1. Introduction
Commercial scientific eye-tracking systems have traditionally relied on near-infrared (NIR) imaging [
1], which offers clear advantages such as high contrast between the pupil and iris under a wide range of lighting conditions. However, NIR-based systems require specialized hardware, limiting their accessibility and application in naturalistic environments where visible-light imaging is more practical and less costly. Thus, the availability of visible-light-based eye-tracking systems, leveraging standard cameras, would provide a breakthrough alternative, particularly when considering the potential large-scale use in consumer devices, such as smartphones, laptops, and augmented reality glasses. Yet, visible-light images taken in unconstrained, natural environments pose unique challenges, including variable lighting conditions, diverse eye colors, and poor contrast between the iris and pupil, particularly in individuals with dark irises or under suboptimal lighting. Hence, segmentation solutions based on classical machine learning algorithms [
2,
3] and even more modern deep learning models have so far yielded suboptimal results under these challenging conditions [
4]. Traditional machine learning approaches have relied on handcrafted features like edge information, intensity histograms, and shape descriptors. While these methods can be effective in controlled environments, they often fail to generalize across different lighting conditions and diverse eye appearances due to their reliance on predefined features [
5].
With the advancement of deep learning, convolutional neural networks (CNNs) have been increasingly employed for pupil and iris segmentation [
6]. Early deep-learning models, such as fully convolutional networks (FCNs) and U-Net architectures [
7,
8,
9], demonstrated improvements in segmentation accuracy by learning spatial hierarchies of features directly from raw image data. More recent developments have explored self-supervised learning transformer-based models to further enhance segmentation robustness. Despite these advancements, deep-learning-based solutions still struggle with visible-light conditions; thus, reliable segmentation across diverse real-world conditions remains an open challenge.
Remarkably, a review of the current literature indicates that no reported baseline with well-tracked accuracy metrics exists for RGB pupil segmentation, making it difficult to evaluate and compare new approaches in this domain.
The Segment Anything Model (SAM), recently introduced by Meta [
10], represents a significant advancement in the field of image segmentation. Unlike traditional models trained for specific segmentation tasks, SAM is a general-purpose segmentation model capable of adapting to a wide range of tasks through prompt-based interactions. Notably, recent studies have demonstrated SAM’s effectiveness in medical imaging applications—particularly for organ segmentation—where the ability to delineate complex anatomical boundaries with high precision is essential [
11,
12]. By leveraging a vast and diverse pre-training dataset (with > 1B samples), SAM demonstrates remarkable generalization capabilities, making it a promising candidate for addressing the challenges inherent to pupil segmentation from RGB image streams.
The main contributions of this work are as follows:
Suggesting a first baseline for RGB pupil segmentation, providing a foundation for future research in this domain.
Introducing a novel multi-stage adaptation of SAM, specifically tailored for pupil segmentation.
Providing comprehensive evaluation across three standard visible-light datasets.
Demonstrating practical viability for real-world applications without specialized hardware, such as NIR sensors.
We propose a multi-staged adaptation of SAM for precise pupil and iris segmentation in visible-light conditions. Our approach leverages three specialized components: SAM-BaseIris for initial iris detection without prompts, SAM-RefinedIris for improved iris segmentation using bounding box prompts, and SAM-RefinedPupil for precise pupil segmentation. By tailoring SAM’s capabilities through this hierarchical fine-tuning strategy, we establish the first baseline for RGB pupil segmentation while maintaining robust performance across diverse real-world conditions. We validate our approach through comprehensive quantitative and qualitative evaluations on three challenging visible-light datasets (UBIRIS.v2, ISocial DB, and MICHE-I), demonstrating its potential for next-generation eye-tracking technologies in naturalistic and low-cost settings where specialized hardware is not accessible. Our results show that adapting foundation models like SAM can effectively address the unique challenges of visible-light pupil segmentation while providing a strong baseline for future research in this domain.
The remainder of this paper is organized as follows:
Section 2 reviews related work in iris and pupil segmentation;
Section 3 details our methodology, including dataset preparation and the multi-stage SAM adaptation;
Section 4 presents experimental results and comparisons with existing approaches; and
Section 5 discusses implications and concludes with future research directions.
2. Related Work
Eye-tracking plays a vital role in diverse fields, including human–computer interaction, healthcare, and behavioral research [
13]. In behavioral studies, eye-tracking is instrumental in understanding cognitive load, attention disorders like ADHD, and social behavior, offering insights into gaze patterns and visual attention [
14]. In human–computer interaction, accurate eye-tracking enhances the development of gaze-based interfaces and augmented reality applications, improving user experience and accessibility [
15]. In the medical context, precise segmentation is vital for diagnosing ocular conditions such as glaucoma, keratoconus, and diabetic retinopathy [
16,
17]. These applications benefit from the enhanced data extraction capabilities provided by reliable iris and pupil segmentation, facilitating decision-making in dynamic, real-world environments.
2.1. Challenges in Visible-Light Imaging for Eye Segmentation
Visible-light imaging has emerged as a practical, cost-effective alternative for mobile eye-tracking applications [
18]. Unlike near-infrared (NIR) imaging, which offers high contrast across different eye colors and lighting conditions [
1], visible-light imaging struggles with consistent feature capture, particularly in individuals with darker irises [
4]. Environmental factors such as reflections, occlusions from eyelashes or eyelids, and variable lighting conditions further complicate the segmentation process. These challenges hinder robust and accurate segmentation, as models designed for controlled environments often fail to generalize to the complexities of natural settings. Advanced, robust systems capable of generalizing across diverse scenarios are needed to address issues like irregular iris boundaries, reflections, and inconsistent lighting while maintaining computational efficiency for mobile deployment [
19,
20]. Without such advancements, the accuracy and reliability of real-world applications remains limited, underscoring the urgent need for continued innovation.
2.2. Classical Machine Learning Approaches to Iris and Pupil Segmentation
Traditional segmentation techniques have relied on handcrafted methods such as Daugman’s integro-differential operator [
21] and the Hough transform [
22] to identify the circular boundaries of the iris and pupil. These methods leverage the high contrast of NIR imaging to achieve accurate ocular feature detection. However, they struggle with occlusions, non-circular boundaries, and variations in pupil size, particularly in degraded datasets like CASIA-IrisV4-Interval [
23]. In visible-light imaging, lower contrast and variable lighting conditions pose additional challenges. Traditional methods, including active contour models and morphological operations, have been used to refine segmentation results but are highly sensitive to noise and environmental inconsistencies, limiting their applicability in real-world scenarios [
4,
24].
2.3. Advancements in Deep Learning for Iris and Pupil Segmentation
The advent of deep learning has significantly advanced iris and pupil segmentation, particularly in NIR imaging. Early models such as U-Net, DenseNet, and other convolutional neural network (CNN) architectures enabled hierarchical feature extraction and robust handling of occlusions and noise [
8]. These methods demonstrated high precision in NIR datasets like ND-Iris-0405 and CASIA, outperforming traditional techniques. The EnhanceDeepIris model, for instance, utilized deep convolutional networks to address challenges like radial deformation of the iris, enhancing recognition performance [
23].
In visible-light imaging, deep learning approaches have focused on overcoming reflections, inconsistent illumination, and occlusions. Models like Dense-U-Net and RefineNet incorporate dense connections and multi-scale processing to handle the inherent variability of visible-light environments. Studies using UBIRIS.v2 have shown that these models improve iris segmentation accuracy under challenging conditions. Additionally, innovations like the BAT-optimized CNN (BOC-IrisNet) utilize evolutionary algorithms to optimize feature extraction, enhancing segmentation performance while reducing computational complexity [
24].
While deep learning models excel in NIR imaging due to uniformity and high contrast, visible-light conditions require advanced data augmentation and anti-aliasing strategies to address environmental variability. Techniques such as heuristic filtering and low-pass filters mitigate reflections and inconsistent pupil boundaries, improving performance in real-world applications [
25].
2.4. The Segment Anything Model and Its Adaptations
Recent studies have explored the adaptation of the SAM [
10] for various purposes, including iris and pupil segmentation in NIR imaging. In general, it was shown that with careful handling of domain-specific knowledge, SAM can be tuned to reach state-of-the-art accuracy for various benchmark problems [
26,
27]. SAM’s zero-shot segmentation capabilities are particularly advantageous in applications requiring minimal annotation [
28]. For example, Iris-SAM demonstrated the effectiveness in segmenting iris structure in NIR images by fine-tuning SAM with domain-specific loss functions, such as Focal Loss, to address class imbalance in iris pixels [
29]. Utilizing datasets like ND-IRIS-0405 and CASIA-Iris-Interval, this approach achieved a segmentation accuracy of 99.58%, significantly outperforming traditional models [
30]. The integration of prior knowledge into bounding box prompts effectively focused SAM on the iris region, enhancing segmentation precision under controlled NIR conditions [
31].
Further investigation evaluated SAM’s zero-shot capabilities for iris and pupil segmentation in virtual reality setups using NIR illumination [
28]. While SAM performed well with bounding box and point prompts, fine-tuning was necessary to achieve consistent accuracy across different datasets. The use of OpenEDS datasets highlighted challenges in handling occlusion and lighting variance, even under NIR conditions, emphasizing the need for prompt refinement and tailored adaptation strategies [
32].
3. Methods
Given the unique challenges of pupil segmentation, including its smaller size (implying limited pixel coverage relative to the iris), low iris-to-pupil contrast and frequent occlusions—our methodology focused specifically on evaluating models for this task. Robustness of our approach was validated by segmentation quality on the iris, which presents a comparatively simpler problem. To provide a comprehensive evaluation, our experiments begin with a baseline setup using the vanilla SAM with prompts. We then demonstrate how our proposed methodology enhances SAM’s performance first for iris and then for pupil segmentation through tailored training strategies, loss functions, and evaluation metrics, as detailed in the subsections below. By addressing the complexities inherent to pupil segmentation, our approach highlights the adaptability and robustness of SAM when fine-tuned for this challenging segmentation task.
3.1. Datasets and Preprocessing
This research utilized several publicly available datasets that are widely recognized in the domains of computer vision and biometrics for their relevance to visible-light iris and pupil segmentation tasks. Each dataset presents unique challenges, including variations in imaging conditions, annotation quality, and real-world artifacts, providing a comprehensive basis for experimentation. A particular challenge in these datasets is the varying quality and methodology of pupil ground truth annotations, which directly impacts the evaluation of pupil segmentation algorithms.
The UBIRIS v2 dataset [
33] comprises over 10,000 color images captured under visible-light conditions at distances ranging from 4 to 8 m. This dataset includes diverse artifacts such as reflections, occlusions from eyelashes or eyeglasses, and motion blur. While the dataset provides ground truth annotations only for iris segmentation, these annotations are particularly valuable for pupil detection as they contain a single, well-defined inner region corresponding to the pupil location, without additional circular artifacts or reflections that could cause ambiguity. This characteristic allowed us to reliably derive pupil masks by isolating the inner circular region of the iris annotations, ensuring accurate pupil ground truth for our experiments. The ISocial DB (ISDB) dataset [
34] includes 3286 ocular images obtained from unconstrained environments. These images exhibit real-world variability, including diverse lighting conditions, reflections, sensor noise, and occlusions caused by hair or eyelashes. While the iris masks in this dataset contain reflection artifacts, the dataset provides precise pupil center coordinates and radius measurements. We leveraged this information to generate accurate circular pupil masks, ensuring reliable ground truth for our pupil segmentation experiments. The MICHE-I dataset [
35], acquired via mobile devices, consists of 481 visible-light images captured in natural, unconstrained scenarios. It emphasizes real-world conditions, with variations in resolution and occlusion. Similar to ISDB, despite the presence of reflections in iris annotations, the dataset uses pupil center and radius data as provided by [
36]. Using these parameters, we constructed precise pupil ground truth masks, enabling robust evaluation of our model’s performance in mobile-captured imagery.
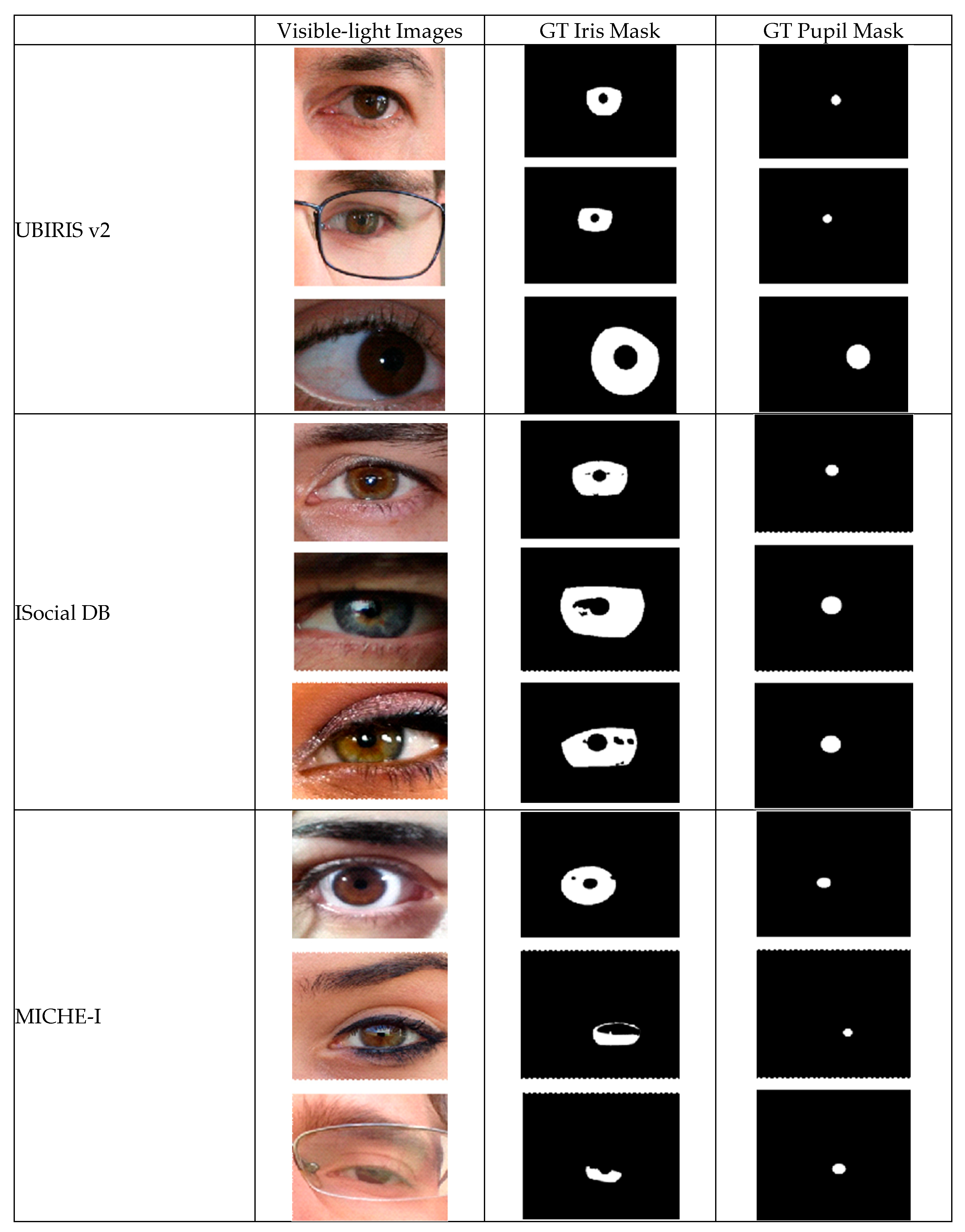
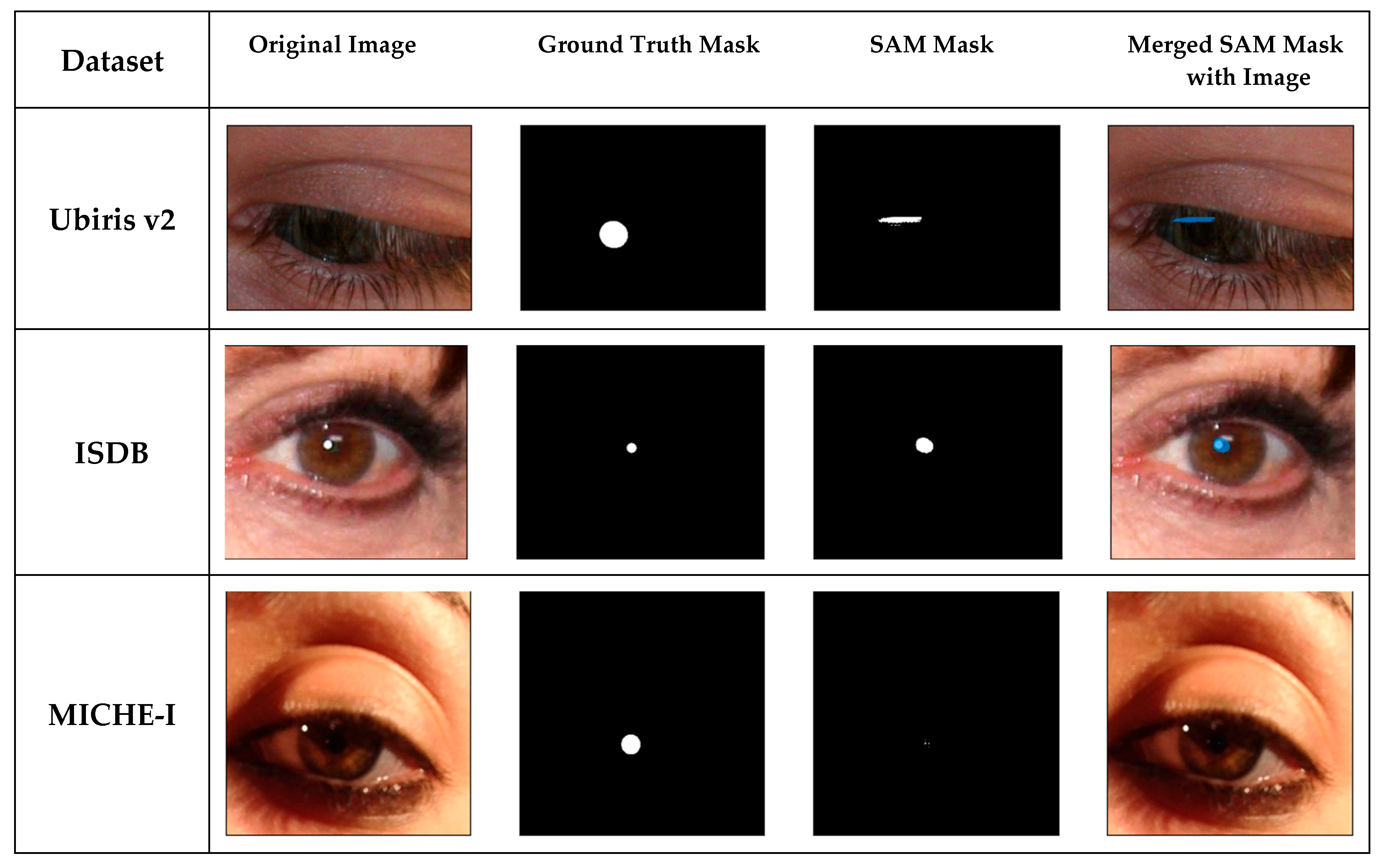
Figure 1 demonstrates representative samples from these datasets, along with their corresponding segmentation masks for iris and pupil regions. The examples highlight the diversity of imaging conditions and ground truth annotation approaches across the three datasets.
To ensure consistency and compatibility across datasets, a systematic preprocessing pipeline was applied. All datasets underwent data cleaning, in which corrupted or incomplete images were removed, and images were standardized to fixed size. Augmentation techniques included horizontal flips (50% probability), random rotations (−10° to +10°), brightness adjustments (0.5 to 1.5), and contrast modifications (0.5 to 1.0). These transformations increased the diversity of training data but were omitted from test sets to avoid information leakage.
3.2. Segmentation with Prompts
We first explored SAM’s baseline capabilities without any fine-tuning. This evaluation focused on understanding SAM’s inherent ability to segment iris and pupil regions through various prompt configurations. For both iris and pupil segmentation tasks, we developed a prompting protocol. This protocol defines the placement strategy for positive points within the region boundaries, negative points in potentially confusing areas (such as reflections or eyelashes), and bounding box construction rules based on approximate region dimensions. All prompts were generated following consistent guidelines to ensure the reproducibility of the approach.
3.3. Proposed Method for SAM Adaptation
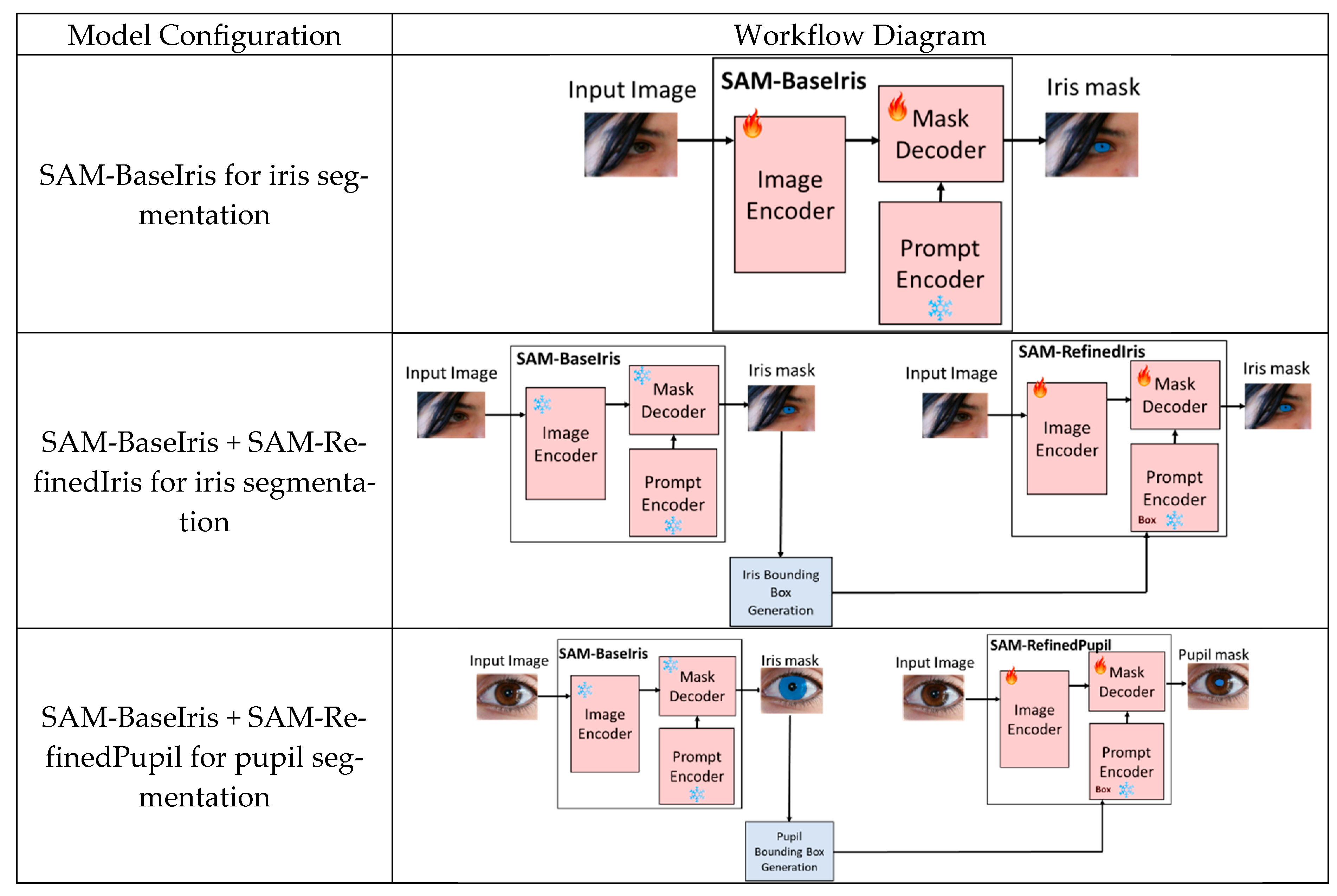
We adapted and evaluated SAM using a modular framework with progressive stages tailored for increasing levels of fine-tuning complexity. These stages involve training SAM-BaseIris for direct iris segmentation, combining SAM-BaseIris and SAM-RefinedIris for improved iris segmentation with guiding prompts, and integrating SAM-BaseIris and SAM-RefinedPupil for simultaneous iris and pupil segmentation.
Figure 2 illustrates these configurations, highlighting the interplay between pre-trained components (marked with a blue snowflake icon) and fine-tuned components (marked with a flame icon).
3.3.1. SAM-BaseIris: Direct Iris Segmentation Without Prompts
The first stage of the framework, SAM-BaseIris, is designed for direct iris segmentation without relying on prompts. The input image is processed by the image encoder, which extracts visual features, and the fine-tuned mask decoder produces the iris mask. The prompt encoder is not used in this configuration. By fine-tuning the image encoder and mask decoder, SAM-BaseIris is optimized to detect the iris despite the variability in visible-light images, which include reflections, inconsistent lighting, and occlusions.
3.3.2. Combining SAM-BaseIris and SAM-RefinedIris: Iris Segmentation with Bounding Box Prompts
In the second stage, SAM-BaseIris is combined with SAM-RefinedIris to enhance segmentation accuracy using bounding box prompts. SAM-BaseIris generates iris segmentation masks; from these masks, a bounding box is inferred after an outlier removal procedure and taking the minimum and maximum values of the width and height of the mask. The iris bounding boxes are then passed to SAM-RefinedIris as input prompts. SAM-RefinedIris refines the segmentation by leveraging both the input image and the bounding box prompts to produce a more accurate iris mask. The prompt encoder and mask decoder in SAM-RefinedIris are fine-tuned to handle the task-specific requirements of prompt-based segmentation. This two-stage combination marginally improved segmentation precision by isolating and refining the iris region.
3.3.3. Combining SAM-BaseIris and SAM-RefinedPupil: Extending to Pupil Segmentation
The final stage incorporates SAM-RefinedPupil to extend the framework for pupil segmentation. SAM-BaseIris, as before, is used to generate iris segmentation masks. From these iris masks, a bounding box is inferred for the pupil. First, outliers are removed from the iris mask, and then morphological operations are carried out, including differencing the mask with a complementary mask and dilation operations for an approximation of the pupil bounding box. These bounding boxes are passed to SAM-RefinedPupil as input prompts. The prompt encoder and mask decoder in SAM-RefinedPupil are fine-tuned specifically for the pupil segmentation task, enabling the framework to effectively segment both iris and pupil regions in a hierarchical manner.
This multi-stage adaptation leverages SAM’s foundational components while introducing task-specific refinements to address the challenges of visible-light segmentation. By progressing from direct segmentation (SAM-BaseIris) to segmentation with prompts (SAM-BaseIris + SAM-RefinedIris) and then to combined iris and pupil segmentation (SAM-BaseIris + SAM-RefinedPupil), the framework ensures robustness and precision in handling real-world variability. The modular design allows for progressive refinement, enabling each stage to focus on a specific task. To prevent information leakage, the datasets were randomly split into 3 main groups: (a) training data for SAM-BaseIris model, (b) training data for SAM-RefinedIris and SAM-RefinedPupil models, and (c) test data for all models, as detailed in
Table 1.
3.4. Loss Function and Evaluation Metrics
3.4.1. Loss Functions
The training process employed a combination of DICE loss and cross-entropy loss, optimizing segmentation performance by addressing the challenges of imbalanced data distributions inherent in iris and pupil segmentation tasks. DICE loss is particularly effective in scenarios with imbalanced datasets, as it maximizes overlap between predicted and ground truth segmentation masks:
where
pi and
gi are the predicted and ground truth values for the
i-th pixel, respectively. This formulation ensures that the model focuses on minimizing the discrepancy between predicted and ground truth regions
Cross-entropy loss complements this by penalizing incorrect predictions on a per-pixel basis, ensuring the model achieves fine-grained accuracy in segmenting intricate features like the iris and pupil. Cross-entropy loss is defined as follows:
where
N is the total number of pixels,
pi is the predicted probability for the
i-th pixel, and
gi is the corresponding ground truth label (0 or 1). The combination of these loss functions ensured robust model training, accommodating the variability in dataset complexity and imaging conditions.
3.4.2. Evaluation Metrics
The evaluation of the segmentation performance was guided by several metrics, each capturing different aspects of accuracy and robustness. Mean Intersection Over Union (mIOU) measures the overlap between predicted and ground truth masks, averaged across all test images. It is calculated as the ratio of the intersection to the union of the predicted and ground truth masks, providing an overall measure of segmentation accuracy across the dataset. This metric emphasizes the balance between correctly identified pixels and the total extent of predicted and ground truth regions, making it particularly effective for evaluating segmentation across large and diverse datasets. Formally, mIOU is defined as follows:
where
N is the total number of test images and
Pi and the
Gi are the predicted and the ground truth segmentation mask for the
i-th image, respectively. Complementing mIOU, the DICE score provides another measure of overlap but places more emphasis on proportionality between the predicted and ground truth regions. Unlike mIOU, which penalizes predictions with large, mismatched areas more heavily, the DICE score is particularly sensitive to small structures and intricate regions, such as the pupil. This makes it well-suited for scenarios where precise localization is critical. The DICE score is defined as follows:
The Hausdorff Distance evaluates the boundary alignment between the predicted and ground truth masks. It measures the maximum distance from a point on the boundary of one mask to the nearest point on the boundary of the other:
where
d (p,g) is the Euclidean distance between a point p on the predicted mask P and a point g on the ground truth mask G. A lower Hausdorff Distance indicates better boundary alignment, making this metric particularly important for tasks where precise edge localization is critical.
4. Experiments and Results
Our experimental evaluation was conducted in two phases: first establishing an initial baseline through prompt engineering with the vanilla SAM, and then developing our fine-tuned models for iris and pupil segmentation. Both quantitative metrics and qualitative results demonstrate the effectiveness of our approach across different datasets and challenging real-world conditions.
4.1. Prompt Engineering
In the initial phase, we established a baseline for iris and pupil segmentation using the unmodified SAM with various prompt configurations. The prompt parameters tested in this step included positive points, negative points, bounding boxes, and different combinations of these prompts. During this phase, only inference was conducted on the UBIRIS.v2 dataset without any alteration to the original model architecture and weights.
Prompt engineering was performed using SAM’s ViT-Huge variant, which comprises 640 million parameters. This variant was selected for its robust performance in segmentation tasks and its ability to facilitate inference without additional training. This approach enabled rapid experimentation with different prompt schemes while maintaining minimal computational overhead, making it suitable for efficient exploration of SAM’s segmentation capabilities.
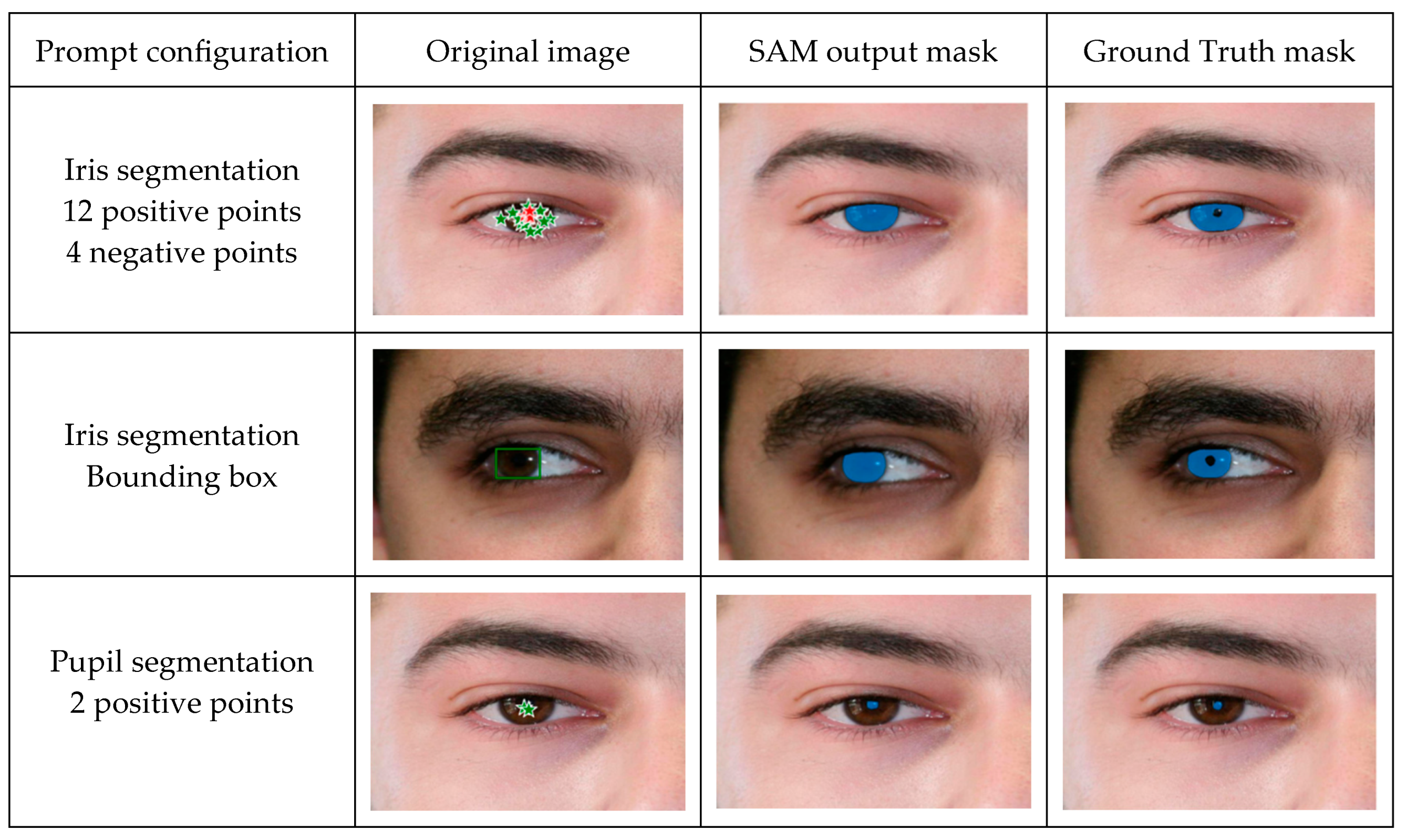
The use of positive and negative prompts, as well as bounding box markings are illustrated in
Figure 3, along with the resulting segmentation and ground truth masks, for three different prompt configurations.
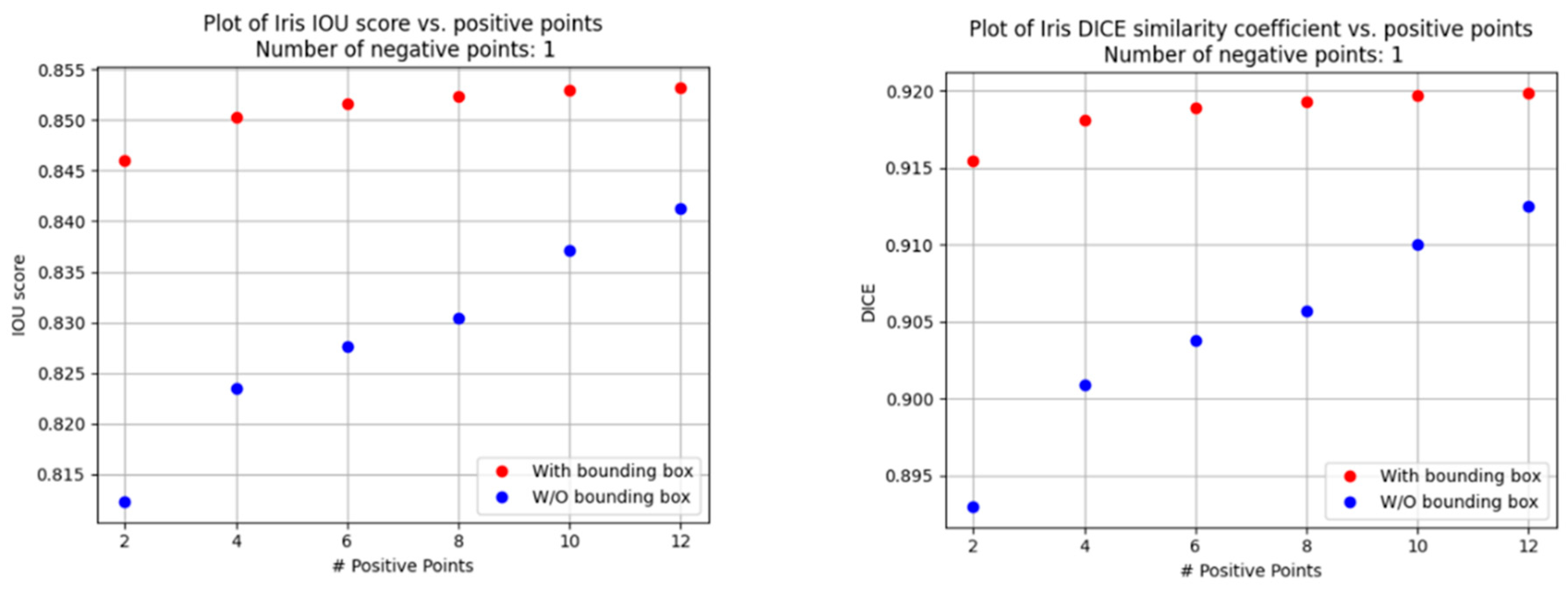
In our experiments, we varied the number of negative points in the prompt from one to four per configuration, with the best performance achieved using a single negative point.
Table 2 summarizes the tested combinations of positive points and bounding boxes.
The results from this phase highlight the impact of different prompt strategies on segmentation accuracy, providing valuable insights for subsequent fine-tuning efforts. The analysis of the abovementioned prompt configurations reveals several key trends, as shown in
Figure 4 and
Figure 5:
Increasing the number of positive points improved the segmentation metrics, with performance gains plateauing after twelve points.
Bounding box prompts provided a considerable quality boost, with score improvements requiring fewer inputs when using positive and negative points.
The performance plateau observed beyond 12 positive points can be attributed to a saturation effect in the attention mechanism of the SAM. As more prompts are added, the model reaches a point where additional spatial cues offer diminishing returns, particularly when the existing prompts already provide dense coverage of the target region. Moreover, excessive prompts may introduce slight inconsistencies or noise, leading to minor degradation or stagnation in performance rather than continued improvement. This behavior reflects a trade-off between prompt information content and redundancy.
Iris and pupil metrics for the optimal prompt configuration are shown in
Table 3. The segmentation results demonstrated that SAM’s pre-trained model could adapt rather well to certain conditions using prompt engineering alone. However, for datasets with substantial variability in lighting and reflections, the model struggled to achieve consistent performance across all cases, motivating the need for fine-tuning.
4.2. Fine-Tuning SAM for Iris and Pupil Segmentation
Fine-tuning experiments were conducted on the ViT-Base SAM variant (90 million parameters), focusing on optimizing the vision encoder and mask decoder components while keeping the prompt encoder’s weights frozen (to avoid loss of generalization). This approach involved training 86 million parameters. All training and inference were performed on an NVIDIA A100 GPU (Nvidia, Santa Clara, California, USA) with 40 GB of memory. The primary reason for selecting the SAM ViT-Base variant over the larger ViT-Large and ViT-Huge models for fine-tuning was that, given our hardware constraints, an initial evaluation would be more manageable using the base model—without the need for techniques such as mixed precision training, smaller batch sizes, or reduced input resolutions. Training spanned 30–40 epochs, depending on the dataset size and complexity. The optimal configuration combined the Adam optimizer with a learning rate gradually decreasing from 1 × 10−4 to 1 × 10−6, no weight decay, and a loss function that integrated DICE and cross-entropy losses (methods).
4.3. Dataset-Specific Tweaking and Results
Separate SAMs were fine-tuned for each dataset due to differences in ground truth annotations. For instance, Ubiris v2 ground truth masks excluded specular reflections, while ISDB and MICHE masks incorporated these artifacts. This dataset-specific approach improved segmentation accuracy by aligning the model with the unique characteristics of each dataset.
The results of fine-tuning SAM for iris segmentation are demonstrated in
Figure 6. The fine-tuned model shows a good distinction between iris and pupil regions. For the ISDB and MICHE-I datasets, the model learned to exclude reflections from iris segmentation masks which matches well with the ground truth mask.
The results of fine-tuning SAM for pupil segmentation are demonstrated in
Figure 7. The fine-tuned model shows a good distinction between iris and pupil regions despite the low-contrast conditions in some of the images. This improvement highlights the model’s capacity to adapt to the inherent variability in visible-light imaging, particularly in naturalistic environments where lighting conditions and eye color diversity can complicate segmentation.
However, the model exhibits limitations in certain cases, as illustrated in
Figure 8. Segmentation errors are primarily attributed to images that have poor illumination, particularly when the iris is dark-colored. The lack of sufficient contrast between the pupil and iris in these scenarios leads to inaccurate segmentation boundaries. Additionally, when such images are cluttered with reflections—such as those caused by ambient light or by glasses—this can pose a significant challenge for the model. These reflections are occasionally misidentified as pupil regions, leading to false positives.
A summary of the test results in terms of evaluation metrics for the different fine-tuned models for all datasets is given in
Table 4.
Table 5 presents our visible-light iris segmentation results in comparison to previously published SOTA methods. Although some recently developed, task-specific iris segmentation models achieve higher accuracy, our results remain competitive and within a close performance range.
As shown in
Table 6, our proposed fine-tuning approach significantly improves pupil segmentation performance compared to prompt engineering with the vanilla SAM. The improvement is particularly notable on the UBIRIS v2 dataset, where fine-tuning increases the DICE score from 80% to 87.64% and mIOU from 68% to 79.22%. Across all datasets, the method achieves consistent DICE scores above 85%, with the best performance on ISDB (DICE 89.1%). This highlights the novelty and importance of our contribution. Our fine-tuned SAM consistently achieves high DICE and mIOU scores for pupil segmentation across all three datasets, providing a first baseline for this challenging task.
While prior work has addressed and benchmarked iris segmentation under RGB conditions, there is a notable lack of standardized benchmarks or reproducible results for pupil segmentation in visible-light images. This limits direct comparisons with existing RGB-only methods. Accordingly, we present our results as a first systematic baseline across three public datasets, aiming to support future reproducibility and comparative evaluations in this domain.
5. Discussion and Conclusions
This work addresses a critical gap in eye-tracking research by proposing the first standardized baseline for pupil segmentation in visible-light (RGB) images using foundation model adaptation. While previous segmentation approaches in this domain have largely focused on infrared imaging or relied on handcrafted or conventional deep learning models, our study demonstrates that adapting a SAM through a task-specific multi-stage fine-tuning process can achieve robust segmentation performance in challenging, real-world RGB conditions.
Our approach capitalizes on SAM’s strong generalization capabilities and modular design, gradually refining the model from general iris segmentation to high-precision pupil segmentation. Through rigorous evaluation on three benchmark visible-light datasets (UBIRIS.v2, ISocial DB, MICHE-I), we show that this hierarchical adaptation yields consistent gains over prompt-based zero-shot SAM inference, particularly for the more challenging pupil segmentation task. The resulting performance not only approaches SOTA benchmarks for iris segmentation but also introduces the first comparative baseline for pupil segmentation, facilitating future progress in this area. Our results demonstrate the fine-tuned model’s ability to handle low contrast, reflections, and other artifacts common in real-world RGB eye images and suggest that adapting foundation models through a structured fine-tuning process may offer a viable solution for accurate pupil segmentation without the need for specialized NIR hardware. Furthermore, we provide a practical method for generating pupil annotations from existing datasets, addressing the lack of ground truth and supporting further research in RGB-based eye segmentation.
Despite high accuracy performance across datasets, we observe failure cases in specific challenging conditions. As shown in
Figure 8, segmentation accuracy degrades when the pupil boundary is poorly defined, particularly due to low contrast with dark irises or inadequate lighting. Additionally, specular reflections—often caused by eyeglasses or ambient light—can lead to false positives, as the model misinterprets them as pupil regions. These limitations reflect known difficulties in RGB-based eye image analysis and motivate further refinement.
This study illustrates how a general-purpose foundation model can be adapted to a specialized computer vision task characterized by high variability and limited annotated data. Our approach offers a practical method and an initial reference point for future efforts. The proposed baseline, model configuration, and annotation strategy may assist future research in visible-light eye-tracking, particularly in settings where reliance on low-cost, widely available imaging hardware is essential.
From an implementation perspective, utilizing SAM for our task, both methodologies (prompt engineering and fine-tuning) needed a GPU for training and inferencing. Specifically, we used an NVIDIA A100 GPU processor. Inference times were in the order of seconds, suggesting this methodology is suitable for a backend server architecture rather than edge device implementation.
Importantly, we identify key limitations and opportunities. Although SAM offers strong generalization, its default configuration is computationally intensive and not optimized for edge devices—a crucial consideration for mobile and consumer-grade eye-tracking applications. Nonetheless, our results suggest that lighter adaptations or recent efficient variants of SAM could bridge this gap. Looking ahead, an important direction for future work lies in constructing models for deployment on edge devices. While our framework leverages the accuracy of large foundation models, such as SAM, these solutions are currently impractical for real-time processing on resource-constrained platforms. Future research may explore model compression and distillation techniques, efficient variants of SAM, or transformer–lightweight hybrids. Recent advancements, such as SAM-EDA and Fast-SAM, address these challenges by introducing lightweight adapters and optimizing specific model components, such as the mask decoder [
44]. These modifications reduce computational overhead while maintaining high segmentation performance. In parallel, enhancing robustness in difficult visual conditions, such as poor illumination, dark irises, and reflection artifacts, remains a key challenge for real-world adoption. Addressing these two fronts together will be crucial for enabling accurate, real-time pupil segmentation in practical RGB eye-tracking scenarios.
Author Contributions
Conceptualization, O.M., D.Y. and Y.A.; methodology, O.M., D.Y. and Y.A.; software, O.M.; validation, O.M., D.Y. and Y.A.; formal analysis, O.M., D.Y. and Y.A.; investigation, O.M., D.Y. and Y.A.; data curation, O.M.; writing—original draft preparation, O.M., D.Y. and Y.A.; writing—review and editing, O.M., D.Y. and Y.A.; visualization, O.M., D.Y. and Y.A.; supervision, D.Y. and Y.A.; project administration, Y.A.. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
References
- Holmqvist, K.; Andersson, R. Eye Tracking: A Comprehensive Guide to Methods, Paradigms, and Measures, 2nd ed.; Lund Eye-Tracking Research Institute: Lund, Sweden, 2017. [Google Scholar]
- Min-Allah, N.; Jan, F.; Alrashed, S. Pupil detection schemes in human eye: A review. Multimed. Syst. 2021, 27, 753–777. [Google Scholar] [CrossRef]
- Rathnayake, R.; Madhushan, N.; Jeeva, A.; Darshani, D.; Subasinghe, A.; Silva, B.N.; Wijesinghe, L.P.; Wijenayake, U. Current Trends in Human Pupil Localization: A. Review. IEEE Access 2023, 11, 115836–115853. [Google Scholar] [CrossRef]
- Nguyen, K.; Proença, H.; Alonso-Fernandez, F. Deep Learning for Iris Recognition: A Survey. ACM Comput. Surv. 2024, 56, 1–35. [Google Scholar] [CrossRef]
- Malgheet, J.R.; Manshor, N.B.; Affendey, L.S. Iris Recognition Development Techniques: A Comprehensive Review. Complexity 2021, 2021, 6641247. [Google Scholar] [CrossRef]
- Jamaludin, S.; Ayob, A.F.M.; Akhbar, M.F.A.; Ali, A.A.I.M.; Imran, M.M.H.; Norzeli, S.M.; Mohamed, S.B. Efficient, accurate and fast pupil segmentation for pupillary boundary in iris recognition. Adv. Eng. Softw. 2023, 175, 103352. [Google Scholar] [CrossRef]
- Lei, S.; Shan, A.; Liu, B.; Zhao, Y.; Xiang, W. Lightweight and efficient dual-path fusion network for iris segmentation. Sci. Rep. 2023, 13, 14034. [Google Scholar] [CrossRef]
- Zambrano, J.E.; Pilataxi, J.I.; Perez, C.A.; Bowyer, K.W. Iris Recognition Using an Enhanced Pre-Trained Backbone Based on Anti-Aliased CNNs. IEEE Access 2024, 12, 94570–94583. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, X.; Gu, Y.; Liu, Y.; Meng, X.; Li, J. A Robust Iris Segmentation Scheme Based on Improved U-Net. IEEE Access 2019, 7, 85082–85089. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything (Version 1). arXiv 2023, arXiv:2304.02643. [Google Scholar] [CrossRef]
- Huang, Y.; Yang, X.; Liu, L.; Zhou, H.; Chang, A.; Zhou, X.; Chen, R.; Yu, J.; Chen, J.; Chen, C.; et al. Segment anything model for medical images? Med. Image Anal. 2024, 92, 103061. [Google Scholar] [CrossRef]
- Ma, J.; He, Y.; Li, F.; Han, L.; You, C.; Wang, B. Segment anything in medical images. Nat. Commun. 2024, 15, 654. [Google Scholar] [CrossRef] [PubMed]
- Mahanama, B.; Jayawardana, Y.; Rengarajan, S.; Jayawardena, G.; Chukoskie, L.; Snider, J.; Jayarathna, S. Eye Movement and Pupil Measures: A Review. Front. Comput. Sci. 2022, 3, 733531. [Google Scholar] [CrossRef]
- Sweere, D.J.J.; Pel, J.J.M.; Kooiker, M.J.G.; Van Dijk, J.P.; Van Gemert, E.J.J.M.; Hurks, P.P.M.; Klinkenberg, S.; Vermeulen, R.J.; Hendriksen, J.G.M. Clinical Utility of Eye Tracking in Assessing Distractibility in Children with Neurological Disorders or ADHD: A Cross-Sectional Study. Brain Sci. 2022, 12, 1369. [Google Scholar] [CrossRef] [PubMed]
- Poole, A.; Ball, L.J. Eye Tracking in HCI and Usability Research: In Encyclopedia of Human Computer Interaction; Ghaoui, C., Ed.; IGI Global: Hershey, PA USA, 2006; pp. 211–219. [Google Scholar] [CrossRef]
- Pauszek, J.R. An introduction to eye tracking in human factors healthcare research and medical device testing. Hum. Factors Healthc. 2023, 3, 100031. [Google Scholar] [CrossRef]
- Tahri Sqalli, M.; Aslonov, B.; Gafurov, M.; Mukhammadiev, N.; Sqalli Houssaini, Y. Eye tracking technology in medical practice: A perspective on its diverse applications. Front. Med. Technol. 2023, 5, 1253001. [Google Scholar] [CrossRef]
- Molina-Cantero, A.J.; Lebrato-Vázquez, C.; Castro-García, J.A.; Merino-Monge, M.; Biscarri-Triviño, F.; Escudero-Fombuena, J.I. A review on visible-light eye-tracking methods based on a low-cost camera. J. Ambient Intell. Humaniz. Comput. 2024, 15, 2381–2397. [Google Scholar] [CrossRef]
- Gunawardena, N.; Lui, G.Y.; Ginige, J.A.; Javadi, B. Smartphone-based eye tracking system using edge intelligence and model optimisation. Internet Things 2025, 29, 101481. [Google Scholar] [CrossRef]
- Venkataswamy, N.G.; Liu, Y.; Singh, S.; Dey, S.; Schuckers, S.; Imtiaz, M.H. Smartphone-Based Iris Recognition Through High-Quality Visible Spectrum Iris Capture (Version 1). arXiv 2024, arXiv:2412.13063. [Google Scholar] [CrossRef]
- Daugman, J. New Methods in Iris Recognition. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2007, 37, 1167–1175. [Google Scholar] [CrossRef]
- Umer, S.; Dhara, B.C.; Chanda, B. Texture code matrix-based multi-instance iris recognition. Pattern Anal. Appl. 2016, 19, 283–295. [Google Scholar] [CrossRef]
- He, S.; Li, X. EnhanceDeepIris Model for Iris Recognition Applications. IEEE Access 2024, 12, 66809–66821. [Google Scholar] [CrossRef]
- Navaneethan, S.; Siva Satya Sreedhar, P.; Padmakala, S.; Senthilkumar, C. The Human Eye Pupil Detection System Using BAT Optimized Deep Learning Architecture. Comput. Syst. Sci. Eng. 2023, 46, 125–135. [Google Scholar] [CrossRef]
- Hernandez-Diaz, K.; Alonso-Fernandez, F.; Bigun, J. One-Shot Learning for Periocular Recognition: Exploring the Effect of Domain Adaptation and Data Bias on Deep Representations. IEEE Access 2023, 11, 100396–100413. [Google Scholar] [CrossRef]
- Chen, T.; Zhu, L.; Ding, C.; Cao, R.; Wang, Y.; Zhang, S.; Li, Z.; Sun, L.; Zang, Y.; Mao, P. SAM-Adapter: Adapting Segment Anything in Underperformed Scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW 2023), Paris, France, 2–6 October 2023; pp. 3359–3367. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Y.; Zhang, Z.; Jiang, Z.; Yu, Y.; Li, L.; Li, L. Exploring Semantic Prompts in the Segment Anything Model for Domain Adaptation. Remote Sens. 2024, 16, 758. [Google Scholar] [CrossRef]
- Maquiling, V.; Byrne, S.A.; Niehorster, D.C.; Nyström, M.; Kasneci, E. Zero-Shot Segmentation of Eye Features Using the Segment Anything Model (SAM). Proc. ACM Comput. Graph. Interact. Tech. 2024, 7, 1–16. [Google Scholar] [CrossRef]
- Farmanifard, P.; Ross, A. Iris-SAM: Iris Segmentation Using a Foundation Model. In Proceedings of the International Conference on Pattern Recognition and Artificial Intelligence, Jeju, Republic of Korea, 3–6 July 2024; Springer Nature: Singapore; pp. 394–409. [Google Scholar]
- Jiang, J.; Zhang, Q.; Wang, C. SAM-Iris: A SAM-Based Iris Segmentation Algorithm. Electronics 2025, 14, 246. [Google Scholar] [CrossRef]
- Lei, T.; Chen, J.; Chen, J. SF-SAM-Adapter: SAM-based segmentation model integrates prior knowledge for gaze image reflection noise removal. Alex. Eng. J. 2025, 111, 521–529. [Google Scholar] [CrossRef]
- Deng, J.; Jia, Z.; Wang, Z.; Long, X.; Du, D.K. Towards Unsupervised Eye-Region Segmentation for Eye Tracking (Version 1). arXiv 2024, arXiv:2410.06131. [Google Scholar] [CrossRef]
- Proenca, H.; Filipe, S.; Santos, R.; Oliveira, J.; Alexandre, L.A. The UBIRIS.v2: A Database of Visible Wavelength Iris Images Captured On-the-Move and At-a-Distance. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1529–1535. [Google Scholar] [CrossRef]
- Donida Labati, R.; Genovese, A.; Piuri, V.; Scotti, F.; Vishwakarma, S. I-SOCIAL-DB: A labeled database of images collected from websites and social media for Iris recognition. Image Vis. Comput. 2021, 105, 104058. [Google Scholar] [CrossRef]
- De Marsico, M.; Nappi, M.; Riccio, D.; Wechsler, H. Mobile Iris Challenge Evaluation (MICHE)-I, biometric iris dataset and protocols. Pattern Recognit. Lett. 2015, 57, 17–23. [Google Scholar] [CrossRef]
- Wang, C.; Muhammad, J.; Wang, Y.; He, Z.; Sun, Z. Towards Complete and Accurate Iris Segmentation Using Deep Multi-Task Attention Network for Non-Cooperative Iris Recognition. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2944–2959. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: New York, NY, USA, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Arsalan, M.; Kim, D.S.; Lee, M.B.; Owais, M.; Park, K.R. FRED-Net: Fully residual encoder–decoder network for accurate iris segmentation. Expert Syst. Appl. 2019, 122, 217–241. [Google Scholar] [CrossRef]
- Zhou, R.; Shen, W. PI-Unet: Research on precise iris segmentation neural network model for heterogeneous iris. Comput. Eng. Appl. 2021, 57, 223–229. [Google Scholar]
- You, X.; Zhao, P.; Mu, X.; Bai, K.; Lian, S. Heterogeneous noise iris segmentation based on attention mechanism and dense multi-scale features. Laser Optoelectron. Prog. 2021, 63, 0410006. [Google Scholar]
- Meng, Y.; Bao, T. Towards More Accurate and Complete Heterogeneous Iris Segmentation Using a Hybrid Deep Learning Approach. J. Imaging 2022, 8, 246. [Google Scholar] [CrossRef]
- Dong, L.; Liu, Y.; Zhu, X. PFSegIris: Precise and Fast Segmentation Algorithm for Multi-Source Heterogeneous Iris. Algorithms 2021, 14, 261. [Google Scholar] [CrossRef]
- Schön, R.; Lorenz, J.; Ludwig, K.; Lienhart, R. Adapting the Segment Anything Model During Usage in Novel Situations. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 3616–3626. [Google Scholar] [CrossRef]
Figure 1.
Sample images and corresponding ground truth (GT) masks from UBIRIS.v2, ISocial DB, and MICHE-I datasets.
Figure 1.
Sample images and corresponding ground truth (GT) masks from UBIRIS.v2, ISocial DB, and MICHE-I datasets.
Figure 2.
Block diagrams of adapted SAMs for iris and pupil segmentation tasks. Top: SAM-BaseIris segments the iris directly without prompts using fine-tuned encoders. Middle: SAM-RefinedIris refines segmentation using bounding boxes from SAM-BaseIris. Bottom: SAM-RefinedPupil segments the pupil using bounding boxes inferred from the iris mask. Snowflake icons indicate frozen modules; flame icons indicate fine-tuned ones. Arrows demonstrate data and mask flow between stages in this modular, progressive framework.
Figure 2.
Block diagrams of adapted SAMs for iris and pupil segmentation tasks. Top: SAM-BaseIris segments the iris directly without prompts using fine-tuned encoders. Middle: SAM-RefinedIris refines segmentation using bounding boxes from SAM-BaseIris. Bottom: SAM-RefinedPupil segments the pupil using bounding boxes inferred from the iris mask. Snowflake icons indicate frozen modules; flame icons indicate fine-tuned ones. Arrows demonstrate data and mask flow between stages in this modular, progressive framework.
Figure 3.
Samples of prompt-engineering-only segmentation masks. Each row shows a different prompt setup: (Top) iris segmentation with 12 positive and 4 negative points; (Middle) iris segmentation with a bounding box; (Bottom) pupil segmentation with 2 positive points. Each case includes the original image, the SAM output, and the ground truth mask, highlighting zero-shot performance under varying prompts.
Figure 3.
Samples of prompt-engineering-only segmentation masks. Each row shows a different prompt setup: (Top) iris segmentation with 12 positive and 4 negative points; (Middle) iris segmentation with a bounding box; (Bottom) pupil segmentation with 2 positive points. Each case includes the original image, the SAM output, and the ground truth mask, highlighting zero-shot performance under varying prompts.
Figure 4.
Iris segmentation scores vs. number of positive points.
Figure 4.
Iris segmentation scores vs. number of positive points.
Figure 5.
Pupil segmentation scores vs. number of positive points.
Figure 5.
Pupil segmentation scores vs. number of positive points.
Figure 6.
Iris segmentation samples based on the fine-tuned SAM (SAM-RefinedIris) for Ubiris v2, ISDB, and MICHE-I datasets.
Figure 6.
Iris segmentation samples based on the fine-tuned SAM (SAM-RefinedIris) for Ubiris v2, ISDB, and MICHE-I datasets.
Figure 7.
Samples of pupil segmentation with a fine-tuned SAM (SAM-RefinedPupil) for Ubiris v2, ISDB, and MICHE-I datasets.
Figure 7.
Samples of pupil segmentation with a fine-tuned SAM (SAM-RefinedPupil) for Ubiris v2, ISDB, and MICHE-I datasets.
Figure 8.
Representative failure cases in pupil segmentation with a fine-tuned SAM (SAM-RefinedPupil) for Ubiris v2, ISDB, and MICHE-I datasets.
Figure 8.
Representative failure cases in pupil segmentation with a fine-tuned SAM (SAM-RefinedPupil) for Ubiris v2, ISDB, and MICHE-I datasets.
Table 1.
Dataset splits (including augmented images) for the different fine-tuned models.
Table 1.
Dataset splits (including augmented images) for the different fine-tuned models.
| Model, Dataset Functionality | Ubiris v2 | ISDB | MICHE-I |
|---|
| SAM-BaseIris Train | 3000 | 3876 | 500 |
| SAM-RefinedIris, SAM-RefinedPupil Train | 3462 | 3876 | 655 |
| All Models Test | 500 | 500 | 250 |
Table 2.
Prompt configurations for testing in the prompt engineering stage.
Table 2.
Prompt configurations for testing in the prompt engineering stage.
| Eye Element to Segment | Positive Points | Bounding Box |
|---|
| Iris | 2, 4, 6, 8, 10, 12 | No |
| Iris | 2, 4, 6, 8, 10, 12 | Yes |
| Pupil | 1, 2, 3, 4 | No |
| Pupil | 1, 2, 3, 4 | Yes |
Table 3.
Best scores for segmentation with out-of-the-box SAM and prompt engineering.
Table 3.
Best scores for segmentation with out-of-the-box SAM and prompt engineering.
| Eye Element | Highest mIOU | Highest DICE |
|---|
| Iris | 85% | 92% |
| Pupil | 68% | 80% |
Table 4.
Iris results for SAM-RefinedIris models on all datasets.
Table 4.
Iris results for SAM-RefinedIris models on all datasets.
| Dataset | mIOU | DICE | Hausdorf Distance |
|---|
| Ubiris v2 | 92.77 | 96.18 | 4.9184 |
| ISDB | 90.73 | 95.10 | 5.4514 |
| MICHE | 87.94 | 93.45 | 13.56 |
Table 5.
Comparison with SOTA iris segmentation methods.
Table 5.
Comparison with SOTA iris segmentation methods.
| Model | Dataset | mIOU | DICE |
|---|
| [37] | Ubiris v2 | 77.72 | 86.85 |
| MICHE | 77.29 | 87.67 |
| [38] | Ubiris v2 | 82.21 | 91.77 |
| MICHE | 81.54 | 90.25 |
| [39] | Ubiris v2 | 91.89 | 93.84 |
| MICHE | 91.03 | 93.15 |
| [40] | Ubiris v2 | 92.33 | 95.52 |
| MICHE | 93.67 | 94.26 |
| [41] | Ubiris v2 | 95.32 | 96.62 |
| MICHE | 94.75 | 96.52 |
| [42] | Ubiris v2 | 95.66 | 97.74 |
| MICHE | - | - |
| [43] | Ubiris v2 | 96.69 | 97.29 |
| MICHE | 96.24 | 97.13 |
| Fine-Tuned SAM(our method) | Ubiris v2 | 92.77 | 95.90 |
| MICHE | 87.94 | 93.45 |
Table 6.
Pupil results for SAM-BaseIris and SAM-RefinedPupil models on all datasets.
Table 6.
Pupil results for SAM-BaseIris and SAM-RefinedPupil models on all datasets.
| Method | Dataset | mIOU | DICE | Hausdorf Distance |
|---|
| SAM with Prompt Engineering | Ubiris v2 | 68 | 80 | - |
| Fine Tuned SAM | Ubiris v2 | 79.22 | 87.64 | 4.8424 |
| ISDB | 81.01 | 89.10 | 3.3805 |
| MICHE | 76.37 | 85.48 | 6.61 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}