
Geographic Routing Decision Method for Flying Ad Hoc Networks Based on Mobile Prediction



Abstract
1. Introduction
- By introducing the extended Kalman filter (EKF) prediction model [16], the prediction of node positions in flying ad hoc networks has been achieved, reducing the problem of position failure caused by the high dynamics of nodes in the time slot interval of position detection.
- Designing a mechanism for dynamically adjusting the Hello packet sending gap, optimizing the neighbor discovery process, reducing the neighbor discovery requirements of high-speed mobile nodes, and significantly reducing routing detection overhead.
- Introducing a Q-learning algorithm with adaptive adjustment of the learning rate and discount factor for intelligent routing decision-making. Taking into account link stability, energy, and distance metrics, a reward function is designed to maximize the reward for routing decisions, thereby improving network performance and stability.
2. Related Work
2.1. Reactive Routing
2.2. Proactive Routing
2.3. Geographic Routing
2.4. Discussion
3. System Model
3.1. Movement Prediction
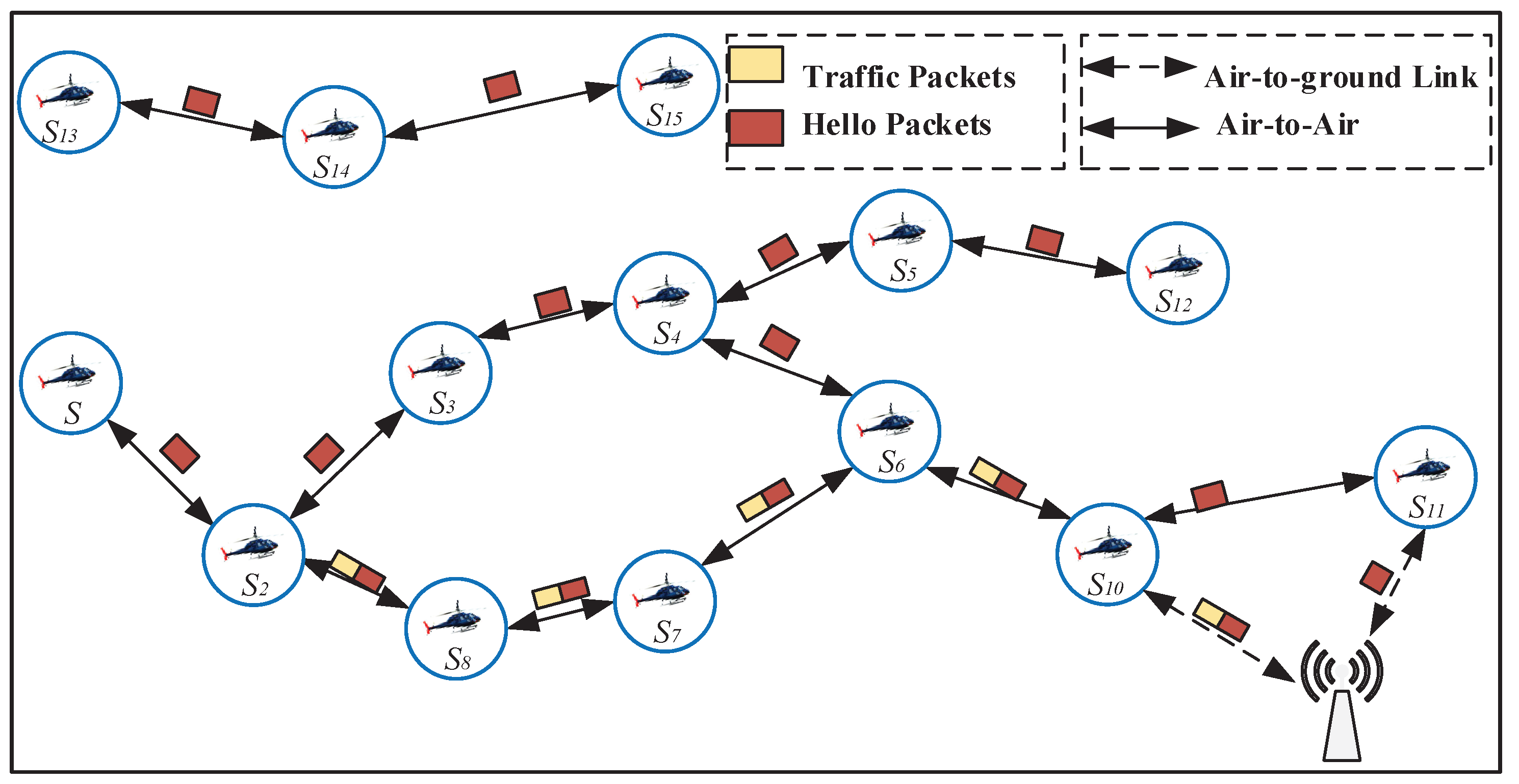
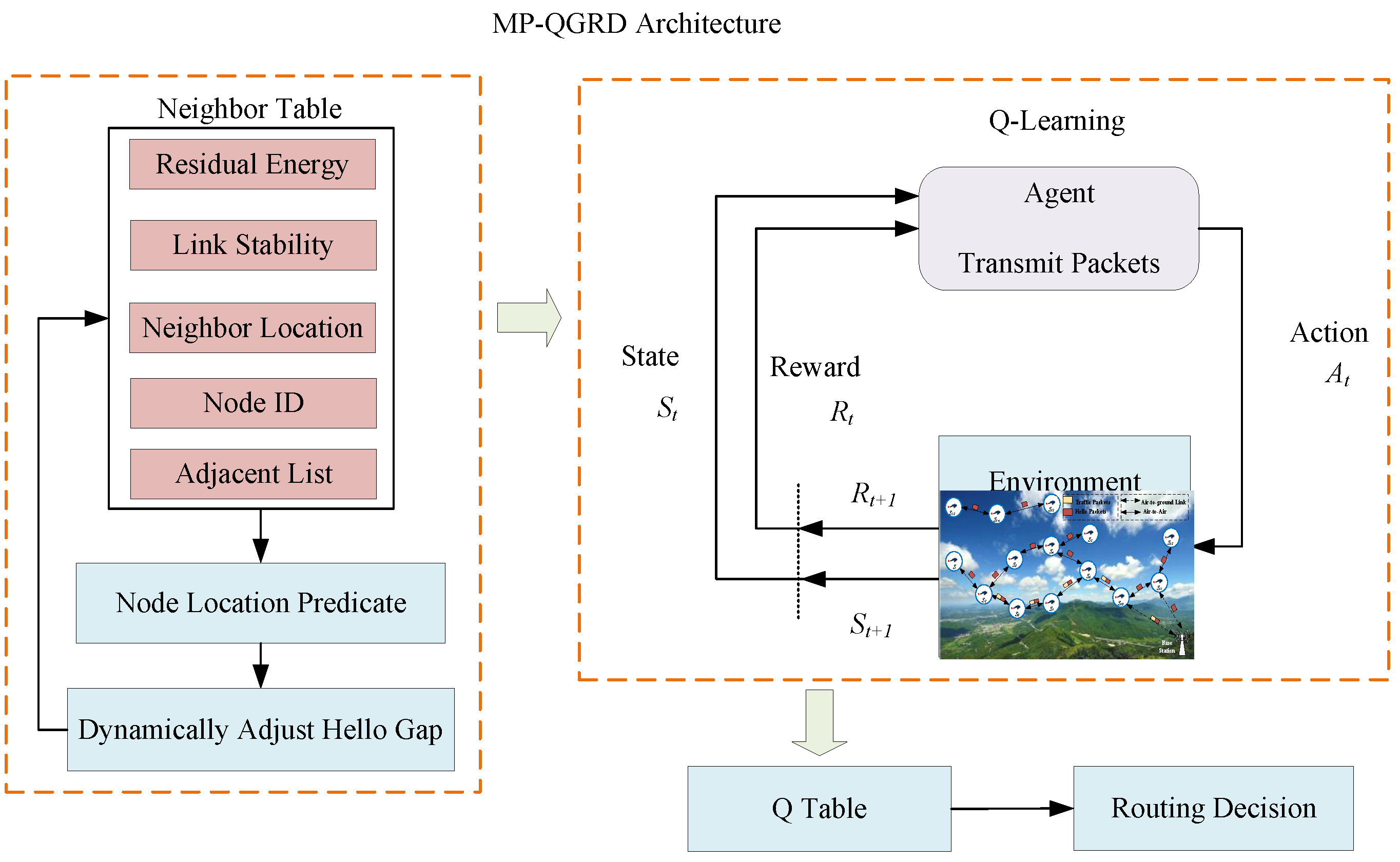
3.2. Neighbors Discovered
3.3. Routing Decisions
- (1)
- Agent: The data packets transmitted by each node in the network represent the agents.
- (2)
- Environment: The entire flying ad hoc network serves as the learning environment for the agents.
- (3)
- State space: The set of all nodes’ states.
- (4)
- Action space: The action space of the agents is the set of neighbor nodes. Selecting a node from the set of neighbors as the next hop for the data packet constitutes an action.
- (5)
- Reward function: The immediate reward value provided by the entire flight network to the nodes. The reward function is designed based on metrics such as link stability, distance to the destination, and energy consumption, aiming to enable nodes to adapt to the dynamic network environment.
3.4. Algorithm Design
| Algorithm 1 Neighbor discovery |
|
| Algorithm 2 Routing decision |
|
4. Evaluation
4.1. Experimental Platform
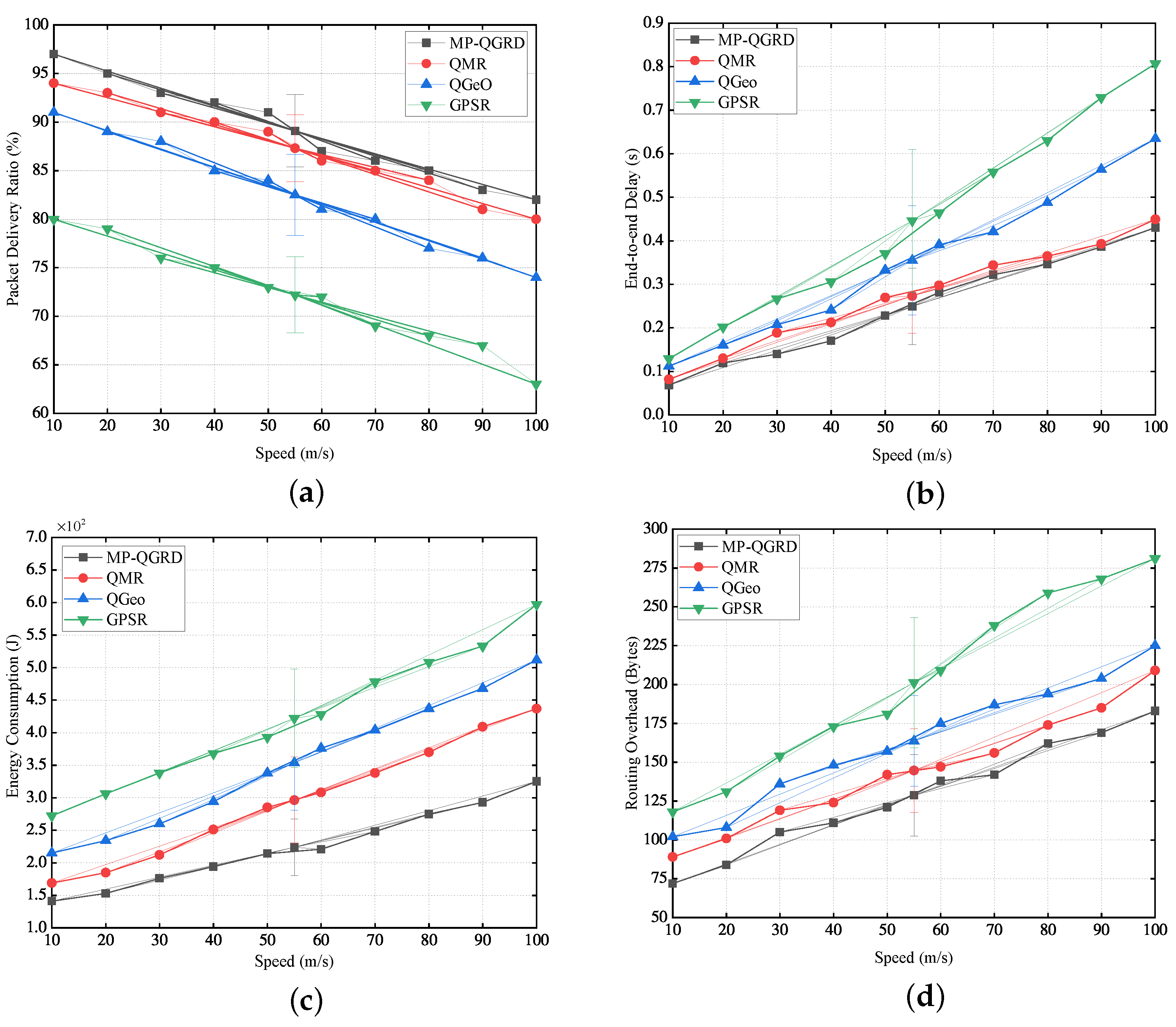
4.2. Comparison of Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pasandideh, F.; Costa, J.P.J.; Kunst, R.; Hardjawana, W.; Freitas, E.P. A systematic literature review of flying ad hoc networks: State-of-the-art, challenges, and perspectives. J. Field Robot. 2023, 40, 955–979. [Google Scholar]
- Lansky, J.; Rahmani, A.M.; Malik, M.H.; Yousefpoor, E.; Yousefpoor, M.S.; Khan, M.U.; Hosseinzadeh, M. An energy-aware routing method using firefly algorithm for flying ad hoc networks. Sci. Rep. 2023, 13, 1323. [Google Scholar]
- Srivastava, A.; Prakash, J. Future FANET with application and enabling techniques: Anatomization and sustainability issues. Comput. Sci. Rev. 2021, 39, 100359. [Google Scholar]
- Ceviz, O.; Sen, S.; Sadioglu, P. A Survey of Security in UAVs and FANETs: Issues, Threats, Analysis of Attacks, and Solutions. IEEE Commun. Surv. Tutorials 2024. [Google Scholar] [CrossRef]
- Gaydamaka, A.; Samuylov, A.; Moltchanov, D.; Ashraf, M.; Tan, B.; Koucheryavy, Y. Dynamic topology organization and maintenance algorithms for autonomous UAV swarms. IEEE Trans. Mob. Comput. 2023, 23, 4423–4439. [Google Scholar] [CrossRef]
- Wang, C.M.; Yang, S.; Dong, W.Y.; Zhao, W.; Lin, W. A Distributed Hybrid Proactive-Reactive Ant Colony Routing Protocol for Highly Dynamic FANETs with Link Quality Prediction. IEEE Trans. Veh. Technol. 2024, 74, 1817–1822. [Google Scholar]
- Tang, F.; Hofner, H.; Kato, N.; Kaneko, K.; Yamashita, Y.; Hangai, M. A deep reinforcement learning-based dynamic traffic offloading in space-air-ground integrated networks (SAGIN). IEEE J. Sel. Areas Commun. 2021, 40, 276–289. [Google Scholar]
- Lin, N.; Huang, J.; Hawbani, A.; Zhao, L.; Tang, H.; Guan, Y.; Sun, Y. Joint routing and computation offloading based deep reinforcement learning for Flying Ad hoc Networks. Comput. Netw. 2024, 249, 110514. [Google Scholar]
- Zhang, Z.; Li, X.; Wang, Y.; Miao, Y.; Liu, X.; Weng, J.; Deng, R.H. TAGKA: Threshold authenticated group key agreement protocol against member disconnect for UANET. IEEE Trans. Veh. Technol. 2023, 72, 14987–15001. [Google Scholar]
- Oubbati, O.S.; Mozaffari, M.; Chaib, N. ECaD: Energy-efficient routing in flying ad hoc networks. Int. J. Commun. Syst. 2019, 32, 41–56. [Google Scholar]
- Pramitarini, Y.; Perdana, R.H.Y.; Shim, K. Federated Blockchain-Based Clustering Protocol for Enhanced Security and Connectivity in FANETs With CF-mMIMO. IEEE Internet Things J. 2025. [Google Scholar] [CrossRef]
- Hong, J.; Zhang, D. TARCS: A topology change aware-based routing protocol choosing scheme of FANETs. Electronics 2019, 8, 274. [Google Scholar] [CrossRef]
- Alsaqour, R.; Abdelhaq, M.; Saeed, R.; Uddin, M.; Alsukour, O.; Al-Hubaishi, M.; Alahdal, T. Dynamic packet beaconing for GPSR mobile ad hoc position-based routing protocol using fuzzy logic. J. Netw. Comput. Appl. 2015, 47, 32–46. [Google Scholar] [CrossRef]
- Zhu, R.; Jiang, Q.; Huang, X.; Li, D.; Yang, Q. A reinforcement-learning-based opportunistic routing protocol for energy-efficient and Void-Avoided UASNs. IEEE Sens. J. 2022, 22, 13589–13601. [Google Scholar]
- Swain, S.; Khilar, P.M.; Senapati, B.R. A reinforcement learning-based cluster routing scheme with dynamic path planning for mutli-uav network. Veh. Commun. 2023, 41, 100605. [Google Scholar] [CrossRef]
- Kayhani, N.; Zhao, W.; McCabe, B.; Schoellig, A.P. Tag-based visual-inertial localization of unmanned aerial vehicles in indoor construction environments using an on-manifold extended Kalman filter. Autom. Constr. 2022, 135, 104112. [Google Scholar] [CrossRef]
- Xiang, X.; Wang, X.; Zhou, Z. Self-adaptive on-demand geographic routing for mobile ad hoc networks. IEEE Trans. Mob. Comput. 2011, 11, 1572–1586. [Google Scholar] [CrossRef]
- Saini, T.K.; Sharma, S.C. Recent advancements, review analysis, and extensions of the AODV with the illustration of the applied concept. Ad Hoc Netw. 2020, 103, 102148. [Google Scholar] [CrossRef]
- Bai, R.; Singhal, M. DOA: DSR over AODV routing for mobile ad hoc networks. IEEE Trans. Mob. Comput. 2006, 5, 1403–1416. [Google Scholar]
- Wang, H.; Li, Y.; Zhang, Y.; Huang, T.; Jiang, Y. Arithmetic optimization AOMDV routing protocol for FANETs. Sensors 2023, 23, 7550. [Google Scholar] [CrossRef]
- Sarkar, D.; Choudhury, S.; Majumder, A. Enhanced-Ant-AODV for optimal route selection in mobile ad-hoc network. J. King Saud-Univ.-Comput. Inf. Sci. 2021, 33, 1186–1201. [Google Scholar]
- Joon, R.; Tomar, P. Energy aware Q-learning AODV (EAQ-AODV) routing for cognitive radio sensor networks. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 6989–7000. [Google Scholar] [CrossRef]
- Mohamed, R.E.; Ghanem, W.R.; Khalil, A.T.; Elhoseny, M.; Sajjad, M.; Mohamed, M.A. Energy efficient collaborative proactive routing protocol for wireless sensor network. Comput. Netw. 2018, 142, 154–167. [Google Scholar]
- Islam, M.A.; Atat, R.; Ismail, M. Software-Defined Networking Based Resilient Proactive Routing in Smart Grids Using Graph Neural Networks and Deep Q-Networks. IEEE Access 2024, 12, 111169–111186. [Google Scholar]
- Gangopadhyay, S.; Jain, V.K. A position-based modified OLSR routing protocol for flying ad hoc networks. IEEE Trans. Veh. Technol. 2023, 72, 12087–12098. [Google Scholar]
- Qiu, X.; Yang, Y.; Xu, L.; Yin, J.; Liao, Z. Maintaining links in the highly dynamic FANET using deep reinforcement learning. IEEE Trans. Veh. Technol. 2022, 72, 2804–2818. [Google Scholar]
- Asaamoning, G.; Mendes, P.; Magaia, N. A dynamic clustering mechanism with load-balancing for flying ad hoc networks. IEEE Access 2021, 9, 158574–158586. [Google Scholar]
- Rahmani, A.M.; Ali, S.; Yousefpoor, E.; Yousefpoor, M.S.; Javaheri, D.; Lalbakhsh, P.; Ahmed, O.H.; Hosseinzadeh, M. OLSR+: A new routing method based on fuzzy logic in flying ad-hoc networks (FANETs). Veh. Commun. 2022, 36, 100489. [Google Scholar]
- Karp, B.; Kung, H.T. GPSR: Greedy perimeter stateless routing for wireless networks. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6–11 August 2000; pp. 243–254. [Google Scholar]
- Zheng, B.; Zhuo, K.; Zhang, H.; Wu, H. A novel airborne greedy geographic routing protocol for flying ad hoc networks. Wirel. Netw. 2022, 30, 4413–4427. [Google Scholar]
- Arafat, M.Y.; Moh, S. A Q-learning-based topology-aware routing protocol for flying ad hoc networks. IEEE Internet Things J. 2021, 9, 1985–2000. [Google Scholar]
- Qiu, X.; Xie, Y.; Wang, Y.; Ye, L.; Yang, Y. QLGR: A Q-learning-based Geographic FANET Routing Algorithm Based on Multiagent Reinforcement Learning. KSII Trans. Internet Inf. Syst. 2021, 15, 4244–4274. [Google Scholar]
- Cui, Y.; Zhang, Q.; Feng, Z.; Wei, Z.; Shi, C.; Yang, H. Topology-aware resilient routing protocol for FANETs: An adaptive Q-learning approach. IEEE Internet Things J. 2022, 9, 18632–18649. [Google Scholar] [CrossRef]
- Jung, W.S.; Yim, J.; Ko, Y.B. QGeo: Q-learning-based geographic ad hoc routing protocol for unmanned robotic networks. IEEE Commun. Lett. 2017, 21, 2258–2261. [Google Scholar]
- Liu, J.; Wang, Q.; He, C.; Jaffrès-Runser, K.; Xu, Y.; Li, Z.; Xu, Y. QMR: Q-learning based multi-objective optimization routing protocol for flying ad hoc networks. Comput. Commun. 2020, 150, 304–316. [Google Scholar]
- Hosseinzadeh, M.; Tanveer, J.; Ionescu-Feleaga, L.; Ionescu, B.S.; Yousefpoor, M.S.; Yousefpoor, E.; Ahmed, O.H.; Rahmani, A.M.; Mehmood, A. A greedy perimeter stateless routing method based on a position prediction mechanism for flying ad hoc networks. J. King Saud-Univ.-Comput. Inf. Sci. 2023, 35, 101712. [Google Scholar] [CrossRef]
- Carneiro, G.; Fontes, H.; Ricardo, M. Fast prototyping of network protocols through ns-3 simulation model reuse. Simul. Model. Pract. Theory 2011, 19, 2063–2075. [Google Scholar] [CrossRef]
- Chen, G.; Dong, W.; Zhao, Z.; Gu, T. Accurate corruption estimation in ZigBee under cross-technology interference. IEEE Trans. Mob. Comput. 2018, 18, 2243–2256. [Google Scholar]
- Dinh, T.D.; Le, D.T.; Tran, T.T.T.; Nguyen, T.A. Flying Ad-Hoc Network for Emergency Based on IEEE 802.11p Multichannel MAC Protocol. In Proceedings of the International Conference on Distributed Computer and Communication Networks, Cham, Switzerland, 14–18 October 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 479–494. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Parameters | Value |
|---|---|
| Simulation area | 1000 × 1000 × 1000 m3 |
| Number of nodes | 20–100 pieces |
| Node speed | 10–100 m/s |
| Physical layer | 802.11 p |
| Max TxPower (transmission power) | 15 dBm |
| MiniRssi (receiving sensitivity) | −80 dBm |
| Signal propagation loss model | ITU-R 1411 log distance propagation |
| Packet size | 64–1024 Bytes |
| 0.6 | |
| Communication radius | about 250 m |
| Mobile model | 3D Gaussian Markov Moving Model |
| the number of repetitions | 20/for each different algorithm |
| update interval | 100 ms |
| , , | 0.4 0.3 0.3 |
| Simulation time | 300 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Fan, M.; Jia, S.; Yang, M.; Wei, X.; Wang, L. Geographic Routing Decision Method for Flying Ad Hoc Networks Based on Mobile Prediction. Electronics 2025, 14, 1456. https://doi.org/10.3390/electronics14071456
Wang G, Fan M, Jia S, Yang M, Wei X, Wang L. Geographic Routing Decision Method for Flying Ad Hoc Networks Based on Mobile Prediction. Electronics. 2025; 14(7):1456. https://doi.org/10.3390/electronics14071456
Chicago/Turabian StyleWang, Guoyong, Mengfei Fan, Saiwei Jia, Meiyi Yang, Xinxin Wei, and Lin Wang. 2025. "Geographic Routing Decision Method for Flying Ad Hoc Networks Based on Mobile Prediction" Electronics 14, no. 7: 1456. https://doi.org/10.3390/electronics14071456
APA StyleWang, G., Fan, M., Jia, S., Yang, M., Wei, X., & Wang, L. (2025). Geographic Routing Decision Method for Flying Ad Hoc Networks Based on Mobile Prediction. Electronics, 14(7), 1456. https://doi.org/10.3390/electronics14071456