This section provides first the relevant background on deep convolutional neural networks and their application to the problem of image classification. Next, the relevant literature concerning deep neural networks on mobile devices motivating the present research is discussed.
2.1. Background on the Convolutional Neural Network for Image Classification
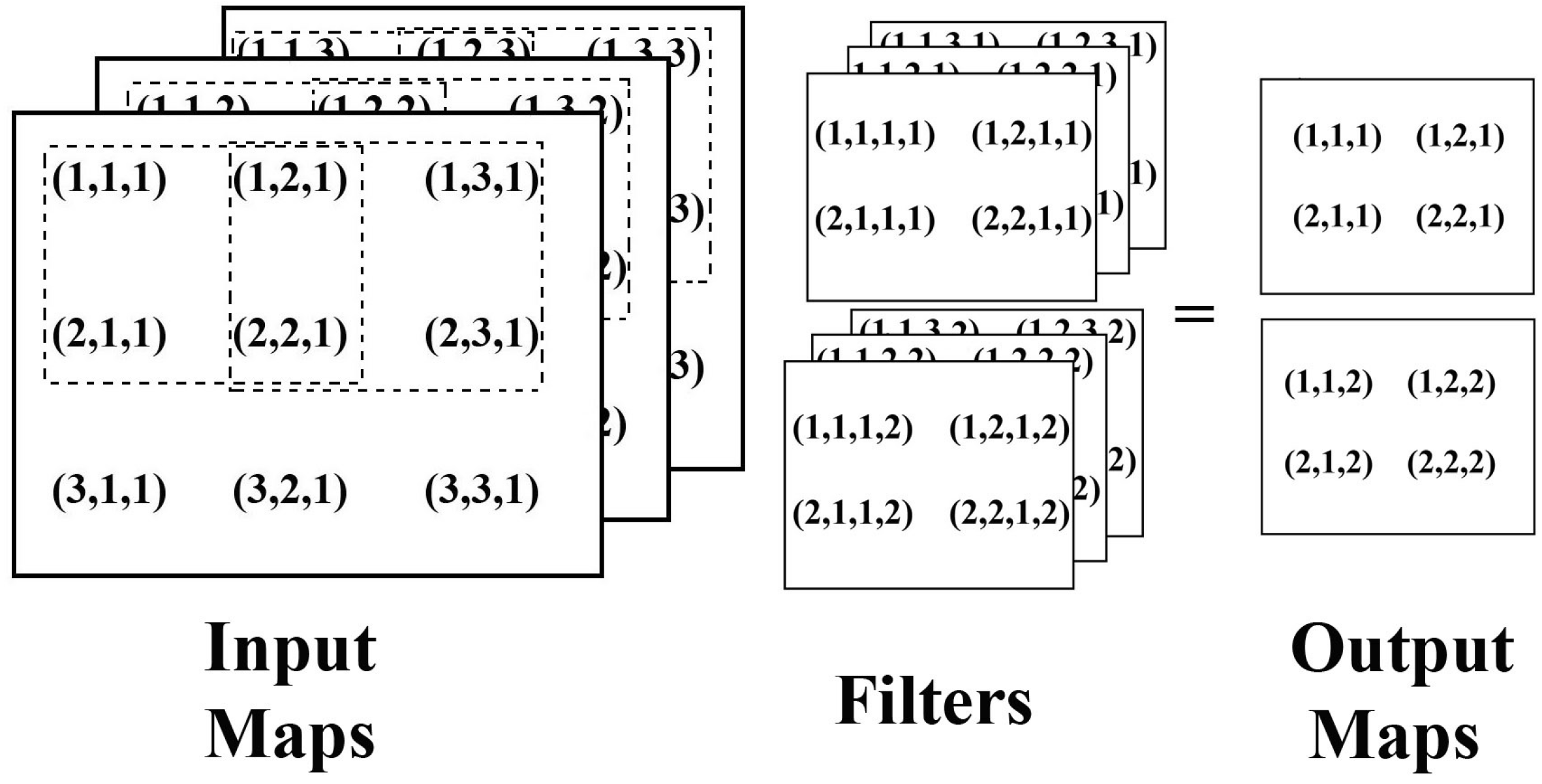
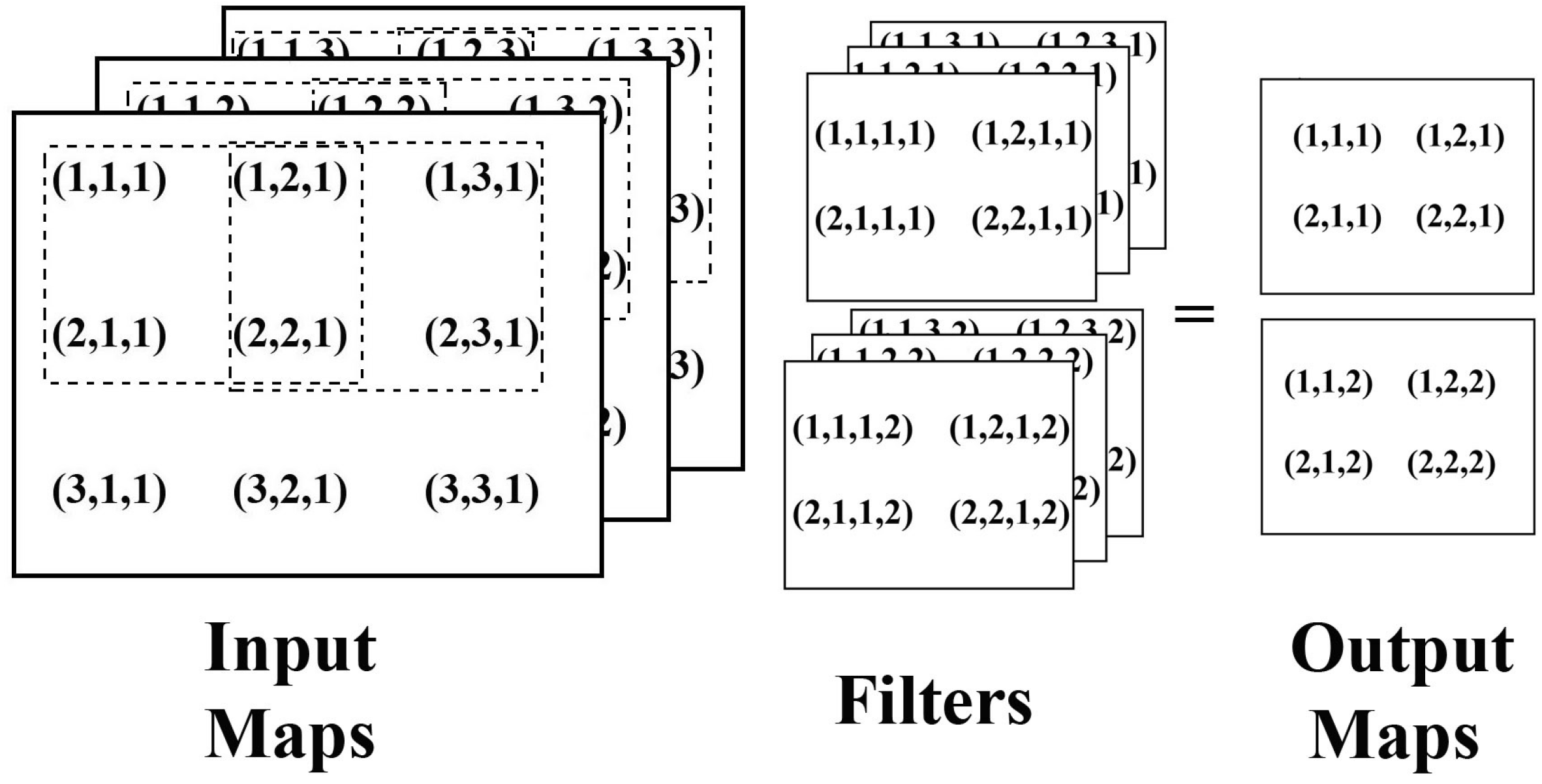
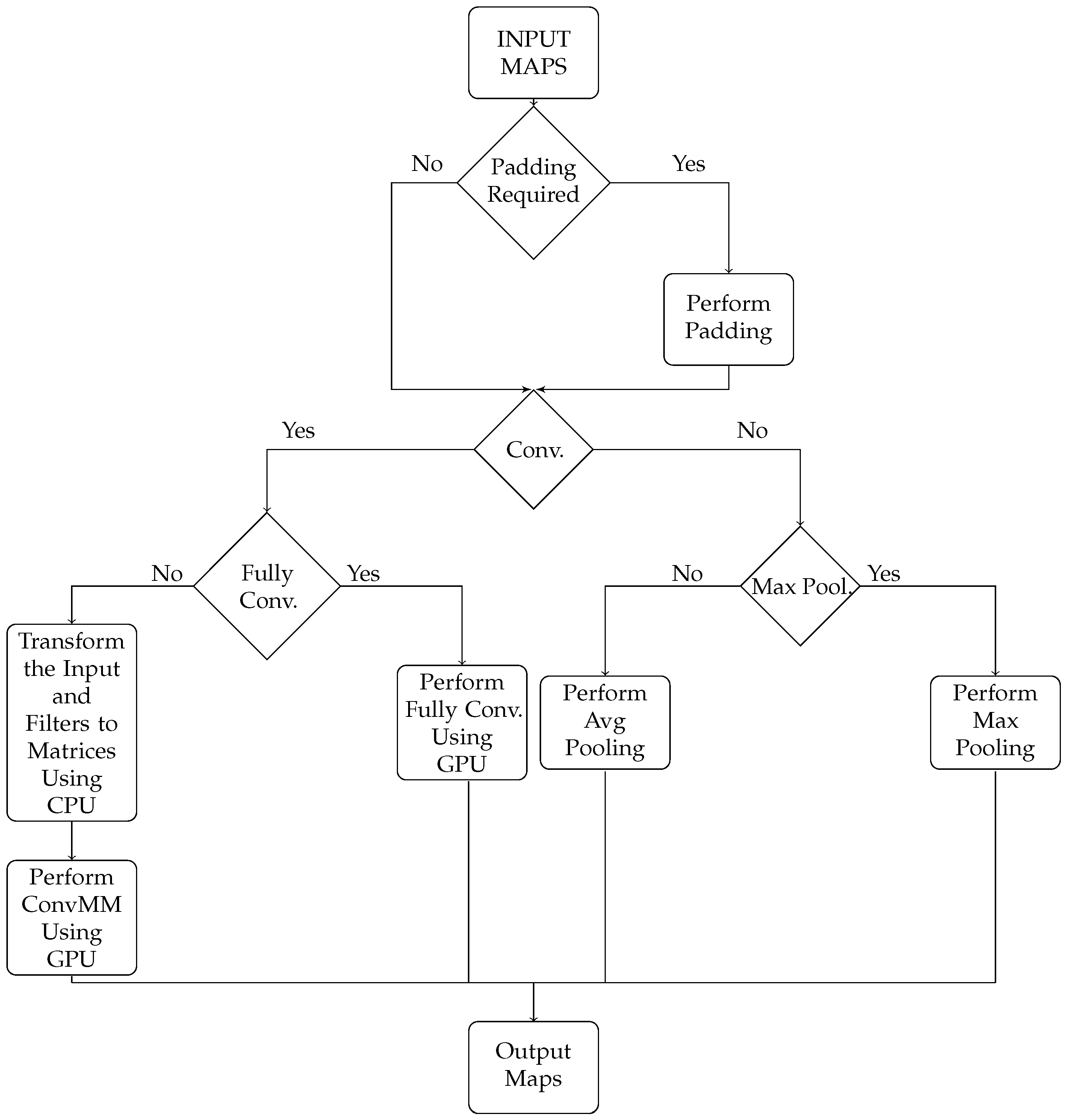
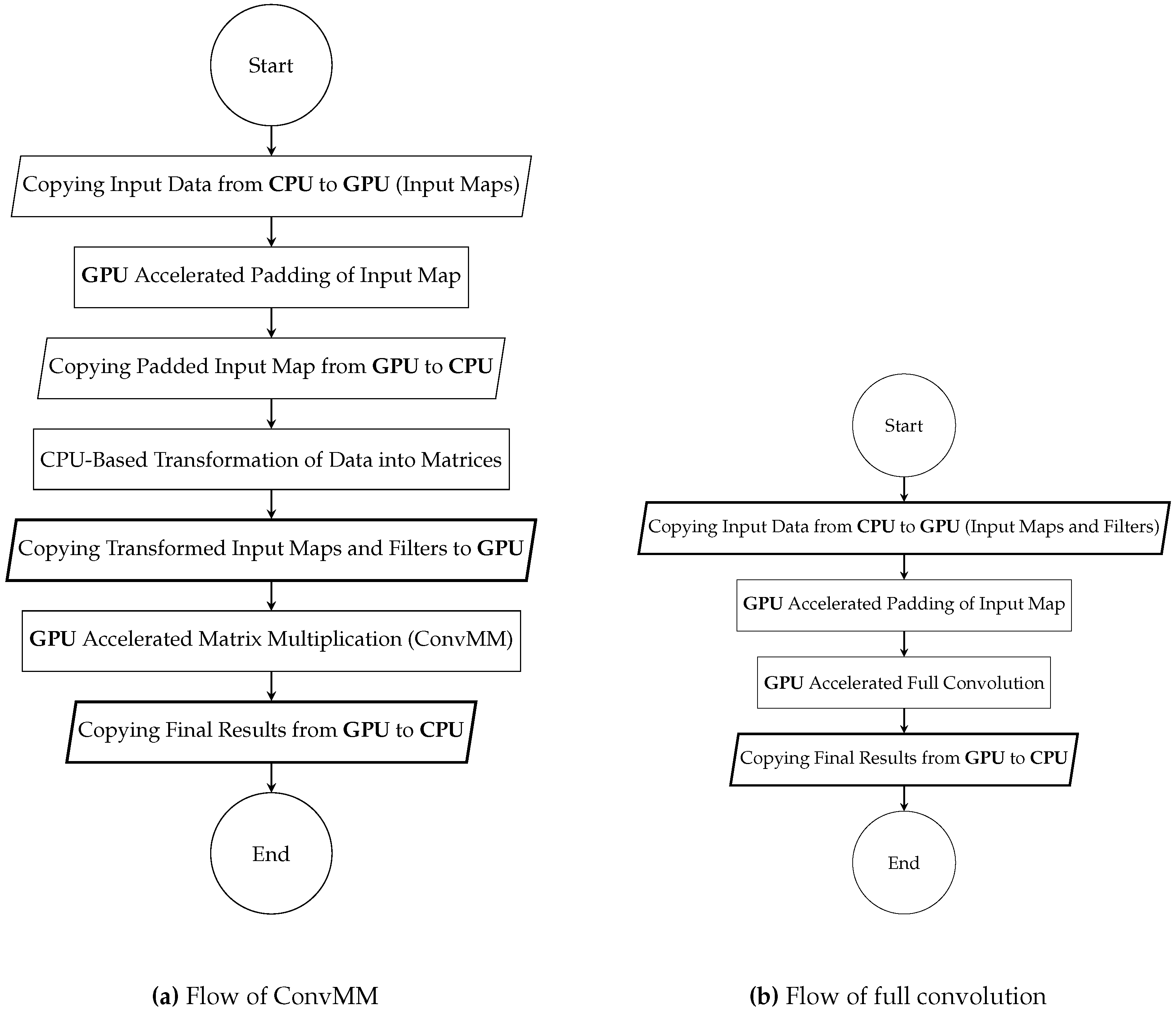
Convolutional neural networks are becoming an all-encompassing package for a number of computer vision and machine learning tasks. Image classification is an important computer vision task that has numerous practical applications. Over the last few years, image classification has been revolutionized by the advent of deep learning-based architectures. Deep classifiers have shattered existing performance records in several image classification contests, enabling a large leap over previous so-called shallow classifiers. A typical deep network for image classification tasks is mainly composed of two stages. The first stage accounts for the extraction of features, also called kernels or filters, that are robust to changes in illumination, size and translations from the input image. A detailed description of such a feature extraction stage is provided in
Section 4. Next, one or more fully-connected layers in the second and final stage performs the feature classification on a highly dimensional space, providing the final output. Recent results show that the depth of a neural network (number of stacked layers) plays an important role in achieving better classification accuracy [
1,
13,
15]. Deep convolutional networks have showed recognition accuracy comparable to humans in many visual analysis tasks [
14,
16,
17]. Larger datasets and deeper models lead to better accuracy, but also increase the training and classification time [
2,
13,
15]. Heterogeneous systems play a pivotal role in the field of visual analysis where the computational capabilities of CPUs and GPUs can be utilized altogether to maximize the performance of deep classifiers in terms of training and classification time. In the following section, the available frameworks for implementing image classification via deep neural architectures are discussed.
2.2. Deep Classifiers on Heterogeneous Mobile Architectures
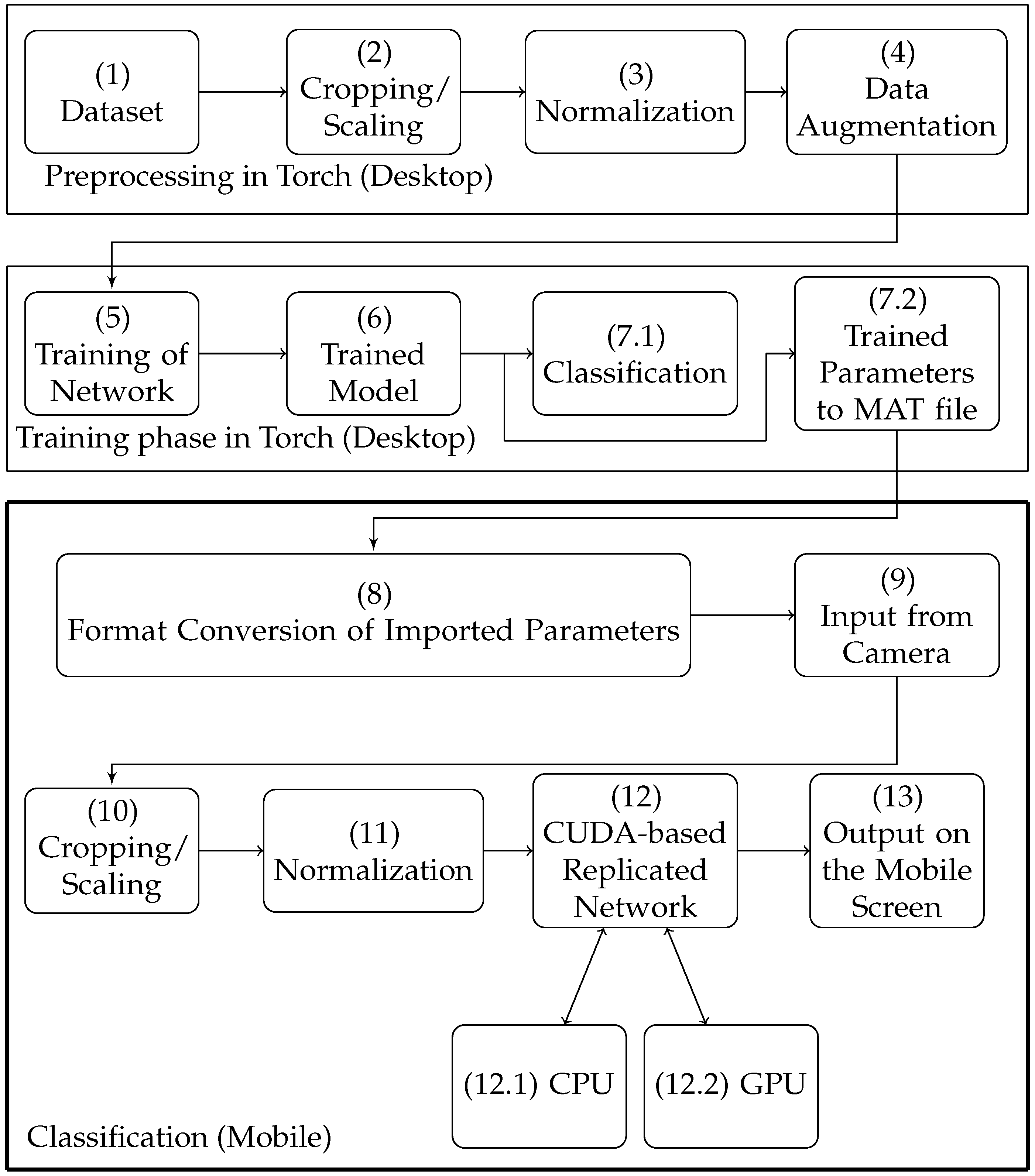
A number of frameworks for implementing deep neural networks are currently available. Such frameworks leverage the parallel computational capabilities of modern GPUs, allowing to practically train and deploy deep neural networks in a reasonable time. However, most of these frameworks are tailored to desktop and server platforms; therefore, they do not take into account the unique peculiarities of mobile devices. Mobile devices’ peculiarities include, among others, reduced memory and limited energy stored in the battery: operations are optimized just for execution speed, without considering the need to extend battery life. In the following, major frameworks that are currently available for implementing deep neural networks are discussed. The shortcomings of these are discussed when it comes to mobile applications, and the need for efficient schemes designed ad hoc for mobile platforms is highlighted and motivated.
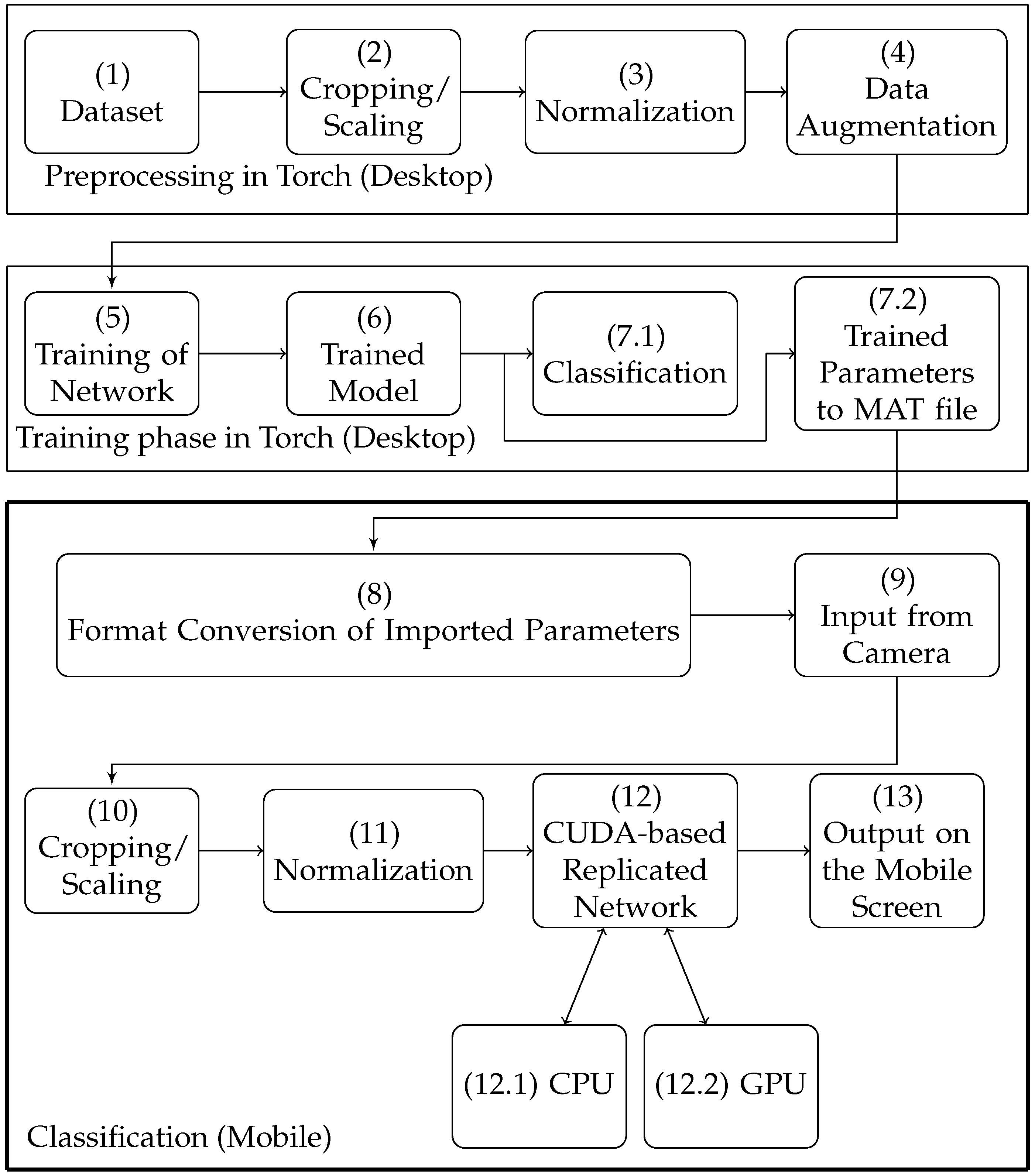
Torch is an open source scientific computing framework that comes with machine learning libraries. Using these open source libraries, deep convolutional networks can be created and trained easily in the Torch environment on a desktop computer. Torch relies on CUDA for efficient operations on NVIDIA GPUs. CUDA also enables clustering of GPUs to accelerate the process of training a network. Torch relies however on a number of third-party libraries for performing ancillary operations on the CPU. However, porting such libraries to mobile CPUs is not always possible because of architecture differences and the memory footprint thereof. In addition, GPU clustering is not applicable to mobile platforms as mobile platforms typically include just one GPU. Finally, there exist a Torch library for mobile terminals; however, this library is not mature in terms of dependencies.
DeepSense [
18] is a deep neural network framework designed specifically for mobile devices. However, such a framework relies on OpenCL, which is less efficient in terms of performance and much slower than the same CUDA-based built-in functions that require much optimization [
19]. Note that OpenCL supports a wide range of embedded devices. However, OpenCL is not directly supported on Android starting from Version 4.3 onwards. OpenCL on Android requires in fact an intermediate library to access the GPU hardware. Such a library not only adds to the deep neural network footprint, but also incurs in additional computational overhead. Therefore, it is currently not feasible to implement the deep classifiers on recent mobile devices using standalone OpenCL. Furthermore, the deep learning community is widely using CUDA libraries.
A unified framework to accelerate and compress the convolutional neural network is presented in [
20]. In order to speed-up the process, deep classifiers are quantized, yielding to sparser parameter sets. However, the paper also shows that the parameter quantization and compression jeopardize the precision of the results [
21,
22,
23,
24]. Because this work only considers narrow neural networks with a maximum of 16 convolutional layers and no experiment is performed on deeper networks such as ResNet-34, it is not clear how the loss of precision is going to propagate through the many layers of a deeper network. In addition, computations are carried out on a single CPU core, without GPU acceleration. Therefore, this approach misses the benefits of GPU-accelerated neural networks as a whole, despite the reportedly high performance due to parameter quantization.
A mobile-GPU accelerated deep neural network flow is presented in [
25]. Different techniques to optimize the various components of a typical neural network flow on mobile devices are discussed. However, the preliminary information that is presented is not sufficient to reproduce the results.
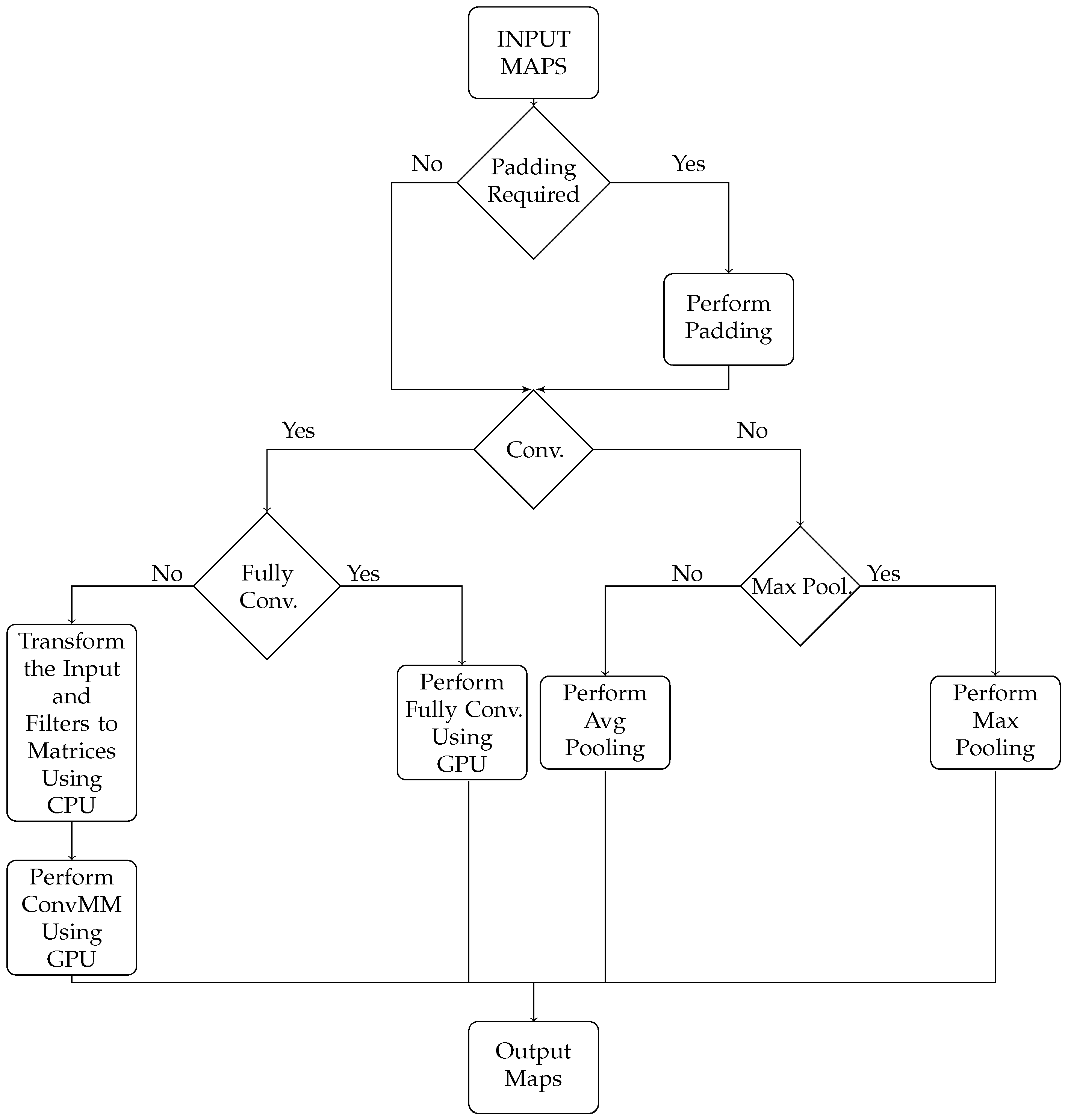
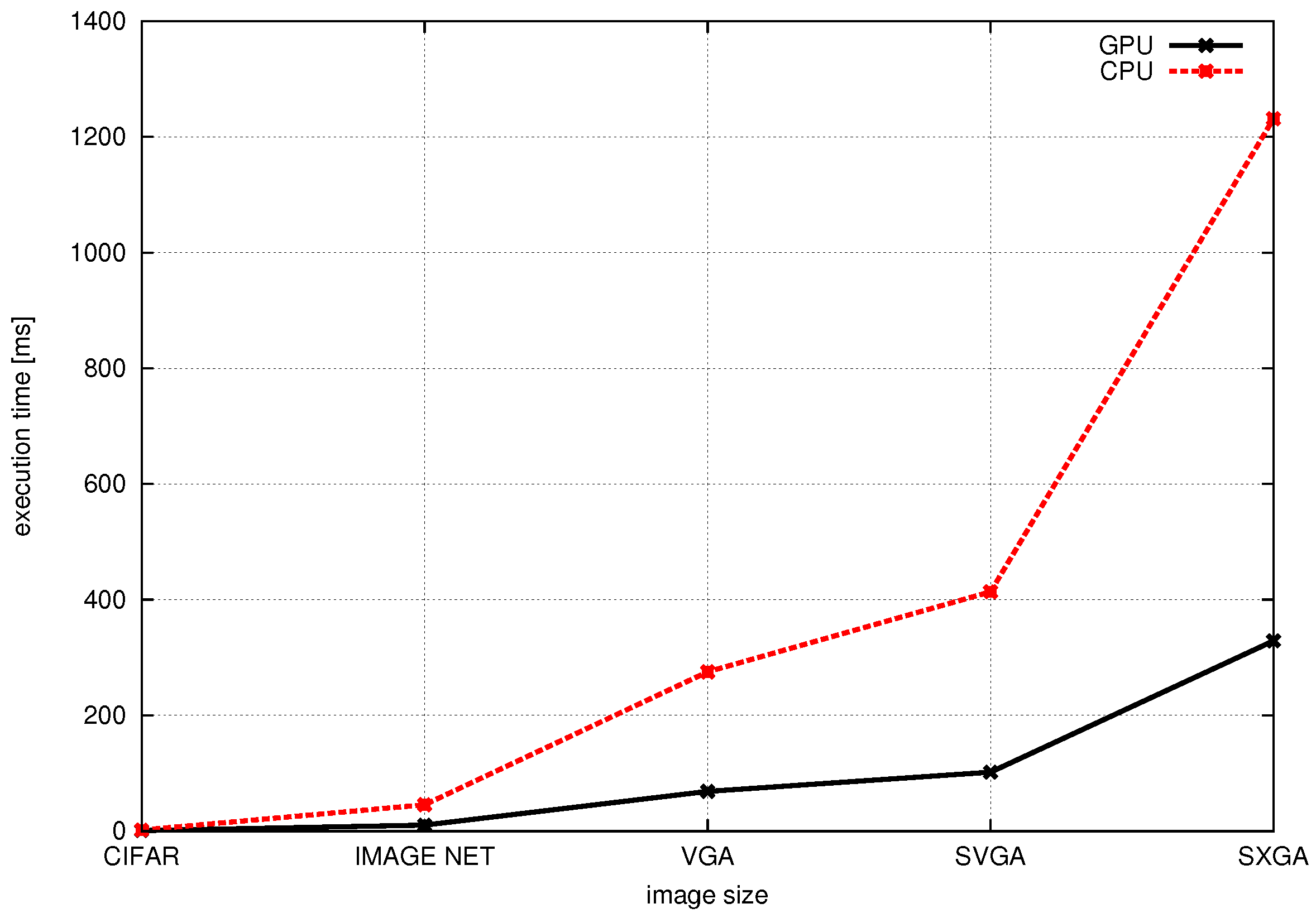
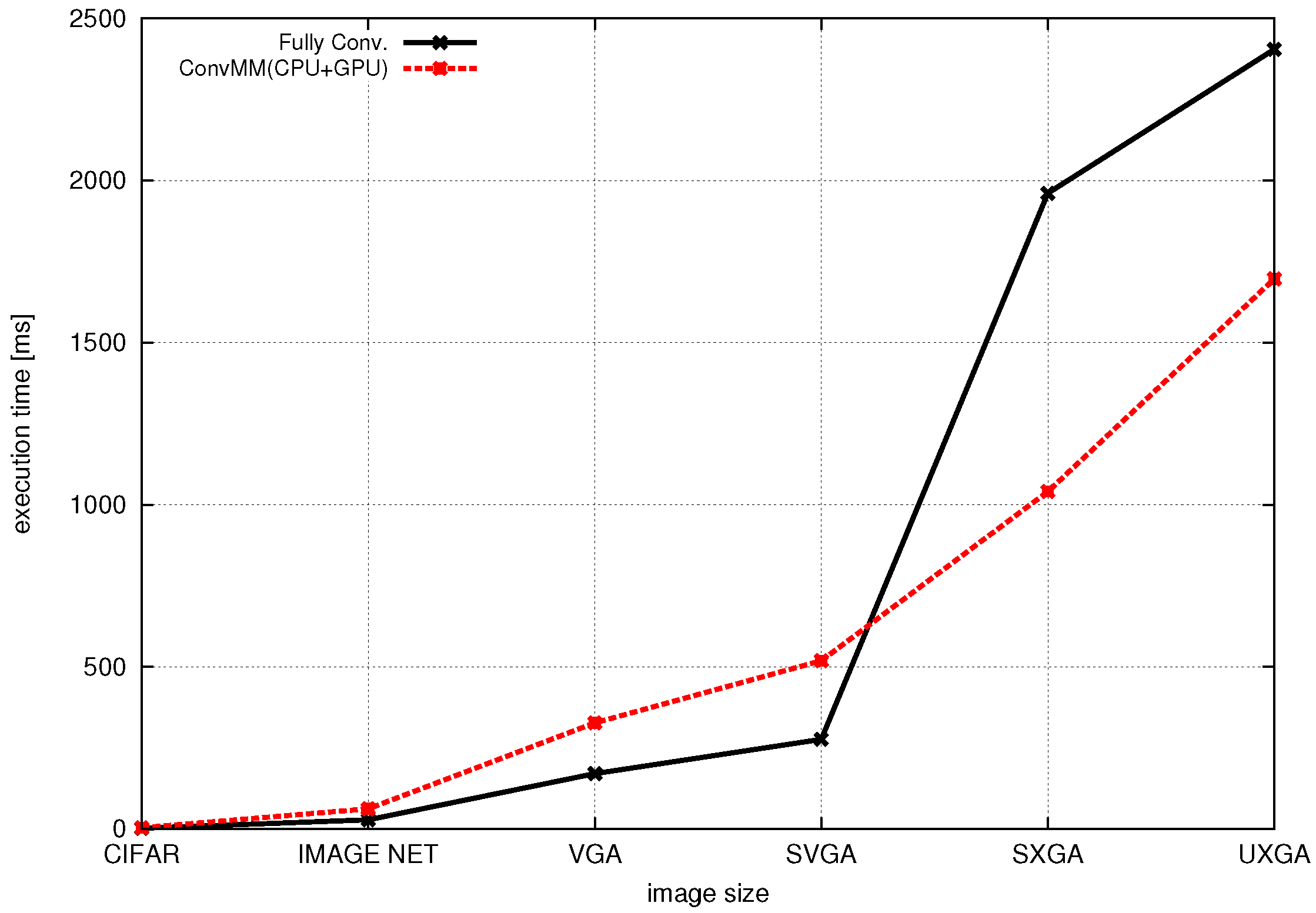
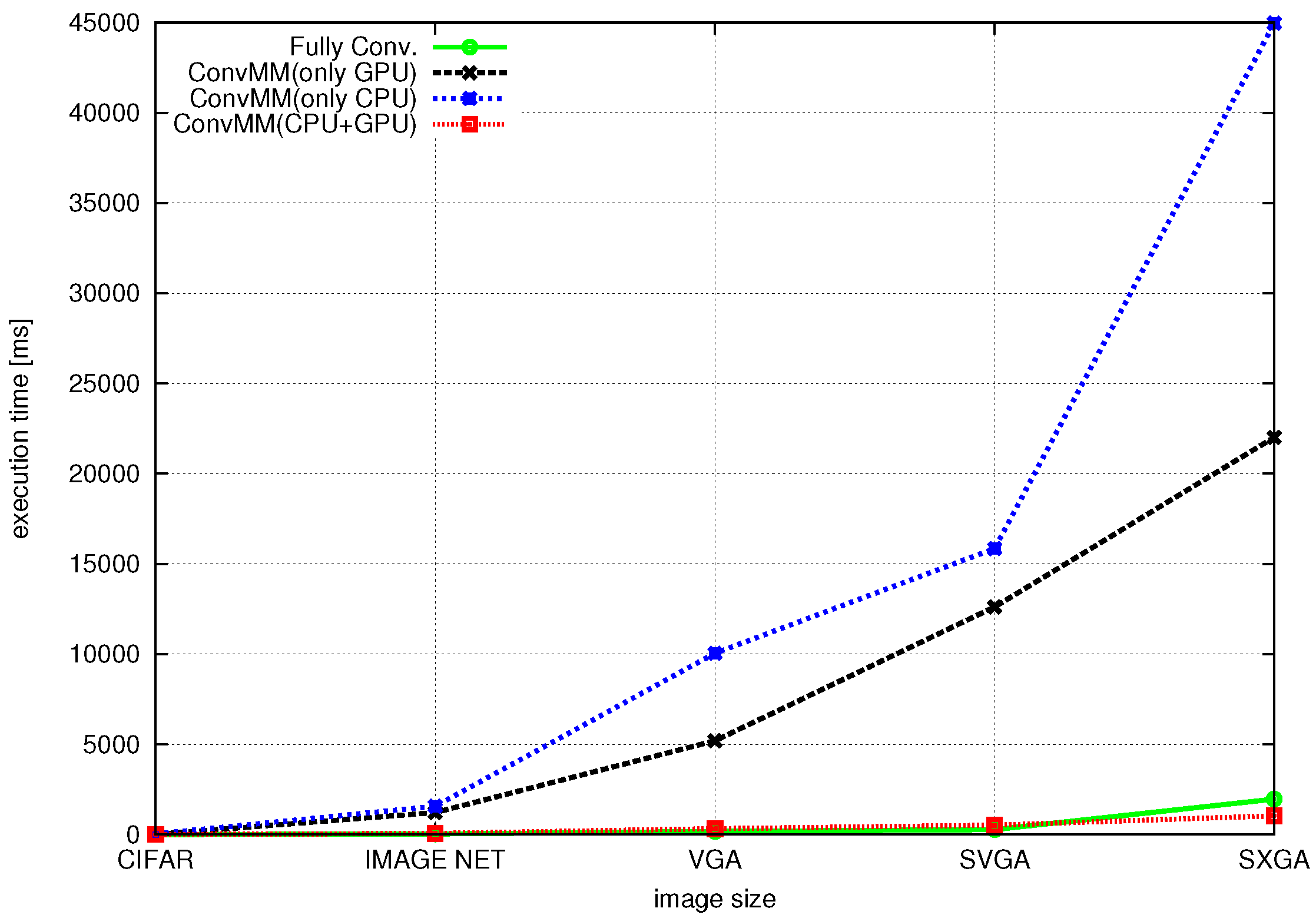
Concluding, the presented work differs from and improves upon the above-mentioned references addressing most of the above-listed issues. First of all, the proposed scheme has the benefits of jointly exploiting the computational capabilities of both the CPU and GPU, enabling true heterogeneous computations. Moreover, this approach has the merit of supporting nearly all layer types of neural networks found in a modern image classification networks and is suitable for deploying very complex topologies. In addition, the accuracy of the presented approach is similar to the existing desktop and server platforms, whereas it does not require an intermediate framework for actual image classification. The proposed scheme can be easily integrated into an android application and provides compatibility for models trained with other desktop/server frameworks.





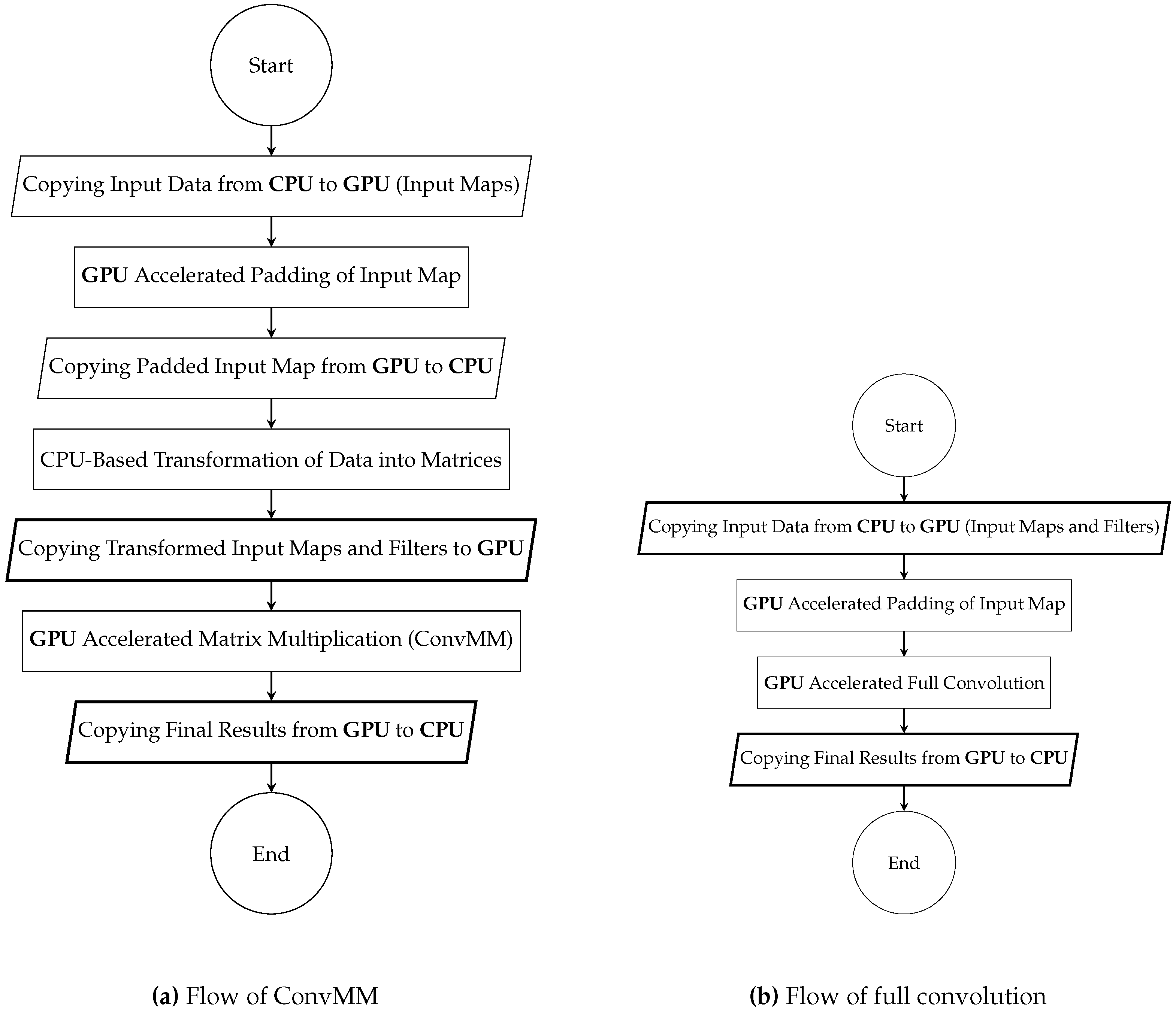
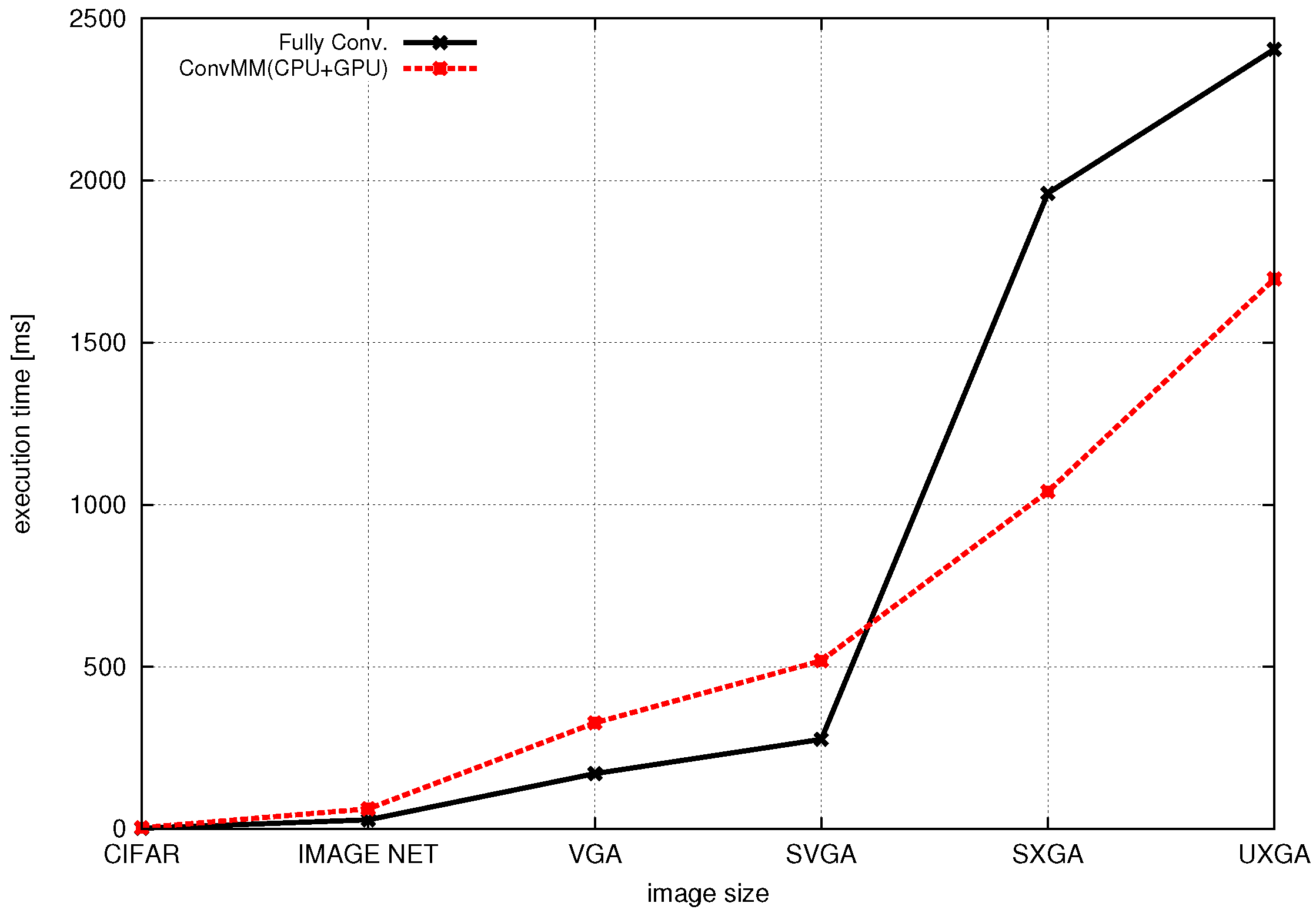

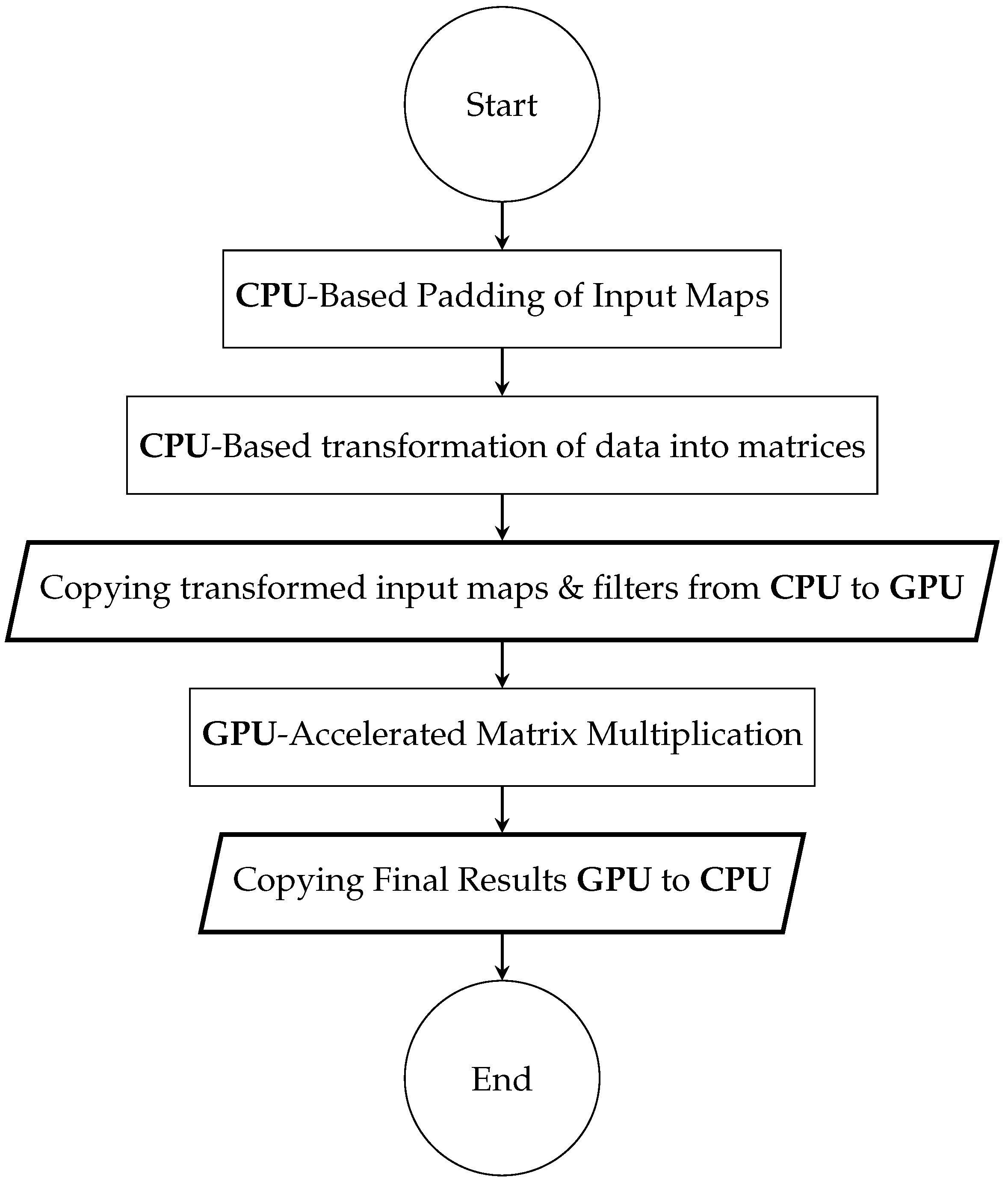
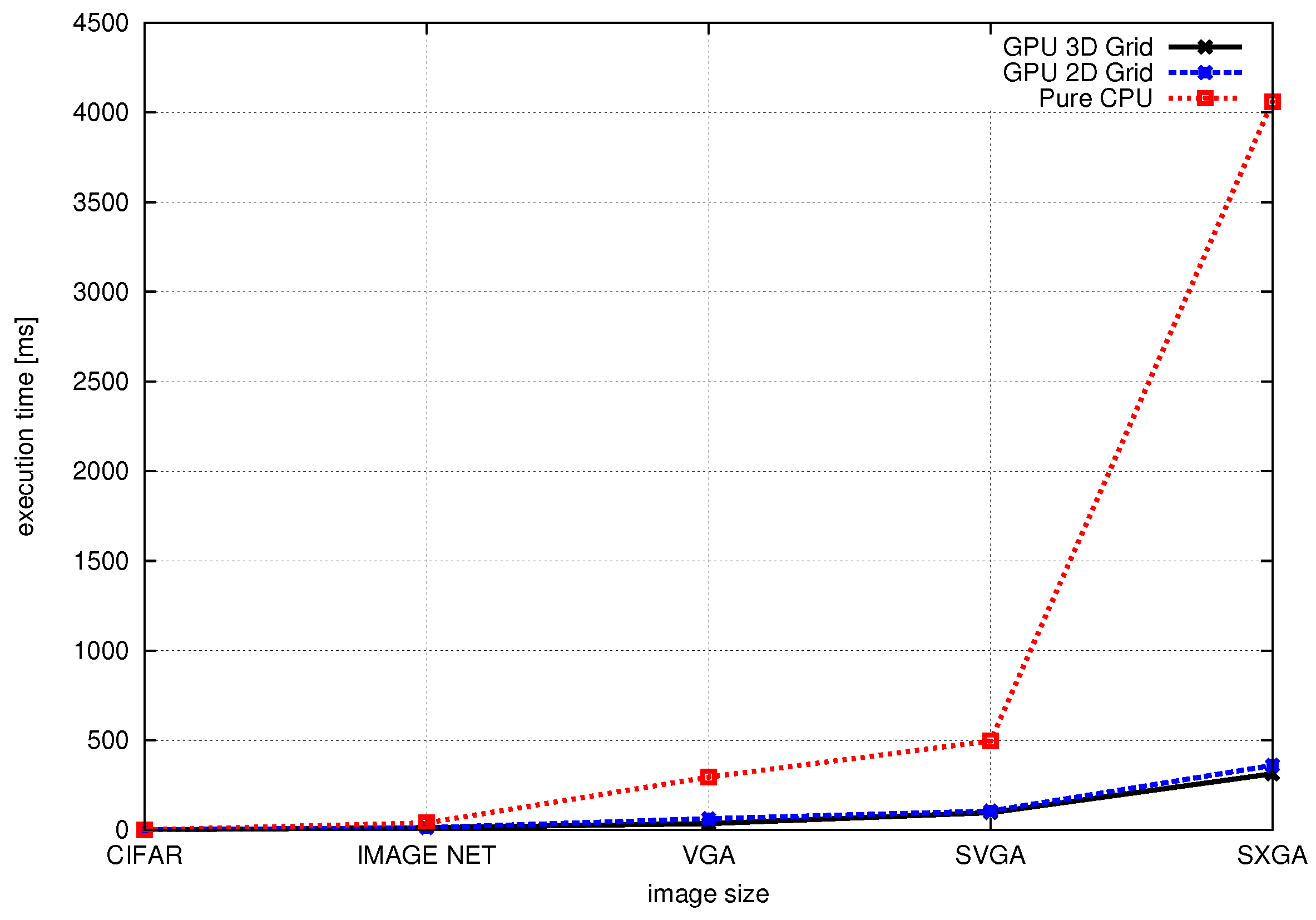

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}