6.1. Platform and Benchmarks
Simulation based experiments are always time-consuming, especially when the benchmarks have large codes and data size. It has also been pointed out that simulation based studies have reported much more performance improvements than reality [
19]. In this paper, we use a hardware platform for our experiments and we implement a classical multicore SoC in Xilinx Virtex-6 FPGA using ISE (Release Version 13.1). The architecture is the same with that in
Figure 1 in
Section 2.1. In addition, some other IPs like timers (TIMER), interrupter controllers (INTC) and UART are also implemented.
Table 3 shows the parameter configurations of the key components used in our experiments. We use dual-core and quad-core processors for the experiments and each processor core is a CK810 [
39]. CK810 core has a 16-entry out-of-order execution buffer. Every core has its private L1 instruction cache and data cache. All cores share a L2 cache and the L2 cache supports way-based cache partitioning. MT16LSDF6464HG is used as the main memory in our system.
We use EEMBC MultiBench to evaluate our proposal. MultiBench is a suite of embedded benchmarks that allows processor and system designers to analyze, test and improve multicore architectures and platforms [
36]. In EEMBC terminology,
benchmark kernel means the algorithm to be executed (e.g., jpeg decompression).
Work item binds a
kernel to specific data (e.g., jpeg decompression of 16 images) whereas
workload consists of one or more
work items (e.g., jpeg decompression of 16 images, rotation of the results and jpeg compression). One or multiple
worker threads can be assigned to each
work item [
40]. Comparing with our previous expressions,
work item is equivalent to task or application and
worker is equivalent to thread. There are 8
benchmark kernels covering automotive, consumer, digital entertainment, networking and office automation. They are listed in
Table 4.
All
workloads are working with these benchmark kernels. There are about 30
workloads in EEMBC MultiBench suite. According to different settings, they can be divided into three categories. First, the
multi-mode workload: only one
work item is contained and one
worker is assigned to the item. It is similar to previous studied single-thread multi-task applications [
3,
4,
5,
11,
12,
18]. Second, the
parallel-mode workload: one
work item is contained but several
workers are assigned to the item. Last, the
mix-mode workload: a
workload has several
work items and each item has several
workers. In this paper, we do not study the multi-mode
workload, because previous studies have studied them extensively. Parallel-mode and mix-mode
workloads are multi-thread
workloads and they are our study objects.
6.2. Shareability Type Categorization Evaluation
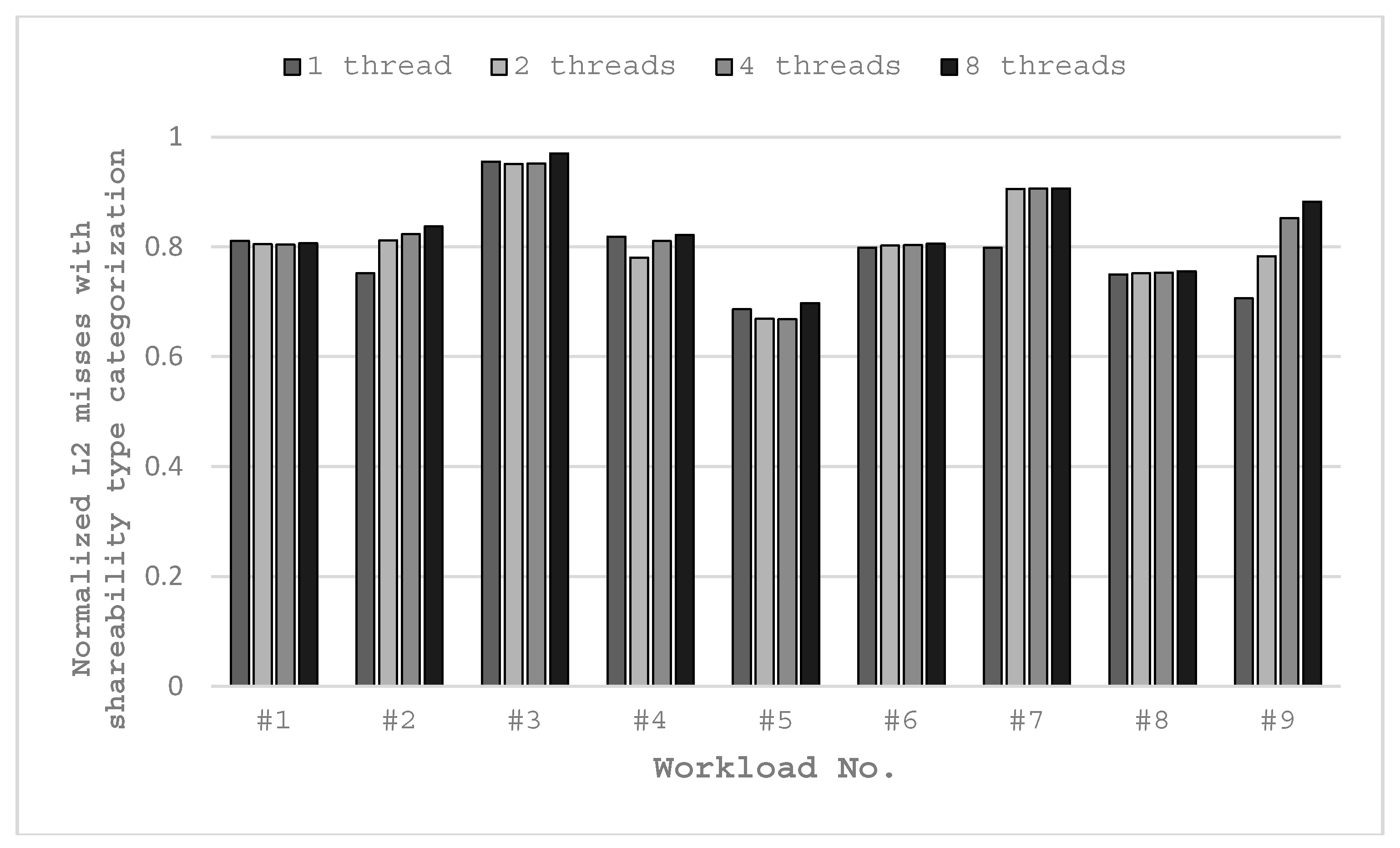
First, we analyze the effect of shareability type categorization by studying the parallel-mode workloads. As parallel-mode workload contains only one work item, the effectiveness of data categorizing can be seen from the results in
Table 5 clearly. A workload runs multiple times with different numbers of threads. It also runs with single thread but without shareability type categorization for the basic configuration. As shown in previous functions, the total number of L2 misses is a reflection of the power dissipation metric. Fewer L2 cache misses will lower the total energy consumption of an application.
The workloads are executed in a quad-core platform. The experimental results in
Figure 9 show that all the workloads running with shareability type categorization have fewer L2 misses compared to those without shareability type categorization, and this is due to the lesser memory boundness of the application.
Table A1 in
Appendix C presents the absolute numbers of L2 misses of 1/2/4/8 threads for the workloads listed in
Table 5. Different WAPR settings are used for different numbers of threads (i.e., workers) and workloads.
Moreover, running in single-thread mode with shareability type categorization results in fewer L2 misses than the basic configuration. This is because we set all the instruction codes to private type and set all the program data to shared type for single-thread mode. Instructions and user data do not disturb each other, although only one thread is used. Most workloads have significant L2 miss reduction with shareability type categorization. The minimum reduction is 3.0% with 8-thread for #3 workload and the maximum reduction is 33.2% with 4-thread for #5 workload. For all workloads except for x264-4Mq, their lowest L2 misses are achieved with 2-thread or 4-thread. In some cases, more threads do not result in fewer L2 misses, such as #1 and #8 workloads. In some other cases, more threads result in more L2 misses, such as #7 and #9 workloads. The reason is that they have too many slices or streaming characters, then the degradation caused by the increased synchronization overrides the benefit of the increased number of threads.
6.3. Energy Consumption of ATCP
Next we evaluate the energy consumption of our ATCP in the quad-core system. In our experiments, we adopt the energy model in Reference [
4] which is described in
Section 2.3. Hardware related information can be obtained from the specifications. We capture the number of access, the number of miss and the number of execution cycles by running the workloads in the FPGA. As multi-thread and multi-task application should be tested, we use mix-mode workloads in EEMBC MultiBench which are listed in
Table 6. Only 6 single-item workloads are in mix-mode and we combine them to construct the multi-item workloads.
For the multi-item workloads, when there are more items than cores, the items with longer execution time will not be scheduled until there are cores available. When the number of items is less than that of cores, some cores are not utilized. All the items in a workload start to work at the beginning and the shared cache is partitioned for them. But if any item is finished, the cache is repartitioned for the remaining executing items.
We evaluate the L2 cache energy consumption of our data adaptive thread-aware cache partitioning scheme (ATCP), by comparing it with three other cache partitioning schemes, that is, non-partitioned (LRU), core-based evenly partitioned (used in Reference [
4], EVEN) and utility-based cache partition (in Reference [
11], UCP). EVEN partitions a shared L2 cache evenly to all cores that each core occupies the same portion of the L2 cache. UCP in this work has minor modifications and we use UCP-M to represent it. The UCP-M algorithm is shown in the Matlab M-file format in
Figure 10. We use a
Threshold to avoid using extremely low utility cache ways.
The energy consumptions of the L2 cache with these cache partitioning schemes are shown in
Figure 11 and
Figure 12, in which
Estatic stands for the leakage energy consumption (J) and
Edynamic stands for the dynamic energy consumption (J). EVEN-2/ATCP-2 means EVEN/ATCP scheme in dual-core system and EVEN-4/ATCP-4 means EVEN/ATCP scheme in quad-core system. LRU/UCP-M partitioning scheme has no different results between dual-core and quad-core systems for single-item workloads, because it only cares about the current running tasks (items) and the number of cores. For multi-item workloads, there are differences between the occasion that items are more than cores and the occasion that items are less than cores. B11 and B12 have these differences and we use LRU-2/UCP-M-2 in dual-core system and LRU-4/UCP-M-4 in quad-core system.
For total energy consumption (Estatic plus Edynamic) in dual-core system: EVEN partitioning and UCP-M partitioning consume no more energy than LRU partitioning for single-item workloads. But EVEN may consume more energy than LRU for multi-item workloads (e.g., B7, B8). ATCP consumes the least energy for all the workloads, not only for single-item ones but also for the multi-item ones. EVEN uses fewer cache ways, so it consumes much less static energy compared with LRU. For most cases, EVEN performs better than LRU, especially when static energy dominates the total energy consumption (e.g., B1, B3). UCP-M benefits from both shutting down the low utility ways (in single-item workloads) and rearranging the idle cache ways for reuse (in multi-item workloads). ATCP also uses relatively small amount of cache ways for single-item workloads, so the static energy of ATCP is less than other schemes. Furthermore, ATCP reduces the interferences between different threads (multi-thread) and it also reduces the interferences between instruction codes and user data (single-thread). So less dynamic energy is consumed by cache misses, which is owed to multi-thread running and shareability type categorization in ATCP. For all workloads running in dual-core system, our ATCP scheme achieves 23.3%, 14.6% and 19.5% energy savings on average compared with LRU, UCP-M and EVEN. The maximum energy saving is 38.2% in B4, 25.3% in B1 and 32.3% in B7, compared with LRU, UCP-M and EVEN respectively.
The experimental results in quad-core system are similar to the results in dual-core system. Our ATCP scheme achieves 29.6%, 19.9% and 15.3% energy savings on average compared with LRU, UCP-M and EVEN. The maximum energy saving is 39.2% in B4, 35.9% in B1 and 23.4% in B9, compared with LRU, UCP-M and EVEN respectively. But there are some changes worthy of mentioning. First, ATCP-4 consumes no more energy than ATCP-2 for all the workloads. The reason is that ATCP-4 contains ATCP-2 in terms of scheduling the same workload. Second, EVEN-4 is not always better than EVEN-2 (e.g., B5). EVEN-4 uses fewer cache ways and consumes less static energy but more dynamic energy may be consumed because there are more cache misses. Third, UCP-M does not always outperform EVEN (e.g., B10 and B12) but it is never any worse than the performance of LRU.
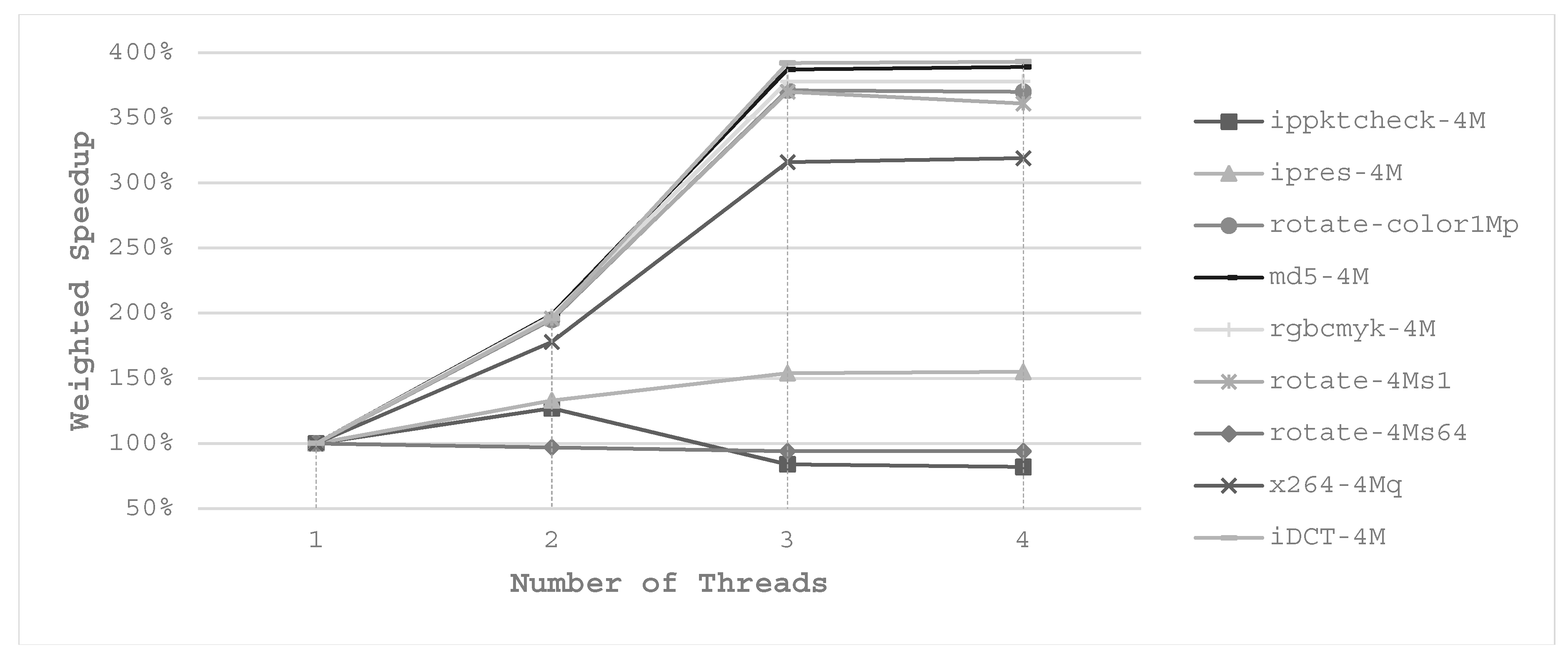
6.4. Weight Speedup Performance of ATCP
We also evaluate the impact on execution time of our ATCP. We use normalized speedup to reflect the differences to the three-cache partitioning scheme. Speedup is 1/time and we normalize the speedup values to LRU. For LRU, EVEN and UCP-M, the execution time is measured in single thread. For ATCP, the execution time is the one when the best energy saving is achieved. All the experimental results are depicted in
Figure 13.
For single-item workloads, EVEN takes more execution time than LRU as a result of using fewer cache ways. UCP-M has approximately the same results as EVEN in both dual-core and quad-core systems for single-item workloads. The differences of UCP-M and EVEN appear in multi-item workloads. EVEN has a degradation in speed with respect to LRU for most multi-item workloads. UCP-M shows speedup compared with LRU for most multi-item workloads. For our ATCP, it shows a great speedup for most workloads in both dual-core and quad-core systems. Maximum speedup arrives at 3.76 which is obtained in B4 in quad-core system, because it is executed with 4 threads. Average speedup is 1.6 for dual-core system and 1.89 for quad-core system. Single-item workloads speedup better than multi-item workloads in average in quad-core system, because they have a higher chance to be executed with more threads. When the number of items equals to the number of cores (e.g., B11 and B12), all items can run in parallel at the beginning, so multi-thread does not obtain much superior speedup compared with other cache partitioning schemes.
6.5. Hardware Overhead
TACM is the major hardware overhead of our ATCP. We use a similar cache monitor as UMON that Qureshi and so forth, proposed in Reference [
11]. The differences are: (1) we count L2 accesses by thread ID rather than core ID; (2) we also use domain attribute when implementing ATDs and SCs. In our implementation, each ATD entry has 1-bit valid, 18-bit tag and 3-bit LRU, totally 22 bits. There are totally 32 sampled sets and 8 ATD entries per set. So an ATD requires 704 Bytes (22 bits/way × 8 ways/set × 32 sets) storage overhead. Another aspect, a SC group has 36 Bytes (9 counters × 4B/counter) overhead. We use private and shared domain ATDs and SCs for each core. Finally, for our quad-core, 1 MB L2 cache system, 5920 Bytes (2 × 4 × 740 Bytes) storage is required. Compared with total L2 cache’s 1108 K Bytes (84 KB tag + 1 M data) storage, only 0.52% hardware overhead is needed for TACM.
Replacement signs array (in
Figure 8) is another major hardware overhead. To support cache partition in way aligned as
Figure 5 shows, replacement block cannot distribute across different partitions. So, each partition region has its own replacement sign (i.e., LRU bits in ours). For the worst case, one sign is for one cache way and 21 bits (7 ways × 3 bits/way) are needed for one set. In our quad-core processor, 5376 Bytes (21 bits/set × 2048 sets) storage is needed, which is 0.47% of the total L2 cache.
In summary, less than 1% storage overhead is required for our ATCP in a quad-core processor. As for a dual-core processor, the overhead is even less, which is about 0.5%. For other resources, the domain bit is stored in MMU but it is only 1-bit hardware overhead. As for software aspect, the domain attribute is programmed with other page table information such as cacheable, writeable and virtual to physical address mapping, so no software overhead exists. WAPRs also require some storage, which is 64 bits in total for a quad-core processor. Other hardware overheads are some ‘AND’ and ‘MUX’ logic, which are negligible in area and timing.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












