
Probabilistic Measurement of CTI Quality for Large Numbers of Unstructured CTI Products



Abstract
1. Introduction
- RQ1: In what ways can the relevance and actionability of unstructured CTI products be defined and quantitatively assessed?
- RQ2: What methodologies can be employed to rigorously assess the CTI products in relation to the organizations willing to use them?
- RQ3: In what manner can the proposed methodologies be systematically applied to extensive datasets?
2. Related Work
3. Background
3.1. Key Concepts
3.1.1. Unstructured CTI Products
3.1.2. Relevance CTI Quality Factor
3.1.3. Actionability CTI Quality Factor
3.1.4. Relevance vs. Actionability
3.2. Problem Definition
3.3. Probabilistic Algorithms and Data Structures
3.3.1. Probabilistic Algorithms and Data Structures of Similarity Category
3.3.2. Probabilistic Algorithms and Data Structures of Membership Problem Category
4. Proposed Algorithms
4.1. Methodology
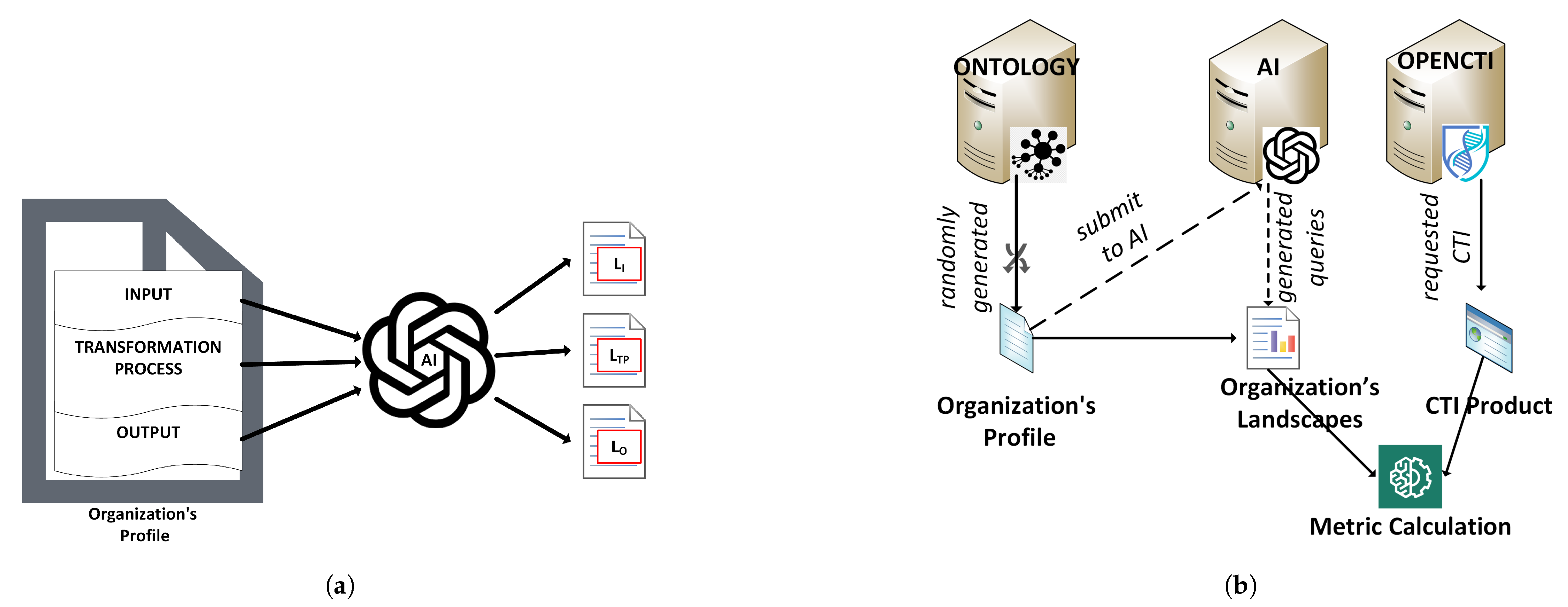
4.2. Defining the Relevance CTI Quality Metric
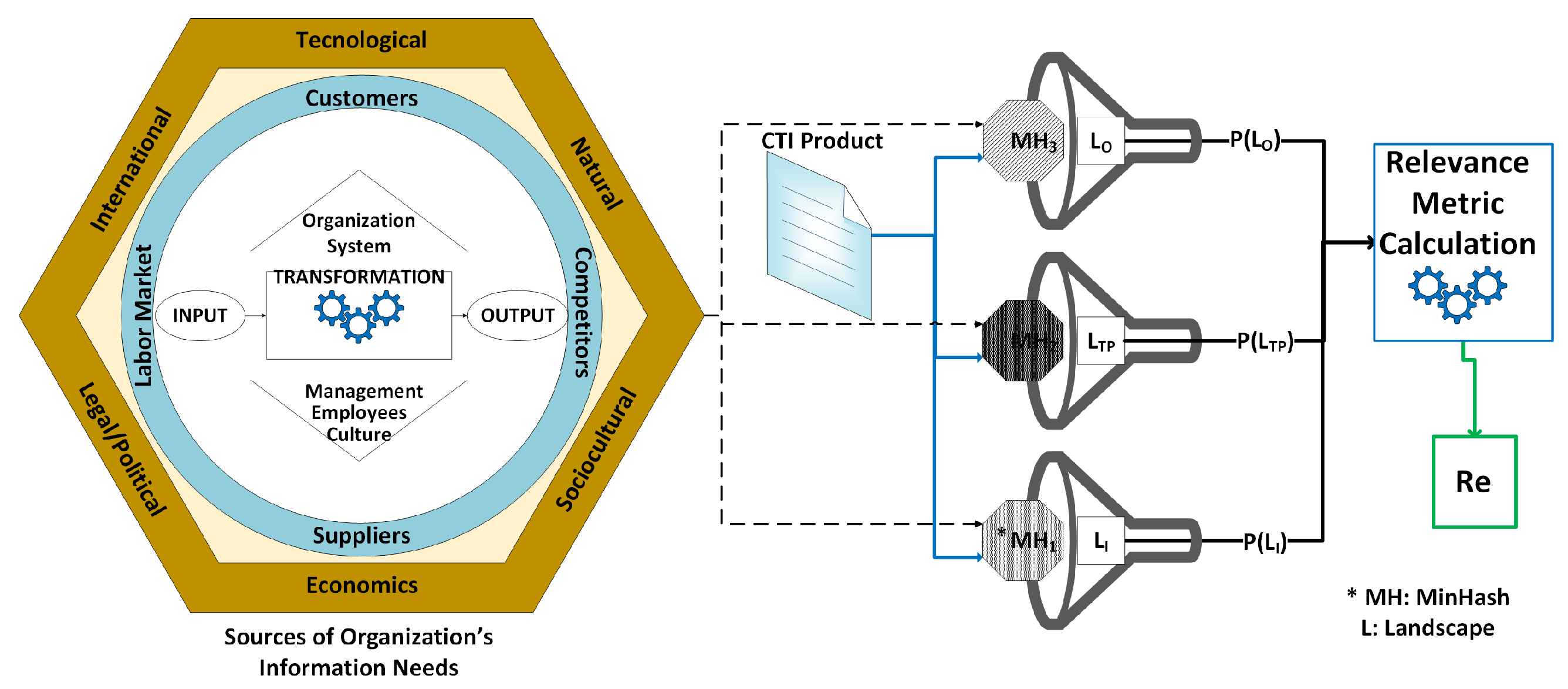
4.2.1. Determining Organization C
- the general environment
- the task environment and the internal environment.
4.2.2. Organization Aspects and the Relevance CTI Quality Metric
4.2.3. Relevance Metric Generic Calculation Mechanism
STEP 1
STEP 2
STEP 3
STEP 4
STEP 5
| Algorithm 1 Metric Calculation Algorithm |
Require: P, , , and |
STEP 6
STEP 7
STEP 8
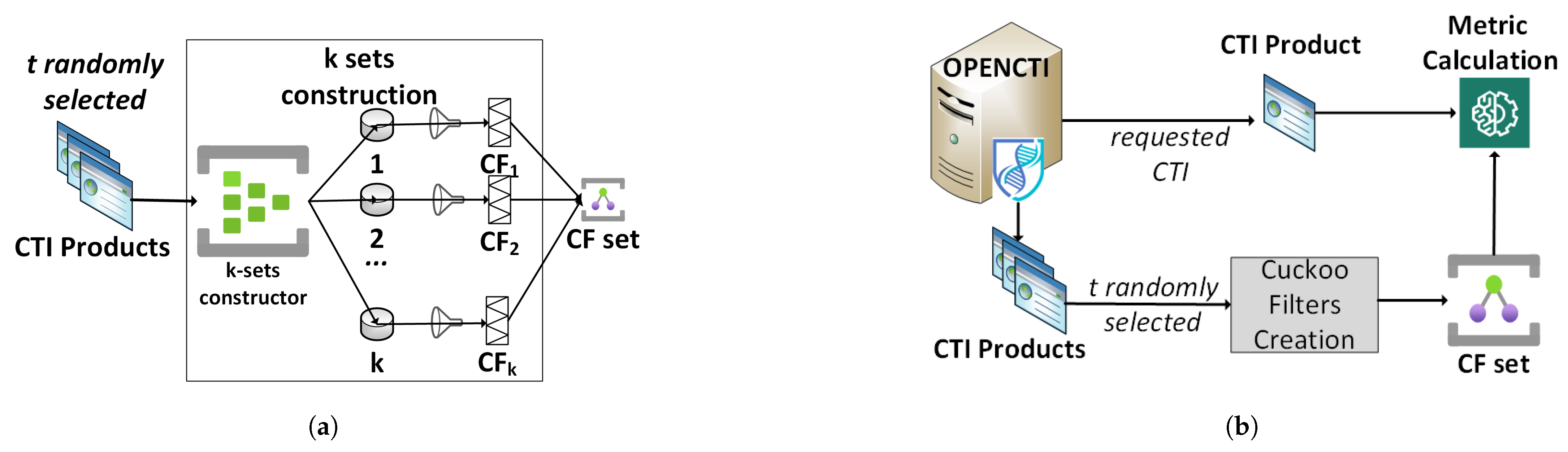
4.3. Defining the Actionability CTI Quality Metric
4.3.1. Cybersecurity Decision-Making Process and Actionability
4.3.2. Defense Mechanism Modeling
4.3.3. Actionability Metric Generic Calculation Mechanism
STEP 1
STEP 2
STEP 3
STEP 4
STEP 5
| Algorithm 2 Metric Calculation Algorithm |
Require: P, ,…, for i in range(1,n) do if then end if end for |
STEP 6
STEP 7
STEP 8
5. Implementation on a Hypothetical System—Experiments
5.1. Experimental Environment of Relevance Metric
- Does face any cyberattack?
- Are products affected by any vulnerability?
5.2. Experimental Environment Actionability Metric
5.3. Analysis of Experimental Results
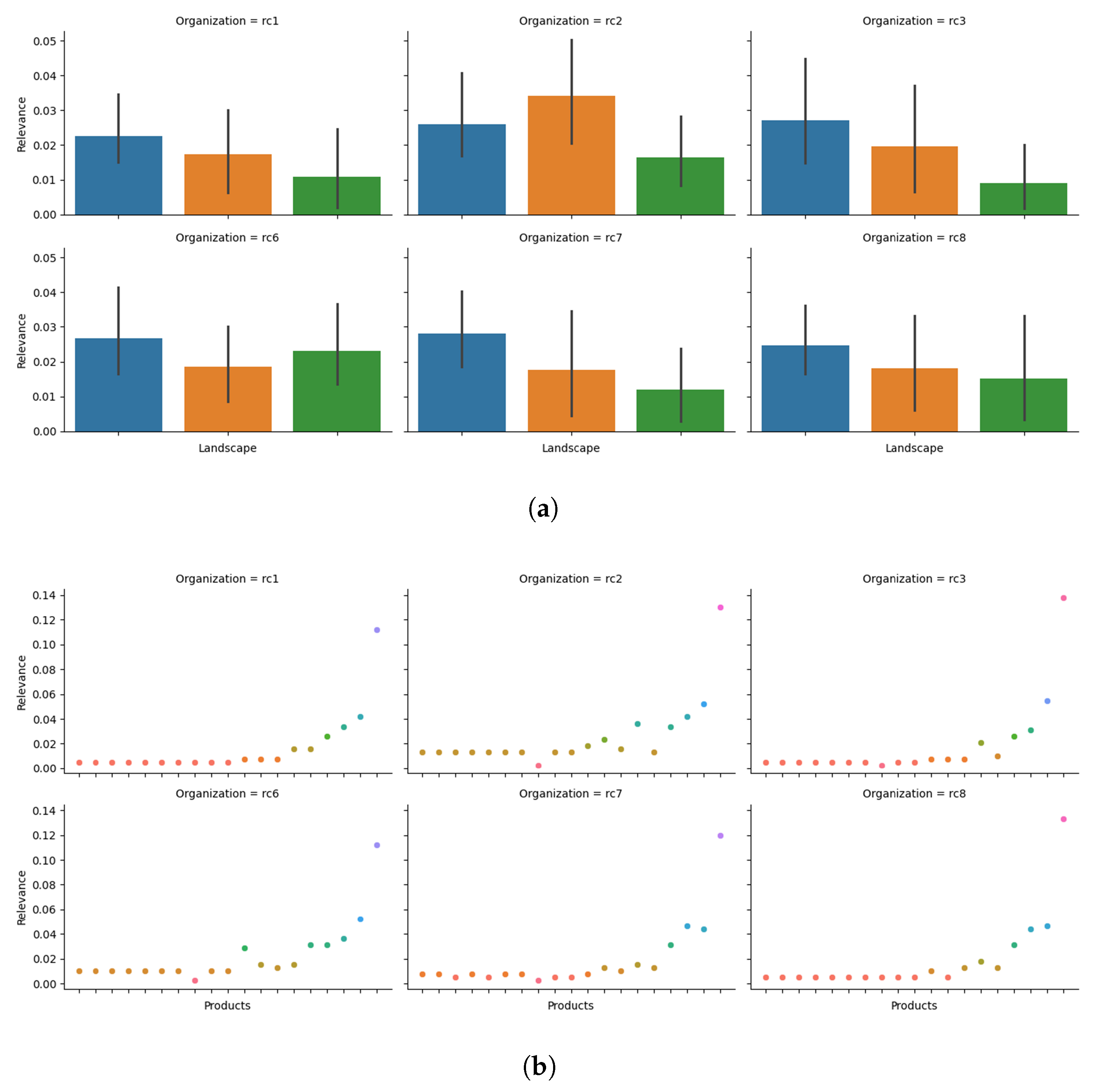
5.3.1. Relevance Metric Experimental Results Analysis
- Serving as a filter for unstructured CTI products. The organization can define a threshold, allowing only those CTI products for further analysis where the calculated surpasses this set threshold.
- Acting as a resource predictor for the assessment of CTI products. This utilizes the distribution traits of calculated from prior unstructured CTI products and the threshold. For instance, if the values for one thousand unstructured CTI products adhere to a normal distribution (i.e., mean and standard deviation ) and the organization establishes a threshold of , then a cybersecurity manager can predict that out of every thousand unstructured CTI products received, only about 10 will necessitate further analysis, enabling efficient resource allocation.
- Functioning as an indicator of how well-defined the organization’s information needs are by analyzing each landscape’s impact on the calculation.
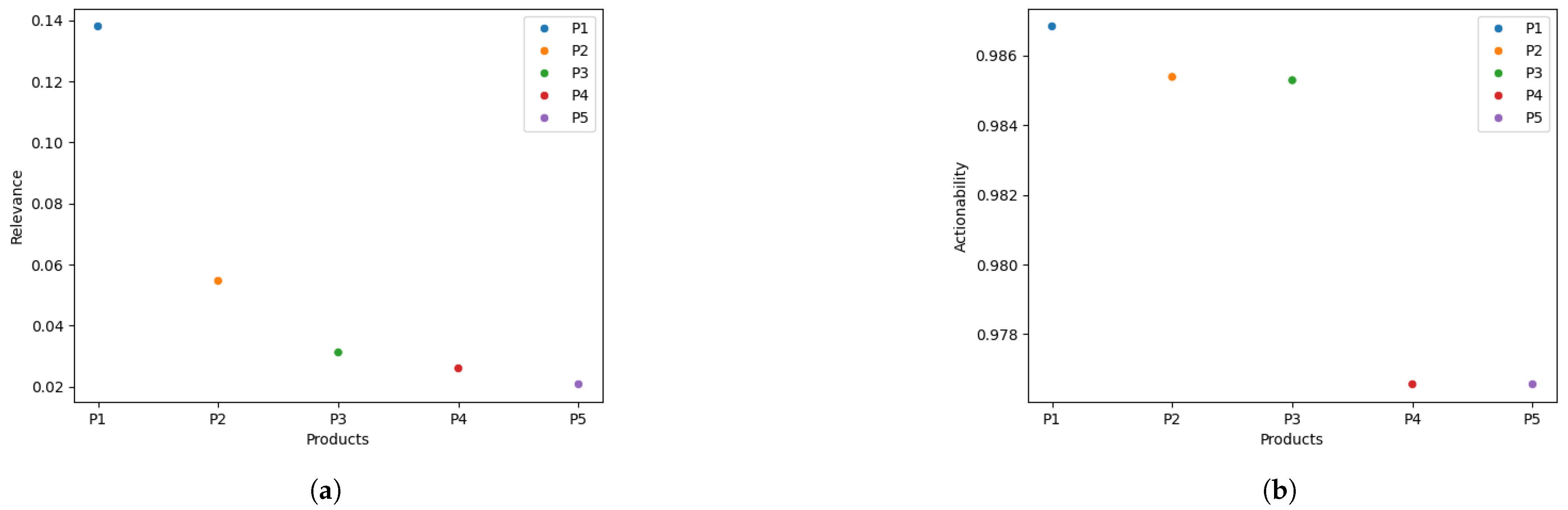
5.3.2. Actionability Metric Experimental Results Analysis
- Analogous to , can be employed as a filter for unstructured CTI products by setting a threshold for and selecting only those CTI products for further review whose calculated is above the threshold.
- It can act as an assessment metric for a CTI source by comparing the average values of unstructured CTI products sourced from different CTI sources.
- It can act as a means to accurately apply a CTI product by evaluating how the CTI product might impact each defense mechanism.
- It can function as a selection criterion for CTI products among organizations that have a similar arsenal of defense mechanisms and are part of a threat intelligence sharing community.
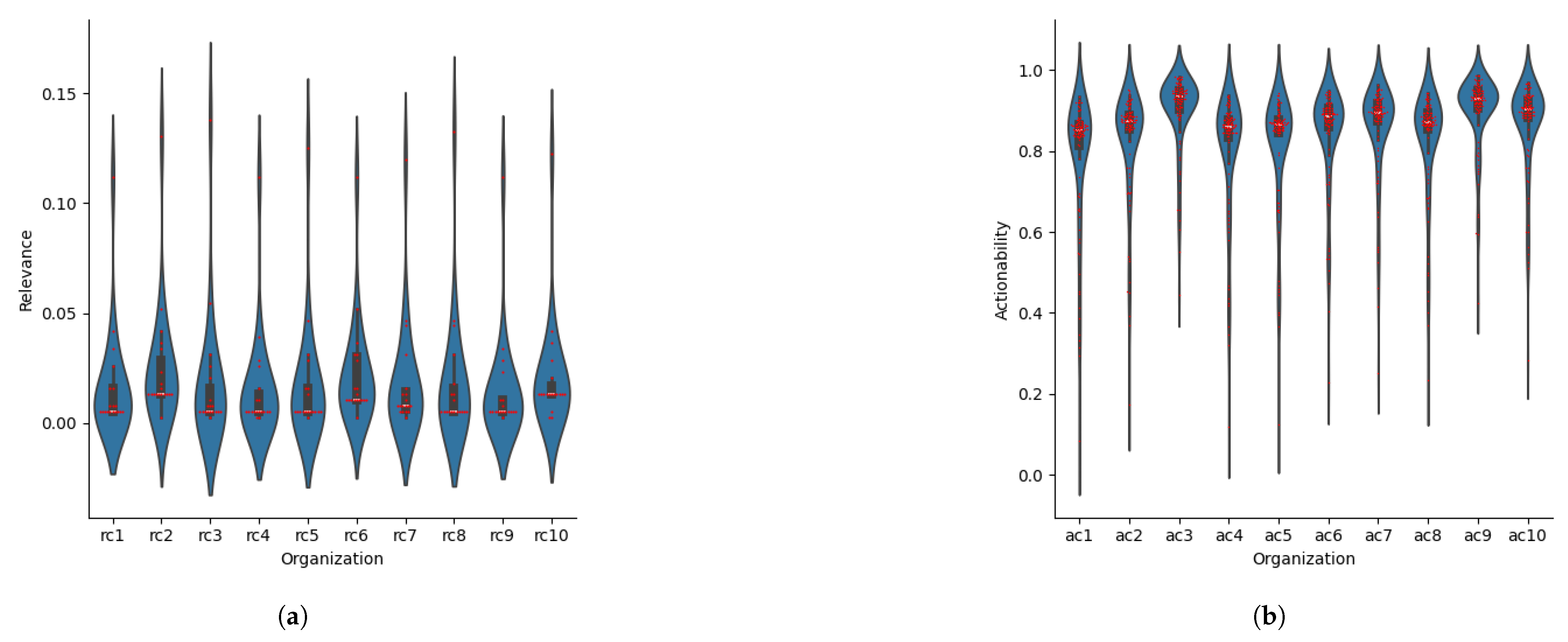
5.3.3. Relevance and Actionability Metrics Experimental Results of an Organization
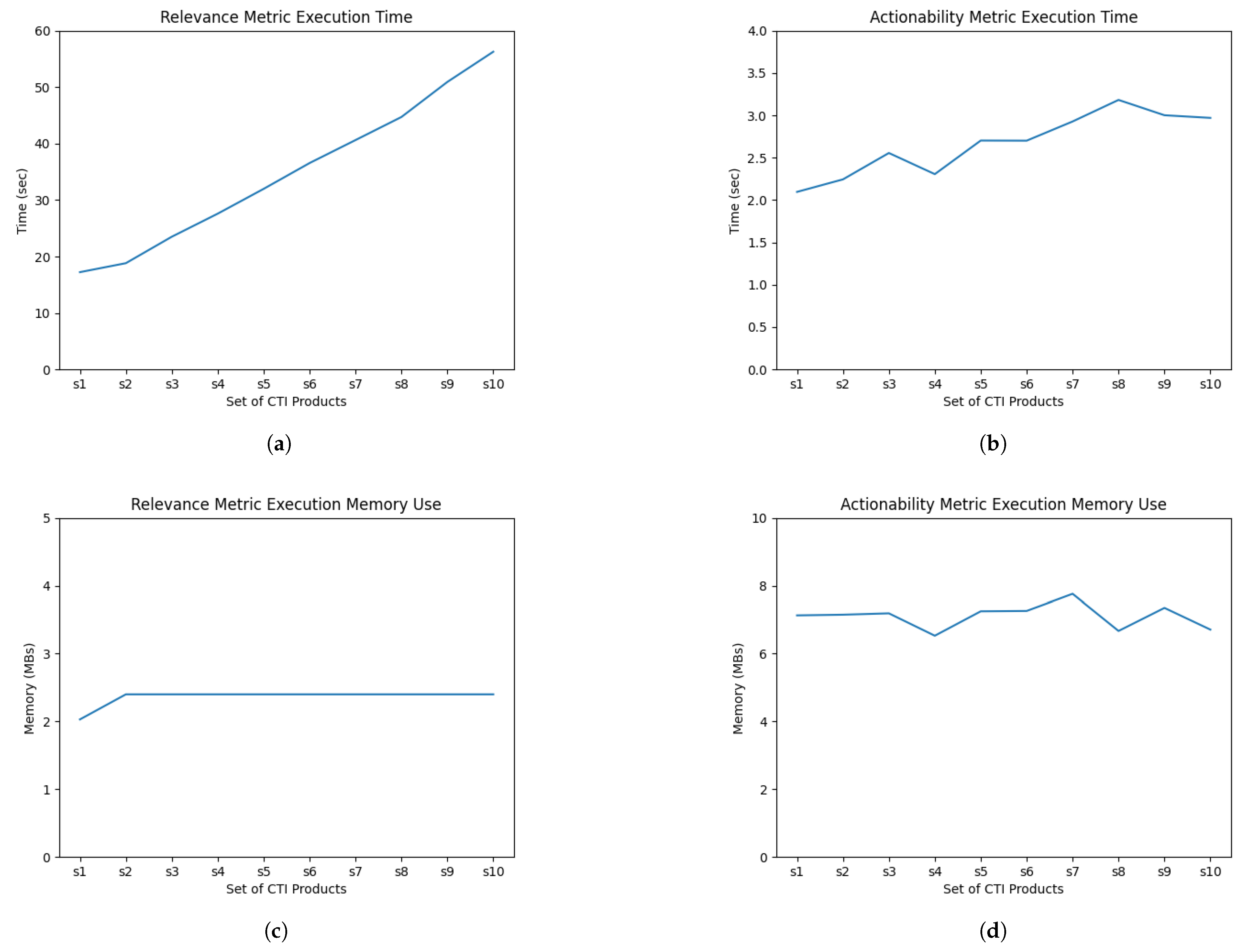
5.3.4. Experimental Results of and Performance
5.3.5. Discussion
6. Conclusions
6.1. Contribution
- Our metrics are designed using a systematic methodology that facilitates a clear analysis of any component.
- The proposed metrics are independent of any specific system, allowing for their integration into existing systems.
- Metrics evaluation yields explicit numerical results, which are essential in data quality metrics [72], and are not part of a comprehensive framework that transparently demonstrates the application of the calculated results.
- The metrics are independent of the CTI product structure, enabling the potential evaluation of structured CTI products, given that a simple data cleaning technique is applied to their inputs.
6.2. Limitations and Assumptions
6.3. Future Work
- How can we experimentally evaluate the CTI quality metrics, including common data analytics methods like precision-recall and confusion matrices?
- How can all characteristics of probabilistic data structures be utilized in the computation of metrics (e.g., dynamic updates in Cuckoo filters)?
- Is it possible to clearly and systematically define organizational information needs in the CTI context?
- How can these metrics be employed to incorporate selected CTI products into the knowledge bases of organizations’ defense mechanisms in real-time?
- In what ways can these metrics be integrated into existing CTI frameworks and systems?
- Developing benchmark datasets specifically for CTI.
- Investigating the experimental comparison of CTI quality metrics.
- Examining the use of alternative probabilistic data structures for measuring CTI quality.
- Formally defining the informational needs of organizations concerning CTI.
- Researching the real-time integration of CTI products into organizational defense mechanisms, grounded in their CTI quality.
- Investigating the integration of CTI quality metrics into existing frameworks and open-source systems.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- ENISA. ENISA Threat Landscape 2022; Technical Report; ENISA: Athens, Greece, 2022. [Google Scholar] [CrossRef]
- Aïmeur, E.; Amri, S.; Brassard, G. Fake news, disinformation and misinformation in social media: A review. Soc. Netw. Anal. Min. 2023, 13, 30. [Google Scholar] [CrossRef] [PubMed]
- Ni, T.; Zhang, X.; Zhao, Q. Recovering Fingerprints from In-Display Fingerprint Sensors via Electromagnetic Side Channel. In Proceedings of the CCS 2023, 2023 ACM SIGSAC Conference on Computer and Communications Security, Copenhagen, Denmark, 26–30 November 2023; pp. 253–267. [Google Scholar] [CrossRef]
- Ni, T.; Zhang, X.; Zuo, C.; Li, J.; Yan, Z.; Wang, W.; Xu, W.; Luo, X.; Zhao, Q. Uncovering User Interactions on Smartphones via Contactless Wireless Charging Side Channels. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 21–25 May 2023; pp. 3399–3415. [Google Scholar] [CrossRef]
- Vishwakarma, R.; Jain, A.K. A survey of DDoS attacking techniques and defence mechanisms in the IoT network. Telecommun. Syst. 2020, 73, 3–25. [Google Scholar] [CrossRef]
- Ohm, M.; Plate, H.; Sykosch, A.; Meier, M. Backstabber’s Knife Collection: A Review of Open Source Software Supply Chain Attacks. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; pp. 23–43. [Google Scholar] [CrossRef]
- Sakellariou, G.; Fouliras, P.; Mavridis, I.; Sarigiannidis, P. A Reference Model for Cyber Threat Intelligence (CTI) Systems. Electronics 2022, 11, 1401. [Google Scholar] [CrossRef]
- MANDIANT. Global Perspectives on Threat Intelligence; Technical Report; MANDIANT: Reston, VA, USA, 2023. [Google Scholar]
- Taleb, I.; Serhani, M.A.; Dssouli, R. Big Data Quality Assessment Model for Unstructured Data. In Proceedings of the 2018 13th International Conference on Innovations in Information Technology, IIT 2018, Al Ain, United Arab Emirates, 18–19 November 2018; pp. 69–74. [Google Scholar] [CrossRef]
- Zibak, A.; Sauerwein, C.; Simpson, A.C. Threat Intelligence Quality Dimensions for Research and Practice. Digit. Threat. Res. Pract. 2022, 3, 44. [Google Scholar] [CrossRef]
- Tundis, A.; Ruppert, S.; Mühlhäuser, M. A Feature-driven Method for Automating the Assessment of OSINT Cyber Threat Sources. Comput. Secur. 2022, 113, 102576. [Google Scholar] [CrossRef]
- Azevedo, R.; Medeiros, I.; Bessani, A. PURE: Generating quality threat intelligence by clustering and correlating OSINT. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering, TrustCom/BigDataSE 2019, Rotorua, New Zealand, 5–8 August 2019; pp. 483–490. [Google Scholar] [CrossRef]
- Schaberreiter, T.; Kupfersberger, V.; Rantos, K.; Spyros, A.; Papanikolaou, A.; Ilioudis, C.; Quirchmayr, G. A quantitative evaluation of trust in the quality of cyber threat intelligence sources. In Proceedings of the ACM International Conference Proceeding Series, New York, NY, USA, 26–29 August 2019; p. 10. [Google Scholar] [CrossRef]
- Chismon, D.; Ruks, M. Threat Intelligence: Collecting, Analysing, Evaluating; Technical Report; MWR InfoSecurity: London, UK, 2015. [Google Scholar]
- Yang, L.; Wang, M.; Lou, W. An automated dynamic quality assessment method for cyber threat intelligence. Comput. Secur. 2025, 148, 104079. [Google Scholar] [CrossRef]
- Schlette, D.; Böhm, F.; Caselli, M.; Pernul, G. Measuring and visualizing cyber threat intelligence quality. Int. J. Inf. Secur. 2021, 20, 21–38. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, P.; Bai, G.; Wang, S.; Zhang, M.; Li, S.; Zhao, C. An Automatic Assessment Method of Cyber Threat Intelligence Combined with ATT&CK Matrix. Wirel. Commun. Mob. Comput. 2022, 2022, 12. [Google Scholar] [CrossRef]
- MITRE MITRE ATT&CK®. 2025. Available online: https://attack.mitre.org/ (accessed on 5 March 2025).
- Wagner, T.D.; Mahbub, K.; Palomar, E.; Abdallah, A.E. Cyber threat intelligence sharing: Survey and research directions. Comput. Secur. 2019, 87, 101589. [Google Scholar] [CrossRef]
- Geras, T.; Schreck, T. The “Big Beast to Tackle”: Practices in Quality Assurance for Cyber Threat Intelligence. In Proceedings of the 27th International Symposium on Research in Attacks, Intrusions and Defens, New York, NY, USA, 30 September–2 October 2024; pp. 337–352. [Google Scholar] [CrossRef]
- Tao, Y.; Zhang, Y.; Ma, S.; Fan, K.; Li, M.; Guo, F.; Xu, Z. Combining the big data analysis and the threat intelligence technologies for the classified protection model. Clust. Comput. 2017, 20, 1035–1046. [Google Scholar] [CrossRef]
- Marchetti, M.; Guido, A.; Pierazzi, F.; Colajanni, M. Countering Advanced Persistent Threats through security intelligence and big data analytics. In Proceedings of the International Conference on Cyber Conflict, CYCON, Tallinn, Estonia, 31 May–3 June 2016; pp. 243–261. [Google Scholar] [CrossRef]
- Wheelus, C.; Bou-Harb, E.; Zhu, X. Towards a big data architecture for facilitating cyber threat intelligence. In Proceedings of the 2016 8th IFIP International Conference on New Technologies, Mobility and Security, NTMS 2016, Larnaca, Cyprus, 21–23 November 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Martins, C.; Medeiros, I. Generating Quality Threat Intelligence Leveraging OSINT and a Cyber Threat Unified Taxonomy. ACM Trans. Priv. Secur. 2022, 25, 39. [Google Scholar] [CrossRef]
- Fujii, S.; Kawaguchi, N.; Shigemoto, T.; Yamauchi, T. CyNER: Information Extraction from Unstructured Text of CTI Sources with Noncontextual IOCs. In Advances in Information and Computer Security; Cheng, C.M., Akiyama, M., Eds.; Springer: Cham, Switzerland, 2022; pp. 85–104. [Google Scholar]
- Jordan, B.; Piazza, R.; Wunder, J. STIX v2.1 Specification. 2025. Available online: http://docs.oasis-open.org/cti/stix/v2.1/ (accessed on 5 March 2025).
- Sakellariou, G.; Fouliras, P.; Mavridis, I. A Methodology for Developing & Assessing CTI Quality Metrics. IEEE Access 2024, 12, 6225–6238. [Google Scholar] [CrossRef]
- Watson, K. Assessing the Potential Value of Cyber Threat Intelligence (CTI) Feeds; Technical Report; Johns Hopkins Applied Physics Laboratory: Laurel, MD, USA, 2020. [Google Scholar]
- Pawlinski, P.; Jaroszewski, P.; Kijewski, P.; Siewierski, L.; Jacewicz, P.; Zielony, P.; Zuber, R. Actionable Information for Security Incident Response; Technical Report; ENISA: Athens, Greece, 2014. [Google Scholar]
- Deliu, I.; Leichter, C.; Franke, K. Collecting Cyber Threat Intelligence from Hacker Forums via a Two-Stage, Hybrid Process using Support Vector Machines and Latent Dirichlet Allocation. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5008–5013. [Google Scholar] [CrossRef]
- Hassani, H.; Beneki, C.; Unger, S.; Mazinani, M.T.; Yeganegi, M.R. Text Mining in Big Data Analytics. Big Data Cogn. Comput. 2020, 4, 1. [Google Scholar] [CrossRef]
- Gakhov, A. Probabilistic Data Structures and Algorithms for Big Data Applications, 1st ed.; BoD–Books on Demand: Norderstedt, Germany, 2022. [Google Scholar]
- Broder, A.Z. On the resemblance and containment of documents. In Proceedings of the International Conference on Compression and Complexity of Sequences, Salerno, Italy, 13 June 1997; pp. 21–29. [Google Scholar] [CrossRef]
- Ebad, S.A.; Darem, A.A.; Abawajy, J.H. Measuring Software Obfuscation Quality—A Systematic Literature Review. IEEE Access 2021, 9, 99024–99038. [Google Scholar] [CrossRef]
- Wang, J.; Dong, Y. Measurement of Text Similarity: A Survey. Information 2020, 11, 421. [Google Scholar] [CrossRef]
- Indyk, P.; Motwani, R. Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the Conference Proceedings of the Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; pp. 604–613. [Google Scholar]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Fan, B.; Andersen, D.G.; Kaminsky, M.; Mitzenmacher, M.D. Cuckoo filter: Practically better than bloom. In Proceedings of the CoNEXT 2014—Proceedings of the 2014 Conference on Emerging Networking Experiments and Technologies, Sydney, Australia, 2–5 December 2014; pp. 75–88. [Google Scholar] [CrossRef]
- Scott, W.R.; Davis, G.F. Organizations and Organizing: Rational, Natural and Open Systems Perspectives, 1st ed.; Routledge: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Von Bertalanffy, L. The theory of open systems in physics and biology. Science 1950, 111, 23–29. [Google Scholar] [CrossRef]
- Daft, R.L. Management; Cengage Learning: Boston, MA, USA, 2015. [Google Scholar]
- Savolainen, R. Information landscapes as contexts of information practices. J. Librariansh. Inf. Sci. 2021, 53, 655–667. [Google Scholar] [CrossRef]
- Joint Task Force Transformation Initiative. NIST Special Publication 800-30 Revision 1—Guide for Conducting Risk Assessments; Technical Report September; NIST: Gaithersburg, MD, USA, 2012.
- RRDG. Domain Industry Taxonomy. 2022. Available online: https://rrdg.centr.org/projects/standards/domain-industry-taxonomy/ (accessed on 5 March 2025).
- Broder, A.Z.; Charikar, M.; Frieze, A.M.; Mitzenmacher, M. Min-wise independent permutations (extended abstract). In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; pp. 327–336. [Google Scholar] [CrossRef]
- Saltelli, A. Sensitivity Analysis for Importance Assessment. Risk Anal. 2002, 22, 579–590. [Google Scholar] [CrossRef]
- M’manga, A.; Faily, S.; McAlaney, J.; Williams, C.; Kadobayashi, Y.; Miyamoto, D. A normative decision-making model for cyber security. Inf. Comput. Secur. 2019, 26, 636–646. [Google Scholar] [CrossRef]
- Cotae, P.; Kang, M.; Velazquez, A. A Cybersecurity Model for Decision-Making Problems under Uncertainty Using Game Theory. In Proceedings of the 2020 13th International Conference on Communications, COMM 2020-Proceedings, Bucharest, Romania, 18–20 June 2020; pp. 15–22. [Google Scholar] [CrossRef]
- Jalali, M.S.; Siegel, M.; Madnick, S. Decision-making and biases in cybersecurity capability development: Evidence from a simulation game experiment. J. Strateg. Inf. Syst. 2019, 28, 66–82. [Google Scholar] [CrossRef]
- Sichman, J.S.A.; Demazeau, Y.; Boissier, O. When can knowledge-based systems be called agents. Proc. Simpósio Bras. De Inteligência Artif. 1992, 9, 172–185. [Google Scholar]
- Akerkar, R.; Sajja, P. Knowledge-Based Systems; Jones & Bartlett Publishers: Burlington, MA, USA, 2009. [Google Scholar]
- BigPicture. Free Dataset-Companies|BigPicture Documentation. 2024. Available online: https://docs.bigpicture.io/docs/free-datasets/companies/ (accessed on 5 March 2025).
- EDM Council. FIBO. 2020. Available online: https://spec.edmcouncil.org/fibo/ (accessed on 5 March 2025).
- EUROSTAT. Glossary: Statistical Classification of Economic Activities in the European Community (NACE)-Statistics Explained. 2006. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Glossary:Statistical_classification_of_economic_activities_in_the_European_Community_(NACE) (accessed on 5 March 2025).
- Fraunhofer ISC. General Process Ontology (GPO). 2021. Available online: https://data.ontocommons.linkeddata.es/vocabulary/GeneralProcessOntology(gpo) (accessed on 5 March 2025).
- NIST, C.F.P. Official Common Platform Enumeration (CPE) Dictionary. 2021. Available online: https://nvd.nist.gov/products/cpe (accessed on 5 March 2025).
- EBWSRG. The Product Types Ontology: Use Wikipedia Pages for Describing Products or Services with GoodRelations and Schema.org. 2024. Available online: http://www.productontology.org/ (accessed on 5 March 2025).
- EU. ECCF Core Ontology-EU Vocabularies-Publications Office of the EU. 2021. Available online: https://op.europa.eu/en/web/eu-vocabularies/dataset/-/resource?uri=http://publications.europa.eu/resource/dataset/54i (accessed on 5 March 2025).
- Filigran. OpenCTI Documentation. 2024. Available online: https://docs.opencti.io/latest/ (accessed on 5 March 2025).
- Palo Alto. What Is Cyber Threat Intelligence (CTI)?—Palo Alto Networks. 2025. Available online: https://www.paloaltonetworks.ca/cyberpedia/what-is-cyberthreat-intelligence-cti (accessed on 5 March 2025).
- CISA. Known Exploited Vulnerabilities Catalog. 2025. Available online: https://www.cisa.gov/known-exploited-vulnerabilities-catalog (accessed on 5 March 2025).
- CVE. Common Vulnerabilities and Exposures. 2025. Available online: https://www.cve.org/ (accessed on 5 March 2025).
- AlienVault. Open Threat Exchange. 2025. Available online: https://otx.alienvault.com/dashboard/new (accessed on 5 March 2025).
- Feedly. Feedly Threat Intelligence. 2025. Available online: https://feedly.com/i/discover (accessed on 5 March 2025).
- Fraunhofer FKIE. Malpedia. 2025. Available online: https://malpedia.caad.fkie.fraunhofer.de/ (accessed on 5 March 2025).
- MISP. MISP Default Feeds. 2025. Available online: https://www.misp-project.org/feeds/ (accessed on 5 March 2025).
- MITRE. MITRE Atlas. 2025. Available online: https://atlas.mitre.org/ (accessed on 5 March 2025).
- TweetFeed. Indicators of Compromise (IOCs) Shared by Infosec Community. 2025. Available online: https://tweetfeed.live/ (accessed on 5 March 2025).
- Sillaber, C.; Sauerwein, C.; Mussmann, A.; Breu, R. Data Quality Challenges and Future Research Directions in Threat Intelligence Sharing Practice. In Proceedings of the 2016 ACM on Workshop on Information Sharing and Collaborative Security, New York, NY, USA, 24 October 2016; pp. 65–70. [Google Scholar] [CrossRef]
- Dimitriadis, A.; Prassas, C.; Flores, J.L.; Kulvatunyou, B.; Ivezic, N.; Gritzalis, D.A.; Mavridis, I.K. Contextualized Filtering for Shared Cyber Threat Information. Sensors 2021, 21, 4890. [Google Scholar] [CrossRef]
- Ehrlinger, L.; Wöß, W. A Survey of Data Quality Measurement and Monitoring Tools. Front. Big Data 2022, 5, 850611. [Google Scholar] [CrossRef]
- Heinrich, B.; Hristova, D.; Klier, M.; Schiller, A.; Szubartowicz, M. Requirements for Data Quality Metrics. J. Data Inf. Qual. (JDIQ) 2018, 9, 12. [Google Scholar] [CrossRef]
- MITRE-C0010. C0010, Campaign C0010|MITRE ATT&CK®. 2025. Available online: https://attack.mitre.org/campaigns/C0010/ (accessed on 5 March 2025).
- MITRE-Night Dragon. Night Dragon, Campaign C0002|MITRE ATT&CK®. 2025. Available online: https://attack.mitre.org/campaigns/C0002/ (accessed on 5 March 2025).
- MITRE-Operation Spalax. Operation Spalax, Campaign C0005|MITRE ATT&CK®. 2025. Available online: https://attack.mitre.org/campaigns/C0005/ (accessed on 5 March 2025).
- Rahman, M.M.; Siddika Arshi, A.; Hasan, M.M.; Farzana Mishu, S.; Shahriar, H.; Wu, F. Security Risk and Attacks in AI: A Survey of Security and Privacy. In Proceedings of the International Computer Software and Applications Conference, Torino, Italy, 26–30 June 2023; pp. 1834–1839. [Google Scholar] [CrossRef]
- Sun, H.; Zhu, T.; Zhang, Z.; Jin, D.; Xiong, P.; Zhou, W. Adversarial Attacks Against Deep Generative Models on Data: A Survey. IEEE Trans. Knowl. Data Eng. 2023, 35, 3367–3388. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Strengths | Weaknesses |
|---|---|---|
| Tale et al. [9] | evaluation of quality on unstructured big data | domain agnostic, not focusing on CTI |
| Zibak et al. [10] | identification of key CTI quality dimensions and CTI quality challenges | lack of analysis on technical implementation |
| Tundis et al. [11] | CTI relevance score, combination of different CTI quality factors | focus on CTI sources and not on the CTI products |
| Azevedo et al. [12] | CTI quality-based enrichment of IoCs | not designed to handle big data |
| Schaberreiter et al. [13] | evaluation of CTI sources trust, continuous estimation of a CTI source indicator | closed-world assumption about the threat intelligence |
| Yang et al. [15] | combination of various quality factors for the measurement of CTI products trustworthiness and availability | not addressing the characteristics of CTI consumers |
| Schlette et al. [16] | introduces a set of STIX-based data quality dimensions | limited to structured CTI products |
| Zhang et al. [17] | quality assessment of large-scale CTI | not exploring the CTI quality factors for the assessment but specific features of IoCs |
| Tao et al. [21] | big-data analysis of CTI for the improvement of defense mechanisms | bulk consumption of CTI remains a problem, no CTI quality evaluation |
| Marchetti et al. [22] | big-data analysis of CTI | no measurement of CTI effectiveness |
| Wheelus et al. [23] | big-data based processing of CTI | not exploring the quality of the produced intelligence |
| Martins et al. [24] | pipeline-based processing of CTI products to improve their quality | not targeting on the improvement of specific quality factors |
| Step | Description |
|---|---|
| 1 | Based on the CTI data or sources, try to identify what can better express their quality and name this metric M. |
| 2 | Determine the set of variables X necessary to calculate M. |
| 3 | Define function F, which computes metric M. |
| 4 | Analyze X and F to determine subjectivity and objectivity . |
| 5 | Analyze F to determine the performance of M (i.e., time complexity of M calculation), P. |
| 6 | Analyze F to determine the precision of M, A. |
| 7 | Conduct sensitivity analysis on M to determine B. |
| 8 | Construct metric |
| Landscape | Information Needs of | Ontology and Datasets |
|---|---|---|
| Input Landscape () | Suppliers | Companies [52] |
| Competitors | ||
| Capital Sources | Financial Industry Business Ontology (FIBO) [53] | |
| Transformation Process Landscape () | Business Activities | Nomenclature statistique des Activites economiques dans la Communaute Europeenne (NACE) [54], Domain Industry Taxonomy (DIT) [44] |
| Internal Operations | General Process Ontology (GPO) [55] | |
| Information Systems | Common Platform Enumeration (CPE) [56] | |
| Output Landscape () | Products Services | FIBO [53], Product Types Ontology (PTO) [57], European Core Conceptual Framework (ECCF) [58] |
| CTI Sources | Num. of CTI Products in Dataset | Num. of CTI Products in Validation Dataset |
|---|---|---|
| MITRE ATT&CK [18], CISA KNOWN VULNERABILITIES [61], CVE [62], ALIENVAULT [63], FEEDLY [64], MALPEDIA [65], MISP FEEDS [66], MITRE ATLAS [67], TWEETFEED [68] | 32,012 | 5000 |
| Org. | Input Landscape () | Transformation Process Landscape () | Output Landscape () | |||||
|---|---|---|---|---|---|---|---|---|
| Num. of Suppliers | Num. of Competitors | Num. of Capital Sources | Num. of Business Activities | Num. of Internal Operations | Num. of Information System | Num. of Products | Num. of Services | |
| 12 | 16 | 10 | 18 | 10 | 18 | 1 | 8 | |
| 12 | 6 | 6 | 8 | 4 | 18 | 3 | 1 | |
| 14 | 19 | 7 | 12 | 10 | 15 | 5 | 9 | |
| 19 | 6 | 6 | 16 | 6 | 18 | 5 | 5 | |
| 17 | 18 | 5 | 10 | 1 | 16 | 7 | 7 | |
| 7 | 12 | 11 | 14 | 7 | 17 | 1 | 2 | |
| 9 | 14 | 4 | 7 | 9 | 19 | 9 | 1 | |
| 12 | 14 | 11 | 19 | 9 | 13 | 5 | 3 | |
| 19 | 5 | 7 | 13 | 10 | 18 | 9 | 3 | |
| 9 | 13 | 2 | 5 | 7 | 11 | 10 | 3 | |
| Org. | Num. of DMs | Num. of CTI Products in KB of a DM | Total Num. of CTI Products in the KBs of the DMs |
|---|---|---|---|
| 17 | 179 | 3043 | |
| 15 | 477 | 7155 | |
| 3 | 1789 | 5367 | |
| 18 | 293 | 293 | |
| 27 | 346 | 346 | |
| 5 | 507 | 507 | |
| 12 | 804 | 804 | |
| 14 | 417 | 417 | |
| 4 | 1917 | 1917 | |
| 8 | 1116 | 8298 |
| Landscape | Profile |
|---|---|
| Input Landscape () | Num. of Suppliers: 14 (e.g., GRIVE) |
| Num. of Competitors: 19 (e.g., M.A.P.L.E) | |
| Num. of Capital Sources: 7 (e.g., SPDR S&P 500 ETF Trust) | |
| Transformation Process Landscape () | Num. of Business Activities: 12 (e.g., “auxiliary to financial services”) |
| Num. of Internal Operations: 10 (e.g., Information Transport Process) | |
| Num. of Information Systems: 15 (e.g., XR3Player) | |
| Output Landscape () | Num. of Products: 5 (e.g., carpets, food products) |
| Num. of Services: 9 (e.g., community services) |
| Number of Defense Mechanisms | Number of CTI Products in Knowledge Base of a Defense Mechanism | Total Number of CTI Products in the Knowledge Bases of the Defense Mechanisms |
|---|---|---|
| 4 | 1917 | 7668 |
| Measurement of Metric | Measurement of | ||
|---|---|---|---|
| Product | Remark | Product | Remark |
| P1 | Poll Vaulting Report | P1 | NETBIOS Scanner Report |
| P2 | Wrong Sphere Vulnerability Report | P2 | Cross-Site Scripting Vulnerability Report |
| P3 | OT URL Activity Report | P3 | SQL Injection Attack Report |
| P4 | Linux Kernel Vulnerability Report | P4 | Wrong HTTP Header Encoding Report |
| P5 | Firmware Buffer Overflow Vulnerability Report | P5 | Wrong HTTP Header Encoding Report |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sakellariou, G.; Katsantonis, M.; Fouliras, P. Probabilistic Measurement of CTI Quality for Large Numbers of Unstructured CTI Products. Electronics 2025, 14, 1826. https://doi.org/10.3390/electronics14091826
Sakellariou G, Katsantonis M, Fouliras P. Probabilistic Measurement of CTI Quality for Large Numbers of Unstructured CTI Products. Electronics. 2025; 14(9):1826. https://doi.org/10.3390/electronics14091826
Chicago/Turabian StyleSakellariou, Georgios, Menelaos Katsantonis, and Panagiotis Fouliras. 2025. "Probabilistic Measurement of CTI Quality for Large Numbers of Unstructured CTI Products" Electronics 14, no. 9: 1826. https://doi.org/10.3390/electronics14091826
APA StyleSakellariou, G., Katsantonis, M., & Fouliras, P. (2025). Probabilistic Measurement of CTI Quality for Large Numbers of Unstructured CTI Products. Electronics, 14(9), 1826. https://doi.org/10.3390/electronics14091826