Angle of Arrival Passive Location Algorithm Based on Proximal Policy Optimization


Abstract
1. Introduction
2. Materials and Methods
2.1. Scenarios
2.2. AoA Passive Location Based on PPO
2.2.1. Traditional AOA Localization Algorithm
2.2.2. Proximal Policy Optimization
2.2.3. Amendment of AOA Measurement Based on PPO
3. Experiment
3.1. Simulation Experiment Parameters
3.2. Simulation and Experimental Analysis
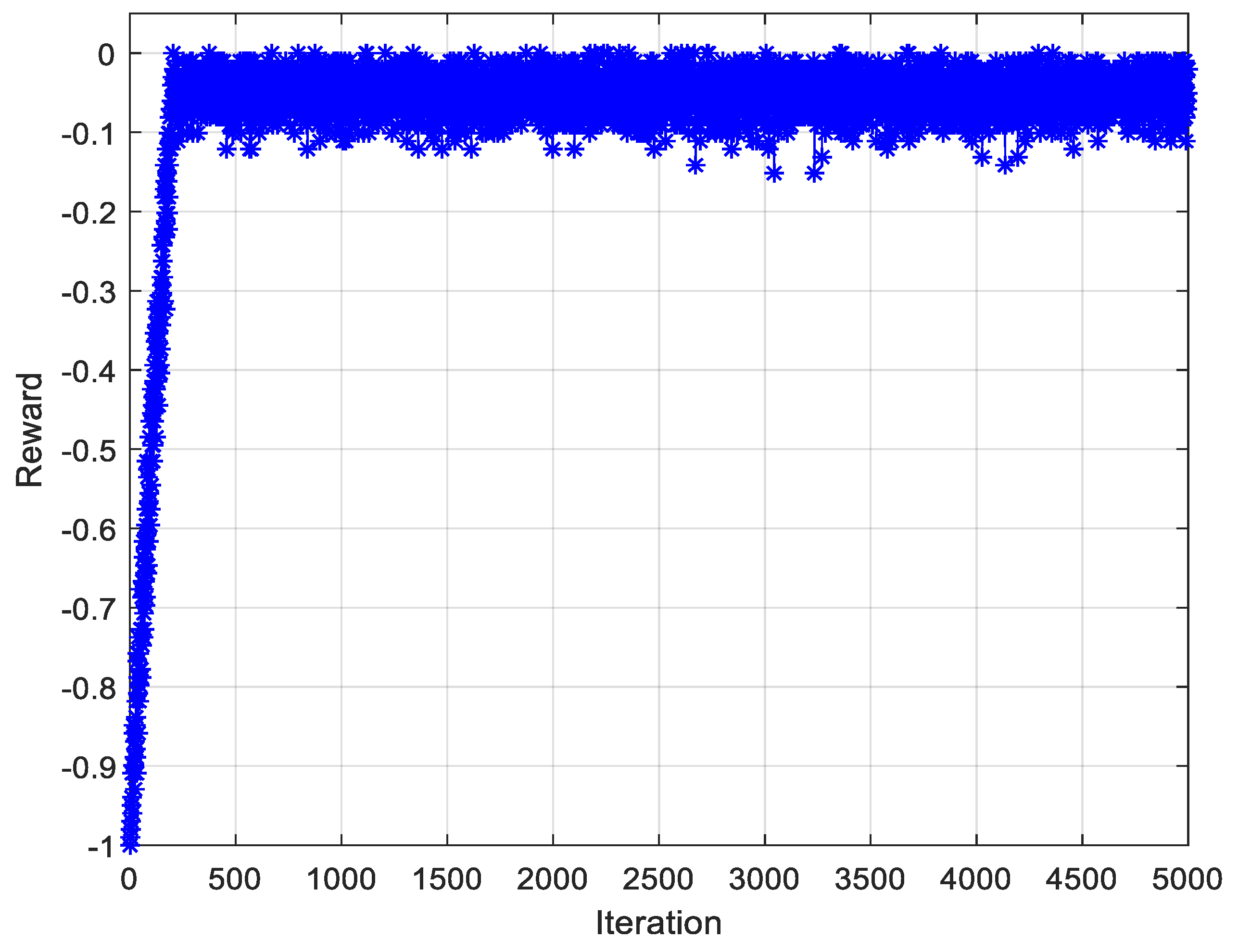
3.2.1. PPO Training
3.2.2. Number of Service Base Stations
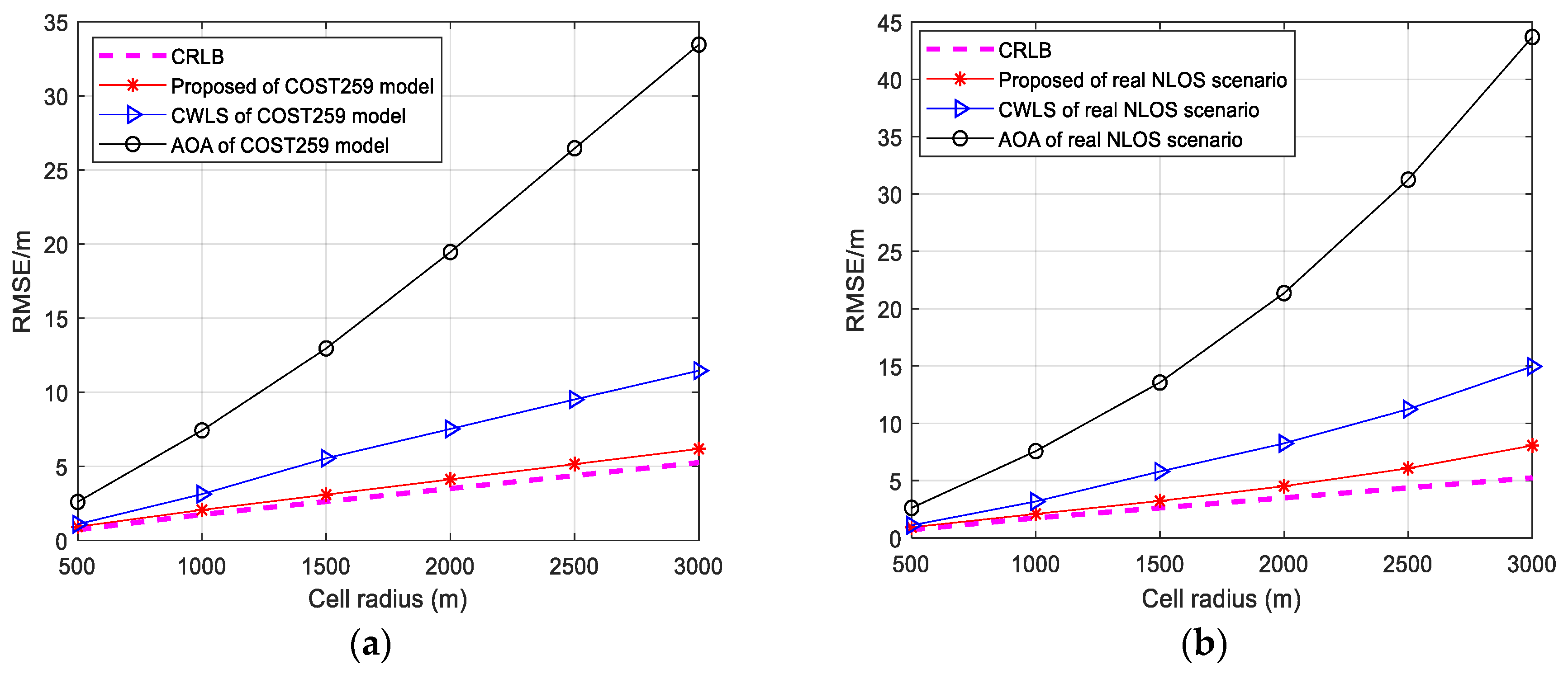
3.2.3. Cell Radius
3.2.4. Channel Environment
3.2.5. MS Velocity
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gazzah, L.; Najjar, L. Enhanced cooperative group localization with identification of LOS/NLOS BSs in 5G dense networks. Ad Hoc Netw. 2019, 89, 88–96. [Google Scholar] [CrossRef]
- Joshi, J.; Grover, N.; Medikonda, P.; Gujral, V. Smart Wireless Communication System for Traffic Management and Localization. In Proceedings of the 6th Glob. Wirel. Summit, GWS 2018, Chiang Rai, Thailand, 25–28 November 2018; pp. 1–5. [Google Scholar]
- Yassin, A.; Nasser, Y.; Awad, M.; Al-Dubai, A.; Liu, R.; Yuen, C.; Raulefs, R.; Aboutanios, E. Recent Advances in Indoor Localization: A Survey on Theoretical Approaches and Applications. IEEE Commun. Surv. Tutor. 2017, 19, 1327–1346. [Google Scholar] [CrossRef]
- Sayed, A.H.; Tarighat, A.; Khajehnouri, N. Network-based wireless location: Challenges faced in developing techniques for accurate wireless location information. IEEE Signal Process. Mag. 2005, 22, 24–40. [Google Scholar] [CrossRef]
- Güvenç, I.; Chong, C.C. A survey on TOA based wireless localization and NLOS mitigation techniques. IEEE Commun. Surv. Tutor. 2009, 11, 107–124. [Google Scholar] [CrossRef]
- Doğançay, K.; Hmam, H. Optimal angular sensor separation for AOA localization. Signal Process. 2008, 88, 1248–1260. [Google Scholar] [CrossRef]
- Shen, J.; Molisch, A.F.; Salmi, J. Accurate Passive Location Estimation Using TOA Measurements. IEEE Trans. Wirel. Commun. 2012, 11, 2182–2192. [Google Scholar] [CrossRef]
- Dersan, A.; Tanik, Y. Passive radar localization by time difference of arrival. In Proceedings of the IEEE Military Communications Conference MILCOM, IEEE, Anaheim, CA, USA, 7–10 October 2002; Volume 2, pp. 1251–1257. [Google Scholar]
- Echigo, H.; Ohtsuki, T.; Jiang, W.; Takatori, Y. Fair pilot assignment based on AOA and pathloss with location information in massive MIMO. In Proceedings of the GLOBECOM 2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Tang, H.; Park, Y.; Qiu, T. A TOA-AOA-based NLOS error mitigation method for location estimation. EURASIP J. Adv. Signal Process. 2007, 2008, 682528. [Google Scholar] [CrossRef]
- Zhang, V.Y.; Wong, A.K.S. Combined AOA and TOA NLOS localization with nonlinear programming in severe multipath environments. In Proceedings of the 2009 IEEE Wireless Communications and Networking Conference, Budapest, Hungary, 5–8 April 2009; pp. 1–6. [Google Scholar]
- Wang, F.; Liu, X. Empirical Analysis of TOA and AOA in Hybrid Location Positioning Techniques. IOP Conf. Ser. 2018, 466, 012089. [Google Scholar] [CrossRef]
- Bianchi, V.; Ciampolini, P.; De Munari, I. RSSI-Based Indoor Localization and Identification for ZigBee Wireless Sensor Networks in Smart Homes. IEEE Trans. Instrum. Meas. 2019, 68, 566–575. [Google Scholar] [CrossRef]
- Hua, J.; Yin, Y.; Lu, W.; Zhang, Y.; Li, F. NLOS identification and positioning algorithm based on localization residual in wireless sensor networks. Sensors 2018, 18, 2991. [Google Scholar] [CrossRef]
- Koledoye, M.A.; Facchinetti, T.; Almeida, L. Mitigating effects of NLOS propagation in MDS-based localization with anchors. In Proceedings of the 2018 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Torres Vedras, Portugal, 25–27 April 2018; pp. 148–153. [Google Scholar]
- Shikur, B.Y.; Weber, T. Tdoa/aod/aoa localization in nlos environments. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6518–6522. [Google Scholar]
- Li, Y.-Y.; Qi, G.-Q.; Sheng, A.-D. Performance metric on the best achievable accuracy for hybrid TOA/AOA target localization. IEEE Commun. Lett. 2018, 22, 1474–1477. [Google Scholar] [CrossRef]
- Zhang, Y.; Yanbiao, X.I.; Gangwei, L.I.; Zhao, K. TDOA/AOA hybrid positioning algorithm based on Kalman filter in NLOS environment. Comput. Eng. Appl. 2015, 2015, 13. [Google Scholar]
- Tian, X.; Yin, J. Position Location Estimation Algorithms for Mobile Station in NLOS Propagation Environment. In Proceedings of the 2018 Joint International Advanced Engineering and Technology Research Conference (JIAET 2018), Xi’an, China, 26–27 May 2018; Atlantis Press: Paris, France, 2018; Volume 137, pp. 272–277. [Google Scholar]
- Hua, J.; Yin, Y.; Wang, A.; Zhang, Y.; Lu, W. Geometry-based non-line-of-sight error mitigation and localization in wireless communications. Sci. China Inf. Sci. 2019, 62, 1–15. [Google Scholar] [CrossRef]
- Wang, Y.; Hang, J.; Cheng, L.; Li, C.; Song, X. A hierarchical voting based mixed filter localization method for wireless sensor network in mixed LOS/NLOS environments. Sensors 2018, 18, 2348. [Google Scholar] [CrossRef]
- Cheng, C.; Hu, W.; Tay, W.P. Localization of a moving non-cooperative RF target in NLOS environment using RSS and AOA measurements. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; pp. 3581–3585. [Google Scholar]
- Yu, H.; Huang, G.; Gao, J.; Liu, B. An efficient constrained weighted least squares algorithm for moving source location using TDOA and FDOA measurements. IEEE Trans. Wirel. Commun. 2011, 11, 44–47. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Mao, S. CiFi: Deep convolutional neural networks for indoor localization with 5 GHz Wi-Fi. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017. [Google Scholar]
- Wu, G.S.; Tseng, P.H. A Deep Neural Network-Based Indoor Positioning Method using Channel State Information. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 290–294. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Hämäläinen, P.; Babadi, A.; Ma, X.; Lehtinen, J. PPO-CMA: Proximal Policy Optimization with Covariance Matrix Adaptation. arXiv 2018, arXiv:1810.02541. [Google Scholar]
- Chen, G.; Peng, Y.; Zhang, M. An Adaptive Clipping Approach for Proximal Policy Optimization. arXiv 2018, arXiv:1804.06461. [Google Scholar]
- Lee, K.; Oh, J.; You, K. TDOA/AOA based geolocation using Newton method under NLOS environment. In Proceedings of the 2016 IEEE International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), ChengDu, China, 5–7 July 2016; pp. 373–377. [Google Scholar]
- Aghaie, N.; Tinati, M.A. Localization of WSN nodes based on NLOS identification using AOAs statistical information. In Proceedings of the 2016 24th Iranian Conference on Electrical Engineering (ICEE), Shiraz, Iran, 10–12 May 2016; pp. 496–501. [Google Scholar]
- Yu, K.; Bengtsson, M.; Ottersten, B.; McNamara, D.; Karlsson, P.; Beach, M. A wideband statistical model for NLOS indoor MIMO channels. In Proceedings of the Vehicular Technology Conference, IEEE 55th Vehicular Technology Conference, VTC Spring 2002 (Cat. No.02CH37367), Birmingham, AL, USA, 6–9 May 2002; pp. 370–374. [Google Scholar]
- Aziz, M.A.; Allen, C.T. Experimental Results of a Differential Angle-of-Arrival Based 2D Localization Method Using Signals of Opportunity. Int. J. Navig. Obs. 2018, 2018. [Google Scholar] [CrossRef]
- Cheung, K.W.; So, H.-C.; Ma, W.-K.; Chan, Y.-T. A constrained least squares approach to mobile positioning: Algorithms and optimality. EURASIP J. Adv. Signal Process. 2006, 2006, 20858. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Performance Index | Value |
|---|---|---|
| 1 | Number of multi-input multi-output (MIMO) transmitting antennas | 4 |
| 2 | Number of MIMO receiving antennas | 4 |
| 3 | Number of service base stations | 4 |
| 4 | Position of service base stations | (0,0) |
| 5 | Number of Moblie Station (MS) | 1000 |
| 6 | Initial position of MS | Random distribution in 400 × 400 region |
| 8 | Observation period | 1 s |
| 9 | Cellradius | 2500 m |
| 10 | Distribution of AOA error | Gaussian(0,0.04) |
| 11 | Channel model | COST259 model |
| 12 | Number of training data | 10000 sets of training data from COST259 model |
| 13 | Number of testing data | 1000 sets of testing data from actual NLOS scenario |
| - | - | 5000 sets of testing data from COST259 model |
| 14 | Number of Monte Carlo cycles | 1000 |
| No. | Performance Index | Value |
|---|---|---|
| 1 | PPO training iteration number | 5000 |
| 2 | Actor learning rate | 0.0001 |
| 3 | Critic learning rate | 0.0002 |
| 4 | Actor iteration number | 10 |
| 5 | Critic iteration number | 10 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Deng, Z.; Gao, Y. Angle of Arrival Passive Location Algorithm Based on Proximal Policy Optimization. Electronics 2019, 8, 1558. https://doi.org/10.3390/electronics8121558
Zhang Y, Deng Z, Gao Y. Angle of Arrival Passive Location Algorithm Based on Proximal Policy Optimization. Electronics. 2019; 8(12):1558. https://doi.org/10.3390/electronics8121558
Chicago/Turabian StyleZhang, Yao, Zhongliang Deng, and Yuhui Gao. 2019. "Angle of Arrival Passive Location Algorithm Based on Proximal Policy Optimization" Electronics 8, no. 12: 1558. https://doi.org/10.3390/electronics8121558
APA StyleZhang, Y., Deng, Z., & Gao, Y. (2019). Angle of Arrival Passive Location Algorithm Based on Proximal Policy Optimization. Electronics, 8(12), 1558. https://doi.org/10.3390/electronics8121558