
SAM-Guided Concrete Bridge Damage Segmentation with Mamba–ResNet Hierarchical Fusion Network


Abstract
1. Introduction
- 1.
- We propose a SAM-guided mask generation network that leverages the segmentation mask generation capabilities of SAM to provide supplementary supervision labels for training concrete bridge damage segmentation networks. This innovation significantly reduces reliance on large annotated datasets, addressing a critical limitation in existing automated damage detection systems.
- 2.
- A novel point-prompting strategy is introduced, which employs saliency information to refine the prompts provided to SAM. This ensures the generation of reliable and accurate segmentation masks, even for complex damage patterns, thereby enhancing the overall segmentation quality.
- 3.
- We design a trainable semantic segmentation network featuring a multi-level feature extraction framework. By integrating MambaVision and ResNet as dual backbone networks, the system captures hierarchical semantic features from concrete bridge damages, simultaneously extracting high-level global semantic features and robust local feature representations.
- 4.
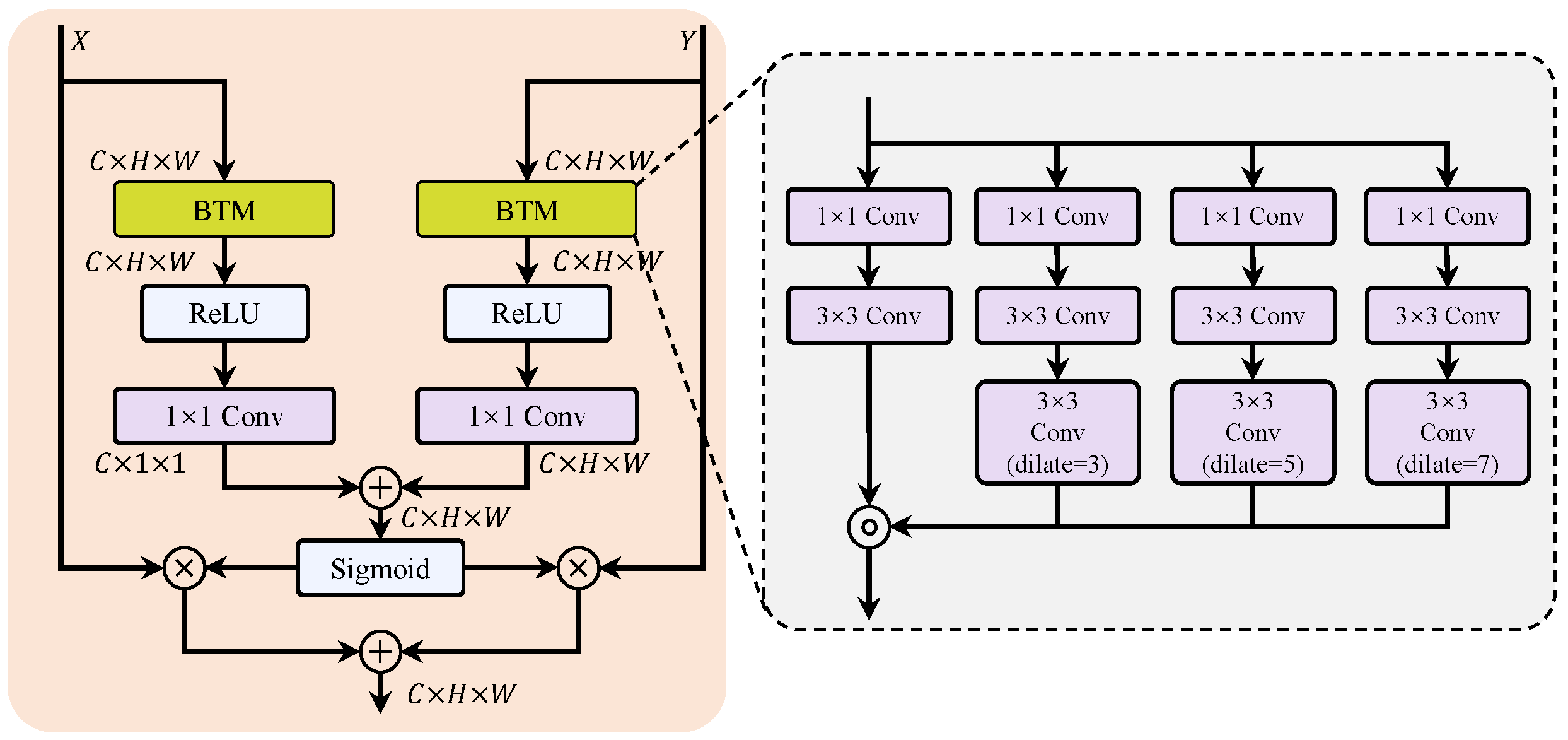
- To effectively integrate multi-level features and enhance segmentation performance, we introduce a Hierarchical Attention Fusion (HAF) mechanism. This includes a Boosting Textures Module (BTM) designed to strengthen the representation of discriminative texture features. Combined with the Polarized Self-Attention (PSA) decoder, our approach achieves high-precision damage segmentation results, demonstrating its robustness and applicability in practical engineering scenarios.
2. Related Works
2.1. Semantic Segmentation Algorithm with Application to Concrete Bridge Damage Segmentation
2.2. Application of Segment Anything Model
- Focus on Single-Class Segmentation: Research on the semantic segmentation of concrete bridge damages leveraging deep learning has predominantly concentrated on single-class segmentation. While effective in isolating specific damage types, this approach often overlooks the complexity and diversity of real-world scenarios where multiple damage types co-exist. As a result, the exploration of multi-class segmentation remains underdeveloped, leaving a critical gap in addressing practical applications.
- Challenges in Multi-Class Segmentation: Multi-class segmentation faces considerable hurdles, with two primary challenges being the scarcity of annotated datasets and the inherent difficulty of the annotation process. The annotation of multi-class datasets demands significant expertise, time, and resources, particularly in scenarios involving subtle or overlapping damage features. These factors have constrained the advancement of robust multi-class segmentation techniques tailored for bridge damage analysis.
- Limitations of SAM in Bridge Damage Segmentation: While the Segment Anything Model (SAM) represents a promising tool for mask generation in general segmentation tasks, its application to bridge damage imagery is not without limitations. The generic nature of SAM’s mask generation requires adaptation to account for the unique visual characteristics of bridge damages, such as irregular shapes, complex textures, and diverse environmental conditions. Therefore, further refinements are necessary to improve the effectiveness of SAM in this specialized domain.
3. Method
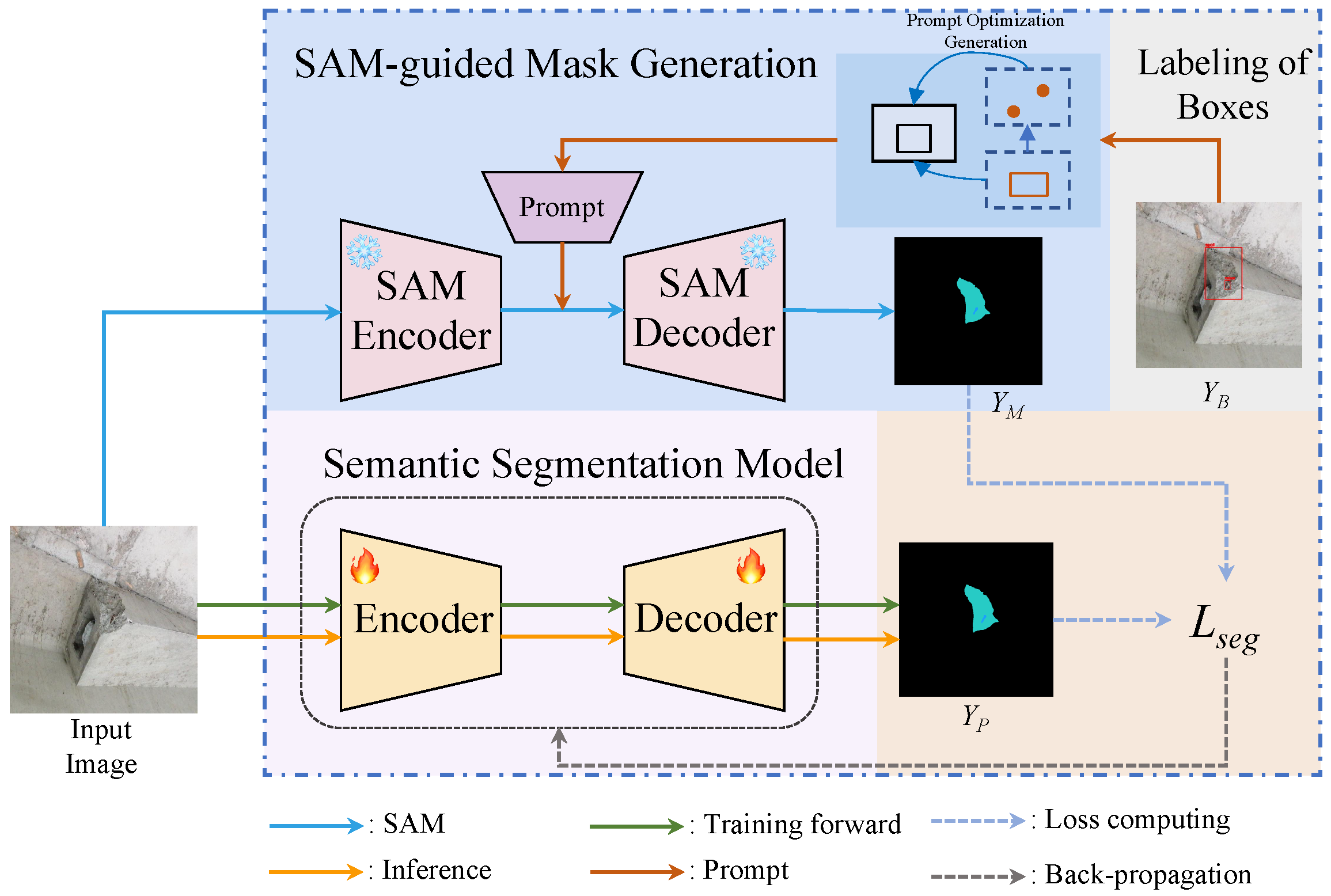
3.1. Overall Architecture
3.2. SAM-Guided Concrete Damage Segmentation Mask Generation
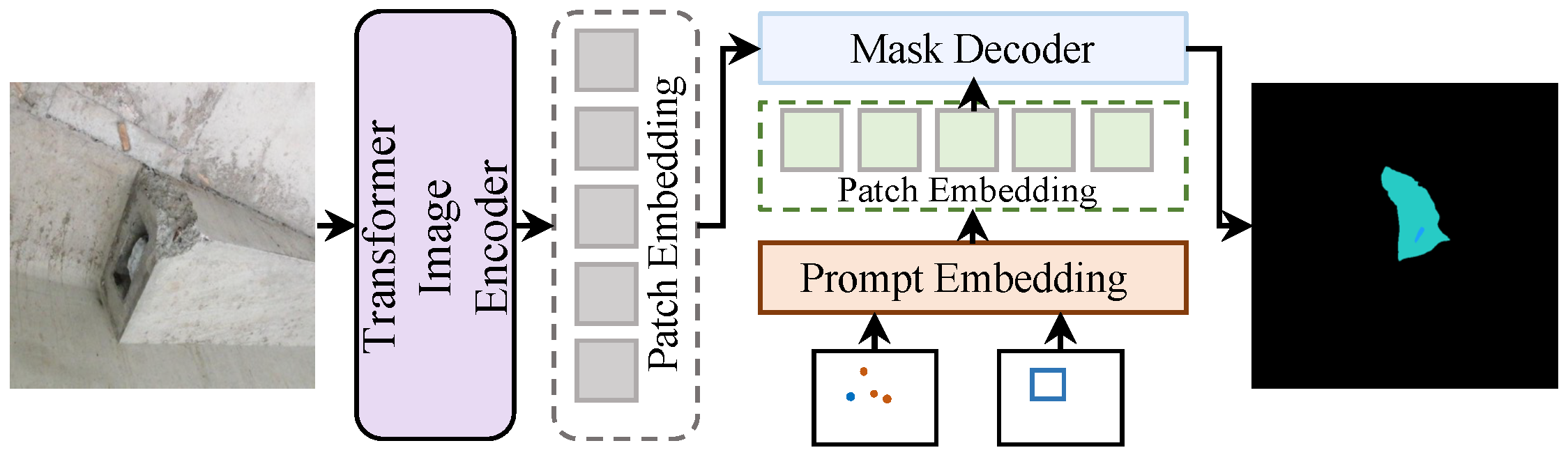
3.2.1. Segment Anything Model
- 1.
- Transformer Image Encoder: The image encoder in SAM leverages a Vision Transformer (ViT) [43] architecture to encode the input image into a high-dimensional latent representation. Formally, let denote the input image, where H,W,C represent height, width, and the number of channels, respectively. The image is partitioned into patches, and each patch is projected into a token embedding , where is the number of patches and d is the embedding dimension. These tokens are then processed through a series of transformer layers, each comprising multi-head self-attention and feed-forward networks. The resulting feature map encodes the spatial and contextual information critical for segmentation tasks.
- 2.
- Mask Decoder: The mask decoder refines the encoded image features to produce segmentation masks. Using the encoded feature map F as input, along with a set of learnable query embeddings (where M is the number of masks), the decoder computes attention weights to localize the object of interest. The mask prediction is then given by , where is the sigmoid activation applied element-wise to generate pixel-wise probabilities. This formulation allows the SAM to generate multiple masks simultaneously while maintaining scalability.
- 3.
- Prompt Embedding: The prompt embedding module allows the SAM to adapt to various inputs, including points, bounding boxes, and textual descriptions. For a point-based prompt, the embedding is represented as a learnable vector , added to the corresponding spatial location in the encoded feature map. For bounding boxes, the embeddings are parameterized as the positional encodings of the box’s corners, integrated into the transformer layers. This versatility enables SAM to function effectively across diverse user-provided guidance signals.
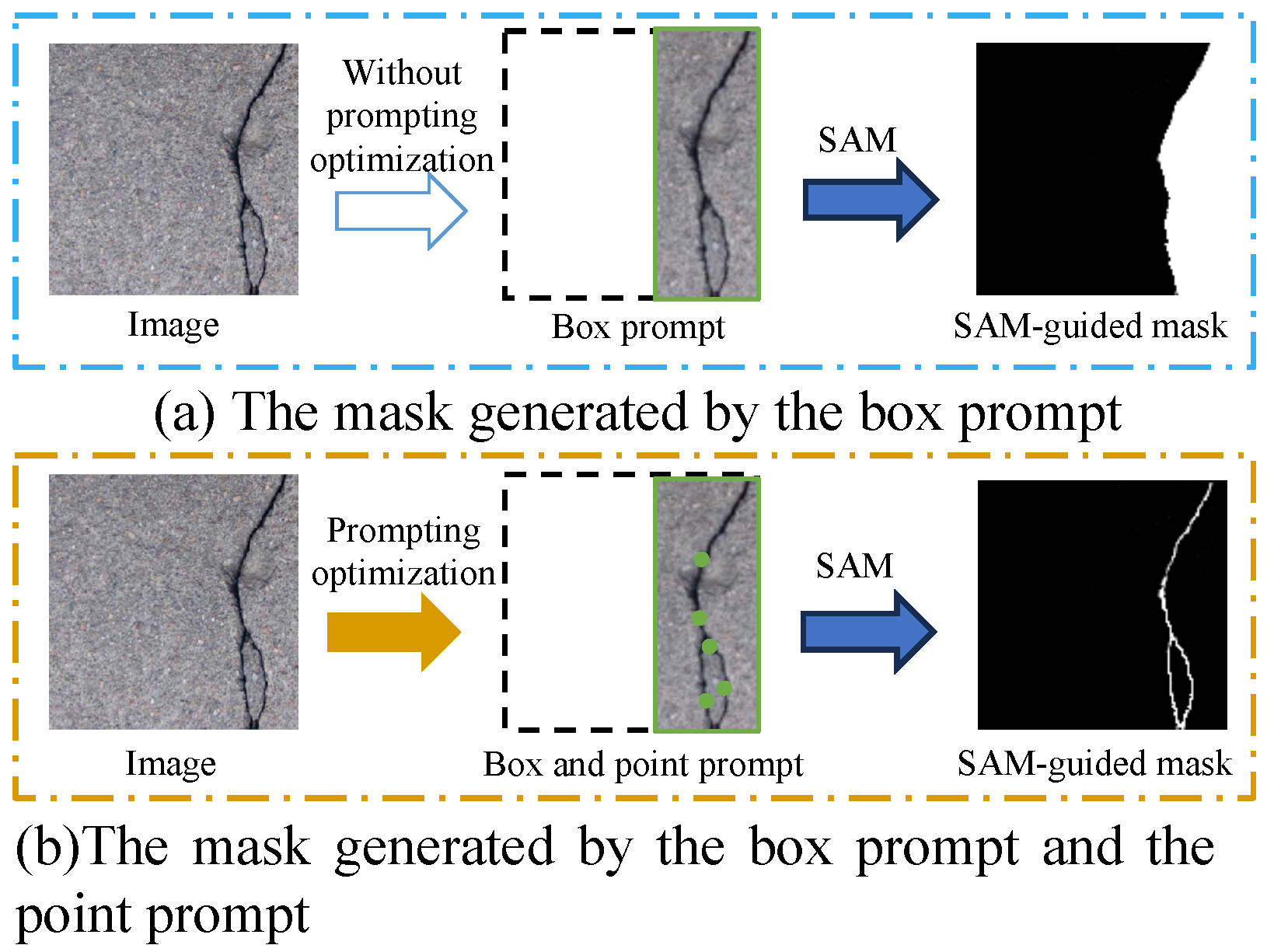
3.2.2. Optimizing Prompting Strategy with Saliency Information
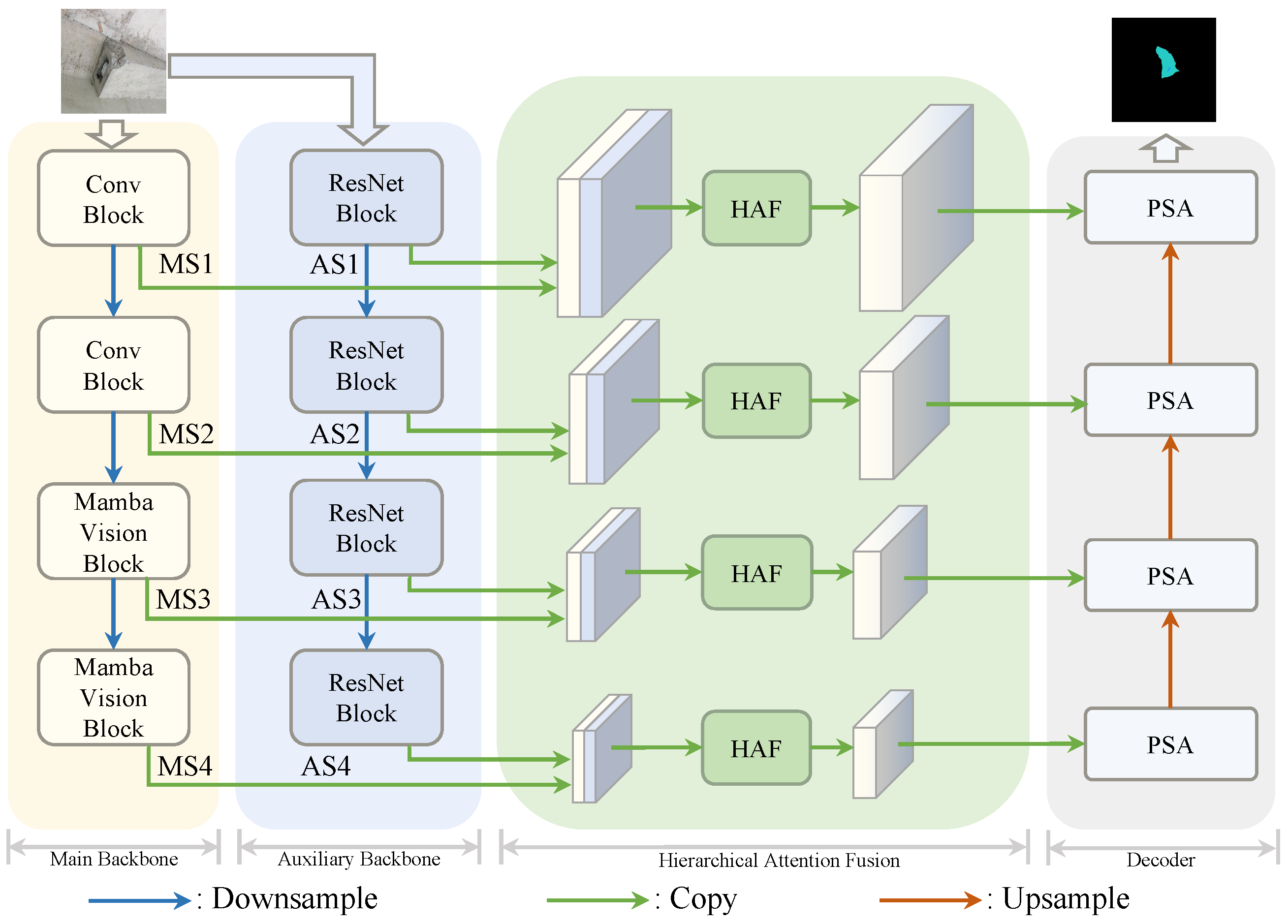
3.3. Mamba–ResNet Hierarchical Fusion Network for Concrete Damage Segmentation
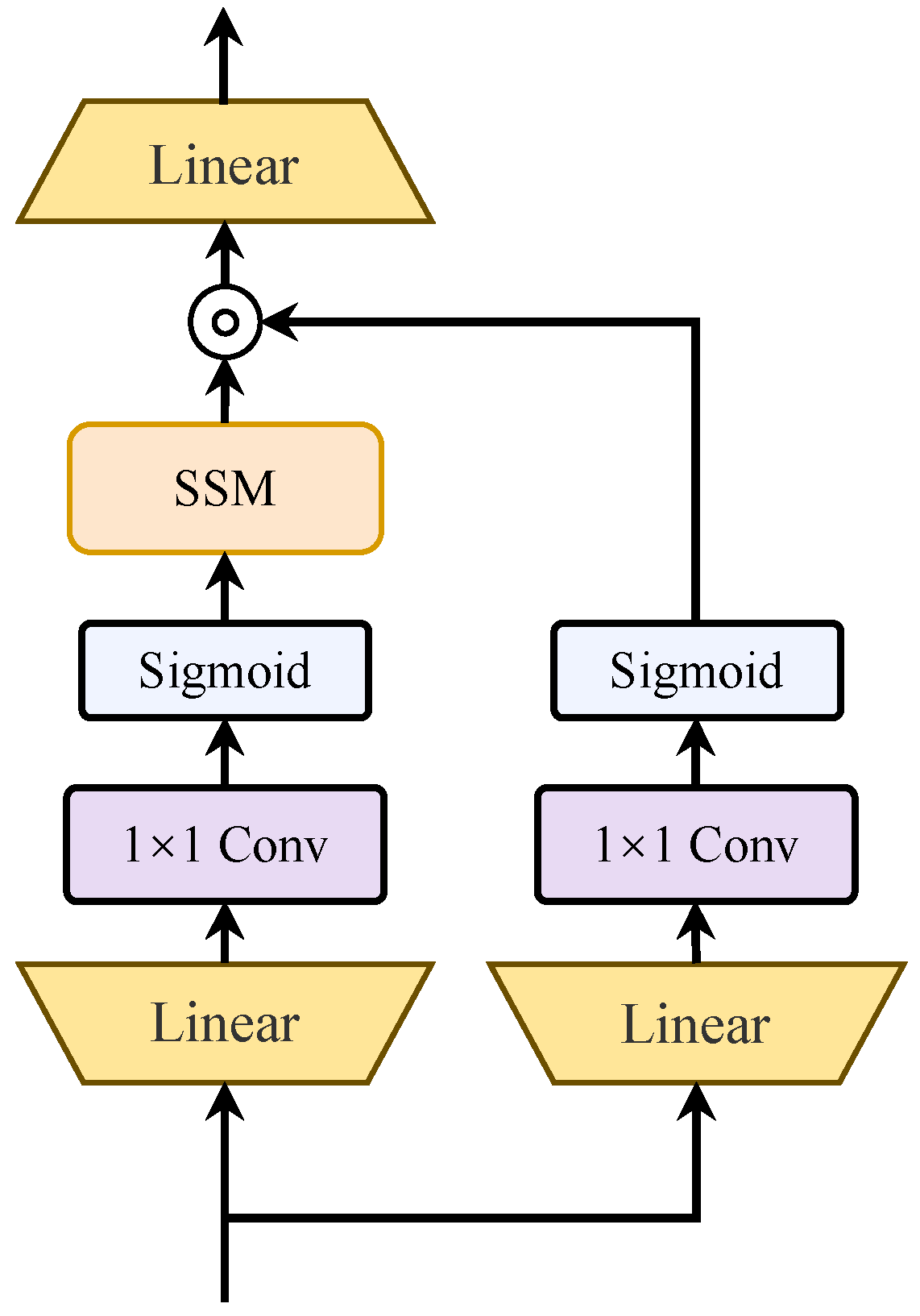
3.3.1. MambaVision Backbone
3.3.2. Hierarchical Attention Fusion
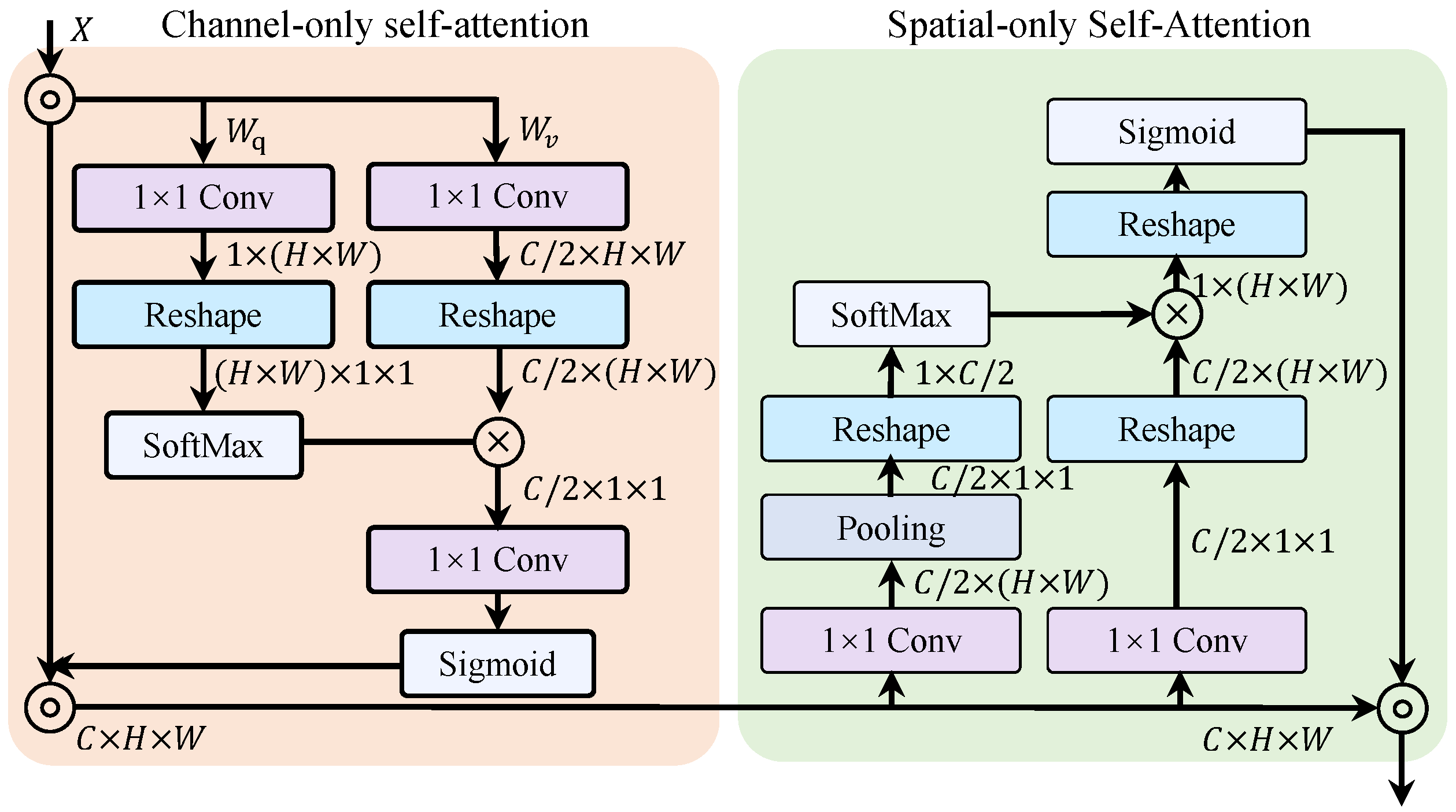
3.3.3. Polarized Self-Attention
3.4. Loss Function
4. Experiments and Results
4.1. Experimental Environment
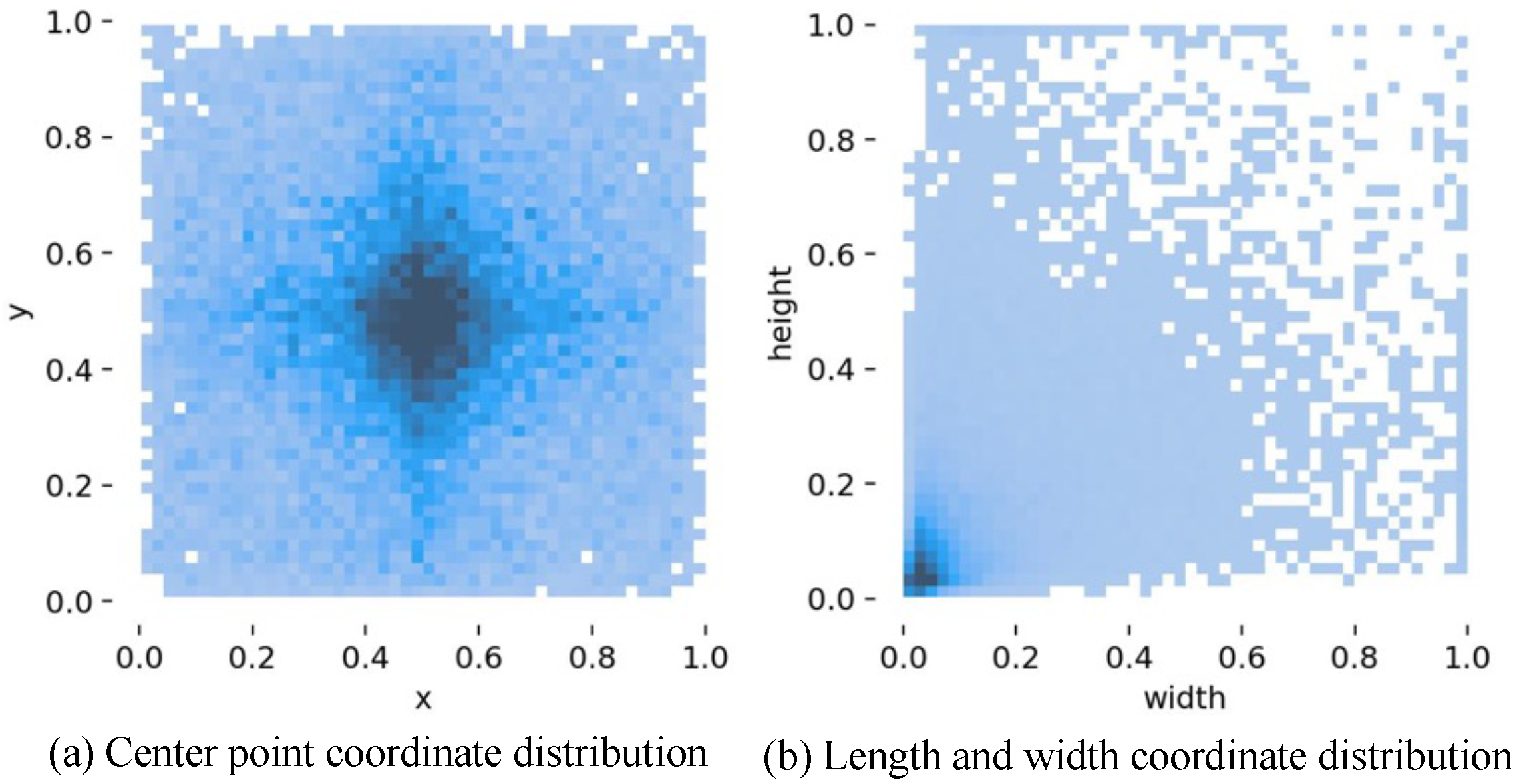
4.1.1. Datasets
4.1.2. Experimental Settings
4.1.3. Evaluation Metrics
4.2. Performance Comparison of Different Models
4.3. Ablation Studies
4.3.1. Ablation Study on Overall Framework
- 1.
- This configuration corresponds to the baseline network, which excludes all the components proposed in this study, including MambaVision, Optimizing Prompting Strategy (OPS), Hierarchical Attention Fusion (HAF), Boosting Textures Module (BTM), and Polarized Self-Attention (PSA). This baseline serves as a reference to evaluate the network’s performance without the optimization and enhancement mechanisms introduced in this work. In the baseline network, the backbone is ResNet, and all feature fusion is performed using simple feature map concatenation.
- 2.
- In this configuration, OPS is used for training the baseline network.
- 3.
- This configuration replaces the baseline backbone with MambaVision as the main network backbone, without employing OPS for training.
- 4.
- Building on the previous configuration, this setup uses MambaVision as the main backbone and incorporates OPS for network training.
- 5.
- This configuration includes the OPS and HAF, but excludes the BTM within HAF.
- 6.
- In this setup, the Boosting Textures Module (BTM) is introduced in addition to OPS and HAF, enabling the evaluation of the role of texture enhancement within the feature fusion framework.
- 7.
- This configuration removes BTM from HAF and includes the Polarized Self-Attention (PSA).
- 8.
- In this configuration, only the PSA module is introduced, allowing for the isolated evaluation of the PSA’s effect on segmentation performance.
- 9.
- This represents the full model configuration proposed in this study.
4.3.2. Ablation Study on Different SAM Prompting Strategies
4.3.3. Ablation Study on Different Backbone Networks
4.3.4. Ablation Study on Different Attention Module Decoders
4.3.5. Ablation Study on Loss Function
4.3.6. Hyperparametric Analysis
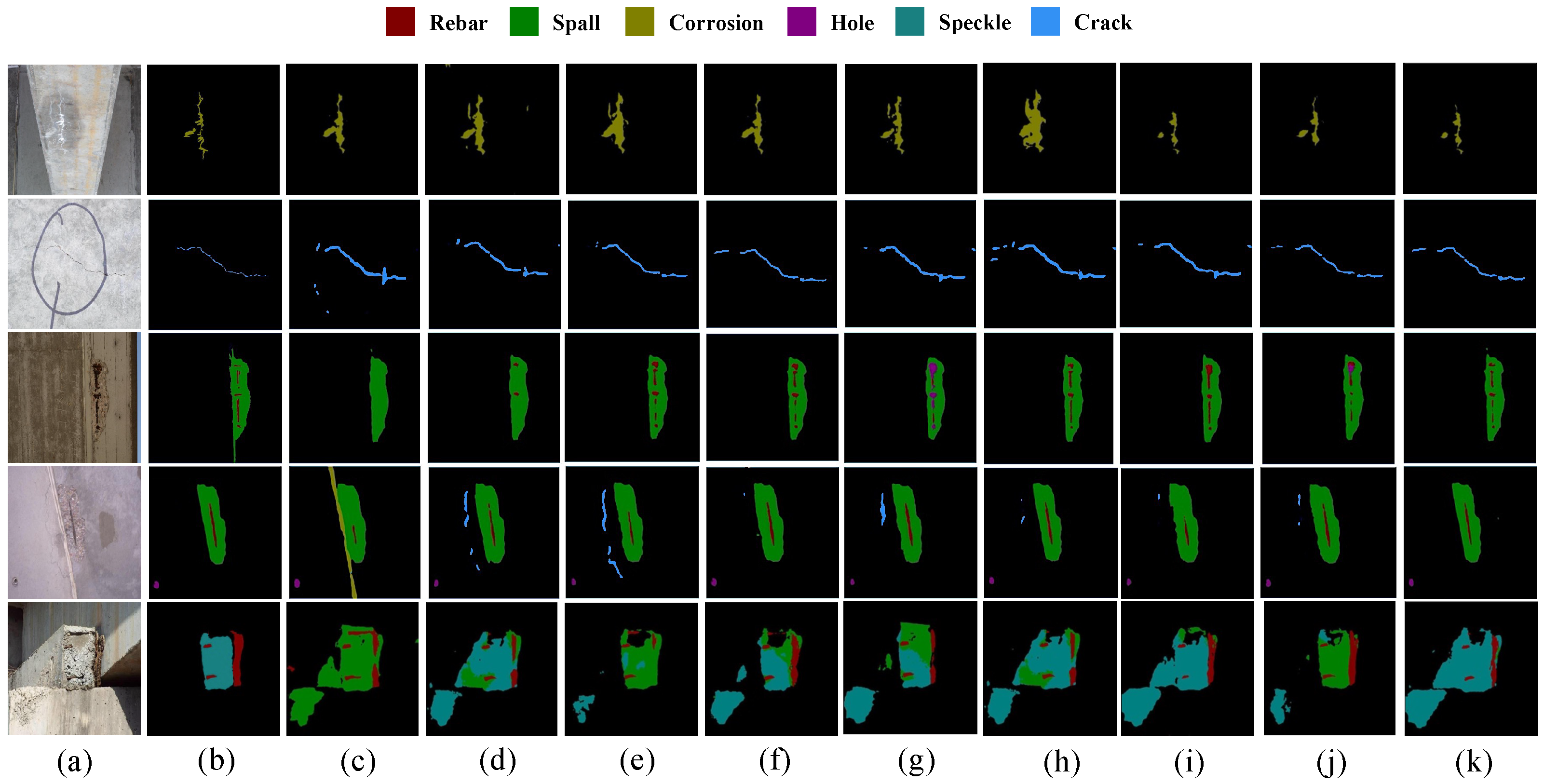
4.4. Visualization Results
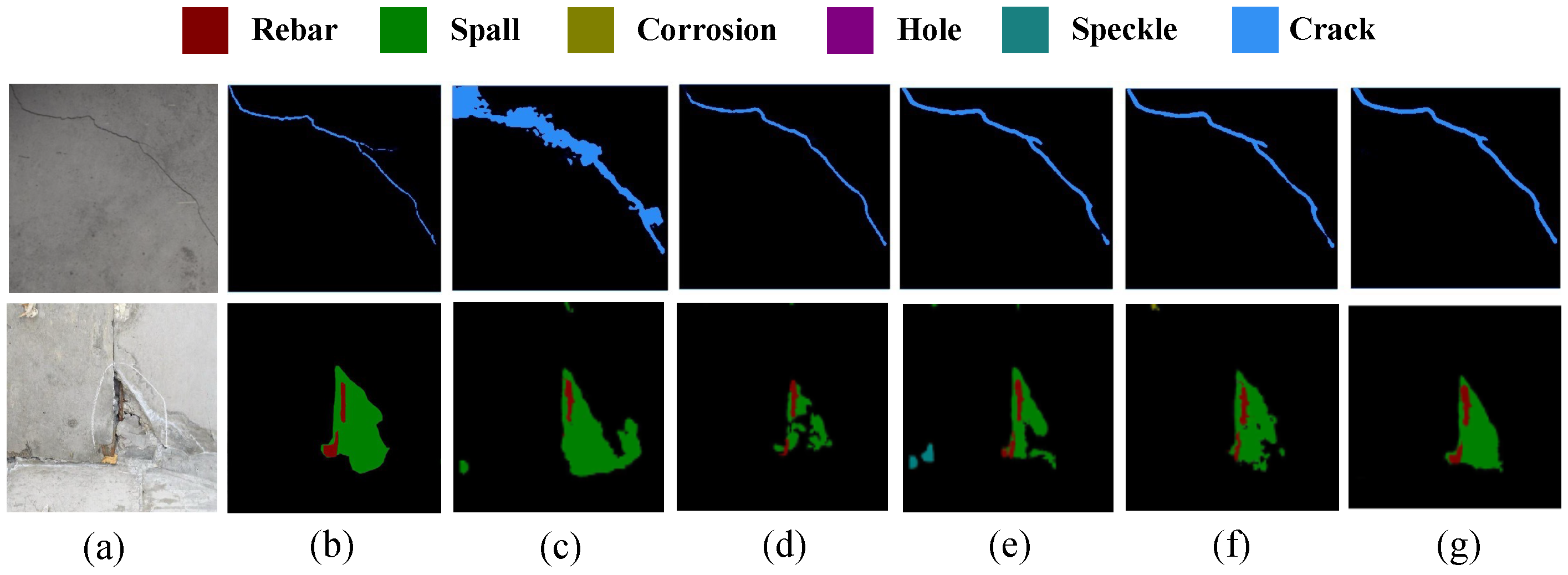
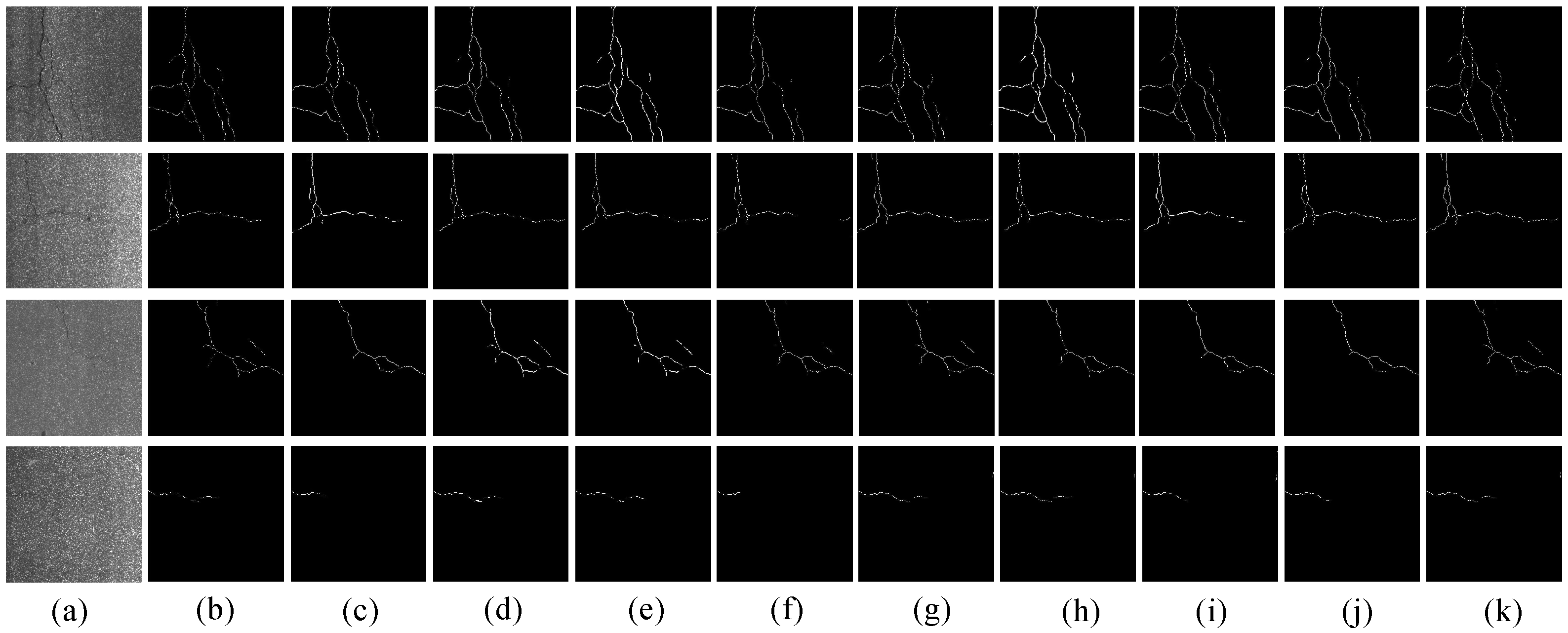
4.5. Diversity Validation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xiao, Q.; Li, R.; Yang, J.; Chen, Y.; Jiang, S.; Wang, D. TPKE-QA: A gapless few-shot extractive question answering approach via task-aware post-training and knowledge enhancement. Expert Syst. Appl. 2024, 254, 124475. [Google Scholar]
- Khan, S.M.; Atamturktur, S.; Chowdhury, M.; Rahman, M. Integration of structural health monitoring and intelligent transportation systems for bridge condition assessment: Current status and future direction. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2107–2122. [Google Scholar]
- Bhattacharya, G.; Mandal, B.; Puhan, N.B. Multi-deformation aware attention learning for concrete structural defect classification. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3707–3713. [Google Scholar]
- Bhattacharya, G.; Mandal, B.; Puhan, N.B. Interleaved deep artifacts-aware attention mechanism for concrete structural defect classification. IEEE Trans. Image Process. 2021, 30, 6957–6969. [Google Scholar]
- Wan, H.; Gao, L.; Yuan, Z.; Qu, H.; Sun, Q.; Cheng, H.; Wang, R. A novel transformer model for surface damage detection and cognition of concrete bridges. Expert Syst. Appl. 2023, 213, 119019. [Google Scholar]
- Jeong, E.; Seo, J.; Wacker, J.P. UAV-aided bridge inspection protocol through machine learning with improved visibility images. Expert Syst. Appl. 2022, 197, 116791. [Google Scholar]
- Hu, X.; Assaad, R.H. The use of unmanned ground vehicles and unmanned aerial vehicles in the civil infrastructure sector: Applications, robotic platforms, sensors, and algorithms. Expert Syst. Appl. 2023, 232, 120897. [Google Scholar]
- Chen, H.M.; Hou, C.C.; Wang, Y.H. A 3D visualized expert system for maintenance and management of existing building facilities using reliability-based method. Expert Syst. Appl. 2013, 40, 287–299. [Google Scholar]
- Huang, L.; Fan, G.; Li, J.; Hao, H. Deep learning for automated multiclass surface damage detection in bridge inspections. Autom. Constr. 2024, 166, 105601. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar]
- Chu, H.; Deng, L.; Yuan, H.; Long, L.; Guo, J. A transformer and self-cascade operation-based architecture for segmenting high-resolution bridge cracks. Autom. Constr. 2024, 158, 105194. [Google Scholar] [CrossRef]
- Amirkhani, D.; Allili, M.S.; Hebbache, L.; Hammouche, N.; Lapointe, J.F. Visual Concrete Bridge Defect Classification and Detection Using Deep Learning: A Systematic Review. IEEE Trans. Intell. Transp. Syst. 2024, 25, 10483–10505. [Google Scholar]
- Gadetsky, A.; Brbic, M. The pursuit of human labeling: A new perspective on unsupervised learning. Adv. Neural Inf. Process. Syst. 2024, 36, 60527–60546. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- Chen, C.; Miao, J.; Wu, D.; Zhong, A.; Yan, Z.; Kim, S.; Hu, J.; Liu, Z.; Sun, L.; Li, X.; et al. Ma-sam: Modality-agnostic sam adaptation for 3d medical image segmentation. Med. Image Anal. 2024, 98, 103310. [Google Scholar] [CrossRef]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Jiang, S.; Tang, C.; Yang, J.; Li, H.; Zhang, T.; Li, R.; Wang, D.; Wu, J. TSCB-Net: Transformer-enhanced semantic segmentation of surface damage of concrete bridges. Struct. Infrastruct. Eng. 2024, 1–10. [Google Scholar]
- Du, H.; Wang, H.; Zhang, X.; Peng, H.; Gao, R.; Zheng, X.; Tong, Y.; Shan, Y.; Pan, Z.; Huang, H. Automated intelligent measurement of cracks on bridge piers using a ring-climbing vision scanning operation robot. Measurement 2024, 237, 115197. [Google Scholar]
- Rubio, J.J.; Kashiwa, T.; Laiteerapong, T.; Deng, W.; Nagai, K.; Escalera, S.; Nakayama, K.; Matsuo, Y.; Prendinger, H. Multi-class structural damage segmentation using fully convolutional networks. Comput. Ind. 2019, 112, 103121. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Shi, J.; Dang, J.; Cui, M.; Zuo, R.; Shimizu, K.; Tsunoda, A.; Suzuki, Y. Improvement of damage segmentation based on pixel-level data balance using vgg-unet. Appl. Sci. 2021, 11, 518. [Google Scholar] [CrossRef]
- Deng, W.; Mou, Y.; Kashiwa, T.; Escalera, S.; Nagai, K.; Nakayama, K.; Matsuo, Y.; Prendinger, H. Vision based pixel-level bridge structural damage detection using a link ASPP network. Autom. Constr. 2020, 110, 102973. [Google Scholar]
- Chen, L.C. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Narazaki, Y.; Hoskere, V.; Yoshida, K.; Spencer, B.F.; Fujino, Y. Synthetic environments for vision-based structural condition assessment of Japanese high-speed railway viaducts. Mech. Syst. Signal Process. 2021, 160, 107850. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. Deepcrack: Learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 2018, 28, 1498–1512. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1525–1535. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Choi, W.; Cha, Y.J. SDDNet: Real-time crack segmentation. IEEE Trans. Ind. Electron. 2019, 67, 8016–8025. [Google Scholar] [CrossRef]
- Beckman, G.H.; Polyzois, D.; Cha, Y.J. Deep learning-based automatic volumetric damage quantification using depth camera. Autom. Constr. 2019, 99, 114–124. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, B.; Wang, J.; Li, J.; Sun, X. APLCNet: Automatic pixel-level crack detection network based on instance segmentation. IEEE Access 2020, 8, 199159–199170. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Li, K.; Wang, B.; Tian, Y.; Qi, Z. Fast and accurate road crack detection based on adaptive cost-sensitive loss function. IEEE Trans. Cybern. 2021, 53, 1051–1062. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Liu, C.; Zhang, D.; Zhang, S. Characteristics and treatment measures of lining damage: A case study on a mountain tunnel. Eng. Fail. Anal. 2021, 128, 105595. [Google Scholar] [CrossRef]
- Xu, Z.; Guan, H.; Kang, J.; Lei, X.; Ma, L.; Yu, Y.; Chen, Y.; Li, J. Pavement crack detection from CCD images with a locally enhanced transformer network. Int. J. Appl. Earth Obs. Geoinf. 2022, 110, 102825. [Google Scholar]
- Shamsabadi, E.A.; Xu, C.; Rao, A.S.; Nguyen, T.; Ngo, T.; Dias-da Costa, D. Vision transformer-based autonomous crack detection on asphalt and concrete surfaces. Autom. Constr. 2022, 140, 104316. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Zhou, W.; Huang, H.; Zhang, H.; Wang, C. Teaching Segment-Anything-Model Domain-Specific Knowledge for Road Crack Segmentation From On-Board Cameras. IEEE Trans. Intell. Transp. Syst. 2024, 25, 20588–20601. [Google Scholar]
- Wang, C.; Chen, H.; Zhou, X.; Wang, M.; Zhang, Q. SAM-IE: SAM-based image enhancement for facilitating medical image diagnosis with segmentation foundation model. Expert Syst. Appl. 2024, 249, 123795. [Google Scholar]
- Zhou, Z.; Lu, Y.; Bai, J.; Campello, V.M.; Feng, F.; Lekadir, K. Segment Anything Model for fetal head-pubic symphysis segmentation in intrapartum ultrasound image analysis. Expert Syst. Appl. 2024, 263, 125699. [Google Scholar] [CrossRef]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Teng, S.; Liu, A.; Situ, Z.; Chen, B.; Wu, Z.; Zhang, Y.; Wang, J. Plug-and-play method for segmenting concrete bridge cracks using the segment anything model with a fractal dimension matrix prompt. Autom. Constr. 2025, 170, 105906. [Google Scholar]
- Li, W.; Liu, W.; Zhu, J.; Cui, M.; Hua, R.Y.X.; Zhang, L. Box2mask: Box-supervised instance segmentation via level-set evolution. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5157–5173. [Google Scholar] [PubMed]
- Ding, Y.; Liu, H. Barely-supervised Brain Tumor Segmentation via Employing Segment Anything Model. IEEE Trans. Circuits Syst. Video Technol. 2024, 35, 2975–2986. [Google Scholar] [CrossRef]
- Hatamizadeh, A.; Kautz, J. Mambavision: A hybrid mamba-transformer vision backbone. arXiv 2024, arXiv:2407.08083. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Mengiste, E.; Mannem, K.R.; Prieto, S.A.; Garcia de Soto, B. Transfer-learning and texture features for recognition of the conditions of construction materials with small data sets. J. Comput. Civ. Eng. 2024, 38, 04023036. [Google Scholar] [CrossRef]
- Xie, J.; Li, G.; Zhang, L.; Cheng, G.; Zhang, K.; Bai, M. Texture feature-aware consistency for semi-supervised honeycomb lung lesion segmentation. Expert Syst. Appl. 2024, 258, 125119. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Wang, J.; Yao, H.; Hu, J.; Ma, Y.; Wang, J. Dual-encoder network for pavement concrete crack segmentation with multi-stage supervision. Autom. Constr. 2025, 169, 105884. [Google Scholar] [CrossRef]
- Ioffe, S. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Zhang, Y.; Yin, J.; Gu, Y.; Chen, Y. Multi-level Feature Attention Network for medical image segmentation. Expert Syst. Appl. 2024, 263, 125785. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Li, X.; Ding, H.; Yuan, H.; Zhang, W.; Pang, J.; Cheng, G.; Chen, K.; Liu, Z.; Loy, C.C. Transformer-based visual segmentation: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10138–10163. [Google Scholar] [CrossRef]
- Azad, R.; Aghdam, E.K.; Rauland, A.; Jia, Y.; Avval, A.H.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.P.; Adeli, E.; Merhof, D. Medical image segmentation review: The success of u-net. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10076–10095. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Gu, J.; Kwon, H.; Wang, D.; Ye, W.; Li, M.; Chen, Y.H.; Lai, L.; Chandra, V.; Pan, D.Z. Multi-scale high-resolution vision transformer for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 12094–12103. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A real-time semantic segmentation network inspired by PID controllers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19529–19539. [Google Scholar]
- Wan, Q.; Huang, Z.; Lu, J.; Gang, Y.; Zhang, L. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Wang, Z.; Zheng, J.Q.; Zhang, Y.; Cui, G.; Li, L. Mamba-unet: Unet-like pure visual mamba for medical image segmentation. arXiv 2024, arXiv:2402.05079. [Google Scholar]
- Xu, Z.; Wu, D.; Yu, C.; Chu, X.; Sang, N.; Gao, C. SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 6378–6386. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Lin, X.; Yan, Z.; Deng, X.; Zheng, C.; Yu, L. ConvFormer: Plug-and-play CNN-style transformers for improving medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer: Cham, Switzerland, 2023; pp. 642–651. [Google Scholar]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going deeper with image transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 32–42. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23–28 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Wang, S.; Jiao, H.; Su, X.; Yuan, Q. An ensemble learning approach with attention mechanism for detecting pavement distress and disaster-induced road damage. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13667–13681. [Google Scholar] [CrossRef]
- Qiu, J.; Liu, D.; Zhao, K.; Lai, J.; Wang, X.; Wang, Z.; Liu, T. Influence spatial behavior of surface cracks and prospects for prevention methods in shallow loess tunnels in China. Tunn. Undergr. Space Technol. 2024, 143, 105453. [Google Scholar] [CrossRef]
- Kang, F.; Huang, B.; Wan, G. Automated detection of underwater dam damage using remotely operated vehicles and deep learning technologies. Autom. Constr. 2025, 171, 105971. [Google Scholar] [CrossRef]
- Li, Z.; Shao, P.; Zhao, M.; Yan, K.; Liu, G.; Wan, L.; Xu, X.; Li, K. Optimized deep learning for steel bridge bolt corrosion detection and classification. J. Constr. Steel Res. 2024, 215, 108570. [Google Scholar] [CrossRef]
- Karimi, N.; Valibeig, N.; Rabiee, H.R. Deterioration detection in historical buildings with different materials based on novel deep learning methods with focusing on isfahan historical bridges. Int. J. Archit. Herit. 2024, 18, 981–993. [Google Scholar]
- Germoglio Barbosa, I.; Lima, A.d.O.; Edwards, J.R.; Dersch, M.S. Development of track component health indices using image-based railway track inspection data. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2024, 238, 706–716. [Google Scholar]
- Zhang, K.; Pakrashi, V.; Murphy, J.; Hao, G. Inspection of floating offshore wind turbines using multi-rotor unmanned aerial vehicles: Literature review and trends. Sensors 2024, 24, 911. [Google Scholar] [CrossRef]
- Yang, X.; Peng, P.; Li, D.; Ye, Y.; Lu, X. Adaptive decoupling-fusion in Siamese network for image classification. Neural Netw. 2025, 187, 107346. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Yang, J.; Li, H.; Zhang, L.; Zhao, L.; Jiang, S.; Xie, H. Multi-label Concrete Bridge Damage Classification Using Graph Convolution. IEEE Trans. Instrum. Meas. 2024, 73, 1–14. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spall | Rebar | Corrosion | Crack | Hole | Speckle | Total | |
|---|---|---|---|---|---|---|---|
| Number of boxes | 6921 | 9901 | 2486 | 2735 | 1260 | 1092 | 30,458 |
| Number of images | 3365 | 2711 | 2486 | 1287 | 633 | 557 | 7354 |
| Method | Backbone | MIoU (%) | PA (%) | MDice (%) | Model Parameters (M) | FPS | IoU (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rebar | Spall | Corrosion | Crack | Hole | Speckle | Background | |||||||
| DeepLabV3+ | ResNet50 | 54.45 | 69.84 | 70.91 | 42.0 | 30.2 | 48.05 | 60.86 | 50.52 | 41.49 | 20.57 | 62.77 | 96.94 |
| SegFormer | Mit B0 | 56.45 | 71.33 | 72.96 | 84.7 | 20.3 | 50.82 | 62.25 | 51.55 | 45.16 | 23.55 | 64.91 | 96.95 |
| HRViT | HRViT-B3 | 57.11 | 72.47 | 73.88 | 28.6 | 50.6 | 51.05 | 63.27 | 52.57 | 46.37 | 23.73 | 65.84 | 96.97 |
| ABCNet | ResNet101 | 58.31 | 72.55 | 74.68 | 14.6 | 40.2 | 51.08 | 64.13 | 56.75 | 48.37 | 24.05 | 66.89 | 96.92 |
| PIDNet | - | 58.20 | 72.35 | 73.72 | 36.9 | 31.1 | 51.12 | 64.06 | 56.72 | 48.16 | 21.77 | 68.65 | 96.95 |
| SeaFormer | MiT-B4 | 58.70 | 73.48 | 73.35 | 17.1 | 62.8 | 50.86 | 63.67 | 57.21 | 48.90 | 23.82 | 69.54 | 96.95 |
| Semi-Mamba | VMamba | 59.09 | 73.21 | 74.8 | 65.5 | 25.6 | 52.23 | 64.34 | 57.34 | 48.73 | 25.88 | 68.23 | 96.93 |
| SCTNet | - | 57.90 | 72.51 | 74.03 | 17.4 | 61.2 | 49.86 | 63.62 | 57.18 | 48.23 | 23.88 | 65.63 | 96.91 |
| OUR | MambaVision | 60.13 | 74.02 | 75.40 | 106.7 | 15.3 | 53.55 | 64.74 | 57.24 | 49.75 | 26.92 | 71.76 | 96.98 |
| Exp. | Baseline | MambaVision | OPS | HAF | BTM | PSA | MIOU (%) | PA (%) | MDice (%) |
|---|---|---|---|---|---|---|---|---|---|
| #1 | ✓ | 53.28 | 68.23 | 70.22 | |||||
| #2 | ✓ | ✓ | 54.67 | 69.93 | 71.03 | ||||
| #3 | ✓ | ✓ | 56.85 | 71.67 | 73.31 | ||||
| #4 | ✓ | ✓ | ✓ | 57.69 | 72.79 | 73.68 | |||
| #5 | ✓ | ✓ | ✓ | ✓ | 58.04 | 73.10 | 73.91 | ||
| #6 | ✓ | ✓ | ✓ | ✓ | ✓ | 59.21 | 73.58 | 74.57 | |
| #7 | ✓ | ✓ | ✓ | ✓ | ✓ | 58.42 | 73.21 | 74.11 | |
| #8 | ✓ | ✓ | ✓ | ✓ | 58.31 | 73.25 | 74.08 | ||
| #9 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 60.13 | 74.02 | 75.40 |
| Point | Box | box + Point | MIOU | MPA | MDice |
|---|---|---|---|---|---|
| ✓ | 57.28 | 72.34 | 73.56 | ||
| ✓ | 58.67 | 73.11 | 74.22 | ||
| ✓ | ✓ | ✓ | 60.13 | 74.02 | 75.40 |
| Backbone Networks | MIOU (%) | PA (%) | MDice (%) |
|---|---|---|---|
| MobileViT | 58.26 | 73.57 | 73.91 |
| Swin Transformer | 59.21 | 73.78 | 74.21 |
| ConvForme | 58.13 | 73.21 | 74.34 |
| CaiT | 58.78 | 73.65 | 74.21 |
| MambaVision | 60.13 | 74.02 | 75.40 |
| ResNet | MambaVision | MIOU | MPA | MDice |
|---|---|---|---|---|
| ✓ | 54.33 | 69.67 | 71.24 | |
| ✓ | 58.42 | 73.36 | 74.11 | |
| ✓ | ✓ | 60.13 | 74.02 | 75.40 |
| Attention Module | MIOU (%) | PA (%) | MDice (%) |
|---|---|---|---|
| SE | 59.32 | 73.68 | 74.77 |
| CBAM | 59.51 | 73.79 | 74.83 |
| SKA | 59.59 | 73.85 | 74.95 |
| EMA | 60.02 | 73.92 | 75.21 |
| GAM | 59.48 | 73.72 | 74.78 |
| SPA | 60.13 | 74.02 | 75.40 |
| Loss Function | MIOU (%) | PA (%) | MDice (%) |
|---|---|---|---|
| 58.11 | 72.56 | 73.62 | |
| 59.52 | 73.73 | 74.76 | |
| 59.89 | 73.95 | 75.32 | |
| 60.13 | 74.02 | 75.40 |
| Lr | MIOU (%) | MPA (%) | MDice (%) |
|---|---|---|---|
| 0.0001 | 58.27 | 73.35 | 73.64 |
| 0.0005 | 59.32 | 73.88 | 74.36 |
| 0.001 | 60.13 | 74.02 | 75.40 |
| 0.005 | 58.77 | 73.72 | 74.41 |
| 0.01 | 58.68 | 73.62 | 74.12 |
| Method | Backbone | MIoU (%) | MPA (%) | MDice (%) | Model Parameters (M) | FPS |
|---|---|---|---|---|---|---|
| DeepLabV3+ | ResNet50 | 65.89 | 75.44 | 74.88 | 42.0 | 30.2 |
| SegFormer | Mit B0 | 66.22 | 76.33 | 75.13 | 84.7 | 20.3 |
| HRViT | HRViT-b3 | 67.22 | 80.62 | 76.12 | 28.6 | 50.6 |
| ABCNet | ResNet101 | 66.41 | 76.21 | 75.78 | 14.6 | 40.2 |
| PIDNet | - | 67.89 | 80.89 | 76.69 | 36.9 | 31.1 |
| SeaFormer | MiT-B4 | 68.06 | 81.86 | 76.85 | 17.1 | 62.8 |
| Semi-Mamba | VMamba | 67.21 | 80.58 | 76.26 | 65.5 | 25.6 |
| SCTNet | - | 66.32 | 80.51 | 76.01 | 17.4 | 61.2 |
| OUR | MambaVision | 69.01 | 82.19 | 77.73 | 106.7 | 15.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Yang, J.; Jiang, S.; Yang, X. SAM-Guided Concrete Bridge Damage Segmentation with Mamba–ResNet Hierarchical Fusion Network. Electronics 2025, 14, 1497. https://doi.org/10.3390/electronics14081497
Li H, Yang J, Jiang S, Yang X. SAM-Guided Concrete Bridge Damage Segmentation with Mamba–ResNet Hierarchical Fusion Network. Electronics. 2025; 14(8):1497. https://doi.org/10.3390/electronics14081497
Chicago/Turabian StyleLi, Hao, Jianxi Yang, Shixin Jiang, and Xiaoxia Yang. 2025. "SAM-Guided Concrete Bridge Damage Segmentation with Mamba–ResNet Hierarchical Fusion Network" Electronics 14, no. 8: 1497. https://doi.org/10.3390/electronics14081497
APA StyleLi, H., Yang, J., Jiang, S., & Yang, X. (2025). SAM-Guided Concrete Bridge Damage Segmentation with Mamba–ResNet Hierarchical Fusion Network. Electronics, 14(8), 1497. https://doi.org/10.3390/electronics14081497