
Quantum-Enhanced Machine Learning for Cybersecurity: Evaluating Malicious URL Detection


Abstract
1. Introduction
2. Literature Review
2.1. Rules-Based/Traditional Detection Techniques
2.1.1. Blacklist-Based Approach
Limitations of the Blacklist-Based Approach
2.1.2. Heuristic-Based Approach
- Signature-based Technique: It relies entirely on malicious patterns and signatures of a URL contained in a database. These signatures are derived from the URLs itself, the web content it is pointed to or the payloads delivered by fraudulent websites.
- Behavior-based Technique: The runtime behavior of webpages or applications linked to a URL are monitored and analyzed utilizing behavior-based techniques. This technique involves observing the actions taken by the web content such as file modifications, network traffic patterns, interactions and system calls with several other processes or services.
- Content-based Technique: This technique searches for and identifies potentially harmful activity by analyzing the content of the files or web pages that are associated to a URL.
Limitations of the Heuristic-Based Approach
2.2. Machine Learning for Malicious URL Detection
2.2.1. Supervised Learning (SL)
Feature Collection
- Lexical Features: “Lexical Features are collected through lexical scanning” [17] derived from the layout and structure of the URL string or name itself, without gaining access to the content of the website or requiring network analysis to be conducted. In summary, it comprises the characteristics of the URL string such as length, hyphens, special characters, number of dots and suspicious keywords present including “update” and “login”. Ref. [13], mentioned that the use of lexical features as a first line of defense in detecting malicious URLs is important due to the possession of a low computational state and reasonable effectiveness.
- Content Features: The content features are extracted directly from the actual web page or a resource that the URL is connected to and can be obtained when the website is visited or downloaded. These webpage contents include HTML and JavaScript codes, embedded links, the presence of iframes, etc. Content features are classified as “heavy weight” due to the requirement of excess information to be extracted, which, in turn, may raise security issues [13]. Although collecting and analyzing the online content is necessary for these features, it can be computationally demanding and frequently yields to a deeper understanding of the page’s nature.
- Network/Host-based Features: “Network features are a union of the domain name system (DNS), network and host features” [17] and these features often require active probing or monitoring of network traffic. These features include WHOIS and DNS information, IP address properties, server location, etc. Ref. [17] further discussed how research has often shown that “legitimate websites” possess additional contents compared to fraudulent sites, and network features can be beneficial in identifying fraudulent sites, which are frequently “hosted by less” reliable “service providers”. Furthermore, these fraudulent websites can be identified using information derived from the DNS, which may be compared with a list of frequently utilized keywords linked to malicious actions.
Feature Preprocessing
Support Vector Machine
- Sigmoid:
- Polynomial of degree k:
- Radial Basis Function (RBF) or Gaussian Kernel:
Logistic Regression
2.2.2. Unsupervised Learning (UL)
2.2.3. Deep Learning (DL)
Challenges with ML Algorithms
- High volume and velocity: On the internet, there is a staggering number of URLs created daily, making “real-world URL” a type of large data (big data) that has “high velocity and volume”. In [26], an estimation indicated that 175 new websites are generated every minute, thus creating about 252,000 new websites everyday throughout the world. This big data of URLs necessitates scalable ML solutions capable of analyzing and processing such vast amounts of data in real-time, which traditional ML algorithms may find difficult and computationally exhausting.
- Difficulty in obtaining labels: As discussed earlier, SL algorithms comprise the majority of ML methods utilized in detecting malicious URLs, in which a requirement for labelled data (malicious and benign) to train on is necessary. Labelling URLs as malicious or benign requires either human expertise to label the data or obtaining it through blacklists and whitelists (where data also go through manual labelling). Unfortunately, as compared to the total amount of accessible URLs on the internet, labelled data are in limited amounts and often unavailable. However, there have been strategies to resolve this issue, aiming to maximize the value of limited labelled data, including exploring active learning and semi-supervised learning.
- Concept Drift and Adversarial attacks: In malicious URL detection, techniques and strategies used by threat actors evolve overtime as ML models become efficient in detecting such URLs. The emergence of new threats and supplicated approaches creates a moving target problem for ML models, as it frequently requires the models to be updated and retrained to cope with new threats, which can be computationally overwhelming.
2.3. Quantum Machine Learning for Detecting Malicious URLs
2.3.1. Quantum Machine Learning
Quantum Sector Vector Machine
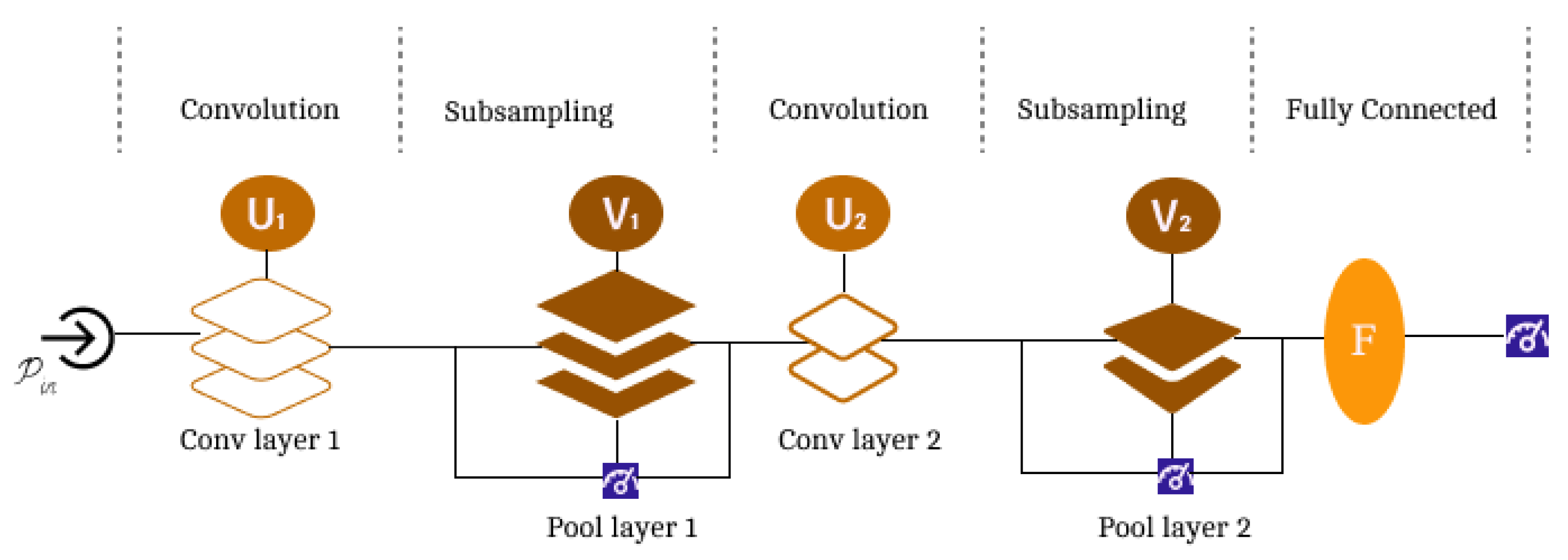
Quantum Convolutional Neural Network
2.3.2. Potential of QML in Detecting Malicious URLs
2.3.3. Challenges and Limitations of QML
2.3.4. Gap in Research and Conclusion
3. Methodology
- Python programming language (https://colab.google/articles/py3.10 (accessed on 23 April 2025)) used to develop calculations.
- Numpy, Pandas, Matplotlib, Seaborn, Scikit-learn and Sklearn (https://scikit-learn.org/stable/install.html (accessed on 23 April 2025)).
- IBM’s Qiskit and Qiskit Machine Learning provides the framework structure for developing QML.
- TensorFlow contains the platform structures for developing CML methods.
3.1. Implementation Process
| Algorithm 1: Compute Disparity Map |
 |
3.1.1. Dataset Description
3.1.2. Data Exploration
Handling Missing Values
Descriptive Statistics
- Count: the quantity of values that are not missing for every variable, verifying the sample size of each calculation.
- Mean and Median: to evaluate any important differences that might point to skewness by comparing the central tendency measures.
- Standard Deviation and Variance: to assess the distribution of data.
- Minimum, Maximum and Range: to understand the entire range of data distribution.
Visualization of Data Distribution
Correlation Analysis
- −1 represents a perfect negative linear relationship;
- 0 represents no linear relationship;
- 1 represents a perfect positive linear relationship.
3.1.3. Data Preprocessing
Encoding Categorical Variables
Handling Outliers
Feature Scaling
Feature Selection
Augmentation
3.1.4. Model Architecture
SVM
- Linear kernel for linearly separable data.
- RBF kernel for non-linear data by mapping data into high-dimensional space.
CNN
- Convolutional Layers: Three 2D matrix convolutional layers were used to extract features from the dataset, for moving across the sequence. The first layer was assigned 32 filters/kernels and the latter two were assigned with 64, with all three layers given a sequence length of (1, 1).
- Activation Functions: The ReLU (rectified linear unit) function was used in this model for its efficiency in handling non-linearity in the network.
- Pooling Layers: A layer of max pooling was added to minimize the size of volume, which speeds up computation to save memory, therefore reducing computational cost and preventing overfitting.
- Flattening: Layer added to convert features from 2D matrix into 1D vector.
- Fully Connected Layers: This layer included two dense layers with activation functions, softmax and relu, to perform classification.
QSVM
- Feature Mapping: ZZFeatureMap with entanglement set as linear. The feature mapping is given by
- Kernel Computation: The kernel computation is defined as
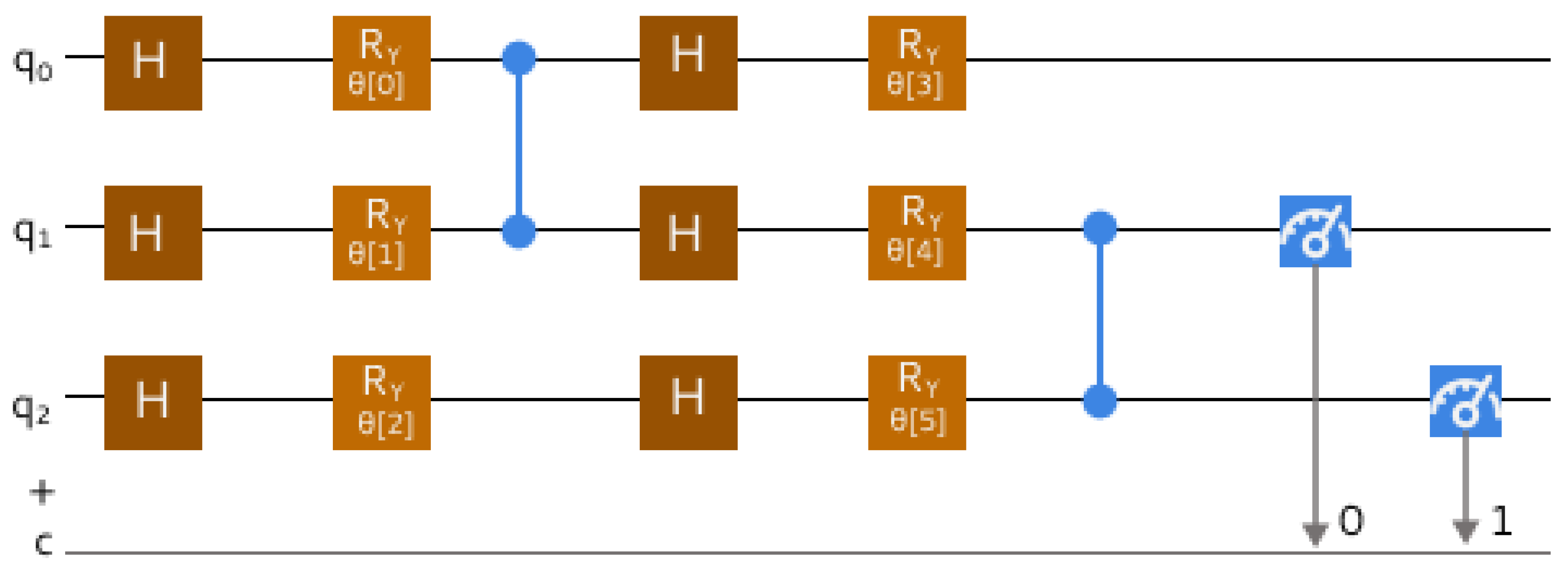
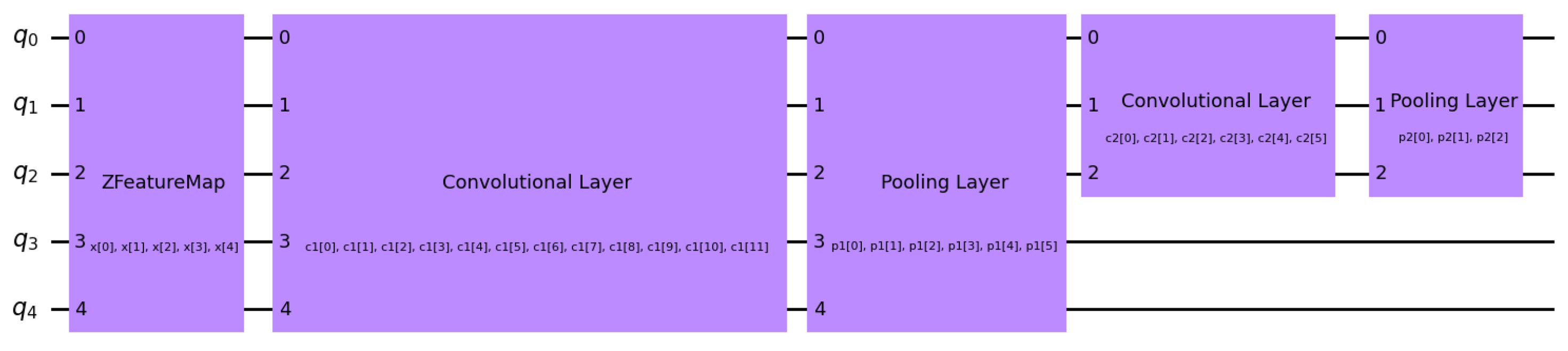
QCNN
- Quantum Convolutional Layers: A total of two convolutional layers were used to apply a series of quantum gates defined in the layer function to the quantum state, to effectively extract features in the quantum space.
- Quantum Pooling Layers: A total number of two pooling layers were used from a defined function to reduce the number of qubits by applying controlled measurements or quantum operations whilst still preserving relevant information.
3.1.5. Training and Testing Procedures
Data Splits
Training Process
- SVM: Grid Search was utilized to find the optimal C and kernel parameters for both undersampled and oversampled datasets.
- CNN: Random search was used to optimize the number of filters, kernel size, and dropout rate, with epochs set at 10. The optimizer used was Adam, and the loss function was set to categorical_crossentropy.
- QSVM: training with SVC callable, SVC precomputed and QSVC functions.
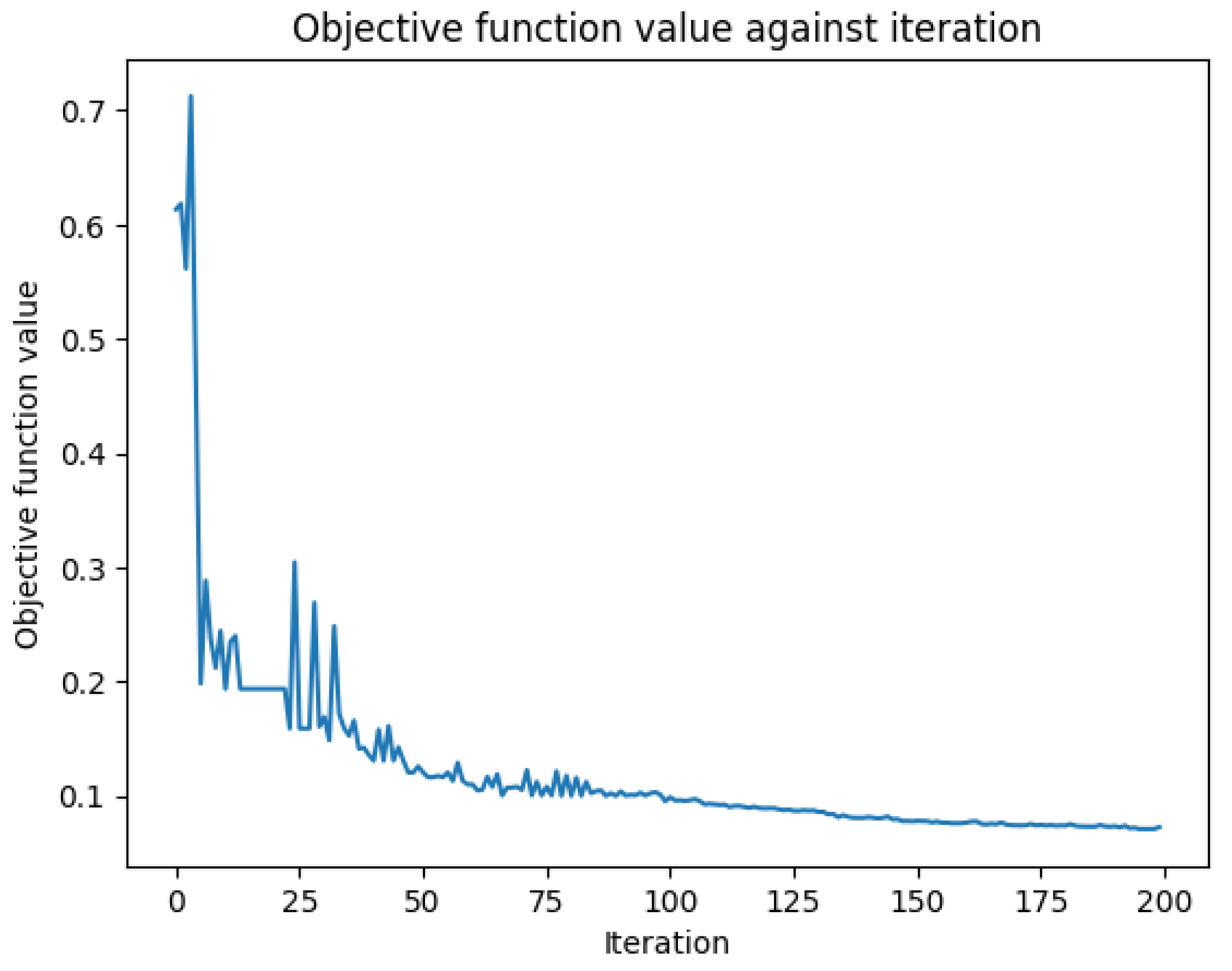
- QCNN: trained the classifier utilizing the COBYLA optimizer often employed for numerical optimization and Pauli-Z expectation values as measurement.
3.1.6. Evaluation Matrix
- True Positives: TP, the number of instances correctly predicted as positive (malicious).
- True Negatives: TN, the number of instances correctly predicted as negative (benign).
- False Positives: FP, the number of instances incorrectly predicted as positive when they are actually negative.
- False Negative: FN, the number of instances incorrectly predicted as negative when they are actually positive.
4. Data Analysis and Critical Discussions
4.1. Model Performance
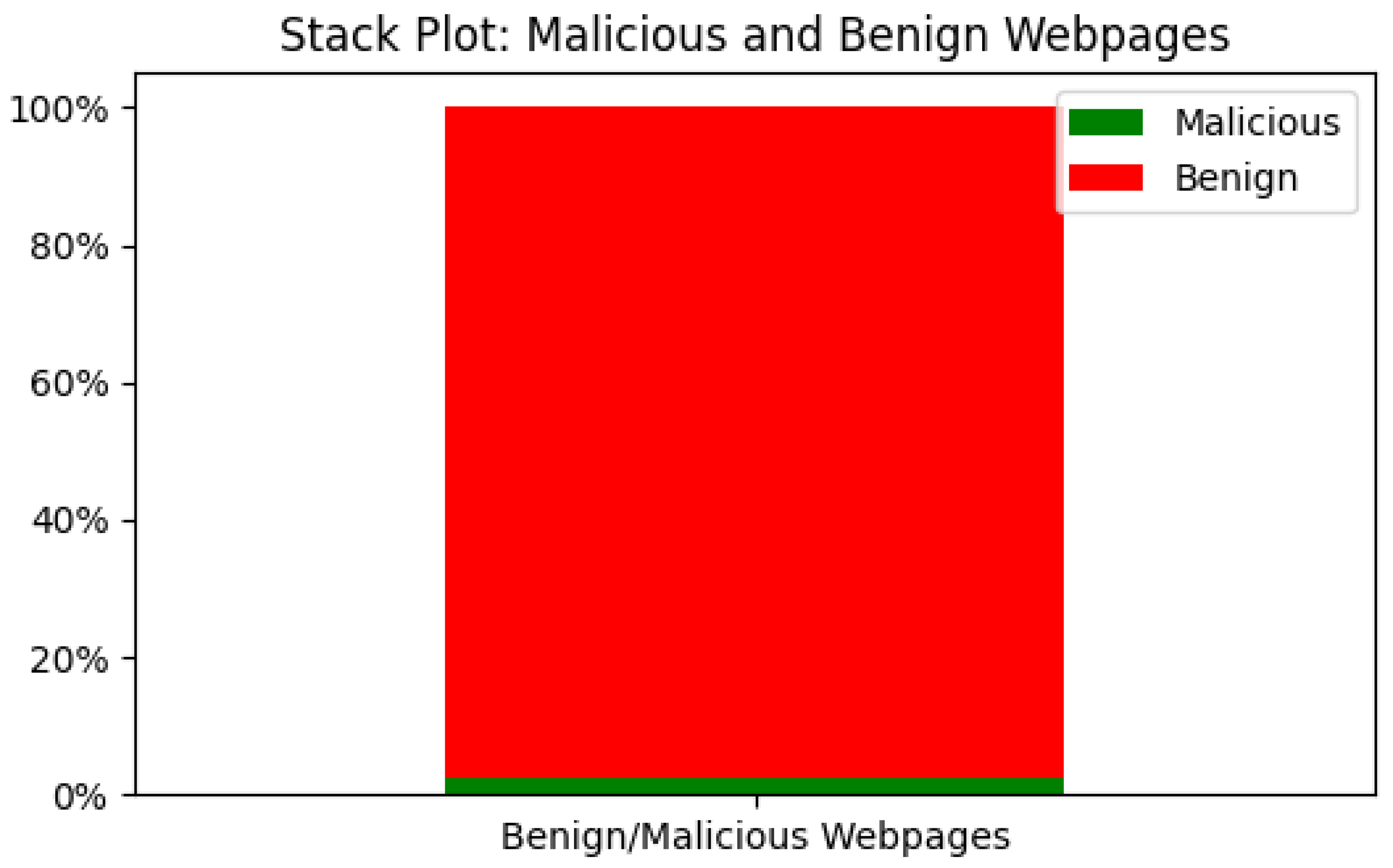
4.1.1. Data Class Imbalance
4.1.2. Performance Analysis
SVM
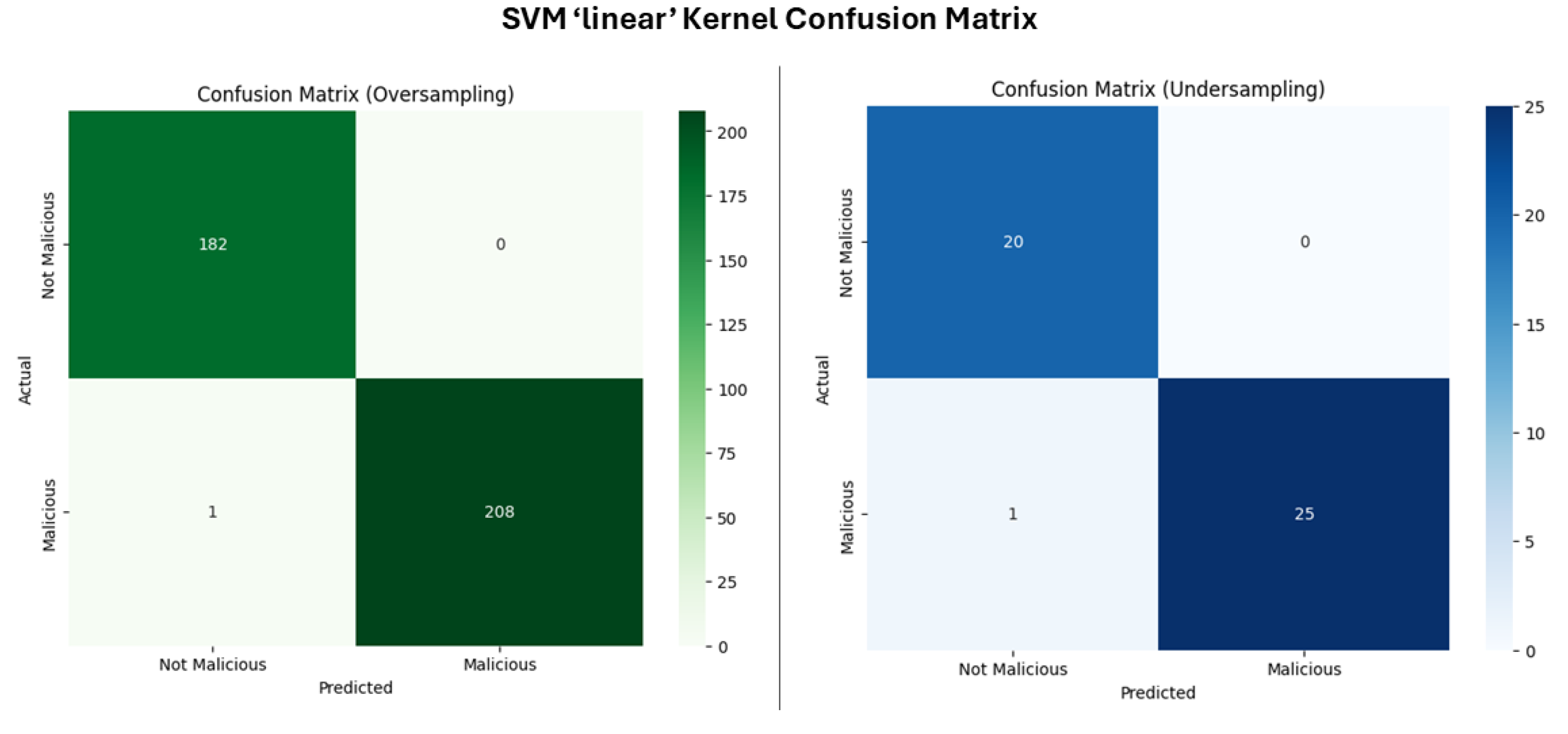
- SVM Linear Kernel
- SVM RBF Kernel
QSVM
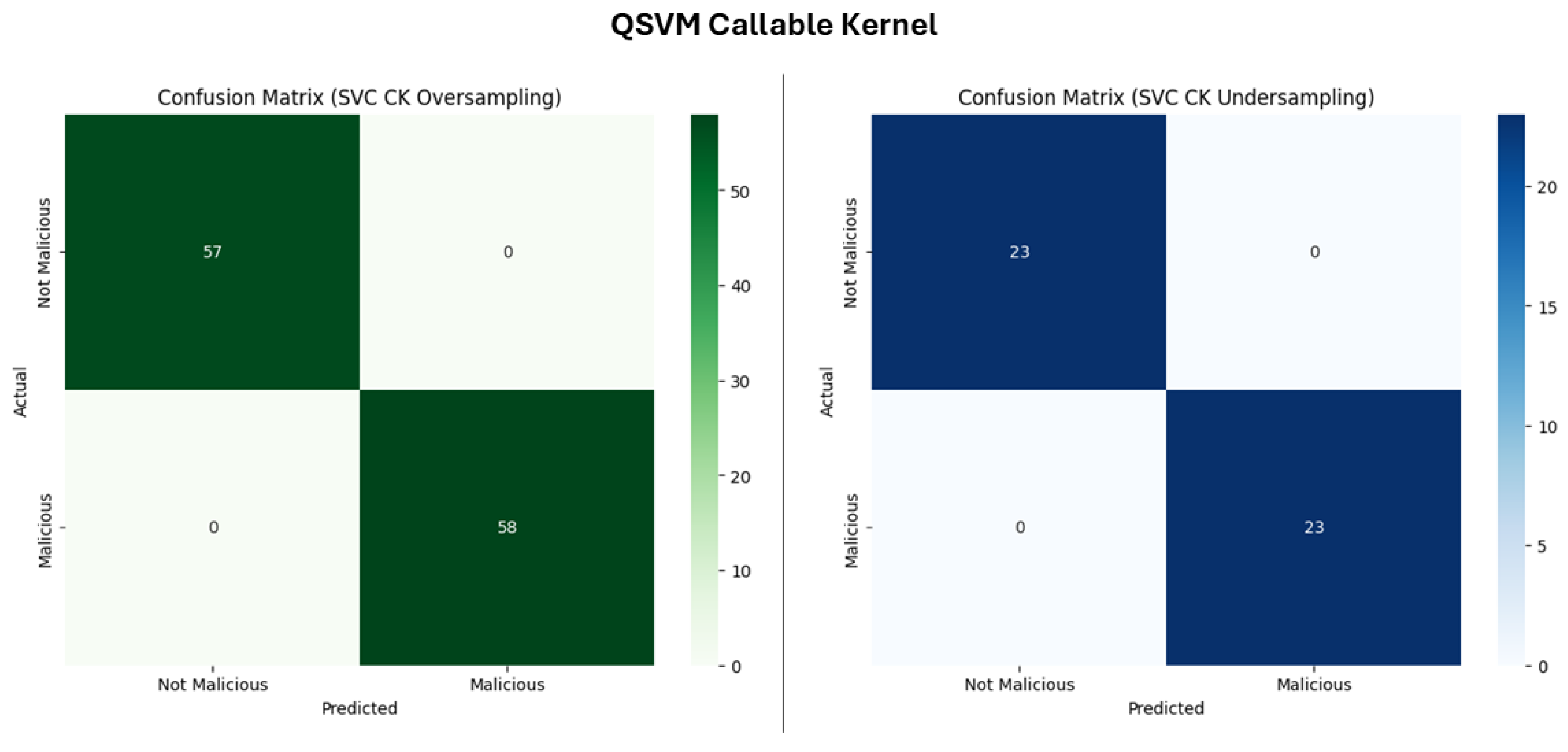
- SVC Callable Kernel
- SVC Precomputed Kernel
- QSVC Function
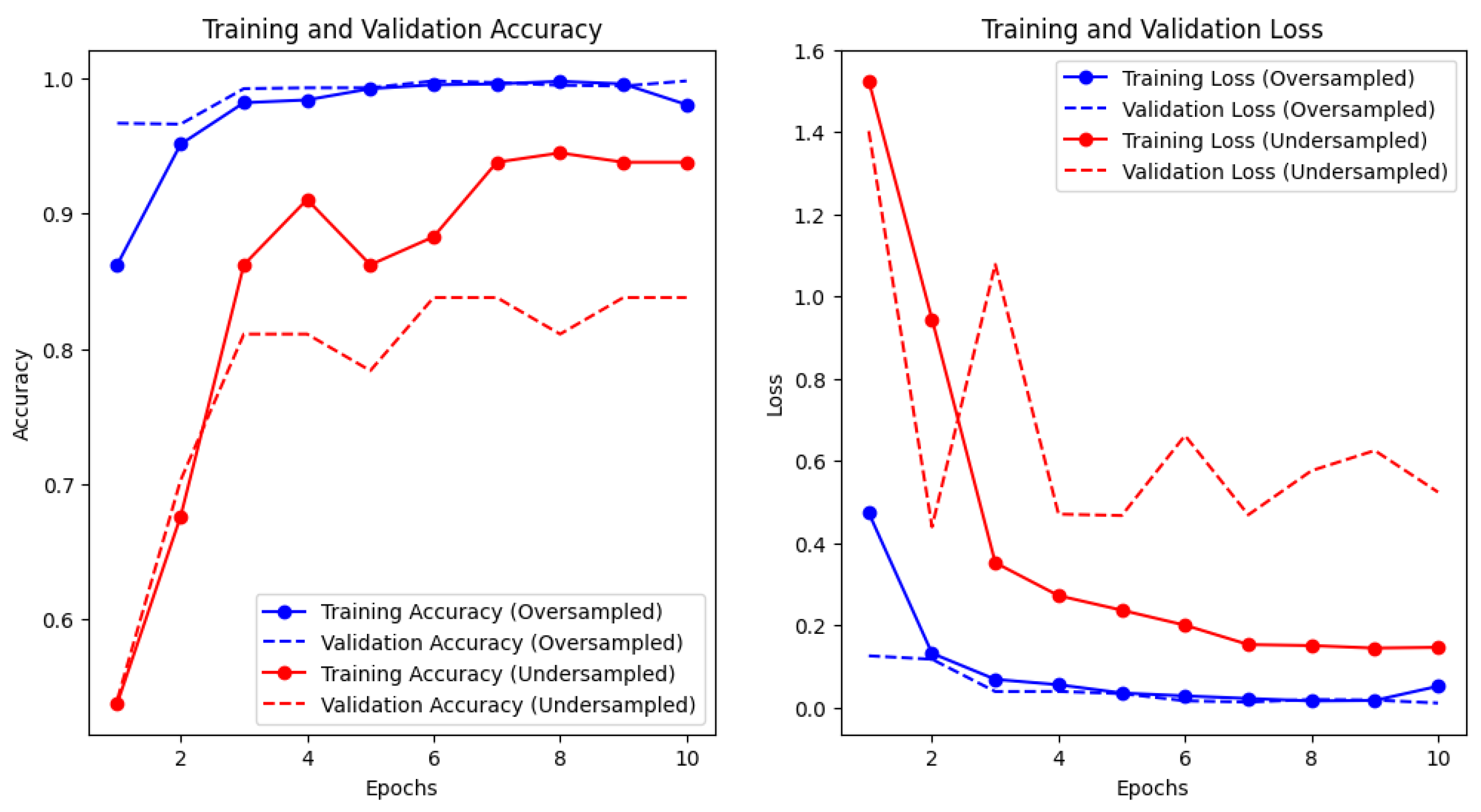
CNN
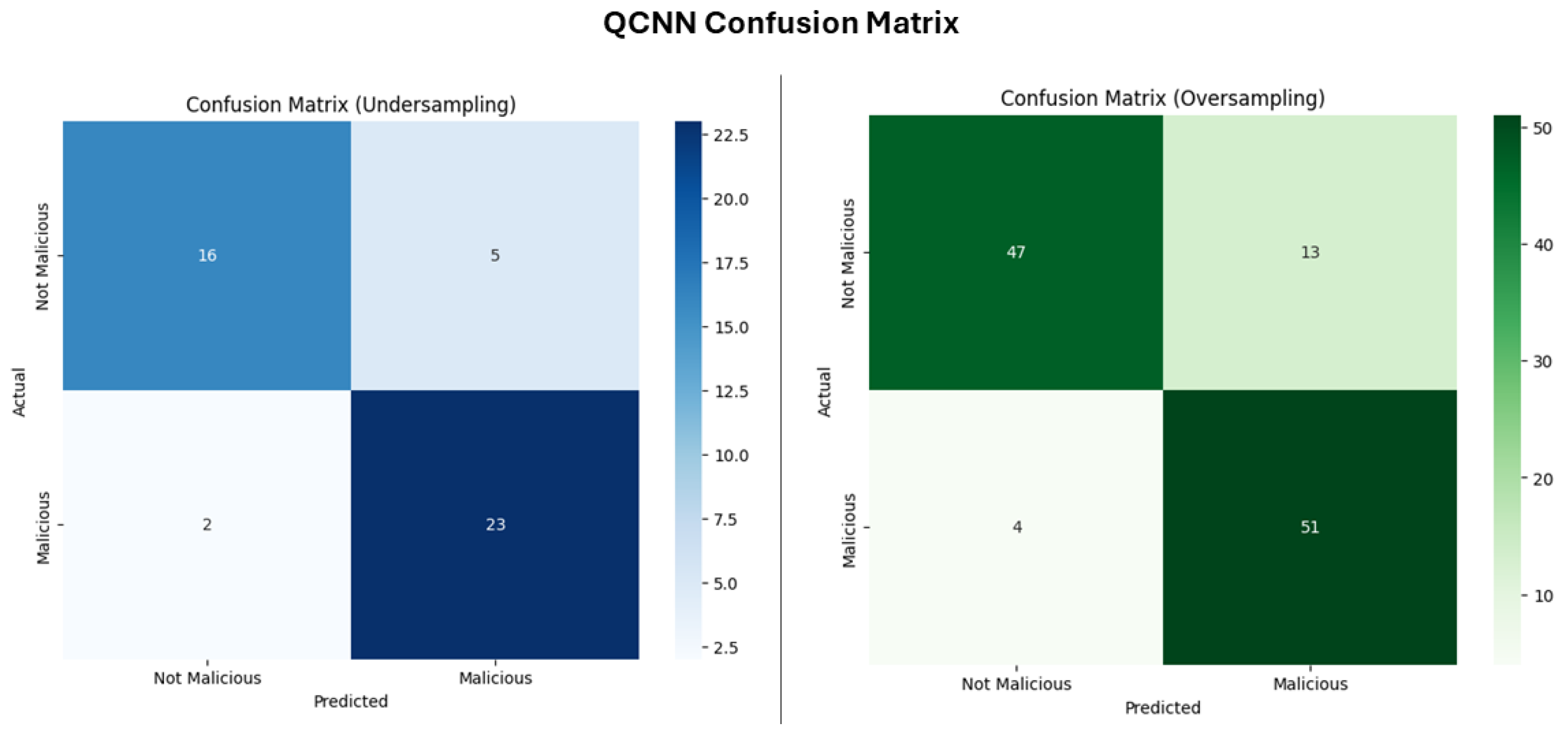
QCNN
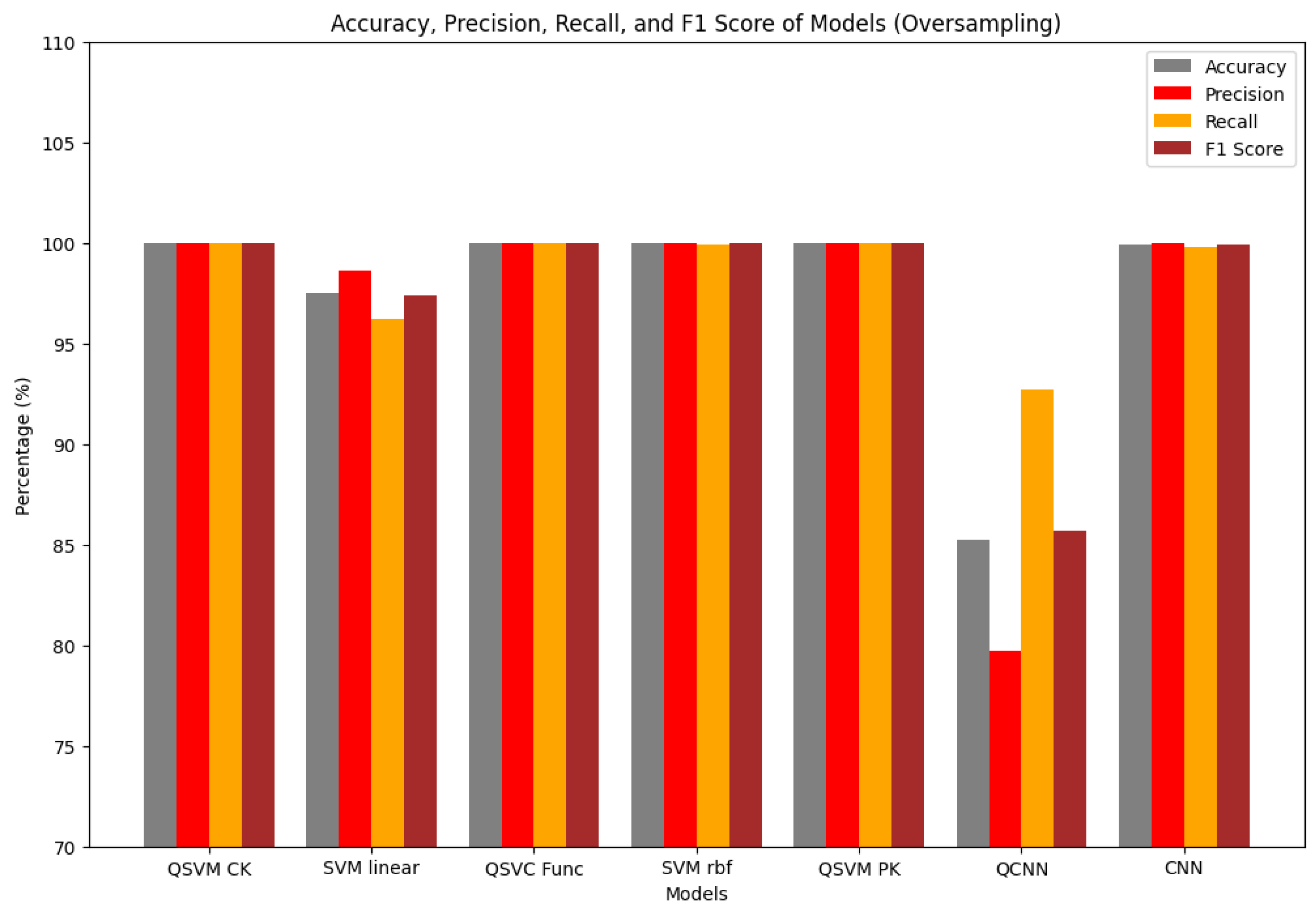
4.2. Comparison of CML and QML Models
4.3. Challenges Faced on Models
5. Conclusions and Future Work
5.1. Unexpected Findings
5.2. Theoretical and Practical Implications
5.3. Challenges and Limitations
5.4. Ethical Considerations for Quantum Computing in Cyber Security
5.5. Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hong, J. The State of Phishing Attacks. Commun. ACM 2012, 55, 74–81. [Google Scholar] [CrossRef]
- Liang, B.; Huang, J.; Liu, F.; Wang, D.; Dong, D.; Liang, Z. Malicious Web Pages Detection Based on Abnormal Visibility Recognition. In Proceedings of the 2009 International Conference on E-Business and Information System Security, Wuhan, China, 23–24 May 2009. [Google Scholar]
- HACKMAGEDDON. 2024 Cyber Attacks Statistics–HACKMAGEDDON. Available online: https://www.hackmageddon.com/category/security/cyber-attacks-statistics/ (accessed on 25 June 2024).
- Kar, A.K.; He, W.; Payton, F.C.; Grover, V.; Al-Busaidi, A.S.; Dwivedi, Y.K. How Could Quantum Computing Shape Information Systems Research–An Editorial Perspective and Future Research Directions. Int. J. Inf. Manag. 2025, 80, 102776. [Google Scholar] [CrossRef]
- Kalinin, M.; Krundyshev, V. Security Intrusion Detection Using Quantum Machine Learning Techniques. J. Comput. Virol. Hacking Tech. 2023, 19, 125–136. [Google Scholar] [CrossRef]
- Reyes-Dorta, N.; Caballero-Gil, P.; Rosa-Remedios, C. Detection of Malicious URLs Using Machine Learning. Wirel. Netw. 2024, 30, 7543–7560. [Google Scholar] [CrossRef]
- Aljofey, A.; Jiang, Q.; Rasool, A.; Chen, H.; Liu, W.; Qu, Q.; Wang, Y. An Effective Detection Approach for Phishing Websites Using URL and HTML Features. Sci. Rep. 2022, 12, 8842. [Google Scholar] [CrossRef]
- Prakash, P.; Kumar, M.; Rao Kompella, R.; Gupta, M. PhishNet: Predictive Blacklisting to Detect Phishing Attacks. In Proceedings of the 2010 Proceedings-IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010. [Google Scholar] [CrossRef]
- Felegyhazi, M.; Kreibich, C.; Paxson, V. On the Potential of Proactive Domain Blacklisting. LEET 2010, 10, 6. [Google Scholar]
- Sheng, S.; Wardman, B.; Cranor, L.; Hong, J.; Zhang, C. An Empirical Analysis of Phishing Blacklists. In Proceedings of the 6th Conference on Email and Anti-Spam (CEAS’09), Mountain View, CA, USA, 16–17 July 2009. [Google Scholar]
- Garera, S.; Provos, N.; Chew, M.; Rubin, A. A Framework for Detection and Measurement of Phishing Attacks. In Proceedings of the 2007 ACM Workshop on Recurring Malcode, Alexandria, VA, USA, 2 November 2007. [Google Scholar]
- Li, S.; Huang, T.; Qin, Z.; Zhang, F.; Chang, Y. Domain Generation Algorithms Detection through Deep Neural Network and Ensemble. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; ACM: New York, NY, USA, 2019; pp. 189–196. [Google Scholar]
- Sahoo, D.; Liu, C.; Hoi, S.C.H. Malicious URL Detection Using Machine Learning: A Survey. arXiv 2017, arXiv:1701.07179. [Google Scholar] [CrossRef]
- Saiful, M.; Mamun, I.; Rathore, M.A.; Lashkari, A.H.; Stakhanova, N.; Ghorbani, A.A. Detecting Malicious URLs Using Lexical Analysis. In Network and System Security: 10th International Conference, NSS 2016, Taipei, Taiwan, 28–30 September 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Hu, Z.; Yuan, Z. A Review of Data-driven Approaches for Malicious Website Detection. In Proceedings of the 2023 7th Asian Conference on Artificial Intelligence Technology (ACAIT), Quzhou, China, 10–12 November 2023. [Google Scholar]
- Aljabri, M.; Altamimi, H.S.; Albelali, S.A.; Al-Harbi, M.; Alhuraib, H.T.; Alotaibi, N.K.; Alahmadi, A.A.; Al Haidari, F.; Mohammad, R.M.A.; Salah, K. Detecting Malicious URLs Using Machine Learning Techniques: Review and Research Directions. IEEE Access 2022, 10, 121395–121417. [Google Scholar] [CrossRef]
- Aljabri, M.; Alhaidari, F.; Mohammad, R.M.A.; Samiha, M.; Alhamed, D.H.; Altamimi, H.S.; Chrouf, S.M.B. An Assessment of Lexical Network and Content-Based Features for Detecting Malicious URLs Using Machine Learning and Deep Learning Models. Comput. Intell. Neurosci. 2022, 2022, 3241216. [Google Scholar] [CrossRef]
- Alfouzan, N.A.; Narmatha, C. A Systematic Approach for Malware URL Recognition. In Proceedings of the 2022 2nd International Conference on Computing and Information Technology (ICCIT 2022), Tabuk, Saudi Arabia, 25–27 January 2022; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2022; pp. 325–329. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A Comprehensive Survey on Support Vector Machine Classification: Applications, Challenges, and Trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Chiramdasu, R.; Srivastava, G.; Bhattacharya, S.; Reddy, P.K.; Gadekallu, T.R. Malicious URL Detection Using Logistic Regression. In Proceedings of the 2021 IEEE International Conference on Omni-Layer Intelligent Systems (COINS 2021), Barcelona, Spain, 23–25 August 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Jain, A.K.; Gupta, B.B. A Machine Learning Based Approach for Phishing Detection Using Hyperlinks Information. J. Ambient Intell. Humaniz. Comput. 2019, 10, 2015–2028. [Google Scholar] [CrossRef]
- Ranganathan, P.; Pramesh, C.; Aggarwal, R. Common Pitfalls in Statistical Analysis: Logistic Regression. Perspect. Clin. Res. 2017, 8, 148. [Google Scholar] [CrossRef] [PubMed]
- Bu, S.J.; Cho, S.B. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics 2021, 10, 1492. [Google Scholar] [CrossRef]
- Saxe, J.; Berlin, K. eXpose: A Character-Level Convolutional Neural Network with Embeddings for Detecting Malicious URLs File Paths and Registry Keys. arXiv 2017, arXiv:1702.08568. [Google Scholar]
- Le, H.; Pham, Q.; Sahoo, D.; Hoi, S.C.H. URLNet: Learning a URL Representation with Deep Learning for Malicious URL Detection. arXiv 2018, arXiv:1802.03162. [Google Scholar]
- Siteefy. How Many Websites Are There in the World? (2024)-Siteefy. Available online: https://siteefy.com/how-many-websites-are-there/ (accessed on 15 July 2024).
- Mercaldo, F.; Ciaramella, G.; Iadarola, G.; Storto, M.; Martinelli, F.; Santone, A. Towards Explainable Quantum Machine Learning for Mobile Malware Detection and Classification †. Appl. Sci. 2022, 12, 12025. [Google Scholar] [CrossRef]
- Power, L.; Guha, K. Feature Importance and Explainability in Quantum Machine Learning. arXiv 2024, arXiv:2405.08917. [Google Scholar]
- Kak, S. On Quantum Neural Computing. Inf. Sci. 1995, 83, 143–160. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Xu, N.; Du, J. Experimental Realization of Quantum Artificial Intelligence. Phys. Rev. Lett. 2014, 114, 140504. [Google Scholar] [CrossRef]
- Mancilla, J.; Pere, C. A Preprocessing Perspective for Quantum Machine Learning Classification Advantage in Finance Using NISQ Algorithms. Entropy 2022, 24, 1656. [Google Scholar] [CrossRef]
- Singh, A.K. Malicious and Benign Webpages Dataset. Data Brief 2020, 32, 106304. [Google Scholar] [CrossRef] [PubMed]
- Gao, K.; Khoshgoftaar, T.M.; Napolitano, A. Combining Feature Subset Selection and Data Sampling for Coping with Highly Imbalanced Software Data. In Proceedings of the 27th International Conference on Software Engineering and Knowledge Engineering, St. Louis, MO, USA, 15–21 May 2005. [Google Scholar] [CrossRef]
- Sadaiyandi, J.; Arumugam, P.; Sangaiah, A.K.; Zhang, C. Stratified Sampling-Based Deep Learning Approach to Increase Prediction Accuracy of Unbalanced Dataset. Electronics 2023, 12, 4423. [Google Scholar] [CrossRef]
- Ahsan, M.; Gomes, R.; Chowdhury, M.M.; Nygard, K.E. Enhancing Machine Learning Prediction in Cybersecurity Using Dynamic Feature Selector. J. Cybersecur. Priv. 2021, 1, 199–218. [Google Scholar] [CrossRef]
- Sujon, K.M.; Hassan, R.B.; Towshi, Z.T.; Othman, M.A.; Samad, M.A.; Choi, K. When to Use Standardization and Normalization: Empirical Evidence from Machine Learning Models and XAI. IEEE Access 2024, 12, 135300–135314. [Google Scholar] [CrossRef]
- Sri Preethaa, K.R.; Munisamy, S.D.; Rajendran, A.; Muthuramalingam, A.; Natarajan, Y.; Abdi, A. Novel ANOVA-Statistic-Reduced Deep Fully Connected Neural Network for the Damage Grade Prediction of Post-Earthquake Buildings. Sensors 2023, 23, 6439. [Google Scholar] [CrossRef]
- Guo, H.; Li, Y.; Shang, J.; Gu, M.; Huang, Y.; Gong, B. Learning from Class-imbalanced Data: Review of Methods and Applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Kovács, G. An Empirical Comparison and Evaluation of Minority Oversampling Techniques on a Large Number of Imbalanced Datasets. Appl. Soft Comput. 2019, 83, 105662. [Google Scholar] [CrossRef]
- Wongvorachan, T.; He, S.; Bulut, O. A Comparison of Undersampling Oversampling and SMOTE Methods for Dealing with Imbalanced Classification in Educational Data Mining. Information 2023, 14, 54. [Google Scholar] [CrossRef]
- Koziarski, M. Radial-Based Undersampling for Imbalanced Data Classification. Pattern Recognit. 2020, 102, 107262. [Google Scholar] [CrossRef]
- Slattery, L.; Shaydulin, R.; Chakrabarti, S.; Pistoia, M.; Khairy, S.; Wild, S.M. Numerical Evidence Against Advantage with Quantum Fidelity Kernels on Classical Data. Phys. Rev. A 2023, 107, 062417. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Classical Machine Learning (CML) | Quantum Machine Learning (QML) |
|---|---|---|
| Data Handling |
|
|
| Model Complexity |
|
|
| Computational Resources |
|
|
| Algorithm Scalability |
|
|
| Hardware and Software Infrastructure |
|
|
| Feature | Description |
|---|---|
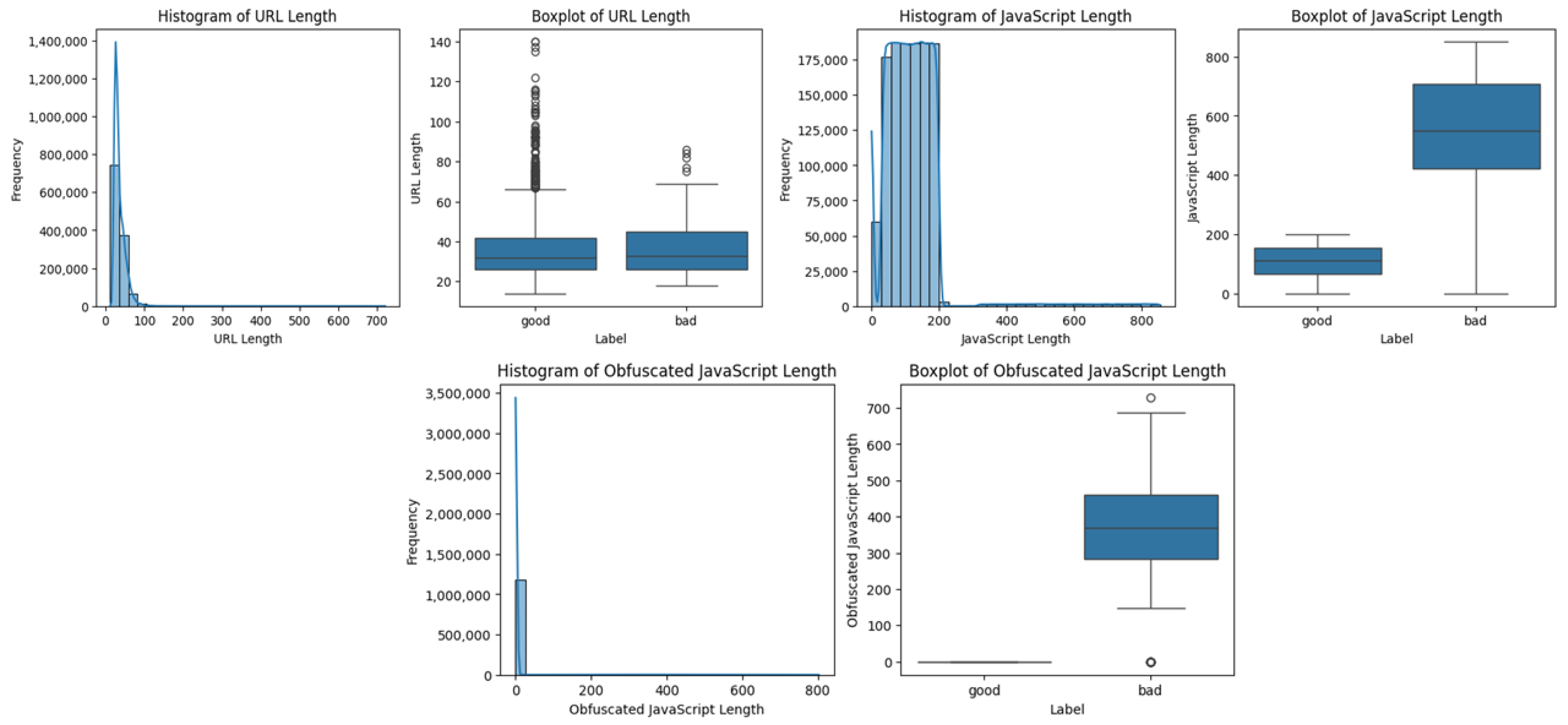
| url | URL of webpage. |
| url_len | Length of URL. |
| ip_add | IP address of webpage. |
| geo_loc | The location of where the webpage is hosted geographically. |
| js_len | Length of JavaScript code on the webpage. |
| js_obf_len | Length of obfuscated JavaScript code. |
| tld | Top level domain of webpage. |
| who_is | Declares whether or not the WHO IS information is complete. |
| https | Declares whether the webpage utilizes https or http protocol. |
| content | Unprocessed webpage content that includes JavaScript code. |
| label | Class label representing malicious and benign webpages denoted as “bad” and “good”, respectively. |
| Technique | Advantages | Disadvantages |
|---|---|---|
| RUS |
|
|
| ROS |
|
|
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| QSVM CK | 100.00 | 100.00 | 100.00 | 100.00 |
| SVM linear | 97.83 | 100.00 | 96.15 | 98.04 |
| QSVC Func | 100.00 | 100.00 | 100.00 | 100.00 |
| SVM rbf | 93.48 | 100.00 | 88.46 | 93.88 |
| QSVM PK | 100.00 | 100.00 | 100.00 | 100.00 |
| QCNN | 84.78 | 82.14 | 92.00 | 86.79 |
| CNN | 91.30 | 95.83 | 88.46 | 92.00 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| QSVM CK | 100.00 | 100.00 | 100.00 | 100.00 |
| SVM linear | 97.49 | 98.60 | 96.21 | 97.39 |
| QSVC Func | 100.00 | 100.00 | 100.00 | 100.00 |
| SVM rbf | 99.95 | 100.00 | 99.89 | 99.95 |
| QSVM PK | 100.00 | 100.00 | 100.00 | 100.00 |
| QCNN | 85.22 | 79.69 | 92.73 | 85.71 |
| CNN | 99.90 | 100.00 | 99.79 | 99.89 |
| Model | Training Time (s) | Testing Time (s) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|
| Undersampling | Oversampling | |||
| QSVM CK | 138.60 | 82.70 | 1053.40 | 505.99 |
| SVM linear | 35.30 | 0.01 | 224.70 | 0.03 |
| QSVC Func | 156.30 | 75.84 | 1150.70 | 572.35 |
| SVM RBF | 2.70 | 0.05 | 17.70 | 0.04 |
| QSVM PK | 221.30 | 0.01 | 1541.80 | 0.01 |
| QCNN | 244.80 | 0.30 | 589.94 | 1.30 |
| CNN | 3.00 | 14.60 | 6.70 | 17.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eze, L.; Chaudhry, U.B.; Jahankhani, H. Quantum-Enhanced Machine Learning for Cybersecurity: Evaluating Malicious URL Detection. Electronics 2025, 14, 1827. https://doi.org/10.3390/electronics14091827
Eze L, Chaudhry UB, Jahankhani H. Quantum-Enhanced Machine Learning for Cybersecurity: Evaluating Malicious URL Detection. Electronics. 2025; 14(9):1827. https://doi.org/10.3390/electronics14091827
Chicago/Turabian StyleEze, Lauren, Umair B. Chaudhry, and Hamid Jahankhani. 2025. "Quantum-Enhanced Machine Learning for Cybersecurity: Evaluating Malicious URL Detection" Electronics 14, no. 9: 1827. https://doi.org/10.3390/electronics14091827
APA StyleEze, L., Chaudhry, U. B., & Jahankhani, H. (2025). Quantum-Enhanced Machine Learning for Cybersecurity: Evaluating Malicious URL Detection. Electronics, 14(9), 1827. https://doi.org/10.3390/electronics14091827