
Improving Dynamic Gesture Recognition with Attention-Enhanced LSTM and Grounding SAM


Abstract
1. Introduction
- 1.
- A text-guided Grounding SAM preprocessing framework is proposed for accurate gesture-region localization and segmentation. By binarizing the extracted features, the method effectively reduces computational complexity while preserving essential spatial information, improving efficiency.
- 2.
- A hybrid recognition model that combines multi-head attention mechanisms with LSTM is introduced to enhance the model’s ability to focus on key hand regions and capture the temporal evolution of gestures. This significantly improves gesture-recognition accuracy and temporal modeling capability in dynamic scenarios.
2. Related Work
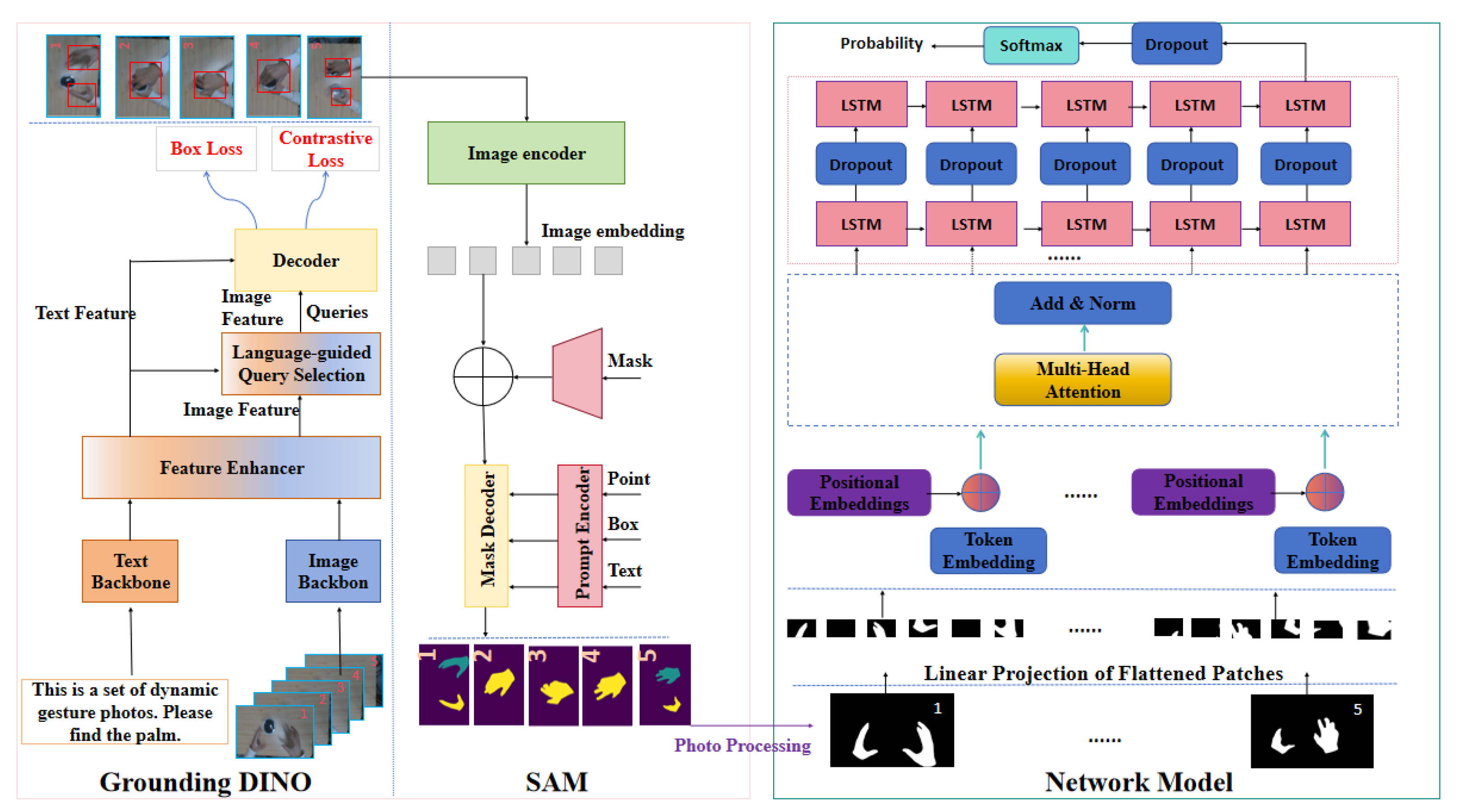
3. Methods
3.1. Grounding SAM Data Preprocessing
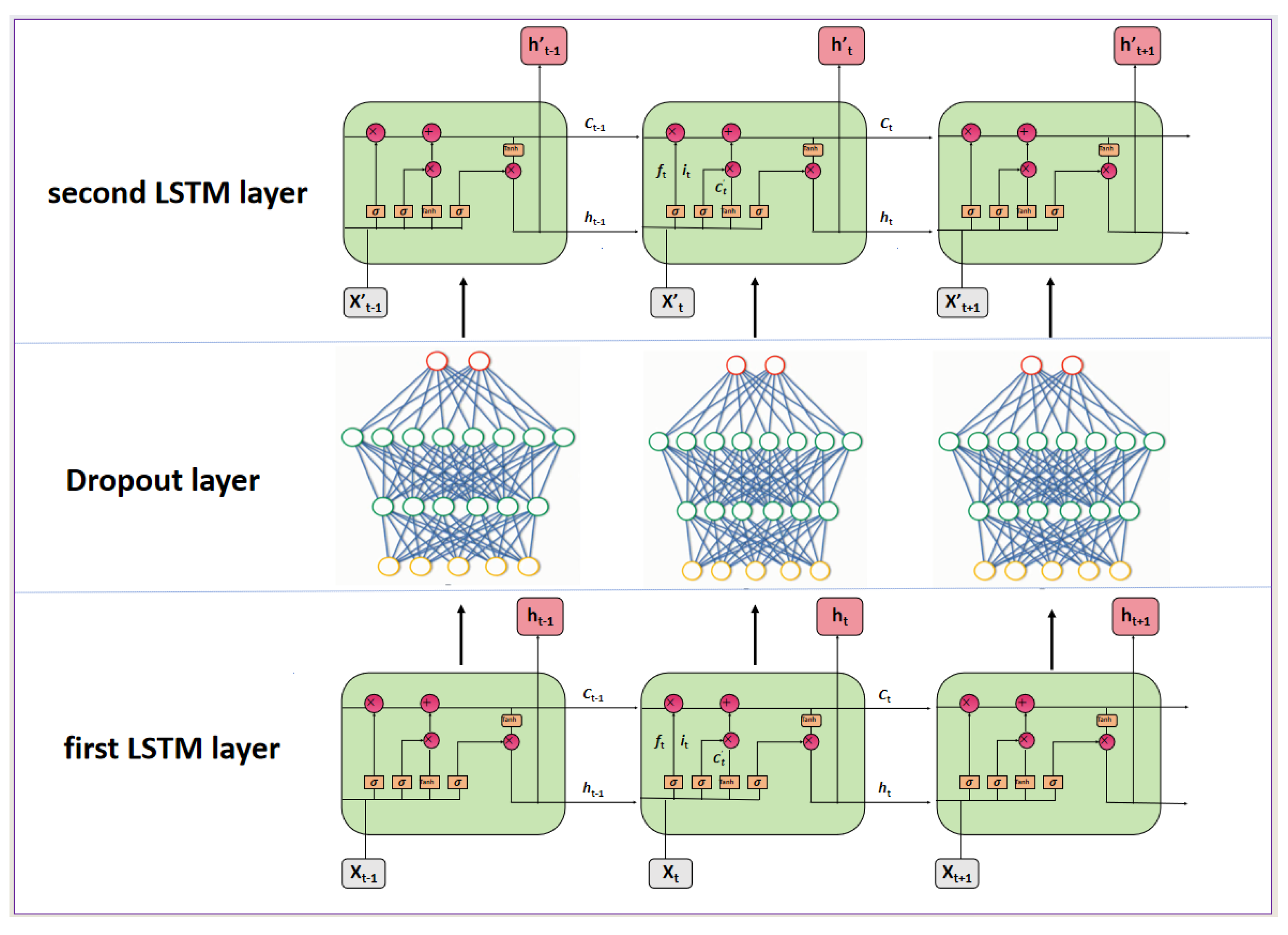
3.2. Network Model
| Algorithm 1 Algorithm for dynamic gesture recognition |
|
- Key Steps:
- Input Processing: The input is a sequence of images representing a dynamic gesture. Each frame is encoded using token and positional encoding, which allows the model to incorporate spatial structure and temporal order.
- Transformer Stage: The encoded sequence is passed through Transformer layers. In each layer, multi-head attention enables the model to attend to different parts of the sequence in parallel. This is followed by residual connections and layer normalization (Add/Norm), which help stabilize training and improve gradient flow [34].
- LSTM Stage: The output of the Transformer is then fed into a two-layer LSTM network, which captures long-term temporal dependencies across the sequence. Dropout is applied between and after the LSTM layers to prevent overfitting and enhance generalization.
- Prediction: The final LSTM output is passed through a Softmax layer to produce the classification result.
4. Experimental Design and Results Analysis
4.1. Introduction to the SHREC 2017 Dataset and Our Dataset
4.2. Ablation Study
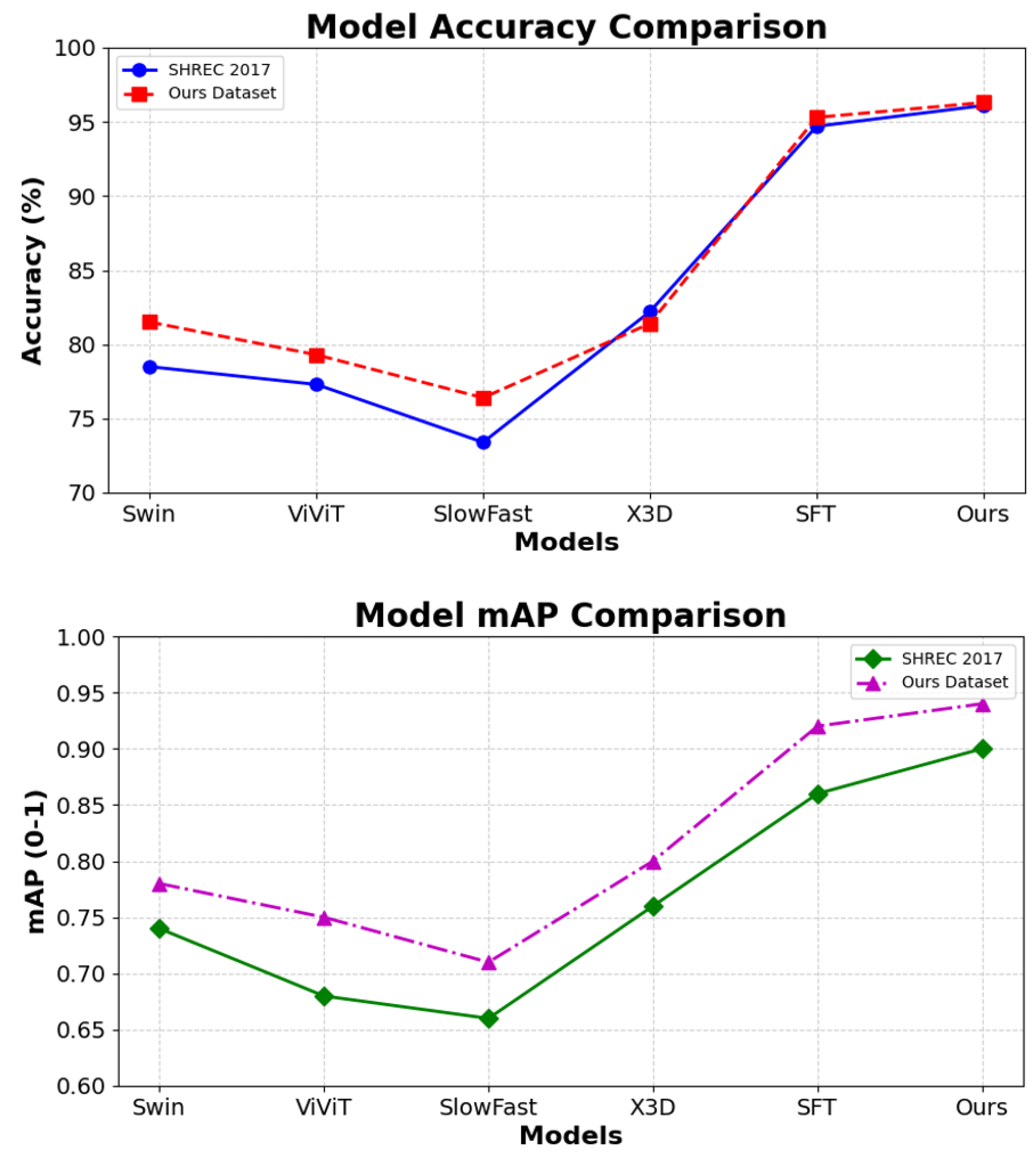
4.3. Performance Comparison on SHREC 2017 and Our Dataset
- Swin Transformer adopts a hierarchical structure with shifted windows to efficiently capture spatial representations.
- ViViT extends Vision Transformers to video tasks by decomposing attention mechanisms for temporal and spatial modeling.
- SlowFast employs a dual-pathway structure to model both slow and fast motion streams, well suited for capturing dynamic changes.
- X3D expands 2D CNNs along spatial–temporal dimensions, offering a good balance between performance and efficiency.
- SFT (Space-Time Fusion Transformer) integrates spatial and temporal features through Transformer modules tailored for hand-gesture tasks.
- Ours combines Transformer encoding with dual-layer LSTM for sequential modeling, enhanced by multi-head attention and normalization layers, yielding superior performance across both benchmark and real-world datasets.
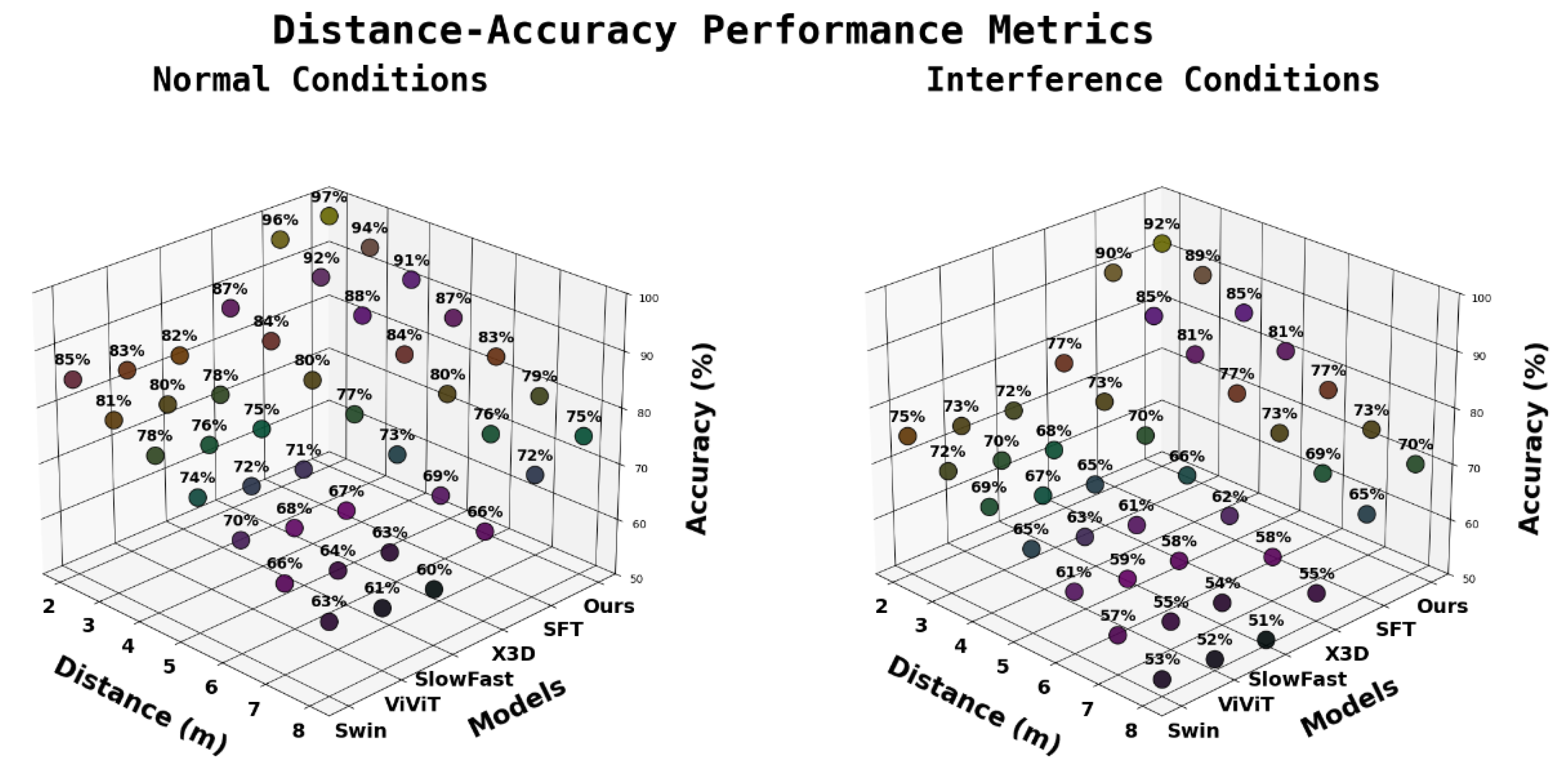
4.4. Model Performance Under Different Conditions
4.5. Computational Cost and Deployment Considerations
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4207–4215. [Google Scholar]
- Wu, D.; Pigou, L.; Kindermans, P.J.; Le, N.D.H.; Shao, L.; Dambre, J.; Odobez, J.M. Deep dynamic neural networks for multimodal gesture segmentation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1583–1597. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Networks Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Suresha, M.; Kuppa, S.; Raghukumar, D. A study on deep learning spatiotemporal models and feature extraction techniques for video understanding. Int. J. Multimed. Inf. Retr. 2020, 9, 81–101. [Google Scholar] [CrossRef]
- Fu, R.; Liang, H.; Wang, S.; Jia, C.; Sun, G.; Gao, T.; Chen, D.; Wang, Y. Transformer-BLS: An efficient learning algorithm based on multi-head attention mechanism and incremental learning algorithms. Expert Syst. Appl. 2024, 238, 121734. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4015–4026. [Google Scholar]
- Liu, R.; Zhang, J.; Peng, K.; Zheng, J.; Cao, K.; Chen, Y.; Yang, K.; Stiefelhagen, R. Open scene understanding: Grounded situation recognition meets segment anything for helping people with visual impairments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 1857–1867. [Google Scholar]
- Liu, C.; Wu, Y.; Liu, J.; Sun, Z. Improved YOLOv3 network for insulator detection in aerial images with diverse background interference. Electronics 2021, 10, 771. [Google Scholar] [CrossRef]
- Bambach, S.; Lee, S.; Crandall, D.J.; Yu, C. Lending a hand: Detecting hands and recognizing activities in complex egocentric interactions. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1949–1957. [Google Scholar]
- Nolker, C.; Ritter, H. Visual recognition of continuous hand postures. IEEE Trans. Neural Netw. 2002, 13, 983–994. [Google Scholar] [CrossRef]
- Lee, M.; Bae, J. Real-time gesture recognition in the view of repeating characteristics of sign languages. IEEE Trans. Ind. Inform. 2022, 18, 8818–8828. [Google Scholar] [CrossRef]
- Zheng, C.; Lin, W.; Xu, F. A Self-Occlusion Aware Lighting Model for Real-Time Dynamic Reconstruction. IEEE Trans. Vis. Comput. Graph. 2022, 29, 4062–4073. [Google Scholar] [CrossRef]
- Iwase, S.; Saito, S.; Simon, T.; Lombardi, S.; Bagautdinov, T.; Joshi, R.; Prada, F.; Shiratori, T.; Sheikh, Y.; Saragih, J. Relightablehands: Efficient neural relighting of articulated hand models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17– 24 June 2023; pp. 16663–16673. [Google Scholar]
- Blunsom, P. Hidden markov models. Lect. Notes August 2004, 15, 48. [Google Scholar]
- Lichtenauer, J.F.; Hendriks, E.A.; Reinders, M.J. Sign language recognition by combining statistical DTW and independent classification. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 2040–2046. [Google Scholar] [CrossRef]
- Lu, P.; Zhang, M.; Zhu, X.; Wang, Y. Head nod and shake recognition based on multi-view model and hidden markov model. In Proceedings of the International Conference on Computer Graphics, Imaging and Visualization (CGIV’05), Beijing, China, 26–29 July 2005; pp. 61–64. [Google Scholar]
- Köpüklü, O.; Gunduz, A.; Kose, N.; Rigoll, G. Real-time hand gesture detection and classification using convolutional neural networks. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Min, Y.; Zhang, Y.; Chai, X.; Chen, X. An efficient pointlstm for point clouds based gesture recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5761–5770. [Google Scholar]
- Zhang, W.; Wang, J.; Lan, F. Dynamic hand gesture recognition based on short-term sampling neural networks. IEEE/CAA J. Autom. Sin. 2020, 8, 110–120. [Google Scholar] [CrossRef]
- Hampiholi, B.; Jarvers, C.; Mader, W.; Neumann, H. Convolutional transformer fusion blocks for multi-modal gesture recognition. IEEE Access 2023, 11, 34094–34103. [Google Scholar] [CrossRef]
- Slama, R.; Rabah, W.; Wannous, H. Online hand gesture recognition using Continual Graph Transformers. arXiv 2025, arXiv:2502.14939. [Google Scholar]
- Hu, Z.; Gao, K.; Zhang, X.; Yang, Z.; Cai, M.; Zhu, Z.; Li, W. Efficient Grounding DINO: Efficient Cross-Modality Fusion and Efficient Label Assignment for Visual Grounding in Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–14. [Google Scholar] [CrossRef]
- Duch, W.; Adamczak, R.; Grabczewski, K. A new methodology of extraction, optimization and application of crisp and fuzzy logical rules. IEEE Trans. Neural Netw. 2001, 12, 277–306. [Google Scholar] [CrossRef]
- Zhai, J.; Tian, F.; Ju, F.; Zou, X.; Qian, S. with Bounding SAM for HIFU Target Region Segmentation. In Pattern Recognition and Computer Vision, Proceedings of the 7th Chinese Conference, PRCV 2024, Urumqi, China, 18–20 October 2024, Proceedings, Part XIV; Springer Nature: Berlin/Heidelberg, Germany, 2024; Volume 15044, p. 118. [Google Scholar]
- Min, R.; Wang, X.; Zou, J.; Gao, J.; Wang, L.; Cao, Z. Early gesture recognition with reliable accuracy based on high-resolution IoT radar sensors. IEEE Internet Things J. 2021, 8, 15396–15406. [Google Scholar] [CrossRef]
- Yao, T.; Li, Y.; Pan, Y.; Wang, Y.; Zhang, X.P.; Mei, T. Dual vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10870–10882. [Google Scholar] [CrossRef]
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man, Cybern. Part C Appl. Rev. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, C.; Song, H.; Li, Y. Multi-head self-attention transformation networks for aspect-based sentiment analysis. IEEE Access 2021, 9, 8762–8770. [Google Scholar] [CrossRef]
- Sauvola, J.; Pietikäinen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wang, J.; Zhang, J.; Wang, X. Bilateral LSTM: A two-dimensional long short-term memory model with multiply memory units for short-term cycle time forecasting in re-entrant manufacturing systems. IEEE Trans. Ind. Inform. 2017, 14, 748–758. [Google Scholar] [CrossRef]
- Jin, R.; Chen, Z.; Wu, K.; Wu, M.; Li, X.; Yan, R. Bi-LSTM-based two-stream network for machine remaining useful life prediction. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Viel, F.; Maciel, R.C.; Seman, L.O.; Zeferino, C.A.; Bezerra, E.A.; Leithardt, V.R.Q. Hyperspectral image classification: An analysis employing CNN, LSTM, transformer, and attention mechanism. IEEE Access 2023, 11, 24835–24850. [Google Scholar] [CrossRef]
- Savva, M.; Yu, F.; Su, H.; Kanezaki, A.; Furuya, T.; Ohbuchi, R.; Zhou, Z.; Yu, R.; Bai, S.; Bai, X.; et al. Shrec’17 track large-scale 3d shape retrieval from shapenet core55. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017; Volume 10. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 203–213. [Google Scholar]
- Beeri, E.B.; Nissinman, E.; Sintov, A. Recognition of Dynamic Hand Gestures in Long Distance using a Web-Camera for Robot Guidance. arXiv 2024, arXiv:2406.12424. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Removed Component | Accuracy (%) | F1 | Epochs |
|---|---|---|---|---|
| Full Model | None | 96.3 | 0.94 | 300 |
| No Transformer | Transformer | 87.5 | 0.85 | 300 |
| No LSTM | LSTM | 89.2 | 0.88 | 300 |
| No Token Enc. | Token Encoding | 91.4 | 0.91 | 300 |
| No Pos. Enc. | Positional Encoding | 92.0 | 0.92 | 300 |
| No Dropout | Dropout | 90.1 | 0.89 | 300 |
| No Softmax | Softmax | 93.0 | 0.92 | 300 |
| No Trans. and LSTM | Transformer and LSTM | 75.3 | 0.75 | 300 |
| Dataset | Model | Accuracy | mAP |
|---|---|---|---|
| SHREC 2017 Dataset | Swin [36] | 78.5 | 0.74 |
| ViViT [37] | 77.3 | 0.68 | |
| SlowFast [38] | 73.4 | 0.66 | |
| X3D [39] | 82.2 | 0.76 | |
| SFT [40] | 94.7 | 0.86 | |
| Ours | 96.1 | 0.90 | |
| Our Dataset | Swin | 81.5 | 0.78 |
| ViViT | 79.3 | 0.75 | |
| SlowFast | 76.4 | 0.71 | |
| X3D | 81.4 | 0.80 | |
| SFT | 95.3 | 0.92 | |
| Ours | 96.3 | 0.94 |
| Distance (m) | Swin [36] | ViViT [37] | SlowFast [38] | X3D [39] | SFT [40] | Ours |
|---|---|---|---|---|---|---|
| 2 | 85 | 83 | 82 | 87 | 96 | 97 |
| 3 | 81 | 80 | 78 | 84 | 92 | 94 |
| 4 | 78 | 76 | 75 | 80 | 88 | 91 |
| 5 | 74 | 72 | 71 | 77 | 84 | 87 |
| 6 | 70 | 68 | 67 | 73 | 80 | 83 |
| 7 | 66 | 64 | 63 | 69 | 76 | 79 |
| 8 | 63 | 61 | 60 | 66 | 72 | 75 |
| Under Interference Conditions | ||||||
| 2 | 75 | 73 | 72 | 77 | 90 | 92 |
| 3 | 72 | 70 | 68 | 73 | 85 | 89 |
| 4 | 69 | 67 | 65 | 70 | 81 | 85 |
| 5 | 65 | 63 | 61 | 66 | 77 | 81 |
| 6 | 61 | 59 | 58 | 62 | 73 | 77 |
| 7 | 57 | 55 | 54 | 58 | 69 | 73 |
| 8 | 53 | 52 | 51 | 55 | 65 | 70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Jin, F.; Jiao, Y.; Zhan, Y.; Qin, X. Improving Dynamic Gesture Recognition with Attention-Enhanced LSTM and Grounding SAM. Electronics 2025, 14, 1793. https://doi.org/10.3390/electronics14091793
Chen J, Jin F, Jiao Y, Zhan Y, Qin X. Improving Dynamic Gesture Recognition with Attention-Enhanced LSTM and Grounding SAM. Electronics. 2025; 14(9):1793. https://doi.org/10.3390/electronics14091793
Chicago/Turabian StyleChen, Jinlong, Fuqiang Jin, Yingjie Jiao, Yongsong Zhan, and Xingguo Qin. 2025. "Improving Dynamic Gesture Recognition with Attention-Enhanced LSTM and Grounding SAM" Electronics 14, no. 9: 1793. https://doi.org/10.3390/electronics14091793
APA StyleChen, J., Jin, F., Jiao, Y., Zhan, Y., & Qin, X. (2025). Improving Dynamic Gesture Recognition with Attention-Enhanced LSTM and Grounding SAM. Electronics, 14(9), 1793. https://doi.org/10.3390/electronics14091793