
Dynamic Client Selection and Group-Balanced Personalization for Data-Imbalanced Federated Speech Recognition

Abstract
1. Introduction
2. Related Foundations
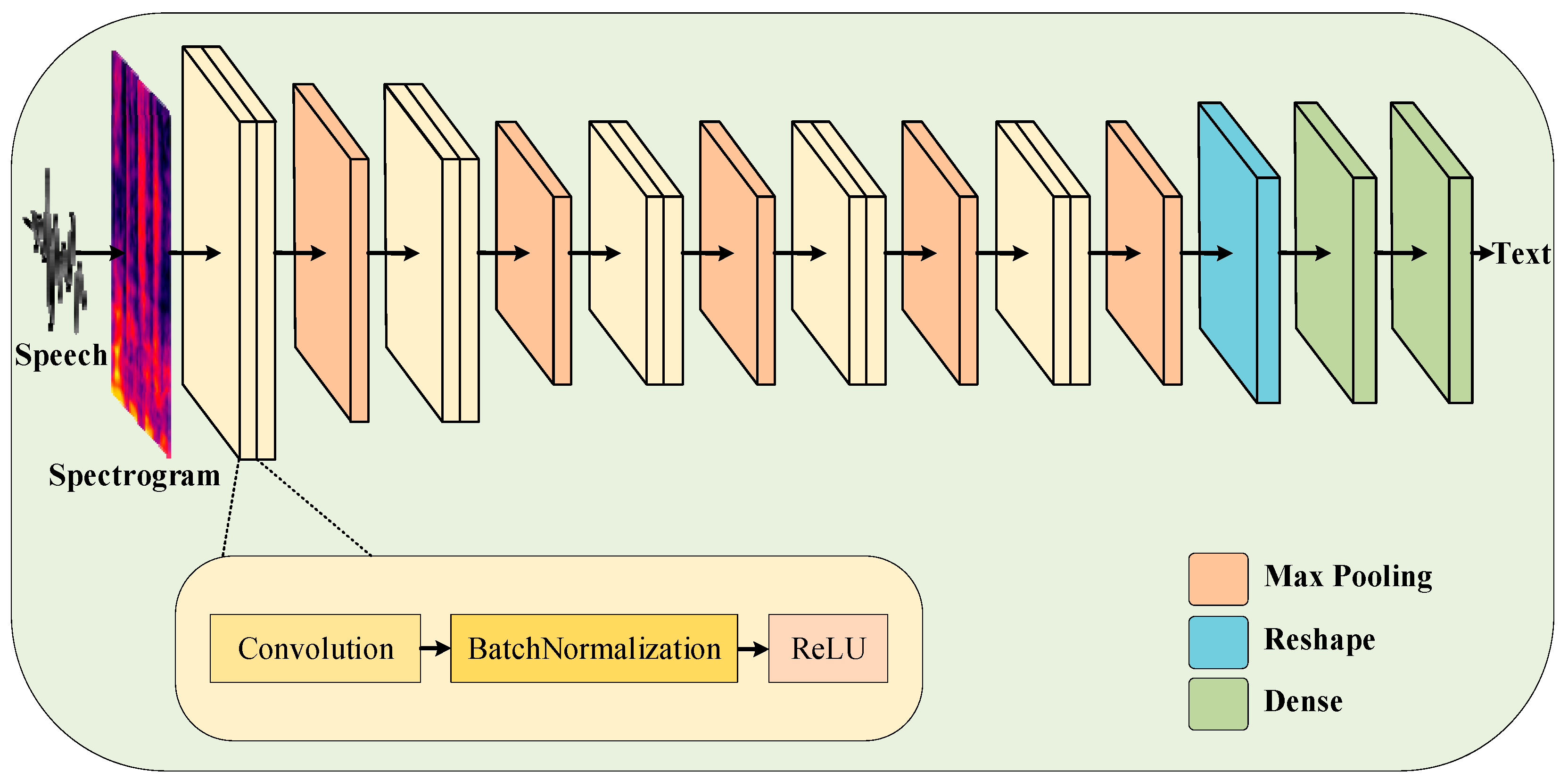
2.1. Architecture of Speech Recognition Model
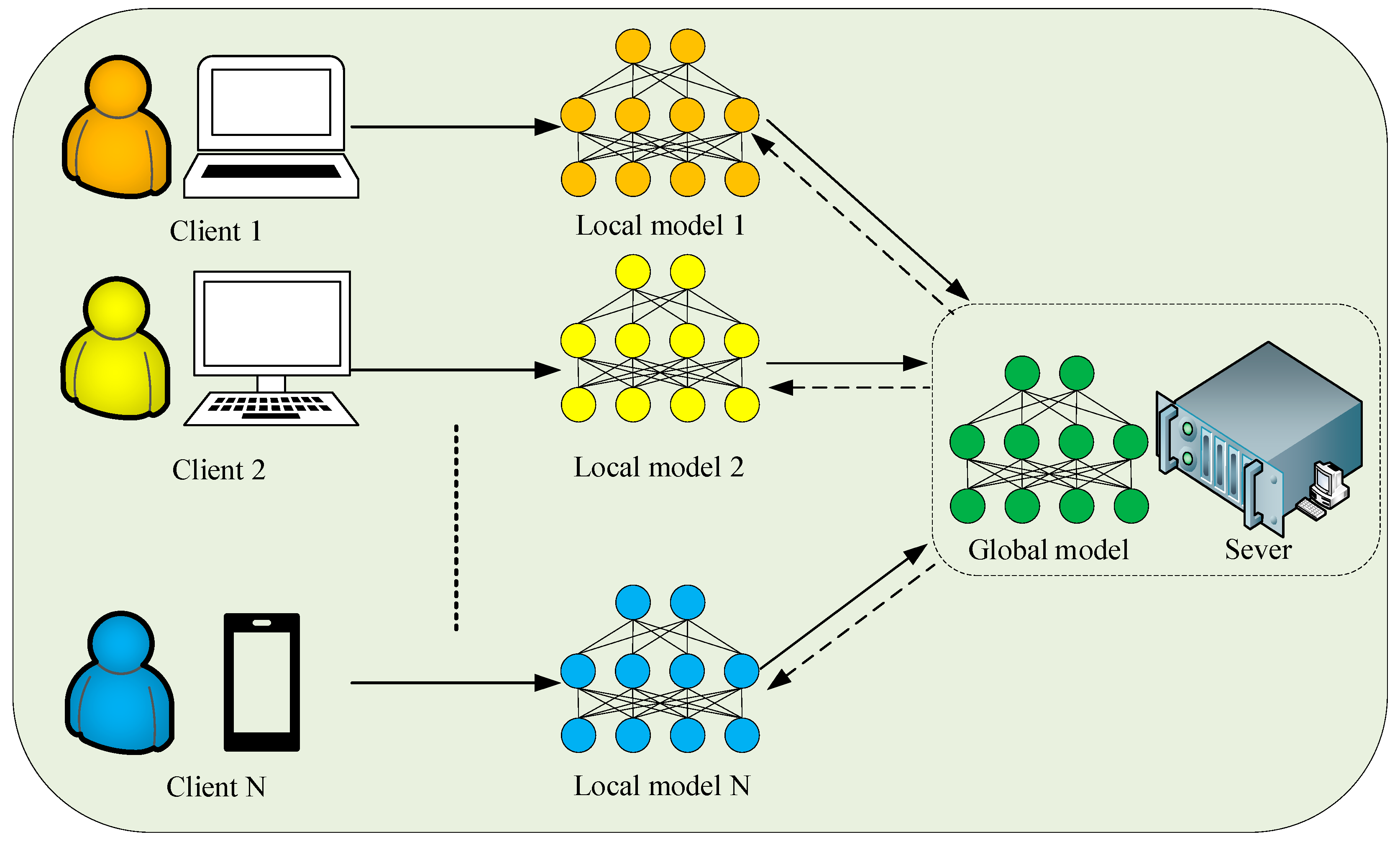
2.2. Associated Federated Learning Algorithms
- (1)
- The model is pre-trained on the server using a centralized method for parameter initialization.
- (2)
- The server randomly selects clients from the entire pool of clients using fixed probabilities and distributes the model parameters to them.
- (3)
- Clients utilize local data to train the parameters and subsequently return the updated model parameters to the server.
- (4)
- The server collects updated model parameters from participating clients, then performs weighted aggregation and update global model parameters. The global model parameter is given as:where is the local model parameters of client , is the dataset size of client , and is the total dataset size of clients.
- (5)
- Repeat steps 2–4 until the global model converges, then distribute the final model parameters to all clients.
3. Methods
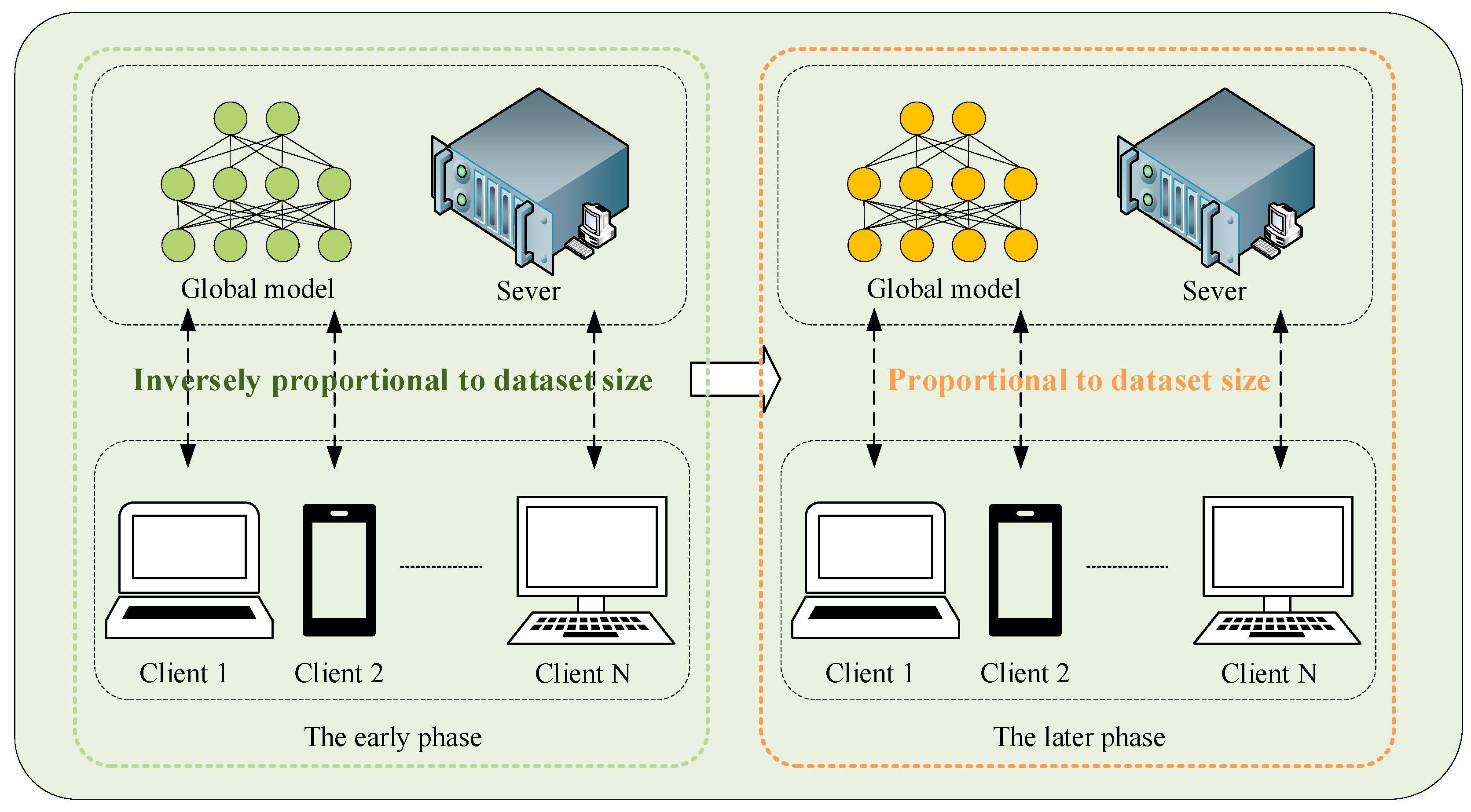
3.1. Dynamic Client Selection
- (1)
- The early phase. Clients with smaller datasets were prioritized with a higher probability of being selected for training. This approach aimed to leverage smaller datasets for rapid initial fitting, thereby minimizing time loss. It also mitigated the disproportionate influence of clients with larger datasets on the global model. In this work, the selection probability for client during this phase was inversely proportional to dataset size across clients.
- (2)
- The later phase. After a certain number of rounds, this algorithm adjusted the strategy to give clients with larger datasets higher priority until the model converges. This approach ensured that more comprehensive data contributed to fine-tuning the global model and enhancing robustness. In this phase, the selection probability for client was proportional to dataset size.
- (1)
- The distribution of client data. If there are serious differences in the distributions of client data, it may hinder the initial convergence of the global model during the early training phase. In such cases, it is necessary to determine an appropriate based on the specific structure of the model and its convergence speed under centralized training conditions. If these conditions are difficult to satisfy, can be set when the value of the loss function remains non-decreasing for a certain number of rounds.
- (2)
- Resource constraints. If computational resources are limited, it might be necessary to adjust probabilities before the initial convergence of the model to conserve resources. However, this approach may prevent the global model from fully learning the characteristics in training data, which could ultimately compromise its recognition performance. In such cases, it is essential to balance training costs and model performance to determine an appropriate .
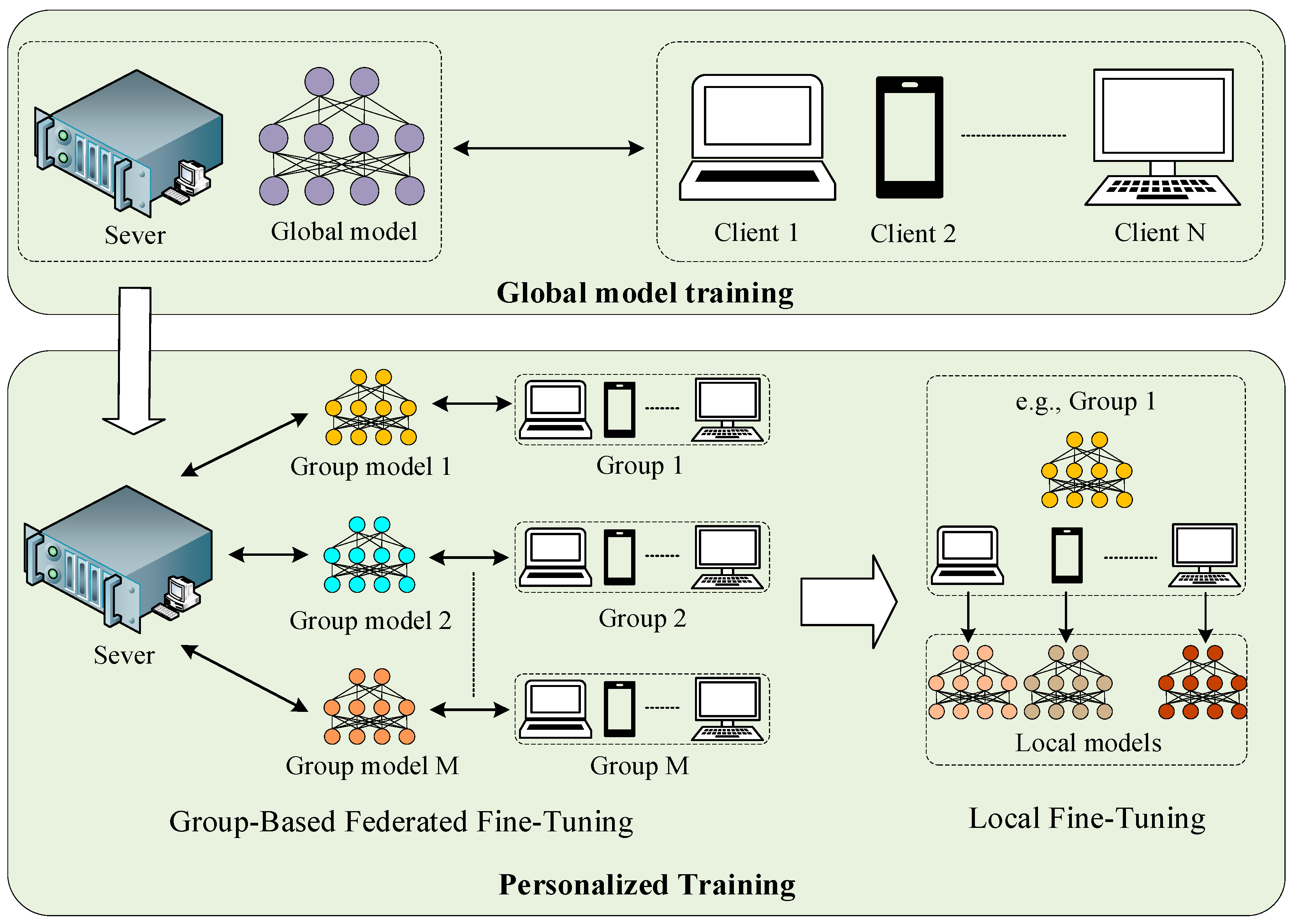
3.2. Group-Balanced Personalization
| Algorithm 1: Proposed group-balanced personalization. is the number of groups, represents models, represents the number of clients. |
| Phase 1 (Group-Based Federated Fine-Tuning): Extract groups by clustering clients with similar dataset size for each group do if consists of clients with smaller datasets do fully federated fine-tuning within else if consists of clients with larger datasets do a small amount of federated fine-tuning or no fine-tuning within end for Return () Phase 2 (Local Fine-Tuning): for each client do if within do utilize the local dataset in to fully fine-turn end for Return ) |
4. Experimental Setup
4.1. System Configuration
4.2. Datasets
- (1)
- Diversity in acoustic features across clients: Typically, the speakers associated with different clients were distinct, and these speakers often exhibited considerable variations in speech rate, intonation, and other characteristics.
- (2)
- Imbalance in dataset size across clients: As different clients serviced distinct speakers with varying speaking habits, there tended to be a noticeable imbalance in the amount of speech data across various clients.
- (3)
- Evaluation of personalized local models on client-specific datasets: The performance of each personalized model was evaluated using the unique dataset of each client.
4.3. Evaluation Metrics
5. Experiment and Comparison
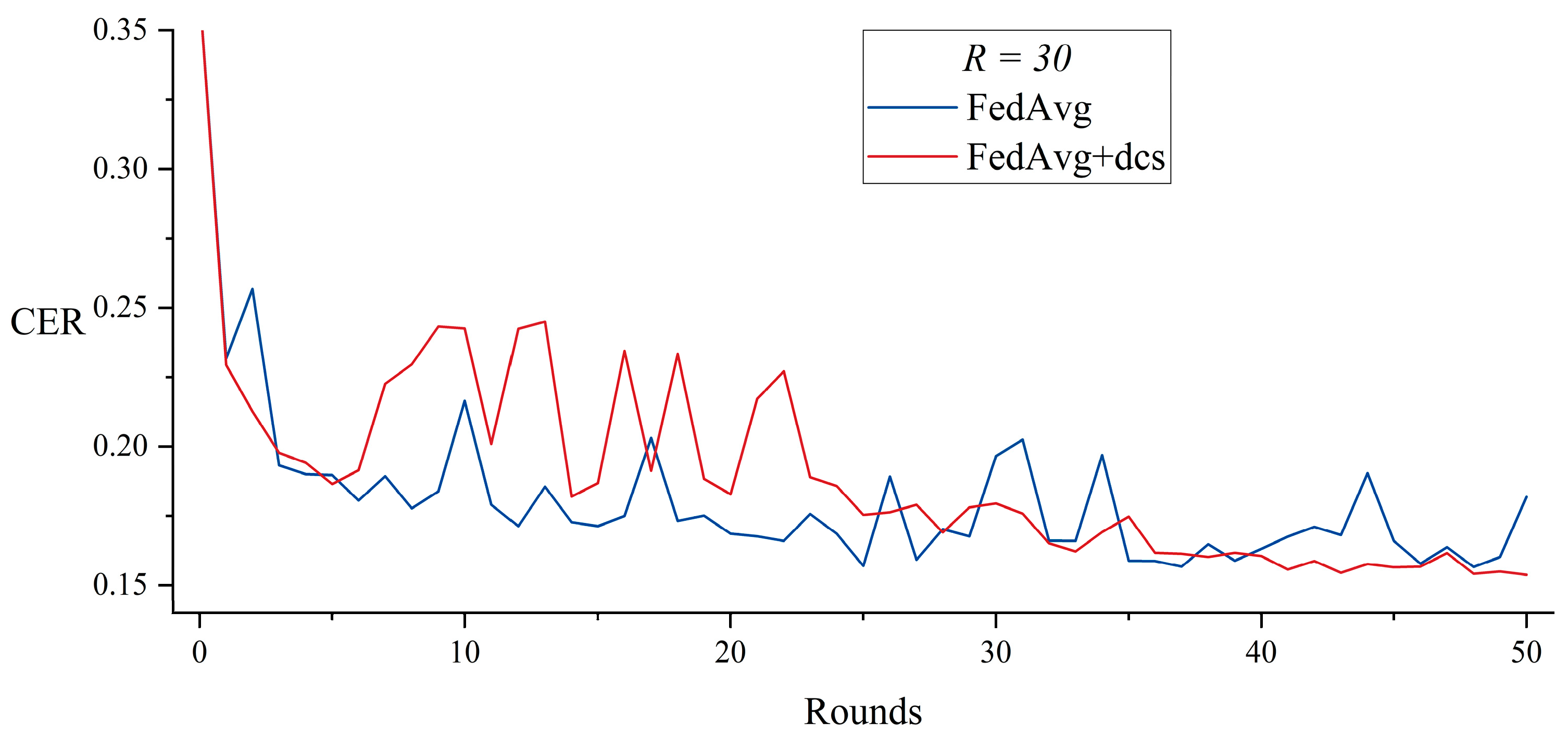
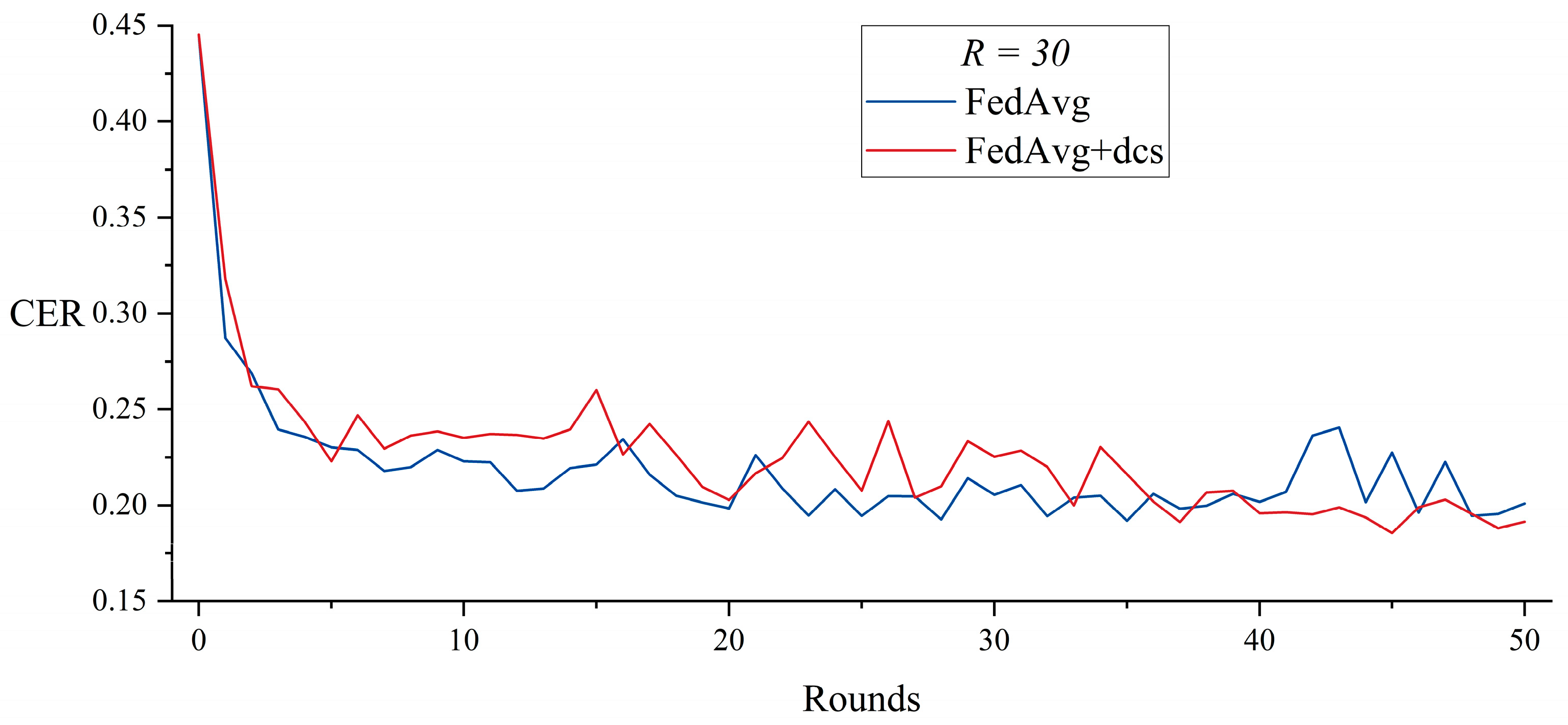
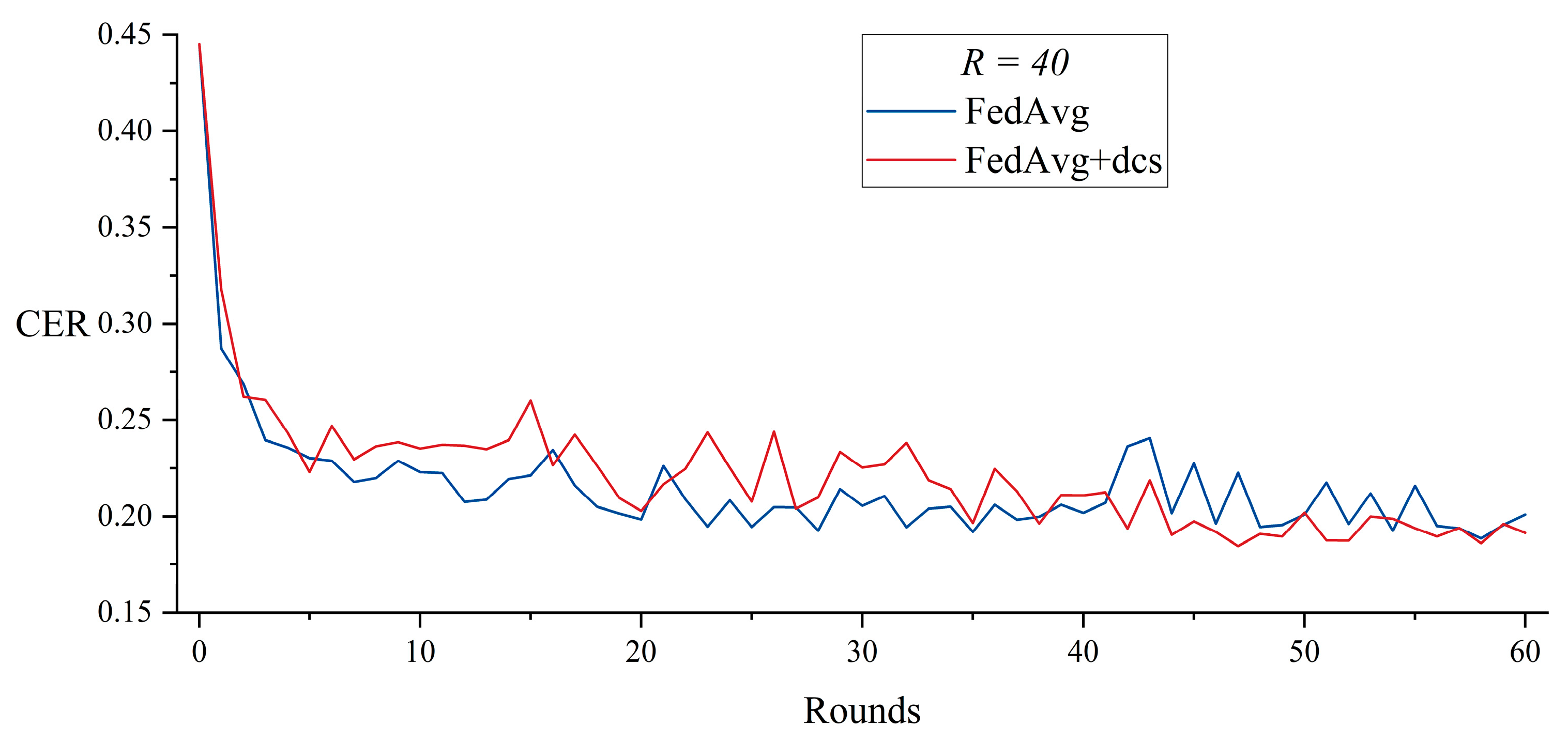
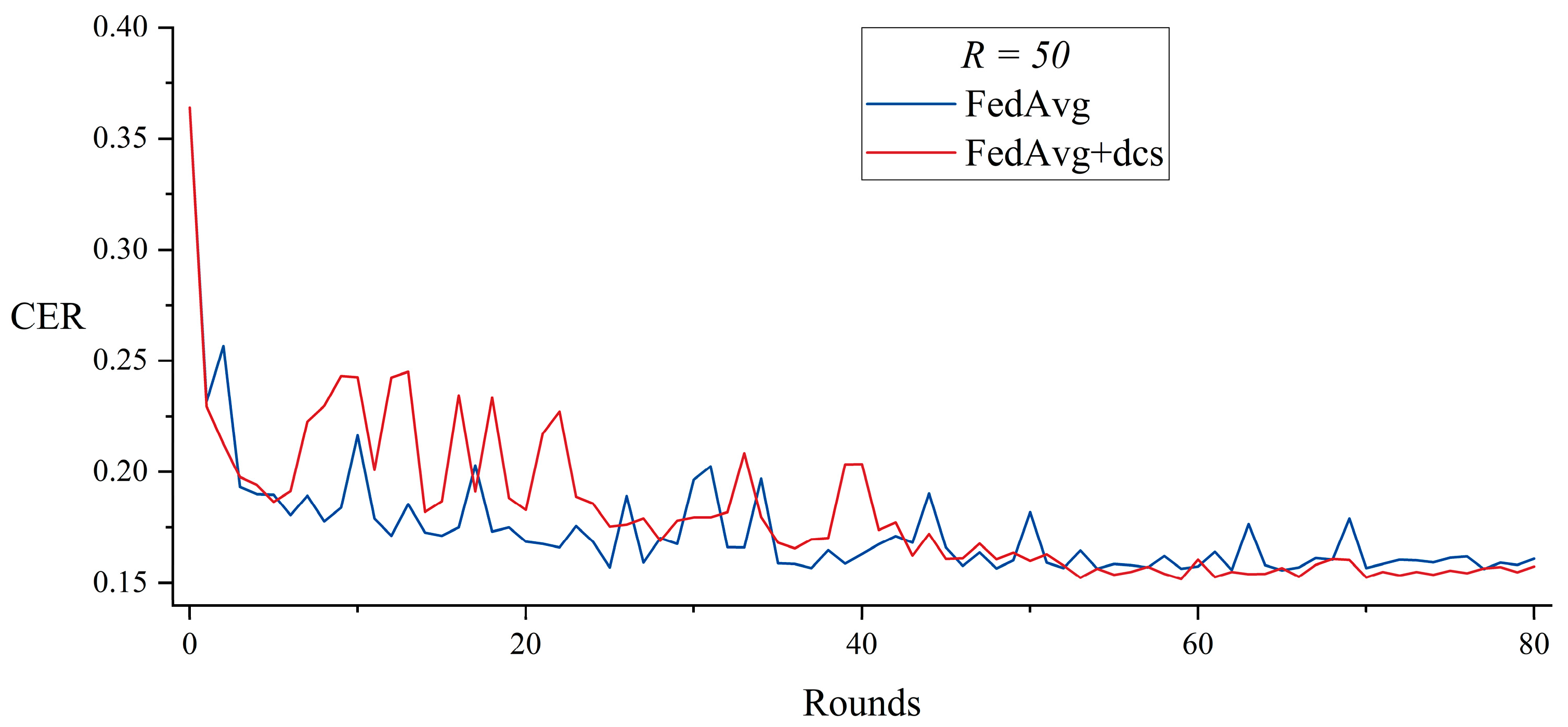
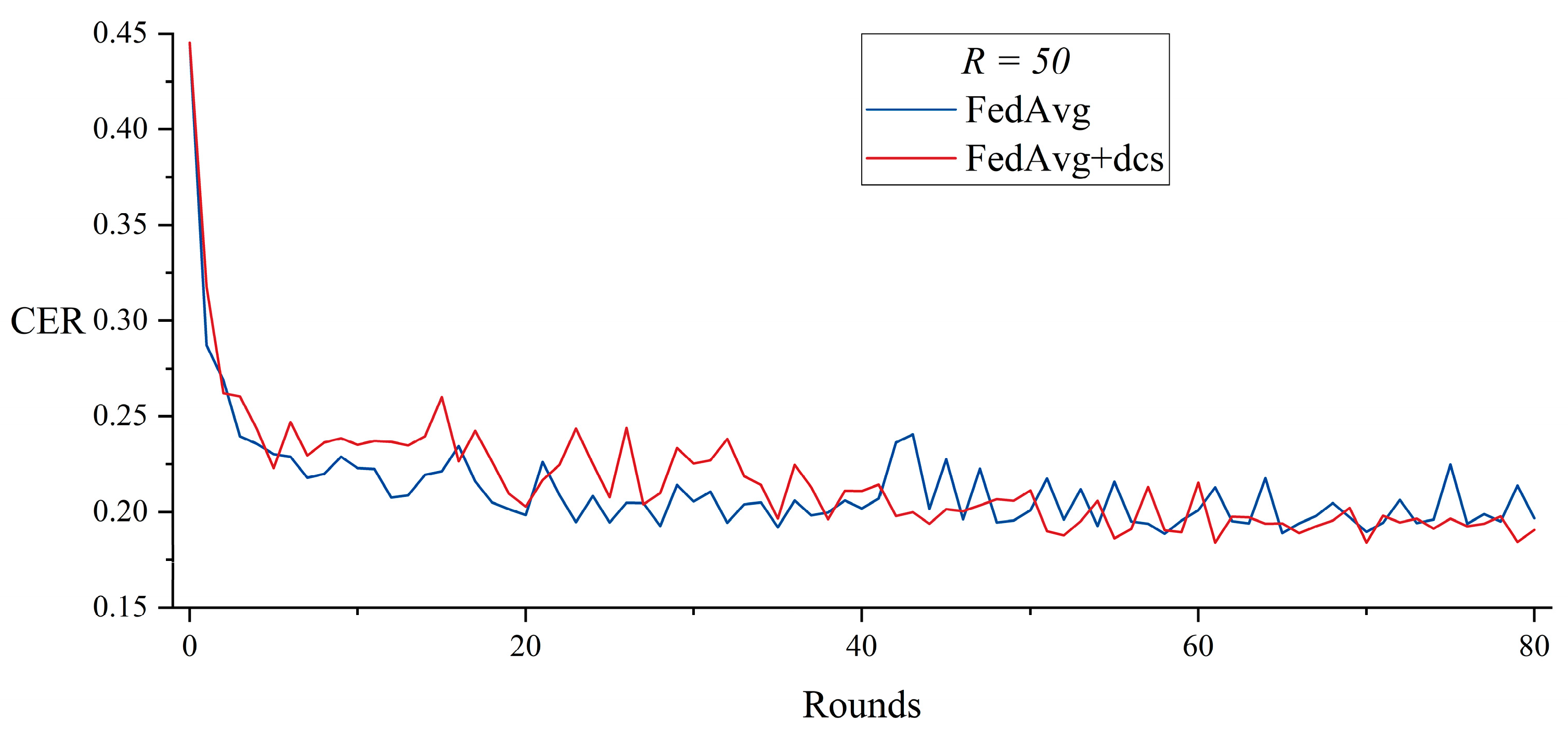
5.1. Dynamic Client Selection with FedAvg
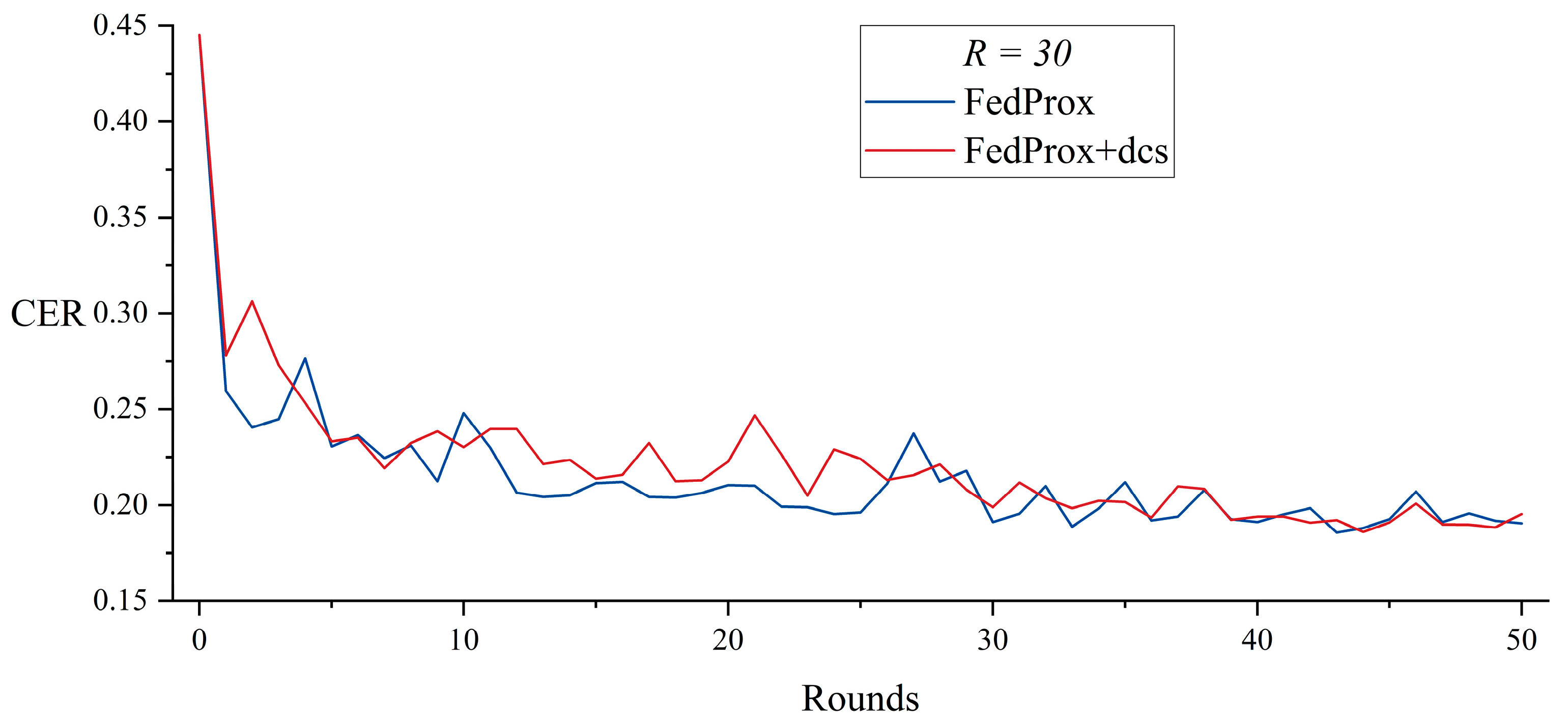
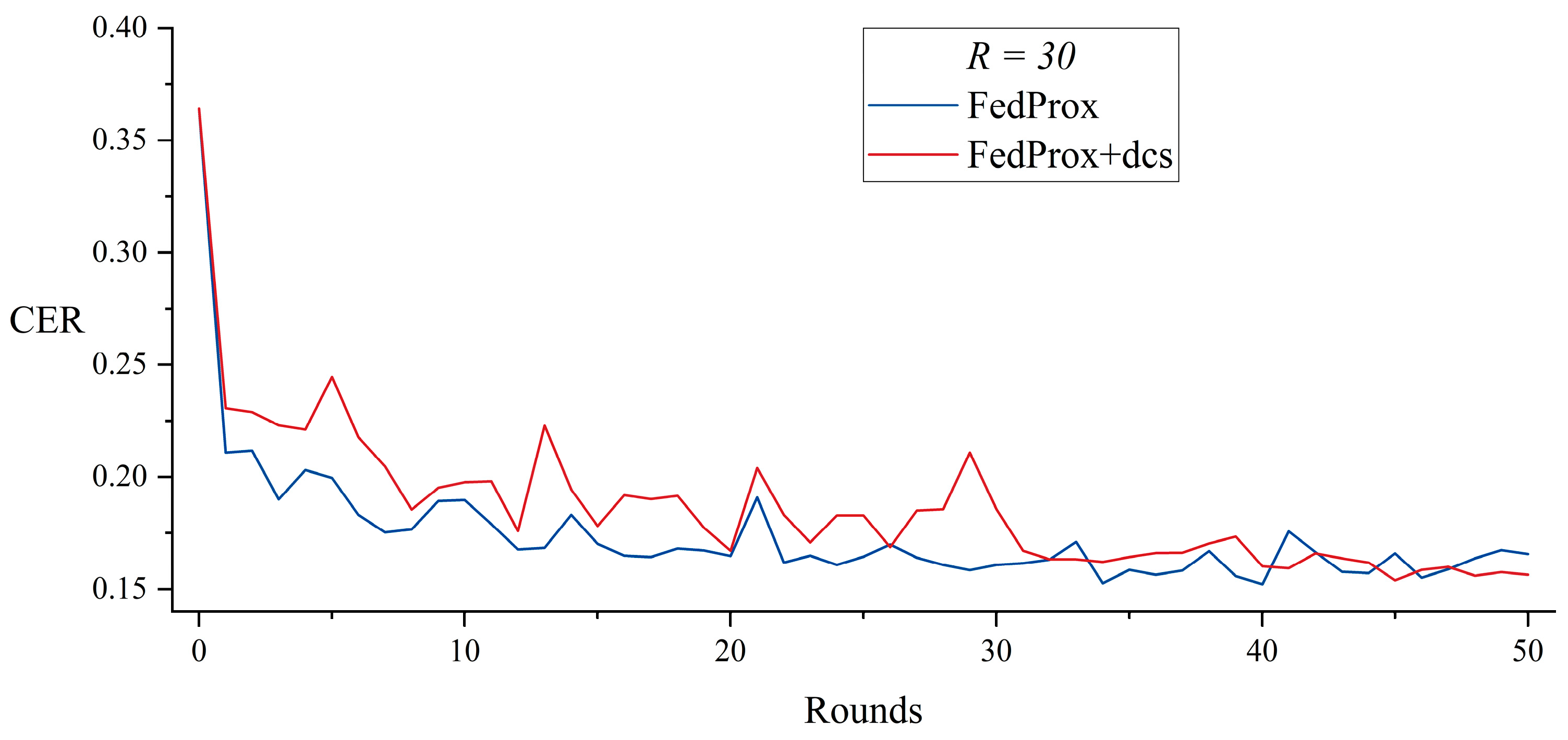
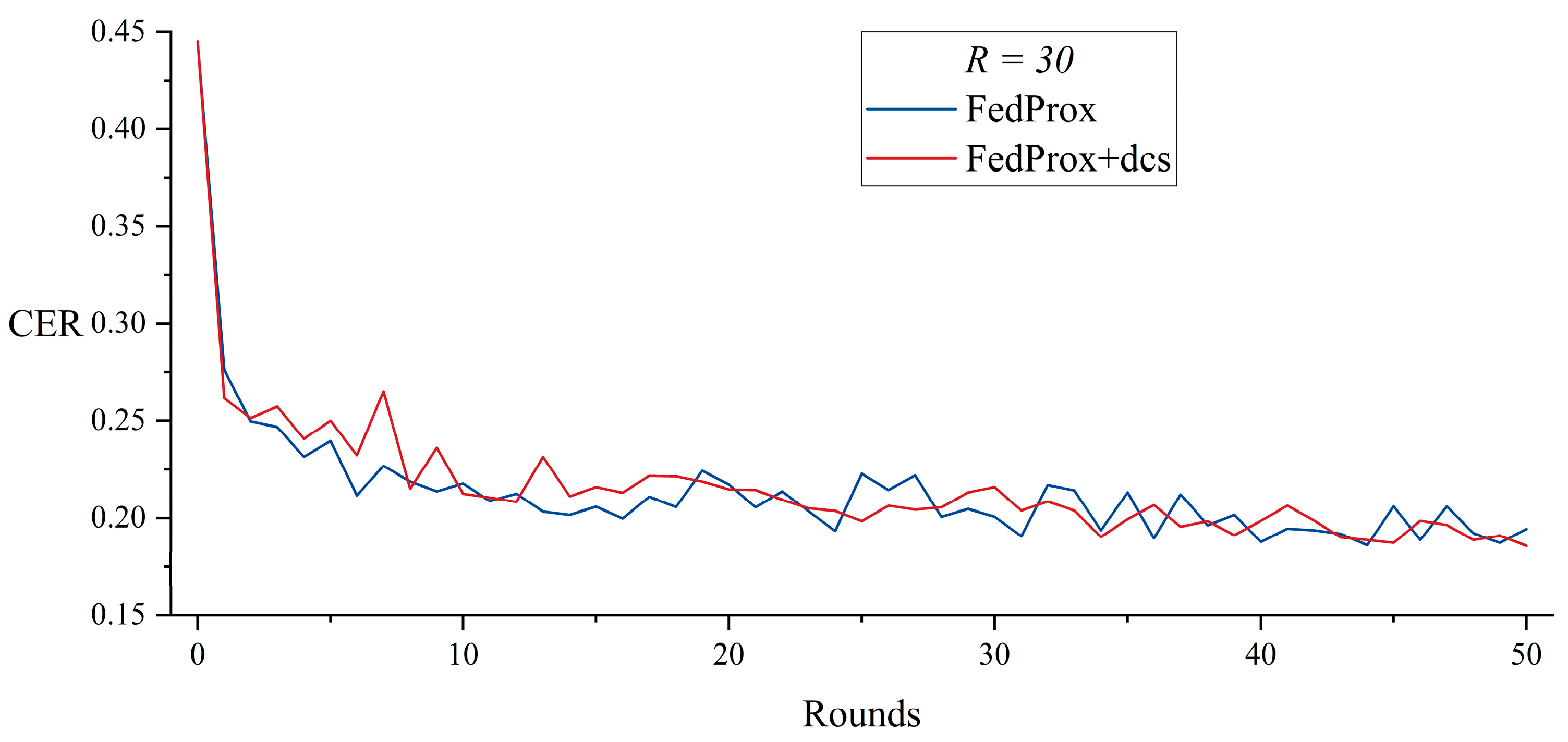
5.2. Dynamic Client Selection with FedProx
5.3. Results of Personalized Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fatehi, K.; Torres, M.T.; Kucukyilmaz, A. An overview of high-resource automatic speech recognition methods and their empirical evaluation in low-resource environments. Speech Commun. 2024, 167, 103151. [Google Scholar]
- Kheddar, H.; Hemis, M.; Himeur, Y. Automatic speech recognition using advanced deep learning approaches: A survey. Inf. Fusion 2024, 109, 102422. [Google Scholar]
- Zhang, L.; Wu, S.; Wang, Z. End-to-End Speech Recognition with Deep Fusion: Leveraging External Language Models for Low-Resource Scenarios. Electronics 2025, 14, 802. [Google Scholar] [CrossRef]
- Jiang, D.; Tan, C.; Peng, J.; Chen, C.; Wu, X.; Zhao, W.; Song, Y.; Tong, Y.; Liu, C.; Xu, Q.; et al. A GDPR-compliant ecosystem for speech recognition with transfer, federated, and evolutionary learning. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–19. [Google Scholar]
- Zhou, Y.; Cui, F.; Che, J.; Ni, M.; Zhang, Z.; Li, J. Elastic Balancing of Communication Efficiency and Performance in Federated Learning with Staged Clustering. Electronics 2025, 14, 745. [Google Scholar] [CrossRef]
- Qi, P.; Chiaro, D.; Guzzo, A.; Ianni, M.; Fortino, G.; Piccialli, F. Model aggregation techniques in federated learning: A comprehensive survey. Future Gener. Comput. Syst. 2024, 150, 272–293. [Google Scholar]
- Nandury, K.; Mohan, A.; Weber, F. Cross-silo federated training in the cloud with diversity scaling and semi-supervised learning. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3085–3089. [Google Scholar]
- Gao, Y.; Parcollet, T.; Zaiem, S.; Fernandez-Marques, J.; De Gusmao, P.P.; Beutel, D.J.; Lane, N.D. End-to-end speech recognition from federated acoustic models. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7227–7231. [Google Scholar]
- Tsouvalas, V.; Saeed, A.; Ozcelebi, T. Federated self-training for data-efficient audio recognition. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 476–480. [Google Scholar]
- Yang, C.H.H.; Chen, I.F.; Stolcke, A.; Siniscalchi, S.M.; Lee, C.H. An experimental study on private aggregation of teacher ensemble learning for end-to-end speech recognition. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; pp. 1074–1080. [Google Scholar]
- Kan, X.; Xiao, Y.; Yang, T.; Chen, N.; Mathews, R. Parameter-Efficient Transfer Learning under Federated Learning for Automatic Speech Recognition. arXiv 2024, arXiv:2408.11873. [Google Scholar]
- Ni, R.; Xiao, Y.; Meadowlark, P.; Rybakov, O.; Goldstein, T.; Suresh, A.T.; Moreno, I.L.; Chen, M.; Mathews, R. FedAQT: Accurate Quantized Training with Federated Learning. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 6100–6104. [Google Scholar]
- Du, Y.; Zhang, Z.; Yue, L.; Huang, X.; Zhang, Y.; Xu, T.; Xu, L.; Chen, E. Communication-Efficient Personalized Federated Learning for Speech-to-Text Tasks. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 10001–10005. [Google Scholar]
- AbdulRahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A survey on federated learning: The journey from centralized to distributed on-site learning and beyond. IEEE Internet Things J. 2020, 8, 5476–5497. [Google Scholar]
- Zhang, F.; Shuai, Z.; Kuang, K.; Wu, F.; Zhuang, Y.; Xiao, J. Unified fair federated learning for digital healthcare. Patterns 2024, 5, 100907. [Google Scholar]
- Solomon, E.; Woubie, A. Federated Learning Method for Preserving Privacy in Face Recognition System. arXiv 2024, arXiv:2403.05344. [Google Scholar]
- Farahani, B.; Tabibian, S.; Ebrahimi, H. Towards a Personalized Clustered Federated Learning: A Speech Recognition Case Study. IEEE Internet Things J. 2023, 10, 18553–18562. [Google Scholar]
- Guliani, D.; Beaufays, F.; Motta, G. Training speech recognition models with federated learning: A quality/cost framework. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3080–3084. [Google Scholar]
- Zhu, H.; Wang, J.; Cheng, G.; Zhang, P.; Yan, Y. Decoupled federated learning for asr with non-iid data. arXiv 2022, arXiv:2206.09102. [Google Scholar]
- Nguyen, T.; Mdhaffar, S.; Tomashenko, N.; Bonastre, J.F.; Estève, Y. Federated learning for asr based on wav2vec 2.0. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Kaur, H.; Rani, V.; Kumar, M.; Sachdeva, M.; Mittal, A.; Kumar, K. Federated learning: A comprehensive review of recent advances and applications. Multimed. Tools Appl. 2024, 83, 54165–54188. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2023, 14, 513–535. [Google Scholar]
- Tan, A.Z.; Yu, H.; Cui, L.; Yang, Q. Towards personalized federated learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9587–9603. [Google Scholar] [CrossRef]
- Xu, J.; Tong, X.; Huang, S.L. Personalized federated learning with feature alignment and classifier collaboration. arXiv 2023, arXiv:2306.11867. [Google Scholar]
- Lin, I.; Yagan, O.; Joe-Wong, C. FedSPD: A Soft-clustering Approach for Personalized Decentralized Federated Learning. arXiv 2024, arXiv:2410.18862. [Google Scholar]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An efficient framework for clustered federated learning. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 19586–19597. [Google Scholar]
- Huang, Y.; Chu, L.; Zhou, Z.; Wang, L.; Liu, J.; Pei, J.; Zhang, Y. Personalized cross-silo federated learning on non-IID data. Proc. AAAI Conf. Artif. Intell. 2021, 35, 7865–7873. [Google Scholar]
- Bai, Z.; Zhang, X.L. Speaker recognition based on deep learning: An overview. Neural Netw. 2021, 140, 65–99. [Google Scholar] [CrossRef]
- Nl8590687. A Deep-Learning-Based Chinese Speech Recognition System. Available online: https://github.com/nl8590687/ASRT_SpeechRecognition (accessed on 26 July 2024).
- Dong, Z.; Ding, Q.; Zhai, W.; Zhou, M. A speech recognition method based on domain-specific datasets and confidence decision networks. Sensors 2023, 23, 6036. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Karim, N.; Mithun, N.C.; Rajvanshi, A.; Chiu, H.P.; Samarasekera, S.; Rahnavard, N. C-sfda: A curriculum learning aided self-training framework for efficient source free domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 24120–24131. [Google Scholar]
- Liu, Y.; Liu, J.; Shi, X.; Cheng, Q.; Huang, Y.; Lu, W. Let’s Learn Step by Step: Enhancing In-Context Learning Ability with Curriculum Learning. arXiv 2024, arXiv:2402.10738. [Google Scholar]
- van de Ven, G.M.; Soures, N.; Kudithipudi, D. Continual Learning and Catastrophic Forgetting. arXiv 2024, arXiv:2403.05175. [Google Scholar]
- Wang, D.; Zhang, X. Thchs-30: A free chinese speech corpus. arXiv 2015, arXiv:1512.01882. Available online: https://www.openslr.org/18 (accessed on 2 August 2024).
- Surfing Tech. ST-CMDS-20170001 1 Free ST Chinese Mandarin Corpus. Available online: https://www.openslr.org/38 (accessed on 2 August 2024).
- Bu, H.; Du, J.; Na, X.; Wu, B.; Zheng, H. Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline. In Proceedings of the 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Republic of Korea, 1–3 November 2017; pp. 1–5. Available online: https://huggingface.co/datasets/AISHELL/AISHELL-1 (accessed on 2 August 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer No. | Type of Layer | Kernel Size | Pooling Size | Step Size | Number of Neurons |
|---|---|---|---|---|---|
| 1 | Conv2D | (3 × 3) | - | 1 | 32 |
| 2 | MaxPooling | - | (2 × 2) | 2 | 32 |
| 3 | Conv2D | (3 × 3) | - | 1 | 64 |
| 4 | MaxPooling | - | (2 × 2) | 2 | 64 |
| 5 | Conv2D | (3 × 3) | - | 1 | 128 |
| 6 | MaxPooling | - | (2 × 2) | 2 | 128 |
| 7 | Conv2D | (3 × 3) | - | 1 | 128 |
| 8 | MaxPooling | - | (1 × 1) | 2 | 128 |
| 9 | Conv2D | (3 × 3) | - | 1 | 128 |
| 10 | MaxPooling | - | (1 × 1) | 2 | 128 |
| 11 | Reshape | - | - | - | 256 |
| 12 | Dense | - | - | - | 128 |
| 13 | Dense | - | - | - | 1428 |
| Server Data Distribution | |||
| Server | Speakers | Development Duration (hours) | Test Duration (hours) |
| 60 | 18 | 10 | |
| Client Data Distribution | |||
| Client ID | Speakers | Train Duration (hours) | Test Duration (hours) |
| 0 | 20 | 8.13 | 1.04 |
| 1 | 20 | 7.36 | 0.97 |
| 2 | 20 | 7.19 | 0.96 |
| 3 | 20 | 7.76 | 0.98 |
| 4 | 20 | 7.52 | 0.97 |
| 5 | 40 | 15.57 | 1.97 |
| 6 | 40 | 15.88 | 2.02 |
| 7 | 40 | 15.72 | 2.00 |
| 8 | 60 | 24.26 | 3.05 |
| 9 | 60 | 24.44 | 3.06 |
| Setting | Method | Total Duration (s) | Convergence | |
|---|---|---|---|---|
| Rounds | Duration (s) | |||
| = 30, Rounds = 50 | FedAvg | 30,146 | N/A | N/A |
| FedAvg + dcs | 26,586 | 43 | 21,591 | |
| = 40, Rounds = 60 | FedAvg | 35,939 | N/A | N/A |
| FedAvg + dcs | 31,545 | 52 | 26,207 | |
| = 50, Rounds = 80 | FedAvg | 46,850 | N/A | N/A |
| FedAvg + dcs | 43,469 | 68 | 35,597 | |
| Setting | Method | Total Duration (s) | Convergence | |
|---|---|---|---|---|
| Rounds | Duration (s) | |||
| FedProx | 38,995 | 43 | 31,650 | |
| FedProx + dcs | 27,850 | 43 | 23,403 | |
| FedProx | 36,734 | 45 | 31,951 | |
| FedProx + dcs | 28,572 | 43 | 23,385 | |
| Client Test ID | Sever_Model 1 | Sever_Model 2 | |||||
|---|---|---|---|---|---|---|---|
| Initial | Traditional Personalization | Ours | Initial | Traditional Personalization | Ours | ||
| Group1 | 0 | 17.92% | 15.02% | 14.56% | 16.28% | 15.19% | 14.92% |
| 1 | 18.12% | 15.75% | 15.45% | 17.60% | 15.75% | 15.48% | |
| 2 | 17.35% | 15.77% | 15.32% | 17.35% | 15.65% | 15.57% | |
| 3 | 19.83% | 16.44% | 16.51% | 19.23% | 16.89% | 16.63% | |
| 4 | 18.07% | 15.47% | 15.27% | 18.60% | 15.50% | 15.29% | |
| Group2 | 5 | 14.92% | 14.35% | 14.38% | 15.19% | 14.35% | 14.51% |
| 6 | 13.33% | 11.57% | 11.46% | 14.13% | 11.47% | 11.47% | |
| 7 | 13.94% | 12.18% | 12.02% | 14.17% | 12.10% | 11.97% | |
| Group3 | 8 | 18.46% | 16.52% | 16.36% | 18.53% | 16.48% | 16.55% |
| 9 | 18.98% | 18.53% | 18.51% | 19.93% | 18.79% | 18.59% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Wu, Z.; Ge, F.; Zhi, Y. Dynamic Client Selection and Group-Balanced Personalization for Data-Imbalanced Federated Speech Recognition. Electronics 2025, 14, 1485. https://doi.org/10.3390/electronics14071485
Xu C, Wu Z, Ge F, Zhi Y. Dynamic Client Selection and Group-Balanced Personalization for Data-Imbalanced Federated Speech Recognition. Electronics. 2025; 14(7):1485. https://doi.org/10.3390/electronics14071485
Chicago/Turabian StyleXu, Chundong, Ziyu Wu, Fengpei Ge, and Yuheng Zhi. 2025. "Dynamic Client Selection and Group-Balanced Personalization for Data-Imbalanced Federated Speech Recognition" Electronics 14, no. 7: 1485. https://doi.org/10.3390/electronics14071485
APA StyleXu, C., Wu, Z., Ge, F., & Zhi, Y. (2025). Dynamic Client Selection and Group-Balanced Personalization for Data-Imbalanced Federated Speech Recognition. Electronics, 14(7), 1485. https://doi.org/10.3390/electronics14071485