1. Introduction
Recently, deep learning technologies combined with modern imaging systems have emerged as key tools for diagnosing various cerebrovascular disorders, such as aneurysms, aortic dissections, and intracerebral hemorrhages. Pan et al. [
1] used wavelet scattering transform to analyze multi-character electroencephalogram (EEG) signals. The team led by Li [
2] reconstructed visual stimulus images through a deep visual representation model. Zhang et al. [
3] verified the optimization effect of intracranial pressure monitoring on intracerebral hemorrhage surgery. These cross-disciplinary advancements provide methodological references for vascular imaging analysis.
An intracranial aneurysm refers to a pathological expansion of the cerebral arterial wall, typically resulting from either inherited vessel fragility or postnatal injury, with an estimated prevalence of 3% [
4]. They are a major cause of subarachnoid hemorrhage [
5]. Aneurysm rupture can be life threatening, with a mortality rate reaching 32% [
6]. After the first rupture, 8% to 32% of patients may die, with a disability and mortality rate exceeding 60% within one year and reaching 85% within two years [
7,
8]. Therefore, early diagnosis and treatment are crucial. Early detection of aneurysms is of great value for the secondary prevention of intracerebral hemorrhage (ICH). The intervention strategy based on intracranial pressure detection can reduce the mortality rate of ICH patients [
3]. At present, the diagnosis of intracranial aneurysms commonly utilizes imaging techniques, such as computed tomography (CT), digital subtraction angiography (DSA), computed tomography angiography (CTA), and magnetic resonance angiography (MRA), among which DSA is widely acknowledged as the most accurate diagnostic modality [
9].
Intracranial aneurysm detection methods are typically divided into traditional techniques and deep learning-based approaches. Early methods relied on handcrafted features. For example, Rahmany et al. [
10] used the MSER algorithm to extract vascular structures from DSA images, and they then combined it with Zernike moments to identify aneurysm regions. However, due to the complexity of aneurysm morphology and location, traditional algorithms have limited generalization ability.
Deep learning recently showed strong effectiveness in analyzing medical images, making it an important tool for assisted diagnosis. The application of convolutional neural networks (CNNs) has driven the automation of intracranial aneurysm detection. Nakao et al. [
11] proposed a detection method combining CNN with maximum intensity projection (MIP), while Claux et al. [
12] adopted a dual-stage U-Net [
13] for MRI-based aneurysm detection, achieving good results but with high computational costs. Mask R-CNN [
14] has shown excellent performance in medical image analysis but is computationally complex, making real-time detection challenging. TransUNet [
15], which integrates Transformer and U-Net, enhances the detection of small aneurysms but requires substantial computational resources, limiting its application in low-power devices. Therefore, while CNNs and their variants perform well in medical image detection, their high computational complexity remains a challenge for real-time detection and lightweight deployment.
In terms of general object detection, the YOLO series algorithms have gained widespread attention due to their efficient end-to-end detection performance. Qiu et al. [
16] successfully utilized YOLOv5 to predict the bounding boxes of intracranial arterial stenosis in MRA images, demonstrating the feasibility of the YOLO series in medical image analysis. However, in the task of intracranial aneurysm detection, YOLO-based algorithms still face several challenges: (1) Limited multi-scale feature fusion capability, making it difficult to detect small or morphologically complex aneurysms. (2) High computational cost, restricting deployment on embedded devices or low-power computing terminals.
In order to tackle these difficulties, this article presents AS-YOLO, a lightweight algorithm designed for detecting intracranial aneurysms, which is specifically optimized for aneurysm detection. The key contributions of this study are listed below.
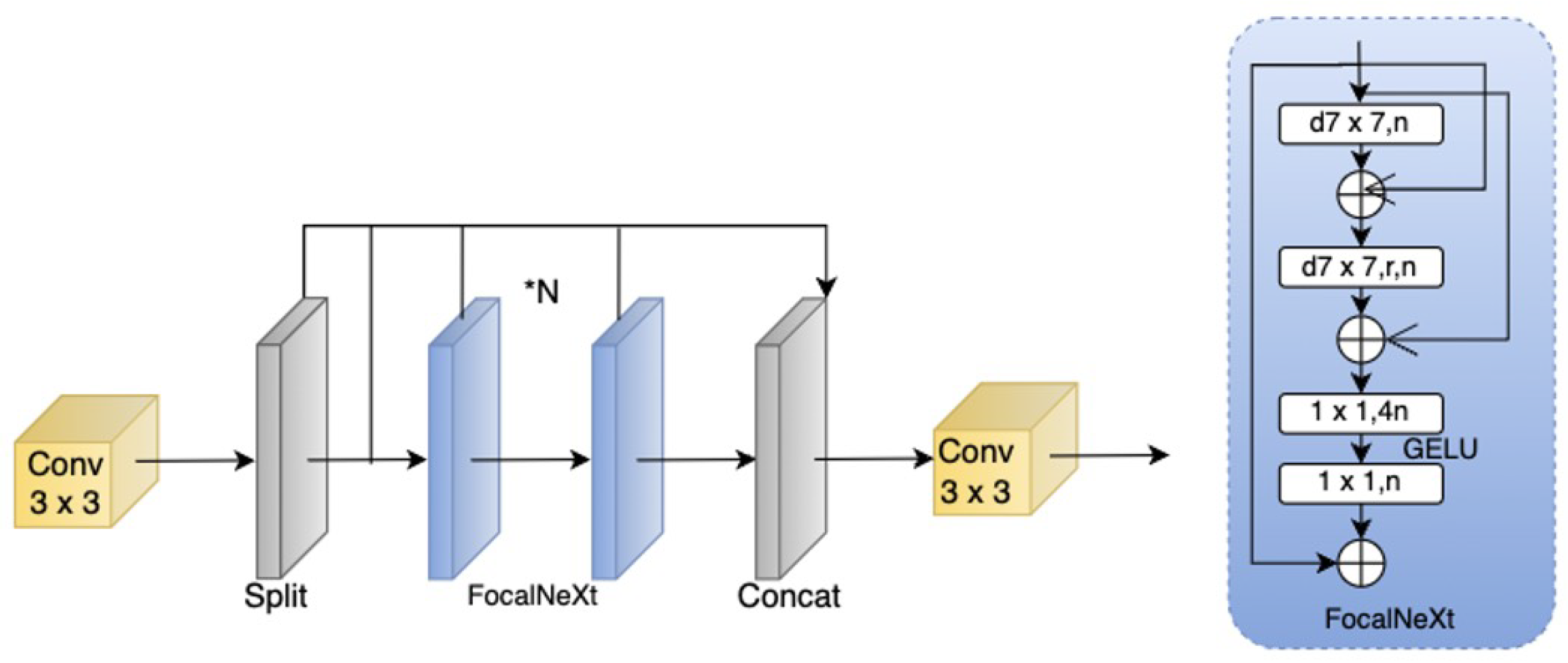
Improved Cascade Fusion Network (CFNeXt): To enhance multi-scale feature fusion capability, this paper introduces the CFNeXt network, which replaces the C2F module in the YOLOv8 backbone with an improved CFocalNeXt module. This modification generates more hierarchical feature representations, improving the recognition of aneurysms of varying scales.
Multi-Level Feature Fusion Module (MLFF): To address the limitations of YOLOv8 in feature fusion, MLFF employs 3D convolution and scale-sequence feature extraction, integrating high-dimensional information from both deep and shallow feature maps. This significantly enhances feature fusion effectiveness, particularly in the detection of small aneurysms.
Efficient Depthwise Separable Convolutional Aggregation (EDSA) Detection Head: The multi-level symmetric compression structure in the YOLOv8 detection head has limitations in flexibility. This paper proposes the EDSA detection head, which allows for more adaptable processing of diverse feature representations and aneurysm size distributions, thereby improving detection speed while reducing computational overhead.
Improved SIoU Loss Function: To address the slow convergence issue of CIOU Loss in the regression process, this work introduces the SIoU loss function. By considering the angular vector between the predicted and ground truth bounding boxes, SIoU enhances bounding box alignment precision and accelerates training convergence.
The experimental findings indicate that AS-YOLO notably enhances multi-scale feature fusion, computational efficiency, and overall model compactness. AS-YOLO outperforms YOLOv8 with 3.51% higher accuracy and 8.7% higher mAP50, while reducing parameters by 8.21% on the DSA intracranial aneurysm dataset, thus offering a tradeoff between accuracy and lightweight deployment. The next section will provide a detailed description of the AS-YOLO algorithm’s foundation and innovations.
3. Results
3.1. Experimental Setup and Dataset Preparation
The model was trained with a batch size of 64 using the SGD optimizer, an initial learning rate of 0.01, a weight decay of 0.0005, and 300 training epochs.
This study employed an NVIDIA GeForce RTX 3090 GPU (24 GB) as the hardware platform. The software setup consisted of Ubuntu 20.04, PyTorch 1.9.0, Python 3.8, and CUDA 11.3 as the primary deep learning environment.
The dataset used consists of DSA images of intracranial aneurysms from the First Affiliated Hospital of Zhejiang University School of Medicine, involving 120 patients who were admitted in 2023. After screening, a total of 867 images were obtained. These images cover the various locations and morphologies of aneurysms. In the annotation process, we collaborated with professional neuro-interventional doctors. With the help of the LabelImg tool, the aneurysm regions were accurately marked with rectangular bounding boxes. The aneurysm lesions are classified into two types: sidewall aneurysms and bifurcation aneurysms, as shown in
Figure 7. The former are mostly located on one side of the arterial wall, while the latter are commonly found at vascular bifurcations. Bifurcation aneurysms have a complex shape, making them more difficult to identify. Classifying and annotating these two types of aneurysms helps to improve the recognition ability of the model.
The dataset is split into training and test sets in an 8:2 ratio, with 694 and 173 images included in each set, respectively. The data of the same patient are only included in either the training set or the test set to prevent data leakage. Meanwhile, the stratified sampling method was adopted, which stratified the images according to the types and sizes of aneurysms to ensure that the distributions of the training set and the test set were consistent. When training the model, the input image size is set to 640 × 640.
Besides preparing and splitting the dataset, we applied several data augmentation strategies to improve the model’s generalization ability and robustness. In terms of geometric transformations, we randomly rotated the images within the range of ±15° to simulate the differences in shooting angles during actual imaging, and we then scaled the images within the range of 0.8 to 1.2 times to enhance the model’s detection performance across various object sizes. During optical transformations, we added Gaussian noise with a standard deviation of = 0.01 to the images to simulate common noise in medical images, and we then adjusted the contrast at the same time to adapt to different imaging devices. In feature space augmentation, we randomly occluded regions of 16 × 16 pixels with a probability of 0.3, thereby enhancing the model’s detection ability in complex backgrounds.
3.2. Experimental Evaluation Index
This study evaluated the model’s detection performance using the metrics of precision (
P), recall (
R),
mAP, number of parameters (params), and FLOPs. Precision (
P) measures the ratio of the true positive predictions to all predicted positives, while recall (
R) indicates the proportion of detected positives out of actual positives. Mean average precision (
mAP) offers a detailed assessment of the model’s performance across categories, effectively evaluating its detection capability in diverse scenarios. Based on the following formulas,
TP denotes the correctly predicted bounding boxes,
FP indicates false positive samples,
FN represents missed positives,
AP is the precision for each category,
mAP is the mean precision across categories, and
k is the number of categories.
Additionally, we considered model parameters (params) and floating point operations (FLOPs) as key performance metrics. The number of parameters reflects the model’s complexity and memory usage. A smaller number of parameters generally indicates a more lightweight model, making it more suitable for deployment in resource-constrained environments. FLOPs, on the other hand, measure the model’s computational demand. Lower FLOPs suggest improved real-time performance. Considering these metrics together allows for a more comprehensive evaluation of the model, confirming its practicality and efficiency in real-world applications.
3.3. Data Analysis
This study evaluated the performance of the YOLOv8n and AS-YOLO models on datasets. Detection results for each category are shown in
Table 5. The detection results using two algorithms are shown in
Figure 8.
The experiments show that AS-YOLO improves the mAP@0.5 by 6.8% over the original YOLOv8 model. Specifically, in the detection tasks for forked-type and side-type targets, AS-YOLO achieves mAP@0.5 scores of 0.834 and 0.814, respectively, showing significant improvements over the original algorithm. Furthermore, as shown in
Figure 9, the P-R curve indicates that AS-YOLO achieves performance enhancements across all categories. Particularly in the more challenging task of detecting side-type targets, AS-YOLO exhibits stronger robustness and higher detection accuracy, fully demonstrating the superiority of the improved algorithm in complex scenarios.
Figure 10 shows AS-YOLO’s performance in detecting intracranial aneurysm targets. The improved model’s heatmap reveals more prominent aneurysm target areas. This indicates AS-YOLO can precisely focus on targets, suppress background attention, and achieve higher detection efficiency and accuracy.
To validate the performance improvement of each module, this study designed a series of ablation experiments. The YOLOv8n network was used as the baseline model, and the CFNeXt module, MLFF module, EDSA module, and SIoU module were introduced separately to evaluate the impact of each module on detection performance.
Table 6 presents the ablation experiment results for the bifurcated and side-type detection tasks.
By analyzing the experimental data, the following conclusions were made.
CFNeXt alone: By enhancing the multi-scale feature extraction through cascade fusion, CFNeXt improves mAP50 and mAP95 to 0.860 and 0.452, respectively. Meanwhile, it also optimizes computational architecture and eliminates redundant calculations, reducing parameters from 3.006 M to 2.662 M and GFLOPs from 8.1 to 7.2.
CFNeXt + MLFF: Adding MLFF enables hybrid pooling and cross-scale interaction, enhancing the fusion of high-level and low-level features. Leveraging CFNeXt’s rich multi-scale feature maps, MLFF further explores inter-scale feature relationships and optimizes feature representation. This synergy boosts mAP50 and mAP95 to 0.865 and 0.465, respectively.
CFNeXt + MLFF + EDSA: EDSA optimizes the feature processing pipeline by filtering and streamlining the features after CFNeXt/MLFF extraction/fusion, removing redundant information and reducing computational complexity. This maintains detection accuracy while lowering computational costs.
CFNeXt + MLFF + EDSA + SIoU: The final integrated model achieves optimal performance. SIoU improves bounding box prediction accuracy by refining the intersection-over-union (IoU) calculation. Building upon CFNeXt/MLFF/EDSA’s efficient feature extraction and fusion framework, SIoU further enhances detection precision while keeping computational costs within reasonable limits, achieving the best balance between performance and efficiency.
3.4. Comparative Analysis
We conducted additional experiments using the Brain-Tumor dataset from Ultralytics to test AS-YOLO’s generalization on medical images. The dataset consists of MRI images and is mainly used for brain tumor detection. Compared with DSA images, these MRI images have richer texture features and more complex background information. The results are as shown in
Table 7.
On the Brain-Tumor MRI dataset, AS-YOLO achieved a 3.6% increase in mAP50, a 19.4% improvement in precision, and a 9.7% reduction in the number of parameters. These results demonstrate that its architecture possesses strong generalization and adaptation capabilities in MRI images, thus providing new possibilities for cross-modal medical image analysis.
This study conducted comparative experiments on a predefined dataset, evaluating AS-YOLO against mainstream object detection algorithms (Faster R-CNN [
41], YOLOv3, YOLOv5, YOLOv6, and YOLOv8) and medical-specific models (Mask R-CNN, U-Net, and TransUNet). All of the models ran for 300 epochs under the same environment and dataset to ensure fair comparison.
Table 8 shows the mAP@0.5 and mAP@0.5:0.95 for both bifurcation and sidewall detection tasks.
The results show that AS-YOLO achieved an mAP0.5 of 0.868 in bifurcation-type aneurysm detection, significantly outperforming other methods. Its mAP0.5:0.95 metric was 0.468, highlighting its advantages in high-precision detection. Algorithms such as Faster R-CNN, YOLOv3, and U-Net performed poorly in both metrics. TransUNet had an mAP0.5 of 0.834 in the detection of bifurcation-type aneurysms, which is close to that of AS-YOLO. However, in the detection of sidewall-type aneurysms, AS-YOLO closely followed TransUNet’s mAP0.5 of 0.790 with a value of 0.760. These results indicate that AS-YOLO significantly improved detection accuracy and exhibits strong generalization ability in multi-scale object detection tasks.
To further evaluate the effectiveness of AS-YOLO, this study conducted a quantitative analysis of mainstream object detection algorithms (
Table 9). The experiments show that AS-YOLO achieved the highest detection accuracy (a mAP0.5 of 0.843 and a mAP0.5:0.95 of 0.428) with a low parameter count and low computational cost. Compared to YOLOv3, YOLOv5, YOLOv6, YOLOv8, and YOLOv11, AS-YOLO improved in mAP50 by 14.2%, 10.1%, 15.7%, 8.1%, and 8.4%, respectively. Additionally, AS-YOLO demonstrated superior computational efficiency over medical-specific algorithms, such as Mask R-CNN and TransUNet, indicating significant advantages in both detection accuracy and computational efficiency.
As shown in
Table 9 and
Figure 11, AS-YOLO has a small number of parameters and low computational complexity, making it highly suitable for deployment on embedded devices. In actual tests, its inference speed is 99.6 FPS, significantly performing above the 30.2 FPS of Mask R-CNN and the 24.3 FPS of TransUNet, thus meeting the requirements for real-time detection. Compared with medical-specific algorithms, it has remarkable advantages in computational and detection speeds. Through the optimization of the network architecture and computational efficiency, the inference speed of AS-YOLO approaches the 112.6 FPS of YOLOv8, while the number of parameters and computational complexity still remain at a low level. The lightweight optimization has not affected the operation efficiency, and its GFLOPs are reduced by 12.3%, resulting in higher operation efficiency in low-power scenarios. It can be seen that AS-YOLO achieves a good balance between real-time performance, inference speed, and the number of parameters.
Based on the experimental results and the detection results shown in
Figure 12, AS-YOLO significantly outperforms other mainstream algorithms in both detection accuracy and computational efficiency. It demonstrates excellent performance in bifurcation-type and sidewall-type detection tasks, with stable high-precision metrics, meeting the requirements for intracranial aneurysm detection and achieving a balance between accuracy and speed. Additionally, the low parameter count and computational complexity of AS-YOLO make it highly suitable for embedded deployment, while its high inference speed (99.6 FPS) fulfills real-time detection needs, providing an efficient and reliable solution for real-time intracranial aneurysm detection.
4. Conclusions
This paper proposes AS-YOLO, a lightweight intracranial aneurysm detection algorithm built on an improved YOLOv8n model. By constructing the Cascade Fusion Network (CFNeXt), the multi-scale feature extraction ability is enhanced, and the recognition performance for aneurysms of different sizes is improved. We employed the MLFF module to integrate shallow and deep feature information, which enhances detection performance for small aneurysms. An efficient depthwise separable convolutional aggregation (EDSA) detection head was designed to reduce computational complexity while maintaining detection accuracy. The SIoU loss function was introduced to optimize the alignment precision of the bounding boxes and accelerate the training convergence speed.
AS-YOLO improves detection accuracy by 2.6%, reduces model size by 0.247 MB, and lowers computational load by 1.0 GFLOP compared to the original version, reflecting excellent detection capability. This algorithm performs well in detecting aneurysms of different sizes. Moreover, with a lightweight design, it reduces model parameters and computational overhead, making it suitable for embedded devices. It can achieve real-time detection with low latency and high accuracy even in resource-constrained environments.
Future work includes refining the model structure to boost generalization in more challenging medical contexts. We will also incorporate more datasets and clinical validations to improve detection accuracy and model efficiency while exploring more optimized embedded deployment solutions to support efficient inference in edge computing environments.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}