
CiTranGAN: Channel-Independent Based-Anomaly Detection for Multivariate Time Series Data


 and
and
Abstract
1. Introduction
- A novel multivariate time series anomaly detection model CiTranGAN is proposed, which integrates the advantages of Transformer architecture, generative adversarial networks, and channel-independence strategies.
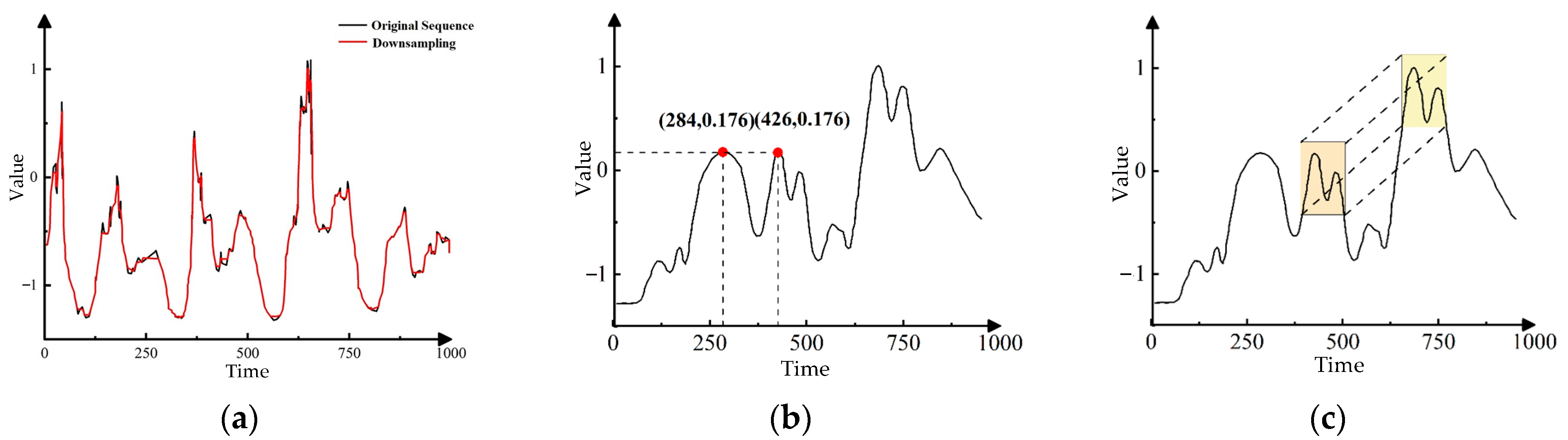
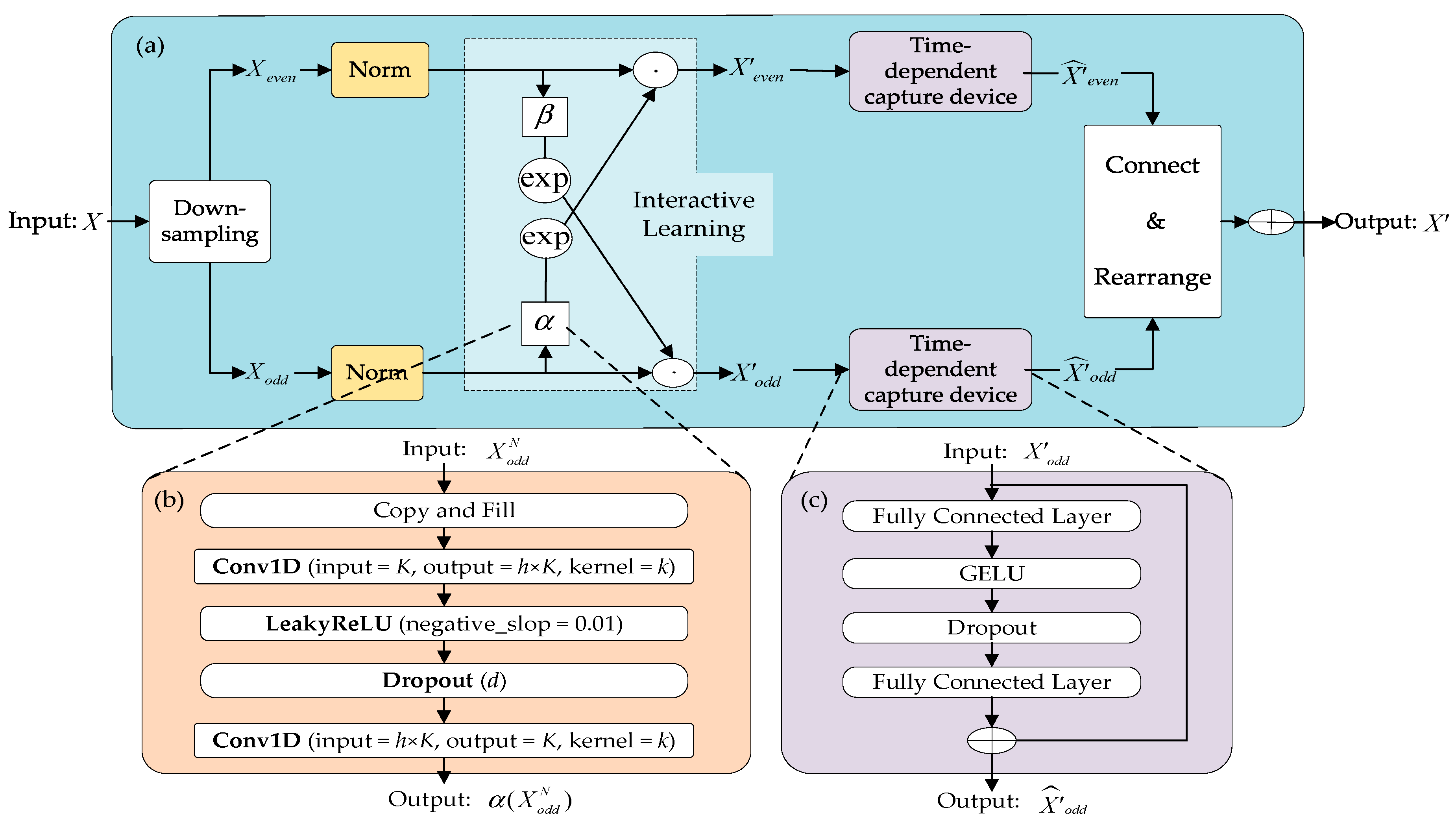
- Temporal feature extraction leveraging downsampling–convolution–interaction learning. Specifically, downsampling serves to reduce redundancy while also enhancing the extraction of long-term trend features. One-dimensional convolution effectively identifies local patterns and detailed features. The interaction operation iterates over different time resolutions, promoting efficient information exchange. This enhances the visibility of features across varying time scales, ultimately improving model performance. This process ultimately leads to an enhancement in the overall performance of the model.
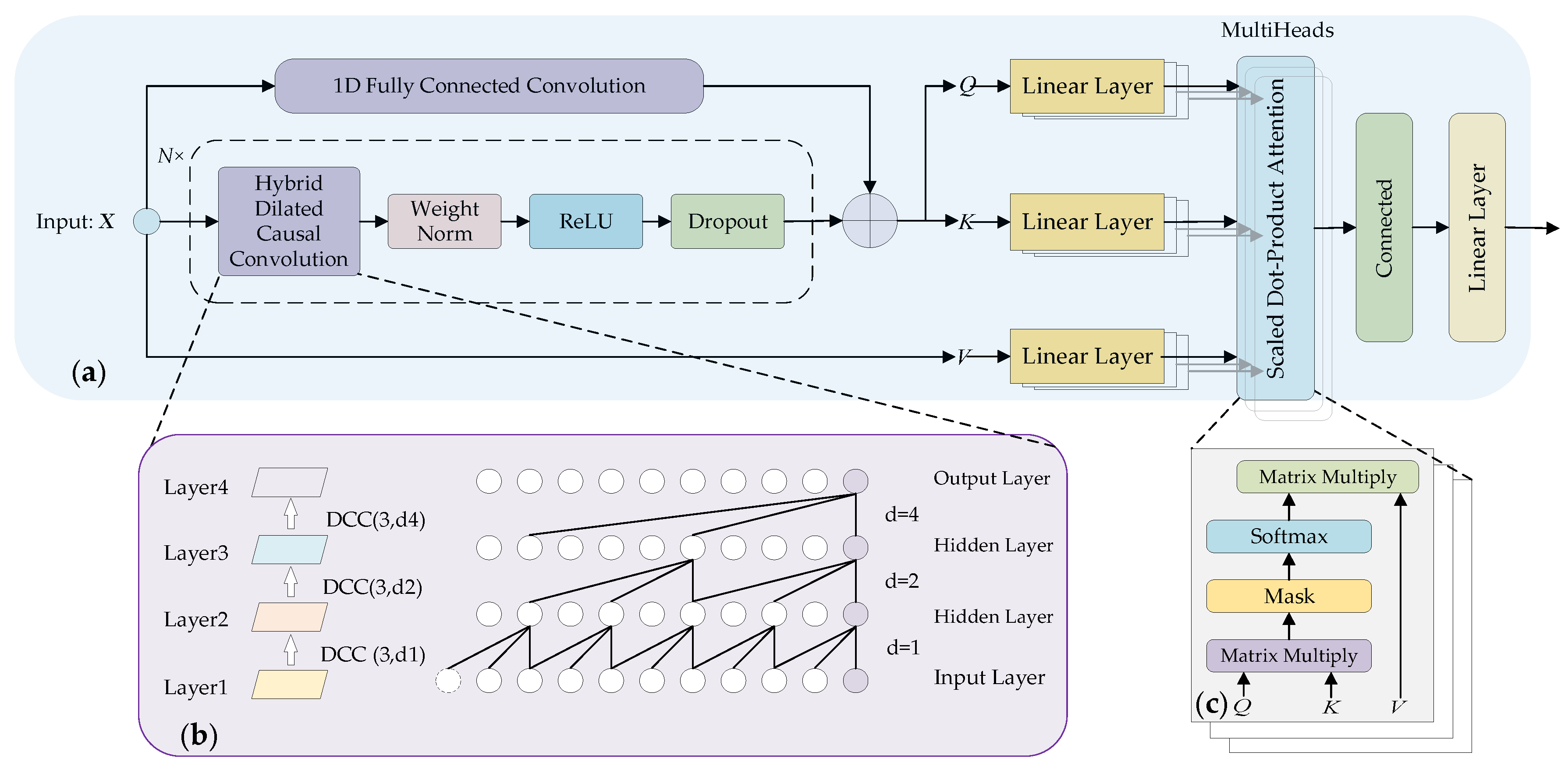
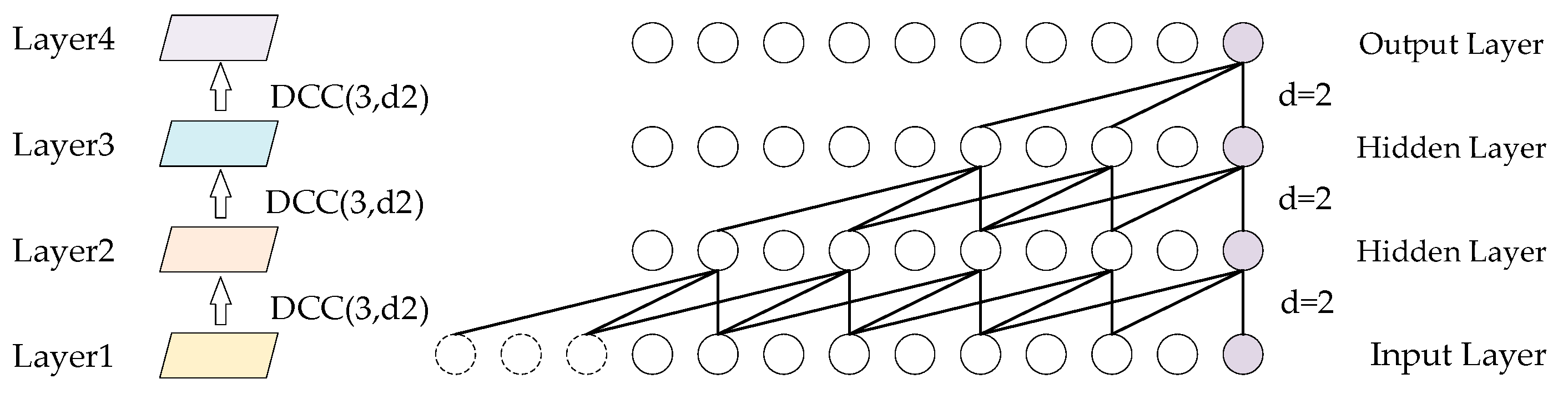
- A multi-scale convolutional self-attention mechanism is designed based on hybrid dilated causal convolutions, which overcomes the limitations of the traditional self-attention mechanism in identifying the local variation trend within subsequences. Specifically, causal convolutions ensure that the model relies only on input features from prior time points, thereby preventing future information leakage. Dilated convolutions expand the receptive field of the model, enabling it to effectively capture nonlinear relationships within long sequences. Additionally, dilation factors are dynamically allocated at different layers according to practical requirements, further enhancing the ability to capture contextual information across varying time scales. By integrating these advantages, the model is better capable of emphasizing the influence between similar subsequences.
2. Related Work
3. Anomaly Detection for Multivariate Time Series Data
3.1. Preliminaries
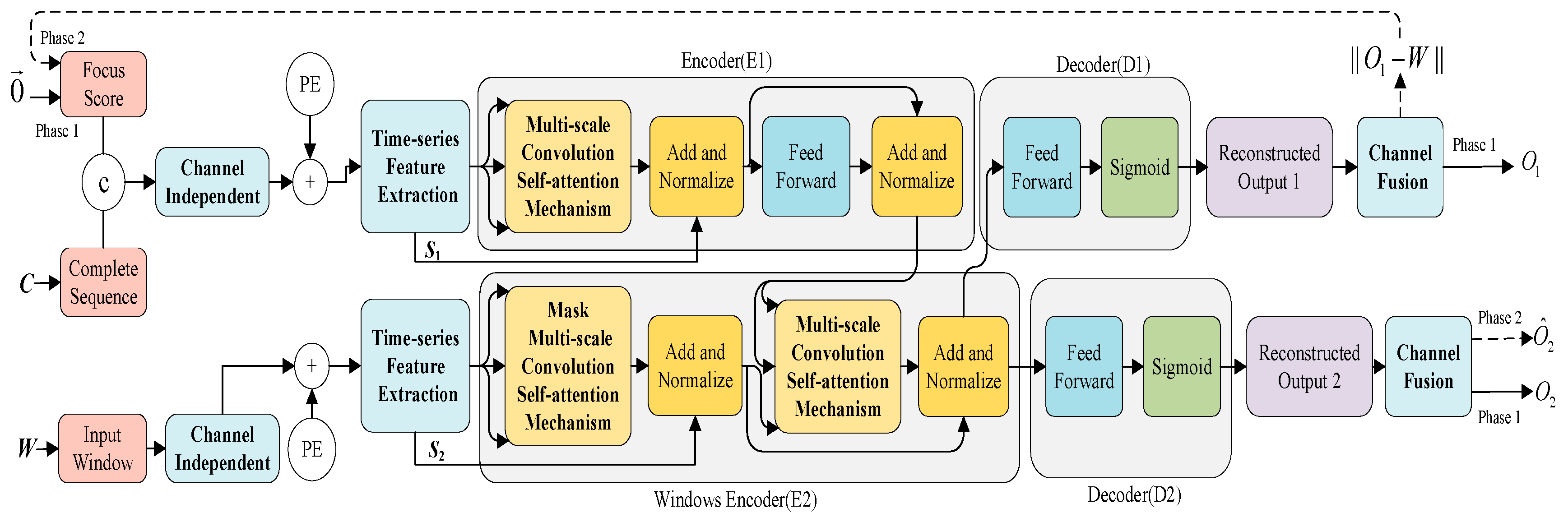
3.2. CiTranGAN
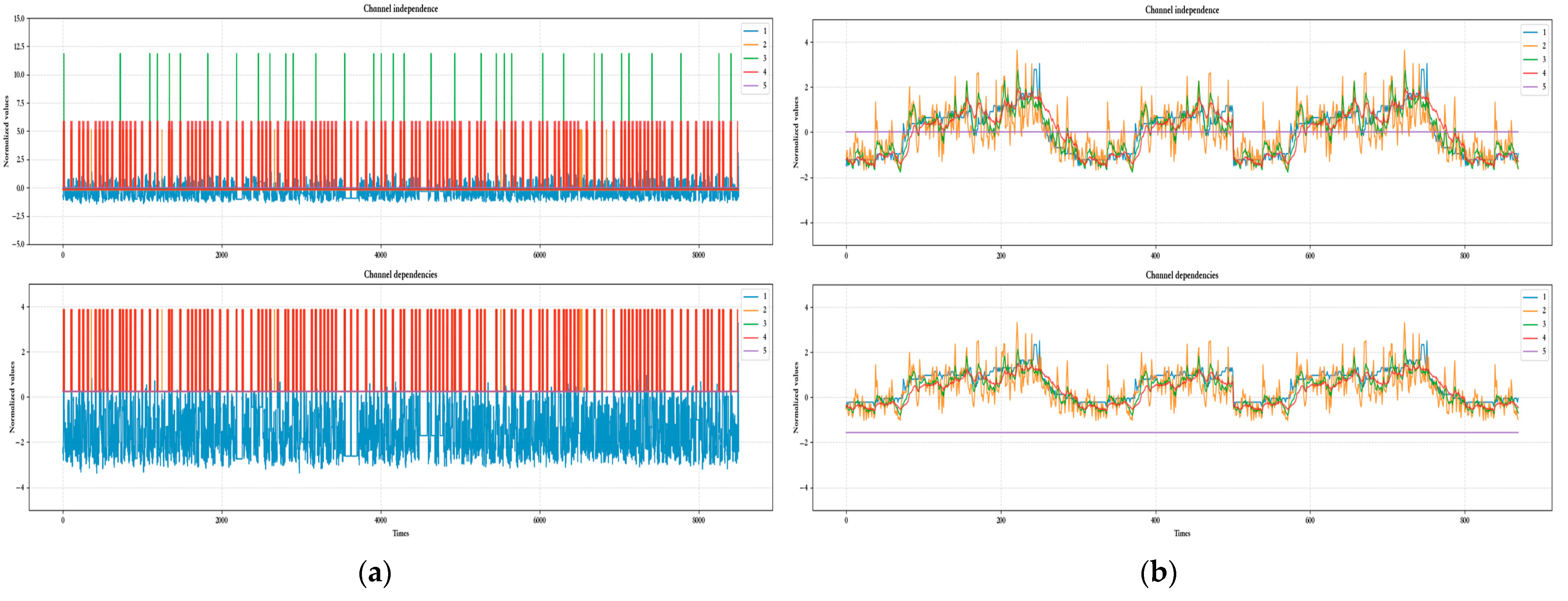
3.2.1. Channel-Independent Module
3.2.2. Temporal Feature Extraction Module
3.2.3. Multi-Scale Convolutional Self-Attention Mechanism
3.2.4. Autoregressive Reasoning and Adversarial Training Module
4. Experiments
4.1. Datasets
- SMAP: The dataset sourced from NASA, comprising soil samples and telemetry data acquired by the Mars rover.
- SWaT: The dataset originates from a real water treatment plant, with operational data collected over 7 days of normal operations and 4 days of abnormal operations. This dataset includes a variety of actuator activities, such as valve and pump operations, as well as sensor readings, including water levels and flow rates.
- WADI: As an extension dataset derived from SWaT, WADI features more than double the number of sensors and actuators found in SWaT. It comprises data records from 14 days of normal operation as well as 2 days of attack scenarios.
- SMD: The dataset encompasses detailed stack trace information and comprehensive resource utilization data from 28 machines within a computing cluster, spanning a period of 5 weeks.
- MSL: Similarly to SMAP, this dataset comprises data records exclusively from the actuators and sensors of the Mars rover.
4.2. Baseline Models
- LSTM-NDT [9]: This model integrates an LSTM-based prediction framework with a dynamic threshold estimation method to detect anomalies through the analysis of prediction errors.
- MAD-GAN [30]: This model integrates LSTM with GAN, utilizing the discriminator to distinguish between original sequences and generated sequences, and employing reconstruction errors for anomaly detection.
- MTAD-GAT [42]: This model utilizes two parallel graph attention layers to learn the intricate dependencies within MvTS data across both temporal and feature dimensions. Anomaly detection is achieved through the joint optimization of prediction and reconstruction models.
- USAD [10]: The unsupervised learning method is constructed by utilizing an autoencoder, demonstrating remarkable stability through the incorporation of adversarial strategies during the training process.
- GDN [43]: Based on attention mechanisms, the graph neural networks explicitly learn the dependencies among variables. The learned relationships are subsequently integrated into a prediction network to detect anomalies.
- TranAD [11]: Based on the Transformer architecture, the representations of time series data are learned, and model-agnostic meta-learning is employed to rapidly capture temporal trends in the input data. Subsequently, anomalies are identified through the analysis of reconstruction errors.
- TimesNet [44]: This model transforms univariate time series into two-dimensional tensors, leveraging its multi-periodicity feature for state-of-the-art anomaly detection performance across a variety of time series tasks.
4.3. Experimental Setup
4.4. Experimental Results and Analysis
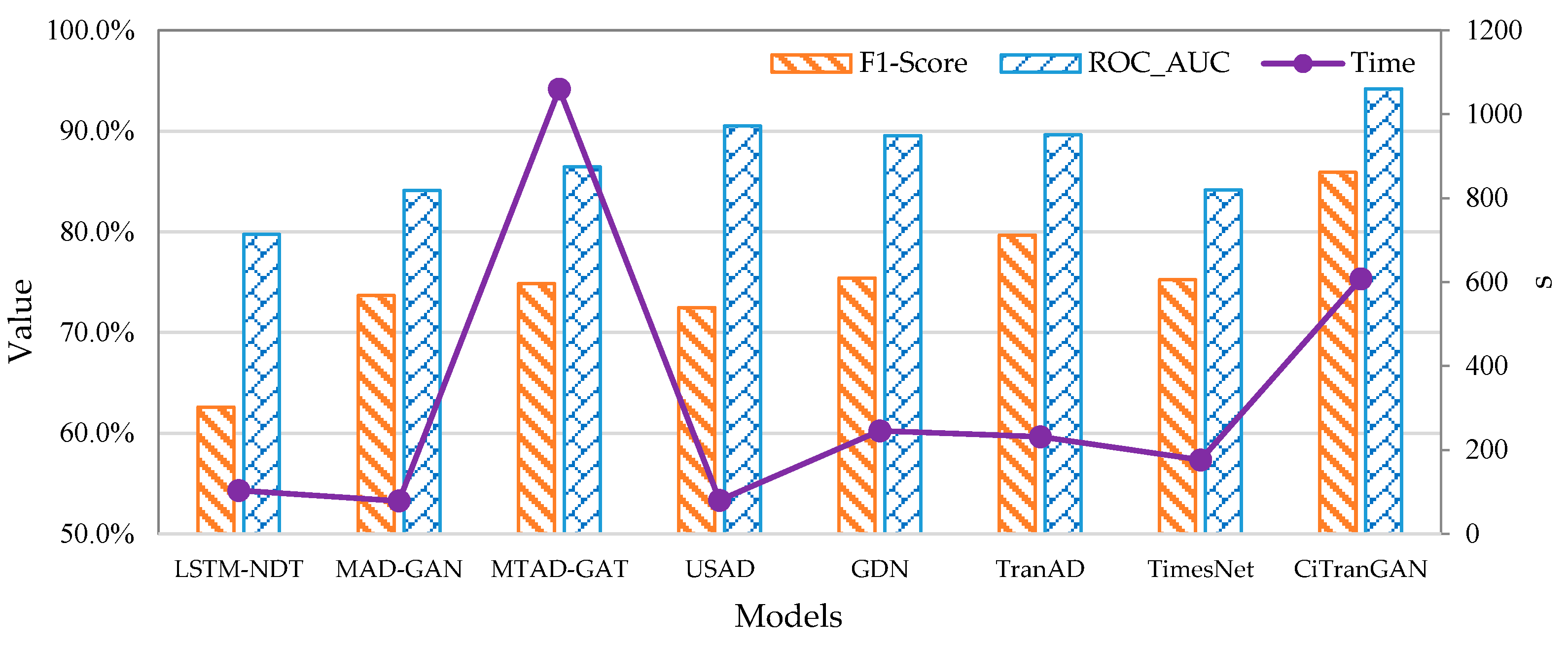
4.4.1. Comparison Experiments with Baseline Models
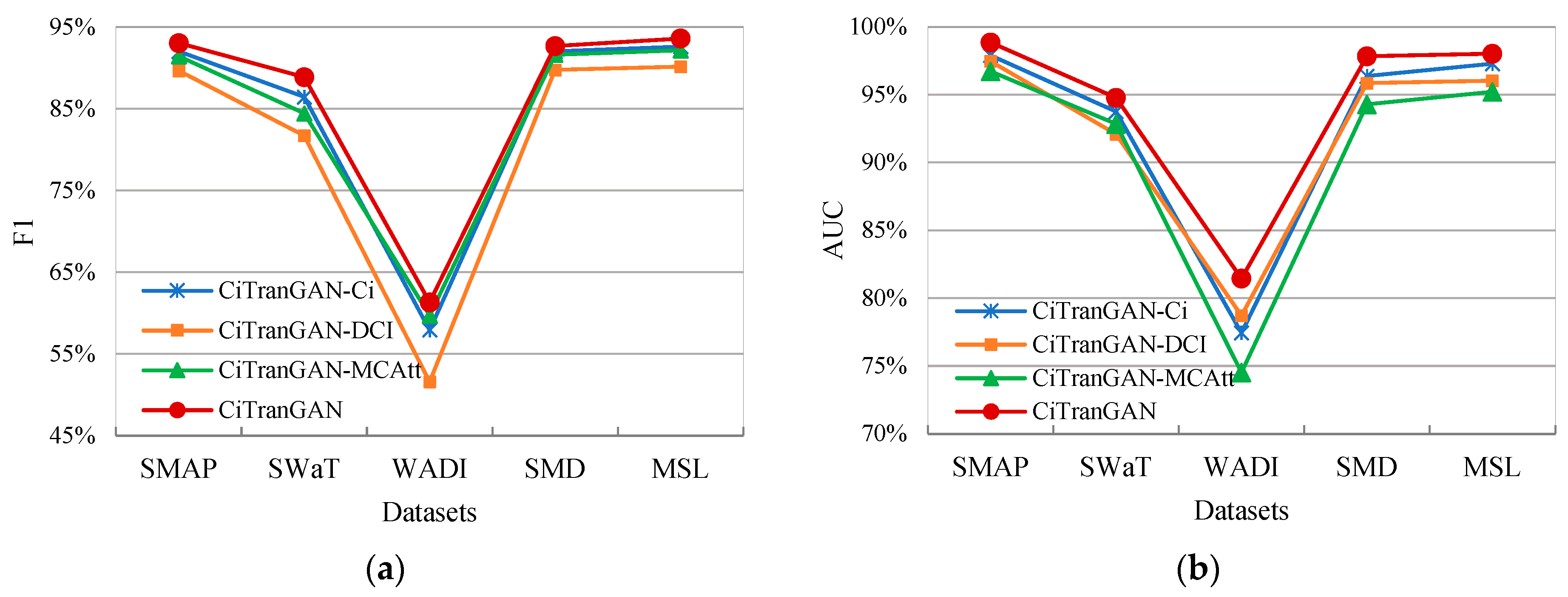
4.4.2. Ablation Experiments
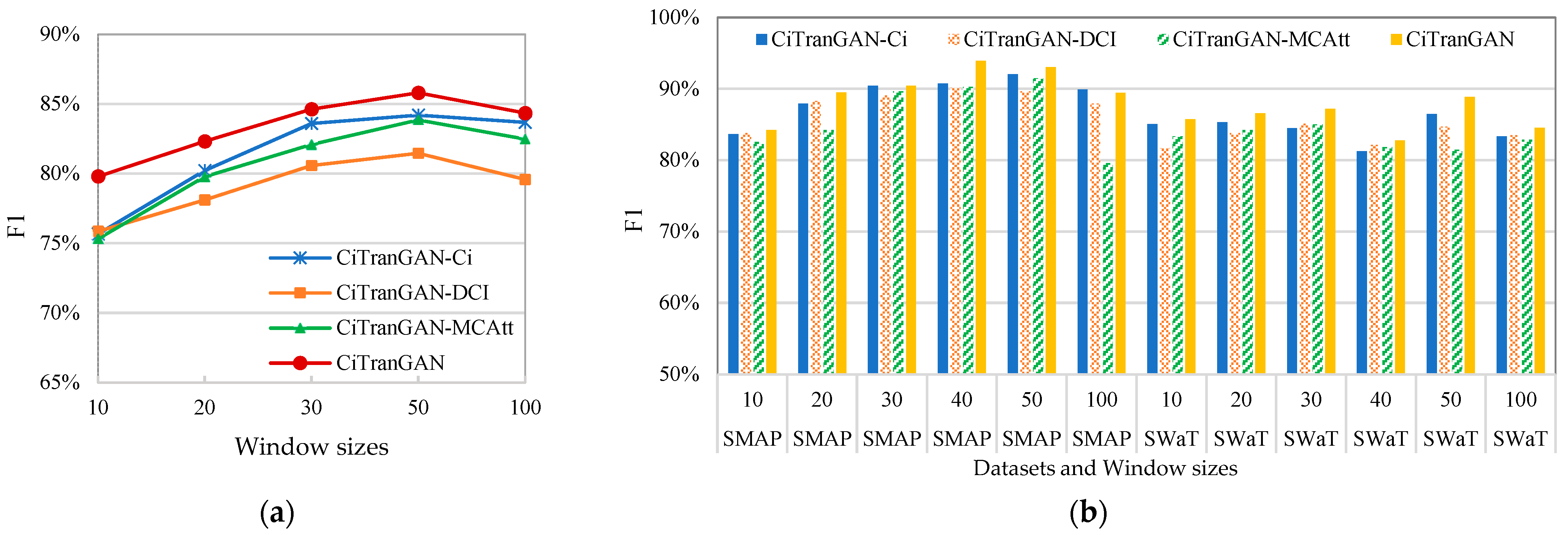
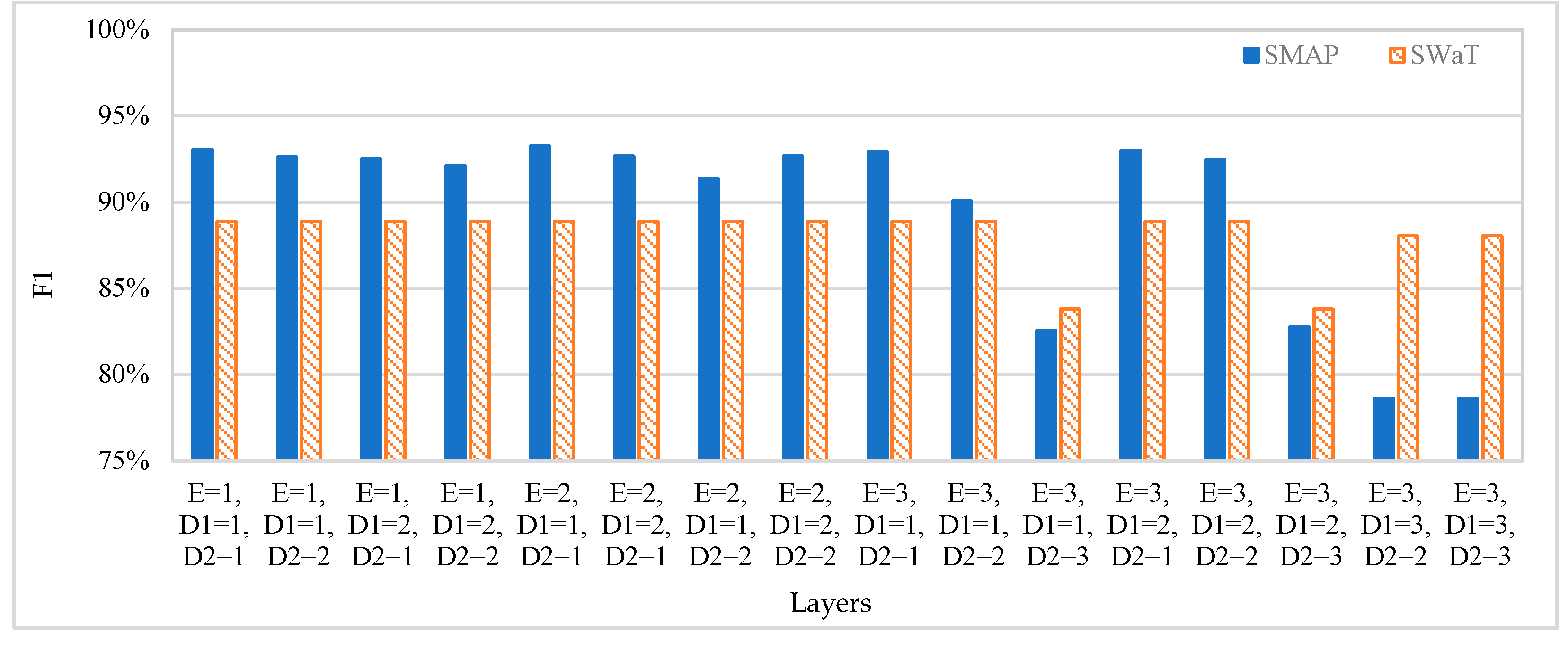
4.4.3. Sensitivity Experiments
4.5. Limitations and Future Work
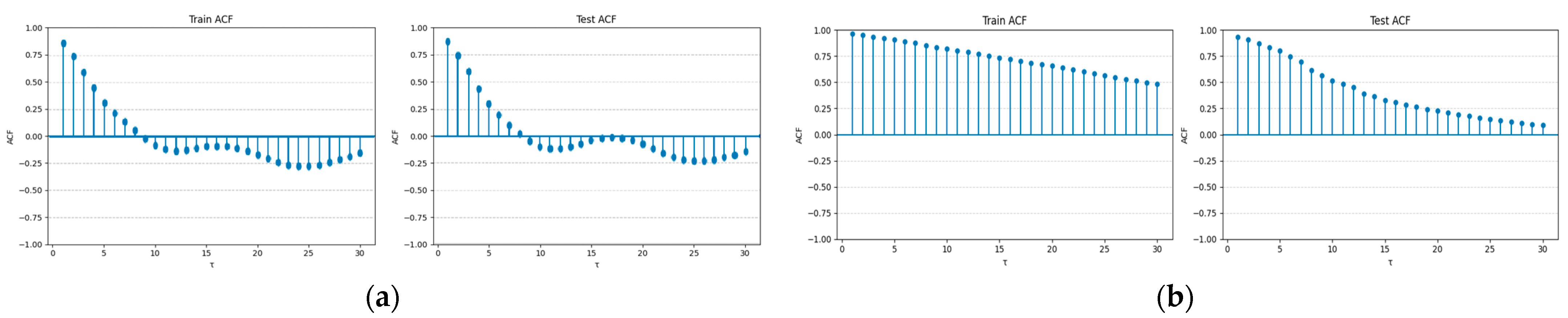
- The CI strategy ignores the inter-variable correlation. Although the strategy effectively alleviates the distribution drift problem in time series data, it treats each variable as an independent single variable and ignores the potential correlation between variables. In some scenarios, inter-variable correlations play a critical role in anomaly detection, and disregarding these relationships may result in reduced model accuracy on specific datasets, as evidenced by the experimental results on the SWaT dataset.
- Limited generalization capability. The experimental results presented in this paper are primarily derived from five public datasets, which, despite their representativeness, may not fully capture the complexities and variations in data in specific domains or scenarios. Consequently, the model’s performance in practical applications could be influenced by domain-specific data characteristics. Further validation is therefore required to comprehensively assess the model’s generalization capability.
- High computational complexity and resource consumption. While the CiTranGAN model demonstrates excellent performance across multiple datasets, its computational demands are relatively high, particularly when processing large-scale time series data. The multi-scale convolutional self-attention mechanism and the generative adversarial network architecture within the model necessitate substantial computational resources and memory capacity, thereby restricting its applicability in resource-constrained environments. This may introduce time constraints during the actual deployment and updating of the model.
- Parameter sensitivity and challenges in tuning. The CiTranGAN model incorporates several hyperparameters, including the size of the sliding window, the number of encoder layers, and the dimension of the convolution kernel. The choice of these parameters significantly influences model performance; however, identifying the optimal parameter combination remains a complex challenge. Moreover, since different datasets may necessitate distinct parameter configurations, this further complicates the tuning process.
- Lack sufficient explanation. While the model demonstrates high accuracy in anomaly detection, its ability to explain anomalies remains inadequate. In practical applications, users are not only interested in identifying the presence of exceptions but also in understanding their underlying causes and sources. Consequently, enhancing the interpretability of the model is crucial for building user trust and providing robust decision support.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CiTranGAN | Channel-Independent Transformer-Based and Generative Adversarial Network |
| MvTS | Multivariate Time Series |
| LSTM-NDT | Long Short-Term Memory-based Nonparametric Dynamic Thresholding |
| USAD | Unsupervised Anomaly Detection |
| TranAD | Transformer Networks for Anomaly Detection |
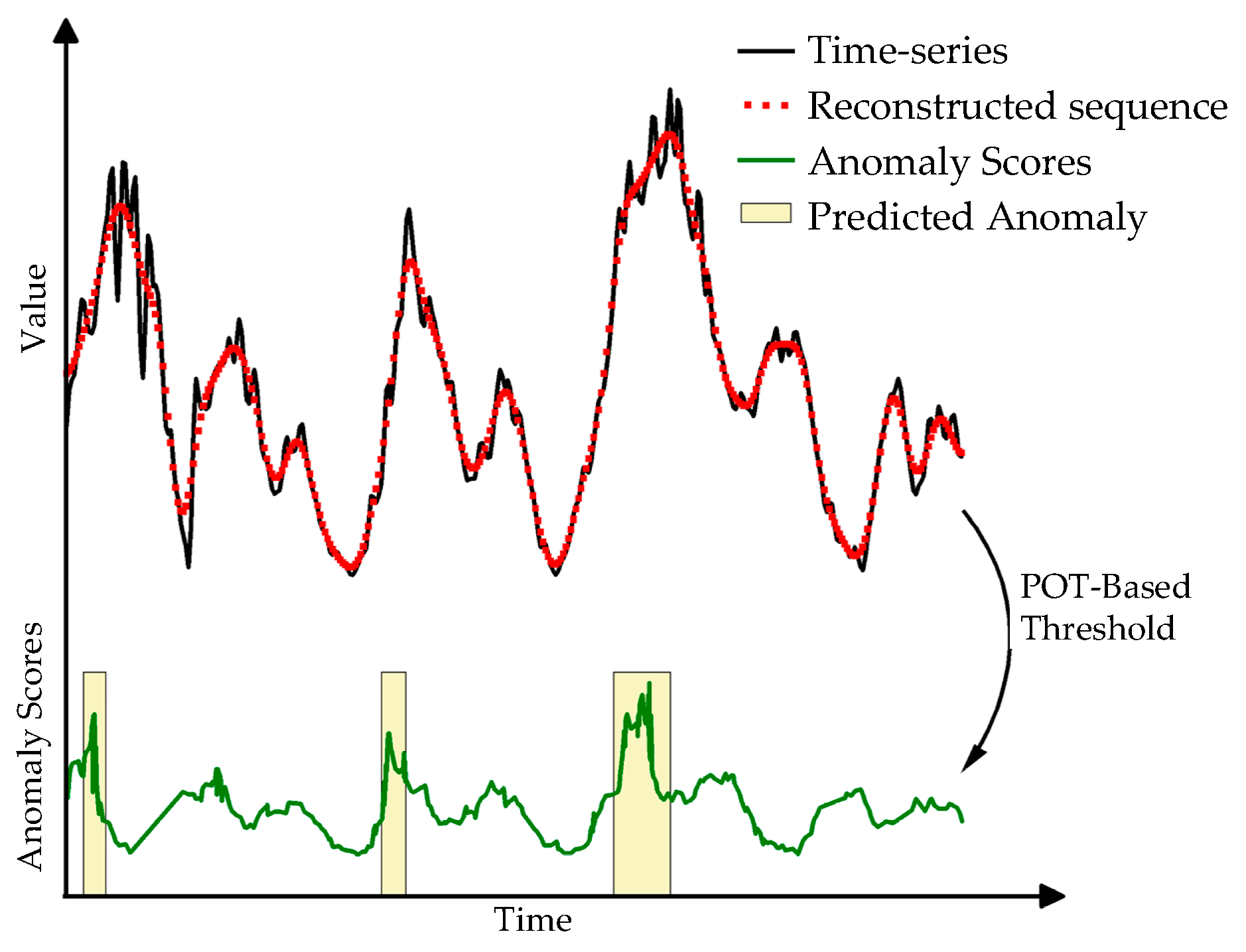
| POT | Peaks Over Threshold |
| GPD | Generalized Pareto Distribution |
| CD | Channel Dependent |
| ACF | Autocorrelation Function |
| CI | Channel Independent |
| MLP | Multilayer Perceptron |
| HDCC | Hybrid Dilated Causal Convolution |
| MAD-GAN | Multivariate Anomaly Detection With GAN |
| GDN | Graph Dynamic Network |
References
- Pau, F.C.; Jose, M.B.; Jorge, G.V. A Review of Graph-Powered Data Quality Applications for IoT Monitoring Sensor Networks. J. Netw. Comput. Appl. 2025, 1, 104116. [Google Scholar] [CrossRef]
- Thudumu, S.; Branch, P.; Jin, J.; Singh, J.J. A comprehensive survey of anomaly detection techniques for high dimensional big data. J. Big Data 2020, 7, 42. [Google Scholar] [CrossRef]
- Chandola, V.; Mithal, V.; Kumar, V. Comparative Evaluation of Anomaly Detection Techniques for Sequence Data. In Proceedings of the 8th IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 743–748. [Google Scholar]
- Leon-lopez, K.M.; Mouret, F.; Arguello, H.; Tourneret, J.Y. Anomaly detection and classification in multispectral time series based on hidden Markov models. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5402311. [Google Scholar] [CrossRef]
- Erhan, L.; Ndubuaku, M.; Di Mauro, M.; Song, W.; Chen, M.; Fortino, G.; Bagdasar, O.; Liotta, A. Smart anomaly detection in sensor systems: A multi-perspective review. Inf. Fusion 2021, 67, 64–79. [Google Scholar] [CrossRef]
- Lu, Y.; Wu, R.; Mueen, A.; Zuluaga, M.A.; Keogh, E.J. Matrix Profile XXIV: Scaling Time Series Anomaly Detection to Tril-lions of Datapoints and Ultra-Fast Arriving Data Streams. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14–18 August 2022; pp. 1173–1182. [Google Scholar]
- Li, Y.; Chen, Z.; Zha, D.; Du, M.; Zhang, D.; Chen, H.; Hu, X. Towards Learning Disentangled Representations for Time Series. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14–18 August 2022; pp. 3270–3278. [Google Scholar]
- Liu, Y.; Zhou, Y.J.; Yang, K.; Wang, X. Unsupervised deep learning for IoT time series. IEEE Internet Things J. 2023, 10, 14285–14306. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: Unsupervised Anomaly Detection on Multivariate Time Series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 23–27 August 2020; pp. 3395–3404. [Google Scholar]
- Tuli, S.; Casale, G.; Jennings, N.R. TranAD: Deep Transformer networks for anomaly detection in multivariate time series data. In Proceedings of the 48th International Conference on Very Large Data Bases, Sydney, Australia, 5–9 September 2022; pp. 1201–1214. [Google Scholar] [CrossRef]
- Rabanser, S.; Januschowski, T.; Flunkert, V.; Salinas, D.; Gasthaus, J. The effectiveness of discretization in forecasting: An empirical study on neural time series models. arXiv 2020, arXiv:2005.10111. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are Transformers Effective for Time Series Forecasting? arXiv 2022, arXiv:2205.13504. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]
- Kim, J.S.; Scott, C.D. Robust kernel density estimation. J. Mach. Learn. Res. 2012, 13, 2529–2565. [Google Scholar]
- Shyu, M.L.; Chen, S.C.; Sarinnapakorn, K.; Chang, L. A Novel Anomaly Detection Scheme Based on Principal Component Classifier. In Proceedings of the IEEE Foundations and New Directions of Data Mining Workshop, Piscataway, NJ, USA, 19–22 November 2003; pp. 172–179. [Google Scholar]
- Candès, E.J.; Li, X.D.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2009, 58, 1–37. [Google Scholar] [CrossRef]
- Hautamaki, V.; Karkkainen, I.; Franti, P. Outlier Detection Using K-Nearest Neighbour Graph. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; IEEE: New York, NY, USA, 2004; pp. 430–433. [Google Scholar]
- Zhang, Y.; Hammn, A.S.; Meratnia, N.; Stein, A.; Van, V.M.; Havinga, J.M. Statistics-based outlier detection for wireless sensor networks. Int. J. Geogr. Inf. Sci. 2012, 26, 1373–1392. [Google Scholar] [CrossRef]
- Fei, T.L.; Kai, M.T.; Zhou, Z.H. Isolation forest. In Proceedings of the 8th IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: New York, NY, USA, 2008; pp. 413–422. [Google Scholar]
- Barrera-Llanga, K.; Burriel-Valencia, J.; Sapena-Bano, A.; Martinez-Roman, J. Fault detection in induction machines using learning models and fourier spectrum image analysis. Sensors 2025, 25, 471. [Google Scholar] [CrossRef] [PubMed]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. In Proceedings of the 23th European Symposium on Artificial Neural Networks, Bruges, Belgium, 22–24 April 2015; pp. 89–94. [Google Scholar]
- Nanduri, A.; Sherry, L. Anomaly Detection in Aircraft Data Using Recurrent Neural Networks (RNN). In Proceedings of the 16th Integrated Communications Navigation and Surveillance, Herndon, VA, USA, 19–24 April 2016; pp. 1–8. [Google Scholar]
- Guo, Y.; Liao, W.; Wang, Q.; Yu, L.X.; Ji, T.X.; Li, P.M. Multidimensional Time Series Anomaly Detection: A Gru-Based Gaussian Mixture Variational Autoencoder Approach. In Proceedings of the Asian Conference on Machine Learning, Tokyo, Japan, 8–10 November 2018; pp. 97–112. [Google Scholar]
- Xia, T.B.; Song, Y.; Zheng, Y.; Pan, E.; Xi, L.F. An ensemble framework based on convolutional bi-directional LSTM with multiple time windows for remaining useful life estimation. Comput. Ind. 2020, 115, 103182–103196. [Google Scholar] [CrossRef]
- Li, T.; Comer, M.L.; Delp, E.J.; Desai, S.R.; Chan, M.W. Anomaly Scoring for Prediction-Based Anomaly Detection in Time Series. In Proceedings of the IEEE Aerospace Conference, Bozeman, MT, USA, 7–14 March 2020; pp. 1–7. [Google Scholar]
- Chen, Z.; Chai, K.Y.; Bu, S.L.; Lau, C.T. Autoencoder-Based Network Anomaly Detection. In Proceedings of the Wireless Tele-communications Symposium Conference, Los Angeles, CA, USA, 4–6 April 2018; pp. 1–5. [Google Scholar]
- Xu, H.; Feng, Y.; Chen, J.; Wang, Z.; Qiao, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z. Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal Kpis in Web Applications. In Proceedings of the 2018 World Wide Web Conference, Paris, France, 23–27 April 2018; pp. 187–196. [Google Scholar]
- Park, D.; Hoshi, Y.; Kemp, C.C. A multimodal anomaly detector for robot-assisted feeding using an lstm-based variational autoencoder. IEEE Robot. Autom. Lett. 2018, 3, 1544–1551. [Google Scholar] [CrossRef]
- Li, D.; Chen, D.; Jin, B.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 16–19 September 2019; pp. 703–716. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 30–40. [Google Scholar]
- Xu, J.H.; Wu, H.X.; Wang, J.M.; Long, M.S. Anomaly Transformer: Time Series Anomaly Detection with Association Dis-crepancy. In Proceedings of the International Conference on Learning Representations, Lyon, France, 25–29 April 2022; pp. 1021–1038. [Google Scholar]
- Du, B.; Sun, X.; Ye, J. GAN-based anomaly detection for multivariate time series using polluted training set. IEEE Transac-Tions Knowl. Data Eng. 2021, 35, 12208–12219. [Google Scholar] [CrossRef]
- Wu, H.; Yang, R.; Qing, H. TSFN: An Effective Time Series Anomaly Detection Approach via Transformer-based Self-feedback Network. In Proceedings of the 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Kunming, China, 24–26 May 2023; pp. 1396–1401. [Google Scholar]
- Wang, Z.; Wang, Y.; Gao, C.; Wang, F.; Lin, T.; Chen, Y. An adaptive sliding window for anomaly detection of time series in wireless sensor networks. Wirel. Netw. 2022, 28, 393–411. [Google Scholar] [CrossRef]
- Shaukat, K.; Alam, T.M.; Luo, S.; Shabbir, S.; Javed, U. A Review of Time-Series Anomaly Detection Techniques: A Step to Future Perspectives. In Proceedings of the 2021 Future of Information and Communication Conference, Beijing, China, 22–24 October 2021; pp. 865–877. [Google Scholar]
- Arnold, B.C. Pareto and generalized Pareto distributions. In Modeling Income Distributions and Lorenz Curves; Springer: New York, NY, USA, 2008; pp. 119–145. [Google Scholar]
- Lazar, N.A. Statistics of Extremes: Theory and Applications. Technometrics 2005, 47, 376–377. [Google Scholar] [CrossRef]
- Han, L.; Ye, H.J.; Zhan, D.C. The capacity and robustness trade-off: Revisiting the channel independent strategy for multivariate time series forecasting. IEEE Trans. Autom. Control. 2024, 36, 14. [Google Scholar] [CrossRef]
- Luo, J.H.; Wu, J. Neural Network Pruning with Residual-Connections and Limited-Data. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1458–1467. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhao, H.; Wang, Y.; Duan, J.; Huang, C.; Cao, D.F.; Tong, Y.H.; Xu, B.X.; Bai, J.; Tong, J.; Zhang, Q. Multivariate Time-Series Anomaly Detection Via Graph Attention Network. In Proceedings of the 2020 IEEE International Conference on Data Mining, Istanbul, Turkey, 30–31 July 2020; pp. 841–850. [Google Scholar]
- Deng, A.; Hooi, B. Graph Neural Network-Based Anomaly Detection in Multivariate Time Series. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 9–12 February 2021; pp. 4027–4035. [Google Scholar]
- Wu, H.X.; Hu, T.G.; Liu, Y.; Zhou, H.; Wang, J.M.; Long, M.S. Timesnet: Temporal 2d-Variation Modeling for General Time Series Analysis. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023; pp. 135–158. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Channels | Train | Test | Anomalies Rate |
|---|---|---|---|---|
| SMAP | 25 | 135,183 | 427,617 | 13.13% |
| SWaT | 51 | 496,800 | 449,919 | 11.98% |
| WADI | 123 | 1,048,571 | 172,801 | 5.99% |
| SMD | 38 | 708,405 | 708,420 | 4.16% |
| MSL | 55 | 58,317 | 73,729 | 10.72% |
| LSTM-NDT | MAD-GAN | MTAD-GAT | USAD | GDN | TranAD | TimesNet | CiTranGAN | ||
|---|---|---|---|---|---|---|---|---|---|
| SMAP | P | 84.13 ± 0.76 | 81.32 ± 0.72 | 79.40 ± 0.31 | 74.33 ± 0.50 | 74.51 ± 0.62 | 81.42 ± 0.52 | 73.01 ± 0.76 | 87.78 ± 0.57 |
| R | 73.32 ± 0.94 | 91.53 ± 0.59 | 97.21 ± 0.32 | 95.75 ± 0.32 | 98.12 ± 0.45 | 98.17 ± 0.41 | 70.09 ± 0.65 | 98.98 ± 0.54 | |
| F1 | 78.35 ± 0.43 | 86.12 ± 0.55 | 87.41 ± 0.34 | 83.69 ± 0.40 | 84.70 ± 0.52 | 89.01 ± 0.46 | 71.52 ± 0.57 | 93.04 ± 0.46 | |
| Auc | 85.58 ± 0.53 | 98.49 ± 0.53 | 97.05 ± 0.36 | 98.10 ± 0.33 | 98.59 ± 0.35 | 98.66 ± 0.36 | 94.29 ± 0.54 | 98.86 ± 0.30 | |
| SWaT | P | 77.23 ± 0.73 | 95.42 ± 0.84 | 96.67 ± 0.89 | 98.74 ± 0.68 | 96.46 ± 0.94 | 97.21 ± 0.87 | 98.34 ± 0.89 | 97.97 ± 0.68 |
| R | 50.67 ± 0.91 | 69.13 ± 0.83 | 69.06 ± 0.95 | 68.51 ± 0.91 | 69.14 ± 1.05 | 69.43 ± 0.83 | 70.14 ± 0.95 | 81.32 ± 0.87 | |
| F1 | 61.19 ± 1.04 | 80.17 ± 0.91 | 80.57 ± 0.95 | 80.89 ± 1.06 | 80.55 ± 1.04 | 81.00 ± 0.95 | 81.88 ± 0.92 | 88.87 ± 0.89 | |
| Auc | 70.92 ± 1.02 | 84.15 ± 1.11 | 84.12 ± 1.06 | 84.06 ± 1.13 | 84.16 ± 1.02 | 84.40 ± 1.06 | 83.74 ± 1.07 | 94.78 ± 0.94 | |
| WADI | P | 11.53 ± 0.65 | 22.21 ± 1.00 | 28.43 ± 0.58 | 18.69 ± 0.57 | 29.45 ± 0.54 | 35.47 ± 0.91 | 38.29 ± 1.09 | 46.64 ± 0.64 |
| R | 78.12 ± 1.01 | 89.23 ± 0.82 | 80.31 ± 0.50 | 82.47 ± 0.59 | 79.18 ± 0.50 | 82.43 ± 0.82 | 80.43 ± 0.74 | 89.47 ± 0.69 | |
| F1 | 20.09 ± 0.50 | 35.57 ± 0.88 | 41.99 ± 0.52 | 30.47 ± 0.58 | 42.93 ± 0.56 | 49.60 ± 0.86 | 51.88 ± 0.88 | 61.32 ± 0.63 | |
| Auc | 64.46 ± 0.72 | 68.26 ± 0.70 | 77.61 ± 0.63 | 88.68 ± 0.66 | 78.07 ± 0.61 | 78.45 ± 0.69 | 69.01 ± 0.87 | 81.45 ± 0.53 | |
| SMD | P | 79.35 ± 0.90 | 88.91 ± 0.96 | 79.10 ± 0.60 | 81.42 ± 0.60 | 72.69 ± 0.71 | 89.56 ± 0.64 | 82.56 ± 0.65 | 90.28 ± 0.64 |
| R | 79.41 ± 1.16 | 73.42 ± 0.61 | 88.12 ± 0.64 | 84.73 ± 0.65 | 91.13 ± 0.65 | 88.24 ± 0.66 | 89.33 ± 1.10 | 95.18 ± 0.68 | |
| F1 | 79.38 ± 0.51 | 80.43 ± 0.64 | 83.37 ± 0.66 | 83.04 ± 0.68 | 80.87 ± 0.74 | 88.9 ± 0.65 | 85.81 ± 0.71 | 92.67 ± 0.63 | |
| Auc | 85.67 ± 0.93 | 85.64 ± 0.60 | 81.53 ± 0.67 | 87.42 ± 0.64 | 96.69 ± 0.64 | 92.59 ± 0.67 | 79.02 ± 0.79 | 97.83 ± 0.61 | |
| MSL | P | 62.84 ± 0.95 | 85.16 ± 0.97 | 78.63 ± 1.06 | 79.12 ± 1.04 | 87.19 ± 1.04 | 90.08 ± 1.14 | 82.51 ± 1.16 | 92.05 ± 0.96 |
| R | 89.91 ± 0.82 | 86.87 ± 0.86 | 83.29 ± 0.87 | 90.13 ± 0.96 | 88.91 ± 1.05 | 89.65 ± 1.02 | 87.97 ± 1.10 | 95.20 ± 0.65 | |
| F1 | 73.98 ± 0.98 | 86.01 ± 0.89 | 80.89 ± 1.00 | 84.27 ± 0.94 | 88.04 ± 1.12 | 89.86 ± 1.02 | 85.15 ± 0.71 | 93.60 ± 0.63 | |
| Auc | 92.09 ± 1.01 | 83.97 ± 0.86 | 91.89 ± 0.92 | 94.00 ± 0.88 | 90.27 ± 1.14 | 94.05 ± 1.04 | 94.61 ± 0.79 | 98.02 ± 0.78 | |
| CiTranGAN-Ci | CiTranGAN-DCI | CiTranGAN-MCAtt | CiTranGAN | ||
|---|---|---|---|---|---|
| SMAP | P | 86.56 ± 0.54 | 82.54 ± 0.58 | 86.45 ± 0.64 | 87.78 ± 0.57 |
| R | 98.21 ± 0.50 | 98.11 ± 0.60 | 97.01 ± 0.57 | 98.98 ± 0.54 | |
| F1 | 92.02 ± 0.52 | 89.65 ± 0.61 | 91.43 ± 0.63 | 93.04 ± 0.46 | |
| AUC | 97.47 ± 0.49 | 97.91 ± 0.54 | 96.72 ± 0.56 | 98.86 ± 0.30 | |
| SWaT | P | 95.11 ± 0.70 | 97.69 ± 0.79 | 96.07 ± 0.74 | 97.97 ± 0.68 |
| R | 79.24 ± 0.74 | 70.21 ± 0.94 | 75.32 ± 0.79 | 81.32 ± 0.87 | |
| F1 | 86.45 ± 0.67 | 81.70 ± 0.85 | 84.44 ± 0.95 | 88.87 ± 0.89 | |
| AUC | 92.09 ± 0.85 | 93.75 ± 0.73 | 92.84 ± 0.76 | 94.78 ± 0.94 | |
| WADI | P | 43.35 ± 0.86 | 37.69 ± 0.59 | 44.63 ± 0.67 | 46.64 ± 0.64 |
| R | 87.23 ± 0.67 | 81.21 ± 0.54 | 90.12 ± 0.73 | 89.47 ± 0.69 | |
| F1 | 57.92 ± 0.71 | 51.59 ± 0.68 | 59.70 ± 0.61 | 61.32 ± 0.63 | |
| AUC | 78.71 ± 0.60 | 77.45 ± 0.46 | 74.53 ± 0.59 | 81.45 ± 0.53 | |
| SMD | P | 89.41 ± 0.55 | 89.09 ± 0.71 | 89.17 ± 0.56 | 90.28 ± 0.64 |
| R | 94.77 ± 0.68 | 90.44 ± 0.58 | 94.14 ± 0.45 | 95.18 ± 0.68 | |
| F1 | 92.01 ± 0.40 | 89.76 ± 0.64 | 91.59 ± 0.65 | 92.67 ± 0.63 | |
| AUC | 95.86 ± 0.87 | 96.38 ± 0.70 | 94.29 ± 0.64 | 97.83 ± 0.61 | |
| MSL | P | 90.22 ± 0.90 | 88.27 ± 0.97 | 90.17 ± 1.03 | 92.05 ± 0.96 |
| R | 95.11 ± 0.64 | 92.11 ± 0.72 | 94.23 ± 0.75 | 95.20 ± 0.65 | |
| F1 | 92.60 ± 0.76 | 90.15 ± 0.67 | 92.16 ± 0.78 | 93.60 ± 0.63 | |
| AUC | 96.03 ± 0.94 | 97.29 ± 0.83 | 95.22 ± 0.73 | 98.02 ± 0.78 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Li, T.; Ma, Z.; Chen, J.; Guo, J.; Liu, Z. CiTranGAN: Channel-Independent Based-Anomaly Detection for Multivariate Time Series Data. Electronics 2025, 14, 1857. https://doi.org/10.3390/electronics14091857
Chen X, Li T, Ma Z, Chen J, Guo J, Liu Z. CiTranGAN: Channel-Independent Based-Anomaly Detection for Multivariate Time Series Data. Electronics. 2025; 14(9):1857. https://doi.org/10.3390/electronics14091857
Chicago/Turabian StyleChen, Xiao, Tongxiang Li, Zuozuo Ma, Jing Chen, Jingfeng Guo, and Zhiliang Liu. 2025. "CiTranGAN: Channel-Independent Based-Anomaly Detection for Multivariate Time Series Data" Electronics 14, no. 9: 1857. https://doi.org/10.3390/electronics14091857
APA StyleChen, X., Li, T., Ma, Z., Chen, J., Guo, J., & Liu, Z. (2025). CiTranGAN: Channel-Independent Based-Anomaly Detection for Multivariate Time Series Data. Electronics, 14(9), 1857. https://doi.org/10.3390/electronics14091857