Evaluating the Impact of Optical Interconnects on a Multi-Chip Machine-Learning Architecture


Abstract
1. Introduction
2. Background and Motivation
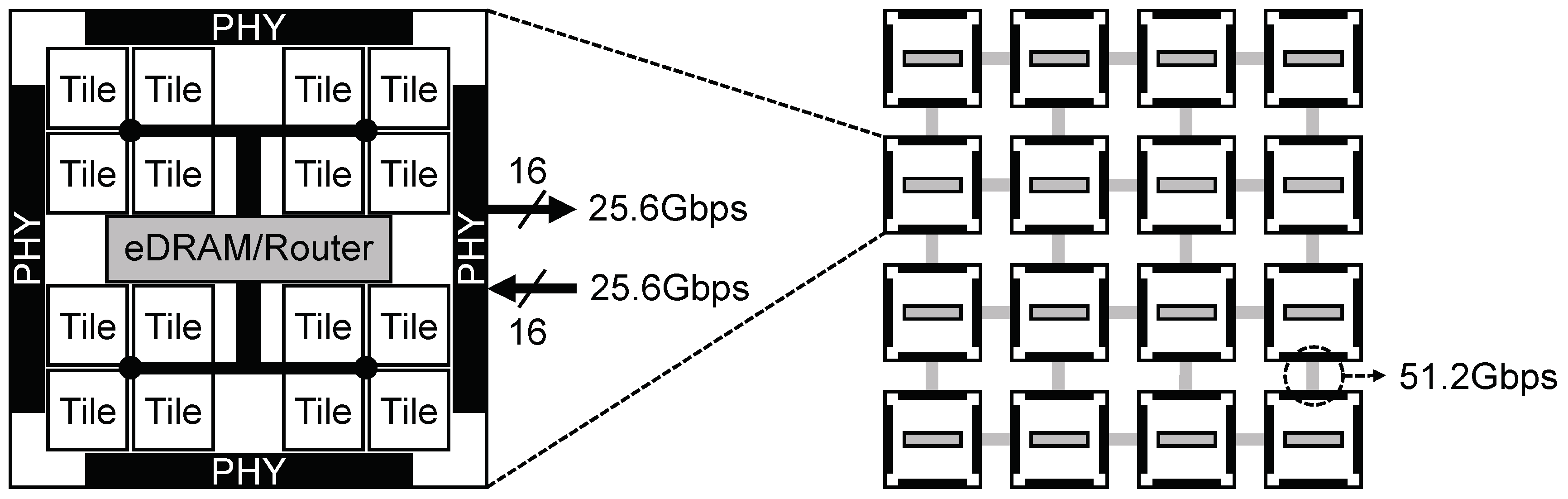
2.1. DaDianNao
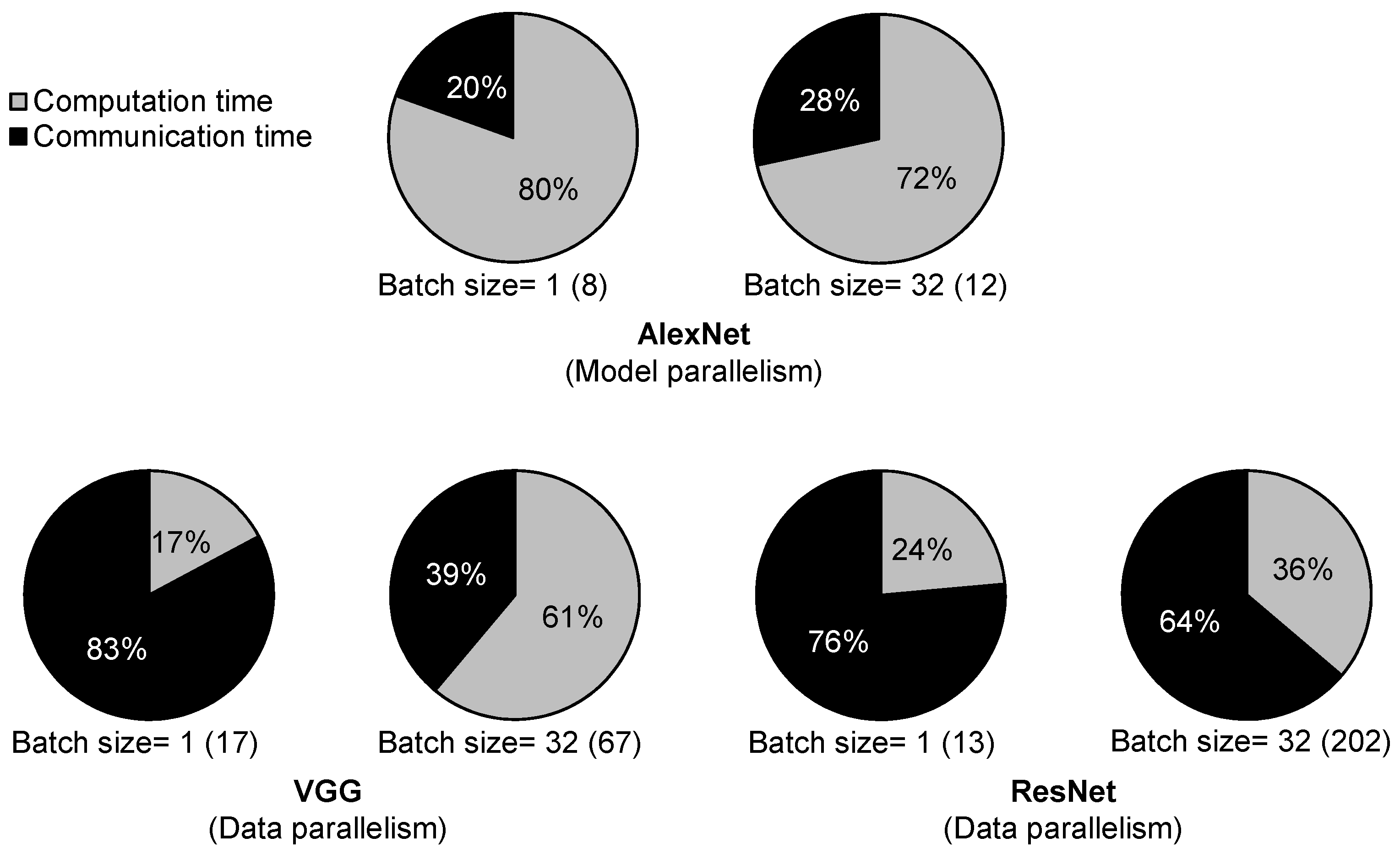
2.2. Impact of Off-Chip Interconnect on Performance
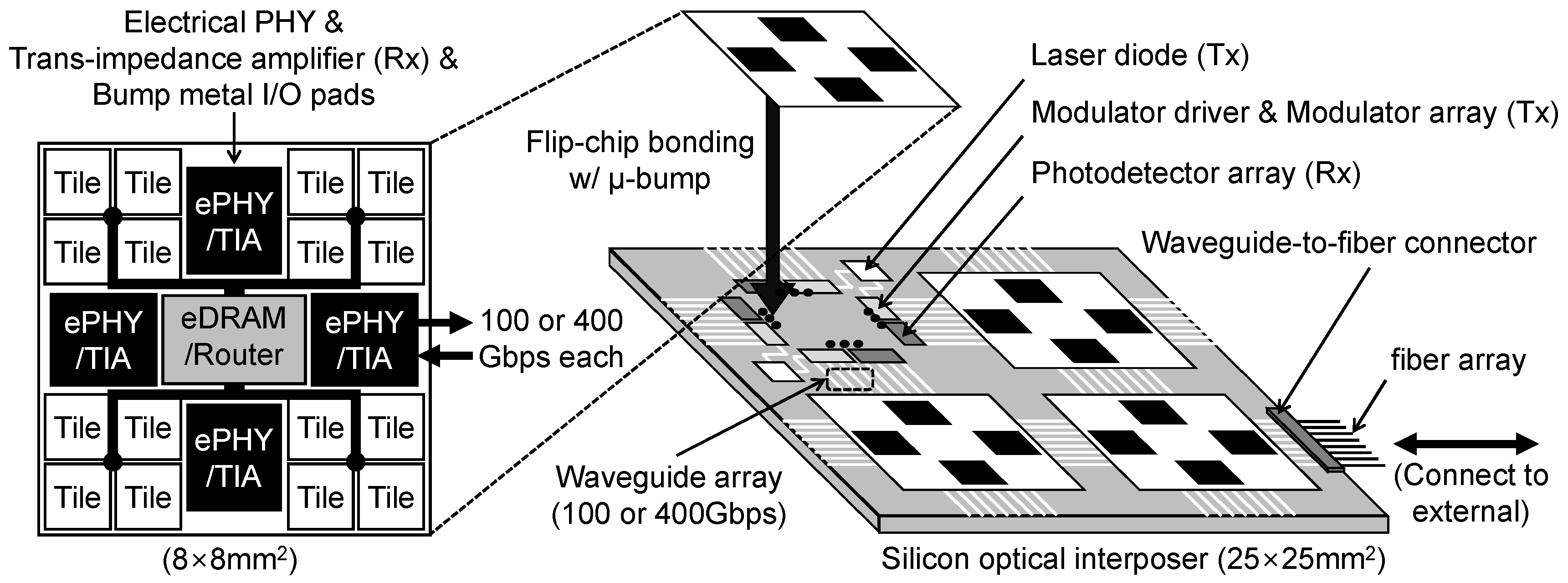
2.3. Current Status of Optical Interconnect Technology
3. Optically Interconnected Multi-Chip Machine-Learning System
3.1. Design Objectives
- Reasonable cost: Although additional cost can be justified by achieving better performance, optical components are still expensive in terms of PHY sizes on silicon and link costs (cable or other forms of waveguides). We keep interconnects from becoming a major factor of the entire system cost.
- Feasibility with current technologies: DaDianNao chip was implemented with a 28 nm process [7]. As discussed in Section 3.2, 100 Gbps of bandwidth can also be achieved by current photonics technology. Our first goal is to apply 100 Gbps interconnects to the current DaDianNao.
- One step forward with the next generation of optical interconnects: In a few years, optical components for 400 G standards will be available. Beyond 100 Gbps, we apply 400 Gbps interconnects to DaDianNao and compare its performance with the existing DaDianNao system.
3.2. Connection to Each Machine-Learning Accelerator
3.3. Network of Multi-Chip Machine-Learning Architecture
4. Experimental Methodology
4.1. Evaluated System and CNN Models
4.2. Arithmetic Performance and Energy Model
- The computational unit of DaDianNao has a simple pipeline structure with only three stages and works by in-order execution.
- The clock frequency of the accelerator is constant, so dynamic frequency scaling is not used.
- Every inter-accelerator communication is all-to-all broadcast through a 2D-mesh network so that the execution time can be calculated by a mathematical model [15].
- The throughputs and delays of the computational unit, eDRAM, and interconnect are clearly defined.
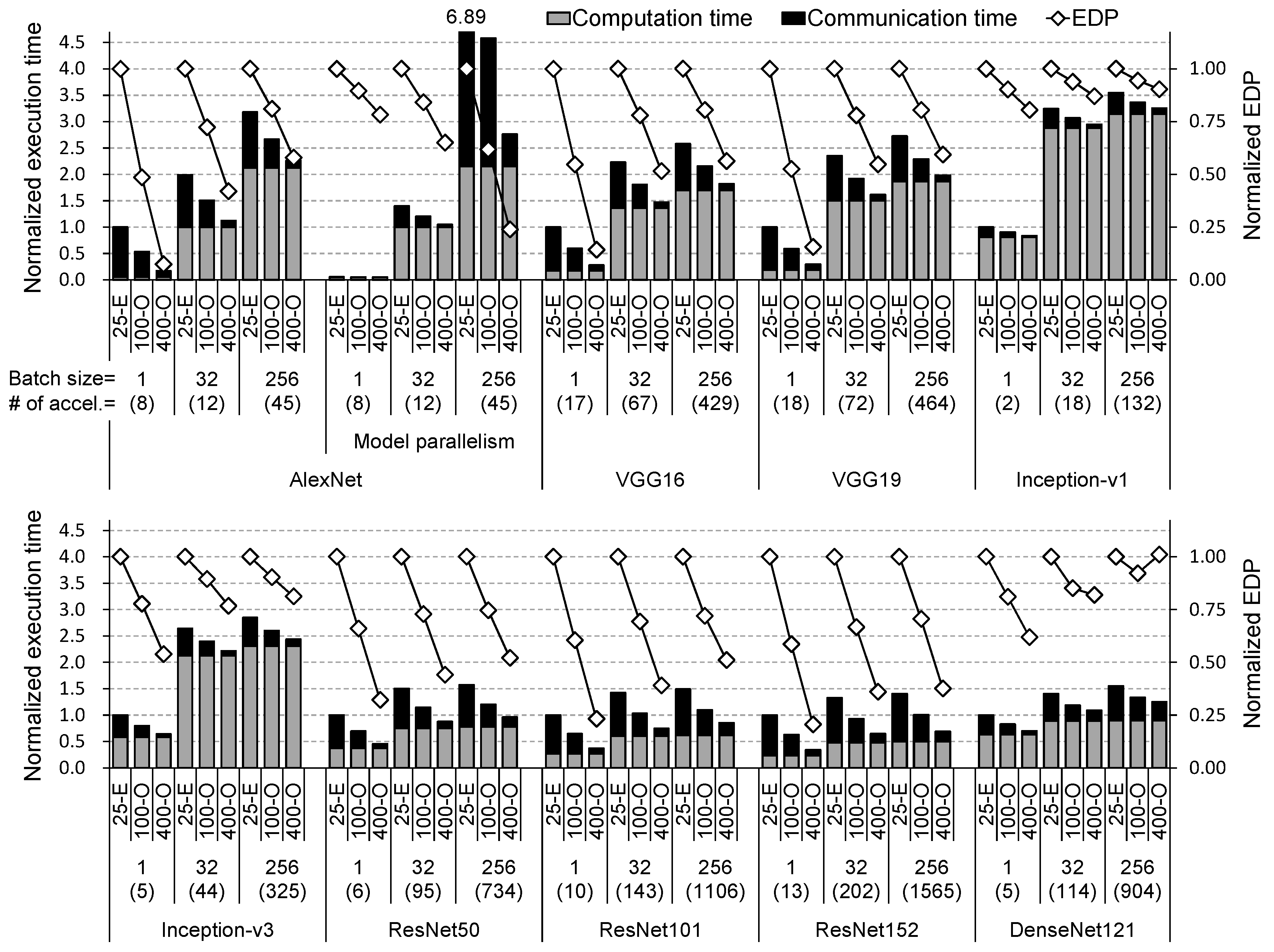
5. Evaluation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Chen, Y.; Luo, T.; Liu, S.; Zhang, S.; He, L.; Wang, J.; Li, L.; Chen, T.; Xu, Z.; Sun, N.; et al. DaDianNao: A machine-learning supercomputer. In Proceedings of the Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Cambridge, UK, 13–17 December 2014; pp. 609–622. [Google Scholar]
- Caulfield, A.M.; Chung, E.S.; Putnam, A.; Angepat, H.; Fowers, J.; Haselman, M.; Heil, S.; Humphrey, M.; Kaur, P.; Kim, J.; et al. A cloud-scale acceleration architecture. In Proceedings of the Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Boston, MA, USA, 15–19 October 2016. [Google Scholar]
- Park, J.; Sharma, H.; Mahajan, D.; Kim, J.K.; Olds, P.; Esmaeilzadeh, H. Scale-out acceleration for machine learning. In Proceedings of the Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Cambridge, MA, USA, 14–18 October 2017; pp. 367–381. [Google Scholar]
- Dean, J.; Corrado, G.S.; Monga, R.; Chen, K.; Devin, M.; Le, Q.V.; Mao, M.Z.; Ranzato, M.A.; Senior, A.; Tucker, P.; et al. Large scale distributed deep networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1223–1231. [Google Scholar]
- EENews EUROPE. Single-Wavelength PAM4 DSP Chip Delivers 100 G. Available online: http://www.eenewseurope.com/news/single-wavelength-pam4-dsp-chip-delivers-100g (accessed on 25 May 2018).
- Okamoto, D.; Urino, Y.; Akagawa, T.; Akiyama, S.; Baba, T.; Usuki, T.; Miura, M.; Fujikata, J.; Shimizu, T.; Okano, M.; et al. Demonstration of 25-Gbps optical data links on silicon optical interposer using FPGA transceiver. In Proceedings of the European Conference on Optical Communications (ECOC), Cannes, France, 21–25 September 2014. [Google Scholar]
- Kim, D.; Au, K.Y.; Li, H.Y.; Luo, X.; Ye, Y.L.; Bhattacharya, S.; Lo, G.Q. 2.5D Silicon optical interposer for 400 Gbps electronic-photonic integrated circuit platform packaging. In Proceedings of the Electronics Packaging Technology Conference (EPTC), Singapore, 6–9 December 2017. [Google Scholar]
- Patterson, D.; Sousa, I.D.; Achard, L.M. The future of packaging with silicon photonics. Chip Scale Rev. 2018, 21, 14–25. [Google Scholar]
- Sun, C.; Wade, M.T.; Lee, Y.; Orcutt, J.S.; Alloatti, L.; Georgas, M.S.; Waterman, A.S.; Shainline, J.M.; Avizienis, R.R.; Lin, S.; et al. Single-chip microprocessor that communicates directly using light. Nature 2015, 528, 534–538. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, R.; Horowitz, M. Energy Dissipation in General Purpose Microprocessors. IEEE J. Solid-State Circuits 1996, 31, 1277–1284. [Google Scholar] [CrossRef]
- Mansuri, M.; Jaussi, J.E.; Kennedy, J.T.; Hsueh, T.; Shekhar, S.; Balamurugan, G.; O’Mahony, F.; Roberts, C.; Mooney, R.; Casper, B. A Scalable 0.128-to-1Tb/s 0.8-to-2.6pJ/b 64-lane Parallel I/O in 32nm CMOS. In Proceedings of the International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 17–21 February 2013; pp. 402–403. [Google Scholar]
- Vantrease, D.; Schreiber, R.; Monchiero, M.; McLaren, M.; Jouppi, N.P.; Fiorentino, M.; Davis, A.; Binkert, N.; Beausoleil, R.G.; Ahn, J. Corona: System Implications of Emerging Nanophotonic Technology. In Proceedings of the International Symposium on Computer Architecture (ISCA), Beijing, China, 21–25 June 2008; pp. 153–164. [Google Scholar]
- Intel. 100G Parallel Single Mode Data Center Connectivity. Available online: https://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/optical-transceiver-100g-psm4-qsfp28-brief.pdf (accessed on 23 June 2018).
- Welch, B. 400G Optics—Technologies, Timing, and Transceivers. In Proceedings of the IEEE P802.3bs 200 GbE & 400 GbE Task Force Interim Meeting, Norfolk, VA, USA, 12–14 May 2014. [Google Scholar]
- Wang, Z.; Xu, J.; Yang, P.; Wang, X.; Wang, Z.; Duong, L.H.K.; Wang, Z.; Maeda, R.K.V.; Li, H. Improve chip pin performance using optical interconnects. IEEE Trans. VLSI Syst. 2016, 24, 1574–1587. [Google Scholar] [CrossRef]
- Chen, G.; Chen, H.; Haurylau, M.; Nelson, N.A.; Albonesi, D.H.; Fauchet, P.M.; Friedman, E.G. On-chip copper-based vs. optical interconnects: delay uncertainty, latency, power, and bandwidth density comparative predictions. In Proceedings of the International Interconnect Technology Conference (IITC), Burlingame, CA, USA, 5–7 June 2006; pp. 39–41. [Google Scholar]
- IEEE LAN/MAN Standards Committee. IEEE Std 802.3bs-2017 (IEEE Standard for Ethernet). Available online: http://www.ieee802.org/3/bs/ (accessed on 25 May 2018).
- Wang, X.; Wang, T.; Yang, W. Proposal for 400 GbE FEC Architecture. In Proceedings of the IEEE P802.3bs 200 GbE & 400 GbE Task Force Plenary Meeting, Berlin, Germany, 9 March 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Frequency | 606 MHz | Local eDRAM latency | 3 cycles |
| # of tiles | 16 | Central eDRAM latency | 10 cycles |
| # of 16-bit multipliers | 288/tile | SRAM buffer capacity | 16 KB/tile |
| # of 16-bit adders | 288/tile | Local eDRAM capacity | 2 MB/tile |
| Peak performance | 2.09 TeraOPS | Central eDRAM capacity | 4 MB |
| Peak power w/o PHY | 7.96 W | Peak per-PHY power | |
| - Electrical 25.6 Gbps | 2.00 W | ||
| - Optical 100 Gbps | 3.50 W | ||
| - Optical 400 Gbps | 6.00 W | ||
| Accel.-to-accel. bandwidth | (bidirectional) | Accel.-to-accel. latency | |
| - Electrical 25.6 Gbps | 6.4 GB/s | - Electrical 25.6 Gbps | 80 ns |
| - Optical 100 Gbps | 25 GB/s | - Optical 100 Gbps | 80 ns |
| - Optical 400 Gbps | 100 GB/s | - Optical 400 Gbps | 160 ns |
| Parameter | AlexNet | VGG | VGG | Inception | Inception | ResNet | ResNet | ResNet | DenseNet |
|---|---|---|---|---|---|---|---|---|---|
| [1] | 16 [2] | 19 [2] | - v1 [4] | -v3 [5] | 50 [3] | 101 [3] | 152 [3] | 121 [6] | |
| Year introduced | 2012 | 2014 | 2014 | 2015 | 2015 | 2015 | 2015 | 2015 | 2016 |
| # of layers | 14 | 22 | 25 | 73 | 111 | 125 | 244 | 363 | 306 |
| (convolution/fully connected) | (5/3) | (13/3) | (16/3) | (20/1) | (56/1) | (49/1) | (100/1) | (151/1) | (120/1) |
| Total synapse [MB] | 233 | 528 | 548 | 27 | 105 | 97 | 170 | 229 | 30 |
| Total neuron * [MB] | 172 | 1860 | 2019 | 587 | 1446 | 3290 | 4956 | 7014 | 4061 |
| Ratio in size (synapse/neuron) | 1.35 | 0.28 | 0.27 | 0.05 | 0.07 | 0.03 | 0.03 | 0.03 | 0.01 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ro, Y.; Lee, E.; Ahn, J.H. Evaluating the Impact of Optical Interconnects on a Multi-Chip Machine-Learning Architecture. Electronics 2018, 7, 130. https://doi.org/10.3390/electronics7080130
Ro Y, Lee E, Ahn JH. Evaluating the Impact of Optical Interconnects on a Multi-Chip Machine-Learning Architecture. Electronics. 2018; 7(8):130. https://doi.org/10.3390/electronics7080130
Chicago/Turabian StyleRo, Yuhwan, Eojin Lee, and Jung Ho Ahn. 2018. "Evaluating the Impact of Optical Interconnects on a Multi-Chip Machine-Learning Architecture" Electronics 7, no. 8: 130. https://doi.org/10.3390/electronics7080130
APA StyleRo, Y., Lee, E., & Ahn, J. H. (2018). Evaluating the Impact of Optical Interconnects on a Multi-Chip Machine-Learning Architecture. Electronics, 7(8), 130. https://doi.org/10.3390/electronics7080130