1. Introduction
Train position and integrity monitoring are of paramount importance in guaranteeing the safety of railway systems, as it prevents collisions between two trains operating on the same line and ensures that trains do not split. The European Railway Traffic Management System (ERTMS/ETCS) offers three levels of automated control to achieve this objective [
1,
2]. Level 1 and Level 2 have been in full operation currently. In these levels, train positioning and integrity monitoring rely on equipment installed along the railway track [
2,
3]. Train position is determined based on the construction of fixed blocks, and additional equipment is employed to detect changes in the electric current of the track circuit to ensure integrity [
4]. Although these methods ensure safety requirements are met, the associated expenses pose a challenge for the widespread implementation of efficient railway systems. It is important to note that the term ‘integrity’ in the context of train transportation refers to ensuring that the train remains intact and does not split, whereas in navigation, ‘integrity’ typically refers to the confidence level in human-safety applications.
To promote a more cost-effective railway system, there is an increasing need for the implementation of the ETCS Level 3, which relies entirely on on-board equipment. This dependence has led to a reduction in the minimum spacing between trains, thus increasing line capacity [
5]. In addition, the removal of trackside equipment at the ETCS Level 3 would result in reduced capital expenditure [
6,
7]. Currently, there are ongoing efforts towards standardizing the deployment of the ETCS Level 3. Hans S. [
8] has put forward the proposal of utilizing a distributed wireless sensor network (WSN) for the purpose of integrity monitoring. However, a limitation of WSN is the need for deploying nodes in each carriage, which can be a resource-intensive and expensive endeavor.
A global navigation satellite system (GNSS) offers an effective solution for train integrity monitoring with minimal infrastructure requirements, that only two GNSS receivers are needed to install on the train head and tail. The GNSS technique leverages global, all-weather, and real-time satellite signals to provide reliable and high-precision integrity solutions [
1,
9,
10,
11,
12]. Jiang W. [
4,
13] proposed a double-difference (DD) baseline method for relative positioning with two GNSS receivers installed on both ends of the train, which uses a Kalman filter to achieve real-time, high-precision train integrity monitoring. In addition, the GNSS also plays an important role in train position determination. Martin L. [
14] proposed a data fusion algorithm for position determination, incorporating the GNSS, odometer, and accelerator. However, utilizing raw GNSS measurements is a challenge due to severe atmosphere influence and satellite errors. To overcome this issue, Neri [
15,
16] proposed a track-constrained snapshot algorithm based on the ‘train and reference station (RS)’ DD baseline model with odometer data fusion, which cancels out the measurement delay in the DD measurement. This approach exploits the DD baseline algorithm to correct the coarse odometer value, with the accuracy of the corrected value being dependent on the noise level of the measurement. The corrected odometer value is then mapped into the track database to obtain more accurate train safety information. This algorithm employs the use of RS and track database information to correct the train’s odometer and accurately determine its location.
Existing techniques are limited to providing either train integrity or position information, which can result in safety or operational risks. To address this, Neri [
17] proposed a track-constrained algorithm using the ‘train head (TH) and train tail (TT)’ DD baseline model to simultaneously derive train location and length. However, its accuracy is insufficient for reliable safety applications.
To address this issue and maintain the provision of qualified integrity information along with a checking function, we propose a dual DD baseline fusion algorithm (Dual DD algorithm). First, the DD baseline model is reviewed and modified in terms of coefficient matrix, enhancing the accuracy of DD model. Then, we apply the enhanced coefficient matrix to the ‘TH and TT’ DD baseline model, along with the track database and onboard odometer data from both ends of the train, to establish a ‘train head (TH) and train tail (TT)’ double-difference (DD) baseline model (Single DD algorithm). Further, we analyze the factors contributing to the noise inflation in the odometer fix obtained from the Single DD algorithm and the primary factor is the small track slope difference between the two ends of the train. To eliminate the effect of track slope difference, a dual DD baseline fusion algorithm (Dual DD algorithm) is introduced. This algorithm integrates a static reference station (RS) into the DD baseline model, thereby increasing the track slope difference and effectively reducing the sensitivity to noise. As a result, the Dual DD algorithm can obtain train location and integrity safety information accurately in real time. To verify the measurements from selected reference station, we further propose a cross-checking scheme by combining the Dual DD algorithm and Single DD algorithm. This scheme compares the disparity in computed train length between the Single DD algorithm and the Dual DD algorithm, assuming that, under normal conditions, the difference remains within a narrow range.
There are two main contributions of this paper: (1) Demonstrating small track slope difference is the main reason that causes odometer fix inflated by noise in the DD baseline model. This finding highlights the key factor contributing to the accuracy limitations in train location estimation. The understanding of this relationship provides valuable insights for future research aimed at enhancing the accuracy of location estimation in the DD baseline model. (2) Based on the analysis of noise inflation, this study proposes a Dual DD scheme that integrates train safety information, including train integrity and location estimation, with cross-checking capabilities to verify the status of reference stations. By addressing the issue of noise inflation with the aid of a static reference station and incorporating cross-checking functions, the proposed scheme improves the accuracy and reliability of train positioning and integrity monitoring.
The structure of this paper is as follows: Firstly, a detailed description of the Single DD algorithm is provided, including the derivation of the refined coefficient matrix and the integration of track database with the iterative least square (ILS) process. Secondly, an analysis of the noise amplification phenomenon observed in the Single DD algorithm is presented, and the characteristics of the Dual DD algorithm along with cross-checking scheme are introduced. Lastly, simulation results are presented for each of the proposed models.
3. Dual DD Baseline Fusion Algorithm
In this section, we start by analyzing ‘the noise amplification issue’ that arises in the Single DD algorithm. Based on our analysis, we propose a Dual DD algorithm to provide more accurate train position and integrity information simultaneously. In addition, by integrating the Dual DD algorithm and Single DD algorithm, we present an additional cross-checking information to validate the measurement reliability of selected stations.
Similarly to the single point positioning (SPP) iterative procedures, the Single DD algorithm may also experience noise amplification due to a poor coefficient matrix. Based on covariance error propagation, a general metric to evaluate the accuracy of the single point position fix influenced by same given error, DOP (dilution of precision), can also be applied in the Single DD algorithm [
21]. Then, the accuracy of the odometer estimate can be expressed as DOP at a point [
22].
where
indicates the trace of the matrix and coefficient matrix
, where
indicates the final iteration step for each epoch, given by Equation (12).
DOP is sensitive to the geometry of the coefficient matrix, and a poor geometry can result in an increase in DOP and subsequent noise inflation. However, it is important to note that DOP cannot determine the underlying cause of a poor coefficient matrix.
Therefore, a ‘vector analysis’ model is introduced to explain some factors that cause large DOP along the track.
Assuming an equation number of (
, Equation (12) in the final iteration step at any epoch can be expressed as a 2 × 2 linear system in a column picture format, with residual noise on the right-hand side presented in Equation (16) [
23]. The column picture transformation allows the linear system to be viewed as a vector equation, with the aim of determining the combination of vectors on the left side to produce the vector on the right side. In practical situations, it is possible for the linear system to be over-determined (
) but can still be considered as a linear combination of vectors. Therefore, for the purpose of illustrating the main contributor of noise inflation, it is more convenient to use the 2 × 2 linear system.
where row vector
comprises
from Equation (4);
refers to
from Equation (10),
; and
and
refer to the odometer fix of the train head and train tail influenced by noise
and
with a sigma of +/−0.0067 m.
We define the column vector before as , the vector before as , and the right-hand side vector as . Two unknowns, and , are multiplication factor for this combination. Given any and , this combination can fill up the two-dimensional noise plane .
For the magnitude of
,
, and
, use the following:
where
refers to the module of vector
(
i = 1,2,3).
In each measurement (row) of
,
where
refers to the cosine between vector
and
d.
With the assumption that satellites are randomly distributed in any epoch and , along with Equation (18), it can be shown that . A similar result can be obtained for , with . And assuming that has a sigma value of 0.0067, it would lead to . In practical terms, assuming the average available satellite number is larger than 7, if , then can be deducted through probability theory. As changes smoothly with real track, . Furthermore, based on the linearity of expectation, the magnitude of and would remain almost constant during the same measurement number. Therefore, any change between and would primarily affect the angle between the two vectors. And these vector changes are caused by , since the impact of matrix on and is equivalent. In other words, any variation in the difference between and would result in a corresponding change in the angle between and .
Since
approximates to
, and
has a relatively tiny module compared with them,
in any direction causes a trivial difference in
and
. Note that the worst case with a small probability that
would be parallel or has a close angle with
and
is not considered in this analysis. Therefore,
is assumed to present in the direction shown in
Figure 3 and
Figure 4.
The cases wherein
would fall outside
and
(Case 1) and that
would fall inside
and
(Case 2) need to be considered. Then,
Figure 3 and
Figure 4 present the first quadrant results of situation A (
similar to
) and situation B (
relatively different with
) in Case 1 and Case 2, respectively.
The blue lines in
Figure 3 and
Figure 4 refer to
and
, and red lines indicate the stretched or shrunk
and
with multiplication factor of
and
. The results demonstrates that in the Single DD algorithm, the difference between
and
would influence the noise impact. Situation A in both Case 1 and Case 2 will result in a lower magnitude of the multiplication factor than that of Situation B. This means that the same noise level (
) would result in many more errors in the odometer fix if the difference between
and
becomes smaller. Besides that, the inference derived above that
makes multiplication factors of
and
present a highly similar magnitude. Then, most of the
and
would cancel each other out for the computation of train length.
A slope inflation factor (SIF) that links with the
difference is therefore produced to evaluate noise amplification phenomenon compared with DOP.
where
represents the absolute value operation.
In practical scenarios, train lengths are typically smaller than 1000 m, which implies that the track slope difference between TH and TT is generally small, leading to a large inflation error, thereby adversely affecting train position determination, even though this influence is eliminated for the train length calculation. In pursuit of greater accuracy in train positioning, a dual DD baseline fusion algorithm (Dual DD algorithm) has been proposed. The Dual DD algorithm utilizes the ‘TH and RS’ DD baseline model and the ‘TT and RS’ DD baseline model, presented in
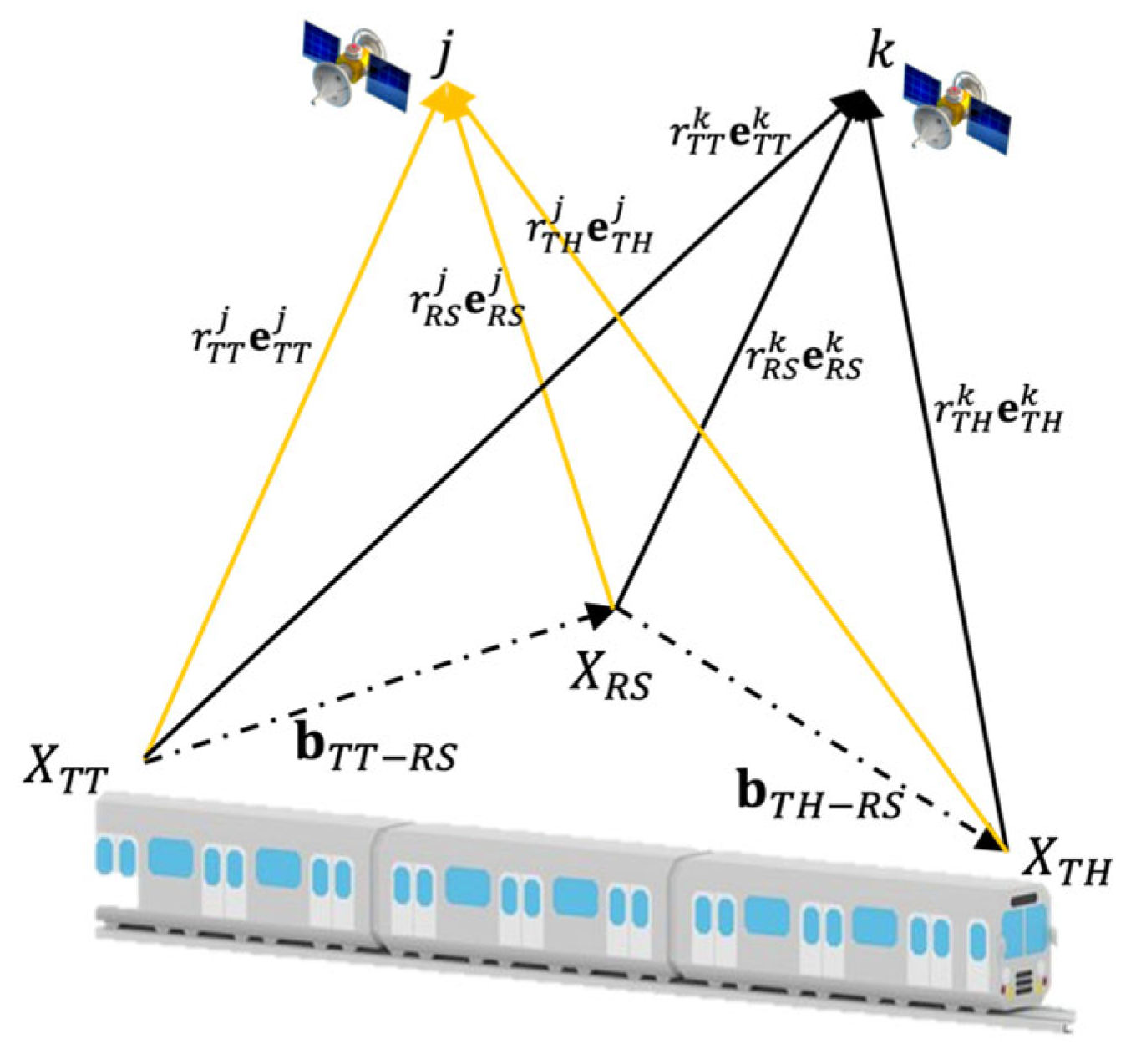
Figure 5. These two DD baseline models run in parallel and follows a similar iterative procedure as
Section 2.2 to correct the coarse odometer of TT (TH) in each baseline model. This algorithm aims to address the impact of track slope difference between the train head and tail. Then, only one odometer correction needs to be created in each DD baseline model. As a result, Equation (10) in each DD baseline model needs to be modified into (20).
where
,
,
;
. The odometer corrections of train head and train tail, therefore, can be obtained accurately from these two DD baseline models when atmospheric error can be ignored. These corrected odometer values can then be used to obtain the corresponding train coordinates in the track database, and the train length information.
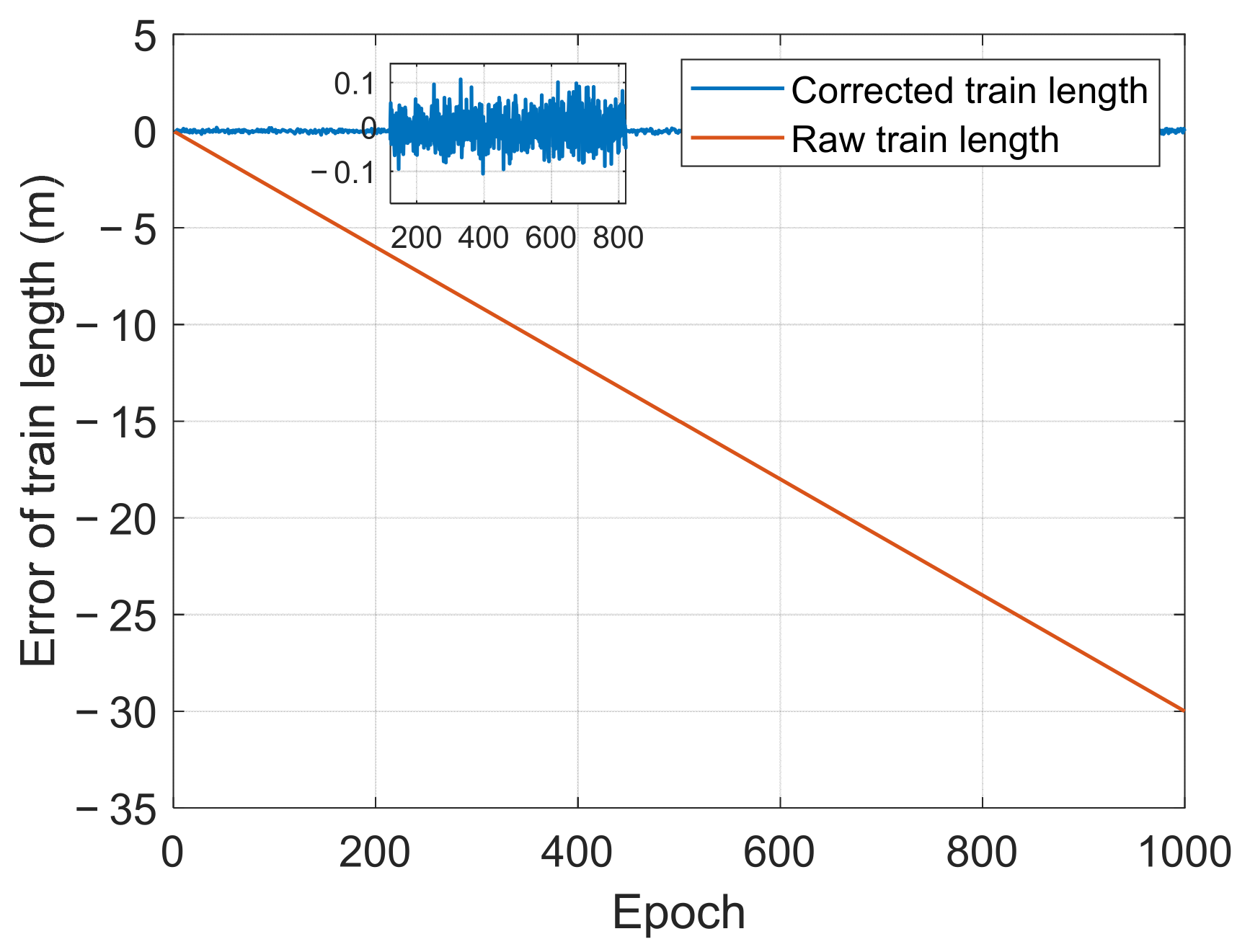
Given that the Dual DD algorithm utilizes a long-baseline model, ensuring the reliability of the measurements from the selected station at all times can be challenging. The cross-checking function is therefore introduced and illustrated in
Figure 6. In this scheme, the Dual DD algorithm is first employed to derive the corrected odometers and position of both the TH and TT, as well as train length information. Additionally, the Single DD algorithm is utilized to calculate a redundant train length, which is then compared to the train length computed by the Dual DD algorithm to evaluate the status of the selected reference stations (RSs). In case the residual atmospheric error in the measurements exceeds a predetermined threshold, the selected RS is deemed unhealthy.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}