



Enhancing Human Pose Transfer with Convolutional Block Attention Module and Facial Loss Optimization




Abstract
1. Introduction
- (1)
- The inability to simultaneously preserve both clothing textures and facial details.
- (2)
- Structural distortions or pixel misalignment under large pose variations.
- (3)
- Difficulty in maintaining identity consistency of the subject.
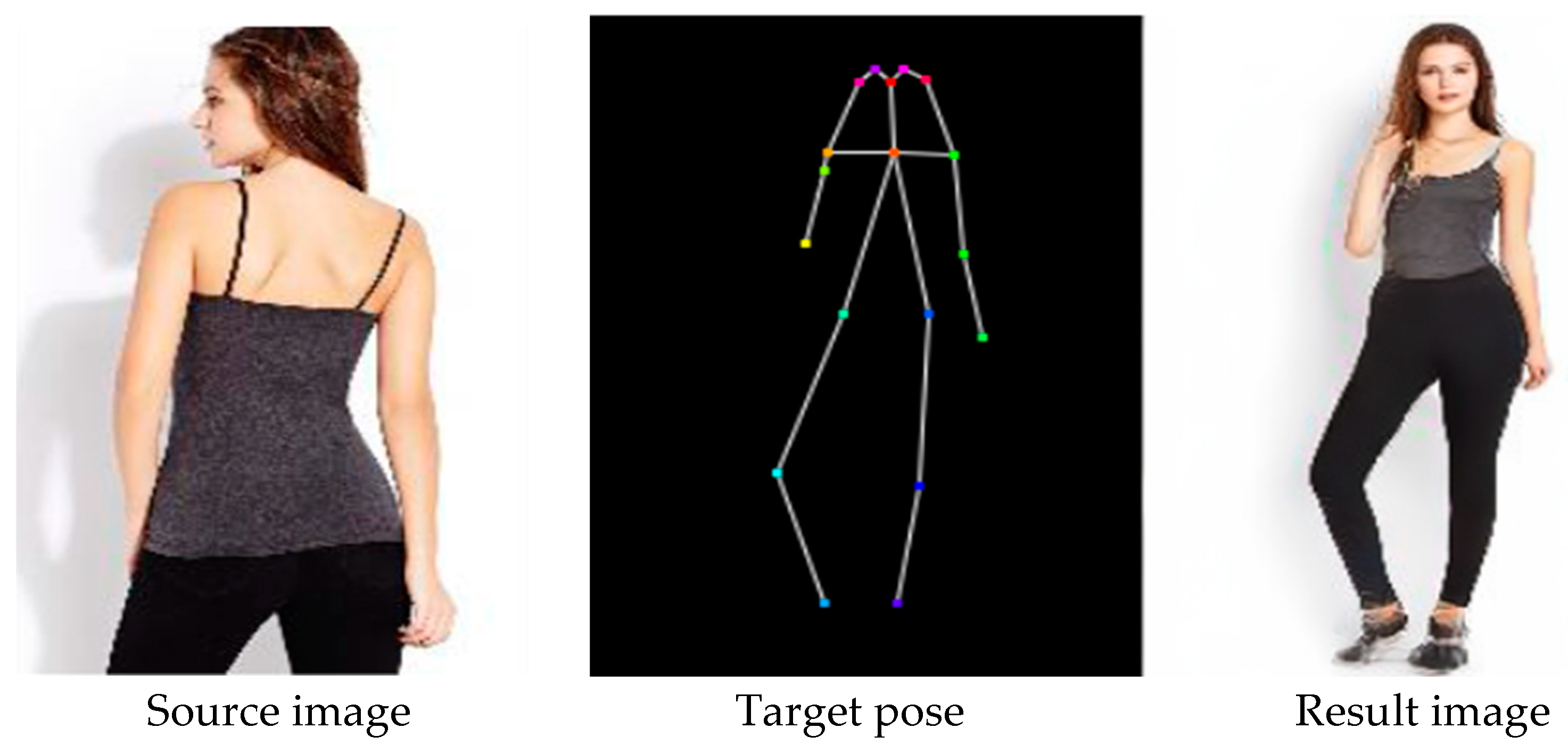
2. Proposed Method
2.1. Network Architecture
2.2. Residual Block with CBAM
2.3. Mish Activation Function
2.4. Head Region Loss
2.5. Face-Focused Loss
2.6. Total Loss
3. Experiments
3.1. Dataset
3.2. Evaluation Metrics
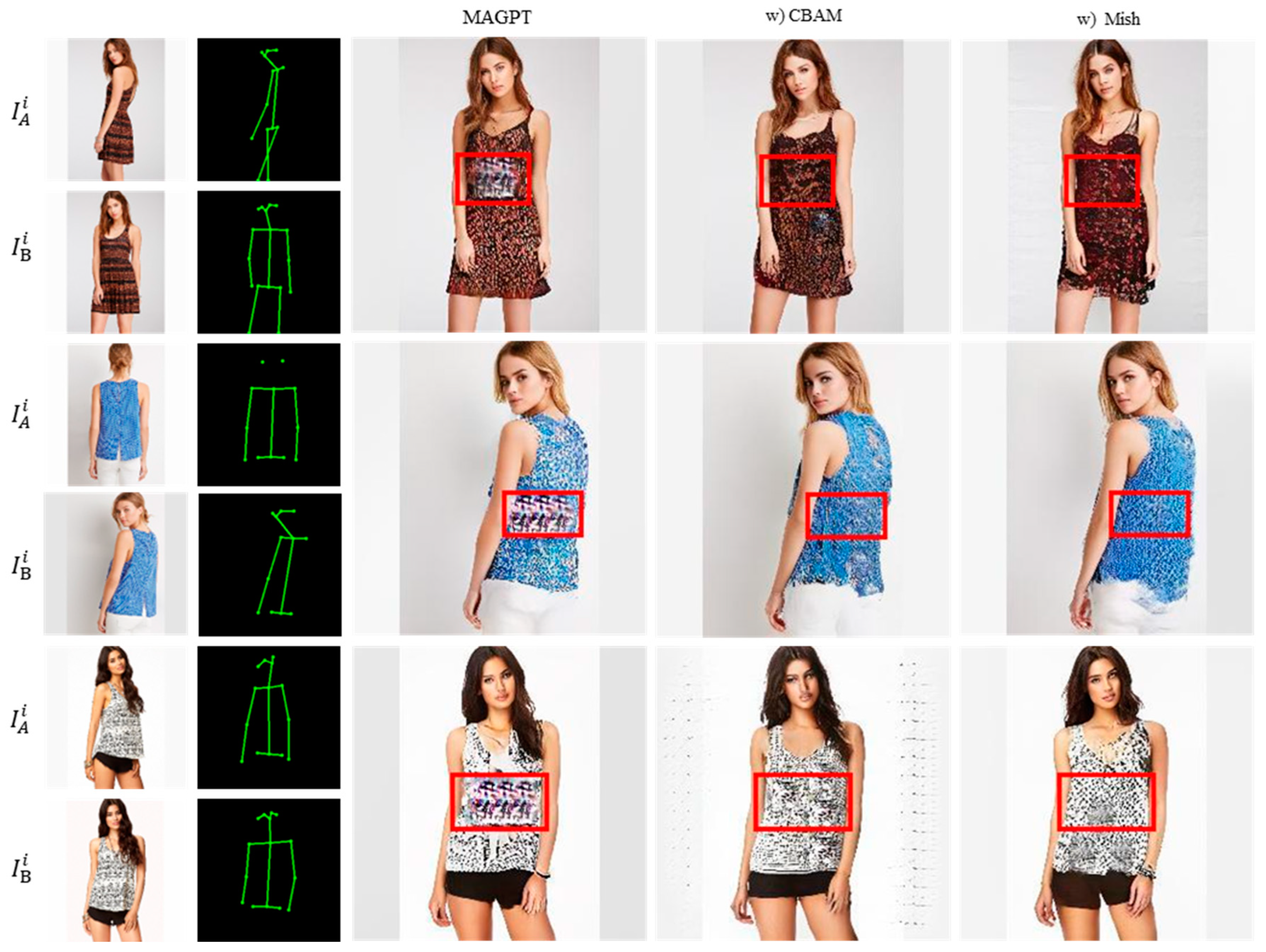
3.3. Qualitative Comparison
3.4. Quantitative Comparison
3.5. Experiment on Handling Diverse Actions
4. Conclusions
- Enhancing hand detail generation, as current models lack training on images with open hands and struggle with hand and finger details.
- Improving handling of complex backgrounds, since current experiments are trained on all-white backgrounds.
- Diversifying the training dataset to include non-Western features, as the current model is predominantly trained on Western faces. Adding a variety of ethnicities could improve performance.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Full Form |
| GAN | Generative Adversarial Networks |
| CGAN | Conditional Generative Adversarial Network |
| MAGPT | Multi-scale Attention Guided Pose Transfer |
| CBAM | Convolutional Block Attention Module |
| SSIM | Structural Similarity Index Measure |
| IS | Inception Score |
| PCKh | Percentage of Correct Keypoints (head-normalized) |
| LPIPS | Learned Perceptual Image Patch Similarity |
| FID | Fréchet Inception Distance |
| HPE | Human Pose Estimator |
| ADGAN | Attention-guided Disentangled GAN |
References
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.-.F. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference; Springer International Publishing: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Lassner, C.; Pons-Moll, G.; Gehler, P.V. A generative model of people in clothing. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 853–862. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Balakrishnan, G.; Zhao, A.; Dalca, A.V.; Durand, F.; Guttag, J. Synthesizing images of humans in unseen poses. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8340–8348. [Google Scholar]
- Chan, C.; Ginosar, S.; Zhou, T.; Efros, A.A. Everybody dance now. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 5933–5942. [Google Scholar]
- Ma, L.; Jia, X.; Sun, Q.; Schiele, B.; Tuytelaars, T.; Van Gool, L. Pose guided person image generation. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ma, L.; Sun, Q.; Georgoulis, S.; Van Gool, L.; Schiele, B.; Fritz, M. Disentangled person image generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 99–108. [Google Scholar]
- Neverova, N.; Guler, R.A.; Kokkinos, I. Dense pose transfer. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 123–138. [Google Scholar]
- Si, C.; Wang, W.; Wang, L.; Tan, T. Multistage adversarial losses for pose-based human image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 118–126. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Sangkloy, P.; Lu, J.; Fang, C.; Yu, F.; Hays, J. Scribbler: Controlling deep image synthesis with sketch and color. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5400–5409. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Yeh, R.A.; Chen, C.; Lim, T.Y.; Alexander, G.S.; Hasegawa-Johnson, M.; Do, M.N. Semantic image inpainting with deep generative models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhao, B.; Wu, X.; Cheng, Z.-Q.; Liu, H.; Jie, Z.; Feng, J. Multi-view image generation from a single-view. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 383–391. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Esser, P.; Sutter, E.; Ommer, B. A variational u-net for conditional appearance and shape generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8857–8866. [Google Scholar]
- Zhu, Z.; Huang, T.; Shi, B.; Yu, M.; Wang, B.; Bai, X. Progressive pose attention transfer for person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2347–2356. [Google Scholar]
- Lu, Y.; Zhang, M.; Ma, A.J.; Xie, X.; Lai, J. Coarse-to-fine latent diffusion for pose-guided person image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 6420–6429. [Google Scholar]
- Shen, F.; Ye, H.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Advancing pose-guided image synthesis with progressive conditional diffusion models. arXiv 2023, arXiv:2310.06313. [Google Scholar]
- Roy, P.; Bhattacharya, S.; Ghosh, S.; Pal, U. Multi-scale attention guided pose transfer. Pattern Recognit. 2023, 137, 109315. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Men, Y.; Mao, Y.; Jiang, Y.; Ma, W.-Y.; Lian, Z. Controllable person image synthesis with attribute-decomposed gan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5084–5093. [Google Scholar]
- Siarohin, A.; Sangineto, E.; Lathuiliere, S.; Sebe, N. Deformable gans for pose-based human image generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3408–3416. [Google Scholar]
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1096–1104. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training Gans; Neural Information Processing Systems Foundation: San Diego, CA, USA, 2016; Volume 29. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | FID ↓ | SSIM ↑ | IS ↑ | PCKh ↑ | LPIPS (VGG) ↓ | LPIPS (SqzNet) ↓ |
|---|---|---|---|---|---|---|
| [9] | - | 0.773 | 3.163 | 0.89 | 0.523 | 0.416 |
| Deform [31] | - | 0.760 | 3.362 | 0.94 | - | - |
| VUNet [22] | - | 0.763 | 3.440 | 0.93 | - | - |
| PATN [23] | 20.73 | 0.773 | 3.209 | 0.96 | 0.299 | 0.170 |
| MAGPT [26] | 10.56 | 0.769 | 3.379 | 0.98 | 0.200 | 0.111 |
| Proposed with Head Region Loss | 10.40 | 0.775 | 3.070 | 0.98 | 0.196 | 0.108 |
| Proposed with Face Focused Loss | 10.20 | 0.774 | 3.411 | 0.96 | 0.196 | 0.108 |
| Real data | 7.68 | 1.000 | 3.864 | 1.00 | 0.000 | 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, H.-Y.; Chiang, C.-C.; Jiang, C.-L.; Yu, C.-C. Enhancing Human Pose Transfer with Convolutional Block Attention Module and Facial Loss Optimization. Electronics 2025, 14, 1855. https://doi.org/10.3390/electronics14091855
Cheng H-Y, Chiang C-C, Jiang C-L, Yu C-C. Enhancing Human Pose Transfer with Convolutional Block Attention Module and Facial Loss Optimization. Electronics. 2025; 14(9):1855. https://doi.org/10.3390/electronics14091855
Chicago/Turabian StyleCheng, Hsu-Yung, Chun-Chen Chiang, Chi-Lun Jiang, and Chih-Chang Yu. 2025. "Enhancing Human Pose Transfer with Convolutional Block Attention Module and Facial Loss Optimization" Electronics 14, no. 9: 1855. https://doi.org/10.3390/electronics14091855
APA StyleCheng, H.-Y., Chiang, C.-C., Jiang, C.-L., & Yu, C.-C. (2025). Enhancing Human Pose Transfer with Convolutional Block Attention Module and Facial Loss Optimization. Electronics, 14(9), 1855. https://doi.org/10.3390/electronics14091855