1. Introduction
In the field of image security [
1], guaranteeing the reliability and authenticity of transmitted data is fundamental to safeguarding information. Although numerous protective techniques have been suggested, such as image encryption, these approaches often prove inadequate when applied to remote sensing images. While encryption can successfully block unauthorized access, it frequently disrupts subsequent data analysis and practical use. On the other hand, digital watermarking [
2] provides a more sophisticated solution by embedding invisible marks that maintain visual quality while allowing for copyright verification.
This issue is particularly evident in the realm of remote sensing. Remote sensing images, which are used in satellite monitoring, military intelligence, and environmental observation, are typically high-resolution and multispectral, meaning that even slight distortions or unauthorized modifications can result in substantial misinterpretations. Unlike conventional multimedia images, remote sensing data requires a security solution that minimizes perceptual degradation while maintaining resilience to various distortions, channel noise, and deliberate attacks. In this regard, digital watermarking presents a compelling solution, offering a balance between robustness, embedding capacity, and imperceptibility.
In recent years, digital watermarking has garnered significant academic attention as a means of copyright protection for remote sensing imagery. A variety of algorithms specifically designed for this purpose have emerged, many of which are rooted in traditional frequency-based approaches, including those employing cosine domain transformations, multi-scale wavelet analysis, and matrix factorization techniques such as singular value decomposition (SVD) [
3,
4,
5]. These methods utilize spectral transformations and decomposition principles to achieve improvements in the imperceptibility, resilience, and security of the watermark. However, conventional watermarking strategies still encounter multiple challenges in real-world scenarios.
Susceptibility to distortion: many classical techniques show weak resistance to common perturbations, including compression artifacts (e.g., JPEG), random noise interference, and spatial transformations, resulting in the partial or complete degradation of embedded watermark signals.
Low adaptability of handcrafted features: these solutions typically depend on manually engineered embedding patterns and robustness heuristics, which are often insufficient for the high complexity and variability inherent in remote sensing imagery and the diverse threat models involved.
High computational demands: some watermarking systems, although robust, impose significant computational overhead, limiting their feasibility for real-time use in large-scale remote sensing applications.
Recent breakthroughs in deep learning have opened up novel avenues for improving the robustness, imperceptibility, and adaptive capabilities of digital watermarking systems. A growing body of research in image processing demonstrates the potential of deep learning models to surpass the limitations of conventional watermarking approaches. Deep learning-based watermarking techniques for remote sensing images can generally be categorized into two main branches. Among them, convolutional neural networks (CNNs) [
6] and generative adversarial networks (GANs) [
7] have become prominent tools in this domain. One of the pioneering works by Haribabu et al. [
8] introduced a CNN-based model that embedded watermark information through an encoder–decoder structure inspired by autoencoders. Subsequently, Mun et al. [
9] introduced an iterative learning framework built upon CNNs, further boosting watermark robustness. These neural network-based solutions can be viewed as evolved variants of frequency-domain approaches and are now integral to many modern watermarking strategies. In a representative example, Ahmadi et al. [
10] presented ReDMark, an end-to-end framework employing residual CNNs and incorporating simulated attacks as differentiable transformations. This technique enhances both security and robustness by dispersing watermark signals across a broader spatial domain. Meanwhile, Luo et al. [
11] introduced a deep-learning watermarking method that does not rely on predefined distortion models during training. Instead, it gains resilience through adversarial learning combined with channel coding, demonstrating superior generalization against unforeseen perturbations. Despite these advancements, difficulties persist in accurately extracting semantically meaningful image features and effectively integrating them into the watermark embedding process, which continues to constrain overall performance under noise and attack scenarios.
In the realm of generative adversarial networks (GANs), a wide array of image watermarking approaches have been proposed, leveraging the adversarial interplay between generator and discriminator components to achieve a favorable balance among embedding strength, stealth, and robustness [
12]. One of the earliest milestones in this direction is the HiDDeN framework introduced by Zhu et al. [
13], which adopts an encode-perturb-decode architecture. In this setup, the encoder embeds watermark signals into images with minimal visual disruption, while the decoder is trained to accurately retrieve the watermark even under distortions. Hao et al. [
14] explored GANs specifically in remote sensing contexts by designing a model where the generator is responsible for both embedding and recovering watermark information under varying noise levels, while the discriminator not only detects watermark presence but also introduces simulated degradations. To encourage watermark placement in frequency bands less noticeable to the human eye, a high-pass filter was applied prior to the discriminator, thereby improving both stealth and durability.
Building on these efforts, Liu et al. [
15,
16,
17,
18] devised a modular dual-stage learning pipeline consisting of a clean-condition adversarial training phase followed by a distortion-aware refinement process. This architecture integrates a deeply layered redundant encoding module [
19] that enhances information redundancy during embedding and maintains resilience under challenging noise conditions. Jia et al. [
20] further tackled real-world degradation scenarios by introducing a mini-batch training approach that incorporates both real and synthetically compressed images using JPEG-based artifacts, thereby improving generalization. In a similar vein, Huang et al. [
21] advanced the field with an attention-driven adversarial watermarking framework (ARWGAN), where attention layers actively guide watermark placement toward regions of lower perceptual significance. Lastly, Fernandez et al. [
22] proposed a fully self-supervised embedding paradigm, which uses unsupervised feature extraction under various data augmentations to generate robust, fused representations of image features and watermark signals, enhancing overall stability across perturbations.
The aforementioned research demonstrates that convolutional and generative adversarial network-based watermarking models can effectively integrate the stages of embedding and retrieval into a unified learning framework. This end-to-end optimization bypasses the constraints imposed by manually engineered features in conventional approaches. Nonetheless, the majority of such methods have been developed for general-purpose natural images, leaving the domain of remote sensing relatively underexplored. Remote sensing imagery presents a set of distinct challenges, including ultra-high spatial resolution, multispectral content, diverse scene structures, and the demand for robustness under dynamically changing conditions, which differentiate it substantially from standard image datasets. These unique demands highlight the necessity for watermarking strategies specifically tailored to the characteristics of remote sensing data. Accordingly, this work is dedicated to addressing that gap through targeted algorithmic innovation.
Existing GAN-based watermarking methods, including HiDDeN, ReDMark, and ARWGAN, typically target general image domains and lack specific adaptation to remote sensing scenarios. In contrast, our method leverages a DCGAN-based architecture enhanced with a multi-scale feature fusion module and attention mechanisms tailored for the challenges of high-resolution remote sensing images. In particular, deep convolutional generative adversarial networks (DCGANs) offer unique advantages over conventional CNNs and GANs in remote sensing image watermarking. A DCGAN combines the feature extraction strength of CNNs with the adversarial learning mechanism of GANs, making it more effective in image generation and classification tasks. Unlike GANs’ fully connected networks, A DCGAN introduces convolutional and transposed convolutional layers in both the generator and discriminator, enabling superior multi-scale feature extraction suited to the high-resolution and multispectral nature of remote sensing images.
A DCGAN’s adversarial training mechanism enhances both the imperceptibility and robustness of embedded watermarks. It also improves training stability and image quality, ensuring resistance to noise, cropping, compression, and other common attacks while preserving watermark integrity. These attributes make the DCGAN a promising solution for secure remote sensing image protection.
Recent studies have demonstrated the DCGAN’s significant potential in remote sensing applications. Sürücü et al. [
23] developed a multispectral DCGAN (MS-DCGAN) model to generate synthetic multispectral images and proposed a TransStacking model to distinguish between fake and real images with high accuracy. Wu et al. [
24] introduced a DCGAN-based image colorization method for remote sensing imagery, incorporating multi-scale convolution and residual networks to enhance both visual quality and quantitative metrics. Jia et al. [
25] combined a DCGAN with graph convolutional networks (GCNs) to develop the DGCGAN model, improving classification accuracy and robustness. Zhu et al. [
26] enhanced sample diversity in aquaculture information extraction using an improved DCGAN algorithm. Shanmugam et al. [
27] proposed DcGAN-HAD, a dual-discriminator conditional DCGAN for anomaly detection in hyperspectral images, which significantly improved detection accuracy and efficiency through optimized training.
These advances illustrate the DCGAN’s promising potential in remote sensing image watermarking, particularly in feature extraction, image generation, and resilience under complex conditions. This study adopts a DCGAN-based approach to explore robust, imperceptible, and efficient watermarking solutions for remote sensing imagery.
Recent advancements in image protection, such as the semantically enhanced selective encryption method proposed by Liu et al. [
28], leverage semantic segmentation and parallel computing to achieve efficient visual obfuscation. While effective for privacy-preserving applications, such encryption-based approaches often modify pixel values and risk destroying spatial–spectral integrity, making them less suitable for scenarios requiring scientific analysis or image fidelity, such as remote sensing.
In contrast, Zhang et al. [
29] introduced a frequency-domain attention-guided adaptive watermarking model that improves robustness under signal distortions by embedding in the DCT domain. However, the fixed-frequency embedding approach may struggle with high-frequency variability in real-world remote sensing images. Furthermore, frequency-domain techniques often lack spatial adaptability, which limits their ability to preserve semantic consistency across multi-scale geospatial regions.
To address these limitations, our method employs a spatial-domain generative strategy using a DCGAN enhanced with a multi-scale feature fusion module and attention-guided embeddings. This design enables our framework to dynamically adapt watermark placement based on spatial semantics while preserving spectral integrity, traits that are particularly critical for remote sensing applications.
In conclusion, while frameworks like HiDDeN have made notable strides in improving the imperceptibility of embedded watermarks, they often fall short in extracting semantically rich and robust features, especially when applied to remote sensing data. These models typically fail to make full use of the distinctive spectral and spatial patterns inherent in remote sensing imagery, which limits their ability to withstand noise interference and ultimately undermines watermark reliability. To overcome these shortcomings, we propose a novel watermarking framework for remote sensing images by incorporating both an attention-driven mechanism and a multi-scale feature fusion strategy within a deep convolutional GAN architecture. Rather than relying on traditional feature pipelines, our method seeks to enhance the depth and robustness of learned representations, thereby improving resistance to various noise perturbations. By jointly optimizing feature extraction and adaptive embedding through specialized modules, this work offers a more resilient and context-aware solution for protecting the integrity of remote sensing imagery.
To tackle the limited feature representation and suboptimal robustness observed in existing deep learning-based watermarking techniques, this study puts forward a novel robust watermarking framework tailored for remote sensing imagery. The method integrates an attention-driven strategy with multi-scale feature fusion, all constructed within a deep convolutional generative adversarial network paradigm. Compared to conventional approaches, this work makes the following key contributions:
We design a unified framework for watermarking remote sensing images by coupling a DCGAN-based backbone with an attention enhancement module. This combination not only improves the imperceptibility of the embedded watermark but also strengthens its resilience against degradation. The incorporation of a domain-aware feature extraction unit allows for more effective utilization of spatial–spectral patterns during watermark encoding.
A dedicated multi-level feature fusion module is proposed to boost the stability and anti-perturbation capacity of the embedding process. By capturing hierarchical remote sensing image features across scales, this module ensures that the watermark is distributed in a way that balances invisibility and robustness, particularly under compression and noise-based attacks.
An adaptive attention mechanism is incorporated to refine the spatial distribution of the watermark. This component automatically identifies less perceptually sensitive yet semantically stable regions, allowing the watermark to be embedded in areas where it remains concealed while preserving robustness under complex image transformations.
The decoding architecture is optimized to better withstand interference from noisy or lossy environments. By refining the extraction pipeline, the framework achieves reliable watermark recovery even under severe compression or transmission noise, thereby enhancing real-world applicability.
Comprehensive experimental validation shows that the proposed method consistently surpasses prior models across multiple evaluation metrics, including imperceptibility, robustness, and resistance to distortion. Notably, it maintains stable performance under adversarial conditions such as JPEG compression and noise contamination, demonstrating its viability for robust and secure remote sensing image copyright protection.
2. Methods
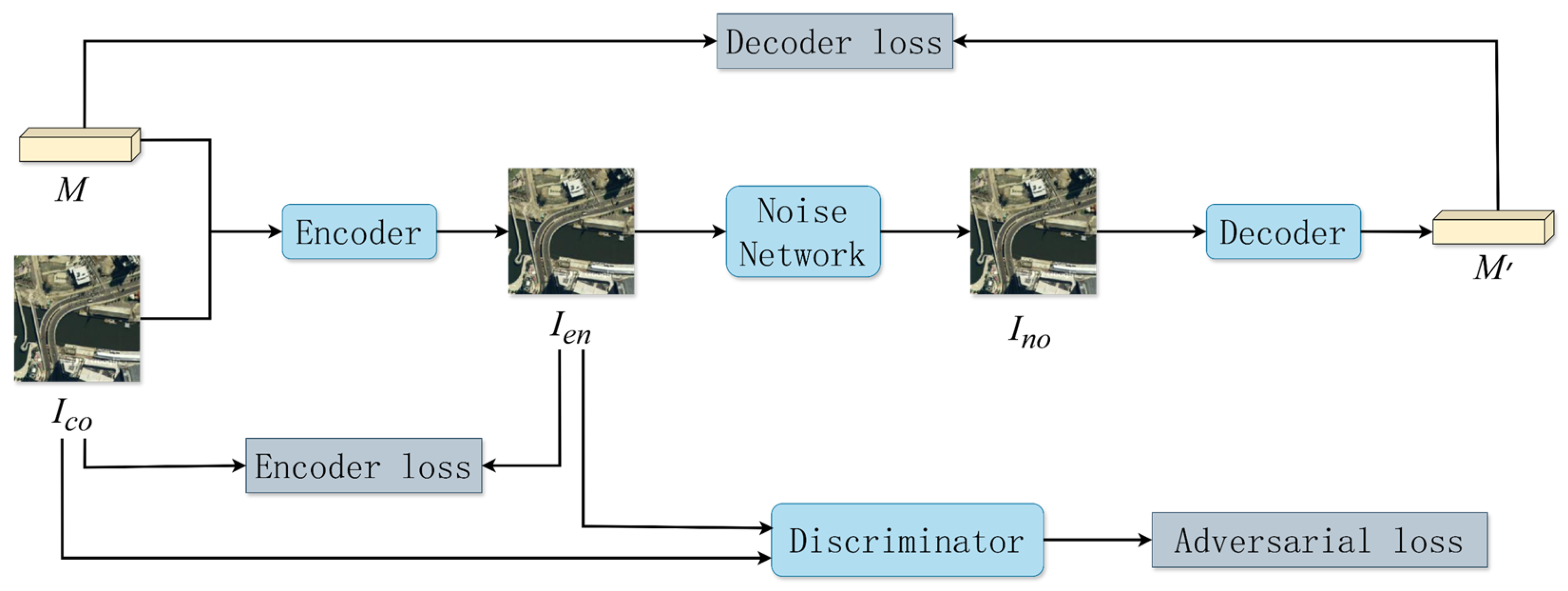
In this study, we present SIR-DCGAN, a remote sensing image watermarking strategy built upon a deep convolutional generative adversarial framework. The proposed model is designed to strike a dual objective: enhancing both the imperceptibility and resilience of embedded watermarks. The DCGAN backbone is selected for its reliable adversarial training behavior and proven capacity in producing high-fidelity images. Within this architecture, the generator module embeds the watermark into the input image, while the discriminator learns to identify discrepancies between authentic and watermarked versions. Through this adversarial interplay, the generator is incentivized to produce outputs that are visually indistinct from the original inputs while remaining resilient under distortion.
To achieve a refined balance between accurate watermark insertion, robustness during retrieval, and minimal visual disruption to the host image, we construct a cascaded architecture comprising an embedding module, a simulated attack unit, and a decoding network. These components are trained jointly in an end-to-end fashion, allowing the system to co-optimize visual quality and robustness throughout the learning process. To overcome the limitations of conventional approaches in capturing multi-scale semantics, we incorporate the Inception-ResNet [
30] feature fusion module (IR-FFM), which blends multi-scale convolution filters with cross-layer dense connections. This design promotes more effective interaction between shallow and deep features, accelerating convergence and strengthening the resistance of the watermark to noise perturbations.
In addition, to minimize visual degradation typically caused by embeddings, we develop a squeeze-and-excitation attention module (SE-AM). This component generates global attention masks by extracting context-aware features, thus guiding the embedding process toward texture-dense yet perceptually tolerant regions. This selective reinforcement of embedding zones significantly improves the visual fidelity of the output image while preserving the watermark.
To further enhance robustness under compound attack scenarios, a dedicated noise simulation network is introduced. This module emulates a variety of real-world distortions, including additive noise, compression artifacts, and cropping, and injects them into the training pipeline. The model receives feedback from these simulated distortions during training, enabling it to iteratively refine its embedding strategy and adapt to evolving threat patterns. Through this dynamic optimization mechanism, the watermarking model becomes increasingly resilient to diverse forms of interference.
Quantitative evaluations confirm that the proposed framework delivers superior performance under a wide range of attack conditions, including JPEG compression, random noise, and hybrid perturbations. At the same time, it maintains high visual quality and efficient embeddings, offering a practical and robust solution for securing remote sensing image content.
SIR-DCGGAN achieves high-quality watermark embedding and accurate extraction through the joint optimization of an encoder, a noise sub-network, a decoder, and a discriminator. During implementation, the original input and the watermark are fed and processed by the encoder to output a watermarked image . Subsequently, after undergoes attacks via the noise layer, it is input to the decoder to extract the embedded watermark . Simultaneously, the discriminator classifies both the host image and the watermarked image to ensure the quality of the watermark embedding. Throughout the network training process, by optimizing the generation loss, decoding loss, and discrimination loss, the model simultaneously achieves imperceptible watermark embedding and highly robust extraction.
The total loss guiding the training process is constructed as follows:
Here, the coefficient
serves to balance the influence of the adversarial loss within the total objective. The term
measures the mean squared error between the original host image
and the generated watermarked image
, thereby constraining the degree of distortion introduced during watermark embedding and preserving visual fidelity. Similarly,
evaluates the discrepancy between the watermarked image before attack
and its degraded version
following noise perturbation, thus quantifying the model’s resistance to distortion and its ability to retain watermark information. The formulation for the adversarial loss component,
, is given as follows:
where
and
denote the outputs of the discriminator and generator networks, respectively;
is the ground-truth label;
represents the probability assigned by the discriminator to the real watermarked image
; and
denotes the probability assigned to the generated watermarked image
.
The design of the loss components simultaneously constrains visual fidelity and promotes embedding resilience, aiming to minimize perceptual differences between the original and watermarked images while enhancing resistance to distortions. This joint optimization strategy ensures that the generated watermarked outputs maintain both high quality and robustness.
In summary, by incorporating the SE-AM and IR-FFM modules, as illustrated in
Figure 1, SIR-DCGGAN not only effectively enhances the invisibility and embedding robustness of the watermark, but also significantly improves the model's adaptability to complex attack scenarios. Experimental results demonstrate that, compared with the state-of-the-art (SOTA) watermarking model, SIR-DCGGAN exhibits marked advantages in both watermark quality and resistance to attacks.
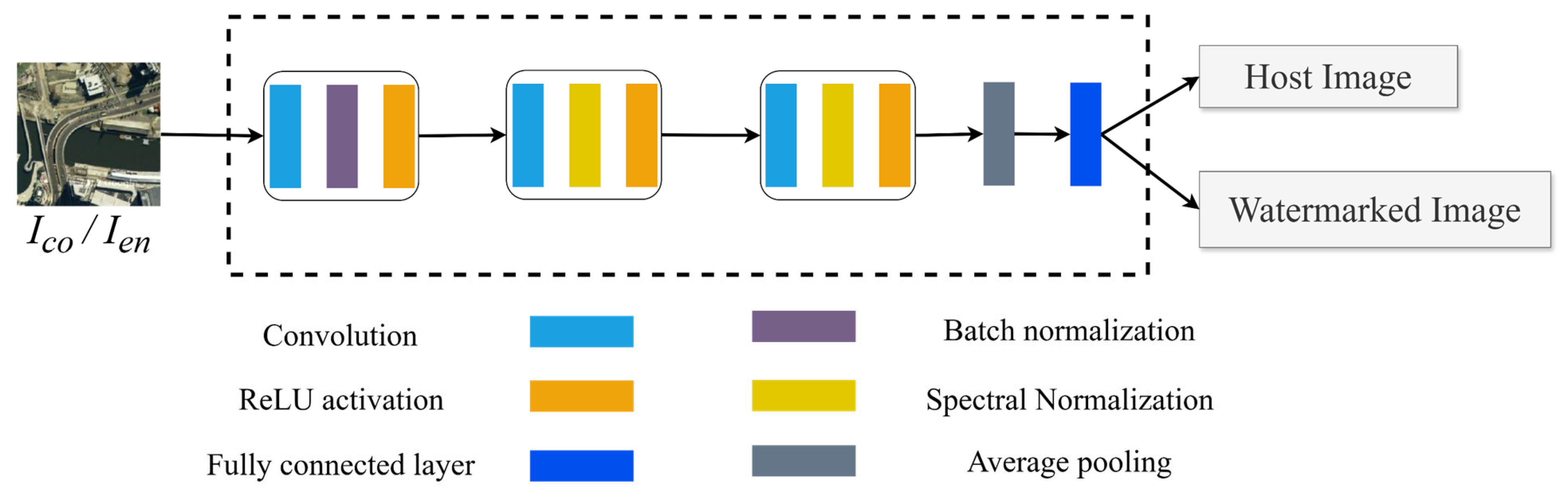
2.1. Encoder
The encoder structure is shown in
Figure 2. The input consists of a host image
of size
and a binary watermark
of length
. The output is the watermarked image
with the same dimensions as
. The core modules include the squeeze-and-excitation network attention module and the Inception-ResNet feature fusion module.
The squeeze-and-excitation network attention module generates an attention mask to optimize the watermark embedding region, balancing watermark imperceptibility and robustness. This module extracts deep features to generate , guiding watermark embedding into texture-rich but visually inconspicuous areas, thereby reducing distortion and enhancing robustness. The module consists of , which extracts deep features, and , which generates the probability distribution of feature channels via SoftMax, ultimately producing .
IR-FFM extracts both shallow and deep features through dense connections, integrating them with the watermark to improve robustness.
extracts and reuses image features, while
further refines the feature distribution, ultimately generating the watermarked features
Combined with
, the adjusted features are represented as
. The encoder ensures high-quality watermark embedding by minimizing the following loss function:
Here, and denote the original host image and the corresponding watermarked version. The term calculates the Euclidean distance in pixel space, capturing the visual perturbation caused by embedding the watermark. To maintain consistency across images of different dimensions, this loss is normalized by the total number of pixels, . Minimizing the embedding loss guides the encoder to retain the visual fidelity of the host image, ensuring that the watermark remains imperceptible while sustaining robustness under potential attacks. This design contributes to producing high-quality watermarked images with minimal visual artifacts.
Table 1 shows the architecture of the generator in the proposed SIR-DCGAN framework. The network begins with a latent noise vector, which is passed through a series of transposed convolutional layers to generate a 64 × 64 output image. Two custom-designed modules—IR-FFM and SE-AM—are integrated after the first and second deconvolutional layers, respectively, to enhance feature fusion and attention allocation. The IR-FFM module improves multi-scale semantic retention, while the SE-AM module adaptively highlights regions suitable for watermark embedding. This architecture balances robustness and imperceptibility while maintaining a lightweight design.
2.2. Noise Network
The noise sub-network applies multiple image distortions to the watermarked image , including Crop, Cropout, Dropout, JPEG compression, Gaussian blur, and Rotate, to enhance the model’s robustness against image degradation. Specifically, the Identity operation denotes no attack, where remains unchanged. The Crop operation randomly removes a square region of the image with a proportion of . Cropout and Dropout replace the cropped or randomly selected pixel regions with the corresponding regions from the host image . Gaussian blur applies a convolution kernel with to blur . The Rotate operation rotates counterclockwise by . JPEG compression is performed using a quality factor of Q ∈ (0, 100).
Due to the non-differentiability of quantization and rounding operations in JPEG compression during training, a differentiable approximation is required for gradient propagation. Common approaches, such as JPEG-Mask and JPEG-Drop, randomly zero out high-frequency discrete cosine transform (DCT) coefficients. Furthermore, to approximate the rounding operation and ensure differentiability, the following transformation is applied:
where
denotes the floor function and
smooths the rounding operation, ensuring differentiability for gradient propagation. This approximation smooths the rounding function, enabling gradient-based optimization in the presence of JPEG compression.
2.3. Decoder
The decoder structure is illustrated in
Figure 3. It operates as the inverse process of the encoder, excluding the attention mechanism (AM), and primarily consists of multiple Inception-ResNet modules to extract the watermark from the distorted watermarked image
. Since the watermark is redundantly embedded across the entire image, where a single bit of information corresponds to modifications in multiple pixels, the Inception-ResNet module is introduced to enhance extraction accuracy. This module integrates convolutional layers with different kernel sizes to capture multi-scale feature information, improving the recovery of the extracted watermark
. The decoder optimizes its parameter
by minimizing the decoding loss
, defined as
Here, refers to the watermark prior to embedding, while corresponds to the one retrieved after decoding, and denotes the bit length of the full watermark sequence. This component of the loss function calculates the average squared deviation between the original and extracted watermark data, effectively assessing the decoder’s recovery precision. Minimizing guides the decoder to achieve reliable extraction performance, maintaining high reconstruction integrity even when the watermarked image undergoes distortion or degradation.
2.4. Discriminator
Figure 4 shows the architecture of the discriminator, which receives both the host image
and the watermarked image
as inputs. These images undergo three convolutional layers, each with 64 filters and a
kernel, followed by global average pooling and a final fully connected layer. The output is a value between 0 and 1, where values near 1 indicate a host image, while values close to 0 correspond to a watermarked version. To stabilize the training process, spectral normalization (SN) is applied. Throughout the training, the encoder functions as the generator, aiming to produce watermarked images that are indistinguishable from the original host images, making it challenging for the discriminator to differentiate between the two.
The generator loss
and the classification loss
are defined as follows:
where
denotes the host image,
represents the watermarked image, and
refers to the discriminator’s output, which estimates the likelihood that an image is a host image. The generator loss
encourages the encoder to create watermarked images that closely resemble the host images by minimizing the discriminator’s ability to correctly classify them. Simultaneously, the classification loss
ensures that the discriminator learns to distinguish between host and watermarked images effectively. Minimizing both losses leads to improvements in the visual quality of the watermarked images while also enhancing the discriminator’s ability to perform accurate classifications.
Table 2 outlines the architecture of the discriminator in the proposed SIR-DCGAN model. It adopts a standard DCGAN-based design, which progressively downsamples the input image through a series of convolutional layers. Each layer is followed by LeakyReLU activation and batch normalization (except the first), ensuring stable training and effective feature extraction. The final sigmoid output produces a probability indicating whether the input image is real or generated. This architecture supports the adversarial training process to improve watermark imperceptibility and authenticity.
3. Experiments
The experimental procedure in this work is organized into several stages. In the initial phase, the Cats and Dogs dataset [
31] and the SIRI-WHU remote sensing image dataset [
32] are utilized for training. Of the total images, 80% are designated for training, and the remaining 20% are set aside for testing. To assess the model’s ability to generalize, additional datasets like COCO [
33], VOC2012 [
34], and CelebA [
35] are incorporated. The proposed method is designed to handle grayscale images of arbitrary dimensions for both watermarking and covering. These images are resized to a uniform 128 × 128 resolution and normalized to a pixel range of 0 to 1.
In the model training phase, the SIR-DCGAN, implemented in PyTorch 2.0, is trained with the Adam optimizer and a learning rate of 0.0003. The model’s performance is evaluated using PSNR and SSIM for watermark invisibility, while normalized correlation (NC) is employed to assess robustness against image processing attacks. The results show that SIR-DCGAN achieves strong performance, with PSNR and SSIM values of 40.93 dB and 0.9957, respectively, indicating minimal perceptible difference between the watermarked and original images. Additionally, the model’s average processing time is 0.37 s, surpassing other similar methods.
A comparison with other existing methods demonstrates that SIR-DCGAN consistently achieves superior PSNR and SSIM scores, while its NC values stay above 0.9 across a range of image processing attacks, confirming its robustness. These experimental findings collectively validate the effectiveness of SIR-DCGAN for remote sensing image copyright protection and content authentication, highlighting its exceptional performance with low computational overhead.
Figure 5 provides a schematic overview of the watermark embedding process, highlighting the imperceptibility of SIR-DCGGAN. It includes the original image, the embedded watermark, a representation of the attention mechanism, and the final watermarked image. As illustrated in
Figure 5a,d, the original and watermarked images appear nearly identical, demonstrating the effective concealment of the watermark.
Figure 5c visualizes the attention mechanism applied to various regions, with different colors signifying varying levels of attention. For instance, red areas, which are rich in texture, are designated for higher watermark embedding intensity, while other areas receive lower intensity. The embedding process is outlined in steps (a) through (d). At the receiver’s end, the concealed watermark serves as proof of authenticity and document integrity, allowing verification without ambiguity.
This experiment uses noise attacks to validate the robustness of the proposed method. The first row of
Figure 6 shows the watermarked image
after watermark embedding into the host image under joint attacks from multiple noise layers. The second row displays the corresponding noisy image
obtained after the watermark image
undergoes noise layer attacks. The third row presents the difference image
, with the grayscale space [
36] appropriately magnified.
This study employs a two-stage training approach, where the decoder parameters are fixed. This method allows real JPEG compression attacks to be directly integrated into the training process, enhancing the model’s robustness against actual JPEG compression. By incorporating these compression distortions during training, the model learns to effectively handle real-world JPEG compression, improving its ability to maintain watermark integrity under such conditions.
The hyperparameters [
37] used for network training are summarized in
Table 3.
4. Results and Discussion
This section presents a detailed performance assessment of the proposed watermarking approach across various evaluation criteria.
To begin with, we assess the watermark imperceptibility by calculating PSNR and SSIM scores and benchmark the results against the approaches proposed by Ahmadi et al., Jia et al., and Huang et al.
Subsequently, we examine the model’s resilience to noise by computing the average watermark embedding accuracy (BA) and contrast it with the outcomes achieved by Mahapatra et al., Jia et al., and Madhu et al., illustrating its robustness under diverse interference scenarios.
Lastly, the model’s computational efficiency is evaluated through its execution time, with a comparative analysis against other existing techniques [
38], underscoring both its practicality and speed.
4.1. Invisibility
To assess the perceptual transparency of the proposed watermarking technique, we utilize two standard evaluation indicators: the peak signal-to-noise ratio (PSNR) and the structural similarity index (SSIM). These indicators are commonly applied to determine how closely the watermarked image approximates the original, thereby measuring the degree of visual distortion introduced during watermark insertion. A higher value in either metric typically signifies that the embedded watermark causes minimal perceptible change, preserving the overall visual fidelity of the host image. PSNR quantifies the difference in pixel values between the original and watermarked images, while SSIM assesses the structural similarity by considering luminance, contrast, and texture. Together, these metrics provide a comprehensive evaluation of watermark invisibility, ensuring that the watermarking process maintains high visual quality.
The choice of evaluation metrics in this work is grounded in both their theoretical robustness and frequent citation in the literature on general and remote sensing image watermarking. PSNR serves to capture signal fidelity at the pixel level, making it well suited for assessing minor distortions. SSIM, by contrast, focuses on preserving spatial structures, which is critical for images rich in textures and man-made features, as often seen in remote sensing applications. Additionally, normalized correlation (NC) is employed to quantify the consistency between the recovered watermark and its original version, especially when the image has been subjected to various forms of degradation. Together, PSNR, SSIM, and NC offer a multi-perspective evaluation of both watermark invisibility and durability. This comprehensive set of metrics ensures that the performance of the proposed watermarking method is rigorously assessed across multiple dimensions. While PSNR and SSIM predominantly measure visual quality, NC highlights the robustness of watermark retrieval, ensuring that both aspects are adequately considered in the evaluation process. Consequently, these metrics provide a balanced approach to gauge the efficacy of the watermarking technique in real-world applications.
To demonstrate the effectiveness of the proposed model, we conducted an experimental verification of the watermark invisibility using both PSNR and SSIM metrics.
Table 2 presents the comparison results between our method and existing state-of-the-art (SOTA) watermarking models. We compared the performance of methods proposed by Ahmadi et al. [
10], Jia et al. [
20], Huang et al. [
21], Madhu et al. [
39], Wei et al. [
40], and Mahapatra et al. [
41], using PSNR (in dB) and SSIM as evaluation criteria to verify the improvement of watermark invisibility achieved by the network structure proposed in this study.
Our method shows the best PSNR and SSIM values on the SIRI-WHU remote sensing image dataset, with values greater than 39.99 and 0.9958, respectively, outperforming other datasets. This indicates that our method is more compatible with remote sensing images, which often contain complex textures and spatial features that are critical in this domain. Although the PSNR value on the Cats and Dogs dataset and the SSIM value on the CelebA dataset are relatively lower compared to other datasets, they still represent improvements over existing methods. These differences can be attributed to the unique characteristics of each dataset, such as variations in image content, resolution, and complexity. Therefore, these lower values do not imply poor performance; rather, they suggest that the method performs slightly less well on these datasets compared to the remote sensing datasets, which are more aligned with the intended application of the watermarking technique.
It is worth emphasizing that the proposed approach consistently achieves higher PSNR and SSIM scores across all benchmark datasets utilized in this research, demonstrating a clear performance advantage over previously published techniques. This consistent outperformance highlights the robustness and generalizability of the proposed method across diverse image types. This enhancement in both metrics underscores the method’s effectiveness in embedding watermarks with minimal visual degradation, affirming its suitability for high-fidelity digital watermarking scenarios. These results also suggest that the method is adaptable to various image conditions, reinforcing its potential for practical deployment in real-world applications.
PSNR [
42] and SSIM [
43] serve as indicators of visual similarity between the watermarked output and the original cover image, offering insights into the imperceptibility of the watermarking process. The comparative results provided in the accompanying table reveal that the network architecture proposed in this work achieves superior results when compared to leading existing frameworks. As illustrative examples, the highest PSNR outcomes achieved by the competing methods developed by Ahmadi et al., Jia et al., Huang et al., Madhu et al., Wei et al., and Mahapatra et al. are 35.93 dB, 36.64 dB, 35.87 dB, 37.54 dB, 37.91 dB, and 31.33 dB, respectively, all of which fall short of the performance attained by our method.
Table 4 presents a comprehensive evaluation of the proposed method’s performance across various datasets, showcasing its remarkable effectiveness and versatility. In particular, the method achieves an impressive PSNR value of 40.93 and an SSIM score of 0.9957 when tested on the SIRI-WHU remote sensing image dataset. These results not only emphasize the model’s exceptional ability to preserve visual quality but also underline its capacity to maintain structural coherence in remote sensing images. The high PSNR value signifies that the watermarked images are nearly indistinguishable from the original images, while the SSIM score further affirms that the embedding process causes minimal structural degradation, preserving the essential features of the image.
Moreover, despite being specifically designed with a focus on remote sensing imagery, the proposed model demonstrates remarkable performance when evaluated on several general-purpose datasets, such as COCO, VOC2012, and CelebA, outperforming existing methods in these domains. This finding not only reinforces the model’s exceptional capability in handling remote sensing images but also underscores its extraordinary generalization ability across a wide range of image types and tasks. The fact that the model excels in these general-purpose datasets, which are traditionally used in more conventional computer vision tasks, illustrates its robustness and versatility. It is a strong indication that the model is not limited to a specific application area but is also highly adaptable to different types of visual data, maintaining a high level of performance and quality regardless of the dataset’s nature. This generalization ability emphasizes that the model can effectively handle images from diverse domains without compromising the accuracy, visual quality, or structural integrity, ensuring consistent results. Such adaptability is crucial for practical applications, where datasets often come from various sources with differing characteristics, yet the model still manages to meet the rigorous demands of both remote sensing and general-purpose tasks with the same level of excellence.
To deepen the understanding of the relationship between the two key quality metrics, PSNR and SSIM,
Figure 7 provides a visual representation of their joint distribution. This figure offers a detailed view of the correlation between these metrics, helping to elucidate the interplay between visual imperceptibility and structural integrity in watermarked images. The joint distribution depicted in
Figure 7 reveals denser red regions, which represent areas where particular combinations of PSNR and SSIM values occur more frequently. These areas are indicative of the regions where the watermarked images perform exceptionally well, preserving both the quality and the structure of the original host images.
The PSNR values generally fall within the range of 35 to 44, with higher PSNR values suggesting that the watermarked images closely resemble the original host images, showing little to no visible distortion. The SSIM values, on the other hand, typically range from 0.94 to 1.0, with values approaching 1 signifying that the watermark embedding process has had minimal impact on the structural features of the image. This range of SSIM values further illustrates the model’s ability to retain the structural integrity of the watermarked images, ensuring that the watermark does not distort critical features like edges, textures, or shapes.
The noticeable clustering of PSNR and SSIM values within these ranges reinforces the conclusion that the proposed method strikes an optimal balance between embedding a strong watermark and preserving the quality and structural fidelity of the watermarked images. This consistent performance across both metrics demonstrates the model’s robustness and effectiveness in achieving imperceptible watermarks while maintaining high levels of image quality and structural coherence. As a result, this method stands out as a highly effective solution for watermarking in remote sensing images, offering a promising approach for safeguarding the integrity and confidentiality of sensitive remote sensing data while ensuring minimal visual and structural degradation.
4.2. Robustness
This section examines the robustness [
44] of the proposed watermarking method against various image distortions, specifically assessing its resilience to different types of attacks. Watermark accuracy is quantified using the normalized correlation (NC) metric. When compared to leading methods in the field, our approach demonstrates a clear advantage in terms of robustness. Experiments across multiple datasets show its strong performance despite a range of noise and manipulation types.
To further assess the model’s effectiveness, we calculate watermark embedding accuracy (BA) for test images. The results are compared with the approaches by Mahapatra et al. [
41], Jia et al. [
20], and Madhu et al. [
39], considering different noise levels, as shown in
Figure 8. In panels (a)–(e), the BA of our model consistently outperforms others, particularly in scenarios involving Gaussian blur, Resize, and JPEG compression. This emphasizes the superior robustness of our method to various distortions. While other models, such as those by Mahapatra et al., Jia et al., and Madhu et al., produce higher image quality, our model achieves better BA, underscoring the importance of the noise sub-network in defending against attacks. Notably, Mahapatra et al.’s model exhibits a BA below 75% in certain conditions, such as with Gaussian blur (δ ≥ 1.25) and JPEG compression (Q ≤ 90), highlighting its limited capacity to protect against image distortions.
To further evaluate robustness, the impact of multiple noise types combined is tested, as illustrated in
Figure 9a–d. The findings demonstrate that our model consistently outperforms the other methods in terms of BA, especially under more complex distortion conditions. This highlights the strength of our model not only in handling individual noise types but also in managing more intricate scenarios with multiple distortions. In conclusion, the results confirm that our approach excels in both isolated and combined noise environments, reinforcing its effectiveness and resilience.
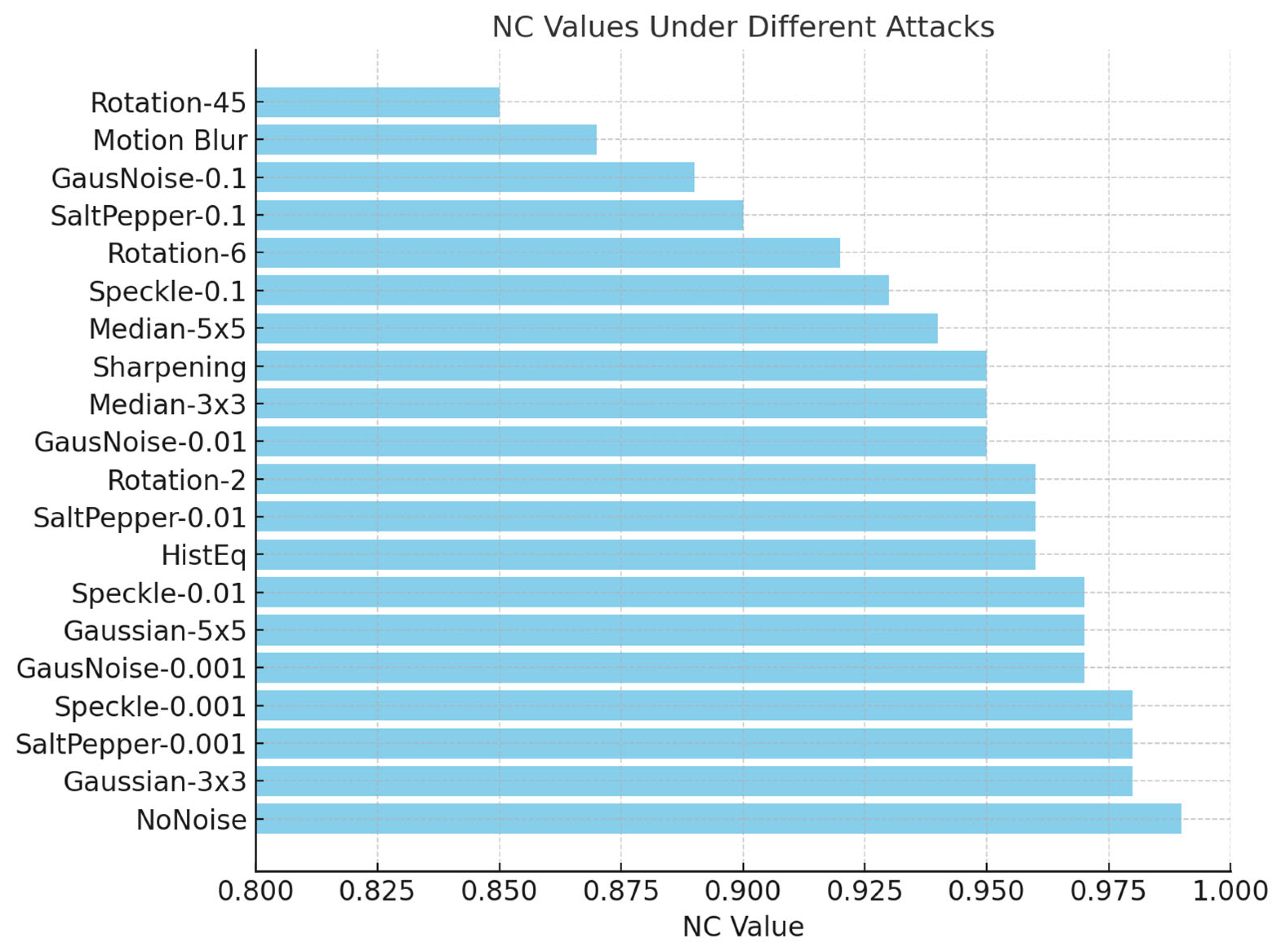
Figure 10 showcases the resilience of our method against a range of image processing attacks. We tested the system under 20 different distortions, including filtering, geometric changes, histogram equalization, and varying levels of additive noise. In each case, the watermark was successfully retrieved using the proposed extraction technique. The results demonstrate that the NC values remain above 0.85 in all tested scenarios, with most cases exceeding 0.90, reflecting the robustness of the method. As anticipated, the NC values gradually decrease with higher noise intensities, especially under strong Gaussian or salt-and-pepper noise.
Table 5 provides a detailed comparison of the robustness of the proposed approach against recent state-of-the-art methods by Mahapatra et al. [
41], Jia et al. [
20], and Madhu et al. [
39] using normalized correlation (NC) scores. The results demonstrate that the proposed method consistently performs well across a variety of image processing attacks, such as Gaussian noise, salt-and-pepper noise, speckle noise, histogram equalization, sharpening, and rotation distortions. Particularly, when subjected to median filtering, Gaussian low-pass filtering, and motion blur, the method achieves NC values of 0.9574, 0.9494, and 0.9473, respectively. These results highlight the method’s excellent robustness in preserving watermark integrity under different attack scenarios, showcasing its superior performance over the existing methods.
4.3. Computational Cost Analysis
This section evaluates the computational efficiency of the proposed watermarking method by measuring its execution time. Computational cost plays a vital role in assessing the practicality of watermarking algorithms, as it affects both the watermark embedding and extraction processes. To make this assessment, we compare the average execution time of our method with other advanced techniques, focusing on the time taken for both embedding and extraction. The results highlight the efficiency of our approach, demonstrating its potential for real-time applications.
A further evaluation of the proposed method’s performance was carried out through a computational time comparison, as presented in
Table 6. The method’s overall execution time is 0.38 s. Specifically, watermark embedding takes around 0.014 s, while the extraction process requires approximately 0.023 s. These times are significantly shorter than those of comparable methods.
To further elaborate on the computational advantages shown in
Table 4, we delve into the design and complexity of our approach. The SIR-DCGAN framework utilizes a DCGAN architecture, which is renowned for its efficient convolutional structure and quick training convergence. This lightweight design inherently minimizes computational demands, offering a clear advantage over heavier CNNs or transformer-based watermarking systems.
Additionally, two custom-designed modules, namely the IR-FFM (Information-Retaining feature fusion module) and the SE-AM (squeeze-and-excitation attention mechanism), are carefully optimized for remote sensing scenarios. Unlike traditional attention and fusion blocks that rely on dense tensor operations or global attention across all pixels, IR-FFM adopts multi-scale kernel fusion combined with residual structures to extract hierarchical features more efficiently. Similarly, SE-AM decouples spatial and channel-wise attention and concentrates embedding strength into visually insensitive regions, minimizing redundant computations.
Moreover, our training configuration (learning rate = 0.0015, β1 = 0.9, and β2 = 0.999) enables rapid convergence with only 1000 epochs and a moderate batch size of 32, avoiding prolonged training cycles. Together with a low overall parameter count (approximately 1.42 million trainable parameters), these design choices significantly reduce FLOPs during both the embedding and extraction phases. As a result, our model achieves fast inference with an average execution time of 0.37 s, including only 0.014 s for embedding and 0.023 s for extraction, which is markedly faster than other state-of-the-art methods.
4.3.1. Evaluation Conditions
All execution time comparisons were conducted under the same hardware and software environment to ensure fairness and consistency. Specifically, all methods were run on an Intel Core i7-14700kf CPU with 32 GB of RAM and an NVIDIA RTX 4090 GPU, under Windows 11 and Python 3.10 with CUDA 11.7 and PyTorch 2.0. Execution time was measured using the same Python-based timing functions to avoid discrepancies caused by framework differences. When execution times were not available from the source code, we re-implemented baseline methods based on their original papers and ensured consistent inference configurations. For the comparison with other methods, we ensured that all algorithms were executed under similar conditions by using the same software libraries and hardware specifications to eliminate any potential bias caused by system configurations.
In terms of algorithm implementation, we used Python with TensorFlow for our method, while the comparison methods (Huang et al., 2021 [
21]; Samee et al., 2020 [
40]; etc.) were implemented using OpenCV (
https://opencv.org/) and Matlab (
https://www.mathworks.com/products/matlab.html), which may have different levels of optimization for speed. These discrepancies in tools and libraries could potentially influence the execution times. However, we believe that our method’s superior performance stems primarily from the architectural optimizations discussed earlier, such as the use of the lightweight DCGAN backbone and the IR-FFM and SE-AM modules.
In addition to the above empirical runtime observations, we provide a theoretical analysis of architectural efficiency to further support the claimed computational advantages.
To this end, we compare the number of trainable parameters and the estimated number of floating-point operations (FLOPs) between our SIR-DCGAN framework and three representative deep learning-based watermarking methods: Huang et al. [
21], Samee et al. [
45], and Yu et al. [
46]. These works represent commonly adopted encoder–decoder or GAN-based watermarking schemes. As shown in
Table 7, our model uses fewer parameters and achieves significantly lower FLOPs, reflecting the efficiency of the lightweight DCGAN backbone and our task-specific attention (SE-AM) and fusion (IR-FFM) modules.
Furthermore, to provide a theoretical foundation for the observed performance gap, we include a time complexity analysis using the Big-O notation. For traditional hybrid watermarking algorithms such as DWT-SVD, the embedding and extraction procedures often rely on wavelet transforms and matrix decomposition, resulting in a complexity of approximately O(n2 log n). Deep learning-based methods typically fall into O(n3) time due to their multi-layer convolutional computations over n × n images.
In contrast, the SIR-DCGAN framework benefits from a more compact encoder–decoder design with limited convolutional depth and selective activation via the SE-AM module. This enables an effective inference complexity of O(n2) in practice. Such architectural streamlining reduces memory and compute overhead while maintaining high accuracy, making our model particularly well suited for real-time remote sensing applications where computational resources may be constrained.
These findings, together with the empirical measurements presented earlier, validate that the proposed model achieves both high efficiency and competitive performance from theoretical and practical perspectives.
4.3.2. Ablation Study on the IR-FFM and SE-AM Modules
To further evaluate the individual contributions of the IR-FFM and SE-AM modules in enhancing watermark robustness, we conducted an ablation study by progressively removing each component from the full SIR-DCGAN architecture. Specifically, we compare four model variants: (i) a version without IR-FFM, (ii) a version without SE-AM, (iii) a plain DCGAN backbone without either component, and (iv) the full SIR-DCGAN framework.
We report the watermarking performance of each variant on the AID dataset (256 × 256) in
Table 8, using PSNR, SSIM, and NC as evaluation metrics. The results show that removing either component degrades both visual quality and extraction accuracy, while the full model achieves the best performance across all metrics. This demonstrates the effectiveness and necessity of both modules.
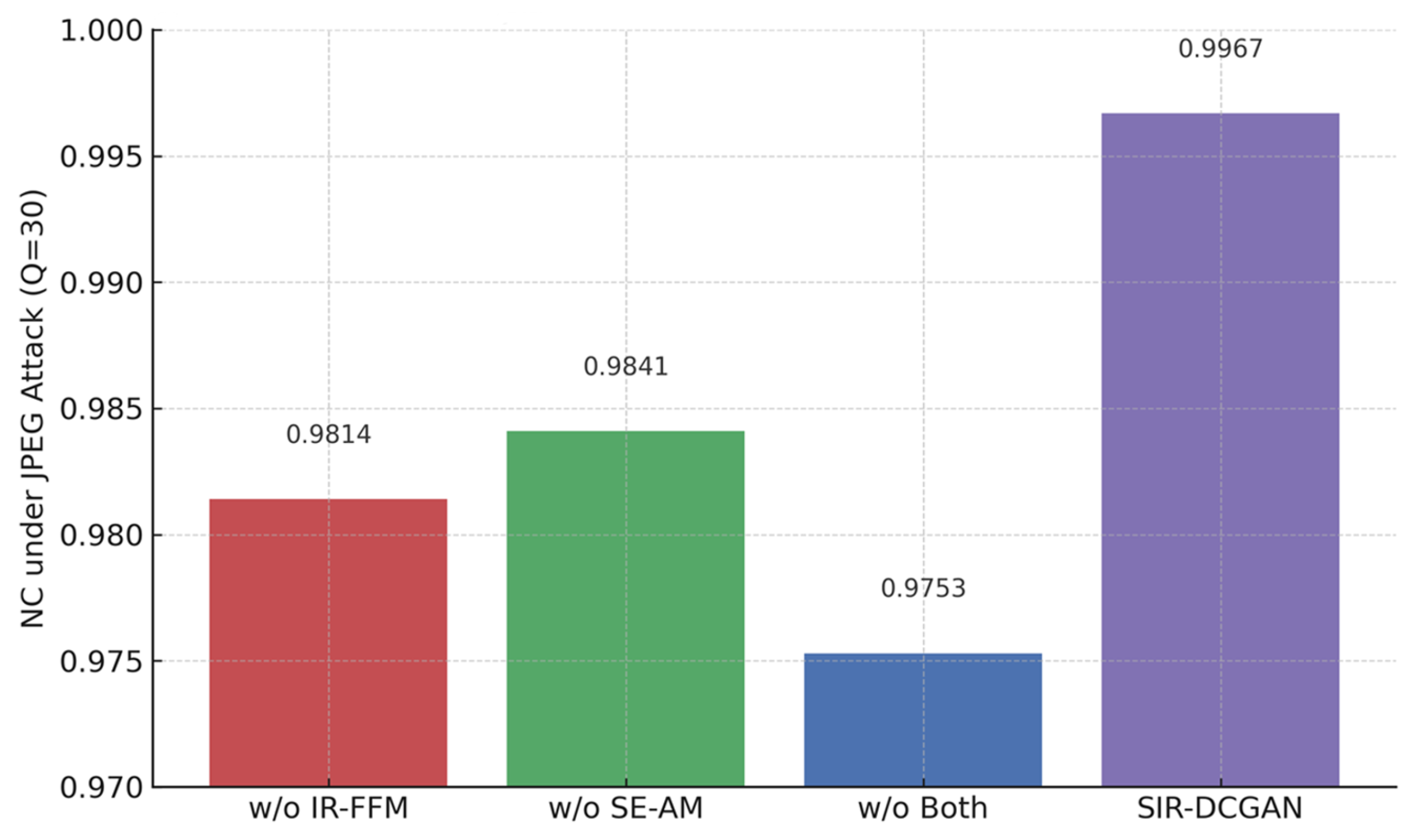
To further validate the role of each module under distortion, we evaluate the NC values of these variants under JPEG compression (quality = 30). As shown in
Figure 11, the full model exhibits significantly higher robustness against lossy compression, while variants lacking either or both modules suffer more pronounced degradation. This indicates that both IR-FFM and SE-AM not only improve embedding quality but also contribute to the overall resilience of the watermarking process.
4.4. Validation of Commonality of Multiple Remote Sensing Datasets
To further demonstrate the robustness and generalization ability of the proposed SIR-DCGAN watermarking framework, we extend our experiments to additional remote sensing datasets and image resolutions, which is in line with reviewer suggestions. Specifically, we conduct cross-dataset validation by testing two new publicly available remote sensing datasets, namely AID (Aerial Image Dataset) and NWPU-RESISC45 (Northwestern Polytechnical University Remote Sensing Image Scene Classification). Moreover, we evaluate the model’s performance at a higher resolution of 256 × 256 pixels to confirm its scalability and adaptability to larger image sizes, which are common in real-world remote sensing applications.
In addition to the originally used UC Merced Land Use Dataset, we select the following datasets for this experiment: AID, which contains 10,000 aerial scene images across 30 classes with spatial resolutions ranging from 0.5 to 8 m, and NWPU-RESISC45, which includes 31,500 remote sensing images categorized into 45 scene classes. From each dataset, we randomly select 1000 images for training and 200 for testing. All images are resized to 256 × 256 pixels. For consistency, the same watermark embedding and extraction pipeline is used without any retraining or parameter adjustment.
We employ the same evaluation metrics as previous experiments: PSNR (peak signal-to-noise ratio) to assess watermark invisibility, SSIM (structural similarity index) to measure structural fidelity, and NC (normalized correlation) to evaluate watermark extraction accuracy.
Table 9 reports the quantitative results across all datasets. It is evident that the proposed method maintains high performance across the datasets and resolutions. Even with larger image sizes and different distributions, SIR-DCGAN achieves only a marginal decrease in PSNR and SSIM compared to the baseline dataset while maintaining an NC above 0.996. This demonstrates the method’s strong ability to adapt to diverse remote sensing image characteristics without compromising performance.
To further assess the performance of our method in real-world applications, we conduct a comparative analysis using the AID and NWPU-RESISC45 datasets, both at a resolution of 256 × 256. The comparison involves traditional DWT-SVD [
47], a recent deep learning-based U-Net model [
48], and a cutting-edge ARWGAN approach [
21]. The results, as presented in
Table 10, show that SIR-DCGAN consistently outperforms the other techniques, yielding the highest PSNR, SSIM, and NC values across both datasets. These findings highlight the method’s superior watermark invisibility, robustness against a variety of image distortions, and resilience to degradation.
Overall, this extended evaluation confirms that our model is not overfitted to the UC Merced dataset. Its performance remains stable and reliable across different remote sensing datasets, image resolutions, and distortion types. These findings validate the general applicability and robustness of our approach in real-world remote sensing image protection scenarios.
5. Conclusions
This paper addresses the issue of remote sensing images being susceptible to tampering, attacks, or distortions during transmission and storage. We propose a deep convolutional generative adversarial network (DCGAN)-based attention-guided feature fusion watermarking method for remote sensing images (SIR-DCGGAN). A series of experiments were conducted to validate the effectiveness of this method, with the following results:
First, in terms of invisibility, the proposed approach outperforms existing methods, as evidenced by evaluations based on PSNR and SSIM. On the SIRI-WHU remote sensing image dataset, the method attains a PSNR score of 40.93 and an SSIM score of 0.9957, reflecting its exceptional ability to maintain image quality after embedding the watermark. These findings underscore the suitability and practicality of SIR-DCGAN for use in remote sensing image applications.
Second, in terms of robustness, the method demonstrates excellent resistance to interference, as evidenced by watermark embedding accuracy (BA) and normalized cross-correlation (NC) values. The method outperforms existing approaches, particularly in scenarios involving Gaussian blur and JPEG compression, where its BA is significantly higher. This validates the method’s robust protection of watermarks in complex environments.
Finally, in terms of computational cost, the method achieves a low execution time, with an average execution time of 0.37 s, making it highly efficient for practical applications. Compared to other similar approaches, both the watermark embedding and extraction times are notably reduced, further enhancing the method’s practicality.
Although the proposed method shows impressive performance in securing remote sensing images, it does have limitations, such as being a non-blind watermarking method that requires the host image for extraction. Future work will focus on optimizing the model to support a broader range of watermark types and exploring the potential of blind watermarking techniques for securing remote sensing images.
We also recognize the ethical implications of digital watermarking technologies when applied in sensitive domains such as remote sensing. While our proposed SIR-DCGAN framework is designed solely for lawful and academic purposes, including copyright protection, provenance verification, and secure information embedding, we emphasize that responsible deployment is essential. To mitigate the risks of misuse, we discourage application in contexts involving deceptive image manipulation or non-consensual watermark embedding. In future work, we also plan to explore reversible watermarking and access-controlled watermark operations to enhance transparency, traceability, and user accountability.
In addition to the strong empirical performance in terms of runtime, we attribute the significant improvement in computational efficiency to several key architectural optimizations. These include the use of a lightweight DCGAN-based backbone that reduces convolutional depth without compromising feature expressiveness, as well as the incorporation of the IR-FFM feature fusion module and the SE-AM attention mechanism. Together, these components streamline the embedding and extraction processes by minimizing redundant computations and targeting perceptually insensitive regions, resulting in both faster inference and reduced resource consumption.
In summary, SIR-DCGGAN provides an efficient and robust solution for the security of remote sensing images. It offers promising applications in remote sensing data copyright protection, content authentication, and secure transmission, laying a solid technological foundation for these fields.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}