
A Graph-Enhanced Dual-Granularity Self-Attention Model for Next POI Recommendation


Abstract
1. Introduction
- To address the ineffectiveness of check-in embedding, a global POI transition graph is constructed to capture initial POI features that contain general movement patterns from users. The initial features are then integrated into spatial–temporal information from user trajectories to obtain more effective embeddings of users’ check-in sequences.
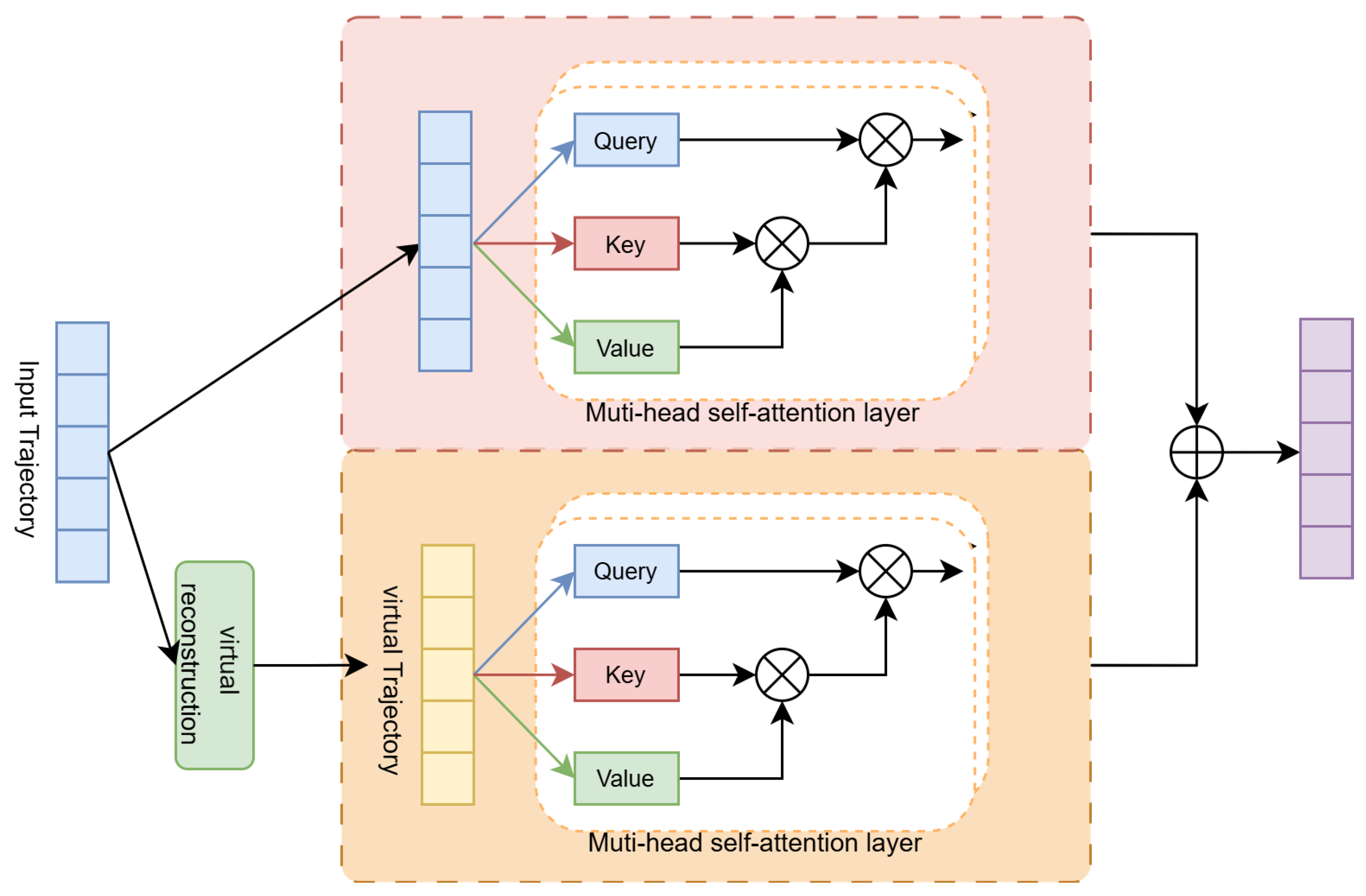
- The proposed DGSA module includes both fine-grained and coarse-grained self-attention layers. The coarse-grained self-attention layer has a virtual trajectory construction operation, which transforms multiple check-in items into a coarse-grained virtual check-in. In this way, the collective influence of multiple check-ins within the sequence can be modeled to analyze users’ preferences.
- Experiments conducted on the Foursquare-NYC and Foursquare-TKY [10] datasets demonstrate that our proposed method outperforms most existing methods.
2. Related Work
2.1. POI Recommendation
2.2. Next POI Recommendation
2.3. Long and Short-Term Preference Modeling for POI Recommendation
3. Problem Definition
4. Proposed Method
4.1. Model Structure Overview
4.2. Graph-Enhanced Embedding Module
4.2.1. Multimodal Feature Embedding
4.2.2. Learning with POI Transfer Graph
4.3. Long-Term Preference Learning
4.3.1. DGSA Layer
4.3.2. Stacking DGSA Layers
4.4. Short-Term Preference Learning
4.5. Model Training
5. Experiments
5.1. Datasets
5.2. Baseline Models
5.3. Evaluation Metrics
5.4. Parameter Settings
5.5. Comparison with Baselines
5.6. Ablation Study
- GEDGSA-G: Removing the global POI transition graph disregards the influence of global information from other users, embedding POIs directly for user preference modeling. The experimental results demonstrate the effectiveness of the global POI transition graph. The graph reveals common patterns in user mobility by extracting information from other users.
- GEDGSA-S: Removing the short-term preference modeling module, employing only LSTM to model user preferences. The experimental results demonstrate the importance of LSTM in capturing temporal information from check-in sequences for user preference modeling.
- GEDGSA-L: Removing the long-term preference modeling module, relying solely on the short-term modeling module to capture the user’s preference. Comparing its results with the complete model highlights the importance of the role of attention mechanisms. It can mitigate noise by assigning varying levels of importance to different items within the sequence.
- GEDGSA-C: Removing the coarse-grained self-attention layer from long-term preference modeling, neglecting the collective influence of grouped check-ins, and considering only the individual impact of each check-in on target item. By comparing the results of this method, it can be proved that modeling user preferences by constructing virtual check-in items is effective. Analyzing user check-in sequences from a coarse-grained perspective further enhances this effectiveness.
5.7. Hyperparameter Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, H.; Chen, L.; Xu, Z.; Lyu, D. Personalized location recommendation using mobile phone usage information. Appl. Intell. 2019, 49, 3694–3707. [Google Scholar] [CrossRef]
- Han, P.; Shang, S.; Sun, A.; Zhao, P.; Zheng, K.; Zhang, X. Point-of-interest recommendation with global and local context. IEEE Trans. Knowl. Data Eng. 2021, 34, 5484–5495. [Google Scholar]
- Wu, Y.; Li, K.; Zhao, G.; Qian, X. Personalized long-and short-term preference learning for next POI recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 1944–1957. [Google Scholar]
- Zhang, Z.; Li, C.; Wu, Z.; Sun, A.; Ye, D.; Luo, X. NEXT: A neural network framework for next POI recommendation. Front. Comput. Sci. 2020, 14, 314–333. [Google Scholar]
- Zhang, J.; Liu, X.; Zhou, X.; Chu, X. Leveraging graph neural networks for point-of-interest recommendations. Neurocomputing 2021, 462, 1–13. [Google Scholar] [CrossRef]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the 2018 World Wide Web Conference, Geneva, Switzerland, 23–27 April 2018; pp. 1459–1468. [Google Scholar]
- Luo, Y.; Liu, Q.; Liu, Z. STAN: Spatio-temporal attention network for next location recommendation. In Proceedings of the Web Conference 2021, New York, NY, USA, 17–21 May 2021; pp. 2177–2185. [Google Scholar]
- Bashir, S.R.; Raza, S.; Misic, V.B. BERT4Loc: BERT for Location—POI recommender system. Future Internet 2023, 15, 213. [Google Scholar] [CrossRef]
- Yang, S.; Liu, J.; Zhao, K. GETNext: Trajectory flow map enhanced transformer for next POI recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2022; pp. 1144–1153. [Google Scholar]
- Yang, D.; Zhang, D.; Zheng, V.W.; Yu, Z. Modeling user activity preference by leveraging user spatial temporal characteristics in LBSNs. IEEE Trans. Syst. Man Cybern. Syst. 2014, 45, 129–142. [Google Scholar] [CrossRef]
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning geographical preferences for point-of-interest recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 11–14 August 2013; pp. 1043–1051. [Google Scholar]
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Content-aware point of interest recommendation on location-based social networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 25–29 January 2015; AAAI Press: Palo Alto, CA, USA, 2015; Volume 29. [Google Scholar]
- Lian, D.; Ge, Y.; Zhang, F.; Yuan, N.J.; Xie, X.; Zhou, T.; Rui, Y. Content-aware collaborative filtering for location recommendation based on human mobility data. In Proceedings of the 2015 IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015; IEEE: New York, NY, USA, 2015; pp. 261–270. [Google Scholar]
- Li, X.; Cong, G.; Li, X.L.; Pham, T.A.N.; Krishnaswamy, S. Rank-geofm: A ranking based geographical factorization method for point of interest recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 433–442. [Google Scholar]
- Zhao, S.; Zhao, T.; King, I.; Lyu, M.R. Geo-teaser: Geo-temporal sequential embedding rank for point-of-interest recommendation. In Proceedings of the 26th International Conference on World Wide Web Companion, Geneva, Switzerland, 3–7 April 2017; pp. 153–162. [Google Scholar]
- Cheng, C.; Yang, H.; Lyu, M.R.; King, I. Where you like to go next: Successive point-of-interest recommendation. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; AAAI Press: Palo Alto, CA, USA, 2013; pp. 2605–2611. [Google Scholar]
- Zhang, J.D.; Chow, C.Y.; Li, Y. Lore: Exploiting sequential influence for location recommendations. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 103–112. [Google Scholar]
- Liu, Y.; Liu, C.; Liu, B.; Qu, M.; Xiong, H. Unified point-of-interest recommendation with temporal interval assessment. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1015–1024. [Google Scholar]
- Zhao, S.; Zhao, T.; Yang, H.; Lyu, M.; King, I. STELLAR: Spatial-temporal latent ranking for successive point-of-interest recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Palo Alto, CA, USA, 2016; pp. 315–321. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Schuurmans, D., Wellman, M.P., Eds.; AAAI Press: Palo Alto, CA, USA, 2016; Volume 30. [Google Scholar]
- Yang, C.; Sun, M.; Zhao, W.X.; Liu, Z.; Chang, E.Y. A neural network approach to jointly modeling social networks and mobile trajectories. ACM Trans. Inf. Syst. (TOIS) 2017, 35, 1–28. [Google Scholar] [CrossRef]
- Zhao, P.; Luo, A.; Liu, Y.; Xu, J.; Li, Z.; Zhuang, F.; Sheng, V.S.; Zhou, X. Where to go next: A spatio-temporal gated network for next poi recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 2512–2524. [Google Scholar] [CrossRef]
- Jiang, S.; He, W.; Cui, L.; Xu, Y.; Liu, L. Modeling long-and short-term user preferences via self-supervised learning for next poi recommendation. ACM Trans. Knowl. Discov. Data 2023, 17, 1–20. [Google Scholar]
- Li, Q.; Xu, X.; Liu, X.; Chen, Q. An attention-based spatiotemporal GGNN for next POI recommendation. IEEE Access 2022, 10, 26471–26480. [Google Scholar] [CrossRef]
- Ou, J.; Jin, H.; Wang, X.; Jiang, H.; Wang, X.; Zhou, C. STA-TCN: Spatial-temporal attention over temporal convolutional network for next point-of-interest recommendation. ACM Trans. Knowl. Discov. Data 2023, 17, 1–19. [Google Scholar] [CrossRef]
- Mikolov, T. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Ying, H.; Zhuang, F.; Zhang, F.; Liu, Y.; Xu, G.; Xie, X.; Xiong, H.; Wu, J. Sequential recommender system based on hierarchical attention network. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Palo Alto, CA, USA, 2018; pp. 3926–3932. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Content | Description |
|---|---|---|
| U | The set of users | |
| L | The set of POIs | |
| T | The set of time slots | |
| Check-in sequence for user u | ||
| The check-in of user u at t | ||
| global POI transition graph |
| Dataset | Users | POIs | Categories | Records |
|---|---|---|---|---|
| NYC | 1083 | 5135 | 314 | 147,938 |
| TKY | 2293 | 7873 | 288 | 447,570 |
| Dataset | Model | Hit@1 | Hit@5 | Hit@10 | Map@1 | Map@5 | Map@10 |
|---|---|---|---|---|---|---|---|
| NYC | ST-RNN | 0.1103 | 0.2171 | 0.2580 | 0.1471 | 0.1614 | 0.1636 |
| LSTM | 0.1147 | 0.2424 | 0.2916 | 0.1629 | 0.1695 | 0.1718 | |
| SHAN | 0.1353 | 0.1779 | 0.1896 | 0.1510 | 0.1526 | 0.1545 | |
| DeepMove | 0.1408 | 0.2946 | 0.3630 | 0.1975 | 0.2071 | 0.2101 | |
| PLSPL | 0.1559 | 0.3252 | 0.3953 | 0.2172 | 0.2266 | 0.2302 | |
| GEDGSA | 0.2401 | 0.4866 | 0.5596 | 0.3335 | 0.3436 | 0.3466 | |
| TKY | ST-RNN | 0.1204 | 0.2437 | 0.2927 | 0.1667 | 0.1733 | 0.1767 |
| LSTM | 0.1339 | 0.2737 | 0.3295 | 0.1868 | 0.1942 | 0.1975 | |
| SHAN | 0.1084 | 0.1527 | 0.184 | 0.1266 | 0.1287 | 0.1296 | |
| DeepMove | 0.1282 | 0.2488 | 0.2923 | 0.1735 | 0.1794 | 0.1820 | |
| PLSPL | 0.1571 | 0.3321 | 0.4020 | 0.2212 | 0.2307 | 0.2352 | |
| GEDGSA | 0.2128 | 0.4597 | 0.5408 | 0.3036 | 0.3146 | 0.3197 |
| Dataset | Model | Hit@1 | Hit@5 | Hit@10 | Map@5 | Map@10 | Map@20 |
|---|---|---|---|---|---|---|---|
| NYC | GEDGSA-G | 0.2392 | 0.4801 | 0.5522 | 0.3308 | 0.3407 | 0.3439 |
| GEDGSA-S | 0.2308 | 0.4820 | 0.5586 | 0.3265 | 0.3374 | 0.3408 | |
| GEDGSA-L | 0.2281 | 0.4524 | 0.5125 | 0.3119 | 0.3201 | 0.3224 | |
| GEDGSA-C | 0.2318 | 0.4848 | 0.5605 | 0.3269 | 0.3372 | 0.3403 | |
| GEDGSA | 0.2401 | 0.4866 | 0.5596 | 0.3335 | 0.3436 | 0.3466 | |
| TKY | GEDGSA-G | 0.2115 | 0.4501 | 0.5338 | 0.2989 | 0.3104 | 0.3147 |
| GEDGSA-S | 0.2089 | 0.4505 | 0.5390 | 0.3014 | 0.3133 | 0.3171 | |
| GEDGSA-L | 0.1814 | 0.3816 | 0.4605 | 0.2561 | 0.2667 | 0.2707 | |
| GEDGSA-C | 0.2102 | 0.4540 | 0.5399 | 0.3007 | 0.3125 | 0.3172 | |
| GEDGSA | 0.2128 | 0.4597 | 0.5408 | 0.3036 | 0.3146 | 0.3197 |
| Hit@1 | Hit@5 | Hit@10 | MAP@5 | MAP@10 | MAP@20 | |
|---|---|---|---|---|---|---|
| 0.0 | 0.2355 | 0.4866 | 0.5586 | 0.3297 | 0.3397 | 0.3428 |
| 0.1 | 0.2382 | 0.4848 | 0.5605 | 0.3315 | 0.3418 | 0.3444 |
| 0.2 | 0.2355 | 0.4866 | 0.5614 | 0.3303 | 0.3403 | 0.3443 |
| 0.3 | 0.2401 | 0.4866 | 0.5596 | 0.3335 | 0.3436 | 0.3466 |
| 0.4 | 0.2355 | 0.4903 | 0.5596 | 0.3323 | 0.3417 | 0.3449 |
| 0.5 | 0.2373 | 0.4866 | 0.5623 | 0.3318 | 0.3420 | 0.3448 |
| 0.6 | 0.2392 | 0.4875 | 0.5614 | 0.3289 | 0.3408 | 0.3458 |
| 0.7 | 0.2392 | 0.4866 | 0.5596 | 0.3282 | 0.3425 | 0.3456 |
| 0.8 | 0.2392 | 0.4894 | 0.5596 | 0.3322 | 0.3417 | 0.3449 |
| 0.9 | 0.2336 | 0.4894 | 0.5586 | 0.3319 | 0.3411 | 0.3433 |
| 1.0 | 0.2318 | 0.4829 | 0.5614 | 0.3281 | 0.3399 | 0.3419 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Xin, M. A Graph-Enhanced Dual-Granularity Self-Attention Model for Next POI Recommendation. Electronics 2025, 14, 1387. https://doi.org/10.3390/electronics14071387
Wang H, Xin M. A Graph-Enhanced Dual-Granularity Self-Attention Model for Next POI Recommendation. Electronics. 2025; 14(7):1387. https://doi.org/10.3390/electronics14071387
Chicago/Turabian StyleWang, Haoqi, and Mingjun Xin. 2025. "A Graph-Enhanced Dual-Granularity Self-Attention Model for Next POI Recommendation" Electronics 14, no. 7: 1387. https://doi.org/10.3390/electronics14071387
APA StyleWang, H., & Xin, M. (2025). A Graph-Enhanced Dual-Granularity Self-Attention Model for Next POI Recommendation. Electronics, 14(7), 1387. https://doi.org/10.3390/electronics14071387