PFDLIS: Privacy-Preserving and Fair Deep Learning Inference Service under Publicly Verifiable Covert Security Setting


Abstract
1. Introduction
1.1. Our Contribution
- Security:Our scheme protects the private input data of the client as well as the pre-trained model of the server. Also, the workers do not need to worry about being framed. Moreover, we do not need to assume that the server would not collude with any one of the workers or the client would not collude with any one of the workers. Cheating behaviours will be caught and be publicly verifiable so that our scheme can act as a deterrent to misbehaviours.
- Accuracy:Our scheme provides identical inference accuracy to the pre-trained deep learning model. That is to say, after secure sharing the pre-trained model and implementing inference based on secure three-party computation in our scheme, the model accuracy does not decrease.
- Efficiency:Since we just utilize simple and technically mature hash function and RSA signature, the extra computational cost of our scheme is acceptable compared to the existing SMPC-based scheme.
1.2. Organization of This Paper
2. Related Work
2.1. Model Training
2.1.1. HE-Based Methods
2.1.2. SMPC-Based Methods
2.2. Inference
2.3. Summary
3. Preliminaries and Problem Definition
3.1. Preliminaries
3.1.1. Publicly Verifiable Covert (PVC) security
3.1.2. Secure Multi-Party Computation
3.1.3. Deep Learning Inference Service
3.2. Problem Definition
4. Our Scheme
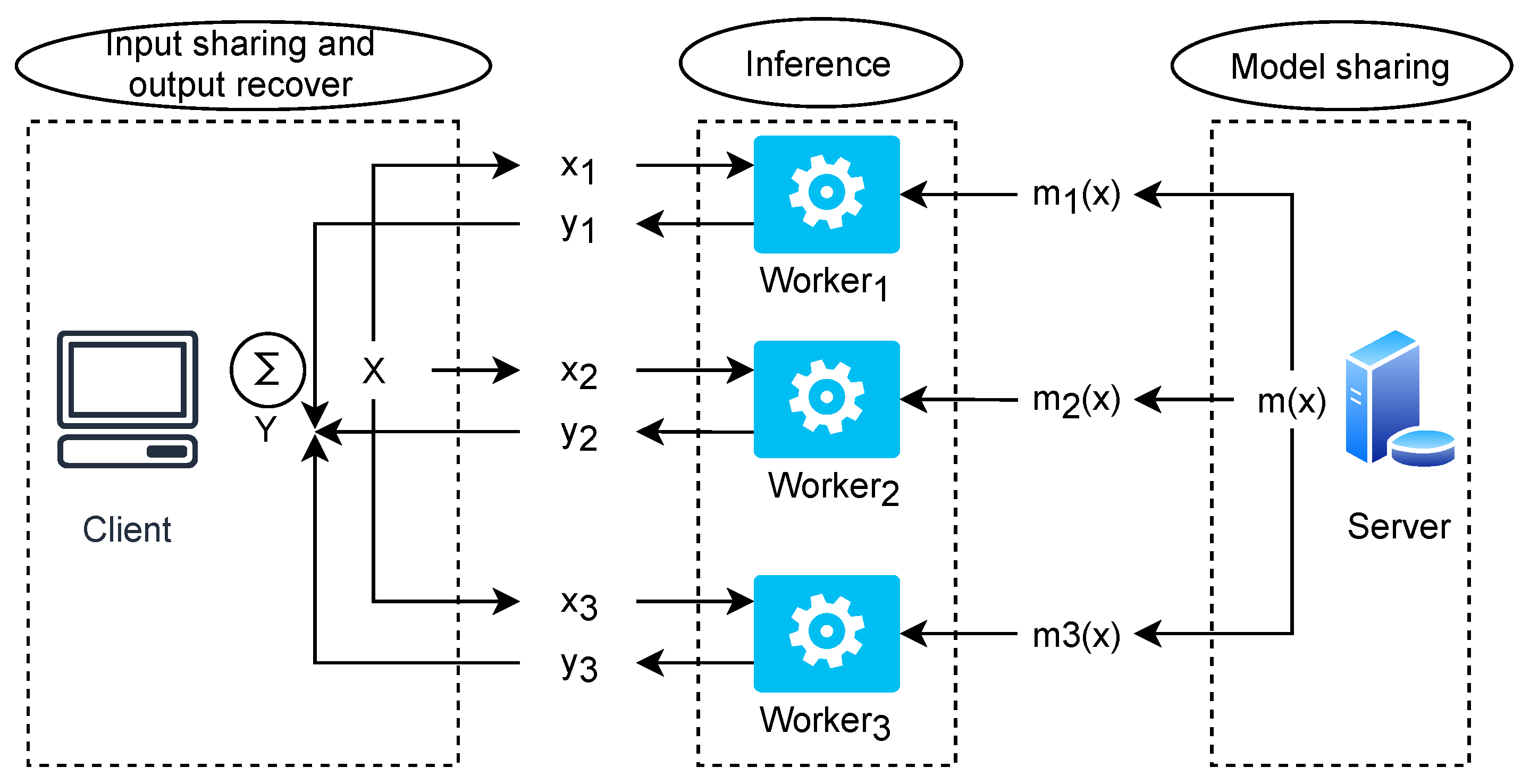
4.1. System Architecture
4.2. Scheme Description
4.2.1. Input Data Preparation
4.2.2. Model preparation
4.2.3. Inference Based on 3PC
4.2.4. Output Recovery and Check
4.2.5. Cheat Forensics and Punishment
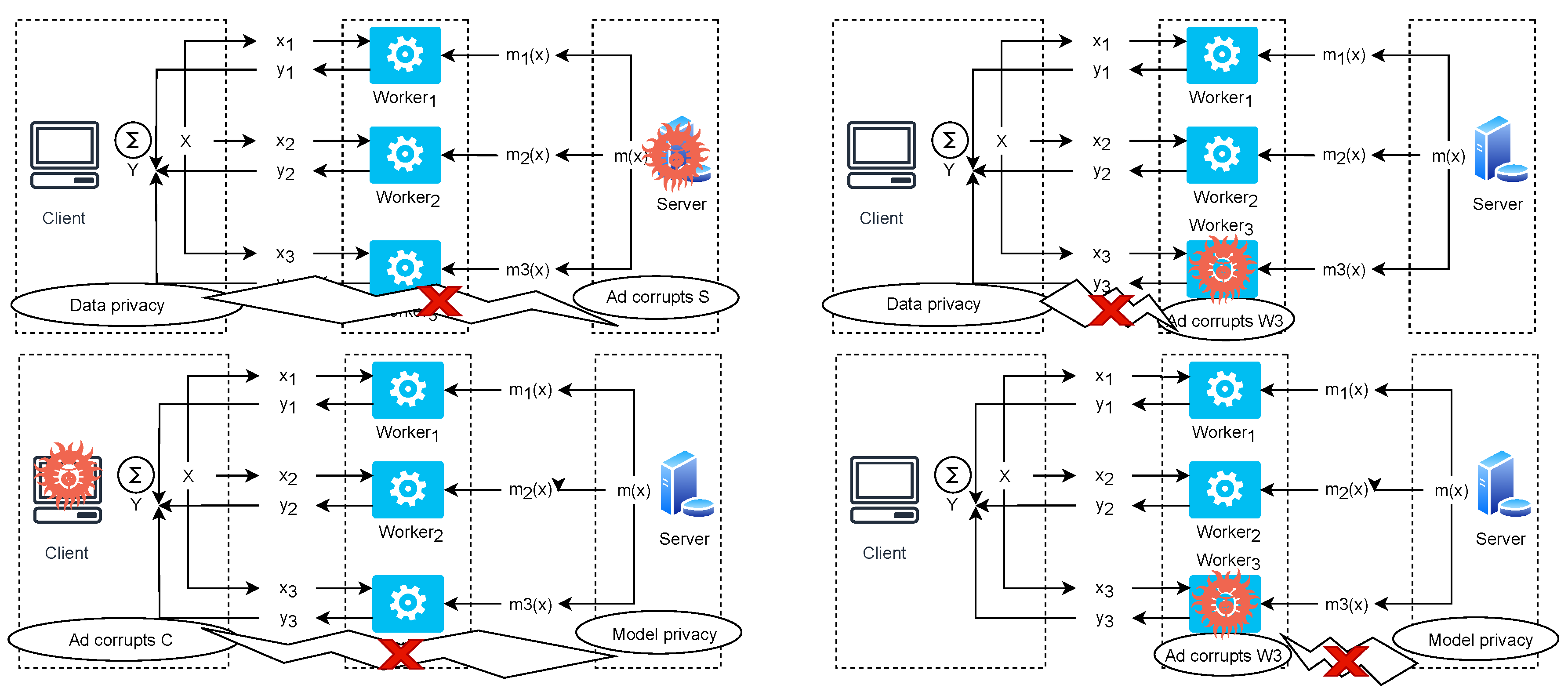
5. Security Analysis
5.1. Input Data Privacy
5.1.1. Corrupts Server S
5.1.2. Corrupts Worker
5.2. Model Privacy
5.2.1. Corrupts Client C
5.2.2. Corrupts Worker
5.3. Defamation Freeness
6. Performance Evaluations
6.1. Theoretical Evaluations
6.2. Empirical Evaluations
6.2.1. Experimental Settings
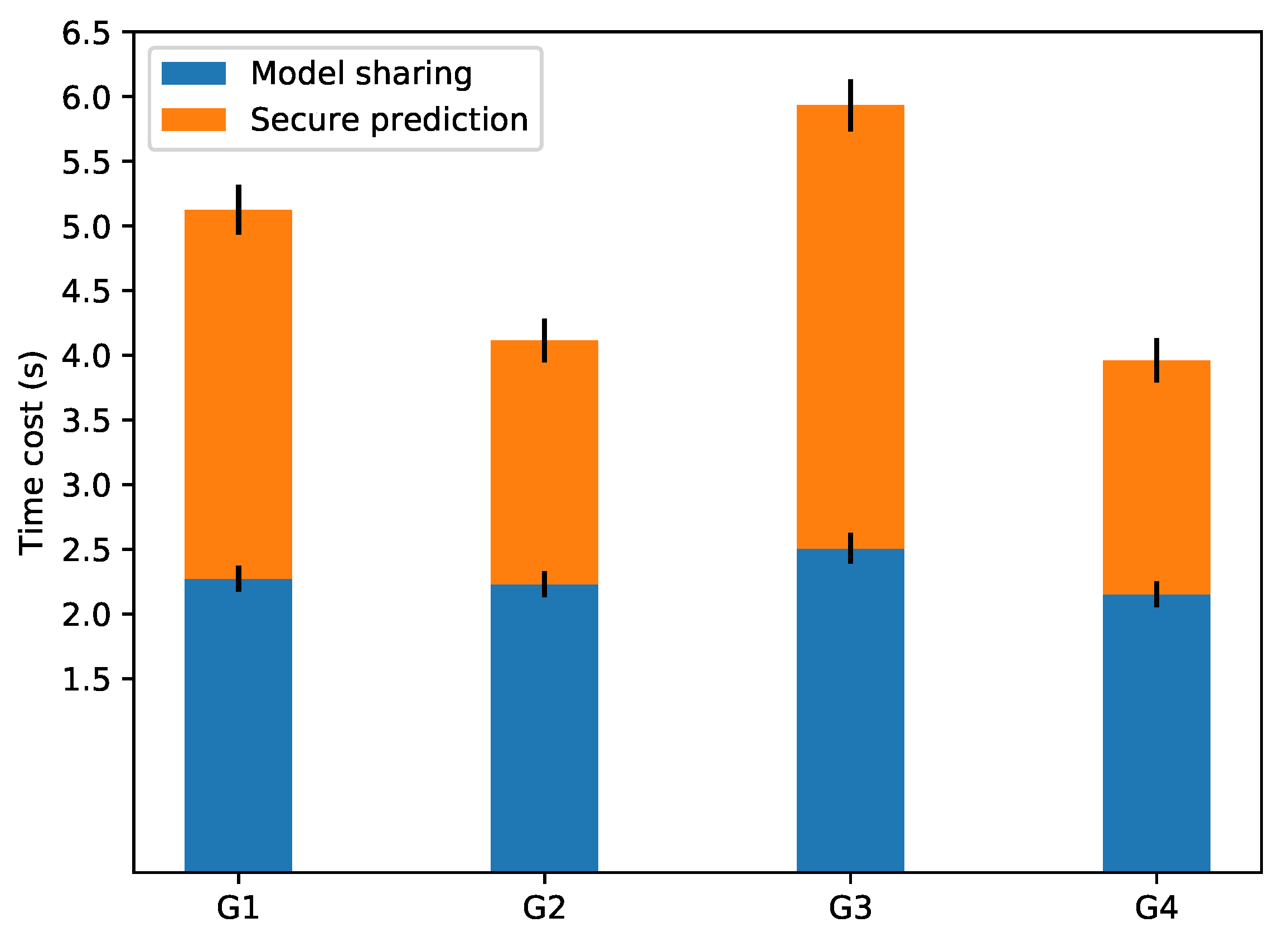
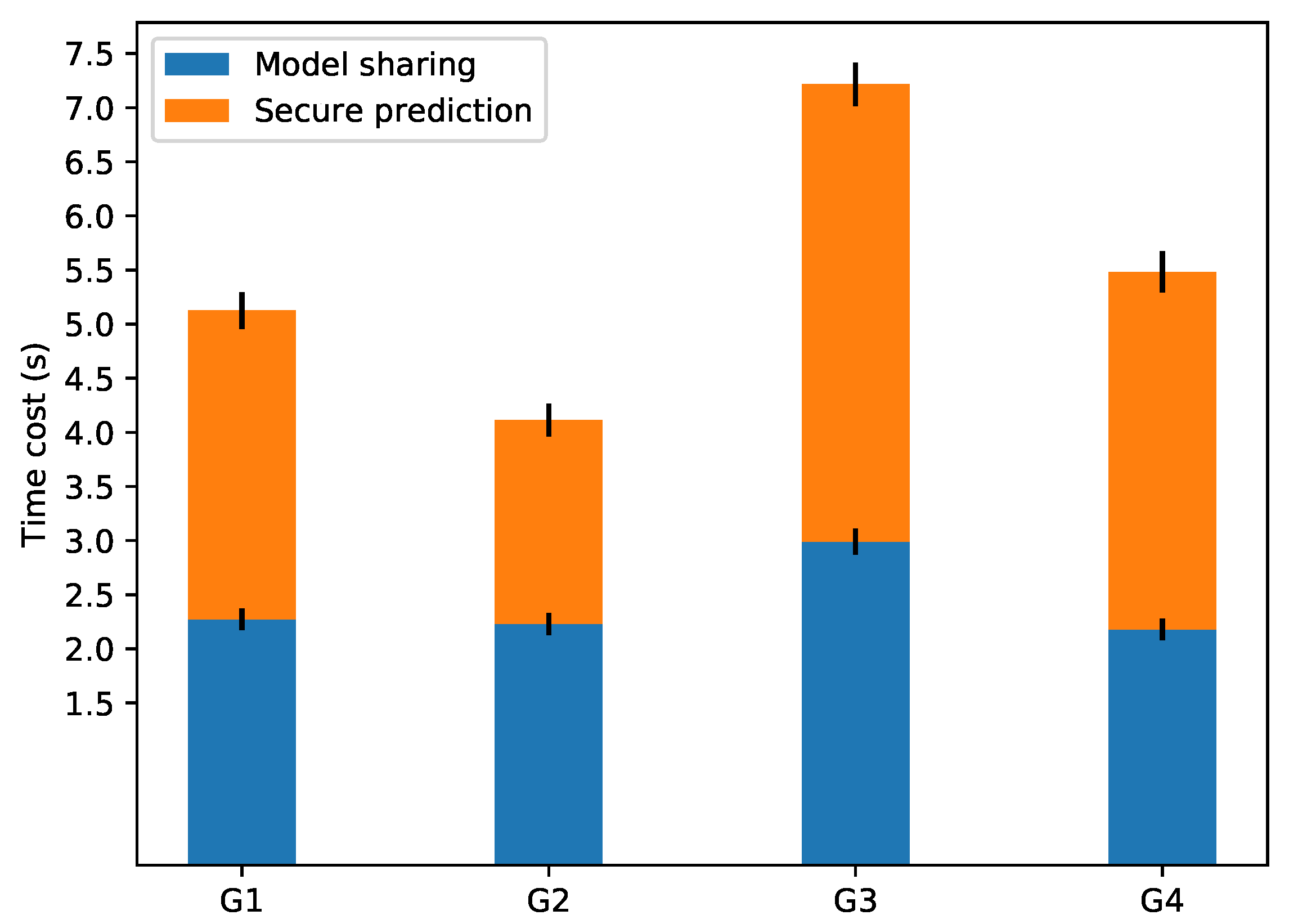
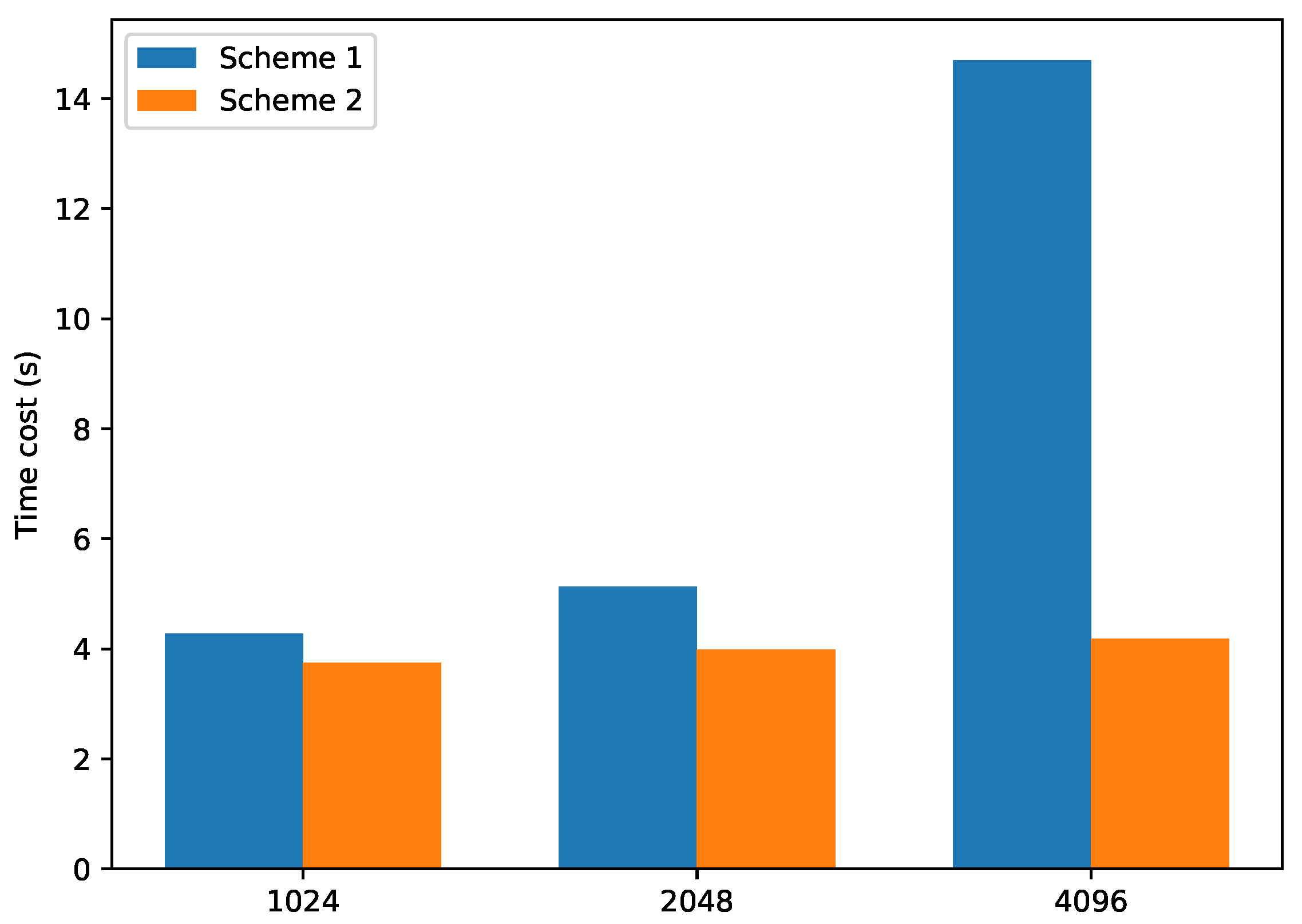
6.2.2. Experimental Results
6.3. Summary
7. Conclusions and Future Work
7.1. Conclusions
7.2. Limits and Suggestions for Future Works
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| C | the client (data provider and service consumer) |
| S | the server (model provider) |
| three workers (computation implementers) | |
| the input data set that client C holds | |
| k | the number of test cases |
| test cases data set | |
| the labels of | |
| m | the number of input data items that C shares |
| the index of test case | |
| the corresponding label of test case | |
| the commitment of the shared data | |
| the signature of input of C | |
| the hash value of input | |
| the operation of concatenate strings | |
| the model accuracy threshold | |
| the commitment of the shared model | |
| the parameter values of the shared model | |
| the inference result obtains | |
| the shared input data worker gets | |
| intermediate inference result | |
| n | the number of test cases judged correctly |
| the recovered output of inference | |
| a malicious adversary | |
| a simulator set to simulate in the ideal world | |
| Scheme 1 | our scheme |
| Scheme 2 | scheme proposed in Reference [31] |
| pre-trained model accuracy | |
| the key length of RSA signature |
References
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Chen, H.; Engkvist, O.; Wang, Y.; Olivecrona, M.; Blaschke, T. The rise of deep learning in drug discovery. Drug Discov. Today 2018, 23, 1241–1250. [Google Scholar] [CrossRef] [PubMed]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef] [PubMed]
- Rajkomar, A.; Oren, E.; Chen, K.; Dai, A.M.; Hajaj, N.; Hardt, M.; Liu, P.J.; Liu, X.; Marcus, J.; Sun, M.; et al. Scalable and accurate deep learning with electronic health records. NPJ Digit. Med. 2018, 1, 18. [Google Scholar] [CrossRef] [PubMed]
- Ching, T.; Himmelstein, D.S.; Beaulieu-Jones, B.K.; Kalinin, A.A.; Do, B.T.; Way, G.P.; Ferrero, E.; Agapow, P.M.; Zietz, M.; Hoffman, M.M.; et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 2018, 15, 20170387. [Google Scholar] [CrossRef] [PubMed]
- Zhong, P.; Gong, Z.; Li, S.; Schönlieb, C.B. Learning to diversify deep belief networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3516–3530. [Google Scholar] [CrossRef]
- Ravanelli, M.; Brakel, P.; Omologo, M.; Bengio, Y. A network of deep neural networks for distant speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4880–4884. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Ranzato, M.A.; Poultney, C.; Chopra, S.; Cun, Y.L. Efficient learning of sparse representations with an energy-based model. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2007; pp. 1137–1144. [Google Scholar]
- Marcus, G. Deep learning: A critical appraisal. arXiv 2018, arXiv:1801.00631. [Google Scholar]
- Bhattacharjee, B.; Boag, S.; Doshi, C.; Dube, P.; Herta, B.; Ishakian, V.; Jayaram, K.; Khalaf, R.; Krishna, A.; Li, Y.B.; et al. IBM deep learning service. IBM J. Res. Dev. 2017, 61, 10:1–10:11. [Google Scholar] [CrossRef]
- Buccafurri, F.; Fotia, L.; Lax, G.; Saraswat, V. Analysis-preserving protection of user privacy against information leakage of social-network Likes. Inf. Sci. 2016, 328, 340–358. [Google Scholar] [CrossRef]
- Phong, L.; Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar] [CrossRef]
- Tang, F.; Wu, W.; Liu, J.; Wang, H.; Xian, M. Privacy-Preserving Distributed Deep Learning via Homomorphic Re-Encryption. Electronics 2019, 8, 411. [Google Scholar] [CrossRef]
- Hesamifard, E.; Takabi, H.; Ghasemi, M. Cryptodl: Deep neural networks over encrypted data. arXiv 2017, arXiv:1711.05189. [Google Scholar]
- Mohassel, P.; Zhang, Y. Secureml: A system for scalable privacy-preserving machine learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 19–38. [Google Scholar]
- Rouhani, B.D.; Riazi, M.S.; Koushanfar, F. Deepsecure: Scalable provably-secure deep learning. In Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018; p. 2. [Google Scholar]
- Mohassel, P.; Rindal, P. ABY 3: A mixed protocol framework for machine learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 35–52. [Google Scholar]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 201–210. [Google Scholar]
- Kwabena, O.; Qin, Z.; Zhuang, T.; Qin, Z. MSCryptoNet: Multi-Scheme Privacy-Preserving Deep Learning in Cloud Computing. IEEE Access 2019, 7, 29344–29354. [Google Scholar] [CrossRef]
- Boemer, F.; Lao, Y.; Wierzynski, C. nGraph-HE: A Graph Compiler for Deep Learning on Homomorphically Encrypted Data. arXiv 2018, arXiv:1810.10121. [Google Scholar]
- Liu, J.; Juuti, M.; Lu, Y.; Asokan, N. Oblivious neural network predictions via minionn transformations. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 619–631. [Google Scholar]
- Juvekar, C.; Vaikuntanathan, V.; Chandrakasan, A. GAZELLE: A Low Latency Framework for Secure Neural Network Inference. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1651–1669. [Google Scholar]
- Hong, C.; Katz, J.; Kolesnikov, V.; Lu, W.-J.; Wang, X. Covert Security with Public Verifiability: Faster, Leaner, and Simpler. In Proceedings of the 38th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Darmstadt, Germany, 19–23 May 2019; pp. 97–121. [Google Scholar]
- Gutub, A.; Al-Juaid, N.; Khan, E. Counting-based secret sharing technique for multimedia applications. Multimed. Tools Appl. 2019, 78, 5591–5619. [Google Scholar] [CrossRef]
- Deshmukh, M.; Nain, N.; Ahmed, M. Efficient and secure multi secret sharing schemes based on boolean XOR and arithmetic modulo. Multimed. Tools Appl. 2018, 77, 89–107. [Google Scholar] [CrossRef]
- Araki, T.; Furukawa, J.; Lindell, Y.; Nof, A.; Ohara, K. High-throughput semi-honest secure three-party computation with an honest majority. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 805–817. [Google Scholar]
- Mohassel, P.; Rosulek, M.; Zhang, Y. Fast and secure three-party computation: The garbled circuit approach. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 591–602. [Google Scholar]
- Ryffel, T.; Trask, A.; Dahl, M.; Wagner, B.; Mancuso, J.; Rueckert, D.; Passerat-Palmbach, J. A generic framework for privacy preserving deep learning. arXiv 2018, arXiv:1811.04017. [Google Scholar]
- Araki, T.; Barak, A.; Furukawa, J.; Keller, M.; Lindell, Y.; Ohara, K.; Tsuchida, H. Generalizing the SPDZ compiler for other protocols. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 880–895. [Google Scholar]
- Soifer, J.; Li, J.; Li, M.; Zhu, J.; Li, Y.; He, Y.; Zheng, E.; Oltean, A.; Mosyak, M.; Barnes, C.; et al. Deep Learning Inference Service at Microsoft. In Proceedings of the 2019 USENIX Conference on Operational Machine Learning (OpML 19), Santa Clara, CA, USA, 20 May 2019; USENIX Association: Santa Clara, CA, USA, 2019; pp. 15–17. [Google Scholar]
- Catanzaro, B.; Chen, J.; Chrzanowski, M.; Elsen, E.; Engel, J.; Fougner, C.; Han, X.; Hannun, A.; Prenger, R.; Satheesh, S.; et al. Deployed End-to-End Speech Recognition. U.S. Patent App. 15/358,083, 25 May 2017. [Google Scholar]
- Buccafurri, F.; Fotia, L.; Lax, G. Social Signature: Signing by Tweeting; Springer: Cham, Switzerland, 2014; pp. 1–14. [Google Scholar]





| Works | Privacy Properties | Techniques | Shortages | Application Scenarios |
|---|---|---|---|---|
| Le [15] | Data privacy | HE | Collusion risk | NNs training |
| Ehsan [17] | Data privacy | HE | High computational overhead | CNNs training |
| Secureml [18] | Data privacy | 2PC | Collusion risk | NNs training |
| DeepSecure [19] | Data privacy, model privacy | Yao’s GC | Need much preprocessing | Deep learning |
| ABY3 [20] | Data privacy | 3PC | Not support CNN | ML |
| CryptoNets [21] | Data privacy | HE | Need efficiency improvement | MLaaS |
| nGraph-HE [23] | Data privacy | HE | Need extra hardware | Benchmark DL models |
| MiniONN [24] | Data privacy | SMPC | Need oblivious transformations | NN Inference |
| Gazelle [25] | Data privacy | HE and SMPC | High communicational costs | NN Inference |
| Our scheme | Data privacy, model privacy, defamation freeness | 3PC | Need expand to large scale CNNs and various networks | MLaaS |
| Security Property | Data Privacy | Model Privacy | Defamation Freeness |
|---|---|---|---|
| Scheme 1 | Yes | Yes | Yes |
| Scheme 2 | Yes | Yes | No |
| Participant | Server | Client | Worker 1 | Worker 2 | Worker 3 |
|---|---|---|---|---|---|
| Hash Function | 3 | 1 | m + 2 | m + 2 | m + 2 |
| RSA Signature | 3 | 1 | m + 2 | m + 2 | m + 2 |
| Layer | Number of neurons | Activation |
|---|---|---|
| Conv2D(10,(3, 3),batch_input_shape = (1, 28, 28, 1)) | - | |
| AveragePooling2D((2, 2)) | - | relu |
| Conv2D(32, (3, 3)) | - | |
| AveragePooling2D((2, 2)) | - | relu |
| Conv2D(64, (3, 3)) | - | |
| AveragePooling2D((2, 2)) | - | relu |
| Flatten | - | - |
| Dense | 10 | logit |
| Time (s) | Scheme 1-1 | Scheme 1-2 | Scheme 2-1 | Scheme 2-2 | Accuracy |
|---|---|---|---|---|---|
| model a | 2.274 | 2.851 | 2.229 | 1.885 | |
| model b | 2.508 | 3.425 | 2.151 | 1.808 |
| Time (s) | Scheme 1-1 | Scheme 1-2 | Scheme 2-1 | Scheme 2-2 | Accuracy |
|---|---|---|---|---|---|
| k = 100 | 2.274 | 2.851 | 2.229 | 1.885 | |
| k = 200 | 2.992 | 4.222 | 2.180 | 3.301 |
| Time (s) | Scheme 1-1 | Scheme 1-2 | Scheme 2-1 | Scheme 2-2 | Accuracy |
|---|---|---|---|---|---|
| len = 1024 | 2.147 | 2.133 | 1.970 | 1.773 | |
| len = 2048 | 2.274 | 2.851 | 2.200 | 1.790 | |
| len = 4096 | 3.529 | 11.171 | 2.388 | 1.792 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, F.; Hao, J.; Liu, J.; Wang, H.; Xian, M. PFDLIS: Privacy-Preserving and Fair Deep Learning Inference Service under Publicly Verifiable Covert Security Setting. Electronics 2019, 8, 1488. https://doi.org/10.3390/electronics8121488
Tang F, Hao J, Liu J, Wang H, Xian M. PFDLIS: Privacy-Preserving and Fair Deep Learning Inference Service under Publicly Verifiable Covert Security Setting. Electronics. 2019; 8(12):1488. https://doi.org/10.3390/electronics8121488
Chicago/Turabian StyleTang, Fengyi, Jialu Hao, Jian Liu, Huimei Wang, and Ming Xian. 2019. "PFDLIS: Privacy-Preserving and Fair Deep Learning Inference Service under Publicly Verifiable Covert Security Setting" Electronics 8, no. 12: 1488. https://doi.org/10.3390/electronics8121488
APA StyleTang, F., Hao, J., Liu, J., Wang, H., & Xian, M. (2019). PFDLIS: Privacy-Preserving and Fair Deep Learning Inference Service under Publicly Verifiable Covert Security Setting. Electronics, 8(12), 1488. https://doi.org/10.3390/electronics8121488