5.1. Case Study I: A Basic Synchronous Dataflow with a Delay Unit
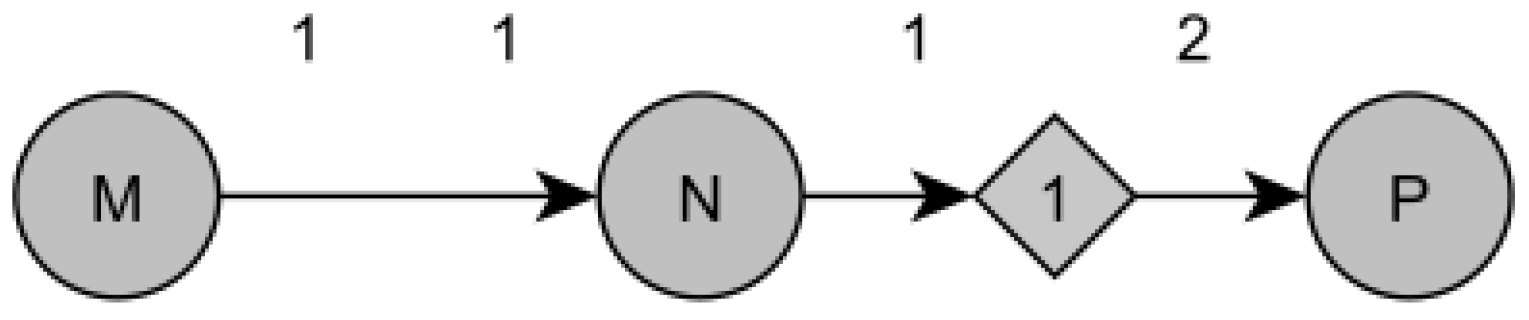
As a first example, consider the SDF model from
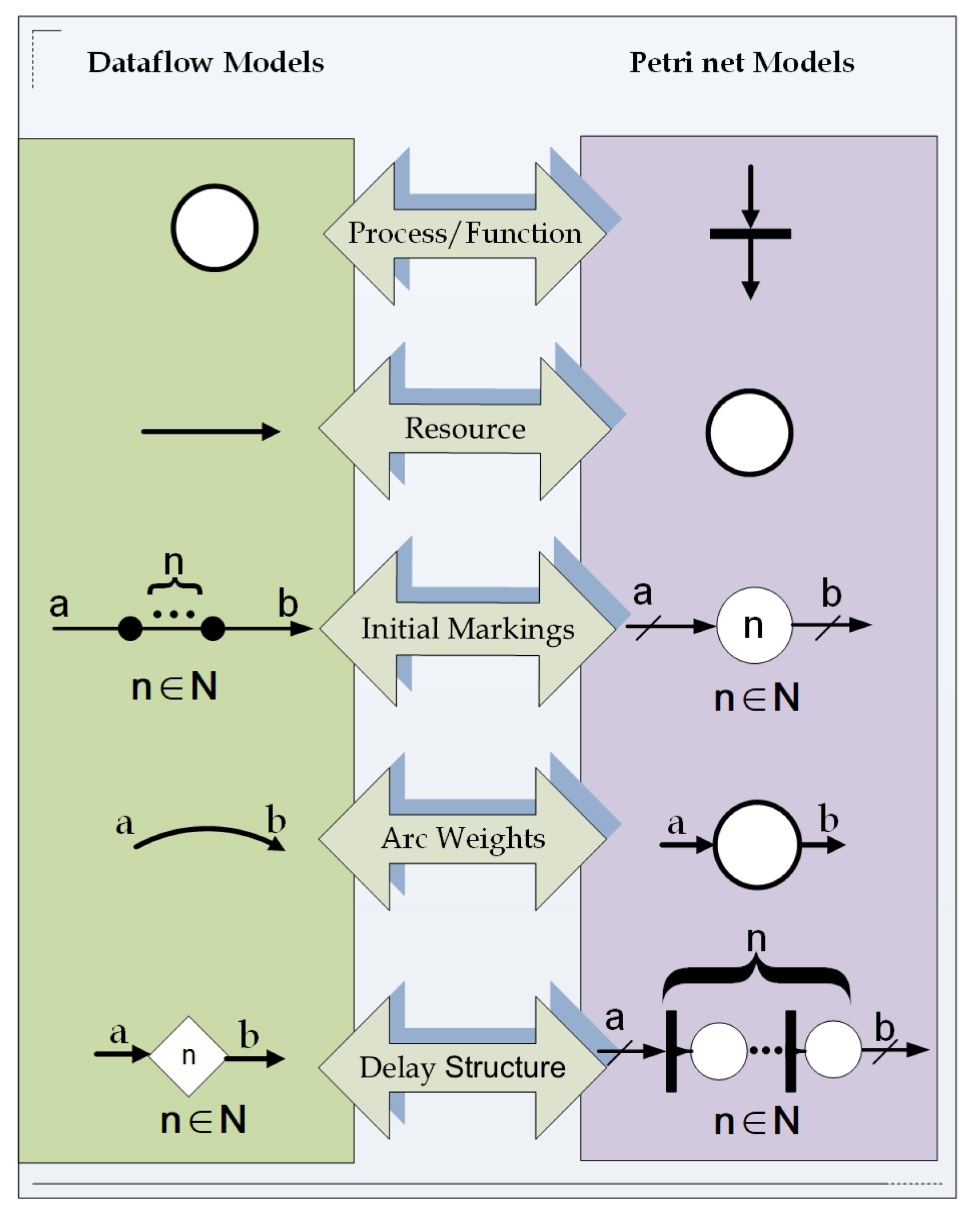
Figure 2. This dataflow has three actors (M, N, and P) and two arcs (buffers), in which an arc has one delay unit attached to it. If a dataflow graph includes delays, an equivalent Petri net delay structure must be inserted in the final Petri net model. In this context, considering the dataflow in
Figure 2 and using the delay structure illustrated in
Figure 3 jointly with the proposed mapping mentioned in
Section 4, an equivalent behaviorally Petri net model was obtained, as stated by Proposition 1; this model is depicted in
Figure 4. However, the model shown in
Figure 4 entails more than following the mapping rules between the two frameworks to achieve an equivalent Petri net model; rather, it is also necessary to exhibit a cyclical behavior, as in the departure dataflow model. In this manner, in each PN model, it is mandatory to include place
for the reversibility rule established by Definition 1 to hold. It should be clarified that Petri nets do not need to be cyclic, but in this case, what is required is to find static schedules; therefore, they should be cyclic.
The Petri net model shown in
Figure 2 will be used as a first and simple example to illustrate the key points about the system’s start-up conditions and their relevance for the system’s evolution.
By finding each and every possible elementary cycle in the state-space, one has the possibility of determining whether the system under analysis can reach a state/event as a result of a prerequisite functional behavior or even know in advance if a firing sequence of a required functional behavior was achieved.
When a transition fires, two approaches or interpretations may be considered: (1) single-server semantics, in which it is always assumed that a transition cannot be fired more than once at a time, even if enabled to fire multiple times; and (2) infinite server semantics, in which enabled transition can be fired multiple times at once [
47]. The firing semantics used in this case (
Figure 4) is the single-server semantics.
In the Petri net shown in
Figure 4, at the start, only state
is marked with two tokens (
). The generated state-space is illustrated in
Figure 5, in which one can see that the Petri net model has ten states. On each state-space, a depth-first search algorithm is performed to identify all elementary circuits [
48] present in the Petri net model. Moreover, from P-invariants of a Petri net, one can know if the net is bounded, simply by verifying that all the elements of the P-invariants are strictly positive.
Table 1 illustrates that choosing the correct initial conditions has a major impact on the state-space dimension. For instance, if place
has at the start four tokens, a state-space with thirty-five states and seventy transitions is engendered. The other rows of
Table 1 depict several possible initial tokens in place
, which ends up with larger state-spaces. Therefore, one can conclude that even for a small dataflow, the corresponding Petri net state-space can be very large if the right initial conditions are missing or not known in advance during the design stage.
To describe a static schedule, T-invariants are used, which correspond to the set of transitions that reproduce the initial marking following a suitable order. The equivalent Petri net of
Figure 4 has just one T-invariant vector,
meaning that in each static schedule, transitions
, and
will fire twice, whereas transition
will fire just once. This invariant yet does not specify the order of transition firings; rather, it only indicates their behavior under a periodic admissible schedule. However, to gain a better insight of how each enrolled transition is in the sequential firing and how many possible static schedules can be reached, a state-space analysis must be performed, since with T-invariants, it is only possible to know in advance how many times each transition will fire in a cycle. Therefore, if one wants to improve the knowledge of the system, it is mandatory to search the generated state-space. To account the number of static schedules in an SDF, an algorithm must be used to find all the elementary circuits in the state-space. This task allows one to find alternative schedules, which can reduce the memory storage demands. By using the Johnson algorithm [
20], this task can be achieved.
Table 2 presents the eleven possible static schedules reached and found after examination of the matching generated state-space depicted in
Figure 5, but only five of the eleven periodic static schedule are in agreement with T-invariant from (
2), to know Cycles 1, 2, 3, 6, and 7, identified by symbol †. The representation
(like for instance
in
Table 2, Periodic Schedule (PS) Number 3) in each of the following tables (
Table 2 and
Table 3) means that transition
will fire sequentially
times. One can conclude that the initial markings of a Petri net will comprise the entire T-invariant space. Thus, only a few will be observable, as indicated in
Table 2. Since the firing semantics used by the IOPT Tool is the maximal step, two or more concurrent fireable transitions can fire, to introduce and unveil parallel and/or distributed processing activities.
Table 2 depicts manifold cases (Cycles 4, 5, 8–11), where each notation
represents a block of concurrent fired transitions (
). Furthermore, the nodes engaged in each Periodic Admissible Static Schedule (PASS) are detected.
Table 4 depicts the node sequences for each PASS, including the solutions that follow (
2).
However, if the aim is to find periodic admissible sequential schedules, then only a single actor can be fired at a time, meaning that on the Petri net side, the adopted firing strategy must be interleaving semantics, instead of the maximal step.
Table 3 presents five possible sequential schedules.
Table 5 also specifies the node sequences enrolled in each sequential schedule.
Table 3 and
Table 5 are as a consequence of the firing strategies subsets of
Table 2 and
Table 4, respectively.
The former case study demonstrated how initial markings can be achieved and their impact when the right initial markings are not known; concomitantly, this introductory case also highlights the possibility of studying a signal-processing system in a broader sense by adopting a different firing strategy, such as the maximal step semantics instead of being tied to a more conservative approach, in which the goal is to reach periodic admissible sequential schedules (interleaving semantics).
5.2. Case Study II: A Signal Processing Application
The experimental results will be supported and illustrated by a well-known model in the dataflow community, MP3 playback [
49].
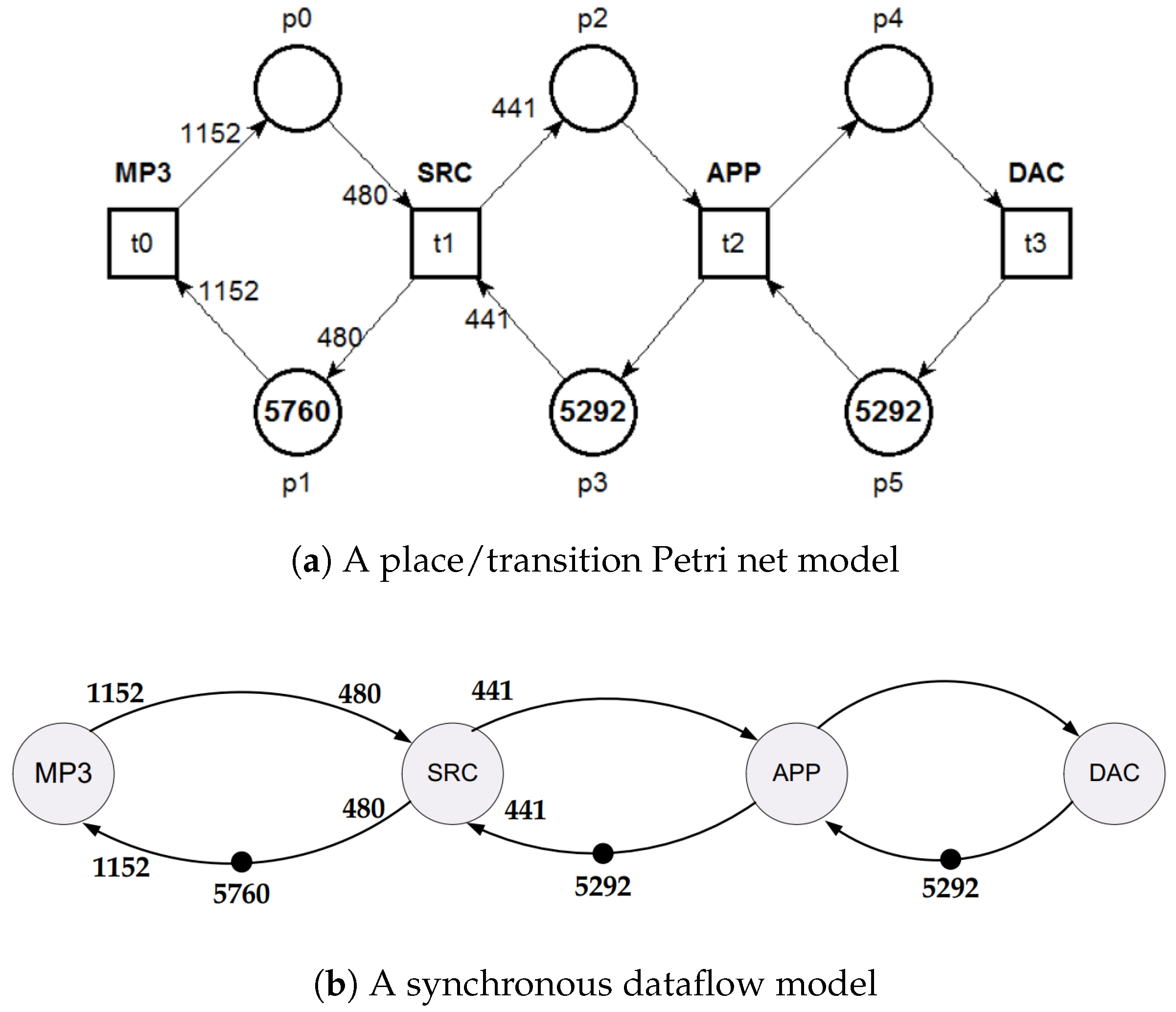
Figure 1b depicts the corresponding dataflow model of the MP3 playback application from [
49]. In this application, compressed audio is decoded by the MP3 actor into a 48-kHz sample stream. Afterwards, these samples are converted by the Sample Rate Converter (SRC) into a 44.1-kHz stream, which is followed by the Audio Post-Processing (APP) actor to enhance the stream audio quality. Finally, the stream sample is converted back to the analog domain using a Digital-to-Analogue Converter (DAC). In spite of being a dataflow with a few actors, the demanded cycles to the MP3 playback application in every static schedule are considerable, since each actor (MP3, SRC, APP, and DAC) performs [5, 12, 5292, 5292] repetitions, respectively.
Figure 1a shows the counterpart of the MP3 playback application in the Petri net domain, wherein the suitable initial markings (in places
,
, and
) were established by performing the invariant analysis, in this case the T-invariants.
Signal-processing system applications, cyber-physical systems, and industrial applications usually have large state-spaces committed to several hundred million states; therefore, it is neither desirable nor feasible to inspect them visually. Moreover, during the design process, models suffer modifications, and the state-space needs to be rechecked to ensure that everything is functioning properly, if a transition or set of transitions was fired, or if a specific net marking was reached.
In this manner, it will be possible with the proposed mapping in
Section 4 to query the state-space to know if those previous requirements (Definition 1 and Proposition 1) were fulfilled, which empowers and strengthens the model-checking system. A further improvement can be achieved if a method for generating a reduced state-space is used, namely using stubborn sets [
46]. This technique takes advantage of the lack of interaction between transitions while preserving their liveness.
Supported by the P-invariant analysis, one can establish that the Petri net model in
Figure 1a has three invariants,
From the previous Equations (
3)–(
5), one can achieve the following maximum buffer requirements for each place (their capacities) in the PN model (arc in the associated dataflow model):
The associated T-invariant for this model is:
From the existence of (
9), one concludes that the MP3 playback application has one static schedule in which
fires five times,
twelve times, and
and
5292 times; moreover,
= 10,601. However, the designer is still faced with the lack of information about the transition firing order in the former static schedule. This further information can be obtained if the state-space is traversed to search for all possible schedules firing sequences founded on the T-invariant expression. Furthermore, Expression (
9) allows one to know in advance the initial conditions for each set of places enrolled in P-invariant analysis (
3)–(
5), as follows in the set of places
,
, and
.
The simulation results were obtained choosing as initial marking conditions for vector marking places
=
, as shown in
Figure 1a, with single-server firing semantics.
To minimize the state-space search effort cost, owing to the large size of the associated state-space of this data stream application, a state-space reduction technique was applied. The stubborn reduction method is a state-space reduction method that takes advantage of concurrency, or of the lack of interaction between transitions preserving the liveness of transitions and all terminal states, as well as the existence of non-termination. Therefore, applying the stubborn reduction over the state-space of the equivalent place/transition Petri net, one can achieve a very large improvement in their dimensionality. A state-space of just 15,929 states was reached, whereas with no reduction, this state-space had several hundreds of millions of states. Supported by the algorithm developed for finding cycles in the generated state-space, a cycle with 10,602 states and 10,601 transitions was found. The cycle began at Node No. 5359 (as observed below in
Table 6) and evolved till State No. 15,929, after which, it returned to State No. 5329.
Table 7 depicts in the first line the maximum capacities (A) foreseen with the support of P-invariant analysis and the following lines show the maximum capacities reached after analyzing the dynamic behavior of the system in a reduced state-space under a PASS (B) and at the start-up phase (C). Examining the state-space, the system’s behavior can be split into two separate phases: (1) the start-up and (2) cyclic phase. The second line of
Table 7 presents the capacity of each node for the cyclic phase, whereas the last line displays the individual node capacities for the start-up phase. This phase is indeed greedier in terms of allocated memory resources. Therefore, the system evolves through a start-up phase to traverse 5328 states. This phase can last longer if the right initial conditions are not met at the design stage. Thus, to overcome this issue, one must foresee the right initial markings in the system, precluding in this way a waste of memory resources. This task is accomplished by finding the interconnection between T-invariant and P-invariant concerning the sets of places engaged with P-invariants and applying the knowledge gained from T-invariant analysis about transition firings. The MP3 playback application took into account this former knowledge. Under a PASS, the sum of maximum required capacity for this case was
= 18,322 units (last column in
Table 7), whilst in the start-up phase, the sum of maximum capacities was equal to
= 32,688. The start-up phase is a more demanding phase, requiring almost twice the data memory as PASS. In the presence of an overhead prologue, if one adopts a shared buffer strategy, then the maximum data memory required is 32,688 units, which is more demanding and time consuming, requiring label information, which is a penalty due to the context switching overhead.
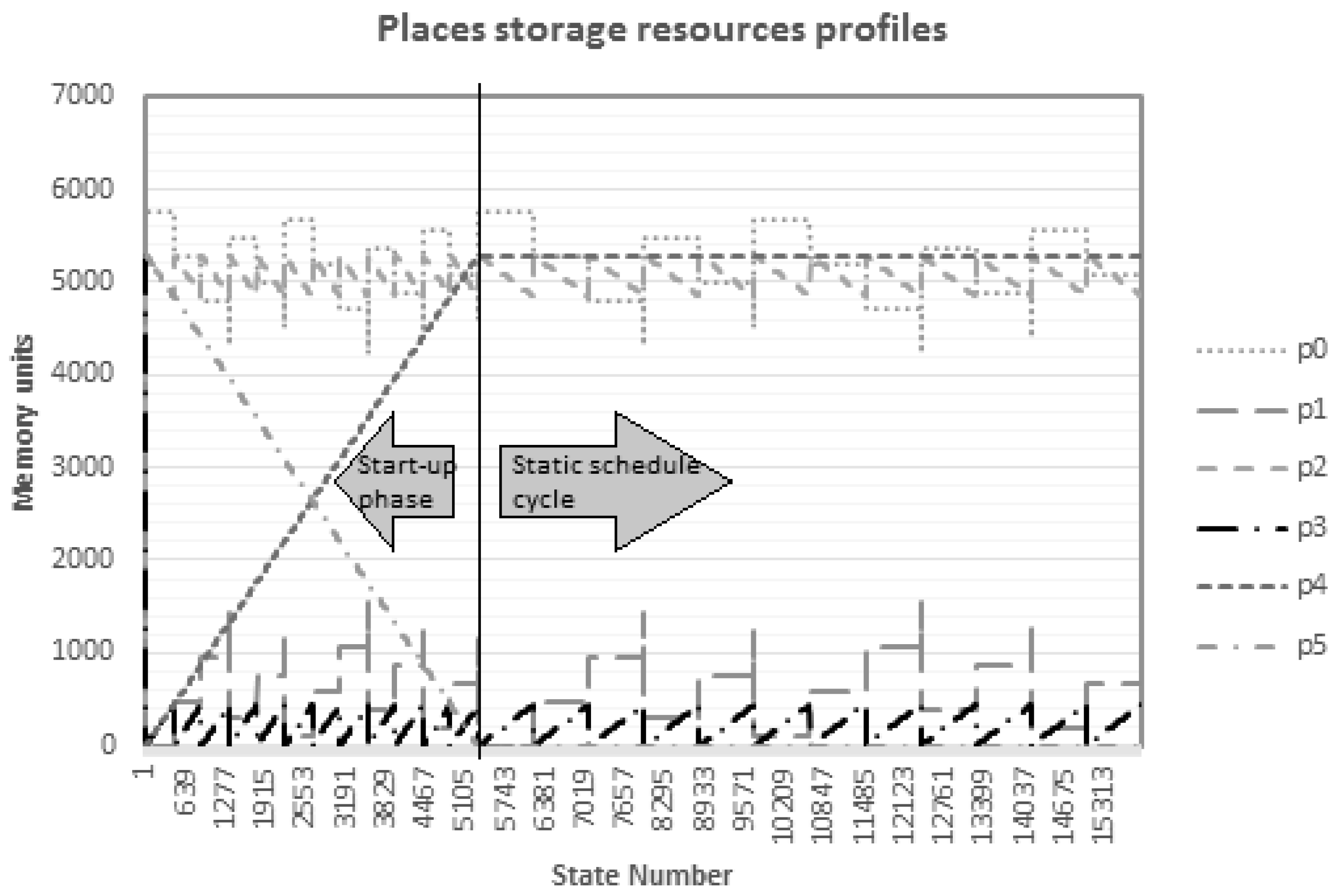
The graph in
Figure 6 depicts the profiles of storage resources allocated to each place (buffer), namely
, into two separate steps: (1) the start-up step; and (2) the static schedule step. Herein, one can follow the memory resources progress at each buffer. On the top of the graph, places
and
dominate and strive for higher resources in both execution steps, reaching a maximum of (5760, 5292) memory units at both phases linked to the generated state-space. Within the static schedule cycle, which started at State Number 5392, two distinct sets of places could be identified,
and
, concerning the allocation of storage resources. The first set of places demanded more memory resources than the former set.
The analysis of the state-space in addition to allowing one to know the states enrolled in the static schedule, also enables the designer to foresee the firing profile within an ongoing cycle. As mentioned previously, T-invariant analysis lays the knowledge base for the firing strategy. Thus, it is known that fires five times, twelve times, and and 5292 times, respectively. This knowledge lets one plan a methodology to reduce memory requirements along the execution cycle just as in the start-up phase.
The buffer requirement for each arc of a dataflow does not require any operational model [
50], and this paper proposes a new strategy as concerns the prologue in each dataflow model. By knowing in advance the optimal initial number of tokens on arcs at the prologue, which may be shared with the buffer requirements of the scheduling list, since the prologue is executed only once, there is no need to demand for a separate data buffer as proposed in [
50]. Our approach allows one to reason about the timing behavior of the system to support scheduling strategies [
51] (fully-static and static order scheduling), [
52].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}