Abstract
Recently, as arising from online social network services such as Facebook and Twitter, people are more actively using social networks to exchange their new information. In this consideration, finding the information source becomes one of the indispensable and useful tasks in detecting a malicious agent and an influential person in the networks. A seminal work by Shah and Zaman in 2010 showed that the detection probability cannot be beyond 31% even for regular trees if time goes to infinity. From the study, extensive researches have been done for this problem, whose major interests lie in constructing an efficient estimator and providing theoretical analysis on its detection performance. However, most of the works assumed the homogeneous diffusion rate of the information, where the diffusion rate does not change at all times over the network. In practice, it is reported that information has a lifetime and it becomes less attractive over time. In this paper, we study the problem of detecting the information source when the diffusion rate decreases by the distance from the source in the network. As a result, we obtain analytical detection performance of Maximum Likelihood Estimator (MLE) and validate our theoretical findings over the regular tree, random and real-world networks.
1. Introduction
In the era of big data that came with the rapid development of the Internet, information spread is universal including the propagation of infectious diseases, the technology diffusion, the computer virus/spam infection on the Internet, and sharing popular topics by the Facebook. Information source estimation is the problem that identifies the initial seed node of the diffused information in the network. This is clearly of practical importance, because harmful diffusion can be mitigated or even blocked, e.g., by vaccinating humans or installing security updates. In the seminal work by Shah and Zaman [1], it is shown that in the regular tree topologies, the detection probability cannot be above 31% under Maximum Likelihood Estimator (MLE), and even worse, in other realistic topologies such as Facebook graphs, scale-free graphs and Internet Autonomous System (AS) graphs, the detection probability is less than 5% under the MLE-based heuristic due to a complex structure of networks. Since then, extensive research attention for this problem have been paid for various network topologies and diffusion models [1,2,3,4,5,6,7,8], whose major interests lie in constructing an efficient estimator and providing theoretical analysis of its detection performance. Prior work directly or indirectly conclude that this information (We use the terms “information” and “rumor” interchangeably through the paper.) source finding turns out to be a challenging task unless sufficient side information or multiple diffusion snapshots are provided. There have been several research efforts which use multiple snapshots [6] or a side information about a restricted suspect set the true source belongs [7], thereby the detection performance is significantly improved. Another type of side information is the one obtained from querying, i.e., asking questions to a subset of infected nodes and gathering more hints about who would be the true information source [9,10]. However, most of the works have focused on the homogeneous diffusion rate which means that the rate is same at all times over the network. This is impractical because it is reported [11] that information has a lifetime and it becomes less attractive over time. In other words, the diffusion power will be reduced over time or the number of distance (hops) to the source as in Figure 1. In this paper, we consider that the diffusion rate of information decays with respect to the distance from the source (We do not consider the diffusion rate decays over time due to some mathematical intractability for analyzing the performance.). Under this scenario, we try to find the source by using a proper estimator.
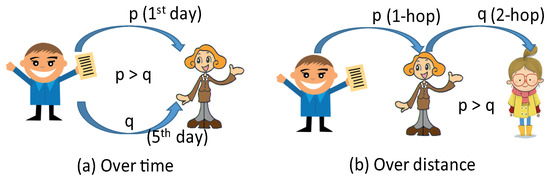
Figure 1.
Examples of decaying diffusion rate of information. (Initial diffusion rate p and decayed rate q: (a) over time and (b) over distance.)
To the best of our knowledge, this is the first work to consider the decaying diffusion rate on the information source detection problem.
Our main contributions are summarized in what follows.
- First, we use the MLE to find the source for decaying diffusion and show that the MLE is same as that of the homogeneous diffusion rate of information if the diffusion decays with respect to the distance from the source. This implies that the MLE of our model also has the same graphical centrality property called rumor center in [1]. This enables us to analyze the detection performance for the decaying rate scenario.
- Second, we define two exponential decaying models: Simple exponential decay and Generalized exponential decay. The simple exponential decay is a kind of light tail distribution, but the generalized exponential decay covers light and heavy tail distribution in the sense of the decaying pattern. We then obtain the closed-form of detection probability of the MLE when the underlying graph is a regular tree for both decaying models. Different to the prior result in [1], the detection probability is larger than zero in the line graph and there is a non-neglectable improvement of detection for any degree of a regular tree.
- Third, we consider the case that the decaying model parameter is hidden for two decaying models above. This is a more realistic scenario because knowing the exact parameter of the model is not easy in practice. To do that, we first derive MLE to estimate this parameter and show that it needs exponential computing time. Hence, we design a heuristic estimation algorithm for the true parameter by using the diffusion snapshot information, appropriately.
- Finally, we validate our theoretical result for the regular tree using the MLE and for over popular random graphs (Erdös-Rényi, scale-free and small-world graphs) and real-world networks (US-power grid, Facebook and Wiki vote) using the heuristic Breath-First-Search (BFS) estimator. As a result, we see that the detection probability can be above 80% for the regular tree and it can be above 30% if the diffusion rate decays, whereas it is about 20% without decaying in the Facebook graph.
The remainder of this paper is organized as follows. Section 2 discusses related literature. In Section 3, we introduce the information diffusion model and estimator. The theoretical results for detection performance of decaying rate will be presented in Section 4, and the corresponding proof will be provided in Section 5. In Section 6, we depict the simulation results and conclude the paper in Section 8. The detailed proof will be presented in the Appendix A.
2. Related Work
The research on information source detection has recently received significant attention. We divide them into the following three categories: single source estimation, multiple sources estimation, and hiding and seeking the sources.
Single source estimation. The first theoretical approach was done by Shah and Zaman [1,2,3], which introduced the metric called rumor centrality—a simple topology-dependent metric for a given diffusion snapshot. They called a node that has maximum rumor centrality by rumor center as a MLE. They proved that the rumor centrality describes the likelihood function when the underlying network is a regular tree and the diffusion follows the Susceptible-Infected (SI) model, which is extended to a random graph network in [2]. Zhu and Ying [4] solved the source detection problem under the Susceptible-Infected-Removed (SIR) model and took a sample path approach to solve the problem, where the Jordan center was used, being extended to the case of sparse observations [5]. There were several attempts to boost up the detection probability. Wang et al. [6] showed that observing multiple different epidemic instances can significantly increase the detection probability. Dong et al. [7] assumed that there exist a restricted set of source candidates, where they showed the increased detection probability based on the Maximum a Posterior Estimator (MAPE). Choi et al. [8] showed that the anti-rumor spreading under some distance distribution of rumor and anti-rumor sources helps to find the rumor source by using the MAPE. Choi et al. [9,10] studied the effects of querying to finding the source and showed how many queries are sufficient to achieve a target detection probability. The authors in [12,13] introduced the notion of set estimation and provided the analytical results on the detection performance. Luo et al. [14] considered the problem of estimating an infection source for the SI model, in which not all infected nodes can be observed.
Multiple sources estimation. Different from the single source estimation, multi-source estimation requires inferring the set of source nodes. Despite the difficulty of the problem, some prior studies tried to solve this problem by appropriate set estimation methods. Prakash et al. [15] proposed to employ the Minimum Description Length (MDL) principle to identify the best set of seed nodes and virus propagation ripple, which describes the infected graph most succinctly. They proposed a highly efficient algorithm to identify likely sets of seed nodes given a snapshot and show that it can optimize the virus propagation ripple in a principled way by maximizing the likelihood. Zhu et al. [16] proposed a new source localization algorithm, named Optimal-Jordan-Cover (OJC). The algorithm first extracts a subgraph using a candidate selection algorithm that selects source candidates based on the number of observed infected nodes in their neighborhoods. Then, in the extracted subgraph, OJC finds a set of nodes that cover all observed infected nodes with the minimum radius. Considering the heterogeneous SIR diffusion in the ER random graph, they proved that OJC can locate all sources with probability one asymptotically with partial observations. Ji et al. [17] developed a theoretical framework to estimate rumor sources, given an observation of the infection graph and the number of rumor sources.
Hiding and seeking the source. As opposed to finding the information source from a given snapshot of the epidemic, hiding the corresponding source approach also has been studied. Fanti et al. [18] first considered this problem and proposed an Adaptive Diffusion (AD) for the information spreading protocol. They showed that AD is near-optimal for hiding the source as well as maximizing the information spreading on the regular tree structures. Luo et al. [19] considered a problem that an information source tries to hide with maximizing the spread of its information, whereas the network adversary seeks the source, simultaneously. They formulated this problem by a game theoretic model and showed that a Nash Equilibrium (NE) exists under some mild condition of the game.
To the best of our knowledge, our paper is the first to quantitatively consider the decaying of diffusion power, which is more realistic scenario compared to the homogeneous diffusion rate. We obtain that the source can be found more easily when the diffusion rate decays with respect to the distance from the source for the real world graphs as well as tree structure.
3. Model and Estimator
We consider an undirected graph where V is a countably infinite set of nodes and E is the set of edges of the form for . Each node represents an individual in human social networks or a computer host in the Internet, and each edge corresponds to a social relationship between two individuals or a physical connection between two Internet hosts [9]. As an information spreading model, we consider a SI model as in [1,2,4], where each node is in either of two states: susceptible or infected. In this model, once a node has the information, it keeps it forever, i.e., it does not allow for any nodes to recover. All nodes are initialized to be susceptible except the information source, and once a node i has information, it is able to spread the information to another node j if and only if there is an edge between them. We denote a random variable by the time it takes for node j to receive the information from node i if i has it. We denote by the information source, which acts as a node that initiates diffusion and denote of N infected nodes under the observed snapshot . In this paper, we consider the case when G is a regular tree and our interest is when the sufficient time has passed, as done in many prior work [1,2,6,7]. Even though the real network may not be the regular tree with high probability, it is shown that many random graphs can be approximated by regular tree due to locally tree-like structure [20]. Note that most of the works have focused on the case that all edge for node pair u and v have same diffusion rate (or probability), say . However, in this work, we assume that the diffusion rate of all edge for node pair u and v is a function of distance from the information source . We assume that are independent and have an exponential distribution with parameter where h is the number of hops of node i from the source. Hence, the diffusion rate only depends on the distance to the source in the graph. Further, we assume that a diffused information has a message about how many hops (h) passed from the source (Using this message, each infected node spreads the information to its neighbors under the diffusion rate ).
Maximum Likelihood Estimator. As an estimator of the source, we consider a MLE for the observed graph (snapshot) when there are N infected nodes in the network:
i.e., the MLE is the node that maximizes the likelihood of the diffusion snapshot . Instead of direct computing the likelihood, which is quite difficult due to heterogeneous diffusion rate, we consider the following proposition that guarantees a useful graphical characterization of the MLE.
Proposition 1.
Let be a set of MLEs (We consider the set of MLEs because it can be multiple nodes.) for the homogeneous diffusion rate and let be the set of MLEs for (1) on the regular tree. Then we have
The proof of Proposition 1 will be presented in Section 5. This proposition indicates that for a given regular tree, the MLE of our decaying diffusion model is the same to that of the homogeneous diffusion rate. Consequently, we have the same graphical property of “rumor center” as described in [1], which is one of the graph centrality concepts. To see more details, we let be the number of nodes in the subtree rooted at node u, assuming v is the root of the tree (see [1] for details). Then the rumor center has the following property.
Corollary 1.
Under d-regular tree G, for a given observation with N infected nodes, the node v is a MLE of (1) if and only if for every neighbor u of v.
For a comparative purpose, we first present the detection probability of MLE for the homogeneous diffusion rate [2] as follows:
Lemma 1
([1]). Under d-regular tree G, let be the detection probability of MLE then for and for
where is the incomplete Beta function (The incomplete Beta function is the probability that a Beta random variable with parameters α and β is less than , whose form is where is the standard Gamma function [1].) with parameters α and β.
Using Lemma 1, one can check that the detection probability for MLE under the homogeneous diffusion rate is at most in the asymptotic case for d-regular trees. In the following section, we define our interesting decaying models and obtain the detection probabilities under these models.
4. Main Results
In this section, we first obtain the asymptotic detection probability (when ) for two decaying models with known model parameters. Next, we consider a case that the model parameter is hidden (unknown) so that we need to estimate it. To do that, we suggest a simple and efficient parameter estimation algorithm.
4.1. Probability of Correct Detection of MLE
As a first decaying model, we define a simple decay function as follows. To do this, we introduce a decaying parameter , which indicates how much the diffusion rate will be decay by the number of hops to the source. Using this, we have the following definition.
Definition 1
(Simple Exponential Decay). Let be the initial diffusion rate from the information source . We call the rate function by simple exponential decay w.r.t. the source with the decaying parameter .
Using this definition, we first obtain the detection probability of the MLE when the underlying graph is a line. To do that, we let be the detection probability of the information source by the MLE for the simple exponential decay. Then we have the following result.
Theorem 1.
For the line graph with the decaying parameter , the detection probability of the information source by the MLE when t goes to infinity is given by
where Furthermore, if then
In this result, we check that if , the detection probability is larger than by using an integral approximation of . Further, we see that if p increases the detection probability also increases. This is a significant enhancement of detection compared to that of the homogeneous diffusion rate where the detection probability is zero for the line graph [2].
Next, we will obtain the source detection probability for d-regular tree () as follows.
Theorem 2.
Under d-regular tree G , if , the MLE can detect the source with probability one as t goes to infinity, i.e.,
This result indicates that for the d-regular tree (, if the decaying rate of the information is larger than , the MLE can detect the source almost surely even though the time goes to infinity. This is because the tendency of great decaying makes the snapshot of diffusion more dense with respect to the source so that the MLE can find it easily (Since the MLE is a rumor center under the decaying model, the estimator has the largest centrality of the graph.). Next, we introduce a more general exponential decaying model where the decay level is parameterized by r from the simple exponential decaying to homogeneous rate by one parameter in what follows:
Definition 2
(Generalized Exponential Decay). Let be the initial diffusion rate of the information source . We call the rate function by generalized exponential decay with respect to the source if
where is the decay level.
We see that this form is parameterized by r. For example, if then it becomes the simple exponential decay as in Definition 1. If then it becomes which is the homogeneous diffusion rate. We plot the rate function with various values of parameters in Figure 2. Using this, we obtain the following result.
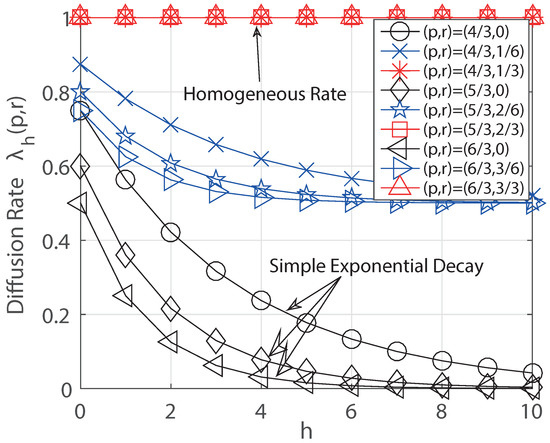
Figure 2.
Example of generalized exponential decay. (If , it becomes a homogeneous rate and if , it is a simple exponential decay.)
Theorem 3.
Under d-regular tree G , let be the detection probability of the information source by the MLE under the generalized exponential decay in (5). If then we have
The result implies that for a given decaying level r, we have the asymptotic detection probability of the MLE as in (6). For example, if then which is the result in Theorem 2 and if then the detection probability becomes the result in [1] which is the case of the homogeneous diffusion rate.
4.2. Decaying Parameter Estimation
In this subsection, we consider the scenario that the parameter p of the decaying model is hidden because it is often hard to know the exact parameter even though the model is given in practice. In this case, under the decaying model, one can estimate it by the following MLE simply using the current snapshot To formalize this, we let be a infection sequence which generates and let be the set of these sequences when v is the source. Then we have
where the equality is due to the uniform prior of the source. Then, we see that computing the MLE has combinatorial complexity because there are exponentially many infection sequences in with respect to the infected nodes N. Hence, instead of using this, we design an approximation algorithm that guarantees simple and efficient to estimate the true parameter as follows.
Algorithm. We now describe our decaying parameter estimation algorithm, named DPE(K), where K is sampling cost of the algorithm in Algorithm 1. Since we do not have any prior information for the parameter p, we set the estimation range , where and are minimum and maximum values of p, respectively. We set (i.e., no decaying) in the algorithm. Then, the algorithm first sets as described in the first line. Next, for each infected node , it calculates the rumor centrality using the given snapshot information as in [1] (Step 1). To approximate the term in (7), we consider that the algorithm samples K infection sequences uniformly at random (The uniform sampling indeed gives a simple approximation for the mean of infection probabilities), where K is a fixed constant and computes:
where is randomly sampled infection sequence on (Step 2). This is regarded as a averaged value of in (7). Clearly, we know that many samples (large K) give more accuracy in general. Then, we multiply to the rumor centrality and we put it into (Step 3). We next sum these values for all infected nodes and save it to We repeat this procedure by increasing to the previous value p. Finally, the algorithm compares all values of within the range and takes the maximum p as the estimation of decaying parameter, denoted by . We see that the algorithm complexity is , where N is the number of infected nodes in the graph. We will show how accurate this algorithm as varying K in the simulation section.
| Algorithm 1 Decaying Parameter Estimation (DPE(K)) |
| Input: Diffusion snapshot , sampling cost K, , , increasing step size |
| Output: Estimation parameter |
| Set the initial decaying parameter ; |
| while do |
| for each do |
| Step1: Compute the rumor centrality by a message passing algorithm [1]; |
| Step2: Choose random samples K times and compute its mean by; |
| Step3: Set ; |
| end for |
| Set ←; |
| ; |
| end while |
| Compute ; |
| Return ; |
5. Proof of Results
In this section, we will provide the proofs of Propositions and Theorems. All proofs of Lemmas will be provided in Appendix A.
5.1. Proof of Proposition 1
To prove this, it is sufficient to show that under d-regular tree G, for a given observation with N infected nodes, v is a MLE of (1) if and only if for every neighbor u of v from the result in [1]. Let be the node which satisfies this condition and let be a node that has for some neighbor node w of u. Then, we will prove for all by using a contradiction method. Suppose there exists a node u such that To determine where is a infection sequence (permitted permutation of ), if v is the source, we let be the subgraph of containing nodes for Then, for every and we have
where is the exponential random variable of the jth node at the boundary of the information spread and the inequality follows from the fact that if we let then by the decreasing diffusion rate, we have and this makes for any permutation To see this more rigorously, we see that for any permutation there exists distinct permutation such that holds due to the fact that for By using the result in [1] such that , we have
which makes contradiction to our hypothesis. Hence, we complete the proof of Proposition 1.
5.2. Proof of Theorem 1
For the line graph, note that there are two independent diffusion processes from the source. We let be those processes that indicate the total number of infections until time t from the source, respectively. Let be the event that the difference of number of infected nodes between and is k after time t and let be the detection event of the MLE at time t. Then, from the Corollary 1, we have following two events for detecting the source: The detection occurs when the MLE is uniquely defined at time t, denoted by and The detection occurs when there are two MLEs at time t as in [1], denoted by and . Hence, the detection probability is described by
To obtain this, we first obtain the probability . From the Markov property of the diffusion process, we see that depends only on or . Then, we obtain the following lemma.
Lemma 2.
If and , then
and
Using this result, the probability can be expressed by the following recursive form:
Since converges for all integer k as , () we delete the index t from now on. To compute each probability in (12), we consider the following lemma.
Lemma 3.
For any integer , we have
where for and for
By using this, we finally obtain and (This is because two random processes and are i.i.d.) from . Then, from the relation of (12) and by taking limit (t goes to infinity), we have the result in Theorem 1 and this completes the proof of Theorem 1.
5.3. Proof of Theorem 2
First, we will prove for . To do that, we let be the set of infected nodes in the subtree rooted at at time t ( is i-th neighbor node of the information source where and we omit the superscript in for the notational simplicity). Then we have the following lemma.
Lemma 4.
Let in . Then, for any
This lemma implies that if we consider the decaying factor , the diffusion rate that a node is infected at any time t in becomes a constant .
Hence, using the Lemma 4, the probability that a node in is infected is always equal to for all Indeed, if we let be a random variable of infection time for a node in then Let be the total number of infections in the network until time Then, we have
Let then, the detection probability is
where is from the fact that all events are mutually excluded and comes from Hoeffding’s bound with the expectation i.e.,,
which converges to 0 as (). Thus, for a fixed as , converges to 1. Next, to see the result for consider the following lemma.
Lemma 5.
Let be the diffusion rate vector where indicates the diffusion rate of i-hop distance node from the source and let be the detection probability of MLE under λ. For two diffusion vectors and if (This means that for all .) then
Using this, we obtain that for any rate , the detection probability goes to one as time goes to infinity. This completes the proof of Theorem 2.
5.4. Proof of Theorem 3
Let then, one can easily check that in (5) satisfies the following recurrence:
This relation means that one infection of any node in a d-regular tree increases exactly . At initial time, and . If an infection occurs in a or , then or increases by . This process can be mapped into Polya’s Urn process [2] and the probability becomes . The rate decreases as k increases with the condition that . If , any infection does not change the sum of rates and it is same as -rate decaying model which has detection probability converging to 1 as t goes to infinity. Furthermore, if , infection rate becomes homogeneous and then the detection probability is same to the result in [2]. This completes the proof of Theorem 3.
6. Numerical and Simulation Results
In this section, we will provide simulation results for the detection probabilities over three types of graph topologies: (i) regular trees, (ii) three random graphs, and (iii) three real-world networks. We propagate the information from a randomly chosen source up to 1000 infected nodes and plot the detection probability from 500 iterations. We obtain the detection probability by varying the decaying parameter p in the generalized exponential decay, which including the simple exponential decay ().
6.1. Regular Trees
For the regular tree, we first plot the theoretical result (asymptotic detection probability) in the Theorem 3 numerically with respect to the decay level r of the generalized decaying model in Figure 3. We have checked that the detection probabilities are almost one for (i.e., simple exponential decaying) and they decrease as t increases for three cases of degrees ( and ). We see that if for , it has the same detection probability to that of the homogeneous rate as our expectation. We further validate our theoretical result by simulation. We also check that the higher degree for the regular tree gives more chances to detect the source because it frequently has the best rumor centrality in the infection graph.
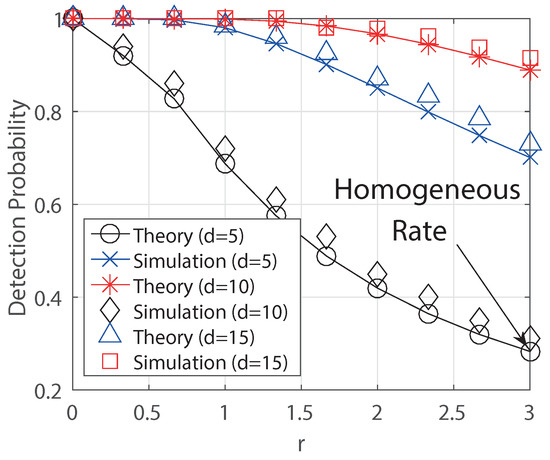
Figure 3.
Theoretical and simulation result for Theorem 3.
In Figure 4, we obtain the error of parameter estimation for p with respect to the sampling cost K for the algorithm DPE(K). We consider the case and we set the error between true parameter p and estimated parameter by using the distance . We plot the error for different values of p () by averaged values of 100 runnings of the algorithm. We use the step size and . In the result, we see that the algorithm DPE(K) estimates the true parameter more accurately when p is large. This is because a large decaying parameter makes the snapshot more balanced from the source, and this enables to estimate the true parameter with less fluctuation.
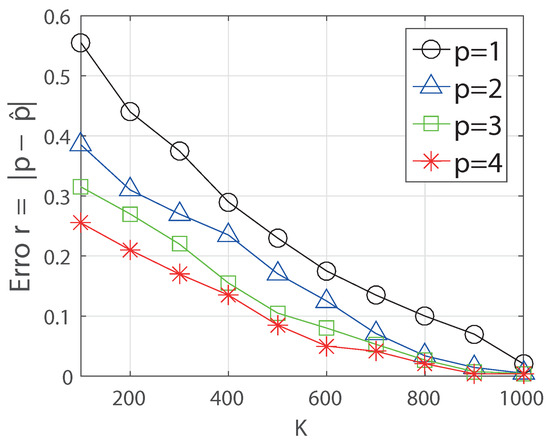
Figure 4.
Simulation result for the estimation error with respect to the sampling cost K for the algorithm DPE(K). (.)
In Figure 5, we obtain the detection probabilities for degree with respect to decaying parameter p. In this simulation, we compare two results known parameter (true) unknown parameter (estimated), respectively. The known parameter means that the true decaying parameter is given a prior, and we use it in the simulation. The unknown parameter means we do not know the true parameter so that we need to estimate it using the algorithm DPE(K) first. Then we obtain the detection probability. In the result, we check that the detection probability increases as p increases and the reduction of detection performance is not much even though we use the estimated parameter using DPE(K) for .
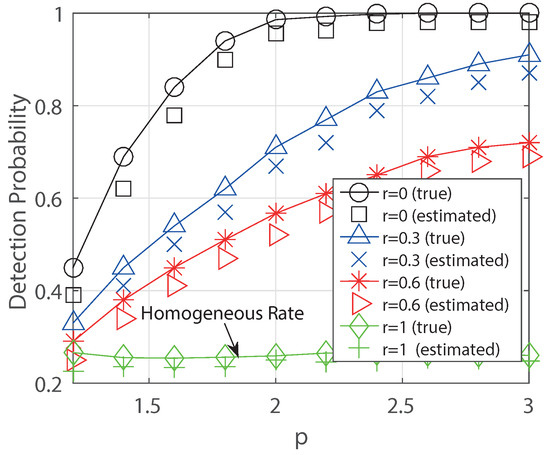
Figure 5.
Detection probability by varying the parameter p for the 3-regular tree. We compare the results between true parameter p (true) and estimated parameter p (estimated) using the algorithm DPE(K). (.)
6.2. Random Graphs
We consider Erdös-Rényi (ER), Scale-Free (SF) and Small World (SW) graphs. In the ER graph, we choose its parameter so that the average degree by 4 for 2000 nodes. In the SF and SW graphs, we choose the parameter so that the average ratio of edges to nodes by 1.5 for 2000 nodes. It is known that obtaining the MLE is hard for the graphs with cycles, which is ♯P-complete. Due to the reason, we first construct a diffusion tree from the Breadth-First Search (BFS) as used in [1]: Let be the infection sequence of the BFS ordering of the nodes in the given graph, then we estimate the source that solves the following:
where is a BFS tree rooted at v and the information spreads along it. The BFS tree is a good approximation for our model because the decaying rates with the same distance to the source are same, and the nodes closer to the source have a higher diffusion rate. Then, we obtain the detection probabilities for each graph by increasing the parameter p as in Figure 6. We first simulate the case for true parameter i.e., it is given as a prior. Next, we also consider the parameter is hidden so that we need to estimate it. In this case, we replace the rumor centrality for chosen node v by in the algorithm DPE(K). As a result, we see that the detection probabilities increase as the parameter p increases and they decrease as the parameter r increases for three random graphs. We also see that if the decay level , the detection probabilities are same as those of homogeneous diffusion rate. Further, we see that the detection is better on ER random graph than the other two networks because ER has symmetric locally tree structure, the decaying effect for large detection probability. Finally, for the unknown parameter p, we estimate the parameter using the algorithm DPE(K) with 100 iterations as in Table 1 and we check that the degradation of detection performance is not much even though we use the estimated parameter using DPE(K) if the sampling cost is sufficient.
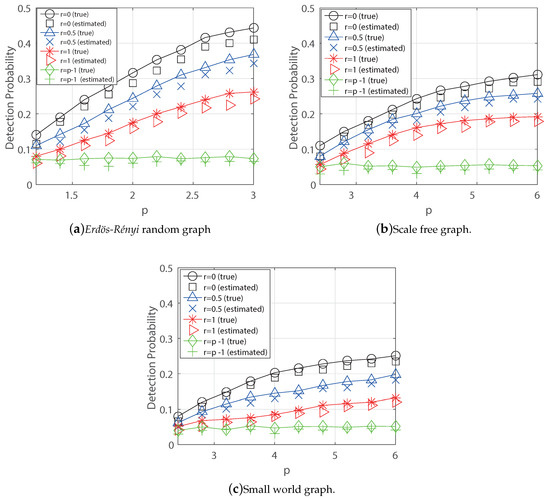
Figure 6.
Detection Probabilities (true and estimated parameter) for Synthetic Graphs ((a) ER random graph, (b) Scale Free graph, and (c) Small World graph ().

Table 1.
Averaged value of estimations of parameter p using DPE(K) for general graphs (). We use the step size and .
6.3. Real World Graphs
For the Facebook network in Figure 7b, we use the data in [21] where generates an undirected graph consisting of 4039 nodes and 88,234 edges. Each edge corresponds to a social relationship (called FriendList) and the diameter is 8 hops. The US power grid network Wiki consists of 4941 nodes and 6594 edges, and the diameter is 46 hops. For the WiKi-vote network, we use the data in [22] where generates 7115 nodes and 103,689 edges, and the diameter is 7 hops. In these networks, we also use the BFS approach in (20) to estimate the source and apply the BFS tree to estimate the parameter p in DPE(K) as in Table 1 with 100 iterations. Further, we see that the detection probabilities for the three networks increase as p increases and if the decal level they become the results of homogeneous rate in Figure 7. We also see that the detection is better on the US power grid network than the other two networks because it has a large network diameter that gives more chances to detect the source using the diffusion snapshot.
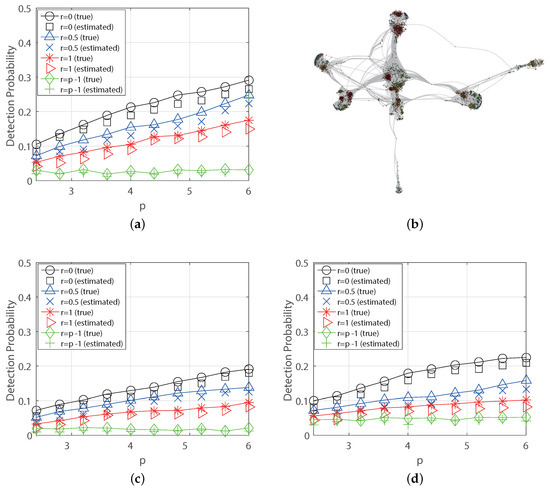
Figure 7.
Detection Probabilities (true and estimated parameter) for Real-world Networks ((a) US power grid network, (b) Facebook Network [21], (c) Facebook network, and (d) Wiki-vote network ().
7. Discussion
Our results show that decaying of information diffusion over distance from the source has a positive effect in most cases on inferring the source of information. In particular, the results show that if only mild conditions are satisfied, the source can be found as probability one no matter how much time passes for the regular tree structure. This is due to the fact that the spreading patterns which corresponding the decaying of information spreads more evenly with respect to the center of the infection graph. This phenomenon also occurs similarly with general graphs, making it easier to find the source.
The first limitation of this result is that the diffusion model under consideration does not cover the various decaying patterns due to some technical problem for analysis. For example, we can also consider the decaying by an exponential function such as for some constant or by power-law function , etc. However, we find some mathematical intractability to obtain analytical detection probability. As a second limitation, we did not consider the decaying with respect to time this is also because of hardness for tracking the infection time of diffusion.
As future work, we will consider more general decaying models that can be explainable of heavy-tail decaying and light-tail decaying patterns. We hope that this direction will give more chances to find some tractability for analysis of various decaying models. Further, we will obtain some analytical results for detecting the source of the Erdös-Rényi random graph because it is the simplest random graph.
8. Conclusions
In this paper, we consider an information source finding problem when the diffusion rate of information decays with respect to the distance from the source. We first show that the MLE is same as that of the homogeneous diffusion rate of information if the diffusion decays with respect to the distance from the source. We then obtain the closed form of detection probability of the MLE when the underlying graph is a regular tree for two exponential decaying models. Different to the prior result, the detection probability is larger than zero in the line graph and there is a non-neglectable improvement of detection for any degree of a regular tree. Next, we consider the case that the decaying model parameter is hidden for two decaying models above. To do that, we design a heuristic estimation algorithm for the true parameter by using the diffusion snapshot information, appropriately. Finally, we validate our theoretical result for the regular tree using the MLE and for over popular random graphs and real-world networks using the heuristic Breath-First-Search (BFS) estimator. We obtain that the detection probability can be above 80% for the regular tree, and it can be above 30% if the diffusion rate decays, whereas it is about 20% without decaying in the real-world graphs.
Author Contributions
Conceptualization, J.C. and J.W.; methodology, J.C.; software, J.W.; validation, J.W. and J.C.; formal analysis, J.C.; investigation, J.C.; resources, J.W.; data curation, J.W.; writing—original draft preparation, J.C.; writing—review and editing, J.C.; visualization, J.W.; supervision, J.C.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No.2019R1G1A1099466) and by research fund from Honam University, 2019.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Lemmas
In this appendix, we will provide the proofs of lemmas in Theorems.
Appendix A.1. Proof of Lemma 2
Suppose that has rate and has rate at time t, respectively. Let be the embedding point of the next infection occur. Then, there are two possible events at time , infection occurs in or . By the exponential distributions, we obtain (13) by
One can easily obtain (14) by similar calculation and this completes the proof of Lemma 2.
Appendix A.2. Proof of Lemma 3
We will prove this by induction on k. First, consider the case then we have
and this implies that Next, If we have and Using Equation (12) and induction hypothesis, we obtain
By the symmetry , and the total sum of all integer k should be one, we obtain
Now let and then the bound of is determined by . Lemma 3 shows which leads to same conclusion on bound of . If , goes to infinity. It means and goes to 0 as time goes to infinity. If , we have
Then, has upper and lower bound because and this completes the proof of Lemma 3.
Appendix A.3. Proof of Lemma 4
We will prove this by induction hypothesis on as follows. If where have boundary edges and each edge has diffusion rate , we have If , Let v be the last infected node in and w be the infected node in which spread rumor to v. Before infections of v, w’s boundary edges having rate equally where is the distance of node w from the source. Since v is one hop further from rumor source than v’s boundary edges having rate equally. When v is infected, one of w’s boundary edges is deleted from and () edges of v are added to . Thus, the total sum of rate of is same as that of . Then, by the induction hypothesis, we have that of as and this completes the proof of Lemma 4.
Appendix A.4. Proof of Lemma 5
To prove this, we first denote for the notational simplicity. Then, we use a mathematical induction on N i.e., the number of infected nodes in the graph. For it is trivial because there is only one infected node which is the rumor source. Hence, for any diffusion rate, we have Now, suppose this is true for and then define three events as
where . We let then by the total probability law, we have
where the equality is from the fact that , for N is odd and for N is even, respectively. From this result, it remains four terms in (A7) to obtain the result First, we see that from the induction hypothesis. Next, we will see that is also satisfied (This is the case that N is even). In this case, all the transition probabilities are one except the case that there are infected nodes in and infected node in one of remained subtree. Let be the transition probability from this state to equally distributed for those two subtrees then one can check that because
where be the random variable of the event that next infection occurs in the subtree when there are infected nodes in the graph. Here, is the rate of this infection occurs in when there are k nodes. The equality is due to the exponential random variable of diffusion process and the inequality is from the fact that
for all k since there are subtrees without any infections of for all . Then we have Next, we consider the probability (This is case that N is odd) and we first focus on In this case, we have by the similar steps as before. Finally, we need to see that To show this is true for all we will show it holds for all as follows.
where the equality comes from the identical random process for all and the inequality follows from the independence of random variables. Indeed, we see that
where the equality follows from the fact that since (In the tree, there is a unique path of any two nodes and the distribution of diffusion time from the rumor source to any node of distance follows hypo-exponential with rate ) takes integer values for all the probability is zero when k is not a multiple of The inequality is from the fact that
since the random process and have same distribution with exponential rates for all of each edge. (We use the fact that if and , respectively. ) Next, we consider that
for an arbitrary small number and consider that
where Then, from this relation and the fact that we have
where is due to the induction hypothesis. Then, by using the fact that and the induction hypothesis, we have
and this completes the proof of Lemma 5.
References
- Shah, D.; Zaman, T. Detecting Sources of Computer Viruses in Networks: Theory and Experiment. In Proceedings of the ACM SIGMETRICS, New York, NY, USA, 14–18 June 2010. [Google Scholar]
- Shah, D.; Zaman, T. Rumor Centrality: A Universal Source Detector. In Proceedings of the ACM SIGMETRICS, London, UK, 11–15 June 2012. [Google Scholar]
- Shah, D.; Zaman, T. Rumors in a Network: Who’s the Culprit? IEEE Trans. Inf. Theory 2011, 57, 5163–5181. [Google Scholar] [CrossRef]
- Zhu, K.; Ying, L. Information Source Detection in the SIR Model: A Sample Path Based Approach. In Proceedings of the IEEE Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 10–15 February 2013. [Google Scholar]
- Zhu, K.; Ying, L. A robust information source estimator with sparse observations. In Proceedings of the IEEE INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014. [Google Scholar]
- Wang, Z.; Dong, W.; Zhang, W.; Tan, C.W. Rumor source detection with multiple observations: Fundamental limits and algorithms. In Proceedings of the ACM SIGMETRICS, Austin, TX, USA, 16–20 June 2014. [Google Scholar]
- Dong, W.; Zhang, W.; Tan, C.W. Rooting Out the Rumor Culprit from Suspects. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Istanbul, Turkey, 7–12 July 2013. [Google Scholar]
- Choi, J.; Shin, J.; Yi, Y. Information Source Localization with Protector Diffusion in Networks. IEEE/KICS J. Commun. Netw. 2017, 21, 136–147. [Google Scholar] [CrossRef]
- Choi, J.; Moon, S.; Woo, J.; Son, K.; Shin, J.; Yi, Y. Rumor Source Detection under Querying with Untruthful Answers. In Proceedings of the IEEE INFOCOM, 2017 IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017. [Google Scholar]
- Choi, J.; Yi, Y. Necessary and Sufficient Budgets in Information Source Finding with Querying: Adaptivity Gap. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018. [Google Scholar]
- Ohsaka, N.; Yamaguchi, Y.; Kakimura, N.; Kwarabayashi, K. Maximizing Time-Decaying Influence in Social Networks. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2016; pp. 132–147. [Google Scholar]
- Bubeck, S.; Devroye, L.; Lugosi, G. Finding Adam in random growing trees. Random Struct. Algorithms 2017, 50, 158–172. [Google Scholar] [CrossRef]
- Khim, J.; Loh, P.-O. Confidence Sets for Source of a Diffusion in Regular Trees. IEEE Trans. Netw. Sci. Eng. 2015, 4, 27–40. [Google Scholar] [CrossRef]
- Luo, W.; Tay, W.P.; Leng, M. How to Identify an Infection Source With Limited Observations. IEEE J. Sel. Top. Signal Process. 2014, 8, 586–597. [Google Scholar] [CrossRef]
- Prakash, B.A.; Vreeken, J.; Faloutsos, C. Efficiently Spotting the Starting Points of an Epidemic in a Large Graph. In Proceedings of the IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Zhu, K.; Chen, Z.; Ying, L. Catch’Em All: Locating Multiple Diffusion Sources in Networks with Partial Observations. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Ji, F.; Tay, W.P. An Algorithmic Framework for Estimating Rumor Sources With Different Start Times. IEEE Trans. Signal Process. 2017, 65, 2517–2530. [Google Scholar] [CrossRef]
- Fanti, G.; Kairouz, P.; Oh, S.; Viswanath, P. Spy vs. In Spy: Rumor Source Obfuscation. In Proceedings of the ACM SIGMETRICS, Portland, OR, USA, 15–19 June 2015. [Google Scholar]
- Luo, W.; Tay, W.P.; Leng, M. Infection Sprading and Source Identification: A Hide and Seek Game. IEEE Trans. Signal Process. 2016, 64, 4228–4243. [Google Scholar] [CrossRef]
- Fanti, G.; Viswanath, P. Anonymity Properties of the Bitcoin P2P Network. arXiv 2017, arXiv:1703.08761. [Google Scholar]
- Leskovec, J.; McAuley, J. Learning to discover social circles in ego networks. In Proceedings of the Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Leskovec, J.; Huttenlocher, D.; Kleinberg, J. Predicting Positive and Negative Links in Online Social Networks. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).