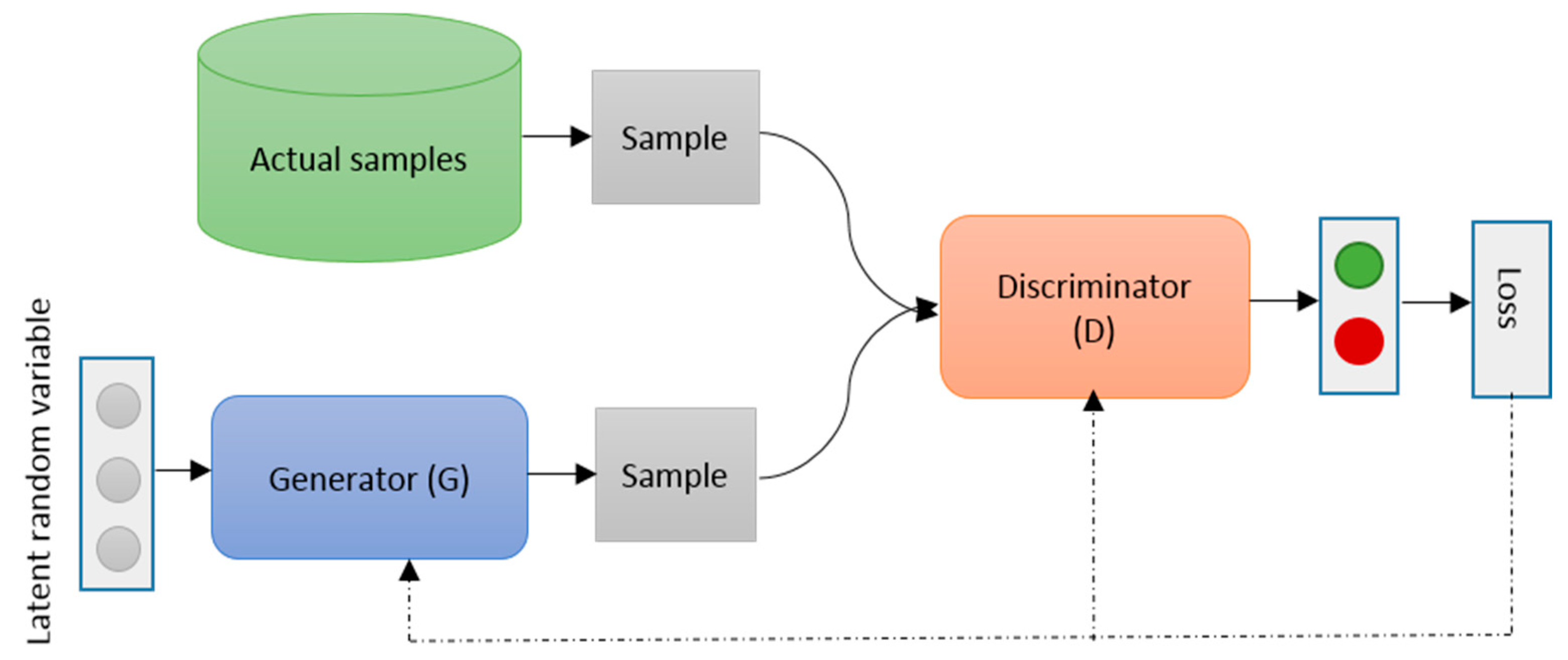


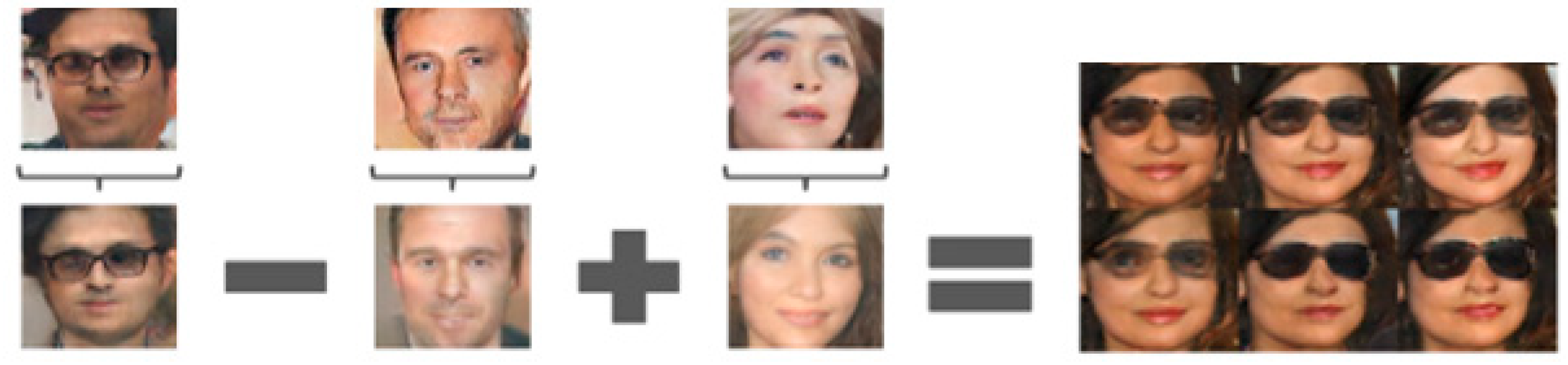

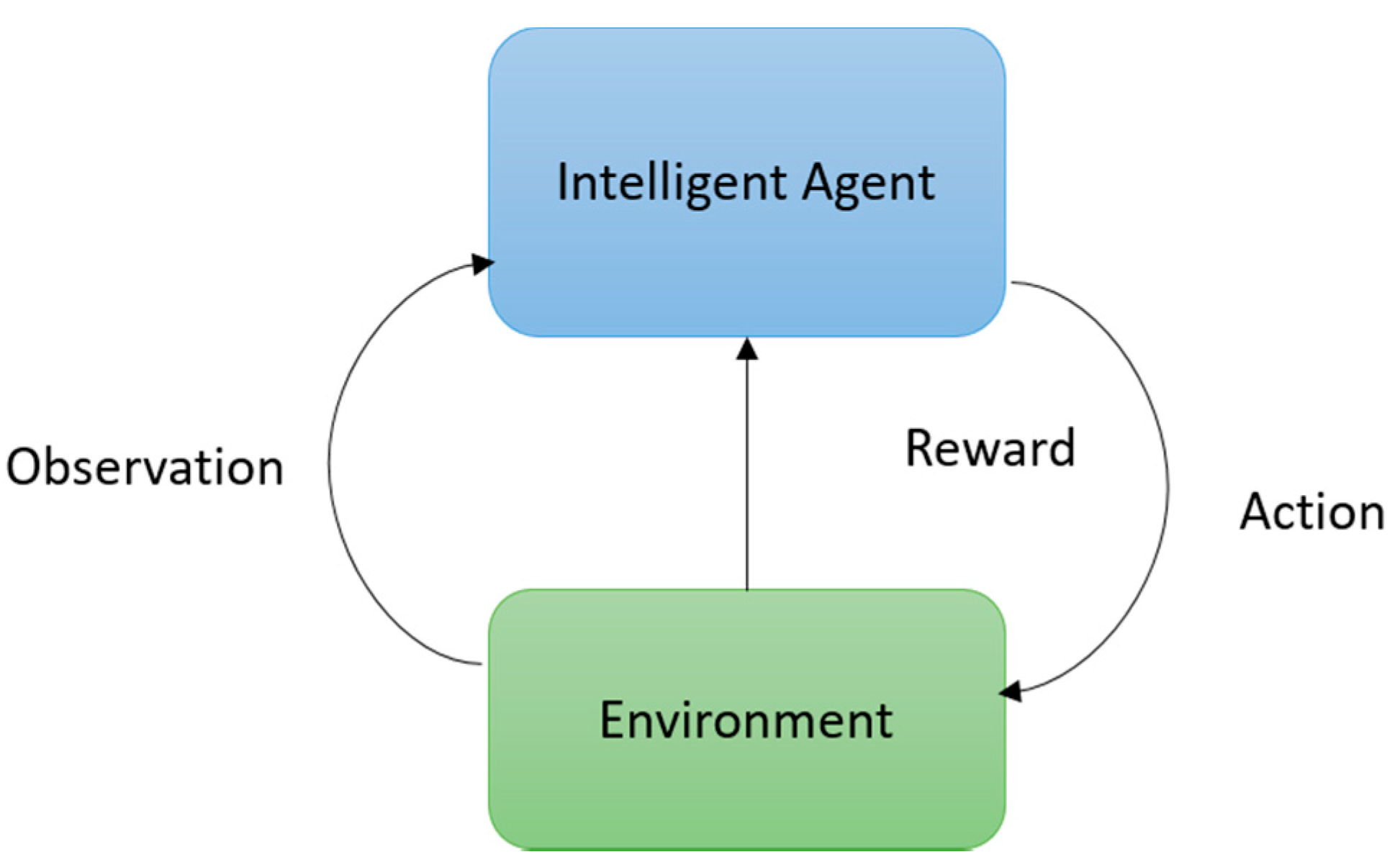
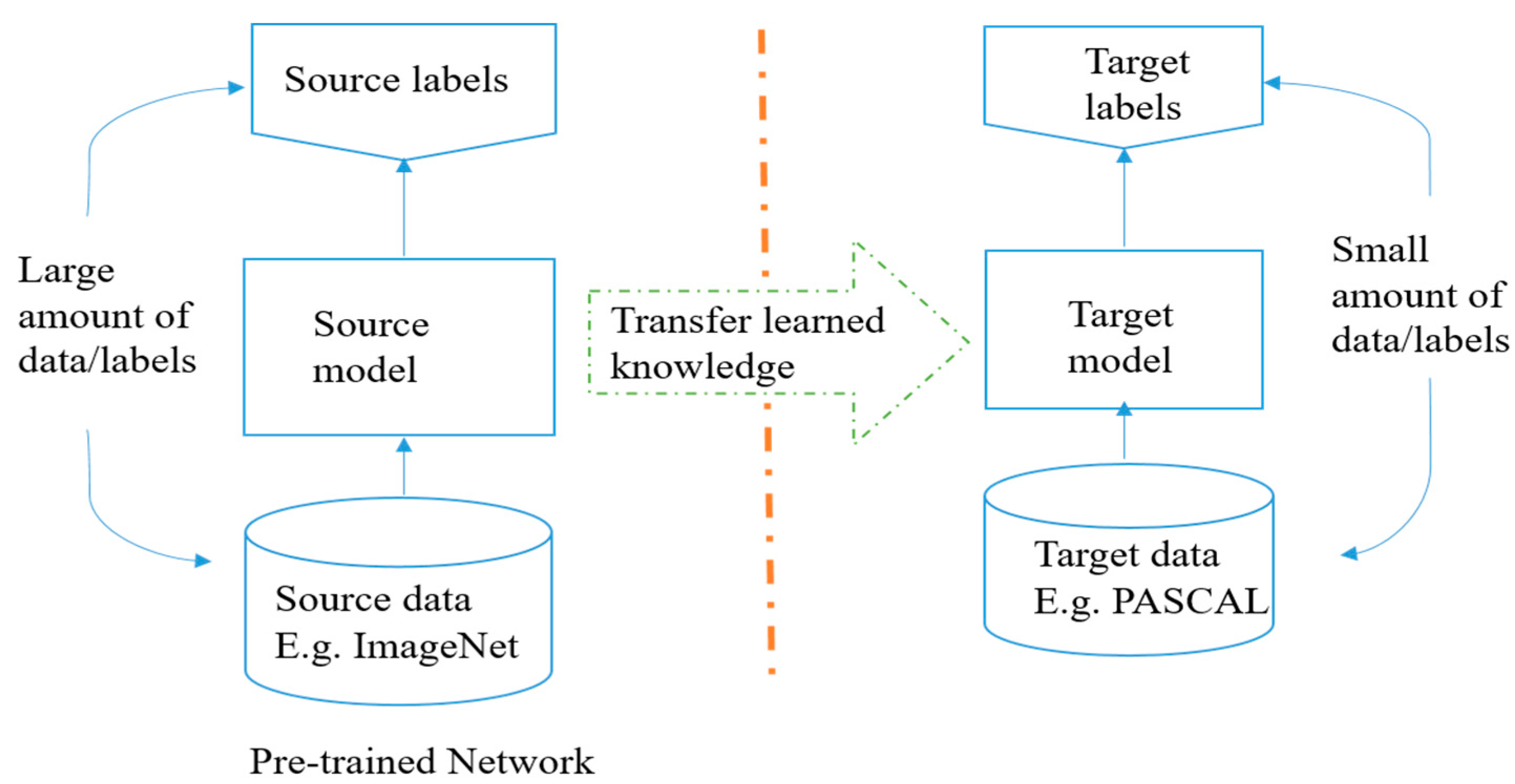

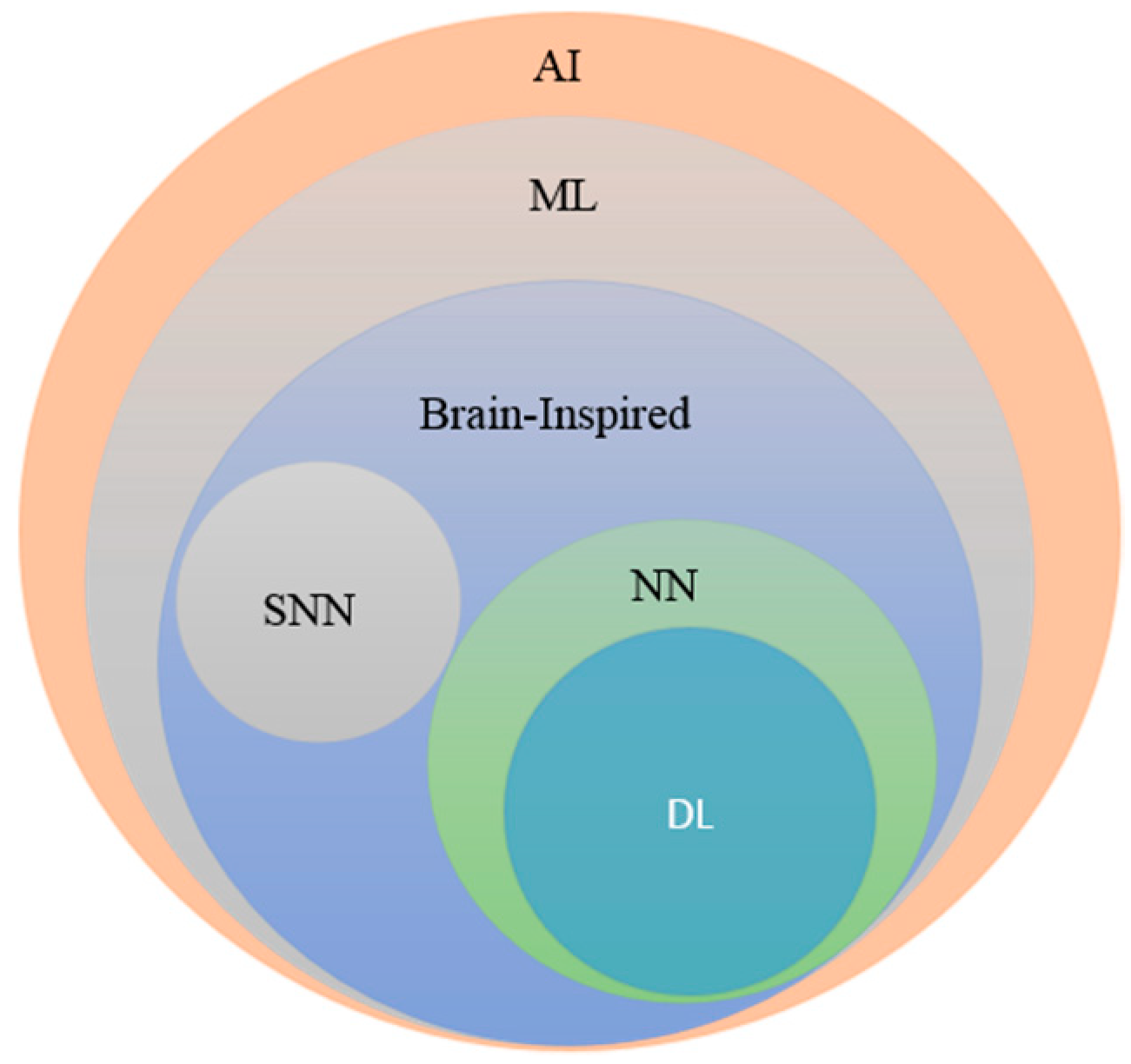{kind=link}
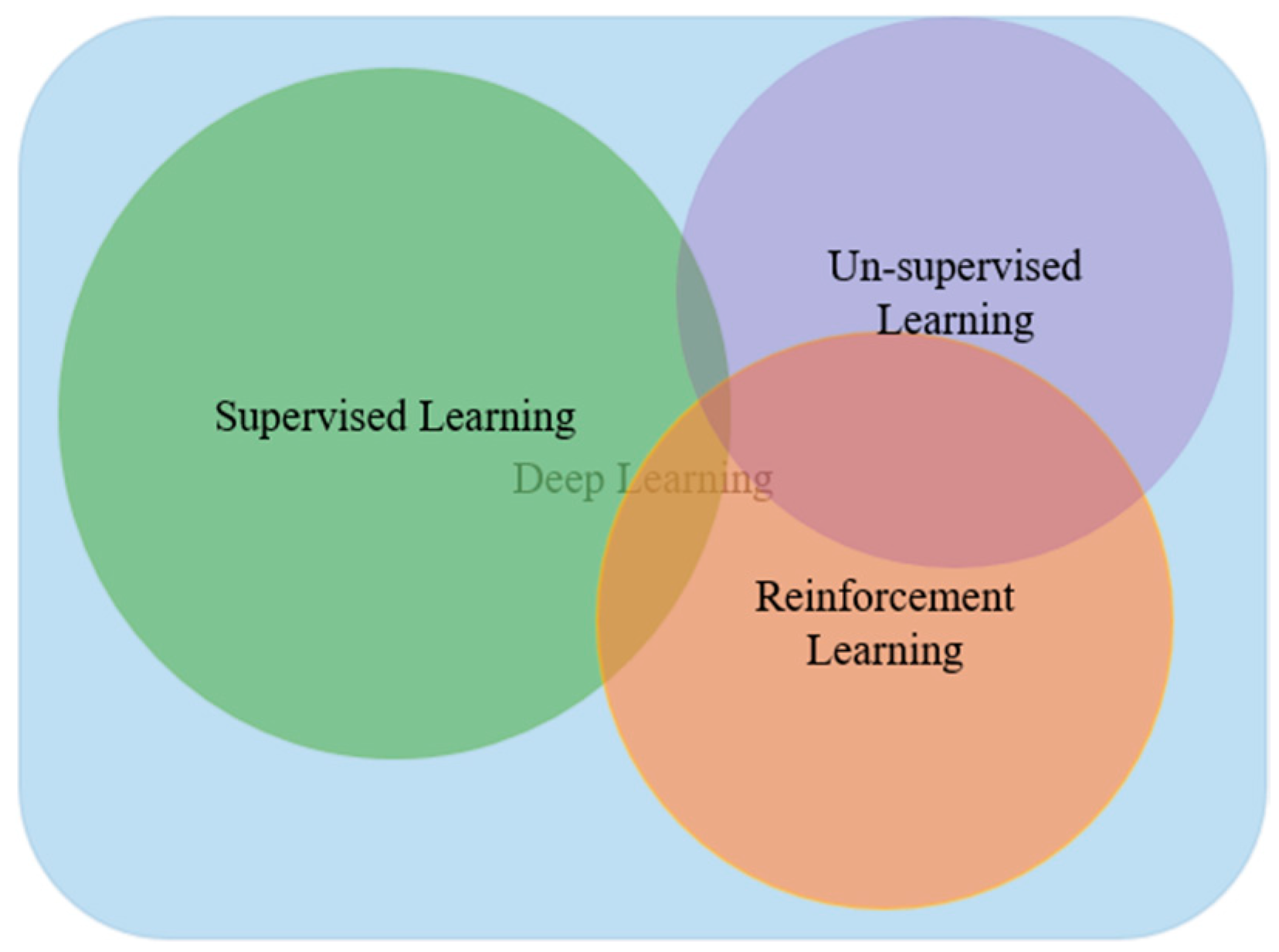{kind=link}
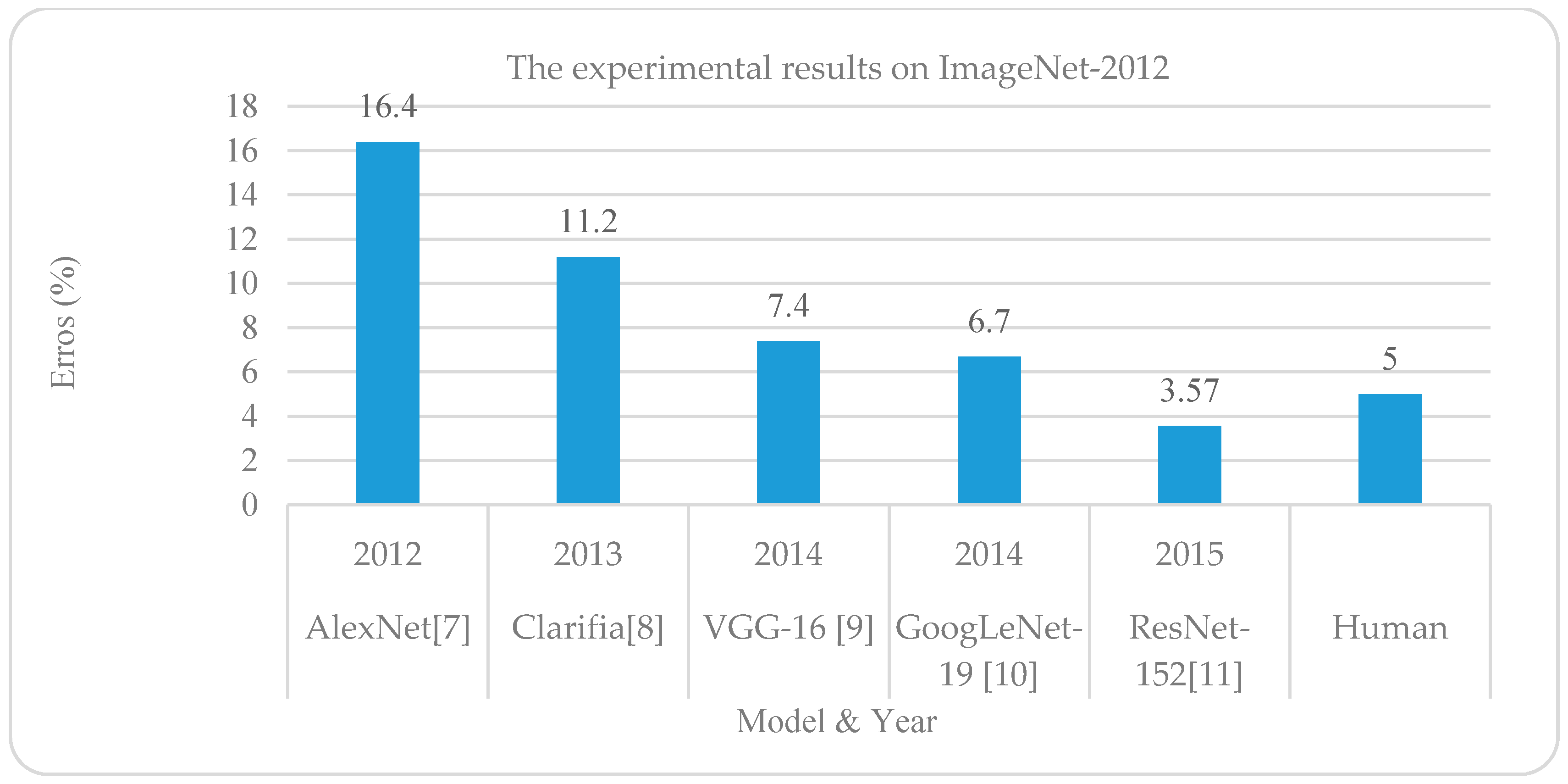{kind=link}
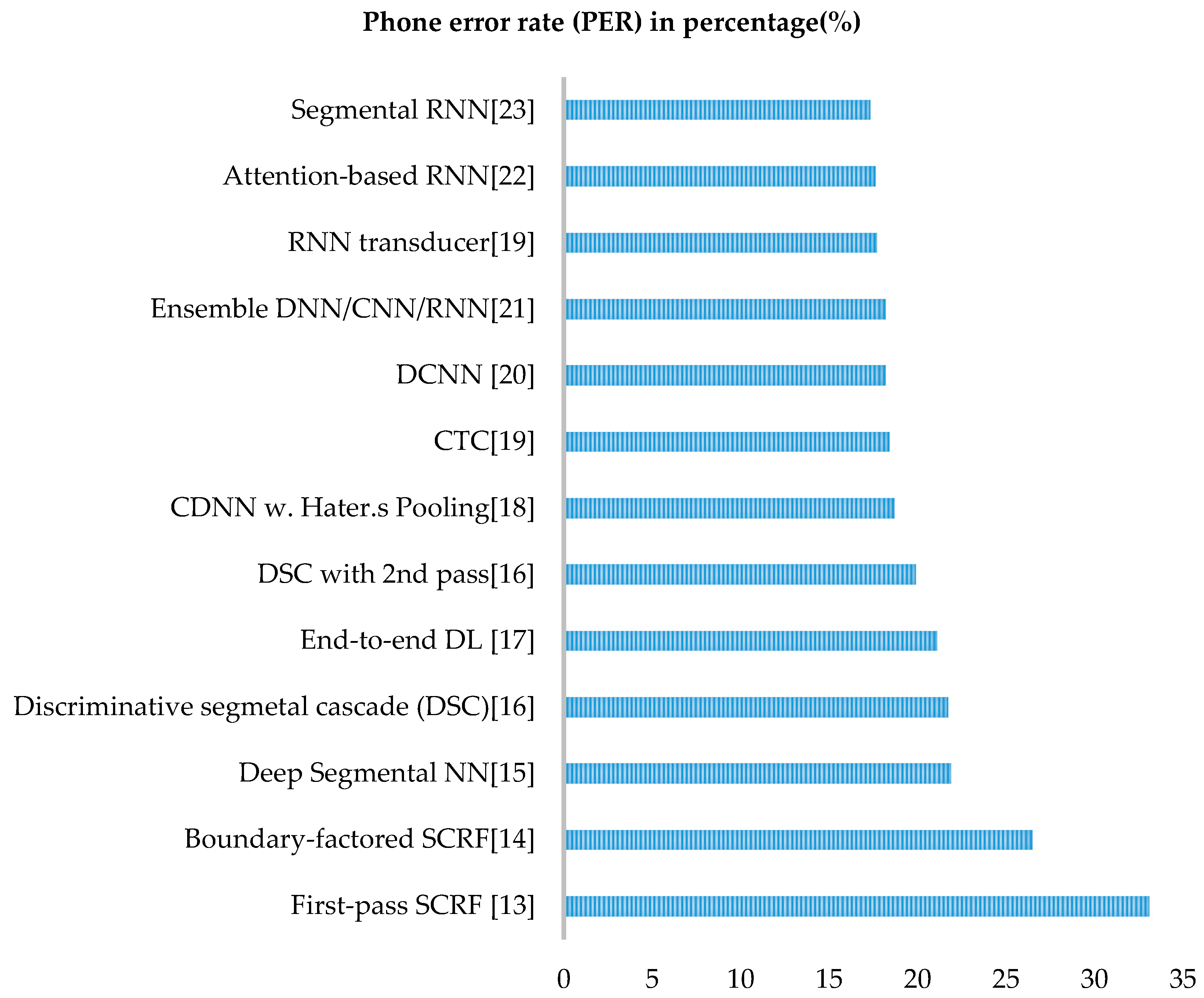{kind=link}
{kind=link}
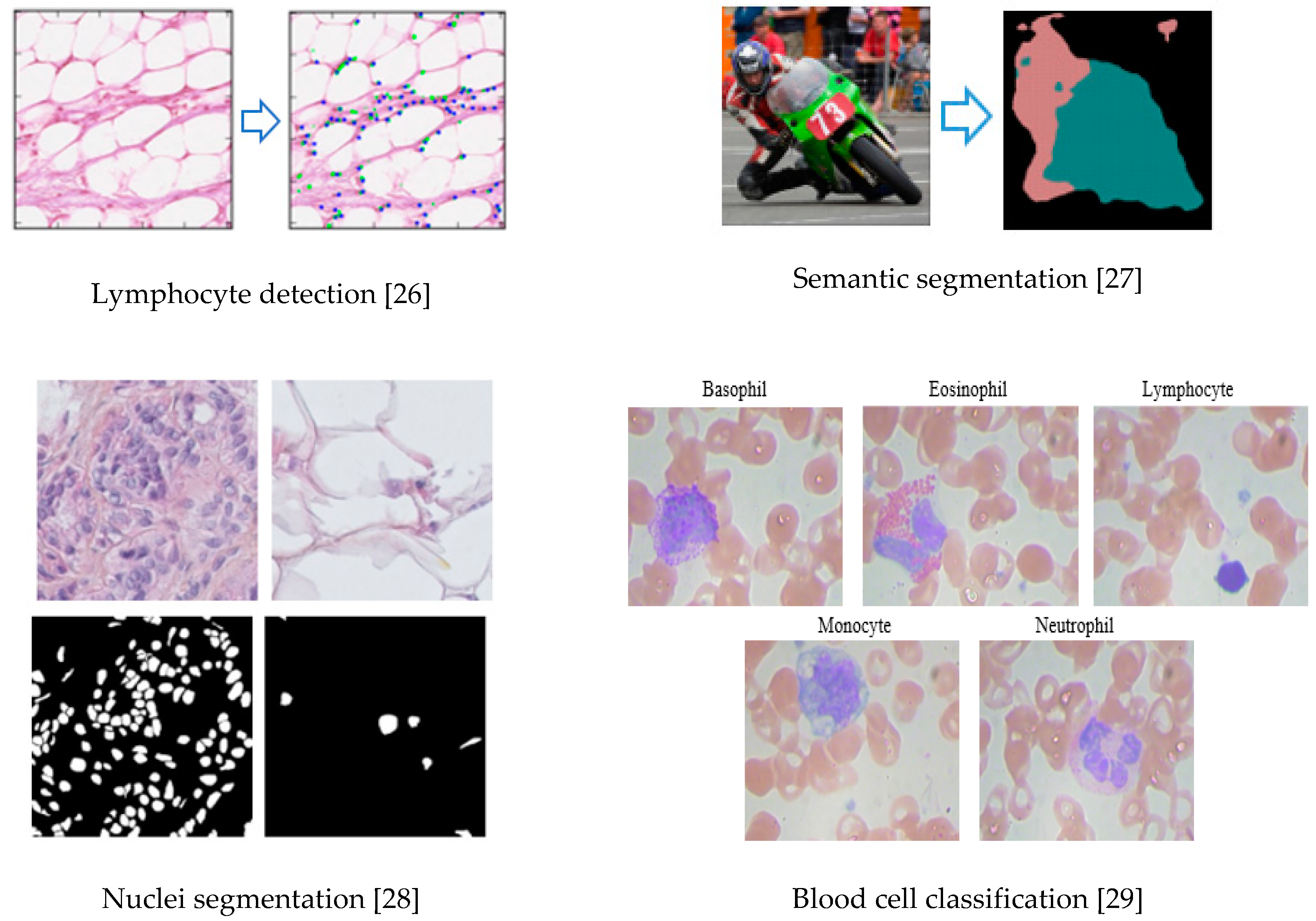{kind=link}
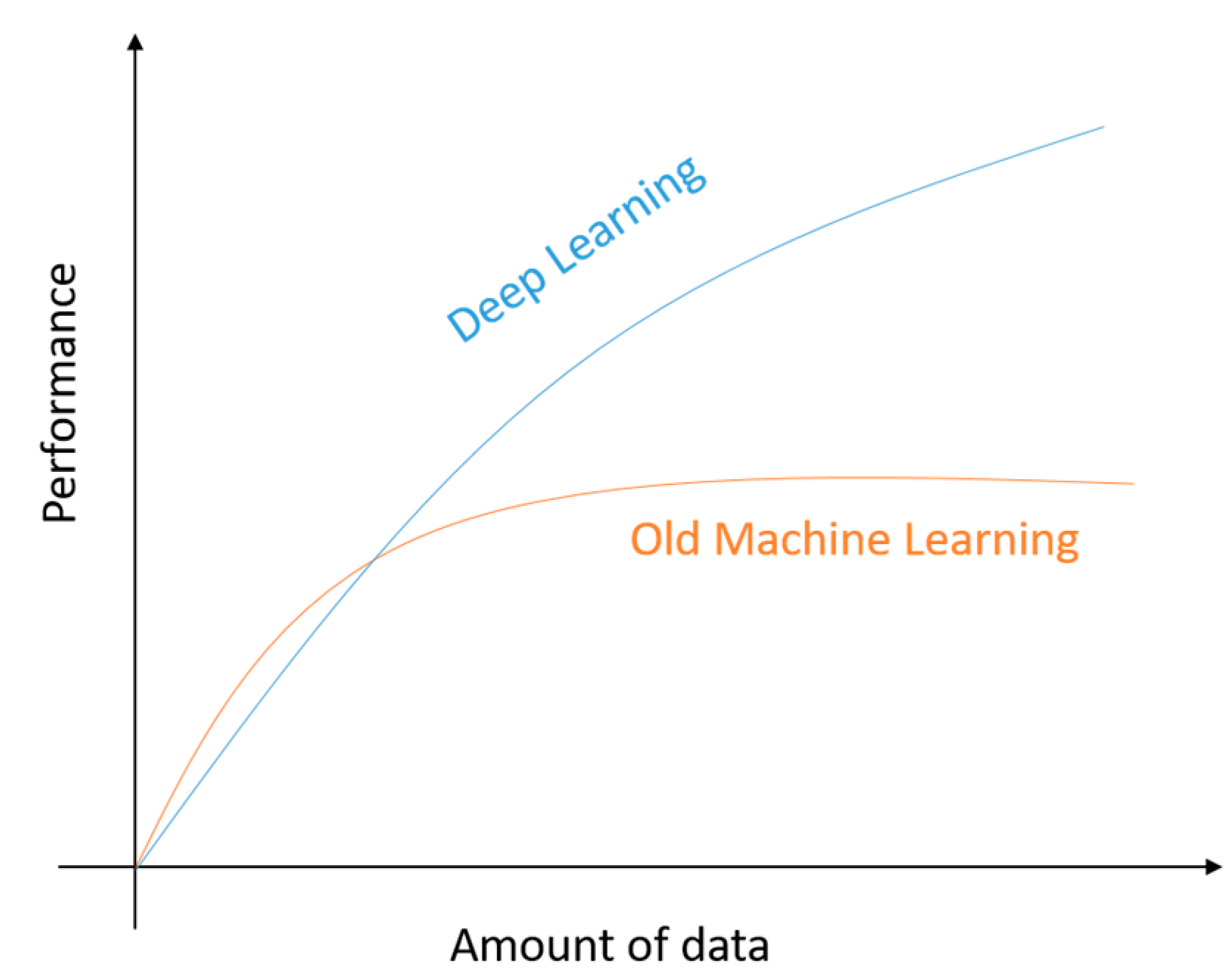{kind=link}
{kind=link}
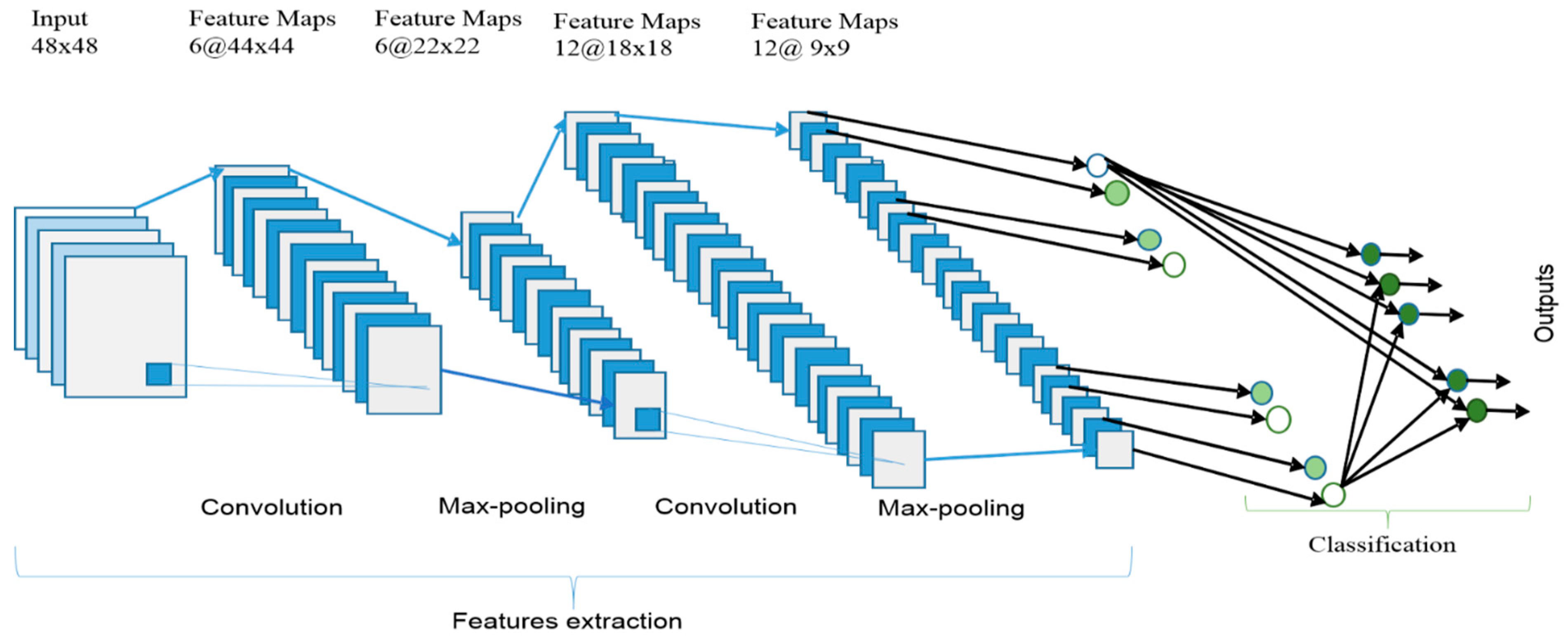{kind=link}
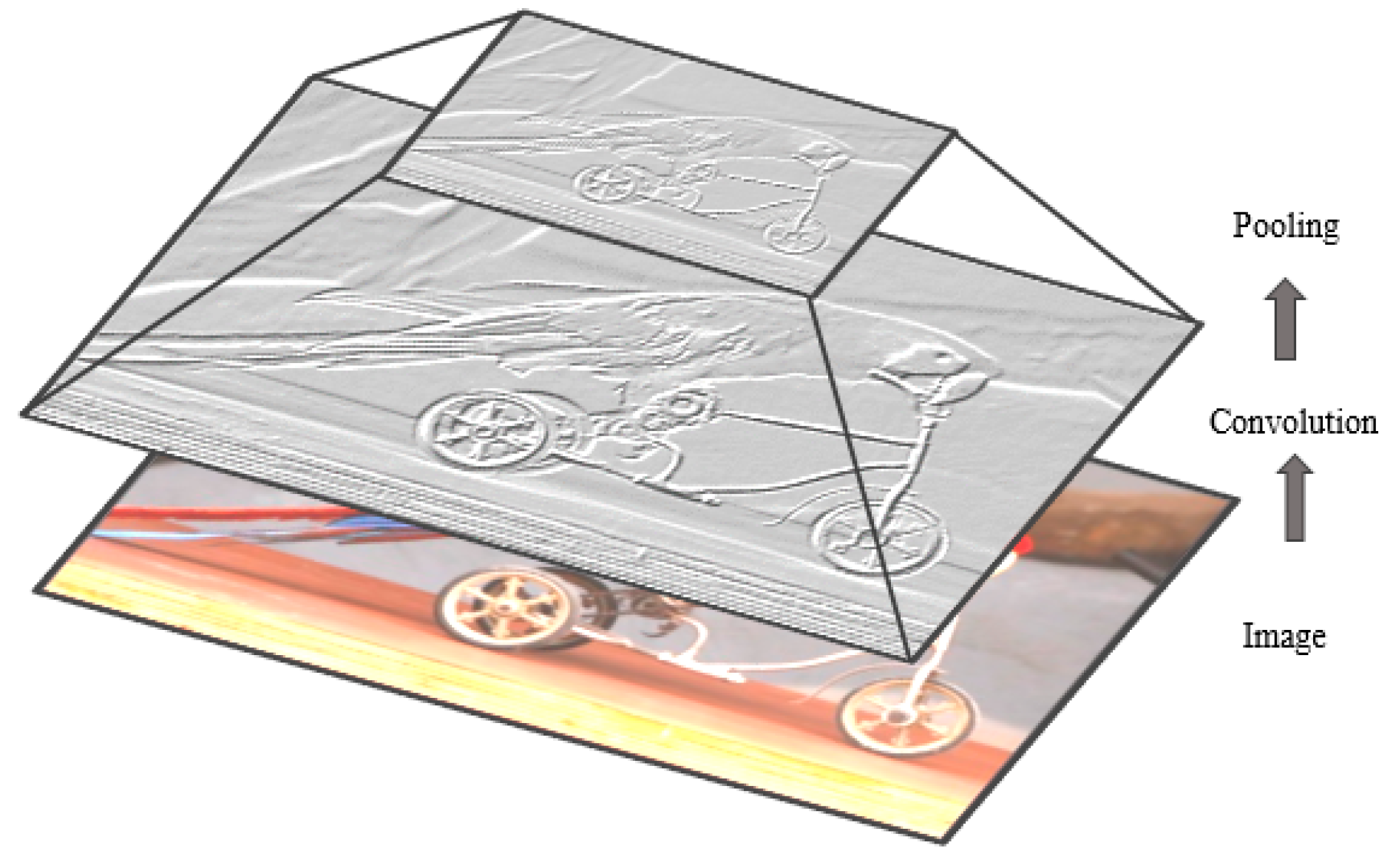{kind=link}
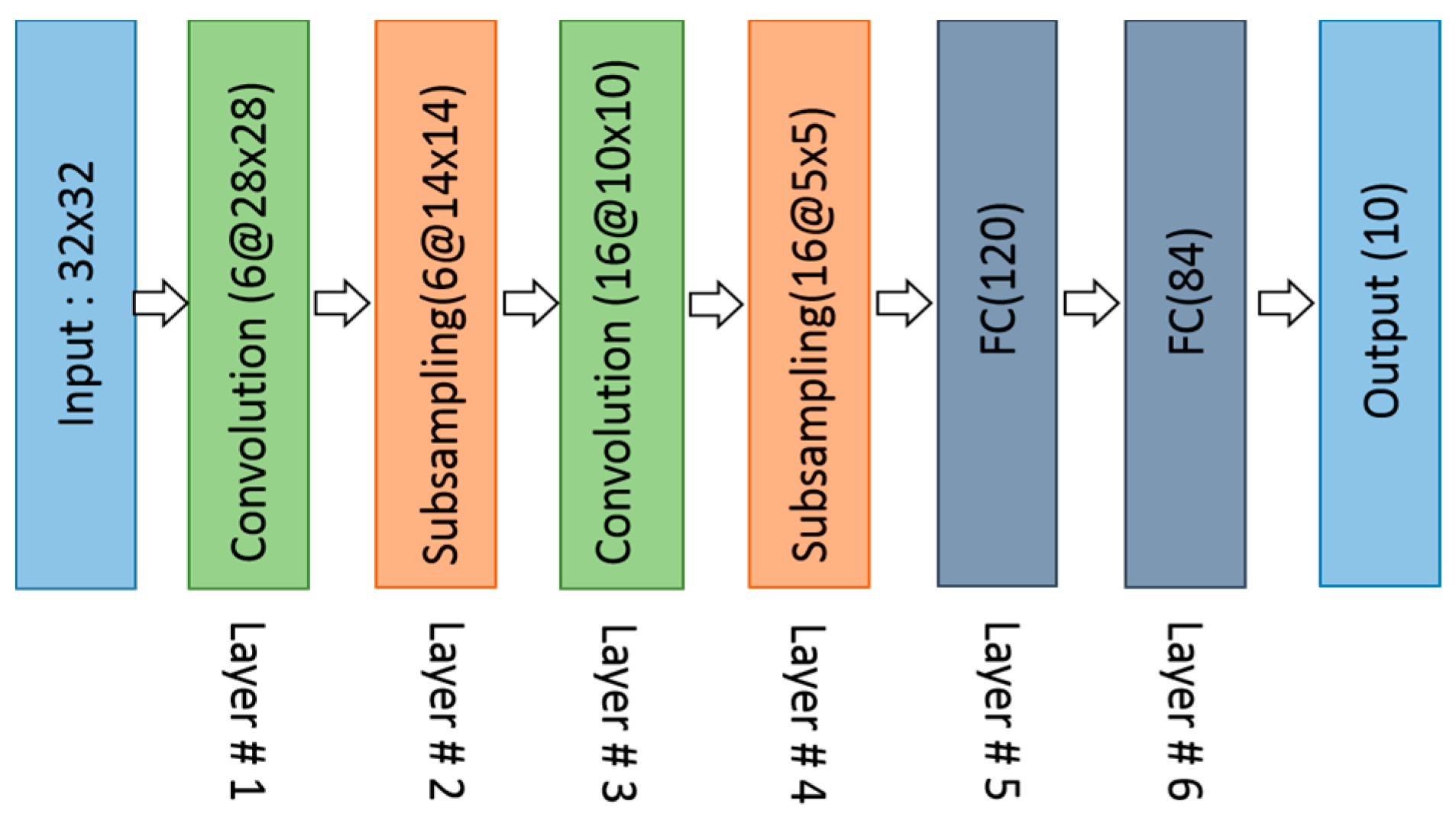{kind=link}
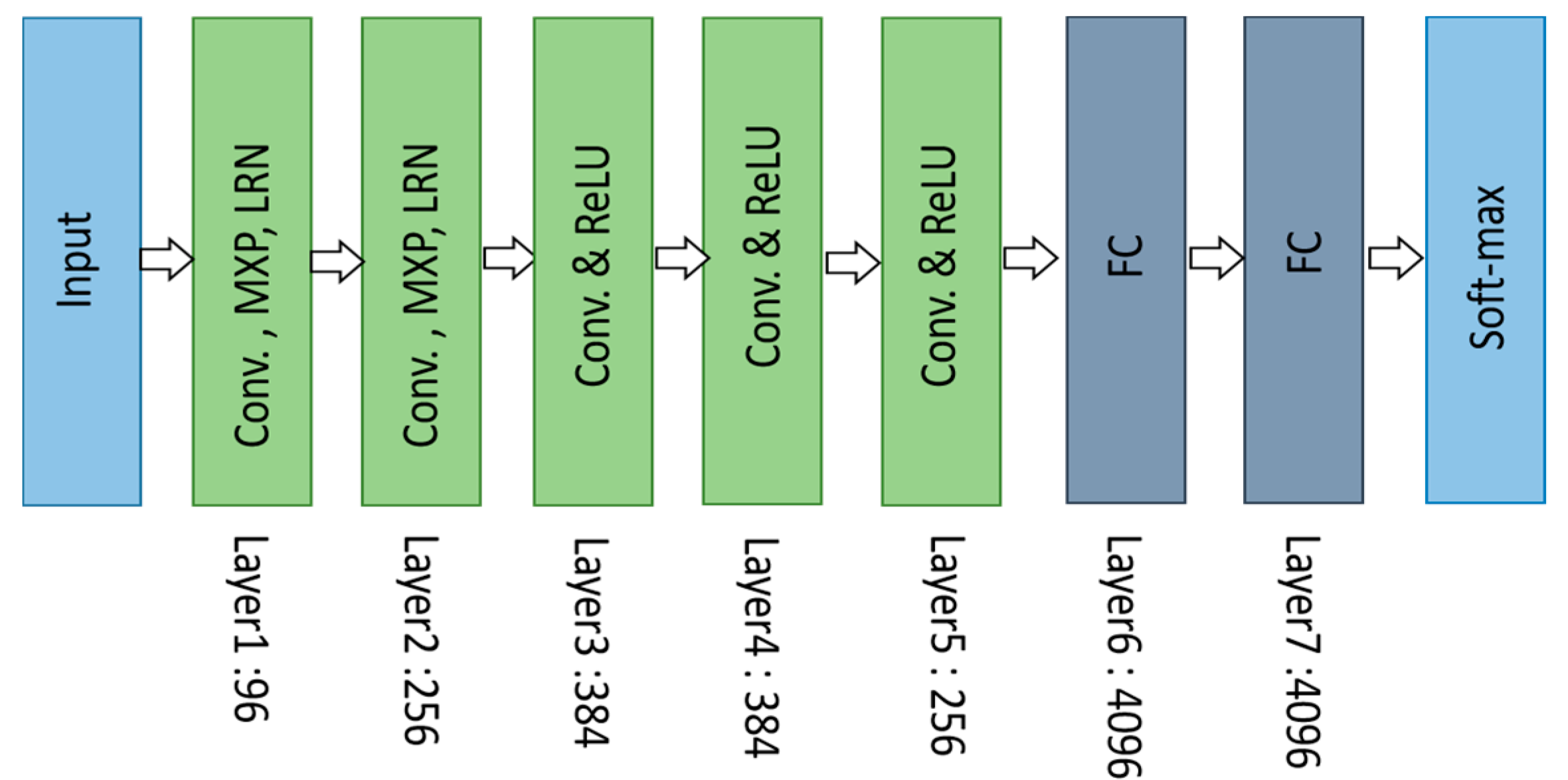{kind=link}
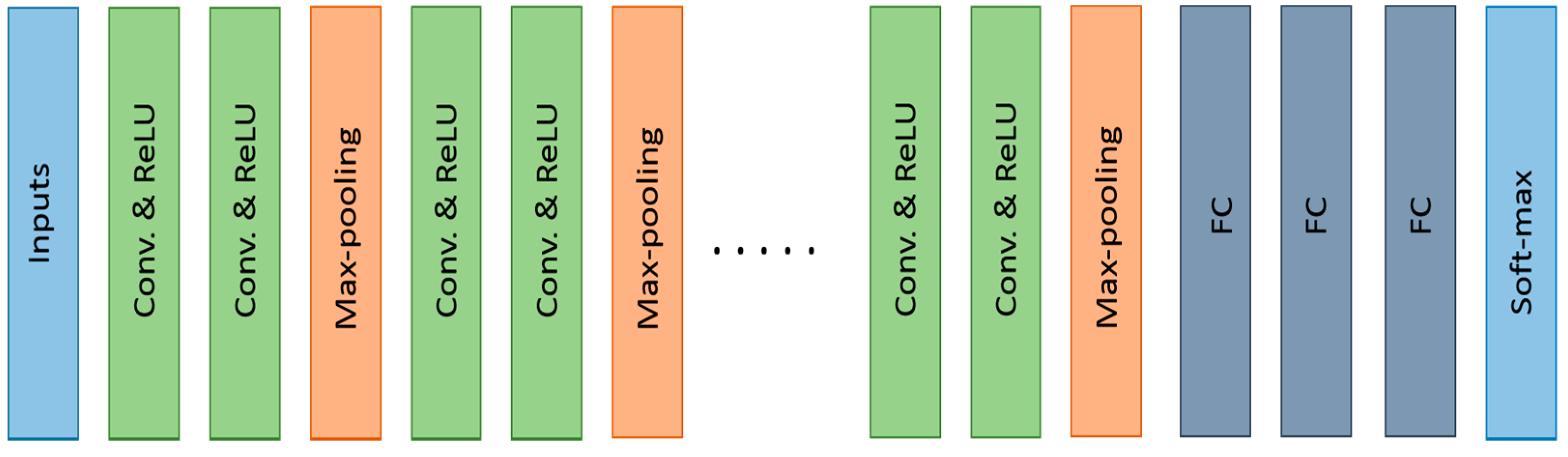{kind=link}
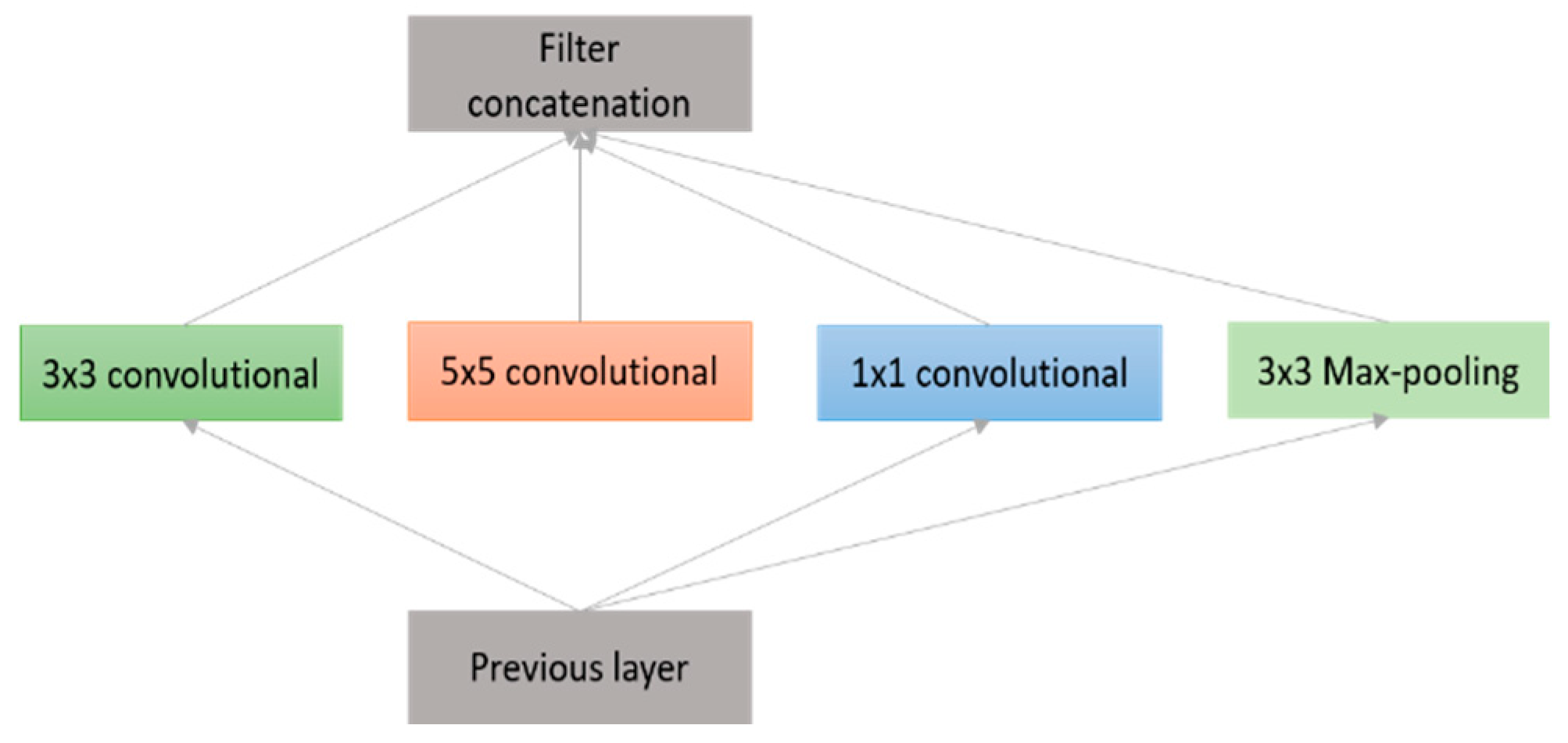{kind=link}
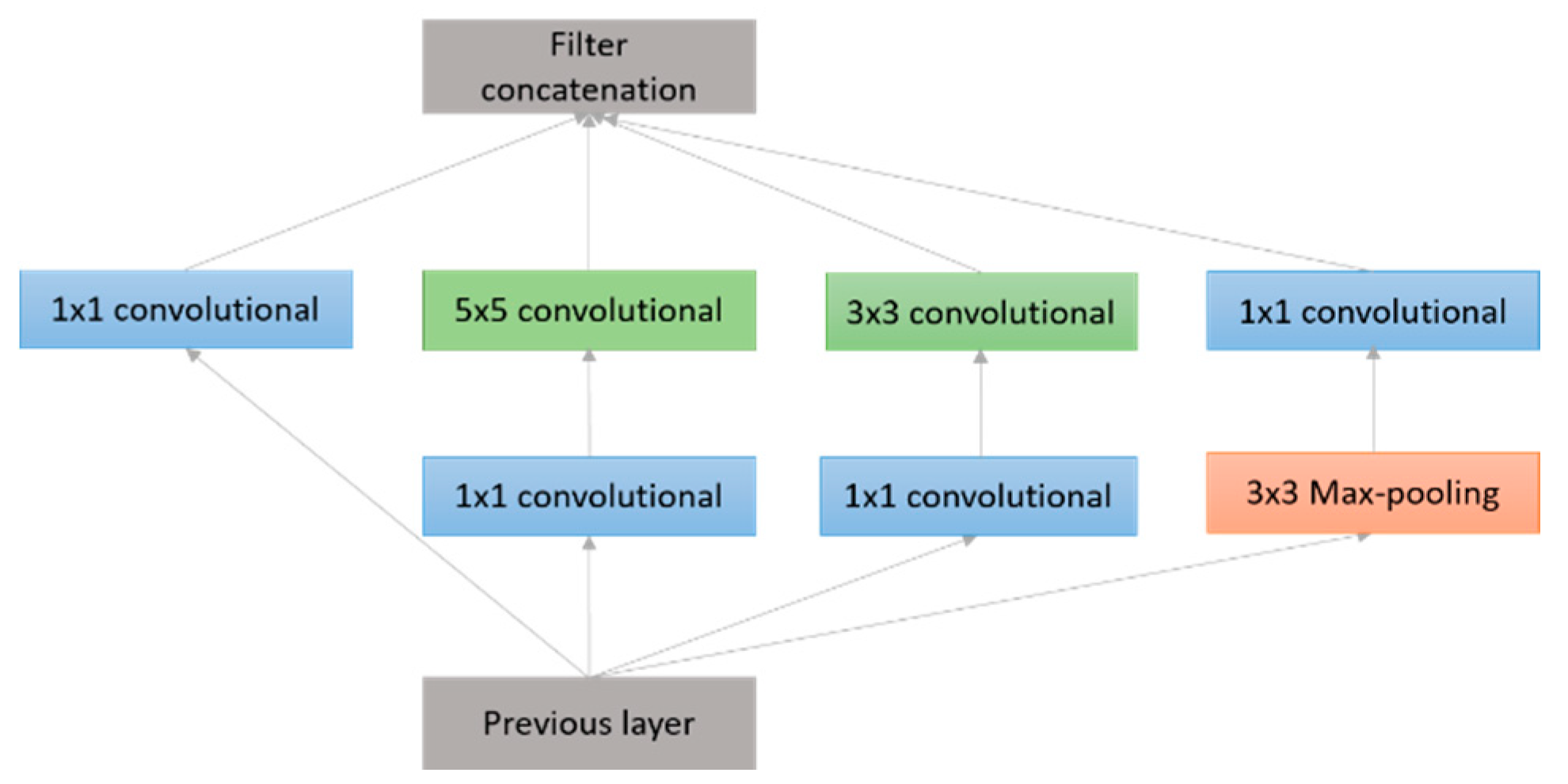{kind=link}
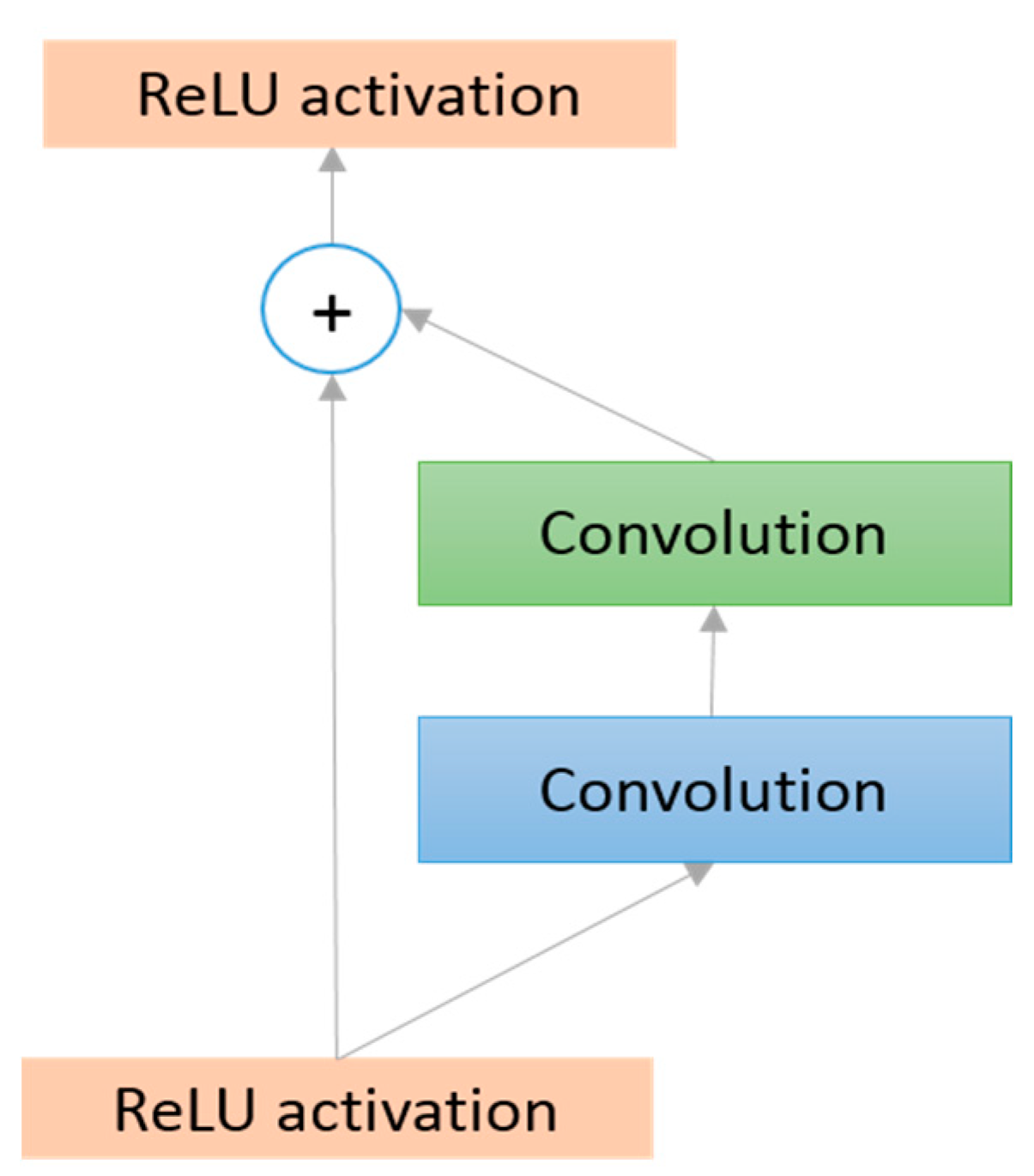{kind=link}
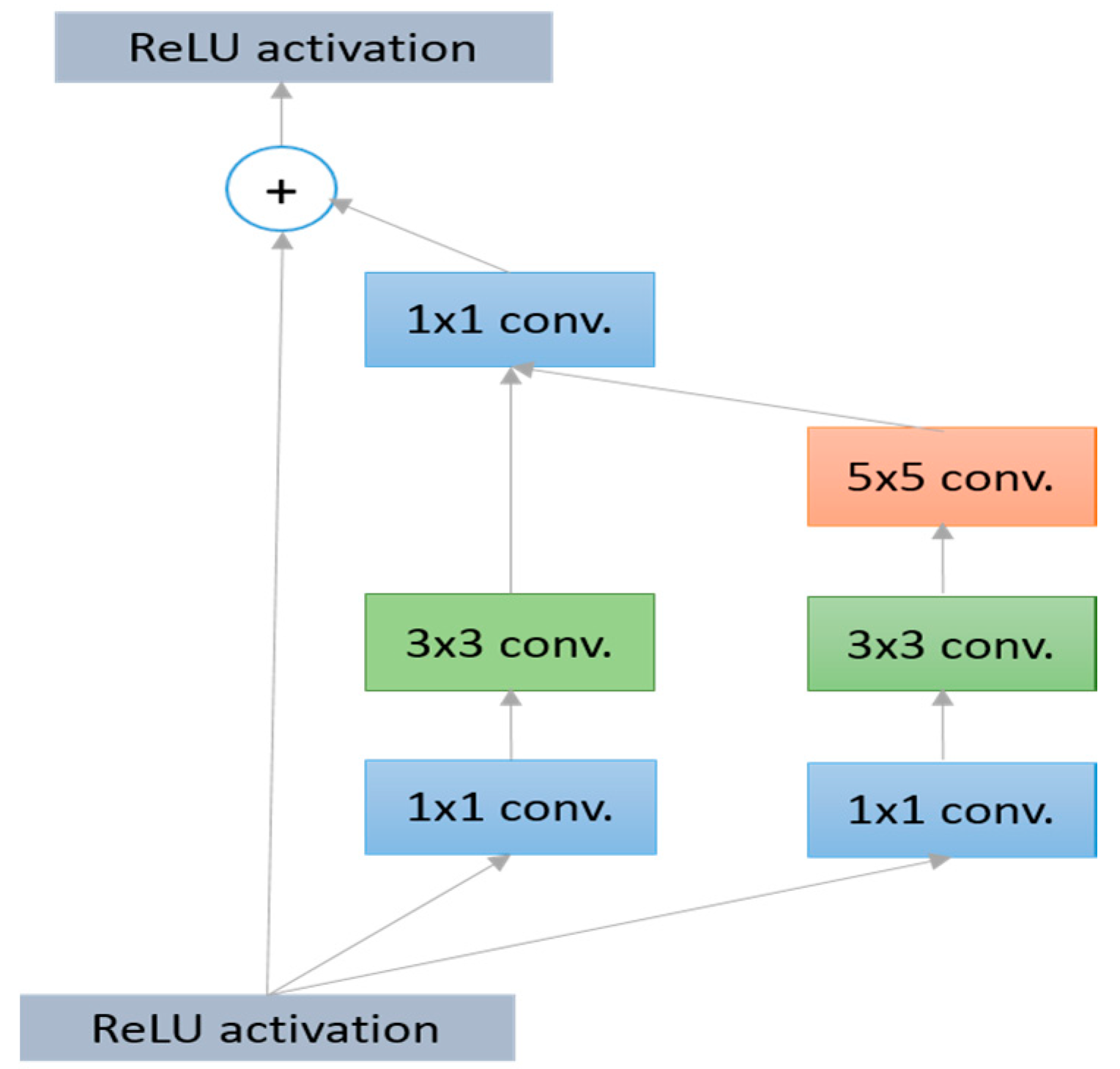{kind=link}
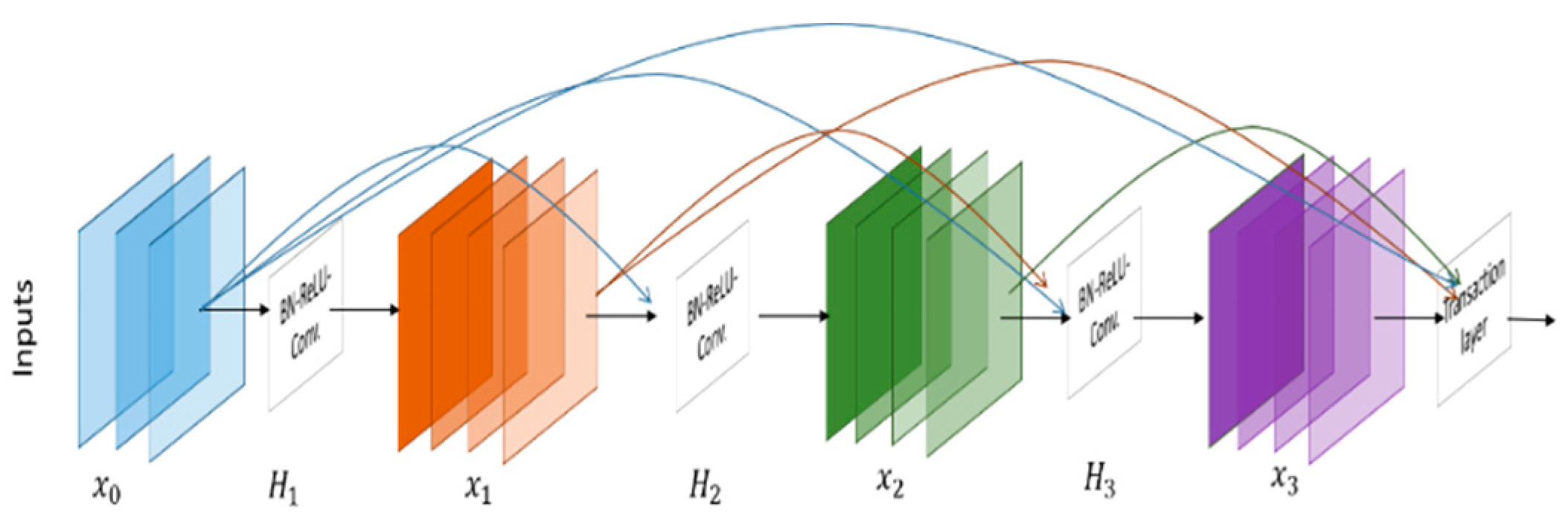{kind=link}
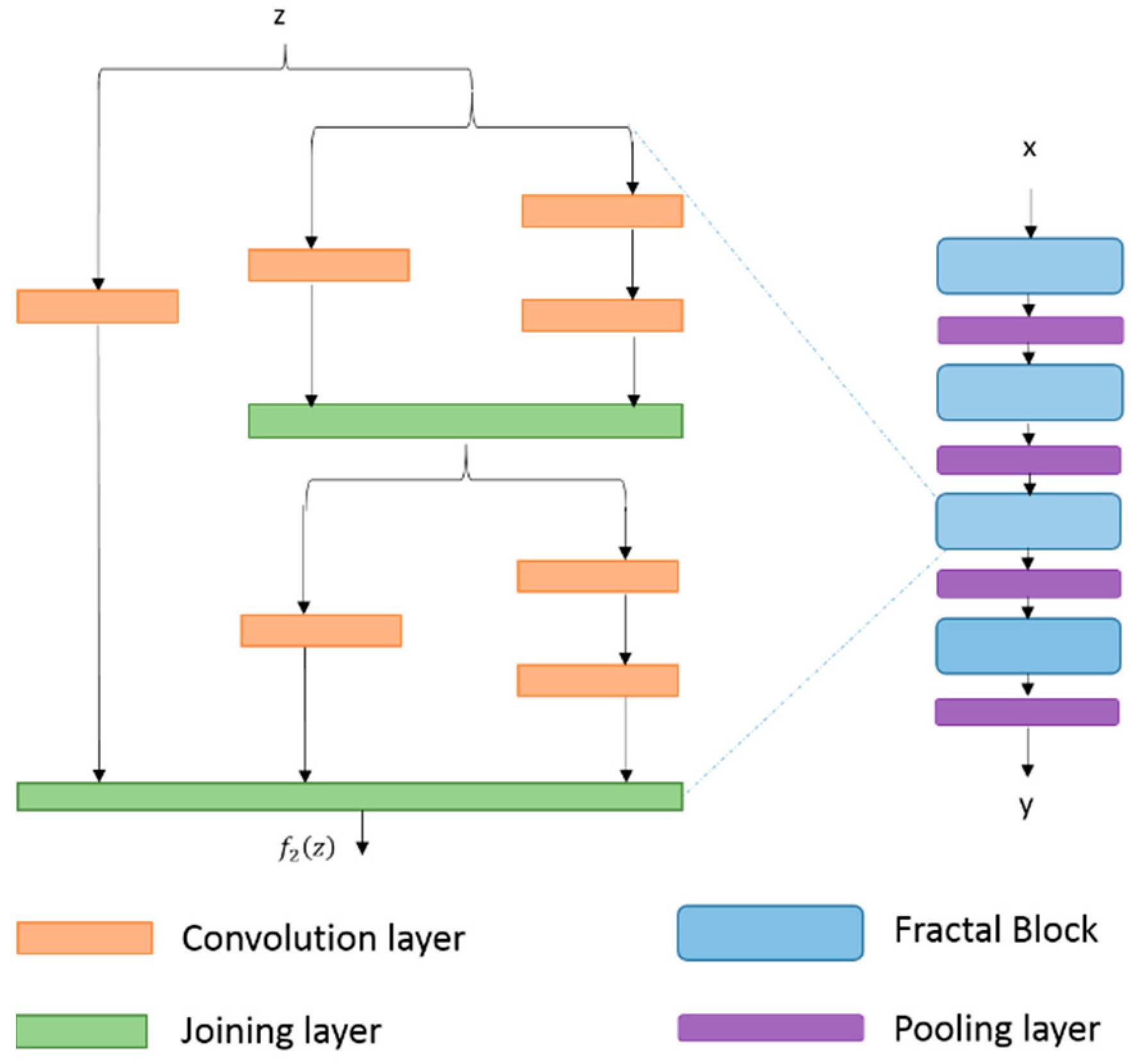{kind=link}
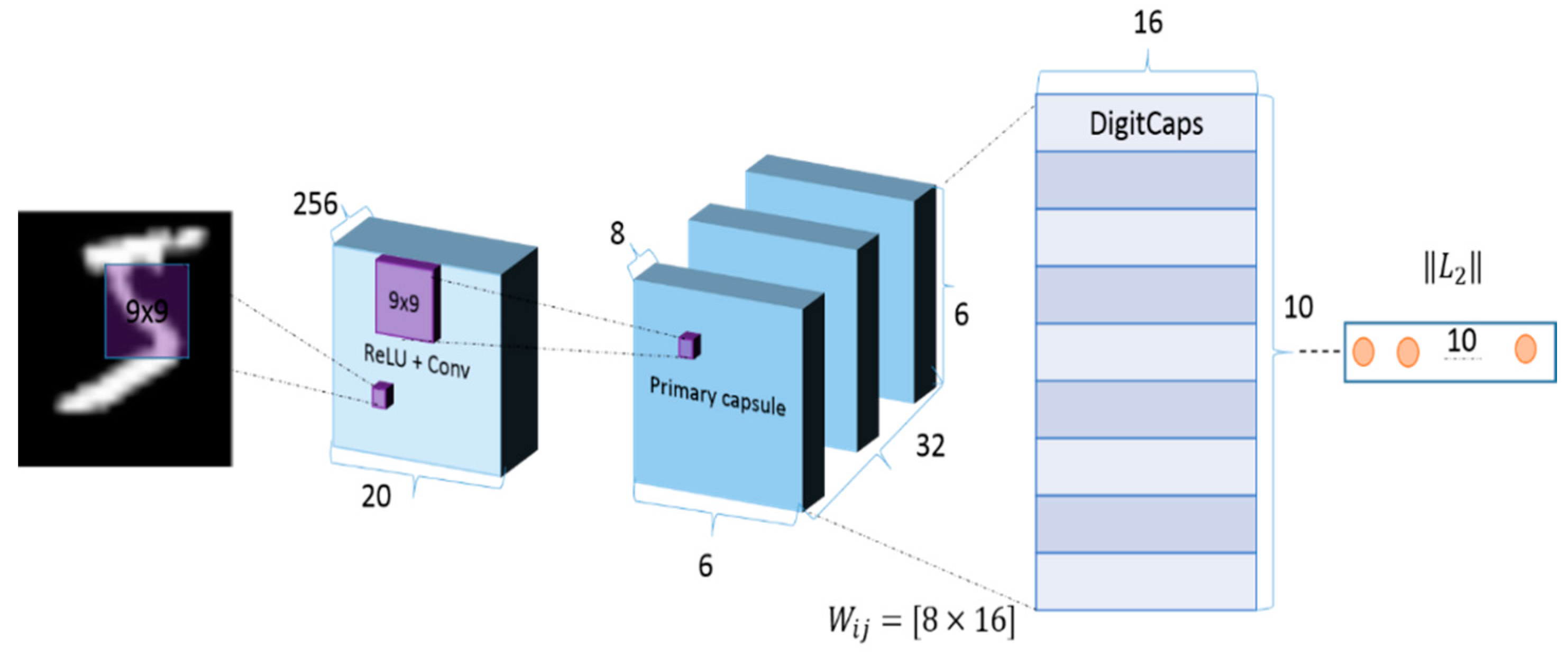{kind=link}
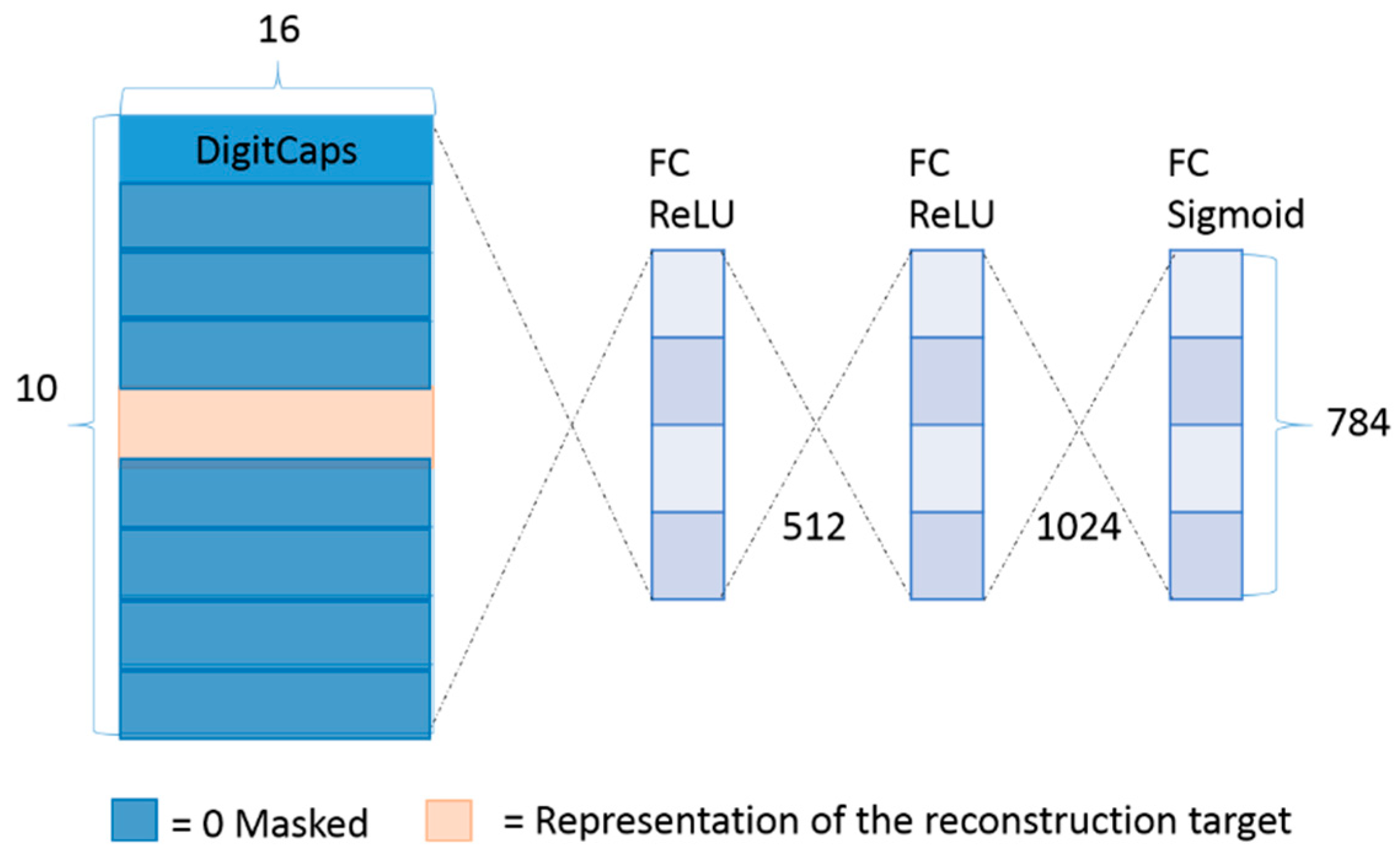{kind=link}
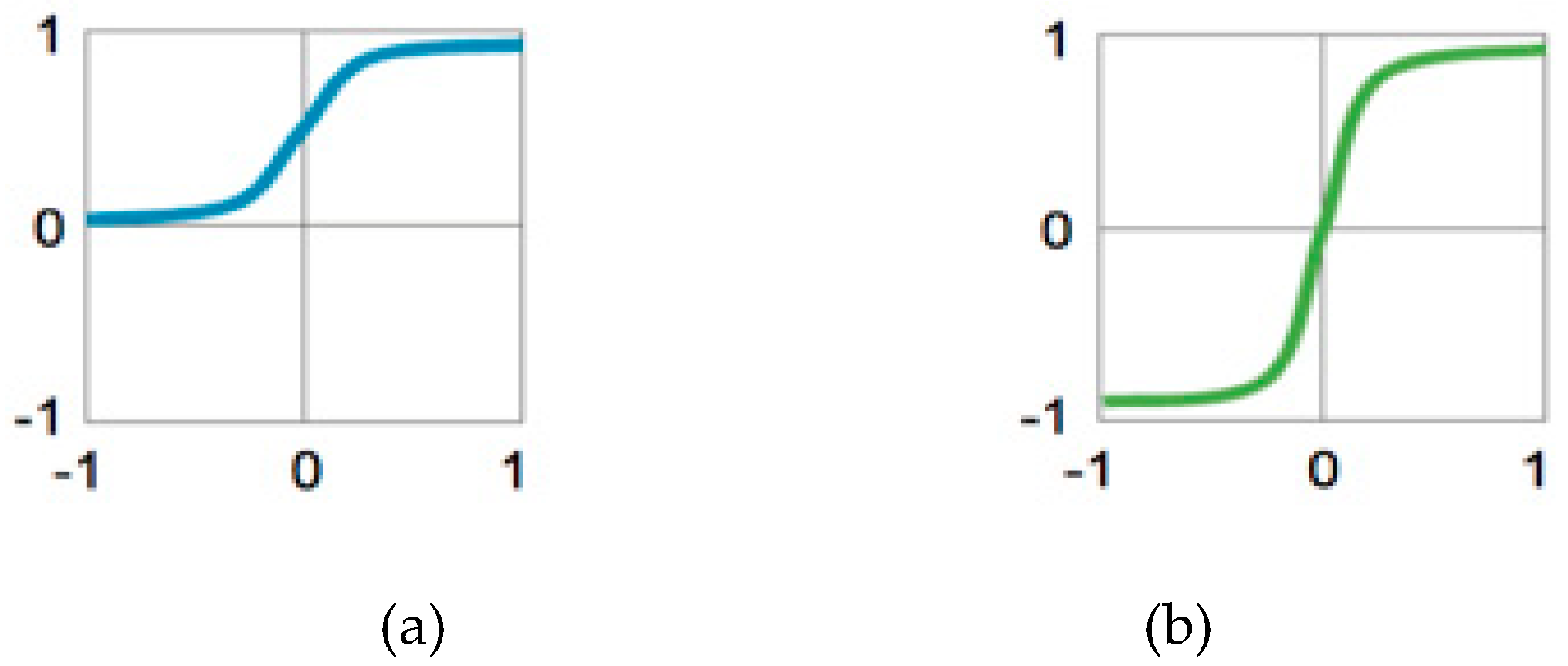{kind=link}
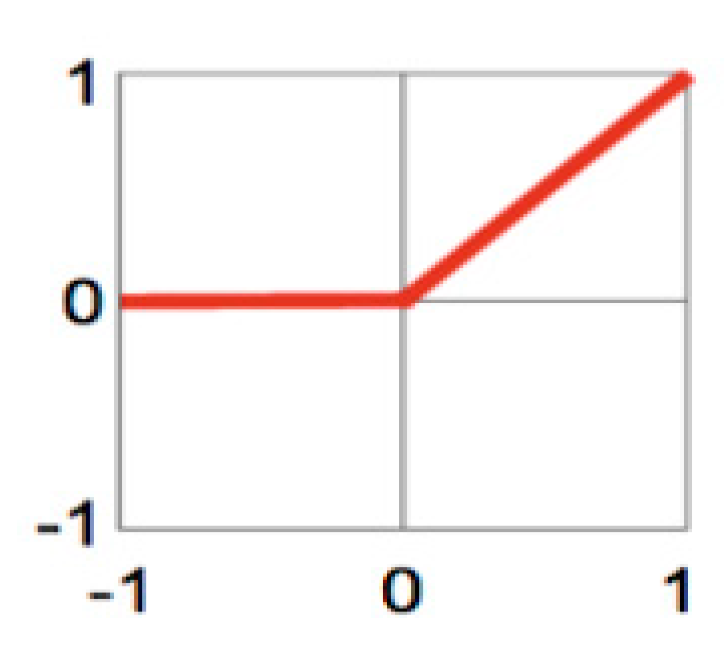{kind=link}
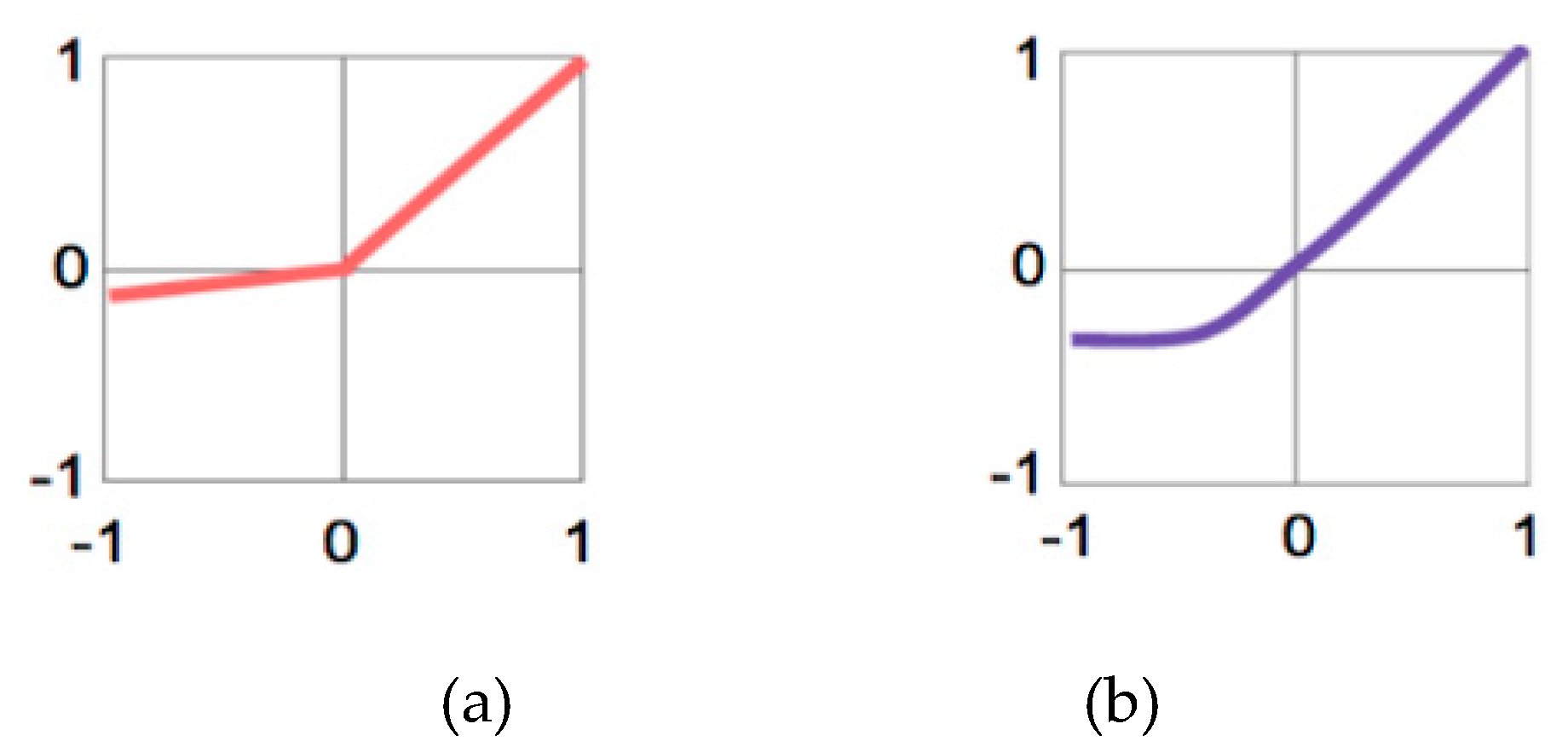{kind=link}
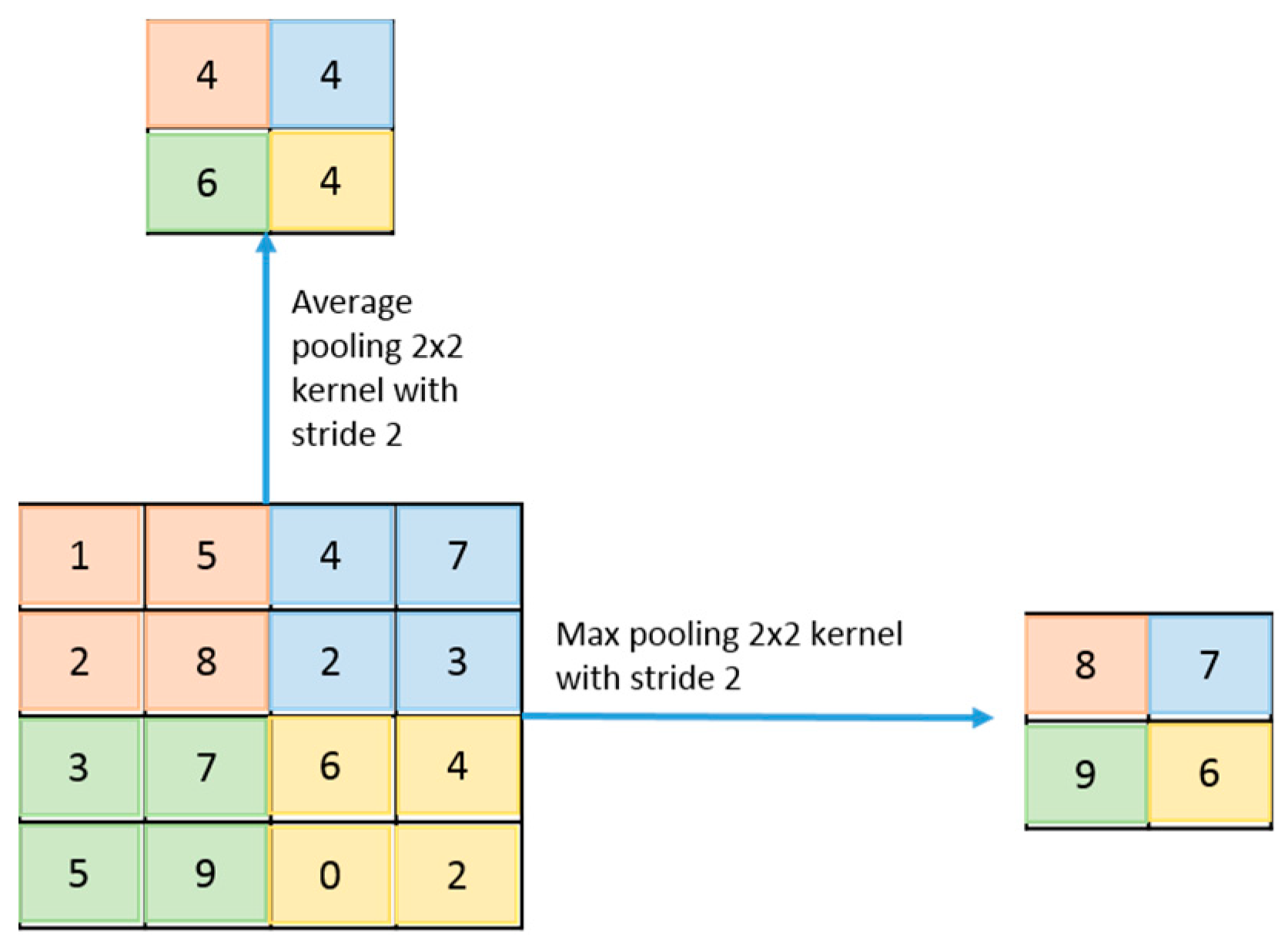{kind=link}
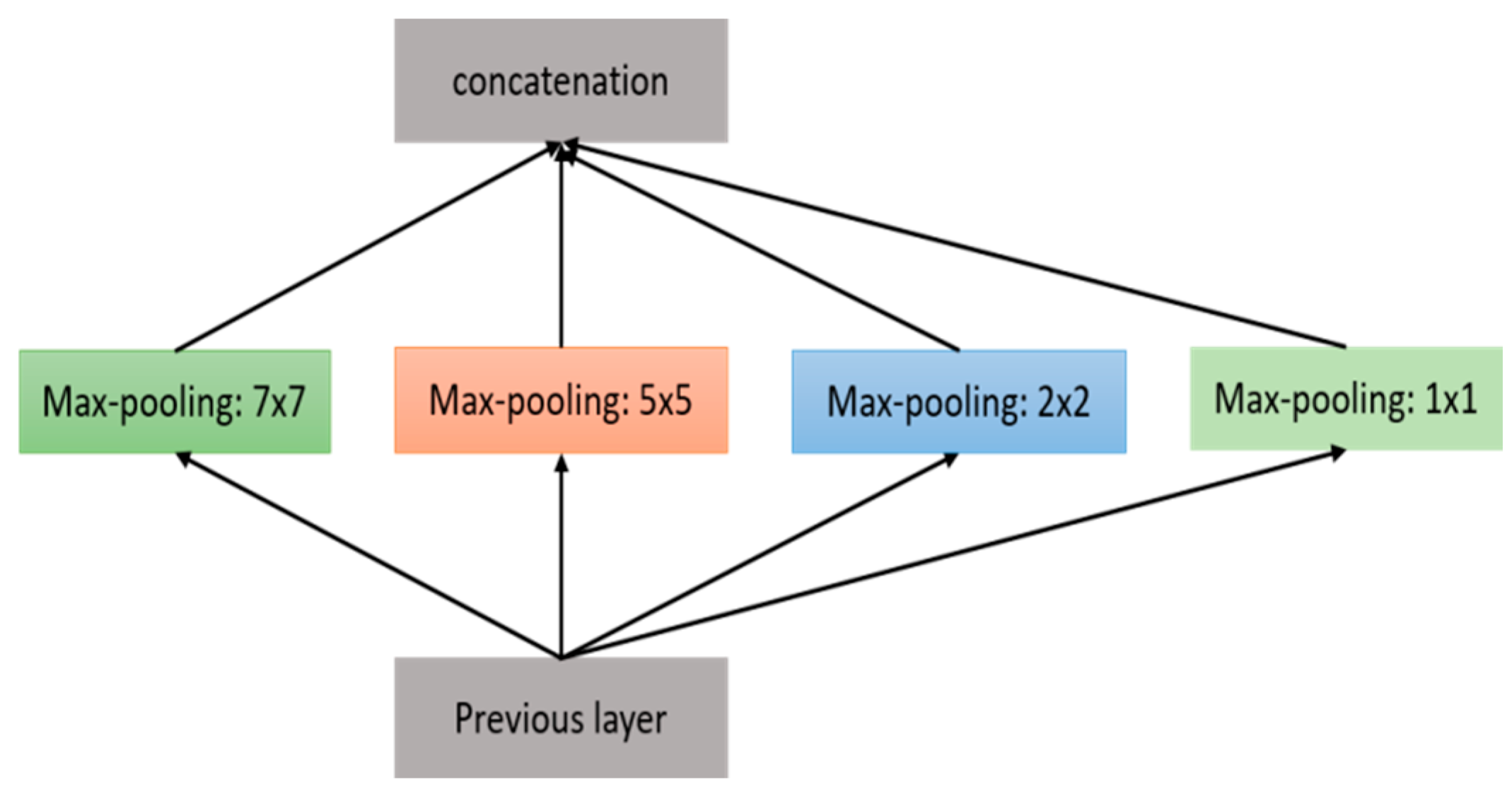{kind=link}
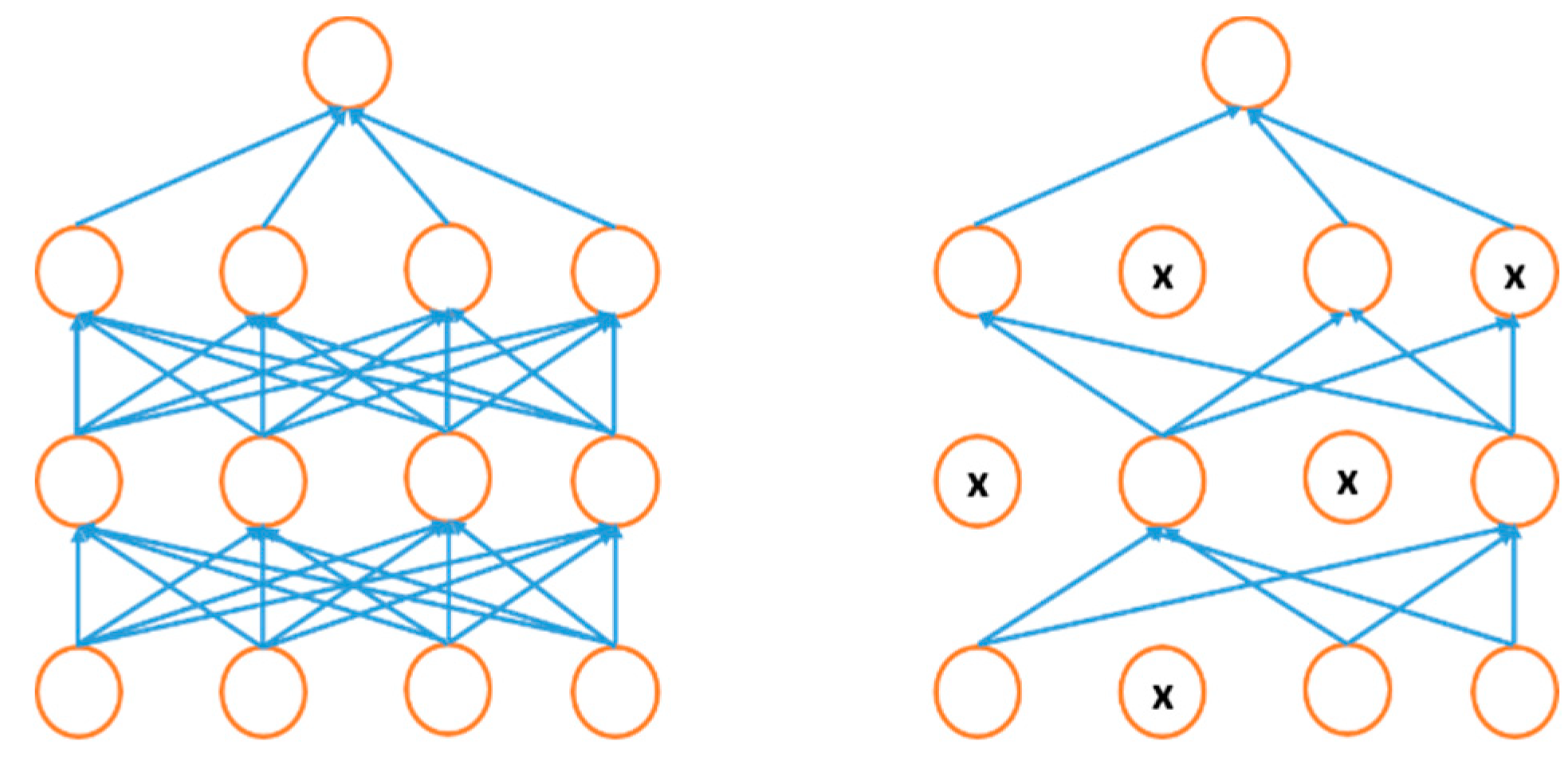{kind=link}
{kind=link}
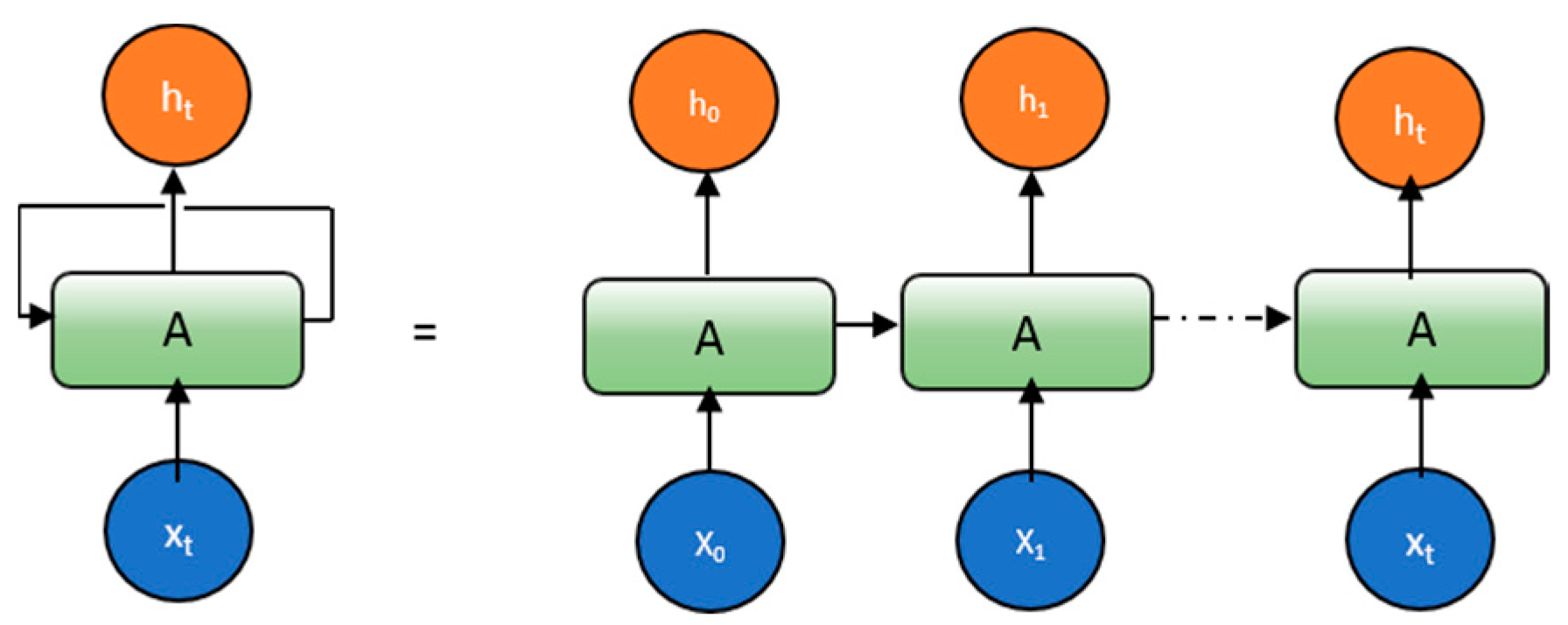{kind=link}
{kind=link}
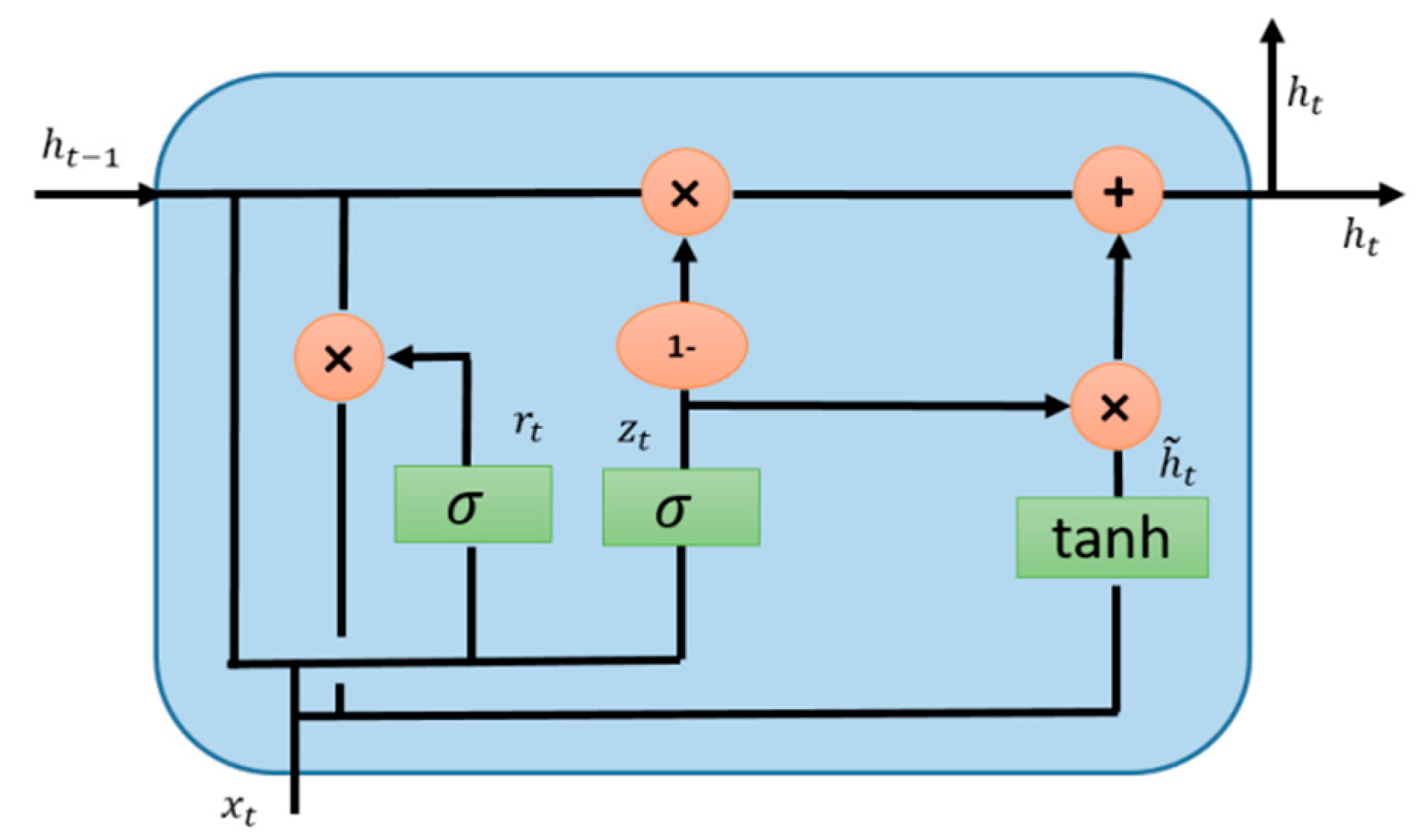{kind=link}
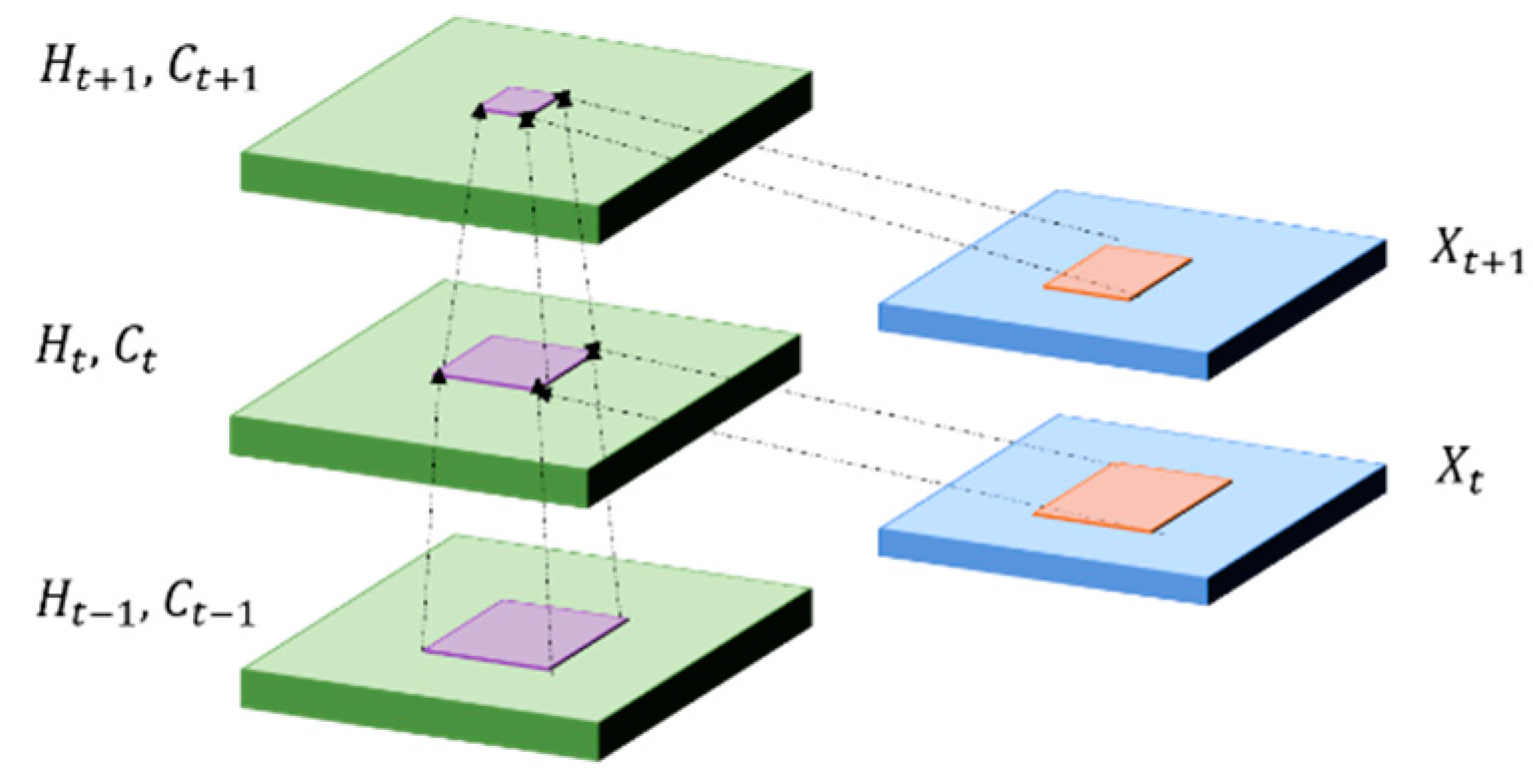{kind=link}
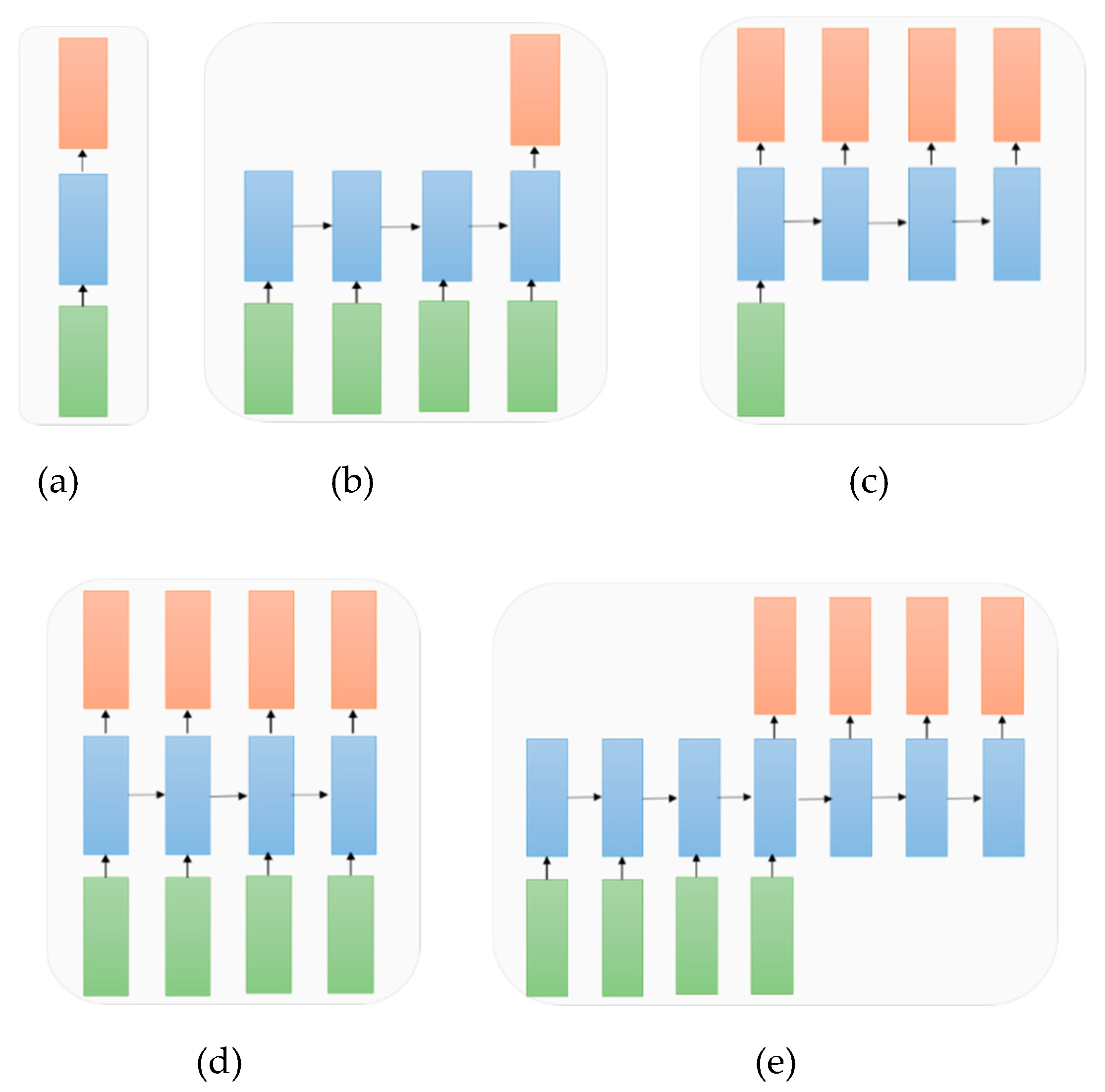{kind=link}
{kind=link}
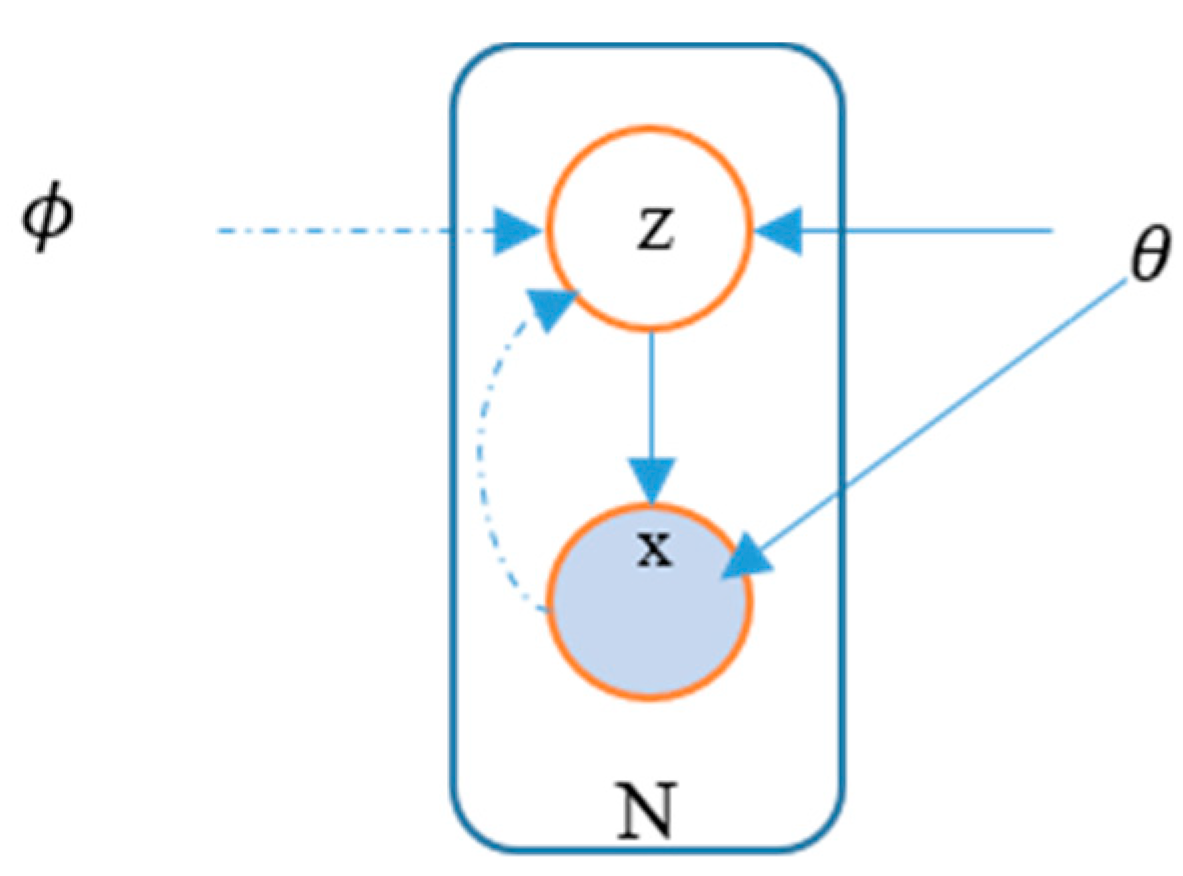{kind=link}
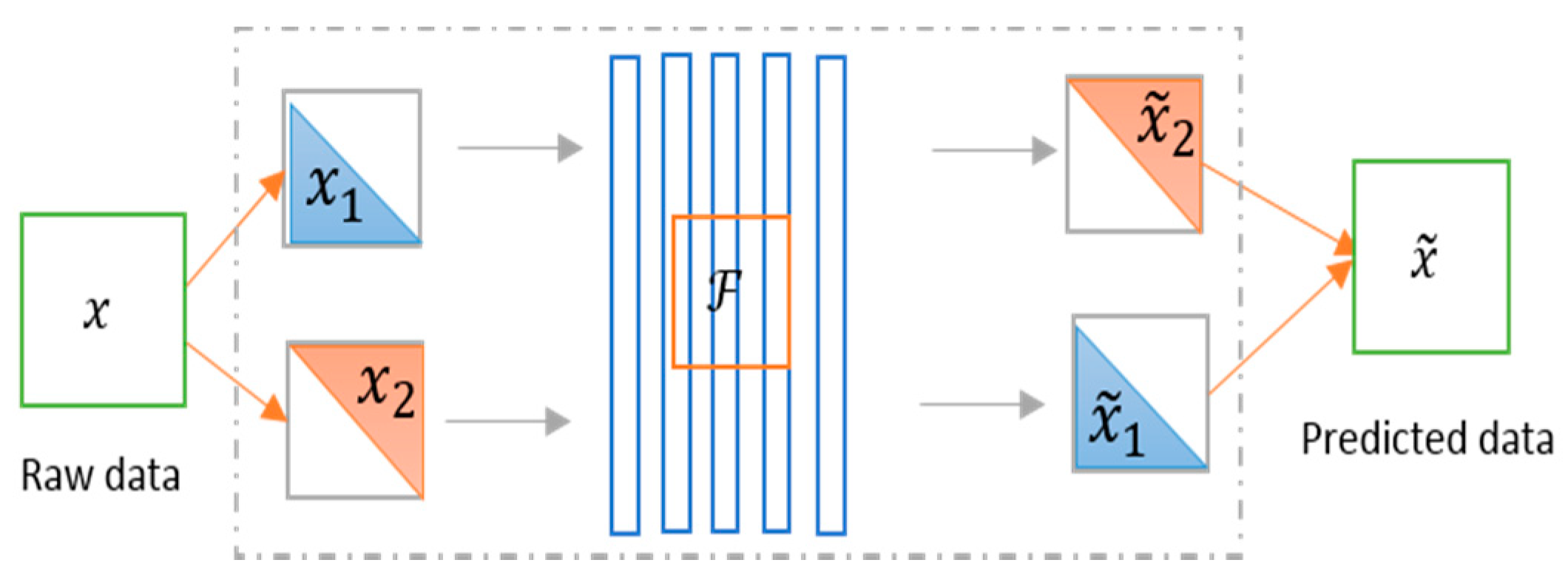{kind=link}
{kind=link}
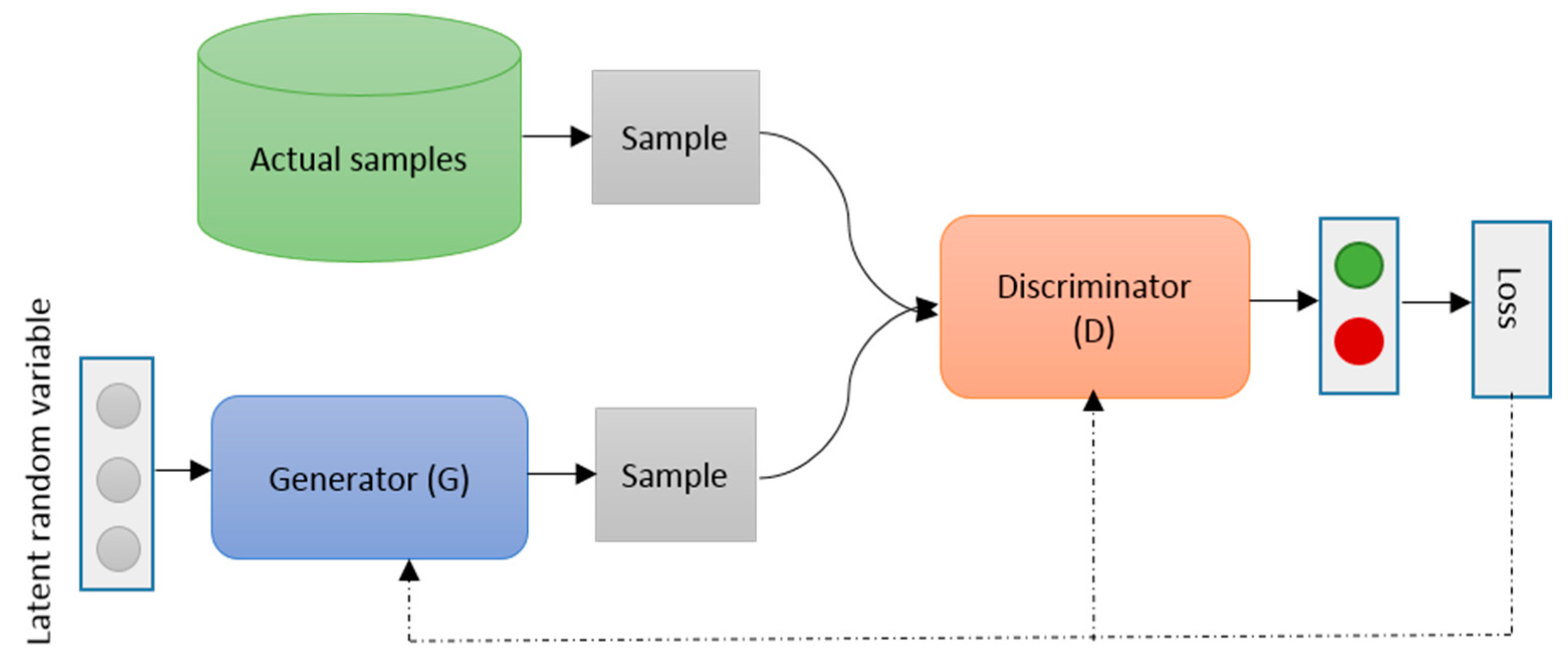{kind=link}
{kind=link}
{kind=link}
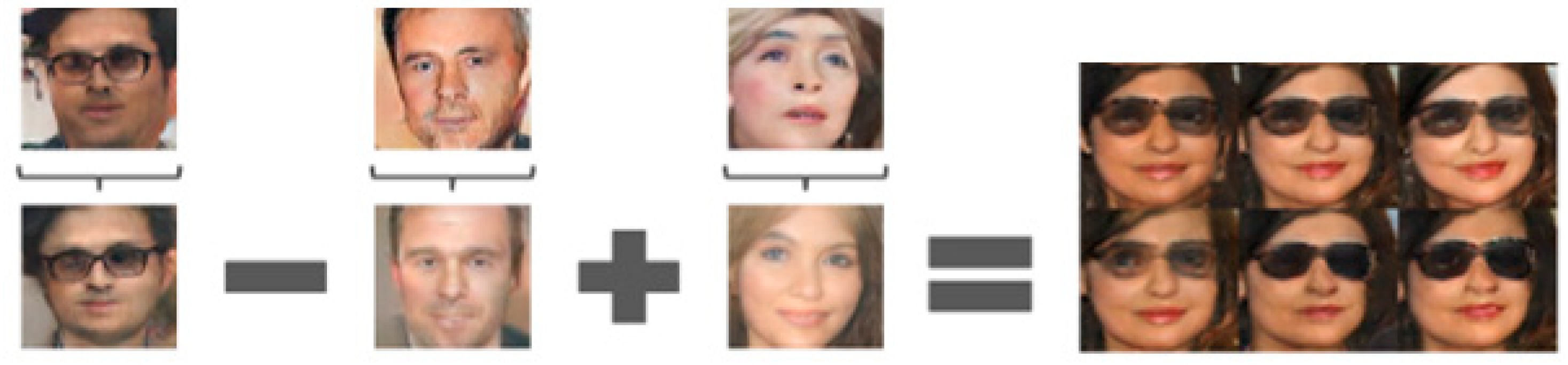{kind=link}
{kind=link}
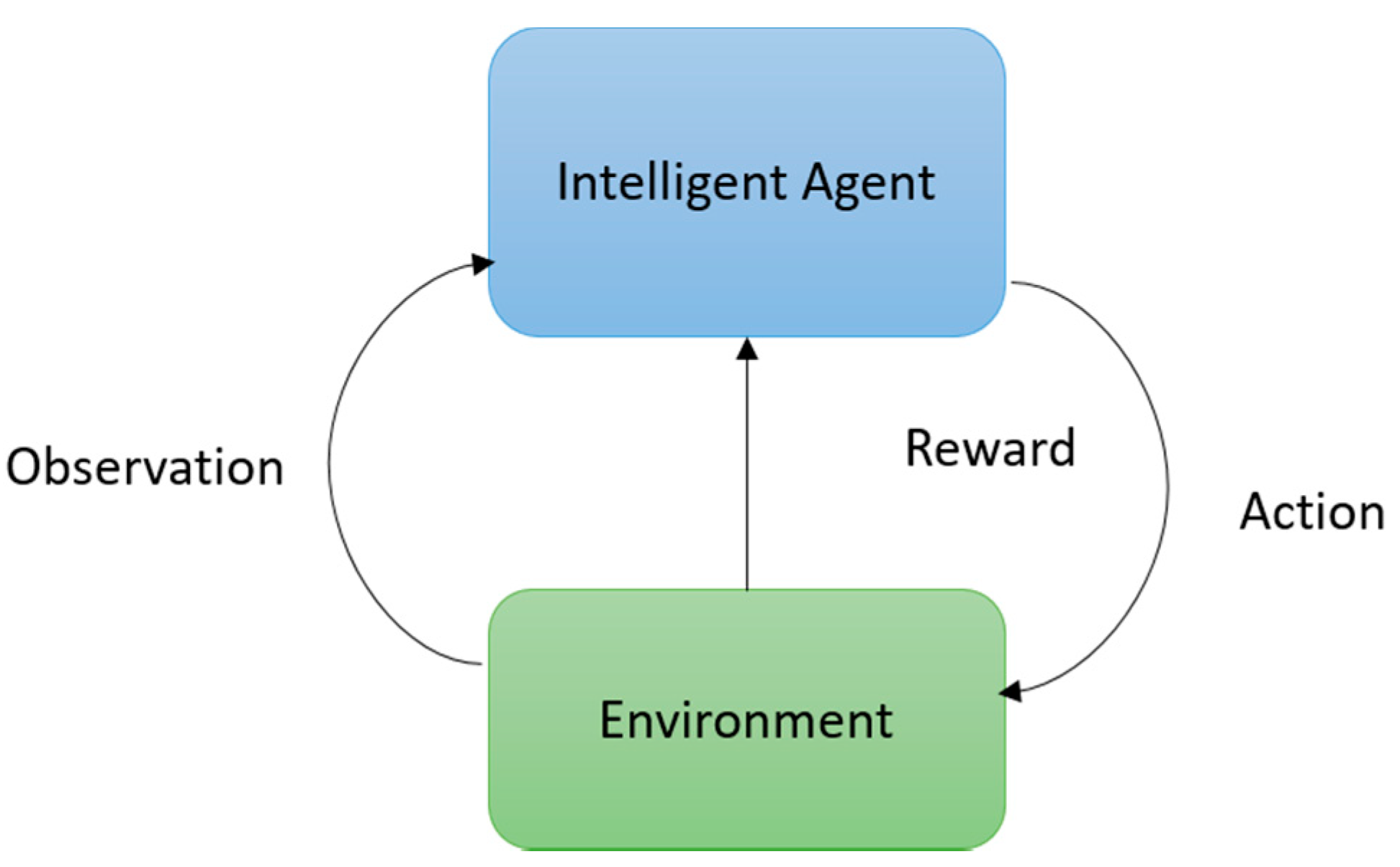{kind=link}
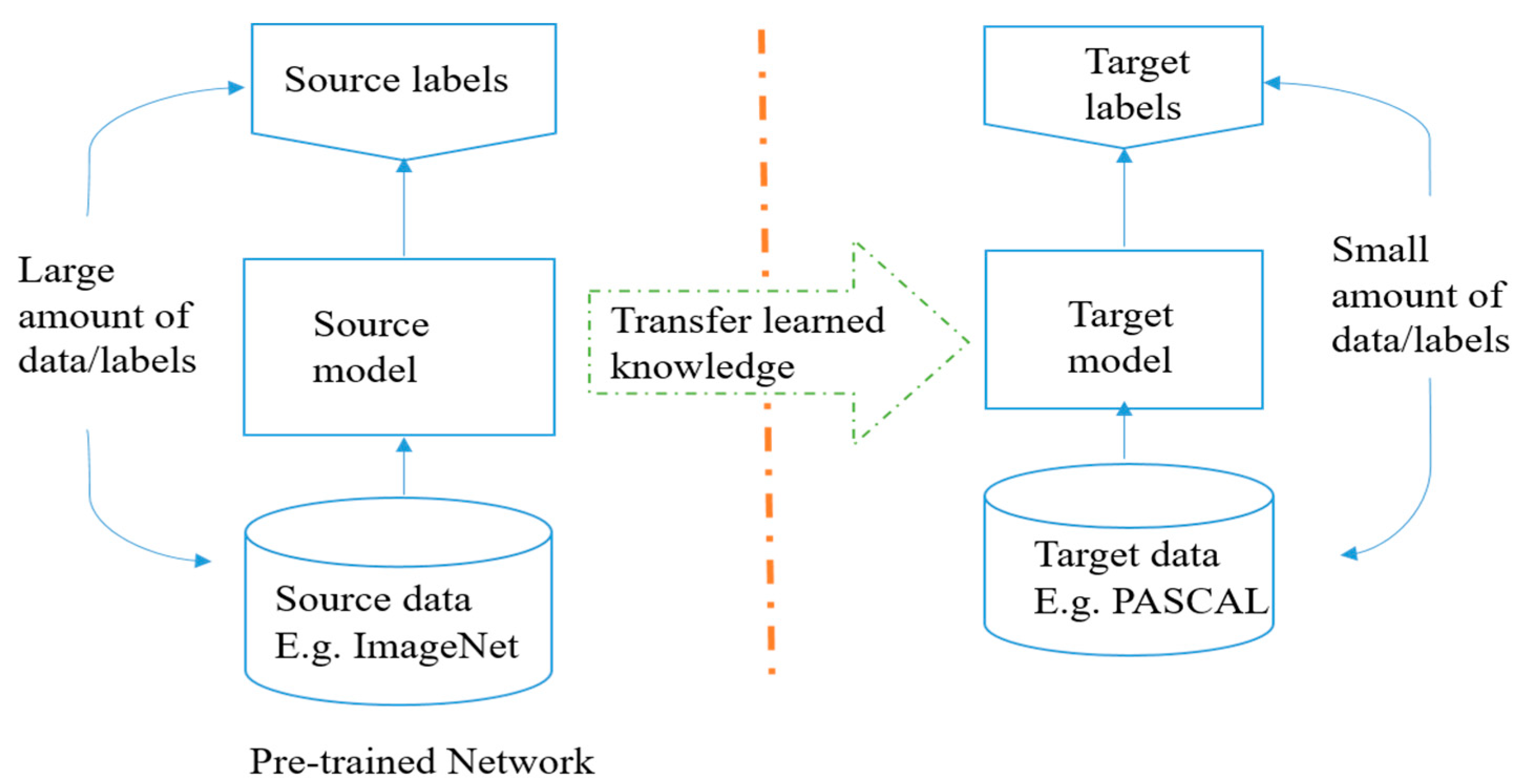{kind=link}
| Approaches | Learning Steps | ||||
|---|---|---|---|---|---|
| Rule-based | Input | Hand-design features | Output | ||
| Traditional Machine Learning | Input | Hand-design features | Mapping from features | Output | |
| Representation Learning | Input | Features | Mapping from features | Output | |
| Deep Learning | Input | Simple features | Complex features | Mapping from features | Output |
| Methods | LeNet-5 [54] | AlexNet [7] | OverFeat (fast) [8] | VGG-16 [9] | GoogLeNet [10] | ResNet-50(v1) [11] |
|---|---|---|---|---|---|---|
| Top-5 errors | n/a | 16.4 | 14.2 | 7.4 | 6.7 | 5.3 |
| Input size | 28 × 28 | 227 × 227 | 231 × 231 | 224 × 224 | 224 × 224 | 224 × 224 |
| Number of Conv Layers | 2 | 5 | 5 | 16 | 21 | 50 |
| Filter Size | 5 | 3,5,11 | 3,7 | 3 | 1,3,5,7 | 1,3,7 |
| Number of Feature Maps | 1,6 | 3–256 | 3–1024 | 3–512 | 3–1024 | 3–1024 |
| Stride | 1 | 1,4 | 1,4 | 1 | 1,2 | 1,2 |
| Number of Weights | 26 k | 2.3 M | 16 M | 14.7 M | 6.0 M | 23.5 M |
| Number of MACs | 1.9 M | 666 M | 2.67 G | 15.3 G | 1.43 G | 3.86 G |
| Number of FC layers | 2 | 3 | 3 | 3 | 1 | 1 |
| Number of Weights | 406 k | 58.6 M | 130 M | 124 M | 1 M | 1 M |
| Number of MACs | 405 k | 58.6 M | 130 M | 124 M | 1 M | 1M |
| Total Weights | 431 k | 61 M | 146 M | 138 M | 7 M | 25.5 M |
| Total MACs | 2.3 M | 724 M | 2.8 G | 15.5 G | 1.43 G | 3.9 G |
| Methods | New Dataset but Small | New Dataset but Large |
|---|---|---|
| Pre-trained model on similar but new dataset | Freeze weights and train linear classifier from top level features | Fine-tune all the layers (pre-train for faster convergence and better generalization) |
| Pre-trained model a on different but new dataset | Freeze weights and train linear classifier from non-top-level features | Fine-tune all the layers (pre-train for enhanced convergence speed) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. https://doi.org/10.3390/electronics8030292
Alom MZ, Taha TM, Yakopcic C, Westberg S, Sidike P, Nasrin MS, Hasan M, Van Essen BC, Awwal AAS, Asari VK. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics. 2019; 8(3):292. https://doi.org/10.3390/electronics8030292
Chicago/Turabian StyleAlom, Md Zahangir, Tarek M. Taha, Chris Yakopcic, Stefan Westberg, Paheding Sidike, Mst Shamima Nasrin, Mahmudul Hasan, Brian C. Van Essen, Abdul A. S. Awwal, and Vijayan K. Asari. 2019. "A State-of-the-Art Survey on Deep Learning Theory and Architectures" Electronics 8, no. 3: 292. https://doi.org/10.3390/electronics8030292
APA StyleAlom, M. Z., Taha, T. M., Yakopcic, C., Westberg, S., Sidike, P., Nasrin, M. S., Hasan, M., Van Essen, B. C., Awwal, A. A. S., & Asari, V. K. (2019). A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics, 8(3), 292. https://doi.org/10.3390/electronics8030292