On Inferring Intentions in Shared Tasks for Industrial Collaborative Robots


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Force based operator’s intention inference. We implemented two different approaches, and both were thoroughly evaluated and compared. Finally, one of them was selected and used during the validation with users. Inference time and the possibility of including contextual information were considered for the comparison. The first approach consisted of a k-nearest neighbor classifier, which uses as the metric dynamic time warping. In this case, the time series data are directly fed to the classifier. The second approach was based on dimensionality reduction together with a support vector machine classifier. The reduction was performed over the concatenation of all force axes of the raw time series.
- Force based dataset of physical human–robot interaction. Due to the lack of similar existent datasets, we present a novel dataset containing force based information extracted from natural human–robot interactions. Geared towards the inference of operators’ intentions, the dataset comprises labeled signals from a force sensor. We aimed to generalize from a few users to several. Therefore, our dataset was only recorded with two users. Indeed, this is compliant with industrial environments in which the system should be used by new operators, preferably with no need for retraining.
- Validation in a use-case inspired by a realistic industrial collaborative robotic scenario. The performance of the selected approach was evaluated in an experiment with fifteen users, who received a short explanation of the collaborative task to execute. The goal of the shared task was to inspect and polish a manufacturing piece where the robot adapted to the operator’s actions. To generalize, recall that the model was trained with data from only two users, while it was evaluated against other fifteen users.
2. Related Work
3. Force Based Dataset of Physical Human–Robot Interaction
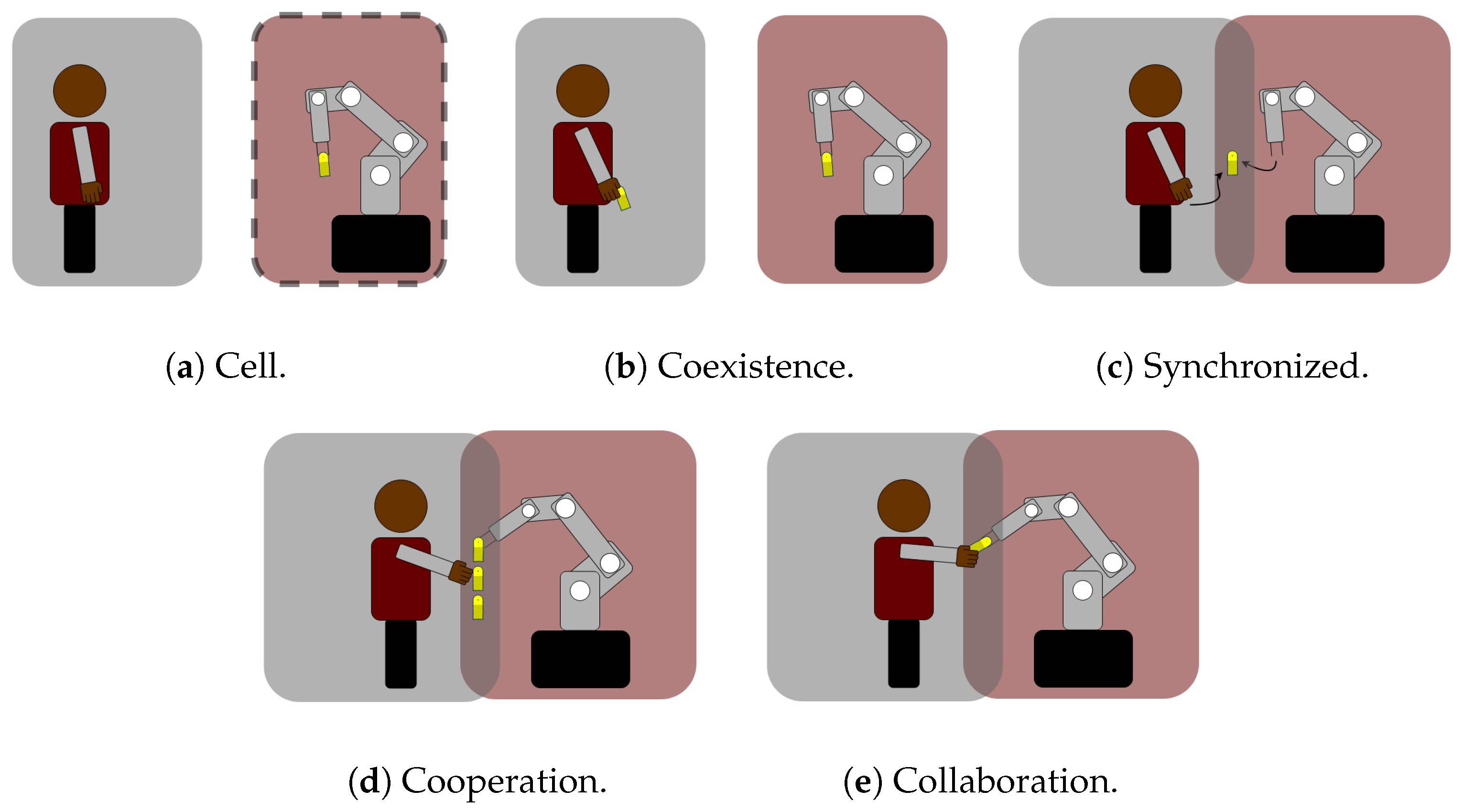
3.1. The Industrial Collaborative Robotic Scenario
3.2. Types of Operator Intents
3.3. Dataset Specifications
4. Force Based Operator’s Intention Inference
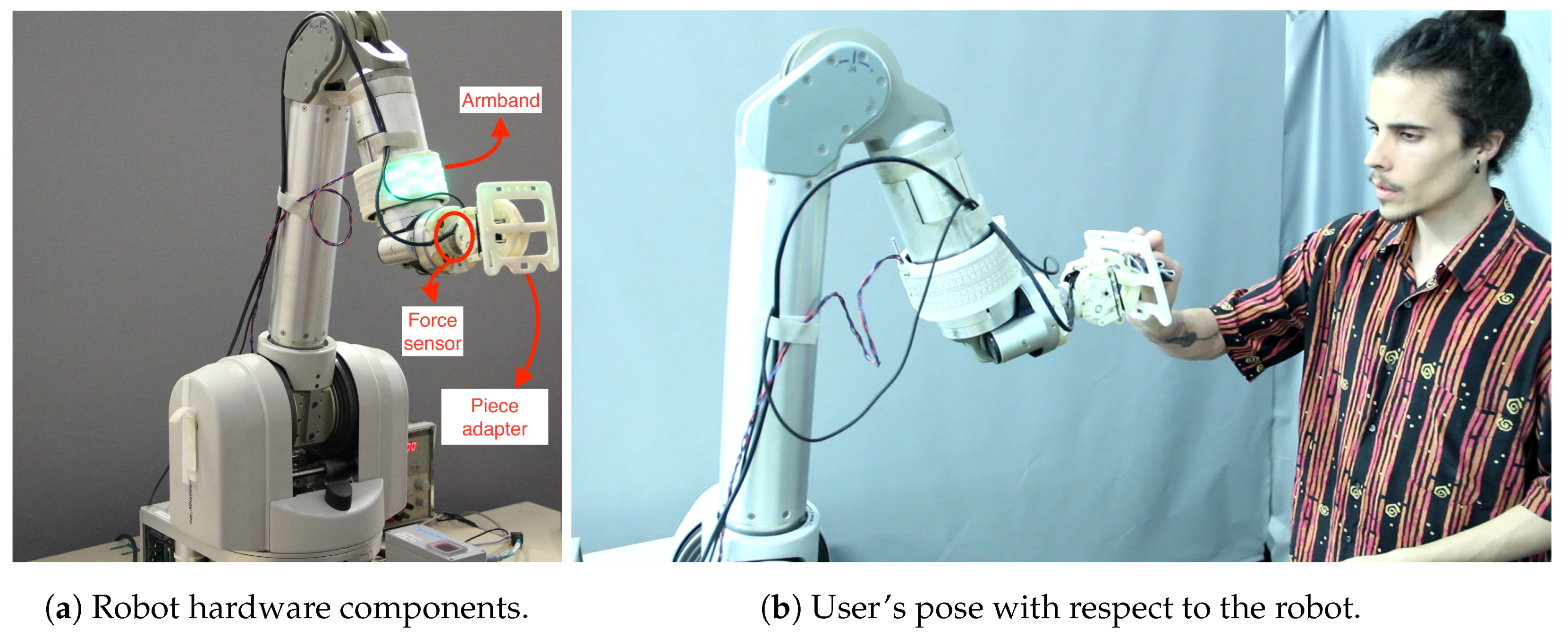
4.1. Evaluation Setup for the Proposed Approaches
4.2. Raw Data Based Classification
4.2.1. Implementation Details of the Raw Data Based Classification
4.2.2. Evaluation of the Raw Data Based Classification
4.3. Feature Based Classification
4.3.1. Implementation Details of the Feature Based Classification
4.3.2. Evaluation of the Feature Based Classification
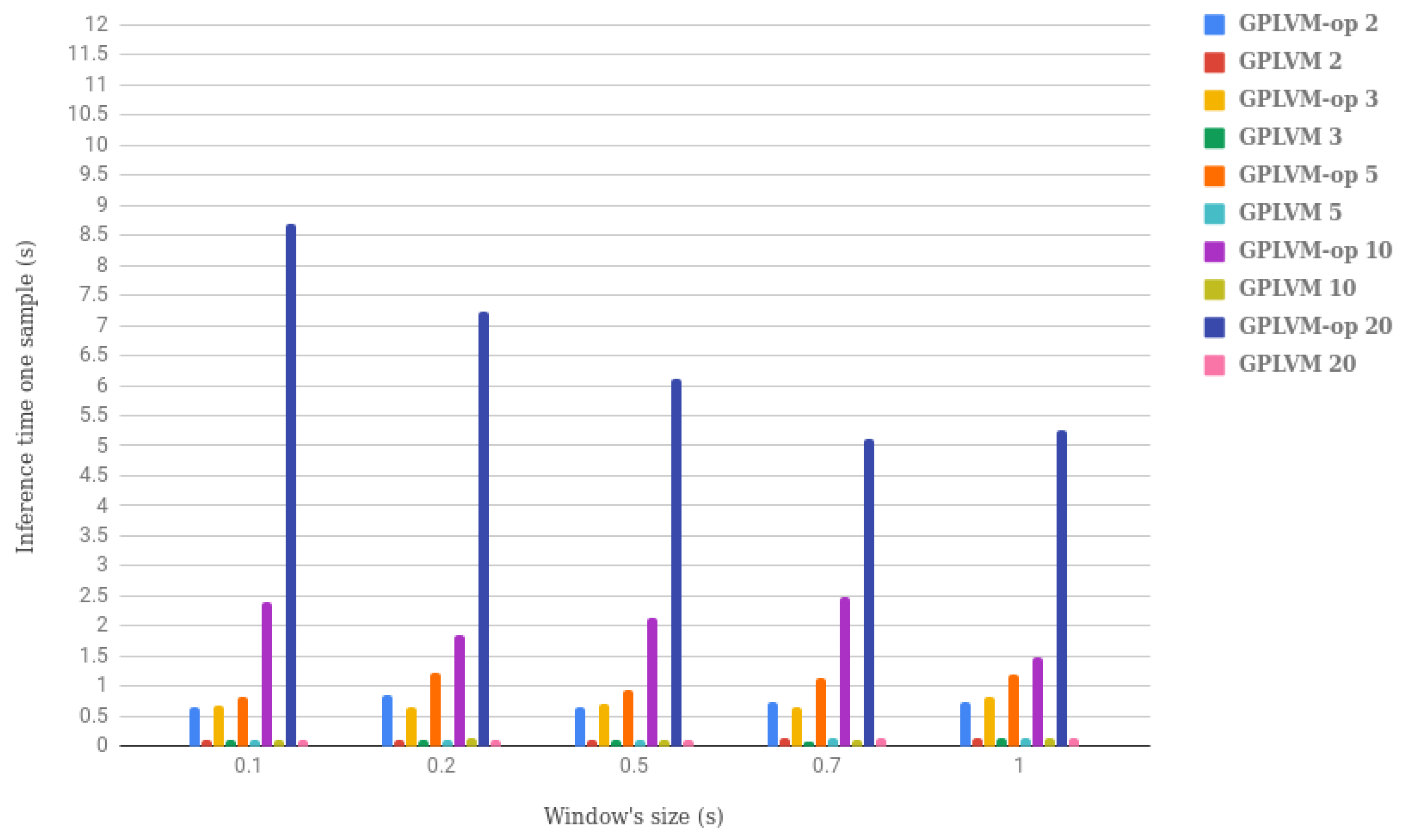
4.4. Raw Data Based vs. Feature Based Classification
- Ease of implementation: Both methods were relatively simple to implement and use. Conceptually and algorithmically, 1NN + DTW was a simple machine learning technique; only the versions of DTW for multivariate data presented a bit of difficulty. GPLVM was theoretically more complex, and reaching a profound understanding of the mathematical background of this technique would require effort. However, the GPy library eased the use of GPLVM without the need to dig too much into the theoretical details.
- Data visualization: GPLVM allowed us to project the sequential data samples into just a few latent variables and then visualize the data distribution in either 2D or 3D. This can be useful to analyze the dataset easily, and it was something that could not be done using 1NN + DTW.
- Generalization to other scenarios: This aspect is rather important for us because in the future, we would like to include heterogeneous environmental variables in the learning pipeline. Examples of contextual variables are: if the grasped object is heavy or not and if the user is inside the workspace or not. In this case, these two variables are binary and could be added to the feature vector of each sample to learn some environmental aspects related to safety. GPLVM could be used to reduce the dimensionality of temporal sequences to just a few features. Then, other contextual variables could be concatenated to the resulted feature vector, and SVM would be used to learn not only the physical interactions but also the contextual information. 1NN + DTW, however, cannot deal with other data apart from sequential. It would be necessary to use a second kNN model with another metric (e.g., Euclidean) and then apply ensemble learning techniques.
4.5. Comparison of Natural and Mechanical Datasets
5. Validation: Inferring Operator’s Intent in a Realistic Scenario
5.1. Setup
| Algorithm 1: Finite state machine of the control of the robot during the validation. |
 |
5.2. Evaluation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Michalos, G.; Makris, S.; Tsarouchi, P.; Guasch, T.; Kontovrakis, D.; Chryssolouris, G. Design considerations for safe human–robot collaborative workplaces. Procedia CIRP 2015, 37, 248–253. [Google Scholar] [CrossRef]
- Villani, V.; Pini, F.; Leali, F.; Secchi, C. Survey on human–robot collaboration in industrial settings: Safety, intuitive interfaces and applications. Mechatronics 2018, 55, 248–266. [Google Scholar] [CrossRef]
- Michalos, G.; Makris, S.; Spiliotopoulos, J.; Misios, I.; Tsarouchi, P.; Chryssolouris, G. ROBO-PARTNER: Seamless human–robot cooperation for intelligent, flexible and safe operations in the assembly factories of the future. Procedia CIRP 2014, 23, 71–76. [Google Scholar] [CrossRef]
- Tsarouchi, P.; Michalos, G.; Makris, S.; Athanasatos, T.; Dimoulas, K.; Chryssolouris, G. On a human–robot workplace design and task allocation system. Int. J. Comput. Integr. Manuf. 2017, 30, 1272–1279. [Google Scholar] [CrossRef]
- Wang, L.; Gao, R.; Váncza, J.; Krüger, J.; Wang, X.V.; Makris, S.; Chryssolouris, G. Symbiotic human–robot collaborative assembly. CIRP Ann. 2019, 68, 701–726. [Google Scholar] [CrossRef]
- Roy, S.; Edan, Y. Investigating joint-action in short-cycle repetitive handover tasks: The role of giver versus receiver and its implications for human–robot collaborative system design. Int. J. Soc. Robot. 2018, 1–16. [Google Scholar] [CrossRef]
- Someshwar, R.; Edan, Y. Givers & receivers perceive handover tasks differently: Implications for human–robot collaborative system design. arXiv 2017, arXiv:1708.06207. [Google Scholar]
- Bauer, W.; Bender, M.; Braun, M.; Rally, P.; Scholtz, O. Lightweight Robots in Manual Assembly—Best to Start Simply. Examining Companies’ Initial Experiences with Lightweight Robots; Fraunhofer IAO: Stuttgart, Germany, 2016. [Google Scholar]
- Someshwar, R.; Meyer, J.; Edan, Y. A timing control model for hr synchronization. IFAC Proc. Vol. 2012, 45, 698–703. [Google Scholar] [CrossRef]
- Someshwar, R.; Kerner, Y. Optimization of waiting time in HR coordination. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1918–1923. [Google Scholar]
- Cherubini, A.; Passama, R.; Crosnier, A.; Lasnier, A.; Fraisse, P. Collaborative manufacturing with physical human–robot interaction. Robot. Comput. Integr. Manuf. 2016, 40, 1–13. [Google Scholar] [CrossRef]
- Maurtua, I.; Ibarguren, A.; Kildal, J.; Susperregi, L.; Sierra, B. Human–robot collaboration in industrial applications: Safety, interaction and trust. Int. J. Adv. Robot. Syst. 2017, 14. [Google Scholar] [CrossRef]
- de Gea Fernández, J.; Mronga, D.; Günther, M.; Wirkus, M.; Schröer, M.; Stiene, S.; Kirchner, E.; Bargsten, V.; Bänziger, T.; Teiwes, J.; et al. iMRK: Demonstrator for Intelligent and Intuitive Human–Robot Collaboration in Industrial Manufacturing. KI-Künstliche Intell. 2017, 31, 203–207. [Google Scholar] [CrossRef]
- Raiola, G.; Restrepo, S.S.; Chevalier, P.; Rodriguez-Ayerbe, P.; Lamy, X.; Tliba, S.; Stulp, F. Co-manipulation with a library of virtual guiding fixtures. Auton. Robot. 2018, 42, 1037–1051. [Google Scholar] [CrossRef]
- Munzer, T.; Toussaint, M.; Lopes, M. Efficient behavior learning in human–robot collaboration. Auton. Robot. 2018, 42, 1103–1115. [Google Scholar] [CrossRef]
- Peternel, L.; Tsagarakis, N.; Caldwell, D.; Ajoudani, A. Robot adaptation to human physical fatigue in human–robot co-manipulation. Autonomous Robots 2018, 42, 1011–1021. [Google Scholar] [CrossRef]
- Rozo, L.; Calinon, S.; Caldwell, D.G.; Jimenez, P.; Torras, C. Learning physical collaborative robot behaviors from human demonstrations. IEEE Trans. Robot. 2016, 32, 513–527. [Google Scholar] [CrossRef]
- Mazhar, O.; Ramdani, S.; Navarro, B.; Passama, R.; Cherubini, A. Towards real-time physical human–robot interaction using skeleton information and hand gestures. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Zhao, R.; Drouot, A.; Ratchev, S. Classification of Contact Forces in Human-Robot Collaborative Manufacturing Environments. SAE Int. J. Mater. Manuf. 2018, 11, 5–10. [Google Scholar] [CrossRef]
- Gaz, C.; Magrini, E.; De Luca, A. A model based residual approach for human–robot collaboration during manual polishing operations. Mechatronics 2018, 55, 234–247. [Google Scholar] [CrossRef]
- Losey, D.P.; McDonald, C.G.; Battaglia, E.; O’Malley, M.K. A review of intent detection, arbitration, and communication aspects of shared control for physical human–robot interaction. Appl. Mech. Rev. 2018, 70, 010804. [Google Scholar] [CrossRef]
- Mohammad, Y.; Xu, Y.; Matsumura, K.; Nishida, T. The H3R explanation corpus human-human and base human–robot interaction dataset. In Proceedings of the 2008 International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Sydney, NSW, Australia, 15–18 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 201–206. [Google Scholar]
- Jayagopi, D.B.; Sheikhi, S.; Klotz, D.; Wienke, J.; Odobez, J.M.; Wrede, S.; Khalidov, V.; Nguyen, L.; Wrede, B.; Gatica-Perez, D. The Vernissage Corpus: A Multimodal Human-Robot-Interaction Dataset; Technical Report; Idiap Research Institute: Martign, Switzerland, 2012. [Google Scholar]
- Bastianelli, E.; Castellucci, G.; Croce, D.; Iocchi, L.; Basili, R.; Nardi, D. HuRIC: A Human Robot Interaction Corpus. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; European Language Resources Association: Paris, France, 2014; pp. 4519–4526. [Google Scholar]
- Lemaignan, S.; Kennedy, J.; Baxter, P.; Belpaeme, T. Towards “machine-learnable” child-robot interactions: The PInSoRo dataset. In Proceedings of the IEEE Ro-Man 2016 Workshop on Long-Term Child-Robot Interaction, New York, NY, USA, 31 August 2016. [Google Scholar]
- Celiktutan, O.; Skordos, E.; Gunes, H. Multimodal human-human–robot interactions (mhhri) dataset for studying personality and engagement. IEEE Trans. Affect. Comput. 2017. [Google Scholar] [CrossRef]
- Yu, K.T.; Bauza, M.; Fazeli, N.; Rodriguez, A. More than a million ways to be pushed. A high-fidelity experimental dataset of planar pushing. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 30–37. [Google Scholar]
- De Magistris, G.; Munawar, A.; Pham, T.H.; Inoue, T.; Vinayavekhin, P.; Tachibana, R. Experimental Force-Torque Dataset for Robot Learning of Multi-Shape Insertion. arXiv 2018, arXiv:1807.06749. [Google Scholar]
- Huang, Y.; Sun, Y. A Dataset of Daily Interactive Manipulation. arXiv 2018, arXiv:1807.00858. [Google Scholar] [CrossRef]
- Berndt, D.J.; Clifford, J. Using dynamic time warping to find patterns in time series. In Proceedings of the 3rd International Conference on KDD Workshop, Seattle, WA, USA, 31 July–1 August 1994; AAAI: Menlo Park, CA, USA; Volume 10, pp. 359–370. [Google Scholar]
- Bagnall, A.; Bostrom, A.; Large, J.; Lines, J. The great time series classification bake off: An experimental evaluation of recently proposed algorithms. Extended version. arXiv 2016, arXiv:1602.01711. [Google Scholar]
- Salvador, S.; Chan, P. Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef]
- Shokoohi-Yekta, M.; Hu, B.; Jin, H.; Wang, J.; Keogh, E. Generalizing DTW to the multi-dimensional case requires an adaptive approach. Data Min. Knowl. Discov. 2017, 31, 1–31. [Google Scholar] [CrossRef]
- k-Nearest Neighbors Classifier (Scikit-Learn). Available online: https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier (accessed on 1 November 2019).
- Lawrence, N.D. Gaussian process latent variable models for visualization of high dimensional data. In Advances in Neural Information Processing Systems; MIT Press: Boston, MA, USA, 2004; pp. 329–336. [Google Scholar]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. R. Stat. Soc. Ser. B Stat. Methodol. 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Su, B.; Ding, X.; Wang, H.; Wu, Y. Discriminative dimensionality reduction for multi-dimensional sequences. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 77–91. [Google Scholar] [CrossRef]
- Villalobos, K.; Diez, B.; Illarramendi, A.; Goñi, A.; Blanco, J.M. I4tsrs: A system to assist a data engineer in time-series dimensionality reduction in industry 4.0 scenarios. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; ACM: New York, NY, USA, 2018; pp. 1915–1918. [Google Scholar]
- Seifert, B.; Korn, K.; Hartmann, S.; Uhl, C. Dynamical Component Analysis (DyCA): Dimensionality reduction for high-dimensional deterministic time-series. In Proceedings of the 2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP), Aalborg, Denmark, 17–20 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- GPy: Gaussian Process (GP) Framework in Python. Available online: https://sheffieldml.github.io/GPy (accessed on 1 November 2019).
- Support Vector Machine (Scikit-Learn). Available online: https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC (accessed on 1 November 2019).
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef]
















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olivares-Alarcos, A.; Foix, S.; Alenyà, G. On Inferring Intentions in Shared Tasks for Industrial Collaborative Robots. Electronics 2019, 8, 1306. https://doi.org/10.3390/electronics8111306
Olivares-Alarcos A, Foix S, Alenyà G. On Inferring Intentions in Shared Tasks for Industrial Collaborative Robots. Electronics. 2019; 8(11):1306. https://doi.org/10.3390/electronics8111306
Chicago/Turabian StyleOlivares-Alarcos, Alberto, Sergi Foix, and Guillem Alenyà. 2019. "On Inferring Intentions in Shared Tasks for Industrial Collaborative Robots" Electronics 8, no. 11: 1306. https://doi.org/10.3390/electronics8111306
APA StyleOlivares-Alarcos, A., Foix, S., & Alenyà, G. (2019). On Inferring Intentions in Shared Tasks for Industrial Collaborative Robots. Electronics, 8(11), 1306. https://doi.org/10.3390/electronics8111306