1. Introduction
With the evolution of cybersecurity threats and the measures taken to address them, malware has remained one of the most alarmingly effective threats against digital systems globally. “Malware” is an umbrella term for malicious software, which refers to several harmful programs designed to gain access to, intercept, or harm the functionality of computer systems and networks. The growth in the number and complexity of malware attacks calls for effective and reliable techniques for malware detection and categorization. The crucial role of accurate malware categorization is beyond doubt. According to the Official Cybercrime Report [
1], in 2023, the global economic losses from cybercrime due to malware abuse were believed to have reached
$8 trillion. Malware attacks lead to expensive losses due to fraud and threats to personal, national, and infrastructural security.
In today’s rapidly evolving digital landscape, malware is increasingly being crafted with sophisticated techniques that allow it to bypass traditional detection systems effectively and efficiently. While signature-based methods of malware detection remain prevalent, their limitations have become apparent over time. Attackers, including both commercial entities and freelance hackers, are leveraging advanced obfuscation and evasion techniques to create new, resilient strains of malware that can avoid conventional detection approaches. As these traditional methods reach their functional limits, there is a pressing need to explore more adaptive and robust alternatives. Machine learning (ML) has emerged as a powerful tool for malware detection and categorization, offering advantages over traditional approaches [
2].
For example, unlike static methods, ML can incorporate dynamic behavior monitoring. It analyzes malware interactions within a system to enable precise malware categorization into families such as adware, ransomware, banking malware, and Trojans, facilitating targeted mitigation strategies [
3]. ML algorithms process vast datasets in real time, identifying subtle anomalies and previously unseen threats, making them particularly effective against zero-day exploits and advanced, persistent threats. Additionally, they can adapt to evolving attack vectors, learning from historical data to improve detection accuracy with low computational overhead [
4]. ML can prioritize critical features to enhance classification accuracy and interpretability [
5]. Furthermore, ML’s scalability allows it to handle increasing data complexity, reduce manual intervention, and enhance response efficiency, making it a vital asset in the ongoing fight against modern malware threats [
6].
On the other hand, ML-based Android malware detection faces several challenges despite its advantages. Malware developers use polymorphism, metamorphism, and obfuscation to evade detection, dynamically altering malware’s features to bypass traditional detection methods [
3,
7]. The high dimensionality of malware attributes, spanning file structures, behaviors, and network activities, increases computational complexity and, thus, the risk of overfitting and reducing generalizability regarding new threats [
8]. Identifying meaningful features remains difficult, as encrypted and obfuscated malware can mask its malicious intent, limiting the effectiveness of structural and code-based analysis [
9]. Additionally, resource constraints on mobile devices make real-time detection challenging, emphasizing the need for adaptive and efficient ML models.
Smartphones and mobile apps have led to an extraordinary increase in mobile malware, especially that targeting Android smartphones, due to their openness and broad use. As of 2023, Android smartphones accounted for approximately 70–72% of the global mobile operating system market, making them a major target for cyber threats and malware attacks [
10]. Android malware has evolved dramatically, from harmless ads to dangerous banking Trojans and ransomware. Signature-based malware detection technologies are ineffective against quickly developing and polymorphic malware. Detecting such malware requires more powerful behavior-based detection algorithms. ML can potentially uncover malware patterns and traits that human analysts may miss. However, using ML for Android malware detection and categorization is difficult. Complications include high-dimensional feature spaces, real-time detection on resource-constrained mobile devices, and malware strategies that evolve to avoid detection. Malware detection and categorization are essential for targeted countermeasures and threat landscape comprehension [
10].
While our study focuses on ML-based Android malware detection, it is important to acknowledge other security challenges, such as side-channel attacks, which exploit device behavior rather than executing malicious code [
2]. One example is RF energy-harvesting attacks, in which adversaries passively analyze the signals emitted from mobile devices to infer user actions and extract sensitive data [
11]. Unlike traditional malware, these attacks operate stealthily and without requiring direct code execution, making them difficult to detect and mitigate [
12].
This study presents a comprehensive two-step ML-based framework for Android malware detection and categorization, addressing the key challenges in this domain. Our work is driven by the following objectives: (1) developing an efficient tool with which to differentiate between safe and malicious Android applications; (2) establishing a reliable approach to categorizing malware into distinct types, thereby enhancing threat comprehension; and (3) investigating the impact of feature selection and scaling on the performance of ML models regarding Android malware analysis. The proposed methodology operates in two stages: malware detection and categorization. During the malware detection stage, binary categorization is employed to identify potentially harmful applications instantly, providing rapid alerts about risky programs. During the malware categorization stage, multi-class categorization is utilized to determine the specific category of malware at work, offering deeper insights into the nature of the threat. This tiered approach is critical for real-world applications, as it balances speed and accuracy, making the system adaptable to various operational scenarios.
To implement the framework, we utilized four widely recognized classifiers, naïve Bayes (NB), K-nearest neighbors (KNN), decision tree (DT), and random forest (RF), for both malware detection and categorization. Feature selection techniques, including chi-squared testing and select-from-model, were applied along with feature scaling to optimize model performance. The proposed system achieves flexibility by separating the detection and categorization tasks into two stages. It can be deployed for rapid detection in high-traffic environments or detailed threat categorization when additional processing time is available.
The key contributions of this study are as follows:
It presents a novel two-step ML framework for Android malware detection using binary classification, followed by malware categorization, addressing key challenges in mobile security;
It provides optimized feature selection for improved performance through implementing chi-squared and SFM feature selection techniques to enhance classification accuracy and computational efficiency, which is critical for real-world applications;
It performs comparative evaluation across features and scaling techniques for multiple ML classifiers, providing new insights into their effectiveness for Android malware detection. The analysis highlights the effects of preprocessing techniques;
The study achieves 97.82% accuracy in malware detection and 96.09% in categorization, outperforming existing methods, including deep learning (DL) approaches;
The framework offers a scalable and interpretable solution suitable for real-world applications, providing an efficient alternative for mobile security against evolving malware threats.
The remainder of this paper is organized as follows:
Section 2 reviews related research on Android malware detection.
Section 3 outlines the methodology, including dataset details, feature engineering techniques, and the ML classifiers used.
Section 4 presents the results and compares them with those of existing studies, and
Section 5 concludes the paper and provides suggestions for future research directions.
2. Literature Review
The rapid evolution of Android malware has driven extensive research into advanced detection and categorization methods. Various research projects have leveraged ML, DL, and innovative techniques to address challenges such as obfuscation, scalability, and computational complexity, thus effectively detecting Android malware. Ansori et al. [
10] employed gain ratio feature selection and ensemble ML techniques, integrating RF, extra trees (ETs), K-nearest neighbors (KNN), Support Vector Machine (SVM), and naïve Bayes (NB) using the CICMalDroid2020 dataset [
13]. Their ensemble classifiers (RF, ETs, and KNN) achieved 94.57% accuracy and a recall of 94.57%, demonstrating strong detection capabilities. However, the ensemble model’s computational complexity increased training and inference time, making it less suitable for real-time applications.
Mohaisen et al. [
14] introduced a behavior-based malware analysis system that leverages dynamic execution traces and ML for classification, achieving over 98% precision and recall in clustering tasks. This high-fidelity approach enhances resilience against evasion techniques, outperforming traditional static analysis. Similarly, Shen et al. [
15] utilized complex information flows to detect malware, achieving 86.5% accuracy and improving resistance to obfuscation. Complementing these methods, Kang et al. [
16] enhanced malware detection using static analysis with creator information, achieving 90% classification accuracy by analyzing permissions and behaviors.
Mohamed et al. [
17] proposed an ML framework that compared static and dynamic API calls and permissions using KNN, naïve Bayes, SVM, and decision trees. Although SVM achieved 86% accuracy, the study did not categorize malware into different types, limiting its usefulness in threat intelligence. Additionally, challenges such as code obfuscation and the limitations of static and dynamic analysis were identified, emphasizing the need for novel methods that enhance adaptability to evolving malware.
Recent studies have explored DL techniques, such as convolutional neural networks (CNNs), long short-term memory (LSTM) networks, and transformer-based models, for Android malware detection using the CICMalDroid dataset. For example, Aboshady et al. [
18] proposed a DL architecture that integrates static and dynamic analysis, utilizing base classifiers at each hidden layer to improve feature extraction. Their model achieved 92% precision and 91% recall, effectively addressing obfuscation, but it was constrained by binary classification, limiting its applicability to diverse malware families. Additionally, its reliance on large amounts of computational resources restricted real-time deployment.
Similarly, Wakhare et al. [
19] applied LSTM-based models to analyze sequential patterns in API calls and developed a hybrid malware detection system that combined static and dynamic analyses. Their model demonstrates promising results, but at the cost of increased computational complexity and susceptibility to overfitting, reducing its scalability. Al-Fawa’reh et al. [
20] introduced an innovative approach by converting binaries into grayscale images for classification using CNNs and transfer learning, achieving 95.9% accuracy on the CICMalDroid2020 dataset. Despite its success, this method was computationally expensive and limited to binary classification, requiring further enhancements to provide malware categorization.
A semi-supervised DL approach was introduced by Mahdavifar et al. [
21], who employed pseudo-label deep neural networks (PLDNNs) to classify malware into five categories. Their study achieved an F1 score of 94%, demonstrating the potential of semi-supervised learning in cases involving limited labeled data. However, issues such as overfitting and the computational demands of neural networks restricted its real-world scalability. Moreover, Zhang [
22] presents a CNN-BiGRU-based malware detection framework that leverages semantic API call sequences for improved accuracy. Using Skip-Gram embeddings and DL, the model achieves 98.28% accuracy. While effective, its static feature extraction and computational complexity may limit adaptability to evolving malware and real-time deployment.
Xu et al. [
23] propose a graph convolutional network (GCN)-based approach to Android malware detection, leveraging API call graphs, sensitive permissions, and opcodes to capture complex malware behaviors. Their model integrates LSTM and attention mechanisms, achieving 98% accuracy. However, GCN models function as black boxes, with limited interpretability, and rely on complex graph-structured processing, making them computationally intensive and unsuitable for real-time deployment in resource-constrained environments. Moreover, the approach relies on static analysis, which may not fully capture dynamic malware behavior. Similarly, Liu et al. [
24] introduce NT-GNN, a graph-based neural model that detects malware through network traffic flow analysis, achieving 97% accuracy. While effective, NT-GNN is resource intensive, relies solely on network traffic data, and is susceptible to malware evasion techniques that manipulate traffic patterns.
Giannakas et al. [
25] evaluated 27 ML models and a deep neural network (DNN) regarding the usefulness in Android malware detection, using Optuna for hyperparameter tuning and SHAP for feature importance analysis. Their results show that a DNN outperforms shallow ML models, achieving 86% accuracy and an F1 score of 86.5%. However, their approach relies on computationally expensive DL models and binary classification, limiting real-world applicability.
Beyond traditional ML and DL techniques, some studies have explored hybrid approaches and proactive detection methods. Musikawan et al. [
3] focused on malware detection during software design, that is, preventing threats before application deployment. They employed semantic query-based detection using reverse engineering, UML diagrams, and OWL ontologies on 600 Trojan-infected apps obtained from the CICMalDroid2020, achieving 92% precision and 91% recall. However, their approach faced scalability issues, as manual ontology construction was time consuming and required expert intervention.
While these methods show potential for robust malware detection, they often require substantial computational resources and large labeled datasets for effective training. Moreover, DL models tend to act as black boxes, limiting their interpretability in cybersecurity applications. Our study, in contrast, employs an ML-based model enhanced through effective feature selection techniques, which reduce the input dimensionality and overall feature set. This approach improves computational efficiency, maintains high detection accuracy, and leverages the inherent interpretability of ML models such as RF, making it more suitable for deployment in resource-constrained environments such as mobile devices.
The reviewed literature highlights significant advancements in ML and DL for Android malware detection. However, as summarized in
Table 1, several challenges remain. Many studies focus on binary classification, limiting their ability to analyze diverse malware families. Others depend on computationally intensive deep learning models, making them less feasible for deployment on resource-constrained devices such as smartphones. Additionally, several models lack interpretability, which is critical in cybersecurity applications for trust and transparency in decision-making. Adaptability to evolving malware threats is also a recurring limitation. Studies that depend heavily on static analysis or predefined features often struggle to detect newly emerging variants. Furthermore, many approaches overlook feature selection and model scalability, both of which are essential for maintaining efficiency without compromising accuracy. These limitations are systematically compared in
Table 1, which provides a concise overview of model types, classification capabilities, and technical constraints of representative studies.
To address these gaps, our study introduces a two-step ML-based malware categorization framework that detects and classifies malware into distinct types. Our approach enhances efficiency, accuracy, and adaptability by incorporating optimized feature selection techniques, making it suitable for real-world cybersecurity applications.
3. Materials and Methods
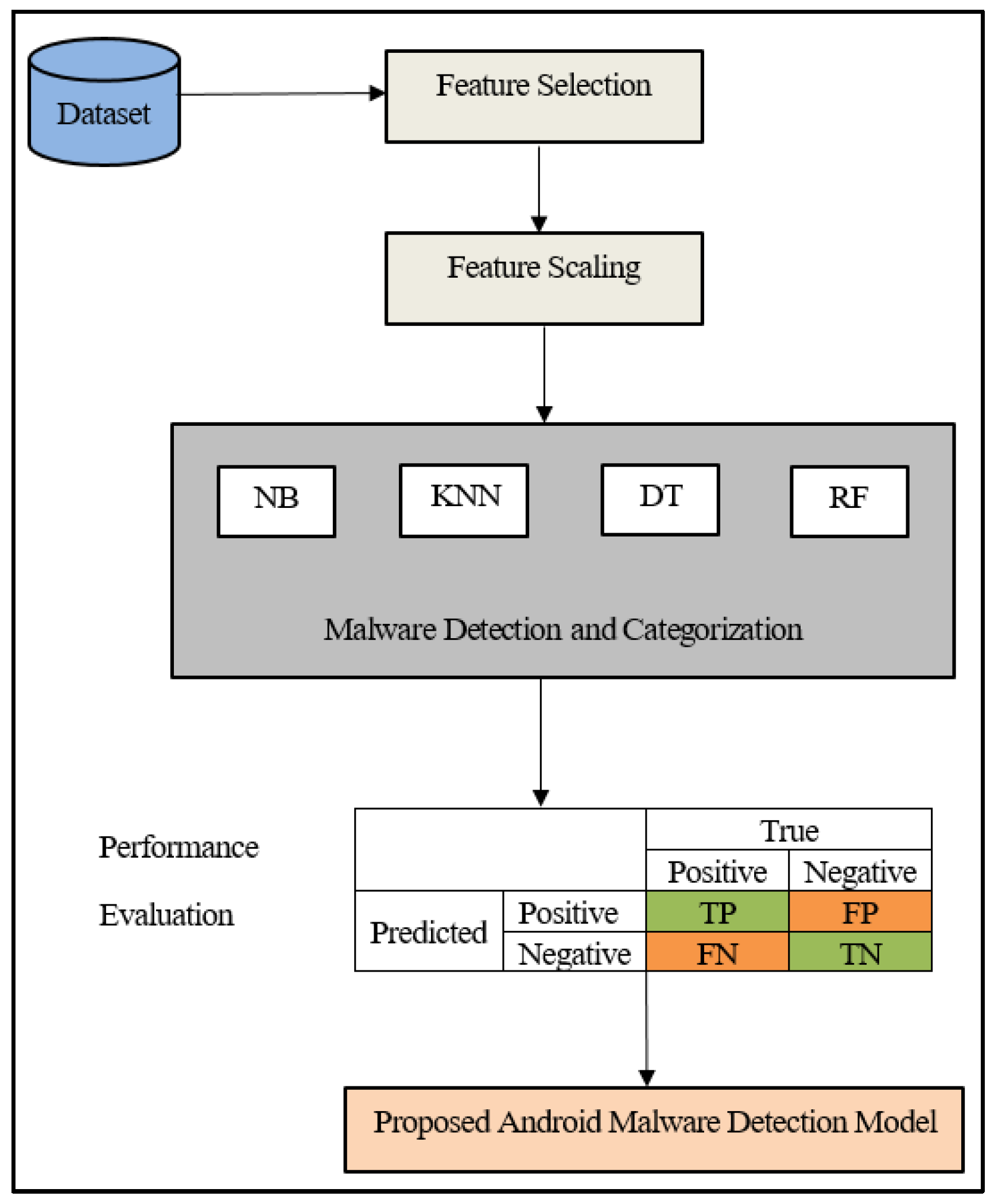
The aim of this study is to employ ML to detect and classify Android malware effectively. This study proposed a two-stem Android malware categorization method that employs feature selection, feature scaling, and ML categorization. All these phases enhance malware detection and help to discover hazardous actions and categorize malware accurately. This approach improves model performance via feature selection and scaling and provides a robust basis for Android malware detection.
Figure 1 shows a general schematic view of the malware detection and categorization techniques proposed in this research project. Feature selection, feature scaling, and malware detection and categorization are described in detail in the following subsections.
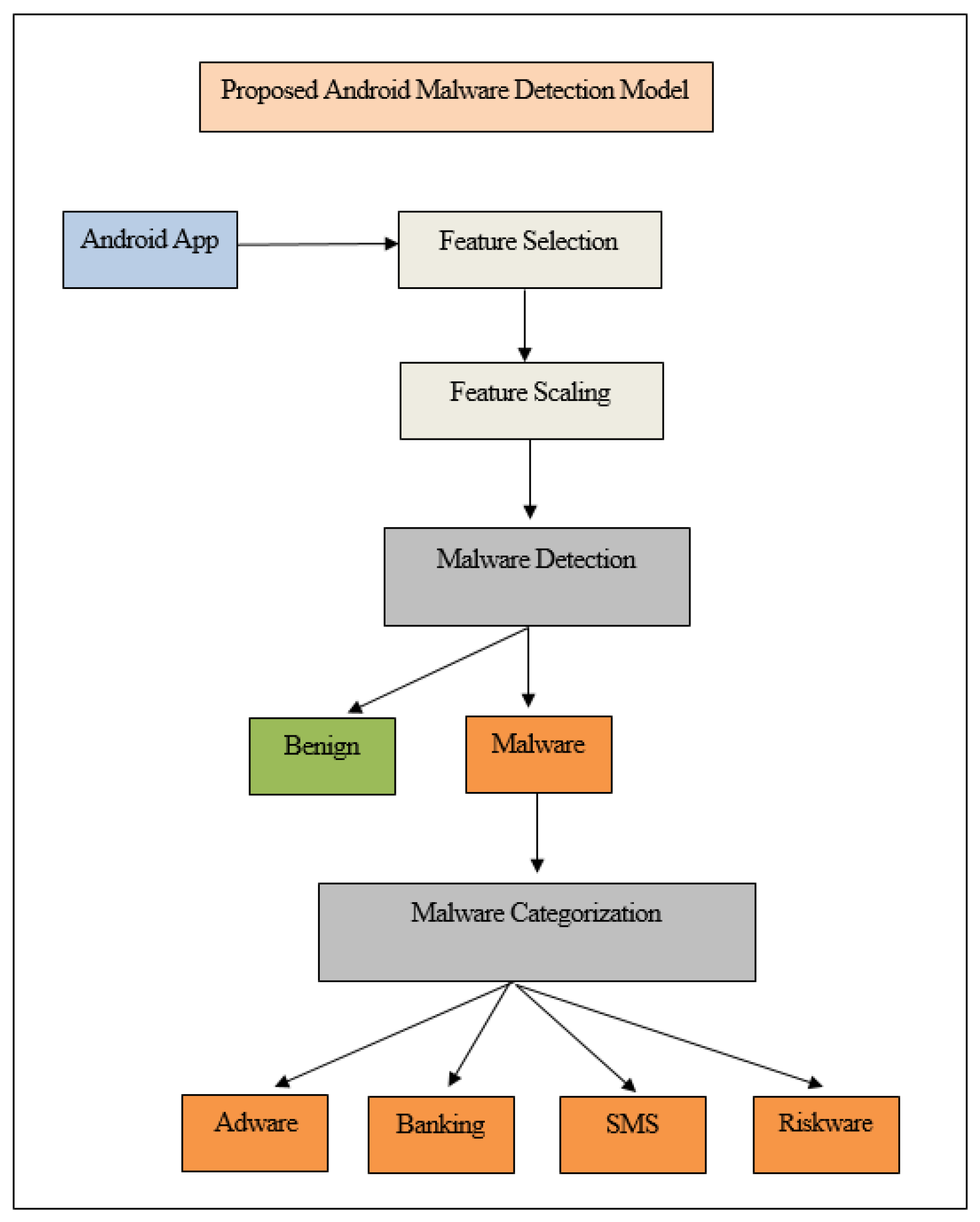
Figure 2 shows a detailed schematic view of the proposed method, in which important features are first selected from an Android application sample. Then, these features are scaled. After that, an ML model is used to classify the Android application as either malware or benign. If the Android application is classified as malware, a second ML model classifies the malware as either adware, banking Trojan, SMS, or riskware.
3.1. Dataset Description
This study utilizes the CICMalDroid 2020 Android Malware dataset [
13], which comprises 11,598 Android malware applications collected from diverse sources, including VirusTotal, Contagio Security Blog, AMD [
26], MalDozer, and other academic and industrial cybersecurity datasets [
27,
28]. The dataset spans a broad spectrum of malware types, including adware, banking malware, SMS malware, riskware, and benign samples. Each malware category exhibits distinct behaviors and potential risks. Adware delivers intrusive advertisements through infected applications, frustrating users and potentially compromising their privacy. Banking malware impersonates legitimate banking applications to steal sensitive financial credentials. SMS malware manipulates or intercepts text messages, often defrauding users. Riskware, while initially legitimate software, can be exploited to cause harm or facilitate ransomware attacks. In contrast, benign samples consist of non-malicious applications that have been carefully verified to eliminate security concerns.
The dataset includes the following distribution across its five categories: 1253 adware samples; 2100 banking malware samples; 3904 SMS malware samples; 2546 riskware samples; and 1795 benign samples. This diversity ensures that the dataset is well suited for analyzing and detecting a wide range of Android malware threats. The main characteristics of the dataset are illustrated in
Table 2.
3.2. Dataset Normalization
The dataset was normalized before training to increase malware classification accuracy and computational efficiency. We applied Z-score normalization and min–max normalization before training. These techniques ensure balanced feature scaling, reducing the risk of skewed learning and improving model generalization.
3.2.1. Z-Score Normalization
Z-score normalization standardizes feature values by transforming them to a mean of 0 and standard deviation of 1, preventing features with larger scales from dominating the learning process. It is based on the following formula: Z = X − μ/σZ. This method is particularly effective for high-dimensional datasets, such as Android malware classification, ensuring stable training across diverse feature distributions.
3.2.2. Min–Max Normalization
Min–max normalization scales feature values between 0 and 1, preserving relative feature relationships while preventing any single feature from dominating the model. This is particularly beneficial for distance-based models such as KNN, in which proportional scaling maintains data distribution with minimal distortion, enhancing classification accuracy. Both normalization methods were sequentially applied to the CICMalDroid2020 after feature selection but before training, as the dataset contained no missing values. Z-score normalization was used for RF, DT, and NB, while min–max normalization was applied for KNN. This step improves model generalization, reduces computational expense, and enhances detection accuracy. These steps proved essential in handling high-dimensional feature spaces, which is a key challenge in Android malware classification.
3.3. Feature Selection
We applied various feature selection techniques to rank features by importance and achieve dimensionality reduction [
29]. This process offers several benefits, including reduced categorization time and model complexity, improved classifier accuracy, and minimal risk of overfitting [
30]. The criteria for feature selection were based on statistical significance, feature importance, and redundancy reduction, allowing the model to focus on the most predictive features while minimizing noise. We utilized the chi-squared testing and select-from-model methods to optimize the performance of our ML models. These methods were selected to maximize classification accuracy, minimize computational burden, and improve model interpretation.
Chi-squared-based feature selection is used to identify key characteristics through statistical testing by analyzing the relationship between individual features and the target variable. The chi-squared values quantify the correlation between each attribute and the target, allowing the selection of the features with the highest scores [
30]. Chi-squared testing was used to test the significance of each feature regarding malware classification. This method quantifies the dependence of the feature and target values, thus giving priority to the most informative ones. In addition, less informative attributes can be discarded. Dimensionality reduction also lowers the risk of overfitting, thus increasing model efficiency. The result is a high level of accuracy in the detection and categorization of malware. This filter-based approach is independent of specific classifiers and evaluates each feature as an isolated entity, making it a versatile method of initial feature evaluation. This technique identified the top 250 features of our method based on their statistical dependence on the target variable.
In contrast, SFM employs a model-centric approach to feature selection [
31]. It uses a pre-defined relevance criterion to identify and eliminate uninformative features from the feature set. SFM uses the importance scores assigned to features by the classifier. This approach determines which features are most relevant to malware detection and classification and ensures that the model is trained on the attributes that will present the best predictive results. It then reduces the dataset by retaining only the features that are essential and discarding non-informative or repetitive attributes, thus enhancing computational efficiency without performance degradation. The combination of these attribute selection methods allows this approach to balance accuracy with computational efficiency within our framework. Such feature subsets grant optimized processing resources while enabling the effective detection and categorization of malware via ML models.
We tested malware detection and categorization models with varying numbers of reduced feature sets to compare the effectiveness of each set. By reducing the feature set, we observed improvements in both accuracy and efficiency. Removing less significant features allowed models to process data more effectively, leading to higher classification performance and reduced training time. This feature selection strategy ensures that our approach remains scalable and practical for real-world malware detection.
3.4. Feature Scaling
To enhance ML model performance in categorization, we tested two feature-scaling strategies: Z-score normalization [
32] and min–max normalization [
33]. Z-score normalization, also known as standardization, rescales data so that they have a mean of 0 and a standard deviation of 1. This approach is particularly effective for datasets with a normal distribution or when it is necessary to compare data points relative to the dataset’s mean and range. By standardizing the data, this method ensures that features with different scales do not disproportionately influence the model. In contrast, min–max normalization rescales data to fit within a specified range, typically between 0 and 1. This method is advantageous for datasets with features on varying scales, as it uniformly adjusts all values to the same range. Min–max normalization is especially useful in algorithms like neural networks and K-nearest neighbors, where the size of data values can significantly impact performance. Both strategies play critical roles in preprocessing, ensuring that ML algorithms can effectively handle data with diverse distributions and scales. By applying these techniques, we aimed to increase the model’s performance, accuracy, and reliability in terms of malware categorization [
34].
3.5. Malware Detection and Categorization
After applying feature selection and scaling, we apply malware detection and categorization. During this phase, malware detection and categorization are designed as two distinct but interconnected stages. This approach is intended to systematically classify Android applications based on their behavior. The process begins with a broad categorization to determine whether an application is malware or benign, followed by a more detailed categorization to identify the specific type of malware at work, as outlined in the following subsections.
3.5.1. Malware Detection
This stage focuses on malware detection, in which programs in the dataset are classified as either benign or malware. This binary categorization assigns a label of “1” to malware and “2” to benign applications. During this stage, malware types, such as adware, banking malware, SMS malware, and riskware, are grouped into a single “malware” class. This simplification allows the detection process to focus solely on determining whether a program is malicious or safe. We evaluated four well-known ML classifiers (NB, KNN, DT, and RF) for malware detection, assessing their performance using various feature selection and scaling techniques on the CICMalDroid2020 dataset. In the following text, each selected classifier is described.
Naïve Bayes (NB): The NB classifier is simple, efficient, and based on probability theory. It assumes that features are conditionally independent, making it well suited for high-dimensional datasets, such as Android malware detection. However, its performance may be limited if the features are highly correlated, as the independence assumption is often violated in complex datasets [
35].
K-nearest neighbors (KNN): KNN classifies malware by comparing unknown applications to the most similar samples in the dataset, making it useful for identifying anomalies. Its ability to detect outliers helps distinguish suspicious applications from benign ones. However, KNN’s performance relies on the choice of the optimal “K” parameter and requires feature scaling to ensure accurate distance computation. Despite its sensitivity to noise, KNN remains a practical choice for initial malware detection due to its simplicity and effectiveness in capturing local patterns [
36].
Decision tree (DT): DT classifiers are known for their simplicity, interpretability, and ability to handle both numerical and categorical data without requiring feature scaling. By breaking down complex decision-making processes into simple, understandable rules, DT helps identify the key patterns distinguishing malware types. While it performs well in terms of identifying Android malware, DT is prone to overfitting, especially with noisy or unbalanced datasets, which can limit its accuracy as compared to ensemble methods [
37].
Random forest (RF): RF is an ensemble method that builds multiple decision trees using random subsets of the dataset and combines their outputs to provide improved accuracy and robustness. This approach reduces overfitting and excels at capturing complex, non-linear relationships between features, making RF particularly effective for malware detection and categorization. Its stability across various feature engineering techniques and ability to process high-dimensional data make it a powerful and reliable tool for use in Android malware detection [
38].
This initial detection stage is critical for real-world applications, in which the rapid identification of potentially harmful programs is essential. By streamlining the categorization process at this level, the system enhances the efficiency and accuracy of detection models. Malware-identified programs can then undergo further evaluation in the second stage, in which a more detailed categorization is performed. This layered approach provides an effective first line of defense, ensuring quick and reliable decisions about program safety.
3.5.2. Malware Categorization
Malware categorization follows the initial malware detection stage, categorizing malware into specific types, such as adware, banking malware, SMS malware, or riskware. This stage transforms malware analysis into a multi-class categorization problem, relying on each malware type’s distinct behaviors and properties. For this stage, we used the NB, KNN, DT, and RF classifiers. Accurate categorization is essential in developing effective responses, as each category poses unique risks and operates differently than the others. By identifying the specific type of malware at work, cybersecurity systems can deploy targeted defenses and mitigation strategies to address the associated threats effectively.
3.6. Performance Evaluation
The proposed framework is evaluated for Android malware detection and categorization using the following key metrics: categorization accuracy, recall, precision, and F1 score [
39]. Categorization accuracy measures the proportion of correct predictions across all instances. We also examined precision and recall, which evaluate the model’s ability to correctly identify positive instances (malware) while minimizing false positives and false negatives. The F1 score is the harmonic mean of precision and recall. The F1 score emphasizes the importance of correctly identifying actual positives while reducing the impact of false positives and false negatives, making it particularly valuable in this context.
We split the dataset into 70% for training and 30% for testing to ensure robust evaluation and generalization. This split allowed the model to train on substantial data while testing its performance on unseen samples. This approach helps prevent overfitting and ensures that the model performs well on new Android malware samples, reflecting real-world evaluation criteria. This evaluation method provides a realistic and reliable comparison of the ML models’ capabilities in detecting and categorizing Android malware.
In the next section, we present and analyze the experimental results obtained in our study. We thoroughly assess the effectiveness of the proposed methodology using performance metrics and conduct a comparative analysis to contrast our findings with those reported in previous research.
3.7. Experiment Environment
The experimental setup for this study utilized a dataset comprising Android applications categorized as either benign or malicious. All experiments were implemented using Python version: 3.11.5 with Anaconda version: 23.7.4, ensuring an efficient and reproducible experimental pipeline. An Acer personal computer with an Intel Core i7 12th Gen processor and 16 GB of RAM was used in the experiments. This study was conducted in November 2024, when the dataset was preprocessed and ML models were trained and evaluated.
4. Results
In this section, we evaluate the detection and categorization of Android malware with different ML classifiers: naïve Bayes (NB), K-nearest neighbors (KNN), decision tree (DT), and random forest (RF). We assess the models using various feature selection and scaling techniques applied to the CICMalDroid 2020 dataset, measuring accuracy, precision, recall, F1 score, and training time.
4.1. Malware Detection Results
To detect malware, we evaluated four classifiers: NB, KNN, DT, and RF. The results, presented in
Table 3,
Table 4,
Table 5 and
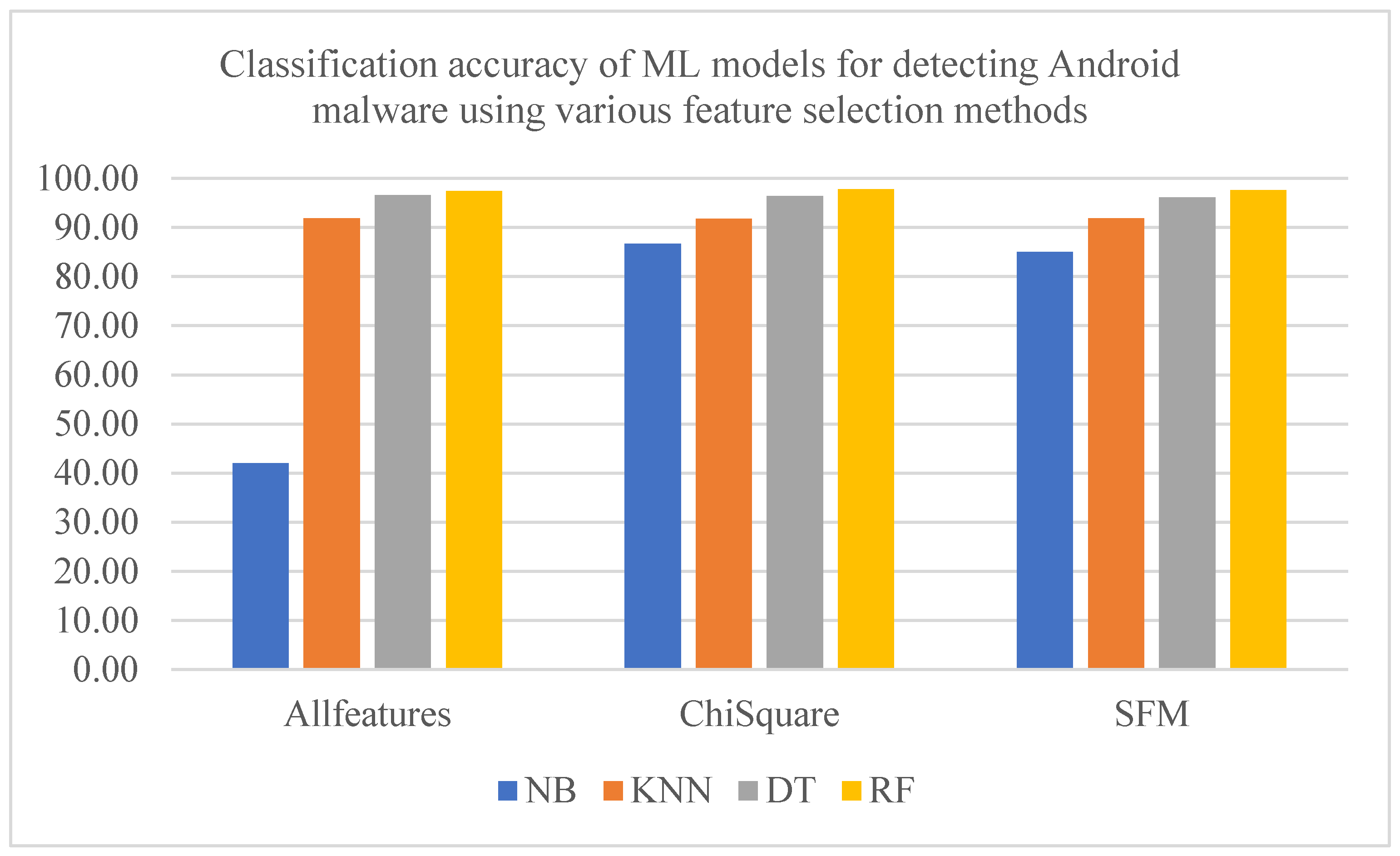
Table 6, show the performance of these models across different feature selection and scaling methods. Chi-squared feature selection with 120 features and no feature scaling yielded the highest accuracy of 97.82% with RF (
Table 3,
Figure 3). This excellent performance remained consistent, with an accuracy of 97.79%, even when applying Z-score or min–max normalization. Random forest’s ability to handle diverse data is attributed to its stability across different feature engineering techniques.
RF demonstrated outstanding accuracy, recall, and F1 scores, ranging from 97.39% to 97.79% (
Table 3,
Table 4,
Table 5 and
Table 6). It performed consistently well across all metrics, with minimal false positives and false negatives when detecting malware and benign applications. This balanced performance highlights its reliability as a robust malware detection tool.
Feature engineering significantly improved the performance of KNN, which is sensitive to high-dimensional input. For instance, using chi-squared feature selection (
Table 3), NB accuracy improved from 42.04% with all features to 86.72%. Similarly, feature scaling substantially impacted distance-based algorithms like KNN. Using SFM feature selection with min–max normalization, KNN accuracy increased to 95.29% (
Table 3). These improvements underline the importance of normalizing features for distance-based methods of KNN.
In contrast, feature scaling had little effect on tree-based algorithms like DT and RF, as these models are inherently less sensitive to variations in feature scale. DT consistently achieved accuracy above 96% in all setups. However, RF outperformed it, demonstrating the advantages of ensemble methods.
These results confirm that our malware detection approach is highly effective. The RF model, in particular, excelled in accurately identifying both benign and malicious Android applications, showcasing its potential for real-world cybersecurity applications.
Moreover, we experimented with oversampling and undersampling techniques to assess the impact of class imbalance in the malware detection task. However, balancing led to a drop in detection accuracy from 97.8% to 95.08%, indicating that oversampling introduced noise rather than improving classification performance. Since the benign class constitutes around 15.5% of the dataset, the imbalance is moderate, and tree-based models like RF are inherently robust to such imbalances. Additionally, evaluation metrics such as precision, recall, and F1 score (97.7%, 97.82%, and 97.7%) confirmed that the model performs well across both classes. Therefore, balancing was unnecessary, and the original dataset was retained to ensure optimal performance.
Table 7 presents the training time results for different ML models used in malware detection with both 470 features and a reduced 120-feature set. These findings highlight how dimensionality reduction impacts training time across different learning algorithms, which is crucial for computational efficiency in real-world applications.
NB showed a 4.4× reduction in training time, decreasing from 0.066 s to 0.015 s, as it relies on conditional probability computations, making it highly sensitive to the number of input features. In contrast, KNN, a lazy learning algorithm, remained unchanged at 0.001 s, as it does not build an explicit model during training, and the reduction of features does not directly impact training time, emphasizing its insensitivity to feature dimensionality as a non-parametric model.
For DT, training time decreased from 0.800 s to 0.467 s, demonstrating how fewer features lead to fewer splits in tree-based methods, reducing computational overhead as it initially splits the feature space iteratively to build a hierarchical tree. Fewer splits mean fewer features, and a simple tree, so there is a reduced computational overhead. However, RF training time remained nearly unchanged, increasing slightly from 2.108 s to 2.115 s. This is due to RF’s random feature selection mechanism, which inherently optimizes feature subsets, making explicit dimensionality reduction less impactful. Additionally, RF’s complexity depends more on the number of trees rather than the number of features. Thus, it demonstrates less loss of RF’s training time on feature reduction compared with DT.
Overall, the results of these demonstrate that the effect of dimensionality on different ML models varies. Probabilistic models like NB and decision-tree-based models like DT benefit substantially from feature reduction in terms of training time. On the other hand, KNN, which is a lazy learning model, is not affected and ensemble models such as RF are hardly influenced.
4.2. Malware Categorization Results
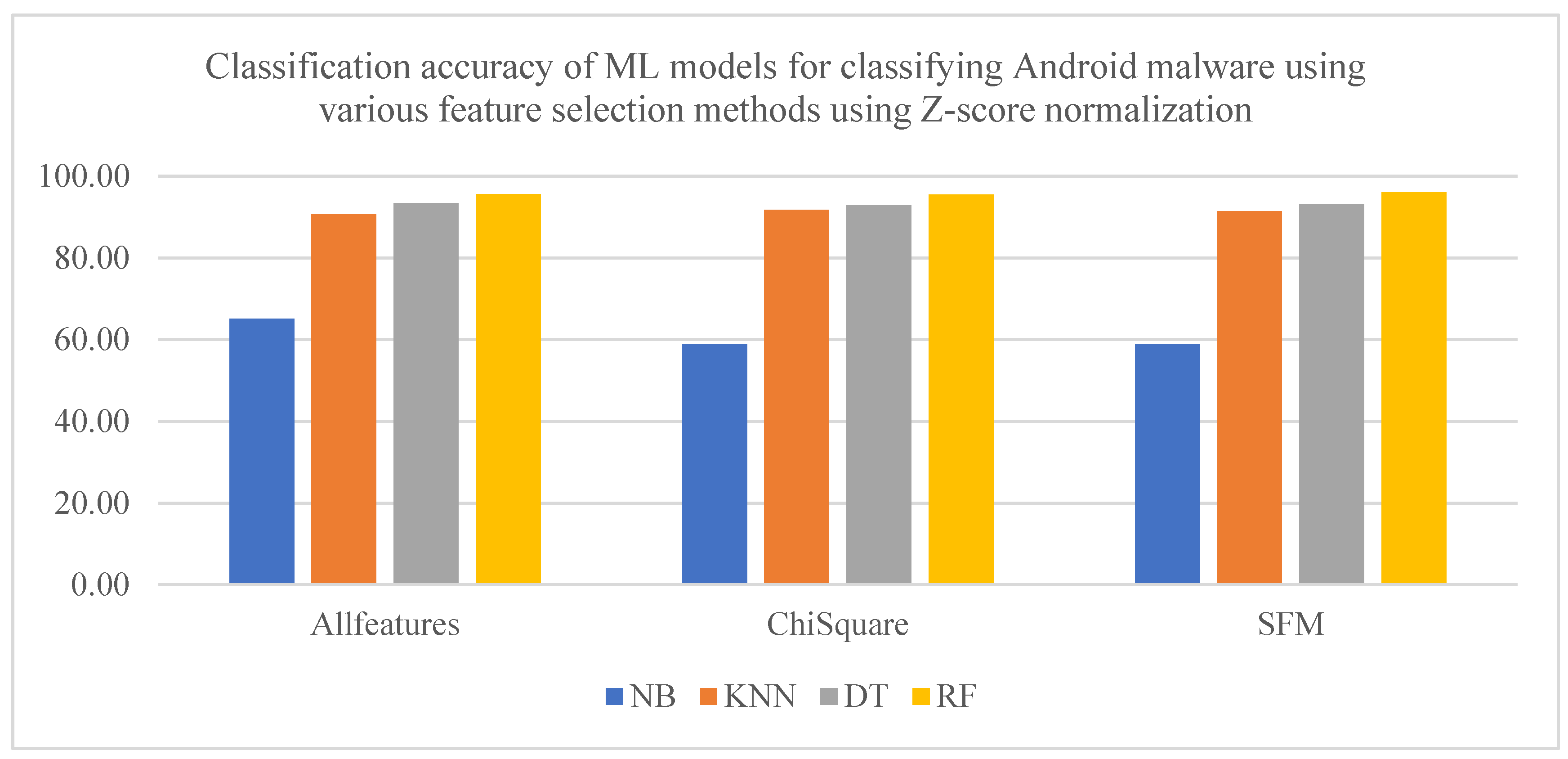
After detecting Android malware, we evaluated the models for multi-class categorization into banking malware, SMS malware, riskware, and adware, using the same ML models and feature engineering methods. The results presented in
Table 8,
Table 9,
Table 10 and
Table 11 and
Figure 4, show that RF consistently outperformed all models, achieving 96.09% accuracy with SFM feature selection (120 features) and Z-score normalization. Its strong performance across accuracy, recall, and F1 score (95.44–96.13%) highlights its ability to distinguish between malware types while handling high-dimensional data effectively and identifying important features without requiring explicit feature selection.
RF maintained stable accuracy across both full and reduced feature sets, ranging from approximately 95.65% to 96.09%, demonstrating its robustness, whereas other models were more sensitive to feature selection and scaling. For instance, NB accuracy improved from 55.49% (no scaling) to 66.51% (min–max normalization), showing the importance of feature engineering for models dependent on feature distributions (
Table 8). Similarly, KNN achieved its highest accuracy (91.77%) using chi-squared feature selection and min–max normalization, confirming the effectiveness of feature selection techniques. DT models consistently performed above 92% but were outperformed by RF, reinforcing the superiority of ensemble methods for complex categorization tasks.
The performance gap between RF in binary detection (97.82%) and multi-class categorization (96.09%) was minimal. This small difference highlights the model’s ability to both detect malware and accurately differentiate between various malware types. In conclusion, our malware categorization approach demonstrated high accuracy and resilience across all malware categories. The RF model, in particular, performed exceptionally well, reliably classifying Android malware with precision. This accurate categorization is crucial for identifying threats and enabling the development of targeted responses in real-world mobile security applications.
Table 12 presents training time results for malware categorization, providing insights into the computational efficiency of different ML classifiers when trained on 470 features versus a reduced set of 120 features. The results indicate that dimensionality reduction impacts training time differently across classifiers.
For NB, reducing the feature set led to a significant decrease in training time from 0.045 s to 0.014 s, consistent with its probabilistic nature, where fewer features directly reduce computational overhead. Similar to malware detection, KNN’s training time remained unchanged at 0.001 s, as it is a lazy learning algorithm that does not perform complex computations during training. Instead, KNN stores data and defers processing to the prediction stage, making training time independent of feature dimensionality.
The training time of the DT classifier decreases considerably when the feature set is reduced from 0.493 to 0.218 s, respectively. The reduction is significant and warrants the high dependency of computational complexity of DT on feature dimensionality. In addition, in malware categorization, rather than malware detection, the reduction in training time is even more significant (from 0.800 to 0.467 s). Thus, it seems that the distributions of feature importance and feature importance may vary slightly for these two tasks, so feature reduction can substantially influence training efficiency.
Interestingly, random forest (RF) increased training time from 1.359 s to 1.518 s when the feature set was reduced. Unlike in malware detection, where RF’s training time remained stable, this result suggests that RF’s random feature selection mechanism requires additional computation when fewer features are available. Since RF builds multiple decision trees by selecting a subset of features at each split, reducing the total feature set may increase processing overhead rather than decrease it.
Several key observations regarding the effect of feature reduction on the training time of different machine learning models are shown by the results. NB and DT benefit the most from feature reduction, significantly lowering training time. While KNN does not build a model during training, it is entirely unaffected by the number of features and remains unaffected. RF has a higher training time with a reduced feature set, which is a good indication that its internal random feature selection needs more work with fewer features and is not the case. Additionally, malware categorization generally requires less training time than malware detection, possibly due to differences in data distribution, feature relevance, or classification complexity. These findings highlight the importance of algorithm-specific evaluations of feature selection strategies, as dimensionality reduction does not always lead to improved training efficiency across all ML models.
5. Discussion
This study demonstrates that ML-based malware detection and categorization can achieve a good balance between accuracy, interpretability, and computational efficiency, making it suitable for deployment on resource-constrained devices such as mobile phones. Among the tested classifiers, RF consistently outperformed the others, achieving 97.82% accuracy in binary detection and 96.09% in multi-class categorization. Its ensemble learning capabilities and robustness to high-dimensional data contributed to its superior performance while avoiding the high computational overhead of deep learning models. Interpretability was maintained through the use of classical ML models like decision trees and RF, which offer transparent decision-making via feature importance—enhancing trust for security analysts. To further improve efficiency, feature selection techniques (chi-squared and select-from-model) were employed to reduce the feature set from 470 to 120, significantly shortening training times for models such as naïve Bayes and decision trees without sacrificing accuracy. Additionally, the use of a two-phase framework—beginning with binary malware detection followed by multi-class categorization—allowed for rapid initial filtering with the option for deeper analysis, supporting flexible, real-time deployment based on available system resources.
While DL models have demonstrated high accuracy in malware detection, they require substantial computational resources and often act as black-box models, limiting interpretability. In contrast, our study shows that well-optimized ML models can rival DL approaches while being more suitable for real-time applications in mobile security. A comprehensive comparison with previous research on Android malware detection and categorization emphasizes the effectiveness of our proposed approach.
Table 13 summarizes this comparison, including various similar studies that proposed Android malware detection methods. Our proposed method outperforms several state-of-the-art ML and DL approaches.
Ansori et al. [
10] employed an ensemble method combining RF, extra trees, and KNN classifiers, achieving an accuracy of 94.57% for multi-class categorization (five classes). Our RF strategy exceeded this by nearly three percentage points, demonstrating the effectiveness of our feature selection and model optimization techniques.
Recent studies have also explored DL methods. For instance, Aboshady et al. [
18] employed a DNN for binary categorization in 2022, achieving 93.5% accuracy, while Al-Fawa’reh et al. [
20] used a CNN in 2020, attaining 95.9% accuracy in binary categorization. Despite their potential, our methodology surpassed these DL approaches by 4.32 and 1.92 percentage points, respectively. This highlights the ability of well-optimized classical ML techniques to rival and even outperform DL models in certain contexts.
Mahdavifar et al. [
21], in their 2020 study using the same dataset (CICMalDroid2020), achieved a multi-class categorization accuracy of 96.7% with a semi-supervised PLDNN. While our multi-class categorization accuracy of 96.09% is slightly lower, the RF model offers key advantages, including lower computational demands and greater interpretability, making it a more practical choice for resource-constrained environments. Wakhare et al. [
19] applied LSTM networks combined with the synthetic minority over-sampling technique (SMOTE) in 2021, achieving a binary categorization accuracy of 94.22%. Similarly, in 2022, Musikawan et al. [
3] achieved 92% binary categorization accuracy using the ontological semantic environment method. While these methods provide unique insights, our categorization accuracy remains notably higher.
Zhang et al. [
22] proposed a malware detection framework that achieved 98.28% accuracy. However, its reliance on static features and predefined API sequences limits its adaptability to evolving malware. Its high computational cost also hinders real-time deployment. In contrast, our approach optimizes feature selection and leverages RF, ensuring high accuracy with low computational overhead, making it more efficient and scalable.
Our malware detection and categorization system is not only accurate but also balanced, achieving 97.82% accuracy in binary categorization and 96.09% accuracy in multi-class categorization. By employing chi-squared and SFM feature selection techniques, combined with feature scaling experiments, we enhanced the efficiency of our framework. This is particularly valuable for real-world applications, such as mobile devices, in which computational resources are often limited. In conclusion, our comparison with previous studies (summarized in
Table 13) demonstrates that our methodology is a highly effective solution for Android malware detection and categorization. It delivers state-of-the-art accuracy while remaining efficient, interpretable, and versatile in both binary and multi-class settings. These qualities position our approach as a significant contribution to the field, with promising applications in mobile security.
The computational efficiency of the proposed framework is critical for real-time deployment, particularly on resource-constrained mobile devices. Our training time analysis demonstrates that NB and DT significantly benefit from feature reduction, reducing computational overhead and making them more suitable for real-time applications. KNN, while it maintains a constant training time, has a computationally expensive inference phase (O(n × k)), making it less ideal for mobile deployment. On the other hand, despite its high accuracy, RF experiences a slight increase in training time when features are reduced, likely due to its internal feature selection mechanism requiring additional processing.
To further assess real-time feasibility, we analyzed the time complexity of the RF model (O(t × n × log n)), and the complexity of RF inference is O(t × d)O(t × d), where d is the number of features. While RF is more computationally demanding than other classifiers, it remains stable, highly accurate, and robust across feature selection methods, making it a strong candidate for mobile security applications. Optimizations such as model pruning, quantization, and federated learning can be explored to reduce computational overhead while maintaining detection accuracy to enhance real-time performance. Future research should focus on deploying RF on mobile devices, assessing its runtime efficiency, memory footprint, and energy consumption to ensure practical implementation in resource-constrained environments.
The practical implementation of our proposed malware detection and categorization framework can significantly enhance mobile security in various real-world applications. Due to its lightweight computational requirements, the system is well suited for integration into mobile security solutions, antivirus applications, and endpoint protection systems. Security firms can deploy the framework within mobile operating systems or cloud-based security platforms to detect and classify Android malware efficiently.
6. Conclusions
This study presents an ML-based framework for Android malware detection and categorization, achieving 97.82% accuracy in detection and 96.09% in multi-class categorization, surpassing similar studies. The approach effectively identifies and classifies malware by integrating feature selection, feature engineering, and a two-step categorization process. Tested on the CICMalDroid 2020 dataset with 11,598 samples, the framework demonstrates strong generalizability across malware variants.
Optimizing chi-squared and SFM feature selection reduced features from 470 to 120, improving computational efficiency, while feature scaling further refined performance. The two-step classification process enables rapid threat detection and detailed malware analysis, making it suitable for real-world security applications requiring speed and precision. The framework’s robust performance across different feature selection and scaling methods, particularly with RF, highlights its adaptability across Android environments and effectiveness in addressing evolving malware threats. These findings establish our approach as a scalable, interpretable, and high-performing solution for Android malware detection.
7. Limitations and Future Work
While our model achieves strong performance on the CICMalDroid 2020 dataset, its ability to detect zero-day malware and evolving threats requires further validation. Future research should explore transfer learning with multiple datasets and adaptive learning techniques such as incremental model updates and real-time data augmentation to improve generalization. Additionally, cross-dataset evaluation could enhance robustness while reducing computational overhead. Additionally, the model may require fine-tuning when deployed in different environments, as variations in malware characteristics could impact classification performance.
To improve real-world applicability, future work should focus on real-time mobile implementation with optimized computational efficiency. Exploring the evolution of feature relevance as new malware types emerge could lead to more adaptable feature selection techniques, ensuring continued model effectiveness. Explainable AI (XAI) can further enhance interpretability, making malware detection more transparent and reliable. Integrating static and dynamic analysis could improve detection accuracy, particularly against sophisticated malware variants.
Our current study focuses on static analysis, which may have limitations against malware using code obfuscation or runtime evasive techniques. Integrating dynamic analysis could improve detection rates by analyzing malware behavior during execution. Moreover, evaluating real-time detection on live malware samples will further validate model robustness.
Moreover, while this study demonstrates that well-optimized machine learning models can achieve high accuracy in malware detection and categorization, we recognize the potential benefits of DL approaches. Future work could explore hybrid models that combine feature-based ML methods with DL architectures such as CNNs, LSTMs, or transformers to enhance malware detection capabilities further. Leveraging pretrained DL models and transfer learning techniques may help reduce computational overhead while improving generalization to new malware variants. Integrating DL models with real-time detection systems could enhance adaptability to evolving malware threats.
While the CICMalDroid 2020 dataset provides diverse Android malware samples, evolving threats require continuous dataset updates to maintain detection effectiveness. Future research should incorporate recent malware datasets or incremental learning techniques for adaptability. Evaluating real-time detection on live malware samples can further validate model robustness. Additionally, federated learning could enable models to learn dynamically from distributed mobile devices while preserving privacy. These advancements will help ensure the framework remains adaptive, scalable, and effective in addressing future malware threats.





{kind=link}
{kind=link}
{kind=link}
{kind=link}